The Universal Blue
project has announced
the fall update for the Fedora-based Bazzite gaming distribution. This
release brings Bazzite up to Fedora 43, includes support for
additional handheld gaming systems, as well as drivers for a number of
steering wheel devices, and more.
The way we interact with the Internet is changing. Not long ago, ordering a pizza meant visiting a website, clicking through menus, and entering your payment details. Soon, you might just ask your phone to order a pizza that matches your preferences. A program on your device or on a remote server, which we call an AI agent, would visit the website and orchestrate the necessary steps on your behalf.
Of course, agents can do much more than order pizza. Soon we might use them to buy concert tickets, plan vacations, or even write, review, and merge pull requests. While some of these tasks will eventually run locally, for now, most are powered by massive AI models running in the biggest datacenters in the world. As agentic AI increases in popularity, we expect to see a large increase in traffic from these AI platforms and a corresponding drop in traffic from more conventional sources (like your phone).
This shift in traffic patterns has prompted us to assess how to keep our customers online and secure in the AI era. On one hand, the nature of requests are changing: Websites optimized for human visitors will have to cope with faster, and potentially greedier, agents. On the other hand, AI platforms may soon become a significant source of attacks, originating from malicious users of the platforms themselves.
Unfortunately, existing tools for managing such (mis)behavior are likely too coarse-grained to manage this transition. For example, when Cloudflare detects that a request is part of a known attack pattern, the best course of action often is to block all subsequent requests from the same source. When the source is an AI agent platform, this could mean inadvertently blocking all users of the same platform, even honest ones who just want to order pizza. We started addressing this problem earlier this year. But as agentic AI grows in popularity, we think the Internet will need more fine-grained mechanisms of managing agents without impacting honest users.
At the same time, we firmly believe that any such security mechanism must be designed with user privacy at its core. In this post, we’ll describe how to use anonymous credentials (AC) to build these tools. Anonymous credentials help website operators to enforce a wide range of security policies, like rate-limiting users or blocking a specific malicious user, without ever having to identify any user or track them across requests.
Anonymous credentials are under development at IETF in order to provide a standard that can work across websites, browsers, platforms. It’s still in its early stages, but we believe this work will play a critical role in keeping the Internet secure and private in the AI era. We will be contributing to this process as we work towards real-world deployment. This is still early days. If you work in this space, we hope you will follow along and contribute as well.
Let’s build a small agent
To help us discuss how AI agents are affecting web servers, let’s build an agent ourselves. Our goal is to have an agent that can order a pizza from a nearby pizzeria. Without an agent, you would open your browser, figure out which pizzeria is nearby, view the menu and make selections, add any extras (double pepperoni), and proceed to checkout with your credit card. With an agent, it’s the same flow —except the agent is opening and orchestrating the browser on your behalf.
In the traditional flow, there’s a human all along the way, and each step has a clear intent: list all pizzerias within 3 Km of my current location; pick a pizza from the menu; enter my credit card; and so on. An agent, on the other hand, has to infer each of these actions from the prompt “order me a pizza.”
In this section, we’ll build a simple program that takes a prompt and can make outgoing requests. Here’s an example of a simple Worker that takes a specific prompt and generates an answer accordingly. You can find the code on GitHub:
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const out = await env.AI.run("@cf/meta/llama-3.1-8b-instruct-fp8", {
prompt: `I'd like to order a pepperoni pizza with extra cheese.
Please deliver it to Cloudflare Austin office.
Price should not be more than $20.`,
});
return new Response(out.response);
},
} satisfies ExportedHandler<Env>;
In this context, the LLM provides its best answer. It gives us a plan and instruction, but does not perform the action on our behalf. You and I are able to take a list of instructions and act upon it because we have agency and can affect the world. To allow our agent to interact with more of the world, we’re going to give it control over a web browser.
Cloudflare offers a Browser Rendering service that can bind directly into our Worker. Let’s do that. The following code uses Stagehand, an automation framework that makes it simple to control the browser. We pass it an instance of Cloudflare remote browser, as well as a client for Workers AI.
import { Stagehand } from "@browserbasehq/stagehand";
import { endpointURLString } from "@cloudflare/playwright";
import { WorkersAIClient } from "./workersAIClient"; // wrapper to convert cloudflare AI
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: { cdpUrl: endpointURLString(env.BROWSER) },
llmClient: new WorkersAIClient(env.AI),
verbose: 1,
});
await stagehand.init();
const page = stagehand.page;
await page.goto("https://mini-ai-agent.cloudflareresearch.com/llm");
const { extraction } = await page.extract("what are the pizza available on the menu?");
return new Response(extraction);
},
} satisfies ExportedHandler<Env>;
Using the screenshot API of browser rendering, we can also inspect what the agent is doing. Here’s how the browser renders the page in the example above:
Stagehand allows us to identify components on the page, such as page.act(“Click on pepperoni pizza”) and page.act(“Click on Pay now”). This eases interaction between the developer and the browser.
To go further, and instruct the agent to perform the whole flow autonomously, we have to use the appropriately named agent mode of Stagehand. This feature is not yet supported by Cloudflare Workers, but is provided below for completeness.
import { Stagehand } from "@browserbasehq/stagehand";
import { endpointURLString } from "@cloudflare/playwright";
import { WorkersAIClient } from "./workersAIClient";
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const stagehand = new Stagehand({
env: "LOCAL",
localBrowserLaunchOptions: { cdpUrl: endpointURLString(env.BROWSER) },
llmClient: new WorkersAIClient(env.AI),
verbose: 1,
});
await stagehand.init();
const agent = stagehand.agent();
const result = await agent.execute(`I'd like to order a pepperoni pizza with extra cheese.
Please deliver it to Cloudflare Austin office.
Price should not be more than $20.`);
return new Response(result.message);
},
} satisfies ExportedHandler<Env>;
We can see that instead of adding step-by-step instructions, the agent is provided control. To actually pay, it would need access to a payment method such as a virtual credit card.
The prompt had some subtlety in that we’ve scoped the location to Cloudflare’s Austin office. This is because while the agent responds to us, it needs to understand our context. In this case, the agent operates out of Cloudflare edge, a location remote to us. This implies we are unlikely to pick up a pizza from this data center if it was ever delivered.
The more capabilities we provide to the agent, the more it has the ability to create some disruption. Instead of someone having to make 5 clicks at a slow rate of 1 request per 10 seconds, they’d have a program running in a data center possibly making all 5 requests in a second.
This agent is simple, but now imagine many thousands of these — some benign, some not — running at datacenter speeds. This is the challenge origins will face.
Protecting origins
For humans to interact with the online world, they need a web browser and some peripherals with which to direct the behavior of that browser. Agents are another way of directing a browser, so it may be tempting to think that not much is actually changing from the origin’s point of view. Indeed, the most obvious change from the origin’s point of view is merely where traffic comes from:
The reason this change is significant has to do with the tools the server has to manage traffic. Websites generally try to be as permissive as possible, but they also need to manage finite resources (bandwidth, CPU, memory, storage, and so on). There are a few basic ways to do this:
Global security policy: A server may opt to slow down, CAPTCHA, or even temporarily block requests from all users. This policy may be applied to an entire site, a specific resource, or to requests classified as being part of a known or likely attack pattern. Such mechanisms may be deployed in reaction to an observed spike in traffic, as in a DDoS attack, or in anticipation of a spike in legitimate traffic, as in Waiting Room.
Incentives: Servers sometimes try to incentivize users to use the site when more resources are available. For instance, a server price may be lower depending on the location or request time. This could be implemented with a Cloudflare Snippet.
While both tools can be effective, they also sometimes cause significant collateral damage. For example, while rate limiting a website’s login endpoint can help prevent credential stuffing attacks, it also degrades the user experience for non-attackers. Before resorting to such measures, servers will first try to apply the security policy (whether a rate limit, a CAPTCHA, or an outright block) to individual users or groups of users.
However, in order to apply a security policy to individuals, the server needs some way of identifying them. Historically, this has been done via some combination of IP addresses, User-Agent, an account tied to the user identity (if available), and other fingerprints. Like most cloud service providers, Cloudflare has a dedicated offering for per-user rate limits based on such heuristics.
Likewise, agentic AI only exacerbates the limitations of fingerprinting. Not only will more traffic be concentrated on a smaller source IP range, the agents themselves will run the same software and hardware platform, making it harder to distinguish honest from malicious users.
Something that could help is Web Bot Auth, which would allow agents to identify to the origin which platform they’re operated by. However, we wouldn’t want to extend this mechanism — intended for identifying the platform itself — to identifying individual users of the platforms, as this would create an unacceptable privacy risk for these users.
We need some way of implementing security controls for individual users without identifying them. But how? The Privacy Pass protocol provides a partial solution.
Privacy Pass and its limitations
Today, one of the most prominent use cases for Privacy Pass is to rate limit requests from a user to an origin, as we have discussed before. The protocol works roughly as follows. The client is issued a number of tokens. Each time it wants to make a request, it redeems one of its tokens to the origin; the origin allows the request through only if the token is fresh, i.e., has never been observed before by the origin.
In order to use Privacy Pass for per-user rate-limiting, it’s necessary to limit the number of tokens issued to each user (e.g., 100 tokens per user per hour). To rate limit an AI agent, this role would be fulfilled by the AI platform. To obtain tokens, the user would log in with the platform, and said platform would allow the user to get tokens from the issuer. The AI platform fulfills the attester role in Privacy Pass parlance. The attester is the party guaranteeing the per-user property of the rate limit. The AI platform, as an attester, is incentivized to enforce this token distribution as it stakes its reputation: Should it allow for too many tokens to be issued, the issuer could distrust them.
The issuance and redemption protocols are designed to have two properties:
Tokens are unforgeable: only the issuer can issue valid tokens.
Tokens are unlinkable: no party, including the issuer, attester, or origin, can tell which user a token was issued to.
These properties can be achieved using a cryptographic primitive called a blind signaturescheme. In a conventional signature scheme, the signer uses its private key to produce a signature for a message. Later on, a verifier can use the signer’s public key to verify the signature. Blind signature schemes work in the same way, except that the message to be signed is blinded such that the signer doesn’t know the message it’s signing. The client “blinds” the message to be signed and sends it to the server, which then computes a blinded signature over the blinded message. The client obtains the final signature by unblinding the signature.
This is exactly how the standardised Privacy Pass issuance protocols are defined by RFC 9578:
Issuance: The user generates a random message $k$
which we call the nullifier. Concretely, this is just a random, 32-byte string. It then blinds the nullifier and sends it to the issuer. The issuer replies with a blind signature. Finally, the user unblinds the signature to get $\sigma$,
a signature for the nullifier $k$. The token is the pair $(k, \sigma)$.
Redemption: When the user presents $(k, \sigma)$,
the origin checks that $\sigma$
is a valid signature for the nullifier $k$
and that $k$
is fresh. If both conditions hold, then it accepts and lets the request through.
Blind signatures are simple, cheap, and perfectly suited for many applications. However, they have some limitations that make them unsuitable for our use case.
First, the communication cost of the issuance protocol is too high. For each token issued, the user sends a 256-byte, blinded nullifier and the issuer replies with a 256-byte blind signature (assuming RSA-2048 is used). That’s 0.5KB of additional communication per request, or 500KB for every 1,000 requests. This is manageable as we’ve seen in a previous experiment for Privacy Pass, but not ideal. Ideally, the bandwidth would be sublinear in the rate limit we want to enforce. An alternative to blind signatures with lower compute time are Oblivious Pseudorandom Functions (VOPRF), but the bandwidth is still asymptotically linear. We’ve discussed them in the past, as they served as the basis for early deployments of Privacy Pass.
Second, blind signatures can’t be used to rate-limit on a per-origin basis. Ideally, when issuing $N$ tokens to the client, the client would be able to redeem at most $N$ tokens at any origin server that can verify the token’s validity. However, the client can’t safely redeem the same token at more than one server because it would be possible for the servers to link those redemptions to the same client. What’s needed is some mechanism for what we’ll call late origin-binding: transforming a token for redemption at a particular origin in a way that’s unlinkable to other redemptions of the same token.
Third, once a token is issued, it can’t be revoked: it remains valid as long as the issuer’s public key is valid. This makes it impossible for an origin to block a specific user if it detects an attack, or if its tokens are compromised. The origin can block the offending request, but the user can continue to make requests using its remaining token budget.
