It will be interesting to watch what will come of this private lawsuit:
Google on Thursday announced filing a lawsuit against the operators of the Badbox 2.0 botnet, which has ensnared more than 10 million devices running Android open source software.
These devices lack Google’s security protections, and the perpetrators pre-installed the Badbox 2.0 malware on them, to create a backdoor and abuse them for large-scale fraud and other illicit schemes.
This reminds me of Meta’s lawauit against Pegasus over its hack-for-hire software (which I wrote about here.) It’s a private company stepping into a regulatory void left by governments.
We love hearing from members of the community and sharing the stories of amazing young people, volunteers, and educators who are using their passion for technology to create positive change in the world around them.
Seung Woo, also known as Tony, is a 17-year-old student from Canada and the co-founder of his school’s Code Club, alongside his teacher, Kay. A curious and driven teen with big ambitions in computer science, Tony is not only passionate about technology, but also dedicated to building a safe, welcoming space where others can learn, explore, and grow alongside him.
A spark of inspiration
Tony’s fascination with computers started early, driven by his love of video games, coding, and, perhaps most memorably, his admiration for Tony Stark, the comic-book and film character who becomes the superhero Iron Man! The idea of building something powerful from scratch stuck with him.
“My whole life, I have been curious about the inner workings of a computer and my inspiration for coding is Tony Stark or Iron Man from the Marvel Cinematic Universe!”
Tony’s early coding journey wasn’t without its challenges. Finding the right resources was difficult, and staying motivated during tough moments was often hard without a support system.
“Like many others, I was independently taught, and during this time of independent learning I’d find many different roadblocks and challenges that I had to overcome alone. A big setback for me was finding the right resources in order to learn how to code. Another big obstacle for me was motivation. I would find myself losing interest in a project. I didn’t have the exterior motivation to help me push through the inevitable hardships that come with coding.”
That’s where the idea for a coding club began to take shape.
Creating a community of coders
Tony co-founded the Code Club at Collège Jeanne-Sauvé in December 2024 with that exact vision in mind — he wanted to provide a fun, collaborative, and welcoming environment where students of all skill levels could explore their love of technology together.
“I created the coding club to help everyone on their journey of computer science, no matter their skill level, and that is exactly what it is turning out to be. Finding resources is easier than ever with a teacher and all of the amazing members.”
Tony’s teacher and co-founder, Kay, shared why Code Club was the right fit for the school.
“I thought Code Club was the best way to start our club for a few reasons. The amount of coding language options was varied and appealed to the different learners in our club. It was also important for us to promote our club and let our community know about the presence of a coding club in our school, and Code Club helped us do so via their online presence.”
What makes Code Club special
For Tony, the secret ingredient behind his club’s success is simple: teamwork.
“Without teamwork, our club wouldn’t really be a club, it would simply be an ensemble of people coding in their own little cubicles, much like a stereotypical office job, and to me, that does not sound too enjoyable. Teamwork is our little secret ingredient in problem-solving and building motivation, we embrace it by creating a safe space where everyone can speak their minds without judgement!”
Members are free to choose their own learning paths. No matter the project, the atmosphere is always filled with laughter, energy, and curiosity.
“Coding should be something that is fun — not stressful like others may make it seem. Celebrating achievements, making short term goals, and problem solving with friends are all great ways that we make coding fun in our club. A second word would be teamwork. Without teamwork, our club wouldn’t really be a club.”
Teamwork, he adds, transforms what could be a solitary activity into something social and deeply motivating.
Looking to the future
Tony hopes the club will continue to grow, bringing more students into the world of coding and helping them feel at home in it. His story is a great reminder that learning to code isn’t just about computers — it’s about building community, confidence, and creativity.
“I wanted to create a space where everyone would be accepted and encouraged to learn more about coding and not be ashamed to ‘nerd out’ about this subject like I do very frequently. I’ve dreamed of creating a space that embraces this beautiful passion.”
If you’d like to explore coding, you can get started at home with over 250 free projects.
For a little more support, or if you’re open to mentoring others, you can also join a Code Club. Check our website to find a club near you and become part of a like-minded and welcoming community.
Amazon MQ is a fully managed service for open-source message brokers such as RabbitMQ and Apache ActiveMQ. Today, we are announcing the availability of AWS Graviton3-based Rabbit MQ brokers on Amazon MQ, which runs on Amazon EC2 M7g instances. AWS Graviton processors are custom designed server processors developed by AWS to provide the best price performance for cloud workloads running on Amazon EC2. It uses the Arm (arm64) instruction set. For example, when running an Amazon MQ for RabbitMQ cluster broker using M7g.4xlarge instances, you can achieve up to 50% higher workload capacity and up to 85% higher throughput compared to M5.4xlarge instances. Additionally, M7g brokers on Amazon MQ offer optimized disk sizes for clusters, providing reduction in storage cost savings over M5 brokers depending on the instance size chosen. To learn more, refer to Amazon EC2 M7g instances.
Amazon MQ helps you reduce the operational overhead of using open source message brokers like RabbitMQ while providing security, high availability, and durability. Many organizations use Amazon MQ to decouple applications, asynchronously process messages, and build event-driven architectures. We tested and validated M7g instances for RabbitMQ version 3.13, so you can run your critical messaging workloads on Amazon MQ brokers with improved performance characteristics, while also saving on costs. Amazon MQ supports M7g instances in a wide variety of sizes, ranging from medium to 16xlarge sizes, to suit your different messaging workloads. M7g instances support Amazon MQ for RabbitMQ features, making it straightforward for you to run your existing RabbitMQ workloads with minimal changes. You can get started by provisioning new brokers or upgrading your existing RabbitMQ brokers using Amazon EC2 M5 instances to Graviton3-based M7g instances as the broker type using the AWS Management Console, APIs using the AWS SDK, and the AWS Command Line Interface (AWS CLI).
The following table lists the specific characteristics of M7g instances on Amazon MQ.
M7g specs for Amazon MQ
Instance Name (MQ.m7g.*)
vCPUs
Memory (GiB)
Network Bandwidth
medium
1
4
Up to 12.5 Gb
large
2
8
Up to 12.5 Gb
xlarge
4
16
Up to 12.5 Gb
2xlarge
8
32
Up to 15 Gb
4xlarge
16
64
Up to 15 Gb
8xlarge
32
128
15 Gb
12xlarge
48
192
22.5 Gb
16xlarge
64
256
30 Gb
M7g instances vs. M5 instances on Amazon MQ
Customers can see both performance improvements and cost savings for their RabbitMQ workloads when moving from M5 instances to M7g instances. In terms of performance, you can size your RabbitMQ brokers for workloads by measuring the workload capacity and throughput. Amazon MQ has improved the performance of RabbitMQ on both workload capacity and throughput for M7g instances. In terms of cost, you pay for the instance per hour, disk usage per Gb-month, and data transfer. Amazon MQ has optimized disk sizes to offer cost savings for customers on disk usage. Let’s first examine the performance improvements.
Workload capacity improvements
Workload capacity represents the total number of connections, channels, and queues that you can use without running into memory alarm. The actual usage of these resources is limited by the high memory watermark value. Every resource (for example, a queue) on creation uses up a small amount of memory, but when these resources are used, the memory used increases depending on the number and size of messages processed up until a memory threshold. The RabbitMQ broker goes into memory alarm when the memory used on a node reaches this pre-defined threshold known as high memory watermark. When a broker raises a memory alarm, it will block all connections that are publishing messages. After the memory alarm has cleared (for example, due to delivering some messages to clients that consume and acknowledge the deliveries), normal service resumes. The open source community guidance for RabbitMQ 3.13 is to configure the memory threshold at 40% of the available memory per node. M5 brokers have the memory threshold set at 40% on Amazon MQ.
We evaluated this recommendation across M7g instances and determined that the memory threshold can be increased for instances on Amazon MQ to more than 40% due to the operational improvements by the service, as illustrated in the following figure. This increase in available memory translates to a higher use of resources like queues, channels, and connections within the resource limits of the broker. The change in available memory results in up to 50% improvement in workload capacity for customers when compared to M5 brokers today.
Throughput improvements
The throughput of a broker varies widely with the queue type and usage pattern of customers. Amazon MQ evaluated the throughput capacity of a RabbitMQ three-node cluster broker by measuring the publish throughput in messages per second for 10 quorum queues with a message size of 1 KB and a ratio of 1:20 for connection to channels. We arrived at this benchmark test after evaluating multiple scenarios with the goal of providing you a simple way to estimate the average throughput you can expect from a RabbitMQ broker when following best practices. You can see up to 85% higher throughput compared to equivalent M5 brokers on Amazon MQ, as illustrated in the following figure.
The performance of a RabbitMQ broker depends on the version, queue type, and usage pattern in addition to the infrastructure used. You might see different performance improvements based on your specific usage patterns and resources used. We recommend using the Amazon MQ sizing guidance to size your broker and benchmarking the performance for your specific workload using M7g instances.
Cost savings on cluster disk usage
Customers using M7g brokers in cluster deployment mode are provisioned with a disk volume per node that varies in size depending on the instance size. For M5 brokers, the RabbitMQ brokers were provisioned with a fixed disk volume of 200 GB per node. The open source guidance around disk sizes is to use a size higher than twice the memory threshold. We tested various disk sizes and identified optimal disk sizes that would provide a better operational posture. With this change, customers using M7g cluster brokers on Amazon MQ will get cost savings due to the smaller disk size provisioned per node as compared to equivalent M5 brokers, as shown in the following table. Single-instance M7g brokers will continue to be provisioned with 200 GB of disk size.
Instance size
Disk Volume M5 cluster(GB)
Disk Volume M7g Cluster(GB)
Cost savings for customersM5 vs. M7g (%)
medium
–
15
–
large
600
45
92.50%
xlarge
600
75
87.50%
2xlarge
600
135
77.50%
4xlarge
600
270
55.00%
8xlarge
–
525
–
12xlarge
–
780
–
16xlarge
–
1035
–
Pricing and Regional availability
M7g instances are available in AWS Regions where Amazon MQ is available at the time of writing except Africa (Cape Town), Canada West (Calgary), and Europe (Milan) Regions. Refer to Amazon MQ Pricing to learn about the availability of specific instance sizes by Region and the pricing for M7g instances.
Summary
In this post, we discussed the performance gains and cost savings achieved while using Graviton-based M7g instances. These instances can provide significant improvement in throughput and workload capacity compared to similar sized M5 instances for Amazon MQ workloads. To get started, create a new broker with M7g brokers using the console, and refer to the Amazon MQ Developer Guide for more information.
About the authors
Vignesh Selvam is the Principal Product Manager for Amazon MQ at AWS. He works with customers to solve their messaging needs and with the open-source communities for innovating with message brokers. Prior to joining AWS, he built products for security and analytics.
Samuel Massé is a Software Development Engineer at AWS. He has been leading the engineering effort to support M7g on the RabbitMQ team. In his free time he enjoys coding unfinished side projects.
Vinodh Kannan Sadayamuthu is a Senior Specialist Solutions Architect at Amazon Web Services (AWS). His expertise centers on AWS messaging and streaming services, where he provides architectural best practices consultation to AWS customers.
The AWS Security Reference Architecture (AWS SRA) provides prescriptive guidance for deploying AWS security services in a multi-account environment. However, validating that your implementation aligns with these best practices can be challenging and time-consuming.
Today, we’re announcing the open source release of SRA Verify, a security assessment tool that helps you assess your organization’s alignment to the AWS SRA.
The AWS SRA is a holistic set of guidelines for deploying the full complement of AWS security services in a multi-account environment. You can use it to design, implement, and manage AWS security services so that they align with AWS recommended practices. The recommendations are built around a single-page architecture that includes AWS security services—how they help achieve security objectives, where they can be best deployed and managed in your AWS accounts, and how they interact with other security services. This overall architectural guidance complements detailed, service-specific recommendations such as those found in AWS Security Documentation.
SRA Verify directly maps to these recommendations by providing automated checks that validate your implementation against the AWS SRA guidance. The tool helps you verify that security services are properly configured according to the reference architecture. To assist with remediation and implementing the guidance in the AWS SRA, review the infrastructure as code (IaC) examples in the AWS Security Reference Architecture Github repo.
Version
141.0 of the Firefox browser it out. Changes include “a local AI
model” that can perform tab grouping, unit conversions in the address
bar, and a change that many of us will find welcome: “On Linux, Firefox
uses less memory and no longer requires a forced restart after an update
has been applied by a package manager“.
On July 19, 2025,Microsoft disclosed CVE-2025-53770, a critical zero-day Remote Code Execution (RCE) vulnerability. Assigned a CVSS 3.1 base score of 9.8 (Critical), the vulnerability affects SharePoint Server 2016, 2019, and the Subscription Edition, along with unsupported 2010 and 2013 versions. Cloudflare’s WAF Managed Rules now includes 2 emergency releases that mitigate these vulnerabilities for WAF customers.
Unpacking CVE-2025-53770
The vulnerability’s root cause is improper deserialization of untrusted data, which allows a remote, unauthenticated attacker to execute arbitrary code over the network without any user interaction. Moreover, what makes CVE-2025-53770 uniquely threatening is its methodology – the exploit chain, labeled “ToolShell.” ToolShell is engineered to play the long-game: attackers are not only gaining temporary access, but also taking the server’s cryptographic machine keys, specifically the ValidationKey and DecryptionKey. Possessing these keys allows threat actors to independently forge authentication tokens and __VIEWSTATE payloads, granting them persistent access that can survive standard mitigation strategies such as a server reboot or removing web shells.
In response to the active nature of these attacks, the U.S. Cybersecurity and Infrastructure Security Agency (CISA) added CVE-2025-53770 to itsKnown Exploited Vulnerabilities (KEV) catalog with an emergency remediation deadline. The security community’s consensus is clear: any organization with an on-premise SharePoint server on the Internet should assume it has been compromised and take immediate action to fully address this vulnerability.
Since releasing our vulnerability patch in Cloudflare’s WAF Managed Ruleset, we’ve tracked the number of HTTP request matches for the vulnerability, which you can see in the graph below. Notably, we observed a significant peak around 11AM UTC, the morning of July 22, at around 300,000 hits at one point in time.
How does the ToolShell exploit chain work?
The ToolShell exploit chain was first demonstrated at the Pwn2Own hacking competition in May 2025, where researchers chained an authentication bypass (CVE-2025-49706) with a deserialization RCE (CVE-2025-49704). Unfortunately, this was not the end of ToolShell’s lifespan. Threat actors evidently analyzed the patches to find weaknesses and exploit them in the wild, forcing Microsoft to assign new identifiers and call out CVE-2025-53771 for the authentication bypass. This rapid exploit → patch → bypass cycle shows that threat actors are not merely discovering vulnerabilities, but also systematically reverse-engineering patches to weaponize bypasses. For responders, this closes the window – or hides it altogether – to respond and put up defenses, highlighting the need for evolving, proactive security postures.
