Post Syndicated from Explosm.net original https://explosm.net/comics/butt-asleep
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/butt-asleep
New Cyanide and Happiness Comic
Post Syndicated from xkcd.com original https://xkcd.com/3027/

Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=tsWZ6MgetBI
Post Syndicated from digiblur DIY original https://www.youtube.com/watch?v=2nQ42QswBuA
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/cxl-is-finally-coming-in-2025-amd-intel-marvell-xconn-inventec-lenovo-asus-kioxia-montage-arm/
After years of hype, we are seeing enough CXL action that it is a technology we expect to see a lot more of in 2025. Here is why
The post CXL is Finally Coming in 2025 appeared first on ServeTheHome.
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=WP8mE4bc4j8
Post Syndicated from Naranjan Goklani original https://aws.amazon.com/blogs/security/aws-completes-the-cccs-pbhva-assessment-with-149-services-and-features-in-scope/
We continue to expand the scope of our assurance programs at Amazon Web Services (AWS) and are pleased to announce the successful completion of our first ever Protected B High Value Assets (PBHVA) assessment with 149 assessed services and features. Completion of this assessment effective October 4, 2024, makes AWS the first cloud service provider (CSP) in Canada to meet this high security bar and provide assurance to our valued customers. This assessment also re-affirms our commitment to helping public and commercial customers achieve and maintain the highest-grade security standard for workloads with increased sensitivity.
The Protected B High Value Asset (PBHVA) overlay seeks to enhance the integrity and availability of customer organizational workloads that are considered to have an increased level of sensitivity. These are systems that the Government of Canada (GC) and its service providers use to support delivery of services at a national scale or that are determined to be significant for handling sensitive information. The overlay is a set of 117 controls from the ITSG-33 security control catalogue (baselined against NIST 800-53), which augments the security safeguards to enhance integrity and availability.
As of October 4, 2024, there are a total of 149 AWS services and features that were assessed by the Canadian Centre for Cyber Security (CCCS) under PBHVA assessment criteria. The assessment covers services and features that are available in both the Canada (Central) and Canada West (Calgary) AWS Regions.
The summary assessment is available through AWS Artifact. You can also learn more about the PBHVA assessment on our AWS PBHVA webpage.
AWS strives to continuously bring services into scope of its compliance programs to help you meet your architectural and regulatory needs. Please reach out to your AWS account team if you have questions or feedback about the PBHVA assessment.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Post Syndicated from Atulsing Patil original https://aws.amazon.com/blogs/security/2024-iso-and-csa-star-certificates-now-available-with-two-additional-services/
Amazon Web Services (AWS) successfully completed a surveillance audit with no findings for ISO 9001:2015, 27001:2022, 27017:2015, 27018:2019, 27701:2019, 20000-1:2018, and 22301:2019, and Cloud Security Alliance (CSA) STAR Cloud Controls Matrix (CCM) v4.0. EY CertifyPoint auditors conducted the audit and reissued the certificates on November 29, 2024. The objective of the audit was to assess the level of compliance with the requirements of the applicable international standards.
During this surveillance audit, we added two additional AWS services to the scope since the last certification issued on July 22, 2024:
For a full list of AWS services that are certified under ISO and CSA STAR, see the AWS ISO and CSA STAR Certified page. Customers can also access the certifications in the AWS Management Console through AWS Artifact.
If you have feedback about this post, submit comments in the Comments section below.
Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/stable-diffusion-3-5-large-is-now-available-in-amazon-bedrock/
As we preannounced at AWS re:Invent 2024, you can now use Stable Diffusion 3.5 Large in Amazon Bedrock to generate high-quality images from text descriptions in a wide range of styles to accelerate the creation of concept art, visual effects, and detailed product imagery for customers in media, gaming, advertising, and retail.
In October 2024, Stability AI introduced Stable Diffusion 3.5 Large, the most powerful model in the Stable Diffusion family at 8.1 billion parameters trained on Amazon SageMaker HyperPod, with superior quality and prompt adherence. Stable Diffusion 3.5 Large can accelerate storyboarding, concept art creation, and rapid prototyping of visual effects. You can quickly generate high-quality 1-megapixel images for campaigns, social media posts, and advertisements, saving time and resources while maintaining creative control.
Stable Diffusion 3.5 Large offers users nearly endless creative possibilities, including:
Today, Stable Image Ultra in Amazon Bedrock has been updated to include Stable Diffusion 3.5 Large in the model’s underlying architecture. Stable Image Ultra, powered by Stability AI’s most advanced models, including Stable Diffusion 3.5, sets a new standard in image generation. It excels in typography, intricate compositions, dynamic lighting, vibrant colors, and artistic cohesion.
With the latest update of Stable Diffusion models in Amazon Bedrock, you have a broader set of solutions to boost your creativity and accelerate image generation workflows.
Get started with Stable Diffusion 3.5 Large in Amazon Bedrock
Before getting started, if you are new to using Stability AI models, go to the Amazon Bedrock console and choose Model access on the bottom left pane. To access the latest Stability AI models, request access for Stable Diffusion 3.5 Large in Stability AI.

To test the Stability AI models in Amazon Bedrock, choose Image/Video under Playgrounds in the left menu pane. Then choose Select model and select Stability AI as the category and Stable Diffusion 3.5 Large as the model.

You can generate an image with your prompt. Here is a sample prompt to generate the image:
High-energy street scene in a neon-lit Tokyo alley at night, where steam rises from food carts, and colorful neon signs illuminate the rain-slicked pavement.

By choosing View API request, you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs. You can use stability.sd3-5-large-v1:0 as the model ID.
To get the image with a single command, I write the output JSON file to standard output and use the jq tool to extract the encoded image so that it can be decoded on the fly. The output is written in the img.png file.
