Post Syndicated from Patrick Galvin original https://aws.amazon.com/blogs/compute/enhance-the-local-testing-experience-for-serverless-applications-with-localstack/
Serverless applications often comprise multiple AWS services, such as AWS Lambda, Amazon Simple Queue Service (Amazon SQS), Amazon EventBridge, and Amazon DynamoDB. Although serverless architectures make it easy to build applications that are generally simple to operate and scale, testing them requires extra steps for developers. Recently, AWS brought you the capability to help developers remotely debug Lambda functions to accelerate the development process. Today, we’re excited to announce new capabilities that further simplify the local testing experience for Lambda functions and serverless applications through integration with LocalStack, an AWS Partner, in the AWS Toolkit for Visual Studio Code.
In this post, we will show you how you can enhance your local testing experience for serverless applications with LocalStack using AWS Toolkit.
Challenges with local serverless development
When building serverless applications with infrastructure as code (IaC) tools like the AWS Serverless Application Model (AWS SAM), developers often face challenges during local integration testing of applications that depend on interactions across multiple AWS services. These friction points slow down the critical code-test-debug cycle. Developers might encounter the following common roadblocks:
- Cloud-based validation slows iteration – Developers previously needed to deploy AWS SAM templates to the cloud to test changes, introducing delays in feedback loops. AWS research shows that developers spend considerable time on deployment and testing, rather than writing code.
- Tool context switching adds friction – Developers routinely shift between integrated development environments (IDEs), command line interfaces (CLIs), and resource emulators like LocalStack, leading to fragmented workflows.
- Manual setup increases configuration complexity – Port mapping and code edits for local service integration tests can introduce inconsistencies between local and cloud environments.
