Post Syndicated from original https://www.backblaze.com/blog/backblaze-drive-stats-for-q1-2022/

A long time ago, in a galaxy far, far away, Backblaze began collecting and storing statistics about the hard drives it uses to store customer data. As of the end of Q1 2022, Backblaze was monitoring 211,732 hard drives and SSDs in our data centers around the universe. Of that number, there were 3,860 boot drives, leaving us with 207,872 data drives under management. This report will focus on those data drives. We will review the hard drive failure rates for those drive models that were active as of the end of Q1 2022, and we’ll also look at their lifetime failure statistics. In between, we will dive into the failure rates of the active drive models over time. Along the way, we will share our observations and insights on the data presented and, as always, we look forward to you doing the same in the comments section at the end of the report.
“The greatest teacher, failure is.”1
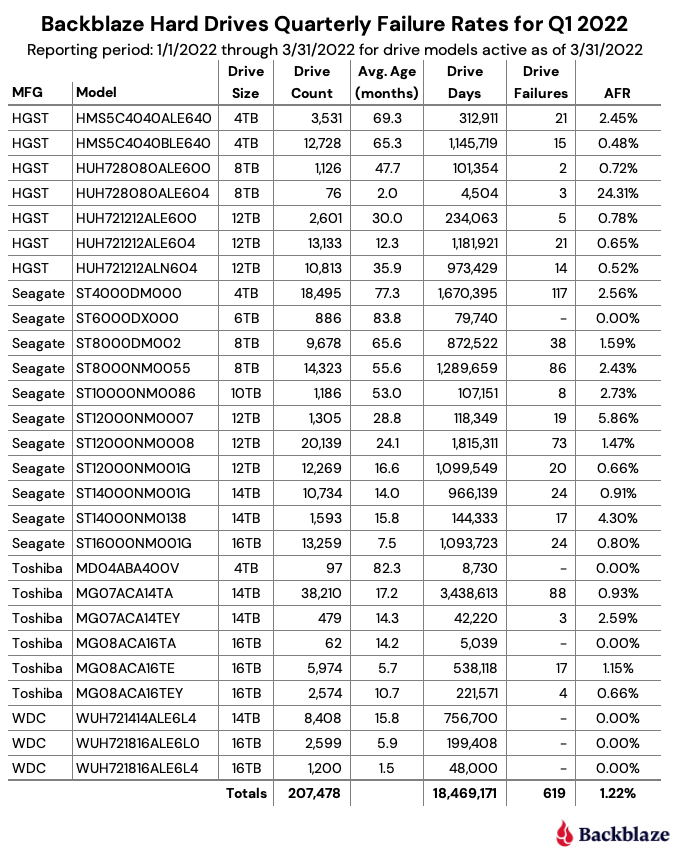
As of the end of Q1 2022, Backblaze was monitoring 207,872 hard drives used to store data. For our evaluation, we removed 394 drives from consideration as they were either used for testing purposes or were drive models which did not have at least 60 active drives. This leaves us with 207,478 hard drives to analyze for this report. The chart below contains the results of our analysis for Q1 2022.
“Always pass on what you have learned.”2
In reviewing the Q1 2022 table above and the data that lies underneath, we offer a few observations and caveats:
- “The Force is strong with this one.”3 The 6TB Seagate (model: ST6000DX000) continues to defy time with zero failures during Q1 2022 despite an average age of nearly seven years (83.7 months). 98% of the drives (859) were installed within the same two-week period back in Q1 2015. The youngest 6TB drive in the entire cohort is a little over four years old. The 4TB Toshiba (model: MD04ABA400V) also had zero failures during Q1 2022 and the average age (82.3 months) is nearly as old as the Seagate drives, but the Toshiba cohort has only 97 drives. Still, they’ve averaged just one drive failure per year over their Backblaze lifetime.
- “Great, kid, don’t get cocky.”4 There were a number of padawan drives (in average age) that also had zero drive failures in Q1 2022. The two 16TB WDC drives (models: WUH721816ALEL0 and WUH721816ALEL4) lead the youth movement with an average age of 5.9 and 1.5 months respectively. Between the two models, there are 3,899 operational drives and only one failure since they were installed six months ago. A good start, but surely not Jedi territory yet.
- “I find your lack of faith disturbing.”5 You might have noticed the AFR for Q1 2022 of 24.31% for the 8TB HGST drives (model: HUH728080ALE604). The drives are young with an average age of two months, and there are only 76 drives with a total of 4,504 drive days. If you find the AFR bothersome, I do in fact find your lack of faith disturbing, given the history of stellar performance in the other HGST drives we employ. Let’s see where we are in a couple of quarters.