Here is a sample of the AWS CLI command:
$ aws bedrock-runtime invoke-model \
--model-id stability.sd3-5-large-v1:0 \
--body "{\"text_prompts\":[{\"text\":\"High-energy street scene in a neon-lit Tokyo alley at night, where steam rises from food carts, and colorful neon signs illuminate the rain-slicked pavement.\",\"weight\":1}],\"cfg_scale\":0,\"steps\":10,\"seed\":0,\"width\":1024,\"height\":1024,\"samples\":1}" \
--cli-binary-format raw-in-base64-out \
--region us-west-2 \
/dev/stdout | jq -r '.images[0]' | base64 --decode > img.jpgHere’s how you can use Stable Image Ultra 1.1 to include Stable Diffusion 3.5 Large in the model’s underlying architecture with the AWS SDK for Python (Boto3). This simple application interactively asks for a text-to-image prompt and then calls Amazon Bedrock to generate the image with stability.stable-image-ultra-v1:1 as the model ID.
import base64
import boto3
import json
import os
MODEL_ID = "stability.stable-image-ultra-v1:1"
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-west-2")
print("Enter a prompt for the text-to-image model:")
prompt = input()
body = {
"prompt": prompt,
"mode": "text-to-image"
}
response = bedrock_runtime.invoke_model(modelId=MODEL_ID, body=json.dumps(body))
model_response = json.loads(response["body"].read())
base64_image_data = model_response["images"][0]
i, output_dir = 1, "output"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
while os.path.exists(os.path.join(output_dir, f"img_{i}.png")):
i += 1
image_data = base64.b64decode(base64_image_data)
image_path = os.path.join(output_dir, f"img_{i}.png")
with open(image_path, "wb") as file:
file.write(image_data)
print(f"The generated image has been saved to {image_path}")The application writes the resulting image in an output directory that is created if not present. To not overwrite existing files, the code checks for existing files to find the first file name available with the img_<number>.png format.
To learn more, visit the Invoke API examples using AWS SDKs to build your applications to generate an image using various programming languages.
Interesting examples
Here are a few images created with Stable Diffusion 3.5 Large.
 |
 |
Prompt: Full-body university students working on a tech project with the words Stable Diffusion 3.5 in Amazon Bedrock, cheerful cursive typography font in the foreground. |
Prompt: Photo of three potions: the first potion is blue with the label "MANA", the second potion is red with the label "HEALTH", the third potion is green with the label "POISON". Old apothecary. |
 |
 |
Prompt: Photography, pink rose flowers in the twilight, glowing, tile houses in the background. |
Prompt: 3D animation scene of an adventurer traveling the world with his pet dog. |
Now available
Stable Diffusion 3.5 Large model is generally available today in Amazon Bedrock in the US West (Oregon) AWS Region. Check the full Region list for future updates. To learn more, check out the Stability AI in Amazon Bedrock product page and the Amazon Bedrock Pricing page.
Give Stable Diffusion 3.5 Large a try in the Amazon Bedrock console today and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
— Channy
Post Syndicated from Nivetha Chandran original https://aws.amazon.com/blogs/security/updated-pci-dss-and-pci-pin-compliance-packages-now-available/
Amazon Web Services (AWS) is pleased to announce enhancements to our Payment Card Industry (PCI) compliance portfolio, further empowering AWS customers to build and manage secure, compliant payment environments with greater ease and flexibility.
PCI Data Security Standard (DSS): Our latest AWS PCI DSS v4 Attestation of Compliance (AOC) is now available and includes six additional AWS services:
This expansion allows you to use these services while maintaining PCI DSS compliance, enabling innovation without compromising security. You can see the full list of services at AWS Services in Scope by Compliance Program.
PCI Personal Identification Number (PIN): We updated our PCI PIN AOC for two critical services:
These refreshed attestations offer you greater flexibility in deploying regulated workloads while significantly reducing your compliance overhead. You can access the PCI DSS and PIN AOC reports through AWS Artifact. This self-service portal provides on-demand access to AWS compliance reports, streamlining your audit processes.
To learn more about our PCI programs and other compliance and security programs, see the AWS Compliance Programs page. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Compliance Support page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Post Syndicated from David Johnson original https://www.backblaze.com/blog/5-ways-event-notifications-strengthens-your-backup-strategy-automatically/
“Our backups are good, right?”
If you’re responsible for backup operations, you’ve probably heard this question more times than you can count. While the answer should be a simple “yes,” staying on top of backup activities often involves checking multiple systems, reviewing logs, and maintaining manual tracking processes.
Today, I’m sharing five ways you can implement Backblaze Event Notifications into your data protection strategy to keep you and your team informed. If you’re interested in Event Notifications for other use cases, check out our posts for media production and application workflows.
Event Notifications monitors your B2 Cloud Storage buckets for data changes that you designate—like completed backups, file deletions, or policy violations—and delivers real-time alerts where you want them. These alerts can trigger automated actions in any system that accepts webhooks, from PagerDuty to Zendesk to Slack channels and more.
Think of it as your storage system’s notification service: instead of discovering changes during routine recovery verification checks, you get instant awareness when something happens to the data in your buckets.
Webhooks, if you’re not familiar, are a way for applications to communicate with each other by sending data automatically based on specific events, e.g., HTTP POST requests with a JSON payload. What sets Backblaze Event Notifications apart is that it works with any service that accepts webhooks. This means you can integrate backup monitoring into your existing tools and processes, rather than being locked into specific vendors’ ecosystems.
Here are specific, practical ways you can take advantage of Event Notifications for immediate benefits to your backup and archive workflows.
When your backup software writes files to B2 Cloud Storage, Event Notifications helps verify successful completion of backup jobs. Each time a backup file lands in a bucket, you’ll receive a notification with key details like file size, timestamp, and backup job name. By feeding this data directly into communication tools like Slack, you can maintain comprehensive logs of backup activity without manual checks.
Backup monitoring workflow
Gone are the days of discovering backup issues hours or days later during routine reviews—you’ll know exactly when backups are uploaded. Teams can configure custom alerts for backup size thresholds, receive immediate confirmation of successful backups, and, with the help of Zapier, you can enable an alert when Event Notifications did not trigger, indicating a backup was not uploaded during a specified window.
Event Notifications can help protect your backup data from unauthorized changes. Security teams can establish automated alerts for suspicious activities like mass deletions or modifications. These alerts integrate with your existing security information and event management (SIEM) systems to provide unified threat monitoring.