The ToolShell exploit works in 3 stages:
Authentication Bypass, leveraging CVE-2025-53771: The attack begins with a POST request sent to the /_layouts/15/ToolPane.aspx endpoint, a legacy component of SharePoint. The crutch of this authentication bypass happens by setting the Referer header to /_layouts/SignOut.aspx, which tricks the SharePoint server into trusting the attacker. With trust in hand, the attacker is able to skip authentication checks and move forward with authenticated access.
Remote Code Execution via Deserialization, CVE-2025-53770: With privileged access, the attacker can interact with the ToolPane.aspx endpoint. The attacker submits a malicious payload in the body of the POST request, triggering the core vulnerability: a deserialization flaw in which the SharePoint application deserializes the object into executable code on the server. At this point, the attacker can execute commands as they wish.
The Long-Game: Possessing Cryptographic Keys: Finally, to play the long-game and maintain continued access, the attacker will use a specific web shell to steal the server’s cryptographic machine keys. By taking the ValidationKey and the DecryptionKey, the attacker obtains the state information used by SharePoint. Possessing these keys allows the attacker to operate independently, long after the original exploit; this means they can continue to execute new malicious payloads on the exploited server. This permanent backdoor makes this attack method uniquely dangerous.
Cloudflare’s new WAF Managed Rules for CVE-2025-53770, CVE-2025-53771
CVE-2025-53770 is a clear example of how modern cyber threats are two-sided, combining an initial breach vector with a mechanism for long-term persistence. This means that a successful defense will address both the immediate RCE vulnerability and the subsequent threat of unwelcome access.
Once a public proof-of-concept became available for this exploit, Cloudflare’s security analysts crafted and tested new patches, ensuring that they would address not only the initial attack, but also the longer-term threat.
The team began researching the exploit the evening of July 20, and on July 21, 2025, Cloudflare deployed our emergency WAF Managed Rules to patch the vulnerability, meaning every customer using the Cloudflare Managed Ruleset will automatically be protected from this critical SharePoint vulnerability. These rules have been announced on the WAF changelog and will take effect immediately.
Data engineering teams face an increasingly complex landscape when building and maintaining analytics environments. From sourcing and organizing data to implementing transformation pipelines and managing access controls, the process of transforming raw data into actionable insights involves numerous interconnected components. While individual tools exist for each task, connecting them into cohesive workflows remains time-consuming and requires deep technical expertise across multiple AWS services.
To address these challenges and enhance developer productivity, we’re excited to introduce the AWS Data Processing MCP Server, an open-source tool that uses the Model Context Protocol (MCP) to simplify analytics environment setup on AWS. We’re also open sourcing a stand-alone Data Processing Agent implementation in AWS Strands SDK to use this MCP server to help customers further customize it for their use cases. This powerful integration enables AI assistants to understand your data processing environment and guide you through complex workflows using natural language interactions.
Understanding the Model Context Protocol advantage
The MCP is an emerging open standard that defines how AI models, particularly large language models (LLMs), can securely access and interact with external tools, data sources, and services. Rather than requiring developers to learn intricate API syntax across multiple services, MCP enables AI assistants to understand your environment contextually and provide intelligent guidance throughout your data processing journey.
The AWS Data Processing MCP Server harnesses this capability by providing AI code assistants with real-time visibility into your AWS data processing pipeline. This includes access to AWS Glue job statuses, Amazon Athena query results, Amazon EMR cluster metrics, and AWS Glue Data Catalog metadata through a unified interface that LLMs can understand and reason about.
AWS analytics integration
The AWS Data Processing MCP Server integrates deeply with AWS Glue for data cataloging and ETL operations, Amazon EMR for big data processing, and Athena for serverless analytics. This integration transforms how developers interact with these services by providing contextual awareness that enables AI assistants and Data Processing Strands Agent to make intelligent recommendations based on your actual infrastructure and data patterns.
Rather than requiring manual navigation between service consoles or memorizing complex API parameters, the MCP server enables natural language interactions that automatically translate to appropriate service operations. This approach reduces the learning curve for new team members while accelerating productivity for experienced developers working across multiple AWS analytics services.
Getting started with the AWS Data Processing MCP Server
You’ll need to follow the steps in the prerequisites section before you can start using MCP servers.
Prerequisites
Before configuring the MCP server, ensure you have the following prerequisites in place:
System requirements:
macOS or supported Linux environment
Python 3.10 or higher
UV package manager for Python dependency management
IAM permissions: Review and configure your security policies for the IAM roles and permissions that would grant necessary access to the AWS Data Processing MCP Server and Agent to execute AWS data processing operations on your behalf. For read-only operations, attach policies that include permissions for Data Catalog access, Amazon CloudWatch metrics, Amazon EMR cluster descriptions, and Athena query operations. For write operations, make sure that your AWS Identity and Access Management (IAM) role includes the AWSGlueServiceRole managed policy along with permissions for creating and managing Amazon EMR clusters and Athena workgroups.
Set up using Amazon Q CLI
Amazon Q Developer CLI provides an intuitive way to interact with the AWS Data Processing MCP Server directly from your terminal. This integration combines the natural language processing capabilities of Amazon Q with the data processing tools, enabling you to manage complex analytics workflows through conversational commands.
Verify your setup by running the /tools command in the Q Developer CLI to see the available Data Processing MCP tools.
Set up using Claude Desktop
Claude Desktop offers another powerful way to interact with the AWS Data Processing MCP Server through Anthropic’s Claude interface, providing a user-friendly chat experience for managing your data processing workflows.
Installation and configuration:
Download and install Claude Desktop for your operating system.
Open Claude Desktop and navigate to Settings (gear icon in the bottom left).
Go to the Developer tab and configure your MCP server by adding same configuration as step 3 in Q CLI setup.
Restart Claude Desktop to activate the MCP server connection.
Test the integration by starting a new conversation and asking: What data processing tools are available to me?
Enhanced developer experience
After being configured with either Amazon Q CLI or Claude Desktop, your workflow transforms dramatically. Instead of constructing complex AWS CLI commands with multiple parameters, you can use natural language requests. For example, rather than memorizing the syntax for creating AWS Glue crawlers, you can ask:
Create a Glue crawler for my S3 bucket that runs weekly and updates the data catalog with any schema changes
Accelerating development with MCP servers
Next, we explore the common patterns that emerge when using MCP in data processing development workflows.
Data onboarding and discovery
One of the most common challenges data teams face is efficiently onboarding new datasets and making them immediately useful for analysis. Consider a scenario where your marketing team receives a CSV file containing customer interaction data that needs to be quickly analyzed for campaign insights. Traditionally, this process involves multiple manual steps: uploading the file to Amazon Simple Storage Service (Amazon S3), configuring an AWS Glue crawler to discover the schema, creating appropriate table definitions, setting up proper partitioning, and finally making the data queriable through Athena.
With the AWS Data Processing MCP Server, this entire workflow becomes conversational. You can describe your goal using natural language:
I have a customer interaction CSV file that I need to analyze for marketing insights. Help me get this data ready for business users to query
The AI assistant, powered by the MCP server’s deep AWS integration, automatically handles the technical implementation details, guides you through uploading the file to an appropriate Amazon S3 location, configures and runs an AWS Glue crawler with optimal settings, creates properly formatted table definitions, and sets up Athena access with appropriate workgroup configurations for cost control.
The following video demonstration showcases how developers can use Amazon Q CLI with Data Processing MCP server for data onboarding.
Business insights and automated reporting
Modern organizations require timely, accurate insights to drive business decisions, but traditional analytics workflows often create bottlenecks between data availability and business consumption. Imagine you need to identify potentially fraudulent transactions across multiple data sources including cardholder information, credit card details, merchant data, and transaction records. Rather than manually writing complex SQL queries with multiple joins and filters, you can describe your analytical goal:
Analyze our transaction data across cardholders, credit cards, and merchants to identify suspicious activities involving transactions over $5,000 and create an automated weekly report.
The MCP server interprets this request and automatically constructs the appropriate analytical workflow. It examines your data catalog to understand table relationships, generates optimized SQL queries with proper joins across your datasets, executes the analysis using Athena with cost-effective query patterns, and formats the results into actionable reports. The system can establish automated delivery mechanisms, such as email reports or dashboard updates, ensuring stakeholders receive timely insights without manual intervention while creating scheduled AWS Glue jobs that continuously monitor for emerging patterns.
We’re also releasing a stand-alone Data Processing Agent developed using AWS Strands SDK that you can customize further with your system prompts and context for your use cases. You can run it locally or deploy it using Amazon Bedrock AgentCore. The following video demonstration showcases how developers can use Data Processing Agent for driving business insights.
Observability and performance monitoring
Maintaining visibility across complex data processing environments requires sophisticated monitoring capabilities that traditional approaches often fail to provide. The AWS Data Processing MCP Server enables intelligent observability by synthesizing real-time telemetry from across your AWS analytics infrastructure into actionable insights. For AWS Glue environments, the MCP server continuously analyzes job metadata, execution logs, resource configurations, and data catalog statistics to provide operational intelligence. Rather than manually navigating CloudWatch dashboards or parsing log files, you can ask questions like Show me performance trends across my ETL jobs and identify optimization opportunities. The following video demonstration showcases how developers can use Claude Desktop with Data Processing MCP Server to monitor Glue jobs and catalogs.
For Amazon EMR clusters, the MCP server aggregates cluster metadata, instance usage patterns, and failure events into unified operational views. This enables proactive management where you can request Analyze my EMR environment for cost optimization opportunities and potential reliability risks. The system responds with detailed analysis of cluster utilization patterns, recommendations for right-sizing instance types, identification of long-running clusters that might represent cost leakage, and alerts about configuration patterns that could impact reliability. The observability capabilities extend beyond simple monitoring to predictive insights by analyzing historical patterns to forecasting resource needs and recommend preventive actions. The following video demonstration showcases how developers can use Claude Desktop with Data Processing MCP Server to monitor EMR clusters.
Security and architectural considerations
All MCP server operations occur within your AWS account boundaries, helping to ensure that sensitive data does not leave your controlled environment. The server provides contextual information to AI assistants through metadata and API responses based on IAM access permissions available to the role being used. Integration with IAM helps ensure that operations respect existing permission boundaries and organizational policies.
The architecture supports graduated autonomy where routine operations can proceed automatically while high-impact changes require human approval. This balanced approach enables productivity gains while maintaining appropriate oversight for critical business operations.
Conclusion
In this post, we explored how the AWS Data Processing MCP Server accelerates analytics solution development across our analytics services. We demonstrated how data engineers can transform raw data into business-ready insights through AI-assisted workflows, significantly reducing development time and complexity. The AWS Data Processing MCP Server offers extensive capabilities beyond these use cases. You can use the MCP’s context-rich APIs to develop customized solutions for observability, automation, and optimization. This flexibility allows you to create workflows tailored to your specific data environments and business needs.By bringing AWS data processing capabilities directly into development workflows—whether through AWS CLI, IDEs, or AI-assisted tools—teams can focus on solving business problems rather than managing infrastructure. We encourage you to explore innovative applications of the MCP Server, combining its powerful context engine with AI-driven analysis to uncover new opportunities for efficiency and insight across their data ecosystems.
Get started today by accessing the open source code, documentation, and setup instructions in the AWS Labs GitHub repository. Integrate the MCP Server into your development workflow and transform how you build analytics solutions on AWS. We’ll continue to iterate based on customer feedback and look forward to seeing how customers extend these capabilities to solve complex data challenges.
Acknowledgment: A special thanks to everyone who contributed to the development and open-sourcing of the AWS Data Processing MCP server and Agent: Raghavendhar Thiruvoipadi Vidyasagar, Chris Kha, Sandeep Adwankar, Nidhi Gupta, Xiaoxi Liu, Kathryn Lin, Alexa Perlov, Alain Krok, Xiaorun Yu, Maheedhar Reddy Chapiddi, and Rajendra Gujja.
About the authors
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies.
Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively.
Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI.
Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI.
Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.
When you think about cloud infrastructure for AI, you immediately think of GPUs and other high-performance compute resources, and how your cloud architecture should be optimized to make the most of these expensive compute plans. But compute isn’t the only cloud product category you need to monitor to both scale your application and maintain a sustainable cloud infrastructure budget.
What ultimately fuels AI? Data—lots and lots of data. As part of a healthy AI pipeline, several versions of the same dataset need to be stored in a centralized repository, or multiple repositories if your strategy requires splitting data into cold vs. hot storage to reduce storage costs. For text-based LLMs, storage costs are minimal compared to compute resources. But as AI innovation increasingly relies on video and other media, both the base storage cost and data retrieval fees can make cloud bills spiral out of control.
In this blog, we’re taking a look at the AI data pipeline, where object storage sits in each stage, and how leveraging both Backblaze B2 and B2 Overdrive helps both increase performance and reduce costs for AI applications.
Data ingest and active archive: Data is gathered from multiple designated sources (including APIs, internet of things (IoT) sensors, relational databases, etc.) and ingested into a centralized repository or multiple repositories.
Data processing: The raw data is transformed and enriched based on the model’s data parameters. This can range from relatively simple text cleanup to adding annotations and metadata. Feature engineering is performed to extract or construct meaningful attributes. All data is then converted into numerical representations (e.g., embeddings, vectors) suitable for model training and inference.
Model experimentation and training: Processed data is used to train models by learning underlying patterns. Iterative experiments in a test environment evaluate, tune, and improve model performance and accuracy.
Model deployment and inference: New data is prepared in the same way as during training and sent to the deployed model to generate predictions, support decision-making, and deliver personalized outputs.
Monitoring: Continuous monitoring tracks model performance, detects data drift, and flags potential bias, ensuring the model remains accurate and reliable over time.
Keep in mind that data ingestion and processing isn’t always sequential, such as when data is collected and ingested, but corruption is detected during processing. Ideally, your pipeline is configured with validation gates so that corrupt data is identified and handled before proceeding to downstream steps like testing, training, and production deployment.
When using cloud object storage as your data repository, one factor of selecting a plan (like cold versus hot storage) is the specific type of data ingestion that’s being utilized based on both the data source and AI model’s specific needs.
Batch ingestion is better suited for mid to lower performance storage, as this is typically used for historical datasets or a set schedule of pre-determined data updates, such as jobs pulling from relational databases or CSV uploads once a day or once per week.
Streaming ingestion is well-suited for hot storage to support a continuous stream of real-time (or near-real-time) data processing, such as from social media feeds and high-volume e-commerce AI helper agents.
Hybrid ingestion uses a combination of batch and streaming ingestion to handle both historical and real-time data requirements for AI models.
Where does cloud object storage sit in the AI data pipeline?
Everywhere. All scalable data pipelines lead to object storage.
