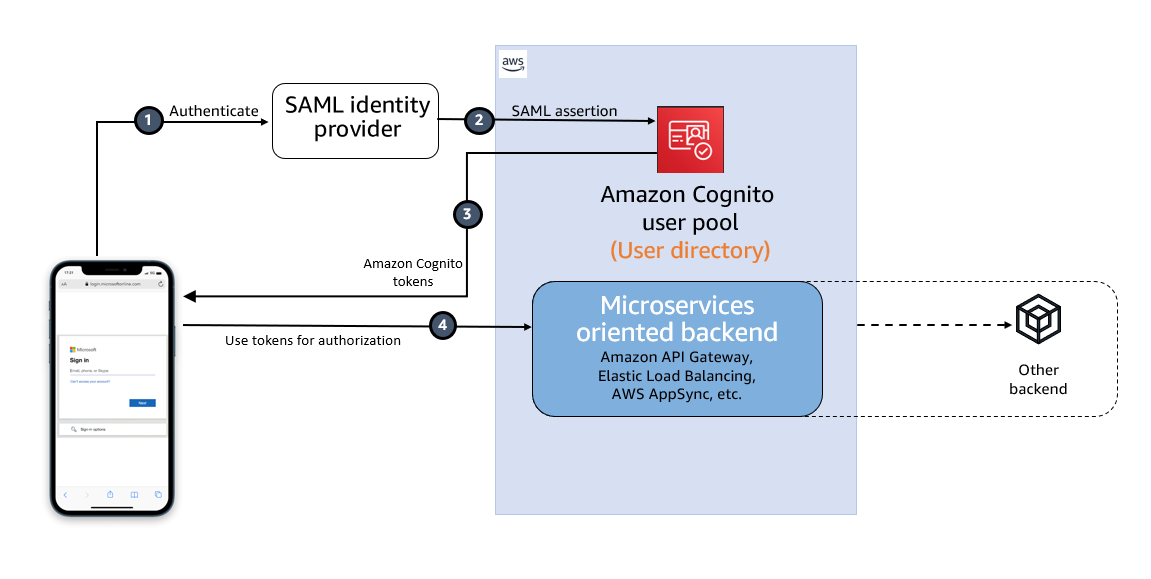
Post Syndicated from Ravi Animi original https://aws.amazon.com/blogs/big-data/breaking-barriers-in-geospatial-amazon-redshift-carto-and-h3/
This post is co-written with Javier de la Torre from CARTO.
In this post, we discuss how Amazon Redshift spatial index functions such as Hexagonal hierarchical geospatial indexing system (or H3) can be used to represent spatial data using H3 indexing for fast spatial lookups at scale. Navigating the vast landscape of data-driven insights has always been an exciting endeavor. As technology continues to evolve, one specific facet of this journey is reaching unprecedented proportions: geospatial data. In our increasingly interconnected world, where every step we take, every location we visit, and every event we encounter leaves a digital footprint, the volume and complexity of geospatial data are expanding at an astonishing pace. From GPS-enabled smartphones to remote sensing satellites, the sources of geospatial information are multiplying, generating an immense gold mine of location-based insights.
However, visualizing and analyzing large-scale geospatial data presents a formidable challenge due to the sheer volume and intricacy of information. This often overwhelms traditional visualization tools and methods. The need to balance detail and context while maintaining real-time interactivity can lead to issues of scalability and rendering complexity.
Because of this, many organizations are turning to novel ways of approaching geospatial data, such as spatial indexes such as H3.

Figure 1 – Map built with CARTO Builder and the native support to visualize H3 indexes
What are spatial indexes?
Spatial indexes are global grid systems that exist at multiple resolutions. But what makes them special? Traditionally, spatial data is represented through a geography or geometry in which features are geolocated on the earth by a long reference string describing the coordinates of every vertex. Unlike geometries, spatial indexes are georeferenced by a short ID string. This makes them far smaller to store and lightning fast to process! Because of this, many organizations are utilizing them as a support geography, aggregating their data to these grids to optimize both their storage and analysis.
