Post Syndicated from Jeff Barr original https://aws.amazon.com/blogs/aws/new-aws-telco-network-builder-deploy-and-manage-telco-networks/
Over the course of more than one hundred years, the telecom industry has become standardized and regulated, and has developed methods, technologies, and an entire vocabulary (chock full of interesting acronyms) along the way. As an industry, they need to honor this tremendous legacy while also taking advantage of new technology, all in the name of delivering the best possible voice and data services to their customers.
Today I would like to tell you about AWS Telco Network Builder (TNB). This new service is designed to help Communications Service Providers (CSPs) deploy and manage public and private telco networks on AWS. It uses existing standards, practices, and data formats, and makes it easier for CSPs to take advantage of the power, scale, and flexibility of AWS.
Today, CSPs often deploy their code to virtual machines. However, as they look to the future they are looking for additional flexibility and are increasingly making use of containers. AWS TNB is intended to be a part of this transition, and makes use of Kubernetes and Amazon Elastic Kubernetes Service (EKS) for packaging and deployment.
Concepts and Vocabulary
Before we dive in to the service, let’s take a look some concepts and vocabulary that are unique to this industry, and are relevant to AWS TNB:
European Telecommunications Standards Institute (ETSI) – A European organization that defines specifications suitable for global use. AWS TNB supports multiple ETSI specifications including ETSI SOL001 through ETSI SOL005, and ETSI SOL007.
Communications Service Provider (CSP) – An organization that offers telecommunications services.
Topology and Orchestration Specification for Cloud Applications (TOSCA) – A standardized grammar that is used to describe service templates for telecommunications applications.
Network Function (NF) – A software component that performs a specific core or value-added function within a telco network.
Virtual Network Function Descriptor (VNFD) – A specification of the metadata needed to onboard and manage a Network Function.
Cloud Service Archive (CSAR) – A ZIP file that contains a VNFD, references to container images that hold Network Functions, and any additional files needed to support and manage the Network Function.
Network Service Descriptor (NSD) – A specification of the compute, storage, networking, and location requirements for a set of Network Functions along with the information needed to assemble them to form a telco network.
Network Core – The heart of a network. It uses control plane and data plane operations to manage authentication, authorization, data, and policies.
Service Orchestrator (SO) – An external, high-level network management tool.
Radio Access Network (RAN) – The components (base stations, antennas, and so forth) that provide wireless coverage over a specific geographic area.
Using AWS Telco Network Builder (TNB)
I don’t happen to be a CSP, but I will do my best to walk you through the getting-started experience anyway! The primary steps are:
- Creating a function package for each Network Function by uploading a CSAR.
- Creating a network package for the network by uploading a Network Service Descriptor (NSD).
- Creating a network by selecting and instantiating an NSD.
To begin, I open the AWS TNB Console and click Get started:

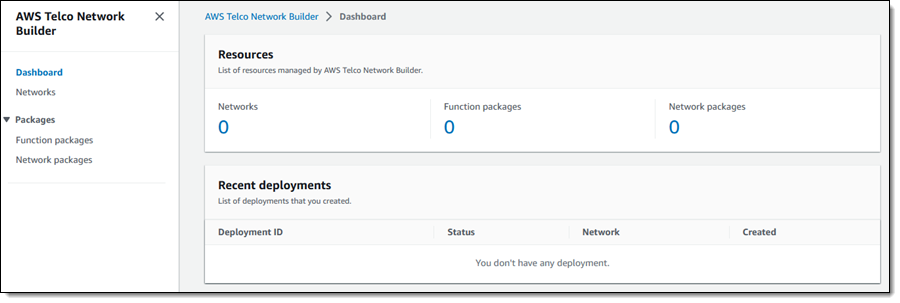
Initially, I have no networks, no function packages, and no network packages:
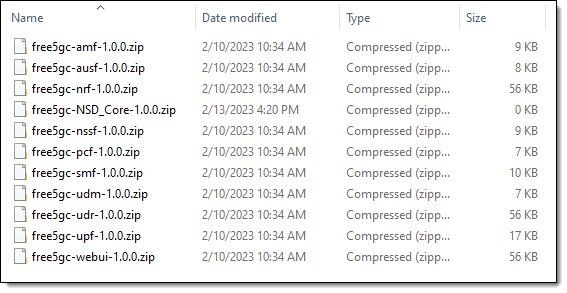
My colleagues supplied me with sample CSARs and an NSD for use in this blog post (the network functions are from Free 5G Core):
Each CSAR is a fairly simple ZIP file with a VNFD and other items inside. For example, the VNFD for the Free 5G Core Session Management Function (smf) looks like this:
The final section (HelmImage) of the VNFD points to the Kubernetes Helm Chart that defines the implementation.
