Last year, our team published a history of the Python GIL. We tapped two contributors, Barry Warsaw, a longtime Python core developer, and Pawel Polewicz, a backend software developer and longtime Python user, to help us write the post.
Today, Pawel is back to revisit the original inspiration for the post: the experiments he did testing different versions of Python with the Backblaze B2 CLI.
If you find the results of Pawel’s speed tests useful, sign up to get more developer content every month in our Backblaze Developer Newsletter. We’ll let Pawel take it from here.
—The Editors
I was setting up and testing a backup solution for one of my clients when I noticed a couple of interesting things I’d like to share today. I realized by using Python 3.9-nogil, I could increase I/O performance by 10x. I’ll get into the tests themselves, but first let me tell you why I’m telling this story on the Backblaze blog.
Durability: The numbers bear out that B2 Cloud Storage is reliable.
Redundancy: If the entire AWS, Google Cloud Platform (GCP), or Microsoft Azure account of one of my clients (usually a startup founder) gets hacked, backups stored in B2 Cloud Storage will stay safe.
Affordability: The price for B2 Cloud Storage is one-fifth the cost of AWS, GCP, or Azure—better than anywhere else.
Availability: You can read data immediately without any special “restore from archive” steps. Those might be hard to perform when your hands are shaking after you accidentally deleted something.
Naturally, I always want to make sure my clients can get their backup data out of cloud storage fast should they need to. This brings us to “The Experiment.”
The Experiment: Speed Testing the Backblaze B2 CLI With Different Python Versions
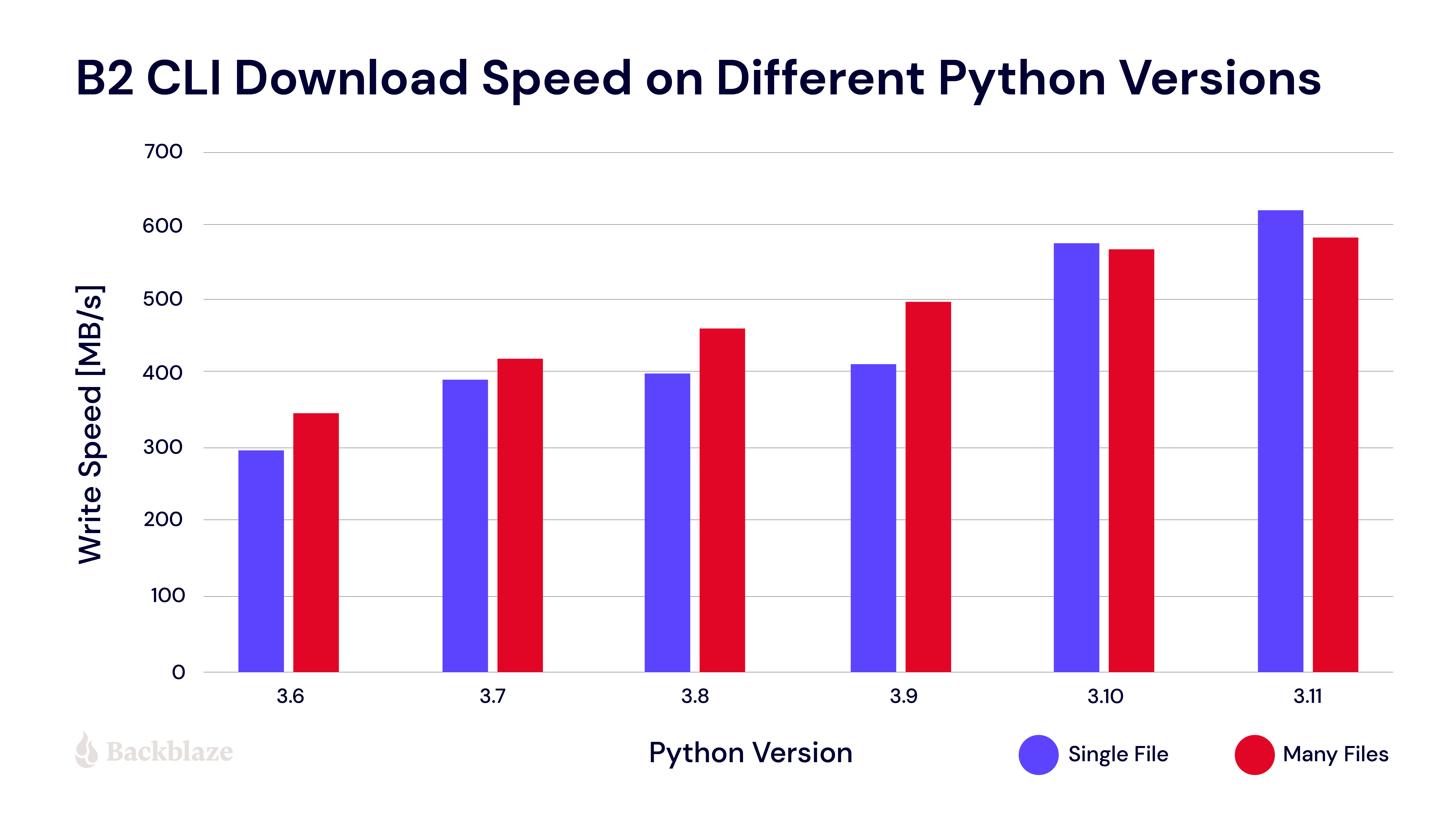
I ran a speed test to see how quickly we could get large files back from Backblaze B2 using the B2 CLI. To my surprise, I’ve found that it depends on the Python version.
The chart below shows download speeds from different Python versions, 3.6 to 3.11, for both single-file and multi-file downloads.
What’s Going On Under the Hood?
The Backblaze B2 CLI is fetching data from the B2 Cloud Storage server using Python’s Requests library. It then saves it on a local storage device using Python threads—one writer thread per file. In this type of workload, the newer versions of Python are much faster than the older ones—developers of CPython (the standard implementation of the Python programming language) have been working hard on performance for many years. CPython 3.10 had the highest performance improvement from the official releases I’ve tested. CPython 3.11 is almost twice as fast as 3.6!
Refresher: What’s the GIL Again?
GIL stands for global interpreter lock. You can check out the history of the GIL in the post from last year for a deep dive, but essentially, the GIL is a lock that allows only a single operating system thread to run the central Python bytecode interpreter loop. It serves to serialize operations involving the Python bytecode interpreter—that is, to run tasks in an order—without which developers would need to implement fine grained locks to prevent one thread from overriding the state set by another thread.
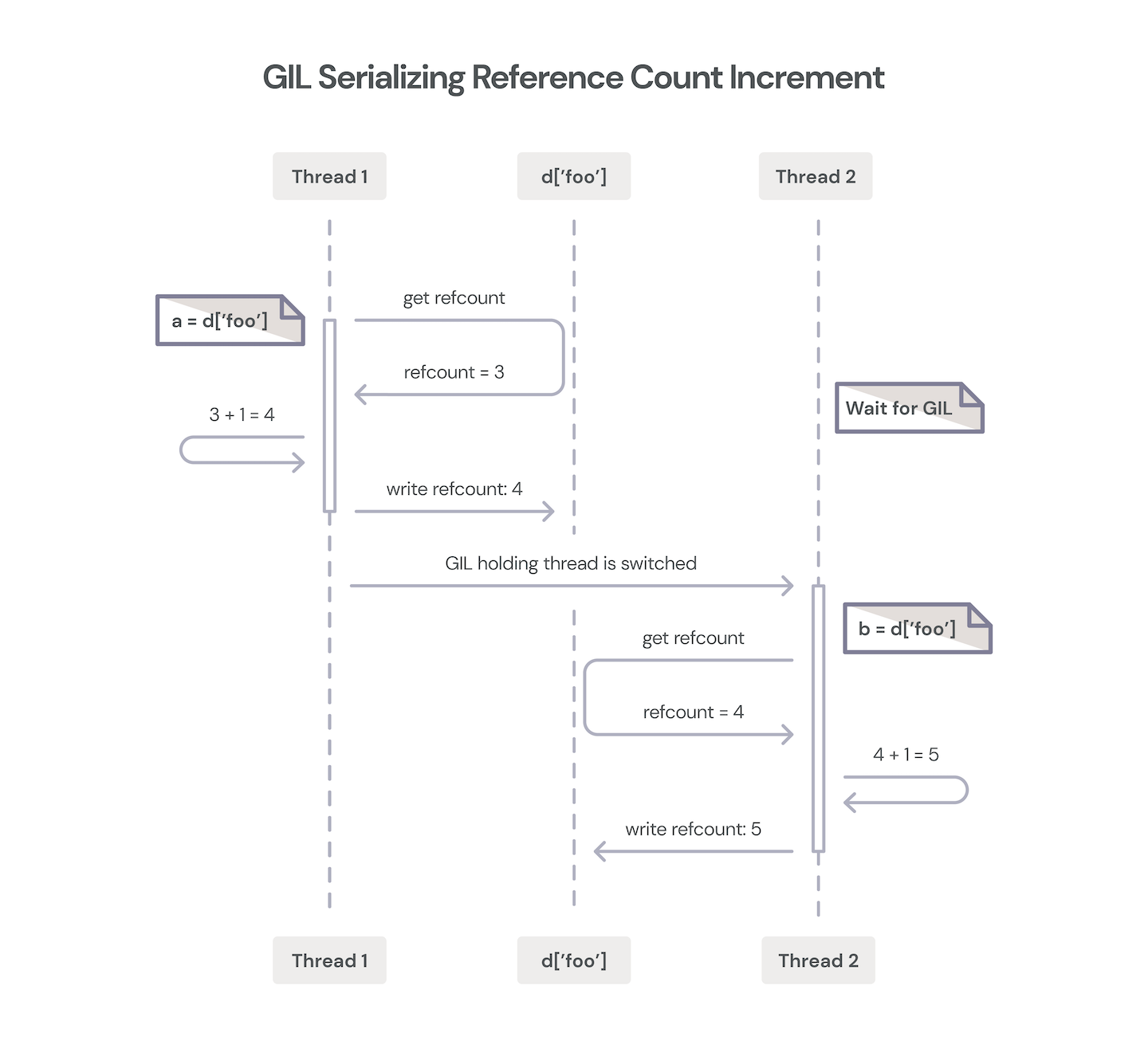
Don’t worry—here’s a diagram.
Two threads incrementing an object reference counter.
The GIL prevents multiple threads from mutating this state at the same time, which is a good thing as it prevents data corruption, but unfortunately it also prevents any Python code from running in other threads (regardless of whether they would mutate a shared state or not).
How Did “nogil” Perform?
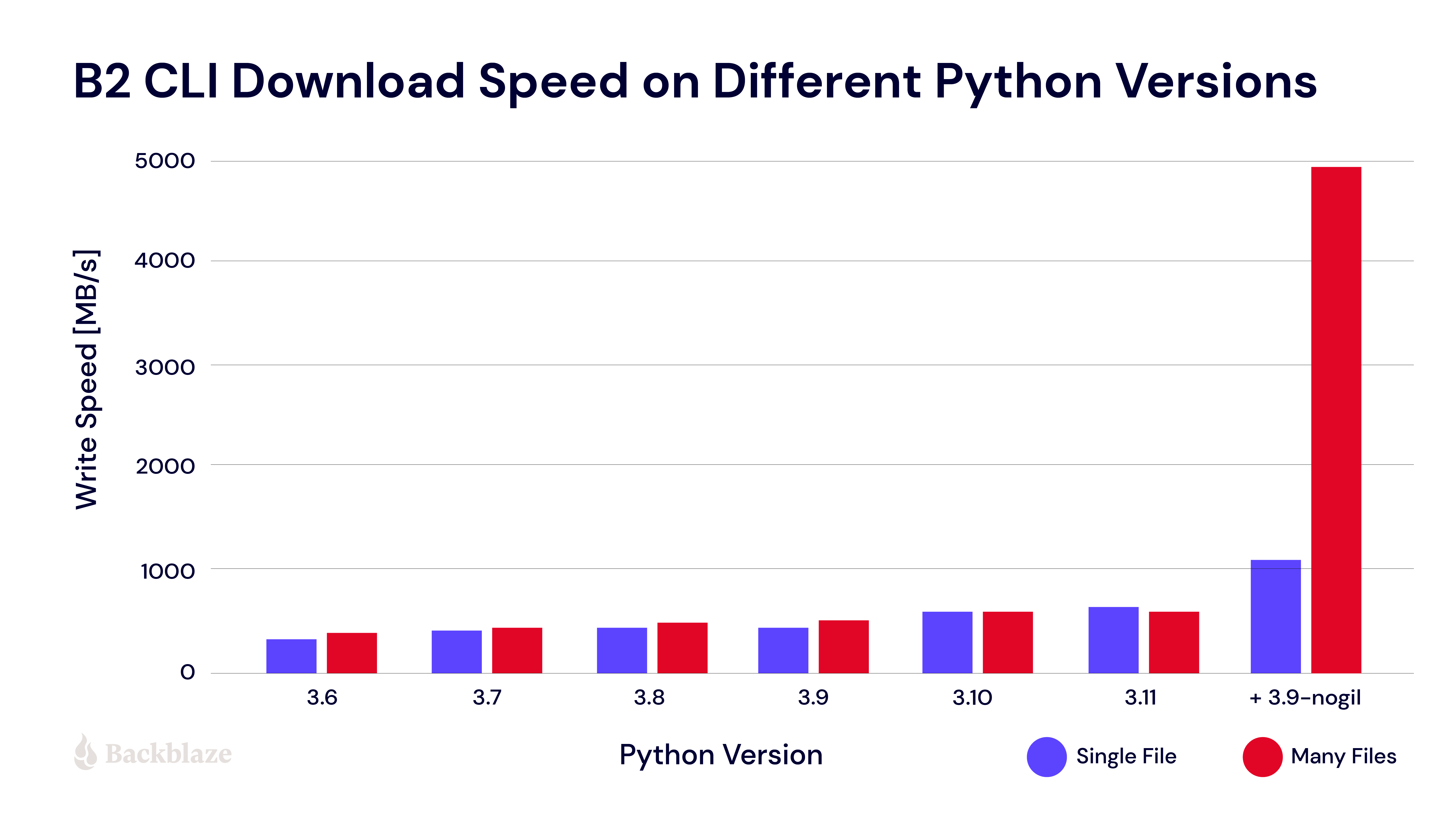
I ran one more test using the “nogil” fork of CPython 3.9. I had heard it improves performance in some cases, so I wanted to try it out to see how much faster my program would be without GIL.
The results of that test were added to the tests run on versions of unmodified CPython and you can see them below:
In this case not being limited by GIL has quite an effect! Most performance benchmarks I’ve seen show how fast the CPython test suite is, but some Python programs move data around. For this type of usage, 3.9-nogil was 2.5 or 10 times faster (for single and multiple files, respectively) on the test than unmodified CPython 3.9.
Why Isn’t nogil Even Faster?
A simple test running parallel writes on the RAID-0 array we’ve set up on an AWS EC2 i3en.24xlarge instance—a monster VM, with 96 virtual CPUs, 768 GiB RAM and 8 x 7500GB of NVMe SSD storage—shows that the bottleneck is not in userspace. The bottleneck is likely a combination of filesystem, raid driver, and the storage device. A single I/O-heavy Python process outperformed one of the fastest virtual servers you can get in 2023, and enabling nogil required just one change—the FROM line of the Dockerfile.
Why Not Use Multiprocessing?
For a single file, POSIX doesn’t guarantee consistency of writes if those are done from different threads (or processes)—that’s why the B2 Cloud Storage CLI uses a single writer thread for each file while the other threads are getting data off the network and passing it to the writer using a queue.Queue object. Using a multiprocessing.Queue in the same place results in degraded performance (approximately -15%).
The cool thing about threading is that it’s easy to learn. You can take almost any synchronous code and run it in threads in a few minutes. Using something like asyncio or multiprocessing is not so easy. In fact, whenever I tried multiprocessing, the serialization overhead was so high that the entire program slowed down instead of speeding up. As for asyncio, it won’t make Python run on 20 cores, and the cost of rewriting a program based on Requests is prohibitive. Many libraries do not support async anyway and the only way to make them work with async is to wrap them in a thread. Performance of clean async code is known to be higher than threads, but if you mix the async code with threading code, you lose this performance gain.
But Threads Can Be Hard Too!
Threads might be easy in comparison to other ways of making your program concurrent, but even that’s a high bar. While some of us may feel confident enough to go around limitations of Python by using asyncio with uvloop or writing custom extensions in C, not everyone can do that. Case in point: over the last three years I’ve challenged 1622 applicants to a senior Python backend developer job opening with a very basic task using Python threads. There was more than enough time, but only 30% of the candidates managed to complete it.
What’s Next for nogil?
On January 9, 2023, Sam Gross (the author of the nogil branch) submitted [PEP-703]—an official proposal to include the nogil mode in CPython. I hope that it will be accepted and that one day nogil will be merged into mainline, so that Python can exceed single core performance when commanded by lots of users of Python and not just those who are talented and lucky enough to be able to benefit from asyncio, multiprocessing, or custom extensions written in C.
If you already use Veeam, you’re probably familiar with using object storage, typically in the cloud, as your secondary repository using Veeam’s Scale-Out Backup Repository (SOBR). But Veeam v12, released on February 14, 2023, introduced a new direct-to-object storage feature that expands the way enterprises can use cloud storage and on-premises object storage for data protection.
Today, I’m talking through some specific use cases as well as the benefits of the direct-to-object storage feature, including fortifying your 3-2-1 backup strategy, ensuring your business is optimizing your cloud storage, and improving cyber resilience.
Meet Us at VeeamON
We hope to see you at this year’s VeeamON conference. Here are some highlights you can look forward to:
Check out our breakout session “Build a DRaaS Offering at No Extra Cost” on Tuesday, May 23, 1:30 p.m. ET to create your affordable, right-sized disaster recovery plan.
Come by the Backblaze booth for demos, swag, and more. Don’t forget to book your meeting time.
The Basics of Veeam’s Direct-to-Object Storage
Veeam’s v12 release added the direct-to-object storage feature that allows you to add object storage as a primary backup repository. This object storage can be an on-premises object storage system like Pure Storage or Cloudian or a cloud object storage provider like Backblaze B2 Cloud Storage’s S3 compatible storage. You can configure the job to run as often as you would like, set your retention policy, and configure all the other settings that Veeam Backup & Replication provides.
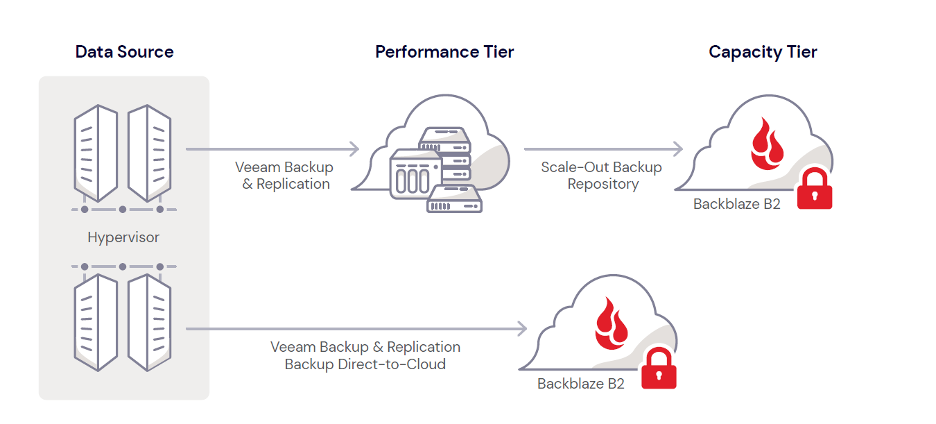
Prior to v12, you had to use Veeam’s SOBR to save data to cloud object storage. Setting up the SOBR requires you to first add a local storage component, called your Performance Tier, as a primary backup repository. You can then add a Capacity Tier where you can copy backups to cloud object storage via the SOBR. Your Capacity Tier can be used for redundancy and disaster recovery (DR) purposes, or older backups can be completely off-loaded to cloud storage to free up space on your local storage component.
The diagram below shows how both the SOBR and direct-to-object storage methods work. As you can see, with the direct-to-object feature, you no longer have to first land your backups in the Performance Tier before sending them to cloud storage.
Why Use Cloud Object Storage With Veeam?
On-premises object storage systems can be a great resource for storing data locally and achieving the fastest recoveries, but they’re expensive especially if you’re maintaining capacity to store multiple copies of your data, and they’re still vulnerable to on-site disasters like fire, flood, or tornado. Cloud storage allows you to keep a backup copy in an off-site, geographically distanced location for DR purposes.
Additionally, while local storage will provide the fastest recovery time objective (RTO), cloud object storage can be effective in the case of an on-premises disaster as it serves the dual purpose of protecting your data and being off-site.
To be clear, the addition of direct-to-object storage doesn’t mean you should immediately abandon your SOBR jobs or your on-premises devices. The direct-to-object storage feature gives you more options and flexibility, and there are a few specific use cases where it works particularly well, which I’ll get into later.
How to Use Veeam’s Direct-to-Object Storage Feature
With v12, you can now use Veeam’s direct-to-object storage feature in the Performance Tier, the Capacity Tier, or both. To understand how to use the direct-to-object storage feature to its full potential, you need to understand the implications of using object storage in your different tiers. I’ll walk through what that means.
Using Object Storage in Veeam’s Performance Tier
In earlier versions of Veeam’s backup software, the SOBR required the Performance Tier to be an on-premises storage device like a network attached storage (NAS) device. V12 changed that. You can now use an on-premises system or object storage, including cloud storage, as your Performance Tier.
So, why would you want to use cloud object storage, specifically Backblaze B2, as your Performance Tier?
Scalability: With cloud object storage as your Performance Tier, you no longer have to worry about running out of storage space on your local device.
Immutability: By enabling immutability on your Veeam console and in your Backblaze B2 account (using Object Lock), you can prevent your backups from being corrupted by a ransomware network attack like they might be if your Performance Tier was a local NAS.
Security: By setting cloud storage as your Performance Tier in the SOBR, you remove the threat of your backups being affected by a local disaster. With your backups safely protected off-site and geographically distanced from your primary business location, you can rest assured they are safe even if your business is affected by a natural disaster.
Understandably, some IT professionals prefer to keep on-premises copies of their backups because they offer the shortest RTO, but for many organizations, the pros of using cloud storage in the Performance Tier can outweigh the slightly longer RTO.
Using Object Storage in the Performance AND Capacity Tiers
If you’re concerned about overreliance on cloud storage but also feeling eager to eliminate often unwieldy, expensive, space-consuming physical local storage appliances, consider that Veeam v12 allows you to set cloud object storage as both your Performance and Capacity tier, which could add redundancy to ease your worries.
For instance, you could follow this approach:
Create a Backblaze B2 Bucket in one region and set that as your primary repository using the SOBR.
Send your Backup Jobs to that bucket (and make it immutable) as often as you would like.
Create a second Backblaze B2 account with a bucket in a different region, and set it as your secondary repository.
Create Backup Copy Jobs to replicate your data to that second region for added redundancy.
This may ease your concerns about using the cloud as the sole location for your backup data, as having two copies of your data—in geographically disparate regions—satisfies the 3-2-1 rule (since, even though you’re using one cloud storage service, the two backup copies of your data are kept in different locations.
Refresher: What is the 3-2-1 Backup Strategy?