Anonymous credentials and the future of Privacy Pass
As noted by Chaum in 1985, an anonymous credential system allows users to obtain a credential from an issuer, and later prove possession of this credential, in an unlinkable way, without revealing any additional information. Also, it is possible to demonstrate that some attributes are attached to the credential.
One way to think of an anonymous credential is as a kind of blind signature with some additional capabilities: late-binding (link a token to an origin after issuance), multi-show (generate multiple tokens from a single issuer response), and expiration distinct from key rotation (token validity decoupled of the issuer cryptographic key validity). In the redemption flow for Privacy Pass, the client presents the unblinded message and signature to the server. To accept the redemption, the server needs to verify the signature. In an AC system, the client only presents a part of the message. In order for the server to accept the request, the client needs to prove to the server that it knows a valid signature for the entire message without revealing the whole thing.
The flow we described above would therefore include this additional presentation step.
Note that the tokens generated through blind signatures or VOPRFs can only be used once, so they can be regarded as single-use tokens. However, there exists a type of anonymous credentials that allows tokens to be used multiple times. For this to work, the issuer grants a credential to the user, who can later derive at most N many single-use tokens for redemption. Therefore, the user can send multiple requests, at the expense of a single issuance session.
The table below describes how blind signatures and anonymous credentials provide features of interest to rate limiting.
Feature
Blind Signature
Anonymous Credential
Issuing Cost
Linear complexity: issuing 10 signatures is 10x as expensive as issuing one signature
Sublinear complexity: signing 10 attributes is cheaper than 10 individual signatures
Proof Capability
Only prove that a message has been signed
Allow efficient proving of partial statements (i.e., attributes)
State Management
Stateless
Stateful
Attributes
No attributes
Public (e.g. expiry time) and private state
Let’s see how a simple anonymous credential scheme works. The client’s message consists of the pair $(k, C)$,
where $k$
is a nullifier and $C$
is a counter representing the remaining number of times the client can access a resource. The value of the counter is controlled by the server: when the client redeems its credential, it presents both the nullifier and the counter. In response, the server checks that signature of the message is valid and that the nullifier is fresh, as before. Additionally, the server also
checks that the counter is greater than zero; and
decrements the counter issuing a new credential for the updated counter and a fresh nullifier.
A blind signature could be used to meet this functionality. However, whereas the nullifier can be blinded as before, it would be necessary to handle the counter in plaintext so that the server can check that the counter is valid (Step 1) and update it (Step 2). This creates an obvious privacy risk since the server, which is in control of the counter, can use it to link multiple presentations by the same client. For example, when you reach out to buy a pepperoni pizza, the origin could assign you a special counter value, which eases fingerprinting when you present it a second time. Fortunately, there exist anonymous credentials designed to close this kind of privacy gap.
The scheme above is a simplified version of Anonymous Credit Tokens (ACT), one of the anonymous credential schemes being considered for adoption by the Privacy Pass working group at IETF. The key feature of ACT is its statefulness: upon successful redemption, the server re-issues a new credential with updated nullifier and counter values. This creates a feedback loop between the client and server that can be used to express a variety of security policies.
By design, it’s not possible to present ACT credentials multiple times simultaneously: the first presentation must be completed so that the re-issued credential can be presented in the next request. Parallelism is the key feature of Anonymous Rate-limited Credential (ARC), another scheme under discussion at the Privacy Pass working group. ARCs can be presented across multiple requests in parallel up to the presentation limit determined during issuance.
Another important feature of ARC is its support for late origin-binding: when a client is issued an ARC with presentation limit $N$, it can safely use its credential to present up to $N$ times to any origin that can verify the credential.
These are just examples of relevant features of some anonymous credentials. Some applications may benefit from a subset of them; others may need additional features. Fortunately, both ACT and ARC can be constructed from a small set of cryptographic primitives that can be easily adapted for other purposes.
Building blocks for anonymous credentials
ARC and ACT share two primitives in common: algebraic MACs, which provide for limited computations on the blinded message; and zero-knowledge proofs (ZKP) for proving validity of the part of the message not revealed to the server. Let’s take a closer look at each.
Algebraic MACs
A Message Authenticated Code (MAC) is a cryptographic tag used to verify a message’s authenticity (that it comes from the claimed sender) and integrity (that it has not been altered). Algebraic MACs are built from mathematical structures like group actions. The algebraic structure gives them some additional functionality, one of them being a homomorphism that we can blind easily to conceal the actual value of the MAC. Adding a random value on an algebraic MAC blinds the value.
Unlike blind signatures, both ACT and ARC are only privately verifiable, meaning the issuer and the origin must both have the issuer’s private key. Taking Cloudflare as an example, this means that a credential issued by Cloudflare can only be redeemed by an origin behind Cloudflare. Publicly verifiable variants of both are possible, but at an additional cost.
Zero-Knowledge Proofs for linear relations
Zero knowledge proofs (ZKP) allow us to prove a statement is true without revealing the exact value that makes the statement true. The ZKP is constructed by a prover in such a way that it can only be generated by someone who actually possesses the secret. The verifier can then run a quick mathematical check on this proof. If the check passes, the verifier is convinced that the prover’s initial statement is valid. The crucial property is that the proof itself is just data that confirms the statement; it contains no other information that could be used to reconstruct the original secret.
For ARC and ACT, we want to prove linear relations of secrets. In ARC, a user needs to prove that different tokens are linked to the same original secret credential. For example, a user can generate a proof showing that a request token was derived from a valid issued credential. The system can verify this proof to confirm the tokens are legitimately connected, all without ever learning the underlying secret credential that ties them together. This allows the system to validate user actions while guaranteeing their privacy.
Proving simple linear relations can be extended to prove a number of powerful statements, for example that a number is in range. For example, this is useful to prove that you have a positive balance on your account. To prove your balance is positive, you prove that you can encode your balance in binary. Let’s say you can at most have 1024 credits in your account. To prove your balance is non-zero when it is, for example, 12, you prove two things simultaneously: first, that you have a set of binary bits, in this case 12=(1100)2, and second, that a linear equation using these bits (8*1 + 4*1 + 2*0 + 1*0) correctly adds up to your total committed balance. This convinces the verifier that the number is validly constructed without them learning the exact value. This is how it works for powers of two, but it can easily be extended to arbitrary ranges.
The mathematical structure of algebraic MACs allows easy blinding and evaluation. The structure also allows for an easy proof that a MAC has been evaluated with the private key without revealing the MAC. In addition, ARC could use ZKPs to prove that a nonce has not been spent before. In contrast, ACT uses ZKPs to prove we have enough of a balance left on our token. The balance is subtracted homomorphically using more group structure.
How much does this all cost?
Anonymous credentials allow for more flexibility, and have the potential to reduce the communication cost, compared to blind signatures in certain applications. To identify such applications, we need to measure the concrete communication cost of these new protocols. In addition, we need to understand how their CPU usage compares to blind signatures and oblivious pseudorandom functions.
We measure the time that each participant spends at each stage of some AC schemes. We also report the size of messages transmitted across the network. For ARC, ACT, and VOPRF, we’ll use ristretto255 as the prime group and SHAKE128 for hashing. For Blind RSA, we’ll use a 2048-bit modulus and SHA-384 for hashing.
Each algorithm was implemented in Go, on top of the CIRCL library. We plan to open source the code once the specifications of ARC and ACT begin to stabilize.
Let’s take a look at the most widely used deployment in Privacy Pass: Blind RSA. Redemption time is low, and most of the cost lies with the server at issuance time. Communication cost is mostly constant and in the order of 256 bytes.
When looking at VOPRF, verification time on the server is slightly higher than for Blind RSA, but communication cost and issuance are much faster. Evaluation time on the server is 10x faster for 1 token, and more than 25x faster when using amortized token issuance. Communication cost per token is also more appealing, with a message size at least 3x lower.
This makes VOPRF tokens appealing for applications requiring a lot of tokens that can accept a slightly higher redemption cost, and that don’t need private verifiability.
Now, let’s take a look at the figures for ARC and ACT anonymous credential schemes. For both schemes we measure the time to issue a credential that can be presented at most $N=1000$ times.
Issuance Credential Generation
ARC
ACT
Time
Message Size
Time
Message Size
Client (Request)
323 µs
224 B
64 µs
141 B
Server (Response)
1349 µs
448 B
251 µs
176 B
Client (Finalize)
1293 µs
128 B
204 µs
176 B
Redemption Credential Presentation
ARC
ACT
Time
Message Size
Time
Message Size
Client (Present)
735 µs
288 B
1740 µs
1867 B
Server (Verify/Refund)
740 µs
–
1785 µs
141 B
Client (Update)
–
–
508 µs
176 B
As we would hope, the communication cost and the server’s runtime is much lower than a batched issuance with either Blind RSA or VOPRF. For example, a VOPRF issuance of 1000 tokens takes 99 ms (99 µs per token) vs 1.35 ms for issuing one ARC credential that allows for 1000 presentations. This is about 70x faster. The trade-off is that presentation is more expensive, both for the client and server.
How about ACT? Like ARC, we would expect the communication cost of issuance grows much slower with respect to the credits issued. Our implementation bears this out. However, there are some interesting performance differences between ARC and ACT: issuance is much cheaper for ACT than it is for ARC, but redemption is the opposite.
What’s going on? The answer has largely to do with what each party needs to prove with ZKPs at each step. For example, during ACT redemption, the client proves to the server (in zero-knowledge) that its counter $C$ is in the desired range, i.e., $0 \leq C \leq N$. The proof size is on the order of $\log_{2} N$, which accounts for the larger message size. In the current version, ARC redemption does not involve range proofs, but a range proof may be added in a future version. Meanwhile, the statements the client and server need to prove during ARC issuance are a bit more complicated than for ARC presentation, which accounts for the difference in runtime there.
The advantage of anonymous credentials, as discussed in the previous sections, is that issuance only has to be performed once. When a server evaluates its cost, it takes into account the cost of all issuances and the cost of all verifications. At present, only accounting for credentials costs, it’s cheaper for a server to issue and verify tokens than verify an anonymous credential presentation.
The advantage of multiple-use anonymous credentials is that instead of the issuer generating $N$ tokens, the bulk of computation is offloaded to the clients. This is more scoped. Late origin binding allows them to work for multiple origins/namespace, range proof to decorrelate expiration from key rotation, and refund to provide a dynamic rate limit. Their current applications are dictated by the limitation of single-use token based schemes, more than by the added efficiency they provide. This seems to be an exciting area to explore, and see if closing the gap is possible.
Managing agents with anonymous credentials
Managing agents will likely require features from both ARC and ACT.
ARC already has much of the functionality we need: it supports rate limiting, is communication-efficient, and it supports late origin-binding. Its main downside is that, once an ARC credential is issued, it can’t be revoked. A malicious user can always make up to N requests to any origin it wants.
We can allow for a limited form of revocation by pairing ARC with blind signatures (or VOPRF). Each presentation of the ARC credential is accompanied by a Privacy Pass token: upon successful presentation, the client is issued another Privacy Pass token it can use during the next presentation. To revoke a credential, the server would simply not re-issue the token:
This scheme is already quite useful. However, it has some important limitations:
Parallel presentation across origins is not possible: the client must wait for the request to one origin to succeed before it can initiate a request to a second origin.
Revocation is global rather than per-origin, meaning the credential is not only revoked for the origin to whom it was presented, but for every origin it can be presented to. We suspect this will be undesirable in some cases. For example, an origin may want to revoke if a request violates its robots.txt policy; but the same request may have been accepted by other origins.
A more fundamental limitation of this design is that the decision to revoke can only be made on the basis of a single request — the one in which the credential was presented. It may be risky to decide to block a user on the basis of a single request; in practice, attack patterns may only emerge across many requests. ACT’s statefulness enables at least a rudimentary form of this kind of defense. Consider the following scheme:
Issuance: The client is issued an ARC with presentation limit $N=1$.
Presentation:
When the client presents its ARC credential to an origin for the first time, the server issues an ACT credential with a valid initial state.
When the client presents an ACT with valid state (e.g., credit counter greater than 0), the origin either:
refuses to issue a new ACT, thereby revoking the credential. It would only do so if it had high confidence that the request was part of an attack; or
issues a new ACT with state updated to reduce the ACT credit by the amount of resources consumed while processing the request.
