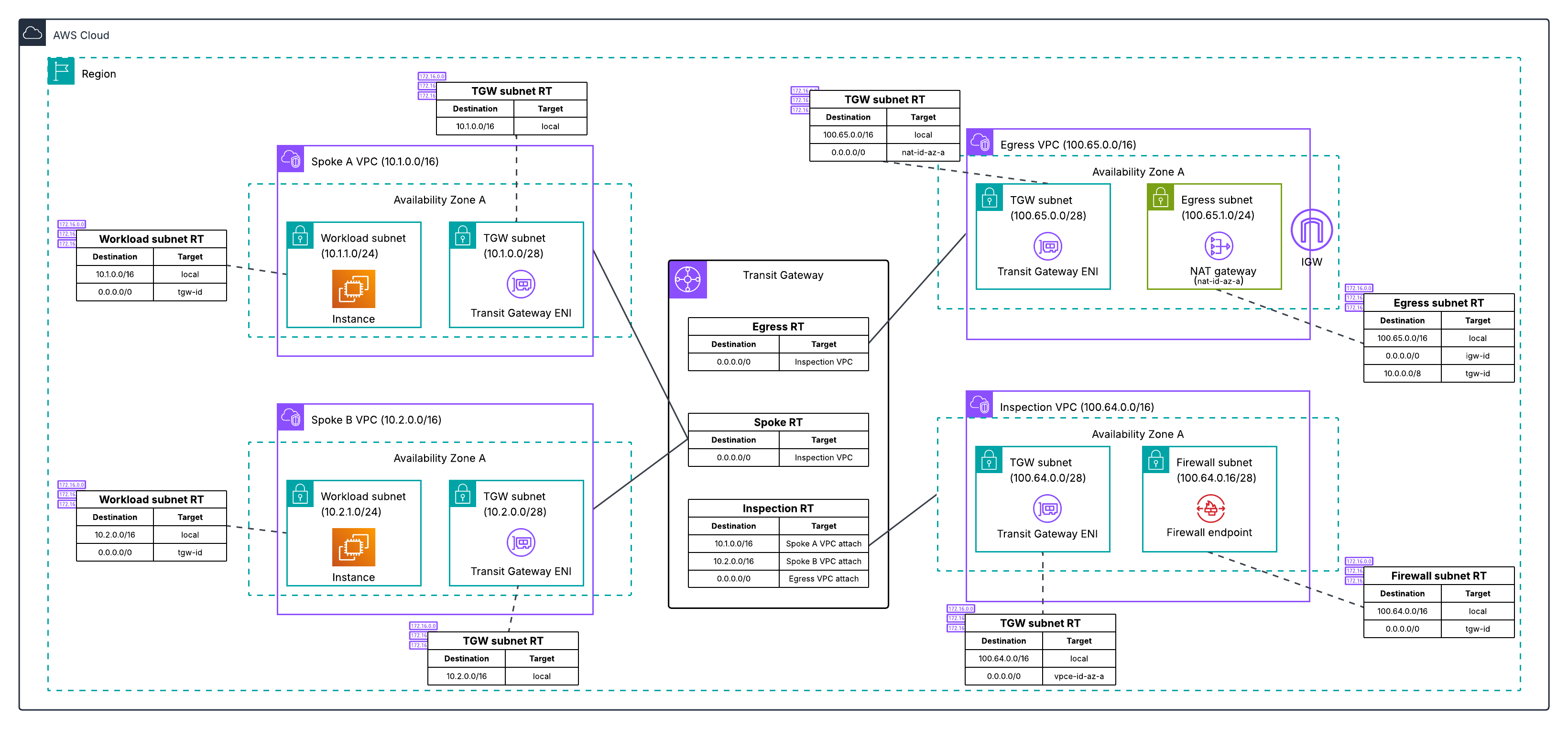
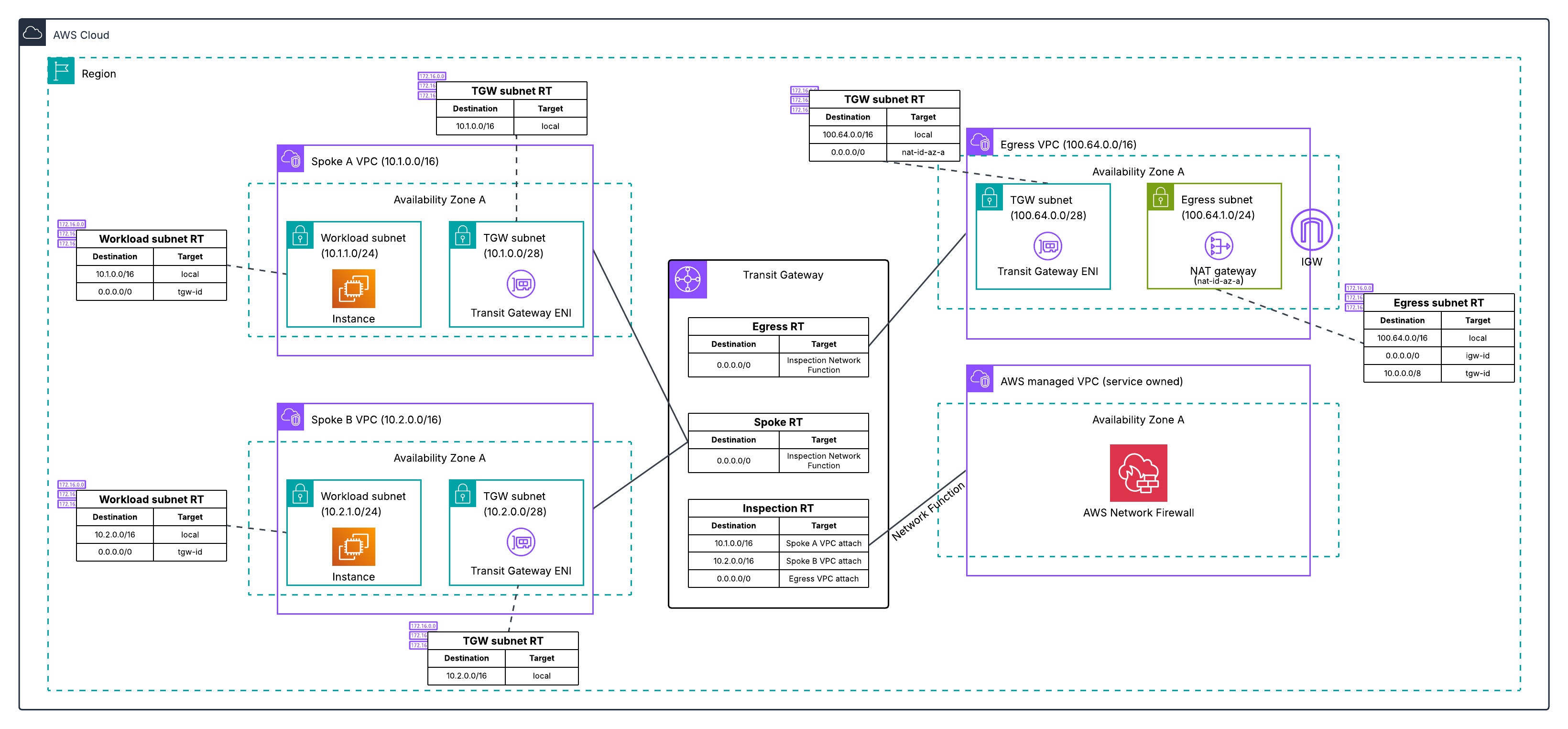
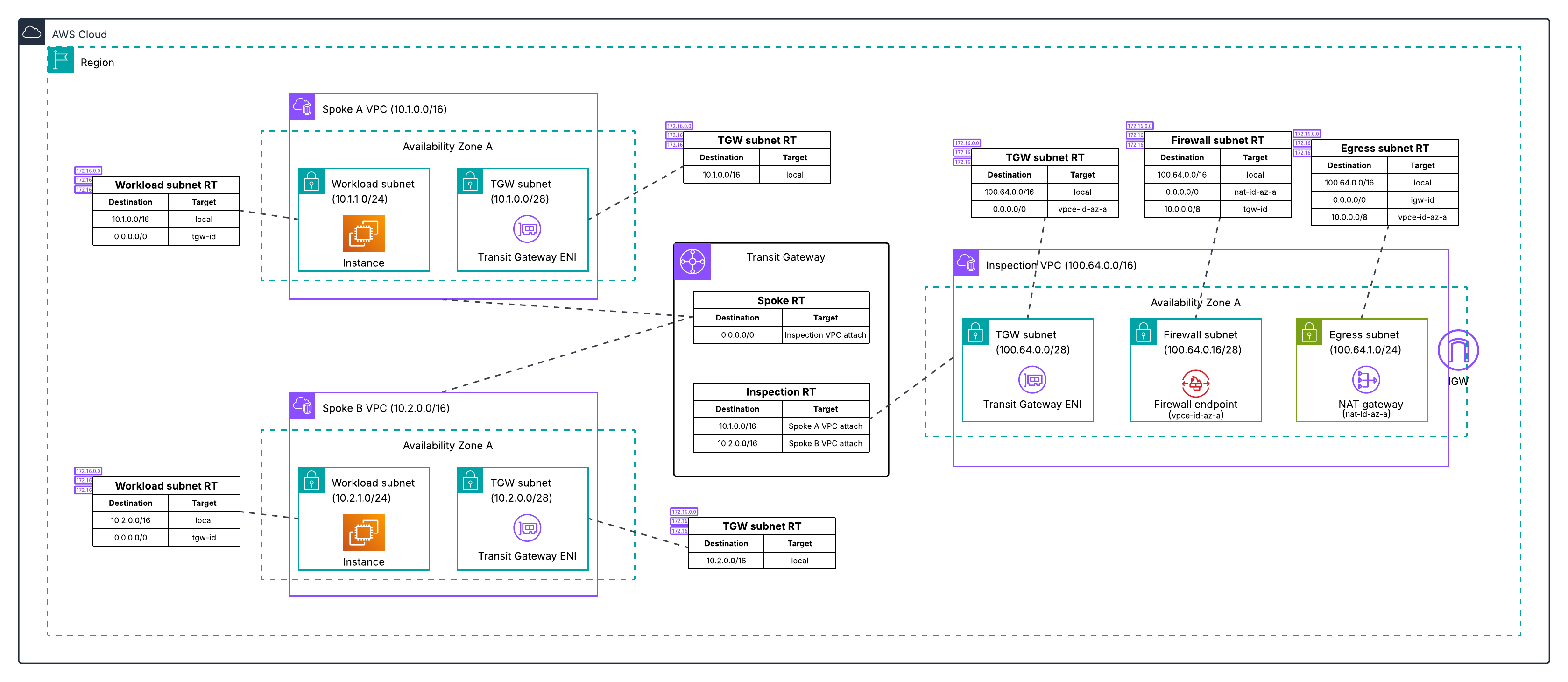
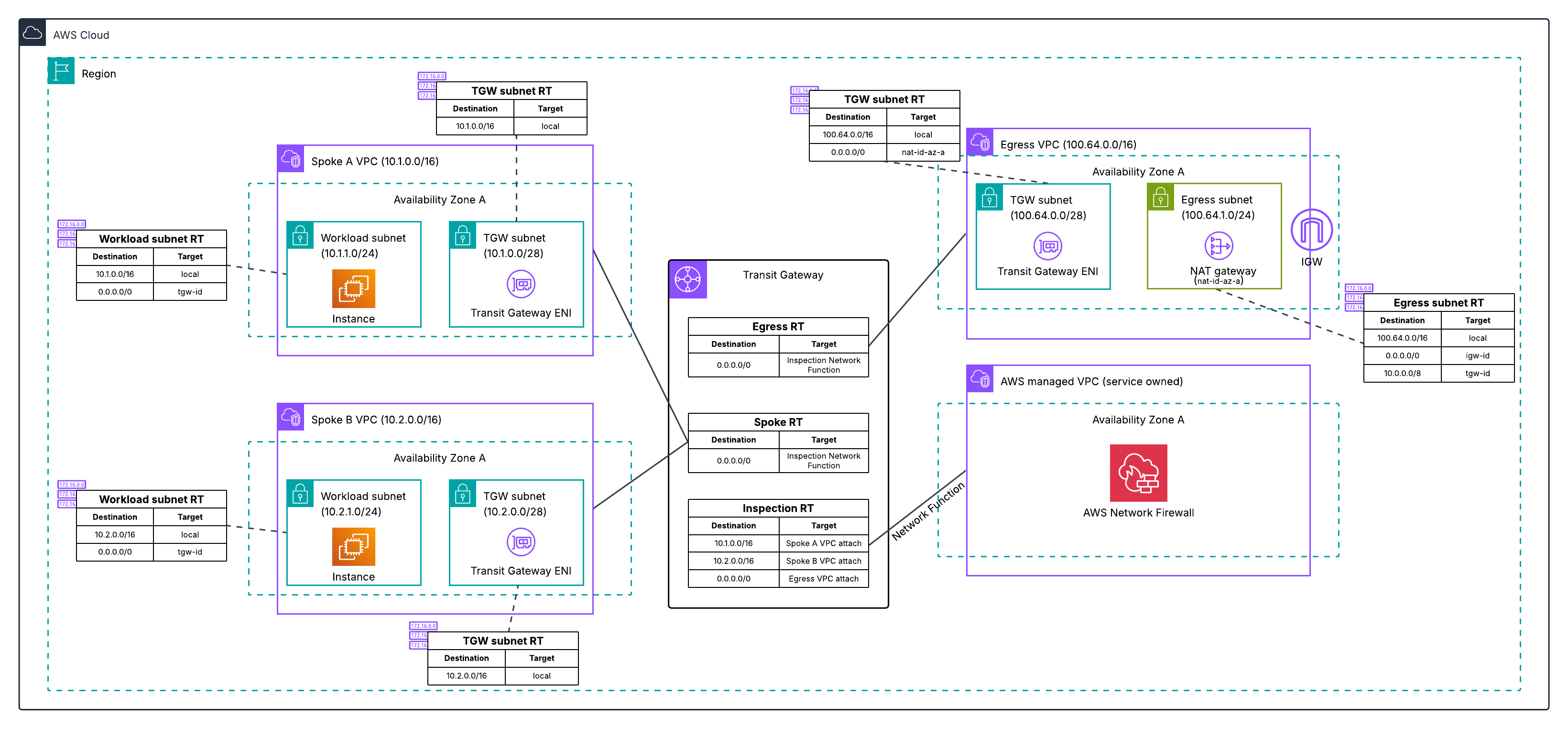
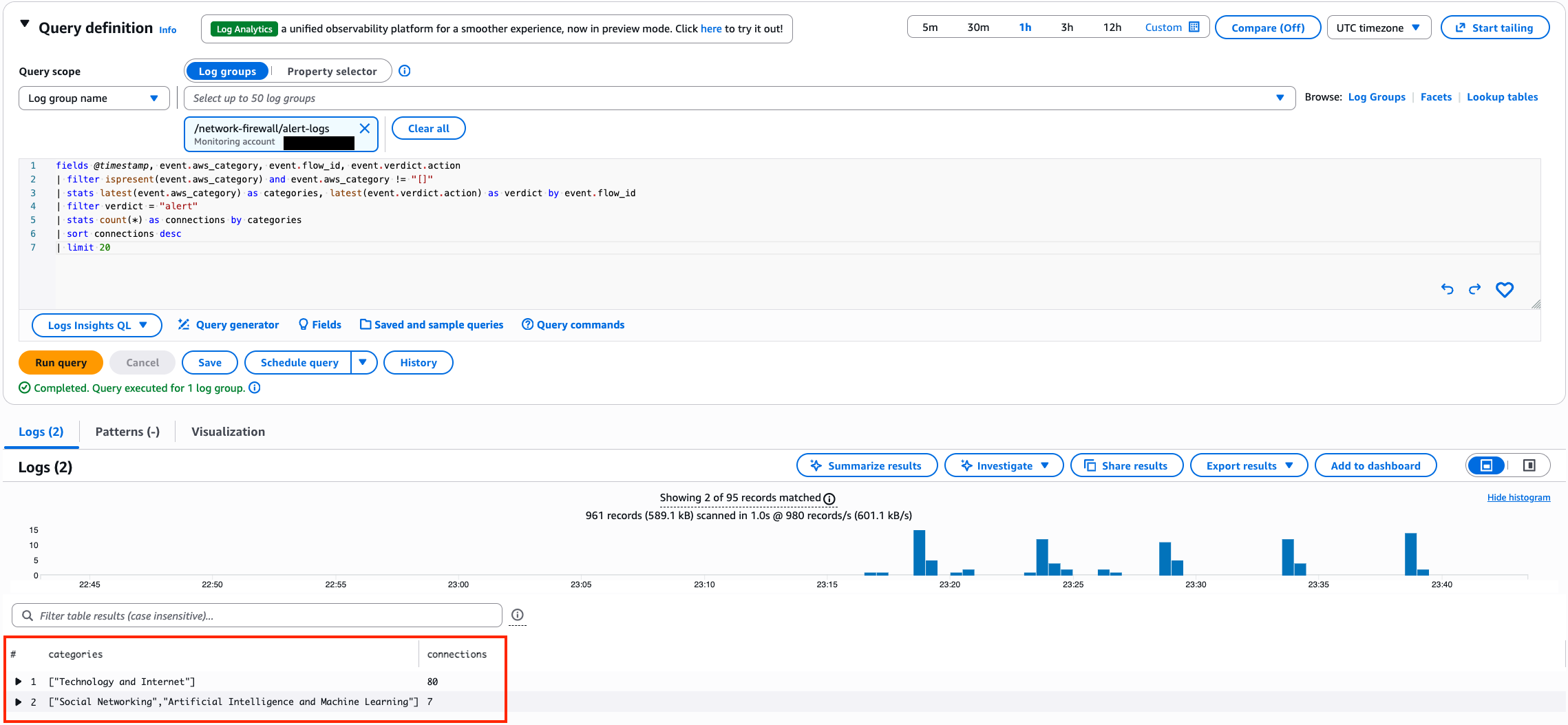
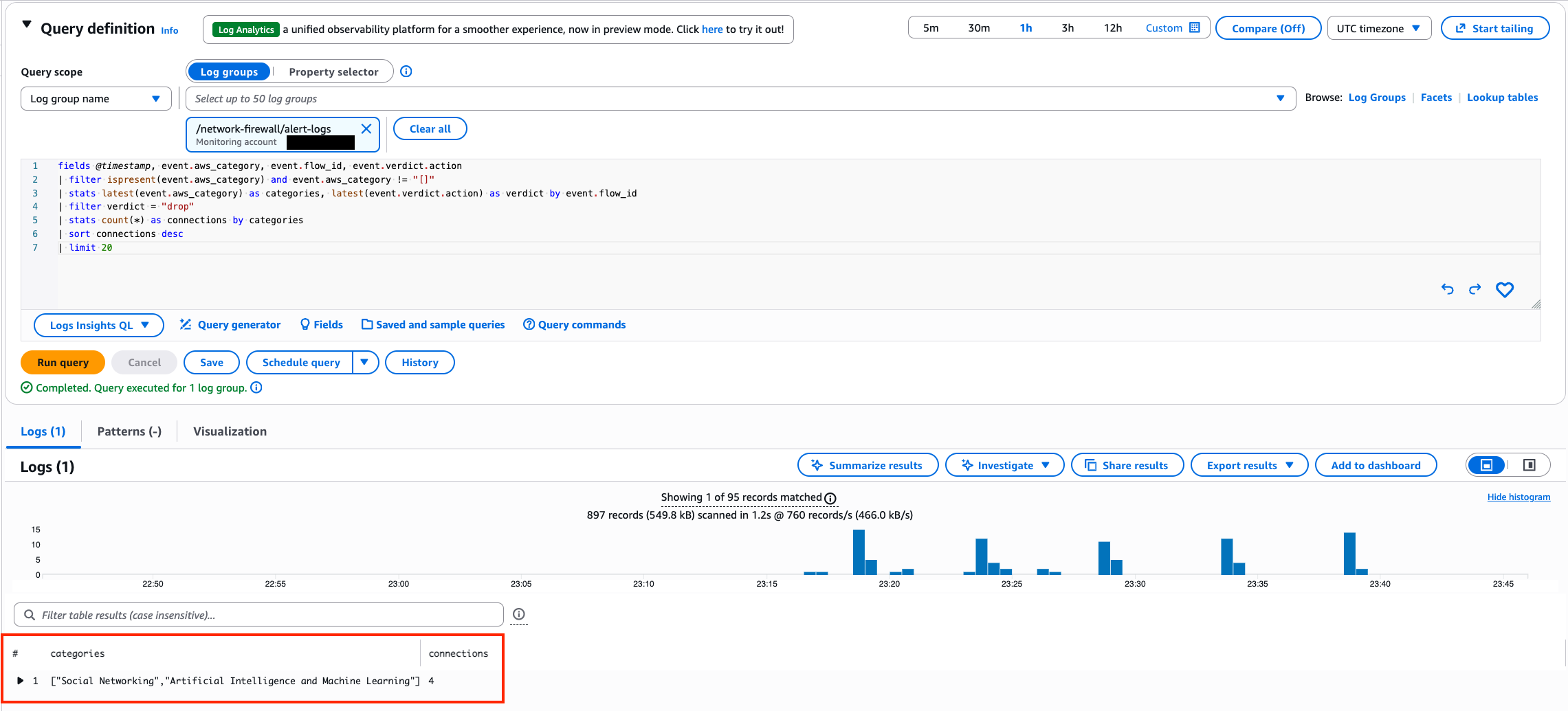
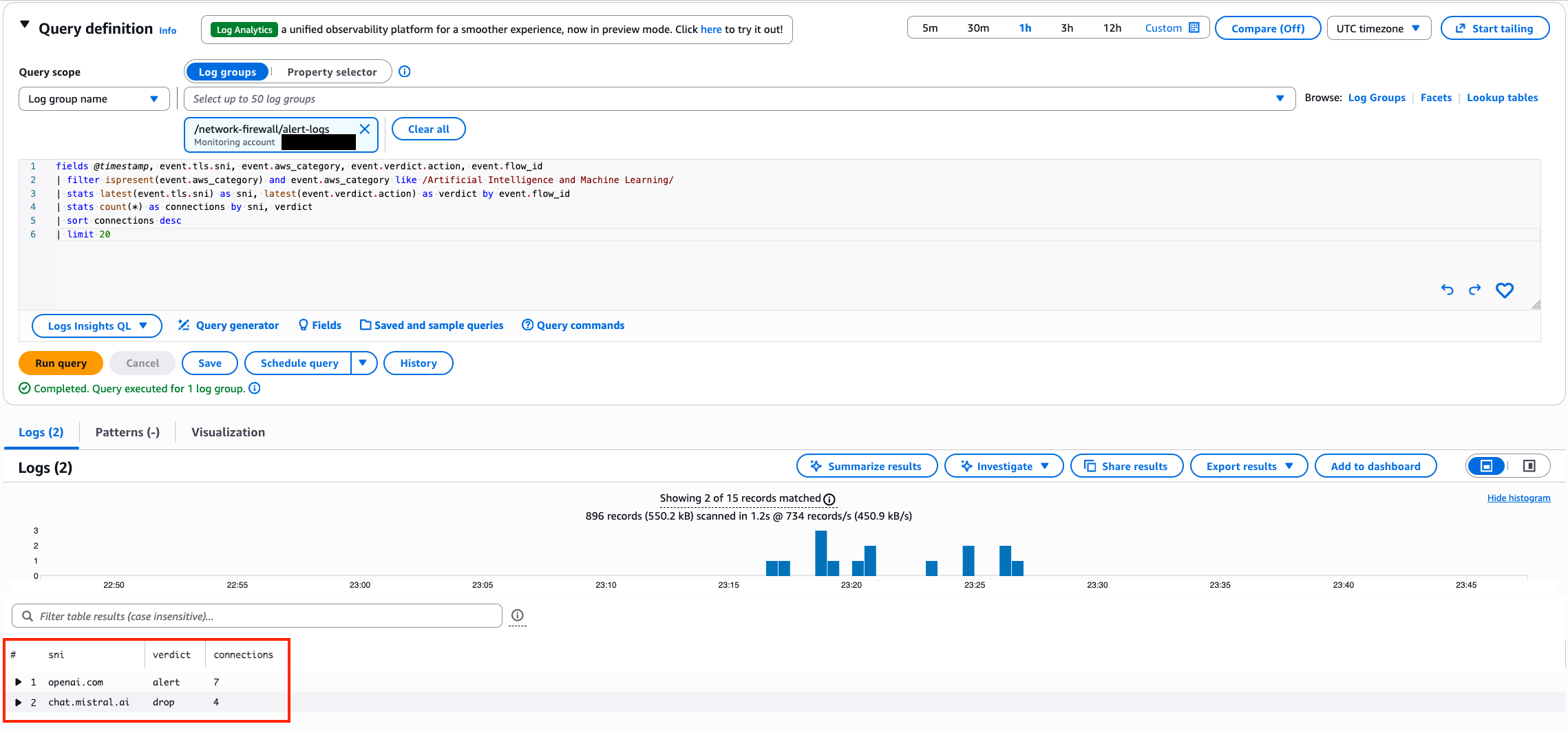
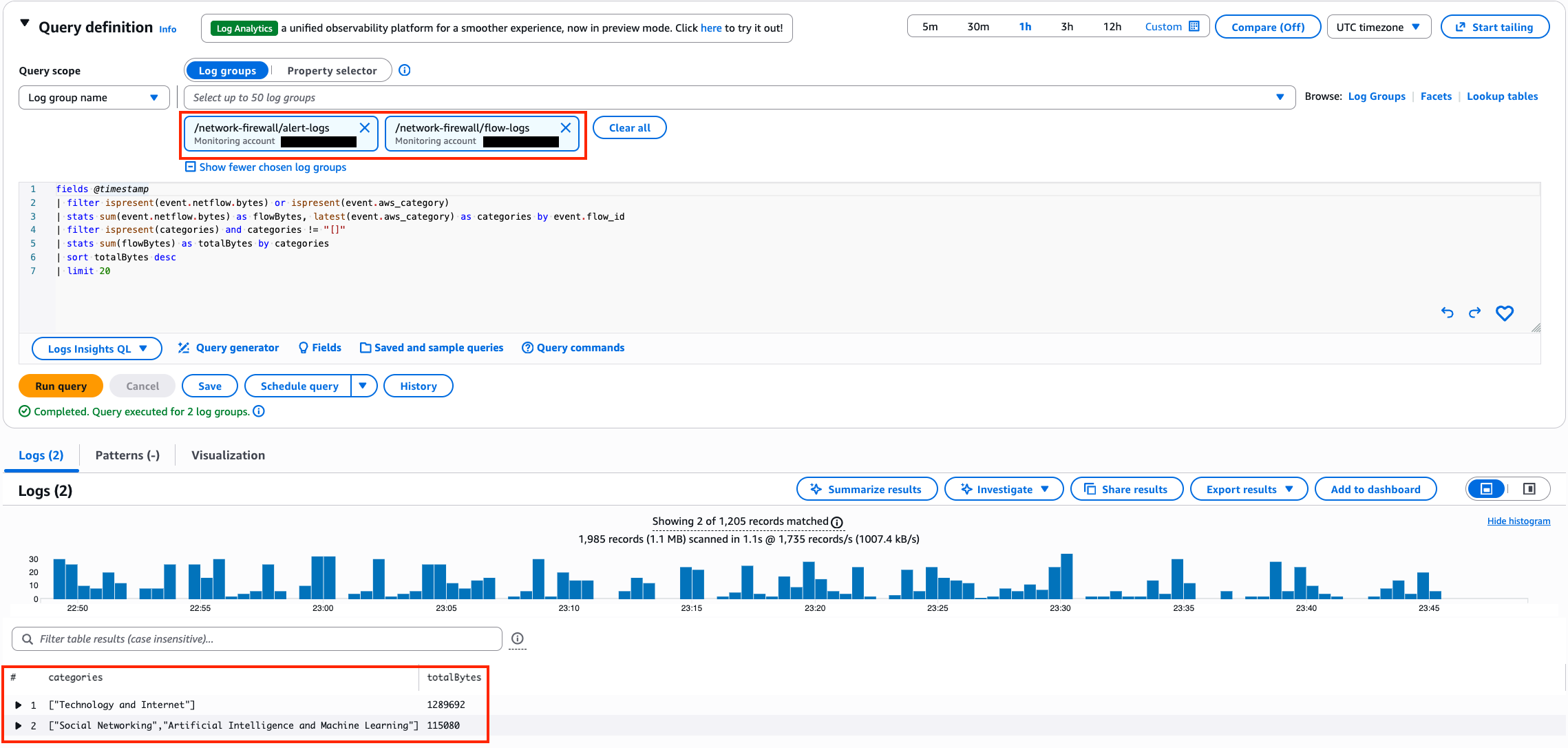
Post Syndicated from Емилия Милчева original https://www.toest.bg/nevidimiyat-premier/

