Post Syndicated from Dr. Rahul Sharad Gaikwad original https://aws.amazon.com/blogs/devops/how-to-enhance-your-application-resiliency-using-amazon-q-developer/
“Everything fails, all the time” – Werner Vogels, Amazon.com CTO
In today’s digital landscape, designing applications with resilience in mind is crucial. Resiliency is the ability of applications to handle failures gracefully, adapt to changing conditions, and recover swiftly from disruptions. By integrating resilience into your application architecture, you can minimize downtime, mitigate the impact of failures, and ensure continuous availability and performance for end-users.
Amazon Q Developer, a generative AI-powered assistant for software development lifecycle (SDLC), helps design resilient architectures and enhance application availability. It recommends best practices, analyzes code, and identifies potential failure points, serving as an expert companion to strengthen application architecture and boost system availability through the following key resiliency practices.
- Resilient design pattern recommendations: Access tailored design patterns like distributed systems, microservices, and serverless architectures. Amazon Q offers recommendations across redundancy, robust failovers, and circuit breakers to boost resilience in your environment.
- Disaster Recovery planning: Amazon Q offers expert guidance on comprehensive disaster recovery (DR), including efficient backups, systematic restorations, strategic data replication, and seamless failovers to ensure rapid recovery from disruptions with minimal impact.