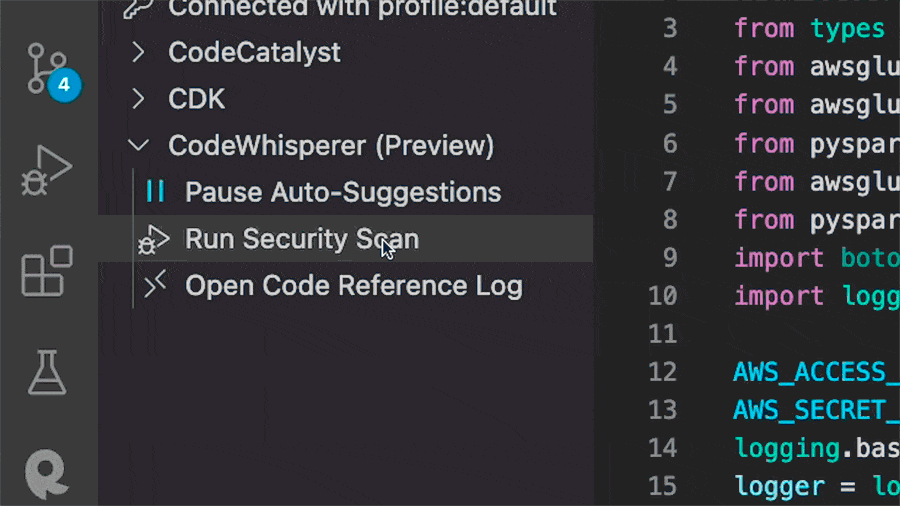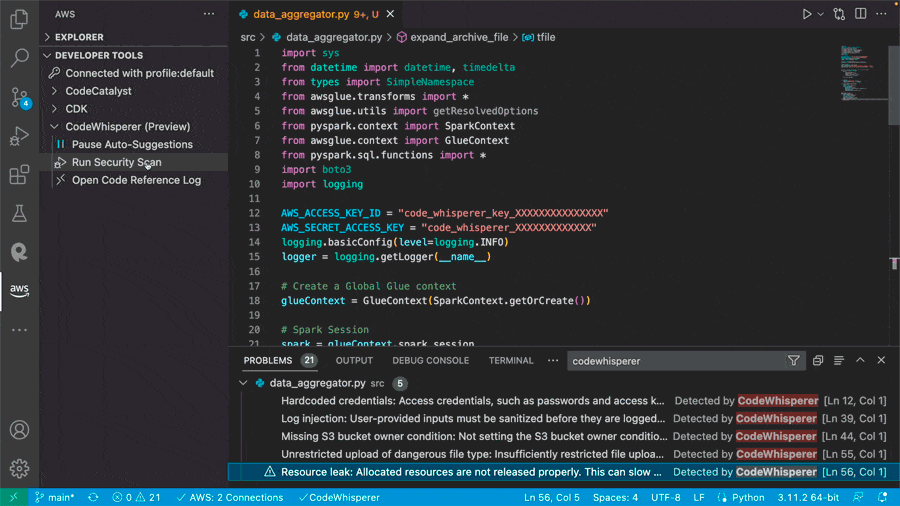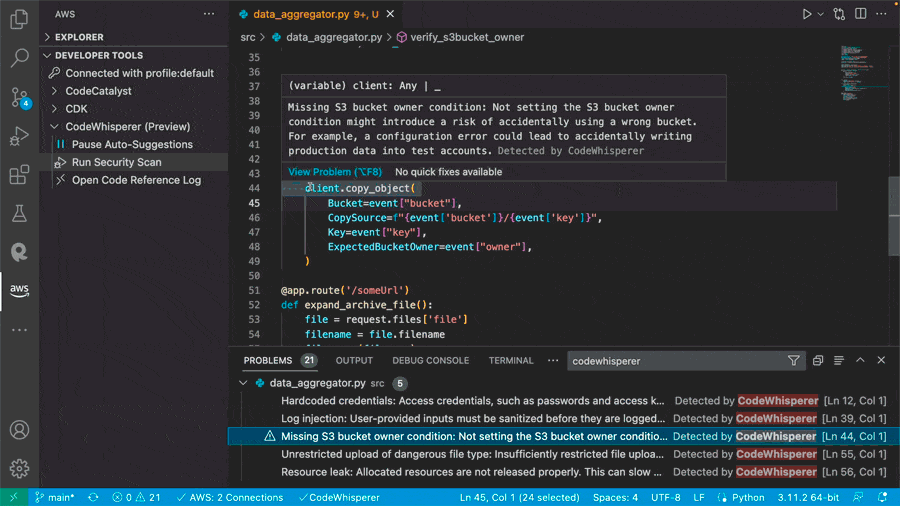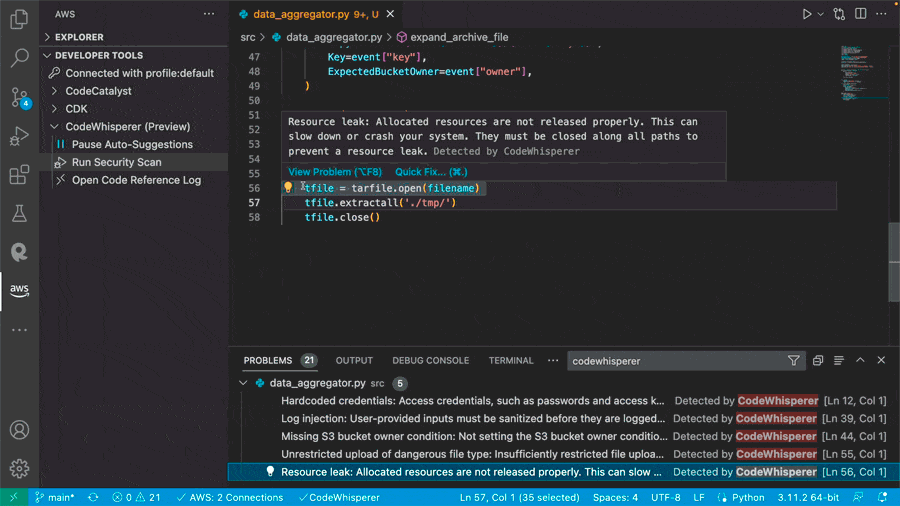
- Service integration debugging is limited – Troubleshooting Lambda functions in the context of AWS service integrations, such as DynamoDB, Amazon Simple Storage Service (Amazon S3), or Amazon SQS, requires manual configuration, extending the duration of troubleshooting efforts.
These challenges directly impact developer productivity and make local testing of integrated serverless applications complex.
Solution overview
Starting today, AWS helps simplify local serverless development by integrating LocalStack directly into the AWS Toolkit for VS Code. This integration helps developers test and debug serverless applications—defined using IaC tools like AWS SAM—entirely within their IDE. The enhanced local testing experience delivers four major improvements:
- Integrated LocalStack experience – Connect to LocalStack directly within VS Code and manage local resources alongside cloud resources through a unified interface.
- Emulated service interactions – Test Lambda functions with their interactions with other AWS services like Amazon SQS, DynamoDB, and EventBridge locally.
- Simplified debugging – Start debugging sessions with LocalStack emulated environment, with a single click – no manual port configurations or code changes required, streamlining the debugging workflow.
- Streamlined workflow – Deploy, test, and debug serverless applications without leaving the IDE, avoiding context switching between tools.
To set up LocalStack in VS Code (either the free version supporting over 30 core services like Lambda, Amazon S3, DynamoDB, Amazon SQS, and Amazon API Gateway, or the Ultimate version with over 110 services and advanced debugging features) you need essential development tools, including Docker, the AWS Command Line Interface (AWS CLI), AWS SAM CLI, and your preferred IDE such as VS Code. This combination enables full local integration testing of AWS services, including Lambda functions, messaging queues, databases, event-driven architectures, and serverless workflows, so you can develop and test your entire AWS application stack locally before deploying to the cloud.
