Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=QYxbSq09lrU
Yearly Archives: 2024
Икони вместо работещи институции
Post Syndicated from Светла Енчева original https://www.toest.bg/ikoni-vmesto-raboteshti-institutsii/

Ако ви предстои да пътувате по автомагистрала, какви мерки за сигурност ще предприемете и на какво ще разчитате, за да пристигнете живи и здрави там, накъдето сте се запътили? Ако шофирате вие, много важно е да сте бодри и с трезв ум, който не е под въздействието на алкохол или други субстанции. Гумите ви трябва да са подходящи за сезона, да карате с указаната скорост и изобщо – да спазвате правилата. Надявате се и другите да ги спазват, както и пътят и маркировката му да са в изправност. Ако минавате през тунел, разчитате той да е построен и поддържан по начин, гарантиращ вашата сигурност. И си мислите, че трябва да има институции, които да се грижат за всички аспекти, свързани с безопасността ви. Институциите обаче може да имат особена визия по въпроса.
Една институционална визия за сигурността на тунелите
Държавната институция, отговаряща за строежа на пътища, тунели и мостове, е Агенция „Пътна инфраструктура“ (АПИ) към Министерството на регионалното развитие и благоустройството. За сигурността на тунелите тя се осланя на… икони. В прессъобщението на АПИ по повод пускането в експлоатация на тунел „Железница“, част от автомагистрала „Струма“, пише (оригиналният правопис е запазен):
При строителството му са вградени и четири икони на Св. „Иван Рилски“, каквито са традициите в тунелното строителство. […] В момента светите изображения не са видими, тъй като са покрити при изграждането на вторичната облицовка на съоръжението. Поверието при вграждането на иконите е, че те пазят работниците при строителството на обекта, а след това и всички пътуващи.
Иконите в тунел „Железница“ впрочем не са нови – чудодейните им свойства вече са популяризирани лично от Бойко Борисов. През 2020 г. част от строежа се срутва и затрупва трима работници, но те оцеляват. Според председателя на ГЕРБ и тогавашен премиер именно иконите на св. Иван Рилски са ги спасили, припомня „Капитал“. От изданието добавят, че пастир, загинал до тунела скоро след това, не е имал същия късмет.
Традициите в тунелното строителство, споменати в прессъобщението, впрочем изглеждат по-хуманни от тези при изграждането на мостове – според преданията в тях се вграждат сенки на невести – с летални последствия за въпросните млади жени. Засега няма яснота дали АПИ разчита на тази древна традиция при изграждането на мостови съоръжения.
Икони и дупки, светци и врачки
Самият св. Иван Рилски впрочем се смята за закрилник не на пътуващите, какъвто е св. Христофор, а на българския народ. А по магистралата, чиято цел е да свързва България и Гърция, пътуват не само българи.
Вграждането на икони в тунели, официално споменато от държавна агенция, може да се разглежда в контекста на все по-малко светската държава, за чието конституционно разделение от религията вече почти никой не се сеща. Но има и нещо друго: подобни актове не са канонична част от православната религия, а проява на суеверие. По-точно – на една специфична сплав от (квази)религия, суеверие, традиционализъм и патриотизъм.
Тази сплав датира още от времето на социализма. Въпреки че тогавашният режим официално е атеистичен и изповядва „научния комунизъм“, в който уж няма място за суеверия, той си има комай официална врачка – Ванга. Способностите ѝ са обект на проучване от Държавния научноизследователски институт по сугестология с благословията лично на диктатора Тодор Живков. СССР също има официална врачка – Джуна.
В началото на 90-те години на ХХ в. с модерните тогава екстрасенси и с Ванга (къде без нея) се забърква Генералният щаб на Българската армия. Става въпрос за известната дупка в село Царичина, в която от Щаба търсят или съкровището на цар Самуил, или първото разумно същество, живяло на Земята, или извънземни. Екстрасенсите, по чийто съвет е изкопана тя, се консултират с Ванга, за да се уверят, че са на прав път. След като от Генералния щаб не намират нищо, дупката е зарита и бетонирана.
Магическо мислене и модерни институции
През 1940 г. Иван Хаджийски публикува студията си „Възстановяване душевността на първобитния български човек“, която по-късно включва в книгата си „Оптимистична теория за нашия народ“. В началото ѝ той уточнява, че под „първобитни“ или „древни“ българи разбира населението по българските земи преди Възраждането. Ако го кажем със съвременни думи, Хаджийски има предвид предмодерните българи, които живеят изцяло в света на традициите, без наука и образование, индустриални технологии или медии.
Единственият метод на познание на тези предмодерни хора е простото наблюдение, а това, което виждат, те уподобяват на човека – придават му човешки качества. Затова се опитват да въздействат на природните стихии с уподобяване, молби, плашене, убеждаване и магии. Примерно, искат да вземат по-голяма част от питката, за да дойде при тях плодородието, карат се на дървото, че не ражда плод, и се заканват да го отсекат, молят се на облаците да пуснат дъжд и плашат болестите.
Вграждането на сенки на невести в мостове е по същество предмодерен вид жертвоприношение – опит да се умилостиви съдбата, като се пожертва „най-скъпото“. Вграждането на икони в мостове пък прилича на някаква смесица между това жертвоприношение и чудотворната изцелителна сила, която се придава на някои икони.
Починалият две десетилетия преди издаването на „Възстановяване душевността на първобитния български човек“ германски социолог Макс Вебер смята, че модерният тип рационалност се отличава от традиционния по „разомагьосването на света“. „Разомагьосаният“ свят е този, в който суеверията и магиите нямат място, а всичко може да бъде пресметнато и да се обясни научно. Всъщност модерният човек знае много по-малко за света си от традиционния човек, защото в света на модерния има много повече неща, отбелязва Вебер. Той може да не знае как точно се движи влакът, но знае, че не е магия, и ако реши, може да схване механизма на локомотива.
Повече от век след смъртта на Макс Вебер пътната агенция на страна членка на Европейския съюз твърди, че иконите могат да пазят строители и пътуващи.
