Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Севда Семер, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.
превод от английски Александър Маринов, изд. „Лист“, 2021
Възможно е да се спечели „Пулицър“ повече от веднъж. (Не е като френската награда „Гонкур“, която се присъжда само еднократно на автор, заради което Ромен Гари си измисли псевдоним, за да я вземе повторно.) Просто в историята на „Пулицър“ подобни случаи не са често срещано явление, особено ако говорим за награждаване в една и съща категория. Сред малкото автори, отличени повече от веднъж за свои романи, е американският писател Колсън Уайтхед.
Уайтхед получава първия си „Пулицър“ през 2017 г. за романа „Подземната железница“ заради „интелигентното смесване на реализъм и алегория и съчетаване на насилието на робството и драмата на бягството в един мит, който говори на съвременната Америка“. Думите са на комитета за наградите и ги цитирам, защото Уайтхед умее да говори за миналото, докато казва неща и за настоящето.
Затова с големи очаквания беше посрещната следващата му книга – „Момчетата от Никел“ от 2019 г. Бях сред тези, които я чакаха с нетърпение, а сега я прочетох за втори път, вече на български. Това, че с този роман Уайтхед отново спечели „Пулицър“, е несъмнено успех за автора, но по-важното е как успява да спечели читателя. Беше интересно да видя как ще реагирам на историята, след като вече я познавам – поне за мен това е най-точният тест доколко наистина е силна. През последните години съм препоръчвала романа и неговия автор многократно. Сега само затвърдих убеждението си, че Уайтхед е един от най-добрите съвременни автори.
„Момчетата от Никел“ е книга, която е, меко казано, просмукана от дълбок мрак. Базира се на истинската история на поправителното училище за момчета „Дозиър“ във Флорида, функционирало 111 години въпреки ужасяващото насилие на надзирателите над децата, влезли там заради дребни провинения. При това са известни около сто убийства на малолетни (поне за толкова има доказателства). От тях чернокожите момчета са три пъти повече от белите.
Колсън Уайтхед разказва за това в своя роман, като кръщава училището „Никел“: това е фабрика за мъчения, без значение дали спиш в сградите на белите, на черните, или пък – като детето с майка мексиканка – те местят от единия в другия лагер според това колко бял изглеждаш сред едните и тъмен сред другите през въпросната седмица. Огромен фактор обаче са расизмът и сегрегацията. Също както и в момента от системите на затворническо-промишления комплекс страдат много хора в Щатите, но диспропорционална част от тях са чернокожи американци. Тази история се съсредоточава върху тях.
Не е лесно да подхванеш подобна тема и да я разработиш, без да излезе, че я експлоатираш. Без да ставаш поредният, който се възползва от момчетата за собствени дивиденти. Затова и авторът още от първата страница разказва за убийствата в училището („Дори мъртви, момчетата създаваха неприятности“). Както още от началото ни става ясно, главният герой Елуд някак ще се озове накрая в поправителното училище. Няма да го спаси нито любознанието му, нито пламенните му идеи за равенство в съзвучие с речите на Мартин Лутър Кинг, които често слуша в дома на баба си. Опознаваме това чудесно дете, става ни симпатично, докато чакаме неизбежното – някъде нещо ще се обърка. Елуд ще стане жертва на системата, защото няма как сам да извърши дори дребно престъпление.
Той иска да преследва амбицията си – да стигне до колеж, за което му помага негов преподавател. Тръгва на стоп, но полицаи спират колата, която се оказва крадена от човека зад волана. Какво значение има, че дори крадецът признава, че не е срещал момчето преди? Кой ще слуша обясненията им? И така вместо в колежа Елуд се озовава в „Никел“, където часовете са посветени на едва сричащите му съученици. Но кой ти гледа академичния прогрес, когато въпросът буквално е дали ще излезеш жив от това място. Тук законите се пишат в Белия дом – бараката, в която водят момчетата посред нощ за удари с камшик заради всякакъв вид провинения.
На Елуд е поверена тайна задача, свързана с корупцията на надзирателите (продават голяма част от храната, предназначена за учениците) – избран е, защото е кротък и няма вид да създава проблеми. Точно тогава той се сближава с Търнър, другия избран за задачата, с когото ще имат не просто приятелство, а изключително силна връзка – като войници на фронта, те се доверяват изцяло един на друг.
Пред автора на тази история има и друга трудност. Как да опишеш това място, без да станеш емоционален до степен да задушаваш читателя си на всяка страница, докато не му остане нито дъх, нито сили да продължи? А и става дума за деца. Уайтхед много съзнателно и последователно страни от сензацията. Най-големите кошмари са оставени на въображението ни. Или вместо да са описани, виждаме единствено последствията от тях върху поведението на момчетата – било свръхестественото им послушание, било желанието за мъст, дори това да означава да се поставят в опасна ситуация. Много думи няма нужда да се изричат и пак имат силно присъствие. Също като някой, който трепва, когато рязко тръгнеш да го прегръщаш – няма нужда да го питаш, вече си видял в очите му, че е очаквал да замахнеш.
Авторът щади децата от воайорство, докато проявява смелостта да говори директно – не само за това какво им се случва в училището, а за една система на корупция и омраза, в която участват всички, включително хората, които би трябвало да се борят срещу тези недъзи. В крайна сметка училището оцелява именно защото въвлича в схемите си целия окръг. Кого да го е грижа за децата, в по-голямата си част изоставени от своите семейства?
Дори само с това – смелостта да се разказва директно, но и с уважение – тази история е достатъчно добра. На ужасното насилие обаче реагираме с ръка пред устата, застинали в шок. Това, което ни разплаква, е надеждата. Именно тя превръща „Момчетата от Никел“ от добър роман в изключителен. Няколко умни обрата, изковани внимателно и с въображение, се появяват точно когато си мислиш, че ти е ясно за какво е тази книга и какво ти казва. Авторът обръща плочата и се оказва, че от другата страна през цялото време е било записано нещо друго.
Няма да я нарека история за силата на човешкия дух, защото това клише не обхваща всичко. Защото толкова много деца излизат с прекършен дух от това място; защото толкова други изобщо не излизат; защото системата ги предава отново и отново и това е наистина сломяващо. Но е история за човешкото. Именно в умението да го демонстрира без патос е силата на Уайтхед.
