Post Syndicated from Kevin Fallis original https://aws.amazon.com/blogs/big-data/ingest-transform-and-deliver-events-published-by-amazon-security-lake-to-amazon-opensearch-service/
With the recent introduction of Amazon Security Lake, it has never been simpler to access all your security-related data in one place. Whether it’s findings from AWS Security Hub, DNS query data from Amazon Route 53, network events such as VPC Flow Logs, or third-party integrations provided by partners such as Barracuda Email Protection, Cisco Firepower Management Center, or Okta identity logs, you now have a centralized environment in which you can correlate events and findings using a broad range of tools in the AWS and partner ecosystem.
Security Lake automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built data lake stored in your account. With Security Lake, you can get a more complete understanding of your security data across your entire organization. You can also improve the protection of your workloads, applications, and data. Security Lake has adopted the Open Cybersecurity Schema Framework (OCSF), an open standard. With OCSF support, the service can normalize and combine security data from AWS and a broad range of enterprise security data sources.
When it comes to near-real-time analysis of data as it arrives in Security Lake and responding to security events your company cares about, Amazon OpenSearch Service provides the necessary tooling to help you make sense of the data found in Security Lake.
OpenSearch Service is a fully managed and scalable log analytics framework that is used by customers to ingest, store, and visualize data. Customers use OpenSearch Service for a diverse set of data workloads, including healthcare data, financial transactions information, application performance data, observability data, and much more. Additionally, customers use the managed service for its ingest performance, scalability, low query latency, and ability to analyze large datasets.
This post shows you how to ingest, transform, and deliver Security Lake data to OpenSearch Service for use by your SecOps teams. We also walk you through how to use a series of prebuilt visualizations to view events across multiple AWS data sources provided by Security Lake.
Understanding the event data found in Security Lake
Security Lake stores the normalized OCSF security events in Apache Parquet format—an optimized columnar data storage format with efficient data compression and enhanced performance to handle complex data in bulk. Parquet format is a foundational format in the Apache Hadoop ecosystem and is integrated into AWS services such as Amazon Redshift Spectrum, AWS Glue, Amazon Athena, and Amazon EMR. It’s a portable columnar format, future proofed to support additional encodings as technology develops, and it has library support across a broad set of languages like Python, Java, and Go. And the best part is that Apache Parquet is open source!
The intent of OCSF is to provide a common language for data scientists and analysts that work with threat detection and investigation. With a diverse set of sources, you can build a complete view of your security posture on AWS using Security Lake and OpenSearch Service.
Understanding the event architecture for Security Lake
Security Lake provides a subscriber framework to provide access to the data stored in Amazon S3. Services such as Amazon Athena and Amazon SageMaker use query access. The solution, in this post, uses data access to respond to events generated by Security Lake.

When you subscribe for data access, events arrive via Amazon Simple Queue Service (Amazon SQS). Each SQS event contains a notification object that has a “pointer” via data used to create a URL to the Parquet object on Amazon S3. Your subscriber processes the event, parses the data found in the object, and transforms it to whatever format makes sense for your implementation.
The solution we provide in this post uses a subscriber for data access. Let’s drill down into what the implementation looks like so that you understand how it works.
Solution overview
The high-level architecture for integrating Security Lake with OpenSearch Service is as follows.

The workflow contains the following steps:
- Security Lake persists Parquet formatted data into an S3 bucket as determined by the administrator of Security Lake.
- A notification is placed in Amazon SQS that describes the key to get access to the object.
- Java code in an AWS Lambda function reads the SQS notification and prepares to read the object described in the notification.
- Java code uses Hadoop, Parquet, and Avro libraries to retrieve the object from Amazon S3 and transform the records in the Parquet object into JSON documents for indexing in your OpenSearch Service domain.
- The documents are gathered and then sent to your OpenSearch Service domain, where index templates map the structure into a schema optimized for Security Lake logs in OCSF format.
Steps 1–2 are managed by Security Lake; steps 3–5 are managed by the customer. The shaded components are your responsibility. The subscriber implementation for this solution uses Lambda and OpenSearch Service, and these resources are managed by you.
If you are evaluating this as solution for your business, remember that Lambda has a 15-minute maximum execution time at the time of this writing. Security Lake can produce up to 256MB object sizes and this solution may not be effective for your company’s needs at large scale. Various levers in Lambda have impacts on the cost of the solution for log delivery. Make cost conscious decisions when evaluating sample solutions. This implementation using Lambda is suitable for smaller companies where to volume of logs for CloudTrail and VPC flow logs are more suitable for a Lambda based approach where the cost to transform and deliver logs to Amazon OpenSearch Service are more budget friendly.
Now that you have some context, let’s start building the implementation for OpenSearch Service!
Prerequisites
Creation of Security Lake for your AWS accounts is a prerequisite for building this solution. Security Lake integrates with an AWS Organizations account to enable the offering for selected accounts in the organization. For a single AWS account that doesn’t use Organizations, you can enable Security Lake without the need for Organizations. You must have administrative access to perform these operations. For multiple accounts, it’s suggested that you delegate the Security Lake activities to another account in your organization. For more information about enabling Security Lake in your accounts, review Getting started.
Additionally, you may need to take the provided template and adjust it to your specific environment. The sample solution relies on access to a public S3 bucket hosted for this blog so egress rules and permissions modifications may be required if you use S3 endpoints.
This solution assumes that you’re using a domain deployed in a VPC. Additionally, it assumes that you have fine-grained access controls enabled on the domain to prevent unauthorized access to data you store as part of the integration with Security Lake. VPC-deployed domains are privately routable and have no access to the public internet by design. If you want to access your domain in a more public setting, you need to create a NGINX proxy to broker a request between public and private settings.
The remaining sections in this post are focused on how to create the integration with OpenSearch Service.
Create the subscriber
To create your subscriber, complete the following steps:
- On the Security Lake console, choose Subscribers in the navigation pane.
- Choose Create subscriber.
- Under Subscriber details, enter a meaningful name and description.

- Under Log and event sources, specify what the subscriber is authorized to ingest. For this post, we select All log and event sources.
- For Data access method, select S3.

- Under Subscriber credentials, provide the account ID and an external ID for which AWS account you want to provide access.
- For Notification details, select SQS queue.
- Choose Create when you are finished filling in the form.
It will take a minute or so to initialize the subscriber framework, such as the SQS integration and the permission generated so that you can access the data from another AWS account. When the status changes from Creating to Created, you have access to the subscriber endpoint on Amazon SQS.