Предложение за реформа на българските институции
Остава само седмица до планираната ротация на правителството „Денков–Габриел“, а една от големите ябълки на раздора е как ще се избират новите ръководства на т.нар. регулатори. Това са държавните институции, които трябва да решават дали правилата във всевъзможни сфери се нарушават. Например дали пътищата, тунелите и мостовете са построени качествено, дали потребителите са защитени от неправомерно повишаване на сметките за телефон, дали ядем здравословна храна, какъв въздух дишаме, дали телевизиите и радиостанциите спазват елементарни стандарти и т.н., и т.н.
Вместо ГЕРБ, подкрепян от ДПС, да се кара с ПП–ДБ кой да овладее регулаторите, с риска да се стигне до предсрочни избори, може тези институции направо да се отменят. А на тяхно място да се сложат икони, които да пазят населението.
Така св. Иван Рилски ще пази пътуващите през тунели, а св. Христофор – пътуващите извън тунелите. Св. Екатерина ще закриля родилките от лекарски грешки, а светиите Лука и Пантелеймон ще помагат на лекарите да не допускат такива. Св. Трифон ще подкрепя лозарския и винарския бизнес, а като покровител на кожарите св. Илия ще бетонира бизнеса с норки на „Градус“. За качеството на образованието ще се грижат светите братя Кирил и Методий, а св. Тодор ще закриля конната езда и ще подобрява нечовешките условия в домовете за психичноболни. За повишените телефонни сметки ще можем да се оплачем на иконата на св. Димитър. И т.н.
По-сложно е положението с правосъдната реформа. За да разчитаме на независимо и некорумпирано правосъдие, май само с икони няма да се мине. За преборването на тайните мрежи на влияние, част от които бяха Петьо Еврото и Мартин Нотариуса, си трябват по-сериозни средства. Например вграждане на сенки на невести. Или за по-сигурно – най-добре би било да се вградят самите невести.
Търсят се родолюбиви български мъже, готови да жертват най-милото си (своите невести, да не помислите друго) в името на едно работещо, справедливо и европейско правосъдие.
A Cyber Insurance Backstop
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/02/a-cyber-insurance-backstop.html
In the first week of January, the pharmaceutical giant Merck quietly settled its years-long lawsuit over whether or not its property and casualty insurers would cover a $700 million claim filed after the devastating NotPetya cyberattack in 2017. The malware ultimately infected more than 40,000 of Merck’s computers, which significantly disrupted the company’s drug and vaccine production. After Merck filed its $700 million claim, the pharmaceutical giant’s insurers argued that they were not required to cover the malware’s damage because the cyberattack was widely attributed to the Russian government and therefore was excluded from standard property and casualty insurance coverage as a “hostile or warlike act.”
At the heart of the lawsuit was a crucial question: Who should pay for massive, state-sponsored cyberattacks that cause billions of dollars’ worth of damage?
One possible solution, touted by former Department of Homeland Security Secretary Michael Chertoff on a recent podcast, would be for the federal government to step in and help pay for these sorts of attacks by providing a cyber insurance backstop. A cyber insurance backstop would provide a means for insurers to receive financial support from the federal government in the event that there was a catastrophic cyberattack that caused so much financial damage that the insurers could not afford to cover all of it.
In his discussion of a potential backstop, Chertoff specifically references the Terrorism Risk Insurance Act (TRIA) as a model. TRIA was passed in 2002 to provide financial assistance to the insurers who were reeling from covering the costs of the Sept. 11, 2001, terrorist attacks. It also created the Terrorism Risk Insurance Program (TRIP), a public-private system of compensation for some terrorism insurance claims. The 9/11 attacks cost insurers and reinsurers $47 billion. It was one of the most expensive insured events in history and prompted many insurers to stop offering terrorism coverage, while others raised the premiums for such policies significantly, making them prohibitively expensive for many businesses. The government passed TRIA to provide support for insurers in the event of another terrorist attack, so that they would be willing to offer terrorism coverage again at reasonable rates. President Biden’s 2023 National Cybersecurity Strategy tasked the Treasury and Homeland Security Departments with investigating possible ways of implementing something similar for large cyberattacks.
There is a growing (and unsurprising) consensus among insurers in favor of the creation and implementation of a federal cyber insurance backstop. Like terrorist attacks, catastrophic cyberattacks are difficult for insurers to predict or model because there is not very good historical data about them—and even if there were, it’s not clear that past patterns of cyberattacks will dictate future ones. What’s more, cyberattacks could cost insurers astronomic sums of money, especially if all of their policyholders were simultaneously affected by the same attack. However, despite this consensus and the fact that this idea of the government acting as the “insurer of last resort” was first floated more than a decade ago, actually developing a sound, thorough proposal for a backstop has proved to be much more challenging than many insurers and policymakers anticipated.
One major point of issue is determining a threshold for what types of cyberattacks should trigger a backstop. Specific characteristics of cyberattacks—such as who perpetrated the attack, the motive behind it, and total damage it has caused—are often exceedingly difficult to determine. Therefore, even if policymakers could agree on what types of attacks they think the government should pay for based on these characteristics, they likely won’t be able to calculate which incursions actually qualify for assistance.
For instance, NotPetya is estimated to have caused more than $10 billion in damage worldwide, but the quantifiable amount of damage it actually did is unknown. The attack caused such a wide variety of disruptions in so many different industries, many of which likely went unreported since many companies had no incentive to publicize their security failings and were not required to do so. Observers do, however, have a pretty good idea who was behind the NotPetya attack because several governments, including the United States and the United Kingdom, issued coordinated statements blaming the Russian military. As for the motive behind NotPetya, the program was initially transmitted through Ukrainian accounting software, which suggests that it was intended to target Ukrainian critical infrastructure. But notably, this type of coordinated, consensus-based attribution to a specific government is relatively rare when it comes to cyberattacks. Future attacks are not likely to receive the same determination.
In the absence of a government backstop, the insurance industry has begun to carve out larger and larger exceptions to their standard cyber coverage. For example, in a pair of rulings against Merck’s insurers, judges in New Jersey ruled that the insurance exclusions for “hostile or warlike acts” (such as the one in Merck’s property policy that excluded coverage for “loss or damage caused by hostile or warlike action in time of peace or war by any government or sovereign power”) were not sufficiently specific to encompass a cyberattack such as NotPetya that did not involve the use of traditional force.
