Post Syndicated from Explosm.net original https://explosm.net/comics/cheating
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/cheating
New Cyanide and Happiness Comic
Post Syndicated from original https://xkcd.com/2780/

Post Syndicated from Let's Encrypt original https://letsencrypt.org/2023/05/24/isrg-10th-anniversary.html

It’s hard to believe 10 years have passed since Eric Rescorla, Alex Halderman, Peter Eckersley and I founded ISRG as a nonprofit home for public benefit digital infrastructure. We had an ambitious vision, but we couldn’t have known then the extent to which that vision would become shared and leveraged by so much of the Internet.
Since its founding in 2013, ISRG’s Let’s Encrypt certificate authority has come to serve hundreds of millions of websites and protect just about everyone who uses the Web. Our Prossimo project has brought the urgent issue of memory safety to the fore, and Divvi Up is set to revolutionize the way apps collect metrics while preserving user privacy. I’ve tried to comprehend how much data about peoples’ lives our work has and will protect, and tried even harder to comprehend what that means if one could quantify privacy. It’s simply beyond my ability.
Some of the highlights from the past ten years include:
May 24, 2013: ISRG is incorporated, intending to build Let’s Encrypt
November 18, 2014: The Let’s Encrypt project is announced publicly
September 14, 2015: Let’s Encrypt issues its first certificate
October 19, 2015: Let’s Encrypt becomes publicly trusted
December 3, 2015: Let’s Encrypt becomes generally available
March 8, 2016: Let’s Encrypt issues its millionth certificate
June 28, 2017: Let’s Encrypt issues its 100 millionth certificate
March 11, 2019: The ACME protocol becomes an IETF standard
February 27, 2020: Let’s Encrypt issues its billionth certificate
October 26, 2020: ISRG board approves a privacy preserving metrics project, now Divvi Up
December 9, 2020: ISRG board approves a memory safety project, now Prossimo
December 18, 2020: Divvi Up starts servicing COVID exposure notification
October 3, 2022: Support for Rust is merged into the Linux kernel
All this wouldn’t be possible without our staff, community, donors, funders, and other partners, all of whom I’d like to thank wholeheartedly.
I feel so fortunate that we’ve been able to thrive. We’re fortunate primarily because great people got involved and funders stepped up, but there’s also just a bit of good fortune involved in any success story. The world is a complicated place, there is complex context that one can’t control around every effort. Despite our best efforts, fortune has a role to play in terms of the degree to which the context swirling around us helps or hinders. We have been fortunate in every sense of the word and for that I am grateful.
Our work is far from over. Each of our three projects has challenges and opportunities ahead.
For Let’s Encrypt, which is more critical than ever and relatively mature, our focus over the next few years will be on long-term sustainability. More and more people working with certificates can’t recall a time when Let’s Encrypt didn’t exist, and most people who benefit from our service don’t need to know it exists at all (by design!). Let’s Encrypt is just part of how the Internet works now, which is great for many reasons, but it also means it’s at risk of being taken for granted. We are making sure that doesn’t happen so we can keep Let’s Encrypt running reliably and make investments in its future.
Prossimo is making a huge amount of progress moving critical software infrastructure to memory safe code, from the Linux kernel to NTP, TLS, media codecs, and even sudo/su. We have two major challenges ahead of us here. The first is to raise the money we need to complete development work. The second is to get the safer software we’ve been building adopted widely. We feel pretty good about our plans but it’s not going to be easy. Things worth doing rarely are.
Divvi Up is exciting technology with a bright future. Our biggest challenge here, like most things involving cryptography, is to make it easy to use. We also need to make sure we can provide the service at a cost that will allow for widespread adoption, so we’ll be doing a lot of optimization. Our hope is that over the next decade we can make privacy respecting metrics the norm, just like we did for HTTPS.
The internet wasn’t built with security or privacy in mind, so there is a bountiful opportunity for us to improve its infrastructure. The Internet is also constantly growing and changing, so it is also our job to look into the future and prepare for the next set of threats and challenges as best we can.
Thanks to our supporters, we’ll continue adapting and responding to help ensure the Web is more secure long into the future. Please consider becoming a sponsor or making a donation in support of our work.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=uB_gpziat0w
Post Syndicated from Antonio Vespoli original https://aws.amazon.com/blogs/big-data/real-time-time-series-anomaly-detection-for-streaming-applications-on-amazon-kinesis-data-analytics/
Detecting anomalies in real time from high-throughput streams is key for informing on timely decisions in order to adapt and respond to unexpected scenarios. Stream processing frameworks such as Apache Flink empower users to design systems that can ingest and process continuous flows of data at scale. In this post, we present a streaming time series anomaly detection algorithm based on matrix profiles and left-discords, inspired by Lu et al., 2022, with Apache Flink, and provide a working example that will help you get started on a managed Apache Flink solution using Amazon Kinesis Data Analytics.
Anomaly detection plays a key role in a variety of real-world applications, such as fraud detection, sales analysis, cybersecurity, predictive maintenance, and fault detection, among others. The majority of these use cases require actions to be taken in near real-time. For instance, card payment networks must be able to identify and reject potentially fraudulent transactions before processing them. This raises the challenge to design near-real-time anomaly detection systems that are able to scale to ultra-fast arriving data streams.
Another key challenge that anomaly detection systems face is concept drift. The ever-changing nature of some use cases requires models to dynamically adapt to new scenarios. For instance, in a predictive maintenance scenario, you could use several Internet of Things (IoT) devices to monitor the vibrations produced by an electric motor with the objective of detecting anomalies and preventing unrecoverable damage. Sounds emitted by the vibrations of the motor can vary significantly over time due to different environmental conditions such as temperature variations, and this shift in pattern can invalidate the model. This class of scenarios creates the necessity for online learning—the ability of the model to continuously learn from new data.
Time series are a particular class of data that incorporates time in their structuring. The data points that characterize a time series are recorded in an orderly fashion and are chronological in nature. This class of data is present in every industry and is common at the core of many business requirements or key performance indicators (KPIs). Natural sources of time series data include credit card transactions, sales, sensor measurements, machine logs, and user analytics.
In the time series domain, an anomaly can be defined as a deviation from the expected patterns that characterize the time series. For instance, a time series can be characterized by its expected ranges, trends, seasonal, or cyclic patterns. Any significant alteration of this normal flow of data points is considered an anomaly.
Detecting anomalies can be more or less challenging depending on the domain. For instance, a threshold-based approach might be suitable for time series that are informed of their expected ranges, such as the working temperature of a machine or CPU utilization. On the other hand, applications such as fraud detection, cybersecurity, and predictive maintenance can’t be classified via simple rule-based approaches and require a more fine-grained mechanism to capture unexpected observations. Thanks to their parallelizable and event-driven setup, streaming engines such as Apache Flink provide an excellent environment for scaling real-time anomaly detection to fast-arriving data streams.
Apache Flink is a distributed processing engine for stateful computations over streams. A Flink program can be implemented in Java, Scala, or Python. It supports ingestion, manipulation, and delivery of data to the desired destinations. Kinesis Data Analytics allows you to run Flink applications in a fully managed environment on AWS.
Distance-based anomaly detection is a popular approach where a model is characterized by a number of internally stored data points that are used for comparison against the new incoming data points. At inference time, these methods compute distances and classify new data points according to how dissimilar they are from the past observations. In spite of the plethora of algorithms in literature, there is increasing evidence that distance-based anomaly detection algorithms are still competitive with the state of the art (Nakamura et al., 2020).
In this post, we present a streaming version of a distance-based unsupervised anomaly detection algorithm called time series discords, and explore some of the optimizations introduced by the Discord Aware Matrix Profile (DAMP) algorithm (Lu et al., 2022), which further develops the discords method to scale to trillions of data points.
A left-discord is a subsequence that is significantly dissimilar from all the subsequences that precede it. In this post, we demonstrate how to use the concept of left-discords to identify time series anomalies in streams using Kinesis Data Analytics for Apache Flink.
Let’s consider an unbounded stream and all its subsequences of length n. The m most recent subsequences will be stored and used for inference. When a new data point arrives, a new subsequence that includes the new event is formed. The algorithm compares this latest subsequence (query) to the m subsequences retained from the model, with the exclusion of the latest n subsequences because they overlap with the query and would therefore characterize a self-match. After computing these distances, the algorithm classifies the query as an anomaly if its distance from its closest non-self-matching subsequence is above a certain moving threshold.
For this post, we use a Kinesis data stream to ingest the input data, a Kinesis Data Analytics application to run the Flink anomaly detection program, and another Kinesis data stream to ingest the output produced by your application. For visualization purposes, we consume from the output stream using Kinesis Data Analytics Studio, which provides an Apache Zeppelin Notebook that we use to visualize and interact with the data in real time.
The Java application code for this example is available on GitHub. To download the application code, complete the following steps:
amazon-kinesis-data-analytics-java-examples/AnomalyDetection/LeftDiscords directory:
Let’s walk through the code step by step.
The MPStreamingJob class defines the data flow of the application, and the MPProcessFunction class defines the logic of the function that detects anomalies.
The implementation is best described by three core components:
The anomaly detection function is implemented as a ProcessFunction<String, String>. Its method MPProcessFunction#processElement is called for every data point:
For every incoming data point, the anomaly detection algorithm takes the following actions:
timeSeriesData.2 * sequenceLength data points, starts computing the matrix profile.initializationPeriods * sequenceLength data points, starts outputting anomaly labels.Following these actions, the MPProcessFunction function outputs an OutputWithLabel object with four attributes:
In the provided implementation, the threshold is learned online by fitting a normal distribution to the matrix profile data:
In this example, the algorithm classifies as anomalies those subsequences whose distance from their nearest neighbor deviates significantly from the average minimum distance (more than two standard deviations away from the mean).
The TimeSeries class implements the data structure that retains the context window, namely, the internally stored records that are used for comparison against the new incoming records. In the provided implementation, the n most recent records are retained, and when the TimeSeries object is at capacity, the oldest records are overridden.
Before you create a Kinesis Data Analytics application for this exercise, create two Kinesis data streams: InputStream and OutputStream in us-east-1. The Flink application will use these streams as its respective source and destination streams. To create these resources, launch the following AWS CloudFormation stack:
![]()
Alternatively, follow the instructions in Creating and Updating Data Streams.
To create your application, complete the following steps:
amazon-kinesis-data-analytics-java-examples/AnomalyDetection/LeftDiscords/core directory.
pom.xml file:mvn package -Dflink.version=1.15.4target/left-discords-1.0.0.jar.target/left-discords-1.0.0.jar.InputStream and OutputStream, respectively.us-east-1.You can populate InputStream by running the script.py file from the cloned repository, using the command python script.py. By editing the last two lines, you can populate the stream with synthetic data or with real data from a CSV dataset.
Kinesis Data Analytics Studio provides the perfect setup for observing data in real time. The following screenshot shows sample visualizations. The first plot shows the incoming time series data, the second plot shows the matrix profile, and the third plot shows which data points have been classified as anomalies.