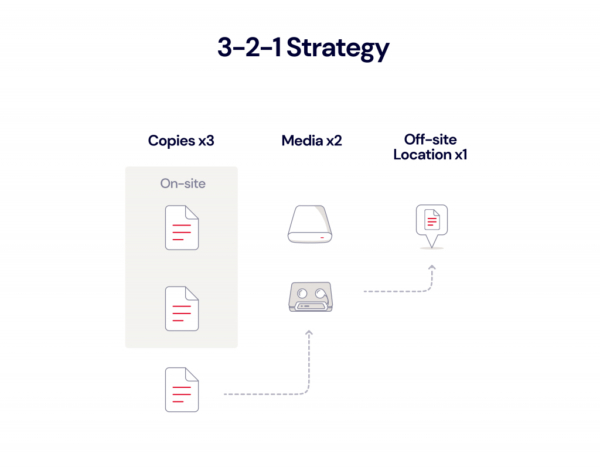
A 3-2-1 strategy means having at least three total copies of your data, two of which are local but on different media, and at least one off-site copy (in the cloud).
Use Cases for Veeam’s Direct-to-Object Storage Feature
Now that you know how to use Veeam’s direct-to-object storage feature, you might be wondering what it’s best suited to do. There are a few use cases where Veeam’s direct-to-object storage feature really shines, including:
In remote offices
For NAS backup
For end-to-end immutability
For Veeam Cloud and Service Providers (VCSP)
Using Direct-to-Object Storage in Remote Offices
The new functionality works well to support distributed and remote work environments.
Veeam had the ability to back up remote offices in v11, but it was unwieldy. When you wanted to back up the remote office, you had to back up the remote office to the main office, where the primary on-premises instance of Veeam Backup & Replication is installed, then use the SOBR to copy the remote office’s data to the cloud. This two-step process puts a strain on the main office network. With direct-to-object storage, you can still use a SOBR for the main office, and remote offices with smaller IT footprints (i.e. no on-premises device on which to create a Performance Tier) can send backups directly to the cloud.
If the remote office ever closes or suffers a local disaster, you can bring up its virtual machines (VMs) at the main office and get back in business quickly.
Using Direct-to-Object Storage for NAS Backup
NAS devices are often used as the Performance Tier for backups in the SOBR, and a business using a NAS may be just as likely to be storing its production data on the same NAS. For instance, a video production company might store its data on a NAS because it likes how easily a NAS incorporates into its workflows. Or a remote office branch may be using a NAS to store its data and make it easily accessible to the employees at that location.
With v11 and earlier versions, your production NAS had to be backed up to a Performance Tier and then to the cloud. And, with many Veeam users utilizing a NAS as their Performance Tier, this meant you had a NAS backing up to …another NAS, which made no sense.
For media and entertainment professionals in the field or IT administrators at remote offices, having to back up the production NAS to the main office (wherever that is located) before sending it to the cloud was inconvenient and unwieldy.
With v12, your production NAS can be backed up directly to the cloud using Veeam’s direct-to-object storage feature.
Direct-to-Object Storage for End-to-End Immutability
As I mentioned, previous versions of Veeam required you to use local storage like a NAS as the Performance Tier in your SOBR, but that left your data vulnerable to security attacks. Now, with direct-to-object storage functionality, you can achieve an end-to-end immutability. Here’s how:
In the SOBR, designate an on-premises appliance that supports immutability as your primary repository (Performance Tier). Cloudian and Pure Storage are popular names to consider here.
Set cloud storage like Backblaze B2 as your secondary repository (Capacity Tier).
Enable Object Lock for immutability in your Backblaze B2 account and set the date of your lock.
With this setup, you check a lot of boxes:
You fulfill a 3-2-1 backup strategy.
Both your local data and your off-site data are protected from deletion, encryption, or modification.
Your infrastructure is provisioned for the fastest RTO with your local storage.
You’ve also fully protected your data—including your local copy—from a ransomware attack.
Immutability for NAS Data in the Cloud
Backing up your NAS straight to the cloud with Veeam’s direct-to-object storage feature means you can enable immutability using the Veeam console and Object Lock in Backblaze B2. Few NAS devices natively support immutability, so using Veeam and B2 Cloud Storage to back up your NAS offers all the benefits of secure, off-site backup plus protection from ransomware.
Direct-to-Object Storage for VCSPs
The direct-to-object storage feature also works well for VCSPs. It changes how VCSPs use Cloud Connect, Veeam’s offering for service partners. A VCSP can send customer backups straight to the cloud instead of first sending them to the VCSP’s own systems.
Veeam V12 and Cyber Resiliency
When it comes to protecting your data, ultimately, you want to make the decision that best meets your business continuity and cyber resilience requirements. That means ensuring you not only have a sound backup strategy, but that you also consider what your data restoration process will look like during an active security incident (because a security incident is more likely to happen than not).
Veeam’s direct-to-object storage feature gives you more options for establishing a backup strategy that meets your RTO and DR requirements while also staying within your budget and allowing you to use the most optimal and preferred kind of storage for your use case.
Veeam + Backblaze: Now Even Easier
Get started today for $5/TB per month, pay-as-you-go cloud storage. Or contact your favorite reseller, like CDW or SHI to purchase Backblaze via B2 Reserve, our all-inclusive, capacity-based bundles.
There’s no doubt we’re living in the era of big data. And, as the amount of data we generate grows exponentially, organizing it becomes all the more challenging. If you don’t organize the data well, especially if it resides in cloud storage, it becomes complex to track, manage, and process.
That’s why I’m sharing six strategies you can use to efficiently organize big data in the cloud so things don’t spiral out of control. You can consider how to organize data from different angles, including within a bucket, at the bucket level, and so on. In this article, I’ll primarily focus on how you can efficiently organize data on Backblaze B2 Cloud Storage within a bucket. With the strategies described here, you can consider what information you need about each object you store and how to logically structure an object or file name, which should hopefully equip you to better organize your data.
Before we delve into the topic, let me give a super quick primer on some basics of object storage. Feel free to skip this section if you’re familiar.
First: A Word About Object Storage
Unlike traditional file systems, when you’re using object storage, you have a simple, flat structure with buckets and objects to store your data. It’s designed as a key-value store so that it can scale to the internet.
There are no real folders in the object store file system. The impact of this is data is not separated into a hierarchical structure. That said, there are times that you actually want to limit what you’re querying. In that instance, prefixes provide a folder-like look and feel, which means that you can get all the benefits of having a folder without any major drawbacks. From here onwards, I’ll generally refer to folders as prefixes and files as objects.
With all that out of the way, let’s dive into the ways you can efficiently organize your data within a bucket. You probably don’t have to employ all these guidelines. Rather, you can pick and choose what best fits your requirements.
1. Standardize Object Naming Conventions
Naming conventions, simply put, are rules about what you and others within your organization name your files. For example, you might decide it’s important that the file name describes the type of file, the date created, and the subject. You can combine that information in different ways and even format pieces of information differently. For example, one employee may think it makes more sense to call a file Blog Post_Object Storage_May 6, 2023, while another might think it makes sense to call that same file Object Storage.Blog Post.05062023.
These decisions do have impact. For instance that second date format would confuse the majority of the world who uses the day/month/year format, as opposed to month/day/year as is common in the United States. . And, what if you take a different kind of object as your example, one that versioning becomes important for? When do code fixes for version 1.1.3 actually become version 1.2.0?
Simply put, having a consistent and well thought out naming convention for your objects makes life easy when it comes to organizing data. You can and should derive and follow a pattern while naming the objects. Based on your requirements, a consistent and well thought out pattern for naming your objects makes it easy to find and sort files.
2. Harness The Power of Prefixes
Prefixes provide a folder-like look and feel on object stores (as there are no real folders). The prefixes are powerful and immensely helpful while effectively organizing your data and allow you to make good use of the wildcard function in your command line interface (CLI). A good way to think about a prefix is that it creates hierarchical categories in your object name. So, if you were creating a prefix about locations and using slashes as a delimiter, you’d create something like this:
North America/Canada/British Columbia/Vancouver
Let’s imagine a scenario where you generate multiple objects per day, you can structure your data per year per month and per day. An example prefix would be year=2022/month=12/day=17/ for the multiple objects generated on December 17, 2022. If you queried for all objects created on that day, you might get results that look like this:
On the Backblaze B2 secure web application, you will notice these prefixes create “folders” three levels deep, year=2022, month=12 and day=17. The folder, day=17, will contain all the objects with the example prefix in their names. Partitioning data is helpful to easily track your data. It is also helpful in the processing workflows that use your data after storing it on Backblaze B2.
3. Programatically Separate Data
After ingesting data into B2 Cloud Storage, you may have multiple workflows to make use of data. These workflows are often tied to specific environments and in turn generate more new data. Production, staging, and test are some examples of environments.
We recommend keeping the copy of raw data and the new data generated by a specific environment separate. This lets you keep track of when and how changes were made to your datasets, which in turn means you can roll back to a native state if you need to or replicate the change if it’s producing the results you want. In occasions of undesirable events like a bug in your processing workflow, you can rerun the workflow with a fix in place on the raw copy of data. To illustrate the data specific to the production environment, an example would be /data/env=prod/type=raw, and /data/env=prod/type=new.
4. Leverage Lifecycle Rules
While your data volume is ever increasing, we recommend reviewing and cleaning up unwanted data from time to time. Doing that process manually is very cumbersome, especially when you have large amounts of data. Never fear: Lifecycle rules to the rescue. You can set up lifecycle rules to automatically hide or delete data based on a certain criteria which you can configure on Backblaze B2.
For example, some workflows create temporary objects during processing. It’s useful to briefly retain these temporary objects to diagnose issues, but they have no long-term value. A lifecycle rule could specify that objects with the /tmp prefix are to be deleted two days after they are created.
5. Enable Object Lock
Object Lock makes your data immutable for a specified period of time. Once you set that period of time, even the data owner can’t modify or delete the data. This helps to prevent an accidental overwrite of your data, creates trusted backups, and so on.
Let’s imagine a scenario where you upload data to B2 Cloud Storage and run a workflow to process the data which in turn generates new data, and use our production, staging, and test example again. Due to a bug, your workflow tries to overwrite your raw data. When you have Object Lock set, the rewrite won’t happen, and your workflow will likely error out.
6. Customize Access With Application Keys
There are two types of application keys on B2 Cloud Storage:
Your master application key. This is the first key you have access to and is available on the web application. This key has all capabilities, access to all buckets, and has no file prefix restrictions or expiration. You only have one master application key—if you generate a new one, your old one becomes invalid.
Non-master application key(s). This is every other application key. They can be limited to a bucket, or even files within that bucket using prefixes, can set read-only, read-write, or write-only access, and can expire.
That second type of key is the important one here. Using application keys, you can grant or restrict access to data programmatically. You can make as many application keys in Backblaze B2 as you need (the current limit is 100 million). In short: you can get detailed in customizing access control.
In any organization, it’s always best practice to only grant users and applications as much access as they need, also known as the principle of least privilege. That rule of thumb reduces risk in security situations (of course), but it also reduces the possibility for errors. Extend this logic to our accidental overwrite scenario above: if you only grant access to those who need to (or know how to) use your original dataset, you’re reducing the risk of data being deleted or modified inappropriately.
Conversely, you may be in a situation where you want to grant lots of people access, such as when you’re creating a cell phone app, and you want your customers to review it (read-only access). Or, you may want to create an application key that only allows someone to upload data, not modify existing data (write-only access), which is useful for things like log files.
And, importantly, this type of application key can be set to expire, which means that you will need to actively re-grant access to people. Making granting access your default (as opposed to taking away access) means that you’re forced to review and validate who has access to what at regular intervals, which in turn means you’re less likely to have legacy stakeholders with inappropriate access to your data.
Two great places to start here are restricting the access to specific data by tying application keys to buckets and prefixes and restricting the read and write permissions of your data. You should think carefully before creating an account-wide application key, as it will have access to all of your buckets, including those that you create in the future. Restrict each application key to a single bucket wherever possible.
What’s Next?
Organizing large volumes by putting some guidelines into practice can make it easy to store your data. Pick and choose the ones that best fit your requirements and needs. So far, we have talked about organizing the data within a bucket, and, in the future, I’ll provide some guidance about organizing buckets on B2 Cloud Storage.
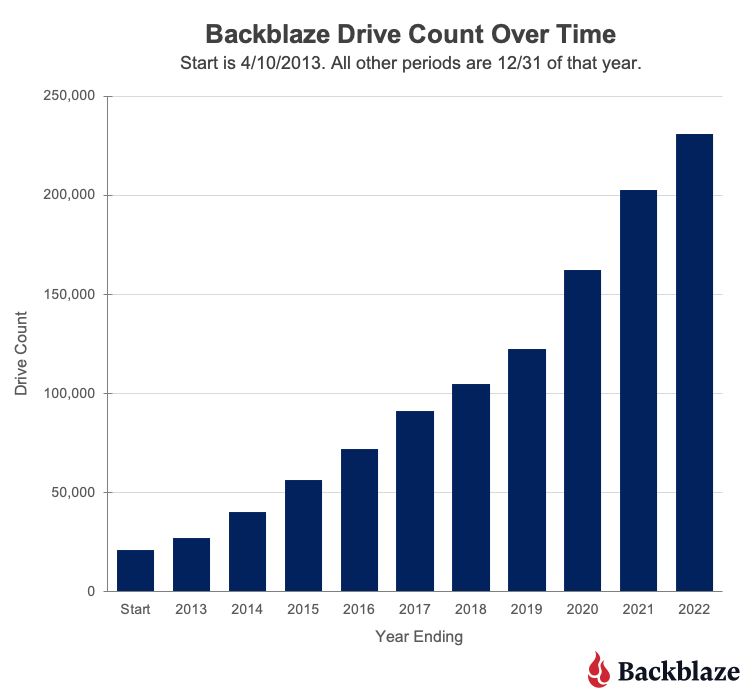
A long time ago in a galaxy far, far away, we started collecting and storing Drive Stats data. More precisely it was 10 years ago, and the galaxy was just Northern California, although it has expanded since then (as galaxies are known to do). During the last 10 years, a lot has happened with the where, when, and how of our Drive Stats data, but regardless, the Q1 2023 drive stats data is ready, so let’s get started.
As of the end of Q1 2023, Backblaze was monitoring 241,678 hard drives (HDDs) and solid state drives (SSDs) in our data centers around the world. Of that number, 4,400 are boot drives, with 3,038 SSDs and 1,362 HDDs. The failure rates for the SSDs are analyzed in the SSD Edition: 2022 Drive Stats review.
Today, we’ll focus on the 237,278 data drives under management as we review their quarterly and lifetime failure rates as of the end of Q1 2023. We also dig into the topic of average age of failed hard drives by drive size, model, and more. Along the way, we’ll share our observations and insights on the data presented and, as always, we look forward to you doing the same in the comments section at the end of the post.
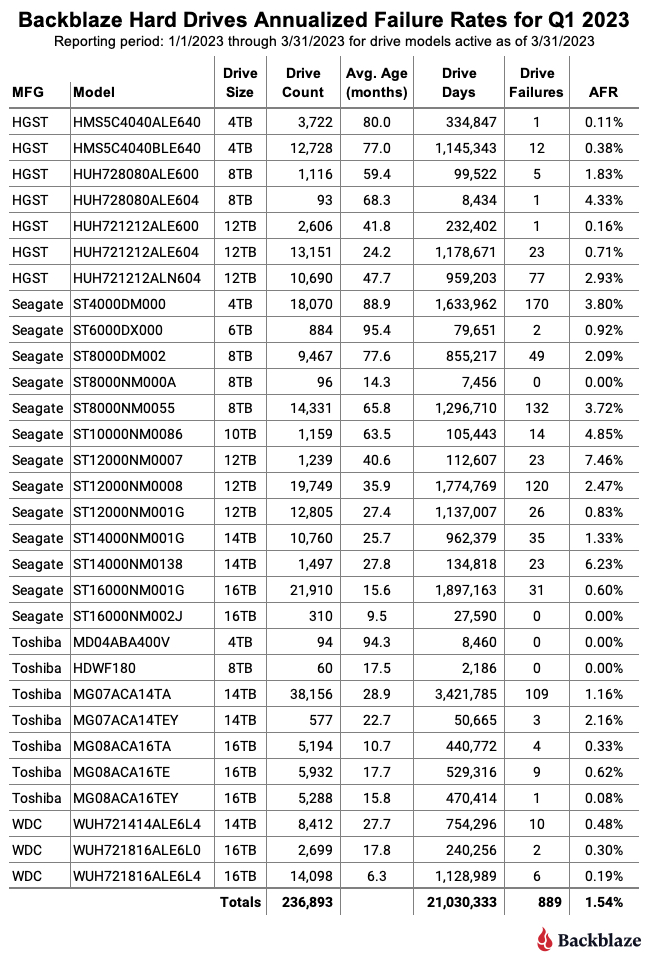
Q1 2023 Hard Drive Failure Rates
Let’s start with reviewing our data for the Q1 2023 period. In that quarter, we tracked 237,278 hard drives used to store customer data. For our evaluation, we removed 385 drives from consideration as they were used for testing purposes or were drive models which did not have at least 60 drives. This leaves us with 236,893 hard drives grouped into 30 different models to analyze.
Notes and Observations on the Q1 2023 Drive Stats
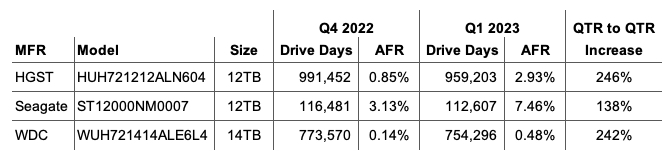
Upward AFR: The annualized failure rate (AFR) for Q1 2023 was 1.54%, that’s up from Q4 2022 at 1.21% and from one year ago, Q1 2022, at 1.22%. Quarterly AFR numbers can be volatile, but can be useful in identifying a trend which needs further investigation. For example, three drives in Q1 2023 (listed below) more than doubled their individual AFR from Q4 2022 to Q1 2023. As a consequence, further review (or in some cases continued review) of these drives is warranted.
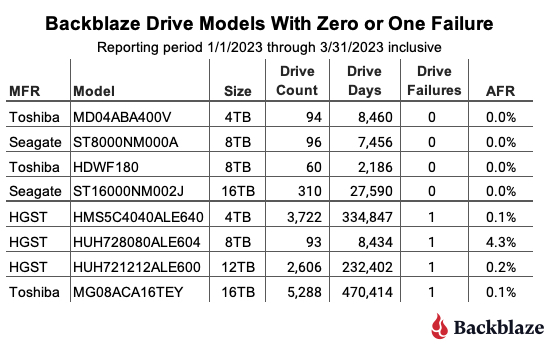
Zeroes and ones: The table below shows those drive models with either zero or one drive failure in Q1 2023.
When reviewing the table, any drive model with less than 50,000 drive days for the quarter does not have enough data to be statistically relevant for that period. That said, for two of the drive models listed, posting zero failures is not new. The 16TB Seagate (model: ST16000NM002J) had zero failures last quarter as well, and the 8TB Seagate (model: ST8000NM000A) has had zero failures since it was first installed in Q3 2022, a lifetime AFR of 0%.
A new, but not so new drive model: There is one new drive model in Q1 2023, the 8TB Toshiba (model: HDWF180). Actually, it is not new, it’s just that we now have 60 drives in production this quarter, so it makes the charts. This model has actually been in production since Q1 2022, starting with 18 drives and adding more drives over time. Why? This drive model is replacing some of the 187 failed 8TB drives this quarter. We have stockpiles of various sized drives we keep on hand for just this reason.
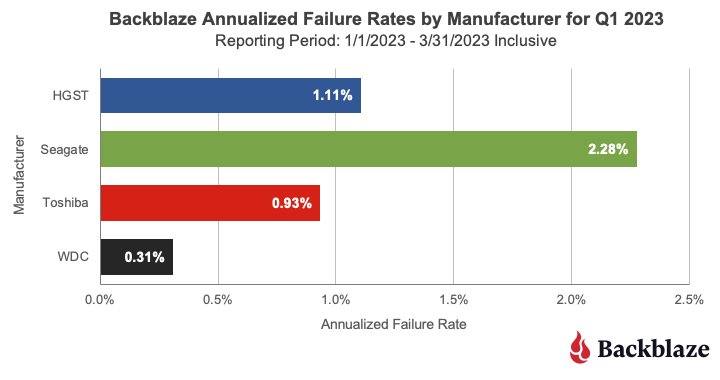
Q1 2023 Annualized Failures Rates by Drive Size and Manufacturer
The charts below summarize the Q1 2023 data first by Drive Size and then by manufacturer.
While we included all of the drive sizes we currently use, both the 6TB and 10TB drive sizes consist of one model for each and each has a limited number of drive days in the quarter: 79,651 for the 6TB drives and 105,443 for the 10TB drives. Each of the remaining drive sizes has at least 2.2 million drive days, making their quarterly annualized failure rates more reliable.
This chart combines all of the manufacturer’s drive models regardless of their age. In our case, many of the older drive models are from Seagate and that helps drive up their overall AFR. For example, 60% of the 4TB drives are from Seagate and are, on average, 89 months old, and over 95% of the 8TB drives in production are from Seagate and they are, on average, over 70 months old. As we’ve seen when we examined hard drive life expectancy using the Bathtub Curve, older drives have a tendency to fail more often.
That said, there are outliers out there like our intrepid fleet of 6TB Seagate drives which have an average age of 95.4 months and have a Q1 2023 AFR of 0.92% and a lifetime AFR of 0.89% as we’ll see later in this report.
The Average Age of Drive Failure
Recently the folks at Blocks & Files published an article outlining the average age of a hard drive when it failed. The article was based on the work of Timothy Burlee at Secure Data Recovery. To summarize, the article found that for the 2,007 failed hard drives analyzed, the average age at which they failed was 1,051 days, or two years and 10 months. We thought this was an interesting way to look at drive failure, and we wanted to know what we would find if we asked the same question of our Drive Stats data. They also determined the current pending sector count for each failed drive, but today we’ll focus on the average age of drive failure.
Getting Started
The article didn’t specify how they collected the amount of time a drive was operational before it failed but we’ll assume they used the SMART 9 raw value for power-on hours. Given that, our first task was to round up all of the failed drives in our dataset and record the power-on hours for each drive. That query produced a list of 18,605 drives which failed between April 10, 2013 and March 30, 2023, inclusive.
For each failed drive we recorded the date, serial_number, model, drive_capacity, failure, and SMART 9 raw value. A sample is below.
To start the data cleanup process, we first removed 1,355 failed boot drives from the dataset, leaving us with 17,250 data drives.
We then removed 95 drives for one of the following reasons:
The failed drive had no data recorded or a zero in the SMART 9 raw attribute.
The failed drive had out of bounds data in one or more fields. For example, the capacity_bytes field was negative or the model was corrupt, that is unknown or unintelligible.
In both of these cases, the drives in question were not in a good state when the data was collected and as such any other data collected could be unreliable.
We are left with 17,155 failed drives to analyze. When we compute the average age at which this cohort of drives failed we get 22,360 hours, which is 932 days, or just over two years and six months. This is reasonably close to the two years and 10 months from the Blocks & Files article, but before we confirm their numbers let’s dig into our results a bit more.
