Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/amazon-s3-compatible-storage-on-aws-snowball-edge-compute-optimized-devices-now-generally-available/
We have added a collection of purpose-built services to the AWS Snow Family for customers, such as Snowball Edge in 2016 and Snowcone in 2020. These services run compute intensive workloads and stores data in edge locations with denied, disrupted, intermittent, or limited network connectivity and for transferring large amounts of data from on-premises and rugged or mobile environments.
 Each new service is optimized for space- or weight-constrained environments, portability, and flexible networking options. For example, Snowball Edge devices have three options for device configurations. AWS Snowball Edge Compute Optimized provides a suitcase-sized, secure, and rugged device that customers can deploy in rugged and tactical edge locations to run their compute applications. Customers modernize their edge applications in the cloud use AWS compute services and storage services such as Amazon Simple Storage Service (Amazon S3), and then deploy these applications on Snow devices at the edge.
Each new service is optimized for space- or weight-constrained environments, portability, and flexible networking options. For example, Snowball Edge devices have three options for device configurations. AWS Snowball Edge Compute Optimized provides a suitcase-sized, secure, and rugged device that customers can deploy in rugged and tactical edge locations to run their compute applications. Customers modernize their edge applications in the cloud use AWS compute services and storage services such as Amazon Simple Storage Service (Amazon S3), and then deploy these applications on Snow devices at the edge.
We heard from customers that they also needed access to local object store to run applications at the edge, such as 5G mobile core and real-time data analytics, to process end-user transactions, and they had limited storage infrastructure availability in these environments. Although the Amazon S3 Adapter for Snowball enables the basic storage and retrieval of objects on a Snow device, customers wanted access to a broader set of Amazon S3 APIs, including flexibility at scale, local bucket management, object tagging, and S3 event notifications.
Today, we’re announcing the general availability of Amazon S3 compatible storage on Snow for our Snowball Edge Compute Optimized devices. This makes it easy for you to store data and run applications with local S3 buckets that require low latency processing at the edge.
With Amazon S3 compatible storage on Snow, you can use an expanded set of Amazon S3 APIs to easily build applications on AWS and deploy them on Snowball Edge Compute Optimized devices. This eliminates the need to re-architect applications for each deployment. You can manage applications requiring Amazon S3 compatible storage across the cloud, on-premises, and at the edge in connected and disconnected environments with a consistent experience.
Moreover, you can use AWS OpsHub, a graphical user interface, to manage your Snow Family services and Amazon S3 compatible storage on the devices at the edge or remotely from a central location. You can also use Amazon S3 SDK or AWS Command Line Interface (AWS CLI) to create and manage S3 buckets, get S3 event notifications using MQTT, and local service notifications using SMTP, just as you do in AWS Regions.
With Amazon S3 compatible storage on Snow, we are now able to address various use cases in limited network environments, giving customers secure, durable local object storage. For example, customers in the intelligence community and in industrial IoT deploy applications such as video analytics in rugged and mobile edge locations.
Getting Started with S3 Compatible Storage on Snowball Edge Compute Optimized
To order new Amazon S3 enabled Snowball Edge devices, create a job in the AWS Snow Family console. You can replace an existing Snow device or cluster with new replacement devices that support S3 compatible storage.
In Step 1 – Job type, input your job name and choose Local compute and storage only. In Step 2 – Compute and storage, choose your preferred Snowball Edge Compute Optimized device.