To visualize the data, complete the following steps:
Create a table and define the shape of the records generated by the application:
Visualize the input data (choose Line Chart from the visualization options):
Visualize the output matrix profile data (choose Scatter Chart from the visualization options):
Visualize the labeled data (choose Scatter Chart from the visualization options):
To delete all the resources that you created, follow the instructions in Clean Up AWS Resources.
In this section, we discuss future developments for this solution.
The online time series discords algorithm is further developed and optimized for speed in Lu et al., 2022. The proposed optimizations include:
The algorithm above operates with parallelism 1, which means that when a single worker is enough to handle the data stream throughput, the above algorithm can be directly used. This design can be enhanced with further distribution logic for handling high throughput scenarios. In order to parallelise this algorithm, you may to design a partitioner operator that ensures that the anomaly detection operators would have at their disposal the relevant past data points. The algorithm can maintain a set of the most recent records to which it compares the query. Efficiency and accuracy trade-offs of approximate solutions are interesting to explore. Since the best solution for parallelising the algorithm depends largely on the nature of the data, we recommend experimenting with various approaches using your domain-specific knowledge.
In this post, we presented a streaming version of an anomaly detection algorithm based on left-discords. By implementing this solution, you learned how to deploy an Apache Flink-based anomaly detection solution on Kinesis Data Analytics, and you explored the potential of Kinesis Data Analytics Studio for visualizing and interacting with streaming data in real time. For more details on how to implement anomaly detection solutions in Apache Flink, refer to the GitHub repository that accompanies this post. To learn more about Kinesis Data Analytics and Apache Flink, explore the Amazon Kinesis Data Analytics Developer Guide.
Give it a try and share your feedback in the comments section.
 Antonio Vespoli is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Antonio Vespoli is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
 Samuel Siebenmann is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Samuel Siebenmann is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
 Nuno Afonso is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Nuno Afonso is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Post Syndicated from Kate Rodgers original https://aws.amazon.com/blogs/security/faster-aws-cloud-connections-with-tls-1-3/
At Amazon Web Services (AWS), we strive to continuously improve customer experience by delivering a cloud computing environment that supports the most modern security technologies. To improve the overall performance of your connections, we have already started to enable TLS version 1.3 globally across our AWS service API endpoints, and will complete this process by December 31, 2023. By using TLS 1.3, you can decrease your connection time by removing one network round trip for every connection request, and can benefit from some of the most modern and secure cryptographic cipher suites available today.
If you are using current software tools (2014 or later) including our AWS SDKs or AWS Command Line Interface (AWS CLI), you will automatically receive the benefits of TLS 1.3 with no action required on your part. This is because AWS services will negotiate the highest TLS protocol version that your client software supports. If you want to continue using TLS 1.2, you will still have full control through your client configurations. AWS will retain support for TLS 1.2, in addition to TLS 1.3, into the foreseeable future. Meanwhile, here’s the latest information on the on-going deprecation of TLS 1.0/1.1.
If you have any questions, start a new thread on AWS re:Post, or contact AWS Support or your technical account manager. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
Post Syndicated from original https://lwn.net/Articles/932734/
Google has announced
the release of the results of internal audits on a number of rust crates.
You can easily import audits done by Googlers into your own
projects that attest to the properties of many open-source Rust
crates. Then, equipped with this data, you can decide whether
crates meet the security, correctness, and testing requirements for
your projects.
This work uses the cargo vet tool covered here one year ago.
Post Syndicated from Carlos Canto original https://blog.rapid7.com/2023/05/23/velocon-2023-submissions-wanted/