- Save the following values found in the subscriber Details section:
- AWS role ID
- External ID
- Subscription endpoint
Use AWS CloudFormation to provision Lambda integration between the two services
An AWS CloudFormation template takes care of a large portion of the setup for the integration. It creates the necessary components to read the data from Security Lake, transform it into JSON, and then index it into your OpenSearch Service domain. The template also provides the necessary AWS Identity and Access Management (IAM) roles for integration, the tooling to create an S3 bucket for the Java JAR file used in the solution by Lambda, and a small Amazon Elastic Compute Cloud (Amazon EC2) instance to facilitate the provisioning of templates in your OpenSearch Service domain.
To deploy your resources, complete the following steps:
- On the AWS CloudFormation console, create a new stack.
- For Prepare template, select Template is ready.
- Specify your template source as Amazon S3 URL.

You can either save the template to your local drive or copy the link for use on the AWS CloudFormation console. In this example, we use the template URL that points to a template stored on Amazon S3. You can either use the URL on Amazon S3 or install it from your device.
- Choose Next.
- Enter a name for your stack. For this post, we name the stack
blog-lambda. Start populating your parameters based on the values you copied from Security Lake and OpenSearch Service. Ensure that the endpoint for the OpenSearch domain has a forward slash / at the end of the URL that you copy from OpenSearch Service.

- Populate the parameters with values you have saved or copied from OpenSearch Service and Security Lake, then choose Next.

- Select Preserve successfully provisioned resources to preserve the resources in case the stack roles back so you can debug the issues.

- Scroll to bottom of page and choose Next.
- On the summary page, select the check box that acknowledges IAM resources will be created and used in this template.

- Choose Submit.
The stack will take a few minutes to deploy.
- After the stack has deployed, navigate to the Outputs tab for the stack you created.
- Save the
CommandProxyInstanceID for executing scripts and save the two role ARNs to use in the role mappings step.

You need to associate the IAM roles for the tooling instance and the Lambda function with OpenSearch Service security roles so that the processes can work with the cluster and the resources within.
Provision role mappings for integrations with OpenSearch Service
With the template-generated IAM roles, you need to map the roles using role mapping to the predefined all_access role in your OpenSearch Service cluster. You should evaluate your specific use of any roles and ensure they are aligned with your company’s requirements.
- In OpenSearch Dashboards, choose Security in the navigation pane.

- Choose Roles in the navigation pane and look up the
all_access role.

- On the role details page, on the Mapped users tab, choose Manage mapping.

- Add the two IAM roles found in the outputs of the CloudFormation template, then choose Map.

Provision the index templates used for OCSF format in OpenSearch Service
Index templates have been provided as part of the initial setup. These templates are crucial to the format of the data so that ingestion is efficient and tuned for aggregations and visualizations. Data that comes from Security Lake is transformed into a JSON format, and this format is based directly on the OCSF standard.
For example, each OCSF category has a common Base Event class that contains multiple objects that represent details like the cloud provider in a Cloud object, enrichment data using an Enrichment object that has a common structure across events but can have different values based on the event, and even more complex structures that have inner objects, which themselves have more inner objects such as the Metadata object, still part of the Base Event class. The Base Event class is the foundation for all categories in OCSF and helps you with the effort of correlating events written into Security Lake and analyzed in OpenSearch.
OpenSearch is technically schema-less. You don’t have to define a schema up front. The OpenSearch engine will try to guess the data types and the mappings found in the data coming from Security Lake. This is known as dynamic mapping. The OpenSearch engine also provides you with the option to predefine the data you are indexing. This is known as explicit mapping. Using explicit mappings to identifying your data source types and how they are stored at time of ingestion is key to getting high volume ingest performance for time-centric data indexed at heavy load.
In summary, the mapping templates use composable templates. In this construct, the solution establishes an efficient schema for the OCSF standard and gives you the capability to correlate events and specialize on specific categories in the OCSF standard.
You load the templates using the tools proxy created by your CloudFormation template.
- On the stack’s Outputs tab, find the parameter
CommandProxyInstanceID.
We use that value to find the instance in AWS Systems Manager.
- On the Systems Manager console, choose Fleet manager in the navigation pane.
- Locate and select your managed node.
- On the Node actions menu, choose Start terminal session.

- When you’re connected to the instance, run the following commands:
cd;pwd
. /usr/share/es-scripts/es-commands.sh | grep -o '{\"acknowledged\":true}' | wc -l

You should see a final result of 42 occurrences of {“acknowledged”:true}, which demonstrates the commands being sent were successful. Ignore the warnings you see for migration. The warnings don’t affect the scripts and as of this writing can’t be muted.
- Navigate to Dev Tools in OpenSearch Dashboards and run the following command:

This confirms that the scripts were successful.
Install index patterns, visualizations, and dashboards for the solution
For this solution, we prepackaged a few visualizations so that you can make sense of your data. Download the visualizations to your local desktop, then complete the following steps:
- In OpenSearch Dashboards, navigate to Stack Management and Saved Objects.
- Choose Import.

- Choose the file from your local device, select your import options, and choose Import.

You will see numerous objects that you imported. You can use the visualizations after you start importing data.
Enable the Lambda function to start processing events into OpenSearch Service
The final step is to go into the configuration of the Lambda function and enable the triggers so that the data can be read from the subscriber framework in Security Lake. The trigger is currently disabled; you need to enable it and save the config. You will notice the function is throttled, which is by design. You need to have templates in the OpenSearch cluster so that the data indexes in the desired format.
- On the Lambda console, navigate to your function.
- On the Configurations tab, in the Triggers section, select your SQS trigger and choose Edit.

- Select Activate trigger and save the setting.

- Choose Edit concurrency.

- Configure your concurrency and choose Save.
Enable the function by setting the concurrency setting to 1. You can adjust the setting as needed for your environment.

You can review the Amazon CloudWatch logs on the CloudWatch console to confirm the function is working.

You should see startup messages and other event information that indicates logs are being processed. The provided JAR file is set for information level logging and if needed, to debug any concerns, there is a verbose debug version of the JAR file you can use. Your JAR file options are:
If you choose to deploy the debug version, the verbosity of the code will show some error-level details in the Hadoop libraries. To be clear, Hadoop code will display lots of exceptions in debug mode because it tests environment settings and looks for things that aren’t provisioned in your Lambda environment, like a Hadoop metrics collector. Most of these startup errors are not fatal and can be ignored.
Visualize the data
Now that you have data flowing into OpenSearch Service from Security Lake via Lambda, it’s time to put those imported visualizations to work. In OpenSearch Dashboards, navigate to the Dashboards page.
You will see four primary dashboards aligned around the OCSF category for which they support. The four supported visualization categories are for DNS activity, security findings, network activity, and AWS CloudTrail using the Cloud API.