- Customized Resiliency testing frameworks: Create custom templates to simulate diverse failure scenarios, such as network degradation and infrastructure outages. This streamlines thorough resilience verification across your systems.
- Failure mode evaluation: Use Amazon Q to conduct comprehensive Failure Mode and Effects Analysis (FMEA) identifying infrastructure vulnerabilities and assessing their impact. Amazon Q then ranks these issues by severity, enabling you to prioritize and address the most critical risks to protect your production environment.
In the following sections, we will demonstrate how Amazon Q improves the resiliency of a foundational application architecture.
Prerequisites
To begin using Amazon Q, the following are required:
- An AWS Account
- An AWS Builder ID or an AWS IAM Identity Center login controlled by your organization
- Visual Studio Code or supported IDEs
- How to set up and chat with Amazon Q Developer
Application Overview
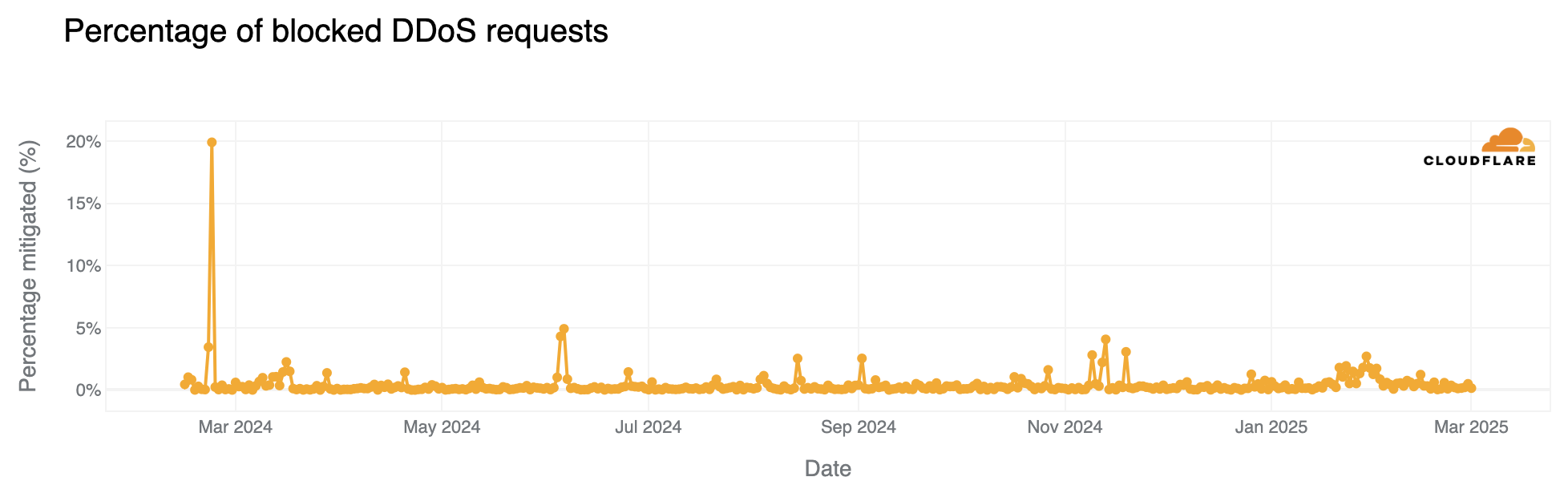
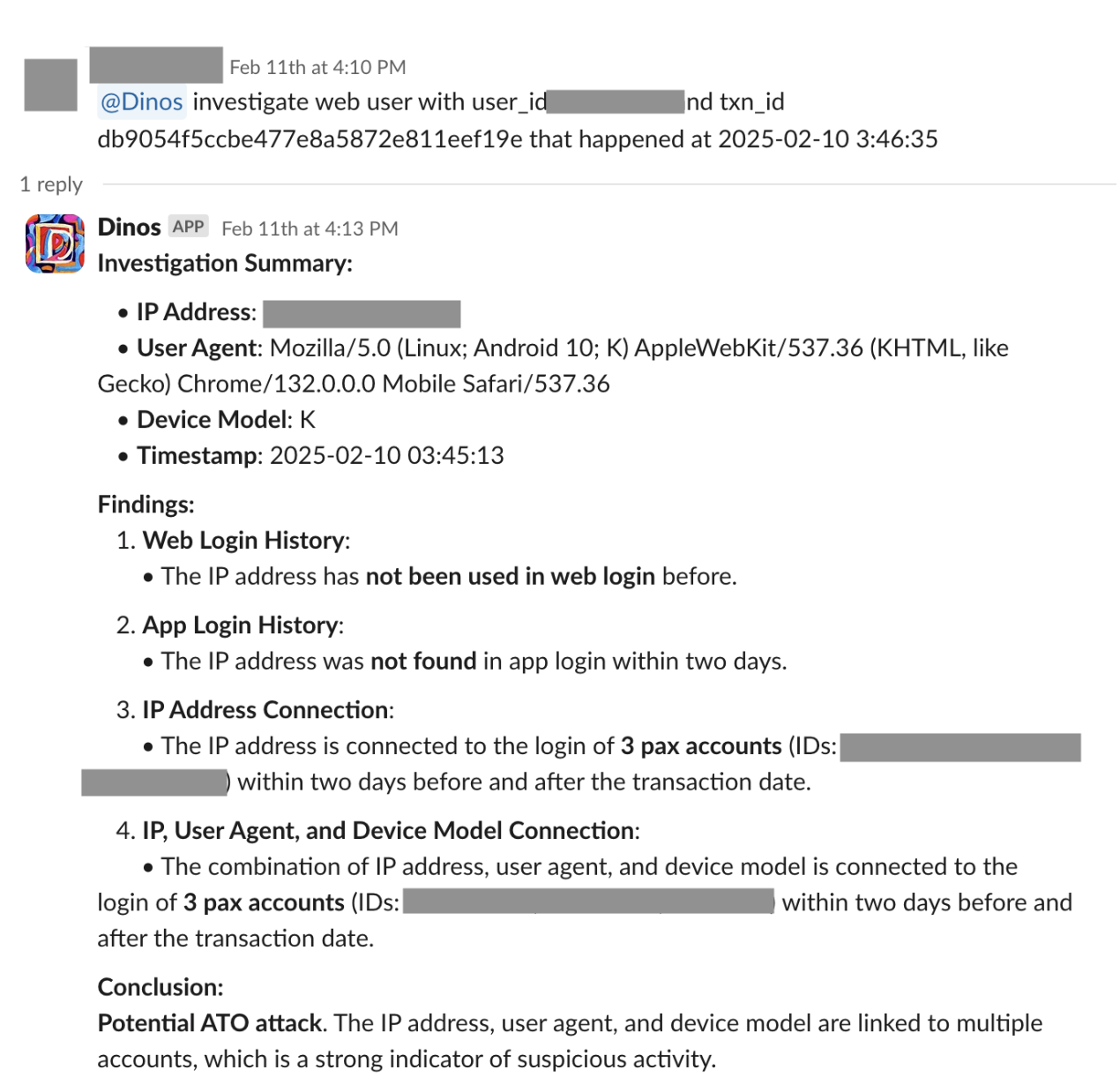
We have a three-tier web application shown below that is running on AWS in a single Availability Zone (AZ). The architecture consists of Application Layer hosted on Amazon Elastic Kubernetes Service (Amazon EKS) cluster with two Amazon Elastic Compute Cloud (Amazon EC2) nodes in a single-AZ and the Data Layer uses Amazon Relational Database Service (Amazon RDS) instance deployed in single-AZ configuration. The architecture is functional but has several limitations. It poses a single point of failure and offers limited application availability with no fault tolerance. High response times may occur because there is no caching layer in front of the database. Additionally, the lack of auto-scaling can lead to resource contention.

