Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=DyejMrwsR9o
Yearly Archives: 2024
[$] LWN.net Weekly Edition for July 18, 2024
Post Syndicated from corbet original https://lwn.net/Articles/981628/
The LWN.net Weekly Edition for July 18, 2024 is available.
Comic for 2024.07.17 – Take A Knee
Post Syndicated from Explosm.net original https://explosm.net/comics/take-a-knee
New Cyanide and Happiness Comic
Масовото образование, което (не) служи на всички
Post Syndicated from Надежда Цекулова original https://www.toest.bg/irina-manusheva-interview/

През последните два месеца критиките за състоянието на българското средно образование идват от различни посоки, но водят до едни и същи общи изводи – ниска мотивация и ниски постижения на учениците, фокус върху зазубрянето на фактология, липса на ключови за ХХI век умения и драматично разширяваща се ножица между малкия дял на постигащите най-високи резултати и все по-големия дял на оставащите под минималния праг на грамотността.
Макар тези изводи да не са нови, сериозен дебат „какво правим“ липсва. „Да държиш децата принудително в училище 12+ години по 8 часа на ден, без да им дадеш нищо смислено, е чисто и просто престъпление“, казва Ирина Манушева. И прави първата крачка към разбутване на кошера с петиция за преразглеждане на националните външни оценявания (НВО) и на задължителното кандидатстване след VII клас.
С нея разговаря Надежда Цекулова.
Ирина, какво мотивира усилията Ви да настоявате за промени в образованието?
Аз съм майка на три деца. Освен това съм преводач и съм философ по образование, а пък преди това съм завършила математическа гимназия, което дава един доста широк поглед върху различни аспекти на образованието. Работила съм години в частно училище, където се ценяха свободата и творчеството на учителите и съществените неща в развитието на децата. В практиката си там за първи път се запознах с такива образователни идеолози като Селестен Френе, Шалва Амонашвили и много други. И видях как може да бъде.
И така, като дойде време децата ми да тръгват на училище, изпаднах в лек ступор. Минахме през частно училище с най-големия. После през държавно училище, където в началото беше страхотно. Но настъпи моментът той да стане V клас и все повече тази работа не ми харесваше – не конкретни учители или конкретни училища, просто не ми харесваше като идея, като принципи, като акценти, приоритети, учебно съдържание, всичко. Точно в този момент приеха закона, в който се разрешава самостоятелна форма на обучение по желание, и аз си оставих децата вкъщи.
Звучи рисково.
Така е, скочихме в дълбокото. Синът ми трябваше да бъде в пети клас, а голямата ми дъщеря – в първи. Всяка година ги питахме: „Вие искате ли сега да тръгнете на училище?“ и до VII клас и двамата не искаха. След това си кандидатстваха за гимназия по общия ред, влязоха там, където желаеха. Сега най-малката продължава по същия начин.
Вашите деца са подготвени вкъщи, явили са се на НВО и през механизмите на НВО са влезли в училищата, в които учат сега, в гимназия?
Да, големият вече завърши Националната природо-математическа гимназия. Влязоха без частни уроци по български и математика. Но бързам да поясня, че когато взехме това решение, нямаше как да знаем, че ще стане така.
Вероятно някой би Ви казал: ето, за Вашите деца НВО е сработило добре. Защо тогава искате да го променяме?
Защото това е самоспасяване. Аз си оставям децата вкъщи, на мен този вариант ми е възможен, защото работя вкъщи като преводач, мога да ги подкрепям педагогически на практика по всичко, да им давам насоки и те сами се занимават. Но това очевидно не може да е вариант за всички, не е вариант за масовото образование. Както и частните уроци са самоспасяване, частните училища – до голяма степен също. Кой каквото може, това прави.
Идеята на масовото образование обаче е да служи на всички – затова е масово. Целта му не е просто да отглежда децата някъде, докато родителите им са на работа. Целта му е да подсигури някакво развитие на тези деца, за да могат след това да бъдат активни граждани на обществото и да работят едни професии, които са необходими на цялото общество, да могат да вземат решения за развитието на цялото общество.
Може би тук трябва да споменем за онези наши читатели, които не са изкушени от темата за образователните резултати, че вече десетилетие всяка година имаме випуски с деца, чието средно ниво не достига общоприетия минимум от 50%.
Така е. Изчислих резултатите за VII клас от НВО по математика тази година. В 9 области 50 и повече процента от учениците не покриват 30 от 100 точки, а в 14 области – 75 и повече процента не покриват 50 от 100. София е единствената област, в която цели 54% от децата покриват над 50 точки. Системата сама си задава целите, сама определя задължителни средства и методи, сама се оценява, сама си пише „слаб“ и накрая се тупа по рамото. Похвалиха се, че резултатите тази година са много по-добри от миналата – при положение че по български език и литература са същите (средно за страната), а по математика са с почти 8 точки по-високи, но времето за първи модул беше увеличено с 25% и вместо 17 задачи със затворени и 3 с отворени отговори, имаше 20 задачи със затворени отговори. Резултатите няма как да бъдат сравнявани.
Това има пряко отражение върху състоянието на обществото, на икономиката, на всичко в живота ни – няма откъде да се вземат нито инженери, нито лекари, нито учители, ако година след година държим образованието на това ниво.
На всичкото отгоре системата уврежда естественото любопитство на децата. Превръща ги в хора, които се отнасят с надменност към идеята за учене, изобщо не можем да говорим за никакво желание за учене цял живот, което сме вписали във всички стратегически документи. В този си вид образователният процес не възпитава лична отговорност, не възпитава инициативност. Децата от малки свикват, че правилата могат да бъдат абсолютно произволни и случайни и се спазват само под страх от наказание, а не защото са важни за функционирането и развитието на една общност. Никой не им показва, че е важно ученето, а не присъствието – ерго свършената работа, а не престоят на работното място.
И това са нещата, които според мен са решаващи наистина за цялото общество.
Защо искате реформиране точно на НВО?
Образованието има нужда от коренно преосмисляне. Разговорът за промените е много по-голям от това, което петицията засяга. Изобщо не можем да говорим за развиване на социално-емоционални умения, творческо и критично мислене и изобщо всичко, което наистина ще им бъде необходимо в бъдеще.
В същото време е трудно този разговор да се осъществи и няма никакви признаци, че е възможно скоро да се проведе реална и толкова дълбока реформа. Но националните външни оценявания сами по себе си пораждат широкообхватни и много дългосрочни последици и поне с тях ми се струва, че трябва да се захванем спешно.