Security alert workflow

Beyond threat detection, Event Notifications enables preemptive policy enforcement. Teams can configure automatic notifications that guide employees when their actions might conflict with backup policies—like modifying file names, moving files, or even deletion. For persistent policy conflicts, managers can receive automated escalation alerts to address potential training needs or process gaps. This systematic approach helps maintain backup integrity through education and awareness before issues occur, rather than just detecting violations after the fact.
Storage management becomes more efficient when Event Notifications feeds activity data directly to your management tools. As files are uploaded to and removed from your buckets over time, Event Notifications provides valuable data that helps you analyze storage utilization trends and backup data growth patterns.
Data usage monitoring workflow
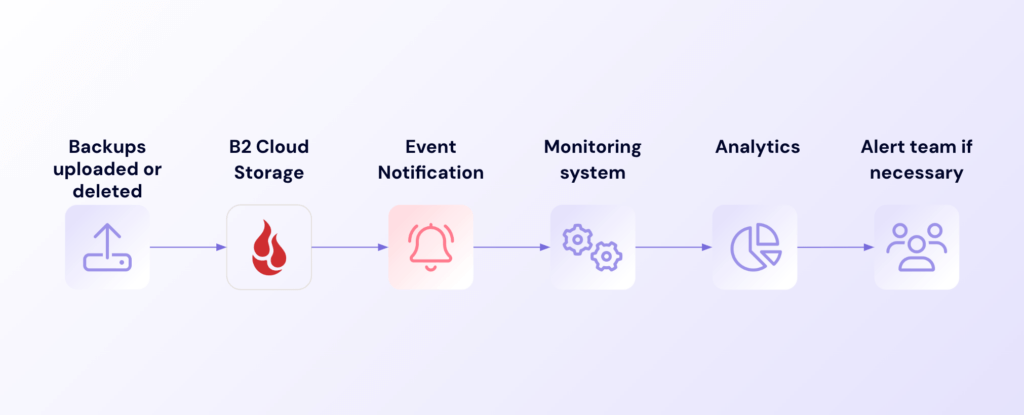
This constant flow of information empowers teams to anticipate capacity needs and optimize resource allocation. Moving from reactive to proactive storage management helps control costs by notifying you when backups become larger on average.
Organizations using Cloud Replication or managing backups across multiple buckets gain valuable oversight through Event Notifications. This capability tracks file replication between regions and monitors backup activity across your entire footprint, giving you a comprehensive view of your distributed backup strategy. Teams can spot replication delays or issues immediately, rather than waiting for scheduled status checks.
Cloud Replication notification workflow
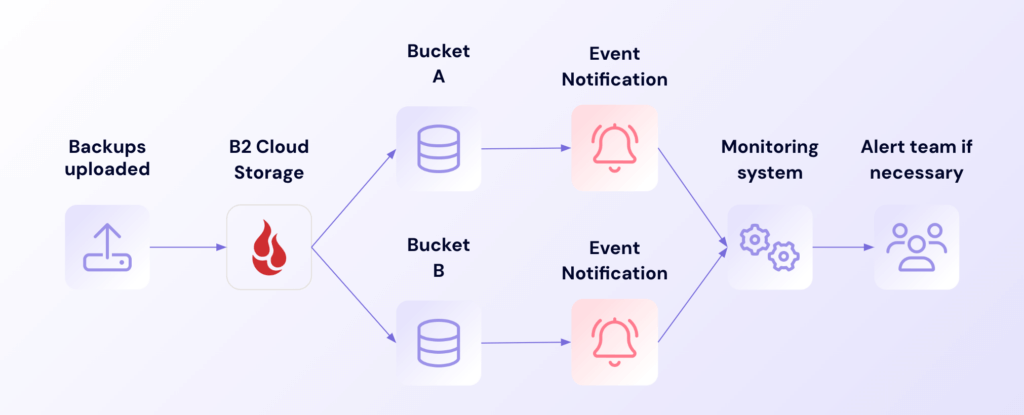
Understanding how data moves and grows across different locations ensures your distributed backup strategy performs as designed. Event Notifications makes it possible to track successful replications, monitor consistency between primary and replica buckets, and receive immediate alerts about any issues. This visibility is especially valuable for organizations maintaining geographic redundancy or managing complex multi-site backup strategies.
Event Notifications connects seamlessly with existing IT tools and processes through standard webhooks. Backup events can automatically flow into ticketing systems like Jira Service Management, monitoring dashboards like Grafana, or team communication channels like Microsoft Teams and Mattermost. This integration means teams can manage backup operations through familiar tools and processes, without needing to constantly switch between different interfaces or learn new systems.
Data integration workflow
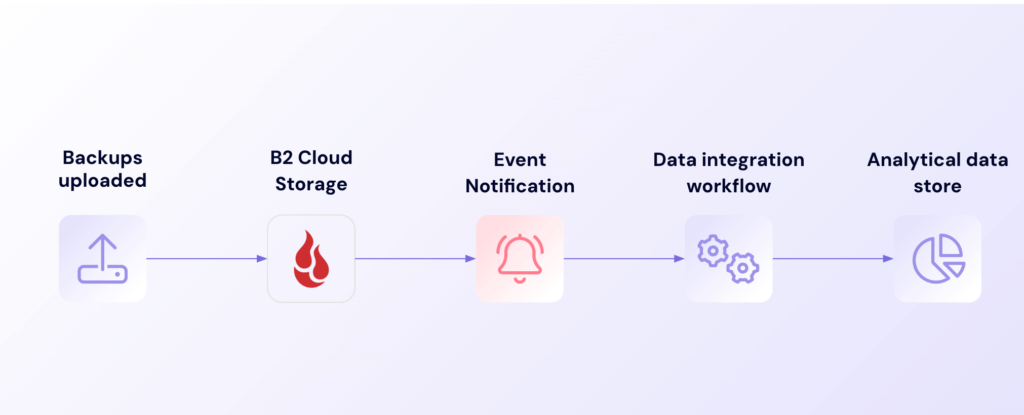
The result is streamlined operations without the need for separate backup monitoring systems, ensuring backup activities receive proper attention within normal IT procedures. Teams can create ServiceNow tickets for failed backups, update Jira boards with backup status, or send notifications to Teams channels—all automatically and in real-time.
