Post Syndicated from turnoff.us original http://turnoff.us/geek/security-engineer-interview/

Post Syndicated from turnoff.us original http://turnoff.us/geek/security-engineer-interview/
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=_26B8YTEYzU
Post Syndicated from Cliff Robinson original https://www.servethehome.com/samsung-hbm3e-12h-36gb-in-production-q2-2024/
Samsung has new HBM slated for Q2 2024 production. Samsung HBM3E 12H will bring 36GB packages to the market in a few months
The post Samsung HBM3E 12H 36GB In Production Q2 2024 appeared first on ServeTheHome.
Post Syndicated from Explosm.net original https://explosm.net/comics/allergies-3
New Cyanide and Happiness Comic
Post Syndicated from xkcd.com original https://xkcd.com/2900/

Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=KUalfc9Hfak
Post Syndicated from daroc original https://lwn.net/Articles/962788/
Nix and
Guix are a pair of unusual package managers
based on the idea of declarative configurations. Their associated Linux
distributions — NixOS and the Guix System — take the idea further by allowing users
to define a single centralized configuration describing the state of the entire
system. Both have
been previously
mentioned on LWN, but not covered extensively. They offer different takes on
the central idea of treating packages like immutable values.
Post Syndicated from Tim Winston original https://aws.amazon.com/blogs/security/aws-payment-cryptography-is-pci-pin-and-p2pe-certified/
Amazon Web Services (AWS) is pleased to announce that AWS Payment Cryptography is certified for Payment Card Industry Personal Identification Number (PCI PIN) version 3.1 and as a PCI Point-to-Point Encryption (P2PE) version 3.1 Decryption Component.
With Payment Cryptography, your payment processing applications can use payment hardware security modules (HSMs) that are PCI PIN Transaction Security (PTS) HSM certified and fully managed by AWS, with PCI PIN and P2PE-compliant key management. These attestations give you the flexibility to deploy your regulated workloads with reduced compliance overhead.
The PCI P2PE Decryption Component enables PCI P2PE Solutions to use AWS to decrypt credit card transactions from payment terminals, and PCI PIN attestation is required for applications that process PIN-based debit transactions. According to PCI, “Use of a PCI P2PE Solution can also allow merchants to reduce where and how the PCI DSS applies within their retail environment, increasing security of customer data while simplifying compliance with the PCI DSS”.
Coalfire, a third-party Qualified PIN Assessor (QPA) and Qualified Security Assessor (P2PE), evaluated Payment Cryptography. Customers can access the PCI PIN Attestation of Compliance (AOC) report, the PCI PIN Shared Responsibility Summary, and the PCI P2PE Attestation of Validation through AWS Artifact.
To learn more about our PCI program and other compliance and security programs, see the AWS Compliance Programs page. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Post Syndicated from Muthu Pitchaimani original https://aws.amazon.com/blogs/big-data/use-amazon-opensearch-ingestion-to-migrate-to-amazon-opensearch-serverless/
Amazon OpenSearch Serverless is an on-demand auto scaling configuration for Amazon OpenSearch Service. Since its release, the interest for OpenSearch Serverless had been steadily growing. Customers prefer to let the service manage its capacity automatically rather than having to manually provision capacity. Until now, customers have had to rely on using custom code or third-party solutions to move the data between provisioned OpenSearch Service domains and OpenSearch Serverless.
We recently introduced a feature with Amazon OpenSearch Ingestion (OSI) to make this migration even more effortless. OSI is a fully managed, serverless data collector that delivers real-time log, metric, and trace data to OpenSearch Service domains and OpenSearch Serverless collections.
In this post, we outline the steps to make migrate the data between provisioned OpenSearch Service domains and OpenSearch Serverless. Migration of metadata such as security roles and dashboard objects will be covered in another subsequent post.
The following diagram shows the necessary components for moving data between OpenSearch Service provisioned domains and OpenSearch Serverless using OSI. You will use OSI with OpenSearch Service as source and an OpenSearch Serverless collection as sink.