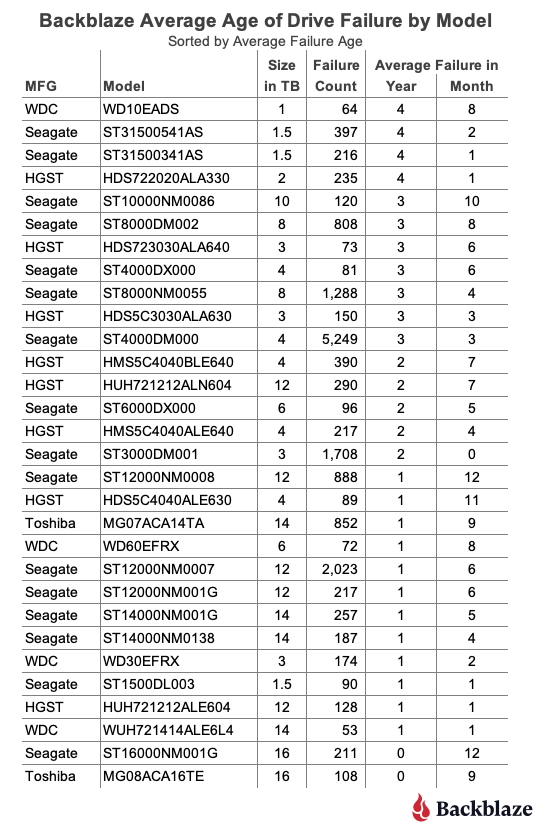
Average Age of Drive Failure by Model and Size
Our Drive Stats dataset contains drive failures for 72 drive models, and that number does not include boot drives. To make our table a bit more manageable we’ve limited the list to those drive models which have recorded 50 or more failures. The resulting list contains 30 models which we’ve sorted by average failure age:
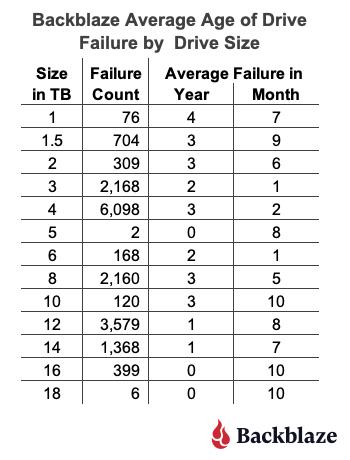
As one would expect, there are drive models above and below our overall failure average age of two years and six months. One observation is that the average failure age of many of the smaller sized drive models (1TB, 1.5TB, 2TB, etc.) is higher than our overall average of two years and six months. Conversely, for many larger sized drive models (12TB, 14TB, etc.) the average failure age was below the average. Before we reach any conclusions, let’s see what happens if we review the average failure age by drive size as shown below.
This chart seems to confirm the general trend that the average failure age of smaller drive models is higher than larger drive models.
At this point you might start pondering whether technologies in larger drives such as the additional platters, increased areal density, or even the use of helium would impact the average failure age of these drives. But as the unflappable Admiral Ackbar would say:
“It’s a Trap”
The trap is that the dataset for the smaller sized drive models is, in our case, complete—there are no more 1TB, 1.5TB, 2TB, 3TB, or even 5TB drives in operation in our dataset. On the contrary, most of the larger sized drive models are still in operation and therefore they “haven’t finished failing yet.” In other words, as these larger drives continue to fail over the coming months and years, they could increase or decrease the average failure age of that drive model.
A New Hope
One way to move forward at this point is to limit our computations to only those drive models which are no longer in operation in our data centers. When we do this, we find we have 35 drive models consisting of 3,379 drives that have a failed average age of two years and seven months.
Trap or not, our results are consistent with the Blocks & Files article as their failed average age of two years and 10 months for their dataset. It will be interesting to see how this comparison holds up over time as more drive models in our dataset finish their Backblaze operational life.
The second way to look at drive failure is to view the problem from the life expectancy point of view instead. This approach takes a page from bioscience and utilizes Kaplan-Meier techniques to produce life expectancy (aka survival) curves for different cohorts, in our case hard drive models. We used such curves previously in our Hard Drive Life Expectancy and Bathtub Curve blog posts. This approach allows us to see the failure rate over time and helps answer questions such as, “If I bought a drive today, what are the chances it will survive x years?”
Let’s Recap
We have three different, but similar, values for average failure age of hard drives, and they are as follows:
Source
Failed Drive Count
Average Failed Age
Secure Data Recovery
2,007 failed drives
2 years, 10 months
Backblaze
17,155 failed drives (all models)
2 years, 6 months
Backblaze
3,379 failed drives (only drive models no longer in production)
2 years, 7 months
When we first saw the Secure Data Recovery average failed age we thought that two years and 10 months was too low. We were surprised by what our data told us, but a little math never hurt anyone. Given we are always adding additional failed drives to our dataset, and retiring drive models along the way, we will continue to track the average failed age of our drive models and report back if we find anything interesting.
Lifetime Hard Drive Failure Rates
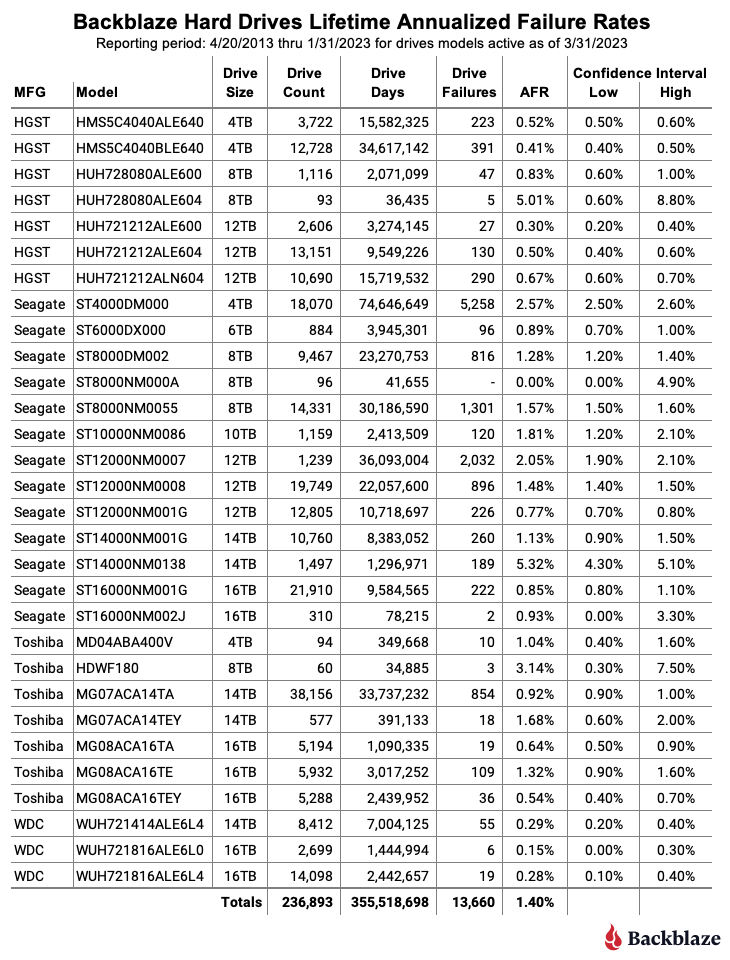
As of March 31, 2023, we were tracking 237,278 hard drives. For our lifetime analysis, we removed 385 drives that were only used for testing purposes or did not have at least 60 drives. This leaves us with 236,893 hard drives grouped into 30 different models to analyze for the lifetime table below.
Notes and Observations About the Lifetime Stats
The lifetime AFR for all the drives listed above is 1.40%. That is a slight increase from the previous quarter of 1.39%. The lifetime AFR number for all of our hard drives seems to have settled around 1.40%, although each drive model has its own unique AFR value.
For the past 10 years we’ve been capturing and storing the Drive Stats data which is the source of the lifetime AFRs listed in the table above. But, why keep track of the data at all? Well, besides creating this report each quarter, we use the data internally to help run our business. While there are many other factors which go into the decisions we make, the Drive Stats data helps to surface potential issues sooner, allows us to take better informed drive related actions, and overall adds a layer of confidence in the drive-based decisions we make.
The Hard Drive Stats Data
The complete dataset used to create the information used in this review is available on our Hard Drive Test Data page. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data to anyone; it is free.
Universities and colleges lead the way in educating future professionals and conducting ground-breaking research. Altogether, higher education generates hundreds of terabytes—even petabytes—of data. But, higher education also faces significant data risks. They are one of the most targeted industries for ransomware, with 79% of institutions reporting they were hit with ransomware in the past year.
While higher education institutions often have robust data storage systems that can even include their own off-site disaster recovery (DR) centers, cloud storage can provide several benefits that legacy storage systems cannot match. In particular, cloud storage allows schools to protect from ransomware with immutability, easily grow their datasets without constant hardware outlays, and protect faculty, student, and researchers’ computers with cloud-based endpoint backups.
Cloud storage is also a promising alternative to cloud drives, traditionally a popular option for higher education institutions. While cloud drives provide easy storage across campus, both Google and Microsoft have announced the end of their unlimited storage tiers for education. Faced with changes to the original service, many higher education institutions are looking for alternatives. Plus, cloud drives do not provide true, incremental backup, do not adequately protect from ransomware, and have limited options for recovery.
Ultimately, cloud storage better protects your school from local disasters and ransomware with a secure, off-site copy of your data. And, with the right cloud service provider, it can be much more affordable than you think. In this article, we’ll look at the benefits of cloud storage for higher education, study some popular use cases, and explore best practices and provisioning considerations.
The Benefits of Cloud Storage in Higher Education
Cloud storage solutions present a host of benefits for organizations in any industry, but many of these benefits are particularly relevant for higher education institutions. Let’s take a look:
1. Enhanced Security
Higher education institutions have emerged as one of ransomware attackers’ favorite targets—63% of higher education CISOs say a cyber attack is likely within the next year. Data backups are a core part of any organization’s security posture, and that includes keeping those backups protected and secure in the cloud. Using cloud storage to store backups strengthens backup programs by keeping copies off-site and geographically distanced, which adheres to the 3-2-1 backup strategy (more on that later). Cloud storage can also be made immutable using tools like Object Lock, meaning data can’t be modified or deleted. This feature is often unavailable in existing data storage hardware.
2. Cost-Effective Storage
Higher education generates huge volumes of data each year. Keeping costs low without sacrificing in other areas is a key priority for these institutions, across both active data and archival data stores. Cloud storage helps higher education institutions use their storage budgets effectively by not paying to provision and maintain on-premises infrastructure they don’t need. It can also help higher education institutions migrate away from linear tape-open (LTO) which can be costly to manage.
3. Improved Scalability
As digital data continues to grow, it’s important for those institutions to be able to easily scale with their storage needs. Cloud storage allows higher education institutions to avoid potentially over-provisioning infrastructure with the ability to affordably tier off data to the cloud.
4. Data Accessibility
Making data easily accessible is important for many aspects of higher education. From the impact of scientific researchers to the ongoing work of attracting students to the university, the increasing quantities of data that higher education creates needs to be easy to access, use, and manage. Cloud storage makes data accessible from anywhere, and with hot cloud storage, there are no access delays like there can be with cold cloud storage or LTO tape.
5. Supports Cybersecurity Insurance Requirements
It’s increasingly common to utilize cyber insurance to offset potential liabilities incurred by a cyber attack. Many of those applications ask if the covered entity has off-site backups or immutable backups. Sometimes they even specify the backup has to be held somewhere other than the organization’s own locations. (We’ve seen other organizations outside of higher ed adding cloud storage for this reason as well). Cloud storage provides a pathway to meeting cyber insurance requirements universities may face.
How Higher Ed Institutions Can Use Cloud Storage Effectively
There are many ways higher education institutions can make effective use of cloud storage solutions. The most common use case is cloud storage for backup and archive systems. Transitioning from on-premises storage to cloud-based solutions—even if an organization is only transitioning a part of their total data footprint while retaining on-premises systems—is a powerful way for higher education institutions to protect their most important data. To illustrate, here are some common use cases with real-life examples:
LTO Replacement
It’s no surprise that maintaining tape is a pain. While it’s the only true physical air-gap solution, it’s also a time suck, and those are precious hours that your IT team should be spending on strategic initiatives. This is particularly applicable in projects that generate huge amounts of data, like scientific research. Cloud storage provides the same off-site protection as LTO with far fewer maintenance hours.
Off-Site Backups
As mentioned, higher ed institutions often keep an off-site copy of their data, but it’s commonly a few miles down the road—perhaps at a different branch’s campus. Transitioning to cloud storage allowed Coast Community College District (CCCD) to quit chauffeuring physical tapes to an off-site backup center about five miles away and instead implement a virtualized, multi-cloud solution with truly geographically distanced backups.
Protection From Ransomware
A ransomware attack is not a matter of if, but when. Cloud storage provides immutable ransomware protection with Object Lock, which creates a “virtual” air gap. Pittsburg State University, for example, leverages cloud storage to protect university data from ransomware threats. They strengthened their protection four-fold by adding immutable off-site data backups, and are now able to manage data recovery and data integrity with a single robust solution (that doesn’t multiply their expenses).
Computer Backup
While S3 compatible object storage provides a secure destination for data from servers, virtual machines (VMs), and network attached storage (NAS), it’s important to remember to back up faculty, staff, student, and researchers’ computers as well. Workstation backup is particularly important for organizations that are leveraging cloud drives, as these platforms are only designed to capture data stored in their respective clouds, leaving local files vulnerable to loss. But, one thing you don’t want is a drain on your IT resources—you want a solution that’s easy to implement, easy to manage ongoing, and simple enough to serve users of varying tech savviness.
Best Practices for Data Backup and Management in the Cloud
Higher education institutions (and anyone, really!) should follow basic best practices to get the most out of their cloud storage solutions. Here are a few key points to keep in mind when developing a data backup and management strategy for higher education:
The 3-2-1 Backup Strategy
This widely accepted foundational structure recommends keeping three copies of all important data (one primary copy and two backup copies) on two different media types (to diversify risk) and storing at least one copy off-site. While colleges and universities frequently have high-capacity data storage systems, they don’t always adhere to the 3-2-1 rule. For instance, a school may have an off-site disaster recovery site, but their backups are not on two different media types. Or, they may be meeting the two-media-type rule but their media are not wholly off-site. Keeping your backups at a different campus location does not constitute a true off-site backup if you’re in the same region, for instance—the closer your data storage sites are, the more likely they’ll be subject to the same risks, like network outages, natural disasters, and so on.
Regular Data Backups
You’re only as strong as your last backup. Maintaining a frequent and regular backup schedule is a tried and true way to ensure that your institution’s data is as protected as possible. Schools that have historically relied on Google Drive, Dropbox, OneDrive, and other cloud drive systems are particularly vulnerable to this gap in their data protection strategy. Cloud drives provide sync functionality; they are not a true backup. While many now have the ability to restore files, restore periods are limited and not customizable and services often only back up certain file types—so, your documents, but not your email or user data, for instance. Especially when you’re talking about larger organizations with complex file management and high compliance needs, they don’t provide adequate protection from ransomware. Speaking of ransomware…
Ransomware Protection
Educational institutions (including both K-12 and higher ed) are more frequently targeted by ransomware today than ever before. When you’re using cloud storage, you can enable security features like Object Lock to offer “air gapped” protection and data immutability in the cloud. When you add endpoint backup, you’re ensuring that all the data on a workstation is backed up—closing a gap in cloud drives that can leave certain types of data vulnerable to loss.
Disaster Recovery Planning
Incorporating cloud storage into your disaster recovery strategy is the best way to plan for the worst. If unexpected disasters occur, you’ll know exactly where your data lives and how to restore it so you can get back to work quickly. Schools will often use cross-site replication as their disaster recovery solution, but such methods can fail the 3-2-1 test (see above) and it’s not a true backup since replication functions much the same way as sync. If ransomware invades your primary dataset, it can be replicated across all your copies. Cloud storage allows you to fortify your disaster recovery strategy and plug the gaps in your data protection.
Regulatory Compliance
Universities work with and store many diverse kinds of information, including highly regulated data types like medical records and research data. It’s important for higher education to use cloud storage solutions that help them remain in compliance with data privacy laws and federal or international regulations. Providers like Backblaze that frequently work with higher education institutions will usually have a HECVAT questionnaire available so you can better understand a vendor’s compliance and security stance, and they go through regular compliance audits via regulatory agencies like StateRAMP or SOC-2 certifications.
Comprehensive Protection
While it’s obvious that data systems like servers, virtual machines, and network attached storage (NAS) should be backed up, consider the other important sources of data that should be included in your protection strategy. For instance, your Microsoft 365 data should be backed up because you cannot rely on Microsoft to provide adequate backups. Under the shared responsibility model, Microsoft and other SaaS providers state that your data is your responsibility to back up—even if it’s stored on their cloud. And don’t forget about your faculty, student, staff, and researchers’ computers. These devices can hold incredibly valuable work and having a native endpoint backup solution is critical.
The Importance of Cloud Storage for Higher Education Institutions
Institutions of higher education were already on the long road toward digital transformation before the pandemic hit, but 2020 forced any reluctant parties to accept that the future was upon us. The combination of schools’ increasing quantities of sensitive and protected data and the growing threat of ransomware in the higher education space reinforce the need for secure and robust cloud storage solutions. As time has gone on, it’s clear that the diverse needs of higher education institutions need flexible, scalable, affordable solutions, and that current and legacy solutions have room for improvement.
Universities that leverage best practices like designing 3-2-1 backup strategies, conducting frequent and regular backups, and developing disaster recovery plans before they’re needed will be well on their way toward becoming more modern, digital-first organizations. And with the right cloud storage solutions in place, they’ll be able to move the needle with measurable business benefits like cost effectiveness, data accessibility, increased security, and scalability.
If you’ve been considering building a website, you’ve probably at least thought about using WordPress. It’s a free, open-source content management system (CMS) with a seemingly endless library of templates and plugins that allow you to easily customize your website, even if you’re not a savvy web designer—and it’s responsible for powering millions of websites.
Today, we’re digging into how to back up WordPress, including what you should be backing up, how you should be backing up, and where you should be storing those backups.
And, once you’ve gone through the trouble of building a website, all sorts of things can happen—accidental deletions, server errors, cyberattacks: the list goes on. No matter the size of your business or blog, you never want to be in the position where you lose data. Backups are an essential safeguard to protect one of your most important tools.
What’s the Diff: WordPress.org vs. WordPress.com
If you decide to build in WordPress, you might get confused by the fact that there are two related websites separated by a measly domain suffix. Once you jump into each website, you’ll even see that WordPress.com was created by a company with the same founder as WordPress.org. So, what gives? Which makes more sense for you to use?
This article will take you in-depth about all the differences between the two options, but here’s the short list of the most important info.
WordPress.org
Pro: Your site is more customizable, you can add your own analytics, and you can monetize your website.
Con: You’re responsible for your own hosting, backups, and, after you download WordPress, your own updates as well.
WordPress.com
Pro: It’s designed to be plug-and-play for less experienced users. You choose your pricing tier, and you don’t have to worry about backups and hosting.
Cons: You have far more limited options for customization (themes and plugins), and you can’t sell ads on your own site. You also can’t create e-commerce or membership sites.
Hosting and backups may sound intimidating, but they’re fairly easy to handle once you’ve got them set up—not to mention that many folks prefer not to outsource two things that are so central to website security concerns, continuity (you don’t want someone else to own your domain name!), and customer or community data, if you happen to store that. So, for the purposes of this article, when we say “WordPress,” we mean WordPress.org.
Now, let’s dive in to how to back up your site.
What to Back Up
There are two main components to your website: the files and the database.
Files are WordPress core files, plugins, theme files, uploaded images and files, code files, and static web pages.
The database contains everything else, like user information, posts, pages, links, comments, and other types of user-generated content.
Basically, the database contains your posts and lots of information created on your site, but it doesn’t include all the building blocks that create the look of your site or the backend information of your site. If you use restoring your computer as an analogy, your files are your photos, Word docs, etc., and your database includes things like your actual Word program, your login info, and so on.
Most of the services you use to host your website (like GoDaddy or Bluehost) will back up the entire server (read: both your files and your database), but it takes time to request a copy of your whole site. So, you’ll want to make sure you back up your data as well.
How to Back Up Your WordPress Files
Your hosting service may have programs or services you can use to back up, so make sure you check with them first. You’ll also want to make sure your site is syncing between your server and a second location, like a hard drive (HDD) or a network attached storage (NAS) device.
But, since syncing is not the same as back up, you’ll also want to periodically download and save your files. WordPress recommends using FTP Clients or UNIX Shell Skills to copy these files onto your computer. Unless you’re familiar with command line interface (CLI), you’ll probably find FTP Clients easier to deal with.
How to Back Up Your WordPress Database
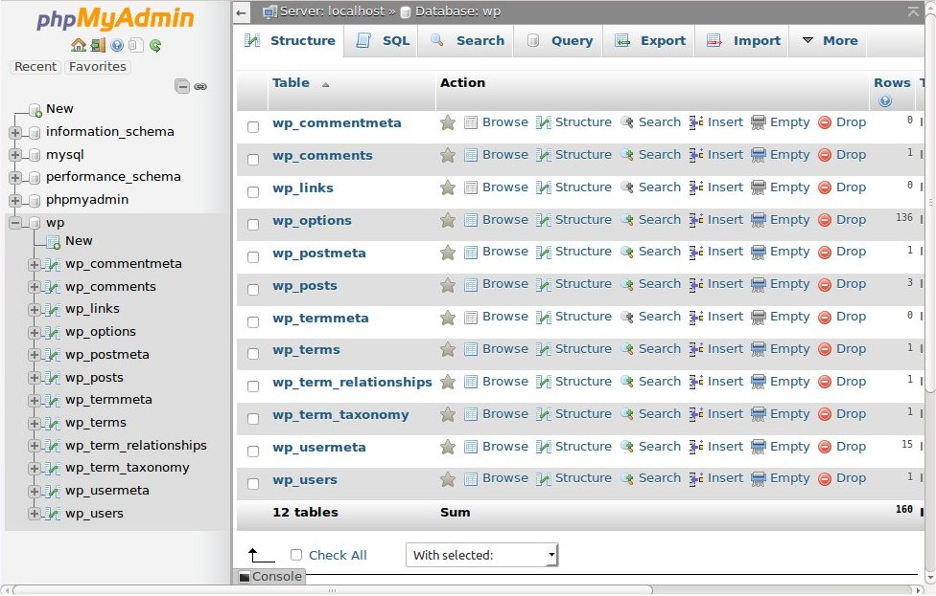
The simplest way to backup your database is with phpMyAdmin. Once you find out how to access your site’s phpMyAdmin, just follow these steps to back up.
Click on Databases in your phpMyAdmin panel. (Sometimes you won’t have to do this, depending on your version of phpMyAdmin.)
You might have several databases, but click the database you created when you installed WordPress.
In the structure view, you’ll see something like this:
Click Export. You can choose Quick or Custom.
If you’re not familiar with SQL tables, select the Quick option. Then, choose SQL from the dropdown menu. (This is the default format used to import and export MySQL databases, and most systems support it.) Then, click Go.
If you want more control over the backup process, click Custom. Then, you’ll want to follow these steps:
In the Output section, choose Save output to a file. Then, decide if you want to compress your files or not.
Select SQL from the Format menu.
Choose Add DROP TABLE, which is useful for overwriting an existing database.
Choose IF NOT EXISTS, which prevents errors if the table is already in your back up or exported file.
Click Go.
With that, the data will be stored on your computer.
That Was a Lot. Is There an Easier Way?
Sure is. One of the reasons that people love WordPress so much is that there are a ton of plugins you can choose to handle tasks just like backing up. You can find those plugins in the Plugin Browser on the WordPress Admin screens or through the WordPress Plugin Directory.
Often, those plugins also allow you to automate your back ups—which is important when you’re thinking about how often to back up, and creating a redundant backup strategy. Make sure you’re backing up regularly, and you’ll want to do this at a time when there’s minimal activity on your site.
We’ll get into more detail about choosing the correct tool for your site, as well as some plugin recommendations, a little later. But first, let’s talk about backup best practices.