Automated setup process
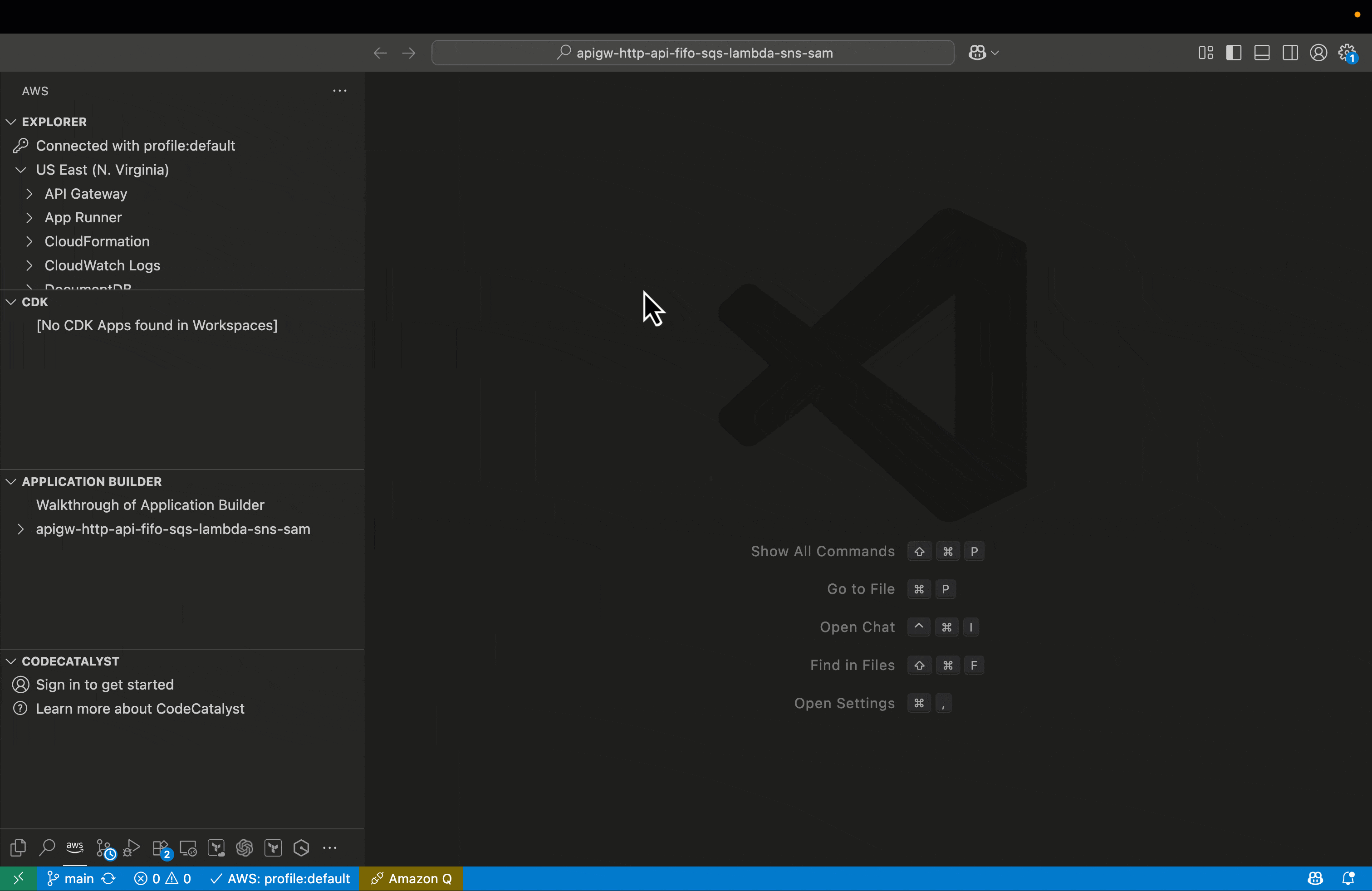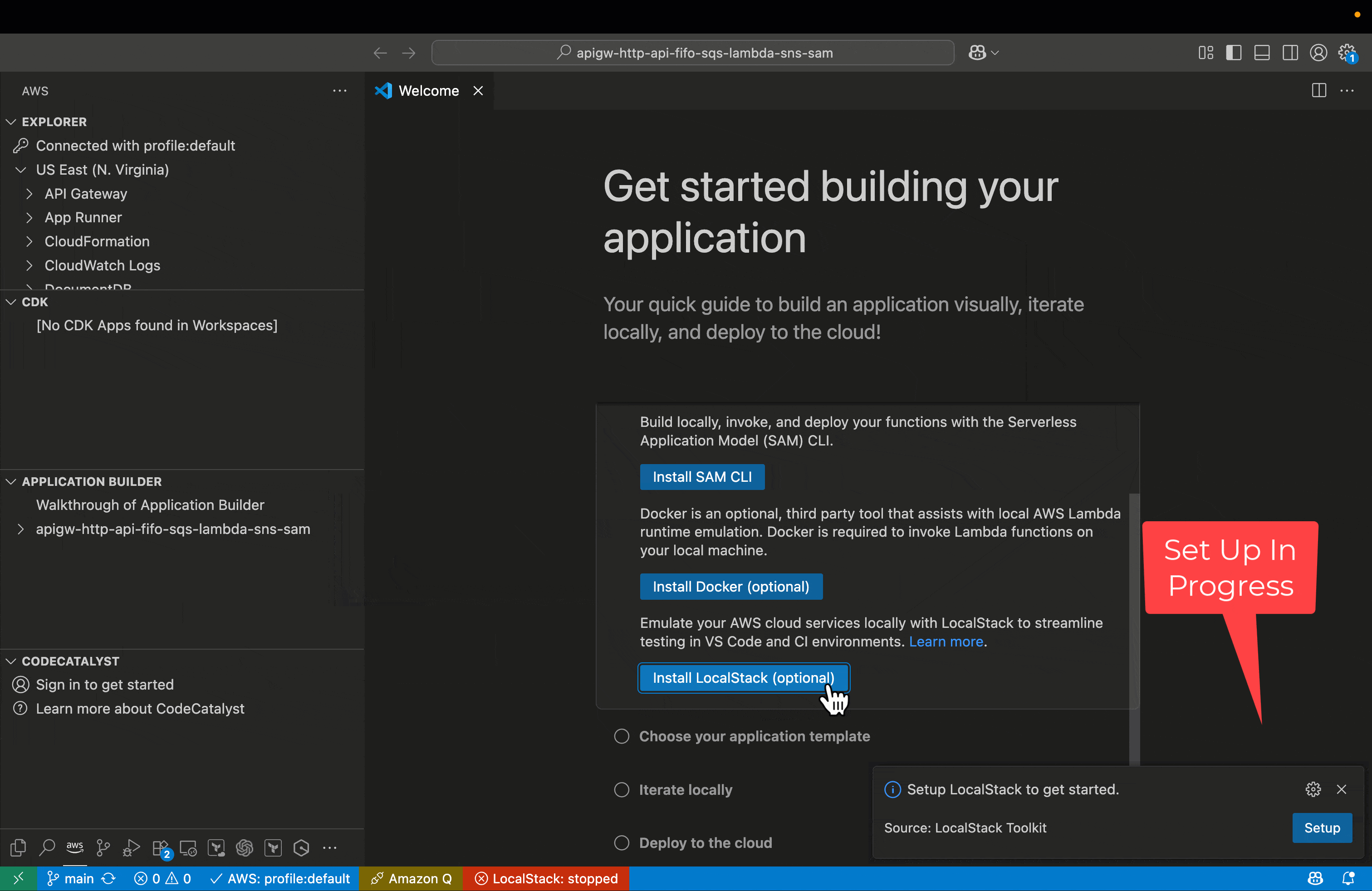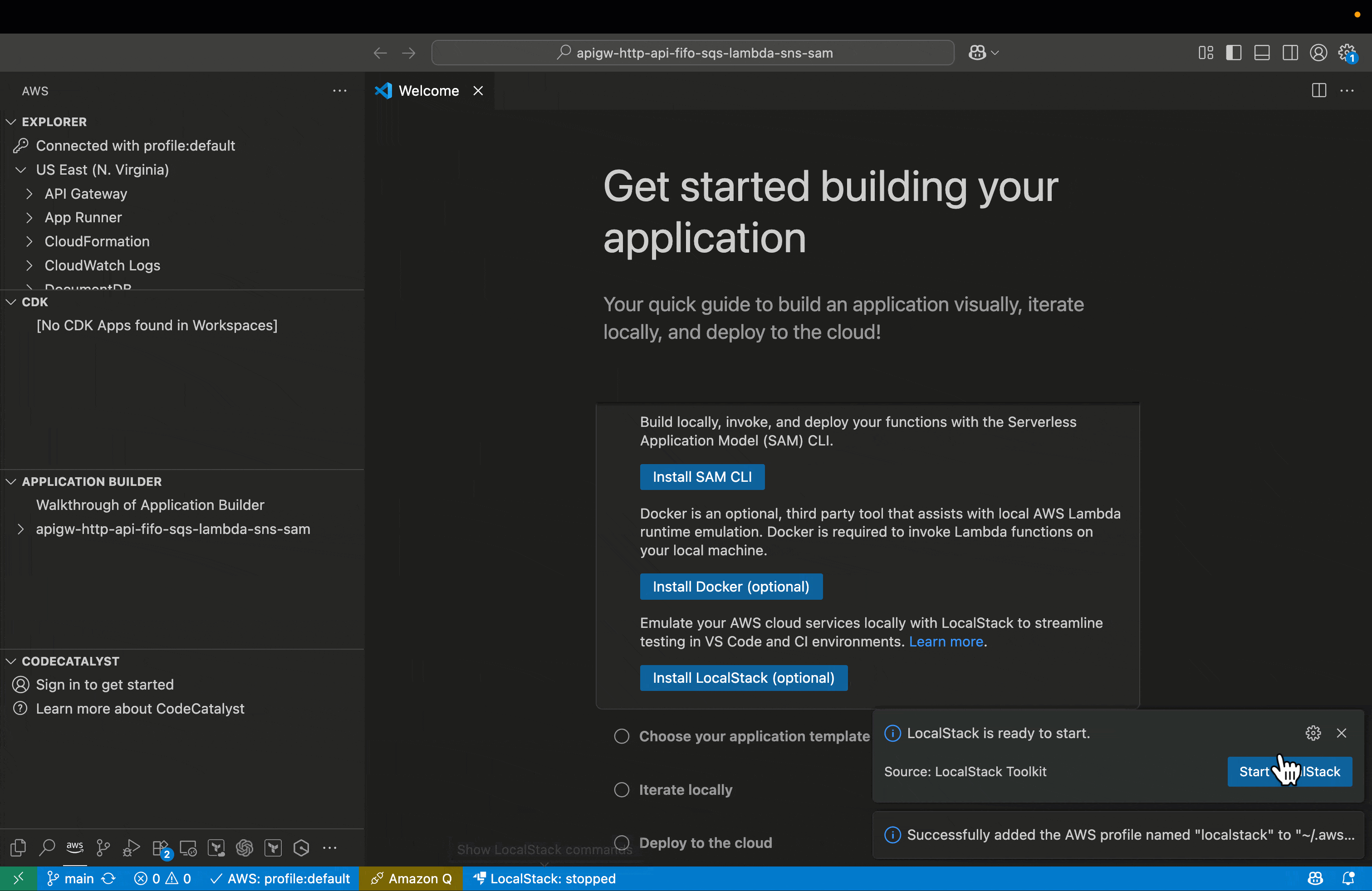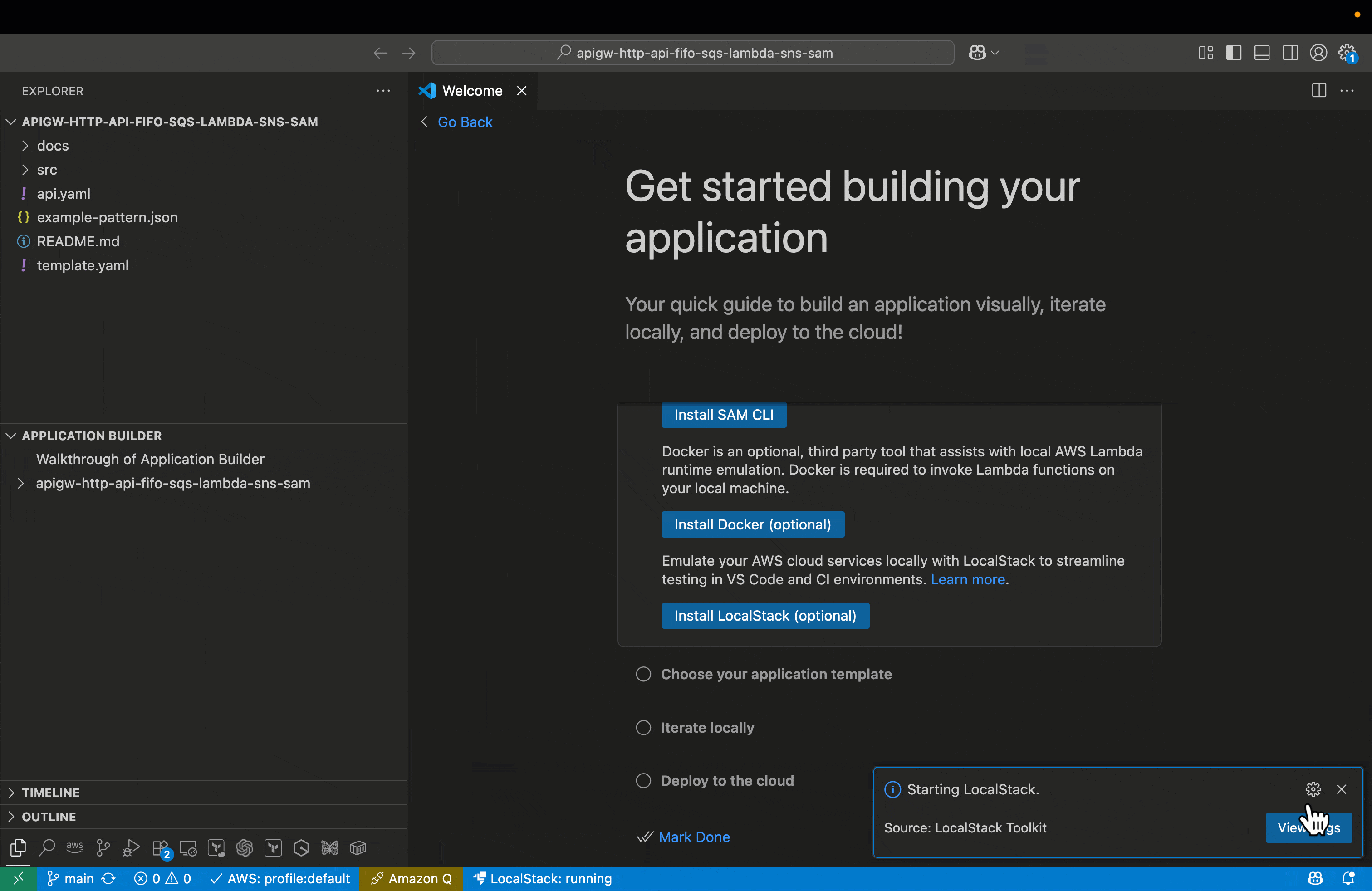
LocalStack is a cloud service emulator that you can use to run AWS applications locally for testing and development. To enhance your local testing capabilities, you can install the LocalStack VSCode Extension directly from AWS Walkthrough in AWS Toolkit, which offers a streamlined setup process through an intelligent wizard. After installation, the extension automatically detects whether LocalStack is configured on your system and prompts you to run the setup wizard through a notification. The entire process is quick and requires no manual configuration.
LocalStack extension has an integrated authentication wizard, that simplifies the process of connecting your development environment to LocalStack. During setup, the wizard opens a browser-based authentication flow and maintains an active connection until authentication completes. After it’s verified, it securely stores the authentication token in the ~/.localstack/auth.json file, enabling communication between your local environment and LocalStack services.
