Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=Uj9AKzB9dL4
Yearly Archives: 2024
Friday Squid Blogging: Squid Sticker
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/12/friday-squid-blogging-squid-sticker.html
A sticker for your water bottle.
Amazon Q data integration adds DataFrame support and in-prompt context-aware job creation
Post Syndicated from Bo Li original https://aws.amazon.com/blogs/big-data/amazon-q-data-integration-adds-dataframe-support-and-in-prompt-context-aware-job-creation/
Amazon Q data integration, introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. This post introduces exciting new capabilities for Amazon Q data integration that work together to make ETL development more efficient and intuitive. We’ve added support for DataFrame-based code generation that works across any Spark environment. We’ve also introduced in-prompt context-aware development that applies details from your conversations, working seamlessly with a new iterative development experience. This means you can refine your ETL jobs through natural follow-up questions—starting with a basic data pipeline and progressively adding transformations, filters, and business logic through conversation. These improvements are available through the Amazon Q chat experience on the AWS Management Console, and the Amazon SageMaker Unified Studio (preview) visual ETL and notebook interfaces.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi, Delta, and Apache Iceberg. Amazon Q can generate ETL jobs for connecting to over 20 different data sources, including relational databases like PostgreSQL, MySQL and Oracle; data warehouses like Amazon Redshift, Snowflake, and Google BigQuery; NoSQL databases like Amazon DynamoDB, MongoDB, and OpenSearch; tables defined in the AWS Glue Data Catalog; and custom user-supplied JDBC and Spark connectors. Your generated jobs can use a variety of data transformations, including filters, projections, unions, joins, and aggregations, giving you the flexibility to handle complex data processing requirements.
In this post, we discuss how Amazon Q data integration transforms ETL workflow development.
Improved capabilities of Amazon Q data integration
Previously, Amazon Q data integration only generated code with template values that required you to fill in the configurations such as connection properties for data source and data sink and the configurations for transforms manually. With in-prompt context awareness, you can now include this information in your natural language query, and Amazon Q data integration will automatically extract and incorporate it into the workflow. In addition, generative visual ETL in the SageMaker Unified Studio (preview) visual editor allows you to reiterate and refine your ETL workflow with new requirements, enabling incremental development.
Solution overview
This post describes the end-to-end user experiences to demonstrate how Amazon Q data integration and SageMaker Unified Studio (preview) simplify your data integration and data engineering tasks with the new enhancements, by building a low-code no-code (LCNC) ETL workflow that enables seamless data ingestion and transformation across multiple data sources.
We demonstrate how to do the following:
- Connect to diverse data sources
- Perform table joins
- Apply custom filters
- Export processed data to Amazon S3
The following diagram illustrates the architecture.

Using Amazon Q data integration with Amazon SageMaker Unified Studio (preview)
In the first example, we use Amazon SageMaker Unified Studio (preview) to develop a visual ETL workflow incrementally. This pipeline reads data from different Amazon S3 based Data Catalog tables, performs transformations on the data, and writes the transformed data back into an Amazon S3. We use the allevents_pipe and venue_pipe files from the TICKIT dataset to demonstrate this capability. The TICKIT dataset records sales activities on the fictional TICKIT website, where users can purchase and sell tickets online for different types of events such as sports games, shows, and concerts.
The process involves merging the allevents_pipe and venue_pipe files from the TICKIT dataset. Next, the merged data is filtered to include only a specific geographic region. Then the transformed output data is saved to Amazon S3 for further processing in future.
Data preparation
The two datasets are hosted as two Data Catalog tables, venue and event, in a project in Amazon SageMaker Unified Studio (preview), as shown in the following screenshots.


Data processing
To process the data, complete the following steps:
- On the Amazon SageMaker Unified Studio console, on the Build menu, choose Visual ETL flow.
An Amazon Q chat window will help you provide a description for the ETL flow to be built.
- For this post, enter the following text:
Create a Glue ETL flow connect to 2 Glue catalog tables venue and event in my database glue_db_4fthqih3vvk1if, join the results on the venue’s venueid and event’s e_venueid, and write output to a S3 location.
(The database name is generated with the project ID suffixed to the given database name automatically). - Choose Submit.


An initial data integration flow will be generated as shown in the following screenshot to read from the two Data Catalog tables, join the results, and write to Amazon S3. We can see the join conditions are correctly inferred from our request from the join node configuration displayed.

Let’s add another filter transform based on the venue state as DC.
- Choose the plus sign and choose the Amazon Q icon to ask a follow-up question.
- Enter the instructions
filter on venue state with condition as venuestate==‘DC’ after joining the resultsto modify the workflow.


The workflow is updated with a new filter transform.

Upon checking the S3 data target, we can see the S3 path is now a placeholder <s3-path> and the output format is Parquet.
- We can ask the following question in Amazon Q:
update the s3 sink node to write to s3://xxx-testing-in-356769412531/output/ in CSV format
in the same way to update the Amazon S3 data target.

- Choose Show script to see the generated code is DataFrame based, with all context in place from all of our conversation.

- Finally, we can preview the data to be written to the target S3 path. Note that the data is a joined result with only the venue state DC included.




With Amazon Q data integration with Amazon SageMaker Unified Studio (preview), an LCNC user can create the visual ETL workflow by providing prompts to Amazon Q and the context for data sources and transformations are preserved. Subsequently, Amazon Q also generated the DataFrame-based code for data engineers or more experienced users to use the automatic ETL generated code for scripting purposes.
Amazon Q data integration with Amazon SageMaker Unified Studio (preview) notebook
Amazon Q data integration is also available in the Amazon SageMaker Unified Studio (preview) notebook experience. You can add a new cell and enter your comment to describe what you want to achieve. After you press Tab and Enter, the recommended code is shown.
For example, we provide the same initial question:
Create a Glue ETL flow to connect to 2 Glue catalog tables venue and event in my database glue_db_4fthqih3vvk1if, join the results on the venue’s venueid and event’s e_venueid, and write output to a S3 location.
Similar to the Amazon Q chat experience, the code is recommended. If you press Tab, then the recommended code is chosen.

The following video provides a full demonstration of these two experiences in Amazon SageMaker Unified Studio (preview).
Using Amazon Q data integration with AWS Glue Studio
In this section, we walk through the steps to use Amazon Q data integration with AWS Glue Studio
Data preparation
The two datasets are hosted in two Amazon S3 based Data Catalog tables, event and venue, in the database glue_db, which we can query from Amazon Athena. The following screenshot shows an example of the venue table.

Data processing
To start using the AWS Glue code generation capability, use the Amazon Q icon on the AWS Glue Studio console. You can start authoring a new job, and ask Amazon Q the question to create the same workflow:
Create a Glue ETL flow connect to 2 Glue catalog tables venue and event in my database glue_db, join the results on the venue’s venueid and event’s e_venueid, and then filter on venue state with condition as venuestate=='DC' and write to s3://<s3-bucket>/<folder>/output/ in CSV format.
You can see the same code is generated with all configurations in place. With this response, you can learn and understand how you can author AWS Glue code for your needs. You can copy and paste the generated code to the script editor. After you configure an AWS Identity and Access Management (IAM) role on the job, save and run the job. When the job is complete, you can begin querying the data exported to Amazon S3.

After the job is complete, you can verify the joined data by checking the specified S3 path. The data is filtered by venue state as DC and is now ready for downstream workloads to process.

The following video provides a full demonstration of the experience with AWS Glue Studio.
Conclusion
In this post, we explored how Amazon Q data integration transforms ETL workflow development, making it more intuitive and time-efficient, with the latest enhancement of in-prompt context awareness to accurately generate a data integration flow with reduced hallucinations, and multi-turn chat capabilities to incrementally update the data integration flow, add new transforms and update DAG nodes. Whether you’re working with the console or other Spark environments in SageMaker Unified Studio (preview), these new capabilities can significantly reduce your development time and complexity.
To learn more, refer to Amazon Q data integration in AWS Glue.
About the Authors
 Bo Li is a Senior Software Development Engineer on the AWS Glue team. He is devoted to designing and building end-to-end solutions to address customers’ data analytic and processing needs with cloud-based, data-intensive technologies.
Bo Li is a Senior Software Development Engineer on the AWS Glue team. He is devoted to designing and building end-to-end solutions to address customers’ data analytic and processing needs with cloud-based, data-intensive technologies.
 Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in big data, ETL, and analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends.
Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in big data, ETL, and analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends.
 Kartik Panjabi is a Software Development Manager on the AWS Glue team. His team builds generative AI features for the Data Integration and distributed system for data integration.
Kartik Panjabi is a Software Development Manager on the AWS Glue team. His team builds generative AI features for the Data Integration and distributed system for data integration.
 Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Metasploit Weekly Wrap-Up 12/20/2024
Post Syndicated from Alan David Foster original https://blog.rapid7.com/2024/12/20/metasploit-weekly-wrap-up-12-20-2024/
New module content (4)
GameOver(lay) Privilege Escalation and Container Escape

