Post Syndicated from Emilie Ma original http://blog.cloudflare.com/introducing-the-2023-intern-ets/


This year, Cloudflare welcomed a class of approximately 40 interns, hailing from five different countries for an unforgettable summer. As we joined both remotely and in-person across Cloudflare’s global offices, our experiences spanned a variety of roles from engineering, product management to internal auditing and marketing. Through invaluable mentorship, continuous learning, and the chance to make a real-world impact, our summer was truly enriched at every step. Join us, Anni and Emilie, as we provide an insider's perspective on a summer at Cloudflare, sharing snippets and quotes from our intern cohort.
printf(“Hello Intern-ets!”)
You might have noticed that we have a new name for the interns: the Intern-ets! Our fresh intern nickname was born from a brainstorm between us and our recruiter, Judy. While “Cloudies”, “Cloudterns”, and “Flaries” made the shortlist, a company-wide vote crowned "Intern-ets" as the favorite. And just like that, we've made Cloudflare history!
git commit -m “Innovation!”
We're all incredibly proud to have gotten the opportunity to tackle interesting and highly impactful projects throughout the duration of our internships. To give you a glimpse of our summer, here are a few that showcase the breadth and depth of our experiences.
Mia M., Product Manager intern, worked on the Cloudflare Secrets Store, which is a new product that will allow Cloudflare customers to store, encrypt, and deploy sensitive data across the product suite. She focused on creating requirements for the core platform and tackling the first milestone, bringing secrets and environment variables from the per-Worker level to the account level in the Workers platform.
Pierre, Research intern, focused on integrating differential privacy—a layer of protection with formal privacy guarantees—into distributed aggregation protocols. This privacy layer is imperative for user trust and data security as these protocols are commonly used for collecting sensitive information, such as browser telemetry or health data.
Johnny, Software Engineer intern, worked on a new feature for API Shield called Object-Level Access Policies as a first step in a solution to combat Broken Object-Level Authorization, which has been ranked as the #1 API Security flaw by OWASP. This feature will enable customers to specify explicit allowlists and blocklists for API traffic per object.
Olivia, Project Manager intern, led the Dissatisfied (DSAT) Customer Outreach Project and JIRA Automations for the Customer Support team. The DSAT project involves reaching out to Premium customers who express dissatisfaction with the goal of providing personalized contact to ensure they feel valued. The JIRA Automation project aims to create zero-touch tickets, removing Customer Support as the middle man.
Also don’t forget to check out the amazing intern projects that got featured in a blog post!
Emilie, Software Engineering intern introduced a debugging feature for Cloudflare Queues.
Joaquin, Software Engineer intern added a new Workers Database integration.
Austin, Software Engineer intern created scheduled deletion for Cloudflare Stream.

No null days here!
Beyond our projects, we had tons of fun getting to meet other Cloudflarians and experience the vibrant Cloudflare culture. Let's dive into some of the standout moments that made our internships truly special!
Remote, office, hybrid
This summer, the interns dotted the globe, working from cozy home setups to bustling offices in cities. Regardless of where we worked, we had a blast. Here's what some fellow interns have to say about their work experiences:
Austin office: Jada loved her colleagues at the Austin office as they were “warm and open to exploring the city, […], and hanging out outside of work”. Anni and Maximo loved attending the Austin-based team summit where they attended strategy sessions and met the team in-person.
San Francisco office: Emmanuel F. enjoyed getting to interact with other engineers during SF Team Lunches. Matthew enjoyed working on the rooftop to a view of the city skyline. Jonathan appreciated the hybrid work model enjoyed by SF employees.
Remote work: Johnny liked the distributed and flexible work style that the company embraces. Daniël, also working remotely and found it amusing how “[s]everal people have noticed the Feynman Lectures on Physics on the shelf behind me in my home and have asked about it.”