Rapid7 is thrilled to announce that the 2nd annual VeloCON virtual summit will be held this September (date TBD), with times oriented to the continental USA time zones. Once again, the conference will be online and completely free!
VeloCON is a one-day event focused on the Velociraptor community. It’s a place to share experiences in using and developing Velociraptor to address the needs of the wider DFIR community and an opportunity to take a look ahead at the future of our platform.
This year’s event calls for even more of the stimulating and informative content that made last year’s VeloCON so much fun. Don’t miss your chance at being a part of this year’s marquee event of the open-source DFIR calendar.
The call for presentations closes Monday, July 17, 2023 (see details below).
Last year’s event was a tremendous success, with over 500 unique participants enjoying our lineup of fascinating discussions, tech talks and the opportunity to get to know real members of our own community.
VeloCON invites contributions in the form of a 30-45 minute presentation. We require a brief proposal (~500 words; not a paper). These proposals undergo a review process to select presentations of maximum interest to VeloCON attendees and the wider Velociraptor community and to filter out sales pitches.
VeloCON focuses on work that pushes the envelope of what is currently possible using Velociraptor. Potential topics to be addressed by submissions include, but are not limited to:
Please email your submission to [email protected] and include the following details:
Submissions are due Monday, July 17, 2023 and a decision will be announced shortly afterwards.
Post Syndicated from Amrit Singh original https://www.backblaze.com/blog/the-free-credit-trap-building-saas-infrastructure-for-long-term-sustainability/
In today’s economic climate, cost cutting is on everyone’s mind, and businesses are doing everything they can to save money. But, it’s equally important that they can’t afford to compromise the integrity of their infrastructure or the quality of the customer experience. As a startup, taking advantage of free cloud credits from cloud providers like Amazon AWS, especially at a time like this, seems enticing.
Using those credits can make sense, but it takes more planning than you might think to use them in a way that allows you to continue managing cloud costs once the credits run out.
In this blog post, I’ll walk through common use cases for credit programs, the risks of using credits, and alternatives that help you balance growth and cloud costs.
This post is part of a series exploring free cloud credits and the hidden complexities and limitations that come with these offers. Check out our previous installments:
As we see it, there have been three stages of “The Cloud” in its history:
Starting around when Backblaze was founded in 2007, the public cloud was in its infancy. Most people weren’t clear on what cloud computing was or if it was going to take root. Businesses were asking themselves, “What is the cloud and how will it work with my business?”
Fast forward to 10 years later, and AWS and “The Cloud” started to become synonymous. Amazon had nearly 50% of market share of public cloud services, more than Microsoft, Google, and IBM combined. “The Cloud” was well-established, and for most folks, the cloud was AWS.
Today, we’re in Phase 3 of the cloud. “The Cloud” of today is defined by the open, multi-cloud internet. Traditional cloud vendors are expensive, complicated, and seek to lock customers into their walled gardens. Customers have come to realize that (see below) and to value the benefits they can get from moving away from a model that demands exclusivity in cloud infrastructure.
In Cloud Phase 3.0, companies are looking to reign in spending, and are increasingly seeking specialized cloud providers offering affordable, best-of-breed services without sacrificing speed and performance. How do you balance that with the draw of free credits? I’ll get into that next, and the two are far from mutually exclusive.
So, you have $100k in free cloud credits from AWS. What do you do with them? Well, in our experience, there are a wide range of use cases for credits, including:
All of this is to say: Proper configuration, long-term management and upkeep, and cost optimization all play a role on how you scale on monolith platforms. It is important to note that the risks and benefits mentioned above are general considerations, and specific terms and conditions may vary depending on the cloud service provider and the details of their free credit offerings. It’s crucial to thoroughly review the terms and plan accordingly to maximize the benefits and mitigate the risks associated with free cloud credits for each specific use case. (And, given the complicated pricing structures we mentioned before, that might take some effort.)
Monument, a photo management service with a strong focus on security and privacy, utilized free startup credits from AWS. But, they knew free credits wouldn’t last forever. Monument’s co-founder, Ercan Erciyes, realized they’d ultimately lose money if they built the infrastructure for Monument Cloud on AWS.
He also didn’t want to accumulate tech debt and become locked in to AWS. Rather than using the credits to build a minimum viable product as fast as humanly possible, he used the credits to develop the AI model, but not to build their infrastructure. Read more about how they put AWS credits to use while building infrastructure that could scale as they grew.