Before getting started, complete the following steps to create the necessary resources:
sts_role_arn parameter of the pipeline configuration.aws:SourceAccount and aws:SourceArn condition keys to the policy for protection against the confused deputy problem:
all_access user) to the domain user. We show a simplified example to use the all_access role. For production scenarios, make sure to use a role with just enough permissions to read and write.
Now you’re ready to move data from your provisioned domain to OpenSearch Serverless.
Post Syndicated from Toney Thomas original https://aws.amazon.com/blogs/big-data/empowering-data-driven-excellence-how-the-bluestone-data-platform-embraced-data-mesh-for-success/
This post is co-written with Toney Thomas and Ben Vengerovsky from Bluestone.
In the ever-evolving world of finance and lending, the need for real-time, reliable, and centralized data has become paramount. Bluestone, a leading financial institution, embarked on a transformative journey to modernize its data infrastructure and transition to a data-driven organization. In this post, we explore how Bluestone uses AWS services, notably the cloud data warehousing service Amazon Redshift, to implement a cutting-edge data mesh architecture, revolutionizing the way they manage, access, and utilize their data assets.
Bluestone was operating with a legacy SQL-based lending platform, as illustrated in the following diagram. To stay competitive and responsive to changing market dynamics, they decided to modernize their infrastructure. This modernization involved transitioning to a software as a service (SaaS) based loan origination and core lending platforms. Because these new systems produced vast amounts of data, the challenge of ensuring a single source of truth for all data consumers emerged.

To address the need for centralized, scalable, and governable data, Bluestone introduced the Bluestone Data Platform. This platform became the hub for all data-related activities across the organization. AWS played a pivotal role in bringing this vision to life.
The following are the key components of the Bluestone Data Platform:
The following diagram illustrates the architecture of their updated data platform.

AWS played a pivotal and multifaceted role in empowering Bluestone’s Data Platform to thrive. The following AWS and third-party services were instrumental in shaping Bluestone’s journey toward becoming a data-driven organization:
AWS’s comprehensive suite of services has been integral in propelling the Bluestone Data Platform towards data-driven success. These services have not only enabled efficient data governance, quality assurance, and orchestration, but have also fostered a culture of data centricity within the organization, ultimately leading to better decision-making and competitive advantage. Bluestone’s journey showcases the power of AWS in transforming organizations into data-driven leaders in their respective industries.
Bluestone’s data architecture has undergone a dynamic transformation, transitioning from a lake house framework to a data mesh architecture. This evolution was driven by the organization’s need for data products with distributed ownership and the necessity for a centralized mechanism to govern and access these data products across various business units.
The following diagram illustrates the solution architecture and its use of AWS and third-party services.