Benign requests wouldn’t change the state by much (if at all), but suspicious requests might impact the state in a way that gets the user closer to their rate limit much faster.
Demo
To see how this idea works in practice, let’s look at a working example that uses the Model Context Protocol. The demo below is built usingMCP Tools. Tools are extensions the AI agent can call to extend its capabilities. They don’t need to be integrated at release time within the MCP client. This provides a nice and easy prototyping avenue for anonymous credentials.
Tools are offered by the server via an MCP compatible interface. You can see details on how to build such MCP servers in a previous blog.
In our pizza context, this could look like a pizzeria that offers you a voucher. Each voucher gets you 3 pizza slices. Mocking a design, an integration within a chat application could look as follows:
The first panel presents all tools exposed by the MCP server. The second one showcases an interaction performed by the agent calling these tools.
To look into how such a flow would be implemented, let’s write the MCP tools, offer them in an MCP server, and manually orchestrate the calls with the MCP Inspector.
The MCP server should provide two tools:
act-issue which issues an ACT credential valid for 3 requests. The code used here is an earlier version of the IETF draft which has some limitations.
act-redeem makes a presentation of the local credential, and fetches our pizza menu.
First, we run act-issue. At this stage, we could ask the agent to run anOAuth flow, fetch an internal authentication endpoint, or to compute a proof of work.
This gives us 3 credits to spend against an origin. Then, we run act-redeem
Et voilà. If we run act-redeem once more, we see we have one fewer credit.
You can test it yourself, here are the source codes available. The MCP server is written inRust to integrate with the ACT rust library. The browser-based client works similarly, check it out.
Moving further
In this post, we’ve presented a concrete approach to rate limit agent traffic. It is in full control of the client, and is built to protect the user’s privacy. It uses emerging standards for anonymous credentials, integrates with MCP, and can be readily deployed on Cloudflare Workers.
We’re on the right track, but there are still questions that remain. As we touched on before, a notable limitation of both ARC and ACT is that they are only privately verifiable. This means that the issuer and origin need to share a private key, for issuing and verifying the credential respectively. There are likely to be deployment scenarios for which this isn’t possible. Fortunately, there may be a path forward for these cases using pairing-based cryptography, as in the BBS signature specification making its way through IETF. We’re also exploring post-quantum implications in a concurrent post.
If you are an agent platform, an agent developer, or a browser, all our code is available on GitHub for you to experiment. Cloudflare is actively working on vetting this approach for real-world use cases.
The specification and discussion are happening within the IETF and W3C. This ensures the protocols are built in the open, and receive participation from experts. Improvements are still to be made to clarify the right performance-to-privacy tradeoff, or even the story to deploy on the open web.
The Internet is in the midst of one of the most complex transitions in its history: the migration to post-quantum (PQ) cryptography. Making a system safe against quantum attackers isn’t just a matter of replacing elliptic curves and RSA with PQ alternatives, such as ML-KEM and ML-DSA. These algorithms have higher costs than their classical counterparts, making them unsuitable as drop-in replacements in many situations.
Nevertheless, we’re making steady progress on the most important systems. As of this writing, about 50% of TLS connections to Cloudflare’s edge are safe against store-now/harvest-later attacks. Quantum safe authentication is further out, as it will require more significant changes to how certificates work. Nevertheless, this year we’ve taken a major step towards making TLS deployable at scale with PQ certificates.
That said, TLS is only the lowest hanging fruit. There are many more ways we have come to rely on cryptography than key exchange and authentication and which aren’t as easy to migrate. In this blog post, we’ll take a look at Anonymous Credentials (ACs).
ACs solve a common privacy dilemma: how to prove a specific fact (for example that one has had a valid driver’s license for more than three years) without over-sharing personal information (like the place of birth)? Such problems are fundamental to a number of use cases, and ACs may provide the foundation we need to make these applications as private as possible.
Just like for TLS, the central question for ACs is whether there are drop-in, PQ replacements for its classical primitives that will work at the scale required, or will it be necessary to re-engineer the application to mitigate the cost of PQ.
We’ll take a stab at answering this question in this post. We’ll focus primarily on an emerging use case for ACs described in a concurrent post: rate-limiting requests from agentic AI platforms and users. This demanding, high-scale use case is the perfect lens through which to evaluate the practical readiness of today’s post-quantum research. We’ll use it as our guiding problem to measure each cryptographic approach.
We’ll first explore the current landscape of classical AC adoption across the tech industry and the public sector. Then, we’ll discuss what cryptographic researchers are currently looking into on the post-quantum side. Finally, we’ll take a look at what it’ll take to bridge the gap between theory and real-world applications.
While anonymous credentials are only seeing their first real-world deployments in recent years, it is critical to start thinking about the post-quantum challenge concurrently. This isn’t a theoretical, too-soon problem given the store-now decrypt-later threat. If we wait for mass adoption before solving post-quantum anonymous credentials, ACs risk being dead on arrival. Fortunately, our survey of the state of the art shows the field is close to a practical solution. Let’s start by reviewing real-world use-cases of ACs.
Real world (classical) anonymous credentials
In 2026, the European Union is set to launch its digital identity wallet, a system that will allow EU citizens, residents and businesses to digitally attest to their personal attributes. This will enable them, for example, to display their driver’s license on their phone or perform ageverification. Cloudflare’s use cases for ACs are a bit different and revolve around keeping our customers secure by, for example, rate limiting bots and humans as we currently do with Privacy Pass. The EU wallet is a massive undertaking in identity provisioning, and our work operates at a massive scale of traffic processing. Both initiatives are working to solve a shared fundamental problem: allowing an entity to prove a specific attribute about themselves without compromising their privacy by revealing more than they have to.
The EU’s goal is a fully mobile, secure, and user-friendly digital ID. The current technical plan is ambitious, as laid out in the Architecture Reference Framework (ARF). It defines the key privacy goals of unlinkability to guarantee that if a user presents attributes multiple times, the recipients cannot link these separate presentations to conclude that they concern the same user. However, currently proposed solutions fail to achieve this. The framework correctly identifies the core problem: attestations contain unique, fixed elements such as hash values, […], public keys, and signatures that colluding entities could store and compare to track individuals.
In its present form, the ARF’s recommendation to mitigate cross-session linkability is limited-time attestations. The framework acknowledges in the text that this would only partially mitigate Relying Party linkability. An alternative proposal that would mitigate linkability risks are single-use credentials. They are not considered at the moment due to complexity and management overhead. The framework therefore leans on organisational and enforcement measures to deter collusion instead of providing a stronger guarantee backed by cryptography.
This reliance on trust assumptions could become problematic, especially in the sensitive context of digital identity. When asked for feedback, cryptographic researchers agree that the proper solution would be to adopt anonymous credentials. However, this solution presents a long-term challenge. Well-studied methods for anonymous credentials, such as those based on BBS signatures, are vulnerable to quantum computers. While some anonymousschemes are PQ-unlinkable, meaning that user privacy is preserved even when cryptographically relevant quantum computers exist, new credentials could be forged. This may be an attractive target for, say, a nation state actor.
New cryptography also faces deployment challenges: in the EU, only approved cryptographic primitives, as listed in the SOG-IS catalogue, can be used. At the time of writing, this catalogue is limited to established algorithms such as RSA or ECDSA. But when it comes to post-quantum cryptography, SOG-IS is leaving the problem wide open.
The wallet’s first deployment will not be quantum-secure. However, with the transition to post-quantum algorithms being ahead of us, as soon as 2030 for high-risk use cases per the EU roadmap, research in a post-quantum compatible alternative for anonymous credentials is critical. This will encompassstandardizing more cryptography.
Finally, ongoing efforts at the Internet Engineering Task Force (IETF)aimto build a more private Internet by standardizing advanced cryptographic techniques. Active individual drafts (i.e., not yet adopted by a working group), such as Longfellow and Anonymous Credit Tokens (ACT), and adopted drafts like Anonymous Rate-limited Credentials (ARC), propose more flexible multi-show anonymous credentials that incorporate developments over the last several years. At IETF 117 in 2023, post-quantum anonymous credentials and deployable generic anonymous credentials were presented as a research opportunity. Check out our post on rate limiting agents for details.
Before we get into the state-of-the-art for PQ, allow us to try to crystalize a set of requirements for real world applications.
Requirements
Given the diversity of use cases, adoption of ACs will be made easier by the fact that they can be built from a handful of powerful primitives. (More on this in our concurrent post.) As we’ll see in the next section, we don’t yet have drop-in, PQ alternatives for these kinds of primitives. The “building blocks” of PQ ACs are likely to look quite different, and we’re going to know something about what we’re building towards.
For our purposes, we can think of an anonymous credential as a kind of fancy blind signature. What’s that you ask? A blind signature scheme has two phases: issuance, in which the server signs a message chosen by the client; and presentation, in which the client reveals the message and the signature to the server. The scheme should be unlinkable in the sense that the server can’t link any message and signature to the run of the issuance protocol in which it was produced. It should also be unforgeable in the sense that no client can produce a valid signature without interacting with the server.
The key difference between ACs and blind signatures is that, during presentation of an AC, the client only presents part of the message in plaintext; the rest of the message is kept secret. Typically, the message has three components:
Private state, such as a counter that, for example, keeps track of the number of times the credential was presented. The client would prove to the server that the state is “valid”, for example, a counter with value $0 \leq C \leq N$, without revealing $C$. In many situations, it’s desirable to allow the server to update this state upon successful presentation, for example, by decrementing the counter. In the context of rate limiting, this is the number of how many requests are left for a credential.
A random value called the nullifier that is revealed to the server during presentation. In rate-limiting, the nullifier prevents a user from spending a credential with a given state more than once.
Public attributes known to both the client and server that bind the AC to some application context. For example, this might represent the window of time in which the credential is valid (without revealing the exact time it was issued).
Such ACs are well-suited for rate limiting requests made by the client. Here the idea is to prevent the client from making more than some maximum number of requests during the credential’s lifetime. For example, if the presentation limit is 1,000 and the validity window is one hour, then the clients can make up to 0.27 requests/second on average before it gets throttled.
It’s usually desirable to enforce rate limits on a per-origin basis. This means that if the presentation limit is 1,000, then the client can make at most 1,000 requests to any website that can verify the credential. Moreover, it can do so safely, i.e., without breaking unlinkability across these sites.
The current generation of ACs being considered for standardization at IETF are only privately verifiable, meaning the server issuing the credential (the issuer) must share a private key with the server verifying the credential (the origin). This will be sufficient for some deployment scenarios, but many will require public verifiability, where the origin only needs the issuer’s public key. This is possible with BBS-based credentials, for example.
Finally, let us say a few words about round complexity. An AC is round optimal if issuance and presentation both complete in a single HTTP request and response. In our survey of PQ ACs, we found a number of papers that discovered neat tricks that reduce bandwidth (the total number of bits transferred between the client and server) at the cost of additional rounds. However, for use cases like ours, round optimality is an absolute necessity, especially for presentation. Not only do multiple rounds have a high impact on latency, they also make the implementation far more complex.
Within these constraints, our goal is to develop PQ ACs that have as low communication cost (i.e., bandwidth consumption) and runtime as possible in the context of rate-limiting.
“Ideal world” (PQ) anonymous credentials
The academic community has produced a number of promising post-quantum ACs. In our survey of the state of the art, we evaluated several leading schemes, scoring them on their underlying primitives and performance to determine which are truly ready for the Internet. To understand the challenges, it is essential to first grasp the cryptographic building blocks used in ACs today. We’ll now discuss some of the core concepts that frequently appear in the field.
Relevant cryptographic paradigms
Zero-knowledge proofs
Zero-knowledge proofs (ZKPs) are a cryptographic protocol that allows a prover to convince a verifier that a statement is true without revealing the secret information, or witness. ZKPs play a central role in ACs: they allow proving statements of the secret part of the credential’s state without revealing the state itself. This is achieved by transforming the statement into a mathematical representation, such as a set of polynomial equations over a finite field. The prover then generates a proof by performing complex operations on this representation, which can only be completed correctly if they possess the valid witness.
General-purpose ZKP systems, like Scalable Transparent Arguments of Knowledge (STARKs), can prove the integrity of any computation up to a certain size. In a STARK-based system, the computational trace is represented as a set of polynomials. The prover then constructs a proof by evaluating these polynomials and committing to them using cryptographic hash functions. The verifier can then perform a quick probabilistic check on this proof to confirm that the original computation was executed correctly. Since the proof itself is just a collection of hashes and sampled polynomial values, it is secure against quantum computers, providing a statistically sound guarantee that the claimed result is valid.
