Post Syndicated from Emily Terrell original https://blog.cloudflare.com/project-jengo-for-sable-final-winners/
With Cloudflare’s victory against patent trolls Sable IP and Sable Networks in the books, it’s time to close out the case’s Project Jengo competition.
In our last update, we talked about the conclusion of Sable’s 3+ year campaign to extort a payment from Cloudflare based on meritless patent infringement claims. After Cloudflare’s victory at trial in February 2024, Sable finally — and fully — capitulated, agreeing to: (1) pay Cloudflare $225,000, (2) grant Cloudflare a royalty-free license to Sable’s entire patent portfolio, and (3) dedicate all of Sable’s patents to the public.
With the fight against Sable ended, we announced the Conclusion of the Case under the Project Jengo Sable Rules. Now that the Grace Period has passed, we are pleased to announce the final winners of Project Jengo for the Sable case!
Read on for background on the case, details on the Project Jengo final winners, and other patent troll-related updates.
For anyone unfamiliar with the Sable case, the story can be traced back all the way to 2006, when patent troll Sable bought patents from a company going out of business. In 2021, fifteen years after buying the patents, Sable filed suit asserting these patents against a huge swath of companies: Cloudflare, Cisco, Fortinet, Check Point, SonicWall, Juniper Networks, and others. Sable knew that, no matter how weak its case, companies were likely to pay it just to avoid the considerable cost and trouble of litigating.
Cloudflare doesn’t pay trolls for meritless patent claims. Rather than paying off Sable to make the suit go away, we aggressively litigated the case, knocking out nearly 100 claims spanning 4 patents. By the time we got to trial, just a single claim was left.
At trial, the jury’s verdict was decisive. After just 2 hours of deliberating, the jury found that Cloudflare didn’t infringe the remaining live claim (claim 25 of the ’919 patent). The jury then went on to also find that claim 25 was invalid in the first place.


In fact, Cloudflare’s victory was so complete that Sable didn’t bother appealing. Instead, Sable agreed to pay Cloudflare $225,000. In other words, not only did Sable miss out on its payday, it had to pay up for its failed litigation.
Even better, Sable granted Cloudflare a royalty-free license to its entire patent portfolio and dedicated all of its patents to the public, meaning Sable can no longer use these patents to profit off of frivolous lawsuits. This case, and Cloudflare’s aggressive defense, put Sable out of the patent troll business for good.
With the Sable litigation resolved, it’s time to close out the Project Jengo contest!
Project Jengo is our prior art bounty program. It plays a fundamental role in our battle against patent trolls, helping us crowdsource key evidence that the trolls’ patents are invalid.
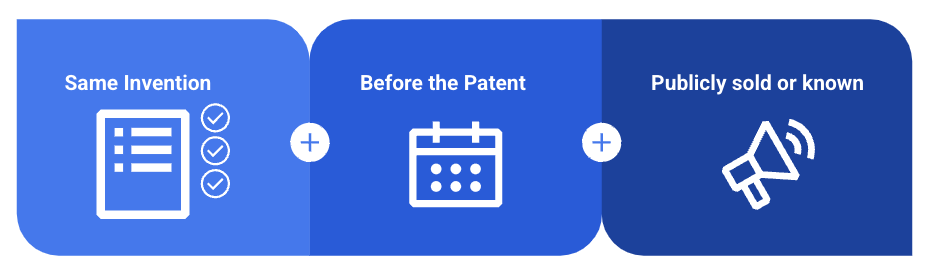
Prior art = instances of the inventions being claimed in the patents already being used or made public before the patent application was filed, meaning the patent is invalid.
Project Jengo began in 2017 when Cloudflare was sued by prolific patent troll Blackbird. We put out a call, offering cash rewards not just for prior art to invalidate the patents asserted against us in the lawsuit, but against any Blackbird patents. We received hundreds of submissions, more than half of which were related to patents that weren’t asserted against Cloudflare. That meant Project Jengo was a threat to Blackbird’s entire portfolio — far more than Blackbird bargained for when it first sued us. After several years of litigation, the program helped us soundly defeat Blackbird in court and put it out of business.
When Sable filed its suit in 2021, we revived Project Jengo for this next round in the fight against patent trolls. Cloudflare committed $100,000 to the Sable prior art search. Winners were announced after each of eight submission periods in blog posts here: Chapter 1, Chapter 2, Chapter 3, Chapters 4-6, and Chapters 7-8. Now, we’re ready to announce the Final Awards based on all of the submissions over the case’s journey. These Final Awards winners will collectively receive $30,000!