Let’s delve deeper into how this architecture shift has unfolded and what it entails:
In essence, Bluestone’s journey from a lake house to a data mesh architecture represents a strategic shift in data management and governance. This transformation empowers different business units to operate autonomously within their data domains while ensuring centralized control, governance, and accessibility. The integration of a centralized catalog and data governance tooling, coupled with the flexibility of Amazon Redshift data sharing, creates a harmonious ecosystem where data-driven decision-making thrives, ultimately contributing to Bluestone’s success in the ever-evolving financial landscape.
Bluestone’s journey from a legacy SQL-based system to a modern data mesh architecture on AWS has improved the way the organization interacts with data and positioned them as a data-driven powerhouse in the financial industry. By embracing AWS services, Bluestone has successfully achieved a centralized, scalable, and governable data platform that empowers its teams to make informed decisions, drive innovation, and stay ahead in the competitive landscape. This transformation serves as compelling proof that Amazon Redshift and AWS Cloud data sharing capabilities are a great pathway for organizations looking to embark on their own data-driven journeys with AWS.
 Toney Thomas is a Data Architect and Data Engineering Lead at Bluestone, renowned for his role in envisioning and coining the company’s pioneering data strategy. With a strategic focus on harnessing the power of advanced technology to tackle intricate business challenges, Toney leads a dynamic team of Data Engineers, Reporting Engineers, Quality Assurance specialists, and Business Analysts at Bluestone. His leadership extends to driving the implementation of robust data governance frameworks across diverse organizational units. Under his guidance, Bluestone has achieved remarkable success, including the deployment of innovative platforms such as a fully governed data mesh business data system with embedded data quality mechanisms, aligning seamlessly with the organization’s commitment to data democratization and excellence.
Toney Thomas is a Data Architect and Data Engineering Lead at Bluestone, renowned for his role in envisioning and coining the company’s pioneering data strategy. With a strategic focus on harnessing the power of advanced technology to tackle intricate business challenges, Toney leads a dynamic team of Data Engineers, Reporting Engineers, Quality Assurance specialists, and Business Analysts at Bluestone. His leadership extends to driving the implementation of robust data governance frameworks across diverse organizational units. Under his guidance, Bluestone has achieved remarkable success, including the deployment of innovative platforms such as a fully governed data mesh business data system with embedded data quality mechanisms, aligning seamlessly with the organization’s commitment to data democratization and excellence.
 Ben Vengerovsky is a Data Platform Product Manager at Bluestone. He is passionate about using cloud technology to revolutionize the company’s data infrastructure. With a background in mortgage lending and a deep understanding of AWS services, Ben specializes in designing scalable and efficient data solutions that drive business growth and enhance customer experiences. He thrives on collaborating with cross-functional teams to translate business requirements into innovative technical solutions that empower data-driven decision-making.
Ben Vengerovsky is a Data Platform Product Manager at Bluestone. He is passionate about using cloud technology to revolutionize the company’s data infrastructure. With a background in mortgage lending and a deep understanding of AWS services, Ben specializes in designing scalable and efficient data solutions that drive business growth and enhance customer experiences. He thrives on collaborating with cross-functional teams to translate business requirements into innovative technical solutions that empower data-driven decision-making.
 Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Post Syndicated from Patrick Chang original https://aws.amazon.com/blogs/security/2023-h2-irap-report-is-now-available-on-aws-artifact-for-australian-customers/
Amazon Web Services (AWS) is excited to announce that a new Information Security Registered Assessors Program (IRAP) report (2023 H2) is now available through AWS Artifact. An independent Australian Signals Directorate (ASD) certified IRAP assessor completed the IRAP assessment of AWS in December 2023.
The new IRAP report includes an additional seven AWS services that are now assessed at the PROTECTED level under IRAP. This brings the total number of services assessed at the PROTECTED level to 151.
The following are the seven newly assessed services:
For the full list of services, see the IRAP tab on the AWS Services in Scope by Compliance Program page.
AWS has developed an IRAP documentation pack to assist Australian government agencies and their partners to plan, architect, and assess risk for their workloads when they use AWS Cloud services.
We developed this pack in accordance with the Australian Cyber Security Centre (ACSC) Cloud Security Guidance and Cloud Assessment and Authorisation framework, which addresses guidance within the Australian Government’s Information Security Manual (ISM, September 2023 version), the Department of Home Affairs’ Protective Security Policy Framework (PSPF), and the Digital Transformation Agency’s Secure Cloud Strategy.
The IRAP pack on AWS Artifact also includes newly updated versions of the AWS Consumer Guide and the whitepaper Reference Architectures for ISM PROTECTED Workloads in the AWS Cloud.
Reach out to your AWS representatives to let us know which additional services you would like to see in scope for upcoming IRAP assessments. We strive to bring more services into scope at the PROTECTED level under IRAP to support your requirements.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Post Syndicated from Amrit Singh original https://www.backblaze.com/blog/navigating-cloud-storage-what-is-latency-and-why-does-it-matter/

