Amazon Virtual Private Cloud (Amazon VPC) provides two options for controlling network traffic: network access control lists (ACLs) and security groups. A network ACL defines inbound and outbound rules that allow or deny traffic based on protocol, IP address range, and port range. Security groups determine which inbound and outbound traffic is allowed on a network interface, but they cannot explicitly deny traffic like a network ACL can. Every VPC subnet is associated with a network ACL that ultimately determines which traffic can enter or leave the subnet, even if a security group allows it. Network ACLs provide a layer of network controls that augment your security groups.
There are situations when you might want to deny specific sources or destinations within the range of network traffic allowed by security groups. For example, you want to deny inbound traffic from malicious sources on the internet, or you want to deny outbound traffic to ports or protocols used by exploits or malware. Security group rules can only control what traffic is allowed. If you want to deny specific traffic within the range of allowed traffic from security groups, you need to use network ACL rules. If you want to deny specific types of traffic in many VPCs, you need to update each network ACL associated with subnets in each of those VPCs. We heard from customers that implementing a baseline of common network ACL rules can be challenging to manage across many Amazon Web Services (AWS) accounts, so we expanded AWS Firewall Manager capabilities to make this easier.
AWS Firewall Manager network ACL security policies allow you to centrally manage network ACL rules for VPC subnets across AWS accounts in your organization. The following sections demonstrate how you can use network ACL policies to manage common network ACL rules that deny inbound and outbound traffic.
Deny inbound traffic using a network ACL security policy
If you have not already set up a Firewall Manager administrator account, see Firewall Manager prerequisites. Note that network ACL policies require your AWS Config configuration recorder to include the AWS::EC2::NetworkAcl and AWS::EC2::Subnet resource types.
Let’s review an example of how you can now use Firewall Manager to centrally manage a network ACL rule that denies inbound traffic from a public source IP range.
To deny inbound traffic:
Sign in to your Firewall Manager delegated administrator account, open the AWS Management Console, and go to Firewall Manager.
In the navigation pane, under AWS Firewall Manager, select Security policies.
On the Filter menu, select the AWS Region where your VPC subnets are defined, and choose Create policy. In this example, we select US East (N. Virginia).
Under Policy details, select Network ACL, and then choose Next.
Figure 1: Network ACL policy type and Region
On Policy name, enter a Policy name and Policy description.
Figure 2: Network ACL policy name and description
In the Network ACL policy rules section, select the Inbound rules tab.
In the First rules section, choose Add rules.
Figure 3: Add rules in the First rules section
In the Inbound rules window, choose Add inbound rules.
Figure 4: Add inbound rules
For Inbound rules, choose the following:
For Type, select All traffic.
For Protocol, select All.
For Port range, select All.
For Source, enter an IP address range that you want to deny. In this example, we use 192.0.2.0/24.
For Action, select Deny.
Choose Add Rules.
Figure 5: Configure a network ACL inbound rule
In Network ACL policy rules, under First rules, review the deny rule.
Figure 6: Review the inbound deny rule
Under Policy action, select the following:
Select Auto remediate any noncompliant resources.
Under Force Remediation, select Force remediate first rules. Firewall Manager compares your existing network ACL rules with rules defined in the policy. A conflict exists if a policy rule has the opposite action of an existing rule and overlaps with the existing rule’s protocol, address range, or port range. In these cases, Firewall Manager will not remediate the network ACL unless you enable force remediation.
Figure 7: Configure the policy action
Choose Next.
Policy scope, select the following:
Under AWS accounts this policy applies to, select the scope of accounts that apply. In this example, we include all accounts.
Under Resource type, select Subnet.
Under Resources, select the scope of resources that apply. In this example, we only include subnets that have a particular tag.
Figure 8: Configure the policy scope
Enable resource cleanup if you want Firewall Manager to remove the rules it added to network ACLs associated with subnets that are no longer in scope. To enable cleanup, select Automatically remove protections from resources that leave the policy scope, and choose Next.
Figure 9: Enable resource cleanup
Under Configure policy tags, define the tags you want to associate with your policy, and then choose Next.
Under Review and create policy, choose Next.
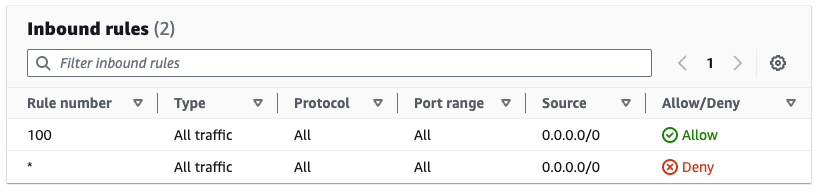
Before creating the Firewall Manager policy, the subnet is associated with a default network ACL, as shown in Figure 10.
Figure 10: Default network ACL rules before the subnet is in scope
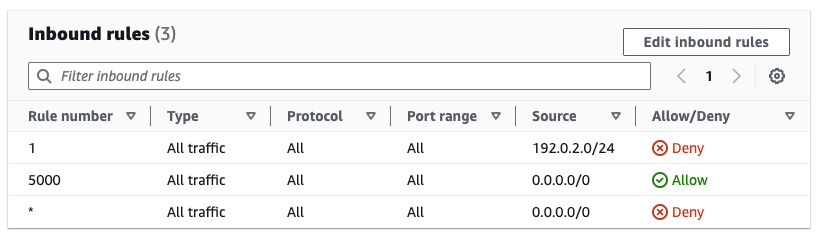
As shown in Figure 11, the subnet is now associated with a network ACL managed by Firewall Manager. The original Allow rule has been preserved and moved to priority 5,000. The Deny rule has been added with priority 1.
