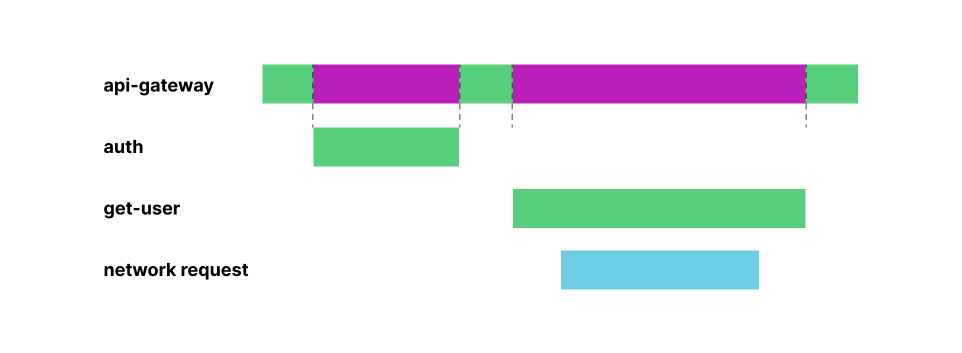Post Syndicated from Annika Garbers original https://blog.cloudflare.com/magic-nat/
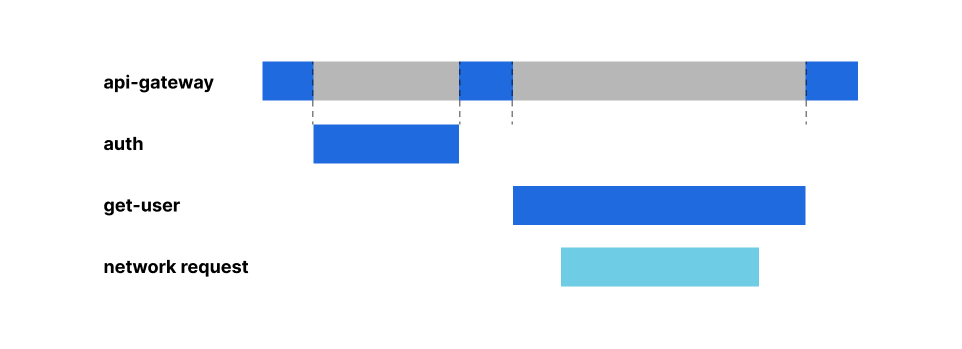
Network Address Translation (NAT) is one of the most common and versatile network functions, used by everything from your home router to the largest ISPs. Today, we’re delighted to introduce a new approach to NAT that solves the problems of traditional hardware and virtual solutions. Magic NAT is free from capacity constraints, available everywhere through our global Anycast architecture, and operates across any network (physical or cloud). For Internet connectivity providers, Magic NAT for Carriers operates across high volumes of traffic, removing the complexity and cost associated with NATing thousands or millions of connections.
What does NAT do?
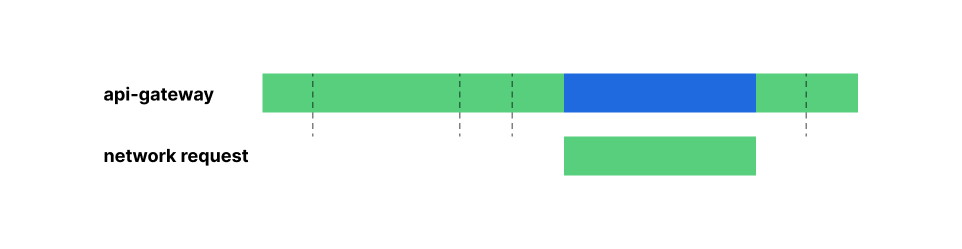
The main function of NAT is in its name: NAT is responsible for translating the network address in the header of an IP packet from one address to another – for example, translating the private IP 192.168.0.1 to the publicly routable IP 192.0.2.1. Organizations use NAT to grant Internet connectivity from private networks, enable routing within private networks with overlapping IP space, and preserve limited IP resources by mapping thousands of connections to a single IP. These use cases are typically accomplished with a hardware appliance within a physical network or a managed service delivered by a cloud provider.
Let’s look at those different use cases.