Managing backup operations has traditionally meant juggling multiple monitoring tools and hoping you catch issues before they impact recovery capabilities. Event Notifications transforms this approach by providing:
Unlike traditional backup monitoring solutions that often require specific software for notification handling, Event Notifications works with any service that accepts webhooks. This fundamental difference means you aren’t locked into specific vendors’ ecosystems or forced to use particular monitoring tools.
Event Notifications is designed for reliability with at-least-once delivery, ensuring critical backup events are never missed. This reliability is especially important for teams building automated workflows that require consistency and transparency in their backup monitoring.
The pricing model is straightforward and predictable: Backblaze B2 Reserve customers receive unlimited notifications at no additional cost, while pay-as-you-go customers get 2,500 notifications free each day and pay just $0.004 per 10,000 additional calls. This transparent pricing applies regardless of which services you’re connecting to, enabling teams to build comprehensive backup monitoring without worrying about unpredictable costs.
If you’re working with a Backblaze account manager, Event Notifications are already enabled—just ask them for setup guidance. Other existing customers can contact our Support team to request access.
New to Backblaze? Contact our Sales team to learn how Event Notifications can strengthen your backup operations.
Once enabled, visit the Event Notifications section in your B2 Cloud Storage buckets to configure your alerts. For detailed setup instructions and best practices, check out our Event Notifications documentation.
The post 5 Ways Event Notifications Strengthens Your Backup Strategy Automatically appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Post Syndicated from Paul Hong original https://aws.amazon.com/blogs/security/fall-2024-soc-1-2-and-3-reports-now-available-with-183-services-in-scope/
We continue to expand the scope of our assurance programs at Amazon Web Services (AWS) and are pleased to announce that the Fall 2024 System and Organization Controls (SOC) 1, 2, and 3 reports are now available. The reports cover 183 services over the 12-month period from October 1, 2023 to September 30, 2024, so that customers have a full year of assurance with the reports. These reports demonstrate our continuous commitment to adhere to the heightened expectations for cloud service providers.
Going forward, we will issue SOC reports covering a 12-month period each quarter as follows:
| Report | Period covered |
| Spring SOC 1, 2, and 3 | April 1–March 31 |
| Summer SOC 1 | July 1–June 30 |
| Fall SOC 1, 2, and 3 | October 1–September 30 |
| WWinter SOC 1 | January 1–December 31 |
Customers can download the Fall 2024 SOC 1, 2, and 3 reports through AWS Artifact, a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact.
AWS strives to continuously bring services into the scope of its compliance programs to help you meet your architectural and regulatory needs. If you have questions or feedback about SOC compliance, reach out to your AWS account team.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=HswpRHu_X-k
Post Syndicated from Bozho original https://blog.bozho.net/blog/4439
Спирането на процедурата за избор на главен прокурор е най-спешният приоритет. Чак такива залпове към парламента и „изтърваният“ Гешев не си позволи.
Днес постигнахме напредък по формирането на комисии, след като вчера приехме правилника. И съм умерен оптимист, че в парламента има воля за спирането на тази процедура за избор на главен прокурор.
Въпросът след това ще бъде „а сега какво?“. ВСС няма да се откаже да инсталира някой следващ Сарафов. Затова внесеният от нас законопроект е важен и отвъд избора на Сарафов. Той подобрава значително правилата, и спира всяка процедура за избор, ако Народното събрание започне смяна на членовете на ВСС. Само че за да се възползваме от тази промяна, трябва да има избор на нов ВСС, а за това трябва траен парламент. Т.е. правителство.
След това прокуратурата няма да стане изведнъж западноевропейска, ефективна, обективна и отчетна. Ще трябва да се поправят много неща – в Закона за съдебната власт, в Наказателно-процесуалния кодека, в Закона за СРС. Все реформи, които също изискват траен парламент.
С всяка алинея Пеевски ще губи инструменти за въздействие. Напр. ако въведем случайно разпределение за мерките за неотклонение и за разрешенията за СРС, изведнъж ще се окаже, че Пеевски няма никакви гаранции дали ще може неговите прокурори да извършват процесуален произвол, разрешен от назначените от него административни ръководители и техни заместници в съда.
Това и много други мерки са част от антикорупционната програма, която представихме в кампанията. И опитваме да осигурим време и консенсус по нейното прилагане. Защото иначе просто ще намерят и инсталират следващ Сарафов.
Материалът След спирането на Сарафов е публикуван за пръв път на БЛОГодаря.
Post Syndicated from jzb original https://lwn.net/Articles/1002903/
Security updates have been issued by AlmaLinux (bluez, edk2:20220126gitbb1bba3d77, gstreamer1-plugins-base, gstreamer1-plugins-good, kernel, kernel-rt, mpg123, php:8.2, python3.11-urllib3, and tuned), Fedora (ColPack, glibc, golang-github-chainguard-dev-git-urls, golang-github-task, icecat, python-nbdime, python3.13, and python3.14), Mageia (kernel, kmod-xtables-addons, kmod-virtualbox, dwarves and kernel-linus), Red Hat (gstreamer1-plugins-base and gstreamer1-plugins-good), SUSE (curl, emacs, git-bug, glib2, helm, kernel, and traefik2), and Ubuntu (gst-plugins-base1.0, gst-plugins-good1.0, gstreamer1.0, libvpx, linux-gcp, phpunit, and yara).
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/12/mailbox-insecurity.html
It turns out that all cluster mailboxes in the Denver area have the same master key. So if someone robs a postal carrier, they can open any mailbox.
I get that a single master key makes the whole system easier, but it’s very fragile security.