Когато бяха въведени преди повече от 15 години, целта на външните оценявания в IV, VII, Х и ХII клас беше да измерват общото състояние на образователната система, да може да се открият някакви проблеми на училищно, регионално или национално ниво, да се проследяват последиците от различни мерки и реформи, които се предприемат. Само че много скоро след това започнаха да се използват за вход в гимназиите и цялата идея се опорочи напълно, защото децата започнаха да се готвят изрично за тези изпити във и извън училище. Това не са само мои наблюдения, но и на много учители, директори и образователни експерти, включително на Анелия Андреева, директорката на Националния инспекторат по образованието, която също подкрепя петицията.
През последните месеци излязоха няколко доклада – от международния PISA до изследването на собствената ни Сметна палата, – които обръщат внимание, че този подход е довел не до отсяване на деца по интереси, а наред с друго – до все по-критично социално сегрегиране. Това не е ли видно отдавна?
Този проблем беше видим още преди кандидатстването след VII клас да стане задължително, но след „реформата“ с новия закон истерията около изпитите и разделението на „елитни и неелитни“ само се задълбочиха.
Системата доведе до разслояване на училищата не толкова според интересите на децата – например дали искат да учат софтуерни и хардуерни науки, или изкуства, или имат математически интереси, – а по някаква псевдоелитност. Естествен стремеж на всички родители е детето да учи в по-добра среда. Така училищата започнаха да се делят на най-елитни, по-елитни, полуелитни…
В другия полюс се образуваха гнезда, в които никой не искаше да учи. В тези училища остават деца, които са страшно немотивирани. Трябва да сме наясно, че те не са нито по-глупави, нито по-малко способни, просто по някаква причина не са се представили добре точно на тези изпити.
Когато оставим в едно училище няколкостотин ученици с ниска мотивация, техните учители нерядко също са с ниска мотивация – това е един порочен кръг, от който почти няма излизане. Шансът тези деца да добият някаква мотивация, докато завършат училище, е почти нулев.
От дискусиите в социалните мрежи обаче виждаме, че и учители, и родители много често вменяват на децата вината за образователните им затруднения. Аз имам сериозно несъгласие с това, защото намирам възрастните за отговорни за създаване на обществото, в което децата растат и се развиват. Вие как смятате?
Децата обикновено нямат проблем с полагането на труд и усилия, а със смисъла. Това, което наричаме мързел или липса на самодисциплина, често е просто липса на усещане за смисъл в нещата, които се искат от тях. И обратното: това, което на пръв поглед изглежда като мотивация и трудолюбие, в много случаи е конформизъм. За детето се оказва по-лесно да се подчини на целите на възрастните, ако щѐ и да ходи на курсове по цяла събота и неделя, отколкото да се противопостави. И тук влиза както кандидатстването, така и всички приоритети и акценти в ученето, цялата култура, която възрастните създават около образованието.
В едно интервю споменавате, че изпитите за НВО не са стандартизирани и ние всъщност не знаем какво се измерва с тях. Това не звучи добре. Десетки хиляди деца се готвят системно, десетки милиони левове излизат от джобовете на родителите всяка година за частни уроци и накрая дори не е ясно какво оценяваме с изпита, около който се върти всичко това?
Точно така. Да започнем от очевидното – не знаем дали по-добрите резултати, където ги има, са резултат от по-добро управление на училището, от по-ефективна работа на учителите, или от частните уроци и амбициите на децата и техните семейства – и финансовите им възможности, не на последно място. Отвъд това изпитите всяка година се променят, което ги прави несравними. Не знаем доколко отговарят на критериите за валидност и надеждност – проблем, на който изпълнителната директорка на Института за изследвания в образованието Асенка Христова неотдавна обърна внимание. Ако трябва да резюмирам изключително грубо този сложен въпрос, това означава, от една страна, изпитът да измерва коректно и прецизно точно каквото искаме да измери, а от друга – да ни дава устойчиви във времето резултати.
В настоящия си вид НВО не отговарят на тези изисквания.
Според петицията обаче форматът на външното оценяване е само върхът на айсберга. Отбелязва се, че сериозните дефицити на задължителното профилиране, вход за което са НВО, „ограничават развитието“ на децата. Защо?
При въвеждането на промените профилирането беше представено като възможност учениците да не учат всичко задължително, а това, което искат. Обаче на практика нищо такова не се случва. Още след VII клас повечето деца имат много ограничен избор изобщо какво могат да кандидатстват, а понякога никакъв.
На всичко отгоре повечето деца на тази възраст всъщност нямат изразен интерес какво искат да учат. Дори тези обаче, които знаят, не учат това, което желаят. Учат каквото може да осигури училището, в което са влезли. Понякога това се решава буквално в последните месеци на предходната учебна година – според натовареността на учителите по различните предмети. Има свободен учител по философия? Значи децата ще се профилират във философия.
В сегашната система профилирането реално става след десети клас, но се предопределя с избор, направен след седми. Това вкарва учениците в една система, от която няма измъкване. В допълнение, повечето деца и родители изобщо не са наясно в бъдеще това какви ограничения може да им донесе. Например кандидатстването в университети от професионална паралелка понякога се оказва трудно, защото не им достига хорариум по някои предмети.
Друг аспект на този проблем е, че за всякакви специалности, които не са особено търсени, но пък за сметка на това са изключително важни в наши дни, става все по-трудно набирането на студенти. Физиката е ярък пример за това. България има изключително добри позиции в съвременната физика, но няма откъде да се вземат млади физици, защото повечето деца не са учили физика в ХI и ХII клас. Има и друго – след VII клас много ученици проявяват интерес към тази наука. Обаче къде да я изучават? В София има три паралелки с физика – една в Националната природо-математическа гимназия и две в Софийската математическа гимназия. Там се влиза с по стотина точки по български и математика. На състезанието по физика на НПМГ всяка година се явяват стотици деца, от които училището приема 26. А останалите?
Но най-тревожното е, че дори от тези, които са влезли точно там, където са желали, в края на образованието едва 10% са удовлетворени.
Аз писах до Министерството на образованието и науката. Отговориха ми, че проследяват работната заетост на тези, които завършват професионални паралелки, и че имат проучване кои предмети затрудняват учениците до Х клас. Нямаме за идея да питаме децата дали всъщност са удовлетворени от образованието си. А нали те ще живеят с това образование после?
Ще ми се петицията да помогне да започнем разговор за всичко това.
Петицията на Ирина Манушева е все още отворена за подпис и може да се присъедините към нейните искания чрез този линк.
Помогнете ни да научим какви са читателските ви възприятия и отношението ви към „Тоест“, като попълните нашата анкета.
Пет отровни дела. Отчаяние и отвращение
Post Syndicated from original https://www.toest.bg/pet-otrovni-dela-otchayanie-i-otvrashtenie/
<< Към предишната част от поредицата
Така, както постъпват вашите институции, могат да постъпят само хора без мозък и сърце,

ми каза Ирина Дмитриева, когато се видяхме в София. От началото на войната на Русия срещу Украйна хиляди украински бежанци напуснаха страната си. Но Ирина не е украинка. Рускиня е.