The 3-2-1 Backup Strategy
When you’re thinking about when and how to back up, you need to consider a few things: what types of files you want to store, where you want to store them, and when you want to back up. We’ve already talked about what you need to back up for your WordPress site, so let’s jump into the other details.
We at Backblaze recommend a 3-2-1 backup strategy, and we’ve talked about the specifics of that strategy for both consumers and businesses. The basics of the strategy are this: Keep three copies of your data in two separate local destinations with one copy of your data offsite.
So, if you’re backing up your WordPress site, you’d want to have one copy of your files on your computer and the second on a NAS device or hard drive (for example). Then, you’d want to keep one copy elsewhere. In the old days, that meant moving LTO tapes or servers from location to location, but, of course, now we have cloud storage.
So, to answer the question of where you want to store your backups, the answer is: on multiple devices and in multiple locations. Having your off-site backup be in the cloud is valuable for a few reasons. First, there is a minimal chance of losing data due to theft, disaster, or accident. Second, cloud services are flexible, and easy to integrate with your existing tech. You can easily add or remove access to your backup data, and if you’re running a business, most include features for things like access controls.
Now that you have selected a place to store your backup data, let’s talk about when you want to back up and different tools you can use to do so.
Choosing the Right WordPress Backup Plugin
When you’re trying to decide which tool to use, you should look at a few things to make sure that the plugin fits your needs and will continue to do so long-term.
So, one of the things that you want to look at is how much customization you can do to your backups. The most important part of this is to make sure that you can schedule your backups. It’s important to set your backup time for periods of low traffic to your site. Otherwise, you run the risk of affecting how the site is working for your users (creating slowdowns), or having incomplete backups (because new information is being added at the same time you’re creating the backups).
To ensure you’re picking a tool that will be with you for the long run, it helps to look at:
The number of active installations: If there are many installations of the plugin, this would suggest that the backup plugin is popular and more likely to stay in business for the long term.
Last updated: There are lots of reasons that tools are updated, but some of the most common are to fix bugs in usage or security vulnerabilities. Cyberattacks are constantly evolving, as are programming languages and programs. If the tool hasn’t been updated in the last 12 months, it’s likely they’re not responding to those changes.
Storage support: What we mean by this is that you can choose where to save your files. That makes it easy to set different endpoints for your backups—for instance, if you want the file to save in your cloud storage provider, you’d be able to choose that.
No Time to Research? Here Are Some of Our Favorite Plugins
While many choices are available, we recommend UpdraftPlus and XCloner for WordPress backups. These plugins have an excellent track record and work well in many environments.
With this plugin, you have several options for where to store your backups, which is always a plus. They have a free version as well as several different premium options with different prices (depending on if you need to manage more sites, want included cloud storage, etc.). That means you can pilot the tool and then upgrade if you need more capability. The premium version of UpdraftPlus supports scheduled backups, offers encryption for backup, and reporting so you can track each backup.
This WordPress backup plugin lets you schedule backups, apply retention policies, and save storage space by using file compression. The best thing about XCloner? It’s free, and not just bare-bones free: they include many features you’d find in paid backup tools. And, just like UpdraftPlus, you can store your backups to the cloud.
What’s Next?
All that’s left, then, is for you to back up your site. Check out the Backblaze blog for more useful content on backup—we’ve covered backing up your site, but it’s only one piece of your overall backup strategy. If you’re a home user running your site solo, you may want to start with Backblaze Personal Backup. If you’re a business looking for backup, check out Backblaze Business Backup and Backblaze B2 Cloud Storage. And, as always, feel free to comment below with your thoughts and suggestions about what content you’d like to see.
You know you need to back up your data. Maybe you’ve developed a backup strategy and gotten the process started, or maybe you’re still in the planning phase. Now you’re starting to wonder: how long do I need to keep all these backups I’m going to accumulate? It’s the right question to ask, but the truth is there’s no one-size-fits-all answer.
How long you keep your backups will depend on your IT team’s priorities, and will include practical factors like storage costs and the operational realities that define the usefulness of each backup. Highly regulated industries like banking and healthcare have even more challenges to consider on top of that. With all that in mind, here’s what you need to know to determine how long you should keep your backups.
First Things First: You Need a Retention Policy
If you’re asking how long you should keep your backups, you’re already on your way to designing a retention policy. Your organization’s retention policy is the official protocol that will codify your backup strategy from top to bottom. The policy should not just outline what data you’re backing up and for how long, but also explain why you’ve determined to keep it for that length of time and what you plan to do with it beyond that point.
Practically speaking, the decision about how long to keep your backups boils down to a balancing act between storage costs and operational value. You need to understand how long your backups will be useful in order to determine when it’s time to replace or dispose of them; keeping backups past their viability leads to both unnecessary spend and the kind of complexity that breeds risk.
Backup vs. Archive
Disposal isn’t the only option when a backup ages. Sometimes it’s more appropriate to archive data as a long-term storage option. As your organization’s data footprint expands, it’s important to determine how you interact with different types of data to make the best decisions about how to safeguard it (and for how long).
While backups are used to restore data in case of loss or damage, or to return a system to a previous state, archives are more often used to off-load data from faster or more frequently accessed storage systems.
Backup: A data recovery strategy for when loss, damage, or disaster occurs.
Archive: A long-term or permanent data retrieval strategy for data that is not as likely to be accessed, but still needs to be retained.
Knowing archiving is an option can impact how long you decide to keep your backups. Instead of deleting them completely, you can choose to move them from short-term storage into a long-term archive. For instance, you could choose to keep more recent backups on premises, perhaps stored on a local server or network attached storage (NAS) device, and move your archives to cloud storage for long-range safekeeping.
How you choose to store your backups can also be a factor into your decision on how long to keep them. Moving archives to cloud storage is more convenient than other long-term retention strategies like tape. Keeping archives in cloud storage could allow you to keep that data for longer simply because it’s less time-consuming than maintaining tape archives, and you also don’t have to worry about the deterioration of tape over time.
Putting your archive in cloud storage can help manage the cost side of the equation, too, but only if handled carefully. While cloud storage is typically cheaper than tape archives in the long run, you might save even more by moving your archives from hot to cold storage. For most cloud storage providers, cold storage is generally a cheaper option if you’re talking dollars per GB stored. But, it’s important to remember that retrieving data from cold storage can incur high egress fees and take 12–48 hours to retrieve data. When you need to recover data quickly, such as in a ransomware attack or cybersecurity breach, each moment you don’t have your data means more time your business is not online—and that’s expensive.
How One School District Balances Storage Costs and Retention
With 200 servers and 125TB of data, Bethel School District outside of Tacoma, Washington needed a scalable cloud storage solution for archiving server backups. They’d been using Amazon S3, but high costs were straining their budget—so much so that they had to shorten needed retention periods.
Moving to Backblaze produced savings of 75%, and Backblaze’s flat pricing structure gives the school district a predictable invoice, eliminating the guesswork they anticipated from other solutions. They’re also planning to reinstate a longer retention period for better protection from ransomware attacks, as they no longer need to control spiraling Amazon S3 costs.
Next Order of Business: The Structure of Your Backup Strategy
The types of backups you’re storing will also factor into how long you keep them. There are many different ways to structure a secure backup strategy, and it’s likely that your organization will interact with each kind of backup differently. Some backup types need to be stored for longer than others to do their job, and those decisions have a lot to do with how the various types interact to form an effective strategy.
The Basics: 3-2-1
The 3-2-1 backup strategy is the widely accepted industry minimum standard. It dictates keeping three copies of your data: two stored locally (on two different types of devices) and one stored off-site. This diversified backup strategy covers all the bases; it’s easy to access backups stored on-site, while off-site (and often offline or immutable) backups provide security through redundancy. It’s probably a good idea to have a specific retention policy for each of your three backups—even if you end up keeping your two locally stored files for the same length of time—because each copy serves a different purpose in your broader backup strategy.
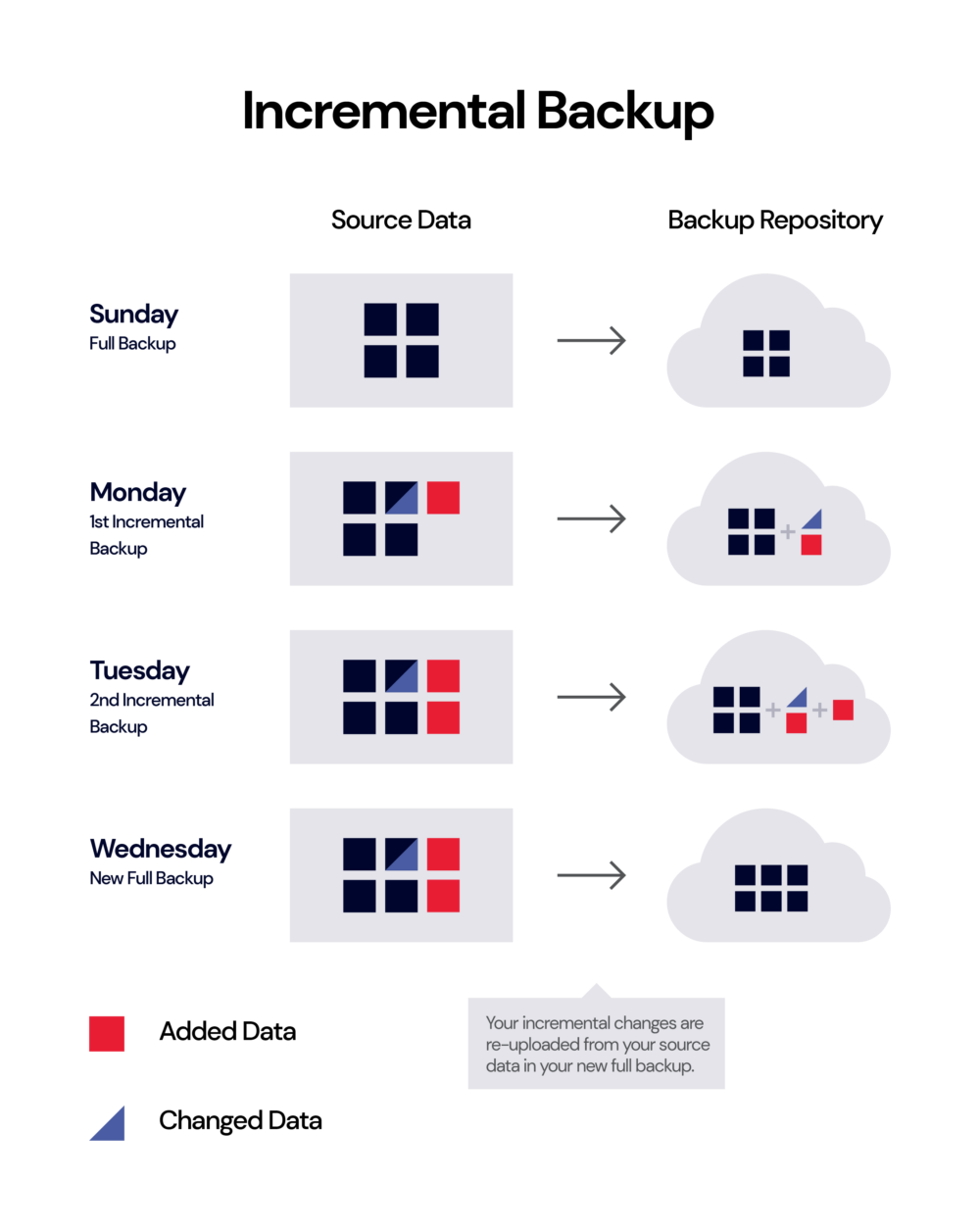
Full vs. Incremental Backups
While designing your backup strategy, you’ll also need to choose how you’re using full versus incremental backups. Performing full backups each time (like completely backing up a work computer daily) requires huge amounts of time, bandwidth, and space, which all inflate your storage usage at the end of the day. Other options serve to increase efficiency and reduce your storage footprint.
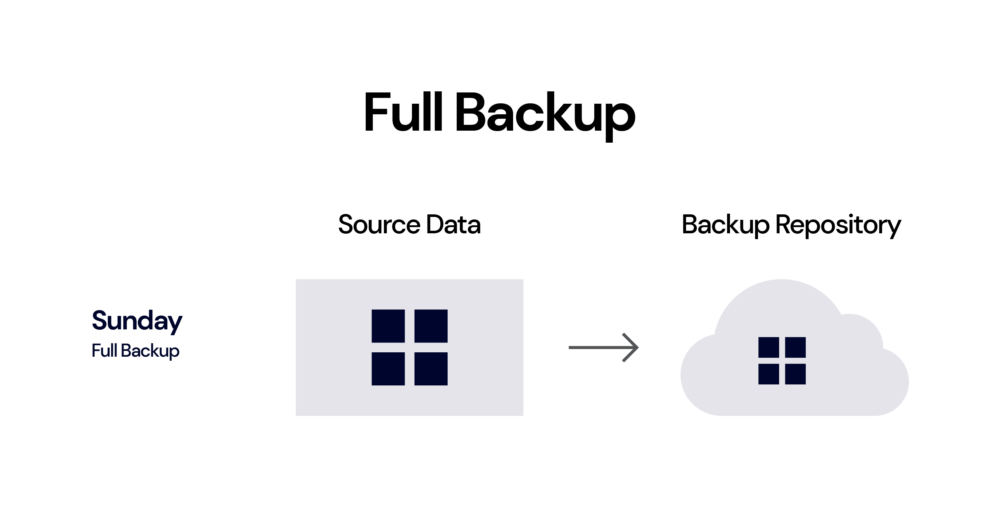
Full backup: A complete copy of your data, starting from scratch either without any pre-existing backups or as if no other backup exists yet.
Incremental backup: A copy of any data that has been added or changed since your last full backup (or your last incremental backup).
When thinking about how long to keep your full backups, consider how far back you may need to completely restore a system. Many cyber attacks can go unnoticed for some time. For instance, you could learn that an employee’s computer was infected with malware or a virus several months ago, and you need to completely restore their system with a full backup. It’s not uncommon for businesses to keep full backups for a year or even longer. On the other hand, incremental backups may not need to be kept for as long because you can always just restore from a full backup instead.
Grandfather-Father-Son Backups
Effectively combining different backup types into a cohesive strategy leads to a staggered, chronological approach that is greater than the sum of its parts. The grandfather-father-son system is a great example of this concept in action. Here’s an example of how it might work:
Grandfather: A monthly full backup is stored either off-site or in the cloud.
Father: Weekly full backups are stored locally in a hot cloud storage solution.
Son: Daily incremental backups are stored as a stopgap alongside father backups.
It makes sense that different types of backups will need to be stored for different lengths of time and in different places. You’ll need to make decisions about how long to keep old full backups (once they’ve been replaced with newer ones), for example. The type and the age of your data backups, along with their role in the broader context of your strategy, should factor into your determination about how long to keep them.
A Note on Minimum Storage Duration Policies
When considering cloud storage to store your backups, it’s important to know that many providers have minimum storage duration policies. These are fees charged for data that is not kept in cloud storage for some period of time defined by the cloud storage provider, and it can be anywhere from 30–180 days. These are essentially delete penalties—minimum retention requirement fees apply not only to data that gets deleted from cloud storage but also any data that is overwritten. Think about that in the context of the backup strategies we’ve just outlined: each time you create a new full backup, you’re overwriting data.
So if, for example, you choose a cloud storage provider with a 90-day minimum storage duration, and you keep your full backups for 60 days, you will be charged fees each time you overwrite or delete a backup. Some cloud storage providers, like Backblaze B2 Cloud Storage, do not have a minimum storage duration policy, so you do not have to let that influence how long you choose to keep backups. That kind of flexibility to keep, overwrite, and delete your data as often as you need is important to manage your storage costs and business needs without the fear of surprise bills or hidden fees.
Don’t Forget: Your Industry’s Regulations Can Tip the Scales
While weighing storage costs and operational needs is the fundamental starting point of any retention policy, it’s also important to note that many organizations face regulatory requirements that complicate the question of how long to keep backups. Governing bodies designed to protect both individuals and business interests often mandate that certain kinds of data be readily available and producible upon request for a set amount of time, and they require higher standards of data protection when you’re storing personally identifiable information (PII). Here are some examples of industries with their own unique data retention regulations:
Insurance: Different types of policies are governed by different rules in each state, but insurance companies do generally need to comply with established retention periods. More recently, companies have also been adding cyber insurance, which comes with its own set of requirements.
Finance: A huge web of legislation (like the Bank Secrecy Act, Electronic Funds Transfer Act, and more) mandates how long banking and financial institutions must retain their data.
Education: Universities sit in an interesting space. On one hand, they store a ton of sensitive data about their students. They’re often public services, which means that there’s a certain amount of governmental regulation attached. They also store vast amounts of data related to research, and often have on-premises servers and private clouds to protect—and that’s all before you get to larger universities which have medical centers and hospitals attached. With all that in mind, it’s unsurprising that they’re subject to higher standards for protecting data.
Federal and regional legislation around general data security can also dictate how long a company needs to keep backups depending on where it does business (think GDPR, CCPA, etc.). So in addition to industry-specific regulations, your company’s primary geographic location—or your customers’ location—can also influence how long you need to keep data backups.
The Bottom Line: How Long You Keep Backups Will Be Unique to Your Business
The answer to how long you need to keep your backups has everything to do with the specifics of your organization. The industry you’re in, the type of data you deal with, and the structure of your backup strategy should all combine to inform your final decision. And as we’ve seen, you’ll likely wind up with multiple answers to the question pertaining to all the different types of backups you need to create and store.
Hey, we can drive! (Pun absolutely intended.) Some days it’s hard to believe that what started as a “crazy” dream in a one-bedroom apartment has evolved into what we’re celebrating today—16 years of blazing on (pun, ahem, also intended).
To mark the occasion, we thought we’d share some of our highlights from past years. If you want to hear co-founder and CEO Gleb Budman talking about our evolution (plus where he thinks cloud storage is going in the future), check out his recent appearance on The Cloudcast podcast.
And, here are some other great moments for your reading and viewing pleasure:
View some of our technical content like our article on Reed-Solomon erasure coding, a history of the Python Gil, and load balancing while managing servers.
You already know there’s much, much more on the Backblaze blog, and we love chatting with folks in article comments and on socials. After all, we wouldn’t be here without all of you!
Thanks for supporting us over the years. If you feel like spreading the love, you can always refer a friend. (You’ll be prompted to log in so that you get credit for the referral.) Your friend will get a month free to try Backblaze, and when they sign up, you’ll get one too!
When you’re creating or refining your backup strategy, it’s important to think ahead to recovery. Hopefully you never have to deal with data loss, but any seasoned IT professional can tell you—whether it’s the result of a natural disaster or human error—data loss will happen.
With the ever-present threat of cybercrime and the use of ransomware, it is crucial to develop an effective backup strategy that also considers how quickly data can be recovered. Doing so is a key pillar of increasing your business’ cyber resilience: the ability to withstand and protect from cyber threats, but also bounce back quickly after an incident occurs. The key to that effective recovery may lie with bare metal recoveries.
In this guide, we will discuss what bare metal recovery is, its importance, the challenges of its implementation, and how it differs from other methods.
Creating Your Backup Recovery Plan
Your backup plan should be part of a broader disaster recovery (DR) plan that aims to help you minimize downtime and disruption after a disaster event.
A good backup plan starts with, at bare minimum, following the 3-2-1 rule. This involves having at least three copies of your data, two local copies (on-site) and at least one copy off-site. But it doesn’t end there. The 3-2-1 rule is evolving, and there are additional considerations around where and how you back up your data.
As part of an overall disaster recovery plan, you should also consider whether to use file and/or image-based backups. This decision will absolutely inform your DR strategy. And it leads to another consideration—understanding how to use bare metal recovery. If you plan to use bare metal recovery (and we’ll explain the reasons why you might want to), you’ll need to plan for image-based backups.
What Is Bare Metal Backup?
The term “bare metal” means a machine without an operating system (OS) installed on it. Fundamentally, that machine is “just metal”—the parts and pieces that make up a computer or server. A “bare metal backup” is designed so that you can take a machine with nothing else on it and restore it to your normal state of work. That means that the backup data has to contain the operating system (OS), user data, system settings, software, drivers, and applications, as well as all of the files. The terms image-based backups and bare metal backups are often used interchangeably to mean the process of creating backups of entire system data.
Bare metal backup is a favored method by many businesses because it ensures absolutely everything is backed up. This allows the entire system to be restored should a disaster result in total system failure. File-based backup strategies are, of course, very effective when just backing up folders and large media files, but when you’re talking about getting people back to work, a lot of man hours go into properly setting up a workstations to interact with internal networks, security protocols, proprietary or specialized software, etc. Since file-based backups do not back up the operating system and its settings, they are almost obsolete in modern IT environments, and operating on a file-based backup strategy can put businesses at significant risk or add downtime in the event of business interruption.
How Does Bare Metal Backup Work?
Bare metal backups allow data to be moved from one physical machine to another, to a virtual server, from a virtual server back to a physical machine, or from a virtual machine to a virtual server—offering a lot of flexibility.
This is the recommended method for backing up preferred system configurations so they can be transferred to other machines. The operating system and its settings can be quickly copied from a machine that is experiencing IT issues or has failing hardware, for example. Additionally, with a bare metal backup, virtual servers can also be set up very quickly instead of configuring the system from scratch.
What is Bare Metal Recovery (BMR) or Bare-Metal Restore?
As the name suggests, bare metal recovery is the process of recovering the bare metal (image-based) backup. By launching a bare metal recovery, a bare metal machine will retrieve its previous operating system, all files, folders, programs, and settings, ensuring the organization can resume operations as quickly as possible.
How Does Bare Metal Recovery Work?
A bare metal recovery (or restore) works by recovering the image of a system that was created during the bare metal backup. The backup software can then reinstate the operating system, settings, and files on a bare metal machine so it is fully functional again.
This type of recovery is typically issued in a disaster situation when a full server recovery is required, or when hardware has failed.
Why Is BMR Important?
The importance of BMR is dependent on an organization’s recovery time objective (RTO), the metric for measuring how quickly IT infrastructure can return online following a data disaster. The need for high-speed recovery, which in most cases is a necessity, means many businesses use bare metal recovery as part of their backup recovery plan.
If an OS becomes corrupted or damaged and you do not have a sufficient recovery plan in place, then the time needed to reinstall it, update it, and apply patches can result in significant downtime. BMR allows a server to be completely restored on a bare metal machine to its exact settings and configured simply and quickly.
Another key factor for choosing BMR is to protect against cybercrime. If your IT team can pinpoint the time when a system was infected with malware or ransomware, then a restore can be executed to wipe the machine clean of any threats and remove the source of infection, effectively rolling the system back to a time when everything was running smoothly.
BMR’s flexibility also means that it can be used to restore a physical or virtual machine, or simply as a method of cloning machines for easier deployment in the future.
The key advantages of bare metal recovery (BMR) are:
Speed: BMR offers faster recovery speeds than if you had to reinstall your OS and run updates and patches. It restores every system element to its exact state as when it was backed up, from the layout of desktop icons to the latest software updates and patches—you do not have to rebuild it step by step.
Security: If a system is subjected to a ransomware attack or any other type of malware or virus, a bare metal restore allows you to safely erase an entire machine or system and restore from a backup created before the attack.
Simplicity: Bare metal recovery can be executed without installing any additional software on the bare machine.
BMR: Some Caveats
Like any backup and recovery method, some IT environments may be more suitable for BMR than others, and there are some caveats that an organization should be aware of before implementing such a strategy.
First, bare metal recovery can experience issues if the restore is being executed on a machine with dissimilar hardware. The reason for this is that the original operating system copy needs to load the correct drivers to match the machine’s hardware. Therefore, if there is no match, then the system will not boot.