Accordingly, insurers such as Lloyd’s have begun to change their policy language to explicitly exclude broad swaths of cyberattacks that are perpetrated by nation-states. In an August 2022 bulletin, Lloyd’s instructed its underwriters to exclude from all cyber insurance policies not just losses arising from war but also “losses arising from state backed cyber-attacks that (a) significantly impair the ability of a state to function or (b) that significantly impair the security capabilities of a state.” Other insurers, such as Chubb, have tried to avoid tricky questions about attribution by suggesting a government response-based exclusion for war that only applies if a government responds to a cyberattack by authorizing the use of force. Chubb has also introduced explicit definitions for cyberattacks that pose a “systemic risk” or impact multiple entities simultaneously. But most of this language has not yet been tested by insurers trying to deny claims. No one, including the companies buying the policies with these exclusions written into them, really knows exactly which types of cyberattacks they exclude. It’s not clear what types of cyberattacks courts will recognize as being state-sponsored, or posing systemic risks, or significantly impairing the ability of a state to function. And for the policyholders’ whose insurance exclusions feature this sort of language, it matters a great deal how that language in their exclusions will be parsed and understood by courts adjudicating claim disputes.
These types of recent exclusions leave a large hole in companies’ coverage for cyber risks, placing even more pressure on the government to help. One of the reasons Chertoff gives for why the backstop is important is to help clarify for organizations what cyber risk-related costs they are and are not responsible for. That clarity will require very specific definitions of what types of cyberattacks the government will and will not pay for. And as the insurers know, it can be quite difficult to anticipate what the next catastrophic cyberattack will look like or how to craft a policy that will enable the government to pay only for a narrow slice of cyberattacks in a varied and unpredictable threat landscape. Get this wrong, and the government will end up writing some very large checks.
And in comparison to insurers’ coverage of terrorist attacks, large-scale cyberattacks are much more common and affect far more organizations, which makes it a far more costly risk that no one wants to take on. Organizations don’t want to—that’s why they buy insurance. Insurance companies don’t want to—that’s why they look to the government for assistance. But, so far, the U.S. government doesn’t want to take on the risk, either.
It is safe to assume, however, that regardless of whether a formal backstop is established, the federal government would step in and help pay for a sufficiently catastrophic cyberattack. If the electric grid went down nationwide, for instance, the U.S. government would certainly help cover the resulting costs. It’s possible to imagine any number of catastrophic scenarios in which an ad hoc backstop would be implemented hastily to help address massive costs and catastrophic damage, but that’s not primarily what insurers and their policyholders are looking for. They want some reassurance and clarity up front about what types of incidents the government will help pay for. But to provide that kind of promise in advance, the government likely would have to pair it with some security requirements, such as implementing multifactor authentication, strong encryption, or intrusion detection systems. Otherwise, they create a moral hazard problem, where companies may decide they can invest less in security knowing that the government will bail them out if they are the victims of a really expensive attack.
The U.S. government has been looking into the issue for a while, though, even before the 2023 National Cybersecurity Strategy was released. In 2022, for instance, the Federal Insurance Office in the Treasury Department published a Request for Comment on a “Potential Federal Insurance Response to Catastrophic Cyber Incidents.” The responses recommended a variety of different possible backstop models, ranging from expanding TRIP to encompass certain catastrophic cyber incidents, to creating a new structure similar to the National Flood Insurance Program that helps underwrite flood insurance, to trying a public-private partnership backstop model similar to the United Kingdom’s Pool Re program.
Many of these responses rightly noted that while it might eventually make sense to have some federal backstop, implementing such a program immediately might be premature. University of Edinburgh Professor Daniel Woods, for example, made a compelling case for why it was too soon to institute a backstop in Lawfare last year. Woods wrote,
One might argue similarly that a cyber insurance backstop would subsidize those companies whose security posture creates the potential for cyber catastrophe, such as the NotPetya attack that caused $10 billion in damage. Infection in this instance could have been prevented by basic cyber hygiene. Why should companies that do not employ basic cyber hygiene be subsidized by industry peers? The argument is even less clear for a taxpayer-funded subsidy.
The answer is to ensure that a backstop applies only to companies that follow basic cyber hygiene guidelines, or to insurers who require those hygiene measures of their policyholders. These are the types of controls many are familiar with: complicated passwords, app-based two-factor authentication, antivirus programs, and warning labels on emails. But this is easier said than done. To a surprising extent, it is difficult to know which security controls really work to improve companies’ cybersecurity. Scholars know what they think works: strong encryption, multifactor authentication, regular software updates, and automated backups. But there is not anywhere near as much empirical evidence as there ought to be about how effective these measures are in different implementations, or how much they reduce a company’s exposure to cyber risk.
This is largely due to companies’ reluctance to share detailed, quantitative information about cybersecurity incidents because any such information may be used to criticize their security posture or, even worse, as evidence for a government investigation or class-action lawsuit. And when insurers and regulators alike try to gather that data, they often run into legal roadblocks because these investigations are often run by lawyers who claim that the results are shielded by attorney-client privilege or work product doctrine. In some cases, companies don’t write down their findings at all to avoid the possibility of its being used against them in court. Without this data, it’s difficult for insurers to be confident that what they’re requiring of their policyholders will really work to improve those policyholders’ security and decrease their claims for cybersecurity-related incidents under their policies. Similarly, it’s hard for the federal government to be confident that they can impose requirements for a backstop that will actually raise the level of cybersecurity hygiene nationwide.
The key to managing cyber risks—both large and small—and designing a cyber backstop is determining what security practices can effectively mitigate the impact of these attacks. If there were data showing which controls work, insurers could then require that their policyholders use them, in the same way they require policyholders to install smoke detectors or burglar alarms. Similarly, if the government had better data about which security tools actually work, it could establish a backstop that applied only to victims who have used those tools as safeguards. The goal of this effort, of course, is to improve organizations’ overall cybersecurity in addition to providing financial assistance.