Why?Data ingestion and active archive are the major areas where object storage fulfills an important purpose. When training AI models, especially in production, data scalability for multiple and diverse data types is a hard requirement. But object storage plays a key role in the other pipeline stages:
Data processing: Stores versioned outputs from data labeling, feature engineering, and cleaning processes.
Model experimentation and training: Provides high-throughput access to training datasets and stores model checkpoints.
Model deployment and inference: Stores serialized model artifacts with API-based retrieval for serving predictions at scale.
Monitoring: Stores synthetic outputs from generative models, logs, feedback, and performance metrics for analysis and reuse.
For both AI data performance and cost optimization, selecting an object storage product or tier is far from one-size-fits-all. You can strategically allocate your data to B2 Cloud Storage or B2 Overdrive, with your most essential model data stored in B2 Overdrive. Here’s a high-level diagram of what Backblaze B2 product to use for each stage, including examples of the data stored at each stage.
Learn more at Ai4 in August
Want to learn more? Backblaze is heading to Las Vegas for Ai4 August 11–13! In addition to booking a meeting to speak with our storage experts and stopping by our booth to pick up some swag, I’m excited to talk more about the AI data pipeline during my talk. If you’re attending Ai4, add The AI Pipeline Starts with Storage: Architecting Scalable Data Foundations to your conference agenda.
Can’t attend live in Vegas? Reach out to our Sales team to talk about your specific use case and how B2 Overdrive can help propel your data.
Modern architectures use many different technologies to achieve their goals. Service-oriented architectures, cloud services, distributed tracing, and more create streams of telemetry and other signal data. Each of these data streams becomes a tenant in your logging backend. If your company runs more than one application, the IT team will frequently centralize the storage and processing of log data, making each application a tenant in the overall observability system.
When you use Amazon OpenSearch Service to store and analyze log data, whether as a developer or an IT admin, you must balance these tenants to make sure you deliver the resources to each tenant so they can ingest, store, and query their data. In this post, we present a multi-layered workload management framework with a rules-based proxy and OpenSearch workload management that can effectively address these challenges.
Example use case
In this post, we discuss GlobalLog, a fictional company supporting healthcare, finance, retail, security, and internal tenants, that built a centralized logging system with OpenSearch Service. Each tenant has unique logging patterns based on their business requirements. Financial tenants generate complex, high-volume queries, healthcare tenants focus on compliance with moderate volume logs and queries, and retail tenants experience seasonal spikes with heavy dashboard usage. Internal operation has steady, low-volume logs and infrequent, simple queries. Security monitoring has a constant, high-volume presence throughout the system.
As the GlobalLog’s tenants scaled, operational challenges emerged: high-priority tenant performance suffered during peak hours, resource-intensive queries caused node crashes, and unpredictable traffic created instability. Limited visibility into tenant resource usage complicated troubleshooting and cross-domain security investigations. The platform required robust handling of varied workload patterns and peak usage times, strong performance isolation to prevent tenant interference, and scalability to manage 30% annual data growth.
Solution overview
GlobalLog implemented a comprehensive workload management strategy to handle the diverse demands of its tenants. The solution manages the tenancy with a tiered tenant placement, a rule-based proxy layer that shapes incoming traffic based on the tenant profile and the status of the OpenSearch cluster, and an OpenSearch workload management plugin that provides granular resource governance, allocating resources such as CPU and memory proportionally to each tenant’s tier. The monitoring component provides the intelligence that the solution needs to do its assessment and make reactive and proactive scaling and performance-related decisions by adjusting the traffic governance rules and policies in a timely manner.
The following diagram illustrates the architecture.
GlobalLog multi tier workload management
Tenant tiering and placement
GlobalLog categorized tenants into four tiers based on their logging requirements (volume, retention, query frequency) and allocated resources accordingly. The tiering system, enforced through the integrated proxy layer and OpenSearch workload management, prevents resource over-allocation while making sure service levels match business priorities. The specification for each tier is detailed in the following table.
Tier
SLA
Resources
Limits
Behavior
Tier 1 (Enterprise Critical)
High-volume complex queries (over 100 concurrent)
24/7 SLA with 99.99% availability
50% CPU
50% Memory
100 concurrent requests
20 MB request size
180-second timeout
Priority query routing and dedicated search threads
Tier 2 (Business Critical)
Moderate volume
compliance-oriented queries
Business hours SLA with 99.9% availability
30% CPU
25% memory
50 concurrent requests
10 MB request size
120-second timeout
Compliance-optimized search pipelines
Tier 3 (Business Standard)
Variable volume
dashboard-heavy usage
Standard business hours support no SLA
10% CPU
20% Memory
25 concurrent requests
5 MB request size
60-second timeout
Burst capacity for seasonal peaks
Tier 4 (Basic)
Internal IT operations
development environments
Best-effort support
no SLA
10% CPU
5%Memory
10 concurrent requests,
2 MB request size
30-second timeout
Automated query optimization for efficiency
Operations, seasonal businesses
GlobalLog’s integrated architecture streamlines its cost allocation and resource distribution model. Financial industry tenants pay premium rates for their guaranteed high-performance resources, effectively subsidizing the infrastructure that supports more variable workloads. These tenants are categorized into Tier 1. Healthcare tenants benefit from isolation that enforces compliance without bearing the full cost of dedicated infrastructure. These tenants are categorized into Tier 2. Retail tenants are categorized into Tier 3 because they appreciate the elastic capacity during peak seasons without maintaining excess capacity year-round. Tier 4 includes the administrative tenants with access to enterprise-grade logging at affordable rates through efficient resource sharing.
This balanced ecosystem helps GlobalLog maintain profitability while delivering appropriate service levels to every tenant regardless of their industry-specific workload characteristics.
In the next sections, we discuss GlobalLog’s workload management system.
Proxy layer
GlobalLog’s continuous feedback loop architecture creates a dynamic ecosystem that optimizes resource allocation across diverse tenant workloads in OpenSearch Service. Rather than depending on static configurations, the architecture monitors performance metrics and tenant usage patterns to drive scaling and remediation decisions. This makes sure the system evolves as workloads change over time.
The proxy layer core component is the OpenSearch Traffic Gateway, which functions as an intermediary between clients and OpenSearch clusters. It features the following key capabilities:
Rule-based traffic shaping through pattern matching for request paths and parameters
Metrics for resource cost allocation
Traffic replay
GlobalLog expanded the capabilities of their OpenSearch Traffic Gateway through a comprehensive set of enhancements focused on centralization, dynamism, and adaptability. At the core of this evolution, they used Amazon DynamoDB as the centralized repository for critical gateway data. This central database houses the complete ecosystem of rules, policies, and tenant profiles, alongside crucial operational data including metrics, usage patterns, SLA requirements, tier configurations, and real-time cluster status information.
Beyond this centralization effort, GlobalLog transformed the gateway with a dynamic mechanism capable of real-time adjustments and responsive decision-making. This architectural shift allows the gateway to react intelligently to changing conditions rather than following predetermined pathways.
Additionally, GlobalLog implemented an adaptive rule system with sophisticated contextual awareness. The system now activates specific rules based on current cluster states and tenant usage patterns, enabling precise resource allocation and protection mechanisms that respond to actual conditions rather than hypothetical scenarios. The system implements time-based rule scheduling, providing flexibility by allowing different limits and policies to automatically engage during specific periods such as maintenance windows. This provides optimal performance while accommodating necessary system operations.
The solution implements a continuous feedback loop between the monitoring system, the OpenSearch cluster, and the proxy layer, where the flow of performance metrics and tenant usage patterns drive automated, rule-based scaling and optimization decisions, helping the system evolve as workloads change over time. In this architecture, Amazon EventBridge triggers an AWS Lambda function when predefined criteria are met (for example, an anomaly is detected in OpenSearch Service), resulting in the Lambda function taking steps to remediate the issues by adjusting the traffic shaping rules and uploading them to the OpenSearch Traffic Gateway. To stabilize the feedback loop, GlobalLog took the following steps:
Added dampening mechanisms to prevent rapid rule changes
Implemented gradual adjustment patterns instead of binary switches
Created circuit breakers for automatic fallback to baseline rules
OpenSearch workload management layer
GlobalLog implemented tenant-level admission control and reactive query management through OpenSearch workload management. The system uses workload management to define resource limits, based on tenant criticality, providing efficient resource allocation and preventing bottlenecks.
A key component of OpenSearch’s workload management is its workload groups. A workload group refers to a logical grouping of queries, typically used for managing resources and prioritizing workloads. GlobalLog uses workload groups to manage resource allocation based on the previously defined tenant tiers. Enterprise-critical workloads receive substantial CPU and memory guarantees, providing consistent performance for financial operations. Business Critical tenants operate with moderate resource guarantees, and Standard and Basic tiers function with more constrained resources, reflecting their lower priority status. The following example shows the workload group setup for Enterprise Critical and Business Critical tiers:
In this section, we discuss two scenarios where GlobalLog’s workload management system helped the company overcome various challenges.
Scenario 1: Security incident response
During a critical security incident, GlobalLog faced a complex challenge of managing simultaneous log access requests from multiple business units, each with different priority levels. At the highest tier were security and financial operations (Tier 1), followed by healthcare operations (Tier 2), retail operations (Tier 3), and internal operations (Tier 4).
At the proxy layer, GlobalLog gave precedence to security and financial tenant queries while implementing specific limitations for other units. Healthcare operations were capped at 15 concurrent queries, retail operations were restricted to 5 queries per minute, and internal operations had their date ranges narrowed.
OpenSearch workload management and the proxy layer played a crucial role by maintaining the security team’s query priority while managing resource pressure, including the cancellation of complex retail queries during high CPU usage.
Scenario 2: End-of-month reporting
During month-end reporting periods, GlobalLog successfully handled intensive analytical workloads from multiple tenants. The implementation of time-based rules proved particularly effective, with prioritizing Tier 4 tenants for batch reporting during regular end-of-month off-peak business hours. The following code shows an example of GlobalLog rules in this context. The first rule allows Tier 4 tenants to run reports during off-peak business hours, and the second rule denies Tier 4 tenants’ requests during business hours:
The system dynamically adjusted resource allocation for Tier 4 tenants for the off-peak hours (6:00 PM – 8:00 AM) using the OpenSearch workload management API.
This comprehensive approach proved highly successful in managing peak reporting periods, facilitating both system stability and optimal performance across all tenant tiers.
Conclusion
The integration of proxy-layer traffic shaping with the OpenSearch workload management plugin in a continuous feedback loop architecture achieved resiliency, stable performance, and fair resource allocation while supporting diverse business priorities. The implementation discussed in this post demonstrates that large-scale, multi-tenant logging environments can effectively serve diverse business needs on shared infrastructure while maintaining performance and cost-efficiency.
Try out these workload management techniques for your own use case and share your feedback and questions in the comments.
About the Authors
Ezat Karimi is a Senior Solutions Architect at AWS, based in Austin, TX. Ezat specializes in designing and delivering modernization solutions and strategies for database applications. Working closely with multiple AWS teams, Ezat helps customers migrate their database workloads to the AWS Cloud.
Jon Handler is a Senior Principal Solutions Architect at AWS based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have vector, search, and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor’s of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
At Amazon Web Services (AWS), customer privacy and security are our top priority. We provide our customers with industry-leading privacy and security when they use the AWS Cloud anywhere in the world. In recent months, we’ve noticed an increase in inquiries about how we manage government requests for data. While many of the questions center around a 2018 U.S. law known as the Clarifying Lawful Overseas Use of Data Act (CLOUD Act), the CLOUD Act in fact did not give the U.S. government any new authority to compel data from providers and provides critical legal guardrails to protect content.
To put this whole issue in context—there have been no data requests to AWS that resulted in disclosure to the U.S. government of enterprise or government content data stored outside the U.S. since we started reporting the statistic in 2020. Our commitment to protecting customer data is underpinned by several layers of legal, technical, and operational protection. For example, AWS has designed its core products and services to prevent anyone but the customer and those authorized by the customer from accessing the customer’s content. And in these instances, any government that wants access to the customer’s content would have to seek that data directly from the customer. Additionally, U.S. law itself provides numerous statutory protections that help lower the risk that AWS could be required to disclose enterprise or government content data, and the U.S. Department of Justice (DOJ) has implemented additional operational protections over the past eight years.
With that in mind, we want to address some common misconceptions about the CLOUD Act and provide some clarity about how this law impacts—or doesn’t impact—AWS customers worldwide. We’re also expanding our FAQs on the CLOUD Act to help our customers and partners better navigate this topic.
Fact 1: The CLOUD Act does not give the U.S. government unfettered or automatic access to data stored in the cloud
The CLOUD Act was passed to address challenges law enforcement faced in obtaining data stored abroad in cross-border investigations involving serious crimes, ranging from terrorism and violent crime to sexual exploitation of children and cybercrime. The CLOUD Act primarily enabled the U.S. to enter into reciprocal executive agreements with trusted foreign partners to obtain access to electronic evidence for investigations of serious crimes, wherever the evidence happens to be located, by lifting blocking statutes under U.S. law. Many governments rely on domestic laws to require providers within their jurisdiction to disclose electronic data under the companies’ control, regardless of where the data is stored. Similarly, The CLOUD Act clarified that U.S. law enforcement can use existing authorities such as a court-approved search warrant to compel data within a provider’s control, regardless of where the data is stored; the executive agreements enable the effectiveness of these reciprocal laws, supported by strong procedural and substantive safeguards.
Access to data under U.S. law is far from unfettered or automatic, and law enforcement must meet strict legal standards. Under U.S. law, providers are actually prohibited from disclosing data to the U.S. government absent a legal exception. To compel a provider to disclose content data, law enforcement must convince an independent federal judge that probable cause exists related to a particular crime, and that evidence of the crime will be found in the place to be searched (that is, a specific electronic account such as an email account). This legal standard must be established through specific and trustworthy facts. Each search warrant must pass this stringent probable cause determination using credible facts, particularity, and legality, must receive approval from an independent judge, and must meet requirements regarding scope and jurisdiction. In May 2023, the DOJ also issued a policy that prosecutors seeking evidence known to be located abroad must obtain approval from Department’s Office of International Affairs (OIA) prior to obtaining an order for such evidence. The DOJ policy on evidence abroad notes that every nation enacts laws to protect its sovereignty; OIA works to address these issues and assist prosecutors in selecting an appropriate mechanism to secure evidence.
Fact 2: AWS has not disclosed any enterprise or government customer content data under the CLOUD Act since we started tracking the statistic
AWS has rigorous procedures in place for handling law enforcement requests from any country to validate legitimacy and verify that they comply with applicable law. AWS recognizes the legitimate needs of law enforcement agencies in investigating criminal and terrorist activity, but they must observe legal safeguards for conducting such investigations. We do not disclose customer data in response to any government request unless we are obligated to do so by a legally valid and binding order. We have publicly committed to this in our legal terms. Additionally, we will challenge government requests that conflict with the law, are overbroad, or are otherwise inappropriate (for example, if such a request would violate individuals’ fundamental rights). When we receive such requests for enterprise customer content, we make every reasonable effort to redirect law enforcement to the customer and notify the customer when legally permitted. If we are required to disclose customer content, we notify customers before disclosure to provide them an opportunity to seek protection from disclosure unless prohibited by law. If after exhausting these steps, AWS remains compelled to disclose customer data, and we have the technical ability to do so (which, as described above, in many instances we do not), we disclose only the minimum necessary to satisfy the legal process.