Fortunately, Backblaze Partner integrations, like MSP360, have features that allow you to restore to dissimilar hardware with no issues. This is a key feature to look for when considering BMR solutions. Otherwise, you have to seek out a new machine that has the same hardware as the corrupted machine.
Second, there may be a reason for not wanting to run BMR, such as a minor data accident when a simple file/folder restore is more practical, taking less time to achieve the desired results. A bare metal recovery strategy is recommended when a full machine needs to be restored, so it is advised to include several different options in your backup recovery plan to cover all scenarios.
Bare Metal Recovery in the Cloud
An on-premises disaster disrupts business operations and can have catastrophic implications for your bottom line. And, if you’re unable to run your preferred backup software, performing a bare metal recovery may not even be an option. Backblaze has created a solution that draws data from Veeam Backup & Replication backups stored in Backblaze B2 Cloud Storage to quickly bring up an orchestrated combination of on-demand servers, firewalls, networking, storage, and other infrastructure in phoenixNAP’s bare metal cloud servers. This Instant Business Recovery (IBR) solution includes fully-managed, affordable 24/7 disaster recovery support from Backblaze’s managed service provider partner specializing in disaster recovery as a service (DRaaS).
IBR allows your business to spin up your entire environment, including the data from your Backblaze B2 backups, in the cloud. With this active DR site in the cloud, you can keep business operations running while restoring your on-premises systems. Recovery is initiated via a simple web form or phone call. Instant Business Recovery protects your business in the case of on-premises disaster for a fraction of the cost of typical managed DRaaS solutions. As you build out your business continuity plan, you should absolutely consider how to sustain your business in the case of damage to your local infrastructure; Instant Business Recovery allows you to begin recovering your servers in minutes to ensure you meet your RTO.
BMR and Cloud Storage
Bare metal backup and recovery should be a key part of any DR strategy. From moving operating systems and files from one physical machine to another, to transferring image-based backups from a virtual machine to a virtual server, it’s a tool that makes sense as part of any IT admin’s toolbox.
Your next question is where to store your bare metal backups, and cloud storage makes good sense. Even if you’re already keeping your backups off-site, it’s important for them to be geographically distanced in case your entire area experiences a natural disaster or outage. That takes more than just backing up to the cloud, really—it’s important to know where your cloud storage provider stores their data for both compliance standards, speed of content delivery (if that’s a concern), and to ensure that you’re not unintentionally storing your off-site backup close to home.
Remember that these are critical backups you’ll need in a disaster scenario, so consider recovery time and expense when choosing a cloud storage provider. While it may seem more economical to use cold storage, it comes with long recovery times and high fees to recover quickly. Using always-hot cloud storage is imperative, both for speed and to avoid an additional expense in the form of a bill for egress fees after you’ve recovered from a cyberattack.
Host Your Bare Metal Backups in Backblaze B2 Cloud Storage
Backblaze B2 Cloud Storage provides S3 compatible, Object Lock-capable hot storage for one-fifth the cost of AWS and other public clouds—with no trade-off in performance.
Get started today, and contact us to support a customized proof of concept (PoC) for datasets of more than 50TB.
The first cybersecurity insurance policy was issued in 1997. In the following 27 years it’s grown from a niche insurance product to an important consideration for organizations large and small to protect their bottom line from cyber threats like malicious data breaches, malware, phishing attacks, and ransomware.
While there are many security tactics to deploy in order to maintain business continuity (BC) should any of the above happen, getting back up and running in the event of a security incident can cost time and money. Cyber insurance is one way to reduce fallout from security events, prepare your business, and support business continuity objectives.
Today, we are breaking down the basics of cyber insurance: What is it? How much will it cost? What do cyber insurance companies provide? And how do you get it?
Does my organization need cyber insurance?
Cyber insurance has become more common as part of BC planning. Like many things in the cybersecurity world, it can be a bit hard to measure precise adoption numbers because there are different industry associations, enforcement agencies, and so on in different geographic markets. According to Fortune Business Insights, the global cyber insurance market size was valued at $16.66 billion in 2023. The market is projected to grow from $20.88 billion in 2024 to $120.47 billion by 2032, exhibiting a compound annual growth rate (CAGR) of 24.5% during the forecast period.
Take a look at these three data points in cybersecurity risk:
According to a 2023 Ransomware Market Report, global ransomware costs are predicted to reach $265 billion annually by 2031, up from $20 billion in 2021.
Whether your company is a 10 person software as a service (SaaS) startup or a global enterprise, cyber insurance could be the difference between a minor interruption of business services and closing up for good. However, providers don’t opt to provide coverage for every business that applies for cyber insurance. If you want coverage (and there are plenty of reasons why you would), it helps to prepare by making your company as attractive (meaning low-risk) as possible to cyber insurers. Some cyber insurance providers like Coalition even offer assistance and services to reduce your cyber risk posture before an attack as part of a “whole package” approach.
Ransomware Protection Resource
Learn about the growing threat of ransomware and what you can do to protect against ransomware attacks.
What is cyber insurance?
Cyber insurance protects your business from losses resulting from a digital attack. This can include business income loss, but it also includes coverage for unforeseen expenses, including:
Forensic post-breach review expenses.
Additional monitoring outflows.
The expenditure for notifying parties of a breach.
It’s not guaranteed that cybercriminals will provide a decryption key to recover your data. They’re criminals after all.
Even with a decryption key, you may not be able to recover your data. This could be intentional, or simply poor design on the part of cybercriminals. Ransomware code is notoriously buggy.
Paying the ransom encourages cybercriminals to keep plying their trade, and can even result in businesses that pay being hit by the same ransomware demand twice.
Ultimately, the most effective way to undermine the motivation of these criminal groups is to reduce the potential for profit.
Types of cyber insurance
What plans cover and how much they cost can vary. Typically, you can choose between first-party coverage, third-party coverage, or both.
First-party coverage protects your own data and includes coverage for business expenses related to things like recovery of lost or stolen data, lost revenue due to business interruption, and legal counsel, and other types of expenses.
Third-party coverage protects your business from liability claims brought by someone outside the company. This type of policy might cover things like payments to consumers affected by a data breach, costs for litigation brought by third parties, and losses related to defamation.
Depending on how substantial a digital attack’s losses could be to your business, your best choice may be both first- and third-party coverage.
Cyber insurance policy coverage considerations
Cyber insurance protects your company’s bottom line by helping you pay for costs related to recovering lost or stolen data and cover costs incurred by affected third parties (if you have third-party coverage).
As you might imagine, cyber insurance policies vary. When reviewing cyber insurance policies, it’s important to ask these questions:
Does this policy cover a variety of digital attacks, especially the ones we’re most susceptible to?
What are the policy’s exclusions? For example, unlikely circumstances like acts of war or terrorism and well-known, named viruses may not be covered in the policy.
How much do the premiums and deductibles cost for the coverage we need?
What are the coverage (payout) amounts or limitations?
Keep in mind that choosing the company with the lowest premiums may not be the best strategy. For further reading, the Federal Trade Commission offers a helpful checklist of additional considerations for choosing a cyber insurance policy.
Errors & omissions (E&O) coverage
Technology errors and omissions (E&O) coverage isn’t technically cyber insurance, but could be part of a comprehensive policy. This type of coverage protects your business from expenses that may be incurred if/when your product or service fails to deliver or doesn’t work the way it’s supposed to. This can be confused with cyber insurance coverage because it protects your business in the case your technology product or service fails. The difference is that E&O coverage comes into effect when that failure is due to the business’ own negligence.
You may want to pay the upcharge for E&O coverage to protect against harm caused if/when your product or service fails to deliver or work as intended. E&O also offers coverage for data loss stemming from employee errors or employee negligence in following data safeguards already in place. Consider whether you also need this type of protection and ask your cyber insurer if they offer E&O policies.
Beyond insurance
Cybersecurity insurance providers often offer a range of holistic services designed to help you manage and mitigate cyber risks. These services go beyond traditional insurance coverage, providing proactive support in the form of risk assessment, incident response, and recovery assistance. This comprehensive approach helps you strengthen your cybersecurity posture and minimize the impact of cyber incidents.
Services potentially offered by cybersecurity insurance providers:
Risk assessment and management: Evaluating your current cybersecurity measures and identifying vulnerabilities.
Incident response planning: Assisting in the development and implementation of incident response plans.
Threat intelligence: Providing real-time information on emerging cyber threats and vulnerabilities.
Employee training and awareness: Offering programs to educate employees on best practices for cybersecurity.
Breach response services: Support during and after a cyber incident, including forensic investigation and legal assistance.
Business continuity and recovery support: Helping to restore operations and recover lost data following an incident.
Regulatory compliance guidance: Assisting in meeting industry-specific cybersecurity regulations and standards.
It’s important to ask if these services are included in your policy or if you can add them if needed.
Premiums, deductibles, and coverage
What are the average premium costs, deductible amounts, and liability coverage for a business like yours? The answer to that question turns out to be more complex than you’d think.
How are premiums determined?
Every insurance provider is different, but here are common factors that affect cyber insurance premiums:
Your industry (e.g., education, healthcare, and financial industries are higher risk)
Your company size (e.g., more employees increase risk)
Amount and sensitivity of your data (e.g., school districts with student and faculty personal identifiable information are at higher risk)
Your revenue (e.g., a profitable bank will be more attractive to cybercriminals)
Your investment in cybersecurity (e.g., lower premiums go to companies with dedicated resources and policies around cybersecurity)
Coverage limit (e.g., the cost per incident will decrease with a lower liability limit).
Deductible (e.g., the more you pay per incident, the less your plan’s premium)
But, generally speaking, if you are willing to cover more of the cost of a data breach, your deductible rises, and your premium falls. Data from TechInsurance reveals that the average cyber insurance premium is around $145 per month depending on your risk profile and the policy limits you choose.
How do I get cyber insurance?
Most companies start with an online quote from a cyber insurance provider, but many will eventually need to compile more detailed and specific information in order to get the most accurate figures.
If you’re a business owner, you may have all the information you need at hand, but for mid-market and enterprise companies, securing a cyber insurance policy should be a cross-functional effort. You’ll need information from finance, legal, and compliance departments, IT, operations, and perhaps other divisions to ensure cyber insurance coverage and policy terms meet your company’s needs.
Before the quote, an insurance company will perform a risk assessment of your business in order to determine the cost to insure you. A typical cyber insurance questionnaire might include specific, detailed questions in the areas of organizational structure, legal and compliance requirements, business policies and procedures, and questions about your technical infrastructure. Here are some questions you might encounter:
Organizational: What kind of third-party data do you store or process on your computer systems?
Legal and compliance: Are you aware of any disputes over your business website address and domain name?
Policies and procedures: Do you have a business continuity plan in place?
Technical: Do you utilize a cloud provider to store data or host applications?
Cyber insurance readiness
Now that you know the basics of cyber insurance, you can be better prepared if and when the time comes to get insured. Shoring up your vulnerability to cyber incidents goes a long way toward helping you acquire cyber insurance and get the best premiums possible. You can start by protecting business workstations with automatic backups and by protecting virtual machines (VMs), servers, and network attached storage (NAS) data for BC and disaster recovery (DR).
On April 10, 2013, Backblaze saved our first daily hard drive snapshot file. We had decided to start saving these daily snapshots to improve our understanding of the burgeoning collection of hard drives we were using to store customer data. That was the beginning of the Backblaze Drive Stats reports that we know today.
Little did we know at the time that we’d be collecting the data for the next 10 years or writing various Drive Stats reports that are read by millions, but here we are.
I’ve been at Backblaze longer than Drive Stats and probably know the drive stats data and history better than most, so let’s spend the next few minutes getting beyond the quarterly and lifetime tables and charts and I’ll tell you some stories from behind the scenes of Drive Stats over the past 10 years.
1. The Drive Stats Light Bulb Moment
I have never been able to confirm whose idea it was to start saving the Drive Stats data. The two Brians—founder Brian Wilson, our CTO before he retired and engineer Brian Beach, our current CTO—take turns eating humble pie and giving each other credit for this grand experiment.
But, beyond the idea, one Brian or the other also had to make it happen. Someone had to write the Python scripts to capture and process the data, and then deploy these scripts across our fleet of shiny red Storage Pods and other storage servers, and finally someone also had to find a place to store all this newly captured data. My money’s on—to paraphrase Mr. Edison—founder Brian being the 1% that is inspiration, and engineer Brian being the 99% that is perspiration. The split could be 90/10 or even 80/20, but that’s how I think it went down.
2. The Experiment Begins
In April 2013, our Drive Stats data collection experiment began. We would collect and save basic drive information, including the SMART statistics for each drive, each day. The effort was more than a skunkworks project, but certainly not a full-fledged engineering project. Conducting such experiments has been part of our DNA since we started and we continue today, albeit with a little more planning and documentation. Still the basic process—try something, evaluate it, tweak it, and try again—still applies, and over the years, such experiments have led to the development of our Storage Pods and our Drive Farming efforts.
Our initial goal in collecting the Drive Stats data was to determine if it would help us better understand the failure rates of the hard drives we were using to store data. Questions that were top of mind included: Which drive models lasted longer? Which SMART attributes really foretold drive health? What is the failure rate of different models? And so on. The answers, we hoped, would help us make better purchasing and drive deployment decisions.
3. Where “Drive Days” Came From
To compute a failure rate of a given group of drives over a given time period, you might start with two pieces of data: the number of drives, and the number of drive failures over that period of time. So, if over the last year, you had 10 drives and one failed, you could say the 10% failure rate for the year. That works for static systems, but data centers are quite different. On a daily basis, drives enter and leave the system. There are new drives, failed drives, migrated drives, and so on. In other words, the number of drives is probably not consistent across a given time period. To address this issue, CTO Brian (current CTO Brian that is) worked with professors from UC Santa Cruz on the problem and the idea of Drive Days was born. A drive day is one drive in operation for one day, so one drive in operation for ten days is ten drive days.
To see this in action you start by defining the cohort of drives and the time period you want and then apply the following formula to get the Annualized Failure Rate (AFR).
AFR = ( Drive Failures / ( Drive Days / 365 ) )
This simple calculation allows you to compute an Annualized Failure Rate for any cohort of drives over any period of time and accounts for a variable number of drives over that period.
4. Wait! There’s No Beginning?
In testing out our elegantly simple AFR formula, we discovered a problem. Not with the formula, but with the data. We started collecting data on April 10, 2013, but many of the drives were present before then. If we wanted to compute the AFR of model XYZ for 2013, we could not count the number of drive days those drives had prior to April 10—there were none.
Never fear, SMART 9 raw value to the rescue. For the uninitiated, the SMART 9 raw value contains the number of power-on hours for a drive. A little math gets you the number of days—that is Drive Days—and you are ready to go. This little workaround was employed whenever we needed to work with drives that came into service before we started collecting data.
Why not use SMART 9 all of the time? A couple of reasons. First, sometimes the value gets corrupted. Especially when the drive is failing, it could be zero or a million or anywhere in between. Second, a new drive can have non-default SMART values. Perhaps it is just part of the burn in process or a test group at the manufacturer, or maybe the drive was a return that passed some qualification process.
Regardless, the starting value of SMART 9 wasn’t consistent across drives, so we just counted operational days in our environment and used SMART 9 as a substitute only when we couldn’t count those days. Using SMART 9 is moot now as these days there are no drives left in the current drive collection which were present prior to April 2013.
5. There’s Gold In That There Data
While the primary objective of collecting the data was to improve our operations, there was always another potential use lurking about—to write a blog post, or two, or 56. Yes, we’ve written 56 blog posts and counting based on our Drive Stats data. And no, we could have never imagined that would be the case when this all started back in 2013.
The very first Drive Stats-related blog post was written by Brian Beach (current CTO Brian, former engineer Brian) in November 2013 (we’ve updated it since then). The post had the audacious title of “How Long Do Disk Drives Last?” and a matching URL of “www.backblaze.com/blog/how-long-do-disk-drives-last/”. Besides our usual blog readers, search engines were falling all over themselves referring new readers to the site based on searches for variants of the title and the post became first page search material for multiple years. Alas, all Google things must come to an end, as the post disappeared into page two and then the oblivion beyond.
Buoyed by the success of the first post, Brian went on to write several additional posts over the next year or so based on the Drive Stats data.
That’s an impressive body of work, but Brian is, by head and heart, an engineer, and writing blog posts meant he wasn’t writing code. So after his post to open source the Drive Stats data in February 2015, he passed the reins of this nascent franchise over to me.
6. What’s in a Name?
When writing about drive failure rates, Brian used the term “Hard Drive Reliability” in his posts. When I took over, beginning with the Q1 2015 report, we morphed the term slightly to “Hard Drive Reliability Stats.” That term lasted through 2015 and in Q1 2016 it was shortened to “Hard Drive Stats.” I’d like to tell you there was a great deal of contemplation and angst that went into the decision, but the truth is the title of the Q1 2016 post “One Billion Drive Hours and Counting: Q1 2016 Hard Drive Stats,” was really long and we left out the word reliability so it wouldn’t be any longer—something about title length, the URL, search terms, and so on. The abbreviated version stuck and to this day we publish “Hard Drive Stats” reports. That said, we often shorten the term even more to just “Drive Stats,” which is technically more correct given we have solid state drives (SSDs), not just hard disk drives (HDDs), in the dataset when we talk about boot drives.
7. Boot Drives
Beginning in Q4 2013, we began collecting and storing failure and SMART stats data from some of the boot drives that we use on our storage servers in the Drive Stats data set. Over the first half of 2014, additional boot drive models were configured to report their data and by Q3 2014, all boot drives were reporting. Now the Drive Stats dataset contained both data from the data drives and the boot drives of our storage servers. There was one problem: there was no field for drive source. In other words, to distinguish a data drive from a boot drive, you needed to use the drive model.
In Q4 2018, we began using SSDs as boot drives and began collecting and storing drive stats data from the SSDs as well. Guess what? There was no drive type field either, so SSD and HDD boot drives had to be distinguished by their model numbers. Our engineering folks are really busy on product and platform features and functionality, so we use some quick-and-dirty SQL on the post-processing side to add the missing information.
On April 10, 2013, data was collected for 21,195 hard drives. The .csv data file for that day was 3.2MB. The numbers of drives and the amount of data has grown just a wee bit since then, as you can see in the following charts.
The current size of a daily Drive Stats .csv file is over 87MB. If you downloaded the entire Drive Stats dataset, you would need 113GB of storage available once you unzipped all the data files. If you are so inclined, you’ll find the data on our Drive Stats page. Once there, open the “Downloading the Raw HD Test Data” link to see a complete list of the files available.
9. Who Uses The Drive Stats Dataset?
Over the years, the Drive Stats dataset has been used in multiple ways for different reasons. Using Google Scholar, you can currently find 660 citations for the term “Backblaze hard drive stats” going back to 2014. This includes 18 review articles. Here are a couple of different ways the data has been used.
As a teaching tool: Several universities and similar groups have used the dataset as part of their computer science, data analytics, or statistics classes. The dataset is somewhat large, but it’s still manageable, and can be divided into yearly increments if needed. In addition, it is reasonably standardized, but not perfect, providing a good data cleansing challenge. The different drive models and variable number of drive counts allows students to practice data segmentation across the various statistical methods they are studying.
For artificial intelligence (AI) and machine learning: Over the years several studies have been conducted using AI and machine learning techniques applied to the Drive Stats data to determine if drive failure or drive health is predictable. We looked at one method from Interpretable on our blog, but there are several others. The results have varied, but the general conclusion is that while you can predict drive failure to some degree, the results seem to be limited to a given drive model.
10. Drive Stats Experiments at Backblaze
Of course, we also use the Drive Stats data internally at Backblaze to inform our operations and run our own experiments. Here are a couple examples:
Inside Backblaze: Part of the process in developing and productizing the Backblaze Storage Pod was the development of the software to manage the system itself. Almost from day one, we used certain SMART stats to help determine if a drive was not feeling well. In practice, other triggers such as ATA errors or FSCKs alerts, will often provide the first indicator of a problem. We then apply the historical and current SMART stats data that we have recorded and stored to complete the analysis. For example, we receive an ATA error on a given drive. There could be several non-drive reasons for such an error, but we can quickly determine that the drive has a history of increasing bad media and command timeouts values over time. Taken together, it could be time to replace that drive.
Trying new things: The Backblaze Evangelism team decided that SQL was too slow when accessing the Drive Stats data. They decided to see if they could use a combination of Parquet and Trino to make the process faster. Once they had done that, they went to work duplicating some of the standard queries we run each quarter in producing our Drive Stats Reports.
What Lies Ahead
First, thank you for reading and commenting on our various Drive Stats Reports over the years. You’ve made us better and we appreciate your comments—all of them. Not everyone likes the data or the reports, and that’s fine, but most people find the data interesting and occasionally useful. We publish the data as a service to the community at large, and we’re glad many people have found it helpful, especially when it can be used in teaching people how to test, challenge, and comprehend data—a very useful skill in navigating today’s noise versus knowledge environment.
We will continue to gather and publish the Drive Stats dataset each quarter for as long as it is practical and useful to our readers. That said, I can’t imagine we’ll be writing Drive Stats reports 10 years from now, but just in case, if anyone is interested in taking over, just let me know.
This post is the second in a two-part series about sharing practical NAS tips and tricks to help readers with their own home or office NAS setups. Check out Part One where Backblazer Vinodh Subramanian walks through how he set up a NAS system at home to manage files and back up devices. And read on to learn how Backblazer James Flores uses a NAS to manage media files as a professional filmmaker.
The modern computer has been in existence for decades. As hardware and software have advanced, 5MB of data has gone from taking up a room and weighing a literal ton to being orders of magnitude more compact than what you would find on a typical smartphone. No matter how much storage there is, though, we—I know I am not alone—have been generating content to fill the space. Industry experts say that we reached 64.2 zettabytes of data created, captured, copied, and consumed globally in 2020, and we’re set to reach more than 180 zettabytes in 2025. And a lot of that is media—from .mp3s and .jpgs to .movs, we all have a stock pile of files sitting somewhere.
If you’re creating content you probably have this problem to the 10th power. I started out creating content by editing videos in high school, and my content collection has only grown from there. After a while, the mix of physical media formats had amassed into a giant box stuffed with VHS tapes, DVCPRO tapes, Mini DVs, DVDs, CD-ROMs, flash drives, external hard disk drives (HDDs), internal laptop HDDs, an Apple TimeCapsule, SD cards, and, more recently, USB 3.0 hard drives. Needless to say, it’s unruly at best, and a huge data loss event waiting to happen at worst.
Today, I’m walking through how I solved a problem most of us face: running into the limits of storage.
The Origin Story
My collection of media started because of video editing. Then, when I embarked on an IT career, the amount of data I was responsible for only grew, and my new position came with the (justifiable) paranoia of data loss. In the corporate setting, a network attached storage device (NAS) quickly became the norm—a huge central repository of data accessible to any one on the network and part of the domain.
A Synology NAS.
Meanwhile in 2018, I returned to creating content again in full swing. What started with small webinar edits on a Macbook Air quickly turned into scripted productions complete with custom graphics and 4K raw footage. And thus the data bloat continued.
But this time (informed by my IT background), the solution was easy. Instead of burning data to several DVDs and keeping them in a shoebox, I used larger volume storage like hard drives (HDDs) and NAS devices. After all, HDDs are cheap and relatively reliable.
And, I had long since learned that a good backup strategy is key. Thus, I embarked on making my backup plan an extension of my data management plan.