Оказва се, че в България, „земята на простичкото щастие“, е възможно всичко, дори немислимото.
Ирина бяга с дъщеря си от Москва на 7 март 2022 г.
Разбрах, че страната ми се е превърнала във фашистка. След като Русия нападна друга суверенна държава, избива мирното ѝ население, наричайки го „нацисти“, и в същото време не позволява на своите граждани да изразят протеста си срещу това нападение, значи няма какво да правя повече там. Основното чувство, което изпитвах, беше отчаяние и отвращение. Бях отчаяна и защото не видях никаква реакция сред съотечествениците си. Щом научих за войната, веднага излязох на улицата, но хора, които да протестират, почти нямаше, което ми доказа, че в нашата страна всичко е загубено. Да, много бяха в шок, но повечето от тях се бояха и не искаха да изкажат възмущението си. Тогава осъзнах безперспективността на всичко. Това e не само ужас за Украйна, а е началото на края на страната, в която досега живеех – Русия. Да нападнеш друга държава не се прощава от историята, защото е най-голямото престъпление, което човек може да извърши в живота си.
Ирина е актриса, театрален режисьор и педагог по изкуства в елитно московско училище. Освен това е част от управлението на неправителствена организация, която се бори с муковисцидозата – заболяването, от което страда дъщеря ѝ.
До началото на войната Ирина често участва в протести срещу режима на Владимир Путин. След въвеждането на редица репресивни закони в Русия за нея става ясно, че рано или късно ще бъде арестувана заради откритите си позиции срещу войната в Украйна и ще трябва да остави болното си дете само. Освен това тя е украинка по баща, което допълнително утежнява положението ѝ в Русия след началото на войната.
Разказва как в училището на дъщеря ѝ учителката по музика принудила децата да учат и пеят песни за възхвала на Владимир Путин. Дъщеря ѝ отказала и заявила на учителката си, че не харесва руския президент, за да пее песни за него.
Слава богу не последваха сериозни последици от това, но аз знам, че не мога да ѝ забраня да говори открито, защото искам детето ми да расте със свободен дух. В същото време знам, че ако тя продължи да говори така, това ще доведе до сериозен риск за нея. Беше ясно, че повече не можем да останем да живеем в Русия.
Докато руски войници и ракети избиват цивилни жени и деца в градовете на Украйна, Ирина започва битка за оцеляването на своето дете в европейска България. Само че когато пристига у нас, все още не знае, че това не е просто една от всичките европейски страни. Това е страната, която е сочена като най-корумпирана в ЕС. България също така има проблеми с тежката бюрокрация на институциите. На всичко отгоре руското влияние сред българите е сред най-високите в Европа.
Държавна агенция за бежанците (ДАБ)
Очаквано Ирина и дъщеря ѝ получават първоначален отказ от ДАБ, след като подават заявление за убежище у нас. Шокиращо е обаче, че Агенцията разглежда делата им поотделно. Не съобразява, че детето е непълнолетно, с вродено заболяване, което го прави изцяло зависимо от грижите на майка му. Не съобразява и че детето не би могло да има своя бежанска история, по която да се водят дела с доказателства, за да придобие закрила. Тази хипотеза е потвърдена и от Върховния административен съд (ВАС).
След няколко съдебни дела Ирина все пак получава статут на бежанец. Относно разделянето на делото ѝ от това на дъщеря ѝ в решението на Съда четем:
Решаващият съдебен състав е счел, че в конкретния случай административният орган е следвало да извърши преценка и относно наличието на хипотезата на чл. 9, ал. 8 ЗУБ, която разпоредба регламентира, че хуманитарен статут може да бъде предоставен и по други причини от хуманитарен характер. Акцентирано е на обстоятелството, че както жалбоподателката, така и нейната дъщеря попадат в определението за уязвими лица, по смисъла на чл. 20, т. 3 от Директива 2011/95/ЕС на Европейския парламент и на Съвета от 13 декември 2011 г. относно стандарти за определянето на граждани на трети държави или лица без гражданство като лица, на които е предоставена международна закрила, за единния статут на бежанците или на лицата, които отговарят на условията за субсидиарна закрила, както и за съдържанието на предоставената закрила, което обаче не е отчетено от издателя на процесния административен акт.




© Личен архив
Дъщерята на Ирина също преминава през няколко съдебни дела. Ирина си спомня:
По време на едно от делата дъщеря ми беше в реанимацията на столична болница, защото трябваше по спешност да оперират белия ѝ дроб. Съдът гледа делото ѝ, а тя в реанимацията се бори за живота си. Как е възможно това в страна членка на ЕС? Тя не е някакъв престъпник, дете е.
През декември 2023 г., след голямо забавяне, ВАС все пак излиза с решение, че дъщерята на Ирина също трябва да получи бежански статут в България. Реакцията на ДАБ е смайваща. Четири месеца по-късно, през април 2024 г.,
Агенцията обжалва решението на ВАС детето да получи закрила у нас, след като майка му вече има такова решение.
Никой не може да си обясни защо от Агенцията обжалват решение на ВАС, което следва логиката: майката получава закрила, следователно и непълнолетното ѝ дете трябва да получи такава.
Процедурата от съдебни дела за момичето започва отначало. Според Ирина
ДАБ просто търсят всякакви начини да затегнат нещата, да ги усложнят и никой не може да им повлияе по никакъв начин. Това е толкова смущаващо.
Последиците
В окончателното решение на ВАС от 2023 г. Съдът постановява ДАБ да предостави на Ирина документи за самоличност, за да може да започне работа и да си открие банкова сметка. Към момента на завършване на този текст Ирина все още не е получила от Агенцията документи за самоличност. Напротив, на всеки три месеца трябва да подновява временната карта за престой в България, което отнема на ДАБ около месец и половина. През това време Ирина ходи с бележка, на която няма дори печат. Тоест на всеки три месеца ДАБ губи по месец и половина за преиздаване на карта за временно пребиваване.
От Агенцията заявяват, че за да издадат постоянни документи на Ирина, им е необходимо решение на съда за бежанския статут на дъщеря ѝ. Така Агенцията, от една страна, не зачита решението на ВАС, а от друга, поставя казуса в порочен кръг.