There are a number of ways this data could be collected. Insurers could do it through their claims databases and then aggregate that data across carriers to policymakers. They did this for car safety measures starting in the 1950s, when a group of insurance associations founded the Insurance Institute for Highway Safety. The government could use its increasing reporting authorities, for instance under the Cyber Incident Reporting for Critical Infrastructure Act of 2022, to require that companies report data about cybersecurity incidents, including which countermeasures were in place and the root causes of the incidents. Or the government could establish an entirely new entity in the form of a Bureau for Cyber Statistics that would be devoted to collecting and analyzing this type of data.
Scholars and policymakers can’t design a cyber backstop until this data is collected and studied to determine what works best for cybersecurity. More broadly, organizations’ cybersecurity cannot improve until more is known about the threat landscape and the most effective tools for managing cyber risk.
If the cybersecurity community doesn’t pause to gather that data first, then it will never be able to meaningfully strengthen companies’ security postures against large-scale cyberattacks, and insurers and government officials will just keep passing the buck back and forth, while the victims are left to pay for those attacks themselves.
This essay was written with Josephine Wolff, and was originally published in Lawfare.
security engineer interview
Post Syndicated from turnoff.us original http://turnoff.us/geek/security-engineer-interview/

Time Tips From the Universe
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=_26B8YTEYzU
Samsung HBM3E 12H 36GB In Production Q2 2024
Post Syndicated from Cliff Robinson original https://www.servethehome.com/samsung-hbm3e-12h-36gb-in-production-q2-2024/
Samsung has new HBM slated for Q2 2024 production. Samsung HBM3E 12H will bring 36GB packages to the market in a few months
The post Samsung HBM3E 12H 36GB In Production Q2 2024 appeared first on ServeTheHome.
Comic for 2024.02.28 – Allergies 3
Post Syndicated from Explosm.net original https://explosm.net/comics/allergies-3
New Cyanide and Happiness Comic
Call My Cell
Post Syndicated from xkcd.com original https://xkcd.com/2900/

How Big Tech is Controlling Your Life
Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=KUalfc9Hfak
[$] A look at Nix and Guix
Post Syndicated from daroc original https://lwn.net/Articles/962788/
Nix and
Guix are a pair of unusual package managers
based on the idea of declarative configurations. Their associated Linux
distributions — NixOS and the Guix System — take the idea further by allowing users
to define a single centralized configuration describing the state of the entire
system. Both have
been previously
mentioned on LWN, but not covered extensively. They offer different takes on
the central idea of treating packages like immutable values.
AWS Payment Cryptography is PCI PIN and P2PE certified
Post Syndicated from Tim Winston original https://aws.amazon.com/blogs/security/aws-payment-cryptography-is-pci-pin-and-p2pe-certified/
Amazon Web Services (AWS) is pleased to announce that AWS Payment Cryptography is certified for Payment Card Industry Personal Identification Number (PCI PIN) version 3.1 and as a PCI Point-to-Point Encryption (P2PE) version 3.1 Decryption Component.
With Payment Cryptography, your payment processing applications can use payment hardware security modules (HSMs) that are PCI PIN Transaction Security (PTS) HSM certified and fully managed by AWS, with PCI PIN and P2PE-compliant key management. These attestations give you the flexibility to deploy your regulated workloads with reduced compliance overhead.
The PCI P2PE Decryption Component enables PCI P2PE Solutions to use AWS to decrypt credit card transactions from payment terminals, and PCI PIN attestation is required for applications that process PIN-based debit transactions. According to PCI, “Use of a PCI P2PE Solution can also allow merchants to reduce where and how the PCI DSS applies within their retail environment, increasing security of customer data while simplifying compliance with the PCI DSS”.
Coalfire, a third-party Qualified PIN Assessor (QPA) and Qualified Security Assessor (P2PE), evaluated Payment Cryptography. Customers can access the PCI PIN Attestation of Compliance (AOC) report, the PCI PIN Shared Responsibility Summary, and the PCI P2PE Attestation of Validation through AWS Artifact.
To learn more about our PCI program and other compliance and security programs, see the AWS Compliance Programs page. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Use Amazon OpenSearch Ingestion to migrate to Amazon OpenSearch Serverless
Post Syndicated from Muthu Pitchaimani original https://aws.amazon.com/blogs/big-data/use-amazon-opensearch-ingestion-to-migrate-to-amazon-opensearch-serverless/
Amazon OpenSearch Serverless is an on-demand auto scaling configuration for Amazon OpenSearch Service. Since its release, the interest for OpenSearch Serverless had been steadily growing. Customers prefer to let the service manage its capacity automatically rather than having to manually provision capacity. Until now, customers have had to rely on using custom code or third-party solutions to move the data between provisioned OpenSearch Service domains and OpenSearch Serverless.
We recently introduced a feature with Amazon OpenSearch Ingestion (OSI) to make this migration even more effortless. OSI is a fully managed, serverless data collector that delivers real-time log, metric, and trace data to OpenSearch Service domains and OpenSearch Serverless collections.
In this post, we outline the steps to make migrate the data between provisioned OpenSearch Service domains and OpenSearch Serverless. Migration of metadata such as security roles and dashboard objects will be covered in another subsequent post.
Solution overview
The following diagram shows the necessary components for moving data between OpenSearch Service provisioned domains and OpenSearch Serverless using OSI. You will use OSI with OpenSearch Service as source and an OpenSearch Serverless collection as sink.

Prerequisites
Before getting started, complete the following steps to create the necessary resources:
- Create an AWS Identity and Access Management (IAM) role that the OpenSearch Ingestion pipeline will assume to write to the OpenSearch Serverless collection. This role needs to be specified in the
sts_role_arnparameter of the pipeline configuration. - Attach a permissions policy to the role to allow it to read data from the OpenSearch Service domain. The following is a sample policy with least privileges:
- Attach a permissions policy to the role to allow it to send data to the collection. The following is a sample policy with least privileges:
- Configure the role to assume the trust relationship, as follows:
- It’s recommended to add the
aws:SourceAccountandaws:SourceArncondition keys to the policy for protection against the confused deputy problem: - Map the OpenSearch Ingestion domain role ARN as a backend user (as an
all_accessuser) to the domain user. We show a simplified example to use theall_accessrole. For production scenarios, make sure to use a role with just enough permissions to read and write.