От истината тук има достатъчно, за да стане историята важна; от въображението на Уайтхед има толкова, че да стане тя напълно нова. Така неочаквано се превръща в съд, направен от болка, но преливащ от надежда.
Заглавно изображение: Колаж от корицата на книгата (худ. Костадин Кокаланов, изд. „Лист“) и снимка на Zia King / Unsplash
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталога на „Лист“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Our very own Grant Willcox has developed a new module which allows users to query a LDAP server for vulnerable Active Directory Certificate Services (AD CS) certificate templates. The module will print the detected certificate details, and the attack it is susceptible to. This module is capable of checking for ESC1, ESC2, and ESC3 vulnerable certificates.
Example module output showing an identified vulnerable certificate template:
Community member h00die has made improvements to a new Metasploit’s SSL scanner modules, and combined the functionality of two existing modules auxiliary/scanner/http/ssl.rbauxiliary/scanner/http/ssl_version.rb into one new module auxiliary/scanner/ssl/ssl_version.rb. This new module has added checks for Deprecated protocols, expired/not valid certs, low key strength, Null cipher suites, certificates signed with MD5, DROWN, RC4 ciphers, exportable ciphers, LOGJAM, and BEAST.
Reduced Python payload sizes
Community member llamasoft has recently contributed improvements to our Python payloads, with the first change being a modification to the Python Meterpreter stage to calculate the necessary data for AES encryption at runtime – which helped reduce the stage size by about 6,000 bytes. This week’s Metasploit release includes compression support using zlib. This change reduces the size of the Python Meterpreter from 95kb to 24kb.
New module content (4)
Misconfigured Certificate Template Finder by Grant Willcox – This adds a module that analyzes certificate templates to identify ones that are vulnerable to ESC1, ESC2 and ESC3. When a template is found to be vulnerable, the necessary information is printed for the user including the template name, the issuing CAs and the SIDs of the users that are able to issue them.
SSL/TLS Version Detection by todb, Chris John Riley, Veit Hailperin, et, and h00die, which detects CVE-2022-3358 – A new module modules/auxiliary/scanner/ssl/ssl_version.rb has been released which replaces the old SSL scanners and offers improved features such as SSL cipher suite checking, improvements to CA Issuers logic, support for expired certs and depreciated protocols, and better error handling.
Reverse Lookup IP Addresses by mubix and bcoles – Adds a new post/multi/recon/reverse_lookup module that reverse resolves an IP address or IP address range to hostnames. The old post/windows/gather/reverse_lookup and post/windows/recon/resolve_ip modules have been removed.
Windows Gather Navicat Passwords by HyperSine and Kali-Team – This adds a post module that retrieves and decrypts passwords saved by Navicat.
Enhancements and features (6)
#17211 from llamasoft – This compresses Python payloads using zlib to make them smaller.
#17219 from jheysel-r7 – Update Zabbix login_scanner to work with version 6.2.4.
#17223 from cgranleese-r7 – The reload_lib functionality has been updated so that its file change tracking logic better takes into account scenarios where files are modified. Previously if a breakpoint was inserted, removed, and then reload_lib -a was run, it would mistakenly use an old copy of the code.
#17234 from cgranleese-r7 – Add references to info -d command in the options and info command outputs. This command allows you to generate a HTML document which you can use to view the full documentation of a module in your browser.
#17235 from jmartin-r7 – Updates auxiliary/scanner/http/manageengine_desktop_central_login module to report the service name correctly as http or https.
#17177 from nzdjb – A bug has been fixed when searching for or attempting to use modules whereby trailing :‘s were not handled appropriately as part of the input, and could lead to all modules in Metasploit being returned.
#17221 from adfoster-r7 -A bug has been fixed that would cause crashes when generating payload sizes. Additionally, the code has been updated to ignore payload metadata for adaptor payloads when determining payload sizes.
#17244 from zeroSteiner – A bug that could cause the hostname command to fail in Mettle versions of Meterpreter has been improved by adding increased validation to the hostname code.
#17220 from adfoster-r7 – This fixes a crash in the peinject stage that would occur when the PE datastore option was not set.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the binary installers (which also include the commercial edition).
What sorts of system? Any system of rules, really. Take the tax code, for example. It’s not computer code, but it’s a series of algorithms—supposedly deterministic—that take a bunch of inputs about your income and produce an output that’s the amount of money you owe. This code has vulnerabilities; we call them loopholes. It has exploits; those are tax avoidance strategies. And there is an entire industry of black-hat hackers who exploit vulnerabilities in the tax code: we call them accountants and tax attorneys.
In my conception, a “hack” is something a system permits, but is unanticipated and unwanted by its designers. It’s unplanned: a mistake in the system’s design or coding. It’s subversion, or an exploitation. It’s a cheat—but only sort of. Just as a computer vulnerability can be exploited over the Internet because the code permits it, a tax loophole is “allowed” by the system because it follows the rules, even though it might subvert the intent of those rules.
Once you start thinking of hacking in this way, you’ll start seeing hacks everywhere. You can find hacks in professional sports, in customer reward programs, in financial systems, in politics; in lots of economic, political, and social systems; against our cognitive functions. A curved hockey stick is a hack, and we know the name of the hacker who invented it. Airline frequent-flier mileage runs are a hack. The filibuster was originally a hack, invented by Cato the Younger, A Roman senator in 60 BCE. Hedge funds are full of hacks.
A system is just a set of rules. Or norms, since the “rules” aren’t always formal. And even the best-thought-out sets of rules will be incomplete or inconsistent. It’ll have ambiguities, and things the designers haven’t thought of. As long as there are people who want to subvert the goals of a system, there will be hacks.
I use this framework in A Hacker’s Mind to tease out a lot of why today’s economic, political, and social systems are failing us so badly, and apply what we have learned about hacking defenses in the computer world to those more general hacks. And I end by looking at artificial intelligence, and what will happen when AIs start hacking. Not the problems of hacking AI, which are both ubiquitous and super weird, but what happens when an AI is able to discover new hacks against these more general systems. What happens when AIs find tax loopholes, or loopholes in financial regulations. We have systems in place to deal with these sorts of hacks, but they were invented when hackers were human and reflect the human pace of hack discovery. They won’t be able to withstand an AI finding dozens, or hundreds, of loopholes in financial regulations. We’re simply not ready for the speed, scale, scope, and sophistication of AI hackers.