Authors: bwatters-r7, g1vi, gardnerapp, and h00die
Type: Exploit
Pull request: #19460 contributed by gardnerapp
Path: linux/local/gameoverlay_privesc
AttackerKB reference: CVE-2023-2640
Description: Adds a module for CVE-2023-2640 and CVE-2023-32629, a local privilege escalation in some Ubuntu kernel versions that abuses overly trusting OverlayFS features.
Clinic’s Patient Management System 1.0 – Unauthenticated RCE
Authors: Aaryan Golatkar and Oğulcan Hami Gül
Type: Exploit
Pull request: #19733 contributed by aaryan-11-x
Path: multi/http/clinic_pms_fileupload_rce
AttackerKB reference: CVE-2022-40471
Description: New exploit module for Clinic’s Patient Management System 1.0 that targets CVE-2022-40471. The module exploits unrestricted file upload, which can be further used to get remote code execution (RCE) through a malicious PHP file.
WordPress WP Time Capsule Arbitrary File Upload to RCE
Authors: Rein Daelman and Valentin Lobstein
Type: Exploit
Pull request: #19713 contributed by Chocapikk
Path: multi/http/wp_time_capsule_file_upload_rce
AttackerKB reference: CVE-2024-8856
Description: This exploits a remote code execution (RCE) vulnerability (CVE-2024-8856) in the WordPress WP Time Capsule plugin (versions ≤ 1.22.21). This vulnerability allows unauthenticated attackers to upload and execute arbitrary files due to improper validation within the plugin.
WSO2 API Manager Documentation File Upload Remote Code Execution
Authors: Heyder Andrade <@HeyderAndrade>, Redway Security <redwaysecurity.com>, and Siebene@ <@Siebene7>
Type: Exploit
Pull request: #19647 contributed by heyder
Path: multi/http/wso2_api_manager_file_upload_rce
AttackerKB reference: CVE-2023-2988
Description: Adds an exploit module for a vulnerability in the ‘Add API Documentation’ feature of WSO2 API Manager (CVE-2023-2988) that allows malicious users with specific permissions to upload arbitrary files to a user-controlled server location. This flaw allows for RCE on the target system.
Enhancements and features (4)
- #19546 from adfoster-r7 – Improves the database module cache performance from ~3 minutes to ~1 minute by performing bulk inserts of module metadata instead of multiple smaller inserts for every
module/reference/author/etc. - #19660 from zeroSteiner – Updates
OptEnumto validate values without being case sensitive while preserving the case the author was expecting. - #19715 from oddlittlebird – Improves
db/README.mddocumentation. - #19718 from sjanusz-r7 – Expose the currently authenticated rpc_token to RPC handlers.
Bugs fixed (4)
- #19719 from bwatters-r7 – Fixed a syntax error in the code generated by fetch payloads when the FETCH_DELETE option was enabled.
- #19721 from bwatters-r7 – This updates the way the module checks the Windows build version to determine if it’s vulnerable to CVE-2020-0668.
- #19726 from pczinser – The reverse HTTP and HTTPS Meterpreter x64 payloads now correctly set the User-Agent HTTP header when connecting back to Metasploit. Before this fix, the
HttpUserAgentoption was not used properly. You can now use this option to customize the User-Agent HTTP header when using these payloads. - #19739 from sjanusz-r7 – Fixes an issue with the
post/multi/recon/local_exploit_suggestermodule which would crash if aTARGETvalue was set.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate and you can get more details on the changes since the last blog post from GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest. To install fresh without using git, you can use the open-source-only Nightly Installers or the commercial edition Metasploit Pro.
Jumia builds a next-generation data platform with metadata-driven specification frameworks
Post Syndicated from Ramon Diez Lejarazu original https://aws.amazon.com/blogs/big-data/jumia-builds-a-next-generation-data-platform-with-metadata-driven-specification-frameworks/
Jumia is a technology company born in 2012, present in 14 African countries, with its main headquarters in Lagos, Nigeria. Jumia is built around a marketplace, a logistics service, and a payment service. The logistics service enables the delivery of packages through a network of local partners, and the payment service facilitates the payments of online transactions within Jumia’s ecosystem. Jumia is present in NYSE and has a market cap of $554 million.
In this post, we share part of the journey that Jumia took with AWS Professional Services to modernize its data platform that ran under a Hadoop distribution to AWS serverless based solutions. Some of the challenges that motivated the modernization were the high cost of maintenance, lack of agility to scale computing at specific times, job queuing, lack of innovation when it came to acquiring more modern technologies, complex automation of the infrastructure and applications, and the inability to develop locally.
Solution overview
The basic concept of the modernization project is to create metadata-driven frameworks, which are reusable, scalable, and able to respond to the different phases of the modernization process. These phases are: data orchestration, data migration, data ingestion, data processing, and data maintenance.
This standardization for each phase was considered as a way to streamline the development workflows and minimize the risk of errors that can arise from using disparate methods. This also enabled migration of different kinds of data following a similar approach regardless of the use case. By adopting this approach, the data handling is consistent, more efficient, and more straightforward to manage across different projects and teams. In addition, although the use cases have autonomy in their domain from a governance perspective, on top of them is a centralized governance model that defines the access control in the shared architectural components. Importantly, this implementation emphasizes data protection by enforcing encryption across all services, including Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB. Furthermore, it adheres to the principle of least privilege, thereby enhancing overall system security and reducing potential vulnerabilities.
The following diagram describes the frameworks that were created. In this design, the workloads in the new data platform are divided by use case. Each use case requires the creation of a set of YAML files for each phase, from data migration to data flow orchestration, and they are basically the input of the system. The output is a set of DAGs that run the specific tasks.

In the following sections, we discuss the objectives, implementation, and learnings of each phase in more detail.
Data orchestration
The objective of this phase is to build a metadata-driven framework to orchestrate the data flows along the whole modernization process. The orchestration framework provides a robust and scalable solution that has the following capacities: dynamically create DAGs, integrate natively with non-AWS services, allow the creation of dependencies based on past executions, and add an accessible metadata generation per each execution. Therefore, it was decided to use Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which, through the Apache Airflow engine, provides these functionalities while abstracting users from the management operation.
The following is the description of the metadata files that are provided as part of the data orchestration phase for a given use case that performs the data processing using Spark on Amazon EMR Serverless:
owner: # Use case owner
dags: # List of DAGs to be created for this use case
- name: # Use case name
type: # Type of DAG (could be migration, ingestion, transformation or maintenance)
tags: # List of TAGs
notification: # Defines notificacions for this DAGs
on_success_callback: true
on_failure_callback: true
spark: # Spark job information
entrypoint: # Spark script
arguments: # Arguments required by the Spark script
spark_submit_parameters: # Spark submit parameters.
The idea behind all the frameworks is to build reusable artifacts that enable the development teams to accelerate their work while providing reliability. In this case, the framework provides the capabilities to create DAG objects within Amazon MWAA based on configuration files (YAML files).
This particular framework is built on layers that add different functionalities to the final DAG:
- DAGs – The DAGs are built based on the metadata information provided to the framework. The data engineers don’t have to write Python code in order to create the DAGs, they are automatically created and this module is in charge of performing this dynamic creation of DAGs.
- Validations – This layer handles YAML file validation in order to prevent corrupted files from affecting the creation of other DAGs.
- Dependencies – This layer handles dependencies among different DAGs in order to handle complex interconnections.
- Notifications – This layer handles the type of notifications and alerts that are part of the workflows.

One aspect to consider when using Amazon MWAA is that, being a managed service, it requires some maintenance from the users, and it’s important to have a good understanding of the number of DAGs and processes that you’re expected to have in order to fine-tune the instance and obtain the desired performance. Some of the parameters that were fine-tuned during the engagement were core.dagbag_import_timeout, core.dag_file_processor_timeout, core.min_serialized_dag_update_interval, core.min_serialized_dag_fetch_interval, scheduler.min_file_process_interval, scheduler.max_dagruns_to_create_per_loop, scheduler.processor_poll_interval, scheduler.dag_dir_list_interval, and celery.worker_autoscale.
One of the layers described in the preceding diagram corresponds to validation. This was an important component for the creation of dynamic DAGs. Because the input to the framework consists of YML files, it was decided to filter out corrupted files before attempting to create the DAG objects. Following this approach, Jumia could avoid undesired interruptions of the whole process. The module that actually builds DAGs only receives configuration files that follow the required specifications to successfully create them. In case of corrupted files, information regarding the actual issues is logged into Amazon CloudWatch so that developers can fix them.
Data migration
The objective of this phase is to build a metadata-driven framework for migrating data from HDFS to Amazon S3 with Apache Iceberg storage format, which involves the least operational overhead, provides scalability capacity during peak hours, and guarantees data integrity and confidentiality.
The following diagram illustrates the architecture.

During this phase, a metadata-driven framework built in PySpark receives a configuration file as input so that some migration tasks can run in an Amazon EMR Serverless job. This job uses the PySpark framework as the script location. Then the orchestration framework described previously is used to create a migration DAG that runs the following tasks:
- The first task creates the DDLs in Iceberg format in the AWS Glue Data Catalog using the migration framework within an Amazon EMR Serverless job.
- After the tables are created, the second task transfers HDFS data to a landing bucket in Amazon S3 using AWS DataSync to sync customer data. This process brings data from all the different layers of the data lake.
- When this process is complete, a third task converts data to Iceberg format from the landing bucket to the destination bucket (raw, process, or analytics) using again another option of the migration framework embedded in an Amazon EMR Serverless job.
Data transfer performance is better when the size of the files to be transferred is around 128–256 MB, so it’s recommended to compress the files at the source. By reducing the number of files, metadata analysis and integrity phases are reduced, speeding up the migration phase.
Data ingestion
The objective of this phase is to implement another framework based on metadata that responds to the two data ingestion models. A batch mode is responsible for extracting data from different data sources (such as Oracle or PostgreSQL) and a micro-batch-based mode extracts data from a Kafka cluster that, based on configuration parameters, has the capacity to run native streams in streaming.
The following diagram illustrates the architecture for the batch and micro-batch and streaming approach.

During this phase, a metadata-driven framework builds the logic to bring data from Kafka, databases, or external services, that will be run using an ingestion DAG deployed in Amazon MWAA.
Spark Structured Streaming was used to ingest data from Kafka topics. The framework receives configuration files in YAML format that indicate which topics to read, what extraction processes should be performed, whether it should be read in streaming or micro-batch, and in which destination table the information should be saved, among other configurations.
For batch ingestion, a metadata-driven framework written in Pyspark was implemented. In the same way as the previous one, the framework received a configuration in YAML format with the tables to be migrated and their destination.
One of the aspects to consider in this type of migration is the synchronization of data from the ingestion phase and the migration phase, so that there is no loss of data and that data is not reprocessed unnecessarily. To this end, a solution has been implemented that saves the timestamps of the last historical data (per table) migrated in a DynamoDB table. Both types of frameworks are programmed to use this data the first time they are run. For micro-batching use cases, which use Spark Structured Streaming, Kafka data is read by assigning the value stored in DynamoDB to the startingTimeStamp parameter. For all other executions, priority will be given to the metadata in the checkpoint folder. This way, you can make sure ingestion is synchronized with the data migration.
Data processing
The objective in this phase was to be able to handle updates and deletions of data in an object-oriented file system, so Iceberg is a key solution that was adopted throughout the project as delta lake files because of its ACID capabilities. Although all phases use Iceberg as delta files, the processing phase makes extensive use of Iceberg’s capabilities to do incremental processing of data, creating the processing layer using UPSERT using Iceberg’s ability to run MERGE INTO commands.
The following diagram illustrates the architecture.

The architecture is similar to the ingestion phase, with just changes to the data source to be Amazon S3. This approach speeds up the delivery phase and maintains quality with a production-ready solution.
By default, Amazon EMR Serverless has the spark.dynamicAllocation.enabled parameter set to True. This option scales up or down the number of executors registered within the application, based on the workload. This brings a lot of advantages when dealing with different types of workloads, but it also brings considerations when using Iceberg tables. For instance, while writing data into an Iceberg table, the Amazon EMR Serverless application can use a large number of executors in order to speed up the task. This can result in reaching Amazon S3 limits, specifically the number of requests per second per prefix. For this reason, it’s important to apply good data partitioning practices.
Another important aspect to consider in these cases is the object storage file layout. By default, Iceberg uses the Hive storage layout, but it can be set to use ObjectStoreLocationProvider. By setting this property, a deterministic hash is generated for each file, with a hash appended directly after write.data.path. This can considerably minimize throttle requests based on object prefix, as well as maximize throughput for Amazon S3 related I/O operations, because the files written are equally distributed across multiple prefixes.
Data maintenance
When working with data lake table formats such as Iceberg, it’s essential to engage in routine maintenance tasks to optimize table metadata file management, preventing a large number of unnecessary files from accumulating and promptly removing any unused files. The objective of this phase was to build another framework that can perform these types of tasks on the tables within the data lake.
The following diagram illustrates the architecture.