Post Syndicated from Luis Campos original https://aws.amazon.com/blogs/big-data/hema-accelerates-their-data-governance-journey-with-amazon-datazone/
This post is cowritten by Tommaso Paracciani and Oghosa Omorisiagbon from HEMA.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. However, many companies today still struggle to effectively harness and use their data due to challenges such as data silos, lack of discoverability, poor data quality, and a lack of data literacy and analytical capabilities to quickly access and use data across the organization. To address these growing data management challenges, AWS customers are using Amazon DataZone, a data management service that makes it fast and effortless to catalog, discover, share, and govern data stored across AWS, on-premises, and third-party sources.
HEMA is a household Dutch retail brand name since 1926, providing daily convenience products using unique design. HEMA’s more than 17,000 employees bring exclusive, sustainably designed products in more than 750 stores in the Netherlands but also in Belgium, Luxembourg, France, Germany, and Austria, with webstores available in all these countries. HEMA built its first ecommerce system on AWS in 2018 and 5 years later, its developers have the freedom to innovate and build software fast with their choice of tools in the AWS Cloud. Today, this is powering every part of the organization, from the customer-favorite online cake customization feature to democratizing data to drive business insight.
This post describes how HEMA used Amazon DataZone to build their data mesh and enable streamlined data access across multiple business areas. It explains HEMA’s unique journey of deploying Amazon DataZone, the key challenges they overcame, and the transformative benefits they have realized since deployment in May 2024. From establishing an enterprise-wide data inventory and improving data discoverability, to enabling decentralized data sharing and governance, Amazon DataZone has been a game changer for HEMA.
After moving its entire data platform from on premises to the AWS Cloud, the wave of change presented a unique opportunity for the HEMA Data & Cloud function to invest and commit in building a data mesh.
HEMA has a bespoke enterprise architecture, built around the concept of services. These services are individual software functionalities that fulfill a specific purpose within the company. Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure.

HEMA runs over 400 services, and 20 of them run extract, transform, and load (ETL) pipelines with dedicated data resources, which produce and consume data assets shared across the data mesh.
Weeks after launch, HEMA’s data platform wasn’t where the company wanted it to be. Building an agile organization that runs on reliable and streamlined processes was the primary goal. Initially, the data inventories of different services were siloed within isolated environments, making data discovery and sharing across services manual and time-consuming for all teams involved.
Implementing robust data governance is challenging. In a data mesh architecture, this complexity is amplified by the organization’s decentralized nature. In this context, HEMA concluded that data governance was no longer a nice-to-have, but had become a foundational piece required to build a healthy data organization.
By exploring the preview, HEMA saw how Amazon DataZone covered all the critical pillars of data management in a single solution. It was clear how Amazon DataZone would bring benefit to both the technical teams as well as the business end-users. The technical organization could take advantage of a robust programmatic solution to manage the availability, accessibility, and quality of the data assets that make the enterprise data catalog. The business end-users were given a tool to discover data assets produced within the mesh and seamlessly self-serve on their data sharing needs.
Features such as AI-generated metadata were key to providing end-users with reliable and use case-driven explanations of what a certain data product could provide and solve, while the subscription feature allowed them to start using a certain data asset within their own environment in a matter of seconds, as opposed to the existing lengthy and human-driven process.
These reasons, as well as the self-service capabilities, resulted in HEMA’s decision to adopt and roll out Amazon DataZone at the enterprise level.
The HEMA data landscape is multifaceted, with various teams across the organization using a range of technologies and systems, including Databricks. To effectively govern this complex data environment, HEMA has adopted a data mesh architecture on AWS. This architecture maintains a central intelligence platform (CIP) that enables the activities of both data producers and data consumers by providing the necessary platform and infrastructure. The overall structure can be represented in the following figure.

Each service uses two AWS accounts, one for pre-production and one for production. This separation means changes can be tested thoroughly before being deployed to live operations.
Amazon DataZone is the central piece in this architecture. It helps HEMA centralize all data assets across disparate data stacks into a single catalog. It plays a pivotal role in bridging the gap and integrating different systems, such as Databricks and native AWS services. The integration of Databricks Delta tables into Amazon DataZone is done using the AWS Glue Data Catalog. Delta tables’ technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog. Access control is enforced using AWS Lake Formation, which manages fine-grained access control and data sharing on data lake data. The following figure illustrates the data mesh architecture.

The Amazon DataZone implementation follows the same approach as individual services: HEMA maintains two distinct domain data catalogs: preprod-hema-data-catalog and prod-hema-data-catalog. These catalogs serve as the backbone for data sharing across pre-production and production accounts, allowing flexible access to data assets based on the environment’s needs.
The prod-hema-data-catalog is the production-grade catalog that supports data sharing across production services and, in some cases, pre-production services. This catalog only facilitates the production of data assets from production services (disallows publishing of assets belonging to pre-production services) and allows pre-production services to access production-grade data. The following diagram illustrates the architecture of both accounts.

To establish isolation between services in the data mesh, a project is dedicated to a unique service account. The environment profiles and environments are configured to be explicitly used only by the service. This Amazon DataZone configuration is managed centrally by the core team using AWS CloudFormation. After projects are created and configured by the central team, project teams have access to self-service capabilities to create their own environments according to their needs.
The following diagram illustrates the full workflow for onboarding HEMA service teams in Amazon DataZone.

The workflow includes the following steps:
In a decentralized data mesh environment, there is a risk of service teams creating resources in service accounts they are not authorized to manage, which may lead to governance issues and data mismanagement. To address this challenge, HEMA followed two principles:
In HEMA’s data mesh, the catalog must be built in collaboration with all the services that produce data, so the key for the central data governance team was ideating an adoption plan that would add value to these teams, rather than disrupting the delivery of their projects. With that in mind, HEMA’s adoption strategy was designed on three core principles:
While deploying the adoption plan for a decentralized data marketplace using Amazon DataZone, HEMA followed a “start small, fine-tune, and iterate” approach. In practice, this meant that the Data & Cloud team started working with one business unit, expanding then to several business units, while focusing on one single feature: data asset subscription. To increase interest and adoption, this process was introduced for the core data assets that were more used in the company.
After this part of the process was well understood and embraced by everyone, the next step was to start supporting the data pipeline adaptation work needed for each business unit.