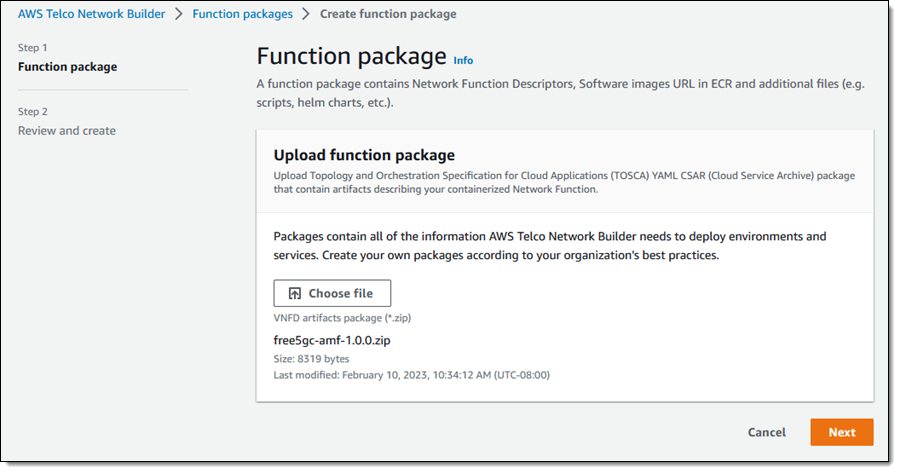
I click Function packages in the console, then click Create function package. Then I upload the first CSAR and click Next:
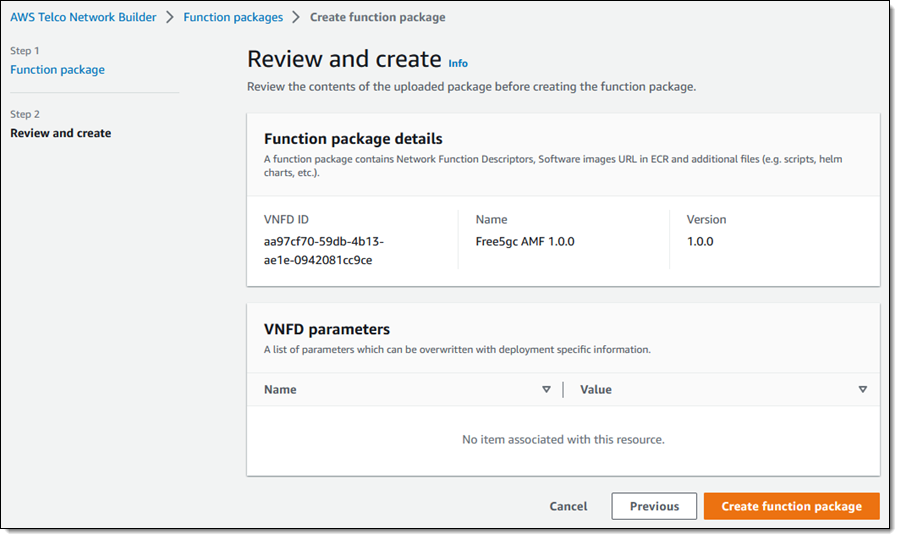
I review the details and click Create function package (each VNFD can include a set of parameters that have default values which can be overwritten with values that are specific to a particular deployment):
I repeat this process for the nine remaining CSARs, and all ten function packages are ready to use:

Now I am ready to create a Network Package. The Network Service Descriptor is also fairly simple, and I will show you several excerpts. First, the NSD establishes a mapping from descriptor_id to namespace for each Network Function so that the functions can be referenced by name:
Then it defines the input variables, including default values (this reminds me of a AWS CloudFormation template):
Next, it uses the variables to create a mapping to the desired AWS resources (a VPC and a subnet in this case):
Then it defines an AWS Internet Gateway within the VPC:
Finally, it specifies deployment of the Network Functions to an EKS cluster; the functions are deployed in the specified order:
I click Create network package, select the NSD, and click Next to proceed. AWS TNB asks me to review the list of function packages and the NSD parameters. I do so, and click Create network package:
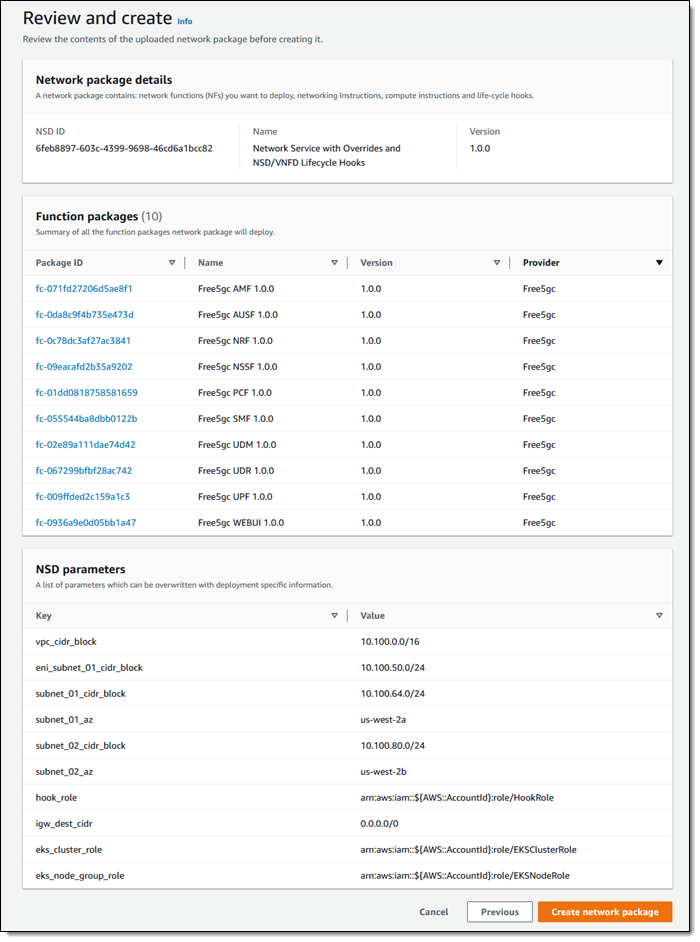