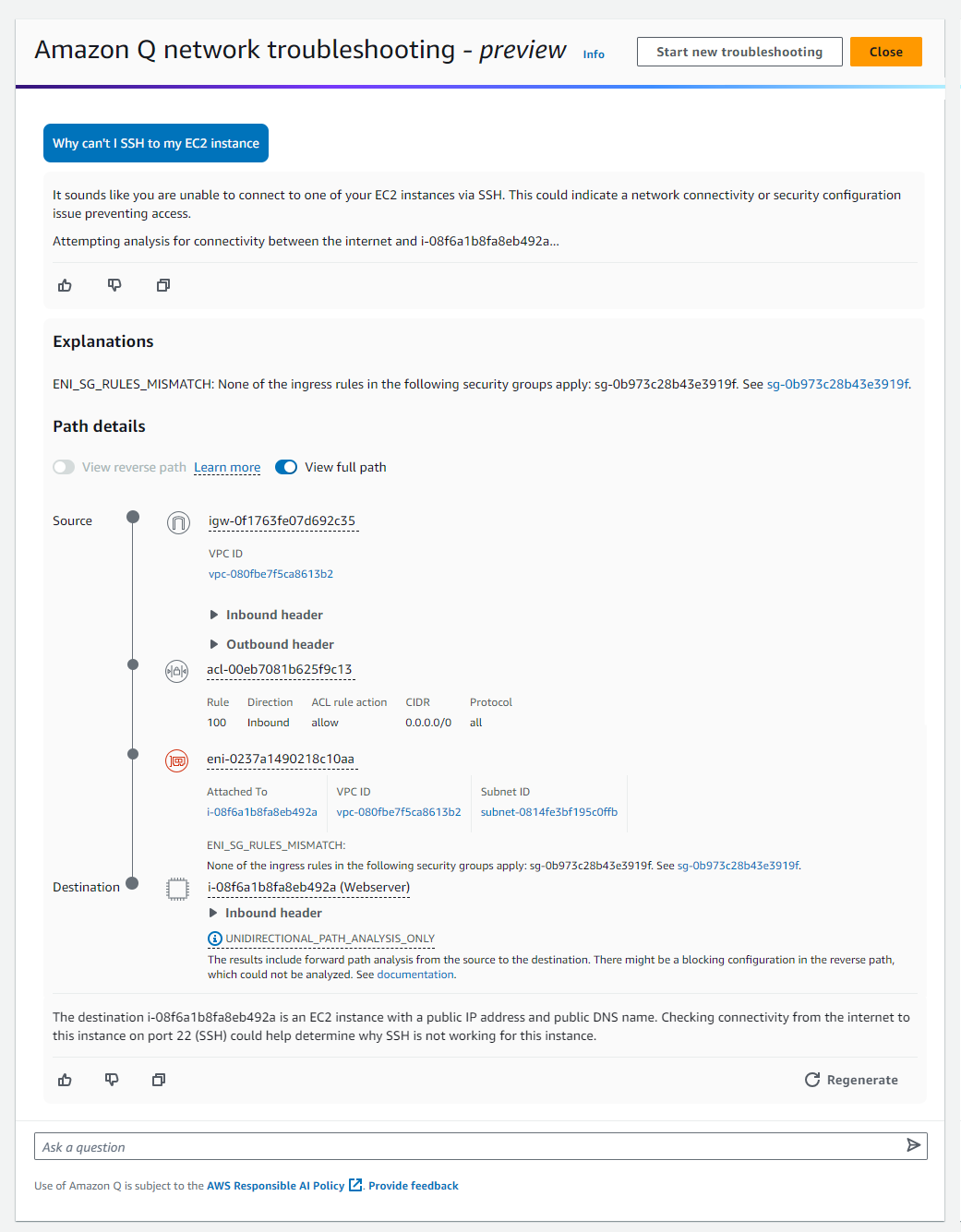
The wizard also checks if LocalStack AWS CLI profiles exist, and if not found, automatically creates them by updating the ~/.aws/config and ~/.aws/credentials files with LocalStack-specific endpoints and credentials. This seamless integration of AWS profiles enhances the development workflow by allowing developers to easily switch between different AWS environments, including the local LocalStack setup. By leveraging these profiles, developers can effortlessly point their AWS CLI or SDK to the appropriate endpoint, whether it’s a real AWS account or the LocalStack instance running on their machine. This configuration not only ensures a clear separation between local and cloud environments but also minimizes the risk of cross-environment interference. The automatic creation of these profiles streamlines the setup process, reducing manual configuration errors and saving valuable development time. Visual Studio Code (VS Code) provides real-time feedback throughout the setup. The status bar initially displays an error or warning indicator when LocalStack is not configured and then transitions to a normal or connected state once a successful connection is established. After setup completes, you’re ready to deploy, test, and debug serverless applications locally—without additional configuration. These settings persist across VS Code sessions, so the setup process is a one-time task.The following figure illustrates the process to start and verify LocalStack from VS Code.
To learn more, including installation steps, configuration examples, and troubleshooting guidance, visit the LocalStack Docs.
Test a serverless application
To demonstrate the enhanced local testing capabilities, let’s explore a practical serverless pattern: building and testing an event-driven order processing system that integrates Lambda with Amazon SQS, API Gateway, and Amazon Simple Notification Service (Amazon SNS). The application processes orders through an event-driven workflow: orders are submitted through API Gateway to an SQS queue and processed by a Lambda function, and the status is published to Amazon SNS to trigger customer email notifications.