Cut-and-Choose
Cut-and-choose is a cryptographic technique designed to ensure a prover’s honest behaviour by having a verifier check a random subset of their work. The prover first commits to multiple instances of a computation, after which the verifier randomly chooses a portion to be cut open by revealing the underlying secrets for inspection. If this revealed subset is correct, the verifier gains high statistical confidence that the remaining, un-opened instances are also correct.
This technique is important because while it is a generic tool used to build protocols secure against malicious adversaries, it also serves as a crucial case study. Its security is not trivial; for example, practical attacks on cut-and-choose schemes built with (post-quantum) homomorphic encryption have succeeded by attacking the algebraic structure of the encoding, not the encryption itself. This highlights that even generic constructions must be carefully analyzed in their specific implementation to prevent subtle vulnerabilities and information leaks.
Sigma Protocols
Sigma protocols follow a more structured approach that does not require us to throw away any computations. The three-move protocol starts with a commitment phase where the prover generates some randomness, which is added to the input to generate the commitment, and sends the commitment to the verifier. Then, the verifier challenges the prover with an unpredictable challenge. To finish the proof, the prover provides a response in which they combine the initial randomness with the verifier’s challenge in a way that is only possible if the secret value, such as the solution to a discrete logarithm problem, is known.
Depiction of a Sigma protocol flow, where the prover commits to their witness $w$, the verifier challenges the prover to prove knowledge about $w$, and the prover responds with a mathematical statement that the verifier can either accept or reject.
In practice, the prover and verifier don’t run this interactive protocol. Instead, they make it non-interactive using a technique known as the Fiat-Shamir transformation. The idea is that the prover generates the challenge itself, by deriving it from its own commitment. It may sound a bit odd, but it works quite well. In fact, it’s the basis of signatures like ECDSA and even PQ signatures like ML-DSA.
MPC in the head
Multi-party computation (MPC) is a cryptographic tool that allows multiple parties to jointly compute a function over their inputs without revealing their individual inputs to the other parties. MPC in the Head (MPCitH) is a technique to generate zero-knowledge proofs by simulating a multi-party protocol in the head of the prover.
The prover simulates the state and communication for each virtual party, commits to these simulations, and shows the commitments to the verifier. The verifier then challenges the prover to open a subset of these virtual parties. Since MPC protocols are secure even if a minority of parties are dishonest, revealing this subset doesn’t leak the secret, yet it convinces the verifier that the overall computation was correct.
This paradigm is particularly useful to us because it’s a flexible way to build post-quantum secure ZKPs. MPCitH constructions build their security from symmetric-key primitives (like hash functions). This approach is also transparent, requiring no trusted setup. While STARKs share these post-quantum and transparent properties, MPCitH often offers faster prover times for many computations. Its primary trade-off, however, is that its proofs scale linearly with the size of the circuit to prove, while STARKs are succinct, meaning their proof size grows much slower.
Rejection sampling
When a randomness source is biased or outputs numbers outside the desired range, rejection sampling can correct the distribution. For example, imagine you need a random number between 1 and 10, but your computer only gives you random numbers between 0 and 255. (Indeed, this is the case!) The rejection sampling algorithm calls the RNG until it outputs a number below 11 and above 0:
Calling the generator over and over again may seem a bit wasteful. An efficient implementation can be realized with an eXtendable Output Function (XOF). A XOF takes an input, for example a seed, and computes an arbitrarily-long output. An example is the SHAKE family (part of the SHA3 standard), and the recently proposed round-reduced version of SHAKE called TurboSHAKE.
Let’s imagine you want to have three numbers between 1 and 10. Instead of calling the XOF over and over, you can also ask the XOF for several bytes of output. Since each byte has a probability of 3.52% to be in range, asking the XOF for 174 bytes is enough to have a greater than 99% chance of finding at least three usable numbers. In fact, we can be even smarter than this: 10 fits in four bits, so we can split the output bytes into lower and higher nibbles. The probability of a nibble being in the desired range is now 56.4%:
Rejection sampling by batching queries.
Rejection sampling is a part of many cryptographic primitives, including many we’ll discuss in the schemes we look at below.
Building post-quantum ACs
Classical anonymous credentials (ACs), such as ARC and ACT, are built from algebraic groups- specifically, elliptic curves, which are very efficient. Their security relies on the assumption that certain mathematical problems over these groups are computationally hard. The premise of post-quantum cryptography, however, is that quantum computers can solve these supposedly hard problems. The most intuitive solution is to replace elliptic curves with a post-quantum alternative. In fact, cryptographers have been working on a replacement for a number of years: CSIDH.
This raises the key question: can we simply adapt a scheme like ARC by replacing its elliptic curves with CSIDH? The short answer is no, due to a critical roadblock in constructing the necessary zero-knowledge proofs. While we can, in theory, build the required Sigma protocols or MPC-in-the-Head (MPCitH) proofs from CSIDH, they have a prerequisite that makes them unusable in practice: they require a trusted setup to ensure the prover cannot cheat. This requirement is a non-starter, as no algorithm for performing a trusted setup in CSIDH exists. The trusted setup for sigma protocols can be replaced by a combination of generic techniques from multi-party computation and cut-and-choose protocols, but that adds significant computation cost to the already computationally expensive isogeny operations.
This specific difficulty highlights a more general principle. The high efficiency of classical credentials like ARC is deeply tied to the rich algebraic structure of elliptic curves. Swapping this component for a post-quantum alternative, or moving to generic constructions, fundamentally alters the design and its trade-offs. We must therefore accept that post-quantum anonymous credentials cannot be a simple “lift-and-shift” of today’s schemes. They will require new designs built from different cryptographic primitives, such as lattices or hash functions.
Prefabricated schemes from generic approaches
At Cloudflare, we explored a post-quantum privacy pass construction in 2023 that closely resembles the functionality needed for anonymous credentials. The main result is a generic construction that composes separate, quantum-secure building blocks: a digital signature scheme and a general-purpose ZKP system:
The figure shows a cryptographic protocol divided into two main phases: (1.) Issuance: The user commits to a message (without revealing it) and sends the commitment to the server. The server signs the commitment and returns this signed commitment, which serves as a token. The user verifies the server’s signature. (2.) Redemption: To use the token, the user presents it and constructs a proof. This proof demonstrates they have a valid signature on the commitment and opens the commitment to reveal the original message. If the server validates the proof, the user and server continue (e.g., to access a rate-limited origin).
The main appeal of this modular design is its flexibility. The experimental implementation uses a modified version of the signature ML-DSA signatures and STARKs, but the components can be easily swapped out. The design provides strong, composable security guarantees derived directly from the underlying parts. A significant speedup for the construction came from replacing the hash function SHA3 in ML-DSA with the zero-knowledge friendly Poseidon.
However, the modularity of our post-quantum Privacy Pass construction incurs a significant performance overhead demonstrated in a clear trade-off between proof generation time and size: a fast 300 ms proof generation requires a large 173 kB signature, while a 4.8s proof generation time cuts the size of the signature nearly in half. A balanced parameter set, which serves as a good benchmark for any dedicated solution to beat, took 660 ms to sign and resulted in a 112 kB signature. The implementation is currently a proof of concept, with perhaps some room for optimization. Alternatively, a different signature like FN-DSA could offer speed improvements: while its issuance is more complex, its verification is far more straightforward, boiling down to a simple hash-to-lattice computation and a norm check.
However, while this construction gives a functional baseline, these figures highlight the performance limitations for a real-time rate limiting system, where every millisecond counts. The 660 ms signing time strongly motivates the development of dedicated cryptographic constructions that trade some of the modularity for performance.
Solid structure: Lattices
Lattices are a natural starting point when discussing potential post-quantum AC candidates. NIST standardized ML-DSA and ML-KEM as signature and KEM algorithms, both of which are based on lattices. So, are lattices the answer to post-quantum anonymous credentials?
The answer is a bit nuanced. While explicit anonymous credential schemes from lattices exist, they have shortcomings that prevent real-world deployment: for example, a recent scheme sacrifices round-optimality for smaller communication size, which is unacceptable for a service like Privacy Pass where every second counts. Given that our RTT is 100ms or less for the majority of users, each extra communication round adds tangible latency especially for those on slower Internet connections. When the final credential size is still over 100 kB, the trade-offs are hard to justify. So, our search continues. We expand our horizon by looking into blind signatures and whether we can adapt them for anonymous credentials.
Two-step approach: Hash-and-sign
A prominent paradigm in lattice-based signatures is the hash-and-sign construction. Here, the message is first hashed to a point in the lattice. Then, the signer uses their secret key, a lattice trapdoor, to generate a vector that, when multiplied with the private key, evaluates to the hashed point in the lattice. This is the core mechanism behind signature schemes like FN-DSA.
Adapting hash-and-sign for blind signatures is tricky, since the signer may not learn the message. This introduces a significant security challenge: If the user can request signatures on arbitrary points, they can mount an attack to extract the trapdoor by repeatedly requesting signatures for carefully chosen arbitrary points. These points can be used to reconstruct a short basis, which is equivalent to a key recovery.
The standard defense against this attack is to require the user to prove in zero-knowledge that the point they are asking to be signed is the blinded output of the specified hash function. However, proving hash preimages leads to the same problem as in the generic post-quantum privacy pass paper: proving a conventional hash function (like SHA3) inside a ZKP is computationally expensive and has a large communication complexity.
This difficult trade-off is at the heart of recent academic work. The state-of-the-art paper presents two lattice-based blind signature schemes with small signature sizes of 22 KB for a signature and 48 kB for a privately-verifiable protocol that may be more useful in a setting like anonymous credential. However, this focus on the final signature size comes at the cost of an impractical issuance. The user must provide ZKPs for the correct hash and lattice relations that, by the paper’s own analysis, can add to several hundred kilobytes and take 20 seconds to generate and 10 seconds to verify.
While these results are valuable for advancing the field, this trade-off is a significant barrier for any large-scale, practical system. For our use case, a protocol that increases the final signature size moderately in exchange for a more efficient and lightweight issuance process would be a more suitable and promising direction.
Best of two signatures: Hash-and-sign with aborts
A promising technique for blind signatures combines the hash-and-sign paradigm with Fiat-Shamir with aborts, a method that relies on rejection sampling signatures. In this approach, the signer repeatedly attempts to generate a signature and aborts any result that may leak information about the secret key. This process ensures the final signature is statistically independent of the key and is used in modern signatures like ML-DSA. The Phoenix signature scheme uses hash-and-sign with aborts, where a message is first hashed into the lattice and signed, with rejection sampling employed to break the dependency between the signature and the private key.
Building on this foundation is an anonymous credential scheme for hash-and-sign with aborts. The main improvement over hash-and-sign anonymous credentials is that, instead of proving the validity of a hash, the user commits to their attributes, which avoids costly zero-knowledge proofs.
The scheme is fully implemented and credentials with attribute proofs just under 80 KB and signatures under 7 kB. The scheme takes less than 400 ms for issuance and 500 ms for showing the credential. The protocol also has a lot of features necessary for anonymous credentials, allowing users to prove relations between attributes and request pseudonyms for different instances.
This research presents a compelling step towards real-world deployability by combining state-of-the-art techniques to achieve a much healthier balance between performance and security. While the underlying mathematics are a bit more complex, the scheme is fully implemented and with a proof of knowledge of a signature at 40 kB and a prover time under a second, the scheme stands out as a great contender. However, for practical deployment, these figures would likely need a significant speedup to be usable in real-time systems. An improvement seems plausible, given recent advances in lattice samplers. Though the exact scale we can achieve is unclear. Still, we think it would be worthwhile to nudge the underlying design paradigm a little closer to our use cases.
Do it yourself: MPC-in-the-head
While the lattice-based hash-and-sign with aborts scheme provides one path to post-quantum signatures, an alternative approach is emerging from the MPCitH variant VOLE-in-the-Head (VOLEitH).