- Create an OpenSearch Serverless collection, which is where data will be ingested.
- Associate a data policy, as shown in the following code, to grant the OpenSearch Ingestion role permissions on the collection:
- If the collection is defined as a VPC collection, you need to create a network policy and configure it in the ingestion pipeline.

Now you’re ready to move data from your provisioned domain to OpenSearch Serverless.


 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat. Rahul Sharma is a Technical Account Manager at Amazon Web Services. He is passionate about the data technologies that help leverage data as a strategic asset and is based out of New York city, New York.
Rahul Sharma is a Technical Account Manager at Amazon Web Services. He is passionate about the data technologies that help leverage data as a strategic asset and is based out of New York city, New York.Empowering data-driven excellence: How the Bluestone Data Platform embraced data mesh for success
Post Syndicated from Toney Thomas original https://aws.amazon.com/blogs/big-data/empowering-data-driven-excellence-how-the-bluestone-data-platform-embraced-data-mesh-for-success/
This post is co-written with Toney Thomas and Ben Vengerovsky from Bluestone.
In the ever-evolving world of finance and lending, the need for real-time, reliable, and centralized data has become paramount. Bluestone, a leading financial institution, embarked on a transformative journey to modernize its data infrastructure and transition to a data-driven organization. In this post, we explore how Bluestone uses AWS services, notably the cloud data warehousing service Amazon Redshift, to implement a cutting-edge data mesh architecture, revolutionizing the way they manage, access, and utilize their data assets.
The challenge: Legacy to modernization
Bluestone was operating with a legacy SQL-based lending platform, as illustrated in the following diagram. To stay competitive and responsive to changing market dynamics, they decided to modernize their infrastructure. This modernization involved transitioning to a software as a service (SaaS) based loan origination and core lending platforms. Because these new systems produced vast amounts of data, the challenge of ensuring a single source of truth for all data consumers emerged.

Birth of the Bluestone Data Platform
To address the need for centralized, scalable, and governable data, Bluestone introduced the Bluestone Data Platform. This platform became the hub for all data-related activities across the organization. AWS played a pivotal role in bringing this vision to life.
The following are the key components of the Bluestone Data Platform:
- Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. Each data producer within the organization has its own data lake in Apache Hudi format, ensuring data sovereignty and autonomy.
- Four-layered data lake and data warehouse architecture – The architecture comprises four layers, including the analytical layer, which houses purpose-built facts and dimension datasets that are hosted in Amazon Redshift. These datasets are pivotal for reporting and analytics use cases, powered by services like Amazon Redshift and tools like Power BI.
- Machine learning analytics – Various business units, such as Servicing, Lending, Sales & Marketing, Finance, and Credit Risk, use machine learning analytics, which run on top of the dimensional model within the data lake and data warehouse. This enables data-driven decision-making across the organization.
- Governance and self-service – The Bluestone Data Platform provides a governed, curated, and self-service avenue for all data use cases. AWS services like AWS Lake Formation in conjunction with Atlan help govern data access and policies.
- Data quality framework – To ensure data reliability, they implemented a data quality framework. It continuously assesses data quality and syncs quality scores to the Atlan governance tool, instilling confidence in the data assets within the platform.
The following diagram illustrates the architecture of their updated data platform.

AWS and third-party services
AWS played a pivotal and multifaceted role in empowering Bluestone’s Data Platform to thrive. The following AWS and third-party services were instrumental in shaping Bluestone’s journey toward becoming a data-driven organization:
- Amazon Redshift – Bluestone harnessed the power of Amazon Redshift and its features like data sharing to create a centralized repository of data assets. This strategic move facilitated seamless data sharing and collaboration across diverse business units, paving the way for more informed and data-driven decision-making.
- Lake Formation – Lake Formation emerged as a cornerstone in Bluestone’s data governance strategy. It played a critical role in enforcing data access controls and implementing data policies. With Lake Formation, Bluestone achieved protection of sensitive data and compliance with regulatory requirements.
- Data quality monitoring – To maintain data reliability and accuracy, Bluestone deployed a robust data quality framework. AWS services were essential in this endeavor, because they complemented open source tools to establish an in-house data quality monitoring system. This system continuously assesses data quality, providing confidence in the reliability of the organization’s data assets.
- Data governance tooling – Bluestone chose Atlan, available through AWS Marketplace, to implement comprehensive data governance tooling. This SaaS service played a pivotal role in onboarding multiple business teams and fostering a data-centric culture within Bluestone. It empowered teams to efficiently manage and govern data assets.
- Orchestration using Amazon MWAA – Bluestone heavily relied on Amazon Managed Workflows for Apache Airflow (Amazon MWAA) to manage workflow orchestrations efficiently. This orchestration framework seamlessly integrated with various data quality rules, which were evaluated using Great Expectations operators within the Airflow environment.
- AWS DMS – Bluestone used AWS Database Migration Service (AWS DMS) to streamline the consolidation of legacy data into the data platform. This service facilitated the smooth transfer of data from legacy SQL Server warehouses to the data lake and data warehouse, providing data continuity and accessibility.
- AWS Glue – Bluestone used the AWS Glue PySpark environment for implementing data extract, transform, and load (ETL) processes. It played a pivotal role in processing data originating from various source systems, providing data consistency and suitability for analytical use.
- AWS Glue Data Catalog – Bluestone centralized their data management using the AWS Glue Data Catalog. This catalog served as the backbone for managing data assets within the Bluestone data estate, enhancing data discoverability and accessibility.
- AWS CloudTrail – Bluestone implemented AWS CloudTrail to monitor and audit platform activities rigorously. This security-focused service provided essential visibility into platform actions, providing compliance and security in data operations.
AWS’s comprehensive suite of services has been integral in propelling the Bluestone Data Platform towards data-driven success. These services have not only enabled efficient data governance, quality assurance, and orchestration, but have also fostered a culture of data centricity within the organization, ultimately leading to better decision-making and competitive advantage. Bluestone’s journey showcases the power of AWS in transforming organizations into data-driven leaders in their respective industries.