The framework, as well as the other ones, receives a configuration file (YAML files) indicating the tables and the list of maintenance tasks with their respective parameters. It was built on PySpark so that it could run as an Amazon EMR Serverless job and could be orchestrated using the orchestration framework just like the other frameworks built as part of this solution.
The following maintenance tasks are supported by the framework:
- Expire snapshots – Snapshots can be used for rollback operations as well as time traveling queries. However, they can accumulate over time and can lead to performance degradation. It’s highly recommended to regularly expire snapshots that are no longer needed.
- Remove old metadata files – Metadata files can accumulate over time just like snapshots. Removing them regularly is also recommended, especially when dealing with streaming or micro-batching operations, which was one of the cases of the overall solution.
- Compact files – As the number of data files increases, the number of metadata stored in the manifest files also increases, and small data files can lead to less efficient queries. Because this solution uses a streaming and micro-batching application writing into Iceberg tables, the size of the files tends to be small. For this reason, a method to compact files was imperative to enhance the overall performance.
- Hard delete data – One of the requirements was to be able to perform hard deletes in the data older than a certain period of time. This implies removing expiring snapshots and removing metadata files.
The maintenance tasks were scheduled with different frequencies depending on the use case and the specific task. For this reason, the schedule information for this tasks is defined in each of the YAML files of the specific use case.
At the time this framework was implemented, there was no any automatic maintenance solution on top of Iceberg tables. At AWS re:Invent 2024, Amazon S3 Tables functionality has been released to automatize the maintenance of Iceberg Tables . This functionality automates file compaction, snapshot management, and unreferenced file removal.
Conclusion
Building a data platform on top of standarized frameworks that use metadata for different aspects of the data handling process, from data migration and ingestion to orchestration, enhances the visibility and control over each of the phases and significantly speeds up implementation and development processes. Furthermore, by using services such as Amazon EMR Serverless and DynamoDB, you can bring all the benefits of serverless architectures, including scalability, simplicity, flexible integration, improved reliability, and cost-efficiency.
With this architecture, Jumia was able to reduce their data lake cost by 50%. Furthermore, with this approach, data and DevOps teams were able to deploy complete infrastructures and data processing capabilities by creating metadata files along with Spark SQL files. This approach has reduced turnaround time to production and reduced failure rates. Additionally, AWS Lake Formation provided the capabilities to collaborate and govern datasets on various storage layers on the AWS platform and externally.
Leveraging AWS for our data platform has not only optimized and reduced our infrastructure costs but also standardized our workflows and ways of working across data teams and established a more trustworthy single source of truth for our data assets. This transformation has boosted our efficiency and agility, enabling faster insights and enhancing the overall value of our data platform.
– Hélder Russa, Head of Data Engineering at Jumia Group.
Take the first step towards streamlining the data migration process now, with AWS.
About the Authors
 Ramón Díez is a Senior Customer Delivery Architect at Amazon Web Services. He led the project with the firm conviction of using technology in service of the business.
Ramón Díez is a Senior Customer Delivery Architect at Amazon Web Services. He led the project with the firm conviction of using technology in service of the business.
 Paula Marenco is a Data Architect at Amazon Web Services, she enjoys designing analytical solutions that bring light into complexity, turning intricate data processes into clear and actionable insights. Her work focuses on making data more accessible and impactful for decision-making.
Paula Marenco is a Data Architect at Amazon Web Services, she enjoys designing analytical solutions that bring light into complexity, turning intricate data processes into clear and actionable insights. Her work focuses on making data more accessible and impactful for decision-making.
 Hélder Russa is the Head of Data Engineering at Jumia Group, contributing to the strategy definition, design, and implementation of multiple Jumia data platforms that support the overall decision-making process, as well as operational features, data science projects, and real-time analytics.
Hélder Russa is the Head of Data Engineering at Jumia Group, contributing to the strategy definition, design, and implementation of multiple Jumia data platforms that support the overall decision-making process, as well as operational features, data science projects, and real-time analytics.
 Pedro Gonçalves is a Principal Data Engineer at Jumia Group, responsible for designing and overseeing the data architecture, emphasizing on AWS Platform and datalakehouse technologies to ensure robust and agile data solutions and analytics capabilities.
Pedro Gonçalves is a Principal Data Engineer at Jumia Group, responsible for designing and overseeing the data architecture, emphasizing on AWS Platform and datalakehouse technologies to ensure robust and agile data solutions and analytics capabilities.
Olympic coaches on the importance of working in a healthy environment
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=643unTJ-1nA
Grml 2024.12 released
Post Syndicated from jzb original https://lwn.net/Articles/1003048/
Version 2024.12 of the Debian-based Grml live Linux system for system administrators has been released. Grml 2024.12 uses packages from the upcoming Debian 13 (“trixie”) release. It drops support for 32-bit x86 PCs and gains support for 64-bit ARM CPUs. See the release notes for a full list of changes and new features.
[$] Process creation in io_uring
Post Syndicated from corbet original https://lwn.net/Articles/1002371/
Back in 2022, Josh Triplett presented a
plan to implement a “spawn new process” functionality in the io_uring
subsystem. There was a fair amount of interest at the time, but developers
got distracted, and the work did not progress. Now, Gabriel Krisman
Bertazi has returned with a patch series
updating and improving Triplett’s work. While interest in this
functionality remains, it may still take some time before it is ready for
merging into the mainline.
Hi Claude, build an MCP server on Cloudflare Workers
Post Syndicated from Dina Kozlov original https://blog.cloudflare.com/model-context-protocol/
In late November 2024, Anthropic announced a new way to interact with AI, called Model Context Protocol (MCP). Today, we’re excited to show you how to use MCP in combination with Cloudflare to extend the capabilities of Claude to build applications, generate images and more. You’ll learn how to build an MCP server on Cloudflare to make any service accessible through an AI assistant like Claude with just a few lines of code using Cloudflare Workers.
MCP is an open standard that provides a universal way for LLMs to interact with services and applications. As the introduction on the MCP website puts it,
“Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.”
From an architectural perspective, MCP is comprised of several components:
-
MCP hosts: Programs or tools (like Claude) where AI models operate and interact with different services
-
MCP clients: Client within an AI assistant that initiates requests and communicates with MCP servers to perform tasks or access resources
-
MCP servers: Lightweight programs that each expose the capabilities of a service
-
Local data sources: Files, databases, and services on your computer that MCP servers can securely access
-
Remote services: External Internet-connected systems that MCP servers can connect to through APIs
Imagine you ask Claude to send a message in a Slack channel. Before Claude can do this, Slack must communicate which tools are available. It does this by defining tools — such as “list channels”, “post messages”, and “reply to thread” — in the MCP server. Once the MCP client knows what tools it should invoke, it can complete the task. All you have to do is tell it what you need, and it will get it done.
What makes MCP so powerful? As a quick example, by combining it with a platform like Cloudflare Workers, it allows Claude users to deploy a Cloudflare Worker in just one sentence, resulting in a site like this:


But that’s just one example. Today, we’re excited to show you how you can build and deploy your own MCP server to allow your users to interact with your application directly from an LLM like Claude, and how you can do that just by writing a Cloudflare Worker.
The new workers-mcp tooling handles the translation between your code and the MCP standard, so that you don’t have to do the maintenance work to get it set up.
Once you create your Worker and install the MCP tooling, you’ll get a worker-mcp template set up for you. This boilerplate removes the overhead of configuring the MCP server yourself:
import { WorkerEntrypoint } from 'cloudflare:workers'
import { ProxyToSelf } from 'workers-mcp'
export default class MyWorker extends WorkerEntrypoint<Env> {
/**
* A warm, friendly greeting from your new Workers MCP server.
* @param name {string} the name of the person we are greeting.
* @return {string} the contents of our greeting.
*/
sayHello(name: string) {
return `Hello from an MCP Worker, ${name}!`
}
/**
* @ignore
**/
async fetch(request: Request): Promise<Response> {
return new ProxyToSelf(this).fetch(request)
}
}Let’s unpack what’s happening here. This provides a direct link to MCP. The ProxyToSelf logic ensures that your Worker is wired up to respond as an MCP server, without any complex routing or schema definitions.
It also provides tool definition with JSDoc. You’ll notice that the `sayHello` method is annotated with JSDoc comments describing what it does, what arguments it takes, and what it returns. These comments aren’t just for human readers, but they’re also used to generate documentation that your AI assistant (Claude) can understand.
When you build an MCP server using Workers, adding custom functionality to an LLM is easy. Instead of setting up the server infrastructure, defining request schemas, all you have to do is write the code. Above, all we did was generate a “hello world”, but now let’s power up Claude to generate an image, using Workers AI:
import { WorkerEntrypoint } from 'cloudflare:workers'
import { ProxyToSelf } from 'workers-mcp'
export default class ClaudeImagegen extends WorkerEntrypoint<Env> {
/**
* Generate an image using the flux-1-schnell model.
* @param prompt {string} A text description of the image you want to generate.
* @param steps {number} The number of diffusion steps; higher values can improve quality but take longer.
*/
async generateImage(prompt: string, steps: number): Promise<string> {
const response = await this.env.AI.run('@cf/black-forest-labs/flux-1-schnell', {
prompt,
steps,
});
// Convert from base64 string
const binaryString = atob(response.image);
// Create byte representation
const img = Uint8Array.from(binaryString, (m) => m.codePointAt(0)!);
return new Response(img, {
headers: {
'Content-Type': 'image/jpeg',
},
});
}
/**
* @ignore
*/
async fetch(request: Request): Promise<Response> {
return new ProxyToSelf(this).fetch(request)
}
}Once you update the code and redeploy the Worker, Claude will now be able to use the new image generation tool. All you have to say is: “Hey! Can you create an image of a lava lamp wall that lives in San Francisco?”

