Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=3wybcrgF-us
Leemhuis: Regression tracking: state of the union early 2024
Post Syndicated from corbet original https://lwn.net/Articles/957252/
Thorsten Leemhuis writes
about his plans for improving the kernel’s regression handling in the
coming year.
Top-priority will be “make regzbot more useful for kernel subsystem
maintainers” from now on. My tracking efforts of course will
continue, but everything except regressions in the current and the
previous mainline cycle might not see much attention from my
side. This refocusing also means that I won’t work much on
resolving some ambiguities around “how regressions are supposed to
be handled” which lead to tension quite a few times. But all that
should be for the best in the long term.
Building a generative AI Marketing Portal on AWS
Post Syndicated from Tristan Nguyen original https://aws.amazon.com/blogs/messaging-and-targeting/building-a-generative-ai-marketing-portal-on-aws/
Introduction
In the preceding entries of this series, we examined the transformative impact of Generative AI on marketing strategies in “Building Generative AI into Marketing Strategies: A Primer” and delved into the intricacies of Prompt Engineering to enhance the creation of marketing content with services such as Amazon Bedrock in “From Prompt Engineering to Auto Prompt Optimisation”. We also explored the potential of Large Language Models (LLMs) to refine prompts for more effective customer engagement.
Continuing this exploration, we will articulate how Amazon Bedrock, Amazon Personalize, and Amazon Pinpoint can be leveraged to construct a marketer portal that not only facilitates AI-driven content generation but also personalizes and distributes this content effectively. The aim is to provide a clear blueprint for deploying a system that crafts, personalizes, and distributes marketing content efficiently. This blog will guide you through the deployment process, underlining the real-world utility of these services in optimizing marketing workflows. Through use cases and a code demonstration, we’ll see these technologies in action, offering a hands-on perspective on enhancing your marketing pipeline with AI-driven solutions.
The Challenge with Content Generation in Marketing
Many companies struggle to streamline their marketing operations effectively, facing hurdles at various stages of the marketing operations pipeline. Below, we list the challenges at three main stages of the pipeline: content generation, content personalization, and content distribution.
Content Generation
Creating high-quality, engaging content is often easier said than done. Companies need to invest in skilled copywriters or content creators who understand not just the product but also the target audience. Even with the right talent, the process can be time-consuming and costly. Moreover, generating content at scale while maintaining quality and compliance to industry regulations is the key blocker for many companies considering adopting generative AI technologies in production environments.
Content Personalization
Once the content is created, the next hurdle is personalization. In today’s digital age, generic content rarely captures attention. Customers expect content tailored to their needs, preferences, and behaviors. However, personalizing content is not straightforward. It requires a deep understanding of customer data, which often resides in siloed databases, making it difficult to create a 360-degree view of the customer.
Content Distribution
Finally, even the most captivating, personalized content is ineffective if it doesn’t reach the right audience at the right time. Companies often grapple with choosing the appropriate channels for content distribution, be it email, social media, or mobile notifications. Additionally, ensuring that the content complies with various regulations and doesn’t end up in spam folders adds another layer of complexity to the distribution phase. Sending at scale requires paying attention to deliverability, security and reliability which often poses significant challenges to marketers.
By addressing these challenges, companies can significantly improve their marketing operations and empower their marketers to be more effective. But how can this be achieved efficiently and at scale? The answer lies in leveraging the power of Amazon Bedrock, Amazon Personalize, and Amazon Pinpoint, as we will explore in the following solution.
The Solution In Action
Before we dive into the details of the implementation, let’s take a look at the end result through the linked demo video.
Use Case 1: Banking/Financial Services Industry
You are a relationship manager working in the Consumer Banking department of a fictitious company called AnyCompany Bank. You are assigned a group of customers and would like to send out personalized and targeted communications to the channel of choice to every members of this group of customer.
Behind the scene, the marketer is utilizing Amazon Pinpoint to create the segment of customers they would like to target. The customers’ information and the marketer’s prompt are then fed into Amazon Bedrock to generate the marketing content, which is then sent to the customer via SMS and email using Amazon Pinpoint.
- In the Prompt Iterator page, you can employ a process called “prompt engineering” to further optimize your prompt to maximize the effectiveness of your marketing campaigns. Please refer to this blog on the process behind engineering the prompt as well as how to apply an additional LLM model for auto-prompting. To get started, simply copy the sample banking prompt which has gone through the prompt engineering process in this page.
- Next, you can either upload your customer group by uploading a .csv file (through “Importing a Segment”) or specify a customer group using pre-defined filter criteria based on your current customer database using Amazon Pinpoint.

E.g.: The screenshot shows a sample filtered segment named ManagementOrRetired that only filters to customers who are management or retirees.
- Once done, you can log into the marketer portal and choose the relevant segment that you’ve just created within the Amazon Pinpoint console.

- You can then preview the customers and their information stored in your Amazon Pinpoint’s customer database. Once satisfied, we’re ready to start generating content for those customers!
- Click on 1:1 Content Generator tab, your content is automatically generated for your first customer. Here, you can cycle through your customers one by one, and depending on the customer’s preferred language and channel, an email or SMS in the preferred language is automatically generated for them.
- Generated SMS in English

-
- A negative example showing proper prompt-engineering at work to moderate content. This happens if we try to insert data that does not make sense for the marketing content generator to output. In this case, the marketing generator refuses to output (justifiably) an advertisement for a 6-year-old on a secured instalment loan.

- Finally, we choose to send the generated content via Amazon Pinpoint by clicking on “Send with Amazon Pinpoint”. In the back end, Amazon Pinpoint will orchestrate the sending of the email/SMS through the appropriate channels.
- Alternatively, if the auto-generated content still did not meet your needs and you want to generate another draft, you can Disagree and try again.
Use Case 2: Travel & Hospitality
You are a marketing executive that’s working for an online air ticketing agency. You’ve been tasked to promote a specific flight from Singapore to Hong Kong for AnyCompany airline. You’d first like to identify which customers would be prime candidates to promote this flight leg to and then send out hyper-personalized message to them.
Behind the scene, instead of using Amazon Pinpoint to manually define the segment, the marketer in this case is leveraging AIML capabilities of Amazon Personalize to define the best group of customers to recommend the specific flight leg to them. Similar to the above use case, the customers’ information and LLM prompt are fed into the Amazon Bedrock, which generates the marketing content that is eventually sent out via Amazon Pinpoint.
- Similar to the above use case, you’d need to go through a prompt engineering process to ensure that the content the LLM model is generating will be relevant and safe for use. To get started quickly, go to the Prompt Iterator page, you can use the sample airlines prompt and iterate from there.
- Your company offers many different flight legs, aggregated from many different carriers. You first filter down to the flight leg that you want to promote using the Filters on the left. In this case, we are filtering for flights originating from Singapore (SRCCity) and going to Hong Kong (DSTCity), operated by AnyCompany Airlines.

- Now, let’s choose the number of customers that you’d like to generate. Once satisfied, you choose to start the batch segmentation job.
- In the background, Amazon Personalize generates a group of customers that are most likely to be interested in this flight leg based on past interactions with similar flight itineraries.
- Once the segmentation job is finished as shown, you can fetch the recommended group of customers and start generating content for them immediately, similar to the first use case.
Setup instructions
The setup instructions and deployment details can be found in the GitHub link.
Conclusion
In this blog, we’ve explored the transformative potential of integrating Amazon Bedrock, Amazon Personalize, and Amazon Pinpoint to address the common challenges in marketing operations. By automating the content generation with Amazon Bedrock, personalizing at scale with Amazon Personalize, and ensuring precise content distribution with Amazon Pinpoint, companies can not only streamline their marketing processes but also elevate the customer experience.
The benefits are clear: time-saving through automation, increased operational efficiency, and enhanced customer satisfaction through personalized engagement. This integrated solution empowers marketers to focus on strategy and creativity, leaving the heavy lifting to AWS’s robust AI and ML services.
For those ready to take the next step, we’ve provided a comprehensive guide and resources to implement this solution. By following the setup instructions and leveraging the provided prompts as a starting point, you can deploy this solution and begin customizing the marketer portal to your business’ needs.
Call to Action
Don’t let the challenges of content generation, personalization, and distribution hold back your marketing potential. Deploy the Generative AI Marketer Portal today, adapt it to your specific needs, and watch as your marketing operations transform. For a hands-on start and to see this solution in action, visit the GitHub repository for detailed setup instructions.
Have a question? Share your experiences or leave your questions in the comment section.
About the Authors

Tristan (Tri) Nguyen
Tristan (Tri) Nguyen is an Amazon Pinpoint and Amazon Simple Email Service Specialist Solutions Architect at AWS. At work, he specializes in technical implementation of communications services in enterprise systems and architecture/solutions design. In his spare time, he enjoys chess, rock climbing, hiking and triathlon.

Philipp Kaindl
Philipp Kaindl is a Senior Artificial Intelligence and Machine Learning Solutions Architect at AWS. With a background in data science and
mechanical engineering his focus is on empowering customers to create lasting business impact with the help of AI. Outside of work, Philipp enjoys tinkering with 3D printers, sailing and hiking.

Bruno Giorgini
Bruno Giorgini is a Senior Solutions Architect specializing in Pinpoint and SES. With over two decades of experience in the IT industry, Bruno has been dedicated to assisting customers of all sizes in achieving their objectives. When he is not crafting innovative solutions for clients, Bruno enjoys spending quality time with his wife and son, exploring the scenic hiking trails around the SF Bay Area.
Is Seeed Studio SenseCAP Indicator too powerful for DIY?
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=7eDzZBD0XYA
Shaw: Python 3.13 gets a JIT
Post Syndicated from corbet original https://lwn.net/Articles/957239/
Anthony Shaw describes
the new copy-and-patch JIT that has been proposed for Python 3.13.
Copy-and-patch was selected because the compilation from bytecodes
to machine code is done as a set of “templates” that are then
stitched together and patched at runtime with the correct
values. This means that your average Python user isn’t running this
complex JIT compiler architecture inside their Python
runtime. Python writing it’s own IL and JIT would also be
unreasonable since so many are available off-the-shelf like LLVMs
and ryuJIT. But a full-JIT would require those being bundled with
Python and all the added overheads. A copy-and-patch JIT only
requires the LLVM JIT tools be installed on the machine where
CPython is compiled from source, and for most people that means the
machines of the CI that builds and packages CPython for python.org.
Solus 4.5 released
Post Syndicated from corbet original https://lwn.net/Articles/957221/
Version 4.5
(“Resilience”) of the Solus distribution has been released. “This
”
release brings updated applications and kernels, refreshed software stacks,
a new installer, and a new ISO edition featuring the XFCE desktop
environment.
Security updates for Tuesday
Post Syndicated from corbet original https://lwn.net/Articles/957236/
Security updates have been issued by Debian (squid), Fedora (podman), Mageia (dropbear), SUSE (eclipse-jgit, jsch, gcc13, helm3, opusfile, qt6-base, thunderbird, and wireshark), and Ubuntu (clamav, libclamunrar, and qemu).
DDoS threat report for 2023 Q4
Post Syndicated from Omer Yoachimik http://blog.cloudflare.com/author/omer/ original https://blog.cloudflare.com/ddos-threat-report-2023-q4