Allowing traffic from private subnets to connect to the Internet
Resources within private subnets often need to reach out to the public Internet. The most common example of this is connectivity from your laptop, which might be allocated a private address like 192.168.0.1, reaching out to a public resource like google.com. In order for Google to respond to a request from your laptop, the source IP of your request needs to be publicly routable on the Internet. To accomplish this, your ISP translates the private source IP in your request to a public IP (and reverse-translates for the responses back to you). This use case is often referred to as public NAT, performed by hardware or software acting as a “NAT gateway.”
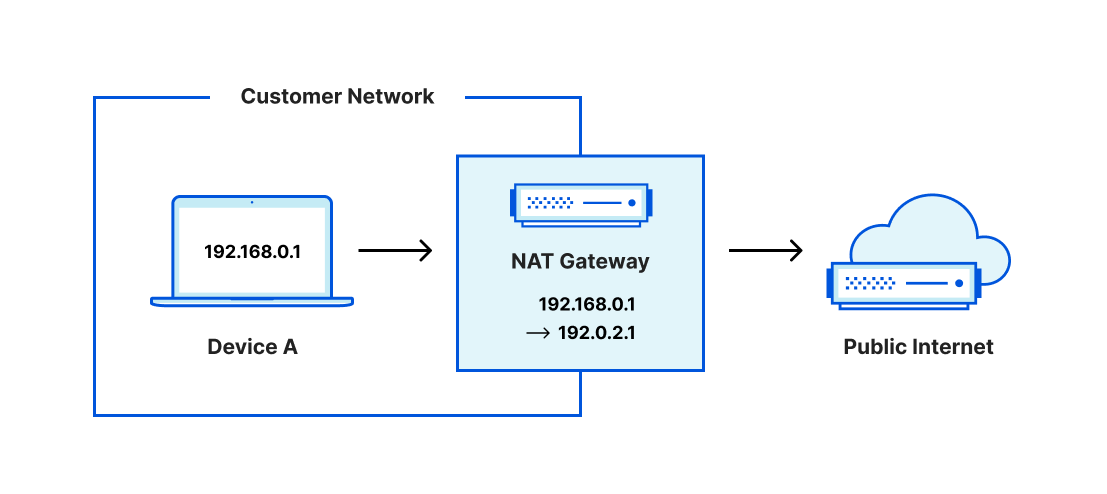
Users might also have requirements around the specific IP addresses that outgoing packets are NAT’d to. For example, they may need packets to egress from only one or a small subset of IPs so that the services they’re reaching out to can positively identify them – e.g. “only allow traffic from this specific source IP and block everything else.” They might also want traffic to NAT to IPs that accurately reflect the source’s geolocation, in order to pass the “pizza test”: are the results returned for the search term “pizza near me” geographically relevant? These requirements can increase the complexity of a customer’s NAT setup.
Enabling communication between private subnets with overlapping IP space
NATs are also used for routing traffic within fully private networks, in order to enable communication between resources with overlapping IP space. One example: imagine that you’re an IT architect at a retail company with a hundred geographically distributed store locations and a central data center. To make your life easier, you want to use the same IP address management scheme for all of your stores – e.g. host all of your printers on 10.0.1.0/24, point of sale devices on 10.0.2.0/24, and security cameras on 10.0.3.0/24. These devices need to reach out to resources hosted in your data center, which is also on your private network. The challenge: if multiple devices across your stores have the same source IP, how do return packets from your data center get back to the right device? This is where private NAT comes in.
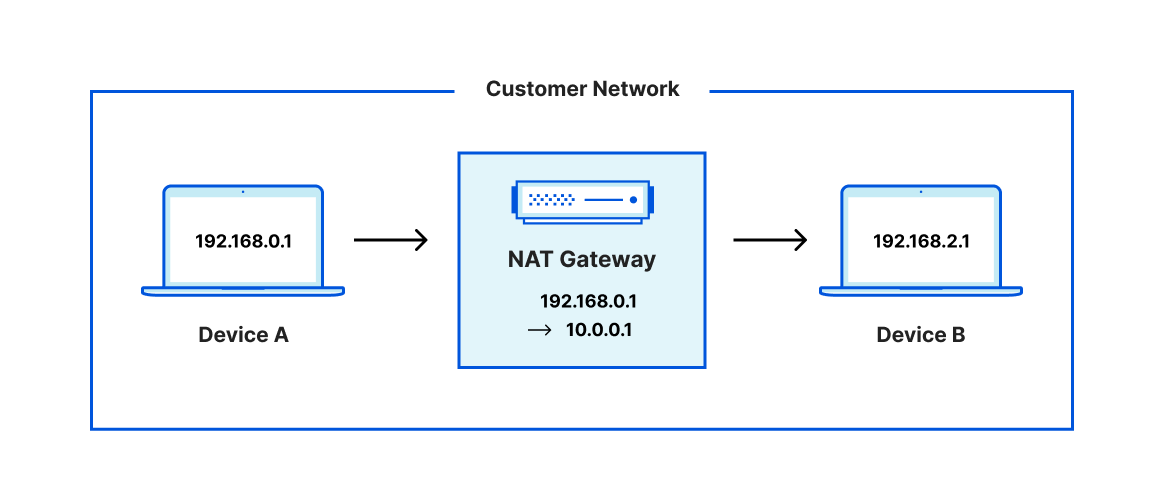
A NAT gateway sitting in a private network can enable connectivity between overlapping subnets by translating the original source IP (the one shared by multiple resources) to an IP in a different range. This can enable communication between mirrored subnets and other resources (like in our store → datacenter example), as well as between the mirrored subnets themselves – e.g. if traffic needed to flow between our store locations directly, such as a VoIP call from one store to another.