- “Try not. Do or do not. There is no try.”6 The saga continues for the 14TB Seagate drives (model: ST14000NM0138). When we last saw this drive, the Seagate/Dell/Backblaze alliance continued to work diligently to understand why the failure rate was stubbornly high. Unusual it is for this model, and the team has employed multiple firmware tweaks over the past several months with varying degrees of success. Patience.
“I like firsts. Good or bad, they’re always memorable.”7
We have been delivering quarterly and annual Drive Stats reports since Q1 2015. Along the way, we have presented multiple different views of the data to help provide insights into our operational environment and the hard drives in that environment. Today we’d like to offer a different way to visualize comparing the average age of many of the different models we currently use versus the annualized failure rate of each of those drive models: the Drive Stats Failure Square:
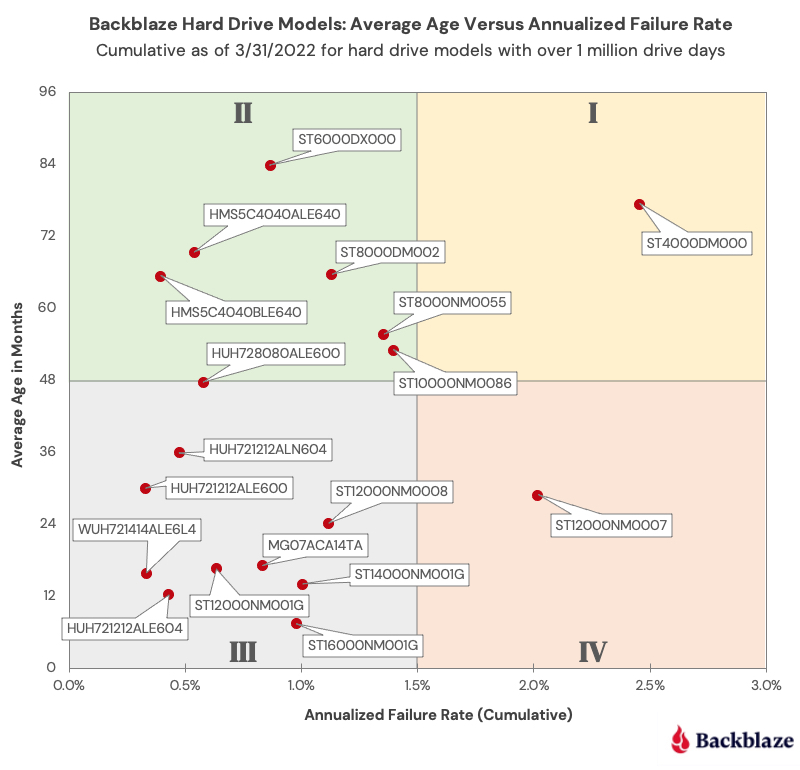
“…many of the truths that we cling to depend on our viewpoint.”8
Each point on the Drive Stats Failure Square represents a hard drive model in operation in our environment as of 3/31/2022 and lies at the intersection of the average age of that model and the annualized failure rate of that model. We only included drive models with a lifetime total of one million drive days or with a confidence interval of all drive models included being 0.6 or less.
The resulting chart is divided into four equal quadrants, which we will categorize as follows:
- Quadrant I: Retirees. Drives in this quadrant have performed well, but given their current high AFR level they are first in line to be replaced.
- Quadrant II: Winners. Drives in this quadrant have proven themselves to be reliable over time. Given their age, we need to begin planning for their replacement, but there is no need to panic.
- Quadrant III: Challengers. Drives in this quadrant have started off on the right foot and don’t present any current concerns for replacement. We will continue to monitor these drive models to ensure they stay on the path to the winners quadrant instead of sliding off to quadrant IV.
- Quadrant IV: Muddlers. Drives in this quadrant should be replaced if possible, but they can continue to operate if their failure rates remain at their current rate. The redundancy and durability built into the Backblaze platform protects data from the higher failure rates of the drives in this quadrant. Still, these drives are a drain on data center and operational resources.
“Difficult to see; always in motion is the future.”9
Obviously, the Winners quadrant is the desired outcome for all of the drive models we employ. But every drive basically starts out in either quadrant III or IV and moves from there over time. The chart below shows how the drive models in quadrant II (Winners) got there.