Finally, when all teams were onboarded and familiar with the subscription feature, HEMA moved to introduce the business units to the second critical feature: data publishing. In summary, HEMA released new features and allowed the domains to pick up the implementation at their preferred pace before moving onto the next one.
When adoption was at a point where all core data assets were being consumed through the Amazon DataZone catalog, the Lake Formation resource links used previously to share data across accounts were decommissioned, and at the same time the Data & Cloud team interrupted their duty to share data between business units, stimulating the peer-to-peer data sharing practice, where teams can directly talk to each other without having to involve a third party.
The popularity of Amazon DataZone across the enterprise ramped up quickly, and all the involved business units started using the service daily to self-serve their needs. The existence of a central data catalog enabled teams to seamlessly search, discover, share, and subscribe to data assets produced within the business. Only a few months after launching the service, HEMA observed stunning statistics:
Additionally, they saw massive benefits that can’t be represented by statistics. Above all, the ability to autonomously discover data produced by other teams is enabling a series of new use cases for the business, which weren’t even visible to them earlier due to the lack of awareness and visibility on what others were producing. For example, the data science team quickly developed a new predictive model for sales by reusing data already available in Amazon DataZone, instead of rebuilding it from scratch. This is resulting in an energized data organization, which can collaborate and contribute to shaping the future of HEMA’s data operations.
At HEMA, Amazon DataZone made data governance a reality, and so the company wants to implement new features in close collaboration with AWS, while continuing to work on the rollout of items that are already in HEMA’s roadmap. The team is continuously developing the service, launching a series of new features that will continue to improve the data operations:
The long-term vision of HEMA is clear: Amazon DataZone is set to become the central solution for data sharing and data cataloging across the enterprise. Although as of today, Amazon DataZone is focused on supporting the teams running ETL pipelines, the goal is to extend the service to all the business teams that work with data, with the ultimate goal of streamlining their daily operations. Data is one of the most valuable resources a company has, and HEMA is determined to democratize its role by building an efficient data organization, who relies on the most advanced data governance solution on the market.
 Luis Campos is the Data & AI Governance GTM Lead for the EMEA market at AWS where he helps customers with their data strategies starting with strong data governance and uses his expertise in end-to-end data & analytics management. Luis is also a public speaking coach, based in the Netherlands, and has two boys with 18 years apart, which has taught him to see problems from both ends of a spectrum.
Luis Campos is the Data & AI Governance GTM Lead for the EMEA market at AWS where he helps customers with their data strategies starting with strong data governance and uses his expertise in end-to-end data & analytics management. Luis is also a public speaking coach, based in the Netherlands, and has two boys with 18 years apart, which has taught him to see problems from both ends of a spectrum.
 Vincent Gromakowski is a Principal Analytics Solutions Architect at AWS where he enjoys solving customers’ data challenges. He uses his strong expertise on analytics, distributed systems and resource orchestration platform to be a trusted technical advisor for AWS customers.
Vincent Gromakowski is a Principal Analytics Solutions Architect at AWS where he enjoys solving customers’ data challenges. He uses his strong expertise on analytics, distributed systems and resource orchestration platform to be a trusted technical advisor for AWS customers.
 Tommaso is the Head of Data & Cloud Platforms at HEMA. He joined the business with the goal of modernising the Data Organization by building cloud-based Data Platform – hosted in AWS – which would power a Data Mesh architecture. With a strong passion for both technical and organizational challenges, Tommaso leads the Solution Architecture efforts as well as all core Data Management and Data Governance initiatives, for which he is also a passionate public speaker. Outside the office, Tommaso is a full-time dad with a passion for traveling and sports.
Tommaso is the Head of Data & Cloud Platforms at HEMA. He joined the business with the goal of modernising the Data Organization by building cloud-based Data Platform – hosted in AWS – which would power a Data Mesh architecture. With a strong passion for both technical and organizational challenges, Tommaso leads the Solution Architecture efforts as well as all core Data Management and Data Governance initiatives, for which he is also a passionate public speaker. Outside the office, Tommaso is a full-time dad with a passion for traveling and sports.
 Oghosa Omorisiagbon is a Senior Data Engineer at HEMA. He focuses on leveraging AWS-native tools to optimise data pipelines, modernise HEMA’s data infrastructure and introduce reliable and scalable end-to-end data architecture solutions. Outside of work, he enjoys traveling, playing video games and outdoor activities.
Oghosa Omorisiagbon is a Senior Data Engineer at HEMA. He focuses on leveraging AWS-native tools to optimise data pipelines, modernise HEMA’s data infrastructure and introduce reliable and scalable end-to-end data architecture solutions. Outside of work, he enjoys traveling, playing video games and outdoor activities.
Post Syndicated from Navnit Shukla original https://aws.amazon.com/blogs/big-data/accelerate-queries-on-apache-iceberg-tables-through-aws-glue-auto-compaction/
Data lakes were originally designed to store large volumes of raw, unstructured, or semi-structured data at a low cost, primarily serving big data and analytics use cases. Over time, as organizations began to explore broader applications, data lakes have become essential for various data-driven processes beyond just reporting and analytics. Today, they play a critical role in syncing with customer applications, enabling the ability to manage concurrent data operations while maintaining the integrity and consistency of information. This shift includes not only storing batch data but also ingesting and processing near real-time data streams, allowing businesses to merge historical insights with live data to power more responsive and adaptive decision-making. However, this new data lake architecture brings challenges around managing transactional support and handling the influx of small files generated by real-time data streams. Traditionally, customers addressed these challenges by performing complex extract, transform, and load (ETL) processes, which often led to data duplication and increased complexity in data pipelines. Additionally, to cope with the proliferation of small files, organizations had to develop custom mechanisms to compact and merge these files, leading to the creation and maintenance of bespoke solutions that were difficult to scale and manage. As data lakes increasingly handle sensitive business data and transactional workloads, maintaining strong data quality, governance, and compliance becomes vital to maintaining trust and regulatory alignment.