Ирина не спира да се учудва:
Не разбирам логиката на ДАБ за пореден път. Първо разделят делата на мен и дъщеря ми, заради което две години и половина преминавахме през унизителни процедури. Сега обаче, когато трябва да ми издадат документите за самоличност, както Съдът постанови, ДАБ вече свързва моята история и я прави зависима от тази на дъщеря ми. Значи хем обжалваха решението на Съда да ѝ даде закрила, хем сега твърдят, че именно нейният документ за закрила им е необходим, за да издадат лични документи на мен. Какво цели ДАБ с всичко това? Изглежда като подигравка или цинизъм, или нещо умишлено. Необяснимо е и как е възможно в страна от ЕС една агенция да не изпълни постановеното от крайна инстанция като Върховния съд.
Ирина внезапно млъква. Очите ѝ се напълват със сълзи.
Сега искам да попитам служителите на ДАБ, които обжалваха решението на Съда детето ми да получи бежански статут: представят ли си какво става в душата на едно дете, когато чуе, че някакви хора от някаква агенция обжалват решението на Върховния съд то да остане с майка си? Как решихте, че детето ми не заслужава да получи бежански статут в България? Откъде събрахте толкова много жестокост, липса на разум и сърце? Защо възрастни хора допускат малко момиче да бъде съдено, без да е направило нищо никому? Нямате представа какво е да видиш болното си дете изправено в съда само, объркано и чакащо непознати за него хора да обявят присъдата си.
Проблемите за Ирина и детето ѝ не спират. Преди месец тя разбира, че
системата на НАП е изхвърлила дъщеря ѝ от списъците на Здравната каса и детето не може да получава повече животоподдържащите го лекарства.
Никой не я уведомява. Научава го в аптеката, когато се опитва да вземе лекарствата.
Ние не получаваме цялата необходима терапия за детето, но най-важните препарати все пак ги има и благодарение на това детето ми успява да ходи на училище и да живее пълноценно. Но животът му зависи от тази терапия.
Ирина отива в НАП, където ѝ казват, че момичето няма право повече да получава лекарствата. Няколко дни чиновници от НАП разхождат Ирина от кабинет в кабинет, но отвсякъде получава отказ.
Обяснявах им, че без лекарствата детето ми може да загуби живота си. А те ми отговориха, че нищо не могат да направят и да съм отидела в ДАБ, които да ми дадат ЕГН за дъщеря ми, и автоматично щяла да влезе в системата. Ако ДАБ не бяха обжалвали решението на ВАС, сега дъщеря ми щеше да има бежански статут и нямаше да изпадаме в такива критични ситуации. Бях в такава безизходица, че се обърнах към български депутати за помощ. В края на краищата някакъв началник от НАП най-после видя, че на детето му се полагат тези лекарства, и то без прекъсване. Въпреки всичко дъщеря ми е в лекарствения списък само до август 2024 г. Не знам какво ще правим после. Всеки ден без лекарства отнема години от живота на детето ми. Не разбирам защо ни се случва всичко това. Бях готова да изляза на гладна стачка пред Министерския съвет, но правителството се смени и сега дори не знам към кого да се обърна. Всички вдигат рамене и казват: „Ами, това е бюрокрацията у нас.“ Никой не се замисля, че когато една държавна агенция като ДАБ не спазва законите и нарушава решения на върховни съдилища и никой не забелязва това, значи в самата държава има проблем.
През декември 2023 г. Ирина и Андрей (следващ герой в „Пет отровни дела“) излизат на протест пред Министерския съвет, като единственото им искане е да внесат жалба за работата на ДАБ. Носят документи, доказващи ужасяващото отношение към тях.
Знаете ли какво се случи? Министерският съвет написа някакво писмо до ДАБ, те му отговориха някакви неща и това е. Нищо! Явно над тази институция ДАБ няма никакъв контрол и никой не се интересува как работи тя.
Историята на Ирина оставя привкус и подозрения за целенасочено протакане и безсърдечно отношение, облечени в букви и алинеи на зле измислени закони. Или пък за липса на професионализъм. По-лошото е, че никой у нас не се интересува и не се стреми да промени каквото и да било. Сега цената би могла да бъде животът на едно дете. Днес това е детето на Ирина, утре – на някого от нас.
Но в „земята на простичкото щастие“ е така – точно както е в Русия, никой не се интересува от нищо, освен ако не му дойде до главата.
Новото дело на дъщерята на Ирина е насрочено за октомври 2024 г. Дотогава те двете ще са абсолютно никой в България, а може би и след това. Като всички нас.
Ужасно съм уморена,
ми казва Ирина в края на разговора ни.
Помогнете ни да научим какви са читателските ви възприятия и отношението ви към „Тоест“, като попълните нашата анкета.
What’s New in Dashboards Chapter 2
Post Syndicated from Home Assistant original https://www.youtube.com/watch?v=9zmXLxQPr1o
AWS Wickr achieves DoD Impact Level 4 and 5 authorization
Post Syndicated from Anne Grahn original https://aws.amazon.com/blogs/messaging-and-targeting/aws-wickr-achieves-dod-impact-level-4-and-5-authorization/
Amazon Web Services (AWS) is excited to announce that AWS Wickr has been authorized for Department of Defense Cloud Computing Security Requirements Guide Impact Level 4 and 5 (DoD CC SRG IL4 and IL5) in the AWS GovCloud (US-West) Region.
What’s the DoD CC SRG?
The DoD CC SRG, which is maintained by The U.S. Defense Information Systems Agency (DISA), outlines the security model for the DoD’s use of cloud computing, detailing the necessary security controls and requirements for cloud-based solutions. The DoD CC SRG defines four impact levels (IL2, IL4, IL5, and IL6) based on the sensitivity of DoD information stored and processed in the cloud, and the potential impact if there were a loss of confidentiality, integrity, or availability of that information.
The launch of AWS Wickr’s DoD CC SRG IL4 and IL5 authorization helps DoD customers maintain the security of, and control over communications that contain controlled classified information (CUI), mission-critical information, and National Security Systems (NSS) information.
| “Wickr at IL5 will provide our US Defense customers with an accredited, compliant, secure, enterprise messaging capability that works on any device whether in the field or headquarters.” – Keith Johnson, Head of Solutions Architects, US DoD at AWS |
What’s AWS Wickr?
Wickr is an end-to-end encrypted messaging and collaboration service with features designed to help you keep communications secure, private, and compliant. Wickr protects one-to-one and group messaging, voice and video calling, file sharing, screen sharing, and location sharing with 256-bit encryption, and provides data retention capabilities. Every message, call, and file is encrypted on the sender’s device using a unique secret key, and remains secure in transit. No one except intended recipients and your organization can access the content.
You can create Wickr networks through the AWS Management Console. Administrative controls allow your Wickr administrators to add, remove, and invite users, and organize them into security groups to manage messaging, calling, security, and federation settings. You maintain full control over data, which includes addressing information governance polices, configuring ephemeral messaging options, and deleting credentials for lost or stolen devices.