If you’re looking for some inspiration, here are a few examples of what you can build with MCP and Workers:
-
Let Claude send follow-up emails on your behalf using Email Routing
-
Ask Claude to capture and share website previews via Browser Automation
-
Store and manage sessions, user data, or other persistent information with Durable Objects
-
Query and update data from your D1 database
-
…or call any of your existing Workers directly!
To build out an MCP server without access to Cloudflare’s tooling, you would have to: initialize an instance of the server, define your APIs by creating explicit schemas for every interaction, handle request routing, ensure that the responses are formatted correctly, write handlers for every action, configure how the server will communicate, and more… As shown above, we do all of this for you.
For reference, an implementation may look something like this:
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
const server = new Server({ name: "example-server", version: "1.0.0" }, {
capabilities: { resources: {} }
});
server.setRequestHandler(ListResourcesRequestSchema, async () => {
return {
resources: [{ uri: "file:///example.txt", name: "Example Resource" }]
};
});
server.setRequestHandler(ReadResourceRequestSchema, async (request) => {
if (request.params.uri === "file:///example.txt") {
return {
contents: [{
uri: "file:///example.txt",
mimeType: "text/plain",
text: "This is the content of the example resource."
}]
};
}
throw new Error("Resource not found");
});
const transport = new StdioServerTransport();
await server.connect(transport);While this works, it requires quite a bit of code just to get started. Not only do you need to be familiar with the MCP protocol, but you need to complete a fair amount of set up work (e.g. defining schemas) for every action. Doing it through Workers removes all these barriers, allowing you to spin up an MCP server without the complexity.
We’re always looking for ways to simplify developer workflows, and we’re excited about this new standard to open up more possibilities for interacting with LLMs, and building agents.
If you’re interested in setting this up, check out this tutorial which walks you through these examples. We’re excited to see what you build. Be sure to share your MCP server creations with us on Discord, X, or Bluesky!
Security updates for Friday
Post Syndicated from jzb original https://lwn.net/Articles/1003019/
Security updates have been issued by Debian (chromium and gunicorn), Fedora (jupyterlab), Oracle (bluez, containernetworking-plugins, edk2:20220126gitbb1bba3d77, edk2:20240524, gstreamer1-plugins-base, gstreamer1-plugins-good, kernel, libsndfile, libsndfile:1.0.31, mpg123, mpg123:1.32.9, pam, python3.11-urllib3, skopeo, tuned, and unbound:1.16.2), SUSE (avahi, docker, emacs, govulncheck-vulndb, haproxy, kernel, libmozjs-128-0, python-grpcio, python310-xhtml2pdf, sudo, and tailscale), and Ubuntu (dpdk, linux-hwe-5.15, and linux-iot).
Bring multimodal real-time interaction to your AI applications with Cloudflare Calls
Post Syndicated from Will Allen original https://blog.cloudflare.com/bring-multimodal-real-time-interaction-to-your-ai-applications-with-cloudflare-calls/
OpenAI announced support for WebRTC in their Realtime API on December 17, 2024. Combining their Realtime API with Cloudflare Calls allows you to build experiences that weren’t possible just a few days earlier.
Previously, interactions with audio and video AIs were largely single-player: only one person could be interacting with the AI unless you were in the same physical room. Now, applications built using Cloudflare Calls and OpenAI’s Realtime API can now support multiple users across the globe simultaneously seeing and interacting with a voice or video AI.
Here’s what this means in practice: you can now invite ChatGPT to your next video meeting:
We built this into our Orange Meets demo app to serve as an inspiration for what is possible, but the opportunities are much broader.
In the not-too-distant future, every company could have a ‘corporate AI’ they invite to their internal meetings that is secure, private and has access to their company data. Imagine this sort of real-time audio and video interactions with your company’s AI:
“Hey ChatGPT, do we have any open Jira tickets about this?”
“Hey Company AI, who are the competitors in the space doing Y?”
“AI, is XYZ a big customer? How much more did they spend with us vs last year?”
There are similar opportunities if your application is built for consumers: broadcasts and global livestreams can become much more interactive. The murder mystery game in the video above is just one example: you could build your own to play live with your friends in different cities.
These interactive multimedia experiences are enabled by the industry adoption of WebRTC, which stands for Web Real-time Communication.
Many real-time product experiences have historically used Websockets instead of WebRTC. Websockets operate over a single, persistent TCP connection established between a client and server. This is useful for maintaining a data sync for text-based chat apps or maintaining the state of gameplay in your favorite video game. Cloudflare has extensive support for Websockets across our network as well as in our AI Gateway.
If you were building a chat application prior to WebSockets, you would likely have your client-side app poll the server every n seconds to see if there are new messages to be displayed. WebSockets eliminated this need for polling. Instead, the client and the server establish a persistent, long-running connection to send and receive messages.
However, once you have multiple users across geographies simultaneously interacting with voice and video, small delays in the data sync can become unacceptable product experiences. Imagine building an app that does real-time translation of audio. With WebSockets, you would need to chunk the audio input, so each chunk contains 100–500 milliseconds of audio. That chunking size, along with the head-of-line blocking, becomes the latency floor for your ability to deliver a real-time multimodal experience to your users.
WebRTC solves this problem by having native support for audio and video tracks over UDP-based channels directly between users, eliminating the need for chunking. This lets you stream audio and video data to an AI model from multiple users and receive audio and video data back from the AI model in real-time.
Historically, setting up the underlying infrastructure for WebRTC — servers for media routing, TURN relays, global availability — could be challenging.
Cloudflare Calls handles the entirety of this complexity for developers, allowing them to leverage WebRTC without needing to worry about servers, regions, or scaling. Cloudflare Calls works as a single mesh network that automatically connects each user to a server close to them. Calls can connect directly with other WebRTC-powered services such as OpenAI’s, letting you deliver the output with near-zero latency to hundreds or thousands of users.
Privacy and security also come standard: all video and audio traffic that passes through Cloudflare Calls is encrypted by default. In this particular demo, we take it a step further by creating a button that allows you to decide when to allow ChatGPT to listen and interact with the meeting participants, allowing you to be more granular and targeted in your privacy and security posture.
Cloudflare Calls has three building blocks: Applications, Sessions, and Tracks:
“A Session in Cloudflare Calls correlates directly to a WebRTC PeerConnection. It represents the establishment of a communication channel between a client and the nearest Cloudflare data center, as determined by Cloudflare’s anycast routing …
Within a Session, there can be one or more Tracks. … [which] align with the MediaStreamTrack concept, facilitating audio, video, or data transmission.”
To include ChatGPT in our video conferencing demo, we needed to add ChatGPT as a track in an ongoing session. To do this, we connected to the Realtime API in Orange Meets:
// Connect Cloudflare Calls sessions and tracks like a switchboard
async function connectHumanAndOpenAI(
humanSessionId: string,
openAiSessionId: string
) {
const callsApiHeaders = {
Authorization: `Bearer ${APP_TOKEN}`,
'Content-Type': 'application/json',
}
// Pull OpenAI audio track to human's track
await fetch(`${callsEndpoint}/sessions/${humanSessionId}/tracks/new`, {
method: 'POST',
headers: callsApiHeaders,
body: JSON.stringify({
tracks: [
{
location: 'remote',
sessionId: openAiSessionId,
trackName: 'ai-generated-voice',
mid: '#user-mic',
},
],
}),
})
// Pull human's audio track to OpenAI's track
await fetch(`${callsEndpoint}/sessions/${openAiSessionId}/tracks/new`, {
method: 'POST',
headers: callsApiHeaders,
body: JSON.stringify({
tracks: [
{
location: 'remote',
sessionId: humanSessionId,
trackName: 'user-mic',
mid: '#ai-generated-voice',
},
],
}),
})
}This code sets up the bidirectional routing between the human’s session and ChatGPT, which would allow the humans to hear ChatGPT and ChatGPT to hear the humans.
You can review all the code for this demo app on GitHub.
Give the Cloudflare Calls + OpenAI Realtime API demo a try for yourself and review how it was built via the source code on GitHub. Then get started today with Cloudflare Calls to bring real-time, interactive AI to your apps and services.
The Great Cross-Word Craze
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=kGzMr3QSl9k
Какво следва? Украйнааа и еврооо
Post Syndicated from Емилия Милчева original https://www.toest.bg/kakvo-sledva-ukraynaaa-i-evrooo/

Ако човек следи комюникетата от преговорите за съставяне на редовно правителство между четирите политически сили, би помислил, че всичко върви по мед, масло и свинско със зеле. В прессъобщенията изобилстват обсъдени теми – законодателни приоритети, социални мерки, инфраструктурни проекти и дори амбициозни намерения за пълен 4-годишен мандат. Изглеждат като съвсем истински преговори за коалиционно управление, а участниците – ГЕРБ–СДС, „Демократична България“ (ДБ), „Има такъв народ“ (ИТН) и БСП – Обединена левица, позиционират себе си като национално отговорни партии, погълнати от задачата да работят за доброто на държавата и нормализацията на политическия живот. И разбира се, за своето собствено добруване.
Онова, което не се вижда зад декорацията, са същинските преговори кой какви ресурси ще контролира, как ще бъдат разпределени постовете в бъдещо правителство, позициите в регулаторите и договореностите за съдебната власт, и най-сетне – кой ще е министър-председател (защото мантрата за Бойко Борисов премиер не върви). Изобщо колко от „добруването“ ще стигне до гражданите?
Но участниците следва да се договорят първо по стратегическите приоритети, които да дадат рамка на бъдещото споразумение: еврозоната, стратегията за българската енергетика, в това число въглищната индустрия, подкрепата за Украйна, концепцията за националната сигурност. А те стъпват на пръсти около тях, един вид превенция да не се развали едва наченалият диалог с… неудобни въпроси. Това е сигурен признак, че ще бъдат направени сериозни компромиси, а власт, която се крепи на такива, бързо се срутва. Неотдавнашната сглобка е доказателство.
Украйна и споразумението за сигурност
Скандалът, избухнал заради споразумението с Украйна в областта на сигурността за срок от 10 години, е ярък пример как стратегически теми, свързани с по-голямата европейска интеграция на България, могат да бъдат превърнати в политически футбол. (Случайно или не, шумът съвпадна с посещението на генералния секретар на НАТО Марк Рюте в България.) Въпреки решението на Министерския съвет от ноември 2023 г. за одобрение на документа, неговото подписване се забави с месеци, включително и заради Украйна. България не го е подписала, също и Унгария, Малта, Кипър, Австрия и Словакия – все държави от ЕС, в които руското присъствие е осезателно или чрез капитали, или чрез енергийни ресурси и влияние, осъществявано чрез политици и медии.
Служебният премиер Димитър Главчев прехвърли отговорността на парламента в навечерието на заминаването си за Брюксел, където се срещна с украинския президент Зеленски, макар ратификация да не е необходима. Председателката на парламента доц. Наталия Киселова (БСП – Обединена левица) не включи точката за споразумението в дневния ред. Олигархът Делян Пеевски от групата, предложила точката (ДПС – Ново начало), се възползва, за да демонстрира евроатлантизъм.
Ако днес не дадем мандат на Главчев да одобри споразумението с Украйна, значи бройте ги… Който не го подкрепи, е слуга на Москва… По гласуването ще видим кои са евроатлантическите партии.
Пред БНР бившата външна министърка Гергана Паси определи случая като дипломатически скандал и отиде по-далеч.
Репликите в пленарна зала на НС показват, че всяко действие ще се използва за объркване на обърканото ни общество. Терминът е „рефлексивен контрол“ – неприятелят Русия се опитва да ни внуши решение, което е в противовес със собствения ни национален интерес.
А изявление на Бойко Борисов даде основания да бъде заподозрян в тръмпистки завой.
Преди 6 месеца категорично щяхме да подкрепим такъв договор. Сега, когато Европа и САЩ, и изказванията на Тръмп за прекратяване на войната в Украйна, ние малко като на 9 септември фабрика купуваме. Ние с Украйна ще работим, ще участваме във възстановяването на мирния процес и просто едно редовно правителство ще подпише изгоден взаимно документ.
Украйна е лакмус за коалиционните намерения и устойчивост. Подписването или отказът от споразумението ще покаже доколко бъдещото правителство е готово да се обвърже с ясна позиция в подкрепа на евроатлантическата ориентация на България. А дали въпросът ще бъде използван като повод за вътрешнополитически разпри? Напълно възможно. Зад въртеливата позиция на Главчев се спотайват онези (сред тях и Пеевски), които работят за нови предсрочни избори.
БСП например се обяви публично – в отворено писмо до Главчев, против споразумението, защото е „срещу интересите на българския народ“. (Но преди две години и половина бившата вече лидерка на БСП Корнелия Нинова, министърка на икономиката в кабинета на Кирил Петков, се кълнеше, че „нито един патрон не е заминал за Украйна“, а военната индустрия не смогваше от поръчки.)
С това споразумение България поема 10-годишен ангажимент към Украйна за политическа, икономическа и социална помощ за украинските бежанци, разселени на територията на Република България, обучение на военни и продължаваща военна помощ. Заложена е възможността то да бъде удължено и след този период.
Как толкова категорично несъгласие се връзва с уверението на Борисов, че редовно правителство ще подпише документа? Или просто ще се „изчегърта“ войната в Украйна от коалиционните договорки, което би означавало отстъпление пред страха от вътрешни противоречия и натиск от Русия вместо ясни ангажименти към националната сигурност и европейската солидарност? За ДБ отстъпление не може да има. Във Facebook депутатът Ивайло Мирчев коментира, че „Украйна остава стратегически приоритет, за който ще преговаряме и в светлината на който ще оценяваме цялостния резултат от преговорите“.
От една страна, бъдещите коалиционни партньори ще трябва да демонстрират единна позиция за Украйна, ако искат да убедят съюзниците. От друга страна, колебание или липса на такава може да бъде тълкувано като слабост, което ще подкопае и без това крехката стабилност на евентуална нова коалиция.
„Македонияааа!“ извика лидерът на ИТН Слави Трифонов през юни 2022 г. и правителството падна.
Сега се плаши с Украйна.
Какво се случва с еврото?
Безпрецедентен фронт от финансисти и анализатори се обяви срещу проектобюджета за 2025-та, внесен от служебното правителство, заради неговия „разходен популизъм“. Някои от изразените опасения са, че мерките в него ще попречат на пътя на България към еврото. А за първи път БНБ си позволи да отправи призив да не се приема бюджетът, внесен от служебното правителство.
„Топката е в политиците“, каза гуверньорът Димитър Радев, според когото за България има шансове да бъде прието решение за еврозоната догодина, защото през януари ще бъде изпълнен последният технически критерий за инфлацията. Ако се случи в средата на годината, то от 1 януари 2026 г. българското евро ще е факт. Но ако бюджетът за догодина бъде приет във вида, в който е внесен, с гигантските разходи за възнаграждения, еврозоната се отдалечава.
Трасирането на пътя към единната европейска валута е особено трудно в държава, в която липсва последователност и ангажимент от страна на правителства и политически лидери да предприемат необходимите стъпки за ускоряване на процеса по приемане на еврото. Проблемът с икономическата подготовка на България за еврозоната е свързан с необходимостта от структурни реформи в публичните финанси, съдебната система и държавните институции. След пълноправното включване в Шенген шансовете нарастват.
Засега ГЕРБ–СДС и ДБ са декларирали, че еврозоната остава приоритет. За този приоритет обаче БСП и ИТН мълчат – те са противници на единната валута, а значи не биха я приели.
Последствията от провала
Първият работен ден на парламента след дългата коледна ваканция, която започва на 23 декември, е 8 януари, седмица преди заседанието на ВСС, насрочено за изслушване на единствения кандидат за главен прокурор – Борислав Сарафов. Конституционният съд даде зелена светлина за избора на бившата дясна ръка на бившия главен прокурор Гешев, като отказа да се произнесе по исканията на партии за това какво може да прави Висшият съдебен съвет (ВСС) с изтекъл мандат.
Законопроектът за промени в Закона за съдебната власт, внесен от ПП–ДБ, спира Сарафов да завземе поста и го сваля и от „изпълняващ функциите“. Но предизвикателството е дали ще бъде приет до изслушването му от ВСС. Ако това не стане, президентът Румен Радев може да откаже да подпише указа за назначението и да върне избора на ВСС – председателката на парламента Наталия Киселова го спомена няколко пъти като възможност. Така Радев би могъл да осигури време за приемане на законопроекта и на второ четене. Освен че ще натрупа рейтинг като радетел за върховенство на закона и борец срещу задкулисието.
Може да се окаже обаче, че Сарафов ще изненада всички, като се оттегли (или бъде оттеглен от кръговете зад себе си). Фигура на обвинител-номер-едно, зад която няма стабилно политическо мнозинство, не е изгодна.
Също като Гешев, който се обърна срещу благодетелите си в последните седмици на поста, и сега прокуратурата развъртя сопата с искания за сваляне на депутатски имунитети. Въпреки опитите за многообразие най-силно пострада ПП, в това число и ударът срещу Асен Василев с ареста на приближения му Лъчезар Ставрев. Лъчо – шофьор, охранител, сътрудник на Василев, е бил и член на политическия му кабинет, когато беше министър на финансите. Показания на обвинени за аферата в митниците замесиха името му като човек, разпореждал кадрови промени и събиращ подкупи. Василев отрича, както и самият Ставрев.
България посреща новата 2025 година в очакване ще има ли редовно правителство. Година по-рано тръпнеше дали ще е успешна ротацията, при която Мария Габриел (ГЕРБ–СДС) трябваше да смени премиера Николай Денков (ПП–ДБ). Борисов я определи тогава като скачване на космически кораб с орбитална станция. Неуспешно.
Сега наблюдаваме едни почти истински преговори за редовно правителство.
Ако не тази неделя, другата
Post Syndicated from Тоест original https://www.toest.bg/ako-ne-tazi-nedelya-drugata/