Consistent with our policy to redirect law enforcement to customers, the DOJ’s Computer Crime and Intellectual Property Section has also issued guidance advising prosecutors to generally seek data directly from an enterprise, such as a company that stores data with a cloud provider, rather than from the provider.
A clear measure of the effectiveness of our measures and the rigorous legal requirements embodied in law is the fact that since we began reporting this statistic in 2020, AWS has not disclosed any enterprise or government customer content data stored outside the U.S. to the U.S. government. This record reflects the technical safeguards AWS offers, the robust legal protections within U.S. law, policies implemented by the DOJ, and the nature of law enforcement investigations which primarily focus on collecting electronic evidence from consumer accounts.
Fact 3: The CLOUD Act does not only apply to U.S.-headquartered companies—it applies to all providers that do business in the United States
The CLOUD Act applies to all electronic communication service or remote computing service providers that operate or have a legal presence in the U.S.—regardless of where their headquarters are located. For example, European-headquartered cloud providers with U.S. operations are also subject to the Act’s requirements. OVHcloud, a French headquartered cloud service provider that operates in the U.S., notes in its CLOUD Act FAQ page that “OVHcloud will comply with lawful requests from public authorities. Under the CLOUD Act, that could include data stored outside of the United States.” Similarly, other cloud providers headquartered in the E.U. and elsewhere, also have operations in the U.S.
Fact 4: The principles in the CLOUD Act are consistent with international law and the laws of other countries
The CLOUD Act did not introduce a new legal concept regarding the scope of electronic data that must be disclosed as part of legitimate criminal investigations. Many countries require disclosure of customer data wherever it’s stored in response to legal process involving serious crimes. The United Kingdom’s (U.K.’s) Crime (Overseas Production Orders) Act, for instance, allows U.K. law enforcement agencies to obtain stored electronic data located outside of the U.K. in connection to a criminal investigation. According to a 2024 filing by the U.S. DOJ, the laws of several European Union member states, including Belgium, Denmark, France, Ireland, and Spain, have similar requirements. In fact, since 2023, most law enforcement requests that AWS receives come from authorities outside of the United States.
This concept is also enshrined within the Budapest Convention on Cybercrime, which was the first international treaty aimed at improving cooperation in investigations of cybercrimes. Additionally, the EU’s e-Evidence Regulation, 2023/1543, adopted in August 2023, authorizes Member States to “order a service provider…to produce or preserve electronic evidence regardless of the location of data.” The GDPR also allows for transfers of personal data in response to compelled disclosure requests from third countries, provided that the relevant party can cite an appropriate legal basis and transfer mechanism or derogation (see EDPB’s recent Guidelines 02/2024 on Article 48).
AWS is advocating for governments to conclude reciprocal executive agreements under the CLOUD Act, including between the U.S. and the European Union, and the U.S. and Canada. We believe these agreements are important to definitively resolve potential conflicts of law and enable effective investigation of serious crimes to advance public safety, while recognizing the strong substantive and procedural safeguards that already exist under U.S. law.
Fact 5: The CLOUD Act does not limit the technical measures and operational controls AWS offers to customers to prevent unauthorized access to customer data
We can only respond to legal requests for data where we have the technical ability to do so. AWS has a number of products and services designed to make sure that no one—not even AWS operators—can access customer content. AWS customers also have a range of additional technical measures and operational controls to prevent access to data. For example, many of the AWS core systems and services are designed with zero operator access, meaning the services don’t have any technical means for AWS operators to access customer data in response to a legal request.
The AWS Nitro System, which is the foundation of AWS computing services, uses specialized hardware and software to protect data from outside access during processing on Amazon Elastic Compute Cloud (Amazon EC2). By providing a strong physical and logical security boundary, Nitro is designed so that no unauthorized person—not even AWS operators—can access customer workloads on EC2. The design of the Nitro System has been validated by the NCC Group, an independent cybersecurity firm. The controls that help prevent operator access are so fundamental to the Nitro System that we’ve added them in our AWS Service Terms to provide an additional contractual assurance to all of our customers.
We also give customers features and controls to encrypt data, whether in transit, at rest, or in memory. All AWS services already support encryption, with most also supporting encryption with customer managed keys that are inaccessible to AWS. AWS Key Management Service (AWS KMS) is the first highly scalable, cloud-native key management system with FIPS 140-3 Security Level 3 certification. In plain English, this means AWS offers encryption that is super strong and where our customers control who gets a key.
Continuing our customer obsession
At AWS, our customer-first approach drives everything we do—from how we design our services to how we protect your data. We understand that your trust is earned through transparency, strong technical controls, and unwavering advocacy for your interests. That’s why we’ve been clear about how we handle government requests for data, including the impact of the CLOUD Act, and the multiple layers of protection—legal, operational, and technical—to safeguard your data.
We encourage you to learn more about this important topic by reviewing our expanded CLOUD Act FAQ. We will continue to innovate on your behalf, building new features and services that put you in control of your data, and maintaining our commitment to the highest standards of privacy and security.
French version
CLOUD Act : cinq points clés pour comprendre son fonctionnement réel
Chez Amazon Web Services (AWS), la confidentialité et la sécurité des clients constituent notre priorité absolue. Nous mettons à leur disposition une confidentialité et une sécurité à la pointe de l’industrie lorsqu’ils utilisent le Cloud AWS, partout dans le monde. Ces derniers mois, nous avons constaté une augmentation des questions concernant notre gestion des demandes d’accès aux données émanant d’autorités gouvernementales. Si de nombreuses interrogations portent sur une loi américaine de 2018 connue sous le nom de Clarifying Lawful Overseas Use of Data Act (CLOUD Act), cette loi n’a en réalité octroyé aucune nouvelle prérogative au gouvernement américain pour contraindre les fournisseurs à divulguer des données. Elle prévoit des garde-fous juridiques essentiels pour protéger les données des utilisateurs.
Replaçons cette question en perspective : depuis que nous avons commencé à publier des rapports sur les demandes d’informations en 2020, aucune demande n’a abouti à la divulgation auprès du gouvernement américain, de données d’entreprises ou de gouvernements stockées hors des États-Unis. Notre engagement à protéger les données de nos clients repose sur plusieurs niveaux de protection juridique, technique et opérationnelle. A titre d’exemple, les principaux produits et services d’AWS ont été conçus by design de manière à empêcher quiconque, hormis le client et les personnes autorisées par celui-ci, d’accéder à ses données. Ainsi, toute autorité gouvernementale souhaitant accéder aux données d’un client doit en faire la demande directement auprès de celui-ci. En outre, la législation américaine prévoit elle-même de nombreuses protections statutaires qui limitent la possibilité qu’AWS soit contrainte de divulguer des données d’entreprises ou de gouvernements. Le Département de la Justice américain (DOJ) a mis en place des mesures de protections supplémentaires au cours des huit dernières années d’un point de vue opérationnel.
Dans ce contexte, nous souhaitons revenir sur certaines idées reçues courantes à propos du CLOUD Act et apporter des éclaircissements sur l’impact – ou l’absence d’impact – de cette loi sur les clients d’AWS dans le monde entier. Afin d’aider nos clients et partenaires à mieux appréhender ce sujet, nous avons également complété notre FAQ sur le CLOUD Act.
Fait n°1 : Le CLOUD Act n’accorde pas au gouvernement américain un accès illimité ou automatique aux données stockées dans le cloud
Le CLOUD Act a été adopté pour répondre aux défis rencontrés par les autorités judiciaires dans l’obtention des données stockées à l’étranger dans le cadre d’enquêtes transfrontalières sur des crimes graves, allant du terrorisme et des crimes violents à l’exploitation sexuelle d’enfants et à la cybercriminalité. Le CLOUD Act a principalement permis aux États-Unis de conclure des accords exécutifs réciproques avec des partenaires étrangers de confiance. Ces accords visent à faciliter l’accès aux preuves électroniques dans le cadre d’enquêtes sur des crimes graves, indépendamment de la localisation de ces preuves. Pour ce faire, le CLOUD Act lève certaines restrictions prévues par la législation américaine.
De nombreux gouvernements s’appuient sur leurs lois nationales pour exiger des fournisseurs assujettis à ces lois qu’ils divulguent des données électroniques sous leur contrôle, indépendamment du lieu de stockage de ces données. De même, le CLOUD Act a clarifié que les autorités judiciaires américaines pouvaient s’appuyer sur les dispositifs légaux existants, tel qu’un mandat de perquisition autorisé par un tribunal, pour exiger d’un fournisseur la divulgation de données sous son contrôle, indépendamment de leur localisation. Les accords exécutifs bilatéraux permettent la mise en œuvre effective de ces accords de réciprocité, encadrée par des garanties procédurales et juridiques rigoureuses.
L’accès à des données en vertu de la loi américaine est loin d’être illimité ou automatique, et les autorités judiciaires doivent respecter des conditions juridiques strictes. En vertu de la loi américaine, il est de fait interdit aux fournisseurs de divulguer des données au gouvernement américain, sauf exception spécifique. Pour contraindre un fournisseur à la divulgation de données, les autorités judiciaires doivent démontrer devant un juge fédéral indépendant qu’il existe des indices graves et concordants relatifs à un crime et qu’il est probable que des éléments de preuve de ce crime se trouvent dans le périmètre visé par la perquisition (par exemple, un compte électronique spécifique tel qu’une messagerie). La mise en œuvre de cette exception doit s’appuyer sur des éléments factuels précis et vérifiables.
Chaque mandat de perquisition est soumis à cette évaluation stricte de la présence d’indices graves et concordants, qui doit reposer sur des faits crédibles, respecter les critères de spécificité et de légalité, être autorisé par un juge indépendant et satisfaire aux conditions de compétence matérielle et juridictionnelle. En mai 2023, le DOJ a par ailleurs publié des directives imposant aux procureurs qui recherchent des preuves localisées à l’étranger d’obtenir préalablement l’autorisation du Bureau des Affaires Internationales (OIA) avant d’obtenir toute ordonnance. La politique du DOJ concernant les preuves situées à l’étranger reconnaît que chaque État adopte des lois pour protéger sa souveraineté. L’OIA intervient pour traiter ces questions et accompagner les procureurs dans l’identification des mécanismes appropriés d’obtention des preuves.
Fait n°2 : Depuis la mise en place du suivi statistique, AWS n’a divulgué aucune donnée d’entreprise ou de gouvernement en vertu du CLOUD Act
AWS applique des procédures strictes pour traiter les demandes des autorités judiciaires de tout pays, en vérifiant leur légitimité et leur conformité à la réglementation applicable. Si AWS reconnaît les besoins légitimes des autorités judiciaires dans leurs enquêtes sur les activités criminelles et terroristes, les autorités doivent respecter les mesures de protection juridiques encadrant ces enquêtes. En effet, notre politique est claire : nous ne divulguons pas les données des clients en réponse à une demande gouvernementale, sauf si nous en sommes contraints par une ordonnance juridiquement valide et contraignante. Nous avons pris cet engagement publiquement dans nos conditions juridiques.
Nous contestons les demandes gouvernementales qui s’avèrent illégales, disproportionnées ou inappropriées (notamment celles qui porteraient atteintes aux droits fondamentaux des individus). Pour les demandes concernant les données d’entreprises clientes, nous mettons tout en œuvre pour rediriger les autorités judiciaires vers le client et l’informer lorsque la loi le permet. En cas d’obligation de divulgation des données d’un client, nous l’en informons au préalable pour lui permettre de se prémunir contre cette divulgation, sauf interdiction par la loi. Si, après ces étapes, AWS reste contrainte de divulguer des données client et dispose de la capacité technique de le faire (ce qui, comme mentionné précédemment, est rarement le cas), nous limitons la divulgation au strict minimum requis par la procédure judiciaire.
Conformément à notre politique de redirection des autorités judiciaires vers les clients, le département des crimes informatiques et de la propriété intellectuelle du DOJ américain a également émis des lignes directrices recommandant aux procureurs de privilégier l’obtention des données directement auprès de l’entreprise concernée, plutôt qu’auprès du fournisseur cloud hébergeant ces données.
Une preuve tangible de l’efficacité de nos mesures et des exigences juridiques rigoureuses inscrites dans la loi : depuis le début du suivi de cette statistique en 2020, AWS n’a divulgué au gouvernement américain aucune donnée de client d’entreprise ou de gouvernement stockée hors des États-Unis. Ce bilan résulte des garanties techniques offertes par AWS, des conditions juridiques strictes prévues par la législation américaine, des politiques mises en œuvre par le DOJ, et de la nature des enquêtes des autorités judiciaires qui ciblent principalement la collecte de preuves électroniques issues de comptes de particuliers.
Fait n°3 : Le CLOUD Act ne s’applique pas uniquement aux entreprises dont le siège est situé aux États-Unis, mais à toute entreprise exerçant une activité commerciale aux États-Unis
Le CLOUD Act s’applique à l’ensemble des fournisseurs de services de communication électronique ou de services informatiques à distance qui exercent une activité ou disposent d’une présence juridique aux États-Unis, indépendamment de la localisation de leur siège social. Par conséquent, les fournisseurs de services cloud européens ayant des activités aux États-Unis sont également assujettis aux dispositions de cette loi. À titre d’exemple, OVHcloud, entreprise française de services cloud présente aux États-Unis, précise dans sa FAQ relative au CLOUD Act qu’”OVHcloud se conformera aux demandes légales des autorités publiques. En vertu du CLOUD Act, cela pourrait inclure des données stockées en dehors des États-Unis.” De même, d’autres fournisseurs de cloud dont le siège est situé dans l’Union européenne ou ailleurs exercent également des activités aux États-Unis.
Fait n°4 : Les principes du CLOUD Act s’inscrivent dans le cadre du droit international et des législations nationales
Le CLOUD Act n’a pas introduit de nouveau concept juridique concernant l’accès aux données électroniques dans le cadre d’enquêtes pénales. De nombreux États exigent la divulgation de données clients quel que soit leur lieu de stockage en réponse à des procédures judiciaires impliquant des crimes graves. La loi britannique Crime (Overseas Production Orders) Act, par exemple, permet aux autorités judiciaires britanniques d’obtenir des données électroniques stockées hors du Royaume-Uni dans le cadre d’une enquête pénale. Selon un document du DOJ américain publié en 2024, plusieurs États membres de l’Union européenne, dont la Belgique, le Danemark, la France, l’Irlande et l’Espagne, disposent d’exigences similaires. En réalité, depuis 2023, la majorité des demandes d’accès aux données reçues par AWS émanent d’autorités situées en dehors des États-Unis.