In today’s bandwidth-intensive world, latency is an important factor that can impact performance and the end-user experience for modern cloud-based applications. For many CTOs, architects, and decision-makers at growing small and medium sized businesses (SMBs), understanding and reducing latency is not just a technical need but also a strategic play.
Latency, or the time it takes for data to travel from one point to another, affects everything from how snappy or responsive your application may feel to content delivery speeds to media streaming. As infrastructure increasingly relies on cloud object storage to manage terabytes or even petabytes of data, optimizing latency can be the difference between success and failure.
Let’s get into the nuances of latency and its impact on cloud storage performance.
In the world of cloud storage, you’ll typically encounter two forms of latency: upload latency and download latency. Each can impact the responsiveness and efficiency of your cloud-based application.
Upload latency refers to the delay when data is sent from a client or user’s device to the cloud. Live streaming applications, backup solutions, or any application that relies heavily on real-time data uploading will experience hiccups if upload latency is high, leading to buffering delays or momentary stream interruptions.
Download latency, on the other hand, is the delay when retrieving data from the cloud to the client or end user’s device. Download latency is particularly relevant for content delivery applications, such as on demand video streaming platforms, e-commerce, or other web-based applications. Reducing download latency, creating a snappy web experience, and ensuring content is swiftly delivered to the end user will make for a more favorable user experience.
Ideally, you’ll want to optimize for latency in both directions, but, depending on your use case and the type of application you are building, it’s important to understand the nuances of upload and download latency and their impact on your end users.
When it comes to cloud storage, how good or bad the latency is can be influenced by a number of factors, each having an impact on the overall performance of your application. Let’s explore a few of these key factors.
Like traffic on a freeway, packets of data can experience congestion on the internet. This can lead to slower data transmission speeds, especially during peak hours, leading to a laggy experience. Internet connection quality and the capacity of networks can also contribute to this congestion.
Often overlooked, the physical distance from the client or end user’s device to the cloud origin store can have an impact on latency. The farther the distance from the client to the server, the farther the data has to traverse and the longer it takes for transmission to complete, leading to higher latency.
The quality of infrastructure, including routers, switches, and cables, may affect network performance and latency numbers. Modern hardware, such as fiber-optic cables, can reduce latency, unlike outdated systems that don’t meet current demands. Often, you don’t have full control over all of these infrastructure elements, but awareness of potential bottlenecks may be helpful, guiding upgrades wherever possible.
Reduced latency and improved application performance are important for businesses that rely on frequently accessing data stored in cloud storage. This may include selecting providers with strategically positioned data centers, fine-tuning network configurations, and understanding how internet infrastructure affects the latency of their applications.
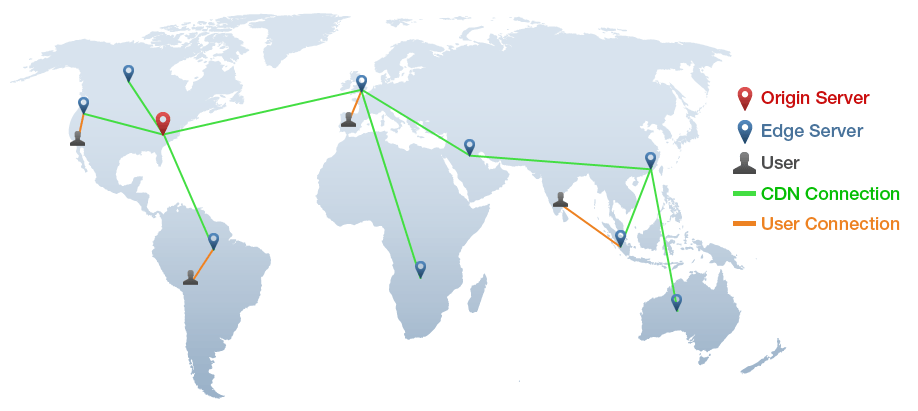
Further reducing latency in your application may be achieved by layering a content delivery network (CDN) in front of your origin storage. CDNs help reduce the time it takes for content to reach the end user by caching data in distributed servers that store content across multiple geographic locations. When your end-user requests or downloads content, the CDN delivers it from the nearest server, minimizing the distance the data has to travel, which significantly reduces latency.
Backblaze B2 Cloud Storage integrates with multiple CDN solutions, including Fastly, Bunny.net, and Cloudflare, providing a performance advantage. And, Backblaze offers the additional benefit of free egress between where the data is stored and the CDN’s edge servers. This not only reduces latency, but also optimizes bandwidth usage, making it cost effective for businesses building bandwidth intensive applications such as on demand media streaming.
To get slightly into the technical weeds, CDNs essentially cache content at the edge of the network, meaning that once content is stored on a CDN server, subsequent requests do not need to go back to the origin server to request data.
This reduces the load on the origin server and reduces the time needed to deliver the content to the user. For companies using cloud storage, integrating CDNs into their infrastructure is an effective configuration to improve the global availability of content, making it an important aspect of cloud storage and application performance optimization.
To illustrate the impact of reduced latency on performance, consider the example of music streaming platform Musify. By moving from Amazon S3 to Backblaze B2 and leveraging the partnership with Cloudflare, Musify significantly improved its service offering. Musify egresses about 1PB of data per month, which, under traditional cloud storage pricing models, can lead to significant costs. Because Backblaze and Cloudflare are both members of the Bandwidth Alliance, Musify now has no data transfer costs, contributing to an estimated 70% reduction in cloud spend. And, thanks to the high cache hit ratio, 90% of the transfer takes place in the CDN layer, which helps maintain high performance, regardless of the location of the file or the user.
As we wrap up our look at the role latency plays in cloud-based applications, it’s clear that understanding and strategically reducing latency is a necessary approach for CTOs, architects, and decision-makers building many of the modern applications we all use today. There are several factors that impact upload and download latency, and it’s important to understand the nuances to effectively improve performance.
Additionally, Backblaze B2’s integrations with CDNs like Fastly, bunny.net, and Cloudflare offer a cost-effective way to improve performance and reduce latency. The strategic decisions Musify made demonstrate how reducing latency with a CDN can significantly improve content delivery while saving on egress costs, and reducing overall business OpEx.
For additional information and guidance on reducing latency, improving TTFB numbers and overall performance, the insights shared in “Cloud Performance and When It Matters” offer a deeper, technical look.
If you’re keen to explore further into how an object storage platform may support your needs and help scale your bandwidth-intensive applications, read more about Backblaze B2 Cloud Storage.
The post Navigating Cloud Storage: What is Latency and Why Does It Matter? appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=vz1oWhPoIwA
Post Syndicated from Julian Lovelock original https://aws.amazon.com/blogs/security/aws-recognized-as-overall-leader-in-2023kuppingercole-leadership-compass/
Amazon Web Services (AWS) was recognized by KuppingerCole Analysts AG as an Overall Leader in the firm’s Leadership Compass report for Policy Based Access Management. The Leadership Compass report reveals Amazon Verified Permissions as an Overall Leader (as shown in Figure 1), a Product Leader for functional strength, and an Innovation Leader for open source security. The recognition is based on a comparison with 14 other vendors, using standardized evaluation criteria set by KuppingerCole.