Jean-Pierre Le Rouzic: Cloudflare user, 12-time patent grantee, and our Chapter Two winner
Jean-Pierre received an additional $10,000 as a final winner for his contributions to the Sable round of Project Jengo!
As detailed in the blog post announcing Jean-Pierre’s chapter two victory, he is a retired telecommunications R&D engineer living in Rennes, France. Since retiring, he has been using Cloudflare for his blog.
After seeing Project Jengo on Hacker News, he decided to join in. He was particularly motivated because of the similar trends he sees within the pharmaceutical industry, of intellectual property (IP) profiteering displacing innovative R&D efforts. He explained:
The challenge faced by Cloudflare is close to my heart. … Cloudflare is facing an entity which is unreasonably stretching the meaning of their patent claims.
Jean-Pierre applied his patent expertise (he wrote 12 patents related to online authentication and identity management in the 2000s) to the Sable case. He followed a methodical process, preparing “two conceptual trees, one started from Sable patents and expanded with possible prior arts, and the other” from the asserted claims. Jean-Pierre ultimately prepared a 24-page submission, including a meticulously detailed claim chart, identifying prior art challenging the ’431 patent asserted against Cloudflare (titled “Micro-Flow Management” and concerning Internet switching technology for network service providers). See our prior post here for a detailed walk-through of his findings.
George J.: engineer, patent attorney, and our Chapter Seven winner
Like Jean-Pierre, George J. won an additional $10,000 for his submission during chapter seven!
George is an electrical engineer and patent attorney who is actively engaged in the IP community. He found out about Project Jengo on the legal site Law360. With a knack for prior art searches and claim charts, he decided to apply his professional background to the Sable challenge.
George’s submissions to Project Jengo included three prior art references for the ’431 patent. He also found that one of those three overlapped with the inventions in the ’919 patent (titled “Micro-Flow Label Switching”), the patent ultimately contested at trial. George provided 39 pages of detailed charts comparing the prior art he found against the Sable patents.
Peter S. and Jatin: our Chapter Four and Eight winners
Peter S. and Jatin have each been awarded $5,000 more for their submissions!
Peter S. is unique among this group of winners in lacking a technical/patent background. But when he saw Project Jengo on Cloudflare’s website, that didn’t stop him from deciding to take a stab at it. We’re glad he did! As we described in our prior post about Peter’s submission, the ʼ593 patent is the Sable patent concerning the detection of “bad” flows. Peter’s prior art reference developed the same thing five years earlier: “This thesis studies a means of using such mechanisms to identify nonadaptive [what Sable calls ‘bad’] network flows, and proposes a protocol to push this information, along with penalization responsibility, towards the flows’ sources.” Since Yang’s work predates the ’593 patent’s alleged new solutions by years, this was a great find.
Jatin, a computer science analyst who also discovered Project Jengo while reading Cloudflare’s blog, submitted two pieces of prior art. As we noted in the Chapter Eight post, they were particularly good references for Sable’s ’919 patent (the one patent that remained contested at trial).
And there’s more! On the heels of the Sable litigation coming to a close, another troll filed but promptly abandoned its case against Cloudflare after realizing what it would have been up against.
Patent troll Touchpoint Projections Innovations sued Cloudflare in May 2024. Cloudflare was clear from the start that we would not back down. Several months later, when the case was still in its early stages, we published our blog post about Sable’s total capitulation — paying Cloudflare and getting out of the patent troll game.
Just two weeks later, Touchpoint voluntarily dismissed the case with prejudice. The “with prejudice” language means it’s final, and that the case can’t restart at any point in the future. In other words, Touchpoint threw in the towel before things had really gotten started.
Sure, the timing could be coincidental. But we have a hunch that when Touchpoint realized what they’d be up against, they took a hard look at their case, and decided it just wasn’t worth it.
We’ve seen this pattern before. Back in 2022, PacSec3 LLC accused Cloudflare of patent infringement. But after we made clear our intention to fight back, PacSec3 called it quits, dismissing its case.
Cloudflare’s trial victories and Project Jengo are sending a clear message to patent trolls. We’re not afraid of a fight! We hope other trolls take note and find other, more productive, avenues for their efforts.