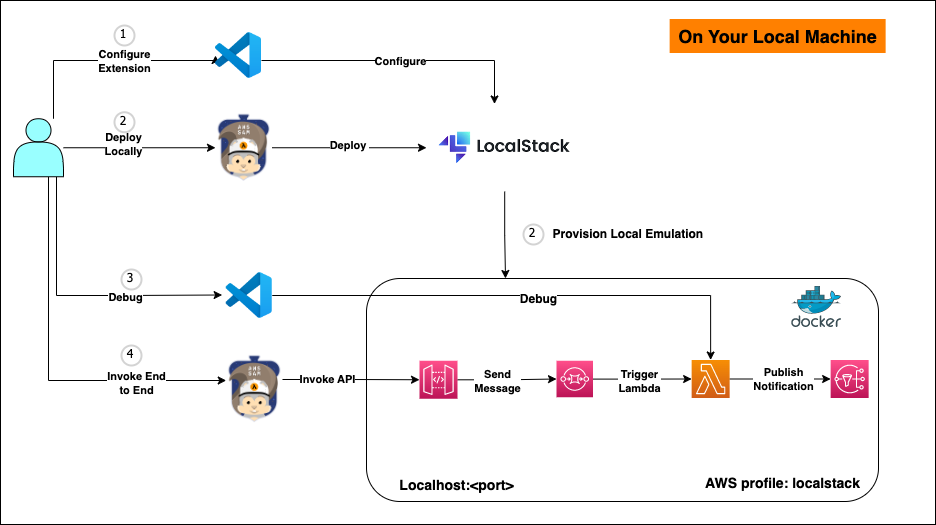
After you set up LocalStack in VS Code, you can test your entire serverless workflow without deploying to the cloud:
- Deploy locally – Use the LocalStack AWS profile to deploy your AWS SAM application. The process mirrors cloud deployment but targets local endpoints. You can use the Application builder pane to initiate the deployment to LocalStack environment. The following figure illustrates the process of deploying a sample serverless application.

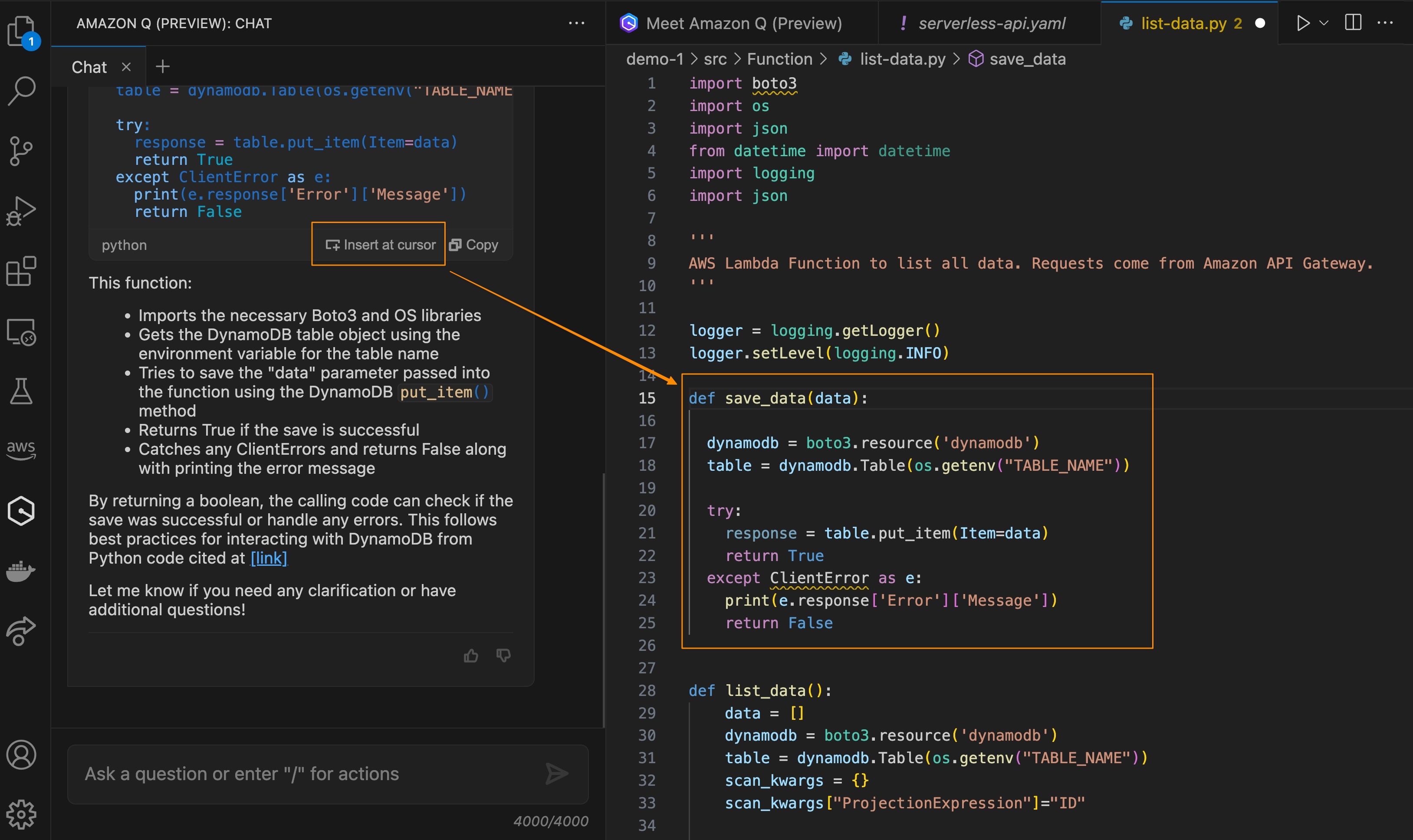
- Debug Lambda function deployed in LocalStack – Set breakpoints in your Lambda function and step through execution using VS Code’s integrated debugger. With the AWS Toolkit extension, you can invoke your Lambda with one click and inspect live interactions across services, all while running against a LocalStack container on your machine. This setup makes it possible to debug your AWS applications in a controlled, local environment that mimics the cloud infrastructure, without the need for deploying actual AWS services.