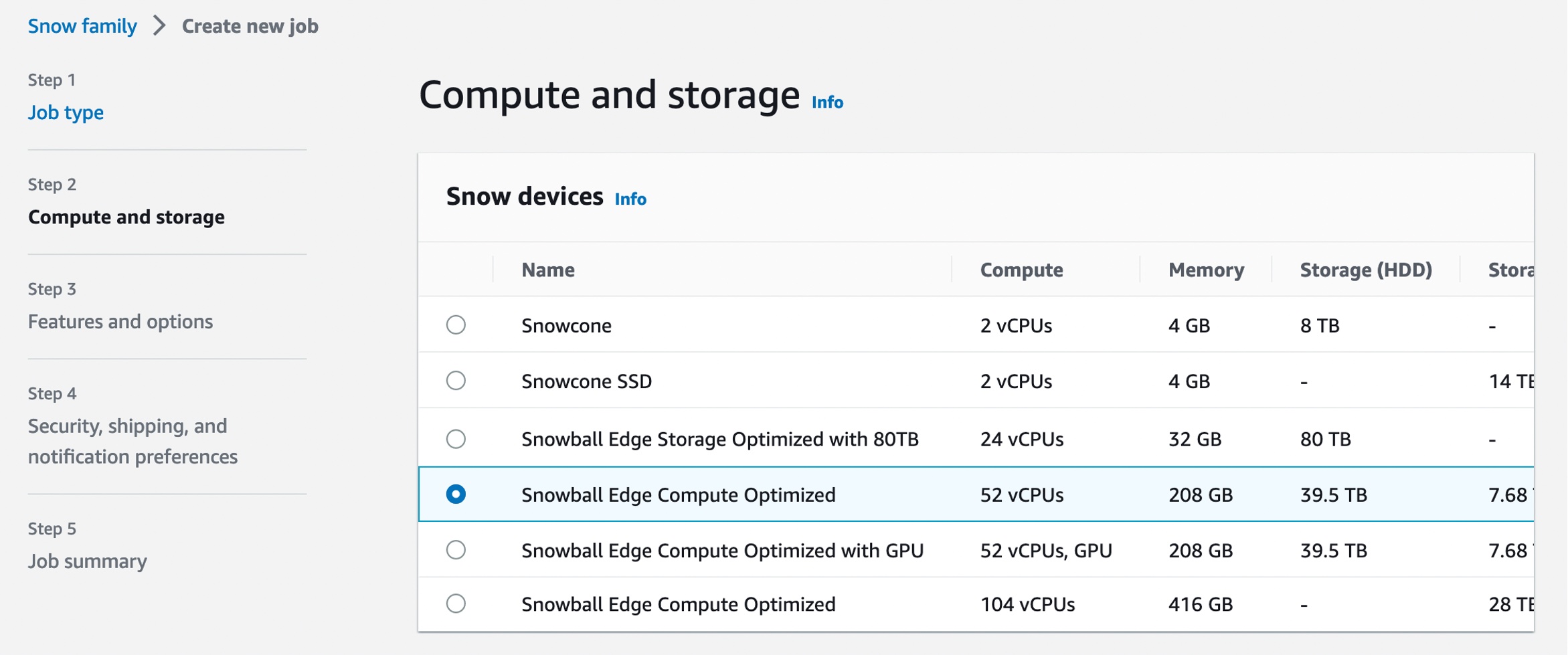
Select Amazon S3 compatible storage, a new option for S3 compatible storage. The current S3 Adapter solution is on deprecation path, and we recommend migrating workloads to use Amazon S3 compatible storage on Snow.

When you select Amazon S3 compatible storage, you can configure Amazon S3 compatible storage capacity for a single device or for a cluster. The Amazon S3 storage capacity depends on the quantity and type of Snowball Edge device.
- For single-device deployment, you can provision granular Amazon S3 capacity up to a maximum of 31 TB on a Snowball Edge Compute Optimized device.
- For a cluster setup, all storage capacity on a device is allocated to Amazon S3 compatible storage on Snow. You can provision a maximum of 500 TB on a 16 node cluster of Snowball Edge Compute Optimized devices.
When you provide all necessary job details and create your job, you can see the status of the delivery of your device in the job status section.