Remote intern events: Emmanuel G., Aaron, and Feiyu enjoyed the intern calls that were held on GatherRound as “it was a fun, quick way to get to meet everyone.” Pradyumna particularly liked it when we played skribbl.io.
 |
 |
|---|---|
 |
 |
Mentorship
With so many exceptional minds at Cloudflare, every interaction became a chance for us to learn and grow. Here are some awe-inspiring individuals who have made our internships unforgettable:
Harshal, Systems Engineer: Aaron is grateful for his mentor Harshall. “I always left our conversations knowing more than I did coming into them”.
Revathy, Systems Engineer: Harshini is thankful to her mentor Revathy for “how she helps me to learn […] the best way possible to do something and ultimately achieve my goals”.
Nevi, Product Manager: Anni admires her manager Nevi who is always thinking about the team and our customers and has invested in the personal growth and mentorship of interns.
Conner, Systems Engineer: Jonathan is grateful that he was always able to count on Conner for great engineering tips, guidance, and NeoVim wizardry.
Malgorzata, Data Scientist: Jada looks up to Malgorzata for being so welcoming, kind, and funny. She has a great attitude and besides being super knowledgeable, she is also willing to share her expertise and support others!

Executive chats
During our internships, we engaged in Executive fireside chats, diving deep with Cloudflare's top leaders. Each chat was insightful and surprising in a different way, and some of our favorite takeaways were…
John, CTO: Shaheen valued John’s humility in emphasizing daily learning from others at work, stating, “As I grow in my career, I intend to keep a similar attitude and try to learn from those around me by keeping myself grounded.”
Doug Kramer, General Counsel: Emilie valued Doug Kramer's advice on identifying a career "north star" to guide intentions while also recognizing "exit-ramps" or alternative paths that may offer unexpected fulfillment.
Matthew Prince, Co-founder and CEO: Yunfan loved hearing “the story about how Cloudflare developed from a start-up till today”.
Michelle Zatlyn, Co-founder and COO: Harsh learned from Michelle about “how they moved across the country, against everyone's advice, to start Cloudflare”, and Mia C. enjoyed learning that “Cloudflare started as a business school project”.
Snack bytes
A bonding point for the Intern-ets was our love for snacks! In July, we gathered the Intern-ets together for a virtual snack break. The University team sent out a box featuring snacks from Indonesia, a country none of us had visited (or tried goodies from… yet!). Below you can see us holding up our favorite snacks from the box!
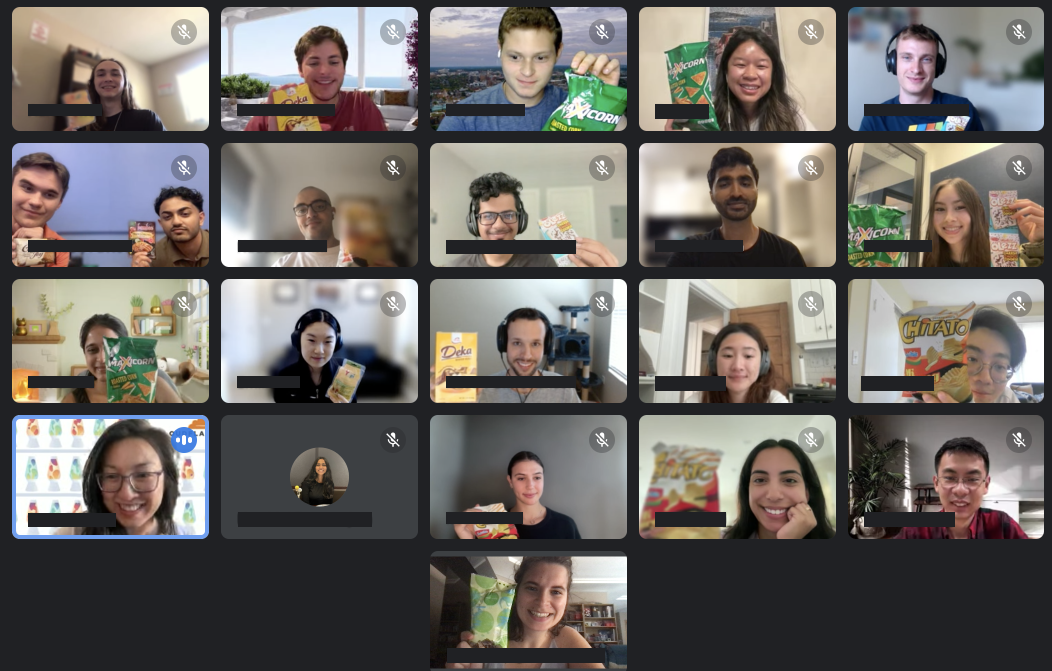
Meanwhile, the on-site interns couldn't get enough of the office snacks. Favorites? Pita chips, Lucky Charms, chocolate almonds, coconut chocolate bars and coconut water. Plus, the Austin and San Francisco offices even have a Sour Patch Kids dispenser! Snack on!