Figure 2 shows some of the possible types of savings with spatial indexes. To learn more details about their benefits, see Introduction to Spatial Indexes.

Figure 2 – Comparison of performance between geometries and spatial indexes. Learn more about these differences in CARTO’s free ebook Spatial Indexes
Benefits of H3
One of the flagship examples of spatial indexes is H3, which is a hexagonal spatial index. Originally developed by Uber, it is now used far beyond the ridesharing industry. Unlike square-based grids, H3’s well-structured hexagons accurately represent intricate geographic features like rivers and roads, enabling precise depiction of nonperpendicular shapes. The hexagonal geometry excels at capturing gradual spatial changes and movement, and its consistent distance between one centroid and neighboring centroids eliminates outliers. This ensures robust data representation in all directions. Learn more about the benefits of using hexagons for location intelligence at Hexagons for Location Intelligence.

Figure 3 – H3: the relationships between different resolutions
H3 available now in Amazon Redshift
Given the immense benefits of H3 for spatial analysis, we’re very excited to announce the availability of H3 in Amazon Redshift. Seamlessly accessible through the powerful infrastructure of Amazon Redshift, H3 unlocks a new realm of possibilities for visualizing, analyzing, and deriving insights from geospatial data.
Amazon Redshift support for H3 offers an easy way to index spatial coordinates into a hexagonal grid, down to a square meter resolution. Indexed data can be quickly joined across different datasets and aggregated at different levels of precision. H3 enables several spatial algorithms and optimizations based on the hexagonal grid, including nearest neighbors, shortest path, gradient smoothing, and more. H3 indexes refer to cells that can be either hexagons or pentagons. The space is subdivided hierarchically, and given a resolution. H3 supports 16 resolutions from 0–15, inclusive, with 0 being the coarsest and 15 being the finest. H3 indexing and related H3 spatial functions are now available for Amazon Redshift spatial analytics.
Support for the three new H3 indexing related spatial functions, H3_FromLongLat, H3_FromPoint, and H3_PolyFill spatial functions, is now available in all commercial AWS Regions. For more information or to get started with Amazon Redshift spatial analytics, see the documentation for querying spatial data, spatial functions, and the spatial tutorial.
Examples of H3 functions in Amazon Redshift:
To create or access the indexed values of the hexagonal tiles, you use one of the three H3 indexing functions Amazon Redshift has released for the particular spatial GEOMETRY object you want to index. For example, a polygon (a series of Cartesian X Y points that makes a closed 2D object), a point (a single Cartesian X Y value) or a point as a latitude, longitude value (a single latitude, longitude value). For example, if you have a spatial polygon already, you would use the H3_PolyFill function to get the index values of the hexagonal tiles that cover or fit the polygon vertices. Imagine you have a polygon with the following Cartesian (X Y) coordinates:
(0 0, 0 1, 1 1, 1 0, 0 0) , which is just a 1 x 1 unit square. You would then invoke the H3_PolyFill() function by converting the text values of the Cartesian coordinates to a GEOMETRY data type and then use the POLYGON() function to convert those coordinates to a polygon object of GEOMETRY data type. This is what you would call:
SELECT H3_Polyfill(ST_GeomFromText('POLYGON((0 0, 0 1, 1 1, 1 0, 0 0))'), 4);
The return values from the this function are the actual index values to the individual hexagonal tiles that cover the 1 x 1 polygon. Of course, you could define arbitrary polygons of any shape just by using vertices of the enclosing 2D polygon of GEOMETRY data type. The actual H3 tile index values that are returned as Amazon Redshift SUPER data type arrays for the preceding example are:
h3_polyfill
_____________________________________________________________________
[596538848238895103,596538805289222143,596538856828829695,596538813879156735,596537920525959167,596538685030137855,596538693620072447,596538839648960511]
_____________________________________________________________________
So there are eight hexagonal tiles when the resolution of four is used when you call the H3_PolyFill function.
Similarly, the following SQL returns the H3 cell ID from longitude 0, latitude 0, and resolution 10.