A Hacker’s Mind is my pandemic book, written in 2020 and 2021. It represents another step in my continuing journey of increasing generalizations. And I really like the cover. It will be published on February 7. It makes an excellent belated holiday gift. Order yours today and avoid the rush.
Signeasy is a leading eSignature company that offers an easy-to-use, cross-platform and cloud-based eSignature and document transaction management software as a service (SaaS) solution for businesses. Over 43,000 companies worldwide use Signeasy to digitize and streamline business workflows. In this blog, you will learn why and how Signeasy used AWS Serverless to create a SaaS dashboard for their tenants.
Signeasy’s SaaS tenants asked for an easier way to get insights into tenant usage data on Signeasy’s eSignature platform. To address that, Signeasy built a self-service usage metrics dashboard for their SaaS tenant using AWS Serverless.
Usage reports
What was it like before the self-service dashboard experience? In the past, tenants requested Signeasy to share their usage metrics through support channels or emails. The Signeasy support team compiled the reports and then emailed the report back to the tenant to service the request. This was a repetitive manual task. It involved querying a database, fetching and collating the results into an Excel table to be emailed to the tenant. The turnaround time on these manual reports was eight hours.
The following table illustrates the report format (with example data) that the tenants received through email.
Figure 1. Archived usage reports
The design
Signeasy deliberated numerous aspects and arrived at the following design considerations:
Enhance tenant experience — Provide the reports to tenants on-demand, using a self-service mechanism.
Scalable aggregation queries — The reports ran aggregation queries on usage data within a time range on a relational database management system (RDBMS). Signeasy considered moving to a data store that has the scalability to store and run aggregation queries on millions of records.
Agility — Signeasy wanted to build the module in a time-bound manner and deliver it to tenants as quickly as possible.
Reduce infrastructure management — The load on the reports infrastructure that stores and processes data increases linearly in relation to the count of usage reports requested. This meant an increase in the undifferentiated heavy lifting of infrastructure management tasks such as capacity management and patching.
With the design considerations and constraints called out, Signeasy began to look for the suitable solution. Signeasy decided to build their usage reports on a serverless architecture. They chose AWS Serverless, because it offers scalable compute and database, application integration capabilities, automatic scaling, and a pay-for-use billing model. This reduces infrastructure management tasks such as capacity provisioning and patching. Refer to the following diagram to see how Signeasy augmented their existing SaaS with self-service usage reports.
Architecture of self-service usage reports
Figure 2. Architecture diagram depicting the data flow of the self-service usage reports
Signeasy’s tenant users log in to the Signeasy portal to authenticate their tenant identity.
The Signeasy portal uses a combination of tenant ID and user ID in JSON Web Tokens (JWT) to distinguish one tenant user from another when storing and processing documents.
The messages are processed by a report writer service (Python script) on AWS Lambda and written to the reports database on Amazon Timestream. The reports database on Timestream stores metadata attributes such as user ID and signature document ID, signature document sent, signature request received, document signed, and signature request cancelled or declined, and timestamp of the data point. To view usage reports, the tenant administrators navigate to the Reports section of the Signeasy portal and select Usage Reports.
The usage reports request from the (tenant) Web Client on the browser is an API call to Amazon API Gateway.
API Gateway works as a front door for the backend reports service running on a separate Lambda function.
The reports service on Lambda uses the user ID from login details to query the Amazon Timestream database to generate the report and send it back to the web client through the API Gateway. The report is immediately available for the administrator to view, which is a huge improvement from having to wait for eight hours before this self-service feature was made available to their SaaS tenants.
Following is a mock-up of the Usage Reports dashboard:
Figure 3. A mock-up of the Usage Reports page of the Signeasy portal
So, how did AWS Serverless help Signeasy?
Amazon SQS persists messages up to 14 days, and enables retry functionality for message processed in Lambda. Lambda is an event-driven serverless compute service that manages deployment and runs code, with logging and monitoring through Amazon CloudWatch. The integration of API Gateway with Lambda helped Signeasy easily deploy and manage the backend processing logic for the reports service. As usage of the reports grew, Timestream continued to scale, without the need to re-architect their application. Signeasy continued to use SQL to query data within the reports database on Timestream in a cost optimized manner.
Signeasy used AWS Serverless for its functionality without the undifferentiated heavy lifting of infrastructure management tasks such as capacity provisioning and patching. Signeasy’s support team is now more focused on higher-level organizational needs such as customer engagements, quarterly business reviews, and signature and payment related issues instead of managing infrastructure.
Conclusion
Going from eight hours to on-demand self-service (0 hours) response time for usage reports is a huge improvement in their SaaS tenant experience.
The AWS Serverless services scale out and in to meet customer needs. Signeasy pays only for what they use, and they don’t run compute infrastructure 24/7 in anticipation of requests throughout the day.
Signeasy’s support and customer success teams have repurposed their time toward higher value customer engagements vs. capacity, or patch management.
Development time for the Usage Reports dashboard was two weeks.
Through Cloudflare’s Impact programs, we provide cyber security products to help protect access to authoritative voting information and the security of sensitive voter data. Two core programs in this space are the Athenian Project, dedicated to protecting state and local governments that run elections, and Cloudflare for Campaigns, a project with a suite of Cloudflare products to secure political campaigns’ and state parties’ websites and internal teams.
However, the weeks ahead of the elections, and Election Day itself, were not entirely devoid of attacks. Using data from Cloudflare Radar, which showcases global Internet traffic, attack, and technology trends and insights, we can explore traffic patterns, attack types, and top attack sources associated with both Athenian Project and Cloudflare for Campaigns participants.