Европейският тур на Румен Радев със сигурност доказа едно – вторият Орбан още не се e родил, след като първият вече е история. Българският премиер не е политикът на големите битки, нито притежава политическата тежест и решителност за открит бунт срещу Европейския съюз.
Първата му обиколка в чужбина като премиер показа, че е достатъчно умерен, за да е приемлив за Брюксел, но и критичен, за да запази образа си пред евроскептичната публика в България. Той имаше срещи с френския президент Макрон, с генералния секретар на НАТО Марк Рюте, с председателя на Европейската комисия Урсула фон дер Лайен и на Европейския съвет – Антонио Коща.
Радев не е човекът на големия разрив, а на голямото „да, но“.
Да, България е част от ЕС, но не бива да помага на Украйна. Най-напред да гарантира стандарта на живот и сигурността на българските граждани и след това може да отделя средства за въоръжаване на чужди армии.
Да, Русия е проблем, но Европа трябвало „да преговаря“ и да бъде водеща.
Европа трябваше да бъде водеща в тези преговори, да не допуска те да се изземват като инициатива от други, трети играчи. Това е важната мисия на Европа. Това, което лично мен ме притеснява, това е стремежът на Европа да постигне конвенционална победа над най-голямата ядрена сила, без да има възможности да прихваща и да противостои на съвременните хиперзвукови оръжия. Това е сериозен риск. Трябва да има смяна на цялостната политика на Европа по отношение на конфликта в Украйна.
Тези изявления на Радев след срещата му с президента Макрон в Елисейския дворец звучат като „реторика за вътрешна употреба“, по определението на анализатора Веселин Желев.
Във френските медии, отбелязва Желев, няма нито една публикация, нито един репортаж, нито дори кратка бележка за визитата на българския премиер. Радев е невидим за France-Presse, както и за водещите всекидневници и седмичници – Le Monde, Le Figaro, Libération, Journal du Dimanche, Le Point, L’Express – плюс сайтовете на основните телевизионни канали и France 24.
В България обаче социологическата агенция „Маркет Линкс“ измери рекордните 56% одобрение за Румен Радев – компенсация за френското пренебрежение, на фона на 77% неодобрение за лидера на ГЕРБ Бойко Борисов.
В Брюксел и Париж Радев всъщност повтори една и съща политическа формула: България е лоялна на ЕС и НАТО, но Европа греши в най-важния си геополитически избор. Според президента континентът е избрал да търси „мир чрез сила“, да инвестира в превъоръжаване и дългосрочна подкрепа за Украйна вместо в преговори. Позиция, която той следва през последните години.