Bluestone data architecture
Bluestone’s data architecture has undergone a dynamic transformation, transitioning from a lake house framework to a data mesh architecture. This evolution was driven by the organization’s need for data products with distributed ownership and the necessity for a centralized mechanism to govern and access these data products across various business units.
The following diagram illustrates the solution architecture and its use of AWS and third-party services.

Let’s delve deeper into how this architecture shift has unfolded and what it entails:
- The need for change – The catalyst for this transformation was the growing demand for discrete data products tailored to the unique requirements of each business unit within Bluestone. Because these business units generated their own data assets in their respective domains, the challenge lay in efficiently managing, governing, and accessing these diverse data stores. Bluestone recognized the need for a more structured and scalable approach.
- Data products with distributed ownership – In response to this demand, Bluestone adopted a data mesh architecture, which allowed for the creation of distinct data products aligned with each business unit’s needs. Each of these data products exists independently, generating and curating data assets specific to its domain. These data products serve as individual data hubs, ensuring data autonomy and specialization.
- Centralized catalog integration – To streamline the discovery and accessibility of the data assets that are dispersed across these data products, Bluestone introduced a centralized catalog. This catalog acts as a unified repository where all data products register their respective data assets. It serves as a critical component for data discovery and management.
- Data governance tool integration – Ensuring data governance and lineage tracking across the organization was another pivotal consideration. Bluestone implemented a robust data governance tool that connects to the centralized catalog. This integration makes sure that the overarching lineage of data assets is comprehensively mapped and captured. Data governance processes are thereby enforced consistently, guaranteeing data quality and compliance.
- Amazon Redshift data sharing for control and access – To facilitate controlled and secure access to data assets residing within individual data product Redshift instances, Bluestone used Amazon Redshift data sharing. This capability allows data assets to be exposed and shared selectively, providing granular control over access while maintaining data security and integrity.
In essence, Bluestone’s journey from a lake house to a data mesh architecture represents a strategic shift in data management and governance. This transformation empowers different business units to operate autonomously within their data domains while ensuring centralized control, governance, and accessibility. The integration of a centralized catalog and data governance tooling, coupled with the flexibility of Amazon Redshift data sharing, creates a harmonious ecosystem where data-driven decision-making thrives, ultimately contributing to Bluestone’s success in the ever-evolving financial landscape.
Conclusion
Bluestone’s journey from a legacy SQL-based system to a modern data mesh architecture on AWS has improved the way the organization interacts with data and positioned them as a data-driven powerhouse in the financial industry. By embracing AWS services, Bluestone has successfully achieved a centralized, scalable, and governable data platform that empowers its teams to make informed decisions, drive innovation, and stay ahead in the competitive landscape. This transformation serves as compelling proof that Amazon Redshift and AWS Cloud data sharing capabilities are a great pathway for organizations looking to embark on their own data-driven journeys with AWS.
About the Authors
 Toney Thomas is a Data Architect and Data Engineering Lead at Bluestone, renowned for his role in envisioning and coining the company’s pioneering data strategy. With a strategic focus on harnessing the power of advanced technology to tackle intricate business challenges, Toney leads a dynamic team of Data Engineers, Reporting Engineers, Quality Assurance specialists, and Business Analysts at Bluestone. His leadership extends to driving the implementation of robust data governance frameworks across diverse organizational units. Under his guidance, Bluestone has achieved remarkable success, including the deployment of innovative platforms such as a fully governed data mesh business data system with embedded data quality mechanisms, aligning seamlessly with the organization’s commitment to data democratization and excellence.
Toney Thomas is a Data Architect and Data Engineering Lead at Bluestone, renowned for his role in envisioning and coining the company’s pioneering data strategy. With a strategic focus on harnessing the power of advanced technology to tackle intricate business challenges, Toney leads a dynamic team of Data Engineers, Reporting Engineers, Quality Assurance specialists, and Business Analysts at Bluestone. His leadership extends to driving the implementation of robust data governance frameworks across diverse organizational units. Under his guidance, Bluestone has achieved remarkable success, including the deployment of innovative platforms such as a fully governed data mesh business data system with embedded data quality mechanisms, aligning seamlessly with the organization’s commitment to data democratization and excellence.
 Ben Vengerovsky is a Data Platform Product Manager at Bluestone. He is passionate about using cloud technology to revolutionize the company’s data infrastructure. With a background in mortgage lending and a deep understanding of AWS services, Ben specializes in designing scalable and efficient data solutions that drive business growth and enhance customer experiences. He thrives on collaborating with cross-functional teams to translate business requirements into innovative technical solutions that empower data-driven decision-making.
Ben Vengerovsky is a Data Platform Product Manager at Bluestone. He is passionate about using cloud technology to revolutionize the company’s data infrastructure. With a background in mortgage lending and a deep understanding of AWS services, Ben specializes in designing scalable and efficient data solutions that drive business growth and enhance customer experiences. He thrives on collaborating with cross-functional teams to translate business requirements into innovative technical solutions that empower data-driven decision-making.
 Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
2023 H2 IRAP report is now available on AWS Artifact for Australian customers
Post Syndicated from Patrick Chang original https://aws.amazon.com/blogs/security/2023-h2-irap-report-is-now-available-on-aws-artifact-for-australian-customers/
Amazon Web Services (AWS) is excited to announce that a new Information Security Registered Assessors Program (IRAP) report (2023 H2) is now available through AWS Artifact. An independent Australian Signals Directorate (ASD) certified IRAP assessor completed the IRAP assessment of AWS in December 2023.
The new IRAP report includes an additional seven AWS services that are now assessed at the PROTECTED level under IRAP. This brings the total number of services assessed at the PROTECTED level to 151.
The following are the seven newly assessed services:
- AWS Clean Rooms
- AWS Fault Injection Service
- AWS IoT Device Defender
- AWS IoT TwinMaker
- AWS Lake Formation
- Amazon MemoryDB for Redis
- AWS Wickr
For the full list of services, see the IRAP tab on the AWS Services in Scope by Compliance Program page.
AWS has developed an IRAP documentation pack to assist Australian government agencies and their partners to plan, architect, and assess risk for their workloads when they use AWS Cloud services.