The Plan
The plan was simple. I wanted to have a 4TB NAS to use as a backup location and to extend my internal storage in case I needed to. After all, my internal drive was 7TB—who’s going to use more than that? (I thought at the time, unable to see my own future.) Setting up NAS is relatively simple: it replicated a standard IT setup, with a switch, a static IP address, and some cables.
But first, I needed hardwired network access in my office which is far away from my router. As anyone who works with media knows, accessing a lot of large files over wifi just isn’t fun. Luckily my house was pre-wired with CAT5—CAT5 cables that were terminated as phone lines. (Who uses a landline these days?) After terminating the cables with CAT5E adapters, installing a small 10-port patch panel and a new switch, I had a small network where my entire office was hardwired to my router/modem.
As far as the NAS goes, I chose a Synology DS214+, a simple two-bay NAS. After all, I didn’t expect to really use it all. I worked primarily off of my internal storage, then files were archived to this Synology device. I could easily move them back and forth between my primary and secondary storage because I’d created my internal network, and life was good.
Data Bloat Strikes Again
Fast forward to 2023. Now, I’m creating content routinely for two different companies, going to film school, and flexing my freelance editing skills on indie films. Even with the extra storage I’d built in for myself, I am at capacity yet again. Not only have I filled up Plan A on my internal drive, but now my Plan B NAS is nearing capacity. And, where are those backups being stored? My on-prem-only solution wasn’t cutting it.
This wasn’t me—but I get it.
Okay, New Plan
So what’s next?
Since I’m already set up for it, there’s a good argument to expand the NAS. But is that really scalable? In an office full of film equipment, a desk, a lightboard, and who knows what else in the future, do I really need another piece of equipment that will run all day?
Like all things tech, the answer is in the cloud. Synology’s NAS was already set up for cloud-based workflows, which meant that I got the best of both worlds: the speed of on-prem and the flexibility of the cloud.
Synology has its own marketplace with add-on packages which are essentially apps that let you add functionality to your device. Using their Cloud Sync app, you can sync an entire folder on your NAS to a cloud object storage provider. For me that means: Instead of buying another NAS device (hardware I have to maintain) or some other type of external storage (USB drives, LTO tapes), I purchase cloud storage, set up Cloud Sync to automatically sync data to Backblaze B2 Cloud Storage, and my data is set. It’s accessible from anywhere, I can easily create off-site backups, and I am not adding hardware to my jam-packed office.
I Need a Hero
This is great for my home office and the small projects I do in my spare time but how is this simple setup being used to modernize media workflows?
A big sticking point for media folks is what we talked about before—that large files can take up too much bandwidth to work well on wifi. However, as the cloud has become more accessible to all, there are many products today on the market designed to solve that problem for media teams specifically.
Up Amongst the Clouds
One problem though: Many of these tools push their own cloud storage. You could opt to play cloud storage hopscotch: sign up for the free tier of Google Drive, drag and drop files (and hope the browser keeps the connection going), hit capacity, then jump to the next cloud storage provider’s free tier and fill that up. With free accounts across the internet, all of the sudden you have your files stored all over the place, and you may not even remember where they all are. So, instead of my cardboard box full of various types of media, we end up with media in silos across different cloud providers.
And you can’t forget the cost. Cloud storage used to be all about the big guys. Beyond the free tiers, pricing was designed for big business, and many cloud storage providers have tiered pricing based on your usage, charges for downloads, throttled speeds, and so on. But, the cost of storage per GB has only decreased over the years, so (in theory), the cost of cloud storage should have gone down. (And I can’t resist a shameless plug here: At Backblaze, storage is ⅕ the cost of other cloud providers.)
It should be news to no one that COVID changed a lot in the media and entertainment industry, bringing remote work to our front door, and readily-available cloud products are powering those remote workflows. However, when you’re storing in each individual tool, it’s like when you have a USB drive over here, and an external hard drive over there.
As the media tech stack has evolved, a few things have changed. You have more options when it comes to choosing your cloud storage provider. And, cloud storage providers have made it a priority for tools to talk to each other through APIs. Here’s a good example: now that my media files are synced to and backed up with Synology and Backblaze, they are also readily accessible for other applications to use. This could be direct access to my Backblaze storage with a nonlinear editing system (NLE) or any modern workflow automation tool. Storing files in the cloud is only an entry point for a whole host of other cloud workflow hacks that can make your life immensely easier.
These days, you can essentially “bring your own storage” (BYOS, let’s make it a thing). Now, the storage is the foundation of how I can work with other tools, and it all happens invisibly and easily. I go about my normal tasks, and my files follow me.
With many tools, it’s as simple as pointing your storage to Backblaze. When that’s not an option, that’s when you get into why APIs matter, a story for another day (or another blog post). Basically, with the right storage, you can write your own rules that your tools + storage execute, which means that things like this LucidLink, iconik, and Backblaze workflow are incredibly easy.
Headline: Cloud Saves the (Media) World
So that’s the tale of how and why I set up my home NAS, and how that’s naturally led me to cloud storage. The “how” has gotten easier over the years. It’s still important to have a hard-wired internet connection for my NAS device, but now that you can sync to the cloud and point your other tools to use those synced files, you have the best of both worlds: a hybrid cloud workflow that gives you maximum speed with the ability to grow your storage as you need to.
Are you using NAS to manage your media at home or for a creative team? We’d love to hear more about your setup and how it’s working for you.
When you start thinking about backup strategies, it tends to get inside your head. Like Dustin Hoffman’s character in “Rain Man”, seeing equations float around him as he calculates his odds in Vegas, the mental exercise of ensuring your backups have backups of their own tends to manifest itself in the strangest places.
Take, for example, the finale of the Netflix show “Dead to Me” starring Christina Applegate and Linda Cardellini. The show wrapped up a few months back and should definitely be moving toward the top of your “I’ve been meaning to watch that” list. And if you have already seen it, I can’t stress enough how much more you pick up on a second time around.
Anyway, to a certain segment of the audience, the climax of the show served as a fitting conclusion to a whole host of storyline threads whose dense weave kept viewers enthralled from the first episode to the last. But to those of us who tend to worry about things like a proper 3-2-1- backup strategy, the final few episodes concealed a subtle message about the importance of proper data backup procedures.
Let’s dig into what “Dead to Me” can teach us about the importance of a good backup strategy.
One: On-site storage on your home device. Your phone, your laptop, your tablet, whatever. If you can physically touch it and your files are in there somewhere, that’s your first copy.
Two: On-site storage on a separate device. This can be an external hard drive, a thumb drive, or if you’re on a Mac, Time Machine. If it’s not physically in the device, but it’s still somewhere close by, that’s your second copy.
Three: Off-site backup. This should automatically scan the files on your device and upload copies to the cloud for safe-keeping. (Pssst, we’re partial to Backblaze’s astonishingly simple cloud back up here).
Okay, So What Does That Have to Do With “Dead to Me”?
There’s kind of a long road ahead, so buckle up.
For those of you who haven’t seen it, or who binged it so long ago you need a refresher, “Dead to Me” follows the story of two friends, Jen (Applegate) and Judy (Cardellini). Jen is a recently widowed mom whose husband Ted had been killed in a hit and run shortly before the show started. Judy is a woman she meets during a group therapy session, who claims to have lost her husband as well.
Only, as it turns out, Judy didn’t lose her husband. They just split up—after an argument that started when they accidentally struck and killed Jen’s husband.
Intrigued yet? We’re only on the first episode.
By the end of the first season, Jen has discovered the truth about Judy (but they’re still friends), Judy is dating a police officer who is investigating the crime she committed, and her ex-husband Steve (James Marsden, playing against his usual type as a jerk) is desperately trying to cover up the crime while avoiding the Greek mafia, who have a contract out on him.
We cannot stress enough that all of this craziness happens in the first season, which ends with Jen accidentally murdering Steve by—of course—cracking him in the head with a wooden bird, which winds up as a critical plot point.
You see tchotchke. I see danger.
From there the plot twists around on itself, throwing every curveball imaginable at you from secret twin brothers to money laundering schemes to torrid affairs (and hey, we already mentioned the Greek mafia). But critical to our point is one plot thread that could have been avoided with a proper backup strategy.
Karen and the… Let’s Call It 2-1 Strategy
A minor character in the first few seasons, Karen is a neighbor of Jen’s who… well, can be kind of a Karen. You know that person in your neighborhood that you suspect reports you to the Homeowner’s Association whenever your grass gets a little too long? That’s her.
As the neighborhood Karen, she has a natural inclination to keep an eye on things. As such, her house is ringed by security cameras. And as we learned in the season two premiere, one of those cameras just happened to spy Steve on his way to Jen’s house the night he was murdered.
Plot twist, right?
Since this is a huge piece of evidence implicating them in the murder they’re actively covering up, Jen and Judy have to ensure that the incriminating footage is destroyed forever. That means deleting the footage, which they discover has been safely stored in the cloud. They first try to convince Jeff, Karen’s ex, to log on and do it (side note: this happens after they discovered he was having an affair with one of Judy’s ex-boyfriends, because this show is bonkers) but unfortunately Karen has changed the password to her cloud storage.
So they have to sweet-talk their way into Karen’s house (greasing the wheels with her favorite dish—Mexican lasagna with extra raisins) and get her to delete the footage off the cloud. It’s a wonderful moment of female camaraderie as they convince Karen that the data on the cloud represents too many painful memories of her time with her ex. And when Karen finally drags the folder to the trash, we cheer her for finding the strength to move on.
Just a couple of friends, deleting files over coffee.
And then, the punchline.
“And if I ever want to see it again, I have it backed up on my hard drive,” she exclaims, holding up her external drive backup. Jen and Judy manage to steal that, and in doing so get away with their crime scot-free.
What Should Karen Have Done?
Look, we get that the show is trying to get us to root for Jen and Judy as our protagonists, but to be honest, murder is one of those things that is a little hard to look past.
Especially given that the FBI was looking into the crime at that point in the show, what Karen did could legally be considered obstruction of justice. Or at least unintended obstruction of justice, which we’re pretty sure is still a crime. (We on the blog team are definitely not lawyers, though.)
Had Karen utilized a proper 3-2-1 strategy, she should have had a third copy—the one on her local drive—even after she was tricked into deleting it from the cloud and handing over her external drive. And, if she was using Backblaze, she would have been able to access an earlier version of her backup with either our standard 30-day version history or Extended Version History. So, she could have pulled a copy even after she deleted it.
The Moral of the Story Is: 3-2-1 Backups Are Still the Best
Karen handed over all the incriminating evidence about the murder to the person who committed it. Which, true, made for a happy ending as far as the show is concerned. But for those of us who can’t seem to get 3-2-1 backup strategies out of our head, she committed a serious blunder. A 2-1 backup strategy just won’t cut it.
And that, folks, is how “Dead to Me” reminds us all once again that a 3-2-1 backup strategy is still the best way to keep your data safe and out of the hands of nefarious, if endearing, murderers.
Today, March 31, is World Backup Day. If you don’t know, now you know! Some years ago, we and other denizens of the internet got together because we felt that the joy of protecting your data was worthy of celebration. Each year on this day, we encourage folks to take the pledge to backup their data. This year, we wanted to share some fun facts we pulled about our Backblaze Personal Backup service, and throw in a few things we’ve learned from our yearly backup poll as well. Spoiler: We do that poll again every year in June for Backup Awareness Month, so come visit us again then and we’ll review the trends.
And, shout out to Simple Maps for providing us with geographic info that we mapped to our data.
The Winners: Which Cities Back Up the Most?
To be clear, we think anyone who’s backing up is a winner. But in this section, we decided to talk about both the cities with the most users per capita and the number of users in a city. Given that the second option rewards bigger cities, we thought it was a little unfair to just present that data.
2022 Top 5 Cities Where You’re Most Likely to Run Into a Backblaze User
Here, we take a look at the cities with the most Backblaze licenses per capita.
Pacific Palisades, CA: 136.6
Winnetka, IL: 129.1
Orinda, CA: 128.2
Beverly Hills, CA: 126.2
Mill Valley, CA: 117.1
Good job California and a very special shout out to Winnetka! Way to go!
2022 Top 5 Cities With the Most Backblaze Users
And, here, we look at cities with the highest number of users.
New York, NY: 8,401
Los Angeles, CA: 6,754
Brooklyn, NY: 5,587
San Francisco, CA: 5,117
Seattle, WA: 5,021
The Potential: The Places We Want to Give Some Back Up Love To
Hey, we get it: we’re passionate about a relatively nerdy thing. (Back up. It’s still back up.) That said, we’re always looking for ways to spread the love and peace of mind that comes from data protection.
2022 Top 5 Cities Least Likely to Run Into a Backblaze User
Here’s where we look at cities with the least Backblaze users per capita.
Lynwood, CA: .14
Arecibo, PR: .17
Trujillo Alto, PR: .17
Carolina, PR: .17
Vega Baja, PR: .18
Clearly, we haven’t been giving Puerto Rico enough love. We’re sorry, Puerto Rico! We’d love to chat about back up with you.
2022 Cities With the Fewest Users
You might be noticing a pattern. Here, we look at cities with the least number of users in our database—so, cities with one license, because there are also cities with zero users. But to figure out which cities those are, we’d have to find a list of ALL the cities in the U.S. and deduplicate it against our list of cities with at least one license. It would be a whole thing. Let it suffice to say, there are cities with zero users, and we hope someday they have more.
Arecibo, PR: 1
Canovanas, PR: 1
Carolina, PR: 1
Lynwood, CA: 1
Trujillo Alto, PR: 1
Vega Baja, PR: 1
Waianae, HI: 1
Given the amount of objectively beautiful places on this list, we’d love to assume you’re all busy outdoors and not stuck behind a computer.
State of Affairs
Okay, we’ve talked about cities, but things get even more interesting when you filter this by state instead. Buckle up, folks!
States With the Most Users Per Capita
Washington, D.C.: 26.04
Vermont: 21.67
Oregon: 21.60
Washington: 20.67
Colorado: 19.99
Finally, a list California didn’t make. (It’s number seven.) It’s super interesting when you compare this to the cities with the most users per capita, especially because our winner in that category has 136.6 compared to our winner here with 26.04.
Even if you take out Washington, D.C. (some folks might argue that it’s more fair to call it a city), Vermont comes in with 21.67 statewide. That’s less than a fifth of the concentration of users you’d find in Pacific Palisades, CA.
States With The Most Cities With Only One License Per Capita
Some nuance here: This doesn’t mean states with the least number users, but rather states with the most cities with only one license. So, in essence, this list favors states that have a lot of cities.
Pennsylvania—177
New York—172
Texas—166
Illinois—126
Ohio—126
Iowa—112
Minnesota—111
Michigan—111
California—106
Indiana—101
Look at that! Some of our standouts above become a little less impressive when you get here. And, we’d like to note that California has made all but one of the lists so far: proof that backup stories are no simple matter of “best” and “worst”.
The Even Bigger Picture
There are even more stories to tell when you compare this to our yearly backup poll. According to our data, only 12% of computer users use a cloud backup service like Backblaze. That means that the numbers we’re showing you here are a portion of the 12% of computer owners overall.
Still, the person most likely to be a backer upper—someone who owns a computer and backs it up at least once a day—likely lives in the Western United States. Even though we’re working with a smaller data set, it’s interesting to see that our data still reflects overall trends.
Celebrate With Us!
We hope you enjoyed our foray into data as much as we did. Feel free to take the World Backup Day pledge, reach out to us on socials, or comment below if you want to know more. And, check back in June to see the newest backup survey.
This article has been updated since it was originally published in 2023.
Solid state drives (SSDs) continue to grow in popularity, and no wonder. Compared to hard disk drives (HDDs), they are faster, smaller, more power efficient, and sturdier since they have no moving parts to jostle around. And, they are becoming available in larger and larger capacities while their cost comes down.
But are they really as dependable as they claim to be? SSDs still have vulnerabilities, and storage tech that lasts thousands of years isn’t commercially viable (yet!).
In this post we’re going to consider the issue of SSD reliability. We’ll take a closer look at:
SSD tech.
SSD storage memory.
Reliability factors.
Signs of SSD failure.
So, how reliable is an SSD? Let’s dig in.
But First, Back It Up
Of course, as a data storage and backup company, you know what we’re going to say right off: No matter how you store your data, you should always back it up. Even if your data is stored on a brand new SSD, it won’t do you any good if your computer is stolen, destroyed by a flood, or lost in a fire or other act of nature. We recommend using a 3-2-1 backup strategy to safeguard your data.
SSD Tech
Almost all types of today’s SSDs use NAND flash memory. NAND isn’t an acronym like a lot of computer terms. Instead, it’s a name that’s derived from its logic gate, the basic building block of its memory cells, called “NOT AND.” (For the curious, a NAND gate is a logic gate that produces an output that is false only if all its inputs are true.)
Flash (the term following NAND) refers to a non-volatile solid state memory that retains data even when the power source is removed.
NAND storage has specific properties that affect how long it will last. NAND flash memory works by storing data in individual memory cells organized in a grid-like array. When data (a 1 or a 0) is written to a NAND cell (also known as programming), the data must be erased before new data can be written to that same cell. When writing and erasing a NAND cell, electrons are sent through an insulator and back, and the insulator starts to wear. Eventually, the insulator wears to the point where it may have difficulty keeping the electrons in their correct (programmed) location, which makes it increasingly more difficult to determine if the electrons are where they should be and to indicate the correct value (1 or 0) of the cell.
This means that flash type memory cells can only be reliably programmed and erased a given number of times. This is measured in programmed/erase cycles, more commonly known as P/E cycles.
P/E cycles are an important measurement of SSD reliability, but there are other factors that are important to consider as well including TBW (terabytes written) and MTBF (mean time between failures). Here are a few definitions to help keep everything straight:
Programmed/Erase Cycles (P/E Cycles)
A P/E cycle in solid state storage involves writing data to a NAND flash memory cell then erasing that data, so it is ready to be rewritten. The endurance of an SSD, measured in P/E cycles, varies depending on the technology, but typically falls somewhere between 500 and 100,000 P/E cycles.
Terabytes Written (TBW)
Terabytes written is the total amount of data that can be written to an SSD before it is likely to fail. For example, here are the TBW warranties for the popular Samsung V-NAND SSD 870 EVO:
250GB model: 150TBW
500GB model: 300TBW
1TB model: 600TBW
2TB model: 1,200TBW
4TB model: 2,400TBW
All of these models are warrantied for five years or TBW, whichever comes first.
Mean Time Between Failures (MTBF)
MTBF is a metric used to gauge the reliability of a hardware component throughout its anticipated lifespan. For most components, the measure is typically in thousands or even tens of thousands of hours between failures. For example, an HDD may have a mean time between failures of 300,000 hours, while an SSD might have 1.5 million hours.
Manufacturers provide these specifications for their products. They can help you understand your drives’ expected lifespan as well as its suitability for specific applications.
Be careful when reviewing the specifications though, as they don’t guarantee your particular SSD will last for that specific duration. Rather, they indicate that, based on a sample set of the SSD model, errors are anticipated to occur at a certain rate. A 1.2 million hour MTBF means that, assuming the drive is used at an average of eight hours a day, a sample size of 1,000 SSDs would be expected to have one failure every 150 days, or about twice a year.
Today, many SSDs come with a utility which monitors the life expectancy of the drive. Their recommendations are based on monitoring the SMART attributes of the drive. As we discussed in a previous post, there is little consistency between the different SSD manufacturers in what attributes they monitor and how they calculate drive life expectancy. Therefore, it is important that you read the manual for your particular SSD if you are interested in using this information to decide when to replace your SSD.
SSD Storage Memory
There are currently five different NAND flash cell technologies based on the number of bits stored per cell, which we’ll discuss below. Generally, as the number of bits stored per cell increases, the cost per bit decreases, but endurance and performance may decrease as well.
SLC (Single Level Cell): One Bit Per Cell
SLC was the first type of NAND flash storage developed. It stores one bit per cell. SLC storage is fast and wear is minimal. On the downside, it’s not space-efficient; that is, the physical size of the SSD form factor used.
MLC (Multi-Level Cell): Two Bits Per Cell
MLC stores two bits per cell. This basically doubled the amount of storage and lowered the cost for a given form factor. But MLC is slower as it has to distinguish between the two bits in a given cell.
TLC (Triple Level Cell): Three Bits Per Cell
The trend continued with TLC where three bits are stored per cell. This advancement had two interesting consequences. First, the unit cost started to be appealing to most audiences. While still two to three times as expensive as a comparable hard drive, a TLC-based SSD was affordable. Second, the TLC technology hastened the introduction of caching within the SSD, as the unaided read/write speeds had dipped to near those of a hard drive.
QLC (Quad Level Cell): Four Bits Per Cell
QLC is the current “standard.” It stores four bits per cell. This increases storage density yet again, lowers the price even more, and, with caching improvements, continues to deliver superior speed. On the downside, the drive can wear out sooner, especially as it fills up.
3D NAND
In the previous technologies the cells are side by side in a single, two-dimensional layer—this design is described as planar. In 3D NAND, the cells are stacked three-dimensionally. This improves storage density and speed, but increases the manufacturing cost and lowers endurance over time.
In general SLC and MLC are faster and last longer, but are limited to the amount of space. TLC and QLC technologies can store data at a lower cost, but may be slower. However, the difference in speed is probably negligible for the average consumer, and is sometimes made up for by things like dynamic caching. The 3D NAND technology is a great choice, but be prepared to pay more.
SSD Reliability Factors to Consider
Compared to HDDs, SSDs are sturdier. Since they don’t have moving parts like actuator arms and spinning platters, they can withstand accidental drops and other shocks, vibration, extreme temperatures, and magnetic fields better than HDDs. Add to that their small size and lower power consumption, and the idea of replacing HDDs with SSDs could be worth the time and effort.
That’s not exactly the whole story though. There are different performance and reliability criteria you should use depending on whether the SSD will be used in a home desktop computer, a data center, or an exploration vehicle on Mars. And SSD manufacturers are increasingly marketing SSDs for specific workloads such as write-intensive, read-intensive, or mixed-use. What that means is that you can select the optimal level of SSD endurance and capacity for a particular use case.
For instance, an enterprise user with a high-transaction database might opt for a drive that can withstand a higher number of writes at the expense of capacity. Or, a user operating a database that doesn’t get frequent writes might choose a lower performance drive with a higher capacity. By doing this, the manufacturers are hiding the complexity embedded in the technology like storage NAND (SLC, MLC, etc), caching, and so on. That said, it does make it easier to match your requirements to the best type of SSD.
Signs of SSD Failure
You’ve likely encountered the dreaded clicking sound that emanates from a dying HDD. An SSD has no moving parts, so you won’t get an audible warning that an SSD is about to fail, but there are usually other signs of when that’s going to happen. If you start to notice any of them, take action by replacing that drive with a new one. Indicators that your SSD is nearing its end of life include:
1) Errors Involving Bad Blocks
Much like bad sectors on HDDs, there are bad blocks on SSDs. If you have a bad block, the computer will typically try to read or save a file, but it takes an unusually long time and ends in failure, so the system eventually gives up and sends an error message.
2) Files Cannot Be Read or Written
There are two ways in which a bad block can affect your files. First, the system detects the bad block while writing data to the drive, and thus refuses to write data, or second, the system detects the bad block after the data has been written, and thus refuses to read that data.
3) The File System Needs Repair
Getting an error message like this on your screen can happen simply because the computer was not shut down properly, but it also could be a sign of an SSD developing bad blocks or other problems.
4) Crashing During Boot
A crash during the computer boot is a sign that your drive could be developing a problem. You should make sure you have a current backup of all your data before it gets worse and the drive fails completely.
5) The Drive Becomes Read-Only
Your drive might refuse to write any more data to disk and can only read data. Fortunately, you can still get your data off the disk, and you should.