To simplify these challenges, organizations have adopted open table formats (OTFs) like Apache Iceberg, which provide built-in transactional capabilities and mechanisms for compaction. OTFs, such as Iceberg, address key limitations in traditional data lakes by offering features like ACID transactions, which maintain data consistency across concurrent operations, and compaction, which helps manage the issue of small files by merging them efficiently. By using features like Iceberg’s compaction, OTFs streamline maintenance, making it straightforward to manage object and metadata versioning at scale. However, although OTFs reduce the complexity of maintaining efficient tables, they still require some regular maintenance to make sure tables remain in an optimal state.
In this post, we explore new features of the AWS Glue Data Catalog, which now supports improved automatic compaction of Iceberg tables for streaming data, making it straightforward for you to keep your transactional data lakes consistently performant. Enabling automatic compaction on Iceberg tables reduces metadata overhead on your Iceberg tables and improves query performance. Many customers have streaming data continuously ingested in Iceberg tables, resulting in a large number of delete files that track changes in data files. With this new feature, as you enable the Data Catalog optimizer. It constantly monitors table partitions and runs the compaction process for both data and delta or delete files, and it regularly commits partial progress. The Data Catalog also now supports heavily nested complex data and supports schema evolution as you reorder or rename columns.
Automatic compaction in the Data Catalog makes sure your Iceberg tables are always in optimal condition. The data compaction optimizer continuously monitors table partitions and invokes the compaction process when specific thresholds for the number of files and file sizes are met. For example, based on the Iceberg table configuration of the target file size, the compaction process will start and continue if the table or any of the partitions within the table have more than the default configuration (for example 100 files), each smaller than 75% of the target file size.
Iceberg supports two table modes: Merge-on-Read (MoR) and Copy-on-Write (CoW). These table modes provide different approaches for handling data updates and play a critical role in how data lakes manage changes and maintain performance:
Whether you are using CoW, MoR, or a hybrid of both, one challenge remains consistent: maintenance around the growing number of small files generated by each transaction. AWS Glue automatic compaction addresses this by making sure your Iceberg tables remain efficient and performant across both table modes.
This post provides a detailed comparison of query performance between auto compacted and non-compacted Iceberg tables. By analyzing key metrics such as query latency and storage efficiency, we demonstrate how the automatic compaction feature optimizes data lakes for better performance and cost savings. This comparison will help guide you in making informed decisions on enhancing your data lake environments.
This blog post explores the performance benefits of the newly launched feature in AWS Glue that supports automatic compaction of Iceberg tables with MoR capabilities. We run two versions of the same architecture: one where the tables are auto compacted, and another without compaction. By comparing both scenarios, this post demonstrates the efficiency, query performance, and cost benefits of auto compacted tables vs. non-compacted tables in a simulated Internet of Things (IoT) data pipeline.
The following diagram illustrates the solution architecture.

The solution consists of the following components:
The data flow consists of the following steps:
In this post, we guide you through setting up an evaluation environment for AWS Glue Iceberg auto compaction performance using the following GitHub repository. The process involves simulating IoT data ingestion, deduplication, and querying performance using Athena.
We simulated IoT data ingestion with over 20 billion events and used MERGE INTO for data deduplication across two time-based partitions, involving heavy partition reads and shuffling. After ingestion, we ran queries in Athena to compare performance between compacted and non-compacted tables using the MoR format. This test aims to have low latency on ingestion but will lead to hundreds of millions of small files.
We use the following table configuration settings:
We use 'write.distribution.mode=none' to lower the latency. However, it will increase the number of Parquet files. For other scenarios, you may want to use hash or range distribution write modes to reduce the file count.
This test makes make append operations because we’re appending new data to the table but we don’t have any delete operations.
The following table shows some metrics of the Athena query performance.
| Execution Time (sec) | Performance Improvement (%) | Data Scanned (GB) | |||
|---|---|---|---|---|---|
| Query | employee (without compaction) | employeeauto (with compaction) | – | employee (without compaction) | employeeauto (with compaction) |
SELECT count(*) FROM "bigdata"."<tablename>" |
67.5896 | 3.8472 | 94.31% | 0 | 0 |
SELECT team, name, min(age) AS youngest_age |
72.0152 | 50.4308 | 29.97% | 33.72 | 32.96 |
SELECT role, team, avg(age) AS average_age |
74.1430 | 37.7676 | 49.06% | 17.24 | 16.59 |
SELECT name, age, start_date, role, teamFROM bigdata."<tablename>"WHERECAST(start_date as DATE) > CAST('2023-01-02' as DATE) andage > 40ORDER BY start_date DESClimit 100 |
70.3376 | 37.1232 | 47.22% | 105.74 | 110.32 |
Because the previous test didn’t perform any delete operations on the table, we conduct a new test involving hundreds of thousands of such operations. We use the previously auto compacted table (employeeauto) as a base, noting that this table uses MoR for all operations.
We run a query that deletes data from each even second on the table:
This query runs with table optimizations enabled, using an Amazon EMR Studio notebook. After running the queries, we roll back the table to its previous state for a performance comparison. Iceberg’s time-traveling capabilities allow us to restore the table. We then disable the table optimizations, rerun the delete query, and follow up with Athena queries to analyze performance differences. The following table summarizes our results.
| Execution Time (sec) | Performance Improvement (%) | Data Scanned (GB) | |||
|---|---|---|---|---|---|
| Query | employee (without compaction) | employeeauto (with compaction) | – | employee (without compaction) | employeeauto (with compaction) |
SELECT count(*) FROM "bigdata"."<tablename>" |
29.820 | 8.71 | 70.77% | 0 | 0 |
SELECT team, name, min(age) as youngest_ageFROM "bigdata"."<tablename>"GROUP BY team, nameORDER BY youngest_age ASC |
58.0600 | 34.1320 | 41.21% | 33.27 | 19.13 |
SELECT role, team, avg(age) AS average_ageFROM bigdata."<tablename>"GROUP BY role, teamORDER BY average_age DESC |
59.2100 | 31.8492 | 46.21% | 16.75 | 9.73 |
SELECT name, age, start_date, role, teamFROM bigdata."<tablename>"WHERECAST(start_date as DATE) > CAST('2023-01-02' as DATE) andage > 40ORDER BY start_date DESClimit 100 |
68.4650 | 33.1720 | 51.55% | 112.64 | 61.18 |
We analyze the following key metrics:
To set up your own evaluation environment and test the feature, you need the following prerequisites:
Create an S3 bucket with the following structure:
Download the descriptor file employee.desc from the GitHub repo and place it in the S3 bucket.