1.
Когато светът свърши,
ще бъде неделя следобед,
късен ноември към 6 вечерта.
Улиците ще бъдат празни,
боклукът ще стои неприбран,
семействата – изпокарани.
Всичко ще бъде
както си е било,
само светът ще свършва
като котка, която умира
тихо, зад къщата.
Светът ще свърши в неделя
(в четвъртък умират поетите).
Светът ще свърши в неделя
(в понеделник вече
няма да има вестници,
съобщаващи края),
затова предварително
за последен път и това е,
да си знаете, макар да е късно,
светът ще свърши в неделя
тихо и кротко, в съня си.
2.
Минах през църквата към
Колумбийския университет –
църква, джамия и синагога,
кораб на всички религии
(византийска основа).
Вратата беше отворена,
надникнах,
две кохорти студенти се молеха.
Молете се, викнах, молете се
и надуйте хубаво органа,
днес светът свършва.
Към колко часа, попита свещеникът.
Към шест – шест и половина, отвърнах,
не мога да кажа точно,
но не чакайте дълго отлагане.
(По-късно извиках същото
през портата на St. John the Divine,
по-долу на 111-а и Амстердам авеню,
но едва ли ме чуха).
И вървях из Горен Манхатън,
който всъщност е Долен Харлем,
и виках на всички:
Светът ще се свършва в неделя следобед,
светът ще се свършва,
приберете се вкъщи навреме,
светът ще се свършва,
казах на някакъв Уитман,
легнал на тротоара,
fuck you, man, кресна ми той,
колко пъти ще свършва
и запали тревата…
Последният
продавач на фалафел
затвори фургона,
седна отвън
и запали цигара,
за днес толкова, вика,
и този свят свърши.
П.П.
Вечерта заваля дъжд.
Една жена се обади на един мъж.
Една изгубена котка се върна вкъщи.
Един отворен прозорец се тръшна.
Някъде готвеха супа,
явно нещо в бульона
спасява от краища,
прибира ножовете.
И краят пак се отложи…
Георги Господинов
Ню Йорк, ноември, 2022
Георги Господинов (р. 1968) e поет, писател, драматург и литературовед. Книгите му са публикувани на повече от 35 езика. Носител на Международен „Букър“ 2023 за романа „Времеубежище“. Влиза в литературата през 90-те със стихосбирката „Лапидариум“ (1992). Автор е на пет поетически книги досега, сред които „Черешата на един народ“ (1996), „Писма до Гаустин“ (2003) и „Там, където не сме“ (2016, Награда за поезия „Перото“). Френското издание на „Там, където не сме“ в превода на Мари Врина-Николов е финалист за наградата „Маларме“. Стихосбирките му са издадени още на италиански, немски, гръцки, румънски, чешки, унгарски и др. Негови стихотворения са публикувани в антологии на световната и европейската поезия. Господинов е поет, който често контрабандира поезия и в романите си. Най-новият му роман е „Градинарят и смъртта“.
Според Екатерина Йосифова „четящият стихотворение сутрин… добре понася другите часове“ от деня. Убедени, че поезията държи умовете ни будни, а сърцата – отворени, в края на всеки месец ви предлагаме по едно стихотворение. Защото и в най-смутни времена доброто стихотворение е добра новина.
На второ четене: „Олив Китридж отново“
Post Syndicated from original https://www.toest.bg/na-vtoro-chetene-oliv-kitridzh-otnovo/
„Олив Китридж отново“ от Елизабет Страут

превод от английски Диляна Георгиева, София: изд. „Кръг“, 2023
Цяло десетилетие и един сериал дели първата и втората книга за Олив Китридж и всъщност е добре, че у нас преводите им се появиха достатъчно скоро един след друг. При всички случаи усещането е, че американската писателка Елизабет Страут, написала междувременно други два романа, изглежда, нито за миг не е изпускала от мисълта си своята необикновена героиня, защото този промеждутък изобщо не се усеща в продължението на едноименния роман.
Срещаме Олив отново малко след като сме я оставили да лежи до Джак, новия мъж в живота ѝ след смъртта на съпруга ѝ Хенри. В продължението Страут ни превежда през решението за повторния брак на героинята си и последвалите осем години съвместен живот до окончателно ѝ настаняване в старчески дом. И макар загубата и разрастващата се с годините самота, бавно изместваща ужаса от живота, да не са я смазали, Олив е неизбежно променена заради осъзнаванията под тежестта на времето. И все пак Олив е просто Олив – това определение, което авторката току използва, за да опише с две думи героинята си, е пределно изчерпателно само по себе си.
Преди няколко години българските читатели се влюбиха в тази директна, безцеремонна, винаги леко намусена и грубовата в отношението си, лишена от филтри и понякога почти аутистична в незачитането на общоприетото героиня. Причината бе, че зад нейния едър, не особено лицеприятен и дори леко занемарен вид, както и въпреки трудно поносимия ѝ нрав се таеше и другата ѝ страна: на емпатичен, справедлив, толерантен човек, интересуващ се от съдбата на другите. На прикрита зад тази фасада жена, обичана в крайна сметка от двама прекрасни мъже. Още повече че този неин едновременно семпъл, но многопластов и труден образ бе пресъздаден до съвършенство от голямата актриса Франсис Макдорманд в сериала на HBO.
Помня как още тогава, непреполовила първата книга, възкликнах:
Добре, защо по нашите ширини не се пише така – просто, но напоително, красиво, но без нито една излишна дума, проникновено, ала без грам претенция?
Не е случайно, че издаденият през 2008 г. първи роман бе отличен с наградата „Пулицър“. И в този
Страут не е изневерила на естествения си стил, на своя мръсен реализъм.
Да, винаги свързвам с американците това майсторство на разказването през несъбитийното, през пределно ежедневното, през уж небрежните разговори. Много трудно е всъщност да се пише за такива книги, в които нещата не са просто „казани“. В които драмата, тежестта, смисълът, големите прозрения се долавят ненатрапливо през рехавата тъкан на битовизмите, на почти случайните действия и лишените от апломб и афекти обстоятелства – и тъкмо затова удрят по-силно, защото са органична част от съществуването, нямат „специален статус“. Моментите на епифания, на преображение и осъзнаване, на съжаление и катарзис са тихи, незабележими, имплодиращи. А понякога просто красиво закъснели и тъжно безполезни.
Изумително е как може да се пише за остаряването (тази едва ли не най-скучна, най-малко привлекателна и досадна за читателите тема) без грам мелодраматичност и сантименталност, без тежест, без съжаление.
Графичният реализъм на старостта – с нейните бавни счупвания, попиващи памперси, напоителна самота, гравитационен колапс и липса на хоризонт – да потъва в меката есенна светлина, да бъде посрещан с олекотяваща ирония, с любимите на Олив изрази „глупости на търкалета“ и „върви по дяволите“.
Втората и може би неизбежно последна книга (макар че кой знае) е организирана по същия начин: в отделни разкази, които образуват рехаво споена романова цялост заради присъствието на Олив и заради общото място – същото провинциално крайбрежно градче Кросби в щата Мейн. И тук разказът е ту пряко за Олив (през нейната гледна точка), ту за други герои (през тяхната гледна точка), в чието ежедневие протагонистката се появява за кратко камео, в случайни срещи, за кратки посещения или просто колкото да размени с тях реплика или да им помаха от другия край на магазина. По този начин обаче се получава един фасетъчен образ, чиято централност оставя място за историите на куп други герои.
Въпросните истории са изпълнени с грешки, вини, лъжи, изневери, тайни, разочарования, предателства, слабости, болести, престъпления, самоубийства, отчуждение, скръб, смърт, срам, самота, провалено родителство и изгубени деца. И парадоксално, тъкмо поради това те звучат не прекомерни, а пределно обикновени, естествени, ежедневни. Страут успява да замаскира този житейски мащаб в лаконичност, в семпли щрихи, разкривайки промените по-късно и епизодично в следващите разкази.
Джак е развалил отношенията с дъщеря си, защото не може да приеме, че е лесбийка; пропилял е връзката с първата си съпруга заради извънбрачните им афери. Олив осъзнава, че се е провалила като майка по отношение на близостта си със своя син и че трудно приема семейството му, а той пък – повторния ѝ брак. Джак е саркастичен екстроверт, Олив е своеволен чешит. Историята на остаряването им обаче е и история на приемането, помиряването, протягането на ръка – било то и по нелеп начин, с всичките му дразнения и несъвършенства.
Недодяланата Олив ще съумее да живее с всичко онова, което я дразни в Джак, с
едрите им тела, захвърлени на брега като след корабокрушение и вкопчени на живот и смърт.
Ще открие женско приятелство насред упорития си индивидуализъм, ще преглътне предателството на поетеса, изложила едно към едно живота ѝ в своя творба, ще прости дори на болногледачката си, чиято ксенофобия и подкрепа за Тръмп категорично не желае да приеме.
Може би остаряването е именно това – загуба на твърдост.