Figure 1: KuppingerCole Leadership Compass for Policy Based Access Management
The report helps organizations learn about policy-based access management solutions for common use cases and requirements. KuppingerCole defines policy-based access management as an approach that helps to centralize policy management, run authorization decisions across a variety of applications and resource types, continually evaluate authorization decisions, and support corporate governance.
Policy-based access management has three major benefits: consistency, security, and agility. Many organizations grapple with a patchwork of access control mechanisms, which can hinder their ability to implement a consistent approach across the organization, increase their security risk exposure, and reduce the agility of their development teams. A policy-based access control architecture helps organizations centralize their policies in a policy store outside the application codebase, where the policies can be audited and consistently evaluated. This enables teams to build, refactor, and expand applications faster, because policy guardrails are in place and access management is externalized.
Amazon Verified Permissions is a scalable, fine-grained permissions management and authorization service for the applications that you build. This service helps your developers to build more secure applications faster, by externalizing authorization and centralizing policy management and administration. Developers can align their application access with Zero Trust principles by implementing least privilege and continual authorization within applications. Security and audit teams can better analyze and audit who has access to what within applications.
Verified Permissions uses Cedar, a purpose-built and security-first open source policy language, to define policy-based access controls by using roles and attributes for more granular, context-aware access control. Cedar demonstrates the AWS commitment to raising the bar for open source security by developing key security-related technologies in collaboration with the community, with a goal of improving security postures across the industry.
The KuppingerCole Leadership Compass report offers insightful guidance as you evaluate policy-based access management solutions for your organization. Access a complimentary copy of the 2024 KuppingerCole Leadership Compass for Policy-Based Access Management.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/02/china-surveillance-company-hacked.html
Last week, someone posted something like 570 files, images and chat logs from a Chinese company called I-Soon. I-Soon sells hacking and espionage services to Chinese national and local government.
Lots of details in the news articles.
These aren’t details about the tools or techniques, more the inner workings of the company. And they seem to primarily be hacking regionally.
Post Syndicated from corbet original https://lwn.net/Articles/963767/
Netflix has announced
the release of a tool called bpftop to help with the performance
optimization of BPF programs in the kernel:
bpftop provides a dynamic real-time view of running eBPF
programs. It displays the average execution runtime, events per
second, and estimated total CPU % for each program. This tool
minimizes overhead by enabling performance statistics only while it
is active.
Post Syndicated from corbet original https://lwn.net/Articles/963805/
Security updates have been issued by Debian (engrampa and libgit2), Fedora (libxls, perl-Spreadsheet-ParseXLSX, and wpa_supplicant), Gentoo (PyYAML), Mageia (packages and thunderbird), Red Hat (firefox, kernel, linux-firmware, thunderbird, and unbound), Slackware (openjpeg), SUSE (golang-github-prometheus-prometheus, installation-images, kernel, python-azure-core, python-azure-storage-blob, salt and python-pyzmq, SUSE Manager 4.2.11, SUSE Manager 4.3, SUSE Manager Server 4.2, and wayland), and Ubuntu (dnsmasq, libde265, libxml2, openjdk-17, openjdk-21, openjdk-lts, and postgresql-12, postgresql-14, postgresql-15).
Post Syndicated from turnoff.us original http://turnoff.us/geek/code-style-2/

