Post Syndicated from Sachin Kulkarni original https://aws.amazon.com/blogs/architecture/simplifying-sustainability-reporting-using-aws-and-generative-ai-in-banking/
European banks face a new challenge with the European Commission’s transition from the Non-Financial Reporting Directive (NFRD) to the Corporate Sustainability Reporting Directive (CSRD) regulations. This transition represents an expansion in sustainability reporting scope that will affect approximately 50,000 companies, a significant increase from the previous 11,700.
This means that banks themselves need to file sustainability reports because they will now be one of those 50,000 companies, but for their own reporting, they also need to assess their clients’ sustainability reports because they lend or finance those companies.
In this post, you learn how you can use generative AI services on Amazon Web Services (AWS) to automate your sustainability reporting requirements, reduce manual effort, and improve accuracy. You do this by implementing an automated solution for extracting, processing, and validating data from corporate reports.
The challenge
Financial institutions and sustainability teams managing sustainability reporting face three critical challenges:
- Scale and complexity: Banks and financial institutions must process thousands of annual reports and sustainability documents, often spanning hundreds of pages each. This process requires extensive data extraction, complex EU Taxonomy alignment calculations, and resource-intensive validation steps. Manual processing introduces significant risks of errors and consumes valuable team resources.
- Regulatory compliance: Banks must now implement detailed CSRD requirements, track specific metrics for turnover, capital expenditure (CapEx), and operating expenses (OpEx), and calculate their Green Asset Ratio (GAR) as well as environmental risks that come with their loans, debt, or equity investments. These new requirements demand robust data collection and processing capabilities.
- Data management: Processing Green House Gas (GHG) emissions data across Scope 1, 2, and 3 categories requires analyzing complex lending and investment activities. With strict reporting deadlines, organizations need efficient tools to process this expanding volume of sustainability data.
The sustainability team point of view
Banks finance a large variety of counterparties and economic activities. While their carbon footprint is primarily linked to the greenhouse gas (GHG) emissions of their counterparties (Scope 3), The direct GHG emissions (Scope 1) of financial institutions or the GHG emissions linked to their energy consumption (Scope 2) are usually limited. For banks, the most critical key performance indicator (KPI) is the GAR, which measures the proportion of a bank’s taxonomy-aligned balance sheet exposures versus its total eligible exposures, as shown in the following figure.

To calculate their GAR, banks must obtain and use sustainability data from annual reports or sustainability reports of up to 50,000 companies (many of which are subject to NFRD and CSRD reporting), and understand how much of their activities are linked to EU Taxonomy.
The manual process
In the example that follows, we use the Amazon 2023 Annual Report. Some of the data that teams would have to manually extract includes: Revenue, Scope 1, Scope 2, and Scope 3 emissions.

As you can see from the page count at the top of the preceding figure, people manually searching for this data would have to go through 92 pages to find the parameters they’re looking for. Next, we might determine that some of the data we need (Scope 1, Scope 2, Scope 3) isn’t available in the annual report, so we need to analyze the sustainability report. As shown in the following figure, to manually retrieve the relevant data from this report, we would have to go through 98 pages of information.
To prepare a GAR, we would have to repeat this process across hundreds or even thousands of companies.
A solution using AWS and generative AI
To address these challenges, we propose an automated approach using AWS services. This approach can help banks streamline their sustainability reporting processes.
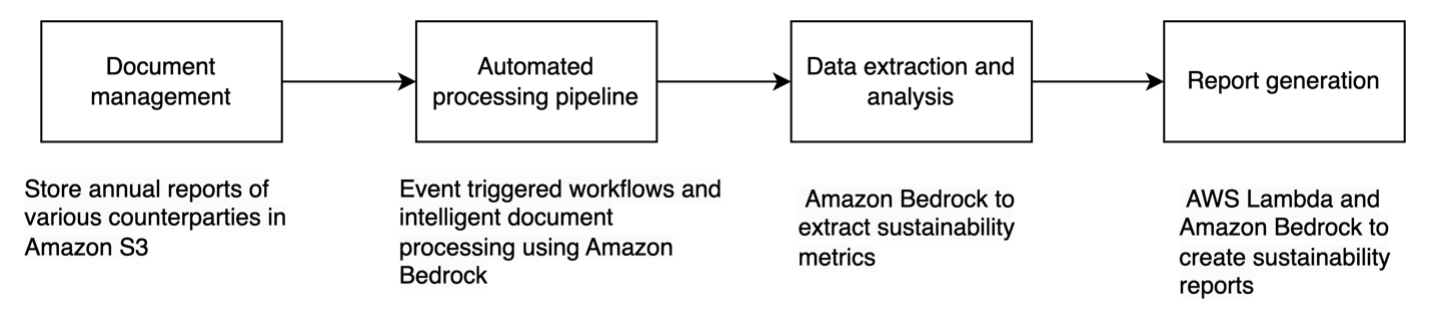
Here’s how this solution works— as shown in the preceding figure:
- Upload your counterparties’ reports to Amazon Simple Storage Service (Amazon S3).