Welcome to the sixteenth edition of Cloudflare’s DDoS Threat Report. This edition covers DDoS trends and key findings for the fourth and final quarter of the year 2023, complete with a review of major trends throughout the year.
What are DDoS attacks?
DDoS attacks, or distributed denial-of-service attacks, are a type of cyber attack that aims to disrupt websites and online services for users, making them unavailable by overwhelming them with more traffic than they can handle. They are similar to car gridlocks that jam roads, preventing drivers from getting to their destination.
There are three main types of DDoS attacks that we will cover in this report. The first is an HTTP request intensive DDoS attack that aims to overwhelm HTTP servers with more requests than they can handle to cause a denial of service event. The second is an IP packet intensive DDoS attack that aims to overwhelm in-line appliances such as routers, firewalls, and servers with more packets than they can handle. The third is a bit-intensive attack that aims to saturate and clog the Internet link causing that ‘gridlock’ that we discussed. In this report, we will highlight various techniques and insights on all three types of attacks.
Previous editions of the report can be found here, and are also available on our interactive hub, Cloudflare Radar. Cloudflare Radar showcases global Internet traffic, attacks, and technology trends and insights, with drill-down and filtering capabilities for zooming in on insights of specific countries, industries, and service providers. Cloudflare Radar also offers a free API allowing academics, data sleuths, and other web enthusiasts to investigate Internet usage across the globe.
To learn how we prepare this report, refer to our Methodologies.
Key findings
- In Q4, we observed a 117% year-over-year increase in network-layer DDoS attacks, and overall increased DDoS activity targeting retail, shipment and public relations websites during and around Black Friday and the holiday season.
- In Q4, DDoS attack traffic targeting Taiwan registered a 3,370% growth, compared to the previous year, amidst the upcoming general election and reported tensions with China. The percentage of DDoS attack traffic targeting Israeli websites grew by 27% quarter-over-quarter, and the percentage of DDoS attack traffic targeting Palestinian websites grew by 1,126% quarter-over-quarter — as the military conflict between Israel and Hamas continues.
- In Q4, there was a staggering 61,839% surge in DDoS attack traffic targeting Environmental Services websites compared to the previous year, coinciding with the 28th United Nations Climate Change Conference (COP 28).
For an in-depth analysis of these key findings and additional insights that could redefine your understanding of current cybersecurity challenges, read on!
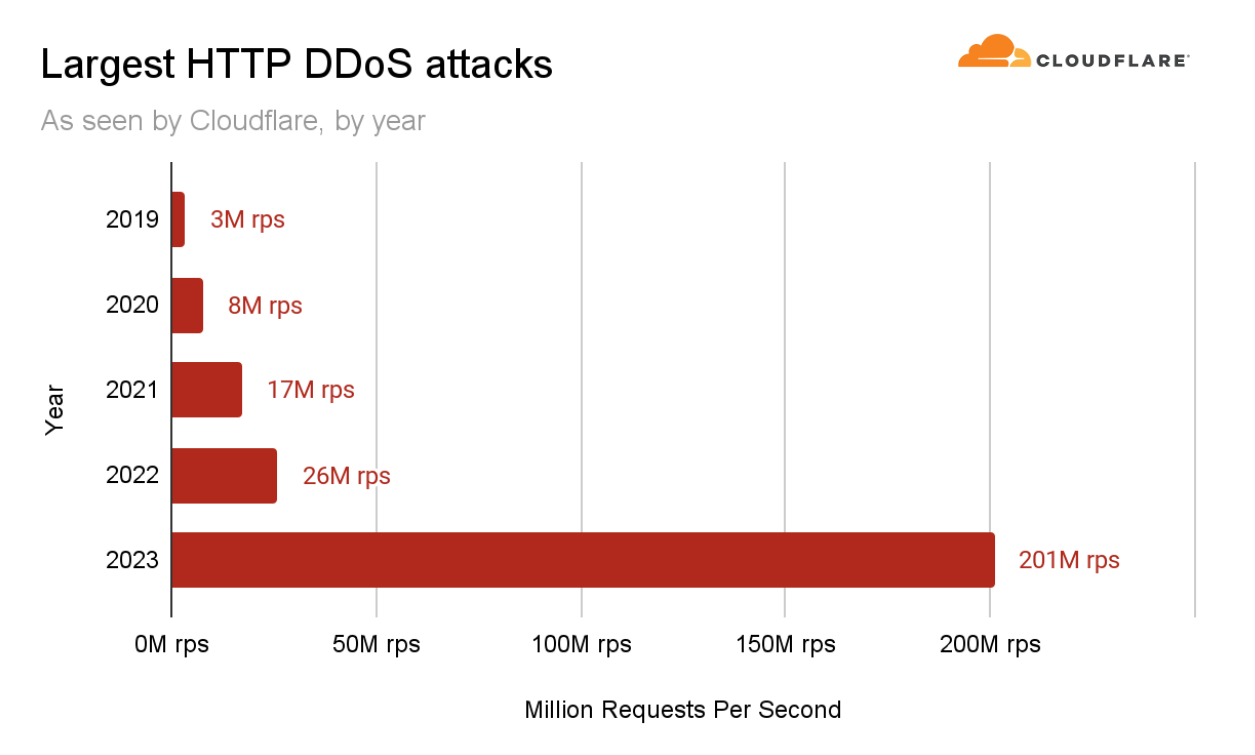
Hyper-volumetric HTTP DDoS attacks
2023 was the year of uncharted territories. DDoS attacks reached new heights — in size and sophistication. The wider Internet community, including Cloudflare, faced a persistent and deliberately engineered campaign of thousands of hyper-volumetric DDoS attacks at never before seen rates.
These attacks were highly complex and exploited an HTTP/2 vulnerability. Cloudflare developed purpose-built technology to mitigate the vulnerability’s effect and worked with others in the industry to responsibly disclose it.
As part of this DDoS campaign, in Q3 our systems mitigated the largest attack we’ve ever seen — 201 million requests per second (rps). That’s almost 8 times larger than our previous 2022 record of 26 million rps.
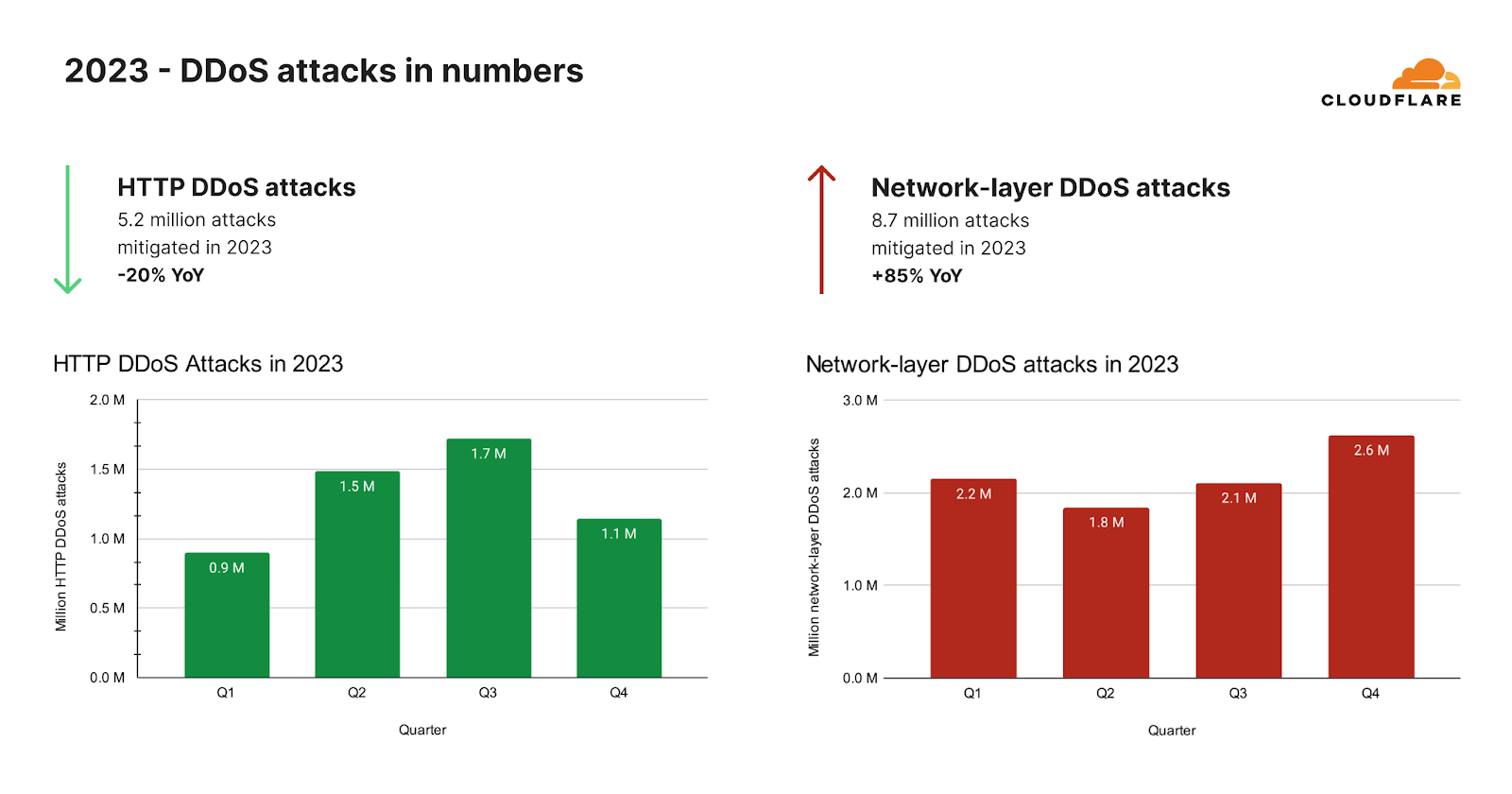
Growth in network-layer DDoS attacks
After the hyper-volumetric campaign subsided, we saw an unexpected drop in HTTP DDoS attacks. Overall in 2023, our automated defenses mitigated over 5.2 million HTTP DDoS attacks consisting of over 26 trillion requests. That averages at 594 HTTP DDoS attacks and 3 billion mitigated requests every hour.
Despite these astronomical figures, the amount of HTTP DDoS attack requests actually declined by 20% compared to 2022. This decline was not just annual but was also observed in 2023 Q4 where the number of HTTP DDoS attack requests decreased by 7% YoY and 18% QoQ.
On the network-layer, we saw a completely different trend. Our automated defenses mitigated 8.7 million network-layer DDoS attacks in 2023. This represents an 85% increase compared to 2022.
In 2023 Q4, Cloudflare’s automated defenses mitigated over 80 petabytes of network-layer attacks. On average, our systems auto-mitigated 996 network-layer DDoS attacks and 27 terabytes every hour. The number of network-layer DDoS attacks in 2023 Q4 increased by 175% YoY and 25% QoQ.
DDoS attacks increase during and around COP 28
In the final quarter of 2023, the landscape of cyber threats witnessed a significant shift. While the Cryptocurrency sector was initially leading in terms of the volume of HTTP DDoS attack requests, a new target emerged as a primary victim. The Environmental Services industry experienced an unprecedented surge in HTTP DDoS attacks, with these attacks constituting half of all its HTTP traffic. This marked a staggering 618-fold increase compared to the previous year, highlighting a disturbing trend in the cyber threat landscape.
This surge in cyber attacks coincided with COP 28, which ran from November 30th to December 12th, 2023. The conference was a pivotal event, signaling what many considered the ‘beginning of the end’ for the fossil fuel era. It was observed that in the period leading up to COP 28, there was a noticeable spike in HTTP attacks targeting Environmental Services websites. This pattern wasn’t isolated to this event alone.
Looking back at historical data, particularly during COP 26 and COP 27, as well as other UN environment-related resolutions or announcements, a similar pattern emerges. Each of these events was accompanied by a corresponding increase in cyber attacks aimed at Environmental Services websites.
In February and March 2023, significant environmental events like the UN’s resolution on climate justice and the launch of United Nations Environment Programme’s Freshwater Challenge potentially heightened the profile of environmental websites, possibly correlating with an increase in attacks on these sites.
This recurring pattern underscores the growing intersection between environmental issues and cyber security, a nexus that is increasingly becoming a focal point for attackers in the digital age.
DDoS attacks and Iron Swords
It’s not just UN resolutions that trigger DDoS attacks. Cyber attacks, and particularly DDoS attacks, have long been a tool of war and disruption. We witnessed an increase in DDoS attack activity in the Ukraine-Russia war, and now we’re also witnessing it in the Israel-Hamas war. We first reported the cyber activity in our report Cyber attacks in the Israel-Hamas war, and we continued to monitor the activity throughout Q4.
Operation “Iron Swords” is the military offensive launched by Israel against Hamas following the Hamas-led 7 October attack. During this ongoing armed conflict, we continue to see DDoS attacks targeting both sides.
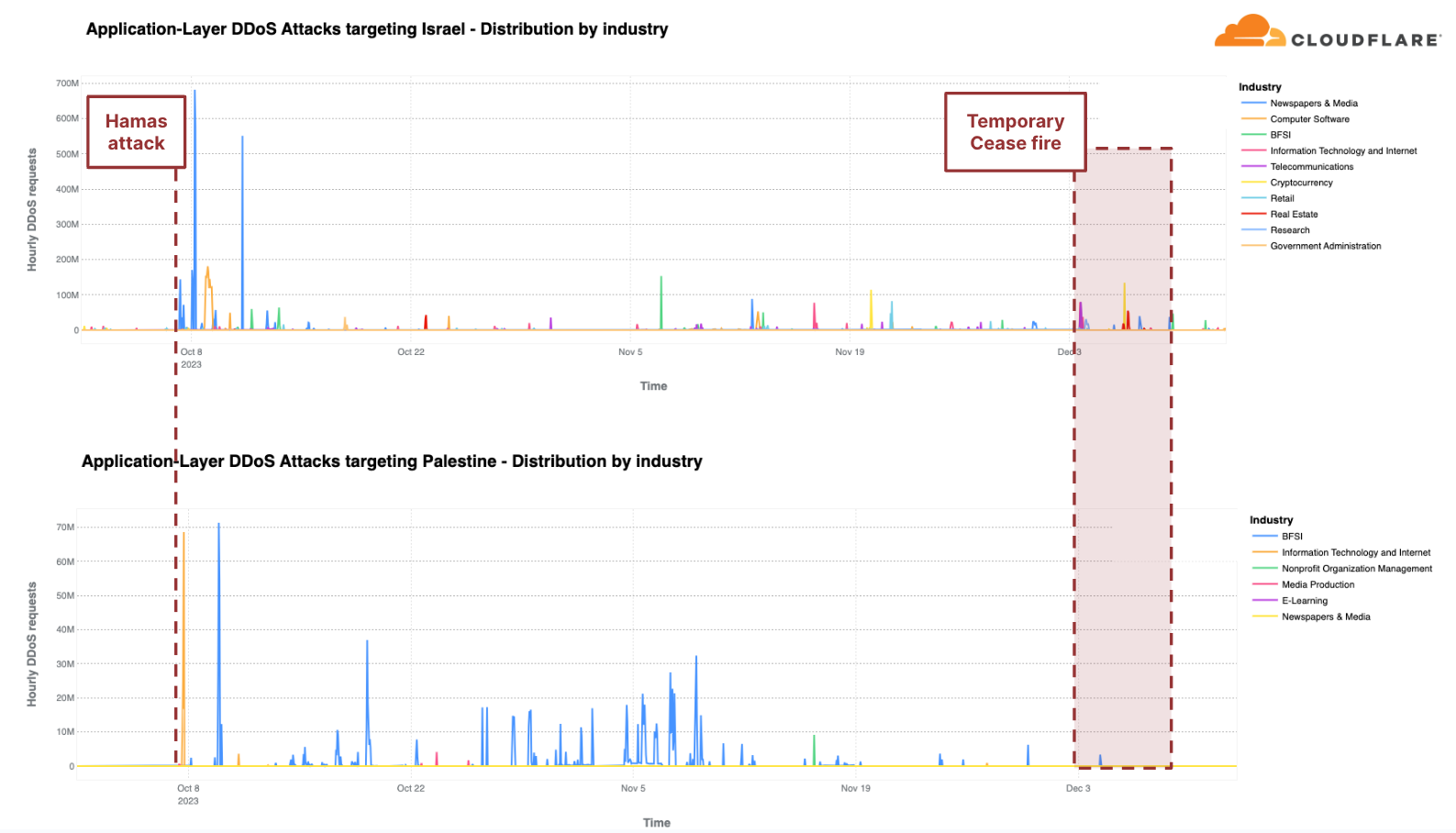
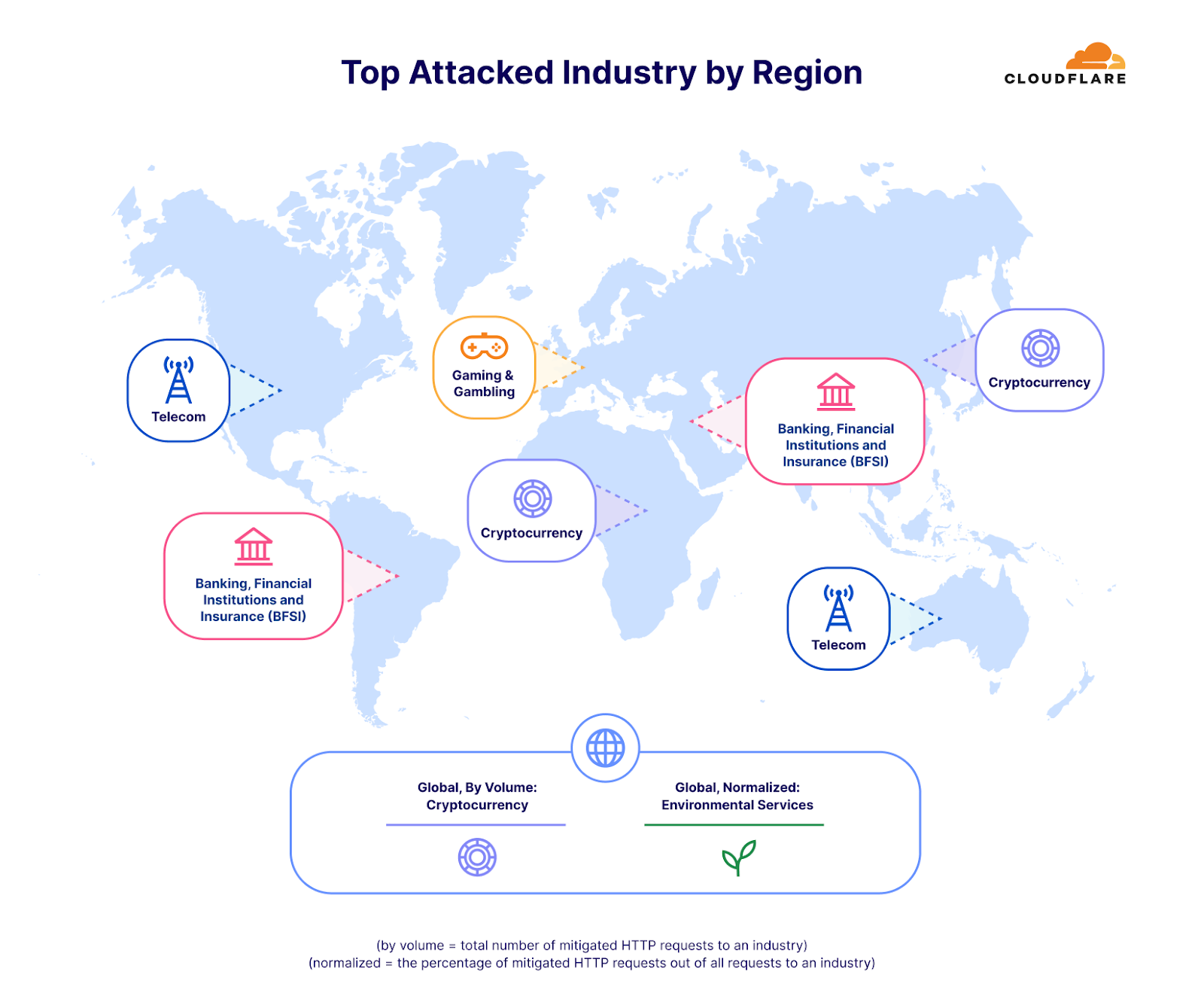
Relative to each region’s traffic, the Palestinian territories was the second most attacked region by HTTP DDoS attacks in Q4. Over 10% of all HTTP requests towards Palestinian websites were DDoS attacks, a total of 1.3 billion DDoS requests — representing a 1,126% increase in QoQ. 90% of these DDoS attacks targeted Palestinian Banking websites. Another 8% targeted Information Technology and Internet platforms.
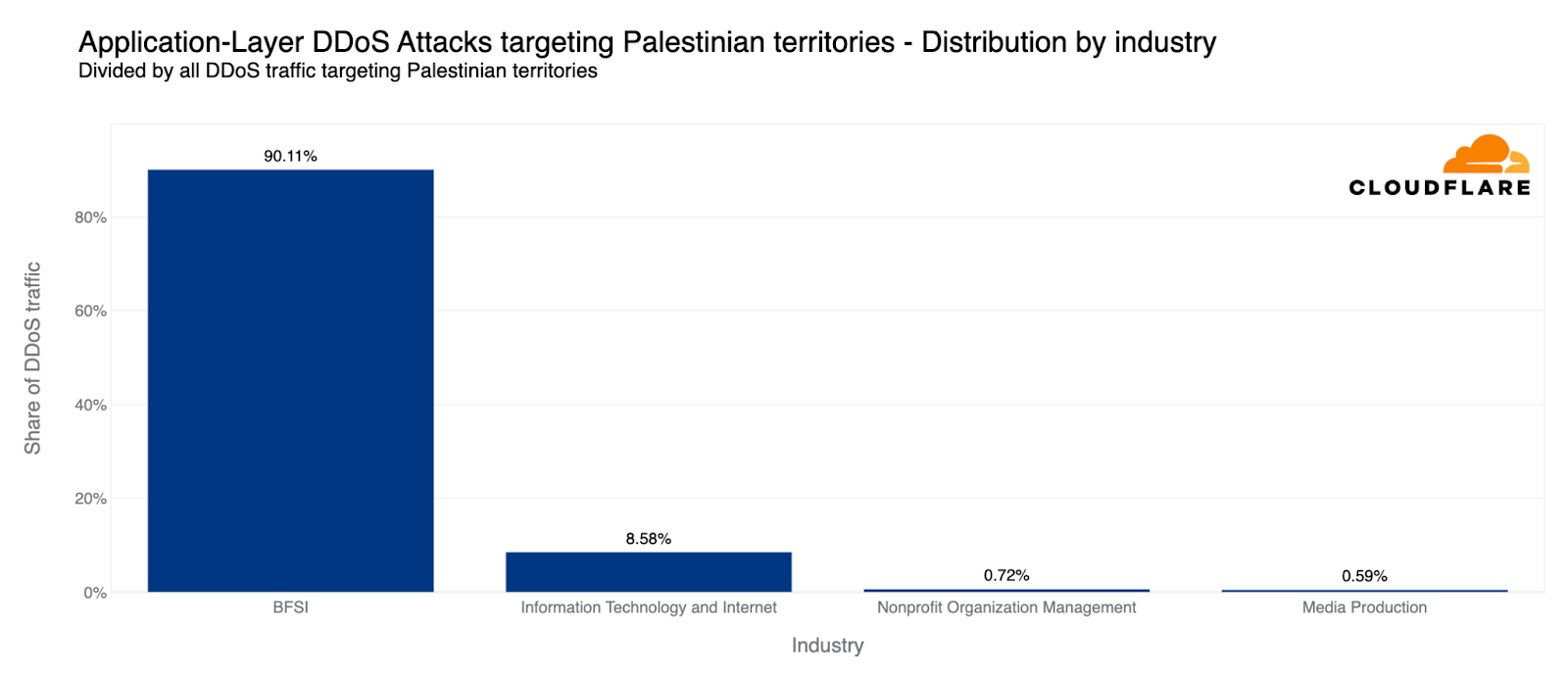
Similarly, our systems automatically mitigated over 2.2 billion HTTP DDoS requests targeting Israeli websites. While 2.2 billion represents a decrease compared to the previous quarter and year, it did amount to a larger percentage out of the total Israel-bound traffic. This normalized figure represents a 27% increase QoQ but a 92% decrease YoY. Notwithstanding the larger amount of attack traffic, Israel was the 77th most attacked region relative to its own traffic. It was also the 33rd most attacked by total volume of attacks, whereas the Palestinian territories was 42nd.
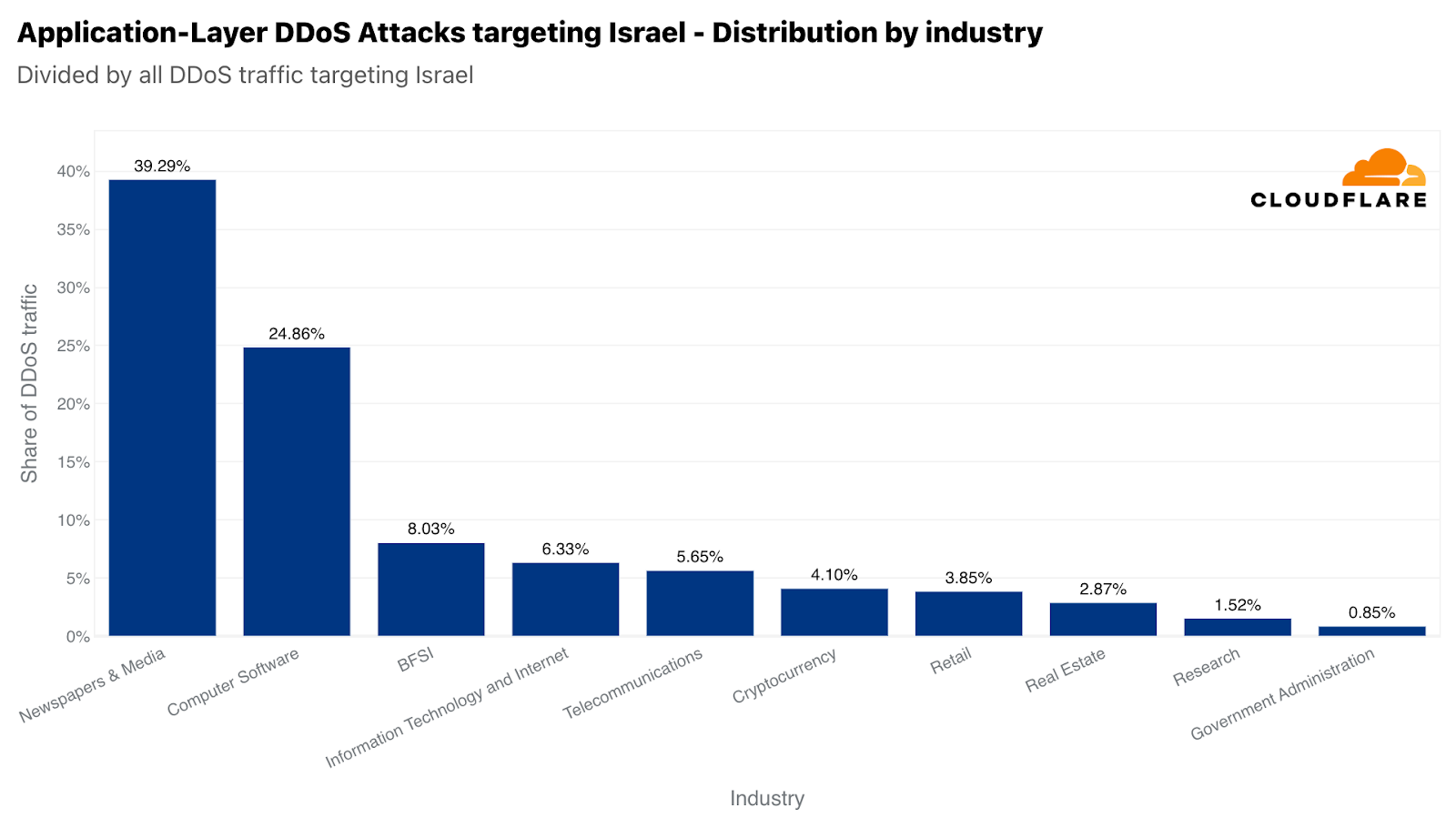
Of those Israeli websites attacked, Newspaper & Media were the main target — receiving almost 40% of all Israel-bound HTTP DDoS attacks. The second most attacked industry was the Computer Software industry. The Banking, Financial Institutions, and Insurance (BFSI) industry came in third.
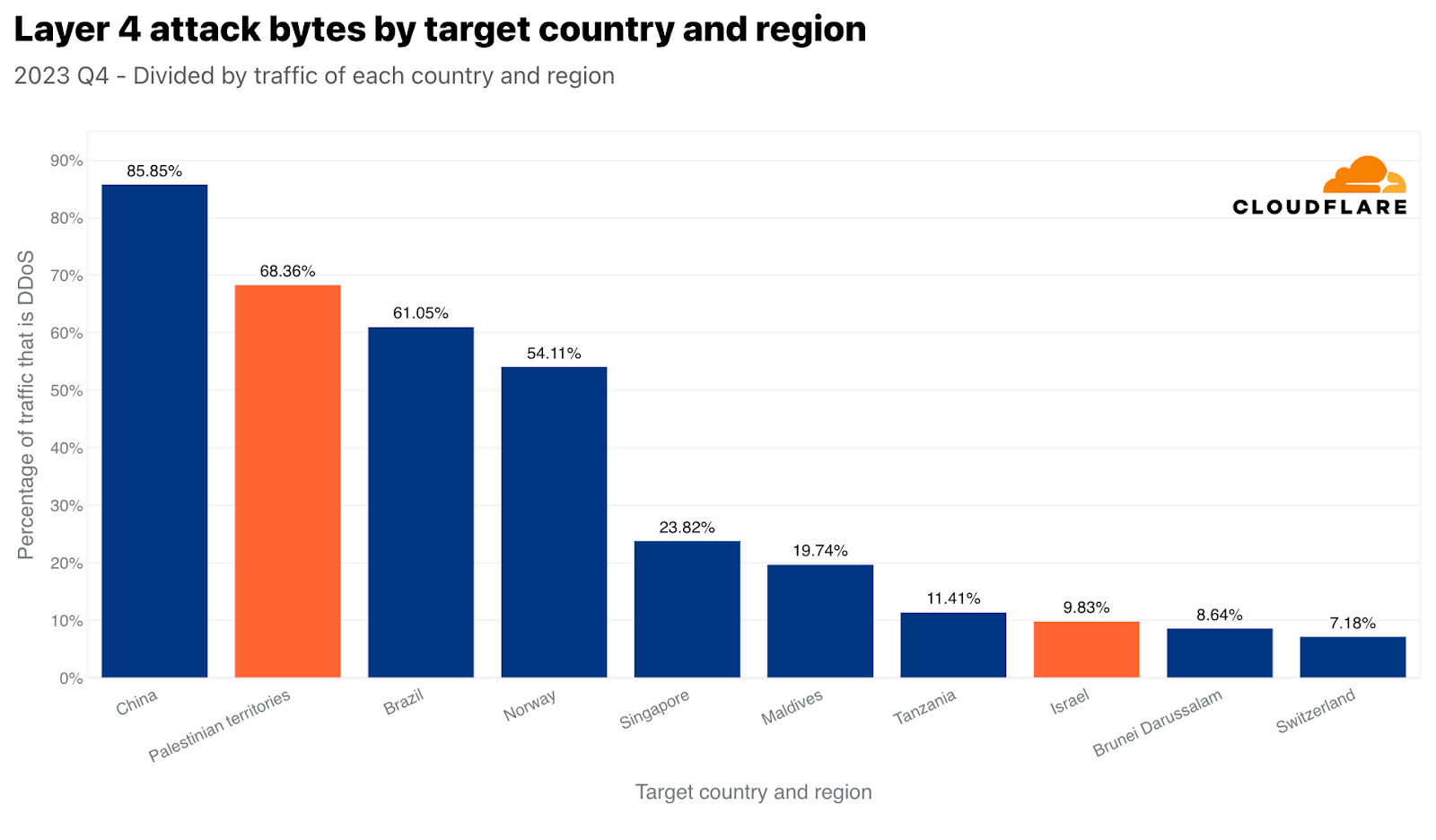
On the network layer, we see the same trend. Palestinian networks were targeted by 470 terabytes of attack traffic — accounting for over 68% of all traffic towards Palestinian networks. Surpassed only by China, this figure placed the Palestinian territories as the second most attacked region in the world, by network-layer DDoS attack, relative to all Palestinian territories-bound traffic. By absolute volume of traffic, it came in third. Those 470 terabytes accounted for approximately 1% of all DDoS traffic that Cloudflare mitigated.
Israeli networks, though, were targeted by only 2.4 terabytes of attack traffic, placing it as the 8th most attacked country by network-layer DDoS attacks (normalized). Those 2.4 terabytes accounted for almost 10% of all traffic towards Israeli networks.
When we turned the picture around, we saw that 3% of all bytes that were ingested in our Israeli-based data centers were network-layer DDoS attacks. In our Palestinian-based data centers, that figure was significantly higher — approximately 17% of all bytes.
On the application layer, we saw that 4% of HTTP requests originating from Palestinian IP addresses were DDoS attacks, and almost 2% of HTTP requests originating from Israeli IP addresses were DDoS attacks as well.
Main sources of DDoS attacks
In the third quarter of 2022, China was the largest source of HTTP DDoS attack traffic. However, since the fourth quarter of 2022, the US took the first place as the largest source of HTTP DDoS attacks and has maintained that undesirable position for five consecutive quarters. Similarly, our data centers in the US are the ones ingesting the most network-layer DDoS attack traffic — over 38% of all attack bytes.
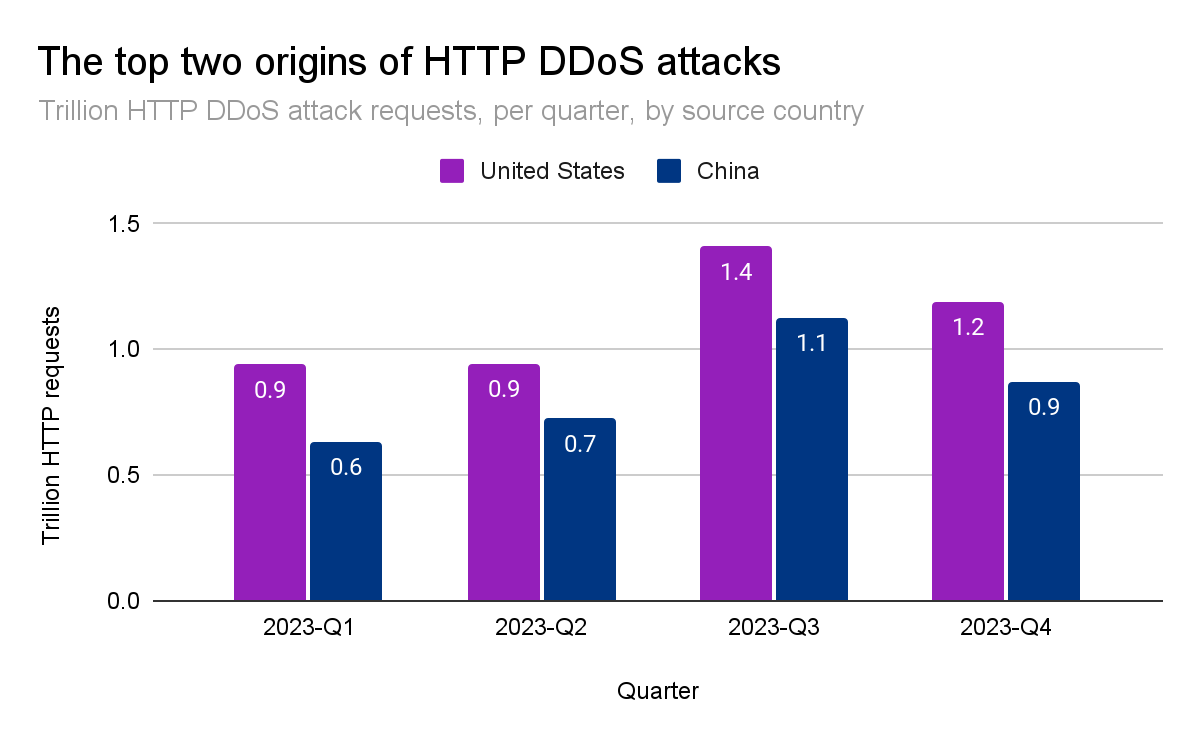
Together, China and the US account for a little over a quarter of all HTTP DDoS attack traffic in the world. Brazil, Germany, Indonesia, and Argentina account for the next twenty-five percent.
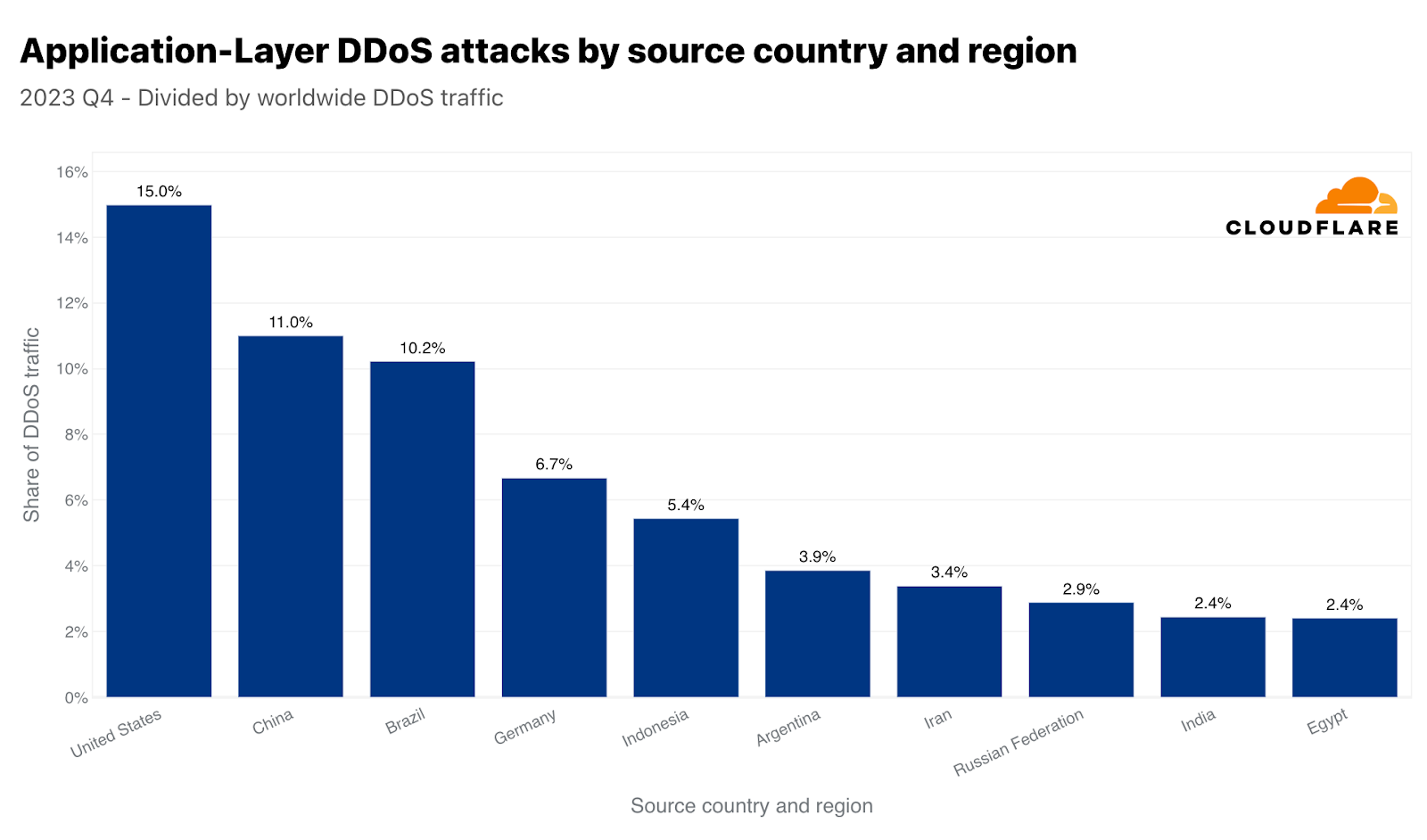
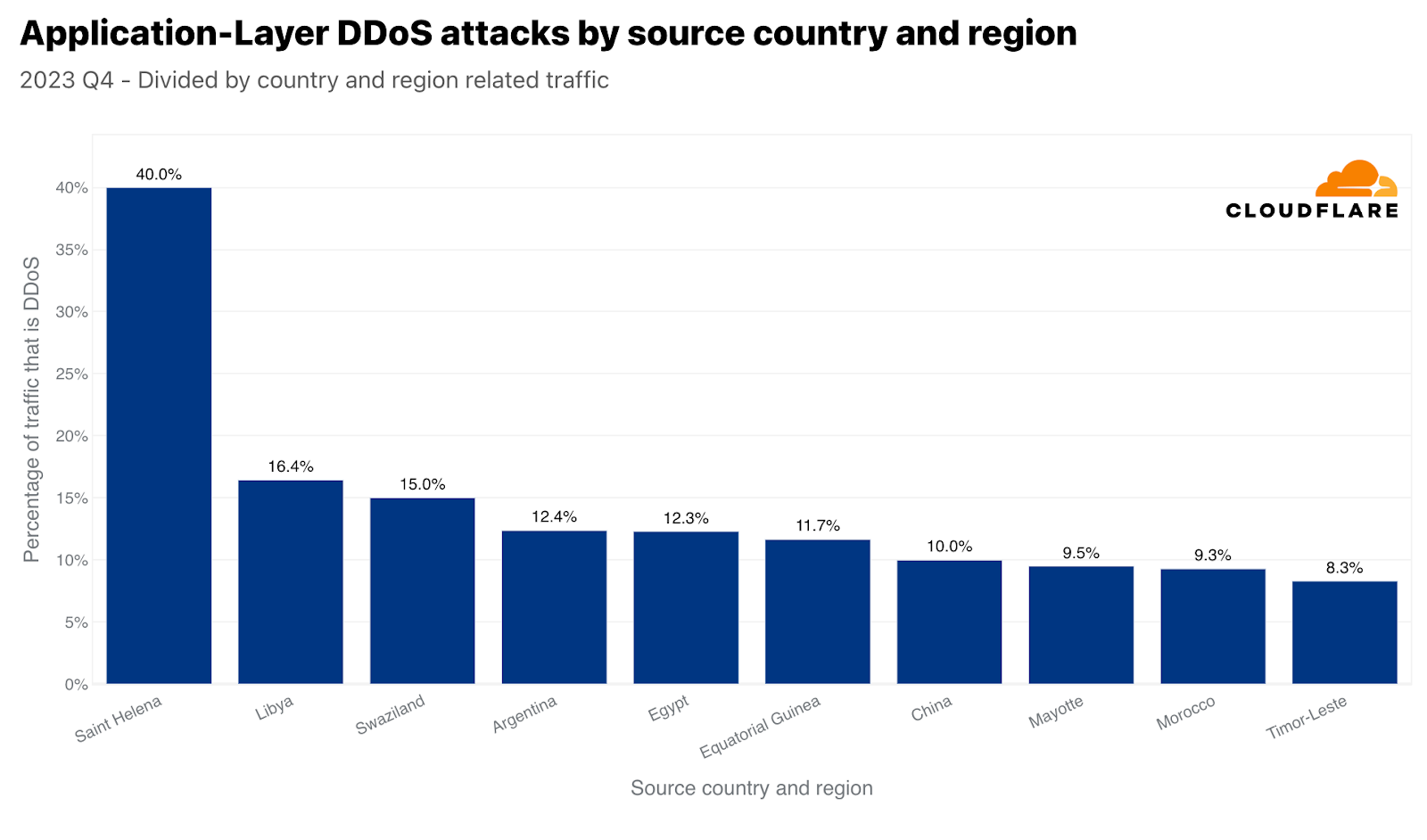
These large figures usually correspond to large markets. For this reason, we also normalize the attack traffic originating from each country by comparing their outbound traffic. When we do this, we often get small island nations or smaller market countries that a disproportionate amount of attack traffic originates from. In Q4, 40% of Saint Helena’s outbound traffic were HTTP DDoS attacks — placing it at the top. Following the ‘remote volcanic tropical island’, Libya came in second, Swaziland (also known as Eswatini) in third. Argentina and Egypt follow in fourth and fifth place.
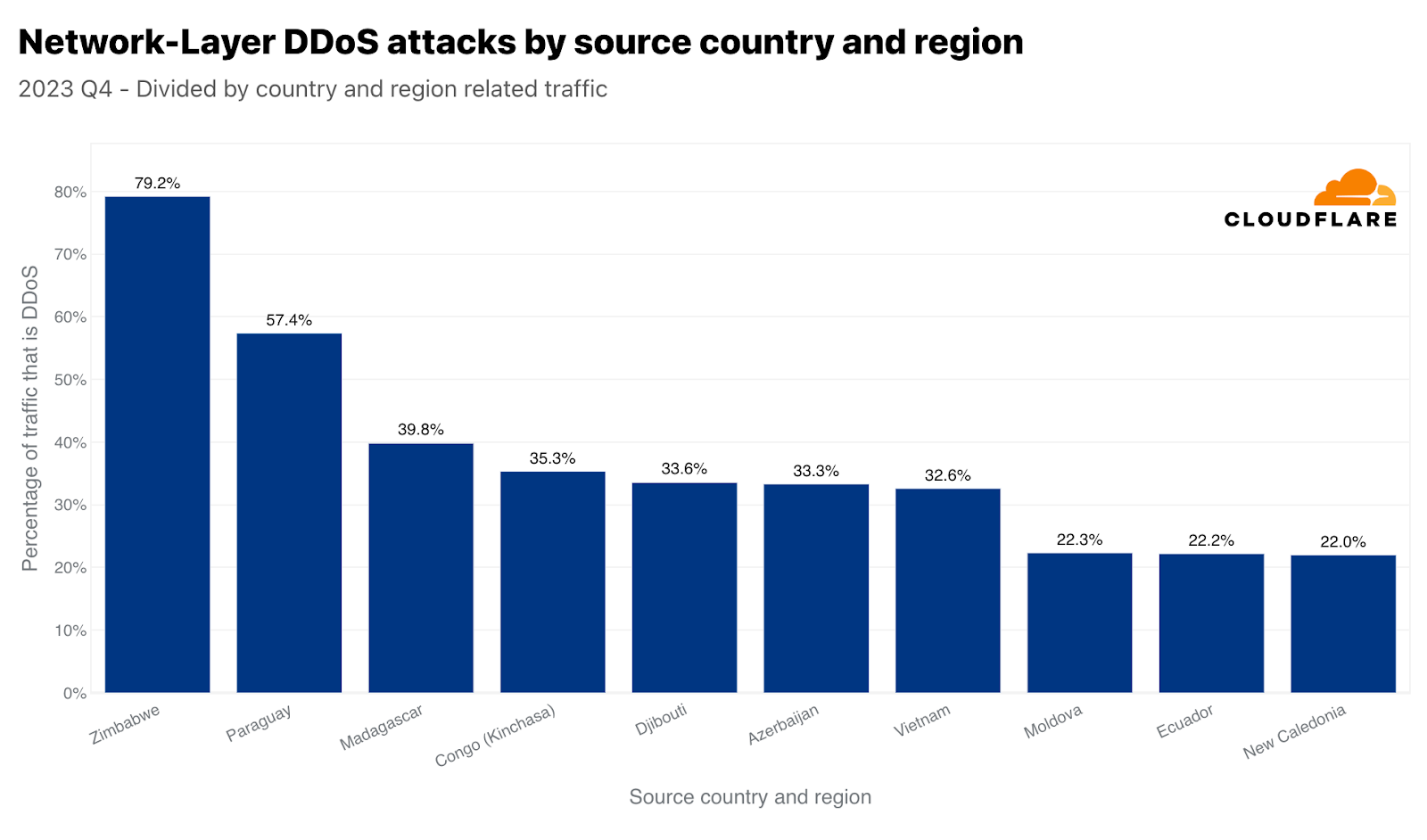
On the network layer, Zimbabwe came in first place. Almost 80% of all traffic we ingested in our Zimbabwe-based data center was malicious. In second place, Paraguay, and Madagascar in third.
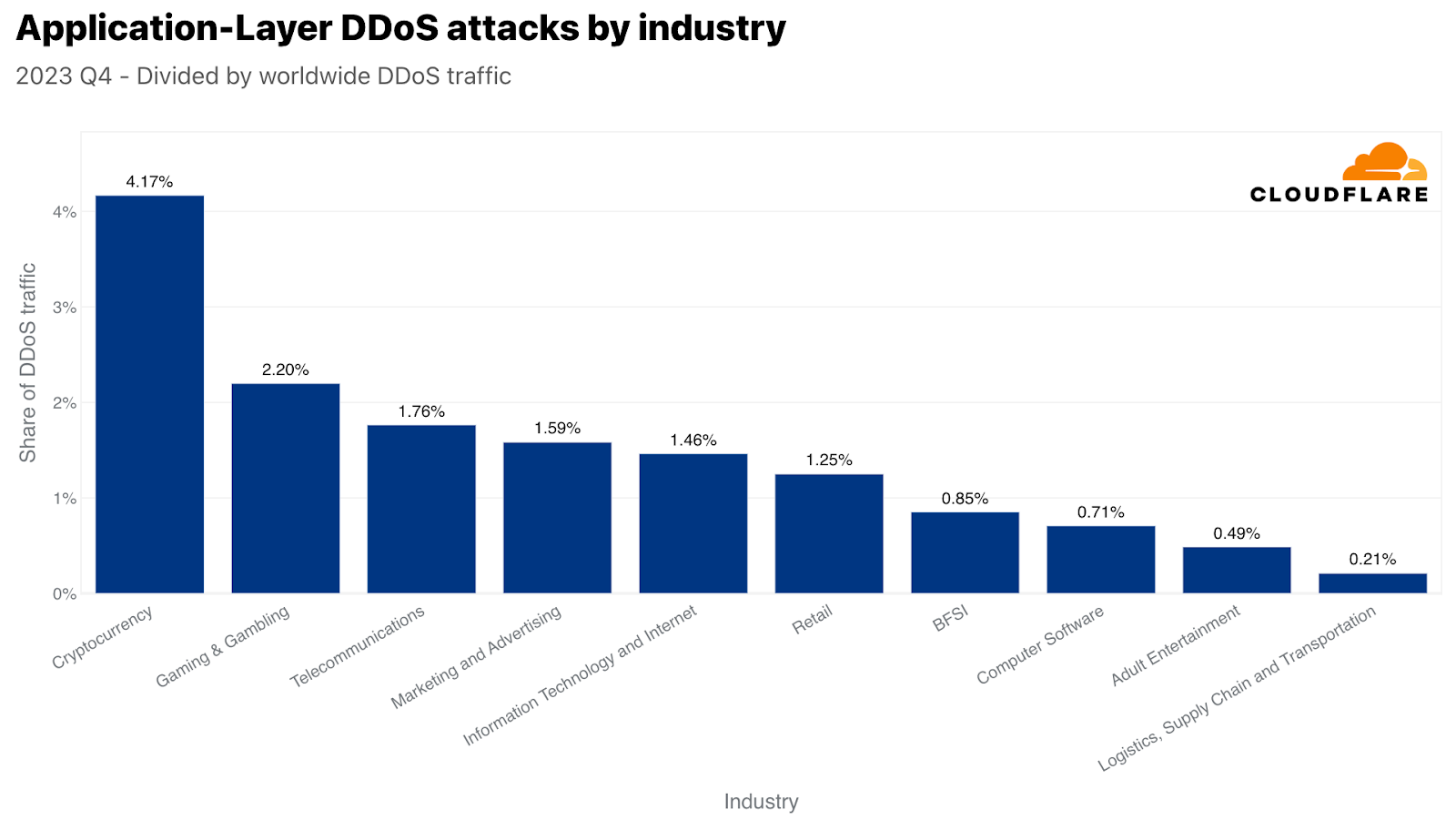
Most attacked industries
By volume of attack traffic, Cryptocurrency was the most attacked industry in Q4. Over 330 billion HTTP requests targeted it. This figure accounts for over 4% of all HTTP DDoS traffic for the quarter. The second most attacked industry was Gaming & Gambling. These industries are known for being coveted targets and attract a lot of traffic and attacks.
On the network layer, the Information Technology and Internet industry was the most attacked — over 45% of all network-layer DDoS attack traffic was aimed at it. Following far behind were the Banking, Financial Services and Insurance (BFSI), Gaming & Gambling, and Telecommunications industries.
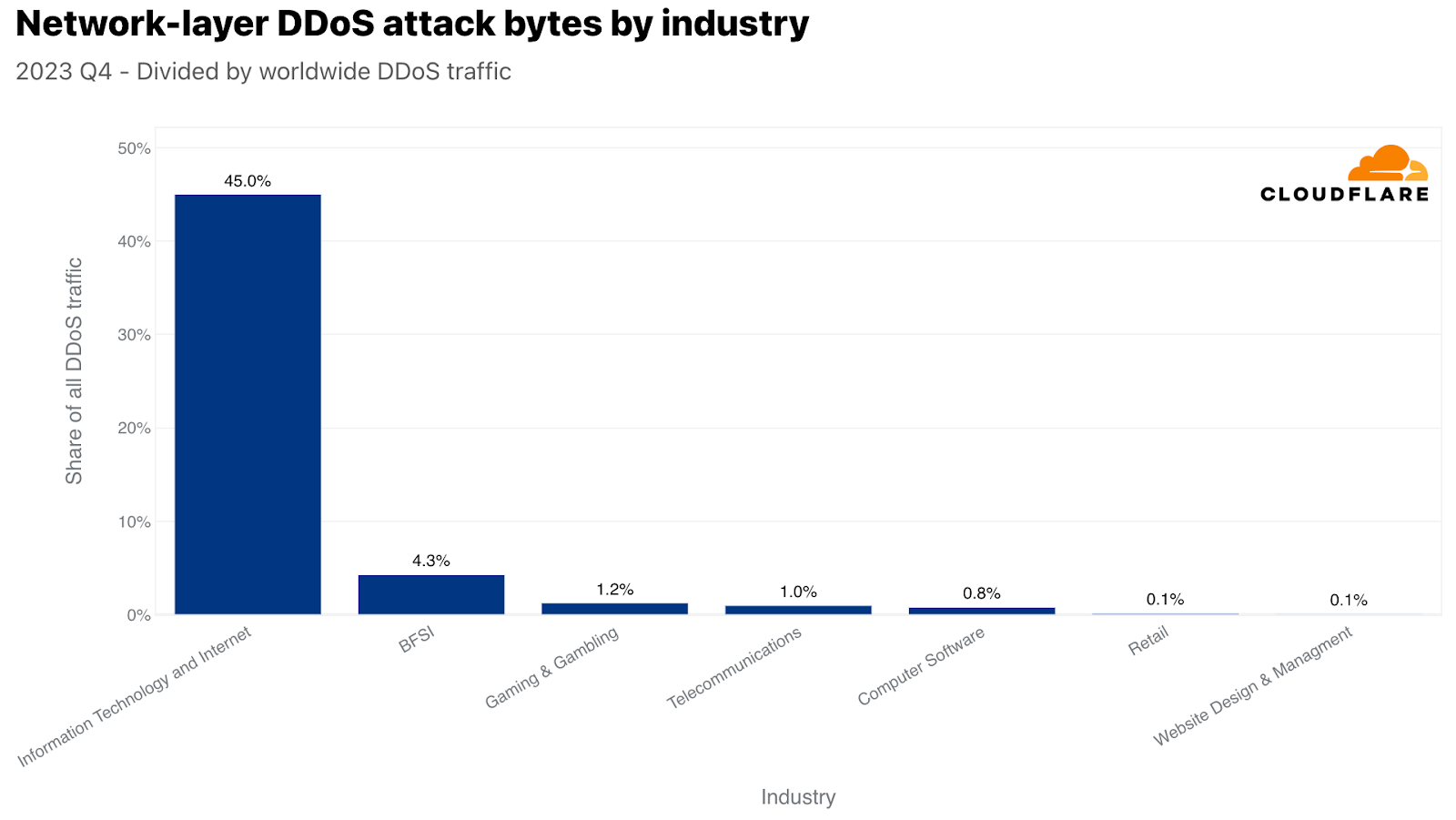
To change perspectives, here too, we normalized the attack traffic by the total traffic for a specific industry. When we do that, we get a different picture.
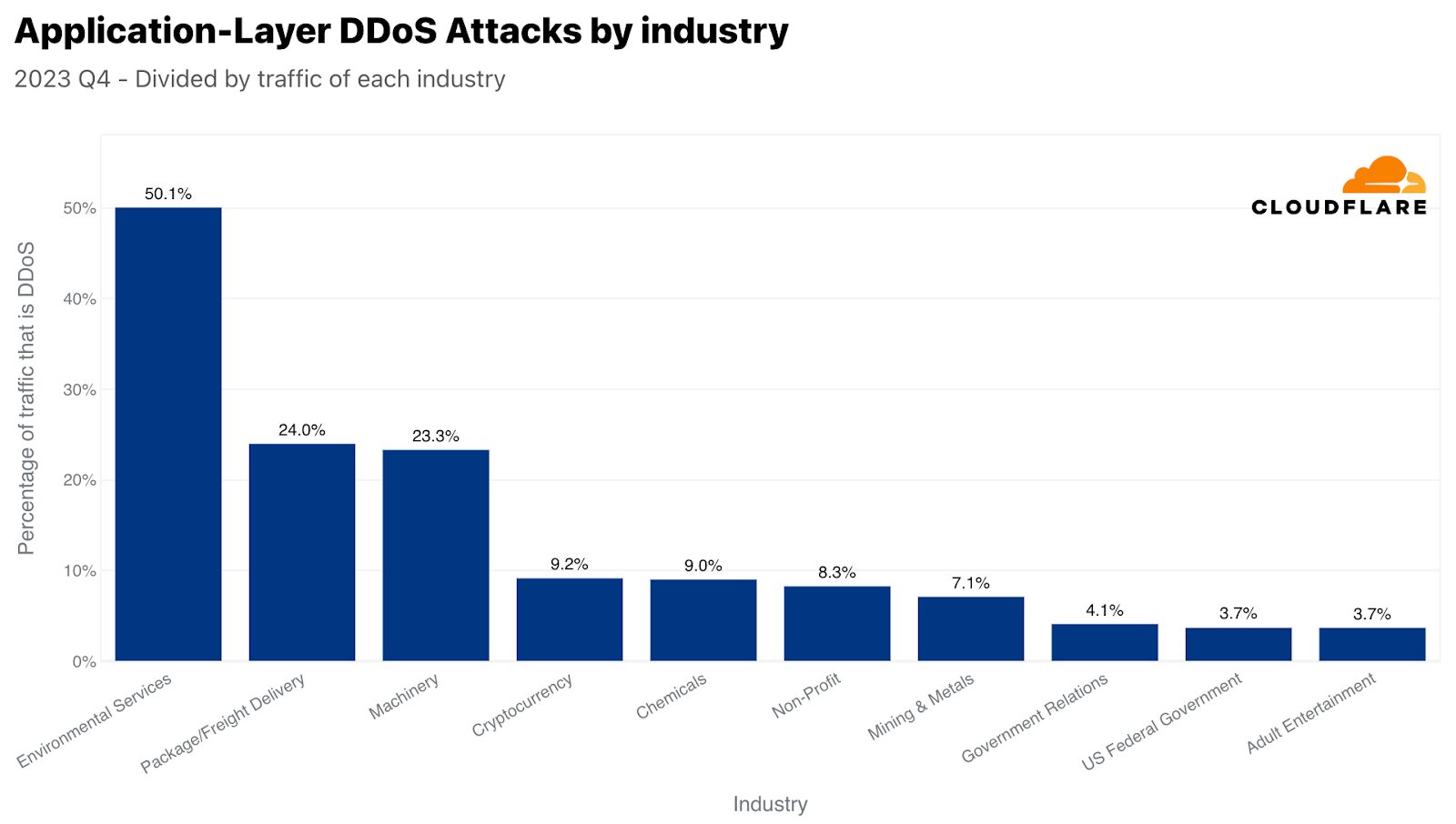
We already mentioned in the beginning of this report that the Environmental Services industry was the most attacked relative to its own traffic. In second place was the Packaging and Freight Delivery industry, which is interesting because of its timely correlation with online shopping during Black Friday and the winter holiday season. Purchased gifts and goods need to get to their destination somehow, and it seems as though attackers tried to interfere with that. On a similar note, DDoS attacks on retail companies increased by 23% compared to the previous year.
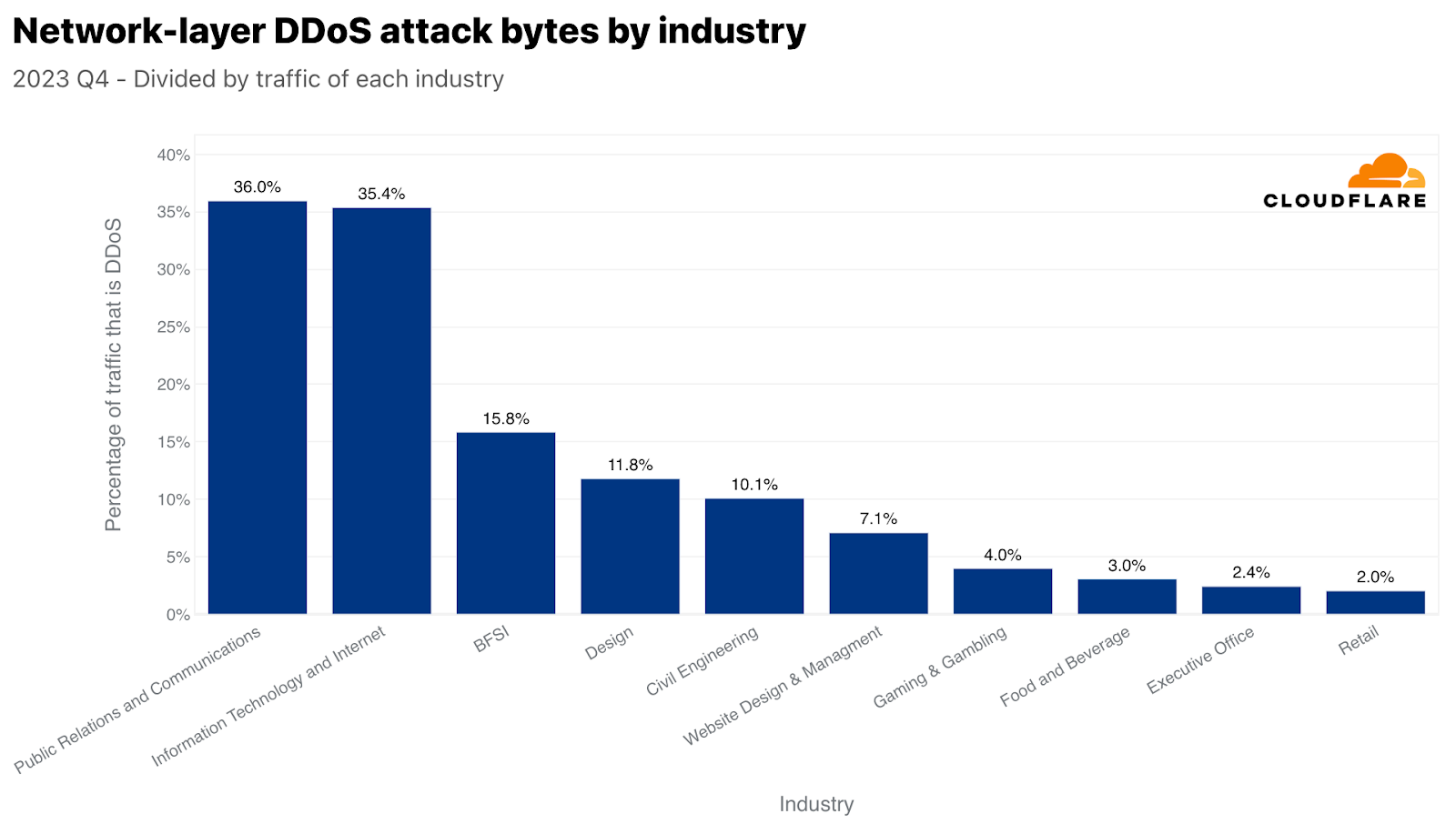
On the network layer, Public Relations and Communications was the most targeted industry — 36% of its traffic was malicious. This too is very interesting given its timing. Public Relations and Communications companies are usually linked to managing public perception and communication. Disrupting their operations can have immediate and widespread reputational impacts which becomes even more critical during the Q4 holiday season. This quarter often sees increased PR and communication activities due to holidays, end-of-year summaries, and preparation for the new year, making it a critical operational period — one that some may want to disrupt.
Most attacked countries and regions
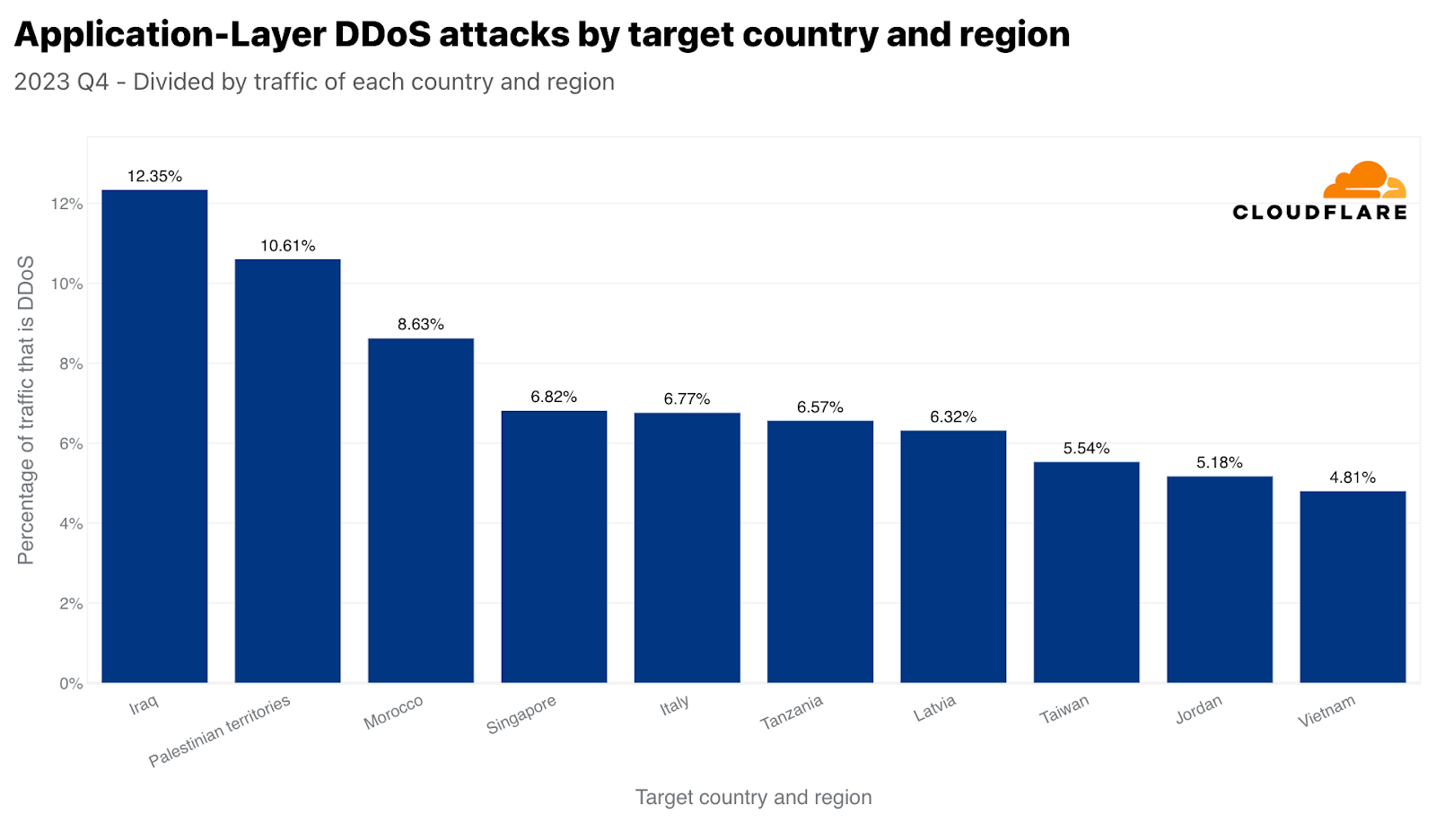