So, How Reliable Is an SSD?
Let’s break down the reliability of SSDs into three, more specific questions:
Question 1: How long can we reasonably expect an SSD to last?
Answer: An SSD should ideally last as long as its manufacturer expects it to last (generally five years), provided that the use of the drive is not excessive for the technology it employs (e.g. using a QLC in an application with a high number of writes). Consult the manufacturer’s recommendations to ensure that how you’re using the SSD matches its best use.
Here at Backblaze we use SSDs for many different applications. The one use case we have rigorous reliability data for is as boot drives in our storage servers. This cohort of drives does more than boot these servers; they also write, store, read, and delete log files of various types recorded by the storage servers on a daily basis. The latest Drive Stats SSD Edition illuminates the reliability of the drive models we use for this purpose.
Question 2: Do SSDs fail faster than HDDs?
Answer: There are many variables in comparing the reliability of HDDs and SSDs, the primary one being how they are used. In the SSD Drive Stats report noted above, we compared SSD and HDD boot drives as they performed the same function in the same types of systems, storage servers. While it seems in the first three years or so the different drives are similar in their failure curves, the curves separate after four years, with the HDDs failing at a higher rate. So far the SSDs have maintained a 1% or less Annualized Failure Rate (AFR) through the first four years.
SSD users are far more likely to replace their storage drive because they’re ready to upgrade to a newer technology, higher capacity, or faster drive, than having to replace the drive due to a short lifespan. Under normal use we can expect an SSD to last years. If you replace your computer every three years, as most users do, then you probably needn’t worry about whether your SSD will last as long as your computer. What’s important is whether the SSD will be sufficiently reliable that you won’t lose your data during its lifetime.
Question 3: Are SSDs good for long-term storage?
Answer: SSDs, like hard drives, are meant to be used. An external drive stuffed into a closet for a couple of years is never a good thing, and it doesn’t matter whether it is an SSD or HDD inside. The evidence of whether an SSD will fare better than a HDD in such a circumstance is anecdotal at best. Still, it is better to use an external drive as a backup of your computer as part of your backup plan—just don’t make it your only backup.
Summary
It’s good to understand how the different SSD technologies affect their reliability, and whether it’s worth it to spend extra money for SLC over MLC or QLC. However, unless you’re using an SSD in a specialized application with more writes than reads as we described above, just selecting a good quality SSD from a reputable manufacturer should be enough to make you feel confident that your SSD will have a useful life span.
Keep an eye out for any signs of failure or bad sectors, and, of course, be sure to have a solid backup plan no matter what type of drive you’re using.
FAQs
1. How do you measure SSD reliability?
There are a number of metrics that can help you understand SSD reliability, including programmed/erase (P/E) cycles, terabytes written (TBW), and mean time between failures (MBTF). These metrics alone won’t be able to tell you how long a given SSD will last, but they can help you understand roughly where your SSD is in its lifecycle. Check the manufacturer’s warranty and endurance rating in TBW. Higher values indicate better durability.
2. What are programmed/erase (P/E) cycles?
A solid-state storage programmed/erase (P/E) cycle is a sequence of events in which data is written to a solid-state NAND flash memory cell, then erased, and then rewritten. How many P/E cycles a SSD can endure varies with the technology used, somewhere between 500 to 100,000 P/E cycles.
3. What SSD should I buy?
The ideal SSD to buy depends on your specific needs. Consider factors like capacity, speed, and budget. For most users, a mid-range SSD from a reputable brand offers a good balance of performance and affordability. SSD manufacturers are increasingly marketing SSDs for specific workloads such as write-intensive, read-intensive, or mixed-use. What that means is that you can select the optimal level of SSD endurance and capacity for a particular use case. For instance, an enterprise user with a high-transaction database might opt for a drive that can withstand a higher number of writes at the expense of capacity. Or, a user operating a database that doesn’t get frequent writes might choose a lower performance drive with a higher capacity.
4. How do I know my SSD is going to fail?
SSDs will eventually fail, but there usually are advance warnings of when that’s going to happen. Some warning signs include errors involving bad blocks, being unable to read or write files, getting error messages that the file system needs repair, crashes during boot, or when your drive becomes read-only. When this happens, make sure you have a good backup.
5. How long can I expect an SSD to last?
An SSD should ideally last as long as its manufacturer expects it to last (generally five years), provided that the use of the drive is not excessive for the technology it employs. Consult the manufacturer’s recommendations to ensure that how you’re using the SSD matches its best use.
6. Do SSDs fail faster than HDDs?
There are many variables in comparing the reliability of HDDs and SSDs, the primary one being how they are used. SSD users are far more likely to replace their storage drive because they’re ready to upgrade to a newer technology, higher capacity, or faster drive, than having to replace the drive due to a short lifespan. Under normal use we can expect an SSD to last years. If you replace your computer every three years, as most users do, then you probably needn’t worry about whether your SSD will last as long as your computer. What’s important is whether the SSD will be sufficiently reliable that you won’t lose your data during its lifetime.
7. Are SSDs good for long-term storage?
SSDs, like hard drives, are meant to be used. An external drive stuffed into a closet for a couple of years is never a good thing, and it doesn’t matter whether it is an SSD or HDD inside. The evidence of whether an SSD will fare better than a HDD in such a circumstance is anecdotal at best. Still, it is better to use an external drive as a backup of your computer as part of your backup plan—just don’t make it your only backup.
Quick! You have 10 minutes to get your most important documents out of your house. What do you need?
Here’s another scenario: you’re away from home and you find out there was a fire. Are you confident that you have all your important information somewhere you can access?
It’s never fun to imagine disaster scenarios, but that doesn’t mean you should avoid the necessary preparation. Building a good emergency kit checklist—and digitizing the things you can—is one of the easiest things you can do to give yourself peace of mind. Today, I’m covering all the things that can and should go into your digital go bag.
Editor’s Note
We’ve had this article on our calendar for a while now, and it’s part of our campaign to celebrate World Backup Day. But, we never want to be the ones shifting the focus from the victims of natural disasters. With the devastating storms that rolled through the U.S. South and beyond this weekend, we wanted to take a moment to say that our thoughts are with everyone affected, and if you have the ability to donate, this is a great boots-on-the-ground charity helping folks out right now.
Disaster Prep: Better Known as Recovery Planning
It may seem far-fetched that you’ll be in the position to get the essentials in only 10 minutes, but speaking from personal experience, that’s exactly what happened to me when the 2003 Cedar Fire struck in San Diego—there’s nothing like seeing your friends’ homes on the national news, let me tell you. And, having spent much of my adult life in hurricane-prone New Orleans, disaster readiness is just a way of life. It’s common to discuss the incoming storms with the old-timers in your neighborhood bar over a $2 afternoon High Life, and they are almost always right in predicting if a hurricane is going to turn and hit Florida.
And you always know it’s a serious weather event when Jim Cantore comes to town. Source.
One of the things these experiences have taught me is that disasters and recovery happen in stages. There’s the inciting event—a house fire, a hurricane, etc.—and then there’s the displacement and recovery. You’re trying to call an insurance company when the lines are all tied up, and when you finally get through, you need to give them information that they need when you’re far from home and in crisis. You may have renter’s insurance, but when you’re trying to re-buy your book collection, really, which ones did you have? And, there are some things that can’t be replaced—photos are a great example. Finding a way to organize and digitize these things means that you don’t have to worry about stuff when you should be worrying about people.
All that to say, the more you can do to be prepared ahead of time, the better. That means not only having your documents in a place you can access, but also knowing what documents you need in the first place. While this type of file organization started out in response to natural disasters, it’s actually helped in many other ways—I always know where my files are to give to my tax guy, and I’ve implemented a good 3-2-1 backup strategy, which means I’m confident my data is protected and accessible.
As it happens, there’s a name for this type of intentional preparation when you’re building an emergency kit: folks call those kits go bags. It makes sense right? You have a bag that holds the things you need to go. These days, though, many of the things that you’d traditionally include in that physical bag can also be digitized. So, with all that in mind, let’s talk about how to build your (digital) go bag.
What Documents Do I Need in My Emergency Kit?
A little caveat here: just because you can digitize something, doesn’t mean that should be your only copy. There are some things that you just flat-out need to have in person, like your driver’s license, though some states have experimented with digital wallets that contain official, legal copies of those things. Nevertheless, having a digital backup of your important physical documents means that you’ll have the information to replace them should you need to.
After that, you can break your go bag checklist into a few different categories.
These are all the things you need to prove you are who you say you are, and to prove that your kids, pets, and spouse are, in fact, your kids, pets, and spouse. It may seem like this isn’t important, but there were whole organizations dedicated to reuniting pets with their rightful owners after Hurricane Katrina—and it wasn’t easy. And, imagine if you’ve divorced and don’t have custody papers in an emergency. Sure, courts have records of those agreements, but sometimes those papers take weeks or months to get copies of.
The List
Vital Records: Birth certificates, marriage agreements, divorce decrees, adoption or custody papers.
Identity Records: Passports, driver’s license, i.d. card, Social Security card, green card, visa, military service i.d.
Pet Records: Pet ownership papers, identification tags, microchip information.
Your dog, blissfully unaware that your legal relationship to each other is documented.
Financial and Legal Information
If your home or income is affected during a disaster, you’ll need documentation to request assistance from your insurance company or government disaster assistance programs. Remember that even after you get assistance, all that comes with tax implications down the road (for better or worse). Both of those processes take time, so in addition to having your information organized and ready to go, try to keep some emergency cash on hand during high-risk time periods.
The List
Housing Documents: Lease or rental agreements, mortgage agreement, home equity line of credit, house or property deed, lists of/receipts for repairs.
Note: Don’t forget to document your property! Make a list of items covered by insurance with their estimated values, and take pictures of all that stuff.
Sources of Income: Pay stubs, government benefits, alimony, child support, rent payments, 1099 income.
Tax Statements: Federal/state income tax returns, property tax, vehicle tax.
Estates Planning: Wills, trusts, powers of attorney.
Medical Information
Even more so than the other sections on this list, it’s important to make sure you have thorough documentation for each member of your household. Remember that there are some items on this list that you’ll need sooner rather than later—think prescription refills. And, make sure that allergy information is front and center, especially life-threatening allergies (like to seafood or nuts).
The List
Insurance Information: Health and dental insurance, Medicare, Medicaid, Veterans Administration (VA) health benefits.
Medical Records: List of medications, illnesses/disabilities, immunizations, allergies, prescriptions, medical equipment and devices, pharmacy information.
Legal Documents: Living will, medical powers of attorney, Do Not Resuscitate (DNR) documents, caregiver agency contracts, disabilities documentations, Social Security (SSI) benefits information.
Contact Information: A list of doctors, specialists, dentists, pediatricians.
(Emergency) Contact Info
Finally, you’ll want all of the contact information you may need in one place—it’ll save you time and headaches when you’re trying to make calls, plus you may be able to delegate some phone calls to others. The exercise itself is useful to help you remember any miscellaneous items you may have forgotten in your other documents. Bonus: you can keep a list of extensions or direct phone lines and skip the automated phone tree.
Press one for more options.
The List
Employers
Schools
Houses of worship
Homeowners’ associations
Home repair services
Relatives/emergency contacts
Utility companies
Insurance companies
Lawyers
Local non-emergency services
Government agencies
Valuables and Priceless Personal Items
Most of the things that fit in this section aren’t able to be digitized—your wedding dress, heirlooms, jewelry, and the like. Still, don’t forget that those things may have a paper trail you want to keep in your records, especially if you have additional insurance on things like the jewelry.
And, you can never forget to mention photos in this section. While most of us are now in the habit of using our smartphones as cameras, so most of our new photos are already stored in the cloud, don’t forget to digitize all of your photos, including the ones passed down by relatives, taken by professionals, and so on. And, even though it seems like our phones are safer than other formats, you’ll want to back up your mobile devices as well.
Go Bag: Go for Backups
Here’s the short answer to the question of what to digitize: anything you can. Even if the digital copies aren’t legally acceptable, like in our i.d. example above, you’ll at least have the information to fill out online forms or re-order the documents as necessary.
Once you have digital copies of all of these documents, it’s also easy to backup your information. We recommend that you follow a 3-2-1 backup strategy: having three copies of your files in two separate locations with one of those locations off-site. That way, you can grab your documents and go if you’re at home, or if the worst happens and you can’t access that on-site information, you can access all that information in the cloud.
The 3-2-1 backup strategy: always a great idea.
Is My Go Bag Safe Online?
Good question. This is the most important information in your life, and we’re asking you to store it all online, the playground of cybercriminals. There’s a lot you can do to protect yourself, though. You’ve already achieved one of those things: setting up a backup strategy. You should also store your data in a secure location. Watch out for clever phishing attempts. And, make sure you follow password best practices, including setting up multi-factor authentication (MFA).
Make It a Holiday to Update Your Information Regularly
Remember that a lot of the information on this list will change over time. Maybe you’re the type of person who remembers to update their files continuously or when something big changes, but it’s a good idea to set one day per year (Around tax day? Maybe going into hurricane season? Groundhog’s Day?) that you intentionally set as Update Important Information Day. (We’re big fans of holidays that combine the whimsical and the practical here at Backblaze.) Feel free to workshop the holiday title and celebrate judiciously. Then, use a backup service like Backblaze Personal Backup that continuously and automatically backs up your data, and you’ll be pretty well prepared for whatever life throws at you.
Twenty years ago, who would have thought going to work would mean spending most of your time on a computer and running most of your applications through a web browser or a mobile app? Today, we can do everything remotely via the power of the internet—from email to gaming, from viewing our home security cameras to watching the latest and greatest movie trailers—and we all have opinions about the best browsers, too…
Along with that easy, remote access, a slew of new cloud technologies are fueling the tech we use day in and day out. To get to where we are today, the tech industry had to rethink some common understandings, especially around data storage and delivery. Gone are the days that you save a file on your laptop, then transport a copy of that file via USB drive or CD-ROM (or, dare we say, a floppy disk) so that you can keep working on it at the library or your office. And, those same common understandings are now being reckoned with in the world of film, video, and content creation.
In this post, I’ll dive into storage, specifically cloud object storage, and what it means for the future of content creation, not only for independent filmmakers and content creators, but also in post-production workflows.
The Evolution of File Management
If you are reading this blog you are probably familiar with a storage file system—think Windows Explorer, the Finder on Mac, or directory structures in Linux. You know how to create a folder, create files, move files, and delete folders. This same file structure has made its way into cloud services such as Google Drive, Box, and Dropbox. And many of these technologies have been adopted to store some of the largest content, namely media files like .mp4, .wav, or .r3d files.
But, as camera file outputs grow larger and larger and the amount of content generated by creative teams soars, folders structures get more and more complex. Why is this important?
Well, ask yourself: How much time have you spent searching for clips you know exist, but just can’t seem to find? Sure, you can use search tools to search your folder structure but as you have more and more content, that means searching for the proverbial needle in a haystack—naming conventions can only do so much, especially when you have dozens or hundreds of people adding raw footage, creating new versions, and so on.
Finding files in a complex file structure can take so much time that many of the aforementioned companies create system limits preventing long searches. In addition, they may limit uploads and downloads making it difficult to manage the terabytes of data a modern production creates. So, this all begs the question: Is a traditional file system really the best for scaling up, especially in data-heavy industries like filmmaking and video content creation? Enter: Cloud object storage.
Refresher: What is Object Storage?
You can think of object storage as simply a big pool of storage space filled with object data. In the past we’ve defined object data as “some assemblage of data with one unique identifier and an infinite amount of metadata.” The three components that comprise objects in object storage are key here. They include:
Unique Identifier: Referred to as a universally unique identifier (UUID) or global unique identifier (GUID), this is simply a complex number identifier.
Infinite Metadata: Data about the data with endless possibilities.
Data: The actual data we are storing.
So what does that actually mean?
It means each object (this can be any type of file—a .jpg, .mp4, .wav, .r3d, etc.) has an automatically generated unique identifier which is just a number (e.g. 4_z6b84cf3535395) versus a folder structure path you must manually create and maintain (e.g. D:\Projects\JOB4548\Assets\RAW\A001\A001_3424OP.RDM\A001_34240KU.RDC\
A001_A001_1005ku_001.R3D).
Interestingly enough, this is where metadata comes from.
It also means each object can have an infinite amount of metadata attached to it. Metadata, put simply, is a “tag” that identifies how the file is used or stored. There are several examples of metadata, but here are just a few:
Descriptive metadata, like the title or author.
Structural metadata, like how to order pages in a chapter.
Administrative metadata, like when the file was created, who has permissions to it, and so on.
Legal metadata, like who holds the copyright or if the file is in the public domain.
So, when you’re saying an image file is 400×400 pixels and in .jpg format, you’ve just identified two pieces of metadata about the file. In filmmaking, metadata can include things like reel numbers or descriptions. And, as artificial intelligence (AI) and machine learning tools continue to evolve, the amount of metadata about a given piece of footage or image only continues to grow. AI tools can add data around scene details, facial recognition, and other identifiers, and since those are coded as metadata, you will be able to store and search files using terms like “scenes with Bugs Bunny” or “scenes that are in a field of wildflowers”—and that means that you’ll spend less time trying to find the footage you need when you’re editing.
When you put it all together, you have one gigantic content pool that can grow infinitely. It uses no manually created complex folder structure and naming conventions. And it can hold an infinite amount of data about your data (metadata), making your files more discoverable.
Let’s Talk About Object Storage for Content Creation
You might be wondering: What does this have to do with the content I’m creating?
Consider this: When you’re editing a project, how much of your time is spent searching for files? A recent study by GISTICS found that the average creative person searches for media 83 times a week. Maybe you’re searching your local hard drive first, then your NAS, then those USB drives in your closet. Or, maybe you are restoring content off an LTO tape to search for that one clip you need. Or, maybe you moved some of your content to the cloud—is it in your Google Drive or in your Dropbox account? If so, which folder is it in? Or was it the corporate Box account? Do you have permissions to that folder? All of that complexity means that the average creative person fails to find the media they are looking for 35% of the time. But you probably don’t need a study to tell you we all spent huge amounts of time searching for content.
Good old “request timed out.”
Here is where object storage can help. With object storage, you simply have buckets (object storage containers) where all your data can live, and you can access it from wherever you’re working. That means all of the data stored on those shuttle drives sitting around your office, your closet of LTO tapes, and even a replica of your online NAS are in a central, easily accessible location. You’re also working from the most recent file.
Once it’s in the cloud, it’s safe from the types of disasters that affect on-premises storage systems, and it’s easy to secure your files, create backups, and so on. It’s also readily available when you need it, and much easier to share with other team members. It’s no wonder many of the apps you use today take advantage of object storage as their primary storage mechanism.
The Benefits of Object Storage for Media Workflows
Object storage offers a number of benefits for creative teams when it comes to streamlining workflows, including:
Instant access
Integrations
Workflow interoperability
Easy distribution
Off-site back up and archive
Instant Access
With cloud object storage, content is ready when you need it. You know inspiration can strike at any time. You could be knee deep in editing a project, in the middle of binge watching the latest limited series, or out for a walk. Whenever the inspiration decides to strike, having instant access to your library of content is a game changer. And that’s the great thing about object storage in the cloud: you gain access to massive amounts of data with a few clicks.
Integrations
Object storage is a key component of many of the content production tools in use today. For example, iconik is a cloud-native media asset management (MAM) tool that can gather and organize media from any storage location. You can point iconik to your Backblaze B2 Bucket and use its advanced search functions as well as its metadata tagging.
Workflow Interoperability
What if you don’t want to use iconik, specifically? What’s great about using cloud storage as a centralized repository is that no matter what application you use, your data is in a single place. Think of it like your external hard drive or NAS—you just connect that drive with a new tool, and you don’t have to worry about downloading everything to move to the latest and greatest. In essence, you are bringing your own storage (BYOS!).
Here’s an example: CuttingRoom is a cloud native video editing and collaboration tool. It runs entirely in your web browser and lets you create unique stories that can instantly be published to your destination of choice. What’s great about CuttingRoom is its ability to read an object storage bucket as a source. By simply pointing CuttingRoom to a Backblaze B2 Bucket, it has immediate access to the media source files and you can get to editing. On the other hand, if you prefer using a MAM, that same bucket can be indexed by a tool like iconik.
Easy Distribution
Now that your edit is done, it’s time to distribute your content to the world. Or, perhaps you are working with other teams to perfect your color and sound, and it’s time to share your picture lock version. Cloud storage is ready for you to distribute your files to the next team or an end user.
Here’s a recent, real-world example: If you have been following the behind-the-scenes articles about creating Avatar: The Way of Water, you know that not only was its creation the spark of new technology like the Sony Venice camera with removable sensors, but the distribution featured a cloud centric flow. Footage (the film) was placed in an object store (read: a cloud storage database), processed into different formats, languages were added with 3D captions, and then footage was distributed directly from a central location.
And, while not all of us have Jon Landau as our producer, a huge budget, and a decade to create our product, this same flexibility exists today with object storage—with the added bonus that it’s usually budget-friendly as well.
Off-Site Back Up and Archive
And last but certainly not least, let’s talk back up and archive. Once a project is done, you need space for the next project, but no one wants to risk losing the old project. Who out there is completely comfortable hitting the delete key as well as saying yes to the scary prompt, “Are you sure you want to delete?”
Well, that’s what you would have to do in the past. These days, object storage is a great place to store your terabytes and terabytes of archived footage without cluttering your home, office, or set with additional hardware. Compared with on-premises storage, cloud storage lets you add more capacity as you need it—just make sure you understand cloud storage pricing models so that you’re getting the best bang for your buck.
If you’re using a NAS device in your media workflow, you’ll find you need to free up your on-prem storage. Many NAS devices, like Synology and QNAP, have cloud storage integrations that allow you to automatically sync and archive data from your device to the cloud. In fact, you could start taking advantage of this today.
No delete key here—just a friendly archive button.
Getting Started With Object Storage for Media Workflows
Migrating to the cloud may seem daunting, but it doesn’t have to be. Especially with the acceleration of hybrid workflows in the film industry recently, cloud-based workflows are becoming more common and better integrated with the tools we use every day. You can test this out with Backblaze using your free 10GB that you get just for signing up for Backblaze B2. Sure, that may not seem like much when a single .r3d file is 4GB. But with that 10GB, you can test upload speeds and download speeds, try out integrations with your preferred workflow tools, and experiment with AI metadata. If your team is remote, you could try an integration with LucidLink. Or if you’re looking to power a video on-demand site, you could integrate with one of our content delivery network (CDN) partners to test out content distribution, like Backblaze customer Kanopy, a streaming service that delivers 25,000 videos to libraries worldwide.
Network attached storage (NAS) devices offer centralized data storage solutions, enabling users to easily protect and access their data locally. You can think of a NAS device as a powerful computer that doesn’t have a display or keyboard. NAS can function as extended hard disks, virtual file cabinets, or centralized storage systems depending on individual needs. While NAS devices provide local data protection, a hybrid setup with cloud storage offers off-site protection by storing files on geographically remote servers.
This blog is the first in a two part series that will focus on home NAS setups, exploring how two Backblazers set up their NAS devices and connected them to the cloud. We’ll aim to present actionable setup tips and explain what each of our data storage needs are so that you can create your own NAS setup strategy.
I’m Vinodh, your first user. In this post, I will walk you through how I use a Synology Single-Bay NAS device and Backblaze B2 Cloud Storage.
Why Did I Need a NAS Device At My Home?
Before I share my NAS setup, let’s take a look at some of the reasons why I needed a NAS device to begin with. Knowing that will give you a better understanding of what I’m trying to accomplish with NAS.