We developed this pack in accordance with the Australian Cyber Security Centre (ACSC) Cloud Security Guidance and Cloud Assessment and Authorisation framework, which addresses guidance within the Australian Government’s Information Security Manual (ISM, September 2023 version), the Department of Home Affairs’ Protective Security Policy Framework (PSPF), and the Digital Transformation Agency’s Secure Cloud Strategy.
The IRAP pack on AWS Artifact also includes newly updated versions of the AWS Consumer Guide and the whitepaper Reference Architectures for ISM PROTECTED Workloads in the AWS Cloud.
Reach out to your AWS representatives to let us know which additional services you would like to see in scope for upcoming IRAP assessments. We strive to bring more services into scope at the PROTECTED level under IRAP to support your requirements.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Navigating Cloud Storage: What is Latency and Why Does It Matter?
Post Syndicated from Amrit Singh original https://www.backblaze.com/blog/navigating-cloud-storage-what-is-latency-and-why-does-it-matter/

In today’s bandwidth-intensive world, latency is an important factor that can impact performance and the end-user experience for modern cloud-based applications. For many CTOs, architects, and decision-makers at growing small and medium sized businesses (SMBs), understanding and reducing latency is not just a technical need but also a strategic play.
Latency, or the time it takes for data to travel from one point to another, affects everything from how snappy or responsive your application may feel to content delivery speeds to media streaming. As infrastructure increasingly relies on cloud object storage to manage terabytes or even petabytes of data, optimizing latency can be the difference between success and failure.
Let’s get into the nuances of latency and its impact on cloud storage performance.
Upload vs. Download Latency: What’s the Difference?
In the world of cloud storage, you’ll typically encounter two forms of latency: upload latency and download latency. Each can impact the responsiveness and efficiency of your cloud-based application.
Upload Latency
Upload latency refers to the delay when data is sent from a client or user’s device to the cloud. Live streaming applications, backup solutions, or any application that relies heavily on real-time data uploading will experience hiccups if upload latency is high, leading to buffering delays or momentary stream interruptions.
Download Latency
Download latency, on the other hand, is the delay when retrieving data from the cloud to the client or end user’s device. Download latency is particularly relevant for content delivery applications, such as on demand video streaming platforms, e-commerce, or other web-based applications. Reducing download latency, creating a snappy web experience, and ensuring content is swiftly delivered to the end user will make for a more favorable user experience.
Ideally, you’ll want to optimize for latency in both directions, but, depending on your use case and the type of application you are building, it’s important to understand the nuances of upload and download latency and their impact on your end users.
Decoding Cloud Latency: Key Factors and Their Impact
When it comes to cloud storage, how good or bad the latency is can be influenced by a number of factors, each having an impact on the overall performance of your application. Let’s explore a few of these key factors.
Network Congestion
Like traffic on a freeway, packets of data can experience congestion on the internet. This can lead to slower data transmission speeds, especially during peak hours, leading to a laggy experience. Internet connection quality and the capacity of networks can also contribute to this congestion.
Geographical Distance
Often overlooked, the physical distance from the client or end user’s device to the cloud origin store can have an impact on latency. The farther the distance from the client to the server, the farther the data has to traverse and the longer it takes for transmission to complete, leading to higher latency.
Infrastructure Components
The quality of infrastructure, including routers, switches, and cables, may affect network performance and latency numbers. Modern hardware, such as fiber-optic cables, can reduce latency, unlike outdated systems that don’t meet current demands. Often, you don’t have full control over all of these infrastructure elements, but awareness of potential bottlenecks may be helpful, guiding upgrades wherever possible.
Technical Processes
- TCP/IP Handshake: Connecting a client and a server involves a handshake process, which may introduce a delay, especially if it’s a new connection.
- DNS Resolution: Latency can be increased by the time it takes to resolve a domain name to its IP address. There is a small reduction in total latency with faster DNS resolution times.
- Data routing: Data does not necessarily travel a straight line from its source to its destination. Latency can be influenced by the effectiveness of routing algorithms and the number of hops that data must make.
Reduced latency and improved application performance are important for businesses that rely on frequently accessing data stored in cloud storage. This may include selecting providers with strategically positioned data centers, fine-tuning network configurations, and understanding how internet infrastructure affects the latency of their applications.
Minimizing Latency With Content Delivery Networks (CDNs)
Further reducing latency in your application may be achieved by layering a content delivery network (CDN) in front of your origin storage. CDNs help reduce the time it takes for content to reach the end user by caching data in distributed servers that store content across multiple geographic locations. When your end-user requests or downloads content, the CDN delivers it from the nearest server, minimizing the distance the data has to travel, which significantly reduces latency.
Backblaze B2 Cloud Storage integrates with multiple CDN solutions, including Fastly, Bunny.net, and Cloudflare, providing a performance advantage. And, Backblaze offers the additional benefit of free egress between where the data is stored and the CDN’s edge servers. This not only reduces latency, but also optimizes bandwidth usage, making it cost effective for businesses building bandwidth intensive applications such as on demand media streaming.
To get slightly into the technical weeds, CDNs essentially cache content at the edge of the network, meaning that once content is stored on a CDN server, subsequent requests do not need to go back to the origin server to request data.
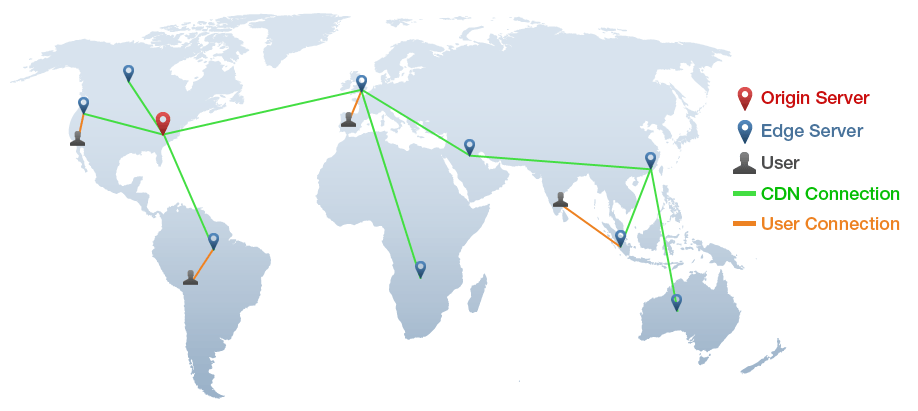
This reduces the load on the origin server and reduces the time needed to deliver the content to the user. For companies using cloud storage, integrating CDNs into their infrastructure is an effective configuration to improve the global availability of content, making it an important aspect of cloud storage and application performance optimization.
