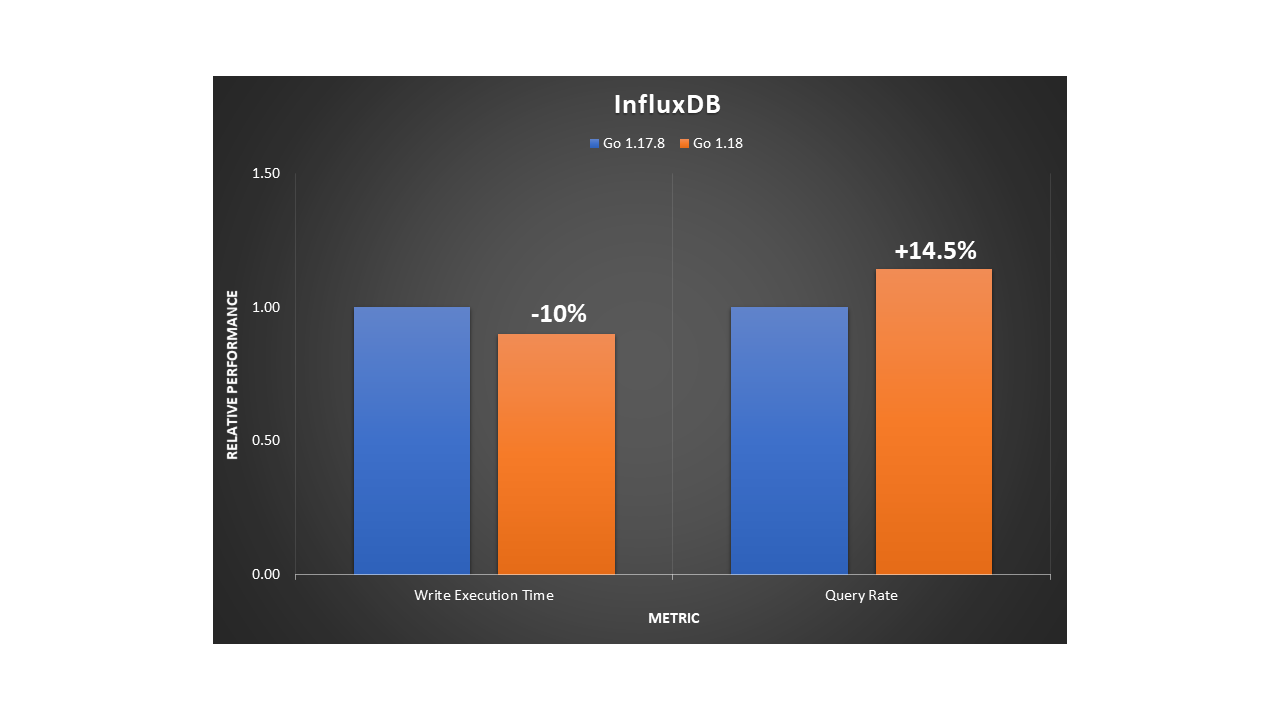
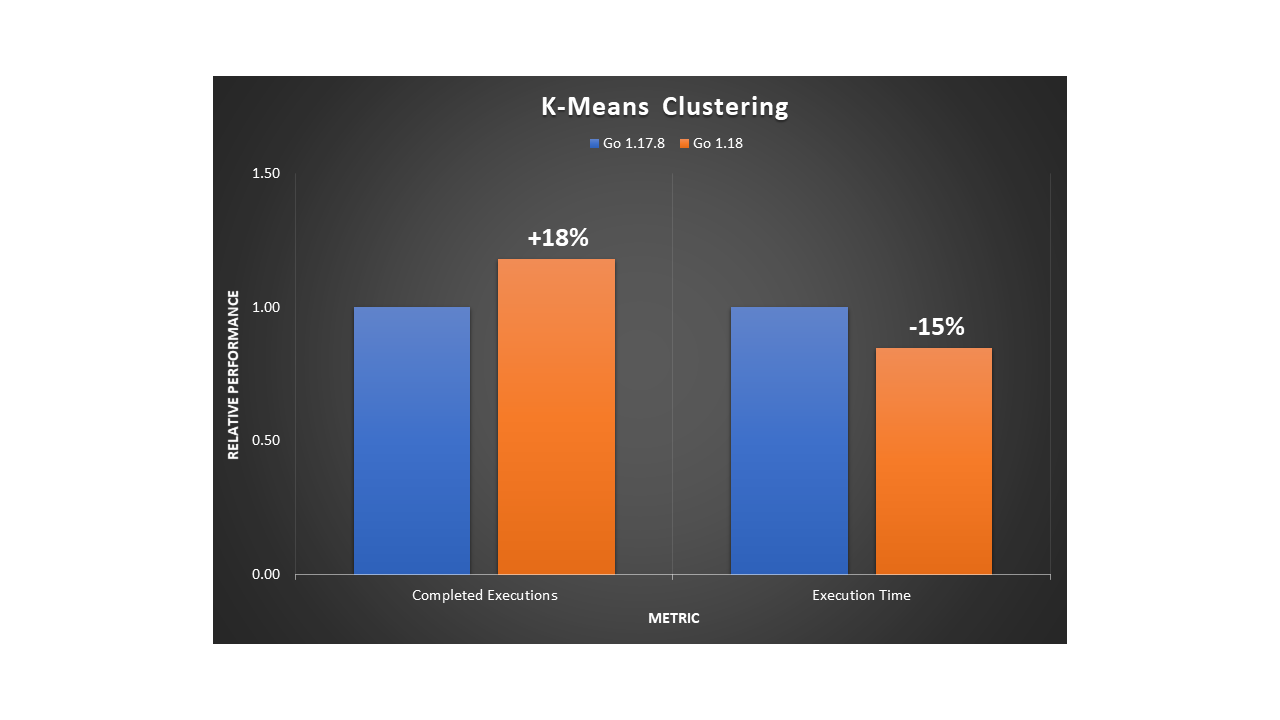
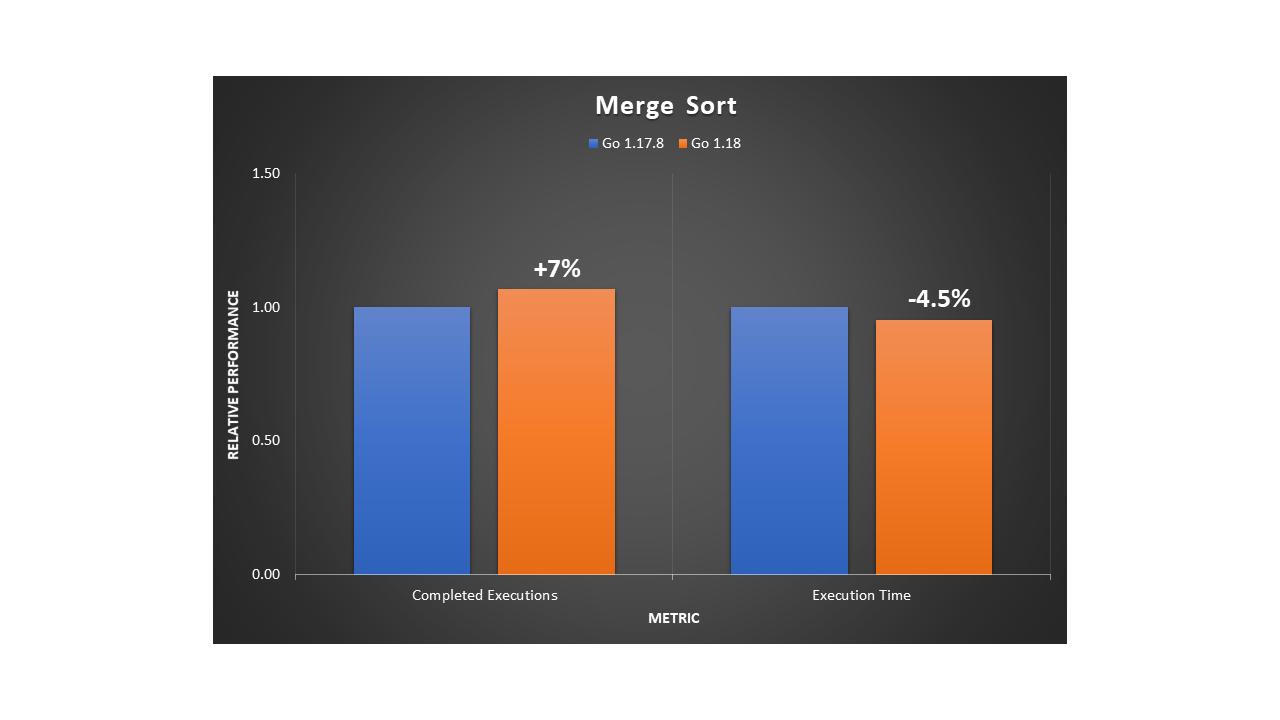
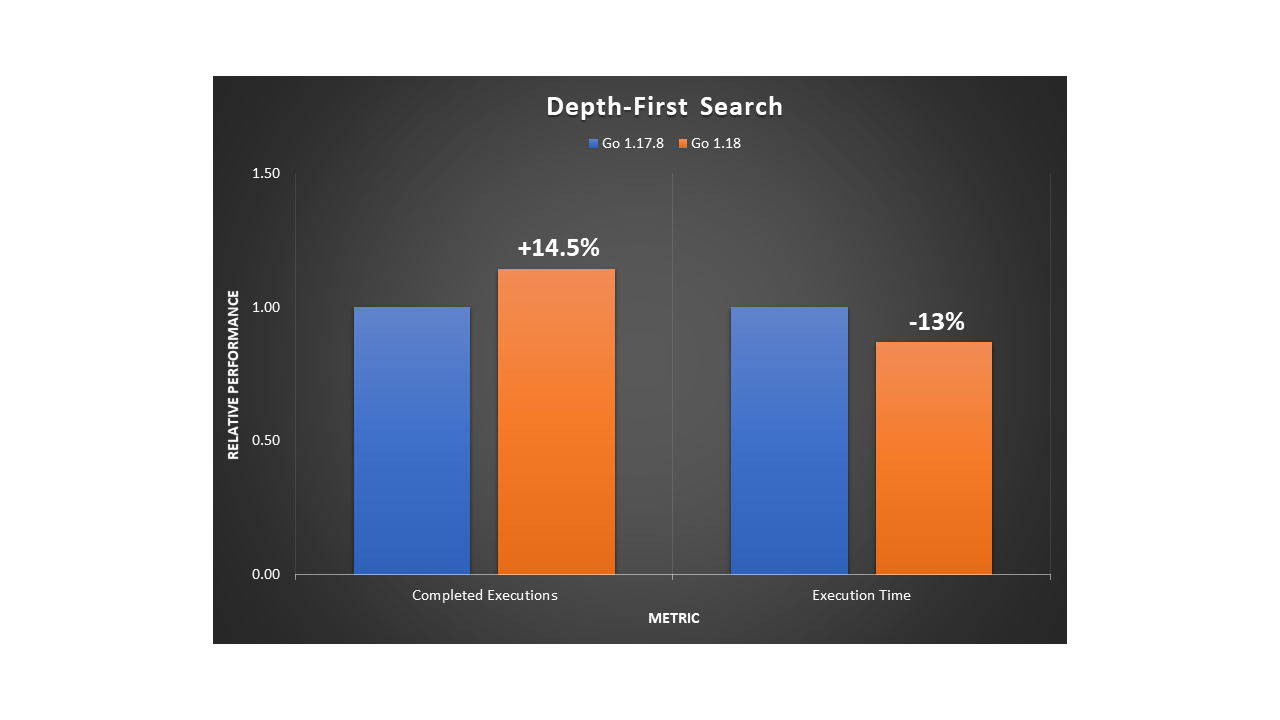
Post Syndicated from aostan original https://aws.amazon.com/blogs/compute/accelerate-your-aws-graviton-adoption-with-the-aws-graviton-savings-dashboard/
This post is written by Rajani Guptan, Rosa Corley and Shankar Gopalan.
Are you looking to optimize your AWS infrastructure costs while maintaining high performance? AWS Graviton is a custom-built CPU developed by Amazon Web Services (AWS), and it is designed to deliver the best price performance for a broad range of cloud workloads running on Amazon Elastic Compute Cloud (Amazon EC2). Graviton-based instances provide up to 40% better price performance while using up to 60% less energy than comparable EC2 instances.
AWS users recognize that migrating existing workloads to Graviton-based instances results in better price performance. However, migrating to Graviton necessitates identifying comparable instance types, understanding the performance impacts, and estimating the savings opportunities. Furthermore, prioritizing and tracking migration efforts at scale across a diverse set of services such as Amazon EC2, Amazon Relational Database Service (Amazon RDS), Amazon ElastiCache, and Amazon OpenSearch can be challenging. Therefore, AWS has developed the AWS Graviton Savings Dashboard to help users address these complexities and accelerate their Graviton migration.