Conserving IP address space
As of 2019, the available pool of allocatable IPv4 space has been exhausted, making addresses a limited resource. In order to conserve their IPv4 space while the industry slowly transitions to IPv6, ISPs have adopted carrier-grade NAT solutions to map multiple users to a single IP, maximizing the mileage of the space they have available. This uses the same mechanisms for address translation we’ve already described, but at a large scale – ISPs need to deploy devices that can handle thousands or millions of concurrent connections without impacting traffic performance.
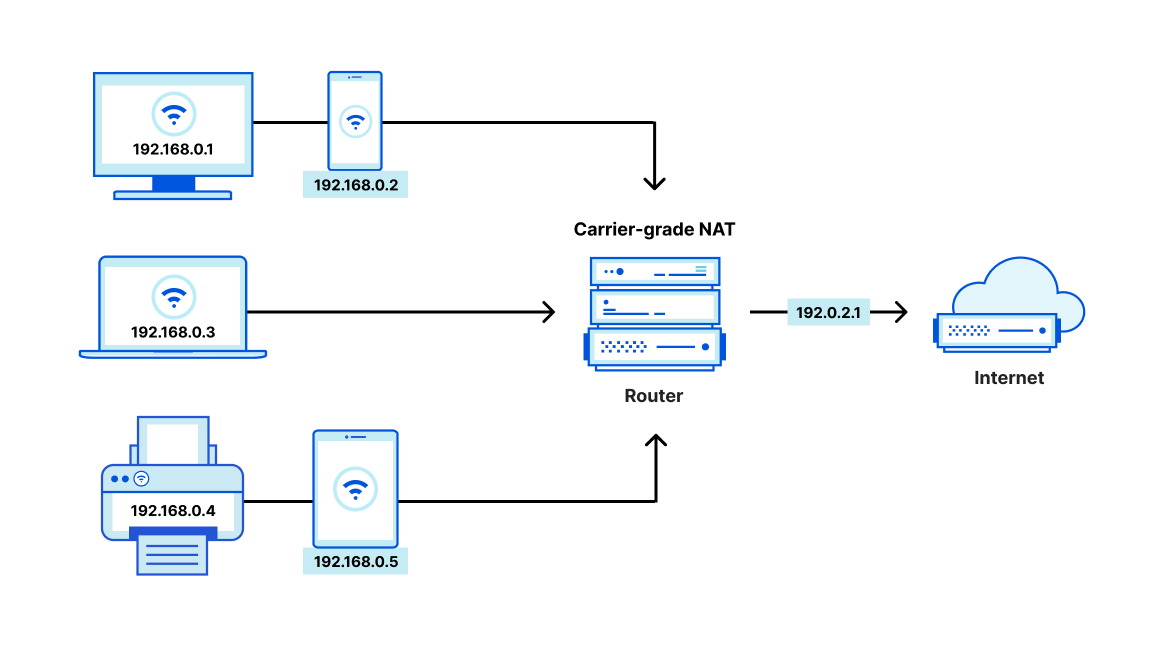
Challenges with existing NAT solutions
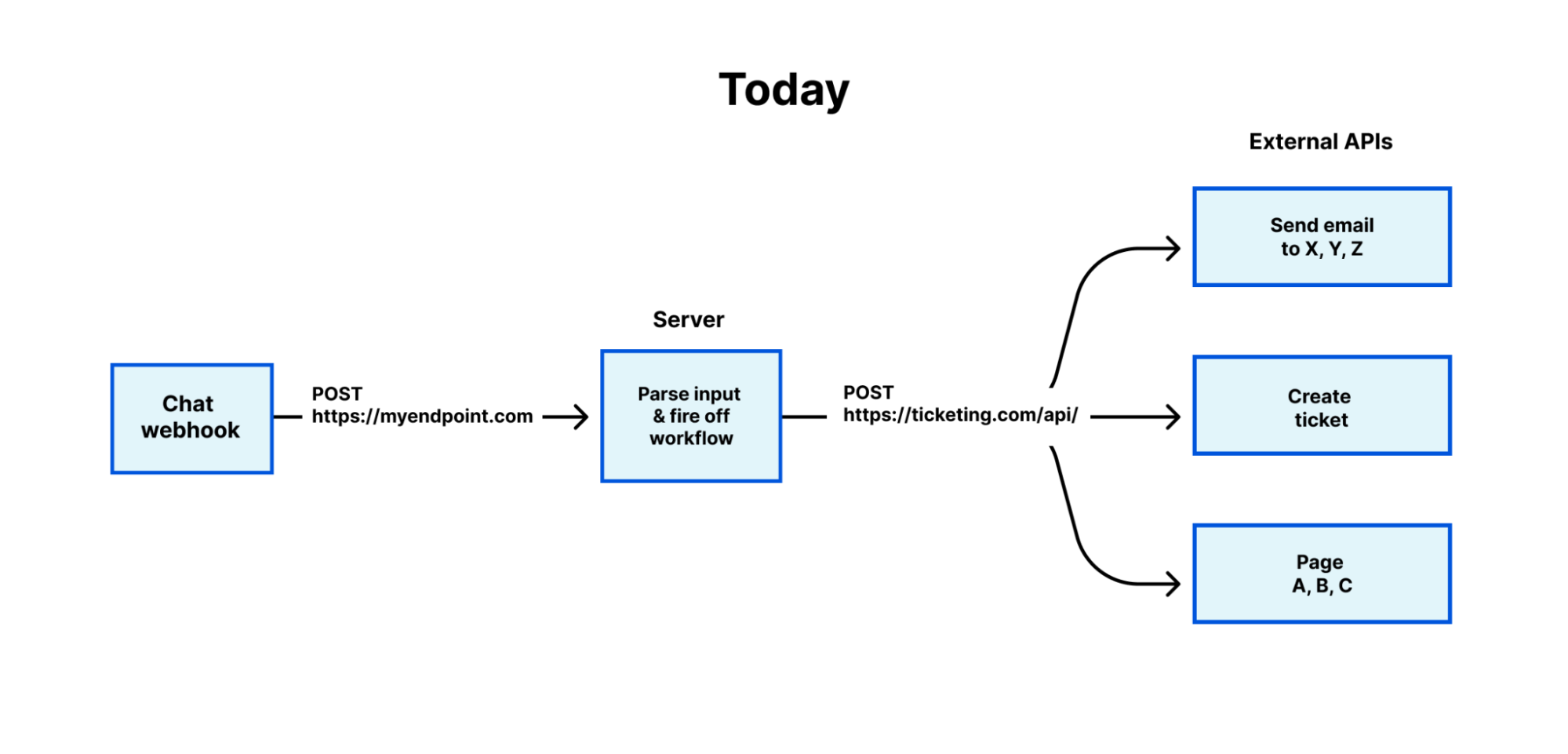
Today, users accomplish the use cases we’ve described with a physical appliance (often a firewall) or a virtual appliance delivered as a managed service from a cloud provider. These approaches have the same fundamental limitations as other hardware and virtualized hardware solutions traditionally used to accomplish most network functions.
Geography constraints
Physical or virtual devices performing NAT are deployed in one or a few specific locations (e.g. within a company’s data center or in a specific cloud region). Traffic may need to be backhauled out of its way through those specific locations to be NAT’d. A common example is the hub and spoke network architecture, where all Internet-bound traffic is backhauled from geographically distributed locations to be filtered and passed through a NAT gateway to the Internet at a central “hub.” (We’ve written about this challenge previously in the context of hardware firewalls.)