Singapore was the main target of HTTP DDoS attacks in Q4. Over 317 billion HTTP requests, 4% of all global DDoS traffic, were aimed at Singaporean websites. The US followed closely in second and Canada in third. Taiwan came in as the fourth most attacked region — amidst the upcoming general elections and the tensions with China. Taiwan-bound attacks in Q4 traffic increased by 847% compared to the previous year, and 2,858% compared to the previous quarter. This increase is not limited to the absolute values. When normalized, the percentage of HTTP DDoS attack traffic targeting Taiwan relative to all Taiwan-bound traffic also significantly increased. It increased by 624% quarter-over-quarter and 3,370% year-over-year.
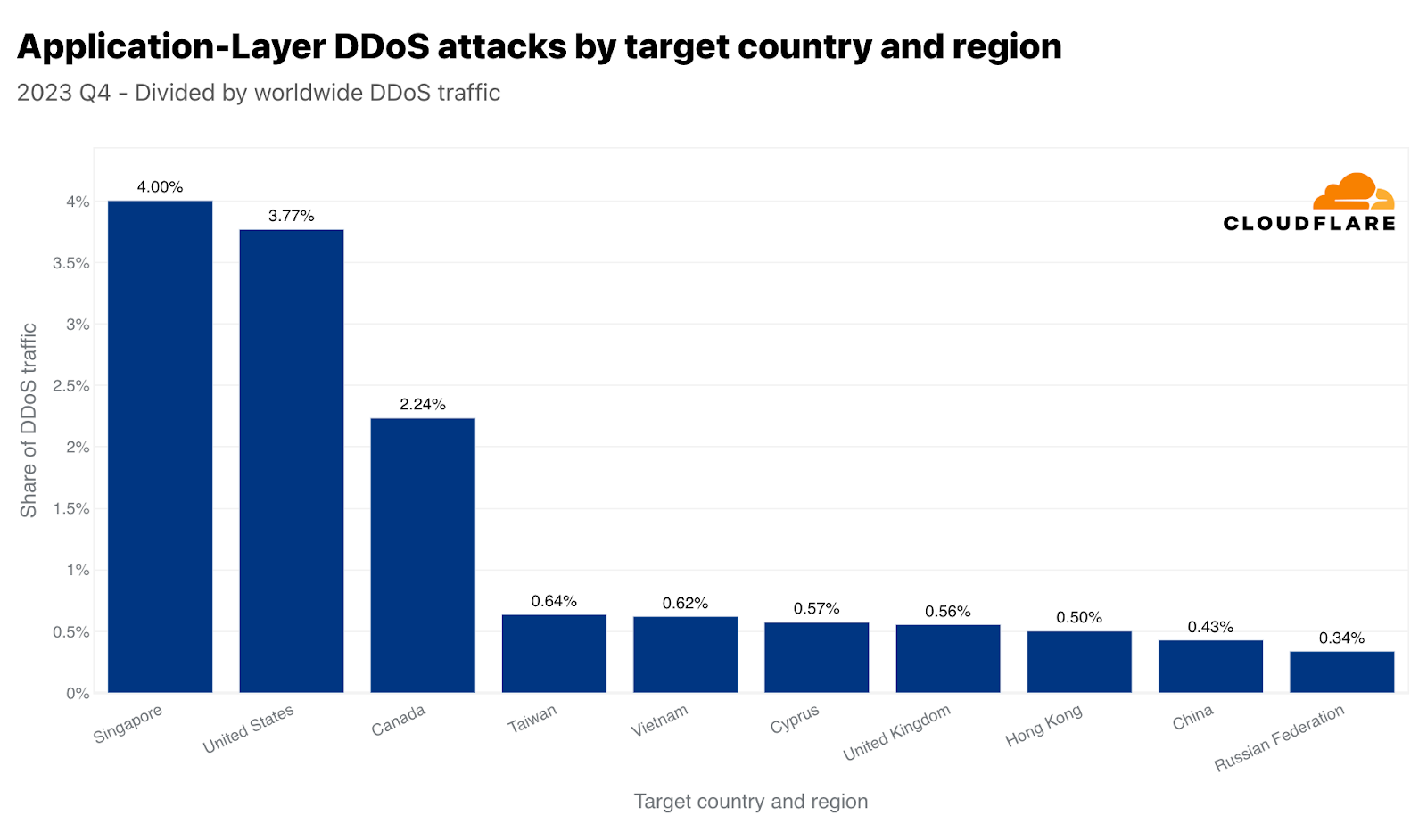
While China came in as the ninth most attacked country by HTTP DDoS attacks, it’s the number one most attacked country by network-layer attacks. 45% of all network-layer DDoS traffic that Cloudflare mitigated globally was China-bound. The rest of the countries were so far behind that it is almost negligible.
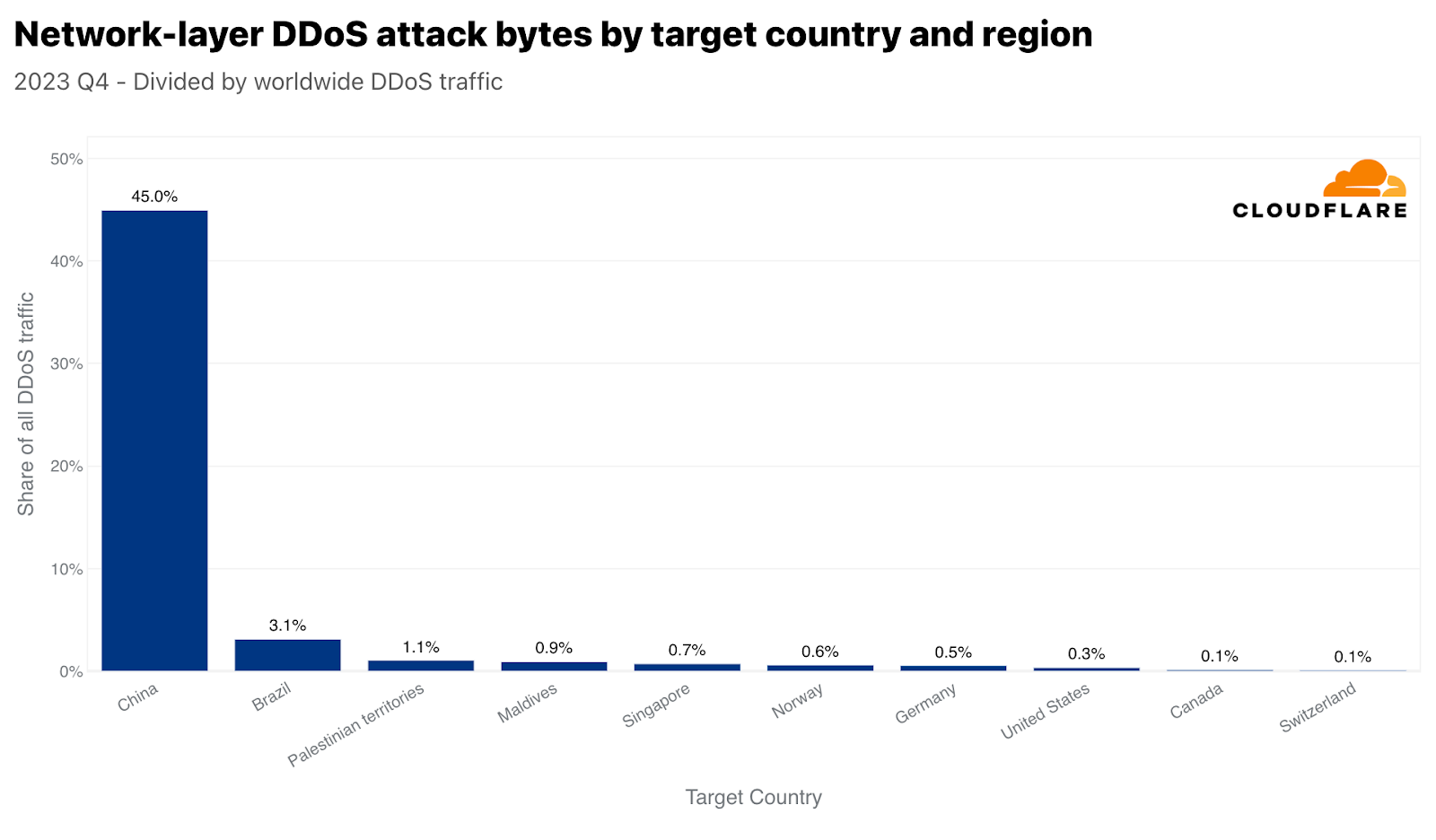
When normalizing the data, Iraq, Palestinian territories, and Morocco take the lead as the most attacked regions with respect to their total inbound traffic. What’s interesting is that Singapore comes up as fourth. So not only did Singapore face the largest amount of HTTP DDoS attack traffic, but that traffic also made up a significant amount of the total Singapore-bound traffic. By contrast, the US was second most attacked by volume (per the application-layer graph above), but came in the fiftieth place with respect to the total US-bound traffic.
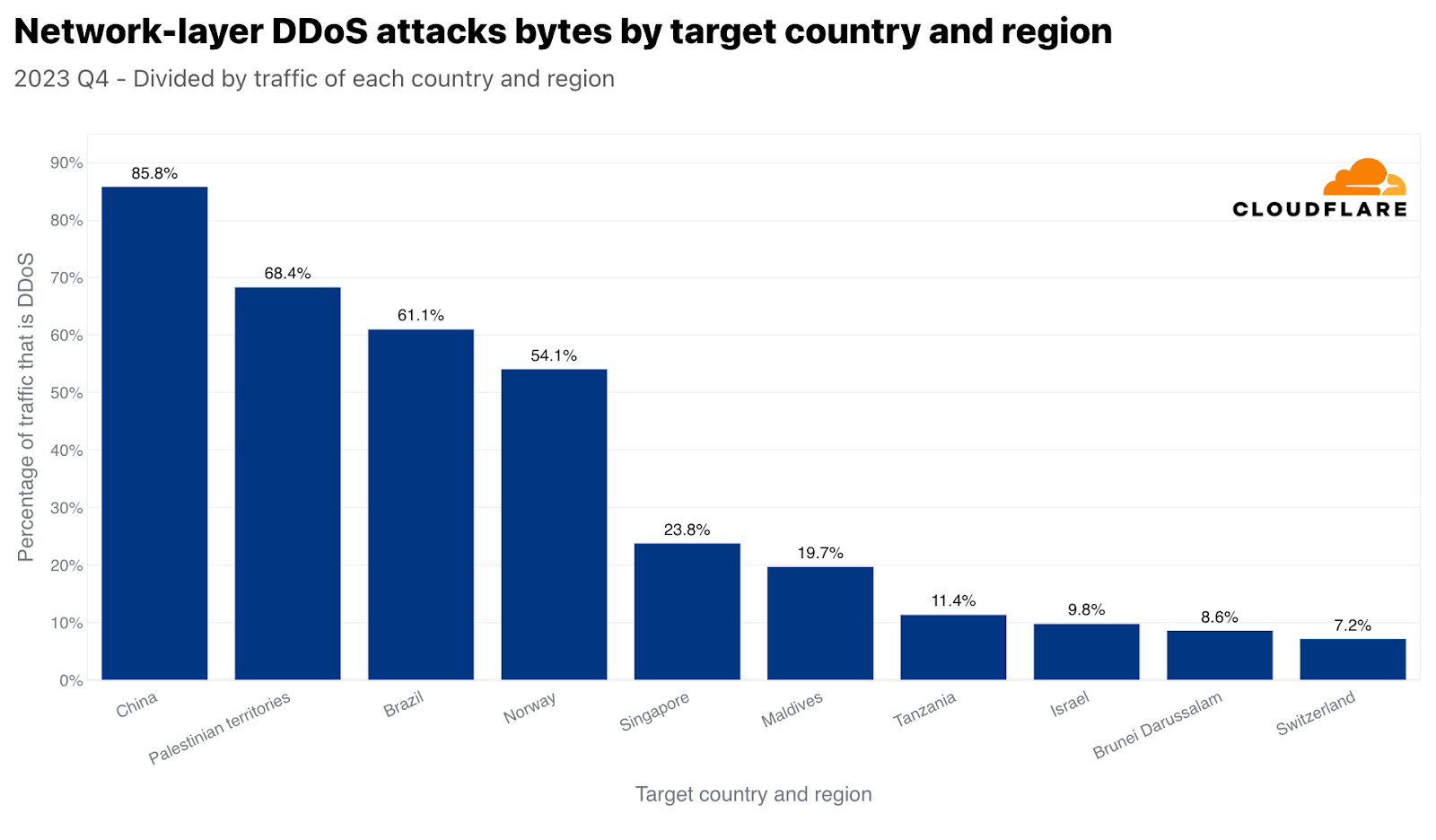
Similar to Singapore, but arguably more dramatic, China is both the number one most attacked country by network-layer DDoS attack traffic, and also with respect to all China-bound traffic. Almost 86% of all China-bound traffic was mitigated by Cloudflare as network-layer DDoS attacks. The Palestinian territories, Brazil, Norway, and again Singapore followed with large percentages of attack traffic.
Attack vectors and attributes
The majority of DDoS attacks are short and small relative to Cloudflare’s scale. However, unprotected websites and networks can still suffer disruption from short and small attacks without proper inline automated protection — underscoring the need for organizations to be proactive in adopting a robust security posture.
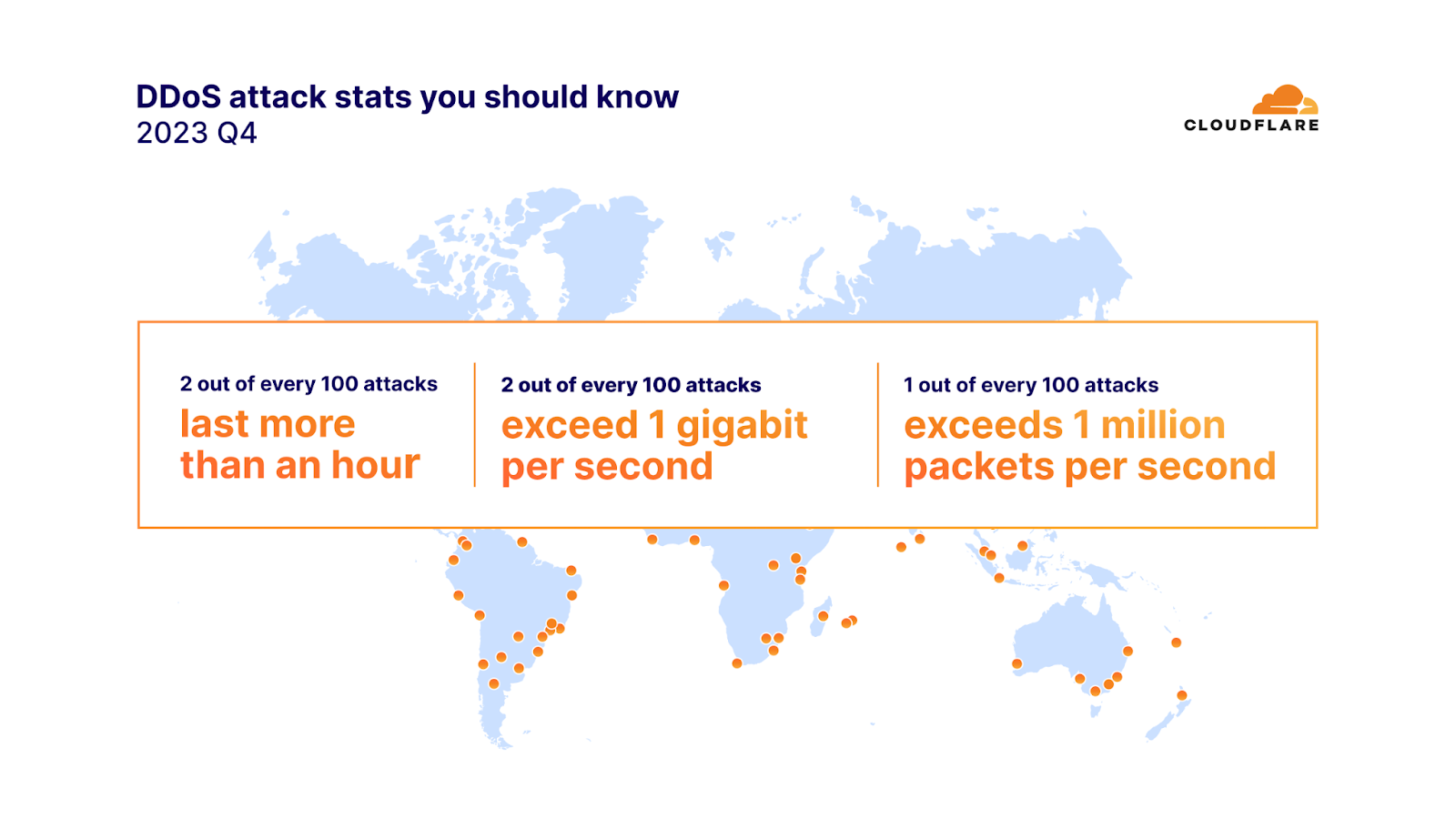
In 2023 Q4, 91% of attacks ended within 10 minutes, 97% peaked below 500 megabits per second (mbps), and 88% never exceeded 50 thousand packets per second (pps).
Two out of every 100 network-layer DDoS attacks lasted more than an hour, and exceeded 1 gigabit per second (gbps). One out of every 100 attacks exceeded 1 million packets per second. Furthermore, the amount of network-layer DDoS attacks exceeding 100 million packets per second increased by 15% quarter-over-quarter.
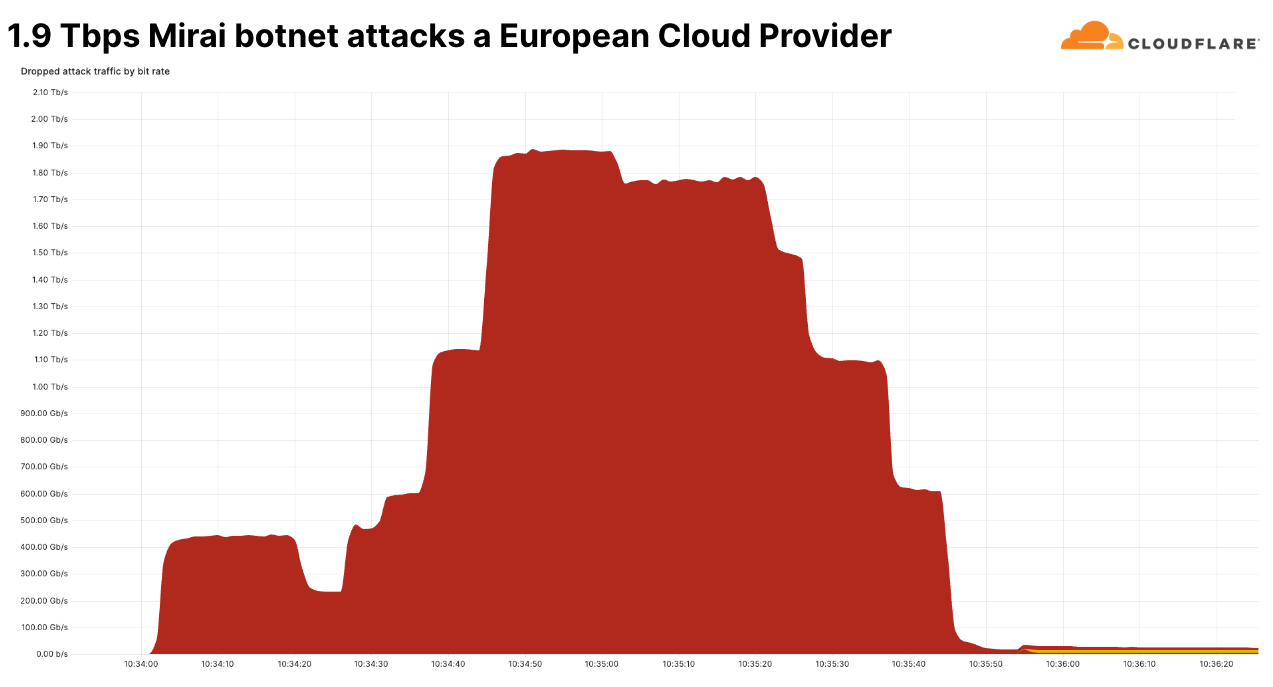
One of those large attacks was a Mirai-botnet attack that peaked at 160 million packets per second. The packet per second rate was not the largest we’ve ever seen. The largest we’ve ever seen was 754 million packets per second. That attack occurred in 2020, and we have yet to see anything larger.
This more recent attack, though, was unique in its bits per second rate. This was the largest network-layer DDoS attack we’ve seen in Q4. It peaked at 1.9 terabits per second and originated from a Mirai botnet. It was a multi-vector attack, meaning it combined multiple attack methods. Some of those methods included UDP fragments flood, UDP/Echo flood, SYN Flood, ACK Flood, and TCP malformed flags.
This attack targeted a known European Cloud Provider and originated from over 18 thousand unique IP addresses that are assumed to be spoofed. It was automatically detected and mitigated by Cloudflare’s defenses.
This goes to show that even the largest attacks end very quickly. Previous large attacks we’ve seen ended within seconds — underlining the need for an in-line automated defense system. Though still rare, attacks in the terabit range are becoming more and more prominent.
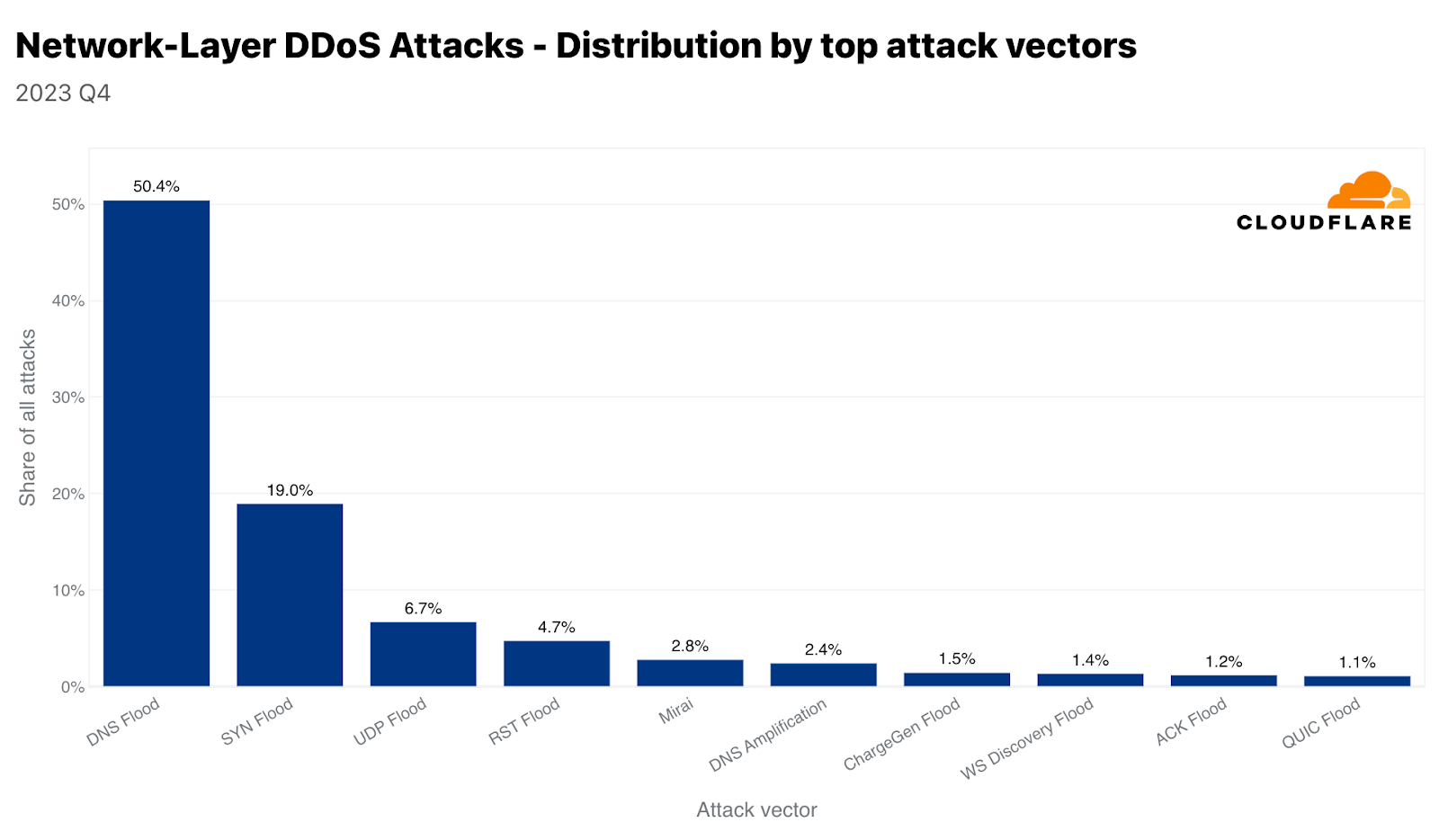
The use of Mirai-variant botnets is still very common. In Q4, almost 3% of all attacks originate from Mirai. Though, of all attack methods, DNS-based attacks remain the attackers’ favorite. Together, DNS Floods and DNS Amplification attacks account for almost 53% of all attacks in Q4. SYN Flood follows in second and UDP floods in third. We’ll cover the two DNS attack types here, and you can visit the hyperlinks to learn more about UDP and SYN floods in our Learning Center.
DNS floods and amplification attacks
DNS floods and DNS amplification attacks both exploit the Domain Name System (DNS), but they operate differently. DNS is like a phone book for the Internet, translating human-friendly domain names like “www.cloudfare.com” into numerical IP addresses that computers use to identify each other on the network.
Simply put, DNS-based DDoS attacks comprise the method computers and servers used to identify one another to cause an outage or disruption, without actually ‘taking down’ a server. For example, a server may be up and running, but the DNS server is down. So clients won’t be able to connect to it and will experience it as an outage.
A DNS flood attack bombards a DNS server with an overwhelming number of DNS queries. This is usually done using a DDoS botnet. The sheer volume of queries can overwhelm the DNS server, making it difficult or impossible for it to respond to legitimate queries. This can result in the aforementioned service disruptions, delays or even an outage for those trying to access the websites or services that rely on the targeted DNS server.
On the other hand, a DNS amplification attack involves sending a small query with a spoofed IP address (the address of the victim) to a DNS server. The trick here is that the DNS response is significantly larger than the request. The server then sends this large response to the victim’s IP address. By exploiting open DNS resolvers, the attacker can amplify the volume of traffic sent to the victim, leading to a much more significant impact. This type of attack not only disrupts the victim but also can congest entire networks.
In both cases, the attacks exploit the critical role of DNS in network operations. Mitigation strategies typically include securing DNS servers against misuse, implementing rate limiting to manage traffic, and filtering DNS traffic to identify and block malicious requests.
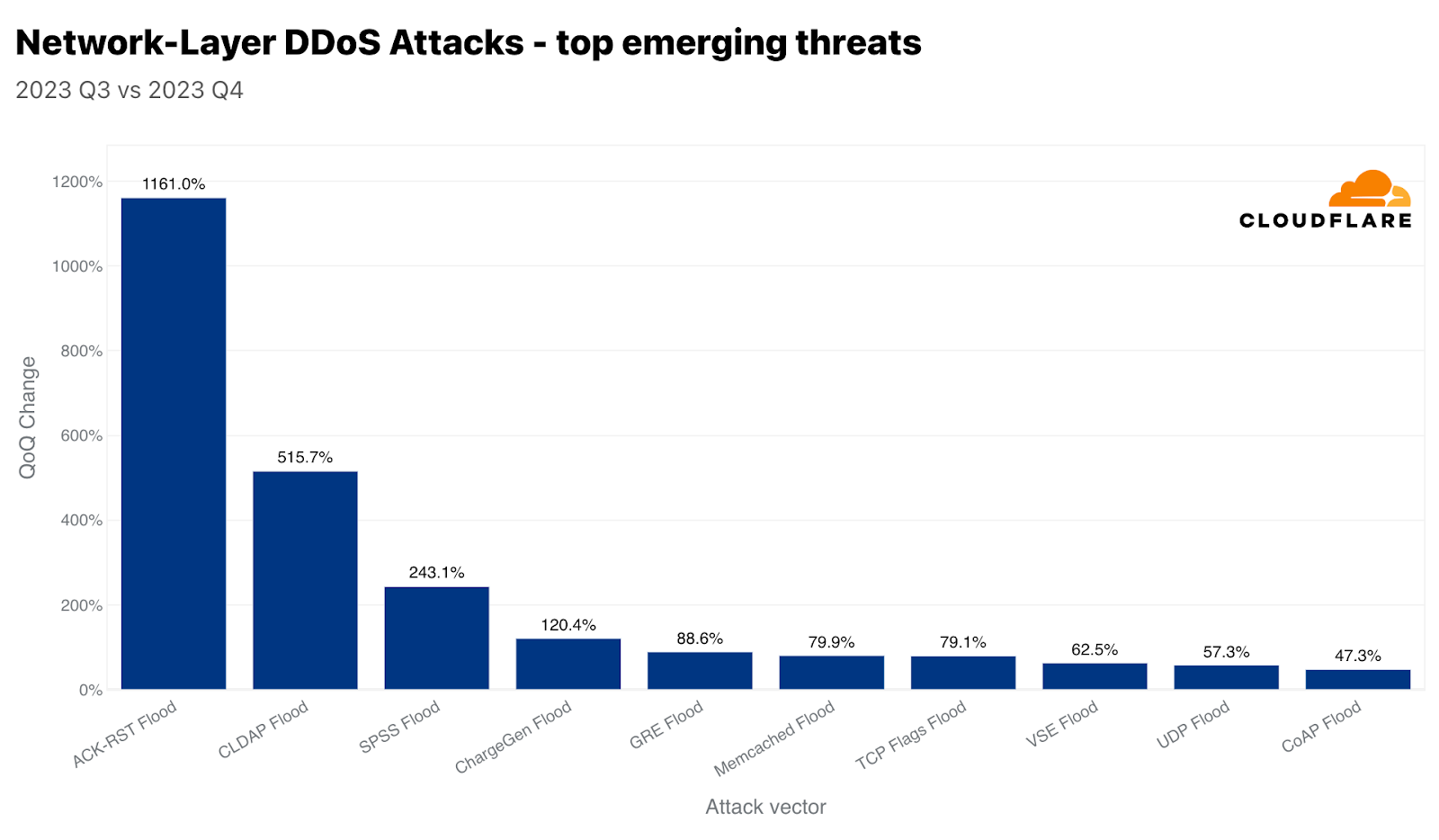
Amongst the emerging threats we track, we recorded a 1,161% increase in ACK-RST Floods as well as a 515% increase in CLDAP floods, and a 243% increase in SPSS floods, in each case as compared to last quarter. Let’s walk through some of these attacks and how they’re meant to cause disruption.
ACK-RST floods
An ACK-RST Flood exploits the Transmission Control Protocol (TCP) by sending numerous ACK and RST packets to the victim. This overwhelms the victim’s ability to process and respond to these packets, leading to service disruption. The attack is effective because each ACK or RST packet prompts a response from the victim’s system, consuming its resources. ACK-RST Floods are often difficult to filter since they mimic legitimate traffic, making detection and mitigation challenging.
CLDAP floods
CLDAP (Connectionless Lightweight Directory Access Protocol) is a variant of LDAP (Lightweight Directory Access Protocol). It’s used for querying and modifying directory services running over IP networks. CLDAP is connectionless, using UDP instead of TCP, making it faster but less reliable. Because it uses UDP, there’s no handshake requirement which allows attackers to spoof the IP address thus allowing attackers to exploit it as a reflection vector. In these attacks, small queries are sent with a spoofed source IP address (the victim’s IP), causing servers to send large responses to the victim, overwhelming it. Mitigation involves filtering and monitoring unusual CLDAP traffic.
SPSS floods
Floods abusing the SPSS (Source Port Service Sweep) protocol is a network attack method that involves sending packets from numerous random or spoofed source ports to various destination ports on a targeted system or network. The aim of this attack is two-fold: first, to overwhelm the victim’s processing capabilities, causing service disruptions or network outages, and second, it can be used to scan for open ports and identify vulnerable services. The flood is achieved by sending a large volume of packets, which can saturate the victim’s network resources and exhaust the capacities of its firewalls and intrusion detection systems. To mitigate such attacks, it’s essential to leverage in-line automated detection capabilities.
Cloudflare is here to help – no matter the attack type, size, or duration
Cloudflare’s mission is to help build a better Internet, and we believe that a better Internet is one that is secure, performant, and available to all. No matter the attack type, the attack size, the attack duration or the motivation behind the attack, Cloudflare’s defenses stand strong. Since we pioneered unmetered DDoS Protection in 2017, we’ve made and kept our commitment to make enterprise-grade DDoS protection free for all organizations alike — and of course, without compromising performance. This is made possible by our unique technology and robust network architecture.
It’s important to remember that security is a process, not a single product or flip of a switch. Atop of our automated DDoS protection systems, we offer comprehensive bundled features such as firewall, bot detection, API protection, and caching to bolster your defenses. Our multi-layered approach optimizes your security posture and minimizes potential impact. We’ve also put together a list of recommendations to help you optimize your defenses against DDoS attacks, and you can follow our step-by-step wizards to secure your applications and prevent DDoS attacks. And, if you’d like to benefit from our easy to use, best-in-class protection against DDoS and other attacks on the Internet, you can sign up — for free! — at cloudflare.com. If you’re under attack, register or call the cyber emergency hotline number shown here for a rapid response.
Introducing Cloudflare’s 2024 API security and management report
Post Syndicated from John Cosgrove http://blog.cloudflare.com/author/john-cosgrove/ original https://blog.cloudflare.com/2024-api-security-report
You may know Cloudflare as the company powering nearly 20% of the web. But powering and protecting websites and static content is only a fraction of what we do. In fact, well over half of the dynamic traffic on our network consists not of web pages, but of Application Programming Interface (API) traffic — the plumbing that makes technology work. This blog introduces and is a supplement to the API Security Report for 2024 where we detail exactly how we’re protecting our customers, and what it means for the future of API security. Unlike other industry API reports, our report isn’t based on user surveys — but instead, based on real traffic data.
If there’s only one thing you take away from our report this year, it’s this: many organizations lack accurate API inventories, even when they believe they can correctly identify API traffic. Cloudflare helps organizations discover all of their public-facing APIs using two approaches. First, customers configure our API discovery tool to monitor for identifying tokens present in their known API traffic. We then use a machine learning model that scans not just these known API calls, but all HTTP requests, identifying API traffic that may be going unaccounted for. The difference between these approaches is striking: we found 30.7% more API endpoints through machine learning-based discovery than the self-reported approach, suggesting that nearly a third of APIs are “Shadow APIs” — and may not be properly inventoried and secured.
Read on for extras and highlights from our inaugural API security report. In the full report, you’ll find updated statistics about the threats we see and prevent, along with our predictions for 2024. We predict that a lack of API security focus at organizations will lead to increased complexity and loss of control, and increased access to generative AI will lead to more API risk. We also anticipate an increase in API business logic attacks in 2024. Lastly, all of the above risks will necessitate growing governance around API security.
Hidden attack surfaces
How are web pages and APIs different? APIs are a quick and easy way for applications to retrieve data in the background, or ask that work be done from other applications. For example, anyone can write a weather app without being a meteorologist: a developer can write the structure of the page or mobile application and ask a weather API for the forecast using the user’s location. Critically, most end users don’t know that the data was provided by the weather API and not the app’s owner.
While APIs are the critical plumbing of the Internet, they’re also ripe for abuse. For example, flaws in API authentication and authorization at Optus led to a threat actor offering 10 million user records for sale, and government agencies have warned about these exact API attacks. Developers in an organization will often create Internet-facing APIs, used by their own applications to function more efficiently, but it’s on the security team to protect these new public interfaces. If the process of documenting APIs and bringing them to the attention of the security team isn’t clear, they become Shadow APIs — operating in production but without the organization’s knowledge. This is where the security challenge begins to emerge.