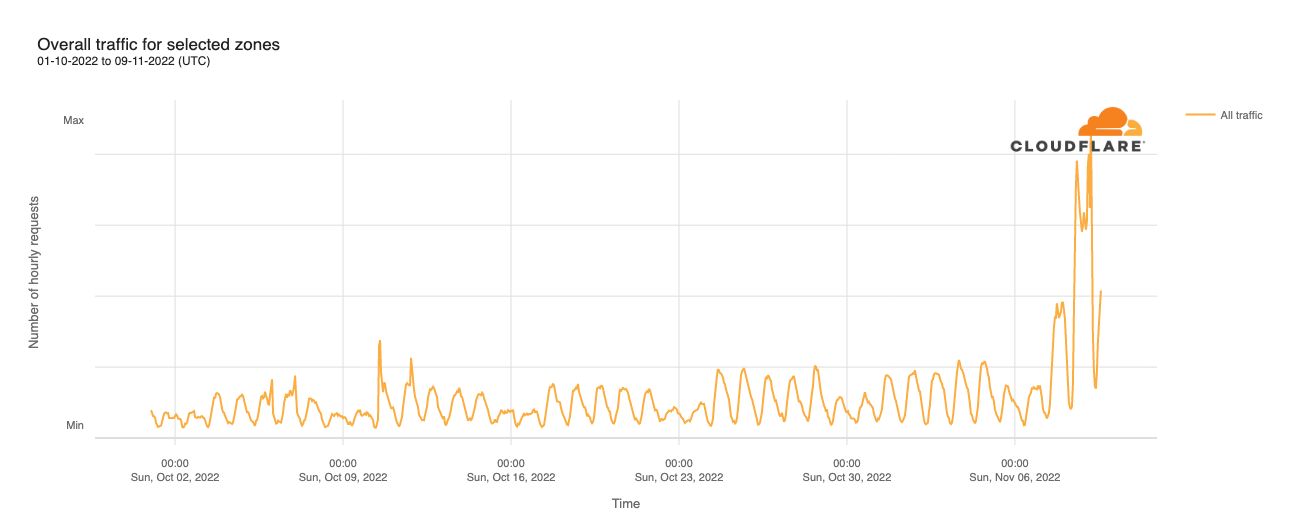
For both programs, overall traffic volume unsurprisingly ramped up as Election Day approached. SQL Injection (SQLi) and HTTP Anomaly attacks were the two largest categories of attacks mitigated by Cloudflare’s Web Application Firewall (WAF), and the United States was the largest source of observed attacks — see more on this last point below.
Below, we explore the trends seen across both customer sets from October 1, 2022, through Election Day on November 8.
Athenian Project
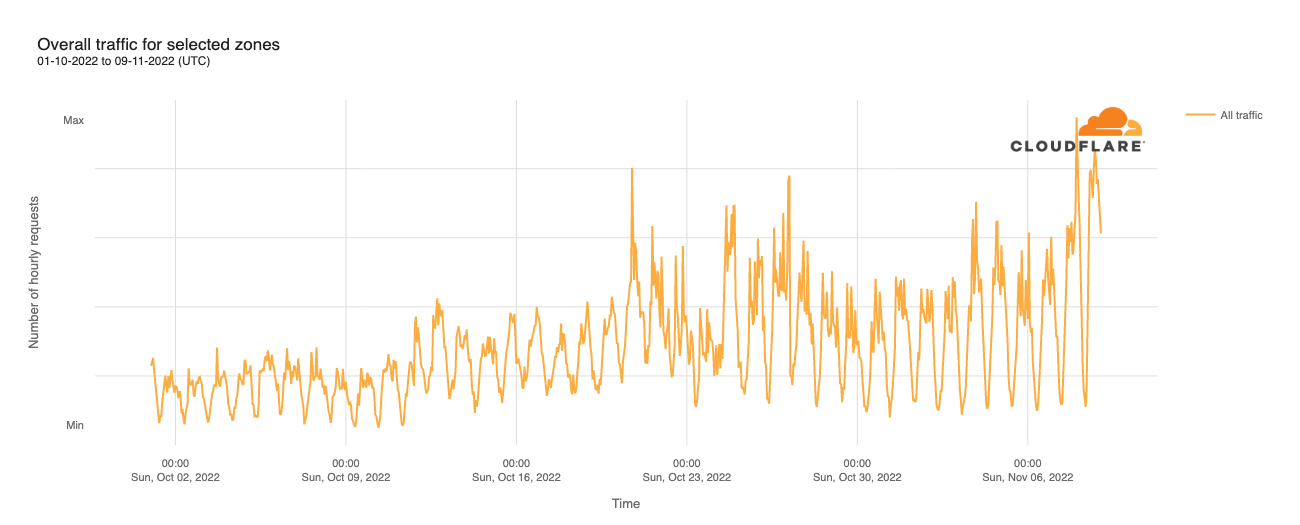
Throughout October, daily peak traffic volumes effectively doubled over the course of the month, with a weekday/weekend pattern also clearly visible. However, significant traffic growth is visible on Monday, November 7, and Tuesday, November 8 (Election Day), with Monday’s peak just under 2x October’s peaks, while Tuesday saw two peaks, one just under 4x higher than October peaks, while the other was just over 4x higher. Zooming in, the first peak was at 1300 UTC (0800 Eastern time, 0500 Pacific time), while the second was at 0400 UTC (2300 Eastern time, 2000 Pacific time). The first one appears to be aligned with the polls opening on the East Coast, while the second appears to be aligned with the time that the polls closed on the West Coast.
However, aggregating the traffic here presents a somewhat misleading picture. While both spikes were due to increased traffic across multiple customer sites, the second one was exacerbated by a massive increase in traffic for a single customer. Regardless, the increased traffic clearly shows that voters turned to local government sites around Election Day.