Figure 11: Inbound rules in network ACL managed by Firewall Manager
Deny outbound traffic using a network ACL security policy
You can also use Firewall Manager to implement outbound network ACL rules to deny the use of ports used by malware or software vulnerabilities. In this example, we’re blocking the use of LDAP port 389.
Sign in to your Firewall Manager delegated administrator account and open the Firewall Manager console.
In the navigation pane, under AWS Firewall Manager, select Security policies.
On the Filter menu, select the AWS Region where your VPC subnets are defined, and choose Create policy. In this example, we select US East (N. Virginia).
Under Policy details, select Network ACL, and then choose Next.
Enter a Policy name and Policy description.
In the Network ACL policy rules section, select the Outbound rules tab.
In the First rules section, choose Add rules.
Figure 12: Add rules in the First rules section
Under Outbound rules, choose Add outbound rules.
In Outbound rules, select the following:
For Type, select LDAP (389).
For Destination, enter 0.0.0.0/0.
For Action, select Deny.
Choose Add Rules.
Figure 13: Configure a network ACL outbound rule
On the Network ACL policy rules page, under First rules, review the deny rule.
Figure 14: Review the outbound deny rule
In Policy action, under Policy action, select the following:
Select Auto remediate any noncompliant resources.
Under Force Remediation, select Force remediate first rules, and then choose Next.
Figure 15: Configure the policy action
Under Policy scope, choose the following:
Under AWS accounts this policy applies to, select the scope of accounts that apply. In this example, we include all accounts by selecting Include all accounts under my organization.
Under Resource type, select Subnet.
Under Resources, select the scope of resources that apply. In this example, we select Include only subnets that all the specified resource tags.
Figure 16: Configure the policy scope
On Resource cleanup, enable resource cleanup if you want Firewall Manager to remove rules it added to network ACLs associated with subnets that are no longer in scope. To enable resource cleanup, select Automatically remove protections from resources that leave the policy scope, and then choose Next.
Figure 17: Enable resource cleanup
Under Configure policy tags, define the tags you want to associate with your policy, and then choose Next.
Under Review and create policy, choose Next.
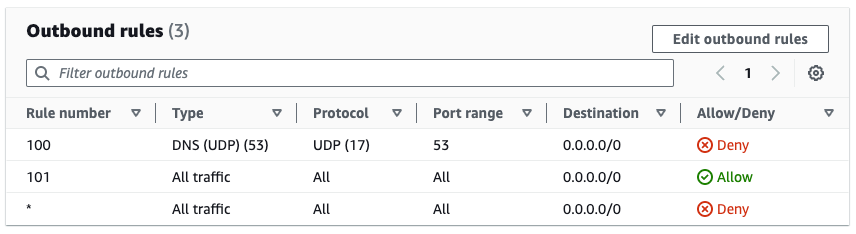
Before creating the Firewall Manager policy, the subnet is associated with a network ACL that already contains rules with priority 100 and 101, as shown in Figure 18.
Figure 18: Rules in original network ACL
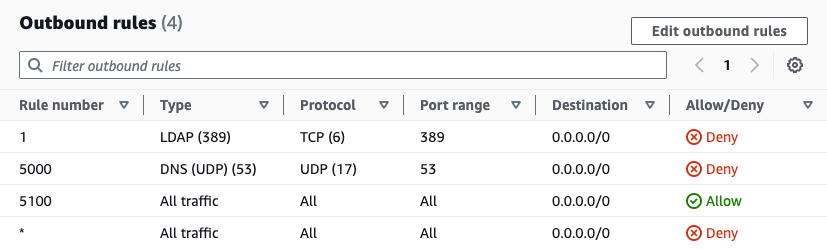
As shown in Figure 19, the subnet is now associated with a network ACL managed by Firewall Manager. The original rules have been preserved and moved to priority 5,000 and 5,100. The Deny rule for LDAP has been added with priority 1.
Figure 19: Outbound rules in network ACL managed by Firewall Manager
Working with network ACLs managed by Firewall Manager
Firewall Manager network ACL policies allow you to manage up to 5 inbound and 5 outbound rules. Network ACLs can support a total of 20 inbound rules and 20 outbound rules by default. This limit can be increased up to 40 inbound rules and 40 outbound rules, but network performance might be impacted. Consider AWS Network Firewall if you need support for more rules and a broader set of features.
AWS accounts that are in scope of your Firewall Manager policy might have identities with permission to modify network ACLs created by Firewall Manager. You can use a service control policy (SCP) to deny AWS Identity and Access Management (IAM) actions that modify network ACLs if you want to make sure that they are exclusively managed by Firewall Manager. Firewall Manager uses service-linked roles, which are not restricted by SCPs. The following example SCP denies network ACL updates without restricting Firewall Manager:
Prior to AWS Firewall Manager network ACL security policies, you had to implement your own process to orchestrate updates to network ACLs across VPC subnets in your organization in AWS Organizations. AWS Firewall Manager network ACL security policies allow you to centrally define common network ACL rules that are automatically applied to VPC subnets across your organization, even as you add new accounts and resources. In this post, we demonstrated how you can use network ACL policies in a variety of scenarios, such as blocking ingress from malicious sources and blocking egress to destinations used by malware and exploits. You can also use network ACL policies to implement an allow list. For example, you might only want to allow egress to your on-premises network.
The Supermicro AOC-STG-b2T is a dual 10GbE adapter for those who need 10Gbase-T connectivity in a server. This is a quick one that continues our series on network adapter reviews. The “b” in the model name tells us that we have a Broadcom-based solution. Let us get into it. Supermicro AOC-STG-b2T Hardware Overview The card […]
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.