SELECT H3_FromLongLat(0, 0, 10);
h3_fromlonglat
______________________________________________________________
623560421467684863
______________________________________________________________
As does this SQL that returns the H3 cell ID from point 0,0 with resolution 10.
SELECT H3_FromPoint(ST_GeomFromText('POINT(0 0)'), 10);
h3_frompoint
_____________________________________________________________________________________
623560421467684863
_____________________________________________________________________________________
Data visualization and analysis made easy with H3 and CARTO
To illustrate how H3 can be used in action, let’s turn to CARTO. As an AWS Partner, CARTO offers a software solution on the curated digital catalog AWS Marketplace that seamlessly integrates distinctive capabilities for spatial visualization, analysis, and app development directly within the AWS data warehouse environment. Notably setting CARTO apart from certain GIS platforms is its strategy of query optimization by using the data warehouse and conducting analytical tasks and computations within Amazon Redshift through the use of user-defined functions (UDFs).

Figure 4 – Basic workflow build with CARTO to polyfill a set of polygons into H3 indexes
Amazon Redshift comes equipped with a variety of preexisting spatial functions, and CARTO enhances this foundation by providing additional spatial functions within its Analytics Toolbox for Amazon Redshift, thereby expanding the range of analytical possibilities even further. Let’s dive into a use case to see how this can be used to solve an example spatial analysis problem.
Unveiling H3 spatial indexes in logistics
Logistics, particularly in last-mile delivery, harness substantial benefits from utilizing H3 spatial indexes in operational analytics. This framework has revolutionized geospatial analysis, particularly in efficiently managing extensive datasets.
H3 divides earth’s surface into varying-sized hexagons, precisely representing different geographic areas across multiple hierarchy levels. This precision allows detailed location representation at various scales, offering versatility in analyses and optimizations—from micro to macro, spanning neighborhoods to cities—efficiently managing vast datasets.
H3-based analytics empower the processing and understanding of delivery data patterns, such as peak times, popular destinations, and high-demand areas. This insight aids in predicting future demand and facilitates operations-related decisions. H3 can also help create location-based profiling features for predictive machine learning (ML) models such as risk-mitigation models. Further use cases can include adjustments to inventory, strategic placement of permanent or temporary distribution centers, or even refining pricing strategies to become more effective and adaptive.
The uniform scalability and size consistency of H3 make it an ideal structure for organizing data, effectively replacing traditional zip codes in day-to-day operations.
In essence, insights derived from H3-based analytics empower businesses to make informed decisions, swiftly adapt to market changes, and elevate customer satisfaction through efficient deliveries.
The feature is eagerly anticipated by Amazon Redshift and CARTO customers. “The prospect of leveraging H3’s advanced spatial capabilities within the robust framework of Amazon Redshift has us excited about the new insights and efficiencies we can unlock for our geospatial analysis. This partnership truly aligns with our vision for smarter, data-driven decision-making,” says the Data Science Team at Aramex.

Figure 5 – Diagram illustrating the process of using H3-powered analytics for strategic decision-making
Let’s talk about your use case
You can experience the future of location intelligence firsthand by requesting a demo from CARTO today. Discover how H3’s hexagonal spatial index, seamlessly integrated with Amazon Redshift, can empower your organization with efficiency in handling large-scale geospatial data.
About Amazon Redshift
Thousands of customers rely on Amazon Redshift to analyze data from terabytes to petabytes and run complex analytical queries.
With Amazon Redshift, you can get real-time insights and predictive analytics on all of your data across your operational databases, data lake, data warehouse, and third-party datasets. It delivers this at a price performance that’s up to three times better than other cloud data warehouses out of the box, helping you keep your costs predictable.
Amazon Redshift provides capabilities likeAmazon Redshift spatial analytics, Amazon Redshift streaming analytics, Amazon Redshift ML and Amazon Redshift Serverless to further simplify application building and make it easier, simpler, and faster for independent software vendors (ISVs) to embed rich data analytics capabilities within their applications.
With Amazon Redshift serverless, ISVs can run and scale analytics quickly without the need to set up and manage data warehouse infrastructure. Developers, data analysts, business professionals, and data scientists can go from data to insights in seconds by simply loading and querying in the data warehouse.