„Олив отново“ е задължителна за прочит, ако вече сте прочели първата книга. Един роман в разкази за свързването дори когато то изглежда невъзможно; за намирането на изход в унинието и безнадеждността; за поемането на отговорност въпреки слабостта и усещането за изгубеност. За човека, който винаги трябва да бъде срещан отвъд политиката, съображенията и формалностите. И за грешките – онази субстанция на пределно човешкото, без която е невъзможно да съществуваме. За грешките със снизходителност и състрадание. Защото, както пише Страут за един от героите си,
тогава осъзна, че никога не бива да се омаловажава дълбоката човешка самота и че решенията, които хората вземат, за да се предпазят от зейналия мрак, изискват уважение.
Може би най-символичният диалог, който осмисля тези две книги за жителите на фиктивното провинциално градче, с привидната му скука и еднообразие, е следният: (Изкушавам се в края да го цитирам целия, защото звучи почти като идейно-програмен за този тип литература, която не се плаши от тривиалността и баналността, а ни превежда през тях, осмисляйки и обглеждайки ги, за да се открият пред нас дълбочините им.)
Бети я погледна:
– Моят живот ли? – попита тя и още сълзи се стекоха по лицето ѝ. – О, нали знаеш. – Тя махна леко с кърпичката във въздуха. – Ужасен – рече и се опита да се усмихне.
– Е, разкажи ми. Ще се радвам да те изслушам.
Бети още подсмърчаше, но и се усмихваше по-широко.
– О, Олив, обикновен живот.
Олив обмисли думите ѝ.
– Но е твоят живот. Има значение.
Активните дарители на „Тоест“ получават постоянна отстъпка в размер нa 20% от коричната цена на всички заглавия от каталога на издателство „Кръг“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Антония Апостолова, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
2024-12-20 почивай в мир, chervarium
Post Syndicated from Vasil Kolev original https://vasil.ludost.net/blog/?p=3489
Снощи е починал Атанас Бъчваров (който повечето хора познават като chervarium).
Още нямам информация за кога ще бъде погребението и какво са плановете там, ако е ок, ще пиша тук.
И бих искал да напиша още нещо по темата, но ще изчака…
По буквите: Линч, Букова, Асенов, Донева
Post Syndicated from Зорница Христова original https://www.toest.bg/po-bukvitie-lynch-bukova-asenov-doneva/
„Пророческа песен“ от Пол Линч

превод от английски Иглика Василева, София: изд. „Лист“, 2024
Когато съпругът на главната героиня изчезна, си казах: „Няма нужда.“ Няма нужда от книга, за да си представям, че това се случва тук – тази пророческа песен кънти в главата ми и бездруго. И да бягаш от новините, пак знаеш: знаеш, че случващото се в диктатурите по света може да се случи и тук. Ставало е, познаваш свидетели. Познаваш хора от други страни, на които се случва сега. Но следобедното слънце беше меко, а героинята гледаше мрака на верандата от топлината на стаята си. И тя, също като мен, знаеше и не знаеше.

Историята се разгръща в Ирландия, авторът е ирландец, тоест за нейните читатели тя звучи така, както би звучала книга, в която сме заменили Дамаск със София или Мариупол с Монтана. Премахната е защитната бариера на чуждото време или място.
Та в Ирландия се установява диктатура под невярващия поглед на хората от моя и вашия балон. Хора, които смятат, че могат да се борят с нея, като излизат на протести, като се сдружават в профсъюзи… Като правят правилните неща, които очакваме от хората по новините. Но „екранът“ в книгата не е този, на който се върти земното кълбо от „По света и у нас“. „Екранът“ е личната перспектива на главната героиня Айлиш, чийто мъж е учител и изчезва съвсем в началото – невярващ, че може да е нещо повече от разпит. Айлиш, която има четири деца. Айлиш, която също като мен не иска да вярва, че нейният свят се разпада. Не иска да вярва, че може да се отнася за нея. До най-покъртителния момент, в който отваря чувал след чувал в моргата и почти механично повтаря: „Не е моят син, не е моят син“. Докато е.
Впрочем другият много важен момент е малко преди това – когато се лута между болниците и вижда хора, седнали на слънце, да пият кафе. Вижда живота да продължава и разбира, че светът свършва, но не навсякъде, само нейният личен свят. Вижда невиждането на другите. Вижда – парадоксално – мен, която четох тази книга в спокойно кафене, обгърната в предпазния уют на красивия стил на Пол Линч, естествената сплитка на синтаксиса, майсторски преведена от Иглика Василева. Вижда мен от предишния си живот на свободна майка, която може да се разпознае в нея, но и да затвори книгата.
Но дори и затворена, „Пророческа песен“ продължава да се носи край нас.
„Черно хайку“ от Яна Букова
Пловдив: изд. „Жанет 45“, 2024
„Черно хайку“ започва радикално точно с тази оптика: с погледа в упор към онова, което не искаме да видим. Още първата страница на стихосбирката на Яна Букова е програмна: гледане в смъртта, в нейната физическа реалност, но гледане отстрани, в спокоен разговор между мъртвите. Кои са тези безплътни гласове, които разговарят? Отвъдни? И да, и не. Това е гласът отвътре, гласът, който присъства само в съзнанието ни – и в литературата.
Авторът решава колко ще знае този глас – дали ще е всевиждащ, дали ще е заблуден, ограничен, неблагонадежден. Яна Букова иска той да знае всичко, и оттатък предела. Смъртта е само мярка, проверка за неговата истинност, преди човекът да види себе си. И тази истинност е винаги убеглива. Не само защото огледалата са сравнително отскоро. (Хубав въпрос е дали Ренесансът е изобретил огледалата, или възможността да се вгледаш в себе си е предизвикала Ренесанса.)

Извън техническата невъзможност да се видиш стои страхът да се видиш. С пленително сурова ерудиция Букова се вглежда в зрителя, който наблюдава катастрофата пред отнесената от торнадо четвърта стена на киносалона; в зрителя, който намира утеха в рамката от бодлива тел пред гледката; в зрителя, който изпитва копнеж по реда или отива да хапне нещо; в зрителя, който се запътва към хладилника, за да се утеши; в зрителя, който изключва звука. В себе си. Яна Букова не пропуска – нейната поезия продължава да чете новините, тяхното по-дълбоко значение, което ни се разкрива като буквална метафора. Като „дезинфекцираните подаръци“, които биха били метафора някога, но не и по време на ковид.
Защо е нужно това литературно всевиждане? Заради възможността за рефлексия, която тези стихотворения предлагат в изобилие. Споделянето на травмата не я лекува, показват изследванията, то само може да я умножи във всяко нейно разказване. Това, което помага, е нейното осмисляне. Стихотворенията в „Черно хайку“ съдържат опит за осмисляне на всичко, включително на черните петна. И да, това осмисляне се случва само в парадокса на коана, който е и парадоксът на поезията. Но се случва.
Хубава корица на Иво Рафаилов с превключвател – „прекъсвач“ на мястото на костта от стихотворението.
„Кайротични прелюди“ от Антоан Асенов
София: изд. „Аквариус“, 2024
„Огледално“ значи и „точно обратното“. И като читателско преживяване стихосбирката „Кайротични прелюди“ изглежда огледална на „Черно хайку“. Тя сама ни предлага аналогията с ранения Андрей от битката при Аустерлиц във „Война и мир“: насред сражението отправяме поглед нагоре и изведнъж виждаме небето – виждаме го за пръв път, „във висотата отвъд навика“, казва авторът. И още: „след дълго гледане проглеждаш, оживяваш след години живот“. Това значи „кайротичен“ момент, внезапна, мимолетна пълнота на живота.
И самата книга е сгъстена в такива моменти – във внезапно отваряне на сетивото, блясване на смисъл, ненадейно насищане на живота. Това отваряне е навън и навътре; авторът описва вътрешните усещания така, както описва птиците – наблюдава ги внимателно, вслушва се в отсенките на песента им, отбелязва особеностите на оперението им – и непринудено ни води към родството на това чувство с музикален пасаж, с книга, с картина.

Ненатрапчива, топла ерудиция – няма значение дали познаваш произведението, още по-хубаво е, ако го срещаш за пръв път. Аз се изкушавам да си пускам музиката, да проверявам картините, да си поръчвам книгите; колко хубаво, че още толкова неща не знам, че мога да ги науча. Но и да науча нещо за себе си, докато се губя в картината. Това е интимно говорене за изкуство, то не занимава егото ми на читател, а чувствата; и не предлага да ги възпитава, а да ги приеме – като равни – сред изразените в изкуството. Подобно е говоренето на Ролан Барт, у нас може би на Цветан Стоянов. Елегантно и без декорации – сводовете са високи, думите са носещи елементи.
Бягство ли е тази височина, погледът нагоре насред сражението? Ни най-малко. Вижте последната глава.
Извънредно ми е приятно, че тази книга е българска, както и предишната от същия автор – „Потос“, която пък беше посветена на копнежа. Много бих се радвала да намерят път и в други страни, защото тяхната дълбочина е универсална. Прекрасно уловена тук от корицата на Кирил Златков – краят на меден духов инструмент и дърво; музиката като високата нота към нашата природа, музиката като вслушване в природата ни. Защото тази тръба може да бъде и слухова.
„Писмото на мравката“ от Мария Донева
илюстрации Елена Панайотова, Пловдив: изд. „Жанет 45“, 2024
Да четеш Мария Донева е като да гледаш финала на „Ново кино Парадизо“, по-точно онази лента, която старият кинооператор Алфредо завещава на порасналия Салваторе, с всички цензурирани целувки, залепени една след друга. Взети заедно, те действат като филм от щастливи завършеци – разделените влюбени се срещат, неизказаната любов се осъществява, изгубеното се намира, устните се допират. Като наниза от начала в „Ако пътник в зимна нощ“, но наобратно.

В стихотворенията и поемите на Мария Донева сякаш има повече милост към читателя, че и към героите, отколкото литературата по принцип допуска; повече радост. Този последователен избор, книга след книга, ми се струва свързан с едно общително разбиране на връзката с читателя, с неговата потребност да види пред себе си и щадящите сценарии.
Умът ни е настроен да човърка катастрофичното, да го отбягва и пак да се връща при него. Да пишеш за възможността за щастие – и то така, че в нея да се разпознаят хора от всякакви разновидности и професии – не е никак лесно. Мария Донева го прави, като засилва цветовете, като изгражда собствен жанр. В него ролята на завръзката играе копнежът – дългият, с години неудовлетворен копнеж по нещо, което би изпълнило живота с живот.