Ce principe est également inscrit dans la Convention de Budapest sur la cybercriminalité, premier traité international visant à renforcer la coopération en matière d’enquêtes sur la cybercriminalité. Par ailleurs, le Règlement européen e-Evidence (2023/1543), adopté en août 2023, habilite les États membres à “ordonner à un fournisseur de services de produire ou de conserver des preuves électroniques, quelle que soit la localisation des données.” Le RGPD prévoit également la possibilité de transferts de données personnelles en réponse aux demandes contraignantes de pays tiers, sous réserve d’une base juridique appropriée et d’un mécanisme de transfert ou d’une dérogation (voir les Lignes directrices 02/2024 du Comité européen de la protection des données sur l’Article 48).
AWS soutient la conclusion d’accords de coopération bilatéraux dans le cadre du CLOUD Act, notamment entre les États-Unis et l’Union européenne, ainsi qu’entre les États-Unis et le Canada. Ces accords sont essentiels pour résoudre les conflits potentiels de lois et permettre des enquêtes efficaces sur les crimes graves afin d’améliorer la sécurité publique, tout en s’appuyant sur les garanties procédurales et juridiques substantielles déjà prévues par la législation américaine.
Fait n°5 : Le CLOUD Act n’a pas d’impact sur les dispositifs techniques et les mesures de contrôle qu’AWS met à disposition de ses clients pour prévenir tout accès non autorisé à leurs données
AWS ne peut répondre aux demandes judiciaires de communication de données que lorsqu’elle dispose de la capacité technique de le faire. Or, AWS a développé de nombreux produits et services garantissant qu’aucun tiers – y compris ses propres employés – ne peut accéder aux données des clients. Les clients d’AWS ont également à leur disposition un ensemble de dispositifs techniques et de mesures de contrôle complémentaires pour protéger leurs données. À titre d’exemple, la plupart des principaux systèmes et services d’AWS sont conçus sans aucune possibilité d’accès technique, selon le principe d’absence d’accès pour les opérateurs (zero operator access). Cela signifie que les services ne disposent d’aucun moyen technique permettant aux opérateurs d’AWS d’accéder aux données des clients en réponse à une demande judiciaire.
Le système AWS Nitro, qui est à la base des services informatiques AWS, utilise des composants matériels et logiciels spécifiques pour protéger les données de tout accès externe lors de leur traitement sur Amazon Elastic Compute Cloud (Amazon EC2). En établissant une barrière physique et logique renforcée, le système Nitro est conçu de sorte qu’aucune personne non autorisée – y compris les opérateurs d’AWS – ne peut accéder aux charges de travail des clients sur EC2. L’architecture du système Nitro a été certifiée par NCC Group, organisme indépendant en cybersécurité. Ces dispositifs de contrôle empêchant tout accès de nos opérateurs sont si essentiels au système Nitro que nous les avons intégrés dans nos Conditions de Service AWS, offrant ainsi une garantie contractuelle supplémentaire à l’ensemble de nos clients.
Nous proposons également à nos clients des fonctionnalités et des mécanismes de chiffrement des données, qu’elles soient en transit, au repos ou en mémoire. L’ensemble des services AWS intègrent le chiffrement, la majorité permettant également le chiffrement via des clés gérées par le client et inaccessibles à AWS. AWS Key Management Service (AWS KMS) est le premier système de gestion de clés natif au cloud, hautement évolutif, à obtenir la certification FIPS 140-3 Niveau 3. Concrètement, AWS propose un chiffrement de niveau supérieur où les clients conservent le contrôle exclusif de l’accès aux clés.
Poursuivre notre obsession client
Chez AWS, notre approche centrée sur le client guide l’ensemble de nos actions, de la conception de nos services à la protection de vos données. La confiance que vous nous accordez repose sur notre transparence, la robustesse de nos dispositifs techniques de contrôle et notre détermination à défendre vos intérêts.
C’est dans cet esprit que nous avons établi une communication claire et transparente sur notre traitement des demandes d’accès aux données émanant des autorités, notamment concernant l’application du CLOUD Act, ainsi que sur les différents niveaux de protection – juridiques, opérationnels et techniques – mis en œuvre pour sécuriser vos données.
Nous vous invitons à approfondir vos connaissances de ce sujet en consultant notre FAQ détaillée sur le CLOUD Act.
Nous poursuivrons nos efforts d’innovation, à votre service, en développant de nouvelles fonctionnalités et de nouveaux services vous garantissant la maîtrise de vos données, tout en maintenant nos engagements en matière de confidentialité et de sécurité.
A propos de l’auteur
Bob Kimball occupe le poste de Chief Regulatory Officer après avoir été General Counsel d’AWS. Dans ses fonctions actuelles, il pilote les questions réglementaires mondiales d’AWS, travaillant en étroite collaboration avec les régulateurs et les clients sur des enjeux tels que l’IA, la souveraineté numérique, l’énergie et d’autres sujets clés liés à l’exploitation des infrastructures et services cloud.
German version
Fünf Fakten zur tatsächlichen Funktionsweise des CLOUD Act
Bei Amazon Web Services (AWS) haben Kundendatenschutz und -sicherheit höchste Priorität. Wir bieten unseren Kunden branchenführenden Datenschutz und erstklassige Sicherheit bei der Nutzung der AWS Cloud – weltweit. In den vergangenen Monaten haben wir ein gestiegenes Interesse zum Umgang mit behördlichen Datenanfragen festgestellt. Viele dieser Fragen beziehen sich auf ein US-amerikanisches Gesetz aus dem Jahr 2018, den Clarifying Lawful Overseas Use of Data Act (CLOUD Act). Tatsächlich hat der CLOUD Act der US-Regierung keinerlei neue Befugnisse eingeräumt, Daten von Anbietern anzufordern, sondern schafft vielmehr wichtige rechtliche Leitplanken zum Schutz von Inhalten.
Um diese Thematik in den richtigen Kontext zu setzen: Seit wir 2020 mit der statistischen Erfassung begonnen haben, gab es keine Datenanfragen an AWS, die zur Offenlegung von außerhalb der USA gespeicherten Kundeninhalten von Unternehmens- oder Regierungsdaten gegenüber der US-Regierung geführt haben. Unser Engagement zum Schutz von Kundendaten wird durch mehrere Ebenen rechtlichen, technischen und operativen Schutzes untermauert. AWS hat beispielsweise seine Kernprodukte und -services so konzipiert, dass nur Kunden selbst und die von ihnen autorisierten Personen auf die Kundeninhalte zugreifen können. In diesen Fällen müsste jede Regierung, die Zugriff auf Kundeninhalte wünscht, diese Daten direkt beim Kunden anfragen. Darüber hinaus bietet das US-Recht selbst zahlreiche gesetzliche Schutzmaßnahmen, die das Risiko verringern, dass AWS zur Offenlegung von Unternehmens- oder Regierungsdaten verpflichtet werden könnte. Das US-Justizministerium (DOJ) hat in den letzten acht Jahren zusätzliche operative Schutzmaßnahmen implementiert.
Vor diesem Hintergrund möchten wir einige häufige Missverständnisse über den CLOUD Act ansprechen und Klarheit darüber schaffen, wie sich dieses Gesetz auf AWS Kunden weltweit auswirkt – oder eben nicht auswirkt. Außerdem erweitern wir unsere FAQ zum CLOUD Act, um unseren Kunden und Partnern den Umgang mit diesem Thema zu erleichtern.
Fakt 1: Der CLOUD Act gewährt der US-Regierung keinen uneingeschränkten oder automatischen Zugriff auf in der Cloud gespeicherte Daten
Der CLOUD Act wurde verabschiedet, um Herausforderungen zu bewältigen, denen Strafverfolgungsbehörden bei der Beschaffung von im Ausland gespeicherten Daten in grenzüberschreitenden Ermittlungen zu schweren Straftaten begegneten. Dazu gehören Terrorismus und Gewaltverbrechen bis hin zu sexueller Ausbeutung von Kindern und Cyberkriminalität. Der CLOUD Act ermöglicht es den USA in erster Linie, gegenseitige Vollzugsvereinbarungen mit vertrauenswürdigen ausländischen Partnern zu schließen, um Zugang zu elektronischen Beweismitteln für Ermittlungen bei schweren Straftaten zu erhalten, unabhängig vom Speicherort der Beweise, indem Sperrgesetze nach US-Recht aufgehoben wurden. Viele Regierungen stützen sich auf nationale Gesetze, um von Anbietern innerhalb ihres Zuständigkeitsbereichs die Offenlegung elektronischer Daten unter der Kontrolle der Unternehmen zu verlangen, unabhängig davon, wo die Daten gespeichert sind. In ähnlicher Weise stellte der CLOUD Act klar, dass US-Strafverfolgungsbehörden bestehende Befugnisse wie einen gerichtlich genehmigten Durchsuchungsbeschluss nutzen können, um Daten unter der Kontrolle eines Anbieters anzufordern, unabhängig vom Speicherort der Daten; die Vollzugsvereinbarungen ermöglichen die Wirksamkeit dieser gegenseitigen Gesetze, unterstützt durch strenge verfahrensrechtliche und materielle Schutzmaßnahmen.
Der Zugriff auf Daten nach US-Recht ist bei weitem nicht uneingeschränkt oder automatisch möglich, und Strafverfolgungsbehörden müssen strenge rechtliche Standards erfüllen. Nach US-Recht ist es Anbietern sogar untersagt, Daten ohne rechtliche Ausnahmeregelung an die US-Regierung weiterzugeben. Um einen Anbieter zur Offenlegung von Inhaltsdaten zu verpflichten, muss die Strafverfolgungsbehörde einen unabhängigen Bundesrichter davon überzeugen, dass ein hinreichender Verdacht bezüglich einer bestimmten Straftat besteht und dass Beweise für diese Straftat am zu durchsuchenden Ort gefunden werden (das heißt in einem bestimmten elektronischen Konto wie einem E-Mail-Account). Dieser Rechtsstandard muss durch konkrete und vertrauenswürdige Fakten belegt werden. Jeder Durchsuchungsbeschluss muss diese strenge Prüfung des hinreichenden Verdachts anhand glaubwürdiger Fakten, Spezifität und Rechtmäßigkeit bestehen, muss von einem unabhängigen Richter genehmigt werden und muss die Anforderungen hinsichtlich Umfang und Zuständigkeit erfüllen. Im Mai 2023 hat das DOJ außerdem eine Richtlinie erlassen, wonach Staatsanwälte, die nachweislich im Ausland gespeicherte Beweismittel anfordern, vor Erhalt einer entsprechenden Anordnung die Genehmigung des Office of International Affairs (OIA) des Ministeriums einholen müssen. Die DOJ-Richtlinie zu Beweismitteln im Ausland weist darauf hin, dass jede Nation Gesetze zum Schutz ihrer Souveränität erlässt; das OIA arbeitet daran, diesbezügliche Fragen zu klären und Staatsanwälte bei der Auswahl eines geeigneten Mechanismus zur Sicherung von Beweismitteln zu unterstützen.
Fakt 2: AWS hat seit Beginn der statistischen Erfassung keine Kundeninhalte von Unternehmens- oder Regierungskundendaten aufgrund des CLOUD Act offengelegt
AWS verfügt über strenge Verfahren zur Bearbeitung von Anfragen von Strafverfolgungsbehörden aus allen Ländern, um deren Legitimität zu prüfen und sicherzustellen, dass sie geltendem Recht entsprechen. AWS erkennt die legitimen Bedürfnisse von Strafverfolgungsbehörden bei der Untersuchung krimineller und terroristischer Aktivitäten an, aber diese müssen die rechtlichen Schutzmaßnahmen für solche Ermittlungen beachten. Wir geben Kundendaten auf keinerlei behördliche Anfragen heraus, es sei denn, wir sind dazu durch eine rechtlich gültige und verbindliche Anordnung verpflichtet. Dies haben wir in unseren rechtlichen Bedingungen öffentlich zugesichert. Darüber hinaus werden wir behördliche Anfragen anfechten, die gegen das Gesetz verstoßen, zu weitreichend oder anderweitig unangemessen sind (beispielsweise, wenn eine solche Anfrage die Grundrechte von Personen verletzen würde). Wenn wir solche Anfragen nach Inhalten von Unternehmenskunden erhalten, unternehmen wir alle angemessenen Anstrengungen, um Strafverfolgungsbehörden an den Kunden zu verweisen und den Kunden zu benachrichtigen, wenn dies rechtlich zulässig ist. Wenn wir zur Offenlegung von Kundeninhalten verpflichtet sind, benachrichtigen wir die Kunden vor der Offenlegung, um ihnen die Möglichkeit zu geben, sich gegen die Offenlegung zu schützen, sofern dies nicht gesetzlich untersagt ist. Wenn AWS nach Ausschöpfung dieser Schritte weiterhin zur Offenlegung von Kundendaten verpflichtet ist und wir die technische Möglichkeit dazu haben (was, wie oben beschrieben, in vielen Fällen nicht der Fall ist), legen wir nur das zur Erfüllung des rechtlichen Verfahrens unbedingt Notwendige offen.
In Übereinstimmung mit unserer Richtlinie, Strafverfolgungsbehörden an die Kunden zu verweisen, hat auch die Computer Crime and Intellectual Property Section des DOJ Leitlinien herausgegeben, die Staatsanwälte anweisen, Daten grundsätzlich direkt von einem Unternehmen anzufordern, wie beispielsweise von einem Unternehmen, das Daten bei einem Cloud-Anbieter speichert, und nicht vom Anbieter selbst.
Ein deutlicher Beleg für die Wirksamkeit unserer Maßnahmen und der strengen gesetzlichen Anforderungen ist die Tatsache, dass AWS seit Beginn der statistischen Erfassung im Jahr 2020 keine außerhalb der USA gespeicherten Kundeninhalte von Unternehmens- oder Regierungskundendaten an die US-Regierung weitergegeben hat. Diese Bilanz spiegelt die technischen Schutzmaßnahmen von AWS, die robusten rechtlichen Schutzmaßnahmen im US-Recht, die vom DOJ umgesetzten Richtlinien und die Art der strafrechtlichen Ermittlungen wider, die sich hauptsächlich auf die Sammlung elektronischer Beweise aus Verbraucherkonten konzentrieren.