To request a demo of Amazon Redshift, visit Amazon Redshift free trial or to get started on your own, visit Getting started with Amazon Redshift.
About CARTO
From smartphones to connected cars, location data is changing the way we live and the way we run businesses. Everything happens somewhere, but visualizing data to see where things are isn’t the same as understanding why they happen there. CARTO is the world’s leading cloud-based location intelligence platform, enabling organizations to use spatial data and analysis for more efficient delivery routes, better behavioral marketing, strategic store placements, and much more.
Data scientists, developers, and analysts use CARTO to optimize business processes and predict future outcomes through the power of spatial data science. To learn more, visit CARTO.
About the authors
 Ravi Animi is a senior product leader in the Amazon Redshift team and manages several functional areas of the Amazon Redshift cloud data warehouse service, including spatial analytics, streaming analytics, query performance, Spark integration, and analytics business strategy. He has experience with relational databases, multidimensional databases, IoT technologies, storage and compute infrastructure services, and more recently, as a startup founder in the areas of artificial intelligence (AI) and deep learning, computer vision, and robotics.
Ravi Animi is a senior product leader in the Amazon Redshift team and manages several functional areas of the Amazon Redshift cloud data warehouse service, including spatial analytics, streaming analytics, query performance, Spark integration, and analytics business strategy. He has experience with relational databases, multidimensional databases, IoT technologies, storage and compute infrastructure services, and more recently, as a startup founder in the areas of artificial intelligence (AI) and deep learning, computer vision, and robotics.
 Ioanna Tsalouchidou is a software development engineer in the Amazon Redshift team focusing on spatial analytics and query processing. She holds a PhD in graph algorithms from UPF Spain and a Masters in distributed systems and computing from KTH Sweden and UPC Spain.
Ioanna Tsalouchidou is a software development engineer in the Amazon Redshift team focusing on spatial analytics and query processing. She holds a PhD in graph algorithms from UPF Spain and a Masters in distributed systems and computing from KTH Sweden and UPC Spain.
 Hinnerk Gildhoff is a senior engineering leader in the Amazon Redshift team leading query processing, spatial analytics, materialized views, autonomics, query languages and more. Prior to joining Amazon, Hinnerk spent over a decade as both an engineer and a manager in the field of in-memory and cluster computing, specializing in building databases and distributed systems.
Hinnerk Gildhoff is a senior engineering leader in the Amazon Redshift team leading query processing, spatial analytics, materialized views, autonomics, query languages and more. Prior to joining Amazon, Hinnerk spent over a decade as both an engineer and a manager in the field of in-memory and cluster computing, specializing in building databases and distributed systems.
Javier de la Torre is founder and Chief Strategy Officer of CARTO, has been instrumental in advancing the geospatial industry. At CARTO, he’s led innovations in location intelligence. He also serves on the Open Geospatial Consortium board, aiding in the development of standards like geoparquet. Javier’s commitment extends to environmental causes through his work with Tierra Pura, focusing on climate change and conservation, demonstrating his dedication to using data for global betterment.


























 Kaarthiik Thota is a Senior Amazon DocumentDB Specialist Solutions Architect at AWS based out of London. He is passionate about database technologies and enjoys helping customers solve problems and modernize applications using NoSQL databases. Before joining AWS, he worked extensively with relational databases, NoSQL databases, and business intelligence technologies for over 15 years.
Kaarthiik Thota is a Senior Amazon DocumentDB Specialist Solutions Architect at AWS based out of London. He is passionate about database technologies and enjoys helping customers solve problems and modernize applications using NoSQL databases. Before joining AWS, he worked extensively with relational databases, NoSQL databases, and business intelligence technologies for over 15 years. Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics o f networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics o f networking and security, and is based out of Austin, Texas.