Тук „Писмото на мравката“ се римува със „Заекът и неговата мечта“ и в известен смисъл дори с „Мишките отиват на опера“ – това са истории за вълнението, предвкусването и дългоочакваната среща. Основен елемент и у трите е достъпността на мечтаното, достъпност, която изглежда нереална само за героите. За читателя тя е двойно подсказана не само защото не е пътешествие до центъра на Земята – а любов между сродни, една среща с морето, една вечер в операта, – а и защото самата форма непрекъснато го подсказва. Звънкостта на стиха е щастливата история на думите – сдвоени в римите и ритъма, изглеждат смислово предопределени една за друга.
Впрочем това е особено при „Писмото на мравката“: тук в центъра е именно писането, писмото, и неговото пътешествие (и притеснение) е самата ос на сюжета. Писмото хвърля и елегантен мост към писмата у Валери Петров, с чийто звънък стих – и абсолютно спокойствие да говори за доброто – Мария Донева звучи вътрешно свързана.
Introducing Configurable Metaflow
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/introducing-configurable-metaflow-d2fb8e9ba1c6
David J. Berg*, David Casler^, Romain Cledat*, Qian Huang*, Rui Lin*, Nissan Pow*, Nurcan Sonmez*, Shashank Srikanth*, Chaoying Wang*, Regina Wang*, Darin Yu*
*: Model Development Team, Machine Learning Platform
^: Content Demand Modeling Team
A month ago at QConSF, we showcased how Netflix utilizes Metaflow to power a diverse set of ML and AI use cases, managing thousands of unique Metaflow flows. This followed a previous blog on the same topic. Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers, or the system that ranks which language subtitles are most valuable for a specific piece of content.
As a central ML and AI platform team, our role is to empower our partner teams with tools that maximize their productivity and effectiveness, while adapting to their specific needs (not the other way around). This has been a guiding design principle with Metaflow since its inception.
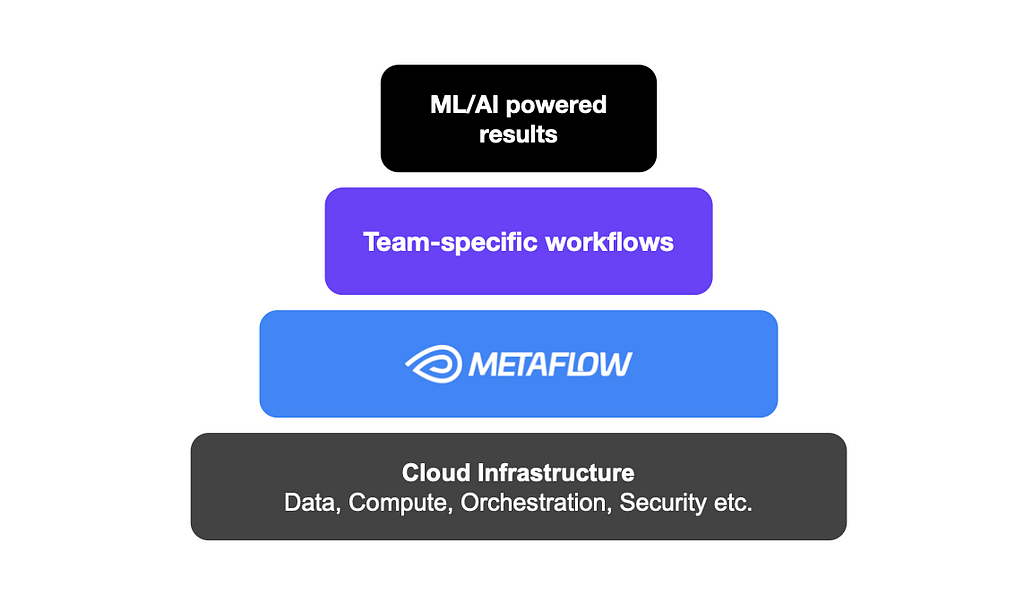
Standing on the shoulders of our extensive cloud infrastructure, Metaflow facilitates easy access to data, compute, and production-grade workflow orchestration, as well as built-in best practices for common concerns such as collaboration, versioning, dependency management, and observability, which teams use to setup ML/AI experiments and systems that work for them. As a result, Metaflow users at Netflix have been able to run millions of experiments over the past few years without wasting time on low-level concerns.
A long standing FAQ: configurable flows
While Metaflow aims to be un-opinionated about some of the upper levels of the stack, some teams within Netflix have developed their own opinionated tooling. As part of Metaflow’s adaptation to their specific needs, we constantly try to understand what has been developed and, more importantly, what gaps these solutions are filling.
In some cases, we determine that the gap being addressed is very team specific, or too opinionated at too high a level in the stack, and we therefore decide to not develop it within Metaflow. In other cases, however, we realize that we can develop an underlying construct that aids in filling that gap. Note that even in that case, we do not always aim to completely fill the gap and instead focus on extracting a more general lower level concept that can be leveraged by that particular user but also by others. One such recurring pattern we noticed at Netflix is the need to deploy sets of closely related flows, often as part of a larger pipeline involving table creations, ETLs, and deployment jobs. Frequently, practitioners want to experiment with variants of these flows, testing new data, new parameterizations, or new algorithms, while keeping the overall structure of the flow or flows intact.
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Thus far, there hasn’t been a built-in solution for configuring flows, so teams have built their bespoke solutions leveraging Metaflow’s JSON-typed Parameters, IncludeFile, and deploy-time Parameters or deploying their own home-grown solution (often with great pain). However, none of these solutions make it easy to configure all aspects of the flow’s behavior, decorators in particular.
Outside Netflix, we have seen similar frequently asked questions on the Metaflow community Slack as shown in the user quotes above:
- how can I adjust the @resource requirements, such as CPU or memory, without having to hardcode the values in my flows?
- how to adjust the triggering @schedule programmatically, so our production and staging deployments can run at different cadences?
New in Metaflow: Configs!
Today, to answer the FAQ, we introduce a new — small but mighty — feature in Metaflow: a Config object. Configs complement the existing Metaflow constructs of artifacts and Parameters, by allowing you to configure all aspects of the flow, decorators in particular, prior to any run starting. At the end of the day, artifacts, Parameters and Configs are all stored as artifacts by Metaflow but they differ in when they are persisted as shown in the diagram below:
Said another way:
- An artifact is resolved and persisted to the datastore at the end of each task.
- A parameter is resolved and persisted at the start of a run; it can therefore be modified up to that point. One common use case is to use triggers to pass values to a run right before executing. Parameters can only be used within your step code.
- A config is resolved and persisted when the flow is deployed. When using a scheduler such as Argo Workflows, deployment happens when create’ing the flow. In the case of a local run, “deployment” happens just prior to the execution of the run — think of “deployment” as gathering all that is needed to run the flow. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters. Configs can of course also be used within your flow.
As an example, you can specify a Config that reads a pleasantly human-readable configuration file, formatted as TOML. The Config specifies a triggering ‘@schedule’ and ‘@resource’ requirements, as well as application-specific parameters for this specific deployment:
[schedule]
cron = "0 * * * *"
[model]
optimizer = "adam"
learning_rate = 0.5
[resources]
cpu = 1
Using the newly released Metaflow 2.13, you can configure a flow with a Config like above, as demonstrated by this flow:
import pprint
from metaflow import FlowSpec, step, Config, resources, config_expr, schedule
@schedule(cron=config_expr("config.schedule.cron"))
class ConfigurableFlow(FlowSpec):
config = Config("config", default="myconfig.toml", parser="tomllib.loads")
@resources(cpu=config.resources.cpu)
@step
def start(self):
print("Config loaded:")
pprint.pp(self.config)
self.next(self.end)
@step
def end(self):
pass
if __name__ == "__main__":
ConfigurableFlow()
There is a lot going on in the code above, a few highlights:
- you can refer to configs before they have been defined using ‘config_expr’.
- you can define arbitrary parsers — using a string means the parser doesn’t even have to be present remotely!
From the developer’s point of view, Configs behave like dictionary-like artifacts. For convenience, they support the dot-syntax (when possible) for accessing keys, making it easy to access values in a nested configuration. You can also unpack the whole Config (or a subtree of it) with Python’s standard dictionary unpacking syntax, ‘**config’. The standard dictionary subscript notation is also available.
Since Configs turn into dictionary artifacts, they get versioned and persisted automatically as artifacts. You can access Configs of any past runs easily through the Client API. As a result, your data, models, code, Parameters, Configs, and execution environments are all stored as a consistent bundle — neatly organized in Metaflow namespaces — paving the way for easily reproducible, consistent, low-boilerplate, and now easily configurable experiments and robust production deployments.
More than a humble config file
While you can get far by accompanying your flow with a simple config file (stored in your favorite format, thanks to user-definable parsers), Configs unlock a number of advanced use cases. Consider these examples from the updated documentation:
- You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. For instance, you can use a Config to define a default value for a parameter which can be overridden by a real-time event as a run is triggered.
- You can define a custom parser to validate the configuration, e.g. using the popular Pydantic library.
- You are not limited to using a single file: you can leverage a configuration manager like OmegaConf or Hydra to manage a hierarchy of cascading configuration files. You can also use a domain-specific tool for generating Configs, such as Netflix’s Metaboost which we cover below.
- You can also generate configurations on the fly, e.g. fetch Configs from an external service, or inspect the execution environment, such as the current GIT branch, and include it as an extra piece of context in runs.
A major benefit of Config over previous more hacky solutions for configuring flows is that they work seamlessly with other features of Metaflow: you can run steps remotely and deploy flows to production, even when relying on custom parsers, without having to worry about packaging Configs or parsers manually or keeping Configs consistent across tasks. Configs also work with the Runner and Deployer.
The Hollywood principle: don’t call us, we’ll call you
When used in conjunction with a configuration manager like Hydra, Configs enable a pattern that is highly relevant for ML and AI use cases: orchestrating experiments over multiple configurations or sweeping over parameter spaces. While Metaflow has always supported sweeping over parameter grids easily using foreaches, it hasn’t been easily possible to alter the flow itself, e.g. to change @resources or @pypi/@conda dependencies for every experiment.
In a typical case, you trigger a Metaflow flow that consumes a configuration file, changing how a run behaves. With Hydra, you can invert the control: it is Hydra that decides what gets run based on a configuration file. Thanks to Metaflow’s new Runner and Deployer APIs, you can create a Hydra app that operates Metaflow programmatically — for instance, to deploy and execute hundreds of variants of a flow in a large-scale experiment.
Take a look at two interesting examples of this pattern in the documentation. As a teaser, this video shows Hydra orchestrating deployment of tens of Metaflow flows, each of which benchmarks PyTorch using a varying number of CPU cores and tensor sizes, updating a visualization of the results in real-time as the experiment progresses:
Metaboosting Metaflow — based on a true story
To give a motivating example of what configurations look like at Netflix in practice, let’s consider Metaboost, an internal Netflix CLI tool that helps ML practitioners manage, develop and execute their cross-platform projects, somewhat similar to the open-source Hydra discussed above but with specific integrations to the Netflix ecosystem. Metaboost is an example of an opinionated framework developed by a team already using Metaflow. In fact, a part of the inspiration for introducing Configs in Metaflow came from this very use case.
Metaboost serves as a single interface to three different internal platforms at Netflix that manage ETL/Workflows (Maestro), Machine Learning Pipelines (Metaflow) and Data Warehouse Tables (Kragle). In this context, having a single configuration system to manage a ML project holistically gives users increased project coherence and decreased project risk.
Configuration in Metaboost