- Amazon Bedrock automatically:
- Determines NFRD eligibility.
- Extracts relevant sustainability data.
- Organizes information for GAR calculations.
- Review and validate the extracted data.
- Generate required regulatory reports.
Architecture
We divide the architecture into two areas:
- Data ingestion flow
- Report generation flow
Data ingestion flow
We use Amazon Bedrock Knowledge Bases to build an automated data ingestion flow. See Prerequisites for your Amazon Bedrock knowledge base data to understand supported document formats and limits for knowledge base data.
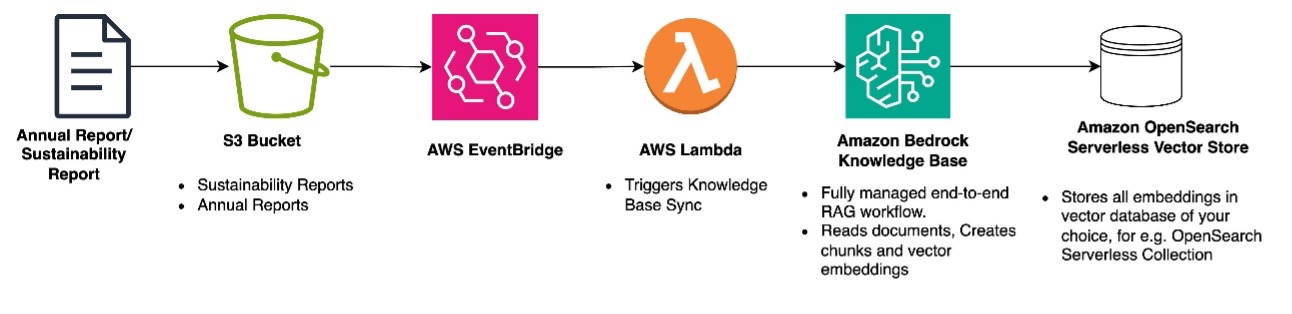
The workflow, shown in the preceding figure, is:
- Annual reports or sustainability reports are uploaded into an S3 bucket.
- On the S3 bucket, we enable event notifications for events such as addition, change, or deletion of the reports.
- These events are sent to Amazon Event Bridge, which trigger an AWS Lambda function.
- The Lambda function syncs the data source to an Amazon Bedrock knowledge base.
- Amazon Bedrock Knowledge Bases processes the documents and converts it into vector embeddings. For more information, see Amazon Bedrock Knowledge Bases supports advanced parsing, chunking, and query reformulation giving greater control of accuracy in RAG based applications
- Amazon Bedrock Knowledge Bases stores the vector embeddings in the vector database of your choice, such as in an Amazon OpenSearch Serverless collection.
Now the data is read, broken into chunks, converted to embeddings and stored in a vector store. You use a report generation flow to ask questions about the information in the knowledge base.