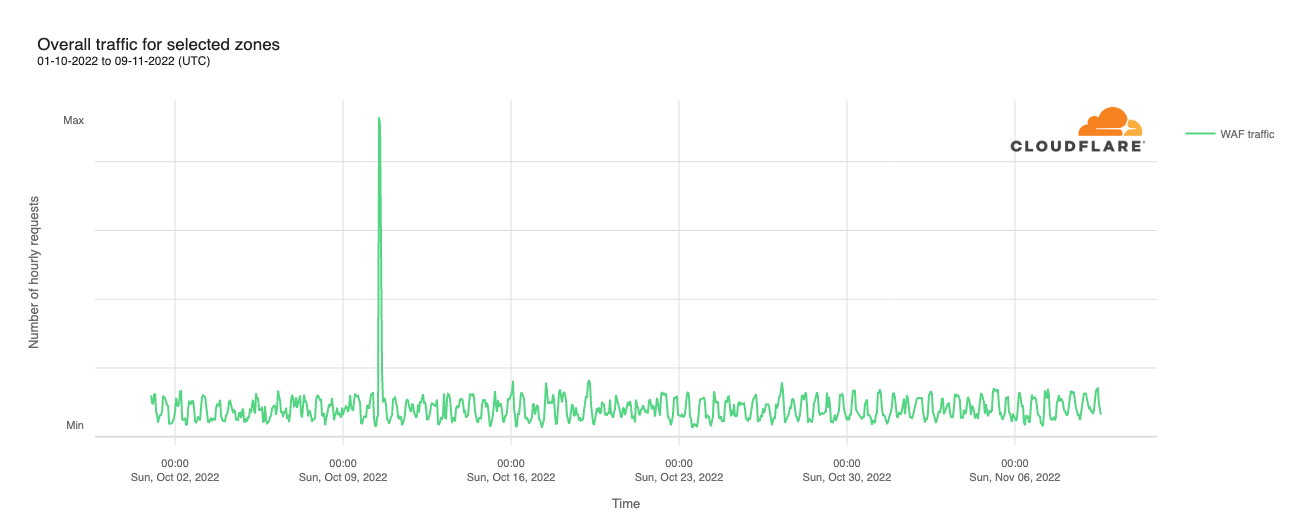
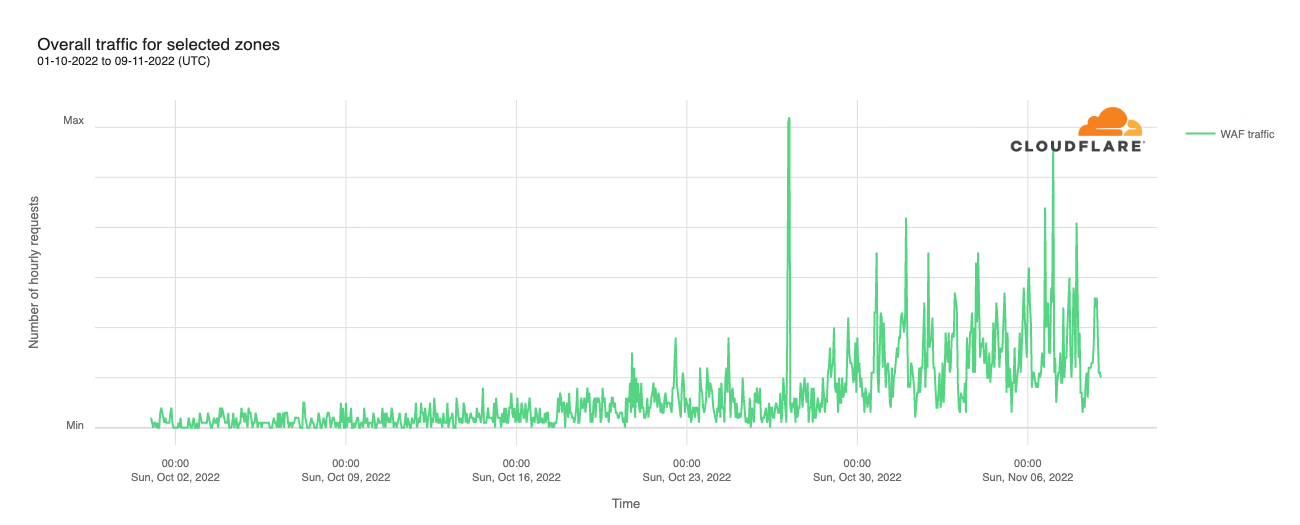
Despite this increase in overall traffic, attack traffic mitigated by Cloudflare’s Web Application Firewall (WAF) remained remarkably consistent throughout October and into November, as seen in the graph below. The obvious exception was an attack that occurred on Monday, October 10. This attack targeted a single Athenian Project participant, and was mitigated by rate limiting the requests.
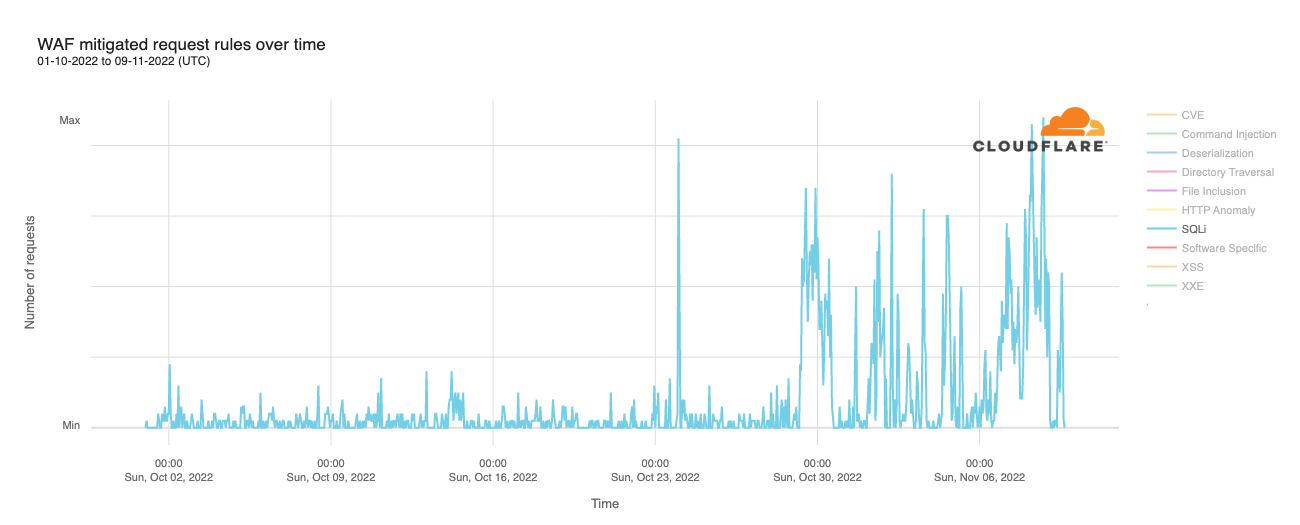
SQL injection (SQLi) attacks saw significant growth in volume in the week and a half ahead of Election Day, along with an earlier significant spike on October 24. While the last weekend in October (October 29 and 30) saw significant SQLi attack activity, the weekend of November 5 and 6 was comparatively quiet. However, those attacks ramped up again heading into and on Election Day, as seen in the graph below.