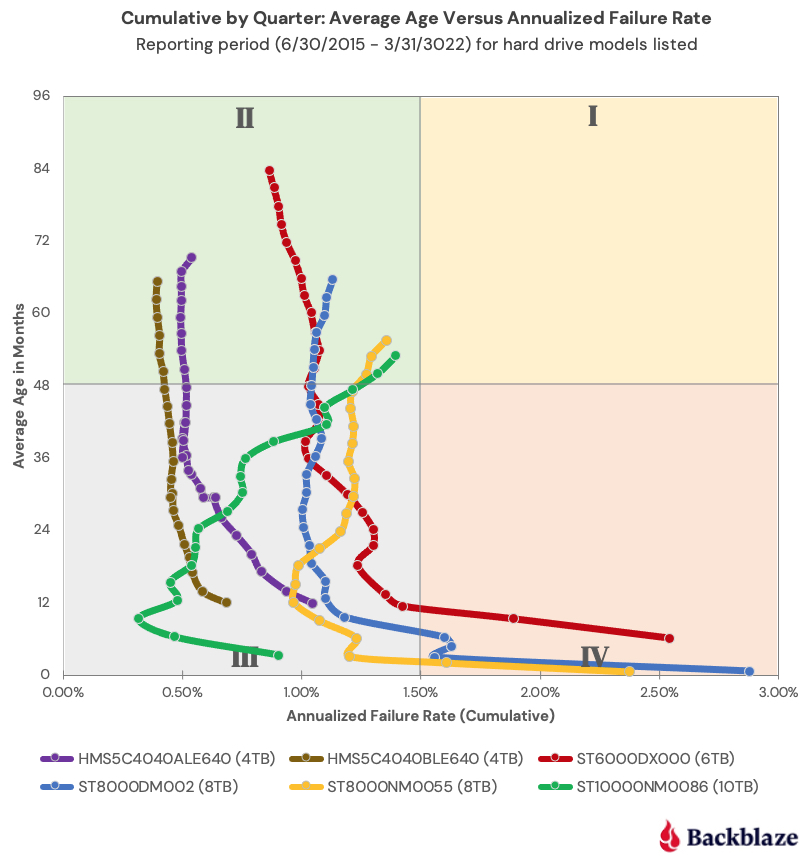
“Your focus determines your reality.”10
Each drive model is represented by a snake-like line (Snakes on a plane!?) which shows the AFR of the drive model as the average age of the fleet increased over time. Interestingly, each of the six models currently in quadrant II has a different backstory. For example, who could have predicted that the 6TB Seagate drive (model: ST6000DX000) would have ended up in the Winners quadrant given its less than auspicious start in 2015. And that drive was not alone; the 8TB Seagate drives (models: ST8000NM0055 and ST8000DM002) experienced the same behavior.
This chart can also give us a visual clue as to the direction of the annualized failure rate over time for a given drive model. For example, the 10TB Seagate drive seems more interested in moving into the Retiree quadrant over the next quarter or so and as such its replacement priority could be increased.
“In my experience, there’s no such thing as luck.”11
In the quarterly Drive Stats table at the start of this report, there is some element of randomness which can affect the results. For example, whether a drive is reported as a failure on the 31st of March at 11:59 p.m. or at 12:01 a.m. on April 1st can have a small effect on the results. Still, the quarterly results are useful in surfacing unexpected failure rate patterns, but the most accurate information regarding a given drive model is captured in the lifetime annualized failures rates.
The chart below shows the lifetime annualized failure rates of all the drive models in production as of March 31, 2022.