My work at Backblaze involves guiding customers through all things NAS and cloud storage. I use a single-bay NAS device to understand its features and performance. I also create demos, test use cases, and develop marketing materials and back them up on my NAS and in the cloud to achieve the requirements of a 3-2-1 backup strategy. That strategy recommends that you have three copies of data stored in two different locations with one copy off-site.
Additionally, I use my NAS setup to off-load the (stunning!) photos and videos from my wife’s and my iPhones to free up space and protect them safely in the cloud. Lastly, I’d also like to mention that I work remotely and collaborate with people as part of my regular work, but today we’re going to talk about how I back up my files using a hybrid cloud storage setup that combines Synology NAS and Backblaze B2. Combining NAS and cloud storage is a great backup and storage solution for both business and personal use, providing a layer of protection in the event of hardware failures, accidental deletions, natural disasters, or ransomware attacks.
Now that you understand a little bit about me and what I’m trying to accomplish with my NAS device, let’s jump into my setup.
What Do I Need From My NAS Device?
Needless to say, there are multiple ways to set up a NAS device. But, the most common setup is for backing up your local devices (computer, phones, etc.) to your NAS device. A basic setup like this, with a few computers and devices backing up to the same NAS device, protects data in that you have a second copy of your data stored locally. However, the data can still be lost if there is hardware failure, theft, fire, or any other unexpected event that poses a threat to your home. This means that your backup strategy needs something more in order to truly protect your data.
Off-site protection with cloud storage solves this problem. So, when I planned my NAS setup, I wanted to make sure I had a NAS device that integrates well with a cloud storage provider to achieve a 3-2-1 backup strategy.
Now that we’ve talked about my underlying data protection strategy, here are the devices and tools I used to create a complete 3-2-1 NAS backup setup at my home:
Devices with data:
MacBook Pro–1
iPhone–2
Storage products:
Synology Device–1
Seagate 4TB internal hard disk drive–1
Backblaze B2 Cloud Storage
Applications:
Synology Hyper Backup
Synology Photos
What Did I Want to Back Up on My NAS Device?
My MacBook Pro is where I create test use cases, demos, and all the files I need to do my job, such as blog posts, briefs, presentation decks, ebooks, battle cards, and so on. In addition to creating files, I also download webinars, infographics, industry reports, video guides, and any other information that I find useful to support our sales and marketing efforts. As I mentioned previously, I want to protect this business data both locally (for quick access) and in the cloud (for off-site protection). This way, I can not only secure the files, but also remotely collaborate with people from different locations so everyone can access, review, and edit the files simultaneously to ensure timely and consistent messaging.
Meanwhile, my wife and I each have an iPhone 12 with 128GB storage space. Clearly, a total of 256GB is not enough for us—it only takes six to nine months for us to run out of storage on our devices. Once in a while, I clean up the storage space to make sure my phone runs at optimal speed by removing any duplicate or unwanted photos or movies. However, my wife doesn’t like to delete anything as she often wants to look back and remember that one time we went to that one place with those friends. But, she has hundreds of pictures of that one place with those friends. As a result, our iPhone family usage is almost always at capacity.
Our shared storage.
As you can see, being able to off-load pictures and movies from our phones to a local device would give us quick access, protect our memories in the cloud, and free up our iPhone storage.
How I Set Up My NAS Device
To accomplish all that, I set up a Synology Single-Bay NAS Diskstation (Model: DS118) which is powered by a 64-bit quad-core processor and 1GB DDR4 memory. As we discussed above, a NAS device is basically a computer without a display and keyboard.
Unboxing my Synology NAS.
Most NAS devices are diskless, meaning we’d need to buy hard disk drives (HDD) and install them on the NAS device. Also, it is important to note that NAS devices work differently than a typical computer. A NAS device is always running even if you turn off your computer or laptop. A regular hard disk drive may not support this operating pressure. Therefore, it’s essential that we get NAS drives that are suitable for NAS devices. For my NAS device, I got a 4TB HDD from Seagate. You can look up compatible drives on Synology’s compatibility list. When you buy your NAS, the manufacturer should give you a list of which hard drives are compatible, and you can always check out Drive Stats if you want to read up on how long drives last.
A 4TB Seagate HDD.
After getting the NAS device and HDD, the next item I wanted to figure out is where to keep it. NAS devices typically plug into routers rather than desktops or laptops. With help from my internet service provider, I was able to connect all rooms in our house with an ethernet connection that’s attached to the router. For now, I set up the NAS device in my home office on a spare desk connected to the router via an RJ45 cable.
My Synology NAS in its new home with an Ethernet connection.
In addition to protecting data locally on the NAS device, I also use B2 Cloud Storage for off-site protection. Every NAS has its own software that helps you set up how your backups occur from your personal devices to your NAS, and that software will also have a way to back up to the cloud. On a Synology NAS, that software is called Hyper Backup, and we’ll talk a little bit more about it below.
How I Back Up My Computer to My NAS Device
The above diagram shows how I use a hybrid setup using Synology NAS and B2 Cloud Storage to protect data locally and off-site.
First, I use Synology File Station to upload critical business data to the NAS device. After I configure B2 Cloud Storage with Hyper Backup, all files uploaded to the NAS device automatically get uploaded and stored in B2 Cloud Storage.
Getting set up with B2 Cloud Storage is a simple process. Check out this video demonstration that shows how to get your NAS data to B2 Cloud Storage in 10 minutes or less.
How I Back Up iPhone Photos and Videos to My NAS Device
That takes care of our computer backups. Now on to photo storage. To off-load photos and movies and create more storage space on my phone, I installed the application “Synology Photos” on my and my wife’s iPhones. Now, whenever we take a picture or shoot a movie on our phones, the Synology Photos application automatically stores a copy of the files to the NAS device. And, the Hyper Backup application then copies those photos and movies to B2 Cloud Storage automatically.
This setup has enabled us to not worry about storage space on our phones. Even if we delete those pictures and movies, we can still access them quickly via the NAS device over our local area network (LAN). But most importantly, a copy of those memories is protected off-site in the cloud, and I can access that cloud storage copy easily from anywhere in the world.
Lessons Learned: What I’d Do Differently The Next Time
So, what can you take from my experience setting up a NAS device at home? I learned a few things along the way that you might find useful. Here is my advice if I were to do things differently the second time around:
Number of bays: I opted for a single bay NAS device for my home setup. After using the device for about three months now, I realize how much space it saved on my MacBook and iPhones. If I were to do it again, I’d choose a NAS device with four or more bays for increased storage options.
Check for Ethernet connectivity: Not all rooms in my house were wired for Ethernet connectivity, and I did not realize that until I started setting up the NAS device. I needed to get in touch with my internet service provider to provide Ethernet connectivity in all rooms—which delayed the setup by two weeks. If you’re looking to set up a NAS device at home, ensure the desired location in your home has an Ethernet connection.
Location: I initially wanted to set up my NAS device in the laundry room. However, I realized NAS devices require a space that is well ventilated with minimum exposure to heat, dust, or moisture. Therefore, I’d chosen to set up the NAS device at my office room instead. Consider factors like ventilation, accessibility, and dust exposure of the location for the longevity and performance of your NAS device.
So, whether you are a home user who wants additional storage, a small business owner who wants to create a centralized file storage system, or an IT admin for a mid-size or enterprise organization who wants to securely protect your critical business data both on-premises and off-site storage, the use of a NAS device along with cloud storage provides the protection you need to secure your data.
What’s Next: Looking Forward to Part Two
In part one of this series, we’ve learned how setting up a NAS device at home and connecting it to the cloud can effectively back up and protect critical business data and personal files while accomplishing a 3-2-1 backup strategy. Stay tuned for part two, where James Flores will share with us how he utilizes a hybrid NAS and cloud storage solution to back up, work on, and share media files with users from different locations. In the meantime, we’d love to hear about your experience setting up and using NAS devices with cloud storage. Please share your comments and thoughts below.
You know that sinking feeling you get in your stomach when you receive a hefty bill you weren’t expecting, especially when you then have to justify it to your finance team or face making cuts elsewhere to cover budget overrun? That is what some content delivery network (CDN) customers experience when they get slammed with bandwidth fees without warning. To avoid those painful conversations, it’s important to understand how bandwidth fees work. Knowing precisely what you are paying for and how you use the cloud service can help prevent eye-popping bills you weren’t prepared for.
A CDN can be an excellent way to speed up your website, improve performance, and boost SEO, but not all vendors are created equal—some charge significantly more for data transfer than others. As a leading provider of specialized cloud storage, Backblaze offers free egress to leading CDN providers like Fastly, bunny.net, and Cloudflare. Backblaze also offers tools for developers that help manage storage efficiently while integrating smoothly with CDN services.
So, let’s talk about bandwidth fees and how they work to help you decide which CDN provider is right for you.
What are CDN bandwidth fees?
Most CDN cloud services work like this: You can configure the CDN to pull data from one or more origins (such as a Backblaze B2 Cloud Storage Bucket) for free or for a flat fee, and then you’re charged fees for usage, namely when data is transferred when a user requests it.
These fees are known as bandwidth, download, or data transfer fees. (We’ll use these terms somewhat interchangeably.) Typically, storage providers also charge fees when data is retrieved by a CDN.
The fees aren’t a problem in and of themselves, but if you don’t have a good understanding of them, it could lead to unexpected costs.
For example, if you’re a game-sharing platform, and one of your games goes viral, bandwidth and egress fees can add up quickly. CDN providers usually charge in arrears, meaning they wait to see how much of the data was accessed each month, and then they apply their fees.
Some of the cost factors to consider include traffic spikes, regional distribution of your users (as some regions have higher transfer rates), and frequency of transferring large media files. Monitoring and managing data transfer fees can be challenging, especially during high-traffic events, as fees can quickly escalate without warning.
Although some CDN services offer calculation tools, these are estimates and may not always account for sudden increases in data transfer. It’s important to know exactly how these fees work so you can plan your workflows better and position your content strategically to reduce fees and increase cost efficiency.
How do CDN bandwidth fees work?
Data transfer occurs when data leaves the network. An example might be when your application server delivers an HTML page to the browser or your cloud object store serves an image via the CDN. Another example is when your data is moved to a different regional server within the CDN to make access faster for users in nearby locations.
Each instance where your data may be accessed or moved incurs a cost, and these fees can quickly add up. Typically, CDN vendors charge a fee per GB or TB up to a specific limit. Once you hit these thresholds, you may advance up another pricing tier or incur expensive overage charges. A busy month could cost you a mint, and traffic spikes for different reasons in different industries—like a Black Friday rush for an e-commerce site or around events like the Super Bowl for a sports betting site, for example.
Price comparison of bandwidth fees across CDN services
To get a better sense of how each CDN service charges for bandwidth, let’s explore the top providers and what they offer and charge. Each CDN varies in bandwidth fees, additional costs, and value-added features such as enhanced security and caching options.
As part of the Bandwidth Alliance and the CDN Alliance, some of these vendors have agreed to discount customer data transfer fees when transferring one or both ways between member companies. What’s more, Backblaze offers free egress with CDN partners Fastly, bunny.net, and Cloudflare, among other vendors, helping reduce costs for businesses with high data transfer fees.
When comparing CDNs, consider not only their per-GB costs but also factors like regional pricing variations, tiered pricing thresholds, and any add-ons for specific services like DDoS protection, web application firewalls (WAF), or dedicated support. These factors can significantly impact total costs, especially for businesses with varying traffic levels.
Note: Prices are as published by vendors as of 11/21/2024.
1. Fastly
Fastly offers edge caches to deliver content instantly around the globe. The company also offers SSL services for $20/per domain per month. They have various additional add-ons for things like web application firewalls (WAFs), managed rules, DDoS protection, and their Gold support.
Their CDN pricing offers flexibility through three main options:
Free Tier: This option provides up to $50 in monthly usage for any product (including CDN), with no request throttling and no cap on redirects or page rules.
Usage Tier: This option at $50 per month plus usage fees. It includes up to $100 in monthly CDN and Compute usage, with no cap on usage, five included TLS domains, mutual TLS, and SSO authentication.
Packages: Start at $1,500 per month and include various features, with tiers designed to support growing and large businesses needing predictable, scalable CDN services.
bunny.net labels itself as the world’s lightning-fast CDN service, with affordable region-based pricing. This makes them another strong alternative to AWS Cloudfront for companies with a limited budget. For the Standard Network (123 PoPs), rates start at $0.01/GB per month for North America and Europe, $0.045/GB for South America, $0.03/GB for Asia and Oceania, and $0.06/GB for the Middle East and Africa.
For businesses with higher bandwidth needs, the Volume Network offers a global rate of $0.005/GB up to 500TB, with tiered discounts available up to 2PB and beyond.
Cloudflare offers a limited free plan for hobbyists and individuals. They also have tiered pricing plans for businesses called Pro, Business, and Enterprise. Instead of charging bandwidth fees, Cloudflare opts for the monthly subscription model, which includes everything.
The Pro plan costs $20/month (for 100MB of upload). The Business plan is $200/month (for 200MB of upload). You must call to get pricing for the Enterprise plan (for 500MB of upload).
Cloudflare partners with Backblaze, and joint customers enjoy free egress between the two services. It also offers dozens of add-ons for load balancing, smart routing, security, serverless functions, etc. Each one costs extra per month.
4. AWS Cloudfront
AWS Cloudfront is Amazon’s CDN and is tightly integrated with its AWS services. The company offers tiered pricing based on bandwidth usage. The specifics are as follows for North America:
First 1TB of data transfer per month is free.
$0.085/GB for the next 9TB per month.
$0.080/GB for the next 40TB per month.
$0.060/GB for the next 100TB per month.
$0.040/GB for the next 350TB per month.
$0.030/GB for the next 524TB per month.
Their pricing extends up to 5PB per month, and there are different pricing breakdowns for different regions.
Amazon offers special discounts for high-data users and those customers who use AWS for their application storage. You can also purchase add-on products that work with the CDN for media streaming and security.
Sure it’s pretty. Until you know all those lights represent possible fees.
5. Google Cloud CDN
Google Cloud CDN offers fast and reliable content delivery services. However, Google charges bandwidth, cache egress fees, and for cache misses. Their pricing structure is as follows:
Cache Egress: $0.02–$0.20 per GB.
Cache Fill: $0.01–$0.04 per GB.
Cache Lookup Requests: $0.0075 per 10,000 requests.
Cache egress fees are priced per region, and in the U.S., they start at $0.08 for the first 10TB. Between 10–150TB costs $0.055, and beyond 500TB, you have to call for pricing.
Google charges $0.01 per GB for cache fill services.
6. Microsoft Azure
The Azure content delivery network is Microsoft’s offering that promises speed, reliability, and a high level of security.
Azure offers a limited free account for individuals to play around with. Depending on the zone, the price will vary for data transfer. For Zone One, which includes North America, Europe, Middle East, and Africa, pricing is as follows:
First 10TB: $0.158/GB per month.
Next 40TB: $0.14/GB per month.
Next 100TB: $0.121/GB per month.
Next 350TB: $0.102/GB per month.
Next 500TB: $0.093/GB per month.
Next 4,000TB: $0.084/GB per month.
Azure charges $.60 per 1,000,000,000 requests per month and $1 for rules per month. You can also purchase WAF services and other products for an additional monthly fee.
Comparing the CDNs
How to save on bandwidth fees
A CDN can significantly enhance the performance of your website or web application and is well worth the investment. However, finding ways to save on bandwidth fees pays dividends. Here are some strategies:
Look for Bandwidth Alliance partners. Many CDN providers, including those in the Bandwidth Alliance, offer discounted rates for bandwidth and egress fees when transferring data between member companies.
Choose affordable origin storage. Select origin storage that integrates seamlessly with your chosen CDN provider, reducing your data transfer costs. Backblaze B2, for example, offers completely free egress to partners like Fastly, bunny.net, and Cloudflare, and free egress up to 3x the amount you store for transfer to other services.
Optimize caching and edge settings. Fine-tuning caching rules to keep frequently accessed data at edge locations can reduce the amount of data transferred, helping to avoid unnecessary bandwidth fees.
Implement data compression. Compressing files, especially large media, reduces the data size served by the CDN, which in turn reduces bandwidth usage.
Minimize redirects and request loops. Reducing redirects and optimizing request loops helps keep data transfer low and avoids additional bandwidth fees.
Use tiered or reserved data transfer plans. Some CDNs offer reserved or tiered data transfer options that provide discounts on larger volumes; consider these if your data transfer needs are predictable and high.
CDN bandwidth refers to the amount of data that is transferred between a content delivery network (CDN) and its end-users. When a user accesses a website or service that uses a CDN, the data they request is delivered from servers closest to them, which speeds up delivery and reduces latency. The total amount of this data transfer over time is considered the CDN bandwidth, and it can significantly affect performance and costs depending on traffic levels.
2. What is a bandwidth fee?
A bandwidth fee is a charge imposed by a CDN provider based on the volume of data transferred from the CDN’s servers to end-users. CDNs use a pay-per-use model for bandwidth, meaning websites or services pay for each unit of data transferred, typically measured in gigabytes (GB) or terabytes (TB). High traffic volumes or large files (like videos) can quickly increase these fees, making it important to monitor and manage bandwidth usage.
3. How can I reduce CDN usage?
Reducing CDN fees involves optimizing data transfer and content delivery practices. A few effective strategies are to look for bandwidth alliance partners, choose affordable origin storage, optimize caching and edge settings, implement data compression, minimize redirects and request loops, and use tiered or reserved data transfer plans.
4. How do I monitor CDN bandwidth usage effectively?
Most CDN providers offer analytics and reporting tools to track bandwidth usage in real time. By regularly reviewing these reports, you can identify high-demand assets, monitor peak traffic times, and adjust your delivery strategy to minimize bandwidth fees.
For many of us, 2020 transformed our work habits. Changes to the way we work that always seemed years away got rolled out within a few months. Fast forward to today, and the world seems to be returning back to some sense of normalcy. But one thing that’s not going back is how we work, especially for media production teams. Virtual production, remote video production, and hybrid cloud have all accelerated, reducing operating costs and moving us closer to a cloud-based reality.
So what’s the difference between virtual production, remote production, and hybrid cloud workflows, and how can you use any or all of those strategies to improve how you work? At first glance, they all seem to be different variations of the same thing. But there are important differences, and that’s what we’re digging into today. Read on to get an understanding of these new ways of working and what they mean for your creative team.
Going to NAB in April?
Want to talk about your production setup at NAB? Backblaze will be there with exciting new updates and hands-on demos for better media workflows. Oh, and we’re bringing some really hot swag. Reserve time to meet with our team (and snap up some sweet goodies) below.
What Is Virtual Production?
Let’s start with virtual production. It sounds like doing production virtually, which could just mean “in the cloud.” I can assure you, it’s way cooler than that. When the pandemic hit, social distancing became the norm. Gathering a film crew together in a studio or in any location of the world went out the door. Never fear: virtual production came to the rescue.
Virtual production is a method of production where, instead of building a set or going to a specific location, you build a set virtually, usually with a gaming engine such as Unreal Engine. Once the environment is designed and lit within Unreal Engine, it can then be fed to an LED volume. An LED volume is exactly what it sounds like: a huge volume of LED screens connected to a single input (the Unreal Engine environment).
With virtual production, your set becomes the LED volume, and Unreal Engine can change the background to anything you can imagine at the click of a button. Now this isn’t just a LED screen as a background—what makes virtual production so powerful is its motion tracking integration with real cameras.
Using a motion sensor system attached to a camera, Unreal Engine is able to understand where your camera is pointed. (It’s way more tech-y than that, but you get the picture.) You can even match the virtual lens in Unreal Engine with the lens of your physical camera. With the two systems combined, a camera following an actor on a virtual set can react by moving the background along with the camera in real time.
Virtual Production in Action
If you were one of the millions who have been watching The Mandalorian on Disney+, check out this behind the scenes look at how they utilized a virtual production.
This also means location scouting can be done entirely inside the virtual set and the assets created for pre-vizualiation can actually carry on into post, saving a ton of time (as the post work actually starts during pre-production.
So, virtual production is easily confused with remote production, but it’s not the same. We’ll get into remote production next.
What Is Remote Production?
We’re all familiar with the stages of production: development, pre-production, production, post-production, and distribution. Remote production has more to do with post-production. Remote production is simply the ability to handle post-production tasks from anywhere.
Here’s how the pandemic accelerated remote production: In post, assets are edited on non-linear editing software (NLEs) connected to huge storage systems located deep within studios and post-production houses. When everyone was forced to work from home, it made editing quite difficult. There were, of course, solutions that allowed you to remotely control your edit bay, but remotely controlling a system from miles away and trying to scrub videos over your at-home internet bandwidth quickly became a nuisance.
To solve this problem, everyone just took their edit bay home along with a hard drive containing what they needed for their particular project. But shuttling drives all over the place and trying to correlate files across all the remote drives meant that the NAS became the next headache. To resolve this confusion over storage, production houses turned to hybrid solutions—our next topic.
What Are Hybrid Cloud Workflows?
Hybrid cloud workflows didn’t originate during the pandemic, but they did make remote production much easier. A hybrid cloud workflow is a combination of a public cloud, private cloud, and an on-premises solution like a network attached storage device (NAS) or storage area network (SAN). When we think about storage, we think about first the relationship of our NLE to our local hard drive, then our relationship between the local computer and the NAS or SAN. The next iteration of this is the relationship of all of these (NLE, local computer, and NAS/SAN) to the cloud.
For each of these on-prem solutions the primary problems faced are capacity and availability. How much can our drive hold, and how do I access the NAS—local area network (LAN) or virtual private network (VPN)? Storage in the cloud inherently solves both of these problems. It’s always available and accessible from any location with an internet connection. So, to solve the problems that remote teams of editors, visual effects (VFX), color, and sound folks faced, the cloud was integrated into many workflows.
Using the cloud, companies are able to store content in a single location where it can then be distributed to different teams (VFX, color, sound, etc.). This central repository makes it possible to move large amounts of data across different regions, making it easier for your team to access it while also keeping it secure. Many NAS devices have native cloud integrations, so the automated file synchronization between the cloud and a local environment is baked in—teams can just get to work.
The hybrid solution worked so well that many studios and post houses have adopted them as a permanent part of their workflow and have incorporated remote production into their day-to-day. A good example is the video team at Hagerty, a production crew that creates 300+ videos a year. This means that workflows that were once locked down to specific locations are now moving to the cloud. Now more than ever, API accessible resources, like cloud storage with S3 compatible APIs that integrates with your preferred tools, are needed to make these workflows actually work.
Just one example of Hagerty’s content.
Hybrid Workflows and Cloud Storage
While the world seems to be returning to a new normal, our way of work is not. For the media and entertainment world, the pandemic gave the space a jolt of electricity, igniting the next wave of innovation. Virtual production, remote production, and hybrid workflows are here to stay. What digital video started 20 years ago, the pandemic has accelerated, and that acceleration is pointing directly to the cloud.
So, what are your next steps as you future-proof your workflow? First, inspect your current set of tools. Many modern tools are already cloud-ready. For example, a Synology NAS already has Cloud Sync capabilities. EditShare also has a tool capable of crafting custom workflows, wherever your data lives. (These are just a few examples.)
Second, start building and testing. Most cloud providers offer free tiers or free trials—at Backblaze, your first 10GB are free, for example. Testing a proof of concept is the best way to understand how new workflows fit into your system without overhauling the whole thing or potentially disrupting business as usual.
And finally, one thing you definitely need to make hybrid workflows work is cloud storage. If you’re looking to make the change a lot easier, you came to the right place. Backblaze B2 Cloud Storage pairs with hundreds of integrations so you can implement it directly into your established workflows. Check out our partners and our media solutions for more.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.