To help customers solve this problem, we shipped API Discovery. When we introduced our latest release, we mentioned how few organizations have accurate API inventories. Security teams sometimes are forced to adopt an “email and ask” approach to build an inventory, and in doing so responses are immediately stale upon the next application release when APIs change. Better is to track API changes by code base changes, keeping up with new releases. However, this still has a drawback of only inventorying actively maintained code. Legacy applications may not see new releases, despite receiving production traffic.
Cloudflare’s approach to API management involves creating a comprehensive, accurate API inventory using a blend of machine learning-based API discovery and network traffic inspection. This is integral to our API Gateway product, where customers can manage their Internet-facing endpoints and monitor API health. The API Gateway also allows customers to identify their API traffic using session identifiers (typically a header or cookie), which aids in specifically identifying API traffic for the discovery process.
As noted earlier, our analysis reveals that even knowledgeable customers often overlook significant portions of their API traffic. By comparing session-based API discovery (using API sessions to pinpoint traffic) with our machine learning-based API discovery (analyzing all incoming traffic), we found that the latter uncovers on average 30.7% more endpoints! Without broad traffic analysis, you may be missing almost a third of your API inventory.
If you aren’t a Cloudflare customer, you can still get started building an API inventory. APIs are typically cataloged in a standardized format called OpenAPI, and many development tools can build OpenAPI formatted schema files. If you have a file with that format, you can start to build an API inventory yourself by collecting these schemas. Here is an example of how you can pull the endpoints out of a schema file, assuming your have an OpenAPI v3 formatted file named my_schema.json:
import json
import csv
from io import StringIO
# Load the OpenAPI schema from a file
with open("my_schema.json", "r") as file:
schema = json.load(file)
# Prepare CSV output
output = StringIO()
writer = csv.writer(output)
# Write CSV header
writer.writerow(["Server", "Path", "Method"])
# Extract and write data to CSV
servers = schema.get("servers", [])
for server in servers:
url = server['url']
for path, methods in schema['paths'].items():
for method in methods.keys():
writer.writerow([url, path, method])
# Get and print CSV string
csv_output = output.getvalue().strip()
print(csv_output)
Unless you have been generating OpenAPI schemas and tracking API inventory from the beginning of your application’s development process, you’re probably missing some endpoints across your production application API inventory.
Precise rate limits minimize attack potential
When it comes to stopping abuse, most practitioners’ thoughts first come to rate limiting. Implementing limits on your API is a valuable tool to keep abuse in check and prevent accidental overload of the origin. But how do you know if you’ve chosen the correct rate limiting approach? Approaches can vary, but they generally come down to the error code chosen, and the basis for the limit value itself.
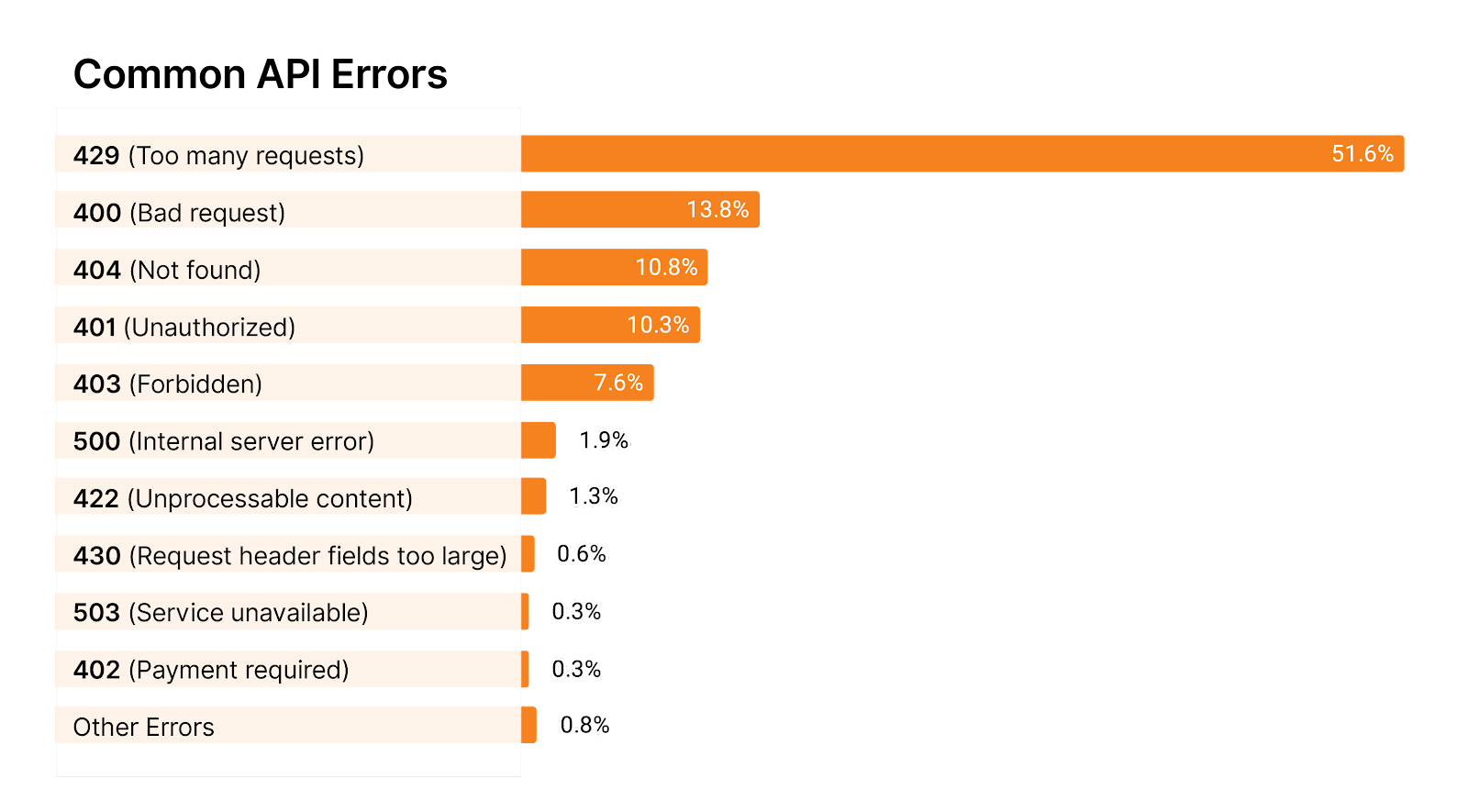
For some APIs, practitioners configure rate limiting errors to respond with an HTTP 403 (forbidden), while others will respond with HTTP 429 (too many requests). Using HTTP 403 sounds innocent enough until you realize that other security tools are also responding with 403 codes. When you’re under attack, it can be hard to decipher which tools are responsible for which errors / blocking.
Alternatively, if you utilize HTTP 429 for your rate limits, attackers will instantly know that they’ve been rate limited and can “surf” right under the limit without being detected. This can be OK if you’re only limiting requests to ensure your back-end stays alive, but it can tip your cards to attackers. In addition, attackers can “scale out” to more API clients to effectively request above the rate limit.
There are pros and cons to both approaches, but we find that by far most APIs respond with HTTP 429 out of all the 4xx and 5xx error messages (almost 52%).
What about the logic of the rate limit rule itself, not just the response code? Implementing request limits on IP addresses can be tempting, but we recommend you base the limit on a session ID as a best practice and only fall back to IP address (or IP + JA3 fingerprint) when session IDs aren’t available. Setting rate limits on user sessions instead of IPs will reliably identify your real users and minimize false positives due to shared IP space. Cloudflare’s Advanced Rate Limiting and API Gateway’s volumetric abuse protection make it easy to enforce these limits by profiling session traffic on each API endpoint and giving one-click solutions to set up the per-endpoint rate limits.
To find values for your rate limits, Cloudflare API Gateway computes session request statistics for you. We suggest a limit by looking at the distribution of requests per session across all sessions to your API as identified by the customer-configured API session identifier. We then compute statistical p-levels — which describe the request rates for different cohorts of traffic — for p50, p90, and p99 on this distribution and use the variance of the distribution to come up with a recommended threshold for every single endpoint in your API inventory. The recommendation might not match the p-levels, which is an important distinction and a reason not to use p-levels alone. Along with the recommendation, API Gateway informs users of our confidence in the recommendation. Generally, the more API sessions we’re able to collect, the more confident we’ll be in the recommendation.
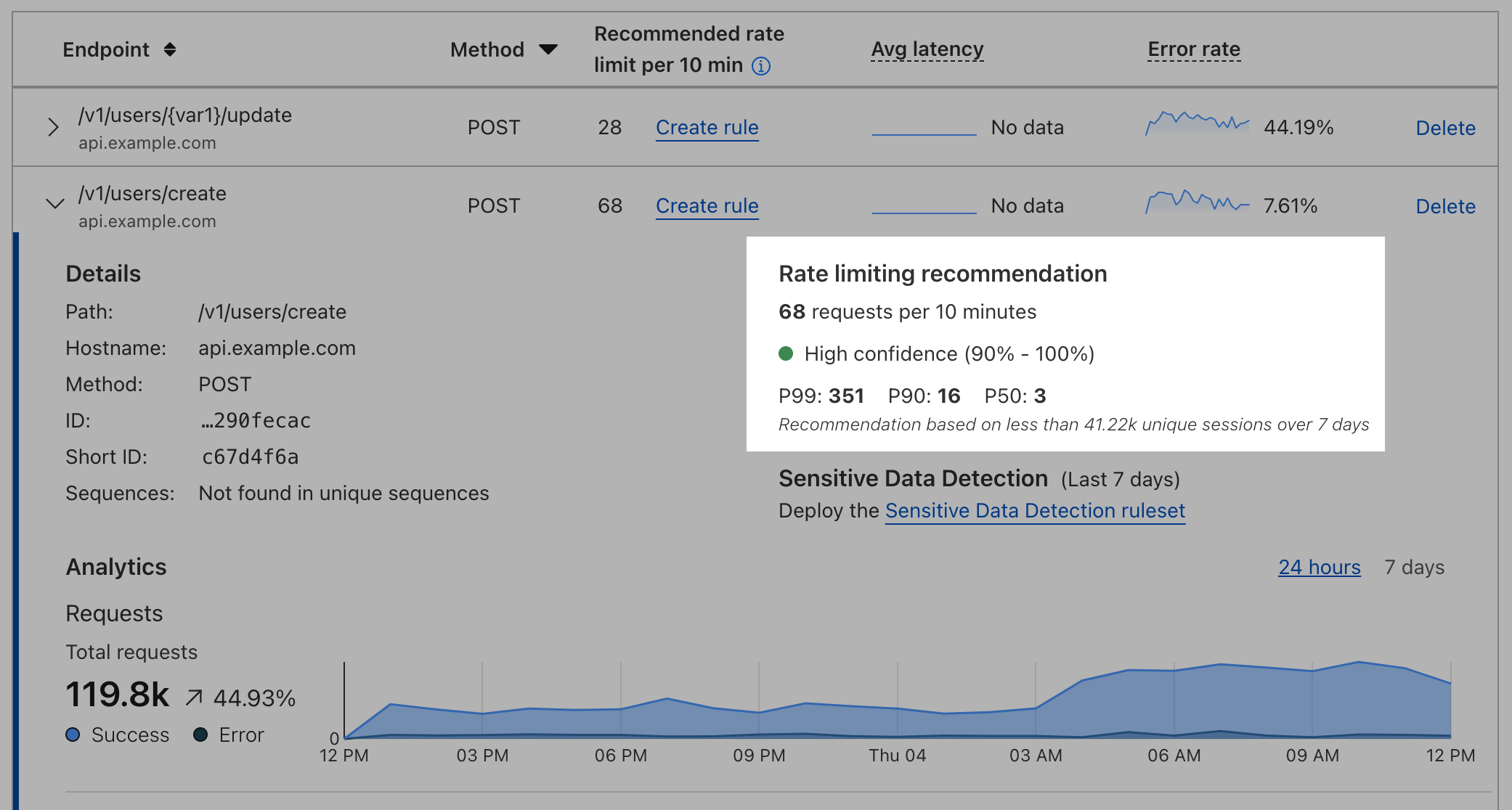
Activating a rate limit is as easy as clicking the ‘create rule’ link, and API Gateway will automatically bring your session identifier over to the advanced rate limit rule creation page, ensuring your rules have pinpoint accuracy to defend against attacks and minimize false positives compared to traditional, overly broad limits.
APIs are also victim to web application attacks
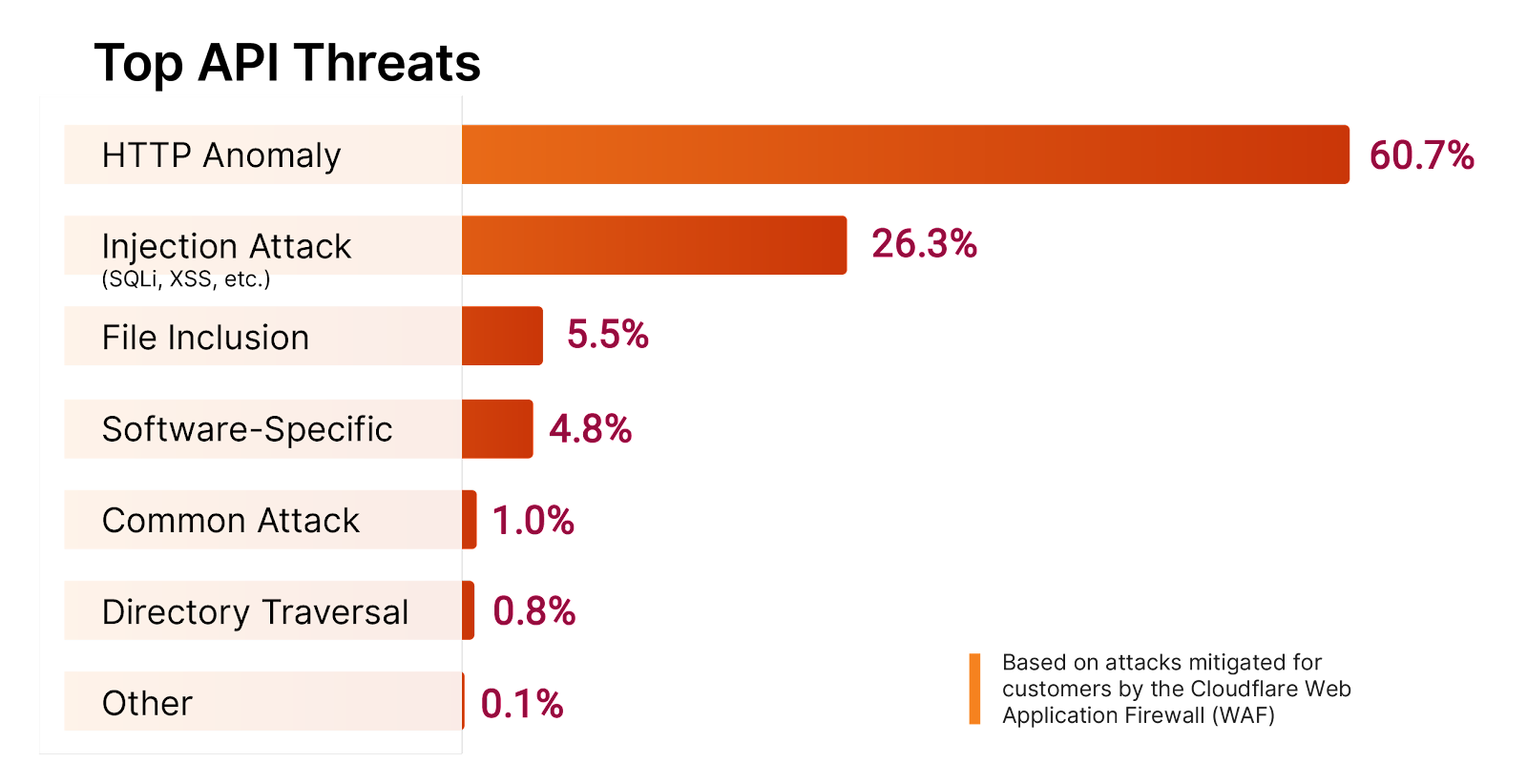
APIs aren’t immune from normal OWASP Top 10 style attacks like SQL injection. The body of API requests can also find its way as a database input just like a web page form input or URL argument. It’s important to ensure that you have a web application firewall (WAF) also protecting your API traffic to defend against these styles of attacks.
In fact, when we looked at Cloudflare’s WAF managed rules, injection attacks were the second most common threat vector Cloudflare saw carried out on APIs. The most common threat was HTTP Anomaly. Examples of HTTP anomalies include malformed method names, null byte characters in headers, non-standard ports or content length of zero with a POST request. Here are the stats on the other top threats we saw against APIs:
Absent from the chart is broken authentication and authorization. Broken authentication and authorization occur when an API fails to check whether the entity sending requests for information to an API actually has the permission to request that data or not. It can also happen when attacks try to forge credentials and insert less restricted permissions into their existing (valid) credentials that have more restricted permissions. OWASP categorizes these attacks in a few different ways, but the main categories are Broken Object Level Authorization (BOLA) and Broken Function Level Authorization (BFLA) attacks.
The root cause of a successful BOLA / BFLA attack lies in an origin API not checking proper ownership of database records against the identity requesting those records. Tracking these specific attacks can be difficult, as the permission structure may be simply absent, inadequate, or improperly implemented. Can you see the chicken-and-egg problem here? It would be easy to stop these attacks if we knew the proper permission structure, but if we or our customers knew the proper permission structure or could guarantee its enforcement, the attacks would be unsuccessful to begin with. Stay tuned for future API Gateway feature launches where we’ll use our knowledge of API traffic norms to automatically suggest security policies that highlight and stop BOLA / BFLA attacks.
Here are four ways to plug authentication loopholes that may exist for your APIs, even if you don’t have a fine-grained authorization policy available:
- First, enforce authentication on each publicly accessible API unless there’s a business approved exception. Look to technologies like mTLS and JSON Web Tokens.
- Limit the speed of API requests to your servers to slow down potential attackers.
- Block abnormal volumes of sensitive data outflow.
- Block attackers from skipping legitimate sequences of API requests.
APIs are surprisingly human driven, not machine driven anymore
If you’ve been around technology since the pre-smartphone days when fewer people were habitually online, it can be tempting to think of APIs as only used for machine-to-machine communication in something like an overnight batch job process. However, the truth couldn’t be more different. As we’ve discussed, many web and mobile applications are powered by APIs, which facilitate everything from authentication to transactions to serving media files. As people use these applications, there is a corresponding increase in API traffic volume.
We can illustrate this by looking at the API traffic patterns observed during holidays, when people gather around friends and family and spend more time socializing in person and less time online. We’ve annotated the following Worldwide API traffic graph with common holidays and promotions. Notice how traffic peaks around Black Friday and Cyber Monday around the +10% level when people shop online, but then traffic drops off for the festivities of Christmas and New Years days.
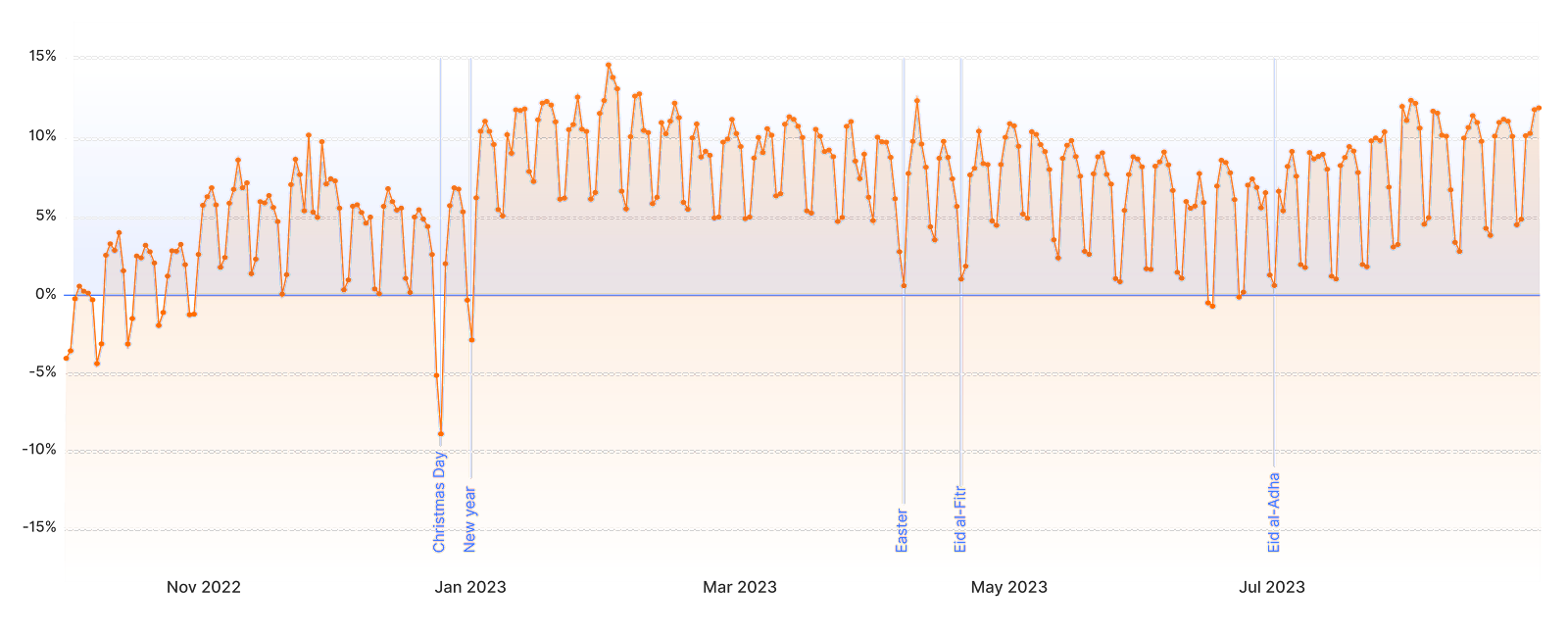
This pattern closely resembles what we observe in regular HTTP traffic. It’s clear that APIs are no longer just the realm of automated processes but are intricately linked with human behaviors and social trends.
Recommendations
There is no silver bullet for holistic API security. For the best effect, Cloudflare recommends four strategies for increasing API security posture:
- Combine API application development, visibility, performance, and security with a unified control plane that can keep an up-to-date API inventory.
- Use security tools that utilize machine learning technologies to free up human resources and reduce costs.
- Adopt a positive security model for your APIs (see below for an explanation on positive and negative security models).
- Measure and improve your organization’s API maturity level over time (also see below for an explanation of an API maturity level).
What do we mean by a ‘positive’ or ‘negative’ security model? In a negative model, security tools look for known signs of attack and take action to stop those attacks. In a positive model, security tools look for known good requests and only let those through, blocking all else. APIs are often so structured that positive security models make sense for the highest levels of security. You can also combine security models, such as using a WAF in a negative model sense, and using API Schema Validation in a positive model sense.
Here’s a quick way to gauge your organization’s API security maturity level over time: Novice organizations will get started by assembling their first API inventory, no matter how incomplete. More mature organizations will strive for API inventory accuracy and automatic updates. The most mature organizations will actively enforce security checks in a positive security model on their APIs, enforcing API schema, valid authentication, and checking behavior for signs of abuse.
Predictions
In closing, our top four predictions for 2024 and beyond:
Increased loss of control and complexity: we surveyed practitioners in the API Security and Management field and 73% responded that security requirements interfere with their productivity and innovation. Coupled with increasingly sprawling applications and inaccurate inventories, API risks and complexity will rise.
Easier access to AI leading to more API risks: the rise in generative AI brings potential risks, including AI models’ APIs being vulnerable to attack, but also developers shipping buggy, AI-written code. Forrester predicts that, in 2024, without proper guardrails, “at least three data breaches will be publicly blamed on insecure AI-generated code – either due to security flaws in the generated code itself or vulnerabilities in AI-suggested dependencies.”
Increase in business logic-based fraud attacks: professional fraudsters run their operations just like a business, and they have costs like any other. We anticipate attackers will run fraud bots efficiently against APIs even more than in previous years.
Growing governance: The first version of PCI DSS that directly addresses API security will go into effect in March 2024. Check your industry’s specific requirements with your audit department to be ready for requirements as they come into effect.
If you’re interested in the full report, you can download the 2024 API Security Report here, which includes full detail on our recommendations.
Cloudflare API Gateway is our API security solution, and it is available for all Enterprise customers. If you aren’t subscribed to API Gateway, click here to view your initial API Discovery results and start a trial in the Cloudflare dashboard. To learn how to use API Gateway to secure your traffic, click here to view our development docs and here for our getting started guide.
2023년 4분기 DDoS 위협 보고서
Post Syndicated from Omer Yoachimik http://blog.cloudflare.com/author/omer/ original https://blog.cloudflare.com/ddos-threat-report-2023-q4-ko-kr