Security findings
The findings dashboard is a series of high-level summary information that you use for visual inspection of AWS Security Hub findings in a time window specified by you in the dashboard filters. Many of the encapsulated visualizations give “filter on click” capabilities so you can narrow your discoveries. The following screenshot shows an example.

The Finding Velocity visualization shows findings over time based on severity. The Finding Severity visualization shows which “findings” have passed or failed, and the Findings table visualization is a tabular view with actual counts. Your goal is to be near zero in all the categories except informational findings.
Network activity
The network traffic dashboard provides an overview for all your accounts in the organization that are enabled for Security Lake. The following example is monitoring 260 AWS accounts, and this dashboard summarizes the top accounts with network activities. Aggregate traffic, top accounts generating traffic and top accounts with the most activity are found in the first section of the visualizations.

Additionally, the top accounts are summarized by allow and deny actions for connections. In the visualization below, there are fields that you can drill down into other visualizations. Some of these visualizations have links to third party website that may or may not be allowed in your company. You can edit the links in the Saved objects in the Stack Management plugin.

For drill downs, you can drill down by choosing the account ID to get a summary by account. The list of egress and ingress traffic within a single AWS account is sorted by the volume of bytes transferred between any given two IP addresses.

Finally, if you choose the IP addresses, you’ll be redirected to Project Honey Pot, where you can see if the IP address is a threat or not.
DNS activity
The DNS activity dashboard shows you the requestors for DNS queries in your AWS accounts. Again, this is a summary view of all the events in a time window.

The first visualization in the dashboard shows DNS activity in aggregate across the top five active accounts. Of the 260 accounts in this example, four are active. The next visualization breaks the resolves down by the requesting service or host, and the final visualization breaks out the requestors by account, VPC ID, and instance ID for those queries run by your solutions.
API Activity
The final dashboard gives an overview of API activity via CloudTrail across all your accounts. It summarizes things like API call velocity, operations by service, top operations, and other summary information.
If we look at the first visualization in the dashboard, you get an idea of which services are receiving the most requests. You sometimes need to understand where to focus the majority of your threat discovery efforts based on which services may be consumed differently over time. Next, there are heat maps that break down API activity by region and service and you get an idea of what type of API calls are most prevalent in your accounts you are monitoring.

As you scroll down on the form, more details present themselves such as top five services with API activity and the top API operations for the organization you are monitoring.