Fakt 3: Der CLOUD Act gilt nicht nur für Unternehmen mit Hauptsitz in den USA – er gilt für alle Anbieter, die Geschäfte in den Vereinigten Staaten tätigen
Der CLOUD Act gilt für alle Anbieter von elektronischen Kommunikationsdiensten oder Remote-Computing-Diensten, die in den USA tätig sind oder dort eine rechtliche Präsenz haben – unabhängig vom Standort ihres Hauptsitzes. Beispielsweise unterliegen auch Cloud-Anbieter mit Hauptsitz in Europa, die Geschäfte in den USA tätigen, den Anforderungen des Gesetzes. OVHcloud, ein Cloud-Service-Anbieter mit Hauptsitz in Frankreich, der in den USA tätig ist, vermerkt auf seiner CLOUD Act FAQ-Seite, dass “OVHcloud rechtmäßigen Anfragen von Behörden nachkommen wird. Im Rahmen des CLOUD Act könnte dies auch Daten einschließen, die außerhalb der Vereinigten Staaten gespeichert sind.” Ähnlich verhält es sich mit anderen Cloud-Anbietern mit Hauptsitz in der EU und anderswo, die ebenfalls in den USA tätig sind.
Fakt 4: Die Grundsätze des CLOUD Act stehen im Einklang mit internationalem Recht und den Gesetzen anderer Länder
Der CLOUD Act hat keine neue Rechtsposition bezüglich des Umfangs elektronischer Daten eingeführt, die im Rahmen legitimer strafrechtlicher Ermittlungen offengelegt werden müssen. Viele Länder verlangen die Offenlegung von Kundendaten, unabhängig vom Speicherort, als Reaktion auf rechtliche Verfahren im Zusammenhang mit schweren Straftaten. Der britische Crime (Overseas Production Orders) Act beispielsweise ermöglicht es britischen Strafverfolgungsbehörden, im Zusammenhang mit strafrechtlichen Ermittlungen auf außerhalb des Vereinigten Königreichs gespeicherte elektronische Daten zuzugreifen. Laut einer Einreichung des US-DOJ von 2024 haben mehrere EU-Mitgliedstaaten, darunter Belgien, Dänemark, Frankreich, Irland und Spanien, ähnliche Anforderungen. Tatsächlich kommt seit 2023 die Mehrheit der Strafverfolgungsanfragen, die AWS erhält, von Behörden außerhalb der Vereinigten Staaten.
Dieses Konzept ist auch in der Budapest-Konvention zur Cyberkriminalität verankert, dem ersten internationalen Vertrag zur Verbesserung der Zusammenarbeit bei der Untersuchung von Cyberkriminalität. Darüber hinaus ermächtigt die EU-Verordnung e-Evidence, 2023/1543, die im August 2023 verabschiedet wurde, die Mitgliedstaaten dazu, “einen Dienstanbieter anzuweisen, elektronische Beweismittel unabhängig vom Standort der Daten zu erstellen oder zu sichern”. Die DSGVO erlaubt ebenfalls die Übermittlung personenbezogener Daten als Reaktion auf verpflichtende Offenlegungsanfragen aus Drittländern – vorausgesetzt, die betreffende Partei kann sich auf eine geeignete Rechtsgrundlage und ein Übertragungsinstrument oder eine Ausnahmeregelung berufen (siehe die aktuellen EDSA Leitlinien 02/2024 zu Artikel 48).
AWS setzt sich dafür ein, dass Regierungen gegenseitige Vollzugsvereinbarungen im Rahmen des CLOUD Act abschließen, einschließlich zwischen den USA und der Europäischen Union sowie den USA und Kanada. Wir glauben, dass diese Vereinbarungen wichtig sind, um potenzielle Gesetzeskonflikte endgültig zu lösen und eine effektive Untersuchung schwerer Straftaten zur Förderung der öffentlichen Sicherheit zu ermöglichen. Dabei werden die bereits bestehenden starken materiell- und verfahrensrechtlichen Schutzmaßnahmen nach US-Recht anerkannt.
Fakt 5: Der CLOUD Act beschränkt nicht die technischen Maßnahmen und operativen Kontrollen, die AWS seinen Kunden zum Schutz vor unbefugtem Zugriff auf Kundendaten anbietet
Wir können auf rechtliche Datenanfragen nur dann reagieren, wenn wir die technische Möglichkeit dazu haben. AWS verfügt über eine Reihe von Produkten und Services, die sicherstellen, dass niemand – nicht einmal Mitarbeiter:innen von AWS – auf Kundeninhalte zugreifen können. AWS Kunden verfügen auch über eine Reihe zusätzlicher technischer Maßnahmen und operativer Kontrollen, um den Zugriff auf Daten zu verhindern. Beispielsweise sind viele der AWS Kernsysteme und Services mit Zero-Operator-Zugriff konzipiert, was bedeutet, dass die Services keine technischen Möglichkeiten für AWS Mitarbeiter:innen bieten, auf Kundendaten als Reaktion auf eine rechtliche Anfrage zuzugreifen.
Das AWS Nitro System, das die Grundlage der AWS Rechendienstleistungen bildet, verwendet spezialisierte Hardware und Software, um Daten während der Verarbeitung auf Amazon Elastic Compute Cloud (Amazon EC2) vor externem Zugriff zu schützen. Durch eine starke physische und logische Sicherheitsgrenze ist Nitro so konzipiert, dass keine unbefugte Person – nicht einmal AWS Mitarbeiter:innen – auf Workloads von Kunden auf EC2 zugreifen kann. Das Design des Nitro Systems wurde von der NCC Group, einem unabhängigen Cybersicherheitsunternehmen, validiert. Die Kontrollen, die den Betreiberzugriff verhindern, sind für das Nitro System so grundlegend, dass wir sie in unsere AWS Servicebedingungen aufgenommen haben, um allen unseren Kunden eine zusätzliche vertragliche Zusicherung zu geben.
Wir bieten Kunden auch Funktionen und Kontrollen zur Verschlüsselung von Daten, sei es während der Übertragung, im Ruhezustand oder im Arbeitsspeicher. Alle AWS Services unterstützen bereits Verschlüsselung, wobei die meisten auch die Verschlüsselung mit kundenverwalteten Schlüsseln unterstützen, die für AWS nicht zugänglich sind. Der AWS Key Management Service (AWS KMS) ist das erste hochskalierbare, Cloud-native Schlüsselverwaltungssystem mit FIPS 140-3 Level 3-Zertifizierung. Vereinfacht ausgedrückt bedeutet dies, dass AWS eine äußerst starke Verschlüsselung anbietet, bei der unsere Kunden kontrollieren, wer einen Schlüssel erhält.
Fortsetzung unserer Kundenorientierung
Bei AWS bestimmt unser kundenorientierter Ansatz alles, was wir tun – von der Gestaltung unserer Services bis zum Schutz Ihrer Daten. Wir verstehen, dass Ihr Vertrauen durch Transparenz, starke technische Kontrollen und unermüdlichen Einsatz für Ihre Interessen verdient wird. Deshalb haben wir klar kommuniziert, wie wir mit behördlichen Datenanfragen umgehen, einschließlich der Auswirkungen des CLOUD Act, und der mehrschichtigen Schutzmaßnahmen – rechtlich, operativ und technisch – zum Schutz Ihrer Daten.
Wir ermutigen Sie, mehr über dieses wichtige Thema zu in unseren erweiterten CLOUD Act FAQs zu lesen. Wir werden weiterhin in Ihrem Interesse innovativ sein, neue Funktionen und Services entwickeln, die Ihnen die Kontrolle über Ihre Daten geben, und unser Engagement für höchste Datenschutz- und Sicherheitsstandards aufrechterhalten.
Über den Autor
Bob Kimball ist Chief Regulatory Officer und ehemaliger General Counsel bei AWS. In seiner aktuellen Position ist Bob ein AWS-Experte für globale regulatorische Fragen und arbeitet eng mit Aufsichtsbehörden und Kunden zu Themen wie KI, digitale Souveränität, Energie und anderen Schlüsselthemen zusammen, die den Betrieb von Cloud-Infrastruktur und -Services betreffen.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
GNOME and Fedora contributor Michael Catanzaro has written a
lengthy blog
post about the future of Fedora Workstation as an image-based
release and the need to enable Flathub by default. He writes that the
Fedora Workstation of the future must be “safe and image-based by
default“, with applications provided through Flathub:
Flathub is drastically more popular than Fedora Flatpaks even among
the most hardcore Fedora community members who participate in change
proposal debate on Fedora Discussion. (At time of writing, nearly 80%
of discussion participants favor filtering out Fedora Flatpaks.)
This is the most important point. Flathub has already
won.
He notes that Fedora should not force users to install an
image-based OS if they do not want to, and there will be a
package-based version for users who prefer or require it: “so no
need to panic“.
Google has announced
the existence of OSS Rebuild, an infrastructure for the creation and
verification of reproducible builds of software projects.
Our aim with OSS Rebuild is to empower the security community to
deeply understand and control their supply chains by making package
consumption as transparent as using a source repository. Our
rebuild platform unlocks this transparency by utilizing a
declarative build process, build instrumentation, and network
monitoring capabilities which, within the SLSA Build framework,
produces fine-grained, durable, trustworthy security metadata. […]
Our vision extends beyond any single ecosystem: We are committed to
bringing supply chain transparency and security to all open source
software development. Our initial support for the PyPI (Python),
npm (JS/TS), and Crates.io (Rust) package registries—providing
rebuild provenance for many of their most popular packages—is just
the beginning of our journey.
The QUIC transport-layer network protocol is not exactly new; it was first covered here in 2013. Despite carrying a
significant part of the traffic on the Internet, QUIC has been anything but
quick when it comes to getting support into the Linux kernel. The pace
might be picking up, though; Xin Long has posted the first set of
patches intended to provide mainline support for this protocol.
Cloudflare’s network currently spans more than 330 cities in over 125 countries, and we interconnect with over 13,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions at both a local and national level, as well as at a network level.
As we have noted in the past, this post is intended as a summary overview of observed and confirmed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter. A larger list of detected traffic anomalies is available in the Cloudflare Radar Outage Center. Note that both bytes-based and request-based traffic graphs are used within the post to illustrate the impact of the observed disruptions — the choice of metric was generally made based on which better illustrated the impact of the disruption.
In our Q1 2025 summary post, we noted that we had not observed any government-directed Internet shutdowns during the quarter. Unfortunately, that forward progress was short-lived — in the second quarter of 2025, we observed shutdowns in Libya, Iran, Iraq, Syria, and Panama. The Internet’s reliance on a stable electric grid was made abundantly clear during the quarter, with a massive power outage impacting Spain and Portugal disrupting connectivity within those countries. Fiber optic cable cuts impacted providers in Haiti and Malawi, major North American providers saw technical problems disrupt Internet traffic, and a Russian provider was once again targeted by a significant cyberattack, knocking the network offline. Unfortunately, official attribution of an Internet outage’s root cause isn’t always available — and we observed several significant, yet unexplained, Internet outages during the quarter.
Government-directed shutdowns
Libya
On May 16, Internet disruptions were observed across multiple Libyan network providers, with connectivity reportedly shut down in response to public protests against the Government of National Unity. Starting at 13:30 UTC (15:30 local time), traffic dropped by more than 50% as compared to the prior week at Libyan International Company for Technology (AS329129), Giga Communication (AS328539), Aljeel Aljadeed for Technology (AS37284), and Awal Telecom (AS328733), with the latter experiencing a complete outage. Lower traffic volumes were observed until around 00:00 UTC (02:00 local time), with traffic restoration occurring within an hour or so on either side. Giga Communication (AS328539) experienced a second disruption on May 17 between 02:00 – 11:30 UTC (04:00 – 13:30 local time).
Iran
Multiple Internet shutdowns occurred in Iran in June following Israel’s initial attacks on the country’s nuclear sites. The first, on June 13, occurred between 07:15 – 09:45 UTC (10:45 – 13:15 local time). Iran’s Ministry of Communications issued a statement that announced the shutdown: “In light of the country’s special circumstances and based on the measures taken by the competent authorities, temporary restrictions have been imposed on the country’s Internet. It is obvious that these restrictions will be lifted once normal conditions are restored.” This shutdown order impacted network providers including FanapTelecom (AS24631), Rasana (AS205647 and AS31549), MCCI (AS197207), and TCI (AS58224), as well as others.
Just a day later, on June 18, an extended third shutdown was put into place, this one lasting from 12:50 UTC (16:20 local time) through 05:00 UTC (08:30 local time) on June 25. Once again, the shutdown was reportedly implemented as a means of protecting against cyberattacks, with a government spokesperson commenting “We have previously stated that if necessary, we will certainly switch to a national internet and restrict global internet access. Security is our main concern, and we are witnessing cyberattacks on the country’s critical infrastructure and disruptions in the functioning of banks. Many of the enemy’s drones are managed and controlled via the internet, and a large amount of information is exchanged this way. A cryptocurrency exchange was also hacked, and considering all these issues, we have decided to impose Internet restrictions.” This shutdown resulted in a near-complete loss of traffic through 02:00 UTC (05:30 local time) on June 21, when some traffic recovery was observed, though at levels remaining well-below pre-shutdown volumes. Traffic from this partial recovery settled into a consistent cycle for several days, until returning to expected levels on June 25. The same network providers impacted by the previous shutdowns were affected by this one as well.
Iraq
Consistent with measures taken over the past several years (2024, 2023, 2022), governments in Iraq again implemented regular Internet shutdowns in an effort to prevent cheating on national exams. (We say “governments” here because the shutdowns took place both in the main part of the country and in the Iraqi Kurdistan region in the northern part of the country.)
As Iraq does, Syria also implements nationwide Internet shutdowns to prevent cheating on exams, and has been doing so for several years (2021, 2022, 2023, 2024). However, in contrast to previous years, in 2025, the government only ordered the cutoff of cellular connectivity, with a published statement noting (translated) “As part of our commitment to ensuring the integrity of public examinations and safeguarding the future of our dear students, and based on our national responsibility to secure a fair and transparent examination environment, a temporary cellular communications blackout will be implemented in areas near examination centers across the Syrian Arab Republic. … The cellular communications blackout will be implemented exclusively within the narrowest possible geographical and timeframe, during the time students are in exam halls.”
During the second quarter, the shutdowns associated with the “Basic Education Certificate” took place on June 21, 24, and 29 between 05:15 – 06:00 UTC (08:15 – 09:00 local time). Exams and associated shutdowns for the “Secondary Education Certificate” are scheduled to take place between July 12 and August 3.
Because these shutdowns only impacted mobile connectivity, they only resulted in a partial drop in announced IP address space, as opposed to a more complete loss as seen in previous years.
Panama
On June 21, an X post from ASEP Panamá (the telecommunications regulating agency) announced that (translated) “…in compliance with Cabinet Decree No. 27 of June 20, 2025, and by formal instruction from the Ministry of Government, the temporary suspension of mobile telephony and residential internet services in the province of Bocas del Toro has been coordinated.” The suspension, according to the post, was supposed to be in place until June 25, however a subsequent X post noted that it would be extended until Sunday, June 29, 2025.
The suspension of Internet connectivity was implemented in response to protests and demonstrations against reforms to the Social Security Fund, retirement, and pensions, specifically in the province of Bocas del Toro.