Unlike popular consumer messaging apps, Wickr allows you to log internal and external communications—including conversations with guest users, contractors, and other partner networks—in a private data store that you manage. This helps you retain messages and files that are sent to and from your organization to meet requirements such as DoD Instruction 8170.01, which prescribes procedures for the collection, distribution, storage, and processing of DoD information through electronic messaging services.
Enhance security and meet your requirements
The DoD CC SRG IL4 and IL5 authorization of Wickr builds on Wickr’s existing DoD SRG IL2 authorization. Wickr is also Federal Risk and Authorization Management Program (FedRAMP) authorized at the Moderate impact level in the AWS US East (N. Virginia) Region, FedRamp High authorized in the AWS GovCloud (US-West) Region, and meets compliance programs and standards such as Health Insurance Portability and Accountability Act (HIPAA) eligibility, International Organization for Standardization (ISO) 27001, and System and Organization Controls (SOC) 1,2, and 3.
| “This authorization illustrates Wickr’s commitment to US DoD customers. Having an easy to use, end-to-end encrypted, IL5 messaging and collaboration tool allows for wider flexibility for effective mission collaboration.” – Arvind Muthukrishnan, Wickr Head of Product at AWS |
To learn more about Wickr visit our AWS Wickr product page, or contact us. For more information about AWS compliance, visit our Services in Scope page.
About the Authors
 Anne Grahn Anne GrahnAnne is a Senior Worldwide Security GTM Specialist at AWS, based in Chicago. She has more than 13 years of experience in the security industry, and focuses on effectively communicating cybersecurity risk. She maintains a Certified Information Systems Security Professional (CISSP) certification. |
 Whiting Chisman Whiting ChismanWhiting is a Sr. Technical Product Manager at AWS Wickr, focusing on US federal customers and their mission requirements. He resides in Arlington, VA. |
Canon R1 & R5ii – Next Gen. AutoFocus
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=JOyqjnQ1Ink
Building a scalable streaming data platform that enables real-time and batch analytics of electric vehicles on AWS
Post Syndicated from Ayush Agrawal original https://aws.amazon.com/blogs/big-data/building-a-scalable-streaming-data-platform-that-enables-real-time-and-batch-analytics-of-electric-vehicles-on-aws/
The automobile industry has undergone a remarkable transformation because of the increasing adoption of electric vehicles (EVs). EVs, known for their sustainability and eco-friendliness, are paving the way for a new era in transportation. As environmental concerns and the push for greener technologies have gained momentum, the adoption of EVs has surged, promising to reshape our mobility landscape.
The surge in EVs brings with it a profound need for data acquisition and analysis to optimize their performance, reliability, and efficiency. In the rapidly evolving EV industry, the ability to harness, process, and derive insights from the massive volume of data generated by EVs has become essential for manufacturers, service providers, and researchers alike.
As the EV market is expanding with many new and incumbent players trying to capture the market, the major differentiating factor will be the performance of the vehicles.
Modern EVs are equipped with an array of sensors and systems that continuously monitor various aspects of their operation including parameters such as voltage, temperature, vibration, speed, and so on. From battery management to motor performance, these data-rich machines provide a wealth of information that, when effectively captured and analyzed, can revolutionize vehicle design, enhance safety, and optimize energy consumption. The data can be used to do predictive maintenance, device anomaly detection, real-time customer alerts, remote device management, and monitoring.
However, managing this deluge of data isn’t without its challenges. As the adoption of EVs accelerates, the need for robust data pipelines capable of collecting, storing, and processing data from an exponentially growing number of vehicles becomes more pronounced. Moreover, the granularity of data generated by each vehicle has increased significantly, making it essential to efficiently handle the ever-increasing number of data points. The challenges include not only the technical intricacies of data management but also concerns related to data security, privacy, and compliance with evolving regulations.
In this blog post, we delve into the intricacies of building a reliable data analytics pipeline that can scale to accommodate millions of vehicles, each generating hundreds of metrics every second using Amazon OpenSearch Ingestion. We also provide guidelines and sample configurations to help you implement a solution.
Of the prerequisites that follow, the IOT topic rule and the Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster can be set up by following How to integrate AWS IoT Core with Amazon MSK. The steps to create an Amazon OpenSearch Service cluster are available in Creating and managing Amazon OpenSearch Service domains.
Prerequisites
Before you begin the implementing the solution, you need the following:
- IOT topic rule
- Amazon MSK Simple Authentication and Security Layer/Salted Challenge Response Mechanism (SASL/SCRAM) cluster
- Amazon OpenSearch Service domain
Solution overview
The following architecture diagram provides a scalable and fully managed modern data streaming platform. The architecture uses Amazon OpenSearch Ingestion to stream data into OpenSearch Service and Amazon Simple Storage Service (Amazon S3) to store the data. The data in OpenSearch powers real-time dashboards. The data can also be used to notify customers of any failures occurring on the vehicle (see Configuring alerts in Amazon OpenSearch Service). The data in Amazon S3 is used for business intelligence and long-term storage.

In the following sections, we focus on the following three critical pieces of the architecture in depth:
1. Amazon MSK to OpenSearch ingestion pipeline
2. Amazon OpenSearch Ingestion pipeline to OpenSearch Service
3. Amazon OpenSearch Ingestion to Amazon S3
Solution Walkthrough
Step 1: MSK to Amazon OpenSearch Ingestion pipeline
Because each electric vehicle streams massive volumes of data to Amazon MSK clusters through AWS IoT Core, making sense of this data avalanche is critical. OpenSearch Ingestion provides a fully managed serverless integration to tap into these data streams.
The Amazon MSK source in OpenSearch Ingestion uses Kafka’s Consumer API to read records from one or more MSK topics. The MSK source in OpenSearch Ingestion seamlessly connects to MSK to ingest the streaming data into OpenSearch Ingestion’s processing pipeline.
The following snippet illustrates the pipeline configuration for an OpenSearch Ingestion pipeline used to ingest data from an MSK cluster.

While creating an OpenSearch Ingestion pipeline, add the following snippet in the Pipeline configuration section.
When configuring Amazon MSK and OpenSearch Ingestion, it’s essential to establish an optimal relationship between the number of partitions in your Kafka topics and the number of OpenSearch Compute Units (OCUs) allocated to your ingestion pipelines. This optimal configuration ensures efficient data processing and maximizes throughput. You can read more about it in Configure recommended compute units (OCUs) for the Amazon MSK pipeline.