Surprises
Every day at Cloudflare presented unexpected joys and challenges. Here's what the interns found most surprising:
High Impact: Simon, Emmanuel F. and Maximo were surprised to “[do] such visible and important work as an intern”. Austin agreed, noting “I was treated like any other member of the team […] It felt like I was working on something important and not just a typical intern project!” Harshini added, “when [colleagues] hear what I am working on they go – ‘that is really cool, I can't wait to see that happen – we need it.’”
Support: Eames “was worried that it would feel like my achievements were the only thing that mattered. But my colleagues always showed concern for how I was feeling and how things were going, and I couldn't be more grateful for that.”
Industry vs Academia: Johnny mentioned “coming from academia, I was amazed by the amount of effort that has been, and is continuing to be, put into the products to really productionize what I have only before seen in research. It is another reminder of the scale in which we work!”
By the numbers
Here are some fun stats from our internship…
- Johnny drove 30 hours from New York to Colorado
- Maximo missed 0 days of going to the Austin office
- Anni drank 86 matcha lattes this summer
- Emilie participated in 38 Cloudfriends calls and coffee chats
- Simon has waited around one week cumulatively for builds to finish
exit(0)
At Cloudflare, our internships aren’t just about work—they're about growth, mentorship, and real impact. We've built more than projects; we've forged lasting relationships. It’s been an unforgettable summer of challenges, bonding, and authentic experiences. For more about our journey this summer, check out our Cloudflare TV segment with Michelle Zatlyn, Co-founder and COO.
Finally, we would love to give a huge thanks to our university recruiters Judy, Trang, and Dani for creating such an amazing internship experience for us this summer!
Want to become an Intern-et or Cloudflarian?
Sign up here to be notified of new grad and internship opportunities for 2024. Cloudflare is also hiring for full-time opportunities: check out open positions and apply today!
















 Anand Komandooru is a Senior Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “
Anand Komandooru is a Senior Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “ Li Liu is a Senior Database Specialty Architect with the Professional Services team at Amazon Web Services. She helps customers migrate traditional on-premise databases to the AWS Cloud. She specializes in database design, architecture, and performance tuning.
Li Liu is a Senior Database Specialty Architect with the Professional Services team at Amazon Web Services. She helps customers migrate traditional on-premise databases to the AWS Cloud. She specializes in database design, architecture, and performance tuning. Neil Potter is a Senior Cloud Application Architect at AWS. He works with AWS customers to help them migrate their workloads to the AWS Cloud. He specializes in application modernization and cloud-native design and is based in New Jersey.
Neil Potter is a Senior Cloud Application Architect at AWS. He works with AWS customers to help them migrate their workloads to the AWS Cloud. He specializes in application modernization and cloud-native design and is based in New Jersey. Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a big data enthusiast and holds 14 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation.
Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a big data enthusiast and holds 14 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation.