If you’re handed $100,000 in credits, it’s crucial to be aware of the risks and implications that come along with it. While it may seem like an exciting opportunity to explore the capabilities of the cloud without immediate financial constraints, there are several factors to consider:
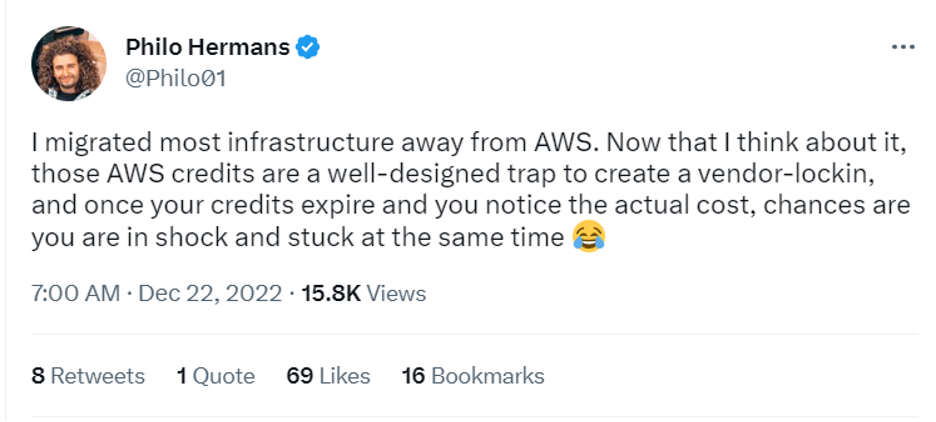
The problems are nothing new for founders, as the online conversation bears out.
First, there’s the old surprise bill:
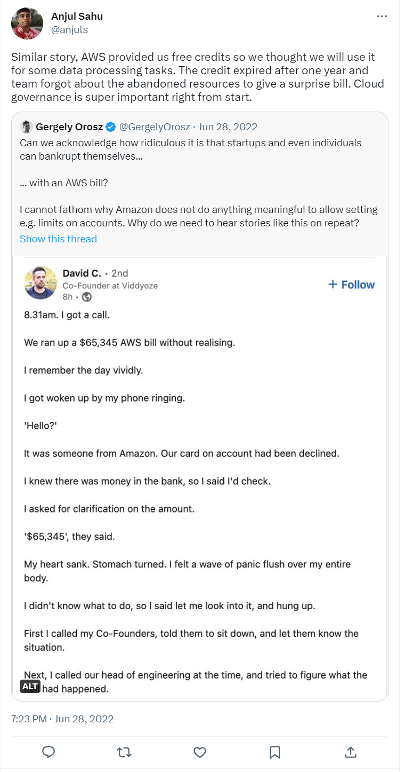
Even with some optimization, AWS cloud spend can still be pretty “obscene” as this user vividly shows:
There’s the founder raising rounds just to pay AWS bills:
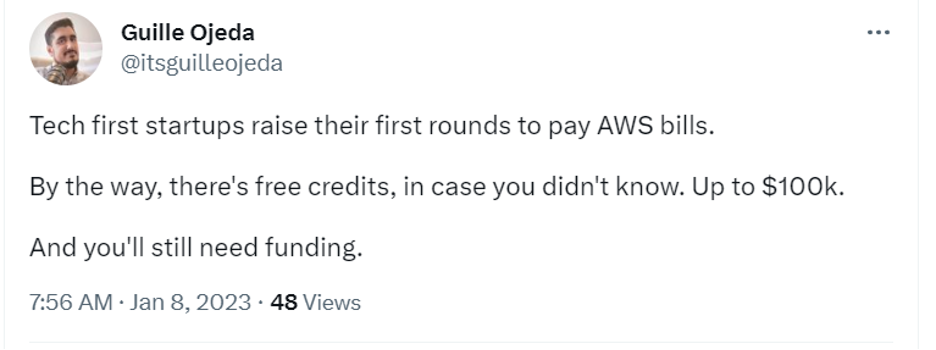
Some use the surprise bill as motivation to get paying customers.
Lastly, there’s the comic relief:
Where does that leave you today? Here are some best practices startups and early founders can implement to balance growth and cloud costs:
Put some time into creating a well-thought-out cloud cost management strategy from the beginning. This includes closely monitoring your usage, optimizing resource allocation, and planning for the expiration of credits to ensure a smooth transition. By understanding the risks involved and proactively managing your cloud usage, you can maximize the benefits of the credits while minimizing potential financial setbacks and vendor lock-in concerns.
Monitoring and optimizing cloud usage plays a vital role in avoiding wasted resources and controlling costs. By regularly analyzing usage patterns, organizations can identify opportunities to right-size resources, adopt automation to reduce idle time, and leverage cost-effective pricing options. Effective monitoring and optimization ensure that businesses are only paying for the resources they truly need, maximizing cost efficiency while maintaining the necessary levels of performance and scalability.
By adopting a multi-cloud strategy, businesses can diversify their cloud infrastructure and services across different providers. This allows them to benefit from each provider’s unique offerings, such as specialized services, geographical coverage, or pricing models. Additionally, it provides a layer of protection against potential service disruptions or price increases from a single provider. Adopting a multi-cloud approach requires careful planning and management to ensure compatibility, data integration, and consistent security measures across multiple platforms. However, it offers the flexibility to choose the best-fit cloud services from different providers, reducing dependency on a single vendor and enabling businesses to optimize costs while harnessing the capabilities of various cloud platforms.
If you’re already deeply invested in a major cloud platform, shifting away can seem cumbersome, but there may be long-term benefits that outweigh the short term “pains” (this leads into the shift to Cloud 3.0). The process could involve re-architecting applications, migrating data, and retraining personnel on the new platform. However, factors such as pricing models, performance, scalability, or access to specialized services may win out in the end. It’s worth noting that many specialized providers have taken measures to “ease the pain” and make the transition away from AWS more seamless without overhauling code. For example, at Backblaze, we developed an S3 compatible API so switching providers is as simple as dropping in a new storage target.
By setting aside credits for future migration, businesses can ensure they have the necessary resources to transition to a different provider without incurring significant up front expenses like egress fees to transfer large data sets. This strategic allocation of credits allows organizations to explore alternative cloud platforms, evaluate their pricing models, and assess the cost-effectiveness of migrating their infrastructure and services without worrying about being able to afford the migration.
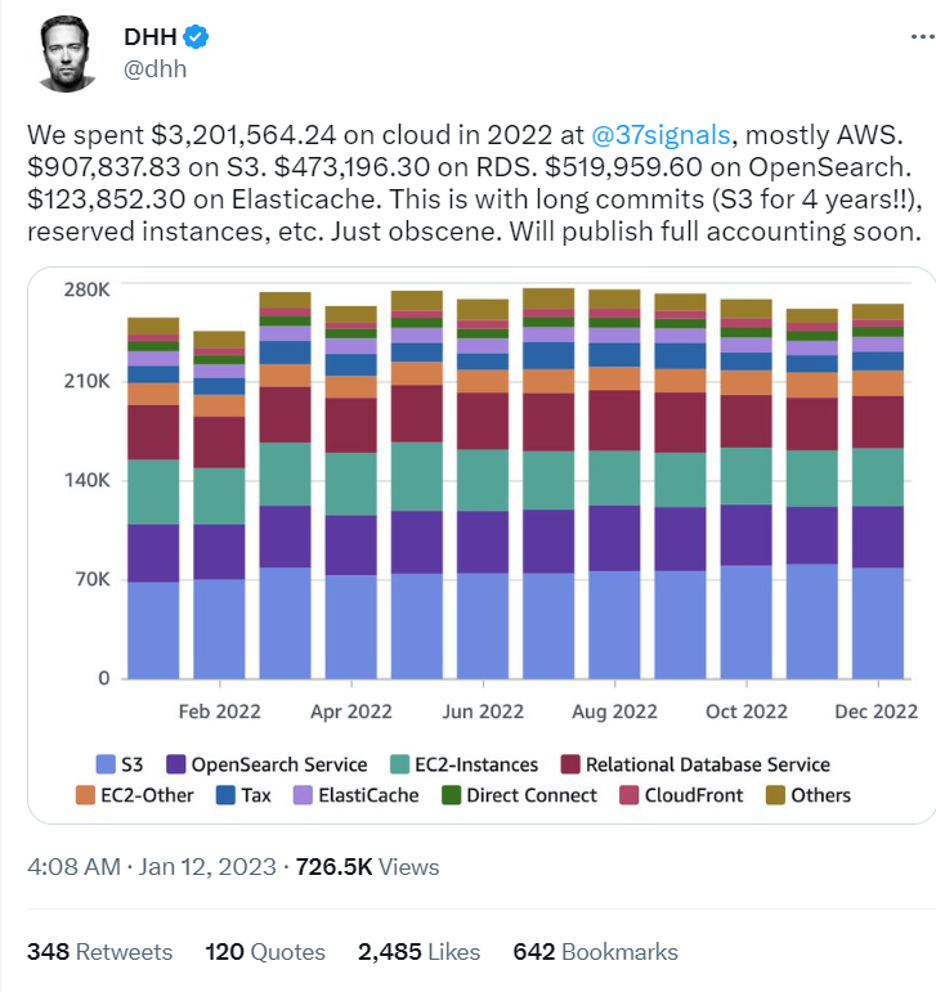
In 2022, David Heinemeier Hansson, the creator of Basecamp and Hey, announced that he was moving Hey’s infrastructure from AWS to on-premises. Hansson cited the high cost of AWS as one of the reasons for the move. His estimate? “We stand to save $7m over five years from our cloud exit,” he said.
Going back to on-premises solutions is certainly one answer to the problem of AWS bills. In fact, when we started designing Backblaze’s Personal Backup solution, we were faced with the same problem. Hosting data storage for our computer backup product on AWS was a non-starter—it was going to be too expensive, and our business wouldn’t be able to deliver a reasonable consumer price point and be solvent. So, we didn’t just invest in on-premises resources: We built our own Storage Pods, the first evolution of the Backblaze Storage Cloud.
But, moving back to on-premises solutions isn’t the only answer—it’s just the only answer if it’s 2007 and your two options are AWS and on-premises solutions. The cloud environment as it exists today has better choices. We’ve now grown that collection of Storage Pods into the Backblaze B2 Storage Cloud, which delivers performant, interoperable storage at one-fifth the cost of AWS. And, we offer free egress to our content delivery network (CDN) and compute partners. Backblaze may provide an even more cost-effective solution for mid-sized SaaS startups looking to save on cloud costs while maintaining speed and performance.
As we transition to Cloud 3.0 in 2023 and beyond, companies are expected to undergo a shift, reevaluating their cloud spending to ensure long-term sustainability and directing saved funds into other critical areas of their businesses. The age of limited choices is over. The age of customizable cloud integration is here.
So, shout out to David Heinemeier Hansson: We’d love to chat about your storage bills some time.
Take a proactive approach to cloud cost management: If you’ve got more than 50TB of data storage or want to check out our capacity-based pricing model, B2 Reserve, contact our Sales Team to test a PoC for free with Backblaze B2.
And, for the streamlined, self–serve option, all you need is an email to get started today.
If you’re thinking about moving to Backblaze B2 after taking AWS credits, but you’re not sure if it’s right for you, we’ve put together some frequently asked questions that folks have shared with us before their migrations:
Backblaze’s Universal Data Migration service can help you off-load some of your data to Backblaze B2 for free. Speak with a migration expert today.
Shifting away from AWS doesn’t mean ditching the workflows you have already set up. You can migrate some of your data storage while keeping some on AWS or continuing to use other AWS services. Moreover, AWS may be overkill for small to midsize SaaS businesses with limited resources.
Identify the specific services and functionalities that your applications and systems require, such as CDN for content delivery or compute resources for processing tasks. Check out our partner ecosystem to identify other independent cloud providers that offer the services you need at a lower cost than AWS.
With the ease of use, predictable pricing, zero egress, our joint solutions are perfect for businesses looking to reduce their IT costs, improve their operational efficiency, and increase their competitive advantage in the market. Our CDN partners include Fastly, bunny.net, and Cloudflare. And, we extend free egress to joint customers.
Our compute partners include Vultr and Equinix Metal. You can connect Backblaze B2 Cloud Storage with Vultr’s global compute network to access, store, and scale application data on-demand, at a fraction of the cost of the hyperscalers.
The post The Free Credit Trap: Building SaaS Infrastructure for Long-Term Sustainability appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=JCKoVymrPiU
Post Syndicated from original https://lwn.net/Articles/932724/
Bootlin has released
a tool called Snagboot that is intended to help with the recovery of
bricked embedded systems.
Thankfully, most embedded platforms almost always include some form
of recovery via USB or UART, which usually involves sending a boot
image to the platform’s ROM code. A few tools exist that leverage
this functionality to offer quick recovery and reflashing via USB,
such as STM32CubeProgrammer, SAM-BA or UUU. However, these tools
are all vendor-specific, which means that developers working on
various kinds of platforms have to switch between different tools
and learn how to use each one.To address this issue, Bootlin is happy to release today a new
recovery and reflashing tool, called Snagboot.
Post Syndicated from Cliff Robinson original https://www.servethehome.com/intel-agilex-7-with-r-tile-launched-integrated-pcie-gen5-and-cxl/
The new Intel Agilex 7 with R-Tile provides hardened PCIe Gen5 and CXL IP to accelerate bringing new solutions to market
The post Intel Agilex 7 with R Tile Launched Integrated PCIe Gen5 and CXL appeared first on ServeTheHome.
Post Syndicated from original https://lwn.net/Articles/932721/
The PyPI package archive has removed support
for PGP signatures on packages.
In other words, out of all of the unique keys that had uploaded
signatures to PyPI, only 36% of them were capable of being
meaningfully verified at the time of audit. Even if all of those
signatures uploaded in that 3 year period of time were made by one
of those 36% of keys that are able to be meaningfully verified,
that would still represent only 0.3% of all of those files.Given all of this, the continued support of uploading PGP
signatures to PyPI is no longer defensible.
Post Syndicated from Sheila Busser original https://aws.amazon.com/blogs/compute/reserving-ec2-capacity-across-availability-zones-by-utilizing-on-demand-capacity-reservations-odcrs/
This post is written by Johan Hedlund, Senior Solutions Architect, Enterprise PUMA.
Many customers have successfully migrated business critical legacy workloads to AWS, utilizing services such as Amazon Elastic Compute Cloud (Amazon EC2), Auto Scaling Groups (ASGs), as well as the use of Multiple Availability Zones (AZs), Regions for Business Continuity, and High Availability.
These critical applications require increased levels of availability to meet strict business Service Level Agreements (SLAs), even in extreme scenarios such as when EC2 functionality is impaired (see Advanced Multi-AZ Resilience Patterns for examples). Following AWS best practices such as architecting for flexibility will help here, but for some more rigid designs there can still be challenges around EC2 instance availability.
In this post, I detail an approach for Reserving Capacity for this type of scenario to mitigate the risk of the instance type(s) that your application needs being unavailable, including code for building it and ways of testing it.
To focus on the problem of Capacity Reservation, our reference architecture is a simple horizontally scalable monolith. This consists of a single executable running across multiple instances as a cluster in an Auto Scaling group across three AZs for High Availability.