Step 2: OpenSearch Ingestion pipeline to OpenSearch Service
OpenSearch Ingestion offers a direct method for streaming EV data into OpenSearch. The OpenSearch sink plugin channels data from multiple sources directly into the OpenSearch domain. Instead of manually provisioning the pipeline, you define the capacity for your pipeline using OCUs. Each OCU provides 6 GB of memory and two virtual CPUs. To use OpenSearch Ingestion auto-scaling optimally, it’s essential to configure the maximum number of OCUs for a pipeline based on the number of partitions in the topics being ingested. If a topic has a large number of partitions (for example, more than 96, which is the maximum OCUs per pipeline), it’s recommended to configure the pipeline with a maximum of 1–96 OCUs. This way, the pipeline can automatically scale up or down within this range as needed. However, if a topic has a low number of partitions (for example, fewer than 96), it’s advisable to set the maximum number of OCUs to be equal to the number of partitions. This approach ensures that each partition is processed by a dedicated OCU enabling parallel processing and optimal performance. In scenarios where a pipeline ingests data from multiple topics, the topic with the highest number of partitions should be used as a reference to configure the maximum OCUs. Additionally, if higher throughput is required, you can create another pipeline with a new set of OCUs for the same topic and consumer group, enabling near-linear scalability.
OpenSearch Ingestion provides several pre-defined configuration blueprints that can help you quickly build your ingestion pipeline on AWS
The following snippet illustrates pipeline configuration for an OpenSearch Ingestion pipeline using OpenSearch as a SINK with a dead letter queue (DLQ) to Amazon S3. When a pipeline encounters write errors, it creates DLQ objects in the configured S3 bucket. DLQ objects exist within a JSON file as an array of failed events.
Step 3: OpenSearch Ingestion to Amazon S3
OpenSearch Ingestion offers a built-in sink for loading streaming data directly into S3. The service can compress, partition, and optimize the data for cost-effective storage and analytics in Amazon S3. Data loaded into S3 can be partitioned for easier query isolation and lifecycle management. Partitions can be based on vehicle ID, date, geographic region, or other dimensions as needed for your queries.
The following snippet illustrates how we’ve partitioned and stored EV data in Amazon S3.
The pipeline can be created following the steps in Creating Amazon OpenSearch Ingestion pipelines.
The following is the complete pipeline configuration, combining the configuration of all three steps. Update the Amazon Resource Names (ARNs), AWS Region, Open Search Service domain endpoint, and S3 names as needed.
The entire OpenSearch Ingestion pipeline configuration can be directly copied into the ‘Pipeline configuration’ field in the AWS Management Console while creating the OpenSearch Ingestion pipeline
Real-time analytics
After the data is available in OpenSearch Service, you can build real-time monitoring and notifications. OpenSearch Service has robust support for multiple notification channels, allowing you to receive alerts through services like Slack, Chime, custom webhooks, Microsoft Teams, email, and Amazon Simple Notification Service (Amazon SNS).
The following screenshot illustrates supported notification channels in OpenSearch Service.

The notification feature in OpenSearch Service allows you to create monitors that will watch for certain conditions or changes in your data and launch alerts, such as monitoring vehicle telemetry data and launching alerts for issues like battery degradation or abnormal energy consumption. For example, you can create a monitor that analyzes battery capacity over time and notifies the on-call team using Slack if capacity drops below expected degradation curves in a significant number of vehicles. This could indicate a potential manufacturing defect requiring investigation.
In addition to notifications, OpenSearch Service makes it easy to build real-time dashboards to visually track metrics across your fleet of vehicles. You can ingest vehicle telemetry data like location, speed, fuel consumption, and so on, and visualize it on maps, charts, and gauges. Dashboards can provide real-time visibility into vehicle health and performance.
The following screenshot illustrates creating a sample dashboard on OpenSearch Service
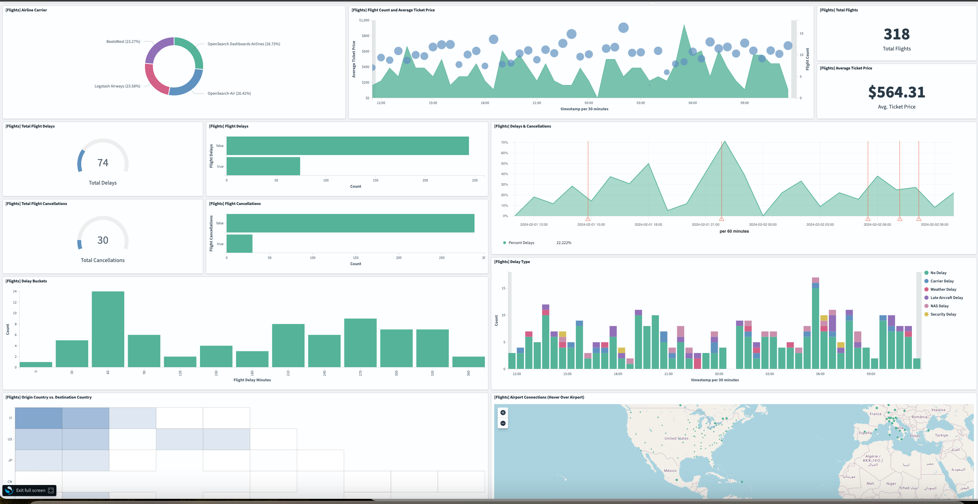
A key benefit of OpenSearch Service is its ability to handle high sustained ingestion and query rates with millisecond latencies. It distributes incoming vehicle data across data nodes in a cluster for parallel processing. This allows OpenSearch to scale out to handle very large fleets while still delivering the real-time performance needed for operational visibility and alerting.
Batch analytics
After the data is available in Amazon S3, you can build a secure data lake to power a variety of analytics use cases deriving powerful insights. As an immutable store, new data is continually stored in S3 while existing data remains unaltered. This serves as a single source of truth for downstream analytics.
For business intelligence and reporting, you can analyze trends, identify insights, and create rich visualizations powered by the data lake. You can use Amazon QuickSight to build and share dashboards without needing to set up servers or infrastructure. Here’s an example of a Quicksight dashboard for IoT device data. For example, you can use a dashboard to gain insights from historical data that can help with better vehicle and battery design.
The Amazon Quicksight public gallery shows examples of dashboards across different domains.
You should consider Amazon OpenSearch dashboards for your operational day-to-day use cases to identify issues and alert in near real time whereas Amazon Quicksight should be used to analyze big data stored in a lake house and generate actionable insights from them.
Clean up
Delete the OpenSearch pipeline and Amazon MSK cluster to stop incurring costs on these services.
Conclusion
In this post, you learned how Amazon MSK, OpenSearch Ingestion, OpenSearch Services, and Amazon S3 can be integrated to ingest, process, store, analyze, and act on endless streams of EV data efficiently.
With OpenSearch Ingestion as the integration layer between streams and storage, the entire pipeline scales up and down automatically based on demand. No more complex cluster management or lost data from bursts in streams.