- Validate end-to-end Flows – Test complete workflows from message ingestion through processing and notification, confirming all service integrations work correctly before cloud deployment.
For an in-depth technical demonstration of this LocalStack integration, refer to this youtube video.
Best practices for local Lambda function testing
In this section, we discuss various strategies and best practices for local Lambda function testing.
Optimizing your development workflow
Consider the following strategies to optimize your development workflow:
- Start with a strong testing foundation – Use the AWS SAM CLI to perform unit tests that validate the core programmatic and business logic of your Lambda functions. Isolating function behavior early helps identify logic errors before introducing external dependencies.
- Establish environment parity early in the development process – Many production issues stem from discrepancies between local and cloud environments. Use consistent service versions, configurations, and data structures across environments to confirm that what works locally behaves the same in production.
- Adopt IaC from day one – Whether you choose AWS SAM, AWS CloudFormation, or another IaC framework, defining your application infrastructure as code reduces configuration drift and makes your deployments reproducible across teams and environments.
- Apply a progressive testing strategy – Follow a structured testing pyramid that starts with fast, isolated unit tests and builds up to broader integration and system-level validation. This layered approach helps you catch issues earlier—when they’re easier and less expensive to fix—while still providing full application coverage.
A strategic approach to testing
Testing should be an integrated part of your serverless development workflow—not an afterthought. Successful teams implement layered testing strategies that use both local and cloud environments to strike a balance between speed and accuracy:
- Begin with unit tests that focus on isolated function logic. Use tools like the AWS SAM CLI, AWS Toolkit for VS Code and LocalStack extensions to run and debug functions locally.
- After validation, proceed to local integration testing using LocalStack to confirm how your Lambda functions interact with services such as Amazon SQS, DynamoDB, and Amazon SNS. These tests typically complete within minutes and catch most service integration issues before they reach production.
- After local testing, validate your application in the actual AWS environment. Cloud testing helps surface issues not present in local emulation, such as AWS Identity and Access Management (IAM) permission mismatches, Amazon Virtual Private Cloud (Amazon VPC) networking challenges, or service-specific nuances such as Lambda concurrency. For troubleshooting issues in the cloud environment, you can also remotely debug your Lambda functions using AWS Toolkit for VS Code.
- Lastly, conduct performance testing in AWS to assess how your application handles real-world traffic. These longer-running tests help validate scaling behavior and system resilience under load.
The result is higher-quality applications delivered faster, with fewer production surprises and more confident deployments.
Security considerations
When using LocalStack for local development, follow these security best practices:
- Isolate the local environment – Use Docker networking to restrict LocalStack access and bind services to
localhostto prevent external connections. - Use placeholder credentials – Use test credentials (for example,
test/test) instead of real AWS credentials. - Protect your data – Use synthetic or anonymized datasets instead of production data and regularly purge local data stores to reduce risk.
When to use local versus cloud testing
Although local testing offers significant advantages, it’s important to understand when to use it versus testing in the cloud. The following table lists the potential use cases for each strategy.
| Testing Scenario | Local Testing | Cloud Testing | Reason |
| Function logic validation | ✓ | Fast feedback for core business logic | |
| Service integration testing | ✓ | Quick validation of AWS service interactions | |
| Rapid iteration during development | ✓ | Immediate feedback without deployment overhead | |
| Cost-sensitive development environments | ✓ | Minimizes cloud resource costs during development | |
| Offline development scenarios | ✓ | No internet connectivity required | |
| Performance and scalability testing | ✓ | Requires actual AWS infrastructure for accurate results | |
| IAM permission validation | ✓ | LocalStack doesn’t fully replicate IAM behavior | |
| VPC networking scenarios | ✓ | Network configurations can’t be accurately emulated | |
| Production-like load testing | ✓ | Real performance metrics only available in AWS | |
| Final validation before deployment | ✓ | Supports compatibility with actual AWS environment |
Conclusion
In this post, we discussed how to streamline local testing for AWS Serverless applications using LocalStack and the AWS Toolkit for VS Code. By running and debugging serverless applications directly in your IDE, you can reduce context switching, test complex integrations locally, and catch issues earlier—without deploying to the cloud.
We also showed how to apply progressive testing strategies that combine local emulation with cloud validation, optimize development costs, and build event-driven workflows with confidence.These enhancements lead to faster test cycles, lower development costs, and higher-quality deployments—all while staying fully in control of your development environment.
Have questions or feedback about this post? Connect with us on the AWS Compute Blog or join the AWS Developer community.