The application in this example is both business critical and memory intensive. It needs six r6i.4xlarge instances to meet the required specifications. R6i has been chosen to meet the required memory to vCPU requirements.
The third-party application we need to run, has a significant license cost, so we want to optimize our workload to make sure we run only the minimally required number of instances for the shortest amount of time.
The application should be resilient to issues in a single AZ. In the case of multi-AZ impact, it should failover to Disaster Recovery (DR) in an alternate Region, where service level objectives are instituted to return operations to defined parameters. But this is outside the scope for this post.
In this solution, the Auto Scaling Group automatically balances its instances across the selected AZs, providing a layer of resilience in the event of a disruption in a single AZ. However, this hinges on those instances being available for use in the Amazon EC2 capacity pools. The criticality of our application comes with SLAs which dictate that even the very low likelihood of instance types being unavailable in AWS must be mitigated.
There are 2 main ways of Reserving Capacity for this scenario: (a) Running extra capacity 24/7, (b) On Demand Capacity Reservations (ODCRs).
In the past, another recommendation would have been to utilize Zonal Reserved Instances (Non Zonal will not Reserve Capacity). But although Zonal Reserved Instances do provide similar functionality as On Demand Capacity Reservations combined with Savings Plans, they do so in a less flexible way. Therefore, the recommendation from AWS is now to instead use On Demand Capacity Reservations in combination with Savings Plans for scenarios where Capacity Reservation is required.
The TCO impact of the licensing situation rules out the first of the two valid options. Merely keeping the spare capacity up and running all the time also doesn’t cover the scenario in which an instance needs to be stopped and started, for example for maintenance or patching. Without Capacity Reservation, there is a theoretical possibility that that instance type would not be available to start up again.
This leads us to the second option: On Demand Capacity Reservations.
Our failure scenario is when functionality in one AZ is impaired and the Auto Scaling Group must shift its instances to the remaining AZs while maintaining the total number of instances. With a minimum requirement of six instances, this means that we need 6/2 = 3 instances worth of Reserved Capacity in each AZ (as we can’t know in advance which one will be affected).

If you want to get hands-on experience with On Demand Capacity Reservations, refer to this CloudFormation template and its accompanying README file for details on how to spin up the solution that we’re using. The README also contains more information about the Stack architecture. Upon successful creation, you have the following architecture running in your account.

Note that the default instance type for the AWS CloudFormation stack has been downgraded to t2.micro to keep our experiment within the AWS Free Tier.
Now we have a fully functioning solution with Reserved Capacity dedicated to this specific Auto Scaling Group. However, we haven’t tested it yet.
The tests utilize the AWS Command Line Interface (AWS CLI), which we execute using AWS CloudShell.
To interact with the resources created by CloudFormation, we need some names and IDs that have been collected in the “Outputs” section of the stack. These can be accessed from the console in a tab under the Stack that you have created.

We set these as variables for easy access later (replace the values with the values from your stack):
export AUTOSCALING_GROUP_NAME=ASGWithODCRs-CapacityBackedASG-13IZJWXF9QV8E export SUBNET_FOR_MANUALLY_ADDED_INSTANCE=subnet-03045a72a6328ef72 export SUBNETS_TO_KEEP=subnet-03045a72a6328ef72,subnet-0fd00353b8a42f251
First, let’s look at what happens if the Auto Scaling Group wants to Scale Out. Our requirements state that we should have a minimum of six instances running at any one time. But the solution should still adapt to increased load. Before knowing anything about how this works in AWS, imagine two scenarios:
The instances section of the Amazon EC2 Management Console can be used to show our existing Capacity Reservations, as created by the CloudFormation stack.
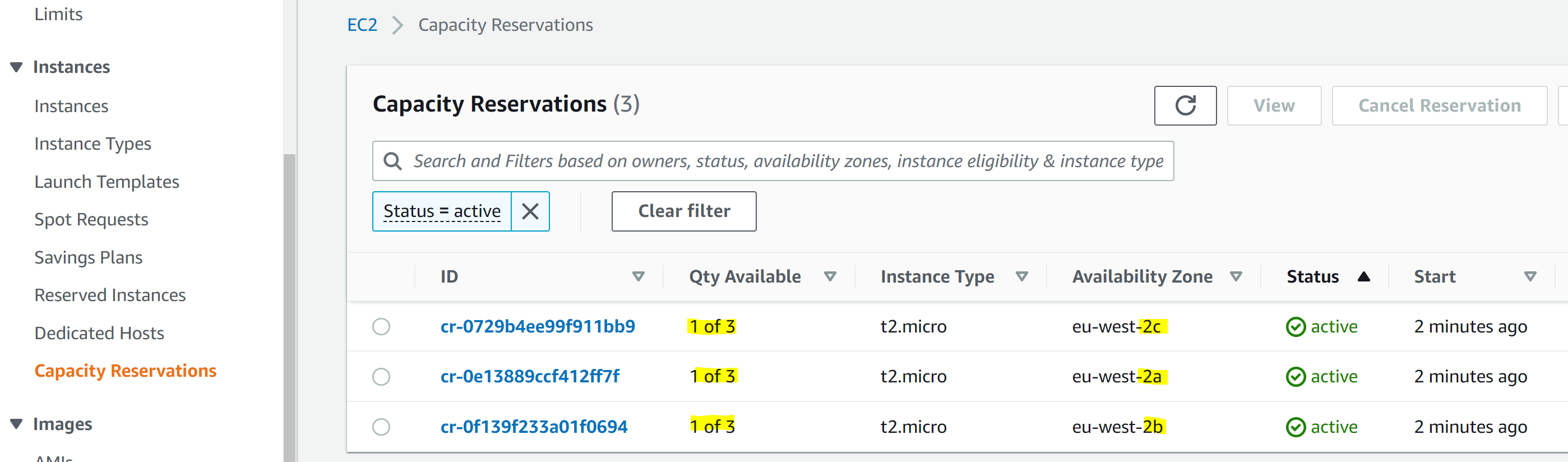
As expected, this shows that we are currently using six out of our nine On Demand Capacity Reservations, with two in each AZ.
Now let’s scale out our Auto Scaling Group to 12, thus using up all On Demand Capacity Reservations in each AZ, as well as requesting one extra Instance per AZ.
aws autoscaling set-desired-capacity \
--auto-scaling-group-name $AUTOSCALING_GROUP_NAME \
--desired-capacity 12The Auto Scaling Group now has the desired Capacity of 12:

And in the Capacity Reservation screen we can see that all our On Demand Capacity Reservations have been used up:
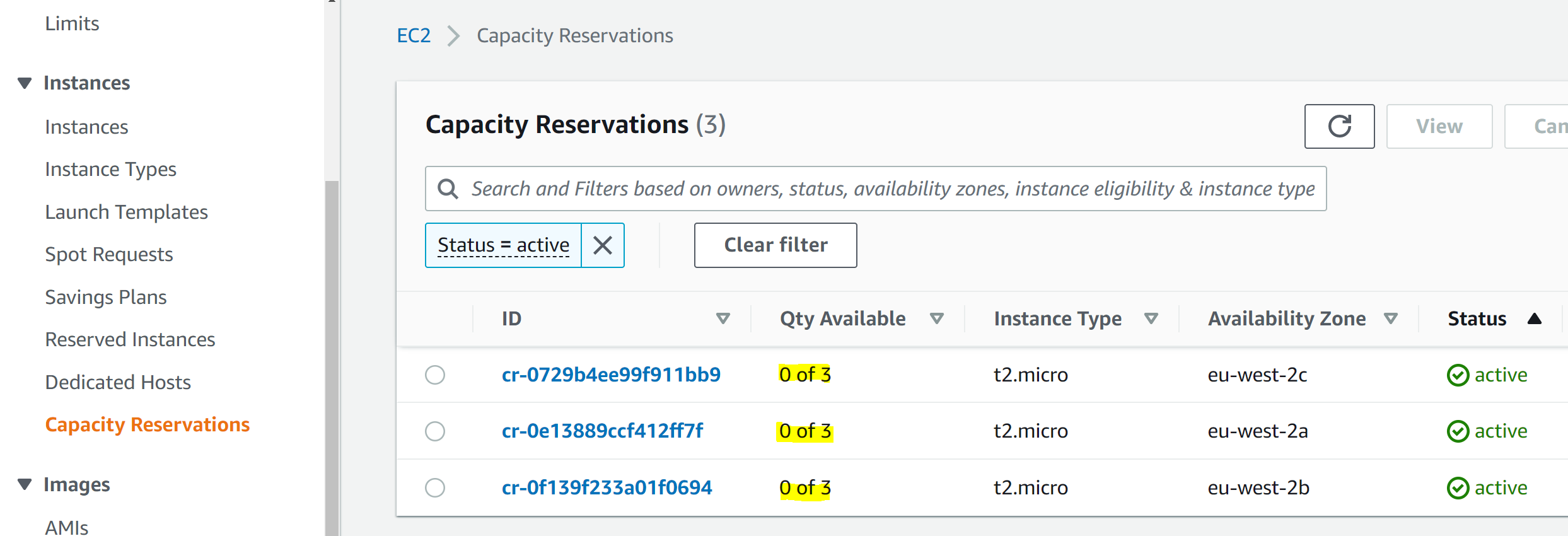
In the Auto Scaling Group we see that – as expected – we weren’t restricted to nine instances. Instead, the Auto Scaling Group fell back on launching unreserved instances when our On Demand Capacity Reservations ran out:

But what if someone else/another process in the account starts an EC2 instance of the same type for which we have the On Demand Capacity Reservations? Won’t they get that Reservation, and our Auto Scaling Group will be left short of its three instances per AZ, which would mean that we won’t have enough reservations for our minimum of six instances in case there are issues with an AZ?
This all comes down to the type of On Demand Capacity Reservation that we have created, or the “Eligibility”. Looking at our Capacity Reservations, we can see that they are all of the “targeted” type. This means that they are only used if explicitly referenced, like we’re doing in our Target Group for the Auto Scaling Group.

It’s time to prove that. First, we scale in our Auto Scaling Group so that only six instances are used, resulting in there being one unused capacity reservation in each AZ. Then, we try to add an EC2 instance manually, outside the target group.
First, scale in the Auto Scaling Group:
aws autoscaling set-desired-capacity \
--auto-scaling-group-name $AUTOSCALING_GROUP_NAME \
--desired-capacity 6

Then, spin up the new instance, and save its ID for later when we clean up:
export MANUALLY_CREATED_INSTANCE_ID=$(aws ec2 run-instances \
--image-id resolve:ssm:/aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2 \
--instance-type t2.micro \
--subnet-id $SUBNET_FOR_MANUALLY_ADDED_INSTANCE \
--query 'Instances[0].InstanceId' --output text) ![]()
We still have the three unutilized On Demand Capacity Reservations, as expected, proving that the On Demand Capacity Reservations with the “targeted” eligibility only get used when explicitly referenced:

Now we’re comfortable that the Auto Scaling Group can grow beyond the On Demand Capacity Reservations if needed, as long as there is capacity, and that other EC2 instances in our account won’t use the On Demand Capacity Reservations specifically purchased for the Auto Scaling Group. It’s time for the big test. How does it all behave when an AZ becomes unavailable?
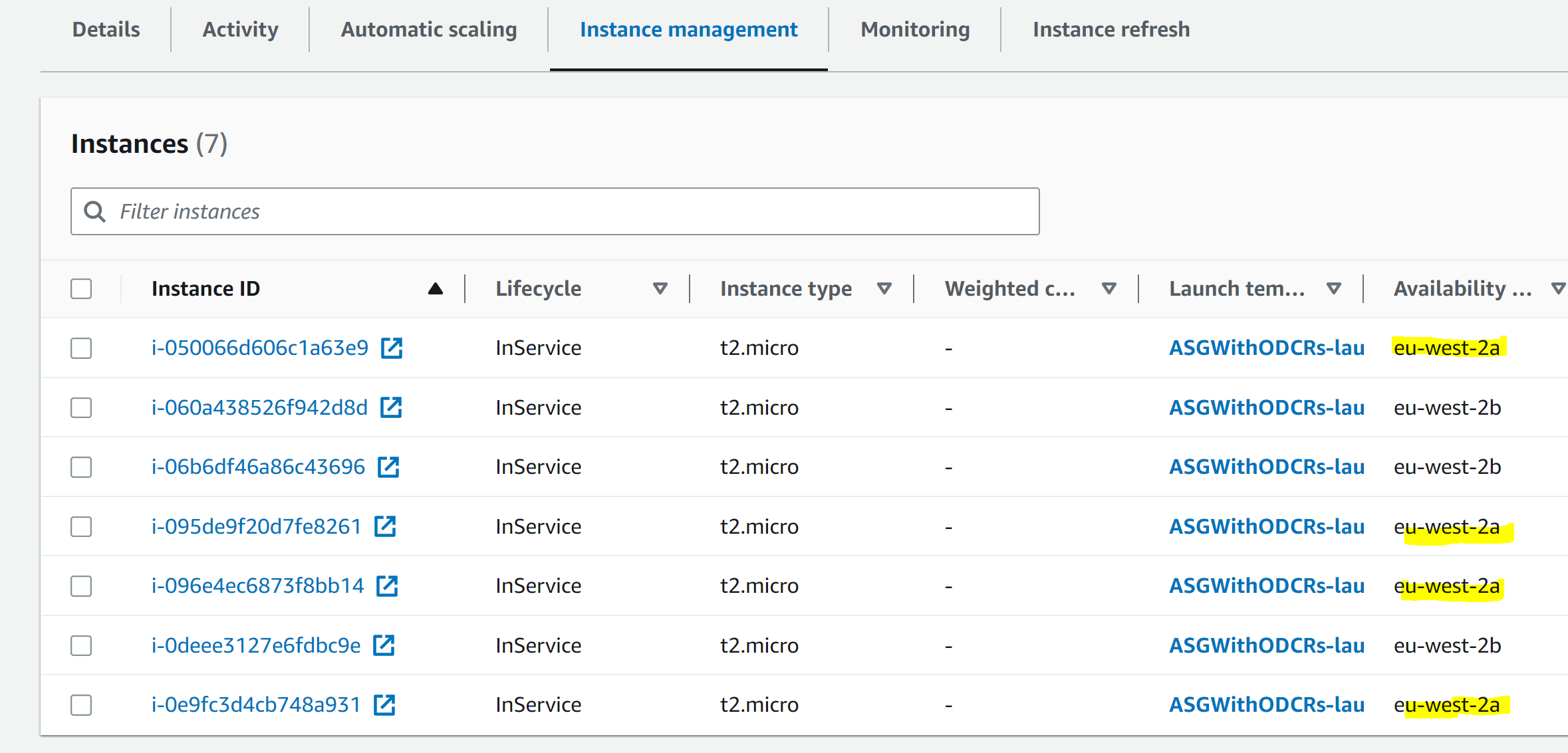
For our purposes, we can simulate this scenario by changing the Auto Scaling Group to be across two AZs instead of the original three.
First, we scale out to seven instances so that we can see the impact of overflow outside the On Demand Capacity Reservations when we subsequently remove one AZ:
aws autoscaling set-desired-capacity \
--auto-scaling-group-name $AUTOSCALING_GROUP_NAME \
--desired-capacity 7
Then, we change the Auto Scaling Group to only cover two AZs:
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name $AUTOSCALING_GROUP_NAME \
--vpc-zone-identifier $SUBNETS_TO_KEEPGive it some time, and we see that the Auto Scaling Group is now spread across two AZs, On Demand Capacity Reservations cover the minimum six instances as per our requirements, and the rest is handled by instances without Capacity Reservation:


It’s time to clean up, as those Instances and On Demand Capacity Reservations come at a cost!
aws ec2 terminate-instances --instance-ids $MANUALLY_CREATED_INSTANCE_ID
Using a combination of Auto Scaling Groups, Resource Groups, and On Demand Capacity Reservations (ODCRs), we have built a solution that provides High Availability backed by reserved capacity, for those types of workloads where the requirements for availability in the case of an AZ becoming temporarily unavailable outweigh the increased cost of reserving capacity, and where the best practices for architecting for flexibility cannot be followed due to limitations on applicable architectures.
We have tested the solution and confirmed that the Auto Scaling Group falls back on using unreserved capacity when the On Demand Capacity Reservations are exhausted. Moreover, we confirmed that targeted On Demand Capacity Reservations won’t risk getting accidentally used by other solutions in our account.
Now it’s time for you to try it yourself! Download the IaC template and give it a try! And if you are planning on using On Demand Capacity Reservations, then don’t forget to look into Savings Plans, as they significantly reduce the cost of that Reserved Capacity..
Post Syndicated from Ryan Blanchard original https://blog.rapid7.com/2023/05/23/casting-a-light-on-shadow-it-in-cloud-environments/

The term “Shadow IT” refers to the use of systems, devices, software, applications, and services without explicit IT approval. This typically occurs when employees adopt consumer products to increase productivity or just make their lives easier. This type of Shadow IT can be easily addressed by implementing policies that limit use of consumer products and services. However, Shadow IT can also occur at a cloud infrastructure level. This can be exceedingly hard for organizations to get a handle on.
Historically, when teams needed to provision infrastructure resources, this required review and approval of a centralized IT team—who ultimately had final say on whether or not something could be provisioned. Nowadays, cloud has democratized ownership of resources to teams across the organization, and most organizations no longer require their development teams to request resources in the same manner. Instead, developers are empowered to provision the resources that they need to get their jobs done and ship code efficiently.
This dynamic is critical to achieving the promise of speed and efficiency that cloud, and more specifically DevOps methodologies, offer. The tradeoff here, however, is control. This paradigm shift means that development teams are spinning up resources without the security team’s knowledge. Obviously, the adage “you can’t secure what you can’t see” comes into play here, and you’re now running blind to the potential risk that this could pose to your organization in the event it was configured improperly
Blind spots: As noted above, since security teams are unaware of Shadow IT assets, security vulnerabilities inevitably go unaddressed. Dev teams may not understand (or simply ignore) the importance of cloud security updates, patching, etc for these assets.
Unprotected data: Unmitigated vulnerabilities in these assets can put businesses at risk of data breaches or leaks, if cloud resources are accessed by unauthorized users. Additionally, this data will not be protected with centralized backups, making it difficult, if not impossible, to recover.
Compliance problems: Most compliance regulations requirements for processing, storing, and securing customers’ data. Since businesses have no oversight of data stored on Shadow IT assets, this can be an issue.
One way to address Shadow IT in cloud environments is to implement a cloud risk and compliance management platform like Rapid7’s InsightCloudSec.
InsightCloudSec continuously assesses your entire cloud environment whether in a single cloud or across multiple clouds and can detect changes to your environment—such as the creation of a new resource—in less than 60 seconds with event-driven harvesting.
The platform doesn’t just stop at visibility, however. Out-of-the-box, users get access to 30+ compliance packs aligned to common industry standards like NIST, CIS Benchmarks, etc. as well as regulatory frameworks like HIPAA, PCI DSS, and GDPR. Teams also have the ability to tailor their compliance policies to their specific business needs with custom packs that allow you to set exceptions and/or add additional policies that aren’t included in the compliance frameworks you either choose or are required to adhere to.
When a resource is spun up, the platform detects it in real-time and automatically identifies whether or not it is in compliance with organization policies. Because InsightCloudSec offers native, no-code automation, teams are able to build bots that take immediate action whenever Shadow IT creeps into their environment by either adjusting configurations and permissions to regain compliance or even deleting the resource altogether if you so choose.
To learn more, check out our on-demand demo.
Post Syndicated from original https://lwn.net/Articles/932215/
At the 2023 Linux Storage, Filesystem,
Memory-Management and BPF Summit, Hannes Reinecke led a plenary session
ostensibly dedicated to the “limits of development”. The actual discussion
focused on the frustrations of the kernel development process as
experienced by both developers and maintainers. It is probably fair to say
that no problems were solved here, but perhaps the nature of some of the
challenges is a bit more clear.
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=s_AS7RLq_Vg
Post Syndicated from Светла Енчева original https://www.toest.bg/glavniyat-prokuror-v-dima-na-beznakazanostta/