Cloudflare DDoS 위협 보고서 제16호에 오신 것을 환영합니다. 이번 호에서는 2023년 4분기이자 마지막 분기의 DDoS 동향과 주요 결과를 다루며, 연중 주요 동향을 검토합니다.
DDoS 공격이란 무엇일까요?
DDoS 공격 또는 분산 서비스 거부 공격은 웹 사이트와 온라인 서비스가 처리할 수 있는 트래픽을 초과하여 사용자를 방해하고 서비스를 사용할 수 없게 만드는 것을 목표로 하는 사이버 공격의 한 유형입니다. 이는 교통 체증으로 길이 막혀 운전자가 목적지에 도착하지 못하는 것과 유사합니다.
이 보고서에서 다룰 DDoS 공격에는 크게 세 가지 유형이 있습니다. 첫 번째는 HTTP 서버가 처리할 수 있는 것보다 더 많은 요청으로 서버를 압도하여 서비스 거부 이벤트를 발생시키는 것을 목표로 하는 HTTP 요청집중형 DDoS 공격입니다. 두 번째는 라우터, 방화벽, 서버 등의 인라인 장비에서 처리할 수 있는 패킷보다 많은 패킷을 전송하여 서버를 압도하는 것을 목표로 하는IP 패킷집중형 DDoS 공격입니다. 세 번째는 비트 집중형 공격으로, 인터넷 링크를 포화 상태로 만들어 막히게 함으로써 앞서 설명한 ‘정체’를 유발하는 것을 목표로 합니다. 이 보고서에서는 세 가지 유형의 공격에 대해 다양한 기법과 인사이트를 중점적으로 다룹니다.
보고서의 이전 버전은 여기에서 확인할 수 있으며, 대화형 허브인Cloudflare Radar에서도 확인할 수 있습니다. Cloudflare Radar는 전 세계 인터넷 트래픽, 공격, 기술 동향, 인사이트를 보여주며, 드릴 다운 및 필터링 기능을 통해 특정 국가, 산업, 서비스 공급자에 대한 인사이트를 확대할 수 있습니다. Cloudflare Radar는 학자, 데이터 전문가, 기타 웹 애호가가 전 세계 인터넷 사용량을 조사할 수 있는 무료 API도 제공합니다.
Cloudflare에서 이 보고서를 작성한 방법을 알아보려면 방법론을 참조하세요.
핵심 결과
- Cloudflare에서 관찰한 바에 따르면, 4분기에는 네트워크 계층 DDoS 공격이 전년 동기 대비 117% 증가했으며, 블랙 프라이데이와 연말연시를 전후해 소매, 배송, 홍보 웹 사이트를 겨냥한 DDoS 활동이 전반적으로 증가했습니다.
- 4분기에 대만을 겨냥한 DDoS 공격 트래픽은 총선이 다가오고 중국과의 긴장이 고조된 가운데 전년 대비 3,370% 증가했습니다. 이스라엘과 하마스 간의 군사적 갈등이 지속됨에 따라 이스라엘 웹 사이트를 겨냥한 DDoS 공격 트래픽의 비율은 전 분기 대비 27% 증가했으며, 팔레스타인 웹 사이트를 의 군사적 갈등이 지속됨에 따라 이스라엘 웹 사이트를 겨냥한 DDoS 공격 트래픽의 비율은 전 분기 대비 1,126% 증가했습니다.
- 4분기에는 제28차 유엔 기후변화회의(COP 28)가 열린 시기와 맞물려 환경 서비스 웹 사이트를 겨냥한 DDoS 공격 트래픽이 전년 대비 무려 61,839% 급증했습니다.
이러한 주요 조사 결과에 대한 심층 분석과 현재의 사이버 보안 과제에 대한 이해를 새롭게 정의할 수 있는 추가 인사이트를 확인하려면 계속 읽어보세요!
대규모 볼류메트릭 HTTP DDoS 공격
2023년은 미지의 영역이 펼쳐지는 해였습니다. DDoS 공격은 규모와 정교함에 있어서 새로운 차원에 도달했습니다. Cloudflare를 포함한 광범위한 인터넷 커뮤니티에서는 전례 없는 속도로 수천 건에 이르며 지속적이고 의도적으로 설계된 대규모 볼류메트릭 DDoS 공격 캠페인에 직면했습니다.
이러한 공격은 매우 복잡하고 HTTP/2 취약점을 악용했습니다. Cloudflare에서는 취약점의 영향을 완화하기 위해 특수하게 마련한 기술을 개발했으며, 업계의 다른 기업들과 협력하여 취약점을 공개하는 일을 담당했습니다.
이러한 DDoS 캠페인의 일환으로 3분기에 Cloudflare의 시스템에서는 초당 2억 100만 건에 달하는 사상 최대 규모의 요청으로 이루어진 공격을 방어했습니다. 이는 지난 2022년의 기록인 초당 2,600만 요청보다 거의 8배나 많은 수치입니다.
네트워크 계층 DDoS 공격의 증가
대규모 캠페인이 진정된 후 우리는 HTTP DDoS 공격이 예상치 않게 감소하는 것을 확인했습니다. 2023년 전체적으로는 26조 건이 넘는 요청으로 이루어진 520만 건 이상의 HTTP DDoS 공격을 자동화된 방어 기능으로 막아냈습니다. 이는 시간당 평균 594건의 HTTP DDoS 공격과 30억 건의 요청을 완화한 수치입니다.
이러한 천문학적 수치에도 불구하고 HTTP DDoS 공격 요청량은 실제로 2022년에 비해 20% 감소했습니다. 이러한 감소세는 연간뿐만 아니라 2023년 4분기에도 관찰되었는데, HTTP DDoS 공격 요청 건수는 전년 동기 대비 7%, 전 분기 대비 18% 감소했습니다.
네트워크 계층에서는 완전히 다른 추세를 확인했습니다. Cloudflare에서는 자동화된 방어 기능으로2023년에 870만 건의 네트워크 계층 DDoS 공격을 방어했습니다. 이는 2022년에 비해 85% 증가한 수치입니다.
2023년 4분기에 Cloudflare에서는 자동화된 방어 기능으로 80페타바이트가 넘는 네트워크 계층 공격을 완화했습니다. 평균적으로 우리 시스템에서는 매시간 996건의 네트워크 계층 DDoS 공격과 27테라바이트를 자동으로 방어했습니다. 2023년 4분기의 네트워크 계층 DDoS 공격 건수는 전년 동기 대비 175%, 전 분기 대비25% 증가했습니다.
COP 28 기간과 그 전후의DDoS 공격 증가
2023년 마지막 분기에는 사이버 위협의 환경이 크게 변화했습니다. 초기에는 암호화폐 분야가 HTTP DDoS 공격 요청량 측면에서 선두를 달리고 있었지만, 새로운 공격 대상이 주요 피해자로 등장했습니다. 환경 서비스 업계를 겨냥한 HTTP DDoS 공격이 전례 없이 급증했으며, 이 공격이 전체 HTTP 트래픽의 절반을 차지했습니다. 이는 전년 대비 무려 618배 증가한 수치로, 사이버 위협 환경의 불안한 추세를 보여줍니다.
이처럼 사이버 공격이 급증한 시기는 2023년 11월 30일부터 12월12일까지 열린 유엔기후변화협약 당사국총회(COP 28)와 맞물렸습니다. 이 회의는 중추적인 이벤트로, 많은 사람이 화석 연료 시대의 ‘종말의 시작’이라고 생각했던 것을 알리는 신호탄이었습니다. COP 28을 앞둔 기간 동안 환경 서비스 웹 사이트를 겨냥한 HTTP 공격이 눈에 띄게 급증한 것으로 관찰되었습니다. 이러한 패턴은 이 이벤트에만 국한된 것이 아니었습니다.
특히 COP 26과 COP 27, 그리고 다른 유엔 환경 관련 결의안이나 발표의 과거 데이터를 살펴보면 비슷한 패턴이 나타납니다. 이러한 이벤트가 있을 때마다 환경 서비스 웹 사이트를 겨냥한 사이버 공격도 함께 증가했습니다.
2023년 2월과 3월, 유엔의 기후 정의 결의안과 유엔환경계획의 담수 챌린지시작과 같은 중요한 환경 이벤트 때문에 환경 웹 사이트의 인지도가 높아졌고, 이는 이러한 사이트에 대한 공격의 증가와 관련이 있을 수 있습니다.
이러한 반복적인 패턴을 보면 환경 문제와 사이버 보안이 점점 더 밀접하게 연관되어 있으며, 사이버 보안은 디지털 시대에 점점 더 공격자의 초점이 되고 있음을 실감할 수 있습니다.
DDoS 공격과 철검
DDoS 공격을 촉발하는 것은 유엔 결의안만이 아닙니다. 사이버 공격, 특히 DDoS 공격은 오랫동안 전쟁과 혼란의 도구로 사용되어 왔습니다. 우크라이나와 러시아 사이의 전쟁에서 DDoS 공격 활동이 증가되는 것이 관찰되었고, 이제는 이스라엘과 하마스 사이의 전쟁에서도 DDoS 공격이 증가하고 있습니다. Cloudflare에서는 이스라엘-하마스 전쟁에서의 사이버 공격 보고서에서 사이버 활동을 처음 보고했으며, 4분기 내내 지속해서 사이버 활동을 모니터링했습니다.
“철검” 작전은 하마스가 주도한 10월 7일 공격 이후 이스라엘이 하마스를 상대로 시작한 군사 공격입니다. 이 무력 충돌이 계속되는 Cloudflare에서는 동안 양측을 겨냥한DDoS 공격을 계속 목격하고 있습니다.
지역별 트래픽을 기준으로 볼 때, 팔레스타인 지역은 4분기에 HTTP DDoS 공격이 두 번째로 많이 발생한 지역이었습니다. 팔레스타인 웹 사이트를 향한 전체 HTTP 요청의 10% 이상이 DDoS 공격이었으며, 총 13억 건의DDoS 요청이 발생하여 전 분기 대비 1,126% 증가했습니다. 이러한 DDoS 공격의 90%는 팔레스타인 은행 웹 사이트를 겨냥했습니다. 또 다른 8%는 정보 기술 및 인터넷 플랫폼을 겨냥했습니다.
유사하게, Cloudflare의 시스템에서는 이스라엘 웹 사이트를 겨냥한 22억 건 이상의 HTTP DDoS 요청을 자동으로 방어했습니다. 22억 건은 전 분기 및 전년 동기 대비 감소한 수치이지만, 이스라엘로 향하는 전체 트래픽 중에서 차지하는 비중은 여전히 높았습니다. 이 정규화 수치는 전 분기 대비 27% 증가했지만, 전년 동기 대비로는 92% 감소한 수치입니다. 공격 트래픽의 양이 많음에도 불구하고 이스라엘은 자국 트래픽 대비 77번째로 공격을 많이 받은 지역이었습니다. 또한 총 공격 건수 기준으로는 33번째로 공격을 많이 받은 반면 팔레스타인 영토는 42번째로 공격을 많이 받았습니다.
공격받은 이스라엘 웹 사이트 중 신문 및 미디어가 주요 표적이었으며, 이스라엘을 향하는 HTTP DDoS 공격의 약 40%를 신문 및 미디어 부문에서 받았습니다. 두 번째로 공격을 많이 받은 산업은 컴퓨터 소프트웨어 산업이었습니다. 은행, 금융 기관 및 보험(BFSI) 산업이 3위를 차지했습니다.
네트워크 계층에서도 동일한 추세를 확인할 수 있습니다. 팔레스타인 네트워크는 470테라바이트에 이르는 공격 트래픽의 표적이 되었으며, 이는 팔레스타인 네트워크에 대한 전체 트래픽의 68% 이상을 차지했습니다. 이는 중국에만 뒤지는 수치로, 팔레스타인 지역으로 향하는 모든 트래픽을 기준으로, 팔레스타인이 네트워크 계층 DDoS 공격이 세계에서 두 번째로 많이 발생한 지역이 되었습니다. 절대적인 트래픽 규모로는 3위를 차지했습니다. 이 470테라바이트는 Cloudflare에서 완화한 전체 DDoS 트래픽의 약 1%를 차지합니다.
하지만 이스라엘 네트워크에서 받은 공격 트래픽은 2.4테라바이트 밖에 되지 않아, 네트워크 계층 DDoS 공격을 가장 많이 받은 국가(정상화 기준) 순위에서 8위에 올랐습니다. 이 2.4테라바이트는 이스라엘 네트워크로 향하는 전체 트래픽의 거의 10%를 차지했습니다.
우리는 이스라엘에 위치한 우리 데이터 센터에서 수집된 전체 바이트의 3%가 네트워크 계층 DDoS 공격이라는 사실을 확인했습니다. 팔레스타인에 위치한 우리 데이터 센터에서는 이 수치가 전체 바이트의 약 17%로 훨씬 더 높았습니다.
애플리케이션 계층에서는 팔레스타인 IP 주소에서 시작된 HTTP 요청의 4%가 DDoS 공격이며, 이스라엘 IP 주소에서 시작된 HTTP 요청의 약 2%도 DDoS 공격인 것으로 나타났습니다.
DDoS 공격의 주요 출처
2022년 3분기에는 중국이 HTTP DDoS 공격 트래픽의 최대 출처였습니다. 그러나 2022년 4분기부터는 미국이 HTTP DDoS 공격의 최대 출처가 되었으며, 이후 5분기 연속으로 이 바람직하지 않은 위치를 유지하고 있습니다. 마찬가지로 미국의 데이터 센터는 전체 공격 바이트의 38%가 넘는 네트워크 레이어 DDoS 공격 트래픽을 가장 많이 수집하는 곳입니다.
중국과 미국은 함께 전 세계 HTTP DDoS 공격 트래픽의 4분의 1 이상을 차지합니다. 브라질, 독일, 인도네시아, 아르헨티나가 그 다음 25%를 차지합니다.
이러한 큰 수치는 일반적으로 큰 시장에 들어맞습니다. 그러한 이유로 각 국가의 아웃바운드 트래픽을 비교하여 각 국가에서 기원하는 공격 트래픽을 정규화하기도 합니다. 이 작업을 수행하면 작은 섬나라나 시장 규모가 작은 국가에서 불균형적인 공격 트래픽이 기원하는 경우가 종종 있습니다. 4분기에는, 세인트 헬레나의 아웃바운드 트래픽 중 40%가 HTTP DDoS 공격으로 1위를 차지했습니다. 이 ‘외딴 열대 화산 섬‘에 이어 리비아가 2위, 스와질란드(에스와티니라고도 함)가 3위를 차지했습니다. 아르헨티나와 이집트가 그 뒤를 이어 각각 4위와 5위를 차지했습니다.
네트워크 계층에서는 짐바브웨가 1위에 올랐습니다. 짐바브웨에 위치한 Cloudflare 데이터 센터에서 수집한 전체 트래픽의 거의 80%가 악의적 트래픽이었습니다. 2위는 파라과이, 3위는 마다가스카르가 차지했습니다.
가장 많이 공격받는 산업
공격 트래픽 규모 기준으로 4분기에 가장 많이 공격을 받은 산업은 암호화폐 산업이었습니다. 3,300억 건 이상의 HTTP 요청이 이 산업을 겨냥했습니다. 이 수치는 해당 분기 전체 HTTP DDoS 트래픽의 4% 이상을 차지합니다. 두 번째로 공격을 많이 받은 산업은 게임 및 도박이었습니다. 이들 산업은 탐나는 표적으로 알려져 있으며 많은 트래픽과 공격을 유발합니다.
네트워크 계층에서는 정보 기술 및 인터넷 산업이 가장 많은 공격을 받았으며, 전체 네트워크 계층 DDoS 공격 트래픽의 45% 이상이 이 산업을 겨냥했습니다. 은행, 금융 서비스, 보험(BFSI), 게임 및 도박, 통신 산업이 그 뒤를 이었습니다.
관점을 바꾸기 위해 여기에서도 공격 트래픽을 특정 산업의 전체 트래픽으로 정규화했습니다. 그럴 경우 그림이 달라집니다.
이 보고서의 서두에서 이미 환경 서비스 산업이 자체 트래픽 대비 가장 많은 공격을 받았다고 언급한 바 있습니다. 2위는 포장 및 화물 배송 산업으로, 블랙 프라이데이 및 겨울 휴가철 온라인 쇼핑과 시기상으로 상관관계가 있다는 점에서 흥미로웠습니다. 판매된 선물과 상품을 어떻게든 목적지에 보내야 하는데, 공격자가 이를 방해하려고 시도한 것으로 보입니다. 마찬가지로 소매업체에 대한 DDoS 공격도 전년 대비 23% 증가했습니다.
네트워크 계층에서 가장 많이 표적이 된 산업은 홍보 및 커뮤니케이션으로, 전체 트래픽의 36%가 악의적 트래픽이었습니다. 이 역시 시기를 고려할 때 매우 흥미롭습니다. 홍보 및 커뮤니케이션 기업은 일반적으로 대중의 인식 및 커뮤니케이션 관리와 관련이 있습니다. 이러한 기업의 운영이 중단되면 평판에 즉각적이고 광범위한 영향이 미칠 수 있으며, 이는 4분기 연말연시 시즌에 더욱 중요해집니다. 이 분기에는 휴일, 연말 결산, 새해 준비 등으로 인해 홍보 및 커뮤니케이션 활동이 증가하는 경우가 많습니다. 따라서 일부에서는 이 시기를 누군가가 업무를 방해하기를 원할 수 있는 중요한 운영 기간으로 여기기도 합니다.
가장 많이 공격받은 국가 및 지역
싱가포르는 4분기에 HTTP DDoS 공격의 주요 표적이었습니다. 전 세계 DDoS 트래픽의 4%인3,170억 건이 넘는 HTTP 요청이 싱가포르 웹 사이트를 겨냥했습니다. 뒤이어 미국이 2위, 캐나다가 3위를 차지했습니다. 대만은 다가오는 총선과 중국과의 긴장 관계로 인해 네 번째로 공격을 많이 받은 지역으로 기록되었습니다. 4분기에 대만을 향한 공격 트래픽은 전년 대비 847%, 전 분기 대비2,858% 증가했습니다. 이러한 증가는 절대값에만 국한되지 않습니다. 정규화했을 때, 대만을 향한 전체 트래픽 대비 대만을 겨냥한HTTP DDoS 공격 트래픽의 비율도 전 분기 대비 624%, 전년 동기 대비 3,370%로 크게 증가했습니다.
중국은 HTTP DDoS 공격을 가장 많이 받은 국가 중 9번째이지만, 네트워크 계층 공격을 가장 많이 받은 국가로는 1위에 올랐습니다. Cloudflare에서 전 세계에 걸쳐 완화한 모든 네트워크 계층 DDoS 트래픽의 45%가 중국을 향한 트래픽이었습니다. 나머지 국가들은 거의 무시할 수 있을 정도로 뒤져 있었습니다.
데이터를 정규화하면 이라크, 팔레스타인 지역, 모로코가 총 인바운드 트래픽 대비 가장 많은 공격을 받은 지역으로 나타났습니다. 흥미롭게도 싱가포르가 4위에 올랐습니다. 따라서 싱가포르는 가장 많은 양의 HTTP DDoS 공격 트래픽에 직면해 있을 뿐만 아니라 해당 트래픽은 싱가포르를 향한 전체 트래픽의 상당 부분을 차지합니다. 이와는 대조적으로, 미국은(위의 애플리케이션 계층 그래프에 따르면) 양적으로는 두 번째로 많은 공격을 받았지만, 미국으로 향하는 전체 트래픽을 기준으로 보면 50위에 그쳤습니다.
싱가포르와 유사하지만, 훨씬 더 극적일 수 있는 중국은 네트워크 계층 DDoS 공격 트래픽 및 중국으로 향하는 모든 트래픽에 있어서 가장 많이 공격받는 국가입니다. 중국으로 향하는 전체 트래픽의 거의 86%가 네트워크 계층 DDoS 공격으로, Cloudflare에 의해 완화되었습니다. 팔레스타인 지역, 브라질, 노르웨이, 그리고 다시 싱가포르가 공격 트래픽 비율이 높은 국가로 그 뒤를 이었습니다.
공격 벡터 및 속성
대부분의 DDoS 공격은 Cloudflare의 기준으로 볼 때 짧고 규모가 작습니다. 그러나 보호되지 않은 웹 사이트와 네트워크는 적절한 인라인 자동 보호 기능이 없으면 짧은 소규모의 공격으로도 중단될 수 있으며, 따라서 조직에서 강력한 보안 태세를 선제적으로 도입해야 할 필요성이 강조됩니다.
2023년 4분기에는 공격의 91%가 10분 이내에 종료되었고, 97%는 정점에서도 초당 500메가비트(mbps) 미만이었으며, 88%는 초당 5만 패킷(pps)을 넘은 적이 없었습니다.
네트워크 계층 DDoS 공격 100건 중 2건은 1시간 이상 지속되었고, 초당 1기가비트(gbps)를 초과했습니다. 100건 중 1건의 공격이 초당 100만 패킷을 초과했습니다. 또한 초당 1억 패킷을 초과하는 네트워크 계층 DDoS 공격의 양은 전 분기 대비 15% 증가했습니다.
이러한 대규모 공격 중 하나는 초당 1억 6천만 개의 패킷을 전송한 Mirai 봇넷 공격이었습니다. 초당 패킷 전송량은 역대 최대가 아니었습니다. 역대 최대 규모는 초당 7억 5,400만 패킷이었습니다. 이 공격은 2020년에 발생했으며, 이보다 더 큰 규모의 공격은 아직 관찰된 적이 없습니다.
하지만 최근에 발생한 이 공격은 초당 비트 전송률이 특이했습니다. 이 공격은 4분기에 발생한 네트워크 계층 공격 중 가장 큰 규모의 DDoS 공격이었습니다. 이 공격은 초당 1.9 테라비트로 최고치를 기록했으며 Mirai 봇넷으로부터 시작되었습니다. 이 공격은 여러 가지 공격 방법이 결합된 멀티 벡터 공격이었습니다. 이러한 방법 중 일부에는 UDP 조각 폭주, UDP/Echo 폭주, SYN 폭주, ACK 폭주, TCP 기형 폭주가 포함되었습니다.
이 공격은 알려진 유럽 클라우드 공급자를 겨냥했으며, 스푸핑된 것으로 추정되는 18,000여 개의 고유 IP 주소에서 시작되었습니다. 이 공격은 Cloudflare의 방어 기능에서 자동으로 감지되어 완화되었습니다.
이는 최대 규모의 공격도 매우 빠르게 종료된다는 것을 보여줍니다. Cloudflare에서 확인한 이전의 대규모 공격들은 몇 초 만에 종료되었으므로 인라인 자동 방어 시스템의 필요성이 강조되었습니다. 아직은 드물지만, 테라비트 규모 범위의 공격이 점점 더 두드러지고 있습니다.
Mirai 변종 봇넷의 사용은 여전히 아주 흔합니다. 4분기에는 전체 공격의 약 3%가 Mirai에서 비롯되었습니다. 하지만 모든 공격 방법 중에서 DNS 기반 공격은 여전히 공격자들이 가장 선호하는 방법입니다. DNS 폭주와 DNS 증폭 공격을 합할 경우 4분기 전체 공격의 약 53%를 차지합니다. SYN 폭주가 뒤를 이어 2위, UDP 폭주가 3위를 차지했습니다. 여기에서는 두 가지 DNS 공격 유형에 대해 다루며, 학습 센터에서 하이퍼링크로 이동하여 UDP 폭주와 SYN 폭주에 대해 자세히 알아볼 수 있습니다.
DNS 폭주 및 증폭 공격
DNS 폭주와 DNS 증폭 공격은 모두 도메인 네임 시스템(DNS)을 악용하지만, 작동 방식은 다릅니다. DNS는 인터넷의 전화번호부와 같습니다. “www.cloudfare.com”과 같이 사람에게 친숙한 도메인 이름을 숫자로 된 IP 주소로 변환하며, 이를 컴퓨터가 네트워크에서 상호 식별하는 데 사용하는 합니다.
간단히 말해, DNS 기반 DDoS 공격은 실제로 서버를 ‘다운’시키지 않고도 컴퓨터와 서버가 서로를 식별하여 서비스 중단 또는 장애를 유발하는 방법입니다. 예를 들어 서버는 가동 중이지만, DNS 서버가 다운되었을 수 있습니다. 따라서 클라이언트는 DNS 서버에 연결할 수 없으며 중단을 경험하게 됩니다.
DNS 폭주 공격은 압도적인 수의 DNS 쿼리로 DNS 서버를 폭주시키는 공격입니다. 이는 일반적으로 DDoS 봇넷을 사용하여 수행됩니다. 엄청난 양의 쿼리로 DNS 서버가 압도되어 정상적인 쿼리에 응답하기 어렵거나 불가능하게 될 수 있습니다. 이로 인해 앞서 언급한 서비스 중단, 지연, 심지어는 웹 사이트나 공격 대상 DNS 서버에 의존하는 서비스에 액세스하려는 사용자의 서비스 중단이 발생할 수 있습니다.
반면, DNS 증폭 공격은 스푸핑된 IP 주소(피해자의 주소)가 포함된 작은 쿼리를 DNS 서버로 전송하는 것입니다. 여기서 비결은 DNS 응답이 요청보다 훨씬 크다는 것입니다. 그러면 서버는 이 큰 응답을 피해자의 IP 주소로 보냅니다. 공격자는 개방형 DNS 확인자를 악용하여 피해자에게 전송되는 트래픽의 양을 증폭시켜 훨씬 더 큰 영향을 미칠 수 있습니다. 이러한 유형의 공격은 피해자를 방해할 뿐만 아니라 전체 네트워크를 정체시킬 수 있습니다.
두 경우 모두 공격자는 네트워크 운영에서DNS의 중요한 역할을 악용합니다. 완화 전략에는 일반적으로 DNS 서버 오용 방지, 트래픽 관리를 위한 레이트 리미팅 구현, 악의적 요청 식별 및 차단을 위한 DNS 트래픽 필터링이 포함됩니다.
Cloudflare에서 추적하는, 새롭게 떠오르는 위협 중 지난 분기에 비해ACK-RST 폭주가 1,161%, CLDAP 폭주가 515%, SPSS 폭주가 243% 각각 증가했습니다. 이들 공격의 종류와 이들 공격이 어떻게 업무 중단을 유발하는지를 살펴보겠습니다.
ACK-RST 폭주
ACK-RST 폭주는 피해자에게 많은 ACK 및 RST 패킷을 전송하여 전송 제어 프로토콜(TCP)을 악용합니다. 이로 인해 피해자가 이 패킷을 처리하고 응답하는 능력이 과부하되어 서비스 중단으로 이어집니다. 이 공격은 각 ACK 또는 RST 패킷이 피해자의 시스템에서 응답을 유도하여 리소스를 소모하기 때문에 효과적입니다. ACK-RST 폭주는 합법적인 트래픽을 모방하므로 필터링이 어려운 경우가 많아 감지 및 방어가 어렵습니다.
CLDAP 폭주
연결 없는 경량 디렉터리 액세스 프로토콜(CLDAP)는 경량 디렉터리 액세스 프로토콜(LDAP)의 변형입니다. CLDAP는 IP 네트워크에서 실행되는 디렉터리 서비스를 쿼리하고 수정하는 데 사용됩니다. CLDAP는 연결이 필요 없고 TCP 대신 UDP를 사용하므로 더 빠르지만, 안정성이 떨어집니다. UDP를 사용하므로 공격자가 IP 주소를 스푸핑할 수 있는 핸드셰이크가 필요하지 않으므로 공격자가 이를 반사 벡터로 악용할 수 있습니다. 이러한 공격에서는 스푸핑된 소스 IP 주소(피해자의 IP)로 작은 쿼리를 전송하여 서버가 피해자에게 대량의 응답을 전송하여 서버를 과부하시키도록 합니다. 완화 조치에는 비정상적인 CLDAP 트래픽을 필터링하고 모니터링하는 것이 포함됩니다.
SPSS 폭주
Source Port Service Sweep(SPSS) 프로토콜을 악용하는 폭주는 무작위 또는 스푸핑된 많은 원본 포트에서 표적 시스템 또는 네트워크의 다양한 대상 포트로 패킷을 전송하는 네트워크 공격 방법입니다. 이 공격의 목적은 두 가지입니다. 첫째, 피해자의 처리 능력을 압도하여 서비스 중단 또는 네트워크 중단을 유발하고, 둘째, 열린 포트를 검색하고 취약한 서비스를 식별하는 데 사용하는 것입니다. 폭주는 대량의 패킷을 전송하여 피해자의 네트워크 리소스를 포화시키고 방화벽과 침입 감지 시스템의 용량을 소진시켜 이루어질 수 있습니다. 이 공격을 완화하려면 인라인 자동 감지 기능을 활용하는 것이 필수적입니다.
공격 유형, 규모, 기간과 관계없이 Cloudflare에서 지원합니다
Cloudflare의 사명은 더 나은 인터넷을 구축하는 것이며, 더 나은 인터넷이란 안전하고 성능이 뛰어나며 누구나 이용할 수 있는 인터넷이라고 믿습니다. 공격 유형, 공격 규모, 공격 지속 시간, 공격의 동기와 상관없이 Cloudflare의 방어는 강력합니다. Cloudflare에서는 2017년 무제한 DDoS 방어를 선도적으로 출시한 이래, 모든 조직에서 성능 저하 없이 엔터프라이즈급 DDoS 방어를 무료로 이용할 수 있도록 하겠다는 약속을 지키기 위해 노력해 왔습니다. 이러한 약속을 지킬 수 있었던 것은 Cloudflare의 독보적인 기술과 강력한 네트워크 아키텍처 덕분입니다.
보안은 하나의 제품이나 스위치 하나로 해결되는 것이 아니라 하나의 프로세스라는 점을 기억해야 합니다. 자동화된DDoS 방어 시스템 외에도 우리는 방화벽, 봇 감지, API 보호, 캐싱 등의 포괄적인 기능을 번들로 제공하여 방어 체계를 강화합니다. Cloudflare에서는 다계층 접근 방식을 통해 보안 태세를 최적화하고 잠재적 영향을 최소화합니다. 또한 DDoS 공격에 대한 방어를 최적화하는 데 도움이 되는 권장 사항 목록을 마련했으며, 고객은 단계별 마법사를 따라 애플리케이션을 보호하고 DDoS 공격을 방지할 수 있습니다. DDoS 및 기타 인터넷 공격에 대한 업계 최고의 보호 기능을 간편하게 이용하고 싶으시면 Cloudflare.com에서 무료로 가입하실 수 있습니다! 공격을 받고 있다면 여기에 표시된 사이버 긴급 핫라인 번호로 등록하거나 전화하여 신속하게 대응하세요.
2023年第4四半期DDoS脅威レポート
Post Syndicated from Omer Yoachimik http://blog.cloudflare.com/author/omer/ original https://blog.cloudflare.com/ddos-threat-report-2023-q4-ja-jp