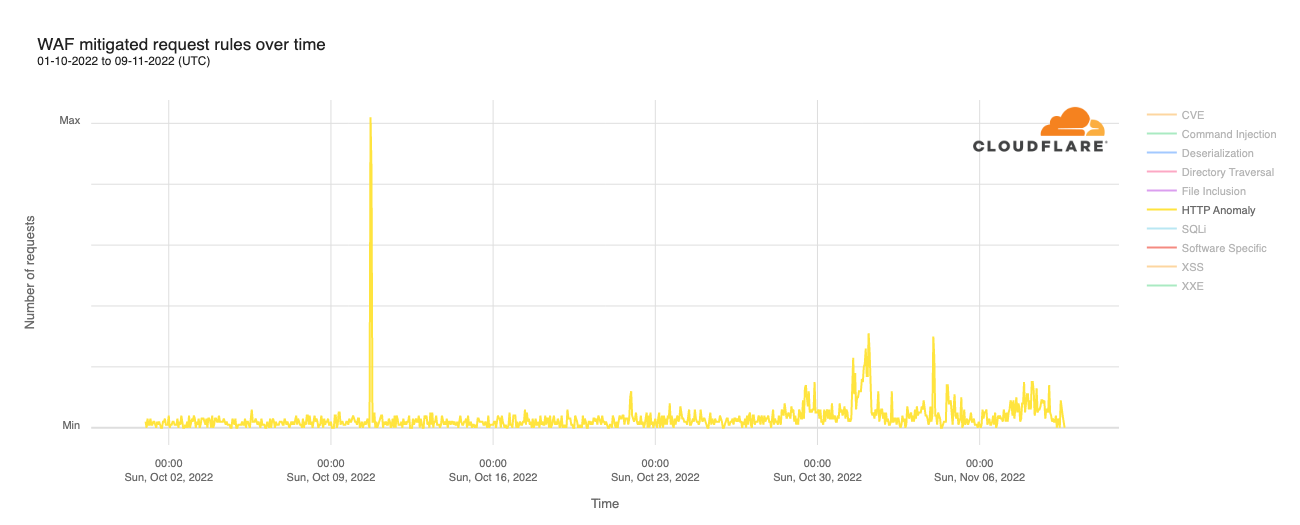
Attempted attacks mitigated with the HTTP Anomaly ruleset also ramped up in the week ahead of Election Day, though to a much lesser extent than SQLi attacks. As the graph below shows, the biggest spikes were seen on October 31/November 1, and just after midnight UTC on November 4 (late afternoon to early evening in the US). Related request volume also grew heading into Election Day, but without significant short-duration spikes. There is also a brief but significant attack clearly visible on the graph on October 10. However, it occurred several hours after the rate limited attack referenced above — it is not clear if the two are related.
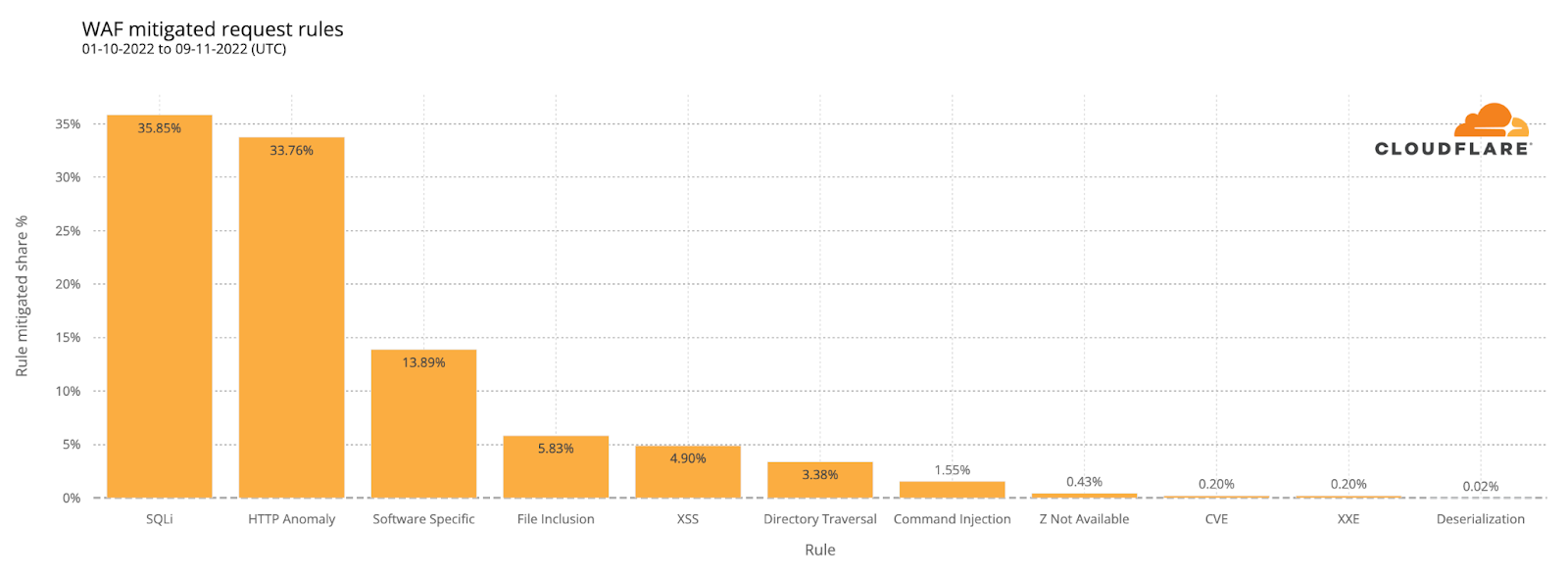
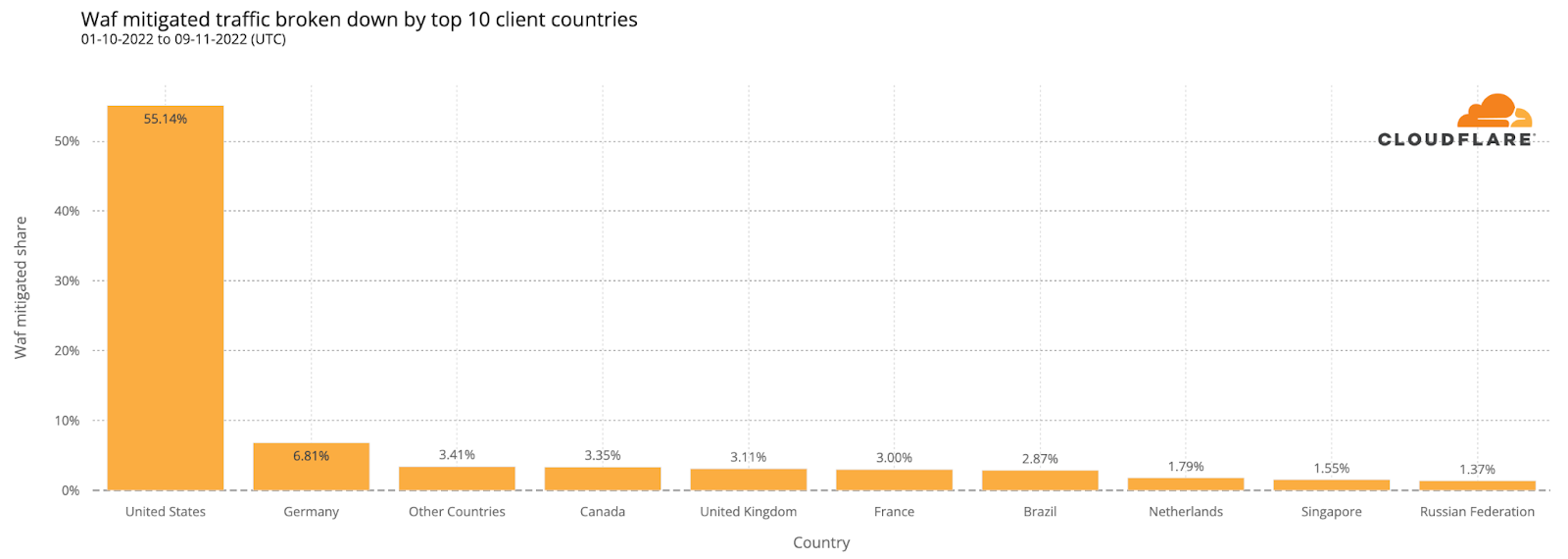
The distribution of attacks over the surveyed period from October 1 through November 9 shows that those categorized as SQLi and HTTP Anomaly were responsible for just