This scheme builds on Vector Oblivious Linear Evaluation (VOLE), an interactive protocol where one party’s input vector is processed with another’s secret value delta, creating a correlation. This VOLE correlation is used as a cryptographic commitment to the prover’s input. The system provides a zero-knowledge proof because the prover is bound by this correlation and cannot forge a solution without knowing the secret delta. The verifier, in turn, just has to verify that the final equation holds when the commitment is opened. This system is linearly homomorphic, which means that two commitments can be combined. This property is ideal for the commit-and-prove paradigm, where the prover first commits to the witnesses and then proves the validity of the circuit gate by gate. The primary trade-off is that the proofs are linear in the size of the circuit, but they offer substantially better runtimes. We also use linear-sized proofs for ARC and ACT.
Example of evaluating a circuit gate by first committing to each wire and then proving the composition. This is easy for linear gates.
This commit-and-prove approach allows VOLEitH to efficiently prove the evaluation of symmetric ciphers, which are quantum-resistant. The transformation to a non-interactive protocol follows the standard MPCitH method: the prover commits to all secret values, a challenge is used to select a subset to reveal, and the prover proves consistency.
Efficient implementations operate over two mathematical fields (binary and prime) simultaneously, allowing these ZK circuits to handle both arithmetic and bitwise functions (like XORs) efficiently. Based on this foundation, a recent talk teased the potential for blind signatures from the multivariate quadratic signature scheme MAYO with sizes of just 7.5 kB and signing/verification times under 50 ms.
The VOLEitH approach, as a general-purpose solution system, represents a promising new direction for performant constructions. There are a numberofcompetingin-the-head schemes in the NIST competition for additional signature schemes, including one based on VOLEitH. The current VOLEitH literature focuses on high-performance digital signatures, and an explicit construction for a full anonymous credential system has not yet been proposed. This means that features standard to ACs, such as multi-show unlinkability or the ability to prove relations between attributes, are not yet part of the design, whereas they are explicitly supported by the lattice construction. However, the preliminary results show great potential for performance, and it will be interesting to see the continued cryptanalysis and feature development from this line of VOLEitH in the area of anonymous credentials, especially since the general-purpose construction allows adding features easily.
Medium: promising research direction, no full solution available so far
Closing the gap
My (that is Lena’s) internship focused on a critical question: what should we look at next to build ACs for the Internet? For us, “the right direction” means developing protocols that can be integrated with real world applications, and developed collaboratively at the IETF. To make these a reality, we need researchers to look beyond blind signatures; we need a complete privacy-preserving protocol that combines blind signatures with efficient zero-knowledge proofs and properties like multi-show credentials that have an internal state. The issuance should also be sublinear in communication size with the number of presentations.
So, with the transition to post-quantum cryptography on the horizon, what are our thoughts on the current IETF proposals? A 2022 NIST presentation on the current state of anonymous credentials states that efficient post-quantum secure solutions are basically non-existent. We argue that the last three years show nice developments in lattices and MPCitH anonymous credentials, but efficient post-quantum protocols still need work. Moving protocols into a post-quantum world isn’t just a matter of swapping out old algorithms for new ones. A common approach on constructing post-quantum versions of classical protocols is swapping out the building blocks for their quantum-secure counterpart.
We believe this approach is essential, but not forward-looking. In addition to identifying how modern concerns can be accommodated on old cryptographic designs, we should be building new, post-quantum native protocols.
For ARC, the conceptual path to a post-quantum construction seems relatively straightforward. The underlying cryptography follows a similar structure as the lattice-based anonymous credentials, or, when accepting a protocol with fewer features, the generic post-quantum privacy-pass construction. However, we need to support per-origin rate-limiting, which allows us to transform a token at an origin without leaking us being able to link the redemption to redemptions at other origins, a feature that none of the post-quantum anonymous credential protocols or blind signatures support. Also, ARC is sublinear in communication size with respect to the number of tokens issued, which so far only the hash-and-sign with abort lattices achieve, although the notion of “limited shows” is not present in the current proposal. In addition, it would be great to gauge efficient implementations, especially for blind signatures, as well as looking into efficient zero-knowledge proofs.
For ACT, we need the protocols for ARC and an additional state. Even for the simplest counter, we need the ability to homomorphically subtract from that balance within the credential itself. This is a much more complex cryptographic requirement. It would also be interesting to see a post-quantum double-spend prevention that enforces the sequential nature of ACT.
Working on ACs and other privacy-preserving cryptography inevitably leads to a major bottleneck: efficient zero-knowledge proofs, or to be more exact, efficiently proving hash function evaluations. In a ZK circuit, multiplications are expensive. Each wire in the circuit that performs a multiplication requires a cryptographic commitment, which adds communication overhead. In contrast, other operations like XOR can be virtually “free.” This makes a huge difference in performance. For example, SHAKE (the primitive used in ML-DSA) can be orders of magnitude slower than arithmetization-friendly hash functions inside a ZKP. This is why researchers and implementers are already using Poseidon or Poseidon2 to make their protocols faster.
Currently, Ethereum is seriously considering migrating Ethereum to the Poseidon hash and calls for cryptanalysis, but there is no indication of standardization. This is a problem: papers increasingly use different instantiations of Poseidon to fit their use-case, and there aremoreandmorezero–knowledgefriendlyhashfunctionscomingout, tailored to different use-cases. We would like to see at least one XOF and one hash each for a prime field and for a binary field, ideally with some security levels. And also, is Poseidon the best or just the most well-known ZK friendly cipher? Is it always secure against quantum computers (like we believe AES to be), and are there other attacks like the recentattacks on round-reduced versions?
Looking at algebra and zero-knowledge brings us to a fundamental debate in modern cryptography. Imagine a line representing the spectrum of research: On one end, you have protocols built on very well-analyzed standard assumptions like the SIS problem on lattices or the collision resistance of SHA3. On the other end, you have protocols that gain massive efficiency by using more algebraic structure, which in turn relies on newer, stronger cryptographic assumptions. Breaking novel hash functions is somewhere in the middle.
The answer for the Internet can’t just be to relent and stay at the left end of our graph to be safe. For the ecosystem to move forward, we need to have confidence in both. We need more research to validate the security of ZK-friendly primitives like Poseidon, and we need more scrutiny on the stronger assumptions that enable efficient algebraic methods.
Conclusion
As we’ve explored, the cryptographic properties that make classical ACs efficient, particularly the rich structure of elliptic curves, do not have direct post-quantum equivalents. Our survey of the state of the art from generic compositions using STARKs, to various lattice-based schemes, and promising new directions like MPC-in-the-head, reveals a field full of potential but with no clear winner. The trade-offs between communication cost, computational cost, and protocol rounds remain a significant barrier to practical, large-scale deployment, especially in comparison to elliptic curve constructions.
To bridge this gap, we must move beyond simply building post-quantum blind signatures. We challenge our colleagues in academia and industry to develop complete, post-quantum native protocols that address real-world needs. This includes supporting essential features like the per-origin rate-limiting required for ARC or the complex stateful credentials needed for ACT.
A critical bottleneck for all these approaches is the lack of efficient, standardized, and well-analyzed zero-knowledge-friendly hash functions. We need to research zero-knowledge friendly primitives and build industry-wide confidence to enable efficient post-quantum privacy.
If you’re working on these problems, or you have experience in the management and deployment of classical credentials, now is the time to engage. The world is rapidly adopting credentials for everything from digital identity to bot management, and it is our collective responsibility to ensure these systems are private and secure for a post-quantum future. We can tell for certain that there are more discussions to be had, and if you’re interested in helping to build this more secure and private digital world, we’re hiring 1,111 interns over the course of next year, and have open positions!
Cloud storage was supposed to simplify infrastructure. Instead, it’s become one of the most unpredictable—and expensive—line items in IT budgets.
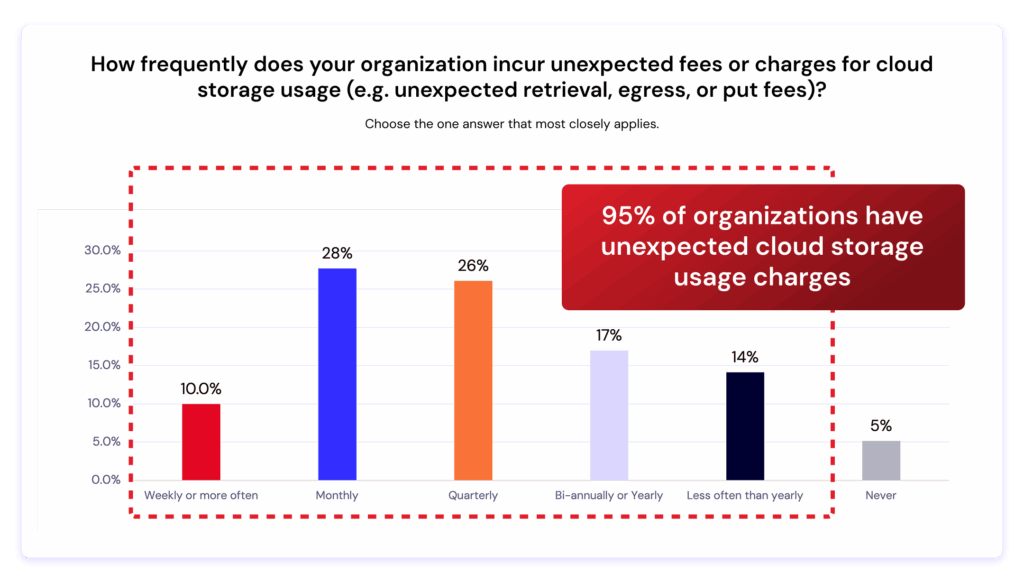
A new Dimensional Research report, commissioned by Backblaze, reveals that 95% of organizations experience unexpected cloud storage charges—costs that disrupt budgets, slow innovation, and limit flexibility.
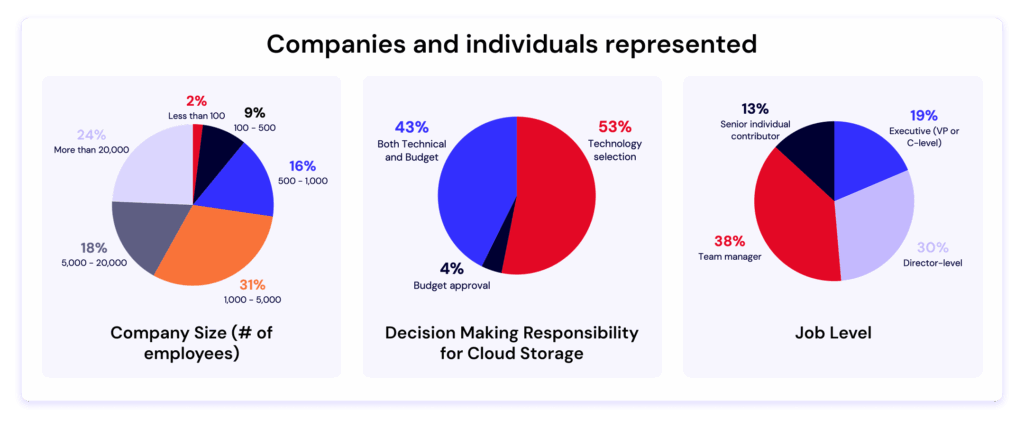
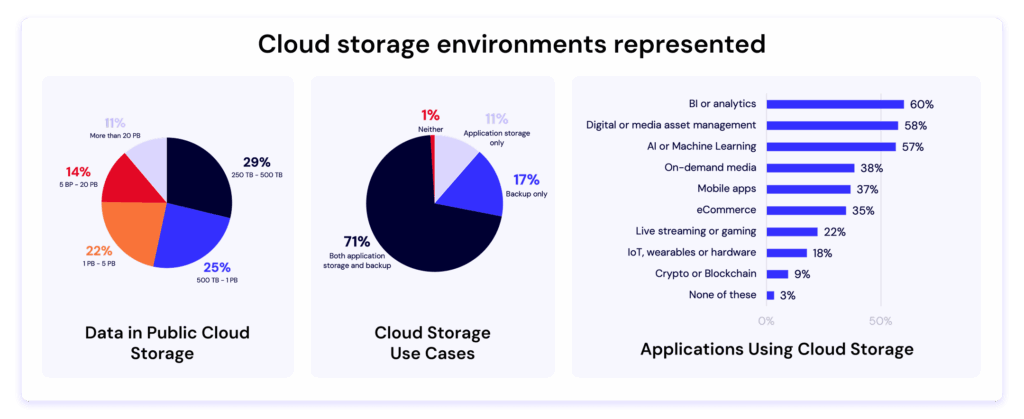
The 2025 study surveyed more than 400 IT decision makers responsible for managing at least 250TB of data in the public cloud. The findings make one thing clear: as AI, analytics, and data-intensive workloads expand, hidden costs and limited interoperability are forcing companies to rethink their cloud strategies.