Manage S3 Compatible Storage on Snow with OpsHub
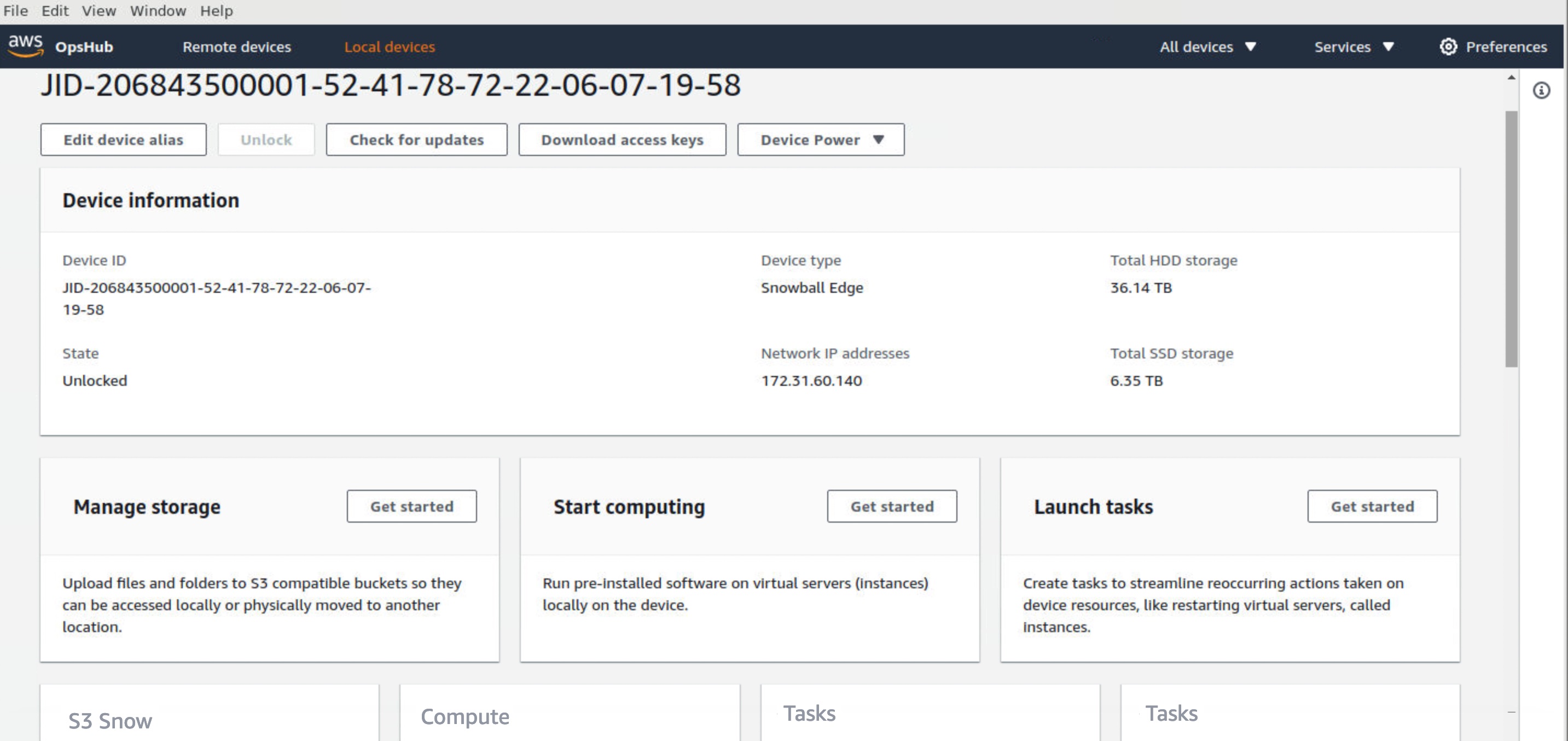
Once your device arrives at your site, power it on, and connect it to your network. To manage your device, download, install, and launch the OpsHub application in your laptop. After installation, you can unlock the device and start managing it and using supported AWS services locally.
OpsHub provides a dashboard that summarizes key metrics, such as storage capacity and active instances on your device. It also provides a selection of AWS services that are supported on the Snow Family devices.