Case Study: Musify Improves Latency and Reduces Cloud Bill by 70%
To illustrate the impact of reduced latency on performance, consider the example of music streaming platform Musify. By moving from Amazon S3 to Backblaze B2 and leveraging the partnership with Cloudflare, Musify significantly improved its service offering. Musify egresses about 1PB of data per month, which, under traditional cloud storage pricing models, can lead to significant costs. Because Backblaze and Cloudflare are both members of the Bandwidth Alliance, Musify now has no data transfer costs, contributing to an estimated 70% reduction in cloud spend. And, thanks to the high cache hit ratio, 90% of the transfer takes place in the CDN layer, which helps maintain high performance, regardless of the location of the file or the user.
Latency Wrap Up
As we wrap up our look at the role latency plays in cloud-based applications, it’s clear that understanding and strategically reducing latency is a necessary approach for CTOs, architects, and decision-makers building many of the modern applications we all use today. There are several factors that impact upload and download latency, and it’s important to understand the nuances to effectively improve performance.
Additionally, Backblaze B2’s integrations with CDNs like Fastly, bunny.net, and Cloudflare offer a cost-effective way to improve performance and reduce latency. The strategic decisions Musify made demonstrate how reducing latency with a CDN can significantly improve content delivery while saving on egress costs, and reducing overall business OpEx.
For additional information and guidance on reducing latency, improving TTFB numbers and overall performance, the insights shared in “Cloud Performance and When It Matters” offer a deeper, technical look.
If you’re keen to explore further into how an object storage platform may support your needs and help scale your bandwidth-intensive applications, read more about Backblaze B2 Cloud Storage.
The post Navigating Cloud Storage: What is Latency and Why Does It Matter? appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Tiny but packs a BIG punch, MSR-1 from Apollo Automation
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=vz1oWhPoIwA
AWS recognized as an Overall Leader in 2024 KuppingerCole Leadership Compass for Policy Based Access Management
Post Syndicated from Julian Lovelock original https://aws.amazon.com/blogs/security/aws-recognized-as-overall-leader-in-2023kuppingercole-leadership-compass/
Amazon Web Services (AWS) was recognized by KuppingerCole Analysts AG as an Overall Leader in the firm’s Leadership Compass report for Policy Based Access Management. The Leadership Compass report reveals Amazon Verified Permissions as an Overall Leader (as shown in Figure 1), a Product Leader for functional strength, and an Innovation Leader for open source security. The recognition is based on a comparison with 14 other vendors, using standardized evaluation criteria set by KuppingerCole.

Figure 1: KuppingerCole Leadership Compass for Policy Based Access Management
The report helps organizations learn about policy-based access management solutions for common use cases and requirements. KuppingerCole defines policy-based access management as an approach that helps to centralize policy management, run authorization decisions across a variety of applications and resource types, continually evaluate authorization decisions, and support corporate governance.
Policy-based access management has three major benefits: consistency, security, and agility. Many organizations grapple with a patchwork of access control mechanisms, which can hinder their ability to implement a consistent approach across the organization, increase their security risk exposure, and reduce the agility of their development teams. A policy-based access control architecture helps organizations centralize their policies in a policy store outside the application codebase, where the policies can be audited and consistently evaluated. This enables teams to build, refactor, and expand applications faster, because policy guardrails are in place and access management is externalized.
Amazon Verified Permissions is a scalable, fine-grained permissions management and authorization service for the applications that you build. This service helps your developers to build more secure applications faster, by externalizing authorization and centralizing policy management and administration. Developers can align their application access with Zero Trust principles by implementing least privilege and continual authorization within applications. Security and audit teams can better analyze and audit who has access to what within applications.
Verified Permissions uses Cedar, a purpose-built and security-first open source policy language, to define policy-based access controls by using roles and attributes for more granular, context-aware access control. Cedar demonstrates the AWS commitment to raising the bar for open source security by developing key security-related technologies in collaboration with the community, with a goal of improving security postures across the industry.
The KuppingerCole Leadership Compass report offers insightful guidance as you evaluate policy-based access management solutions for your organization. Access a complimentary copy of the 2024 KuppingerCole Leadership Compass for Policy-Based Access Management.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
China Surveillance Company Hacked
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/02/china-surveillance-company-hacked.html
Last week, someone posted something like 570 files, images and chat logs from a Chinese company called I-Soon. I-Soon sells hacking and espionage services to Chinese national and local government.
Lots of details in the news articles.
These aren’t details about the tools or techniques, more the inner workings of the company. And they seem to primarily be hacking regionally.
The bpftop tool
Post Syndicated from corbet original https://lwn.net/Articles/963767/
Netflix has announced
the release of a tool called bpftop to help with the performance
optimization of BPF programs in the kernel:
bpftop provides a dynamic real-time view of running eBPF
programs. It displays the average execution runtime, events per
second, and estimated total CPU % for each program. This tool
minimizes overhead by enabling performance statistics only while it
is active.
Security updates for Tuesday
Post Syndicated from corbet original https://lwn.net/Articles/963805/
Security updates have been issued by Debian (engrampa and libgit2), Fedora (libxls, perl-Spreadsheet-ParseXLSX, and wpa_supplicant), Gentoo (PyYAML), Mageia (packages and thunderbird), Red Hat (firefox, kernel, linux-firmware, thunderbird, and unbound), Slackware (openjpeg), SUSE (golang-github-prometheus-prometheus, installation-images, kernel, python-azure-core, python-azure-storage-blob, salt and python-pyzmq, SUSE Manager 4.2.11, SUSE Manager 4.3, SUSE Manager Server 4.2, and wayland), and Ubuntu (dnsmasq, libde265, libxml2, openjdk-17, openjdk-21, openjdk-lts, and postgresql-12, postgresql-14, postgresql-15).