In this post, we walk you through the dashboard architecture, deployment steps, features, and capabilities. Whether you are an Executive, FinOps Practitioner, Product Owner, or in Engineering, you can use the dashboard to get the following:
- Centralized visibility across accounts/workloads: The dashboard consolidates and tracks Graviton adoption across multiple management accounts, member accounts, and AWS Regions in a single view.
- Graviton support across key AWS services: There are dedicated tabs allowing users to review current Graviton usage and potential savings across AWS compute and managed services.
- Granular resource-level visibility for managed services: The dashboard provides granular resource level visibility for managed services such as Amazon RDS, ElastiCache, and OpenSearch.
- Accurate savings and unit cost estimations: The dashboard provides accurate cost estimations for existing and comparable Graviton-based instance types by using the existing AWS Cost and Usage Report (CUR) data with the AWS public pricing API.
- Categorization of migration effort: The dashboard categorizes Graviton migration opportunities into two main groups: Typically Easy and Requires Additional Planning, for EC2 instances. It also identifies Graviton-eligible resources for managed services, which may need version or database upgrades. This categorization helps users prioritize their engineering efforts for migration.
Architecture overview
The solution integrates AWS CUR, the AWS SDK, and AWS Public pricing API to generate comprehensive data on the usage, cost, and resource inventory. This data is stored in Amazon S3 and analyzed using Amazon Athena, providing deep insights into potential cost savings. Then, the results are visualized through Amazon QuickSight, enabling stakeholders to collaborate effectively and make informed, data-driven decisions, as shown in the following figure.

Figure 1: Graviton Savings Dashboard architecture diagram
Although the solution typically costs between $50–$100 per month, the potential return on investment is substantial. The dashboard often identifies measurable cost savings that significantly outweigh its operational expenses. Moreover, it offers additional productivity benefits by streamlining the process of adopting Graviton, saving valuable time and effort for your team. For a detailed breakdown of the dashboard’s cost structure, we invite you to explore our comprehensive Graviton Savings Dashboard Cost Breakdown guide.
Deployment
The Graviton Savings Dashboard is part of the Cloud Intelligence Dashboards framework. You can deploy it using AWS CloudFormation Templates and a ‘cid-cmd’ command line tool. Prior to deploying the dashboard, make sure that you’ve met the prerequisites. These include the following:
- Setting up your AWS CUR: We highly recommend that you complete Steps 1 and 2 from the Cloud Intelligence Dashboard Deployment Guide. This makes sure that your CUR is set up with settings that allow for easy installation and troubleshooting if necessary.
- Setting up the Inventory Collector Module of the Optimization Data Collection lab: This provides automation to collect metadata and pricing for Amazon RDS, ElastiCache, and OpenSearch for all accounts in your AWS Organizations and AWS Regions.
- Preparing QuickSight: If you’re an existing QuickSight user, then you can skip this step. If not, then you must complete Step 3.1 to Prepare QuickSight.
When the prerequisites are in place, you can deploy the dashboard by running three simple commands (shown as follows) using a terminal application with permissions to run API requests in your AWS account.
python3 -m ensurepip --upgrade
pip3 install --upgrade cid-cmd
cid-cmd deploy --dashboard-id graviton-savings
For detailed instructions about the deployment and prerequisites, refer to the AWS Well-Architected Cost Optimization lab.
Examining the results: unlocking insights from your Graviton Savings Dashboard
Now that you’ve successfully deployed the dashboard, we can explore its powerful features and uncover valuable insights. As you read through this section, we encourage you to interact with your dashboard to familiarize yourself with the dashboard’s intuitive interface and functionality.
The Graviton Savings Dashboard is organized into service-specific tabs, each containing two key sections:
Current Graviton Usage and Savings (top section): This section highlights the tangible benefits you’ve already achieved by migrating workloads to Graviton. You can explore the following:
-
- Monthly Graviton adoption trends
- Usage distribution across different accounts, Regions, and processor types
- Popular Graviton instance families
- Unit cost trends
- Realized Graviton savings
These metrics are calculated by comparing your Graviton usage to comparable non-Graviton instances, which provides a clear picture of your cost optimization efforts, as shown in the following figure.