Basic Application Overview
Enhance Application Resiliency
Let’s explore how Amazon Q helps incorporate resiliency best practices that enhance system availability in our basic application architecture.
Resilient architecture recommendations
The initial architecture faced challenges with reliability, performance and scalability, largely due to its single-point of failure and lacked redundancy. To address this, we described the existing application design and its challenges to Amazon Q using a natural language prompt to seek resiliency recommendations.
Prompt for improving the architecture design:
I have manually setup an application that runs within an EKS cluster on two EC2 nodes in single AZ. My application is not highly available and scalable. It talks to an RDS database which is single AZ. However, there is high response times from database. Provide me only the recommendations to re-design this application architecture at each layer that will addresses all these issues.

Amazon Q offering resiliency architecture recommendations
Amazon Q analyzed the provided context and recommended improvements such as introducing Multi-AZ deployments for high availability, adding auto-scaling groups for elasticity, and incorporating caching layers to enhance performance. These targeted recommendations helped redesign the architecture to be more resilient and scalable, directly addressing the initial shortcomings.
Disaster Recovery (DR) recommendations to improve the architecture
To further enhance resiliency, we prompted Amazon Q for disaster recovery (DR) recommendations. We asked for guidance aligned with the AWS Well-Architected Framework. This built upon the previously improved architecture design.
Prompt for recommendations on Disaster Recovery (DR) and architecture based on RTO/RPO
Based on the above improvements on AWS architecture design, share recommendations for Disaster Recovery (DR) based on AWS Well Architected Framework
Optionally, we can use advanced prompts like the below with additional context:
Please provide a recommendations to redesign my application that is running on an EKS cluster with two EC2 nodes and a single-AZ RDS database, addressing high database latency, low availability, and scalability issues. Suggest improvements across all architectural layers including presentation tier, application tier and data tier to enhance performance, resiliency, and scalability. Also, recommend DR strategies aligned with the AWS Well-Architected Framework focusing on resilience, data protection, and recovery.

Amazon Q tailoring recommendations based on business requirements using AWS Well-Architected Framework
Amazon Q provided detailed DR strategies. These included multi-region configuration, backup and restore procedures, and best practices for meeting specific Recovery Time Objective (RTO) and Recovery Point Objective (RPO) requirements.
Prepare DR strategy based on RTO and RPO requirements:
Diving further, asking for a specific disaster recovery strategy that meets the application RTO requirements of 2 hours and RPO requirements of 30 minutes.
Prompt for DR strategy based on RTO/RPO values
Which DR strategy should I use if my RTO is less than 2 hours and RPO is less than 30 minutes?

Amazon Q recommending disaster recovery strategy
Amazon Q recommended a Pilot light approach, detailing the setup and components needed to achieve the specified disaster recovery objectives.
Define resiliency testing workflow, identify key metrics and tools
As we incorporate resiliency best practices into the application architecture, its is important to employ a resiliency test workflow to ensure application’s resiliency requirements are met. To do this, we are asking for guidance to define an end-to-end resiliency testing process workflow. We also want to identify the key metrics and tools needed to test the resilience of each AWS service involved in the architecture.
Prompt for defining the resiliency testing workflow:
Define the end-to-end resiliency testing process workflow. Also, identify the key metrics and tools that should be used to test the resilience of each AWS service involved in the improved architecture design.