Managed NAT services offered by cloud providers require customers to deploy NAT gateway instances in specific availability zones. This means that if customers have origin services in multiple availability zones, they either need to backhaul traffic from one zone to another, incurring fees and latency, or deploy instances in multiple zones. They also need to plan for redundancy – for example, AWS recommends configuring a NAT gateway in every availability zone for “zone-independent architecture.”
Capacity constraints
Each appliance or virtual device can only support up to a certain amount of traffic, and higher supported traffic volumes usually come at a higher cost. Beyond these limits, users need to deploy multiple NAT instances and design mechanisms to load balance traffic across them, adding additional hardware and network hops to their stack.
Cost challenges
Physical devices that perform NAT functionality have several costs associated – in addition to the upfront CAPEX for device purchases, organizations need to plan for installation, maintenance, and upgrade costs. While managed cloud services don’t carry the same cost line items of traditional hardware, leading providers’ models include multiple costs and variable pricing that can be hard to predict. A combination of hourly charges, data processing charges, and data transfer charges can lead to surprises at the end of the month, especially if traffic experiences momentary spikes.
Hybrid infrastructure challenges
More and more customers we talk to are embracing hybrid (datacenter/cloud), multi-cloud, or poly-cloud infrastructure to diversify their spend and leverage the best of breed features offered by each provider. This means deploying separate NAT instances across each of these networks, which introduces additional complexity, management overhead, and cost.
Magic NAT: everywhere, unbounded, cross-platform, and predictably priced
Over the past few years, as we’ve been growing our portfolio of network services, we’ve heard over and over from customers that you want an alternative to the NAT solutions currently available on the market and a better way to address the challenges we described. We’re excited to introduce Magic NAT, the latest entrant in our “Magic” family of services designed to help customers build their next-generation networks on Cloudflare.
How does it work?
Magic NAT is built on the foundational components of Cloudflare One, our Zero Trust network-as-a-service platform. You can follow a few simple steps to get set up:
- Connect to Cloudflare. Magic NAT works with all of our network-layer on-ramps including Anycast GRE or IPsec, CNI, and WARP. Users set up a tunnel or direct connection and route privately sourced traffic across it; packets land at the closest Cloudflare location automatically.
- Upgrade for Internet connectivity. Users can enable Internet-bound TCP and UDP traffic (any port) to access resources on the Internet from Cloudflare IPs.
- (Optional) Enable dedicated egress IPs. Available if you need traffic to egress from one or multiple dedicated IPs rather than a shared pool. Dedicated egress IPs may be useful if you interact with services that “allowlist” specific IP addresses or otherwise care about which IP addresses are seen by servers on the Internet.
- (Optional) Layer on security policies for safe access. Magic NAT works natively with Cloudflare One security tools including Magic Firewall and our Secure Web Gateway. Users can add policies on top of East/West and Internet-bound traffic to secure all network traffic with L3 through L7 protection.
Address translation between IP versions will also be supported, including 4to6 and 6to4 NAT capabilities to ensure backwards and forwards compatibility when clients or servers are only reachable via IPv4 or IPv6.