Log in to OpsHub, then choose Manage Storage. This takes you to the Amazon S3 compatible storage on Snow landing page.
For Start service setup type, choose Simple if your network uses dynamic host configuration protocol (DHCP). With this option, the virtual network interface cards (VNICs) are created automatically on each device when you start the service. When your network uses static IP addresses, you need to create VNICs for each device manually, so choose the Advanced option.
Once the service starts, you’ll see its status is active with a list of endpoints. The following example shows the service activated in a single device:
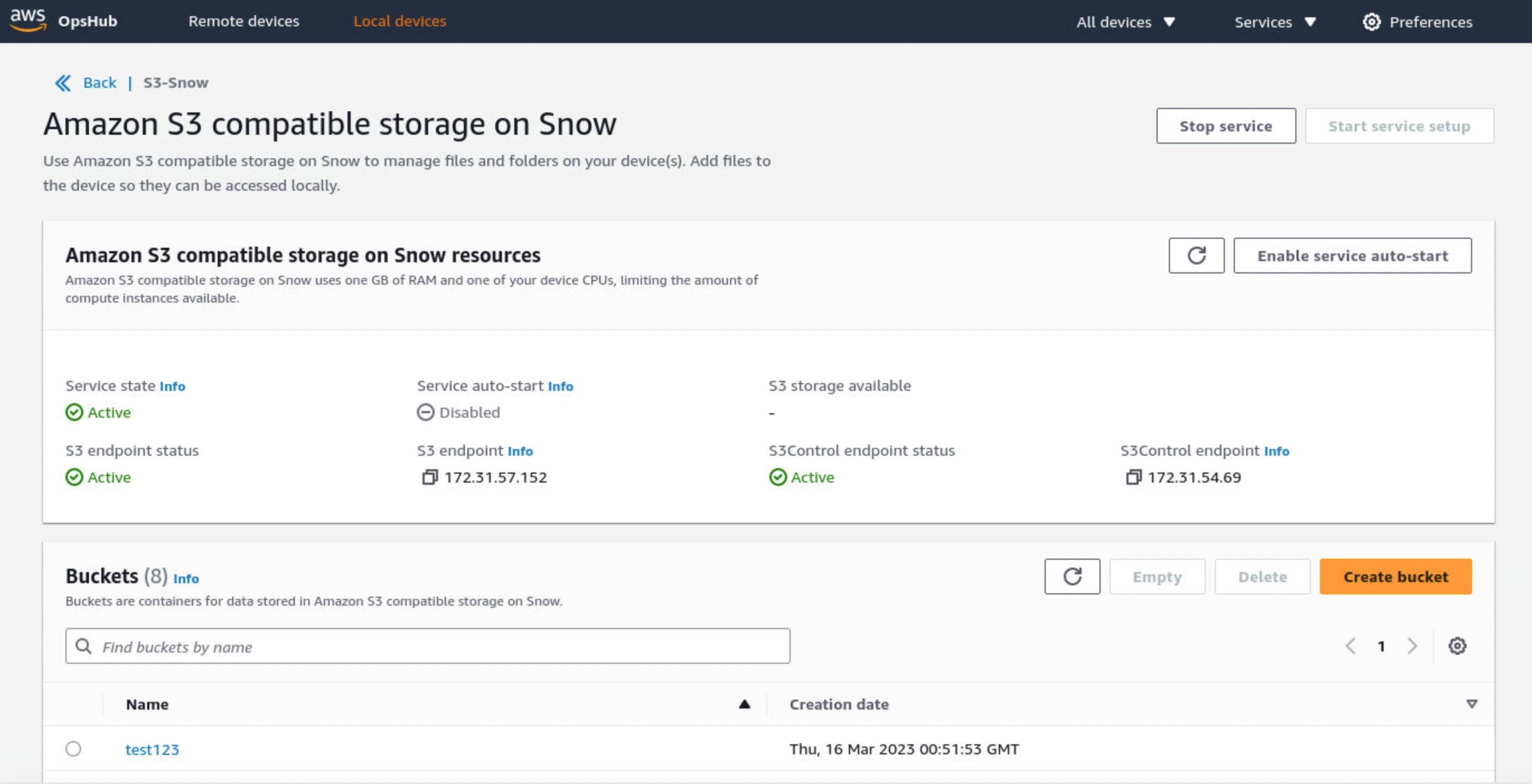
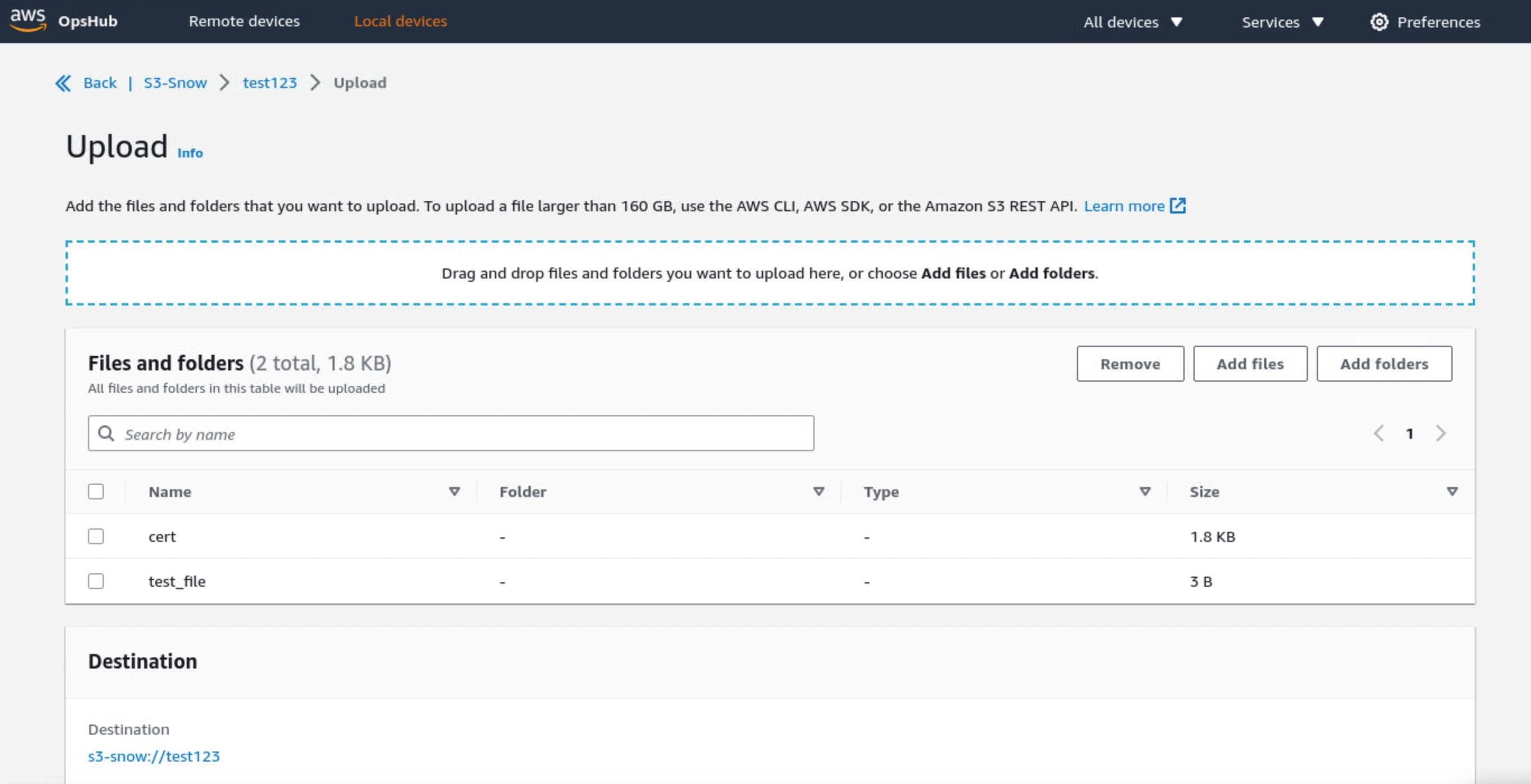
Choose Create bucket if you want the new S3 bucket in your device. Otherwise, you can upload files to your selected bucket. New uploaded objects have destination URLs such as s3-snow://test123/test_file with the unique bucket name in the device or cluster.