Get the packaged application from the GitHub repo, then upload the JAR file to the jars directory on the S3 bucket. The warehouse will be where the Iceberg data and metadata will live and checkpoint will be used for the Structured Streaming checkpointing mechanism. Because we use two streaming job runs, one for compacted and one for non-compacted data, we also create a checkpointAuto folder.
Create a database in the Data Catalog (for this post, we name our database bigdata). For instructions, see Getting started with the AWS Glue Data Catalog.
Create an EMR Serverless application with the following settings (for instructions, see Getting started with Amazon EMR Serverless):
Configure the network (VPC, subnets, and default security group) to allow the EMR Serverless application to reach the MSK cluster.
Take note of the application-id to use later for launching the jobs.
Create an MSK cluster on the Amazon MSK console. For more details, see Get started using Amazon MSK.
You need to use custom create with at least two brokers using 3.5.1, Apache Zookeeper mode version, and instance type kafka.m7g.xlarge. Do not use public access; choose two private subnets to deploy it (one broker per subnet or Availability Zone, for a total of two brokers). For the security group, remember that the EMR cluster and the Amazon EC2 based producer will need to reach the cluster and act accordingly. For security, use PLAINTEXT (in production, you should secure access to the cluster). Choose 200 GB as storage size for each broker and do not enable tiered storage. For network security groups, you can choose the default of the VPC.
For the MSK cluster configuration, use the following settings:
Log in to your EC2 instance. Because it’s running on a private subnet, you can use an instance endpoint to connect. To create one, see Connect to your instances using EC2 Instance Connect Endpoint. After you log in, issue the following commands:
Create two Kafka topics—remember that you need to change the bootstrap server with the corresponding client information. You can get this data from the Amazon MSK console on the details page for your MSK cluster.

Issue job runs for the non-compacted and auto compacted tables using the following AWS Command Line Interface (AWS CLI) commands. You can use AWS CloudShell to run the commands.
For the non-compacted table, you need to change the s3bucket value as needed and the application-id. You also need an IAM role (execution-role-arn) with the corresponding permissions to access the S3 bucket and to access and write tables on the Data Catalog.
For the auto compacted table, you need to change the s3bucket value as needed, the application-id, and the kafkaBootstrapString. You also need an IAM role (execution-role-arn) with the corresponding permissions to access the S3 bucket and to access and write tables on the Data Catalog.
Enable auto compaction for the employeeauto table in AWS Glue. For instructions, see Enabling compaction optimizer.
Download the JAR file to the EC2 instance and run the producer:
Now you can start the protocol buffer producers.
For non-compacted tables, use the following commands:
For auto compacted tables, use the following commands:
For the delete test, we use an EMR Studio. For setup instructions, see Set up an EMR Studio. Next, you need to create an EMR Serverless interactive application to run the notebook; refer to Run interactive workloads with EMR Serverless through EMR Studio to create a Workspace.
Open the Workspace, select the interactive EMR Serverless application as the compute option, and attach it.

Download the Jupyter notebook, upload it to your environment, and run the cells using a PySpark kernel to run the test.
This evaluation is for high-throughput scenarios and can lead to significant costs. Complete the following steps to clean up your resources:
The Data Catalog has improved automatic compaction of Iceberg tables for streaming data, making it straightforward for you to keep your transactional data lakes always performant. Enabling automatic compaction on Iceberg tables reduces metadata overhead on your Iceberg tables and improves query performance.
Many customers have streaming data that is continuously ingested in Iceberg tables, resulting in a large set of delete files that track changes in data files. With this new feature, when you enable the Data Catalog optimizer, it constantly monitors table partitions and runs the compaction process for both data and delta or delete files and regularly commits the partial progress. The Data Catalog also has expanded support for heavily nested complex data and supports schema evolution as you reorder or rename columns.
In this post, we assessed the ingestion and query performance of simulated IoT data using AWS Glue Iceberg with auto compaction enabled. Our setup processed over 20 billion events, managing duplicates and late-arriving events, and employed a MoR approach for both ingestion/appends and deletions to evaluate the performance improvement and efficiency.
Overall, AWS Glue Iceberg with auto compaction proves to be a robust solution for managing high-throughput IoT data streams. These enhancements lead to faster data processing, shorter query times, and more efficient resource utilization, all of which are essential for any large-scale data ingestion and analytics pipeline.
For detailed setup instructions, see the GitHub repo.
 Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled Data Wrangling on AWS. He can be reached through LinkedIn.
Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled Data Wrangling on AWS. He can be reached through LinkedIn.
 Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to data analytics and artificial intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.
Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to data analytics and artificial intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.
 Amit Singh currently serves as a Senior Solutions Architect at AWS, specializing in analytics and IoT technologies. With extensive expertise in designing and implementing large-scale distributed systems, Amit is passionate about empowering clients to drive innovation and achieve business transformation through AWS solutions.
Amit Singh currently serves as a Senior Solutions Architect at AWS, specializing in analytics and IoT technologies. With extensive expertise in designing and implementing large-scale distributed systems, Amit is passionate about empowering clients to drive innovation and achieve business transformation through AWS solutions.
 Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Post Syndicated from jzb original https://lwn.net/Articles/1002450/
The Fedora Engineering Steering Council (FESCo) has made a series of
missteps in deciding to revoke a longtime Fedora contributor’s provenpackager
status. FESCo made the decision during a closed session, based on private
complaints. It then publicly announced its decision, including the
contributor’s name, while only supplying a vague account of the
contributor’s actions. This has left the Fedora community with more
questions than answers, and raised a number of complaints about the
transparency of FESCo’s process. In addition, the sequence of events has
sparked discussions about package ownership, as well as when and how it’s
appropriate to push changes to packages that a developer doesn’t own.