Post Syndicated from Michael Kammer original https://blog.zabbix.com/keeping-remote-teams-connected-the-zabbix-advantage/27551/
The popularity of remote teams may have exploded in popularity during the COVID-19 pandemic, but it’s not a phenomenon that’s likely to trend downward anytime soon. High-profile organizations like 3M, Dropbox, Shopify, and LinkedIn are continuing to enthusiastically embrace remote working, essentially making it the “default setting” for their employees.
The shift toward remote working is not without its challenges, however. Organizations of all sizes often have little time to set up the kind of networking infrastructure and efficient processes that make sure remote workers are just as connected and productive as their on-site counterparts. In this article, we’ll take a quick look at some of the most important network monitoring challenges that remote teams face and show how Zabbix can help you tackle them as efficiently as possible.
Table of Contents
A remote network is essentially a grouping of multiple smaller network setups, each with their own set of variables that can affect performance. The differences between network system and infrastructure quality at different remote destinations can often lead to low overall network performance, which in turn makes it a challenge to provide the kind of high-speed communication needed to run the remote automation tools and software applications used by remote employees and teams.
By providing straightforward and easy-to-understand visibility into a network’s connected devices and how data moves between them, Zabbix makes it easy to automatically compare data and identify any drop in network performance.
With Zabbix, you can easily keep an eye on network routers and switches, especially internet provider and uplink ports up/down. You can also monitor network latency, the error rate on ports, the packet loss to important devices, and network utilization on important ports with net.if.in/net.if.out. Here are some example triggers:
High Network Utilization: avg(/Router ABC/net.if.in[eth0],5m)>80MB
High Packet Loss: avg(/Router ABC/icmppingloss,5m)>5
High Latency: avg(/Router ABC/icmppingsec,5m)>0.1
What’s more, Zabbix allows you to create network maps with important network devices and real-time data, as well as dashboards with maps and single item/gauge widgets, all of which makes it far easier to achieve the uninterrupted connectivity that remote teams depend on.