Conclusion
Security Lake integration with OpenSearch Service is easy to achieve by following the steps outlined in this post. Security Lake data is transformed from Parquet to JSON, making it readable and simple to query. Enable your SecOps teams to identify and investigate potential security threats by analyzing Security Lake data in OpenSearch Service. The provided visualizations and dashboards can help to navigate the data, identify trends and rapidly detect any potential security issues in your organization.
As next steps, we recommend to use the above framework and associated templates that provide you with easy steps to visualize your Security Lake data using OpenSearch Service.
In a series of follow-up posts, we will review the source code and walkthrough published examples of the Lambda ingestion framework in the AWS Samples GitHub repo. The framework can be modified for use in containers to help address companies that have longer processing times for large files published in Security Lake. Additionally, we will discuss how to detect and respond to security events using example implementations that use OpenSearch plugins such as Security Analytics, Alerting, and the Anomaly Detection available in Amazon OpenSearch Service.
About the authors
 Kevin Fallis (@AWSCodeWarrior) is an Principal AWS Specialist Search Solutions Architect. His passion at AWS is to help customers leverage the correct mix of AWS services to achieve success for their business goals. His after-work activities include family, DIY projects, carpentry, playing drums, and all things music.
Kevin Fallis (@AWSCodeWarrior) is an Principal AWS Specialist Search Solutions Architect. His passion at AWS is to help customers leverage the correct mix of AWS services to achieve success for their business goals. His after-work activities include family, DIY projects, carpentry, playing drums, and all things music.
 Jimish Shah is a Senior Product Manager at AWS with 15+ years of experience bringing products to market in log analytics, cybersecurity, and IP video streaming. He’s passionate about launching products that offer delightful customer experiences, and solve complex customer problems. In his free time, he enjoys exploring cafes, hiking, and taking long walks
Jimish Shah is a Senior Product Manager at AWS with 15+ years of experience bringing products to market in log analytics, cybersecurity, and IP video streaming. He’s passionate about launching products that offer delightful customer experiences, and solve complex customer problems. In his free time, he enjoys exploring cafes, hiking, and taking long walks
 Ross Warren is a Senior Product SA at AWS for Amazon Security Lake based in Northern Virginia. Prior to his work at AWS, Ross’ areas of focus included cyber threat hunting and security operations. When he is not talking about AWS he likes to spend time with his family, bake bread, make sawdust and enjoy time outside.
Ross Warren is a Senior Product SA at AWS for Amazon Security Lake based in Northern Virginia. Prior to his work at AWS, Ross’ areas of focus included cyber threat hunting and security operations. When he is not talking about AWS he likes to spend time with his family, bake bread, make sawdust and enjoy time outside.
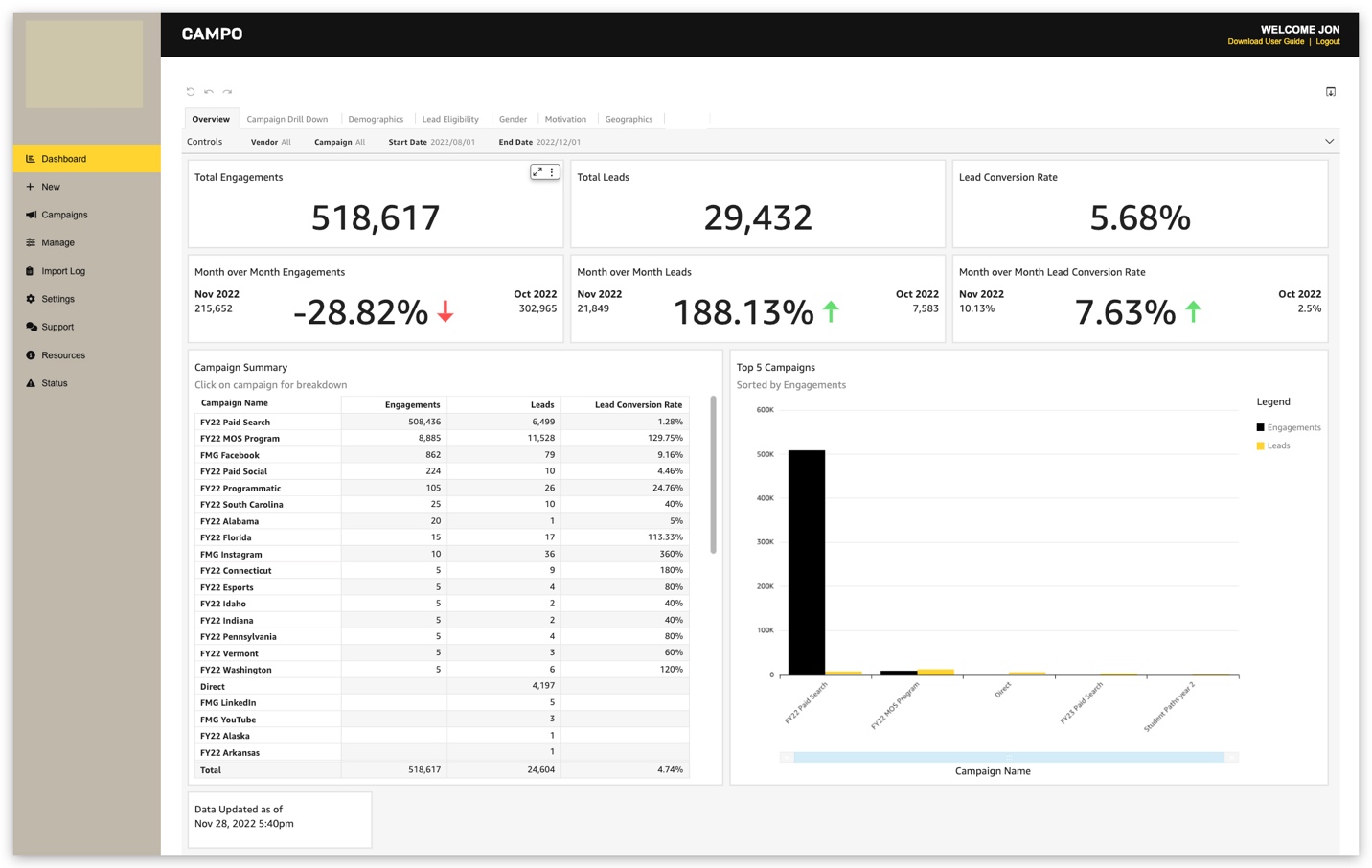
 Jon Walker, Senior Director of Engineering, is a native Nashvillian who has been in the technology field for over 19 years. He oversees enterprise-wide system engineering, development, and technology programs for large federal and DoD clients, as well as iostudio’s commercial clients.
Jon Walker, Senior Director of Engineering, is a native Nashvillian who has been in the technology field for over 19 years. He oversees enterprise-wide system engineering, development, and technology programs for large federal and DoD clients, as well as iostudio’s commercial clients. Ari Orlinsky, Director of Information Services, leads iostudio’s Information Systems Department, responsible for AWS Cloud, SaaS applications, on-premises technology, risk assessment, compliance, budgeting, and human resource management. With nearly 20 years’ experience in strategic IS and technology operations, Ari has developed a keen enthusiasm for emerging technologies, DOD security and compliance, large format interactive experiences, and customer service communication technologies. As iostudio’s Technical Product Owner across internal and client-facing applications including a cloud-based omni-channel contact center platform, he advocates for secure deployment of applicable technologies to the cloud while ensuring resilient on-premises data center solutions.
Ari Orlinsky, Director of Information Services, leads iostudio’s Information Systems Department, responsible for AWS Cloud, SaaS applications, on-premises technology, risk assessment, compliance, budgeting, and human resource management. With nearly 20 years’ experience in strategic IS and technology operations, Ari has developed a keen enthusiasm for emerging technologies, DOD security and compliance, large format interactive experiences, and customer service communication technologies. As iostudio’s Technical Product Owner across internal and client-facing applications including a cloud-based omni-channel contact center platform, he advocates for secure deployment of applicable technologies to the cloud while ensuring resilient on-premises data center solutions. Sumitha AP is a Sr. Solutions Architect at AWS. Sumitha works with SMB customers to help them design secure, scalable, reliable, and cost-effective solutions in the AWS Cloud. She has a focus on data and analytics and provides guidance on building analytics solutions on AWS.
Sumitha AP is a Sr. Solutions Architect at AWS. Sumitha works with SMB customers to help them design secure, scalable, reliable, and cost-effective solutions in the AWS Cloud. She has a focus on data and analytics and provides guidance on building analytics solutions on AWS.



 Nicolas Jacob Baer is a Senior Cloud Application Architect with a strong focus on data engineering and machine learning, based in Switzerland. He works closely with enterprise customers to design data platforms and build advanced analytics/ml use-cases.
Nicolas Jacob Baer is a Senior Cloud Application Architect with a strong focus on data engineering and machine learning, based in Switzerland. He works closely with enterprise customers to design data platforms and build advanced analytics/ml use-cases. Luca Mazzaferro is a Senior DevOps Architect at Amazon Web Services. He likes to have infrastructure automated, reproducible and secured. In his free time he likes to cook, especially pizza.
Luca Mazzaferro is a Senior DevOps Architect at Amazon Web Services. He likes to have infrastructure automated, reproducible and secured. In his free time he likes to cook, especially pizza. Kemeng Zhang is a Cloud Application Architect with a strong focus on machine learning and UX, based in Switzerland. She works closely with customers to design user experiences and build advanced analytics/ml use-cases.
Kemeng Zhang is a Cloud Application Architect with a strong focus on machine learning and UX, based in Switzerland. She works closely with customers to design user experiences and build advanced analytics/ml use-cases. Mark Walser, a Senior Global Data Architect at Amazon Web Services, collaborates with customers to develop innovative Big Data solutions that solve business problems and speed up the adoption of AWS services. Outside of work, he finds pleasure in running, swimming, and all things related to technology.
Mark Walser, a Senior Global Data Architect at Amazon Web Services, collaborates with customers to develop innovative Big Data solutions that solve business problems and speed up the adoption of AWS services. Outside of work, he finds pleasure in running, swimming, and all things related to technology. Gal Heyne is a Product Manager for AWS Glue with a strong focus on AI/ML, data engineering and BI, based in California. She is passionate about developing a deep understanding of customer’s business needs and collaborating with engineers to design easy to use data products.
Gal Heyne is a Product Manager for AWS Glue with a strong focus on AI/ML, data engineering and BI, based in California. She is passionate about developing a deep understanding of customer’s business needs and collaborating with engineers to design easy to use data products.
