Ease of configuration and templatizing are core values of Metaboost. Templatizing in Metaboost is achieved through the concept of bindings, wherein we can bind a Metaflow pipeline to an arbitrary label, and then create a corresponding bespoke configuration for that label. The binding-connected configuration is then merged into a global set of configurations containing such information as GIT repository, branch, etc. Binding a Metaflow, will also signal to Metaboost that it should instantiate the Metaflow flow once per binding into our orchestration cluster.
Imagine a ML practitioner on the Netflix Content ML team, sourcing features from hundreds of columns in our data warehouse, and creating a multitude of models against a growing suite of metrics. When a brand new content metric comes along, with Metaboost, the first version of the metric’s predictive model can easily be created by simply swapping the target column against which the model is trained.
Subsequent versions of the model will result from experimenting with hyper parameters, tweaking feature engineering, or conducting feature diets. Metaboost’s bindings, and their integration with Metaflow Configs, can be leveraged to scale the number of experiments as fast as a scientist can create experiment based configurations.
Scaling experiments with Metaboost bindings — backed by Metaflow Config
Consider a Metaboost ML project named `demo` that creates and loads data to custom tables (ETL managed by Maestro), and then trains a simple model on this data (ML Pipeline managed by Metaflow). The project structure of this repository might look like the following:
├── metaflows
│ ├── custom -> custom python code, used by
| | | Metaflow
│ │ ├── data.py
│ │ └── model.py
│ └── training.py -> defines our Metaflow pipeline
├── schemas
│ ├── demo_features_f.tbl.yaml -> table DDL, stores our ETL
| | output, Metaflow input
│ └── demo_predictions_f.tbl.yaml -> table DDL,
| stores our Metaflow output
├── settings
│ ├── settings.configuration.EXP_01.yaml -> defines the additive
| | config for Experiment 1
│ ├── settings.configuration.EXP_02.yaml -> defines the additive
| | config for Experiment 2
│ ├── settings.configuration.yaml -> defines our global
| | configuration
│ └── settings.environment.yaml -> defines parameters based on
| git branch (e.g. READ_DB)
├── tests
├── workflows
│ ├── sql
│ ├── demo.demo_features_f.sch.yaml -> Maestro workflow, defines ETL
│ └── demo.main.sch.yaml -> Maestro workflow, orchestrates
| ETLs and Metaflow
└── metaboost.yaml -> defines our project for
Metaboost
The configuration files in the settings directory above contain the following YAML files:
# settings.configuration.yaml (global configuration)
model:
fit_intercept: True
conda:
numpy: '1.22.4'
"scikit-learn": '1.4.0'
# settings.configuration.EXP_01.yaml
target_column: metricA
features:
- runtime
- content_type
- top_billed_talent
# settings.configuration.EXP_02.yaml
target_column: metricA
features:
- runtime
- director
- box_office
Metaboost will merge each experiment configuration (*.EXP*.yaml) into the global configuration (settings.configuration.yaml) individually at Metaboost command initialization. Let’s take a look at how Metaboost combines these configurations with a Metaboost command:
(venv-demo) ~/projects/metaboost-demo [branch=demoX]
$ metaboost metaflow settings show --yaml-path=configuration
binding=EXP_01:
model: -> defined in setting.configuration.yaml (global)
fit_intercept: true
conda: -> defined in setting.configuration.yaml (global)
numpy: 1.22.4
"scikit-learn": 1.4.0
target_column: metricA -> defined in setting.configuration.EXP_01.yaml
features: -> defined in setting.configuration.EXP_01.yaml
- runtime
- content_type
- top_billed_talent
binding=EXP_02:
model: -> defined in setting.configuration.yaml (global)
fit_intercept: true
conda: -> defined in setting.configuration.yaml (global)
numpy: 1.22.4
"scikit-learn": 1.4.0
target_column: metricA -> defined in setting.configuration.EXP_02.yaml
features: -> defined in setting.configuration.EXP_02.yaml
- runtime
- director
- box_office
Metaboost understands it should deploy/run two independent instances of training.py — one for the EXP_01 binding and one for the EXP_02 binding. You can also see that Metaboost is aware that the tables and ETL workflows are not bound, and should only be deployed once. These details of which artifacts to bind and which to leave unbound are encoded in the project’s top-level metaboost.yaml file.
(venv-demo) ~/projects/metaboost-demo [branch=demoX]
$ metaboost project list
Tables (metaboost table list):
schemas/demo_predictions_f.tbl.yaml (binding=default):
table_path=prodhive/demo_db/demo_predictions_f
schemas/demo_features_f.tbl.yaml (binding=default):
table_path=prodhive/demo_db/demo_features_f
Workflows (metaboost workflow list):
workflows/demo.demo_features_f.sch.yaml (binding=default):
cluster=sandbox, workflow.id=demo.branch_demox.demo_features_f
workflows/demo.main.sch.yaml (binding=default):
cluster=sandbox, workflow.id=demo.branch_demox.main
Metaflows (metaboost metaflow list):
metaflows/training.py (binding=EXP_01): -> EXP_01 instance of training.py
cluster=sandbox, workflow.id=demo.branch_demox.EXP_01.training
metaflows/training.py (binding=EXP_02): -> EXP_02 instance of training.py
cluster=sandbox, workflow.id=demo.branch_demox.EXP_02.training
Below is a simple Metaflow pipeline that fetches data, executes feature engineering, and trains a LinearRegression model. The work to integrate Metaboost Settings into a user’s Metaflow pipeline (implemented using Metaflow Configs) is as easy as adding a single mix-in to the FlowSpec definition:
from metaflow import FlowSpec, Parameter, conda_base, step
from custom.data import feature_engineer, get_data
from metaflow.metaboost import MetaboostSettings
@conda_base(
libraries=MetaboostSettings.get_deploy_time_settings("configuration.conda")
)
class DemoTraining(FlowSpec, MetaboostSettings):
prediction_date = Parameter("prediction_date", type=int, default=-1)
@step
def start(self):
# get show_settings() for free with the mixin
# and get convenient debugging info
self.show_settings(exclude_patterns=["artifact*", "system*"])
self.next(self.get_features)
@step
def get_features(self):
# feature engineers on our extracted data
self.fe_df = feature_engineer(
# loads data from our ETL pipeline
data=get_data(prediction_date=self.prediction_date),
features=self.settings.configuration.features +
[self.settings.configuration.target_column]
)
self.next(self.train)
@step
def train(self):
from sklearn.linear_model import LinearRegression
# trains our model
self.model = LinearRegression(
fit_intercept=self.settings.configuration.model.fit_intercept
).fit(
X=self.fe_df[self.settings.configuration.features],
y=self.fe_df[self.settings.configuration.target_column]
)
print(f"Fit slope: {self.model.coef_[0]}")
print(f"Fit intercept: {self.model.intercept_}")
self.next(self.end)
@step
def end(self):
pass
if __name__ == "__main__":
DemoTraining()
The Metaflow Config is added to the FlowSpec by mixing in the MetaboostSettings class. Referencing a configuration value is as easy as using the dot syntax to drill into whichever parameter you’d like.
Finally let’s take a look at the output from our sample Metaflow above. We execute experiment EXP_01 with
metaboost metaflow run --binding=EXP_01
which upon execution will merge the configurations into a single settings file (shown previously) and serialize it as a yaml file to the .metaboost/settings/compiled/ directory.
You can see the actual command and args that were sub-processed in the Metaboost Execution section below. Please note the –config argument pointing to the serialized yaml file, and then subsequently accessible via self.settings. Also note the convenient printing of configuration values to stdout during the start step using a mixed in function named show_settings().
(venv-demo) ~/projects/metaboost-demo [branch=demoX]
$ metaboost metaflow run --binding=EXP_01
Metaboost Execution:
- python3.10 /root/repos/cdm-metaboost-irl/metaflows/training.py
--no-pylint --package-suffixes=.py --environment=conda
--config settings
.metaboost/settings/compiled/settings.branch_demox.EXP_01.training.mP4eIStG.yaml
run --prediction_date20241006
Metaflow 2.12.39+nflxfastdata(2.13.5);nflx(2.13.5);metaboost(0.0.27)
executing DemoTraining for user:dcasler
Validating your flow...
The graph looks good!
Bootstrapping Conda environment... (this could take a few minutes)
All packages already cached in s3.
All environments already cached in s3.
Workflow starting (run-id 50), see it in the UI at
https://metaflowui.prod.netflix.net/DemoTraining/50
[50/start/251640833] Task is starting.
[50/start/251640833] Configuration Values:
[50/start/251640833] settings.configuration.conda.numpy = 1.22.4
[50/start/251640833] settings.configuration.features.0 = runtime
[50/start/251640833] settings.configuration.features.1 = content_type
[50/start/251640833] settings.configuration.features.2 = top_billed_talent
[50/start/251640833] settings.configuration.model.fit_intercept = True
[50/start/251640833] settings.configuration.target_column = metricA
[50/start/251640833] settings.environment.READ_DATABASE = data_warehouse_prod
[50/start/251640833] settings.environment.TARGET_DATABASE = demo_dev
[50/start/251640833] Task finished successfully.
[50/get_features/251640840] Task is starting.
[50/get_features/251640840] Task finished successfully.
[50/train/251640854] Task is starting.
[50/train/251640854] Fit slope: 0.4702672504331096
[50/train/251640854] Fit intercept: -6.247919678070083
[50/train/251640854] Task finished successfully.
[50/end/251640868] Task is starting.
[50/end/251640868] Task finished successfully.
Done! See the run in the UI at
https://metaflowui.prod.netflix.net/DemoTraining/50
Takeaways
Metaboost is an integration tool that aims to ease the project development, management and execution burden of ML projects at Netflix. It employs a configuration system that combines git based parameters, global configurations and arbitrarily bound configuration files for use during execution against internal Netflix platforms.
Integrating this configuration system with the new Config in Metaflow is incredibly simple (by design), only requiring users to add a mix-in class to their FlowSpec — similar to this example in Metaflow documentation — and then reference the configuration values in steps or decorators. The example above templatizes a training Metaflow for the sake of experimentation, but users could just as easily use bindings/configs to templatize their flows across target metrics, business initiatives or any other arbitrary lines of work.
Try it at home
It couldn’t be easier to get started with Configs! Just
pip install -U metaflow
to get the latest version and head to the updated documentation for examples. If you are impatient, you can find and execute all config-related examples in this repository as well.
If you have any questions or feedback about Config (or other Metaflow features), you can reach out to us at the Metaflow community Slack.
Acknowledgments
We would like to thank Outerbounds for their collaboration on this feature; for rigorously testing it and developing a repository of examples to showcase some of the possibilities offered by this feature.
![]()
Introducing Configurable Metaflow was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Бисер Лазов от делото за КТБ “наднича” от джипа на поморийския кмет Кметът на Поморие и Областен на ГЕРБ – лукс за чужда сметка
Post Syndicated from Стоян Тончев original https://bivol.bg/pomorie-lux-kmet.html
петък 20 декември 2024

Кметът на третия по големина град на Българското Черноморие, Поморие – Иван Алексиев, е засечен заедно със семейството си да консумира луксозен живот чрез чужда собственост – частна и общинска.…
Kicked in the Head
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=UGxHpovIPEs