The problem: Hidden fees are everywhere
According to the research, nearly every organization surveyed has been hit by surprise charges like retrieval, egress, or PUT fees.
95% of respondents reported unexpected costs for cloud storage usage.
Larger organizations—those with more than 5PB of data—were even more likely to experience frequent charges.
These hidden costs have become such a burden that 85% of companies are taking steps to manage them. The top tactics include:
Reducing the size of datasets stored in the cloud (56%)
Shortening storage duration policies (45%)
Cutting spending elsewhere in the tech stack (40%)
In short: IT teams are making trade-offs to avoid surprise costs—trade-offs that can limit innovation and reduce the value of their data
Egress costs are locking companies in
One of the most striking findings:
55% of respondents said that the cost of egressing and moving data is the biggest barrier to switching cloud storage providers.
That means many organizations feel trapped in their current solutions—not because the technology is best-in-class, but because moving their data would be too expensive.
This dynamic creates what’s often called a “walled garden” effect—where providers profit from data lock-in rather than delivering value through performance or innovation.
The result? Slower cloud adoption, limited agility, and higher total cost of ownership for IT teams trying to scale modern workloads.
Flexibility and interoperability are the new imperatives
If cost surprises weren’t enough, nearly all respondents (99%) said that limited flexibility and lack of interoperability are impacting their ability to deliver and scale.
In other words: even when data is stored safely, it’s often stuck—difficult to move, integrate, or use across tools and platforms.
This friction hits hardest at large enterprises and data-heavy organizations that depend on cross-cloud workflows, hybrid architectures, or AI pipelines that require moving large volumes of data frequently.
A turning point for cloud storage strategy
With 62% of respondents preferring to select best of breed providers vs. one-stop-shops, these findings highlight a growing shift:
IT teams are no longer choosing cloud providers solely based on performance or ecosystem.
They’re prioritizing predictability, transparency, and interoperability—the ability to move and use data freely, without hidden penalties.
Backblaze has long championed this model with open cloud storage that puts customers—not pricing structures—in control. Our egress fee transparency, S3 compatible APIs, and simple pricing are designed to eliminate the pain points identified in this report.As one respondent put it: “We need a cloud partner that helps us use our data, not pay to move it.”
What’s next: Join the conversation
The full report—The Hidden Cost of Cloud Object Storage—is now available for download. Inside, you’ll find all the data, charts, and insights from 400+ IT leaders across industries and company sizes.
And, to dive deeper into the findings, join us for an upcoming live webinar with experts from Dimensional Research and Backblaze. We’ll unpack the key trends, share real-world stories from IT leaders, and discuss how to build a more transparent, flexible cloud strategy.
About the research
The survey, conducted by Dimensional Research in May–June 2025, included responses from 403 qualified technology stakeholders responsible for cloud storage strategy and budgets. All participants represented companies with over 250TB of data stored in the public cloud.
Current artificial intelligence (AI) methods, especially machine learning (ML), rely heavily on data. To complement our work on AI literacy, we have been investigating what data science teaching resources and education research are currently available. Our goal is to work out what data science concepts should be taught in a data science curriculum for schools.
Read on to find out what resources and materials we have reviewed, and what concept themes we have identified.
What is data science? Why is teaching it important?
Data science is an interdisciplinary science of learning from large datasets, aided by modern computational tools and methods (Ow‑Yeong et al., 2023). We see data science skills as fundamental for using, creating, and thinking critically about:
Insights from data, generally
Data-driven computational tools and methods (such as machine learning) and their outputs and predictions, specifically
To navigate a world where decision making in many areas is influenced by data-driven insights and predictions, young people need to be taught about data science. Data science skills empower young people to become critical thinkers, discerning consumers, adaptable professionals, and informed citizens.
In some countries, such as India and Israel, data science education is an established school subject. It is taught as part of the curriculum in at least one of the primary, secondary, or post-16 age phases. Meanwhile in other countries, for example Canada, Germany, and Poland, data science is a very new school subject, or there are still only recommendations to develop it into a school subject.
While we are currently considering what a comprehensive data science curriculum should include, we already offer several resources to support you with your teaching about data science and data-driven technologies. You can find a list of these resources at the end of this blog. Now, however, I’ll give you an overview of our recent work to identify concepts for a data science curriculum that fits with our approach to AI literacy.
Data science education: What should we teach?
To answer the question ‘What should we teach about data science to learners aged 5 to 19?’, we undertook a grey literature review of data science teaching materials. A grey literature review is structured like an academic literature review and conducted with the same rigour. The difference is that a grey literature review also considers publications that have not been peer-reviewed, including reports, white papers, curriculum materials, and similar resources.
To orient our work, we combined four frameworks for data science and AI/ML education:
With these combined frameworks as our map, we reviewed 79 data science learning resources. The resources varied:
In quality in terms of clarity and teaching approach
In their focus, e.g. on maths, coding, or a specific field such as biology
In their perspective on data science, with some prioritising theory and others real-world applications
From among the 79 resources, we chose 9 that included clear learning outcomes, and that together covered a wide field of concepts. We examined these 9 in detail to extract 181 explicit and implicit data science concepts. Next, we grouped the concepts into themes, and finally we refined these themes by comparing them against the four frameworks listed above.
The themes we have identified for a data science curriculum are:
Fundamentals of data literacy: Key terms and definitions
Understanding bias in data
Ethical responsibility in data use
Data creation, curation, and transformation
Analysis and modelling: Maths and statistics fundamentals
ML principles
Deploying and maintaining ML applications
Software tools and programming
Data visualisation
Presenting findings effectively
This set of themes both fits with the frameworks by Olari and Romeike and Data Science 4 Everyone, and expands them by covering ML principles and programming approaches and calling out data bias and ethics.
What’s next for this work?
Through our grey literature review on data science education, we’ve:
Pinpointed a large set of candidate concepts that could be taught within a data science curriculum
Created a set of clear themes to structure our work going forward
Our next step is to shape these candidate concepts into a progression framework to describe their relationships and establish which concepts could be taught at each age or phase of schooling.
The literature review also gave us an overview of the pedagogical approaches and tools used for teaching data science concepts. These findings will become useful once we start designing learning activities.
You’ll hear more about how this work is going here on our blog and on our social channels. In the meantime, comment below to let us know what you think about the themes, or to tell us what you’d like to see in a data science curriculum for the learners you work with.
The report lists the data-related units within The Computing Curriculum materials, which we no longer update but continue to offer as free downloads. Updated classroom materials are available as part of the Computing materials we created for Oak National Academy in the UK for ages 5–11 and ages 12–19.
The Ada Computer Science platform offers learning materials on data and information, and on AI and ML, for ages 14–19.
You might also be interested in exploring the Experience AI programme, which offers everything teachers need to help students develop a foundational understanding of data-driven AI technologies, their social and ethical implications, and the role that AI can play in their lives.
Teacher training and development resources
Our free online course ‘Teach teens computing: Machine learning and AI‘ helps teachers understand and explain the types of problems that ML can help to solve, discuss how AI is changing the world, and think about the ethics of collecting data to train a ML model.
Teaching young people to understand data-driven AI technologies means teaching them thinking skills that are different to those needed to understand rule-based computer systems. You can read about these Computational Thinking 2.0 skills in our Quick Read PDF.
Interesting article about the arms race between AI systems that invent/design new biological pathogens, and AI systems that detect them before they’re created:
The team started with a basic test: use AI tools to design variants of the toxin ricin, then test them against the software that is used to screen DNA orders. The results of the test suggested there was a risk of dangerous protein variants slipping past existing screening software, so the situation was treated like the equivalent of a zero-day vulnerability.
[…]
Details of that original test are being made available today as part of a much larger analysis that extends the approach to a large range of toxic proteins. Starting with 72 toxins, the researchers used three open source AI packages to generate a total of about 75,000 potential protein variants.
And this is where things get a little complicated. Many of the AI-designed protein variants are going to end up being non-functional, either subtly or catastrophically failing to fold up into the correct configuration to create an active toxin.
[…]
In any case, DNA sequences encoding all 75,000 designs were fed into the software that screens DNA orders for potential threats. One thing that was very clear is that there were huge variations in the ability of the four screening programs to flag these variant designs as threatening. Two of them seemed to do a pretty good job, one was mixed, and another let most of them through. Three of the software packages were updated in response to this performance, which significantly improved their ability to pick out variants.
There was also a clear trend in all four screening packages: The closer the variant was to the original structurally, the more likely the package (both before and after the patches) was to be able to flag it as a threat. In all cases, there was also a cluster of variant designs that were unlikely to fold into a similar structure, and these generally weren’t flagged as threats.
The research is all preliminary, and there are a lot of ways in which the experiment diverges from reality. But I am not optimistic about this particular arms race. I think that the ability of AI systems to create something deadly will advance faster than the ability of AI systems to detect its components.
Светослав Драганов е режисьор, сценарист и продуцент, член на Европейската филмова академия и председател на Гилдия „Режисьори“ към СБФД. Преподава кино в Нов български университет. Автор е на документални и игрални филми, отличаващи се с човечност, наблюдателност и деликатно чувство за хумор, сред които „Живот почти прекрасен“ (2013) и „Смирен“ (2022). В работата му личи интерес към личните съдби, през които се отразяват по-големите обществени и исторически промени.
„Снежа и Франц“ е документален филм за любов, изкуство и свободата да живееш отвъд границите. Чрез богат архив от любителски филми, писма и фотографии Светослав Драганов разказва историята на една двойка – българката Снежа и австриеца Франц, чиято връзка прекосява време, разстояния и политически разделения. Филмът е нежно размишление върху паметта, избора и цената на независимостта. Той е част от по-широк проект, в който киното и визуалното изкуство се преплитат в обща любовна и художествена хроника.
Премиерата на „Снежа и Франц“ е на 3 ноември 2025 г. от 18:30 ч. в Дома на киното в София. Изложбата „Снежа и Франц“ в галерия „Райко Алексиев“ може да се види от 4 до 15 ноември, 17–20 ч.
Казвате, че от години сте мечтал да направите филм за леля си и чичо си. Какво се промени у Вас като човек и като режисьор, за да сте готов да разкажете тази история именно сега?
Винаги съм се възхищавал на чичо ми по някакъв начин. Като на човек, който все потегля към нови приключения. Особено като открих, че е снимал и филми в края на 90-те, началото на 2000-те години, когато едната ми братовчедка ги беше прехвърлила на VHS. После открих и други филми, които стояха в едно мазе. Най-интересното за мен се крие в тази еволюция, че аз всъщност винаги съм искал да направя филм за Франц. Постепенно фокусът се измести и към леля ми, към Снежа – тя е „обикновеният човек“, който седи и чака, докато Франц обикаля света.
Франц какви приключения е имал? С какво се е занимавал?
Той е бил наистина много спортен тип. От малък кара ски в Тирол. Почва да се занимава с катерене, прави експедиции, които стават все по-екстремни и по-екстремни. През 1967 г. семейството му пътува до Турция, отиват на море, и минават през България на връщане. Отбиват се в Слънчев бряг, където по онова време е имало и къмпинг. Леля ми тогава за първи път отива сама на море, при най-добрата си приятелка, която е в Несебър. Там в един ресторант се запознават с Франц. Те са танцували, а най-добрата приятелка – Юлия, е знаела немски и е превеждала, за да могат да си говорят.
Какво се случва след това?
Почват да си пишат. Той идва в България, пламва любов. Но след това Снежа е приета да учи в Москва, в текстилен институт за дизайн на дрехи. Тя заминава през 1968-ма за пет години. След това се връща и отново пламва епистоларната любов. Пишат си писма, всъщност тя ги пише пак с помощта на Юлия, която превежда. После двамата се събират, женят се и леля ми заминава за Австрия.
Имала ли е някакви проблеми да замине?
Тя е била с държавна поръчка и е трябвало да плати 6000 долара, за да може да замине за чужбина. Или да работи тук шест години, или да плати тези пари. Това са били вариантите. Леля ми работи почти една година и събират тази сума от приятели. Франц от своя страна идва до България със ски оборудване, щеки, обувки. Напълнил е догоре един ситроен, за да продава тук – тогава у нас е имало дефицит на такива неща. Даже веднъж му разбиват колата в София и го ограбват.