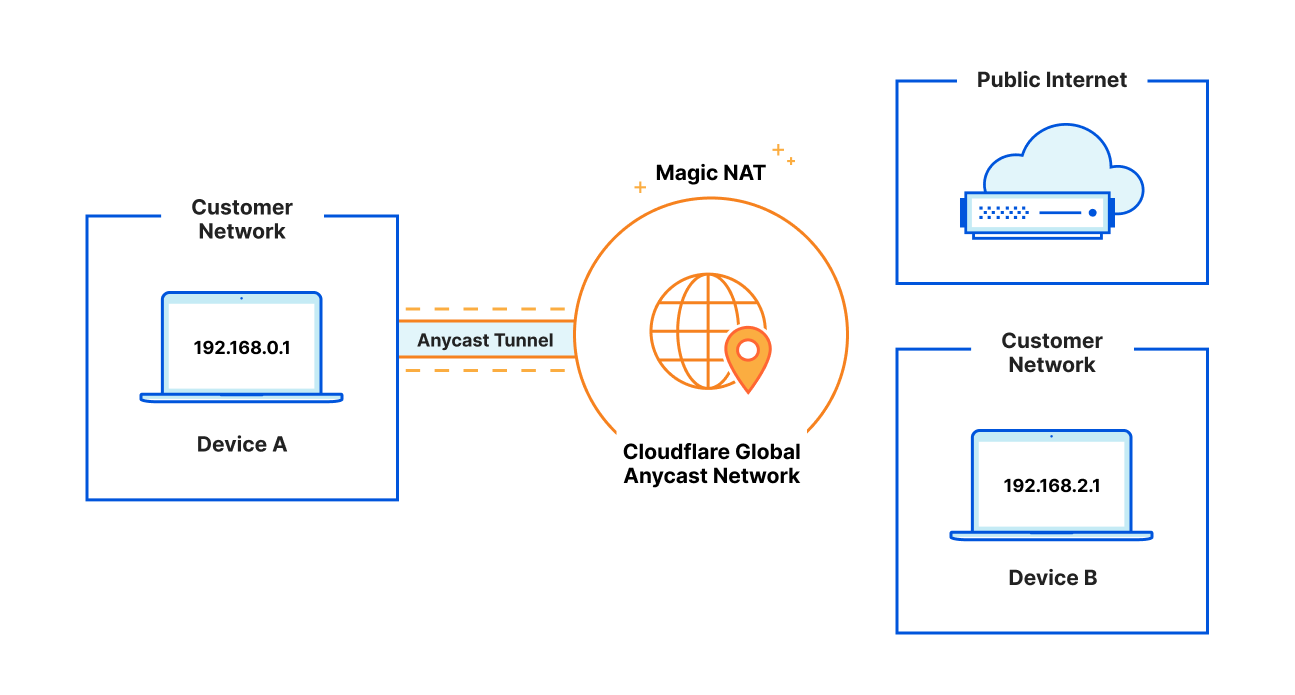
Anycast: Magic NAT is everywhere, automatically
With Cloudflare’s Anycast architecture and global network of over 275 cities across the world, users no longer need to think about deploying NAT capabilities in specific locations or “availability zones.” Anycast on-ramps mean that traffic automatically lands at the closest Cloudflare location. If that location becomes unavailable (e.g. for maintenance), traffic fails over automatically to the next closest – zero configuration work from customers required. Failover from Cloudflare to customer networks is also automatic; we’ll always route traffic across the healthiest available path to you.
Scale: Magic NAT leverages Cloudflare’s entire network capacity
Cloudflare’s global capacity is at 141 Tbps and counting, and automated traffic management systems like Unimog allow us to take full advantage of that capacity to serve high volumes of traffic smoothly. We absorb some of the largest DDoS attacks on the Internet, process hundreds of Gbps for customers through Magic Firewall, and provide privacy for millions of user devices across the world – and Magic NAT is built with this scale in mind. You’ll never need to provision and load balance across multiple instances or worry about traffic throttling or congestion again.
Cost: no more hardware costs and no surprises
Magic NAT, like our other network services, is priced based on the 95th percentile of clean bandwidth for your network: no installation, maintenance, or upgrades, and no surprise charges for data transfer spikes. Unlike managed services offered by cloud providers, we won’t charge you for traffic twice. This means fair, predictable billing based on what you actually use.
Hybrid and multi-cloud: simplify networking across environments
Today, customers deploying NAT across on-prem environments and cloud properties need to manage separate instances for each network. As with Cloudflare’s other products that provide an overlay across multiple environments (e.g. Magic Firewall), we can dramatically simplify this architecture by giving users a single place for all their traffic to NAT through regardless of source/origin network.
Summary
| Traditional NAT solutions | Magic NAT |
|---|---|
| Location-dependent Deploy physical or virtual appliances in one or more locations; additional cost for redundancy. |
Anycast No more planning availability zones. Magic NAT is everywhere and extremely fault-tolerant, automatically. |
| Capacity-limited Physical and virtual appliances have upper limits for throughput; need to deploy and load balance across multiple devices to overcome. |
Scalable No more planning for capacity and deploying multiple instances to load balance traffic across – Magic NAT leverages Cloudflare’s entire network capacity, automatically. |
| High (hardware) and/or unpredictable (cloud) cost CAPEX plus installation, maintenance, and upgrades or triple charge for managed cloud service. |
Fairly and predictably priced No more sticker shock from unexpected data processing charges at the end of the month. |
| Tied to physical network or single cloud Need to deploy multiple instances to cover traffic flows across the entire network. |
Multi-cloud Simplify networking across environments; one control plane across all of your traffic flows. |
Learn more
Magic NAT is currently in beta, translating network addresses globally for a variety of workloads, large and small. We’re excited to get your feedback about it and other new capabilities we’re cooking up to help you simplify and future-proof your network – learn more or contact your account team about getting access today!