See Amazon OpenSearch Ingestion to learn more.
About the authors
 Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible.
Ayush Agrawal is a Startups Solutions Architect from Gurugram, India with 11 years of experience in Cloud Computing. With a keen interest in AI, ML, and Cloud Security, Ayush is dedicated to helping startups navigate and solve complex architectural challenges. His passion for technology drives him to constantly explore new tools and innovations. When he’s not architecting solutions, you’ll find Ayush diving into the latest tech trends, always eager to push the boundaries of what’s possible.
 Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.
Fraser Sequeira is a Solutions Architect with AWS based in Mumbai, India. In his role at AWS, Fraser works closely with startups to design and build cloud-native solutions on AWS, with a focus on analytics and streaming workloads. With over 10 years of experience in cloud computing, Fraser has deep expertise in big data, real-time analytics, and building event-driven architecture on AWS.
Migrate data from an on-premises Hadoop environment to Amazon S3 using S3DistCp with AWS Direct Connect
Post Syndicated from Vicky Jacob original https://aws.amazon.com/blogs/big-data/migrate-data-from-an-on-premises-hadoop-environment-to-amazon-s3-using-s3distcp-with-aws-direct-connect/
This post demonstrates how to migrate nearly any amount of data from an on-premises Apache Hadoop environment to Amazon Simple Storage Service (Amazon S3) by using S3DistCp on Amazon EMR with AWS Direct Connect.
To transfer resources from a target EMR cluster, the traditional Hadoop DistCp must be run on the source cluster to move data from one cluster to another, which invokes a MapReduce job on the source cluster and can consume a lot of cluster resources (depending on the data volume). To avoid this problem and minimize the load on the source cluster, you can use S3DistCp with Direct Connect to migrate terabytes of data from an on-premises Hadoop environment to Amazon S3. This process runs the job on the target EMR cluster, minimizing the burden on the source cluster.
This post provides instructions for using S3DistCp for migrating data to the AWS Cloud. Apache DistCp is an open source tool that you can use to copy large amounts of data. S3DistCp is similar to DistCp, but optimized to work with AWS, particularly Amazon S3. When compared to Hadoop DistCp, S3DistCp is more scalable, with higher throughput and efficient for parallel copying of large numbers of objects across s3 buckets and across AWS accounts.
Solution overview
The architecture for this solution includes the following components:
- Source technology stack:
- A Hadoop cluster with connectivity to the target EMR cluster over Direct Connect
- Target technology stack:
- Amazon Virtual Private Cloud (Amazon VPC)
- EMR cluster
- Direct Connect
- Amazon S3
The following architecture diagram shows how you can use the S3DistCp from the target EMR cluster to migrate huge volumes of data from an on-premises Hadoop environment through a private network connection, such as Direct Connect to Amazon S3.
 This migration approach uses the following tools to perform the migration:
This migration approach uses the following tools to perform the migration:
- S3DistCp – S3DistCp is similar to DistCp, but optimized to work with AWS, particularly Amazon S3. The command for S3DistCp in Amazon EMR version 4.0 and later is s3-dist-cp, which you add as a step in a cluster or at the command line. With S3DistCp, you can efficiently copy large amounts of data from Amazon S3 into Hadoop Distributed Filed System (HDFS), where it can be processed by subsequent steps in your EMR cluster. You can also use S3DistCp to copy data between S3 buckets or from HDFS to Amazon S3. S3DistCp is more scalable and efficient for parallel copying of large numbers of objects across buckets and across AWS accounts.
- Amazon S3 – Amazon S3 is an object storage service. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere on the web.
- Amazon VPC – Amazon VPC provisions a logically isolated section of the AWS Cloud where you can launch AWS resources in a virtual network that you’ve defined. This virtual network closely resembles a traditional network that you would operate in your own data center, with the benefits of using the scalable infrastructure of AWS.
- AWS Identity and Access Management (IAM) – IAM is a web service for securely controlling access to AWS services. With IAM, you can centrally manage users, security credentials such as access keys, and permissions that control which AWS resources users and applications can access.
- Direct Connect – Direct Connect links your internal network to a Direct Connect location over a standard ethernet fiber-optic cable. One end of the cable is connected to your router, the other to a Direct Connect router. With this connection, you can create virtual interfaces directly to public AWS services (for example, to Amazon S3) or to Amazon VPC, bypassing internet service providers in your network path. A Direct Connect location provides access to AWS in the AWS Region with which it’s associated. You can use a single connection in a public Region or in AWS GovCloud (US) to access public AWS services in all other public Regions.
In the following sections, we discuss the steps to perform the data migration using S3DistCp.
Prerequisites
Before you begin, you should have the following prerequisites:
- Amazon EMR version 4.0 or greater. Refer to Plan and configure an Amazon EMR cluster for steps to create an EMR cluster.
- S3DistCp installed on the target EMR cluster (installed by default).
- An active AWS account with a private network connection between your on-premises data center and the AWS Cloud.
- A Hadoop user with access to the migration data in the HDFS.
- The AWS Command Line Interface (AWS CLI) installed and configured.
- An IAM role with permissions to put objects into an S3 bucket. For more information, refer to Customize IAM roles.
Get the active NameNode from the source Hadoop cluster
Sign in to any of the nodes on the source cluster and run the following commands on bash to get the active NameNode on the cluster.
In newer versions of Hadoop, run the following command to get the service status, which will list the active NameNode on the cluster:
On older versions of Hadoop, run the following method on bash to get the active NameNode on the cluster:
Validate connectivity from the EMR cluster to the source Hadoop cluster
As mentioned in the prerequisites, you should have an EMR cluster and attach a custom IAM role for Amazon EMR. Run the following command to validate the connectivity from the target EMR cluster to the source Hadoop cluster:
Alternatively, you can run the following command:
Validate if the source HDFS path exists
Check if the source HDFS path is valid. If the following command returns 0, indicating that it’s valid, you can proceed to the next step:
Transfer data using S3DistCp
To transfer the source HDFS folder to the target S3 bucket, use the following command:
To transfer large files in multipart chunks, use the following command to set the chuck size:
This will invoke a MapReduce job on the target EMR cluster. Depending on the volume of the data and the bandwidth speed, the job can take a few minutes up to a few hours to complete.
To get the list of running yarn applications on the cluster, run the following command:
Validate the migrated data
After the preceding MapReduce job completes successfully, use the following steps to validate the data copied over:
If the source and target size aren’t equal, perform the cleanup step in the next section and repeat the preceding S3DistCp step.