over two-thirds of WAF-mitigated requests. Nearly 14% were categorized as “Software Specific,” which includes attacks related to specific CVEs. The balance of the attacks were mitigated by WAF rules in categories including File Inclusion, XSS (Cross Site Scripting), Directory Traversal, and Command Injection.
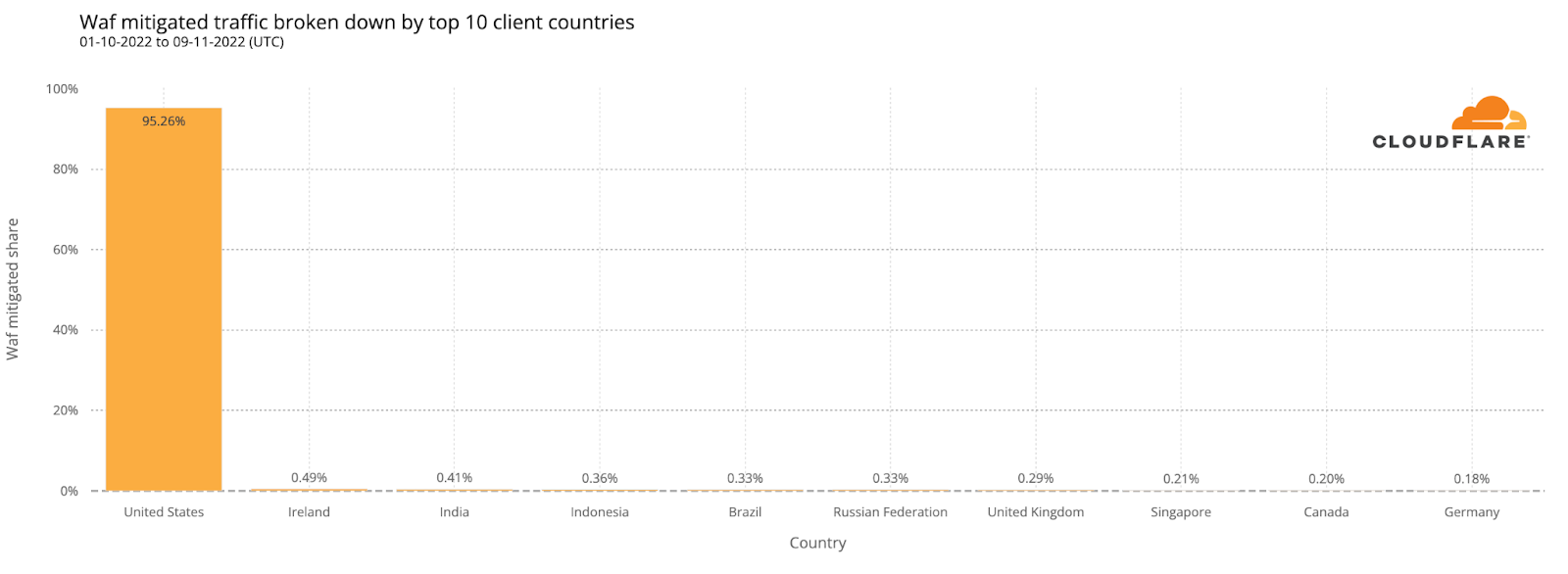
Media reports suggest that foreign adversaries actively try to interfere with elections in the United States. While this may be the case, analysis of the mitigated attacks targeting Athenian Project customers found that over 95% of the mitigated requests (attacks) came from IP addresses that geolocate to the United States. However, that does not mean that the attackers themselves are necessarily located in the country, but rather that they appear to be using compromised systems and proxies within the United States to launch their attacks against these sites protected by Cloudflare.