Желязната завеса като че ли е работила само за нас?
Да, тя е работила само за хората от Изтока. Ние не сме могли да пътуваме, но те са могли да идват и да оставят шилингите, марките, доларите си. Има един много интересен рекламен филм за Черноморието, в който се казва: „Заповядайте в България, тук валутният курс е перфектен. Харчете с кеф!“ След като се женят официално, леля ми вече също може да идва. Те даже са идвали заедно.
Франц разказвал ли Ви е за приключенията си?
Чичо ми почина през 1987-ма, а аз не говорех немски. Той беше чудо. Най-хубавите ми снимки от детството са негови, защото са цветни. Проявявал ги е, копирал ги е и ги е пращал по пощата. Това са много ценни спомени.
С какво се е занимавал той?
Намирал си е работа, която да му позволява да пътува. Живели са в Иран преди революцията, около 1977 г. Занимавал се е с почви, бил е микробиолог и е специализирал в това как неплодородната почва да се направи плодородна. После е работил и в Кабо Верде, където е изследвал как и защо вулканичната почва на тези острови е толкова плодородна. Бил е алпинист и катерач. Започва с алпинизъм – според мен заради Райнхолд Меснер, който е бил, а и сега е голяма поп звезда в Австрия и немскоезичния свят. Меснер издава книга за всяко пътешествие, появява се по медиите. В един момент чичо ми се отказва от алпинизма и почва да пътешества. Тогава и в Австрия има глад за хора, които да разказват на обикновения човек за местата, които са посетили. Та той е правил такива сказки. С леля ми са пътували, тя е събирала парите от билети за вход. А чичо ми се е подготвял, снимал е филми, имал е и диапозитиви, за да разказва за посетените места.
Има ли негови книги?
Да, има една издадена книга – „Памир 81“, самиздат. Това е книга за изкачването му на Исмаил Самани (7495 м), известен по онова време като връх Комунизъм, най-високия връх в бившия Съветски съюз. Книгата е много интересна, защото е и социологическа, не е само за катеренето. Това е дневник на пътешествието му плюс наблюденията му на света и живота там и в Москва.
Когато си намира работа в Кабо Верде за една година, той взема семейството си. Праща ги със самолет заедно с една от сестрите си, защото децата са малки. А той трябва с другата сестра да кара до Дакар със старата си кола „Опел Рекорд“. В един момент колата се чупи в Африка и те я качват на влак. Идеята е все пак колата да стигне до Дакар – важното е не те самите да се доберат дотам, а те заедно с колата. Когато пристигат, намират кой да я ремонтира, оправят я и продължават към океана. После остават в Кабо Верде. Това е най-хубавият период от съвместния им живот. Една година заедно, без той да мърда никъде, без да обикаля и да търси приключения. Рай. След като се връщат, леля ми и братовчедките ми остават във Виена, а той поема с лодка по Нигер.
Как фокусът Ви се премести от Франц към Снежа?
Фокусът ми се насочи и към двамата. Как леля ми се справя с неговите екстремни ситуации. Голяма част от филма е за смъртта му и как тя я преживява. Как трябва да се промени, да стане глава на семейството. И това е само върхът на айсберга.
Ако можеха сега да гледат филма заедно, какво мислите, че биха си казали един на друг след прожекцията?
Основният проблем при правенето на филма беше огромната травма на моите братовчедки. Те страшно много обичат баща си, с когото са прекарвали приказно време – играли са си, спортували са, правили са походи. Тези моменти са били много ценни за тях.След като той умира, им е отнето нещо безценно. И затова никак не искаха някой да се рови и да го показва. Трябваше много време да убеждавам тях и леля ми да влязат в тази история така, че да я споделят с външни хора.От друга страна, той е снимал непрекъснато, писал е, искал е да разкаже за тази част от живота си. Най-интересното е, че в книгата „Памир 81“ има включено писмо – „Едно кратко писмо по една дълга тема“. В него той обяснява, че не бяга от тях, че иска да намери себе си, но по някакъв начин, пътувайки, ги намира. Много е поетично и честно.Тези неща са го занимавали точно толкова, колкото самите пътешествия. Анализирал е как егото му и желанието му да пътува могат да наранят най-близките му хора. И как, наранявайки ги, да им обясни защо го прави. Имал е желанието да разкаже своята версия и истина.
Какво Ви казаха леля Ви и братовчедките Ви, след като гледаха филма?
Едната ми братовчедка участва във филма и това е много силен момент. Другите две казаха, че ако не им хареса филмът, няма да мога да ползвам кадрите с тях. Ние сме много близки и това е тяхно право. Беше страшно преживяване да им покажа филма. И впоследствие беше много хубаво, защото получих разрешението им. Дори сега, на премиерата, всички те ще дойдат в София. Леля ми, трите ми братовчедки, сестрите на Франц и други роднини.
Ще има ли събития освен филма?
Ще има изложба и за първи път в едно пространство – в галерия „Райко Алексиев“, ще бъдат изложени заедно Франц с неговите филми и Снежа с нейните текстилни релефи и текстилни абстрактни картини. След филма ще могат да се видят като допълнение нещата, които са показани на екрана, а и физически ще могат да се пипнат. След прожекцията ще отидем до галерията. Голяма част от работите са направени от Снежа след смъртта на Франц. Тя преработва цялата си травма и изобщо техните взаимоотношения в тези произведения. Георги Дончев, един от композиторите на филма, ще направи музикален пърформанс. Изложбата ще е вечерна, ще може да се гледа от 17 до 20 часа. Няма да бъде отворена през деня.
Как Снежа се е справяла в Австрия?
Като се е върнала от Москва, е работила в ЦНСМ – Центъра за нови стоки и мода. В Австрия забременява, ражда двете близначки, пътуват с Франц в Иран. В един момент решава да прави тези „текстилни релефи“, както ги наричат заедно с Франц. Той ѝ помага. Има някаква симбиоза между двамата. Чичо ми не е бил такъв тип – „ти стой вкъщи, аз ще пътувам“. Той иска да прави каквото иска, но по някакъв начин държи да ѝ даде и на нея възможността да прави каквото ѝ се иска. На леля ми винаги ѝ е било трудно да напише концептуалните си текстове, защото, когато правиш изкуство, трябва да опишеш какво искаш да кажеш с него. Тя е трябвало да го напише на немски, обаче немският ѝ не е бил толкова добър. Затова Франц е писал тези текстове. Много е тъжно, че точно когато нейната кариера на артист започва да върви нагоре, той… След смъртта му тя няколко години просто е в тотален стрес и скръб. Спира въобще да се занимава с изкуство. Най-истинските ѝ работи се появяват няколко години след смъртта му, когато отново почва да работи и да преработва и допълва тези произведения. Най-силните всъщност не ги е и продавала, прекалено лични са били. През 90-те години леля ми прави доста добра кариера в Австрия. Тя никога не е имала изложба в България. Сега ще е за първи път.
Имаше два варианта. Да го направя много артистичен, защото има страхотен и ефектен архив. Или да го направя така, че да разкажа тази история, както трябва да бъде разказана – коректно и човешки. Идеята ми беше да оставя пространство за хората, които участват, да не влагам толкова режисьорската си гледна точка. Да не играя много с естетически амбиции, а по-скоро да направя нещата етически акуратни.
Как реагират хората около Вас на филма?
Една позната го гледа и каза: „Снежа нещо не ми харесва.“ Тя очаквала в края на филма Снежа да се разбунтува, да отрече из основи тази любов. Леля ми всъщност вижда и тази перспектива, но пази това, което е било между тях двамата, иска то да остане ненакърнимо.
Светослав Драганов на снимачната площадка
А Вие ще тръгнете ли скоро към нови приключения и какви ще бъдат те?
Правя няколко филма. Скоро ще излезе филм, който продуцирам, за едно малко село близо до Дунава. Режисьорката Елена Стойчева отива там и селото се отваря за нея. Опитват се да я засмучат, да я направят кметица, да се ожени за местно момче. Много любопитен филм. Скоро ще излезе и филмът ми за Мария Статулова, с която много се сближихме покрай „Смирен“. Правя филм и за Babyface Clan, за групата и за цялото това поколение. Занимавам се и с нов игрален проект също. Продуцирам и дебютния филм на един колега, Лазар Иванов, млад режисьор – пак документален. Той е на 28 години и прави филм за баща си, а баща му е мой приятел от 90-те години, много интересна фигура от ъндърграунда. Дойде времето, когато децата ни откриват родителите си, които са малко странни хора.
Филмът „Снежа и Франц“ и едноименната изложба са създадени с подкрепата на: Cineaste Maudit production, Контраст филм, Right Solutions, Sonus, Програма „Творческа Европа МЕДИА“, ИА „Национален филмов център“, Филмов архив на града и провинцията Виена, БНТ, Столична община, Национален фонд „Култура“, Австрийски културен форум, хотел „Кооп“, КиноКлас, Дневник и винарна „Типченица“.
As Grab transitions to derive more valuable insights from our wealth of operational data, we are witnessing a steep increase in stream-processing applications. Over the past year, the number of Flink applications grew 2.5 times, driven by interest in real-time stream processing and the improved accessibility of developing such applications with Flink SQL. At this scale, it has become crucial for the internal Flink platform team to provide a cost-effective and self-service offering that supports users of diverse backgrounds.
Background: Flink at Grab
Flink at Grab is deployed in application mode, each pipeline has its own isolated resources for JobManager and TaskManager. Flink pipeline creators control both application logic and deployment configuration that affect throughput and performance, including OSS configurations:
Number of TaskManagers and task slots per TaskManager
CPU cores per TaskManager
Memory per TaskManager
As pipeline creation has become more accessible, users of different backgrounds (analyst, data scientist, engineers, etc.) often struggle to choose a set of configurations that work for their applications. Many go through a long process of trial and error and still end up over-provisioning their applications, leading to huge resource waste. Moreover, pipeline behavior changes over time due to changes in application logic or data pattern, invalidating previous efforts in tuning and causing users to repeat the exercise.
In this article, we focus on addressing the challenge of efficient CPU provisioning for TaskManagers, as CPU constraints are a common bottleneck in our clusters. Our solution specifically targets Flink applications sourcing data from our message bus system (eg. Kafka, Change Data Capture Streams, DynamoDB Streams) , which represents the majority of our use cases. These workloads offer significant opportunities for cost savings due to their clear seasonal patterns, making them an ideal starting point for optimising autoscaling strategies.
Limits of reactive autoscaling
Our initial reactive setup
Our first automated solution relied on Flink’s Adaptive Scheduler in Reactive Mode. In this mode, each Flink application is deployed as its own individual Flink cluster running a dedicated job. The cluster greedily uses all available TaskManagers and scales its job parallelism accordingly. Running on Kubernetes, the cluster relies on Horizon Pod Autoscaler (HPA) to scale the number of TaskManager pods based on metrics such as CPU usage or custom metrics such as the pipeline’s consumer latency. While this solution was helpful initially, we quickly observed multiple issues with it.
It is important to note that while the below issues can be solved by fine-tuning, it is a tedious trial and error effort that only works for specific applications, requiring users to repeat the process for every pipeline they own.
Restart spike: root cause of many issues
When autoscaling a Flink pipeline, the job restarts from the last checkpoint. This triggers an immediate spike in load, as the pipeline must reprocess records from the period between the last checkpoint and job restart, along with any new records that were backlogged at the source during the downtime. As a result, CPU usage and P99 consumer latency typically spikes after scaling events, for example, at 00:05 and 00:55, as shown in Figure 1. These spikes occur even though there is no change in source topic throughput. In this case, CPU usage surges from 0.5 cores to near provision limit of 2.5 cores, while consumer latency temporarily spiked from sub-second levels to as high as three minutes.
Figure 1: CPU usage and consumer latency spike after a pipeline restart.
Reactive spiral and fluctuation
Typically, HPA scales on metrics such as CPU usage, consumer latency, or backpressure crossing a defined threshold. The challenge arises if these thresholds are misconfigured. The HPA’s reactive nature, when combined with restart spikes, can become detrimental to your Flink application. It piles additional load onto a system that’s already degrading, further amplifying the problem.