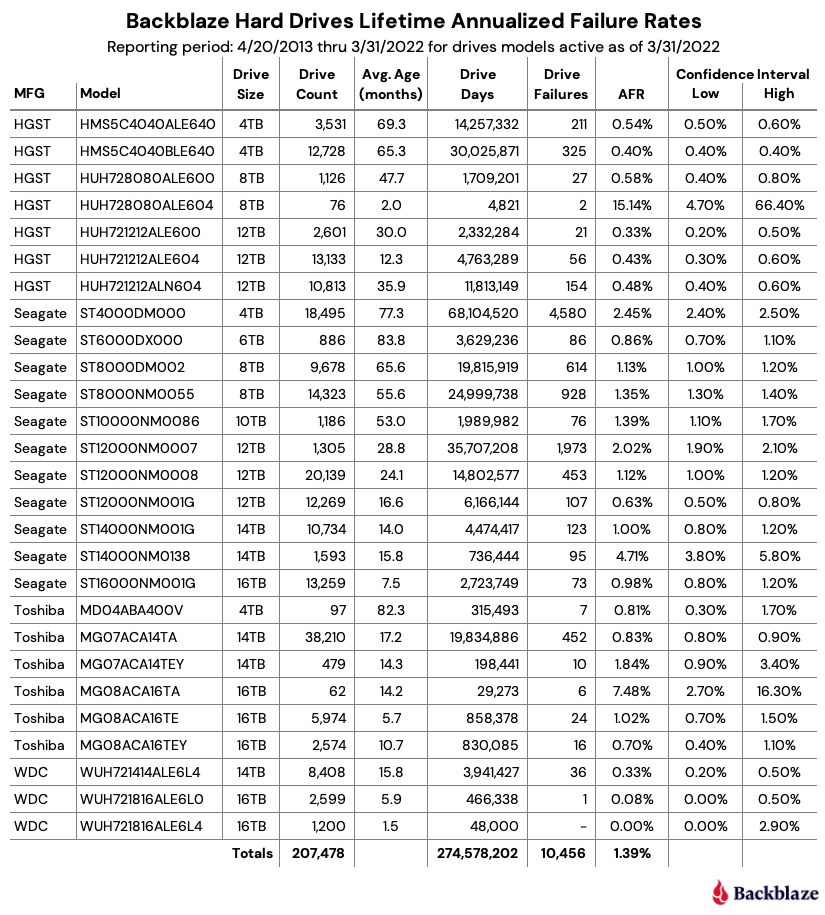
“You have failed me for the last time…”12
The lifetime annualized failure rate for all the drives listed above is 1.39%. That was down from 1.40% at the end of 2021. One year ago (3/31/2021), the lifetime AFR was 1.49%.
When looking at the lifetime failure table above, any drive models with less than 500,000 drive days or a confidence interval greater than 1.0% do not have enough data to be considered an accurate portrayal of their performance in our environment. The 8TB HGST drives (model: HUH728080ALE604) and the 16TB Toshiba drives (model: MG08ACA16TA) are good examples of such drives. We list these drives for completeness as they are also listed in the quarterly table at the beginning of this review.
Given the criteria above regarding drive days and confidence intervals, the best performing drive in our environment for each manufacturer is:
- HGST: 12TB, model: HUH721212ALE600. AFR: 0.33%
- Seagate: 12TB model: ST12000NM001G. AFR 0.63%
- WDC: 14TB model: WUH721414ALE6L4. AFR: 0.33%
- Toshiba: 16TB model: MG08ACA16TEY. AFR 0.70%
“I never ask that question until after I’ve done it!”13
For those of you interested in how we produce this report, the data we used is available on our Hard Drive Test Data webpage. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell the data itself to anyone; it is free.
Good luck and let us know if you find anything interesting. And no, it’s not a trap.
Quotes Referenced
- “The greatest teacher, failure is.”—Yoda, “The Last Jedi”
- “Always pass on what you have learned.”—Yoda, “Return of the Jedi”
- “The Force is strong with this one.”—Darth Vader, “A New Hope”
- “Great, kid, don’t get cocky.”—Han Solo, “A New Hope”
- “I find your lack of faith disturbing.”—Darth Vader, “A New Hope”
- “Try not. Do or do not. There is no try.”—Yoda, “The Empire Strikes Back”
- “I like firsts. Good or bad, they’re always memorable.”—Ahsoka Tano, “The Mandalorian”
- “…many of the truths that we cling to depend on our viewpoint.”—Obi-Wan Kenobi, “Return of the Jedi”
- “Difficult to see; always in motion is the future.”—Yoda, “The Empire Strikes Back”
- “Your focus determines your reality.”—Qui-Gon Jinn, “The Phantom Menace”
- “In my experience, there’s no such thing as luck.”—Obi-Wan Kenobi, “A New Hope”
- “You have failed me for the last time…”—Darth Vader, “The Empire Strikes Back”
- “I never ask that question until after I’ve done it!”—Han Solo, “The Force Awakens”
The post Backblaze Drive Stats for Q1 2022 appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.

















!['We're shocked by the Notre Dame fire. Click for our tribute to--' [okay] 'Now that we're all staying at home these past few weeks thanks to this new coronavirus, we--' [okay]](https://imgs.xkcd.com/comics/welcome_back.png "'We're shocked by the Notre Dame fire. Click for our tribute to--' [okay] 'Now that we're all staying at home these past few weeks thanks to this new coronavirus, we--' [okay]")







 John Benninghoff is a AWS Professional Services Sr. Data Architect, focused on Data Lake architecture and implementation.
John Benninghoff is a AWS Professional Services Sr. Data Architect, focused on Data Lake architecture and implementation.