 Anderson Santos is a Senior Solutions Architect at Amazon Web Services. He works with AWS Enterprise customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS.
Anderson Santos is a Senior Solutions Architect at Amazon Web Services. He works with AWS Enterprise customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Arun Pradeep Selvaraj is a Senior Solutions Architect and is part of Analytics TFC at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build and reinvent. He is creative, fast-paced, deeply customer-obsessed and leverages the working backwards process to build modern architectures to help customers solve their unique challenges.
Arun Pradeep Selvaraj is a Senior Solutions Architect and is part of Analytics TFC at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build and reinvent. He is creative, fast-paced, deeply customer-obsessed and leverages the working backwards process to build modern architectures to help customers solve their unique challenges. Patrick Muller is a Senior Solutions Architect and a valued member of the Datalab. With over 20 years of expertise in analytics, data warehousing, and distributed systems, he brings extensive knowledge to the table. Patrick’s passion lies in evaluating new technologies and assisting customers with innovative solutions. During his free time, he enjoys watching soccer.
Patrick Muller is a Senior Solutions Architect and a valued member of the Datalab. With over 20 years of expertise in analytics, data warehousing, and distributed systems, he brings extensive knowledge to the table. Patrick’s passion lies in evaluating new technologies and assisting customers with innovative solutions. During his free time, he enjoys watching soccer.



















 Chaitanya Shah is a Sr. Technical Account Manager(TAM) with AWS, based out of New York. He has over 22 years of experience working with enterprise customers. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their AWS Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.
Chaitanya Shah is a Sr. Technical Account Manager(TAM) with AWS, based out of New York. He has over 22 years of experience working with enterprise customers. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their AWS Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.


















































 Jimish Shah is a Senior Product Manager at AWS with 15+ years of experience bringing products to market in log analytics, cybersecurity, and IP video streaming. He’s passionate about launching products that offer delightful customer experiences, and solve complex customer problems. In his free time, he enjoys exploring cafes, hiking, and taking long walks
Jimish Shah is a Senior Product Manager at AWS with 15+ years of experience bringing products to market in log analytics, cybersecurity, and IP video streaming. He’s passionate about launching products that offer delightful customer experiences, and solve complex customer problems. In his free time, he enjoys exploring cafes, hiking, and taking long walks Ross Warren is a Senior Product SA at AWS for Amazon Security Lake based in Northern Virginia. Prior to his work at AWS, Ross’ areas of focus included cyber threat hunting and security operations. When he is not talking about AWS he likes to spend time with his family, bake bread, make sawdust and enjoy time outside.
Ross Warren is a Senior Product SA at AWS for Amazon Security Lake based in Northern Virginia. Prior to his work at AWS, Ross’ areas of focus included cyber threat hunting and security operations. When he is not talking about AWS he likes to spend time with his family, bake bread, make sawdust and enjoy time outside.









 Anwar Ali is a Specialist Solutions Architect for Amazon QuickSight. Anwar has over 18 years of experience implementing enterprise business intelligence (BI), data analytics and database solutions . He specializes in integration of BI solutions with business applications, helping customers in BI architecture design patterns and best practices.
Anwar Ali is a Specialist Solutions Architect for Amazon QuickSight. Anwar has over 18 years of experience implementing enterprise business intelligence (BI), data analytics and database solutions . He specializes in integration of BI solutions with business applications, helping customers in BI architecture design patterns and best practices. Salim Khan is a Specialist Solutions Architect for Amazon QuickSight. Salim has over 16 years of experience implementing enterprise business intelligence (BI) solutions. Prior to AWS, Salim worked as a BI consultant catering to industry verticals like Automotive, Healthcare, Entertainment, Consumer, Publishing and Financial Services. He has delivered business intelligence, data warehousing, data integration and master data management solutions across enterprises.
Salim Khan is a Specialist Solutions Architect for Amazon QuickSight. Salim has over 16 years of experience implementing enterprise business intelligence (BI) solutions. Prior to AWS, Salim worked as a BI consultant catering to industry verticals like Automotive, Healthcare, Entertainment, Consumer, Publishing and Financial Services. He has delivered business intelligence, data warehousing, data integration and master data management solutions across enterprises. Gil Raviv is a Principal Product Manager for Amazon QuickSight, AWS’ cloud-native, fully managed SaaS BI service. As a thought-leader in BI, Gil accelerated the growth of global BI practices at AWS and Avanade, and has guided Fortune 1000 enterprises in their Data & AI journey. As a passionate evangelist, author and blogger of low-code/no-code data prep and analytic tools, Gil was awarded 5 times as a Microsoft MVP (Most Valuable Professional).
Gil Raviv is a Principal Product Manager for Amazon QuickSight, AWS’ cloud-native, fully managed SaaS BI service. As a thought-leader in BI, Gil accelerated the growth of global BI practices at AWS and Avanade, and has guided Fortune 1000 enterprises in their Data & AI journey. As a passionate evangelist, author and blogger of low-code/no-code data prep and analytic tools, Gil was awarded 5 times as a Microsoft MVP (Most Valuable Professional).









 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community. Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.















 Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS. Dr. Dawn Heisey-Grove is the public health analytics leader for Amazon Web Services’ state and local government team. In this role, she’s responsible for helping state and local public health agencies think creatively about how to achieve their analytics challenges and long-term goals. She’s spent her career finding new ways to use existing or new data to support public health surveillance and research.
Dr. Dawn Heisey-Grove is the public health analytics leader for Amazon Web Services’ state and local government team. In this role, she’s responsible for helping state and local public health agencies think creatively about how to achieve their analytics challenges and long-term goals. She’s spent her career finding new ways to use existing or new data to support public health surveillance and research. Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.
Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.
 Ketan Verma is a Senior SDE working on Amazon OpenSearch Service. He is passionate about building large-scale distributed systems, improving performance, and simplifying complex ideas with simple abstractions. Outside work, he likes to read and improve his home barista skills.
Ketan Verma is a Senior SDE working on Amazon OpenSearch Service. He is passionate about building large-scale distributed systems, improving performance, and simplifying complex ideas with simple abstractions. Outside work, he likes to read and improve his home barista skills. Suresh N S is a Senior SDE working on Amazon OpenSearch Service. He is passionate towards solving problems in large scale distributed systems.
Suresh N S is a Senior SDE working on Amazon OpenSearch Service. He is passionate towards solving problems in large scale distributed systems. Pritkumar Ladani is an SDE-2 working on Amazon OpenSearch Service. He likes to contribute to open source software development, and is passionate about distributed systems. He is an amateur badminton player and enjoys trekking.
Pritkumar Ladani is an SDE-2 working on Amazon OpenSearch Service. He likes to contribute to open source software development, and is passionate about distributed systems. He is an amateur badminton player and enjoys trekking. Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.