Remote locations aren’t islands that can be completely isolated from external traffic. Staying vigilant and doing everything possible to eliminate data breaches is important, and taking advantage of strong encryption methods, network scanning tools, and firewalls to protect your systems is a good start. However, using a whole suite of tools to protect security can add more difficulty when it comes to integrating and monitoring them.
With Zabbix, you can count on enterprise-grade security, including encrypted communication between components, a flexible user permission schema that can be easily applied to a distributed environment, and custom user roles with a granular set of permissions for different types of users.
Zabbix also provides native support for HTTP, LDAP, and SAML authentication (which gives you an additional layer of security and improves your user experience while working with Zabbix), the ability to restrict access to sensitive information by limiting which metrics can be collected in your environment, and the ability to track changes in your environment by utilizing the Audit log. It’s all designed to make sure that there are no compromises on the security of your data when you decide to go remote.
As a remote organization grows and its distributed systems expand, a good monitoring solution needs to be able to grow along with it in order to prevent gaps in coverage while maintaining performance and reliability. Zabbix gives you limitless scalability in the form of Zabbix proxies, which act as independent intermediaries that collect performance and availability data on behalf of a Zabbix server. You can roll out new proxies as fast as you need them, and because Zabbix is free and open source, you don’t have to worry about additional licensing costs.
Zabbix proxies allow you to see at a glance what resources are being used on your network at any given moment, which is especially handy if, like most remote teams, you have tens or even hundreds of servers and network appliances to monitor. You can also execute remote commands in remote locations – either on the proxies themselves or on the agents monitored by the proxy, and multiple frontends can be deployed for load balancing as well as for improved security and connectivity. Proxy docker containers and cloud options are available as well, enhancing flexibility and making Zabbix ideal for any organization that spans the globe (or aspires to).
The legacy software and systems you use were most likely designed to work in a traditional networking model. Remote working, as we’ve seen, presents a whole new range of challenges when it comes to compatibility and support.
We’ve created Zabbix to be as easy as possible to integrate with existing systems. You can easily monitor any operating system, cloud service, IP telephony service, docker container, or web server/database backend. We provide out-of-the-box monitoring for the world’s leading hardware and software vendors, and our extensively documented API makes it easy to create workflows and integrate with other systems. In addition, you can also integrate Zabbix with the most popular helpdesk, messaging, and ITSM systems, such as Slack, Jira, MS Teams, and many others.

Not only that, Zabbix is designed to serve as the ideal monitoring solution for multi-tenant environments. It serves as a single pane of glass for your entire infrastructure, and it’s easy to visualize everything that’s happening with your network with unique maps, dashboards, and templates.
The days of large teams all working together under the same roof are a thing of the past – the remote working trend will only accelerate as technology improves and employees get more accustomed to working with colleagues across multiple locations. That’s why it’s of paramount importance to make sure your monitoring solution has the built-in flexibility and scalability to grow with your team and your business.
If you want to see for yourself how Zabbix can help you effectively monitor a globally distributed network, contact us.
The post Keeping Remote Teams Connected: The Zabbix Advantage appeared first on Zabbix Blog.
Post Syndicated from Kevin Johnson original https://www.raspberrypi.org/blog/black-history-month-2024/
It’s the last week of Black History Month 2024 in the USA, but by no means is the celebration over. The beautiful thing about history is that it’s not an isolated narrative about the past, but an ongoing dialogue in which we talk about how our collective past informs our present, and what more can be achieved in the future. The fact is this: we make history every single day. That’s why it’s so important for everyone to actively engage with history, and for us to celebrate the achievements of all.