My network package is created and ready to use within seconds:
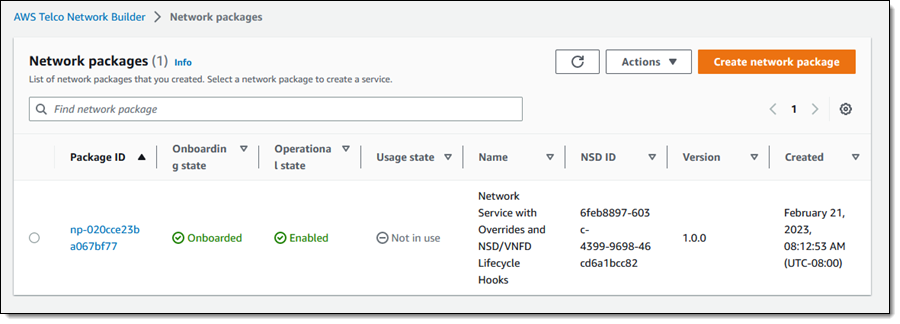
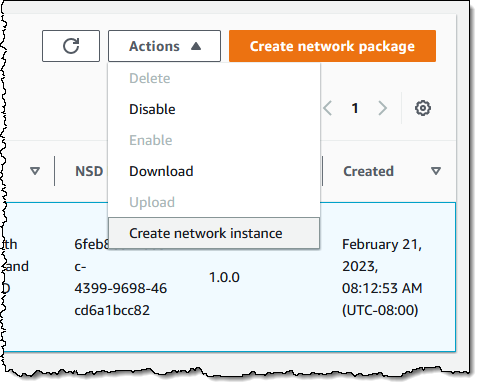
Now I am ready to create my network instance! I select the network package and choose Create network instance from the Actions menu:
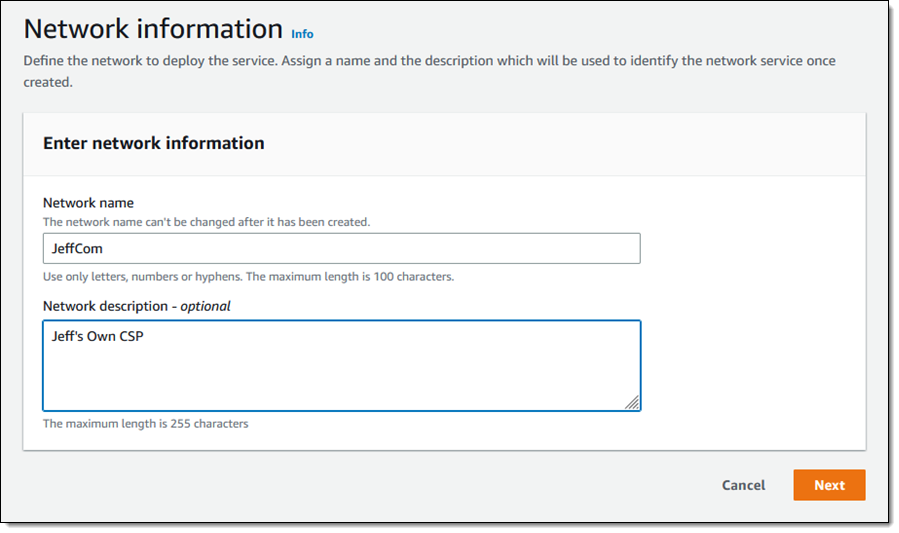
I give my network a name and a description, then click Next:
I make sure that I have selected the desired network package, review the list of functions packages that will be deployed, and click Next:
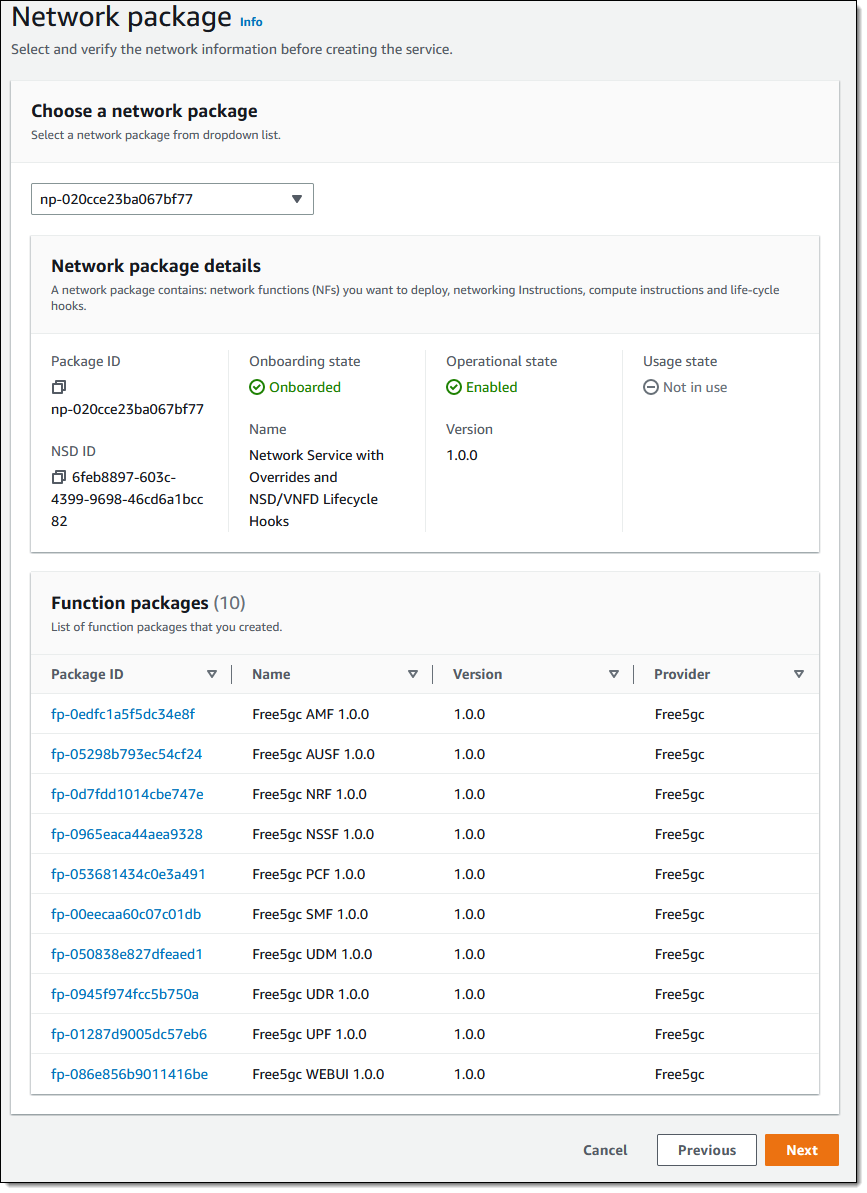
Then I do one final review, and click Create network instance:
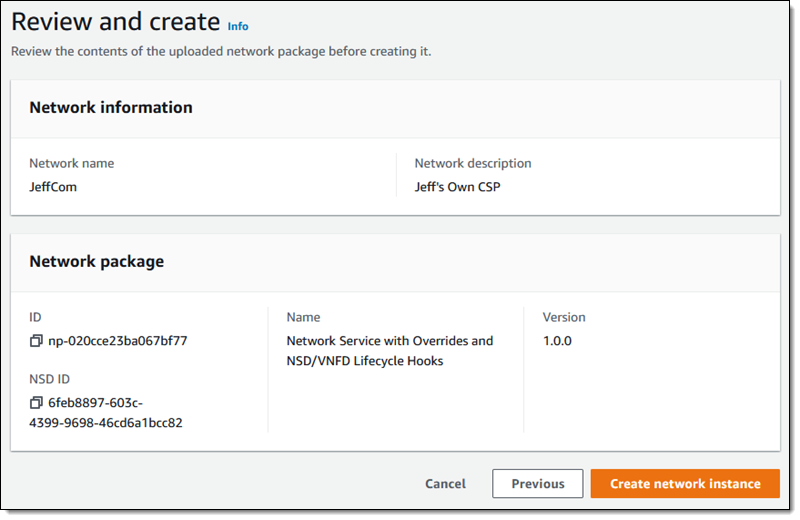
I select the new network instance and choose Instantiate from the Actions menu:
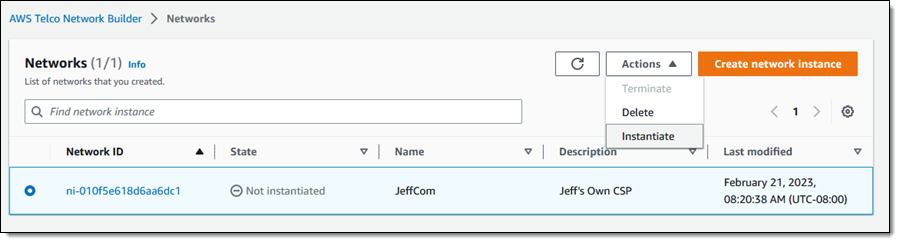
I review the parameters, and enter any desired overrides, then click Instantiate network:
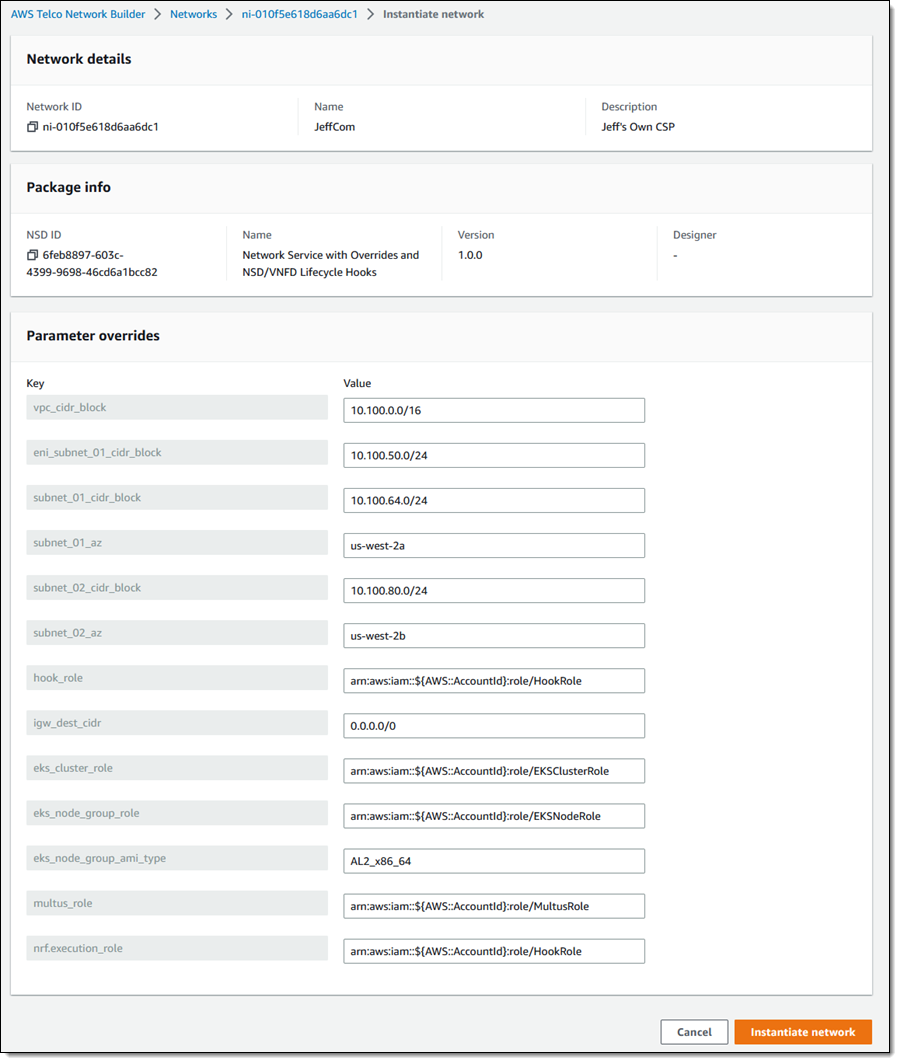
AWS Telco Network Builder (TNB) begins to instantiate my network (behind the scenes, the service creates a AWS CloudFormation template, uses the template to create a stack, and executes other tasks including Helm charts and custom scripts). When the instantiation step is complete, my network is ready to go. Instantiating a network creates a deployment, and the same network (perhaps with some parameters overridden) can be deployed more than once. I can see all of the deployments at a glance:
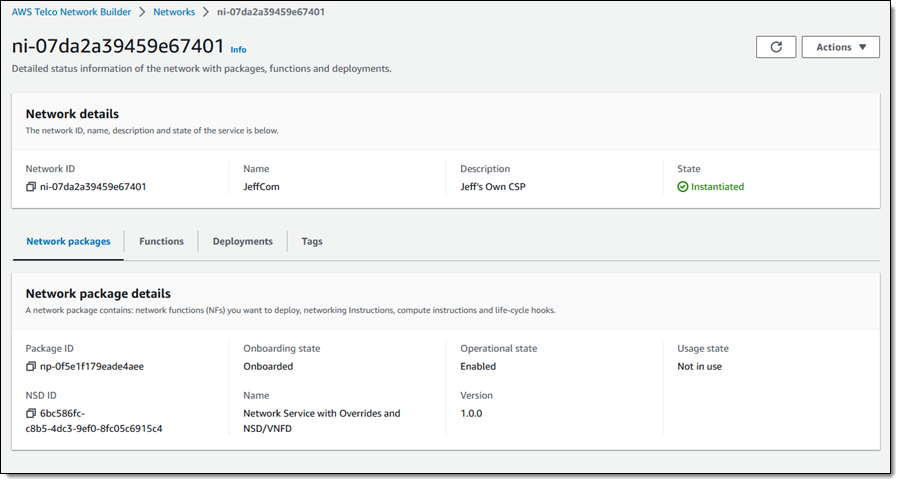