The graph below shows an effective loss of traffic from Cable Onda (AS18809) in Bocas Del Toro, Panama around 03:30 UTC on June 21 (22:30 local time on June 20), recovering around 06:00 UTC (01:00 local time) on June 30. The recovery is in line with the final related X post from ASEP, which noted (translated) “… Internet and cellular telephone services in the province of Bocas del Toro have been restored as of 12:01 a.m. on Monday, June 30…”.
In Portugal, Internet traffic dropped as the power grid failed — when compared with the previous week, traffic fell ~50 % immediately and within five hours it was ~90% below the week before.
In Spain, Internet traffic dropped as the power grid failed, with traffic immediately dropping by around 60% as compared to the previous week, falling to approximately 80% below the previous week within the next five hours.
In both countries, traffic returned to expected levels around 01:00 local time (midnight UTC) on April 29. More details about the outage can be found in the blog post linked above.
Morocco
It appears that Morocco may have also been impacted in some fashion by the Portugal/Spain power outage, or at least Orange Maroc was. In a post on X, the provider stated (translated) “Internet traffic has been disrupted following a massive power outage in Spain and Portugal, which is affecting international connections.” Traffic from the network (AS36925) fell sharply around 12:00 UTC (13:00 local time), 90 minutes after the power outage began, with a full outage beginning around 15:00 UTC (16:00 local time). Traffic returned to expected levels around 23:30 UTC on April 28 (00:30 local time on April 29).
Puerto Rico
Genera PR, a power company in Puerto Rico, posted on X on April 16 that they had (translated) “…experienced a massive power outage across the island due to the unexpected shutdown of all generating plants, including those of Genera PR and other private generators. This situation has caused a significant disruption to electrical service…” Luma Energy, the private power company that is responsible for power distribution and power transmission in Puerto Rico, published their own X post that stated (translated) “Approximately at 12:40pm, an event was recorded that affects the service island-wide.”
Although the reported power outage was “massive” and “island-wide”, it did not have an outsized impact on Puerto Rico’s Internet traffic, which initially dropped by about 40%. Over the next several days, both companies published multiple updates to their X accounts detailing the progress being made in restoring service. By 15:00 UTC (11:00 local time) on April 18, traffic had returned to expected levels, in line with a post from Luma Energy that noted (translated) “As of 10:00 a.m. on April 18, and thanks to LUMA’s extraordinary response and the tireless efforts of the island’s workforce—in coordination with the Puerto Rico government and generating companies—LUMA has restored electric service to 1,450,367 customers, representing 98.8% of total customers, in less than 38 hours since the island-wide outage began.”
As seen in the graphs below, the power outage not only impacted end-user connectivity, driving the observed drop in traffic, but also had some impact on local Internet infrastructure, with some disturbance visible to announced IP address space.
Saint Kitts and Nevis
A Facebook post from SKELEC (The St. Kitts Electricity Company) on May 9 alerted customers on St. Kitts and Nevis that “…a fault developed at our Needsmust Power Plant resulting in an island wide outage. Restoration has begun, and complete restoration will be in two hours.” The post was published at 17:31 UTC (13:31 local time), approximately 30 minutes after the island’s Internet traffic initially dropped. Traffic recovery initially began around 17:45 UTC (13:45 local time), well within the two-hour estimate for complete power restoration. However, Internet traffic did not fully return to expected levels until 20:15 UTC (16:15 local time).
North Macedonia
On May 18, it was reported that “High voltages in the regional 400 kV network amid low consumption caused a short-term outage in North Macedonia‘s 110 kV transmission network…”, according to state-owned power company MEPSO. While the outage reportedly impacted most of the country, MEPSO also noted that the country’s power supply was normalized within an hour after the outage began. Although brief, the power outage caused the country’s Internet traffic to drop by nearly 60% as compared to the previous week during the disruption, which occurred between 03:00 – 04:45 UTC (05:00 – 06:45 local time).
Maldives
On June 1, Internet traffic in the Maldives dropped by nearly half as compared to the previous week when a widespread power outage affected the Greater Malé region. Local Internet service providers including Ooredoo and Dhiraagu took to social media to warn subscribers of potential interruptions to both fixed and mobile broadband connections. At a country level, Internet traffic was disrupted between 07:30 – 13:00 UTC (12:30 – 18:00 local time).
The power outage also had a nominal impact on Internet infrastructure, as announced IPv4 address space saw a nominal drop (from 355 to 350 /24s) that began shortly after the initial drop in traffic was observed, but returned to normal as the disruption ended.
Curaçao
A near-complete Internet outage at provider Flow Curaçao (AS52233) on June 14-15 sparked outrage and demands for answers by the country’s telecommunications regulator. Flow’s Internet traffic dropped significantly at 18:00 UTC (14:00 local time) on June 14, falling further in the following hours. Signs of recovery became visible around 11:00 UTC (07:00 local time) on June 15, with more complete recovery occurring at 14:00 UTC (10:00 local time). A Facebook post from Flow Barbados, posted on June 18, referenced a local disruption that began on June 14, but pointed at a commercial power outage at one of their key regional network facilities in Curaçao, which was likely the driver of this Internet outage.
Fiber optic cable damage
Digicel Haiti
Two instances of damage to its fiber optic infrastructure caused a complete Internet outage at Digicel Haiti (AS27653) as of 21:00 UTC (17:00 local time) on May 28, according to a (translated) X post from the company’s Director General. The cable damage took the network completely off the Internet, as announced IPv4 and IPv6 address space also dropped to zero. Digicel Haiti remained offline until 00:45 on May 29 (20:45 local time on May 28), when both traffic and announced IP address space returned to expected levels.
Airtel Malawi
Airtel Malawi (AS37440) experienced a 90-minute Internet outage on June 24, caused by ongoing vandalism on their fiber network. Although traffic effectively disappeared between 12:30 – 14:00 UTC (14:30 – 16:00 local time), the network remained at least partially online as at least some of the network’s IPv4 address space continued to be announced to the Internet. Announced IPv6 address space, however, fell to zero during the duration of the outage.
Technical problems
Bell Canada
A router update gone awry disrupted Internet service for Bell Canada (AS577) customers in Ontario and Quebec on May 21. An initial X post from the provider, posted at 13:52 UTC (09:52 local time), alerted customers to the service interruption. The post trailed the start of the disruption by approximately a half hour, as traffic dropped around 13:15 UTC (09:15 local time), falling by as much as 70% as compared to the same time a week prior. Request traffic to Cloudflare’s 1.1.1.1 DNS Resolver also saw a significant drop. A negligible decline in announced IPv4 address space was also observed.
The disruption was fairly short-lived, with traffic returning to expected levels just an hour later. A subsequent X post confirmed that services had been fully restored by 15:00 UTC (11:00 local time), with another post noting that the initial update had been rolled back quickly to restore service.
Lumen/CenturyLink
Across parts of the United States, Lumen/CenturyLink (AS209) customers experienced a widespread Internet service disruption on June 19. Traffic volumes dropped by over 50% as compared to the prior week starting around 21:45 UTC. The disruption only lasted a couple of hours, with traffic returning to normal by 00:00 UTC on June 20.
Social media posts from affected subscribers suggested that the problem might have been DNS related, as those that switched their DNS resolver to Cloudflare’s 1.1.1.1 were once again able to access the Internet. The graph below shows that traffic to 1.1.1.1 from Lumen/CenturyLink exceeded levels seen the previous week as the disruption began, and remained elevated through June 20. Problems with an Internet service provider’s DNS resolver can appear to subscribers like an Internet outage, as they become unable to access anything requiring a DNS lookup (effectively, all Internet resources), ultimately resulting in a drop in traffic to those resources (from the affected user base), as seen in the graph above.
Cyberattack impact
ASVT (Russia)
Russian Internet provider ASVT (AS8752) was reportedly targeted by a major DDoS attack that resulted in a multi-day complete Internet outage. This attack followed one targeting Russian provider Nodex (AS29329) in March, which also caused a complete service outage. Reaching 70.07 Gbps/6.92 million packets/second, the attack caused traffic to drop to near zero around 05:00 UTC on May 28 (08:00 Moscow time), with the effective outage lasting for approximately 10 hours. Although traffic began to return around 15:00 UTC (18:00 Moscow time), it remained below expected levels throughout the following week.
Interestingly, query volume to Cloudflare’s 1.1.1.1 DNS Resolver from ASVT saw a rapid increase as traffic began to return after the initial outage, and remained elevated throughout the duration of the disruption. It isn’t clear whether the increase could be related to problems with ASVT’s native DNS resolver during the attack, forcing users to seek alternative resolvers, or if it could be related to ASVT subscribers seeking ways around damage from the attack.
Unexplained disruptions
Telia Finland (April 1)
According to a (now unavailable) “Disturbance bulletin” and an associated X post from Telia Finland (AS1759), the company acknowledged that “A widespread disruption has been detected in the operation of mobile network data connections and fixed broadband.” The widespread disruption resulted in a brief near-complete outage for subscribers between 06:30 – 07:15 UTC (09:30 – 10:15 local time).
Telia Finland did not disclose the cause of the disruption, but it is clear that it impacted IPv4 connectivity, as seen in the graph below showing announced IPv4 address space. (Announced IPv6 address space did not see any change.) This loss of IPv4 connectivity resulted in a concurrent spike in the share of traffic from Telia Finland over IPv6 — normally below 5%, it spiked above 30% during the disruption. Request traffic to Cloudflare’s 1.1.1.1 resolver from Telia Finland also spiked at that time.
SkyCable
Around 19:15 UTC on May 7 (03:15 local time on May 8), subscribers of SkyCable (AS23944) in the Philippines experienced a complete Internet outage. Internet traffic from the network dropped to zero, as did announced IPv4 address space. The disruption lasted until 03:00 UTC on May 8 (11:00 local time), and SkyCable did not publish any information regarding the cause of the eight-hour service outage.
TrueMove H
On May 22, Thai mobile provider TrueMove H (AS132061)suffered a nationwide outage, impacting connectivity for subscribers. The provider acknowledged and apologized for the disruption, but did not provide an official reason for the outage. (An article in the local press reported “that the outage was caused by technical errors on True’s computer servers” and also stated that others suggested that “the problem might have been caused by an error on True’s DNS servers”.)
At 03:00 UTC (10:00 local time), traffic initially dropped by over 80% as compared to the prior week. Almost immediately, traffic began to slowly recover, and returned to expected levels around 08:00 UTC (15:00 local time). A brief partial drop in announced IPv4 address space was also observed during the first hour of the disruption.
Digicel Haiti
Two days after experiencing an outage due to cable damage, Digicel Haiti (AS27653) experienced another complete outage on May 30. In contrast to the previous outage, no additional information about this one was published on social media by Digicel Haiti or its Director General. The network effectively disappeared from the Internet at 14:15 UTC (10:15 local time), with both traffic and announced IP address space (IPv4 & IPv6) dropping to zero. The outage lasted nearly three hours, with traffic and announced IP space all returning around 17:00 UTC (13:00 local time).
Syria
On June 10, an Internet outage in Syriareportedly affected the ADSL landline network across multiple provinces. Traffic dropped by as much as two-thirds below the same time the previous week at 08:15 UTC (11:15 local time), with the disruption lasting two hours. Announced IPv4 address space also fell during the course of the outage, indicating a potential infrastructure issue. However, as seen below, request volume from Syria to Cloudflare’s 1.1.1.1 DNS resolver was also elevated during the outage. This behavior has been observed in the past during government-directed shutdowns of Internet connectivity in Syria, when traffic can leave the country, but not return. There was no other indication that this outage was due to an intentional shutdown, but no official explanation for the disruption was available.
Conclusion
Government-directed Internet shutdowns returned with a vengeance in the second quarter, and that trend continues into the third quarter, though the latest ones have been exam-related, and not driven by protests. And while power-outage related Internet disruptions have frequently been observed in the past, often in smaller countries with less stable infrastructure, the massive outage in Spain and Portugal on April 28 reminds us that much like the Internet, electrical infrastructure is often interconnected across countries, meaning that problems in one can potentially cause significant problems in others.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


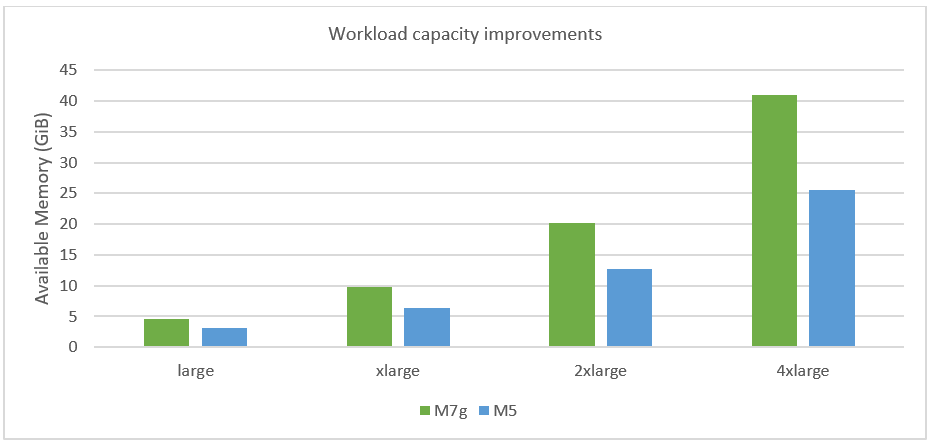
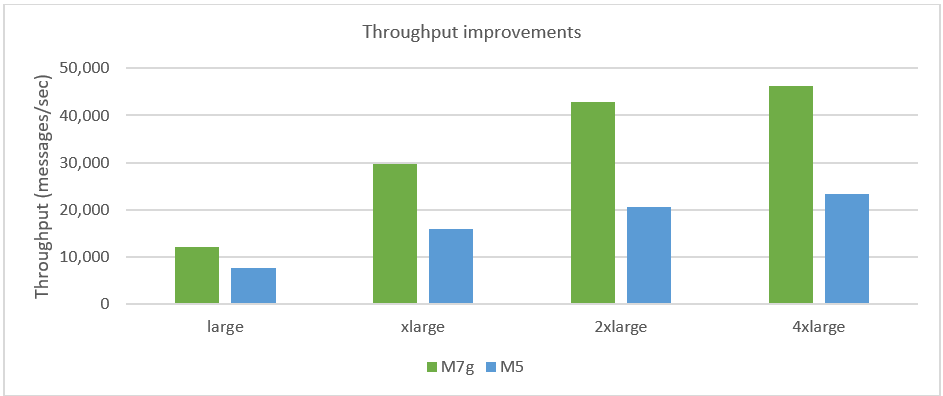
 Vignesh Selvam is the Principal Product Manager for Amazon MQ at AWS. He works with customers to solve their messaging needs and with the open-source communities for innovating with message brokers. Prior to joining AWS, he built products for security and analytics.