В последните седмици не е проява на гражданска смелост да се критикува главният прокурор. Част от прокурорската колегия във Висшия съдебен съвет се обяви срещу Иван Гешев. А отявлени критици на прокурорската институция като съдийките Нели Куцкова и Мирослава Тодорова стават желани гости в телевизионните студиа. Всичко това означава, че пластовете се разместват. И е много вероятно да се окаже вярна прогнозата на Мирослава Тодорова, че Гешев, заместникът му и ръководител на следствието Борислав Сарафов, както и заместникът на Сарафов Ясен Тодоров няма да изкарат мандата си докрай.
На фона на оголването на проблемите в прокуратурата един дребен детайл остана незабелязан. Той обаче символизира цялото беззаконие на тази институция, а и в държавата изобщо. Фактът, че остана незабелязан, означава, че дотолкова сме свикнали с беззаконието, че дори не ни прави впечатление. На него обръща внимание Павел Антонов, който е журналист, социален изследовател, активен гражданин, потомък на Владимир Димитров – Майстора и стои зад гражданската мрежа Bluelink.net, както и зад инициативата „България без дим“.
Като активист срещу пушенето на обществени места, на Павел Антонов му прави впечатление, че на заседанието на ВСС на 18 май 2023 г., част от което е излъчено по новините на bTV, Иван Гешев пуши пура. А според чл. 56, ал. 2 от Закона за здравето тютюнопушенето на обособени работни места е забранено. Самото заседание се провежда онлайн, така че Гешев не опушва директно присъстващите. Той обаче вероятно е в кабинета си (ако съдим по сводестия прозорец, какъвто се отразява на публикувани в сайта на прокуратурата снимки и записи) или поне на служебно място. Публичните заседания на ВСС се излъчват на живо на сайта на институцията.
Ето защо Павел Антонов подава сигнал до институциите, които би следвало да контролират спазването на Закона за здравето. В коментарите към поста му във Facebook реакциите са различни – от поздравления, през съмнения в професионалните качества на Гешев, включително съмнения, че той си дава сметка, че е извършил нарушение, до упрек към самия Антонов – „прекален светец и Богу не е драг“.
„Тоест“ попита Павел Антонов знак за какво е фактът, че главният прокурор – т.е. човекът в България, който най-добре трябва да знае какво е нарушение на закона – си позволява да го нарушава, и то пред камера. В отговор той предложи две хипотези – безобидна и небезобидна.
Повече от 10 години след забраната на пушенето на обществени места то още се радва на широка обществена подкрепа, а нарушенията на забраната се приемат не просто като човещина, а и с криворазбран правозащитен патос. Криворазбран, защото личната свобода свършва там, където започва свободата (в случая – дихателният апарат) на другия.
„Най-безобидното би било, че [на Иван Гешев] и през ум не му минава, че прави нещо нередно“, разсъждава Антонов и прави асоциация с доскорошни статистики, с които е запознат. Според тях в повечето развити страни пушат най-вече хората с ниски приходи и образование, докато у нас – заможните и успелите.
Но не само пушенето се приема за нормално поведение в България, отбелязва Павел Антонов. Всъщност „въобще не става дума само за пушене – нарушават се всички правила. Това е състояние, обратно на върховенство на закона – подчиняване на закона. Тоест законът е нещо, което се спазва по изключение, когато някой изрично активира държавния апарат да го прилага“. Ужасяващото в конкретния случай според основателя на „България без дим“ е, че така постъпва именно човекът, от когото на теория се очаква да отстоява законността повече от всеки друг.
Това обаче все още е невинната хипотеза. След нея Антонов стига и до по-сериозната: „Страхувам се, че в случая сме свидетели на нещо по-лошо – нарушение на закона като демонстрация на власт.“ Според него тази нагласа е наследство от времето на социализма, когато „уж равноправното соцобщество се градеше на привилегии“ и както гласи старият виц, „има равни, равни и по-равни“.
Според журналиста и граждански активист този манталитет не е изкоренен: „Напротив, стремежът към власт се асоциира постоянно с достъп до някакви привилегии, които останалите нямат. Нарушението на забраната за пушене е най-лесната манифестация на този управленски манталитет. „Няма кой на мен да ми каже какво да правя, аз съм над закона, ерго, над всички останали“ е посланието, което излъчва запалената от Гешев пура.“
Към това може да се добави, че за разлика от запалването на обикновена цигара, което може да се обясни със зависимостта от никотина, пурите са символ на статус. А това допълнително усилва невербалното послание „Аз съм над закона“. Времената на Чърчил и Фидел Кастро са отдавна отминали и днес пушенето на пури се асоциира по-скоро с демонстрирането на статус по начина, по който го правят мафиотите.
Когато човекът, който според настоящата правосъдна система стои на нейния връх, си позволява публично да нарушава закона, с това той дава сигнал на всички надолу по веригата, смята Павел Антонов.
Проблемът е, че когато главният прокурор прави това, започват да го правят всички по йерархията под него. До последния редови полицай, който демонстративно си паркира патрулната кола така, че да пречи на движението. Смачкан от висшестоящите си, той също иска да покаже на някого, че има власт, че е над него.
Това е и механизмът, по силата на който непрекъснатото нарушаване на закона се е превърнало в своеобразна норма. Затова много хора най-искрено не схващат какъв пък толкова е проблемът. „Така всички живеем в постоянно беззаконие, в лепкава токсична обществена среда, в която правилата и законите важат само за „нисшите“, „балъците“, заключава Антонов.
Пушенето на работното място е закононарушение, което се наказва с глоба, но не е престъпление. Далеч по-сериозни неща са огласяването на записи от телефонни разговори, държането на дела „на трупчета“, „замитането“ на данни за престъпления „под килима“, заплашването на опоненти със съдебни дела… списъкът може да продължи още дълго.
Демонстрацията на беззаконие от страна на най-силните в правосъдната ни система съвсем не започва с Гешев. Бившият главен прокурор Иван Татарчев например се заканваше да докара от Виена несимпатично нему лице „в чувал“. Името на наследника му Иван Филчев пък се свързва с две убийства, които така и си останаха неразкрити. Има сериозни подозрения, че той е поръчител на едното от тях, както и клетвени показания на двама свидетели, че Филчев е потвърдил, че е извършил другото убийство лично.
На този фон действията на Гешев са направо кокошкарски. Но тяхната популистка нелепост е капката, която доведе законовата уредба на институцията на главния прокурор до нейния предел. И за първи път изглежда, че този път някаква смислена промяна на правосъдната система може и да се състои.
„Може“ обаче не означава непременно „ще“. Правосъдната система в България няма традиции да бъде независима. Наслояването на определени професионални стереотипи в нея няма да се разсее толкова бързо, колкото димът от пурата на Гешев. Ала дори правосъдната система да се промени, ще трябва да минат още десетилетия, за да престане да бъде законът „врата у равно поле“ за всички надолу по веригата.
Post Syndicated from original https://lwn.net/Articles/932693/
Security updates have been issued by Debian (node-nth-check), Mageia (mariadb and python-reportlab), Slackware (c-ares), SUSE (geoipupdate and qt6-svg), and Ubuntu (linux, linux-aws, linux-azure, linux-azure-5.4, linux-gcp, linux-gcp-5.4,
linux-gke, linux-gkeop, linux-hwe-5.4, linux-ibm, linux-ibm-5.4, linux-kvm, linux-bluefield, linux-gcp, linux-hwe, linux-raspi2, linux-snapdragon, and linux-gcp, linux-hwe-5.19).
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/05/credible-handwriting-machine.html
In case you don’t have enough to worry about, someone has built a credible handwriting machine:
This is still a work in progress, but the project seeks to solve one of the biggest problems with other homework machines, such as this one that I covered a few months ago after it blew up on social media. The problem with most homework machines is that they’re too perfect. Not only is their content output too well-written for most students, but they also have perfect grammar and punctuation something even we professional writers fail to consistently achieve. Most importantly, the machine’s “handwriting” is too consistent. Humans always include small variations in their writing, no matter how honed their penmanship.
Devadath is on a quest to fix the issue with perfect penmanship by making his machine mimic human handwriting. Even better, it will reflect the handwriting of its specific user so that AI-written submissions match those written by the student themselves.
Like other machines, this starts with asking ChatGPT to write an essay based on the assignment prompt. That generates a chunk of text, which would normally be stylized with a script-style font and then output as g-code for a pen plotter. But instead, Devadeth created custom software that records examples of the user’s own handwriting. The software then uses that as a font, with small random variations, to create a document image that looks like it was actually handwritten.
Watch the video.
My guess is that this is another detection/detection avoidance arms race.
![A tweet from user Leo Guinan @leo_guinan that says (I also got my AWS bill for last month and it was about 4x what I was expecting after my credits ran out, so a little more push to get paid users [laughing emoji])](https://www.backblaze.com/blog/wp-content/uploads/2023/05/5_Cloud-Credits-Tweet.png)