 Ameya Agavekar is a results-driven, highly skilled data strategist. Ameya leads the data engineering and data science function for AWS Professional Services World-Wide Business Insights & Analytics team. Outside of work, Ameya is a professional pilot. He enjoys serving community by applying his unique flying skills with the US Airforce auxiliary Civil Air Patrol.
Ameya Agavekar is a results-driven, highly skilled data strategist. Ameya leads the data engineering and data science function for AWS Professional Services World-Wide Business Insights & Analytics team. Outside of work, Ameya is a professional pilot. He enjoys serving community by applying his unique flying skills with the US Airforce auxiliary Civil Air Patrol. Tucker Shouse leads the AWS Professional Services World-Wide Business Insights & Analytics team. Prior to AWS, Tucker worked with financial services, retail, healthcare, and non-profit clients to develop digital and data products and strategies as a Manager at Alvarez & Marsal Corporate Performance Improvement. Outside of work, Tucker enjoys spending time with his wife and daughter enjoying the outdoors and music.
Tucker Shouse leads the AWS Professional Services World-Wide Business Insights & Analytics team. Prior to AWS, Tucker worked with financial services, retail, healthcare, and non-profit clients to develop digital and data products and strategies as a Manager at Alvarez & Marsal Corporate Performance Improvement. Outside of work, Tucker enjoys spending time with his wife and daughter enjoying the outdoors and music.

 Nagarjuna Koduru is a Principal Engineer in AWS, currently working for AWS Managed Streaming For Kafka (MSK). He led the teams that built MSK Serverless and MSK Tiered storage products. He previously led the team in Amazon JustWalkOut (JWO) that is responsible for realtime tracking of shopper locations in the store. He played pivotal role in scaling the stateful stream processing infrastructure to support larger store formats and reducing the overall cost of the system. He has keen interest in stream processing, messaging and distributed storage infrastructure.
Nagarjuna Koduru is a Principal Engineer in AWS, currently working for AWS Managed Streaming For Kafka (MSK). He led the teams that built MSK Serverless and MSK Tiered storage products. He previously led the team in Amazon JustWalkOut (JWO) that is responsible for realtime tracking of shopper locations in the store. He played pivotal role in scaling the stateful stream processing infrastructure to support larger store formats and reducing the overall cost of the system. He has keen interest in stream processing, messaging and distributed storage infrastructure. Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.
Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.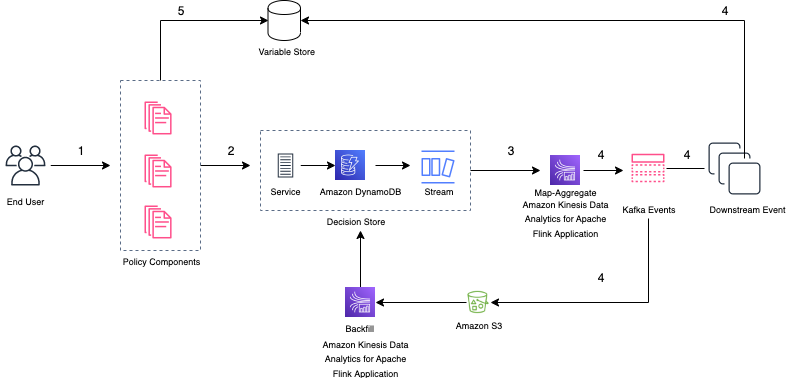
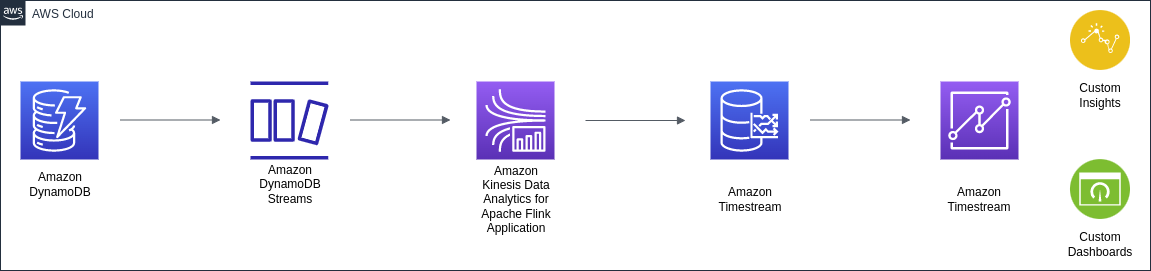
 Nir Tsruya is a Lead Engineer in Klarna. He leads 2 engineering teams focusing mainly on real time data processing and analytics at large scale.
Nir Tsruya is a Lead Engineer in Klarna. He leads 2 engineering teams focusing mainly on real time data processing and analytics at large scale. Ankit Gupta is a Senior Solutions Architect at Amazon Web Serves based in Stockholm, Sweden, where we helps customers across the Nordics succeed in Cloud. He’s particularly passionate about building strong Networking foundation in Cloud.
Ankit Gupta is a Senior Solutions Architect at Amazon Web Serves based in Stockholm, Sweden, where we helps customers across the Nordics succeed in Cloud. He’s particularly passionate about building strong Networking foundation in Cloud. Daniel Arenhage is a Solutions Architect at Amazon Web Services based in Gothenburg, Sweden.
Daniel Arenhage is a Solutions Architect at Amazon Web Services based in Gothenburg, Sweden.






 Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product. Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics.
Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics. Srikanth Baheti is a Specialized World Wide Principal Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.
Srikanth Baheti is a Specialized World Wide Principal Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.
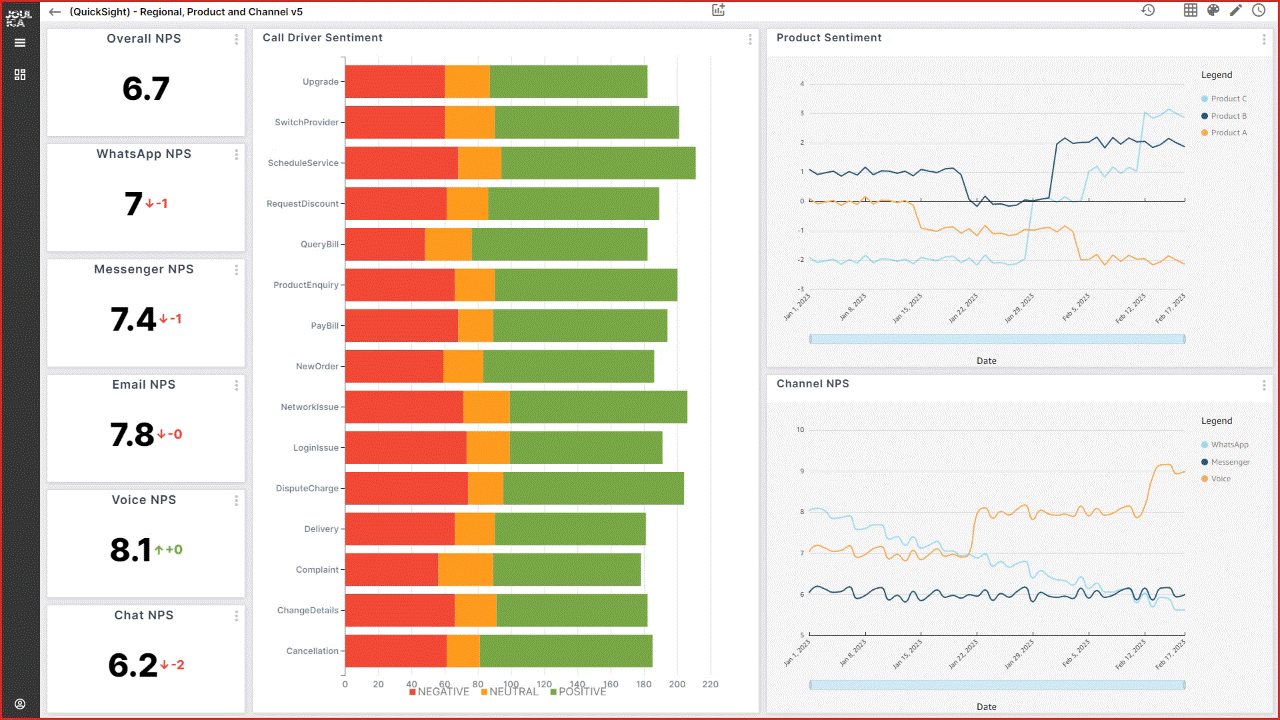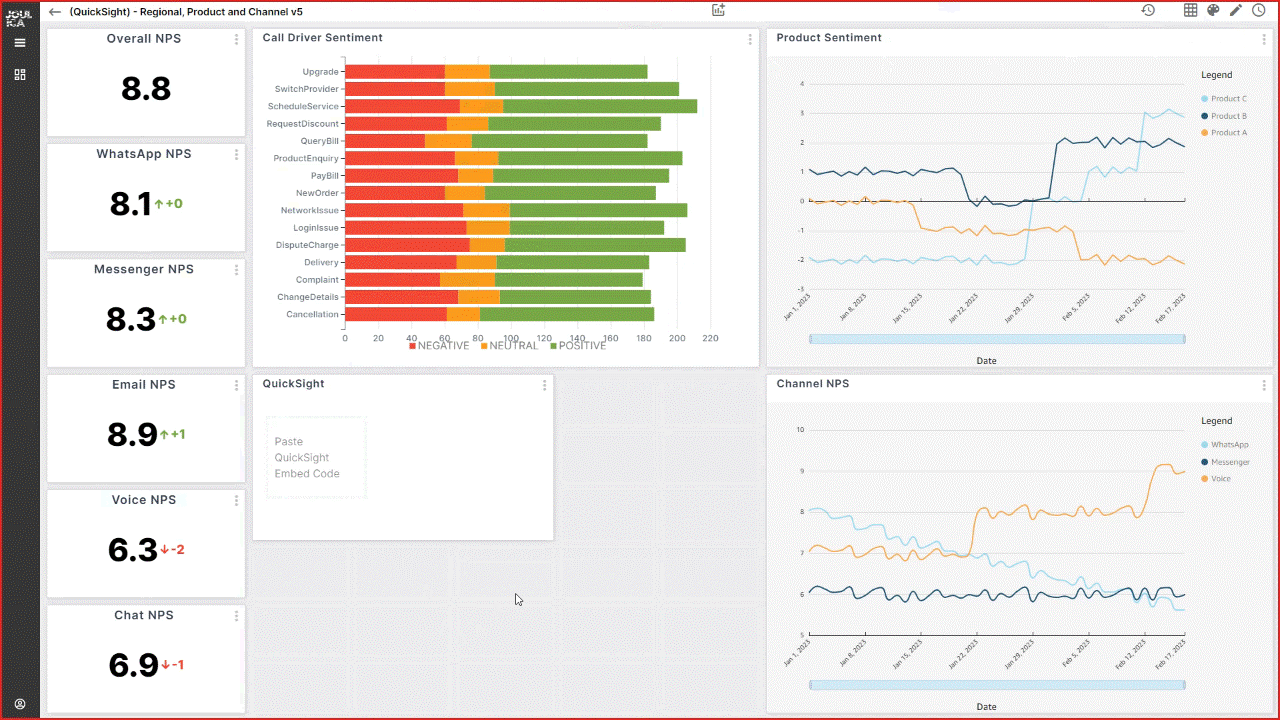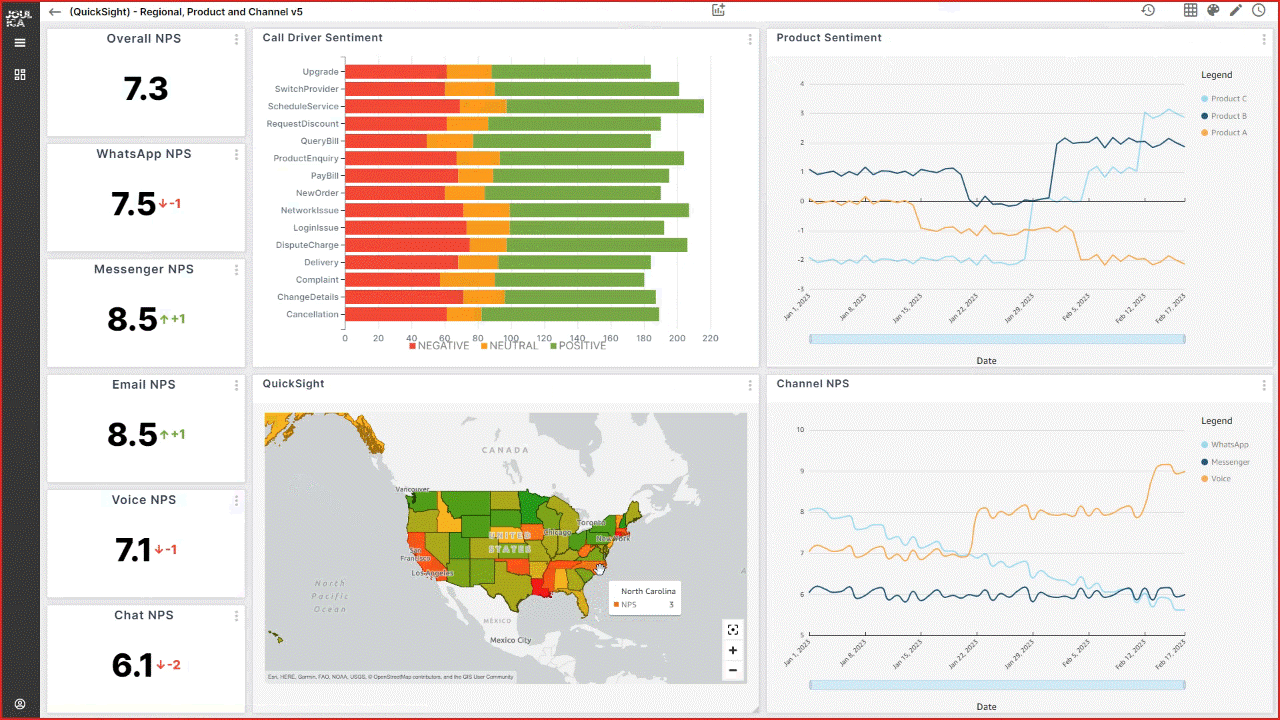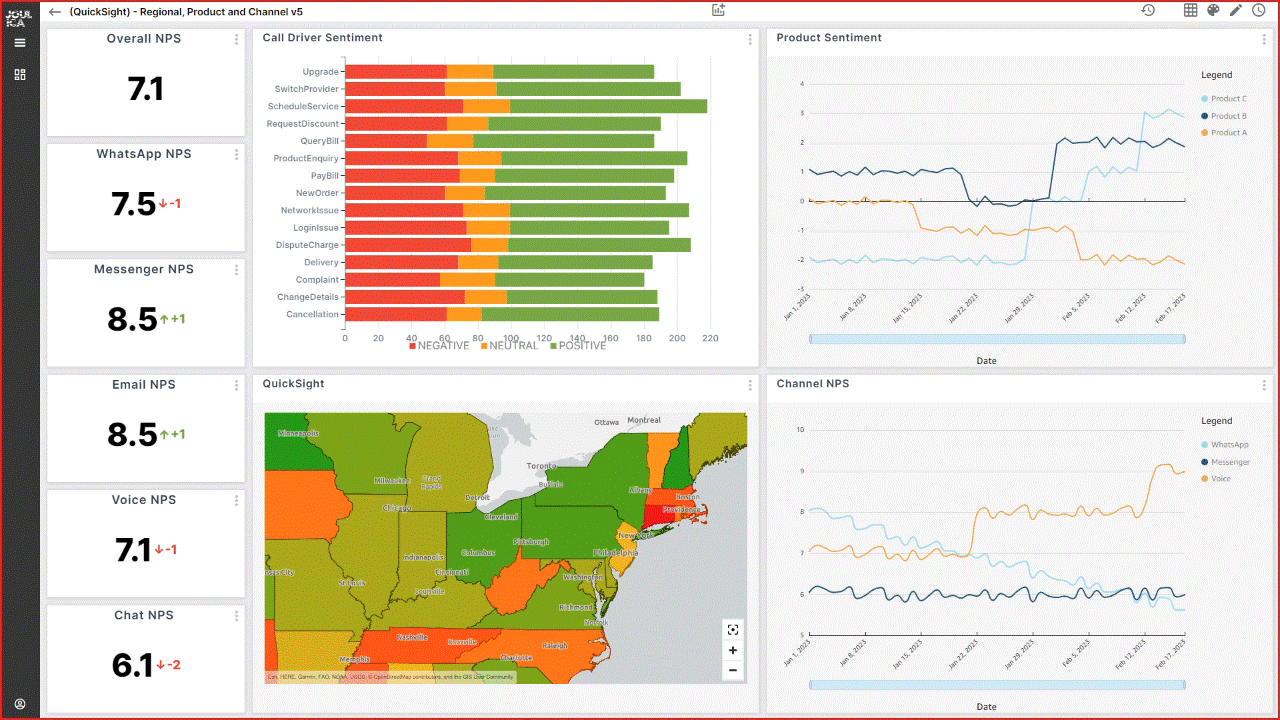
 Tony McCormack is the CEO and Co-founder of Joulica. Based in Galway, Ireland, he is focused on providing enterprise-grade reporting and analytics for Amazon Connect, Salesforce Service Cloud, and other platforms in the customer experience market. He has extensive experience in the contact center domain, with a passion for real-time analytics and their integration into end-user applications.
Tony McCormack is the CEO and Co-founder of Joulica. Based in Galway, Ireland, he is focused on providing enterprise-grade reporting and analytics for Amazon Connect, Salesforce Service Cloud, and other platforms in the customer experience market. He has extensive experience in the contact center domain, with a passion for real-time analytics and their integration into end-user applications. Shana Schipers is an Analytics Specialist Solutions Architect at AWS, focusing on big data. She supports customers worldwide in building transactional data lakes using open table formats like Apache Hudi, Apache Iceberg and Delta Lake on AWS.
Shana Schipers is an Analytics Specialist Solutions Architect at AWS, focusing on big data. She supports customers worldwide in building transactional data lakes using open table formats like Apache Hudi, Apache Iceberg and Delta Lake on AWS. Ian Meyers is a Director of Product Management for AWS Analytics Services. He works with many of AWS largest customers on emerging technology needs, and leads several data and analytics initiatives within AWS including support for Data Mesh.
Ian Meyers is a Director of Product Management for AWS Analytics Services. He works with many of AWS largest customers on emerging technology needs, and leads several data and analytics initiatives within AWS including support for Data Mesh.