 Mansi Bhutada is an ISV Solutions Architect based in the Netherlands. She helps customers design and implement well-architected solutions in AWS that address their business problems. She is passionate about data analytics and networking. Beyond work, she enjoys experimenting with food, playing pickleball, and diving into fun board games.
Mansi Bhutada is an ISV Solutions Architect based in the Netherlands. She helps customers design and implement well-architected solutions in AWS that address their business problems. She is passionate about data analytics and networking. Beyond work, she enjoys experimenting with food, playing pickleball, and diving into fun board games. Kartikay Khator is a Solutions Architect within the Global Life Sciences at AWS, where he dedicates his efforts to developing innovative and scalable solutions that cater to the evolving needs of customers. His expertise lies in harnessing the capabilities of AWS Analytics services. Extending beyond his professional pursuits, he finds joy and fulfillment in the world of running and hiking. Having already completed two marathons, he is currently preparing for his next marathon challenge.
Kartikay Khator is a Solutions Architect within the Global Life Sciences at AWS, where he dedicates his efforts to developing innovative and scalable solutions that cater to the evolving needs of customers. His expertise lies in harnessing the capabilities of AWS Analytics services. Extending beyond his professional pursuits, he finds joy and fulfillment in the world of running and hiking. Having already completed two marathons, he is currently preparing for his next marathon challenge. Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on 

























 Ravi Animi is a senior product leader in the Amazon Redshift team and manages several functional areas of the Amazon Redshift cloud data warehouse service, including spatial analytics, streaming analytics, query performance, Spark integration, and analytics business strategy. He has experience with relational databases, multidimensional databases, IoT technologies, storage and compute infrastructure services, and more recently, as a startup founder in the areas of artificial intelligence (AI) and deep learning, computer vision, and robotics.
Ravi Animi is a senior product leader in the Amazon Redshift team and manages several functional areas of the Amazon Redshift cloud data warehouse service, including spatial analytics, streaming analytics, query performance, Spark integration, and analytics business strategy. He has experience with relational databases, multidimensional databases, IoT technologies, storage and compute infrastructure services, and more recently, as a startup founder in the areas of artificial intelligence (AI) and deep learning, computer vision, and robotics. Ioanna Tsalouchidou is a software development engineer in the Amazon Redshift team focusing on spatial analytics and query processing. She holds a PhD in graph algorithms from UPF Spain and a Masters in distributed systems and computing from KTH Sweden and UPC Spain.
Ioanna Tsalouchidou is a software development engineer in the Amazon Redshift team focusing on spatial analytics and query processing. She holds a PhD in graph algorithms from UPF Spain and a Masters in distributed systems and computing from KTH Sweden and UPC Spain. Hinnerk Gildhoff is a senior engineering leader in the Amazon Redshift team leading query processing, spatial analytics, materialized views, autonomics, query languages and more. Prior to joining Amazon, Hinnerk spent over a decade as both an engineer and a manager in the field of in-memory and cluster computing, specializing in building databases and distributed systems.
Hinnerk Gildhoff is a senior engineering leader in the Amazon Redshift team leading query processing, spatial analytics, materialized views, autonomics, query languages and more. Prior to joining Amazon, Hinnerk spent over a decade as both an engineer and a manager in the field of in-memory and cluster computing, specializing in building databases and distributed systems. Javier de la Torre is founder and Chief Strategy Officer of CARTO, has been instrumental in advancing the geospatial industry. At CARTO, he’s led innovations in location intelligence. He also serves on the Open Geospatial Consortium board, aiding in the development of standards like geoparquet. Javier’s commitment extends to environmental causes through his work with Tierra Pura, focusing on climate change and conservation, demonstrating his dedication to using data for global betterment.
Javier de la Torre is founder and Chief Strategy Officer of CARTO, has been instrumental in advancing the geospatial industry. At CARTO, he’s led innovations in location intelligence. He also serves on the Open Geospatial Consortium board, aiding in the development of standards like geoparquet. Javier’s commitment extends to environmental causes through his work with Tierra Pura, focusing on climate change and conservation, demonstrating his dedication to using data for global betterment.