I can return to the dashboard to see my networks, function packages, network packages, and recent deployments:
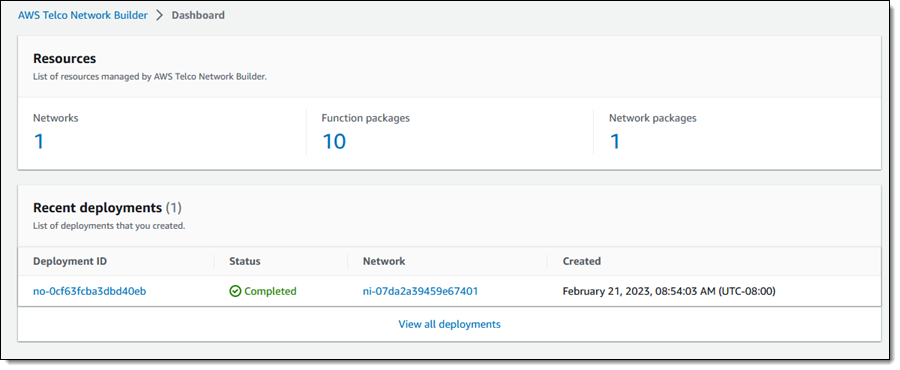
Inside an AWS TNB Deployment
Let’s take a quick look inside my deployment. Here’s what AWS TNB set up for me:
Network – An Amazon Virtual Private Cloud (Amazon VPC) with three subnets, a route table, a route, and an Internet Gateway.
Compute – An Amazon Elastic Kubernetes Service (EKS) cluster.
CI/CD – An AWS CodeBuild project that is triggered every time a node is added to the cluster.
Things to Know
Here are a couple of things to know about AWS Telco Network Builder (TNB):
Access – In addition to the console access that I showed you above, you can access AWS TNB from the AWS Command Line Interface (AWS CLI) and the AWS SDKs.
Deployment Options – We are launching with the ability to create a network that spans multiple Availability Zones in a single AWS Region. Over time we expect to add additional deployment options such as Local Zones and Outposts.
Pricing – Pricing is based on the number of Network Functions that are managed by AWS TNB and on calls to the AWS TNB APIs, but the first 45,000 API requests per month in each AWS Region are not charged. There are also additional charges for the AWS resources that are created as part of the deployment. To learn more, read the TNB Pricing page.
Getting Started
To learn more and to get started, visit the AWS Telco Network Builder (TNB) home page.
— Jeff;
 In late 2021 we
In late 2021 we