С Урсула фон дер Лайен Радев говори за върховенство на закона, за борба с корупцията и общи европейски решения. Тя пък, освен новината за размразените 370 млн. евро по Плана за възстановяване и устойчивост, отбеляза, че разчита на българската подкрепа за Украйна, както и за противодействие на хибридните атаки срещу ЕС.
В НАТО Румен Радев подчерта българския принос към сигурността на Алианса. Абсурдизмът в позициите му е, че поставя под съмнение самата логика на европейската политика към Украйна, а в същото време е повече от ентусиазиран за още инвестиции в отбраната и за развитие на потенциала на военната индустрия, в това число чрез инструмента SAFE.
Двойни стандарти
Симпатизантите на Радев не улавят тези противоречия. В действителност България е облагодетелствана от продължаващата четвърта година война в Украйна, взела близо 2 милиона жертви от двете страни.
За периода 2022–2025 г. военнопромишленият комплекс e изнесъл оръжие за над 6,65 млрд. евро. Въоръжението и боеприпасите са около 5,5% от целия експорт. Зад тези цифри стоят хиляди нови работни места и заплати, което пък означава ръст на потреблението и подкрепа и за други сектори на икономиката.
България укрепва отбранителните си способности, модернизирайки армията си. Постигната е целта за инвестиции в отбраната, равни на 2% от БВП и се върви към повишаване до 5%, потвърди самият Радев, бивш главнокомандващ Военновъздушните сили, преди да бъде избран за президент.

Специално внимание заслужава инструментът SAFE, който предвижда до 150 млрд. евро заеми за общи военни поръчки, развитие на европейската отбранителна индустрия и намаляване на зависимостта от американско оръжие.
Украйна не може да взема заеми по програмата „Действие за сигурност за Европа“, но пък е изцяло асоциирана със SAFE. Нейни компании могат да участват в производството и доставките. За да бъде финансиран даден проект, европейските правила изискват крайният продукт (например боеприпаси или бронирана техника) да съдържа поне 65% компоненти, произведени в ЕС, Европейската асоциация за свободна търговия или Украйна.
Полша води инициативата с одобрен мащабен национален план на стойност 43,7 млрд. евро за 139 отбранителни проекта. Като гранична държава, голяма част от нейните съвместни поръчки са насочени към укрепване на източния фланг и интеграция с украинското производство.
Румъния се нарежда на второ място по обем на финансиране с одобрен план за 17 млрд. евро. Тя играе критична логистична и производствена роля в проектите, свързани с Украйна.
Балтийските държави (Естония, Латвия и Литва) първи получиха одобрение за своите планове и настояват за съвместни поръчки на артилерия и дронове, в които украинските компании участват като подизпълнители. България ще вземе 3,261 млрд. евро нисколихвени заеми по SAFE, като част от тези средства ще бъдат насочени към съвместно дружество между германския концерн Rheinmetall и държавните ВМЗ – Сопот. Целта е изграждане на завод за производство на 155-милиметрови артилерийски снаряди и барут по стандартите на НАТО.
Как неподкрепата за Украйна се съчетава с ползите от войната – икономически, индустриални и стратегически, е тема, която Радев не коментира. Защото България едновременно печели от европейското превъоръжаване, разширява военната си индустрия, модернизира армията си с европейски средства и участва в общата отбранителна архитектура на ЕС. В същото време премиерът продължава да говори така, сякаш подкрепата за Украйна е чужд, наложен отвън проект.
Политиката, която демонстрира при срещите си с европейските лидери, не е на открит конфликт с ЕС, а постепенно отстъпление с внушението, че европейската решителност е опасна, а европейската солидарност – прекалено скъпа.
Абсолютното мнозинство, което спечели в България обаче, притъпява остротата на политическите реакции. Липсваха коментари от парламентарно представените политически сили, с изключение на „Да, България“, част от „Демократична България“.
Не Украйна започна войната, а Русия, и не Украйна и Европа отказват преговори, както казва Румен Радев, но Русия иска капитулация… Ако не само символно, но и реално Радев започне да откъсва България от сърцето на Европа и застане срещу българския интерес, ще реагираме светкавично и остро.
Божидар Божанов, съпредседател на „Да, България“, пред Дарик радио
Засега премиерът показва двойни стандарти. От една страна, казва сбогом на оръжията за Украйна, от друга, одобрява инвестициите в отбрана, но не се осмелява да защити тази сигурност с ясна политическа позиция. Иска ЕС да плаща цената на сигурността си, без да има смелостта да назове откъде идва заплахата.
Затова остава невидим за Европа и толкова удобен у дома.