CloudflareのDDoS脅威レポート第16版へようこそ。本版では、2023年第4四半期および最終四半期のDDoS動向と主要な調査結果について、年間を通じた主要動向のレビューとともにお届けします。
DDoS攻撃とは?
DDoS攻撃(分散型サービス妨害攻撃)とは、Webサイトやオンラインサービスを混乱させることを目的としたサイバー攻撃の一種で、処理能力を超えるトラフィックで圧倒することでユーザーが利用不能になります。DDoS攻撃は、道路を渋滞させ、ドライバーが目的地にたどり着けなくする車の渋滞に似ています。
このレポートで取り上げるDDoS攻撃には、主に3つのタイプがあります。1つ目はHTTPリクエスト集中型DDoS攻撃で、HTTPサーバーを処理能力を超えるリクエストで圧倒し、サービス妨害イベントを引き起こすことを狙います。2つ目はIPパケット集中型のDDoS攻撃で、ルーターやファイアウォール、サーバーなどのインラインアプライアンスを、処理能力を超えるパケットで圧倒することを狙います。3つ目は、ビット集中型の攻撃で、インターネット・リンクを飽和させ、詰まらせることを目的とし、前述の「グリッドロック」(渋滞)を引き起こします。このレポートでは、この3つのタイプの攻撃に関するさまざまなテクニックと洞察を紹介します。
また、このレポートの前の版はこちらまたは当社のインタラクティブハブであるCloudflare Radarでご覧いただけます。Cloudflare Radarは、世界のインターネットトラフィック、攻撃、テクノロジーのトレンドと洞察を紹介し、特定の国、業界、サービスプロバイダーの洞察を掘り下げるための検索・フィルタリング機能を備えています。また、Cloudflare Radarは無料のAPIも提供しており、学者、データ調査者、その他Webの愛好家が世界中のインターネット利用状況を調査することができます。
本レポートの作成方法については、「メソドロジー」を参照してください。
主な調査結果
- 第4四半期には、ネットワーク層のDDoS攻撃が前年同期比で117%増加し、ブラックフライデーとホリデーシーズン前後には、小売、出荷、広報のWebサイトを標的としたDDoS攻撃が全体的に増加しました。
- 第4四半期には、総選挙を控え、中国との緊張が伝えられる中、台湾を標的としたDDoS攻撃トラフィックが前年比3,370%増となりました。イスラエルとハマスの軍事衝突が続く中、イスラエルのWebサイトを標的としたDDoS攻撃トラフィックの割合は前四半期比で27%増加し、パレスチナのWebサイトを標的としたDDoS攻撃トラフィックの割合は前四半期比で1,126%増加しました。
- 第4四半期には、第28回国連気候変動会議(COP28)が開催されたこともあり、環境サービスWebサイトを標的にしたDDoS攻撃トラフィックが前年比61,839%という驚異的な急増を見せました。
これらの主要な調査結果の詳細な分析と、現在のサイバーセキュリティの課題に対する理解を再定義するその他の洞察については、こちらをお読みください!
超帯域幅消費型HTTP DDoS攻撃
2023年は未開の領域の年でした。DDoS攻撃は、その規模と巧妙さにおいて、新たな高みに達しました。Cloudflareを含むより広範なインターネットコミュニティは、かつてない速度で何千もの超帯域幅消費型DDoS攻撃を行う、執拗かつ意図的に仕組まれたキャンペーンに直面しました。
これらの攻撃は非常に複雑で、HTTP/2の脆弱性を悪用していました。Cloudflareはこの脆弱性の影響を軽減するために専用の技術を開発し、業界の他の企業と協力して責任を持って公開しました。
このDDoSキャンペーンの一環として、当社のシステムは第3四半期に、1秒当たり2億100万リクエスト(rps)という過去最大の攻撃を軽減しました。これは、これまでの2022年の記録である2,600万RPSの約8倍に相当します。
ネットワーク層DDoS攻撃の増加
超帯域幅消費型キャンペーンが沈静化した後、HTTP DDoS攻撃が予想外に減少しました。2023年全体では、当社の自動化された防御は、26兆リクエストを超えるHTTP DDoS攻撃を520万回以上軽減しました。これは、毎時平均594件のHTTP DDoS攻撃と30億件の軽減リクエストに相当します。
このような天文学的な数字にもかかわらず、HTTP DDoS攻撃リクエストの量は2022年と比べて20%減少しました。この減少は年間だけでなく、2023年第4四半期にも見られ、HTTP DDoS攻撃リクエスト数は前年比で7%、前四半期比で18%減少しました。
ネットワーク層では、まったく異なる傾向が見られました。当社の自動化された防御は、2023年に870万件のネットワーク層DDoS攻撃を軽減しました。これは2022年と比較して85%の増加です。
2023年第4四半期、Cloudflareの自動化された防御は、80ペタバイトを超えるネットワーク層の攻撃を軽減しました。当社のシステムは、平均して毎時996件のネットワーク層DDoS攻撃、27テラバイトを自動軽減しました。2023年第4四半期のネットワーク層DDoS攻撃数は前年比175%増、前四半期比25%増となりました。
COP28期間中とその前後にDDoS攻撃が増加
2023年最終四半期、サイバー脅威の状況は大きく変化しました。当初、HTTP DDoS攻撃リクエストの量では暗号通貨セクターが主導的な役割を果たしていましたがが、新たな標的が主要な被害者として現れました。環境サービス業界では、HTTP DDoS攻撃がかつてないほど急増し、HTTPトラフィック全体の半分を占めています。これは前年比618倍という驚異的な増加であり、サイバー脅威の状況における不穏な傾向を浮き彫りにしています。
このサイバー攻撃の急増は、2023年11月30日から12月12日まで開催されたCOP28と重なりました。この会議は、多くの人が化石燃料時代の「終わりの始まり」を告げる重要なイベントでした。COP28までの期間、環境サービスWebサイトを標的としたHTTP攻撃が顕著に急増したことが観察されましたが、このパターンはこのイベントだけに限定されたものではありませんでした。
過去のデータを振り返ってみると、特にCOP26やCOP27の際、また他の国連環境関連の決議や発表の際に同じようなパターンが見られます。これらのイベントにはそれぞれ、環境サービスWebサイトを狙ったサイバー攻撃の増加が伴っていました。
2023年2月と3月にかけて、国連の気候正義に関する決議や国連環境プログラムの淡水チャレンジの開始といった重要な環境イベントがあり、環境Webサイトの注目度が高まった可能性があり、これが、これらのサイトに対する攻撃の増加と関連している可能性があります。
このように繰り返されるパターンは、環境問題とサイバーセキュリティの接点が増えつつあることを示しています。サイバーセキュリティは、デジタル時代の攻撃者にとってますます焦点となっています。
DDoS攻撃と鉄の剣
DDoS攻撃の引き金は国連決議だけではない。サイバー攻撃、特にDDoS攻撃は、長い間、戦争や混乱を引き起こす手段となってきました。私たちは、ウクライナとロシアの戦争でDDoS攻撃活動の増加を目の当たりにし、そして今、イスラエルとハマスの戦争でも同様の状態を目撃しています。私たちは、イスラエル・ハマス戦争におけるサイバー攻撃のレポートにおいてサイバー活動を初めて報告しており、第4四半期を通じてその活動を監視し続けました。
「鉄の剣」作戦は、10月7日にハマスによる攻撃を受け、イスラエルがハマスに対して行った軍事攻撃です。この武力紛争が続いている間、私たちは双方を標的にしたDDoS攻撃を観察し続けています。
各地域のトラフィックと比較すると、第4四半期にHTTP DDoS攻撃で2番目に攻撃を受けたのはパレスチナ地域でした。パレスチナのWebサイトに対するHTTPリクエストの10%以上がDDoS攻撃であり、合計13億件のDDoSリクエストが前四半期比で1,126%増加しました。これらのDDoS攻撃の90%は、パレスチナの金融機関のWebサイトを標的にしています。別の8%は、情報技術とインターネットプラットフォームを標的としていました。
同様に、当社のシステムは、イスラエルのWebサイトを標的とした22億を超えるHTTP DDoSリクエストを自動的に軽減しました。22億件という数は、前四半期や前年と比較すると減少していますが、イスラエル向けのトラフィック全体に占める割合は大きくなっています。この数値は前四半期比では27%増だが、前年比では92%減です。攻撃トラフィックの多さにもかかわらず、イスラエルは自国のトラフィックに対して77番目に多く攻撃された地域でした。また、パレスチナ自治区が42番目だったのに対し、攻撃の総量は33番目に多くなりました。
イスラエルのWebサイトが攻撃を受けたうち、新聞およびメディアが主な標的で、イスラエル向けのHTTP DDoS攻撃のほぼ40%が攻撃対象のトラフィックでした。攻撃対象業界2位は、コンピューター・ソフトウェア業界でした。次いで、3位に銀行・金融機関・保険(BFSI)業界が位置しました。
ネットワーク層でも同じ傾向が見られます。パレスチナのネットワークは、470テラバイトの攻撃トラフィックの標的にされ、パレスチナのネットワークに対する全トラフィックの68%以上を占めています。この数字は、パレスチナ自治区に向かうすべてのトラフィックと比較して、ネットワーク層のDDoS攻撃によって、中国に次いでパレスチナ自治区が世界で2番目に多く攻撃された地域であることを示しています。トラフィックの絶対量では3位でした。この470テラバイトは、Cloudflareが軽減したDDoSトラフィック全体の約1%に相当します。
しかし、イスラエルのネットワークは、わずか2.4テラバイトの攻撃トラフィックの標的にされただけで、正規化した場合にネットワーク層のDDoS攻撃で8位に位置づけました。この2.4テラバイトは、イスラエルのネットワークに向かう全トラフィックのほぼ10%を占めています。
裏を返せば、イスラエルを拠点とするデータセンターで受信された全バイトの3%がネットワーク層のDDoS攻撃だったことが示されました。パレスチナを拠点とするデータセンターでは、この数字はかなり高く、全バイトの約17%となっています。
アプリケーション層では、パレスチナのIPアドレスから発信されたHTTPリクエストの4%がDDoS攻撃であり、イスラエルのIPアドレスから発信されたHTTPリクエストのほぼ2%もDDoS攻撃であることが分かりました。
DDoS攻撃の主な発生源
2022年第3四半期には、中国がHTTP DDoS攻撃トラフィックの最大の発生源でした。しかし、2022年第4四半期以降、米国がHTTP DDoS攻撃の最大の発生源として第1位となり、5四半期連続でその好ましくない地位を維持しています。同様に、米国のデータセンターは、ネットワーク層のDDoS攻撃トラフィックを最も多く受診しています。これは、前攻撃バイト数の38%超です。
中国と米国は、世界のHTTP DDoS攻撃トラフィックの4分の1強を占めています。次いでブラジル、ドイツ、インドネシア、アルゼンチンが25%を占めています。
このような大きな数値は通常、大きな市場に対応しています。このため、各国の発信トラフィックを比較することで、各国から発信される攻撃トラフィックも正規化しています。これを行うと、小さな島国や市場の小さい国から不釣り合いな量の攻撃トラフィックが発生することがよくあります。第4四半期には、セントヘレナの発信トラフィックの40%がHTTP DDoS攻撃であり、トップとなりました。「僻地の火山・熱帯地帯の島」に続いて、2位はリビア、3位はスワジランド(エスワティニとしても知られる)でした。4位と5位にはアルゼンチンとエジプトが続いています。
ネットワーク層ではジンバブエが1位となりました。ジンバブエを拠点とするデータセンターで受信したトラフィックのほぼ80%が悪意のあるものでした。それに次いで、2位はパラグアイ、3位はマダガスカルでした。
最も攻撃された業界
攻撃トラフィック量では、第4四半期に最も攻撃された業界は暗号通貨業界でした。3,300億回を超えるHTTPリクエストが暗号通貨業界を標的としました。この数字は、当四半期のHTTP DDoSトラフィック全体の4%以上を占めています。攻撃対象業界の2位は、ゲーミング&ギャンブルでした。これらの業界は、多くのトラフィックや攻撃を引き付けていることで知られています。
ネットワーク層では、情報技術およびインターネット業界が最も攻撃を受け、ネットワーク層のDDoS攻撃トラフィックの45%以上がこの業界を狙ったものでした。銀行・金融サービス・保険(BFSI)、ゲーミング&ギャンブル、電気通信業界がそれに続きました。
視点を変えるために、ここでも攻撃トラフィックを特定の業界の総トラフィックで正規化しました。そうすることで、私たちは違った見方をすることができるようになります。
本レポートの冒頭で、環境サービス業界が自社のトラフィックに比して最も攻撃を受けたことを述べました。2位は包装・貨物配送業界で、興味深いことに、ブラックフライデーや冬のホリデーシーズンのオンラインショッピングとのタイムリーな相関関係が見られます。購入したギフトや商品は、どうにかして目的地に届ける必要がありますが、攻撃者たちはそれを妨害しようとしたようです。同様に、小売企業に対するDDoS攻撃も前年比で23%増加が見られました。
ネットワーク層では、広報・通信が最も標的とされた業種で、トラフィックの36%が悪意あるものでした。このタイミングも非常に興味深いものでした。広報・通信会社は通常、大衆の認識と通信を管理することに関連しています。業務に支障をきたすと、即座に広範囲に風評被害が及ぶ可能性があり、第4四半期のホリデーシーズンにはさらに深刻になります。今四半期は、年末年始の休暇、年度末の総括、新年度の準備のため、PRや通信活動が増加することが多く、重要な業務期間となっています。
最も攻撃された国と地域
第4四半期はシンガポールがHTTP DDoS攻撃の主な標的となりました。全世界のDDoSトラフィックの4%にあたる3,170億以上のHTTPリクエストがシンガポールのWebサイトを狙ったものでした。米国が2位、カナダが3位と僅差で続きました。台湾は、総選挙を控え、中国との緊張が高まる中、攻撃対象地域の4位となりました。第4四半期の台湾向け攻撃は、前年比で847%、前四半期比で2,858%増加しました。この増加は絶対値だけにとどまりません。正規化すると、全台湾向けトラフィックに対する台湾を標的としたHTTP DDoS攻撃トラフィックの割合も大幅に増加し、前四半期比で624%、前年比で3,370%増加しています。
中国はHTTP DDoS攻撃では9位に位置づけていますが、ネットワーク層攻撃では1位となっています。Cloudflareが全世界で軽減したネットワーク層のDDoSトラフィックの45%は中国向けでした。他の国々は、ほとんど無視できるほど中国への攻撃が顕在化しています。
データを正規化すると、イラク、パレスチナ自治区、モロッコが、総受信トラフィックに関して最も攻撃された地域となります。興味深いのは、シンガポールが4位に入っていることです。つまり、シンガポールはHTTP DDoS攻撃トラフィックの最大量に直面しているだけでなく、そのトラフィックはシンガポール行きのトラフィック全体のかなりの量を占めていました。対照的に、米国は(上記のアプリケーション層のグラフによれば)量的には2番目に多く攻撃されたことが示されましたが、米国向けのトラフィック全体に関しては50番目でした。
シンガポールと類似していますが、間違いなくもっと劇的なのは、中国がネットワーク層のDDoS攻撃トラフィックならびに中国向けの全トラフィックに関しても最も攻撃されている国であることです。中国向けトラフィックのほぼ86%は、ネットワーク層のDDoS攻撃としてCloudflareによって軽減されました。次いで、パレスチナ自治区、ブラジル、ノルウェー、そしてまたもやシンガポールが攻撃トラフィックで大きな割合を示しました。
攻撃ベクトルと属性
DDoS攻撃の大半は、Cloudflareの規模に比べれば短時間で小規模なものです。しかし、保護されていないWebサイトやネットワークは、適切な自動化されたインライン保護がなければ、短時間の小規模な攻撃によって混乱に見舞われる可能性があり、組織が積極的に堅牢なセキュリティ体制を採用する必要性を強調しています。
2023年第4四半期には、攻撃の91%が10分以内に終了し、97%がピーク時に毎秒500メガビット(mbps)を下回り、88%が毎秒5万パケット(pps)を超えることはありませんでした。
ネットワーク層のDDoS攻撃の100回に2回は1時間以上続き、毎秒1ギガビット(gbps)を超えました。毎秒100万パケットを超える攻撃は100回に1回でした。さらに、毎秒1億パケットを超えるネットワーク層のDDoS攻撃は、前四半期比で15%増加しました。
このような大規模な攻撃のひとつが、ピーク時に毎秒1億6,000万パケットを記録したMiraiボットネット攻撃でしたが、1秒あたりのパケット数は、これまでで最大ではありませんでした。過去最大は毎秒7億54,00万パケットでした。この攻撃は2020年に発生したもので、それ以上のものはまだ観察されたことがありません。
しかし、この最近の攻撃は、そのビット/秒の速度においてユニークでした。これは、当社が第4四半期に見た中で最大のネットワーク層DDoS攻撃でした。ピークは毎秒1.9テラビットで、Miraiボットネットが発生源でした。この攻撃はマルチベクトル攻撃で、複数の攻撃手法を組み合わせています。その中には、UDPフラグメントフラッド、UDP/Echoフラッド、SYNフラッド、ACKフラッド、TCPマルフォームドフラッグなどが含まれていました。
この攻撃は欧州の有名なクラウドプロバイダーを標的としており、なりすましと思われる18,000以上のユニークなIPアドレスから送信されていました。この攻撃はCloudflareの防御機能によって自動的に検出され、軽減されました。
このことは、最大規模の攻撃であっても、あっという間に終わってしまうことを物語っています。私たちが過去に経験した大規模な攻撃は数秒以内に終了しており、インラインの自動防御システムの必要性を強調しています。また、まだまれではありますが、テラビット級の攻撃が目立つようになってきています。
Mirai変種ボットネットの使用は依然として非常に一般的です。第4四半期では、全攻撃のほぼ3%がMiraiから発生しています。しかし、すべての攻撃手法の中で、攻撃者はDNSベースの攻撃を依然として好んでいます。DNSフラッドとDNSアンプ攻撃を合わせると、第4四半期の全攻撃のほぼ53%を占めています。2番目にSYNフラッド、3番目にUDPフラッドが続いています。ここでは、2つのDNS攻撃タイプを取り上げます。UDPフラッドとSYNフラッドについては、ラーニングセンターのハイパーリンクをご覧ください。
DNSフラッドとアンプ攻撃
DNSフラッドとDNSアンプ攻撃はどちらもドメイン名システム(DNS)を悪用しますが、その動作は異なります。DNSはインターネットの電話帳のようなもので、”www.cloudfare.com”のような人間にとって使いやすいドメイン名を、コンピューターがネットワーク上でお互いを識別するために使用する数値のIPアドレスに変換します。
簡単に言えば、DNSベースのDDoS攻撃は、実際にサーバーを「ダウン」させることなく、コンピュータとサーバーがお互いを識別し、停止や中断を引き起こすために使用される方法です。たとえば、サーバーは稼働していても、DNSサーバーがダウンしていることがあります。そのため、クライアントは接続できず、「障害」を経験することになります。
DNSフラッド攻撃は、圧倒的な数のDNSクエリーをDNSサーバーに浴びせます。これは通常、DDoSボットネットを使用して行われます。膨大な量のクエリがDNSサーバーを圧倒し、正当なクエリへの応答が困難または不可能になります。その結果、前述のようなサービスの中断、遅延、あるいはWebサイトや標的となったDNSサーバーに依存するサービスにアクセスしようとする人たちの停止につながる可能性があります。
一方、DNSアンプ攻撃では、DNSサーバーになりすましたIPアドレス(被害者のアドレス)で小さなクエリーを送信します。ここでのトリックは、DNSレスポンスがリクエストよりもかなり大きいことです。次に、サーバーはこの大きなレスポンスを被害者のIPアドレスに送信します。オープンDNSリゾルバーを悪用することで、攻撃者は被害者に送信されるトラフィック量を増幅させ、より大きな影響を与えることができます。このタイプの攻撃は、被害者を混乱させるだけでなく、ネットワーク全体を輻輳させる可能性もあります。
いずれの場合も、攻撃はネットワーク運用におけるDNSの重要な役割を悪用しています。通常、軽減策には、悪用に対するDNSサーバーの保護、トラフィックを管理するためのレート制限の実装、悪意のあるリクエストを特定しブロックするためのDNSトラフィックのフィルタリングなどが含まれます。
当社が追跡している新たな脅威のうち、ACK-RSTフラッドは前四半期比1,161%増、CLDAPフラッドは同515%増、SPSSフラッドは同243%増を記録しました。このような攻撃と、それがどのように混乱を引き起こすのかを見ていきましょう。
ACK-RSTフラッド
ACK-RSTフラッドは、多数のACKおよびRSTパケットを被害者に送信することで伝送制御プロトコル(TCP)を悪用します。これにより、被害者がこれらのパケットを処理し応答する能力が圧倒され、サービスの中断につながります。ACKパケットやRSTパケットの1つ1つが被害者のシステムからのレスポンスを促し、そのリソースを消費するため、この攻撃は効果的です。ACK-RSTフラッドは、正規のトラフィックを模倣しているため、フィルタリングが困難な場合が多く、検知と軽減を困難にします。
CLDAPフラッド
CLDAP(Connectionless Lightweight Directory Access Protocol)は、LDAPLDAP(Lightweight Directory Access Protocol)の亜種です。これは、IPネットワーク上で動作するディレクトリサービスの照会と変更に使用されます。CLDAPはコネクションレスで、TCPの代わりにUDPを使用するため、高速だが信頼性が低くなります。UDPを使用するため、ハンドシェイクの要件がなく、攻撃者がIPアドレスを詐称できるため、攻撃者はこれをリフレクションベクトルとして悪用できます。これらの攻撃では、小さなクエリーがなりすました送信元IPアドレス(被害者のIP)で送信されるため、サーバーは被害者に大きなレスポンスを送信し、被害者を圧倒します。対策には、異常なCLDAPトラフィックのフィルタリングと監視が含まれます。
SPSSフラッド
SPSS(Source Port Service Sweep)プロトコルを悪用したフラッドは、多数のランダムまたは偽装されたソースポートから、標的となるシステムやネットワーク上のさまざまな宛先ポートにパケットを送信するネットワーク攻撃手法です。この攻撃の目的は2つあります。1つ目は、被害者の処理能力を圧倒し、サービスの中断やネットワークの停止を引き起こすこと、2つ目は、オープンポートをスキャンし、脆弱なサービスを特定することです。フラッドは大量のパケットを送信することで実現され、被害者のネットワークリソースを飽和させ、ファイアウォールや侵入検知システムの能力を使い果たします。このような攻撃を軽減するためには、インラインの自動検知機能を活用することが不可欠です。
Cloudflareは攻撃のタイプ、規模、持続時間にかかわらず、お客様を支援いたします
Cloudflareの使命は、より良いインターネットの構築を支援することです。より良いインターネットとは、安全で、パフォーマンスが高く、誰もが利用できるインターネットであると私たちは考えています。攻撃のタイプ、攻撃規模、攻撃時間、攻撃の背後にある動機にかかわらず、Cloudflareの防御は強固です。2017年に非従量課金型のDDoS攻撃対策のパイオニアとなって以来、私たちはエンタープライズグレードのDDoS攻撃対策をすべての組織で同様に、そしてもちろんパフォーマンスを損なうことなく無料で提供することを約束し、守り続けてきました。これは、当社独自のテクノロジーと堅牢なネットワークアーキテクチャによって実現されています。
セキュリティはプロセスであり、単一の製品やスイッチの切り替えではないことを覚えておくことが重要です。私たちは、自動化されたDDoS攻撃対策システムの上に、ファイアウォール、ボット検知、API保護、キャッシングなどの包括的なバンドル機能を提供し、お客様の防御を強化します。当社の多層的なアプローチは、お客様のセキュリティ体制を最適化し、潜在的な影響を最小限に抑えます。また、DDoS攻撃に対する防御を最適化するのに役立つ推奨事項のリストをまとめましたので、ステップバイステップのウィザードに従ってアプリケーションを保護し、DDoS攻撃を防ぐことができます。また、DDoS攻撃やインターネット上のその他の攻撃に対する、使いやすく業界最高の保護機能をご利用になりたい場合は、Cloudflare.comから無料でご登録いただけます!攻撃を受けている場合は、登録するか、こちらに記載されているサイバー緊急ホットライン番号に電話すると、迅速な対応が受けられます。
Serverless ICYMI Q4 2023
Post Syndicated from Eric Johnson original https://aws.amazon.com/blogs/compute/serverless-icymi-q4-2023/
Welcome to the 24th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, live streams, and other interesting things that you might have missed!
In case you missed our last ICYMI, check out what happened last quarter here.