Report generation flow
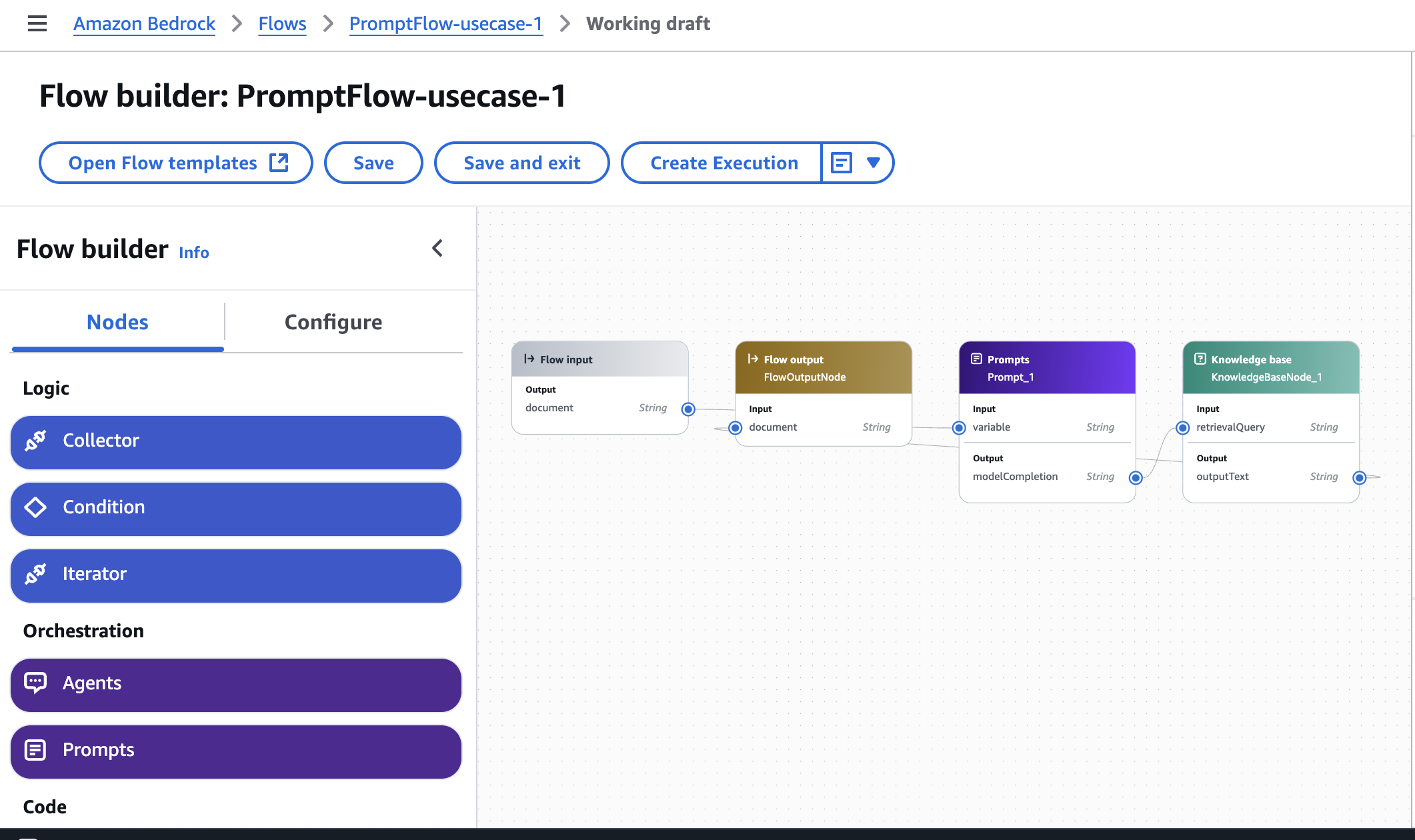
To automate the report generation for sustainability teams, we created the report generation flow shown in the following figure.
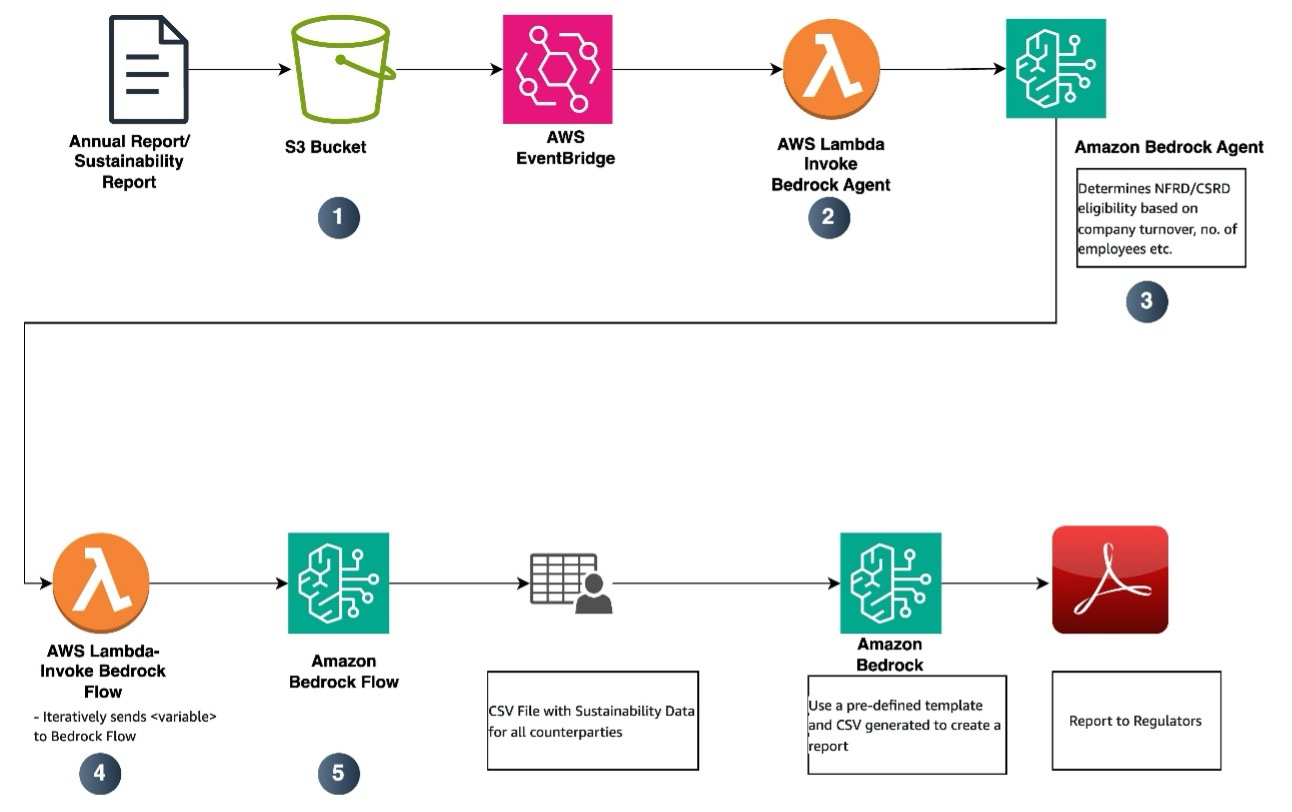
The report generation flow includes the following steps:
- When user uploads an annual report, the data from the report is ingested into the knowledge base, as shown in the data ingestion flow.
- A Lambda function—
Invoke Bedrock Agent—is triggered to invoke an Amazon Bedrock agent. - The Amazon Bedrock agent determines NFRD or CSRD applicability based on various parameters such as employee numbers and annual revenues. This agent then passes on what kind of regulation to apply to a Lambda function.
- The Lambda function
Retrieve Sustainability Metricsretrieves various parameters needed for NFRD or CSRD from the annual report.- The function receives NFRD or CSRD applicability from the Amazon Bedrock agent.
- Based on NFRD or CSRD applicability, there are specific sustainability metrics that need to be retrieved. For NFRD, there are about 15 metrics that need to be retrieved, and for CSRD, there are about 30 metrics.
- The function iteratively sends
{variable}to the Amazon Bedrock flow. For example, if the metric to be retrieved isScope 1 emission, then the Lambda function will sendvariable=‘Scope 1 emission’ - The function gets the metric value from the Amazon Bedrock flow and when the required metrics are retrieved, creates a CSV file with the details.
- Amazon Bedrock flow:
- Retrieve