Figure 2: Current Amazon EC2 Graviton Usage and Savings
Potential Graviton Savings Opportunities (bottom section): This section identifies areas where you can further optimize costs by adopting Graviton instances. It provides the following:
- Actionable migration insights
- Estimated implementation effort
- Potential savings breakdowns by account, instance family/type, OS, and purchase option
These insights compare potential Graviton savings across various attributes, enabling targeted decision-making for future Graviton migrations and cost optimizations, as shown in the following figure.

Figure 3: Amazon EC2 Graviton Opportunity
Using dashboard insights: a FinOps team use case
In this section we explore a use case where you, as the lead of the Cloud Center of Excellence Team, use the insights from this dashboard to address concerns raised by your Chief Technology Officer (CTO).
Your CTO at your company approaches you with the following questions:
- Is our organization using the price-performance benefits of Graviton-based EC2 instances?
- How does our Graviton usage and spend and savings compare to other processor types within our overall EC2 compute spend?
Step 1: Initial analysis
You begin generating summary reports from the Current Graviton Usage (Figure 2) and Graviton Opportunity (Figure 3) sections of the dashboard. After reviewing these reports, the CTO asks you to engage with the Engineering team to evaluate potential opportunities for increasing Graviton coverage.
Step 2: Engaging with Engineering on Graviton Migration
When presenting the summary reports to the engineering manager, they expressed interest in understanding the effort level required for this project. This information can help them allocate resources and prioritize workloads, thus identifying what can be started in the short-term and what needs additional planning.
Step 3: Detailed analysis
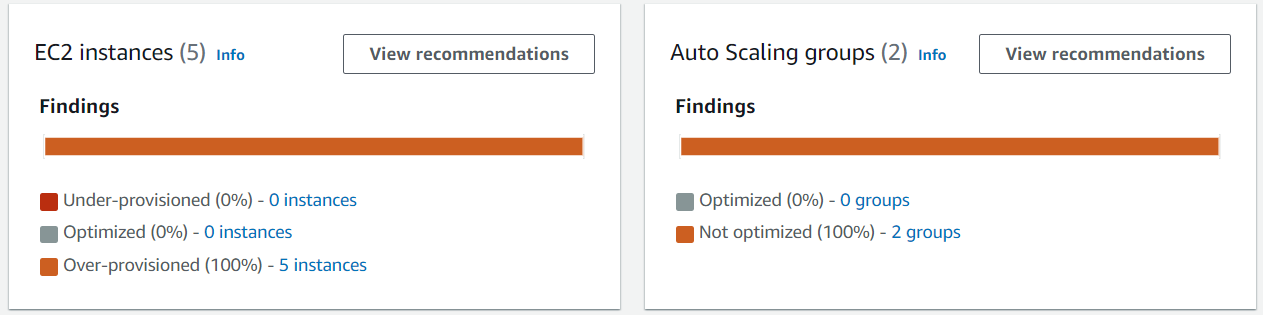
As shown in the following figure, the Engineering team can focus on identifying candidate workloads with the most significant savings impact by segmenting the dashboard data by:
- Implementation efforts
- Linked accounts
- Regions
- Instance types
- Operating systems

Figure 4: Amazon EC2 Graviton opportunity breakdown
Furthermore, the team can use the dashboard to determine comparable Graviton-based instances for migration and their potential savings, as shown in the following figure.

Figure 5: Potential graviton Savings Details
Step 4: Tracking progress
Over time, the FinOps team and Engineering team can showcase the Graviton migration successes by highlighting the increasing Graviton coverage and realized savings using the dashboard’s charts (Figure 2).
Broader application:
Although this post primarily focuses on EC2 instance migration, the dashboard also provides similar insights for AWS managed services such as Amazon RDS, ElastiCache, and OpenSearch. Individual tabs with visualizations guide your Graviton adoption across these services, as shown in the following figure.

Figure 6: Graviton Savings Dashboard
As demonstrated by this use case, the Graviton Savings Dashboard enables various stakeholders in an organization to collaborate effectively, which leads to efficient outcomes and potential cost savings.
Conclusion
In summary, we showed how the Graviton Savings Dashboard provides clear insights into suitable workloads for Graviton migration, offers easy-to-understand visualizations for monitoring adoption, and automates resource matching and savings calculations. Streamlining the process of identifying and implementing cost-saving opportunities with Graviton-based instances means that the dashboard enables more informed decision-making about your AWS infrastructure. To learn more and get started with the Graviton Savings Dashboard, visit the Graviton Savings Dashboard page and take the first step toward more efficient and cost-effective cloud computing.