2023 Q4 Calendar
ServerlessVideo

ServerlessVideo at re:Invent 2024
ServerlessVideo is a demo application built by the AWS Serverless Developer Advocacy team to stream live videos and also perform advanced post-video processing. It uses several AWS services including AWS Step Functions, Amazon EventBridge, AWS Lambda, Amazon ECS, and Amazon Bedrock in a serverless architecture that makes it fast, flexible, and cost-effective. Key features include an event-driven core with loosely coupled microservices that respond to events routed by EventBridge. Step Functions orchestrates using both Lambda and ECS for video processing to balance speed, scale, and cost. There is a flexible plugin-based architecture using Step Functions and EventBridge to integrate and manage multiple video processing workflows, which include GenAI.
ServerlessVideo allows broadcasters to stream video to thousands of viewers using Amazon IVS. When a broadcast ends, a Step Functions workflow triggers a set of configured plugins to process the video, generating transcriptions, validating content, and more. The application incorporates various microservices to support live streaming, on-demand playback, transcoding, transcription, and events. Learn more about the project and watch videos from reinvent 2023 at video.serverlessland.com.
AWS Lambda
AWS Lambda enabled outbound IPv6 connections from VPC-connected Lambda functions, providing virtually unlimited scale by removing IPv4 address constraints.
The AWS Lambda and AWS SAM teams also added support for sharing test events across teams using AWS SAM CLI to improve collaboration when testing locally.
AWS Lambda introduced integration with AWS Application Composer, allowing users to view and export Lambda function configuration details for infrastructure as code (IaC) workflows.
AWS added advanced logging controls enabling adjustable JSON-formatted logs, custom log levels, and configurable CloudWatch log destinations for easier debugging. AWS enabled monitoring of errors and timeouts occurring during initialization and restore phases in CloudWatch Logs as well, making troubleshooting easier.
For Kafka event sources, AWS enabled failed event destinations to prevent functions stalling on failing batches by rerouting events to SQS, SNS, or S3. AWS also enhanced Lambda auto scaling for Kafka event sources in November to reach maximum throughput faster, reducing latency for workloads prone to large bursts of messages.
AWS launched support for Python 3.12 and Java 21 Lambda runtimes, providing updated libraries, smaller deployment sizes, and better AWS service integration. AWS also introduced a simplified console workflow to automate complex network configuration when connecting functions to Amazon RDS and RDS Proxy.
Additionally in December, AWS enabled faster individual Lambda function scaling allowing each function to rapidly absorb traffic spikes by scaling up to 1000 concurrent executions every 10 seconds.
Amazon ECS and AWS Fargate
In Q4 of 2023, AWS introduced several new capabilities across its serverless container services including Amazon ECS, AWS Fargate, AWS App Runner, and more. These features help improve application resilience, security, developer experience, and migration to modern containerized architectures.
In October, Amazon ECS enhanced its task scheduling to start healthy replacement tasks before terminating unhealthy ones during traffic spikes. This prevents going under capacity due to premature shutdowns. Additionally, App Runner launched support for IPv6 traffic via dual-stack endpoints to remove the need for address translation.
In November, AWS Fargate enabled ECS tasks to selectively use SOCI lazy loading for only large container images in a task instead of requiring it for all images. Amazon ECS also added idempotency support for task launches to prevent duplicate instances on retries. Amazon GuardDuty expanded threat detection to Amazon ECS and Fargate workloads which users can easily enable.
Also in November, the open source Finch container tool for macOS became generally available. Finch allows developers to build, run, and publish Linux containers locally. A new website provides tutorials and resources to help developers get started.
Finally in December, AWS Migration Hub Orchestrator added new capabilities for replatforming applications to Amazon ECS using guided workflows. App Runner also improved integration with Route 53 domains to automatically configure required records when associating custom domains.
AWS Step Functions
In Q4 2023, AWS Step Functions announced the redrive capability for Standard Workflows. This feature allows failed workflow executions to be redriven from the point of failure, skipping unnecessary steps and reducing costs. The redrive functionality provides an efficient way to handle errors that require longer investigation or external actions before resuming the workflow.
Step Functions also launched support for HTTPS endpoints in AWS Step Functions, enabling easier integration with external APIs and SaaS applications without needing custom code. Developers can now connect to third-party HTTP services directly within workflows. Additionally, AWS released a new test state capability that allows testing individual workflow states before full deployment. This feature helps accelerate development by making it faster and simpler to validate data mappings and permissions configurations.
AWS announced optimized integrations between AWS Step Functions and Amazon Bedrock for orchestrating generative AI workloads. Two new API actions were added specifically for invoking Bedrock models and training jobs from workflows. These integrations simplify building prompt chaining and other techniques to create complex AI applications with foundation models.
Finally, the Step Functions Workflow Studio is now integrated in the AWS Application Composer. This unified builder allows developers to design workflows and define application resources across the full project lifecycle within a single interface.
Amazon EventBridge
Amazon EventBridge announced support for new partner integrations with Adobe and Stripe. These integrations enable routing events from the Adobe and Stripe platforms to over 20 AWS services. This makes it easier to build event-driven architectures to handle common use cases.
Amazon SNS
In Q4, Amazon SNS added native in-place message archiving for FIFO topics to improve event stream durability by allowing retention policies and selective replay of messages without provisioning separate resources. Additional message filtering operators were also introduced including suffix matching, case-insensitive equality checks, and OR logic for matching across properties to simplify routing logic implementation for publishers and subscribers. Finally, delivery status logging was enabled through AWS CloudFormation.
Amazon SQS
Amazon SQS has introduced several major new capabilities and updates. These improve visibility, throughput, and message handling for users. Specifically, Amazon SQS enabled AWS CloudTrail logging of key SQS APIs. This gives customers greater visibility into SQS activity. Additionally, SQS increased the throughput quota for the high throughput mode of FIFO queues. This was significantly increased in certain Regions. It also boosted throughput in Asia Pacific Regions. Furthermore, Amazon SQS added dead letter queue redrive support. This allows you to redrive messages that failed and were sent to a dead letter queue (DLQ).
Serverless at AWS re:Invent

Serverless videos from re:Invent
Visit the Serverless Land YouTube channel to find a list of serverless and serverless container sessions from reinvent 2023. Hear from experts like Chris Munns and Julian Wood in their popular session, Best practices for serverless developers, or Nathan Peck and Jessica Deen in Deploying multi-tenant SaaS applications on Amazon ECS and AWS Fargate.
EDA Day Nashville

EDA Day Nashville
The AWS Serverless Developer Advocacy team hosted an event-driven architecture (EDA) day conference on October 26, 2022 in Nashville, Tennessee. This inaugural GOTO EDA day convened over 200 attendees ranging from prominent EDA community members to AWS speakers and product managers. Attendees engaged in 13 sessions, two workshops, and panels covering EDA adoption best practices. The event built upon 2022 content by incorporating additional topics like messaging, containers, and machine learning. It also created opportunities for students and underrepresented groups in tech to participate. The full-day conference facilitated education, inspiration, and thoughtful discussion around event-driven architectural patterns and services on AWS.
Videos from EDA Day are now available on the Serverless Land YouTube channel.
Serverless blog posts
October
- Filtering events in Amazon EventBridge with wildcard pattern matching
- Enhancing runtime security and governance with the AWS Lambda Runtime API proxy extension
- Archiving and replaying messages with Amazon SNS FIFO
- Sending and receiving webhooks on AWS: Innovate with event notifications
November
- Orchestrating dependent file uploads with AWS Step Functions
- Introducing faster polling scale-up for AWS Lambda functions configured with Amazon SQS
- Scaling improvements when processing Apache Kafka with AWS Lambda
- Introducing the Amazon Linux 2023 runtime for AWS Lambda
- Enhanced Amazon CloudWatch metrics for Amazon EventBridge
- The serverless attendee’s guide to AWS re:Invent 2023
- Introducing logging support for Amazon EventBridge Pipes
- Converting Apache Kafka events from Avro to JSON using EventBridge Pipes
- Node.js 20.x runtime now available in AWS Lambda
- Managing AWS Lambda runtime upgrades
- Introducing AWS Step Functions redrive to recover from failures more easily
- Triggering AWS Lambda function from a cross-account Amazon Managed Streaming for Apache Kafka
- Introducing the AWS Integrated Application Test Kit (IATK)
- Introducing advanced logging controls for AWS Lambda functions
- Introducing support for read-only management events in Amazon EventBridge
December
- Python 3.12 runtime now available in AWS Lambda
- Introducing Amazon MQ cross-Region data replication for ActiveMQ brokers
Serverless container blog posts
October
- Start Spring Boot applications faster on AWS Fargate using SOCI
- PBS speeds deployment and reduces costs with AWS Fargate
- Scale to 15,000+ tasks in a single Amazon Elastic Container Service (ECS) cluster
- Run time sensitive workloads on ECS Fargate with clock accuracy tracking
November
- A deep dive into Amazon ECS task health and task replacement
- Securing API endpoints using Amazon API Gateway and Amazon VPC Lattice
- Serverless containers at AWS re:Invent 2023
- Migration considerations – Cloud Foundry to Amazon ECS with AWS Fargate
- Build Generative AI apps on Amazon ECS for SageMaker JumpStart
- How Smartsheet optimized cost and performance with AWS Graviton and AWS Fargate
December
- AWS App Runner improves performance for image-based deployments
- Use SMB storage with Windows containers on AWS Fargate
- A deep dive into resilience and availability on Amazon Elastic Container Service
- Run Monte Carlo simulations at scale with AWS Step Functions and AWS Fargate
- Effective use: Amazon ECS lifecycle events with Amazon CloudWatch Logs Insights
Serverless Office Hours