Clean up partially copied or errored out partitions and files
S3DistCp doesn’t clean up partially copied files and partitions if it fails while copying. Clean up partially copied or errored out partitions and files before you reinitiate the S3DistCp process. To clean up objects on Amazon S3, use the following AWS CLI command to perform the delete operation:
Best practices
To avoid copy errors when using S3DistCP to copy a single file (instead of a directory) from Amazon S3 to HDFS, use Amazon EMR 5.33.0 or later, or Amazon EMR 6.3.0 or later.
Limitations
The following are limitations of this approach:
- If S3DistCp is unable to copy some or all of the specified files, the cluster step fails and returns a non-zero error code. If this occurs, S3DistCp doesn’t clean up partially copied files.
- S3DistCp doesn’t support concatenation for Parquet files. Use PySpark instead. For more information, see Concatenating Parquet files in Amazon EMR.
- VPC limitations apply to Direct Connect for Amazon S3. For more information, see AWS Direct Connect quotas.
Conclusion
In this post, we demonstrated the power of S3DistCp to migrate huge volumes of data from a source Hadoop cluster to a target S3 bucket or HDFS on an EMR cluster. With S3DistCp, you can migrate terabytes of data without affecting the compute resources on the source cluster as compared to Hadoop DistCp.
For more information about using S3DistCp, see the following resources:
- S3DistCp (s3-dist-cp)
- Seven Tips for Using S3DistCp on Amazon EMR to Move Data Efficiently Between HDFS and Amazon S3
About the Author
 Vicky Wilson Jacob is a Senior Data Architect with AWS Professional Services Analytics Practice. Vicky specializes in Big Data, Data Engineering, Machine Learning, Data Science and Generative AI. He is passionate about technology and solving customer challenges. At AWS, he works with companies helping customers implement big data, machine learning, analytics, and generative AI solutions on cloud. Outside of work, he enjoys spending time with family, singing, and playing guitar.
Vicky Wilson Jacob is a Senior Data Architect with AWS Professional Services Analytics Practice. Vicky specializes in Big Data, Data Engineering, Machine Learning, Data Science and Generative AI. He is passionate about technology and solving customer challenges. At AWS, he works with companies helping customers implement big data, machine learning, analytics, and generative AI solutions on cloud. Outside of work, he enjoys spending time with family, singing, and playing guitar.
Crucial P310 Review A Tiny 2TB M.2 2230 NVMe SSD
Post Syndicated from Will Taillac original https://www.servethehome.com/crucial-p310-review-a-tiny-2tb-m-2-2230-nvme-ssd/
Today, we are looking at the Crucial P310 2TB NVMe SSD. This is the first 2TB M.2 2230 I have looked at in my coverage of the 2230 market. All previous entries into this series are 1TB in capacity. In addition, the P310 is the newest drive I have covered, having just been released. 2230-sized […]
The post Crucial P310 Review A Tiny 2TB M.2 2230 NVMe SSD appeared first on ServeTheHome.
Cloudflare Reports that Almost 7% of All Internet Traffic Is Malicious
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/07/cloudflare-reports-that-almost-7-of-all-internet-traffic-is-malicious.html
6.8%, to be precise.
From ZDNet:
However, Distributed Denial of Service (DDoS) attacks continue to be cybercriminals’ weapon of choice, making up over 37% of all mitigated traffic. The scale of these attacks is staggering. In the first quarter of 2024 alone, Cloudflare blocked 4.5 million unique DDoS attacks. That total is nearly a third of all the DDoS attacks they mitigated the previous year.
But it’s not just about the sheer volume of DDoS attacks. The sophistication of these attacks is increasing, too. Last August, Cloudflare mitigated a massive HTTP/2 Rapid Reset DDoS attack that peaked at 201 million requests per second (RPS). That number is three times bigger than any previously observed attack.
It wasn’t just Cloudflare that was hit by the largest DDoS attack in its history. Google Cloud reported the same attack peaked at an astonishing 398 million RPS. So, how big is that number? According to Google, Google Cloud was slammed by more RPS in two minutes than Wikipedia saw traffic during September 2023.
Blender 4.2 LTS released
Post Syndicated from jzb original https://lwn.net/Articles/982286/
Version
4.2 LTS of the Blender
open-source 3D creation suite has been released. Major improvements
include a rewrite of the EEVEE
render engine, faster rendering, and much more. See the showcase
reel for examples of work created by the Blender community with
this release.
See the text release
notes for even more about 4.2 LTS, which will be maintained until
July 2026.
[$] Changing the filesystem-maintenance model
Post Syndicated from jake original https://lwn.net/Articles/981854/
Maintenance of the kernel is a difficult, often thankless, task; how it is
being handled, the role of maintainers, burnout, and so on are recurring
topics at kernel-related conferences. At
the 2024 Linux Storage,
Filesystem, Memory Management, and BPF Summit, Josef Bacik and
Christian Brauner led a session to discuss possible changes to the way
filesystems are maintained, though Bacik took the lead role (and the podium). There are a number of interrelated topics,
including merging new filesystems, removing old ones, making and testing changes
throughout the filesystem tree, and more.
digiKam 8.4.0 released
Post Syndicated from jzb original https://lwn.net/Articles/982276/
Version 8.4.0 of the digiKam photo editing and management
application has been released. This
release includes an update of the LibRaw RAW decoder which
brings support for many new cameras, a new version of the LensFun
toolkit, a feature for automatic translation of image tags, GMIC-Qt 3.4.0, and many
bug fixes. See the announcement for full details.
Home Automation Matters – Stop Projecting!
Post Syndicated from digiblur DIY original https://www.youtube.com/watch?v=XvQllwlN2pc
Silva: How to use the new counted_by attribute in C (and Linux)
Post Syndicated from corbet original https://lwn.net/Articles/982275/
Gustavo A. R. Silva describes
the path to safer flexible arrays in the kernel, thanks to the
counted_by attribute supported by Clang 18 and GCC 15.
There are a number of requirements to properly use the
counted_by attribute. One crucial requirement is that the
counter must be initialized before the first reference to the
flexible-array member. Another requirement is that the array must
always contain at least as many elements as indicated by the
counter.
See also: this article from 2023.
Security updates for Wednesday
Post Syndicated from jzb original https://lwn.net/Articles/982270/
Security updates have been issued by Debian (kernel), Fedora (golang and krb5), Red Hat (cups, firefox, git, java-21-openjdk, kernel, linux-firmware, nghttp2, nodejs, and podman), SUSE (libndp, nodejs18, nodejs20, tomcat, and xen), and Ubuntu (gtk+2.0, gtk+3.0 and linux-hwe-5.4, linux-oracle-5.4).
Classic Kitsch: Lawn Flamingos
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=VpBiAJPYj7M
Comic for 2024.07.17 – Neo Nazi
Post Syndicated from Explosm.net original https://explosm.net/comics/neo-nazi
New Cyanide and Happiness Comic