{variable}(for example,‘Scope 1 emission’) from the annual report. For this, we create a prompt, as shown in the following diagram. - Use the prompt to fetch the value from the knowledge base.
-
- Prompt:
-
- Return the value to the Lambda function in Step 4.
- Retrieve
Breakdown of key components
Amazon S3 is used for storing annual statements and sustainability reports, providing highly durable and secure object storage that facilitate immediate access when needed for processing.
Amazon Bedrock Knowledge Bases enables using Retrieval-Augmented Generation (RAG) to optimize the output of a large language model by giving it the context of companies’ annual reports and regulatory requirements. It does so by creating chunks and vector embeddings from the annual reports to enable efficient information retrieval from a vector database of your choice.
Amazon Bedrock foundation models (FMs) extract information from an Amazon Bedrock knowledge base and generate standardized PDF reports for regulators, providing consistent formatting and alignment with CSRD requirements. We encourage you to choose the best foundational model for your use case through the flexibility and enterprise-grade controls of Amazon Bedrock. For this solution, we used Anthropic’s Claude Sonnet 3.5 as the model, but by using Amazon Bedrock, you can choose from over 50 different models to see which one best fits your use case.
Amazon Bedrock Flows orchestrates the document processing pipeline, coordinating between services to automatically extract required sustainability metrics and validate compliance requirements. This feature helps us manage the workflow from initial document ingestion through to final report generation.