October
- Oct 3 – Governance in depth for serverless apps
- Oct 10 – Serverless observability
- Oct 17 – Super serverless tools with Lars Jacobsson
- Oct 24 – Building GenAI apps
- Oct 31 – Visually build AWS applications
November
- Nov 7 – Bring chaos into serverless
- Nov 14 – Ampt: Just write code!
- Nov 21 – pre:Invent 2023
December
- Dec 5 – Step Functions: what’s new
- Dec 19 – 2023 Year in review
Containers from the Couch

October
- Oct 12 – Introducing ContainersOnAWS.com
- Oct 26 – Amazon ECS Console v2 updates
November
- Nov 9 – ECS Builder Series – John Mille (Sainsbury’s)
- Nov 16 – Diving into Finch 1.0
December
- Dec 15 – Cost optimization on AWS Fargate
FooBar

October
- Oct 5 – Build Applications with Bedrock and Lambda
- Oct 12 – Kinesis Data Streams and Lambda in production – What to do when something fails
- Oct 26 – Build applications with generative AI and Serverless – Amazon Bedrock and AWS Lambda Node.js
November
- Nov 2 – Lambda response streaming | get faster responses from AWS Lambda
- Nov 9 – Stream responses back from Bedrock using Lambda response streaming
December
- Dec 7 – Build generative AI apps using AWS Step Functions and Amazon Bedrock
- Dec 14 – Test State API for Step Functions
- Dec 21 – Invoke external endpoints from AWS Step Functions
Still looking for more?
The Serverless landing page has more information. The Lambda resources page contains case studies, webinars, whitepapers, customer stories, reference architectures, and even more Getting Started tutorials.
You can also follow the Serverless Developer Advocacy team on Twitter to see the latest news, follow conversations, and interact with the team.
|
|
And finally, visit the Serverless Land and Containers on AWS websites for all your serverless and serverless container needs.
PIN-Stealing Android Malware
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/01/pin-stealing-android-malware.html
This is an old piece of malware—the Chameleon Android banking Trojan—that now disables biometric authentication in order to steal the PIN:
The second notable new feature is the ability to interrupt biometric operations on the device, like fingerprint and face unlock, by using the Accessibility service to force a fallback to PIN or password authentication.
The malware captures any PINs and passwords the victim enters to unlock their device and can later use them to unlock the device at will to perform malicious activities hidden from view.
Comic for 2024.01.09 – Hitler’s Mom
Post Syndicated from Explosm.net original https://explosm.net/comics/hitlers-mom
New Cyanide and Happiness Comic
Happy New Year! AWS Weekly Roundup – January 8, 2024
Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/happy-new-year-aws-weekly-roundup-january-8-2024/
 Happy New Year! Cloud technologies, machine learning, and generative AI have become more accessible, impacting nearly every aspect of our lives. Amazon CTO Dr. Werner Vogels offers four tech predictions for 2024 and beyond:
Happy New Year! Cloud technologies, machine learning, and generative AI have become more accessible, impacting nearly every aspect of our lives. Amazon CTO Dr. Werner Vogels offers four tech predictions for 2024 and beyond:
- Generative AI becomes culturally aware
- FemTech finally takes off
- AI assistants redefine developer productivity
- Education evolves to match the speed of technology
Read how these technology trends will converge to help solve some of society’s most difficult problems. Download the Werner Vogels’ Tech Predictions for 2024 and Beyond ebook or read Werner’s All Things Distributed blog.
![]() To hear insights from AWS and industry thought leaders, grow your skills, and get inspired, watch AWS re:Invent 2023 videos on demand for keynotes, innovation talks, breakout sessions, and AWS Hero guide playlists.
To hear insights from AWS and industry thought leaders, grow your skills, and get inspired, watch AWS re:Invent 2023 videos on demand for keynotes, innovation talks, breakout sessions, and AWS Hero guide playlists.
Launches from the last few weeks
Since our last week in review on December 18, 2023, I’d like to highlight some launches from year end, as well as last week:
New AWS Canada West (Calgary) Region – We are opening a new and second Region and in Canada, AWS Canada West (Calgary). At the end of 2023, AWS had 33 AWS Regions and 105 Availability Zones (AZs) globally. We preannounced 12 additional AZs in four future Regions in Malaysia, New Zealand, Thailand, and the AWS European Sovereign Cloud. We will share more information on these Regions in 2024. Please stay tuned.
DNS over HTTPS in Amazon Route 53 Resolver – You can use the DNS over HTTPS (DoH) protocol for both inbound and outbound Route 53 Resolver endpoints. As the name suggests, DoH supports HTTP or HTTP/2 over TLS to encrypt the data exchanged for Domain Name System (DNS) resolutions.
Automatic enrollment to Amazon RDS Extended Support – Your MySQL 5.7 and PostgreSQL 11 database instances running on Amazon Aurora and Amazon RDS will be automatically enrolled into Amazon RDS Extended Support starting on February 29, 2024. You can have more control over when you want to upgrade the major version of your database after the community end of life (EoL).
New Amazon CloudWatch Network Monitor – This is a new feature of Amazon CloudWatch that helps monitor network availability and performance between AWS and your on-premises environments. Network Monitor needs zero manual instrumentation and gives you access to real-time network visibility to proactively and quickly identify issues within the AWS network and your own hybrid environment. For more information, read Monitor hybrid connectivity with Amazon CloudWatch Network Monitor.

Amazon Aurora PostgreSQL integrations with Amazon Bedrock – You can use two methods to integrate Aurora PostgreSQL databases with Amazon Bedrock to power generative AI applications. You can use the SQL query with Aurora ML integration with Amazon Bedrock and Aurora vector store with Knowledge Bases for Amazon Bedrock for Retrieval Augmented Generation (RAG).

New WordPress setup on Amazon Lightsail – Set up your WordPress website on Amazon Lightsail with the new workflow to eliminate complexity and time spent configuring your website. The workflow allows you to complete all the necessary steps, including setting up a Secure Sockets Layer (SSL) certificate to secure your website with HTTPS.

For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Other AWS News
Here are some other news items that you may find interesting in the new year:
Book recommendations for AWS customer executives – Plan for the new year and catch up on what others are doing and thinking. AWS Enterprise Strategy team recommends what books are most important for our AWS customer executives to read.
Best practices for scaling AWS CDK adoption with Platform Engineering – A recent evolution in DevOps is the introduction of platform engineering teams to build services, toolchains, and documentation to support workload teams. This blog post introduces strategies and best practices for accelerating CDK adoption within your organization. You can learn how to scale the lessons learned from the pilot project across your organization through platform engineering.
High performance running HPC applications on AWS Graviton instances – When running the Parallel Lattice Boltzmann Solver (Palabos) on Amazon EC2 Hpc7g instances to solve computational fluid dynamics (CFD) problems, performance increased by up to 70% and price performance was up to 3x better than on the previous generation of Graviton instances.
The new AWS open source newsletter, #181 – Check up on all the latest open source content, which this week includes AWS Amplify, Amazon Corretto, dbt, Apache Flink, Karpenter, LangChain, Pinecone, and more.
Upcoming AWS Events
Check your calendars and sign up for these AWS events in the new year:
AWS at CES 2024 (January 9-12) – AWS will be representing some of the latest cloud services and solutions that are purpose built for the automotive, mobility, transportation, and manufacturing industries. Join us to learn about the latest cloud capabilities across generative AI, software define vehicles, product engineering, sustainability, new digital customer experiences, connected mobility, autonomous driving, and so much more in Amazon Experience Area.
APJ Builders Online Series (January 18) – This online conference is designed for you to learn core AWS concepts, and step-by-step architectural best practices, including demonstrations to help you get started and accelerate your success on AWS.
You can browse all upcoming AWS-led in-person and virtual events, and developer-focused events such as AWS DevDay.
That’s all for this week. Check back next Monday for another Week in Review!
— Channy
Looking beyond code coverage with Amazon CodeWhisperer
Post Syndicated from Saurabh Kumar original https://aws.amazon.com/blogs/devops/looking-beyond-code-coverage-with-amazon-codewhisperer/
Code coverage is a code quality metric leveraging unit tests. Coming up with test cases with every combination of parameters requires developer’s time, which is already scarce. Developers’ focus is (mis)directed at just meeting the coverage threshold. In doing so, quality of code may be compromised and resulting code may still result in unexpected outcomes.
In this blog, we will walk you through a Java application and demonstrate how to look beyond code coverage by leveraging Amazon CodeWhisperer, an AI coding companion, for generating a combination of test cases, including boundary conditions which are often overlooked due to time and resource constraints. Taking this approach, you can improve code quality as well as improve your productivity.
Prerequisites
- Create an AWS Account. If you don’t already have an AWS account, you’ll need to create one in order to follow the steps outlined to AWS Management Console. For this, it is recommended to create a new user.
- To set up CodeWhisperer for your development environment, follow the setup instructions AWS Toolkit.
- Download and set up Java: Install the Java SE Development Kit.
- Install Maven.
- You can use any IDE of your choice such as Eclipse, Spring Tools, VS Code or IntelliJ. For this blog, we have used IntelliJ community edition which you can download from here. You can use IntelliJ Ultimate if you have a license for it.
- Clone repo: Looking beyond code coverage with CodeWhisperer.
- Import cloned project in IntelliJ following importing-a-project guide.
Following the above steps, you would have setup the project locally. Figure1 below shows how the initial project should look after you have imported it as maven project in your IDE:

Figure1. initial Java project
The following screen recording shows how you can use CodeWhisperer to generate code for ‘add’ method using the comment “//method for adding two numbers”.

ScreenRecording 1. Initial application code generation
Now let’s generate one simple test case using CodeWhisperer as shown in the ScreenRecording 2. First test case generation:

ScreenRecording 2. First test case generation
Let’s run the test case with code coverage. In figure2. “First test with code coverage”, you can see that we have achieved 100% coverage on the Calculator class. If we just go by the coverage, we can conclude that the code is ready.

Figure2. First test with code coverage
Just one unit test is not sufficient to ensure quality and side-effect-free code. Next, you will see how CodeWhisperer can assist in generating additional test cases. As soon as you begin typing a comment like, “// Test,” it provides suggestions for new test cases, such as “// test with one negative number,” “// test with two negative numbers,” “Test with one zero number,” etc. This feature, as shown in the ScreenRecording 3 titled ‘Generating additional test cases’ below, makes the task of generating a variety of test cases easier and enables developers to create more tests in a shorter amount of time.

ScreenRecording 3. Generating additional test cases
So far, we have generated test cases with different arguments and still have 100% code coverage. Let’s now turn our focus towards safety of the code and think about different arguments that can lead to unexpected outcomes. Each argument should fall within the range of -2,147,483,648 (the minimum value of type int) to 2,147,483,647 (the maximum value of type int). Let’s use CodeWhisperer to generate additional test cases to challenge code safety as shown in the screen recording below:
ScreenRecording 4. Generating test for boundary conditions
Here, CodeWhisperer first generated a test case which adds 1 to maximum value of integer. We have also added a statement to print the result to console so that we can see the actual value ‘add’ method returns when this use case is executed. Point to note here: the generated test case is expecting the output to be the MINIMUM value of type int. Upon execution, the test case prints something unexpected. Because of the way signed integer operations work, adding 1 to max int results in the min value.
Let’s consider this in more practical terms. Imagine using the ‘add’ method in a banking system, where every time a customer deposits money into their bank account, you add up the recent deposit to calculate the final amount in their account. Now, imagine a customer’s reaction when they find their balance to be negative after depositing $2.14 billion, and they now owe huge overdraft charges.
This example demonstrates that even code with 100% coverage has unexpected side effects. The focus should be identifying combinations of parameters which can potentially produce unexpected outcomes so that code can be corrected before it manifests this behavior in production.
Now, let’s use CodeWhisperer to generate another test case that could create an unexpected result: “add -1 to the minimum value of ‘int’”. Again, adding -1 to the minimum int value results in the MAXIMUM value. Using the same example as above, a customer would be more than happy to notice that they still have money in their bank account, even after withdrawing $2.14 billion.
Again, the point is that developers should focus on ensuring that the code doesn’t have unwanted, unexpected consequences, rather than chasing a coverage target.
Now that we have seen that the add methods runs into integer overflow in certain conditions, let’s improve the code using CodeWhisperer using comment “check a and b for integer overflow”:

ScreenRecording 5. Code improvement- overflow check
After adding the safety checks, the test cases are not resulting in unexpected outcomes and resulting in ArithmaticException as shown in the above screen recording. However, the test cases are failing, and failing test cases can interrupt the CI/CD pipeline. So, let’s refactor these test cases to expect this runtime exception and pass the test case as shown in the screen recording below.
ScreenRecording 6. Test case improvement- overflow checks
Having rerun the test cases with coverage, you can see that the test cases are not only passing, but also have 100% code coverage.
For this blog, the majority of the code and its corresponding test cases are generated by CodeWhisperer, an AI coding companion. This tool enables us to enhance code by easily exploring libraries. In our example, this led us to the ‘Math.addExact’ method, which provides checks for boundary conditions relevant to our task. Let’s refactor the code to utilize this method, as shown below in Figure 3 final code.

Figure 3. Final code
If we rerun the test suite with coverage, we find that all the test cases are passing and coverage is also maintained at 100%.

Figure 4. Final tests with coverage
Conclusion:
Through this blog post, we have demonstrated that high code coverage alone does not guarantee high quality code. Tools like Amazon CodeWhisperer can boost developer productivity by generating code and as well as corresponding test suite, including boundary conditions. This frees up developers to concentrate on business logic and to learn new frameworks and libraries, thereby resulting in overall improvement in quality and safety of code.
While our example focused on Java, this concept applies to other programming languages as well. Checkout the complete list of programming languages and IDEs supported by CodeWhisperer in the FAQs.
Try out CodeWhisperer Individual Tier for free to see how it can help you write high-quality code more efficiently using CodeWhisperer getting started guides.
Happy coding!
Architectural patterns for real-time analytics using Amazon Kinesis Data Streams, part 1
Post Syndicated from Raghavarao Sodabathina original https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
We’re living in the age of real-time data and insights, driven by low-latency data streaming applications. Today, everyone expects a personalized experience in any application, and organizations are constantly innovating to increase their speed of business operation and decision making. The volume of time-sensitive data produced is increasing rapidly, with different formats of data being introduced across new businesses and customer use cases. Therefore, it is critical for organizations to embrace a low-latency, scalable, and reliable data streaming infrastructure to deliver real-time business applications and better customer experiences.
This is the first post to a blog series that offers common architectural patterns in building real-time data streaming infrastructures using Kinesis Data Streams for a wide range of use cases. It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built data analytics services.
In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices. In the subsequent post in our series, we will explore the architectural patterns in building streaming pipelines for real-time BI dashboards, contact center agent, ledger data, personalized real-time recommendation, log analytics, IoT data, Change Data Capture, and real-time marketing data. All these architecture patterns are integrated with Amazon Kinesis Data Streams.
Real-time streaming with Kinesis Data Streams
Amazon Kinesis Data Streams is a cloud-native, serverless streaming data service that makes it easy to capture, process, and store real-time data at any scale. With Kinesis Data Streams, you can collect and process hundreds of gigabytes of data per second from hundreds of thousands of sources, allowing you to easily write applications that process information in real-time. The collected data is available in milliseconds to allow real-time analytics use cases, such as real-time dashboards, real-time anomaly detection, and dynamic pricing. By default, the data within the Kinesis Data Stream is stored for 24 hours with an option to increase the data retention to 365 days. If customers want to process the same data in real-time with multiple applications, then they can use the Enhanced Fan-Out (EFO) feature. Prior to this feature, every application consuming data from the stream shared the 2MB/second/shard output. By configuring stream consumers to use enhanced fan-out, each data consumer receives dedicated 2MB/second pipe of read throughput per shard to further reduce the latency in data retrieval.
For high availability and durability, Kinesis Data Streams achieves high durability by synchronously replicating the streamed data across three Availability Zones in an AWS Region and gives you the option to retain data for up to 365 days. For security, Kinesis Data Streams provide server-side encryption so you can meet strict data management requirements by encrypting your data at rest and Amazon Virtual Private Cloud (VPC) interface endpoints to keep traffic between your Amazon VPC and Kinesis Data Streams private.
Kinesis Data Streams has native integrations with other AWS services such as AWS Glue and Amazon EventBridge to build real-time streaming applications on AWS. Refer to Amazon Kinesis Data Streams integrations for additional details.
Modern data streaming architecture with Kinesis Data Streams
A modern streaming data architecture with Kinesis Data Streams can be designed as a stack of five logical layers; each layer is composed of multiple purpose-built components that address specific requirements, as illustrated in the following diagram:

The architecture consists of the following key components:
- Streaming sources – Your source of streaming data includes data sources like clickstream data, sensors, social media, Internet of Things (IoT) devices, log files generated by using your web and mobile applications, and mobile devices that generate semi-structured and unstructured data as continuous streams at high velocity.
- Stream ingestion – The stream ingestion layer is responsible for ingesting data into the stream storage layer. It provides the ability to collect data from tens of thousands of data sources and ingest in real time. You can use the Kinesis SDK for ingesting streaming data through APIs, the Kinesis Producer Library for building high-performance and long-running streaming producers, or a Kinesis agent for collecting a set of files and ingesting them into Kinesis Data Streams. In addition, you can use many pre-build integrations such as AWS Database Migration Service (AWS DMS), Amazon DynamoDB, and AWS IoT Core to ingest data in a no-code fashion. You can also ingest data from third-party platforms such as Apache Spark and Apache Kafka Connect
- Stream storage – Kinesis Data Streams offer two modes to support the data throughput: On-Demand and Provisioned. On-Demand mode, now the default choice, can elastically scale to absorb variable throughputs, so that customers do not need to worry about capacity management and pay by data throughput. The On-Demand mode automatically scales up 2x the stream capacity over its historic maximum data ingestion to provide sufficient capacity for unexpected spikes in data ingestion. Alternatively, customers who want granular control over stream resources can use the Provisioned mode and proactively scale up and down the number of Shards to meet their throughput requirements. Additionally, Kinesis Data Streams can store streaming data up to 24 hours by default, but can extend to 7 days or 365 days depending upon use cases. Multiple applications can consume the same stream.
- Stream processing – The stream processing layer is responsible for transforming data into a consumable state through data validation, cleanup, normalization, transformation, and enrichment. The streaming records are read in the order they are produced, allowing for real-time analytics, building event-driven applications or streaming ETL (extract, transform, and load). You can use Amazon Managed Service for Apache Flink for complex stream data processing, AWS Lambda for stateless stream data processing, and AWS Glue & Amazon EMR for near-real-time compute. You can also build customized consumer applications with Kinesis Consumer Library, which will take care of many complex tasks associated with distributed computing.
- Destination – The destination layer is like a purpose-built destination depending on your use case. You can stream data directly to Amazon Redshift for data warehousing and Amazon EventBridge for building event-driven applications. You can also use Amazon Kinesis Data Firehose for streaming integration where you can light stream processing with AWS Lambda, and then deliver processed streaming into destinations like Amazon S3 data lake, OpenSearch Service for operational analytics, a Redshift data warehouse, No-SQL databases like Amazon DynamoDB, and relational databases like Amazon RDS to consume real-time streams into business applications. The destination can be an event-driven application for real-time dashboards, automatic decisions based on processed streaming data, real-time altering, and more.
Real-time analytics architecture for time series
Time series data is a sequence of data points recorded over a time interval for measuring events that change over time. Examples are stock prices over time, webpage clickstreams, and device logs over time. Customers can use time series data to monitor changes over time, so that they can detect anomalies, identify patterns, and analyze how certain variables are influenced over time. Time series data is typically generated from multiple sources in high volumes, and it needs to be cost-effectively collected in near real time.
Typically, there are three primary goals that customers want to achieve in processing time-series data:
- Gain insights real-time into system performance and detect anomalies
- Understand end-user behavior to track trends and query/build visualizations from these insights
- Have a durable storage solution to ingest and store both archival and frequently accessed data.
With Kinesis Data Streams, customers can continuously capture terabytes of time series data from thousands of sources for cleaning, enrichment, storage, analysis, and visualization.
The following architecture pattern illustrates how real time analytics can be achieved for Time Series data with Kinesis Data Streams:

The workflow steps are as follows:
- Data Ingestion & Storage – Kinesis Data Streams can continuously capture and store terabytes of data from thousands of sources.
- Stream Processing – An application created with Amazon Managed Service for Apache Flink can read the records from the data stream to detect and clean any errors in the time series data and enrich the data with specific metadata to optimize operational analytics. Using a data stream in the middle provides the advantage of using the time series data in other processes and solutions at the same time. A Lambda function is then invoked with these events, and can perform time series calculations in memory.
- Destinations – After cleaning and enrichment, the processed time series data can be streamed to Amazon Timestream database for real-time dashboarding and analysis, or stored in databases such as DynamoDB for end-user query. The raw data can be streamed to Amazon S3 for archiving.
- Visualization & Gain insights – Customers can query, visualize, and create alerts using Amazon Managed Service for Grafana. Grafana supports data sources that are storage backends for time series data. To access your data from Timestream, you need to install the Timestream plugin for Grafana. End-users can query data from the DynamoDB table with Amazon API Gateway acting as a proxy.
Refer to Near Real-Time Processing with Amazon Kinesis, Amazon Timestream, and Grafana showcasing a serverless streaming pipeline to process and store device telemetry IoT data into a time series optimized data store such as Amazon Timestream.
Enriching & replaying data in real time for event-sourcing microservices
Microservices are an architectural and organizational approach to software development where software is composed of small independent services that communicate over well-defined APIs. When building event-driven microservices, customers want to achieve 1. high scalability to handle the volume of incoming events and 2. reliability of event processing and maintain system functionality in the face of failures.
Customers utilize microservice architecture patterns to accelerate innovation and time-to-market for new features, because it makes applications easier to scale and faster to develop. However, it is challenging to enrich and replay the data in a network call to another microservice because it can impact the reliability of the application and make it difficult to debug and trace errors. To solve this problem, event-sourcing is an effective design pattern that centralizes historic records of all state changes for enrichment and replay, and decouples read from write workloads. Customers can use Kinesis Data Streams as the centralized event store for event-sourcing microservices, because KDS can 1/ handle gigabytes of data throughput per second per stream and stream the data in milliseconds, to meet the requirement on high scalability and near real-time latency, 2/ integrate with Flink and S3 for data enrichment and achieving while being completely decoupled from the microservices, and 3/ allow retry and asynchronous read in a later time, because KDS retains the data record for a default of 24 hours, and optionally up to 365 days.
The following architectural pattern is a generic illustration of how Kinesis Data Streams can be used for Event-Sourcing Microservices:

The steps in the workflow are as follows:
- Data Ingestion and Storage – You can aggregate the input from your microservices to your Kinesis Data Streams for storage.
- Stream processing – Apache Flink Stateful Functions simplifies building distributed stateful event-driven applications. It can receive the events from an input Kinesis data stream and route the resulting stream to an output data stream. You can create a stateful functions cluster with Apache Flink based on your application business logic.
- State snapshot in Amazon S3 – You can store the state snapshot in Amazon S3 for tracking.
- Output streams – The output streams can be consumed through Lambda remote functions through HTTP/gRPC protocol through API Gateway.
- Lambda remote functions – Lambda functions can act as microservices for various application and business logic to serve business applications and mobile apps.
To learn how other customers built their event-based microservices with Kinesis Data Streams, refer to the following:
Key considerations and best practices
The following are considerations and best practices to keep in mind:
- Data discovery should be your first step in building modern data streaming applications. You must define the business value and then identify your streaming data sources and user personas to achieve the desired business outcomes.
- Choose your streaming data ingestion tool based on your steaming data source. For example, you can use the Kinesis SDK for ingesting streaming data through APIs, the Kinesis Producer Library for building high-performance and long-running streaming producers, a Kinesis agent for collecting a set of files and ingesting them into Kinesis Data Streams, AWS DMS for CDC streaming use cases, and AWS IoT Core for ingesting IoT device data into Kinesis Data Streams. You can ingest streaming data directly into Amazon Redshift to build low-latency streaming applications. You can also use third-party libraries like Apache Spark and Apache Kafka to ingest streaming data into Kinesis Data Streams.
- You need to choose your streaming data processing services based on your specific use case and business requirements. For example, you can use Amazon Kinesis Managed Service for Apache Flink for advanced streaming use cases with multiple streaming destinations and complex stateful stream processing or if you want to monitor business metrics in real time (such as every hour). Lambda is good for event-based and stateless processing. You can use Amazon EMR for streaming data processing to use your favorite open source big data frameworks. AWS Glue is good for near-real-time streaming data processing for use cases such as streaming ETL.
- Kinesis Data Streams on-demand mode charges by usage and automatically scales up resource capacity, so it’s good for spiky streaming workloads and hands-free maintenance. Provisioned mode charges by capacity and requires proactive capacity management, so it’s good for predictable streaming workloads.
- You can use the Kinesis Shared Calculator to calculate the number of shards needed for provisioned mode. You don’t need to be concerned about shards with on-demand mode.
- When granting permissions, you decide who is getting what permissions to which Kinesis Data Streams resources. You enable specific actions that you want to allow on those resources. Therefore, you should grant only the permissions that are required to perform a task. You can also encrypt the data at rest by using a KMS customer managed key (CMK).
- You can update the retention period via the Kinesis Data Streams console or by using the IncreaseStreamRetentionPeriod and the DecreaseStreamRetentionPeriod operations based on your specific use cases.
- Kinesis Data Streams supports resharding. The recommended API for this function is UpdateShardCount, which allows you to modify the number of shards in your stream to adapt to changes in the rate of data flow through the stream. The resharding APIs (Split and Merge) are typically used to handle hot shards.
Conclusion
This post demonstrated various architectural patterns for building low-latency streaming applications with Kinesis Data Streams. You can build your own low-latency steaming applications with Kinesis Data Streams using the information in this post.
For detailed architectural patterns, refer to the following resources:
- Build highly available streams with Amazon Kinesis Data Streams
- Amazon Kinesis Data Streams increases On-Demand write throughput limit to 2 GB/s
- Scale Kinesis Data Streams for high throughput and low latency
- Best practices for consuming Amazon Kinesis Data Streams using AWS Lambda
- Driving Business Outcomes with Clickstream Data
- Implementing architectural patterns with Amazon EventBridge Pipes
If you want to build a data vision and strategy, check out the AWS Data-Driven Everything (D2E) program.
About the Authors
 Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and cloud security. He engages with customers to create innovative solutions that address customer business problems and to accelerate the adoption of AWS services. In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies.
Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and cloud security. He engages with customers to create innovative solutions that address customer business problems and to accelerate the adoption of AWS services. In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies.
 Hang Zuo is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enable customers to achieve their business goals.
Hang Zuo is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enable customers to achieve their business goals.
 Shwetha Radhakrishnan is a Solutions Architect for AWS with a focus in Data Analytics. She has been building solutions that drive cloud adoption and help organizations make data-driven decisions within the public sector. Outside of work, she loves dancing, spending time with friends and family, and traveling.
Shwetha Radhakrishnan is a Solutions Architect for AWS with a focus in Data Analytics. She has been building solutions that drive cloud adoption and help organizations make data-driven decisions within the public sector. Outside of work, she loves dancing, spending time with friends and family, and traveling.
 Brittany Ly is a Solutions Architect at AWS. She is focused on helping enterprise customers with their cloud adoption and modernization journey and has an interest in the security and analytics field. Outside of work, she loves to spend time with her dog and play pickleball.
Brittany Ly is a Solutions Architect at AWS. She is focused on helping enterprise customers with their cloud adoption and modernization journey and has an interest in the security and analytics field. Outside of work, she loves to spend time with her dog and play pickleball.
Comic for 2024.01.08 – Nature Is Beautiful
Post Syndicated from Explosm.net original https://explosm.net/comics/nature-is-beautiful
New Cyanide and Happiness Comic
[$] Some 6.7 development statistics
Post Syndicated from corbet original https://lwn.net/Articles/956765/
The 6.7 kernel was released
on January 7 after a ten-week development cycle. This was, as it
turns out, the busiest cycle ever with regard to the number of changesets
merged. The time has come for our usual look at where all those changesets
came from, with a side trip into how long kernel developers tend to stick
around.
NVIDIA GeForce RTX 4080 Super at CES 2024
Post Syndicated from Cliff Robinson original https://www.servethehome.com/nvidia-geforce-rtx-4080-super-at-ces-2024/
For CES 2024, we get the mid-cycle NVIDIA GeForce RTX 4000 Super refresh with cards like the new NVIDIA GeForce RTX 4080 Super
The post NVIDIA GeForce RTX 4080 Super at CES 2024 appeared first on ServeTheHome.