When we talk about the history of STEM and computing, it’s necessary to highlight the achievements of people from groups that are still underrepresented in these fields: communities of colour, female and gender non-conforming people, people with disabilities, and underresourced communities. When we highlight their achievements, everyone can gain a fuller understanding of this history, and more young people from these groups can see they have a place in these fields and in moving them forward.
[When young kids of colour help inform the technology they use,] we end up with technology that is more inclusive to diverse communities […], and we help the kids become creators instead of just consumers.
Qumisha Goss
So to keep the conversation going about Black history in STEM and computing and how people make it every day, today we’re highlighting stories of Black community members. You’ll find out how they got involved in coding and creating with technology, and who their Black role models in tech are — past and present.
Meet Qumisha Goss, a brilliant source of inspiration and a shining light for youth in the ‘Motor City’ of Detroit, Michigan, USA.

Growing up, Qumisha always had an interest in tech, often tinkering and putting projects together, and her interest quickly transformed into a dream of becoming an engineer one day. Fast forward to now, and Qumisha has done exactly that and so much more.
She’s the Interim Executive Director of Peer 2 Peer University, the Digital Literacy Subject Matter Expert for Connect 313, the Creator and Lead Instructor of Code Grow, and a Raspberry Pi Certified Educator. Talk about impact! We asked Qumisha a few questions to explore her incredible story and to learn how she’s giving back to her community today:
Qumisha: “When I was a kid, my grandmas, Gloria and Cassandra, helped my brother and I make a shrinking machine out of a cardboard box, some batteries, and some lights. There was a minimum of science used, but my grandma swapped out our test ear of corn for a baby corn and my curiosity was rewarded with success. In elementary school, my ‘hero’ was Mae Carol Jemison, engineer, doctor, and astronaut. She was the first African American woman to go to space, in 1992 on the Endeavor. I found someone who looked like me who was doing something that I wanted to do, and that was encouraging.”

Qumisha: “It’s important that young kids of colour help inform the technology that they use. The benefits are twofold: we end up with technology that is more inclusive to diverse communities because it is informed by them, and we help the kids become creators instead of just consumers.”
Qumisha: “I eventually went to college to study engineering. I ended up switching majors and studying history and classical languages, but later returned to the tech world when I joined the Python and Raspberry Pi communities. I learned how to code outside of a traditional classroom and have been running physical computing classes and workshops for kids in my hometown of Detroit.”

Qumisha: “Even if kids don’t stick with it, they learn that coding — and lots of things — are not beyond them. The next Bill Gates might be sitting on the library stoop. The difference between them being able to make it or not is: ‘Did they ever get the opportunity to touch the thing that really sparks their genius?’ And for me, I want to help as many kids as possible interact with tech in a fun and engaging way so that they know that they can be technologists too.”
The difference between [kids] being able to make it or not is: ‘Did they ever get the opportunity to touch the thing that really sparks their genius?’
Qumisha Goss
To connect with Qumisha and learn how you can support the incredible, history-making work that she’s doing, follow her on X at @QatalystGoss.
Keep reading to meet more Black history makers across the USA, and to find resources to learn how you can help increase diversity in the technology sector in your community.
Explore our research seminars for educators who want to learn how to make computer science more accessible to all.
Listen to the stories of other Black community members who are making history all over the US. Siblings Sophia and Sebastian, researcher Randi Williams, and aspiring filmmaker Jordan chatted to us about their interest in coding, tech, and getting creative with digital tools.

Try out one of our guided projects for young people to get creative with tech. Check out Coolest Projects, our free online showcase for young tech creators, and how you can get young people involved.
And if you want to share the story of how you got into tech and how you’re inspiring kids to do the same, reach out to us on social media so we can amplify your voice.
Happy Black History Month!
The post Black role models in tech are making history every day appeared first on Raspberry Pi Foundation.


 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat. Rahul Sharma is a Technical Account Manager at Amazon Web Services. He is passionate about the data technologies that help leverage data as a strategic asset and is based out of New York city, New York.
Rahul Sharma is a Technical Account Manager at Amazon Web Services. He is passionate about the data technologies that help leverage data as a strategic asset and is based out of New York city, New York.