You can also use the bucket lifecycle rule to define when to trigger object deletion based on age or date. Choose Create lifecycle rule in the Management tab to add a new lifecycle rule.

You can select either Delete objects or Delete incomplete multipart uploads as a rule action. Configure the rule trigger that schedules deletion based on a specific date or object’s age. In this example, I set two days to delete objects after being uploaded.

You can also use the Amazon S3 SDK/CLI for all API operations supported by S3 for Snowball Edge. To learn more, see API Operations Supported on Amazon S3 for Snowball Edge in the AWS documentation.
Things to know
Keep these things in mind regarding additional features and considerations when you use Amazon S3 compatible storage on Snow:
- Capacity: If you fully utilize Amazon S3 capacity on your device or cluster, your write (
PUT) requests return an insufficient capacity error. Read (GET) operations continue to function normally. To monitor the available Amazon S3 capacity, you can use the OpsHub S3 on the Snow page or use thedescribe-serviceCLI command. Upon detecting insufficient capacity on the Snow device or cluster, you must free up space by deleting data or transferring data to an S3 bucket in the Region or another on-premises device. - Resiliency: Amazon S3 compatible storage on Snow stores data redundantly across multiple disks on each Snow device and multiple devices in your cluster, with built-in protection against correlated hardware failures. In the event of a disk or device failure within the quorum range, Amazon S3 compatible storage on Snow continues to operate until hardware is replaced. Additionally, Amazon S3 compatible storage on Snow continuously scrubs data on the device to make sure of data integrity and recover any corrupted data. For workloads that require local storage, the best practice is to back up your data to further protect your data stored on Snow devices.
- Notifications: Amazon S3 compatible storage on Snow continuously monitors the health status of the device or cluster. Background processes respond to data inconsistencies and temporary failures to heal and recover data to make sure of resiliency. In the case of nonrecoverable hardware failures, Amazon S3 compatible storage on Snow can continue operations and provides proactive notifications through emails, prompting you to work with AWS to replace failed devices. For connected devices, you have the option to enable the “Remote Monitoring” feature, which will allow AWS to monitor service health online and proactively notify you of any service issues.
- Security: Amazon S3 compatible storage on Snow supports encryption using server-side encryption with Amazon S3 managed encryption keys (SSE-S3) or customer-provided keys (SSE-C) and authentication and authorization using Snow IAM actions namespace (
s3:*) to provide you with distinct controls for data stored on your Snow devices. Amazon S3 compatible storage on Snow doesn’t support object-level access control list and bucket policies. Amazon S3 compatible storage on Snow defaults to Bucket Owner is Object Owner, making sure that the bucket owner has control over objects in the bucket.
Now Available
Amazon S3 compatible storage on Snow is now generally available for AWS Snowball Edge Compute Optimized devices in all AWS Commercial and GovCloud Regions where AWS Snow is available.
To learn more, see the AWS Snowball Edge Developer Guide and send feedback to AWS re:Post for AWS Snowball or through your usual AWS support contacts.
– Channy

 .NET Developer Day –
.NET Developer Day – 
 AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work:
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: 


















 Last weekend, I enjoyed the spring vibes at
Last weekend, I enjoyed the spring vibes at