Figure 2: A reactive scaling incident that demonstrates scaling fluctuations and restarts.
Figure 2 provides us a case study of reactive spiral and fluctuation, assuming we are having a pipeline that consumes a Kafka topic of 300 partitions:
07:00: As the source topic throughput increases, the P99 consumer latency rises due to insufficient processing power.
07:15: Reactive scaling is triggered, resulting in a scale out event. This is reflected in the increased TaskManager and task slot count. The pipeline continues to operate, as there is no increase in restart count.
07:30: As the P99 consumer latency remains high, reactive scaling continues to scale out incrementally. The records in rate by task rises rapidly as the pipeline reprocesses data from the checkpoint. During this period, the pipeline repeatedly restarts CPU usage drops significantly, and P99 consumer latency spikes to nearly one hour. This marks the onset of a spiral failure.
08:00: Reactive scaling reaches its upper limit of 300 slots, corresponding to the number of partitions in the source topic. This halts the spiral effect as it cannot scale out any further. Without disruption from autoscaling restart, the pipeline begins to process the backlog since the last successful checkpoint, as observed by the significant increase in records in rate by task. As the pipeline catches up, it eventually stabilizes, and the P99 consumer latency returns to normal levels.
08:30 – 10:15: The P99 consumer latency returns to normal levels, below the threshold. Reactive scaling triggers scale-in events despite the source topic throughput continuing to trend upward. During these scale-in events, P99 latency fluctuates, occasionally spiking up to 15 minutes. However, these fluctuations are not severe enough to prevent the repeated scale in process.
10:15: The P99 consumer latency rises again, triggering a scale-out event back to the upper limit of 300 slots.
11:15-11:45: Despite the source topic throughput maintaining an upward trend, the pipeline undergoes multiple scale-in events in quick succession, encounters latency issues due to reprocessing data from checkpoints, and scales out again shortly after. This is an example of fluctuation after scaling in, resulting in 6 restarts within a 30 minutes window.
Limited parallelism constraints
Even with HPA, we frequently encounter a bottleneck when trying to scale our applications’ throughput. This is primarily because some of our connectors, most notably the Kafka connector, don’t inherently support dynamic parallelism changes.
Kafka topics, by design, have a fixed number of partitions. This directly limits the number of parallel consumers we can run. Consequently, once we reach this maximum parallelism for our consumers, we often have to scale up resources, for example, increase memory/CPU per instance instead of scaling out (adding more instances).
Predictive Resource Advisor
Assumptions and hypothesis
To tackle the issue of reactive spirals and fluctuations, the new solution should have the following characteristics:
Vertical scaling: To tackle the issue of limited parallelism with our dependencies, we should be looking at vertical instead of horizontal scaling.
Predictive: Adjust CPU to scale up or down before demand spikes or dips occur, ensuring the system is prepared for changes in workload. This prevents artificial workload increases caused by processing backlogs on top of actual workload increase, further straining the system.
Deterministic: The CPU configuration must be precisely calculated based on the workload demand, ensuring predictable and consistent resource allocation. For a given workload, the calculated CPU value should remain the same every time, eliminating variability and uncertainty in scaling decisions.
Accurate: Determine the optimal CPU configuration required to handle workload demand in a single, precise calculation, avoiding the inefficiencies of multi-step, trial-and-error tuning.
Key observations
Our solution is conceptualized based on key observations of our Flink applications:
The CPU usage of Flink applications is primarily driven by the input load.
The input load of our Flink applications can be accurately forecasted using time-series forecasting techniques.
Time-based autoscaling that relies solely on historical CPU usage is not robust enough to adapt to evolving workloads. This approach also carries the risk of a negative self-amplifying feedback loop: each autoscaling restart causes a CPU usage spike (as illustrated in Figure 1), which, if anomalies are not properly handled, inflates subsequent CPU calculations.
Model formulation
We then formulate the relationship between CPU usage and input load using a regression model to provide a mathematical framework for predicting CPU requirements based on workload patterns, expressed as:
Ct = f(xt)
In this equation:
Ct represents the CPU required at a specific point in time.
xt represents the input workload at the corresponding point in time.
f() represents the regression function that maps the input load to the required CPU capacity.
Input load, represented by Kafka source topic throughput in our case, is chosen as the independent variable xt because it reflects true business demand and is entirely independent of Flink consumers. This metric is influenced solely by the business logic of upstream producers and remains unaffected by any changes or behaviors in the Flink consumer pipeline.
Proposed solution
Our predictive autoscaler operates through four key stages as shown in Figure 3.
Figure 3: The predictive autoscaling system operates through four key stages.
Stage 1: Workload forecast model
The workload forecast model is a time-series forecasting model trained on actual workload data, specifically source topic throughput from our Kafka cluster (1). This approach is particularly effective as our workload exhibits seasonal patterns. While historical data could be directly used as input for CPU prediction, time-series forecasting offers a more robust solution by enabling the model to account for organic traffic growth over time. Through periodic retraining, the model adapts to evolving workload trends, ensuring more accurate and reliable predictions for resource provisioning.
Stage 2: Resource prediction model
This follows the regression-based model Ct = f(xt) defined earlier. We use the same source topic throughput from our Kafka cluster (2a) as input feature xt, and the Flink application’s Kubernetes CPU usage metric (2b) as output label Ct for model training. To ensure clean and representative data for model training, we collect CPU usage metrics under conditions that simulate infinite resource availability. We include data exclusively from periods of continuous and stable operation, as determined by latency, uptime, and restart metrics (2b), eliminating biases caused by hardware limitations or disruptions.
Stage 3: Workload forecasting
To prepare for autoscaling, we forecast the workload for the future t-hour window (3) using our trained time-series forecast model.
Stage 4: Predict CPU usage
The forecasted workload (3) is fed into the resource prediction model to estimate the CPU usage required to handle that workload. The predicted value is then refined using custom safety feature adjustments to account for variability and ensure stability. This adjusted prediction is passed to the custom autoscaler controller, which evaluates the current CPU configuration of the TaskManager deployment. If the adjusted predicted value differs from the existing CPU configuration, the controller initiates vertical scaling to update the TaskManager deployment accordingly.
Proof of concept and results
Experiment setup
To validate our hypothesis, we present a deep dive into one of our experiments. This pipeline features complex business logic, aggregates from multiple Kafka sources, with a checkpoint interval of one minute and a maximum consumer latency of five minutes.
We set up an experimental pipeline with configurations identical to the production pipeline (the control). Both applications sourced data from the same Kafka topics but sank data to alternative topics to maintain isolation. The Predictive Resource Advisor was enabled on the experimental pipeline, while the control pipeline operated with fixed CPU provisioning.
Results
Figure 4 demonstrates a strong correlation between CPU usage (yellow, green) and the total Kafka topics throughput. The variable CPU provisioning (blue) for the experimental pipeline is calculated by our autoscaler models, which were trained exclusively on data collected from the experiment pipeline. The CPU usage trend of the experimental pipeline closely mirrors that of the control pipeline and remains aligned with the Kafka throughput trend. However, the experimental pipeline’s CPU provisioning is dynamically adjusted to more closely match its actual CPU usage, whereas the control pipeline maintains a static CPU allocation (purple). This illustrates the model’s effectiveness in dynamically adjusting CPU allocation to meet variable workload demands.
Figure 4: CPU usage closely correlates with source throughput for both the experimental and control pipelines.
Without autoscaler enabled, the control pipeline experienced no disruptions and maintained latency (blue) consistently below one second, which is not visible in Figure 5. On the other hand, the experiment pipeline latency (red) experienced a highest recorded peak latency of just over four minutes during a single disruption window. Other latency spikes observed were comparable to or lower than the three minutes peak latency previously identified as part of the restart spike issue analysis. The varied durations and amplitudes of these spikes showed some correlation with the heavy Kafka topic throughput during those periods. Importantly, there were only nine autoscaling events throughout the day, resulting in nine restarts for the experiment pipeline.
Figure 5: Autoscaling impacts service-level agreement requirements through latency spikes during scaling events.
Outcome
The Predictive Resource Advisor solution has been successfully deployed across more than 50% of applicable production applications, specifically those consuming from Kafka topics and exhibiting seasonal workload patterns with some tolerance for disruptions. This implementation has delivered significant results across three key areas, stability, efficiency, and user experience.
Stability
With autoscaling becoming more predictable and controllable, our Flink applications experience fewer disruptions caused by autoscaling fluctuations. The machine learning and predictive capabilities of the solution also ensure that applications remain operational during periods of increased workload by automatically learning and adapting to organic growth trends and workload surges.
Efficiency
Applications powered by the Predictive Resource Advisor demonstrated significant improvements in CPU provisioning, aligning CPU configuration more closely with actual requirements, particularly during low traffic periods. As a result of this optimization, on average, these applications made approximately >35% savings in cloud infrastructure cost.
User experience
The solution has simplified the deployment process for users, allowing them to simply deploy Flink applications with default configurations. The Predictive Resource Advisor automatically collects data, trains autoscaling models, and applies configuration changes, thus eliminating the need for manual fine-tuning. This significantly enhances the user experience by streamlining pipeline maintenance and enabling self-service capabilities, such as effortless onboarding. It empowers users to explore and derive value from real-time features with minimal effort.
What’s next?
Our journey doesn’t stop here. We’re continuously working to enhance our predictive autoscaler, with the following key areas of focus:
Tackling memory configuration (Predictive Resource Advisor’s next frontier)
Memory is critical yet often misconfigured that can lead to unrecoverable failures for example, OOMKilled. Our next major goal for the Predictive Resource Advisor is to take on memory tuning, completely removing the burden of complex memory configuration from our users and further empowering them.
Enhancing model accuracy
To further improve the robustness of our predictions, we are actively exploring advanced techniques in input feature engineering and anomaly detection, especially for workloads exhibiting frequent bursting patterns. By refining these aspects, we aim to extend the applicability of our solution to a broader range of Flink applications, including those connected to diverse sources such as change data capture systems or batch-like, spiky workloads, such as the Flink applications powering our real-time data lake.
Streamlining model training
We’re developing a more efficient model training workflow. A particularly exciting avenue we’re investigating is the use of pretrained time-series forecasting models based on large language model architectures.
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Alejandro Colomar has announced the release of version 6.16 of the GNU/Linux man pages. This release includes new or rewritten man pages for fsconfig(), fsmount(), and fsopen(), as well as a number of newly documented interfaces in existing man pages. The release is also available as a PDF book.
ICANN’s Security and
Stability Advisory Committee (SSAC) has announced
a report
on “the critical role of Free and Open Source Software (FOSS)
within the Domain Name System (DNS)“. The report is aimed at
policymakers and examines recent cybersecurity regulations in the US,
UK, and EU as they apply to FOSS in the DNS system; it includes
findings and guidelines “to strengthen the FOSS ecosystem that is
critical to the secure and stable operation of the Internet“. From
the report’s summary:
This ecosystem depends on a global network of maintainers and
contributors who are often unpaid volunteers. While many are unpaid
volunteers, the DNS space is unique in also relying on a handful of
long-lived maintenance organizations. This creates a model based on
community collaboration rather than the commercial contracts that
define a traditional software supply chain, which introduces unique
risks related to financial sustainability for the maintenance
organizations and maintainer burnout for volunteers.
These unique characteristics mean that regulatory frameworks
designed for proprietary software may not be well-suited for FOSS and
therefore could have severe unintended consequences to the stability
of critical Internet infrastructure.
Thanks to SSAC member Maarten Aertsen for the tip.
A new class of attacks on Android phones, called “Pixnapping“, was announced on
October 13. It allows a malicious app to gather output rendered in a
victim app, pixel-by-pixel, by exploiting a GPU side-channel. Depending on
what the victim app displays, anything from sensitive email and chats to
two-factor authentication (2FA) codes could be captured—and shipped off to
an attacker’s site.
This is our first stable release based on Firefox ESR 140,
incorporating a year’s worth of changes that have been shipped
upstream in Firefox. As part of this process, we’ve also completed our
annual ESR transition audit, where we reviewed and addressed around
200 Bugzilla issues for changes in Firefox that may negatively affect
the privacy and security of Tor Browser users. Our final reports from
this audit are now available in the tor-browser-spec
repository on our GitLab instance.
This release inherits the vertical tabs feature, unified search
button, as well as other new features and usability improvements in
Firefox that have passed the Tor Project’s audit.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.