Vignesh Selvam is the Principal Product Manager for Amazon MQ at AWS. He works with customers to solve their messaging needs and with the open-source communities for innovating with message brokers. Prior to joining AWS, he built products for security and analytics. Samuel Massé is a Software Development Engineer at AWS. He has been leading the engineering effort to support M7g on the RabbitMQ team. In his free time he enjoys coding unfinished side projects.
Samuel Massé is a Software Development Engineer at AWS. He has been leading the engineering effort to support M7g on the RabbitMQ team. In his free time he enjoys coding unfinished side projects. Vinodh Kannan Sadayamuthu is a Senior Specialist Solutions Architect at Amazon Web Services (AWS). His expertise centers on AWS messaging and streaming services, where he provides architectural best practices consultation to AWS customers.
Vinodh Kannan Sadayamuthu is a Senior Specialist Solutions Architect at Amazon Web Services (AWS). His expertise centers on AWS messaging and streaming services, where he provides architectural best practices consultation to AWS customers.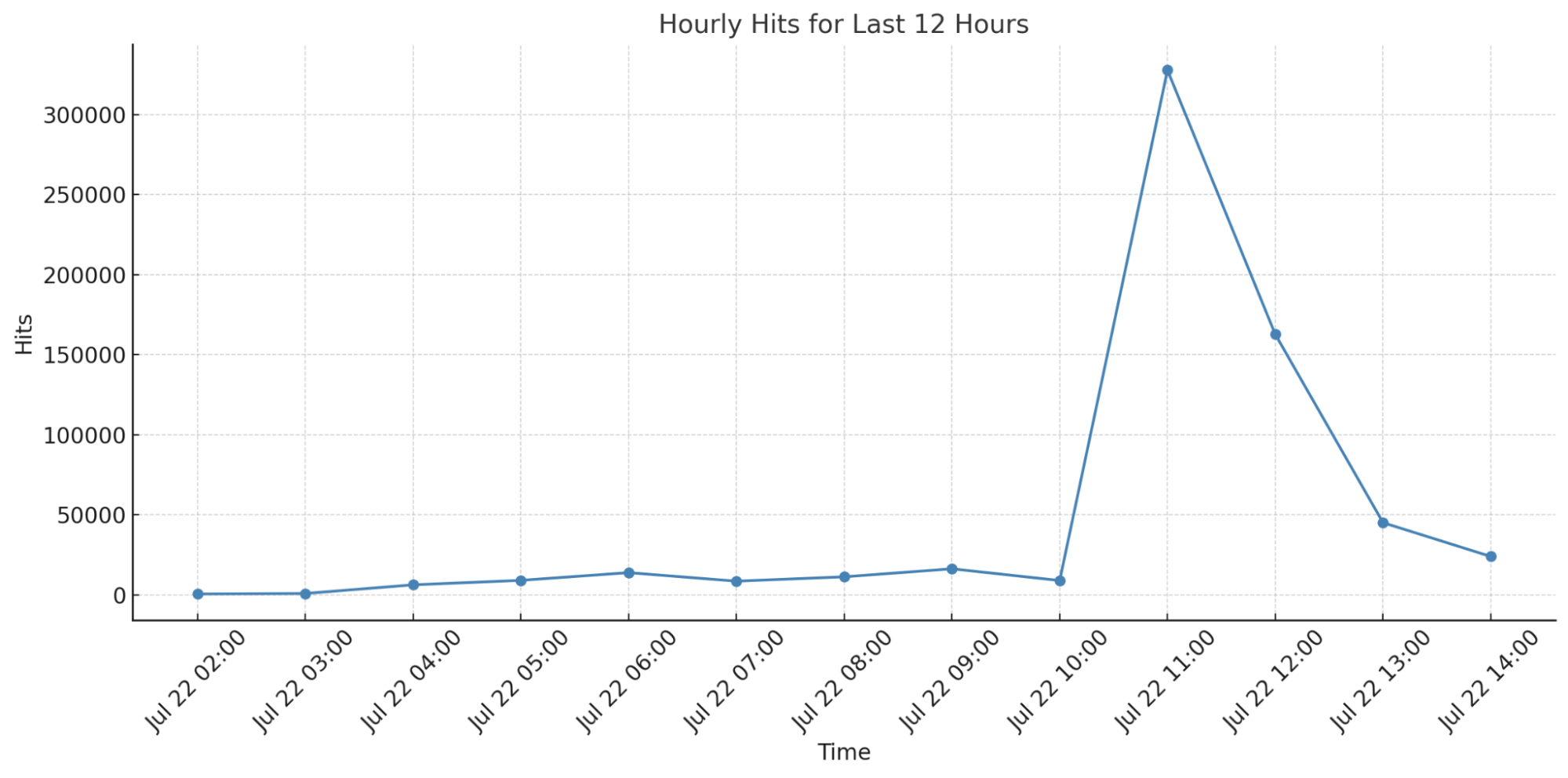
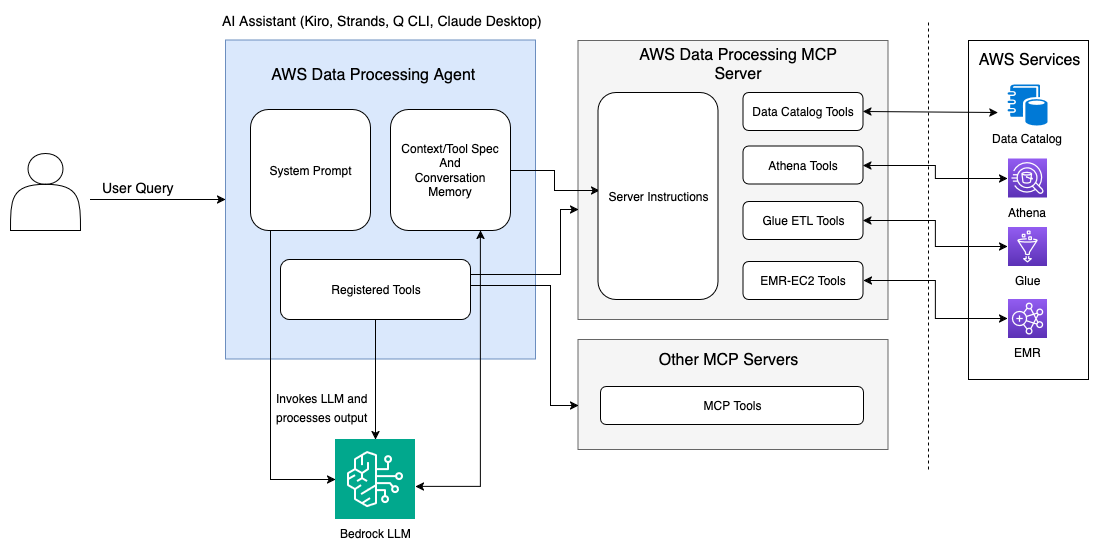
 Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS. Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies.
Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies. Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively.
Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively. Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family. Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI.
Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI. Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI.
Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI. Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.
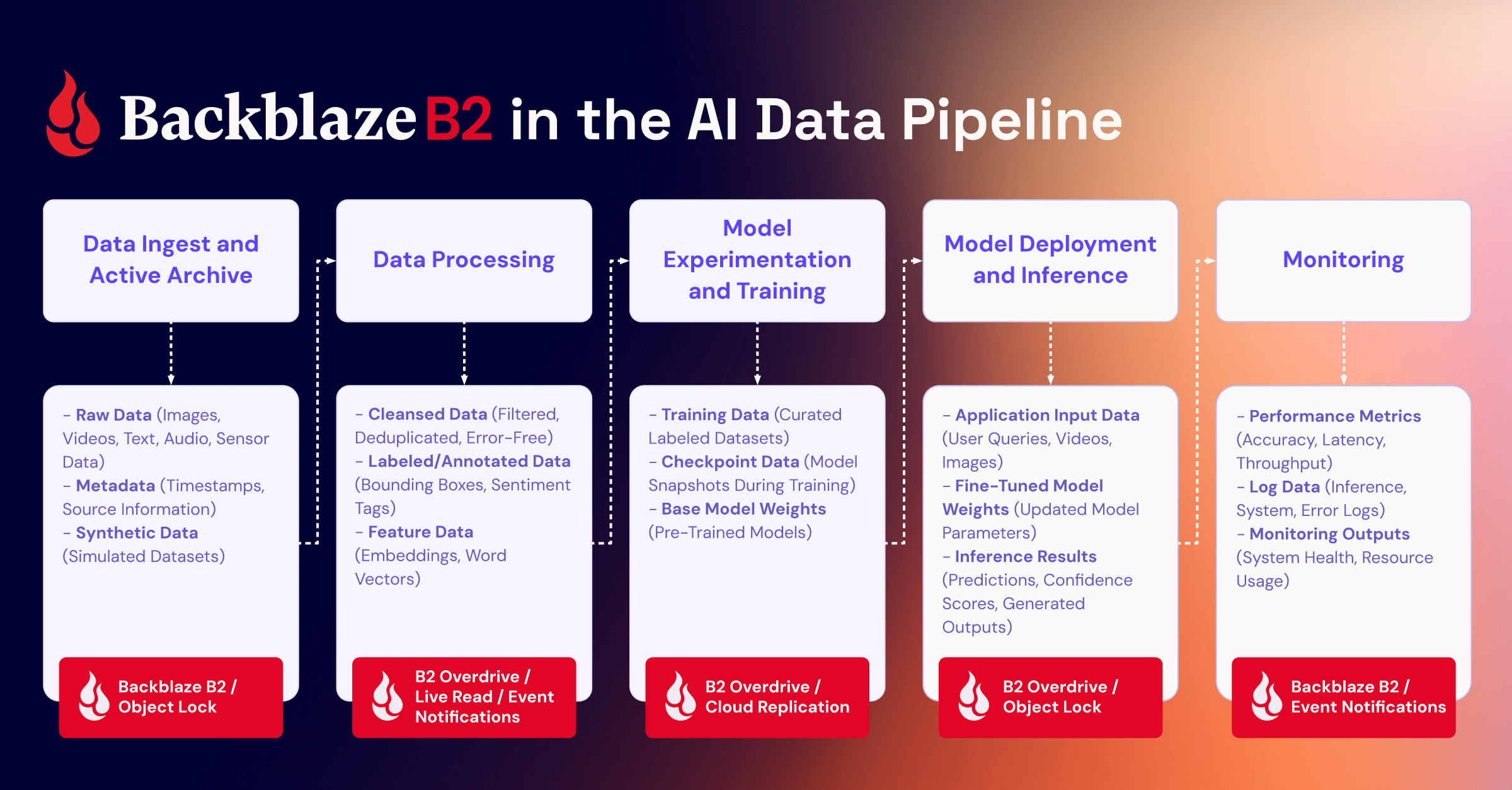
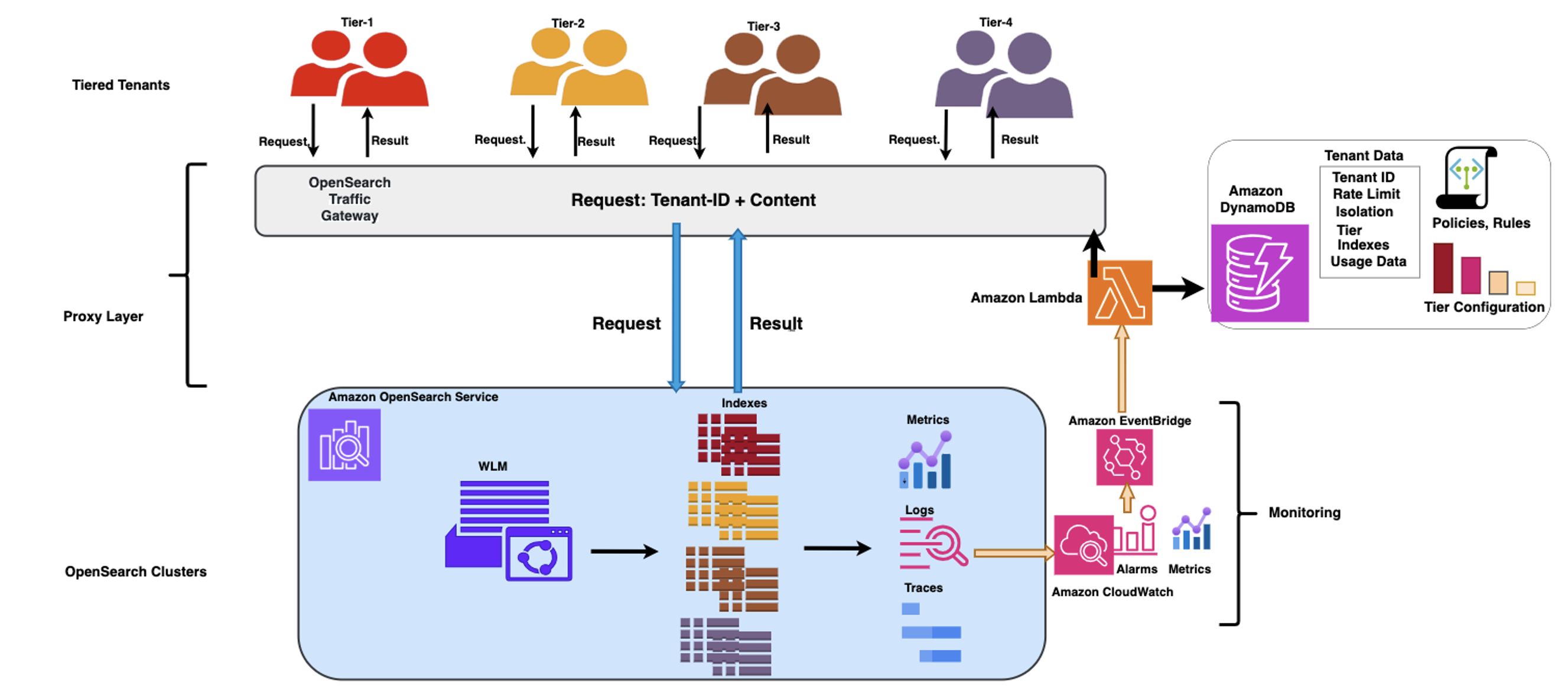
 Ezat Karimi is a Senior Solutions Architect at AWS, based in Austin, TX. Ezat specializes in designing and delivering modernization solutions and strategies for database applications. Working closely with multiple AWS teams, Ezat helps customers migrate their database workloads to the AWS Cloud.
Ezat Karimi is a Senior Solutions Architect at AWS, based in Austin, TX. Ezat specializes in designing and delivering modernization solutions and strategies for database applications. Working closely with multiple AWS teams, Ezat helps customers migrate their database workloads to the AWS Cloud. Jon Handler is a Senior Principal Solutions Architect at AWS based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have vector, search, and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor’s of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at AWS based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have vector, search, and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor’s of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.