Amazon Bedrock Prompt Management creates and helps manage precise prompts that help retrieve multiple sustainability metrics from reports for example: turnover, Scope 1, Scope 2, and Scope 3 emissions data. These structured prompts facilitate consistent data extraction across different document formats.
Amazon Bedrock Agents evaluates each uploaded document to determine NFRD or CSRD eligibility by analyzing company revenue, employee count, and incorporation details. The agents retrieve these parameters by using a Lambda function that’s part of the actions the agent can perform.
Lambda handles event-driven processing when new documents are uploaded. Lambda functions are also used by the agent to retrieve data from companies’ annual reports and trigger the appropriate workflows based on document type.
Amazon EventBridge is used to build event-driven applications at scale across AWS and manages workflow orchestration, automatically initiating document processing when new reports are uploaded through S3 event notifications.
This architecture enables banks to process thousands of sustainability reports efficiently. The solution scales automatically to handle increasing document volumes while keeping security a top priority.
Additional considerations
You can use the following additional AWS service to help further increase the accuracy of information retrieval from sustainability documents.
Amazon Bedrock Guardrails to make sure that the solution caters to responsible AI policies. Specifically, we have added contextual grounding checks to reduce hallucinations. This is important for the solution because we’re trying to find a few specific values in a large document, and these checks make sure that the metrics retrieved are based on the documents.
Automated reasoning checks which help to verify the metrics returned by the solution. Consider the metric Number of employees. There can be multiple places in the annual report where the number of employees is mentioned; for example, temporary workers, part-time employees, employees from various departments, employees from a company that was taken over last year, and so on. To arrive at the right number, automated reasoning checks help.
Benefits
This sustainability reporting solution cuts document processing time from 8—10 weeks to few hours. Banks get clear audit trails showing exactly how they extracted and validated sustainability data. When regulations are updated, the system adapts through its knowledge base without disrupting operations. Built-in security protects company data through the entire process. Access controls and encryption are in place to secure information. The output delivers standardized, accurate reports. This automation lets sustainability teams concentrate on environmental improvements rather than paperwork. Teams can instead analyze trends and develop initiatives instead of hunting through reports for data points.
Conclusion
As sustainability reporting requirements evolve, having a flexible and automated solution will become crucial. While we focused on NFRD reporting, the same pattern can be adapted for CSRD compliance reporting, SFDR reporting requirements, and Internal sustainability metrics, or EU Taxonomy alignment.
Customers looking to build their products in the Financial Services industry have access to industry and domain AWS specialists; contact us for help in your cloud journey.
You can also learn more about AWS services and solutions for financial services by visiting AWS for Financial Services and Generative AI on AWS.



























 Sid Vantair is a Solutions Architect with AWS covering Strategic accounts. He thrives on resolving complex technical issues to overcome customer hurdles. Outside of work, he cherishes spending time with his family and fostering inquisitiveness in his children.
Sid Vantair is a Solutions Architect with AWS covering Strategic accounts. He thrives on resolving complex technical issues to overcome customer hurdles. Outside of work, he cherishes spending time with his family and fostering inquisitiveness in his children.












































 Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms. Sushmita Barthakur is a Senior Data Solutions Architect at Amazon Web Services (AWS), supporting Strategic customers architect their data workloads on AWS. With a background in data analytics, she has extensive experience helping customers architect and build enterprise data lakes, ETL workloads, data warehouses and data analytics solutions, both on-premises and the cloud. Sushmita is based in Florida and enjoys traveling, reading and playing tennis.
Sushmita Barthakur is a Senior Data Solutions Architect at Amazon Web Services (AWS), supporting Strategic customers architect their data workloads on AWS. With a background in data analytics, she has extensive experience helping customers architect and build enterprise data lakes, ETL workloads, data warehouses and data analytics solutions, both on-premises and the cloud. Sushmita is based in Florida and enjoys traveling, reading and playing tennis. Jonathan Katz is a Principal Product Manager – Technical on the Amazon Redshift team and is based in New York. He is a Core Team member of the open source PostgreSQL project and an active open source contributor, including PostgreSQL and the pgvector project.
Jonathan Katz is a Principal Product Manager – Technical on the Amazon Redshift team and is based in New York. He is a Core Team member of the open source PostgreSQL project and an active open source contributor, including PostgreSQL and the pgvector project.






