Amazon Q offering resiliency testing best practices and tools
Amazon Q offers a step-by-step approach to define resiliency testing experiments and prepare the environment for testing.
Failure mode evaluation to prioritize resiliency tests
Failure Mode and Effects Analysis (FMEA) can further assist with designing the resiliency tests. It is a proactive method to identify potential failures in processes or systems, assess their impact, and prioritize critical issues. It evaluates failure modes across hardware, software, human factors, and external events, enabling teams to develop strategies for prevention, detection, and mitigation, ultimately enhancing system resilience.
Leveraging Amazon Q, we requested a comprehensive FMEA report that includes components, cause, effect and their respective Risk Priority Numbers (RPN). RPNs are calculated by multiplying three key factors: Severity (S), Occurrence (O), and Detection (D). It helps organizations understand and prioritize which risks to address first.
Prompt for designing the FMEA template and scoring:
Create the FMEA in tabular format with scoring for improved architecture design above keeping in mind the RTO/RPO values and provide the steps for execution as well.

Amazon Q assisting with systematic risk assessment and FMEA report
Amazon Q intelligently incorporated previously defined RTO and RPO requirements to identify critical failure scenarios and calculated RPN for each potential incident.
Enhanced Architecture Implementing Resiliency Best Practices
After identifying the key pain points in our original architecture such as single points of failure, limited scalability, and lack of automated recovery, we leveraged Amazon Q to analyze our architecture to get targeted recommendations to elevate the resiliency. By describing our requirements and challenges to Amazon Q, we received actionable guidance on AWS best practices and service configurations, which we then implemented to transform our infrastructure for high resilience and availability.

Resilient Application Architecture
The original Application Layer was running in a single Availability Zone without auto-scaling, leading to potential downtime and performance bottlenecks. Amazon Q recommended distributing Amazon EKS worker nodes across multiple Availability Zones and enabling the Cluster Autoscaler to dynamically adjust node capacity based on traffic patterns. Additionally, it suggested implementing horizontal pod autoscaling within Amazon EKS to automatically scale application resources according to CPU utilization and custom metrics. Following these recommendations, we deployed Amazon EKS worker nodes across three Availability Zones, configured Cluster Autoscaler and horizontal pod autoscaling, and integrated an Application Load Balancer, to intelligently distribute incoming traffic. These changes significantly improved scalability, fault tolerance, and performance.
The Data Layer initially relied on a single-instance Amazon RDS deployment, which posed a risk of downtime and limited read performance. Upon review, Amazon Q advised implementing a Multi-AZ Amazon RDS configuration to enable automated failover and improve availability. It also recommended deploying read replicas to offload read-heavy workloads and enhance performance. Furthermore, Amazon Q suggested adding a Multi-AZ Amazon ElastiCache for Redis to reduce database load and speed up data access. We incorporated these recommendations, resulting in a more resilient and performant data layer capable of handling failover scenarios and scaling read operations efficiently.
The Presentation Layer lacked an optimized content delivery mechanism and comprehensive security controls. Amazon Q recommended integrating Amazon CloudFront as a content delivery network to accelerate the delivery of static content and reduce load on application servers. It also suggested deploying AWS WAF to protect against common web exploits. To improve operational visibility, Amazon Q emphasized the importance of comprehensive monitoring using Amazon CloudWatch, combining logs, metrics, and traces for rapid issue detection and resolution. Implementing these recommendations enhanced both the performance and security posture of the presentation layer.
Conclusion
Amazon Q Developer transforms how teams build resilient applications by serving as your expert companion throughout the development journey. Its guidance helps create systems that excel in resilience, scalability, and availability—critical factors for today’s demanding digital landscape. Amazon Q goes beyond theoretical advice by providing practical, step-by-step implementation guidance. In the above, we’ve witnessed how Amazon Q’s expertise can transform basic architectures into robust, failure-resistant systems. Its recommendations such as Multi-AZ redundancy, elastic scaling, strategic caching, and proactive resilience testing create applications that maintain performance and availability even during significant disruptions.
Ready to strengthen your applications against unexpected challenges? Harness Amazon Q’s capabilities to create resilient infrastructure that consistently delivers for your customers, regardless of conditions. Unlock the full potential of your AWS infrastructure and deliver uninterrupted service to your customers, today. To learn more about Amazon Q refer to the documentation.
About the authors:

































 .
.