Cloudflare for Campaigns
In contrast to Athenian Project participants, traffic to candidate sites that are participants in Cloudflare for Campaigns began to grow several weeks ahead of Election Day. The graph below shows a noticeable increase (~50%) in peak traffic volumes starting on October 12, with an additional growth (50-100%) starting a week later. Traffic to these sites appeared to quiet a bit toward the end of October, but saw significant growth again heading into, and during, Election Day.
However, once again, this aggregate traffic data presents something of a misleading picture, as one candidate site saw multiple times more traffic than the other participating sites. While those other sites saw similar shifts in traffic as well, they were dwarfed by those experienced by the outlier site.
The WAF-mitigated traffic trend for campaign sites followed a similar pattern to the overall traffic. As the graph below shows, attack traffic also began to increase around October 19, with a further ramp near the end of the month. The October 27 spike visible in the graph was due to an attack targeting a single customer’s site, and was addressed using “Security Level” mitigation techniques, which uses IP reputation information to decide if and how to present challenges for incoming requests.
The top two rule categories, HTTP Anomaly and SQLi, together accounted for nearly three-quarters of the mitigated requests, and Directory Traversal attacks were just under 10% of mitigated requests for this customer set. The HTTP Anomaly and Directory Traversal percentages were higher than those for attacks targeting Athenian Project participants, while the SQLi percentage was slightly lower.
Once again, a majority of the WAF-mitigated attacks came from IP addresses in the United States. However, among Cloudflare for Campaigns participants, the United States only accounted for 55% of attacks, significantly lower than the 95% seen for Athenian Project participants. The balance is spread across a long tail of countries, with allies including Germany, Canada, and the United Kingdom among the top five. As noted above, however, the attackers may be elsewhere, and are using botnets or other compromised systems in these countries to launch attacks.
Improving security with data
We are proud to be trusted by local governments, campaigns, state parties, and voting rights organizations to protect their websites and provide uninterrupted access to information and trusted election results. Sharing information about the threats facing these websites helps us further support their valuable work by enabling them, and other participants in the election space, to take proactive steps to improve site security.
Welcome to the first post in our multi-part series on how Netflix is developing and using machine learning (ML) to help creators make better media — from TV shows to trailers to movies to promotional art and so much more.
Media is at the heart of Netflix. It’s our medium for delivering a range of emotions and experiences to our members. Through each engagement, media is how we bring our members continued joy.
This blog series will take you behind the scenes, showing you how we use the power of machine learning to create stunning media at a global scale.
At Netflix, we launch thousands of new TV shows and movies every year for our members across the globe. Each title is promoted with a custom set of artworks and video assets in support of helping each title find their audience of fans. Our goal is to empower creators with innovative tools that support them in effectively and efficiently create the best media possible.
With media-focused ML algorithms, we’ve brought science and art together to revolutionize how content is made. Here are just a few examples:
We maintain a growing suite of video understanding models that categorize characters, storylines, emotions, and cinematography. These timecode tags enable efficient discovery, freeing our creators from hours of categorizing footage so they can focus on creative decisions instead.
We arm our creators with rich insights derived from our personalization system, helping them better understand our members and gain knowledge to produce content that maximizes their joy.
We invest in novel algorithms for bringing hard-to-execute editorial techniques easily to creators’ fingertips, such as match cutting and automated rotoscoping/matting.
One of our competitive advantages is the instant feedback we get from our members and creator teams, like the success of assets for content choosing experiences and internal asset creation tools. We use these measurements to constantly refine our research, examining which algorithms and creative strategies we invest in. The feedback we collect from our members also powers our causal machine learning algorithms, providing invaluable creative insights on asset generation.
In this blog series, we will explore our media-focused ML research, development, and opportunities related to the following areas:
Computer vision: video understanding search and match cut tools
VFX and Computer graphics: matting/rotoscopy, volumetric capture to digitize actors/props/sets, animation, and relighting
Audio and Speech
Content: understanding, extraction, and knowledge graphs
Infrastructure and paradigms
We are continuously investing in the future of media-focused ML. One area we are expanding into is multimodal content understanding — a fundamental ML research that utilizes multiple sources of information or modality (e.g. video, audio, closed captions, scripts) to capture the full meaning of media content. Our teams have demonstrated value and observed success by modeling different combinations of modalities, such as video and text, video and audio, script alone, as well as video, audio and scripts together. Multimodal content understanding is expected to solve the most challenging problems in content production, VFX, promo asset creation, and personalization.
We are also using ML to transform the way we create Netflix TV shows and movies. Our filmmakers are embracing Virtual Production (filming on specialized light and MoCap stages while being able to view a virtual environment and characters). Netflix is building prototype stages and developing deep learning algorithms that will maximize cost efficiency and adoption of this transformational tech. With virtual production, we can digitize characters and sets as 3D models, estimate lighting, easily relight scenes, optimize color renditions, and replace in-camera backgrounds via semantic segmentation.
Most importantly, in close collaboration with creators, we are building human-centric approaches to creative tools, from VFX to trailer editing. Context, not control, guides the work for data scientists and algorithm engineers at Netflix. Contributors enjoy a tremendous amount of latitude to come up with experiments and new approaches, rapidly test them in production contexts, and scale the impact of their work. Our leadership in this space hinges on our reliance on each individual’s ideas and drive towards a common goal — making Netflix the home of the best content and creative experience in the world.
Working on media ML at Netflix is a unique opportunity to push the boundaries of what’s technically and creatively possible. It’s a cutting edge and quickly evolving research area. The progress we’ve made so far is just the beginning. Our goal is to research and develop machine learning and computer vision tools that put power into the hands of creators and support them in making the best media possible.
We look forward to sharing our work with you across this blog series and beyond.
If these types of challenges interest you, please let us know! We are always looking for great people who are inspired by machine learning and computer vision to join our team.
Streaming services serve content to millions of users all over the world. These services allow users to stream or download content across a broad category of devices including mobile phones, laptops, and televisions. However, some restrictions are in place, such as the number of active devices, the number of streams, and the number of downloaded titles. Many users across many platforms make for a uniquely large attack surface that includes content fraud, account fraud, and abuse of terms of service. Detection of fraud and abuse at scale and in real-time is highly challenging.
Data analysis and machine learning techniques are great candidates to help secure large-scale streaming platforms. Even though such techniques can scale security solutions proportional to the service size, they bring their own set of challenges such as requiring labeled data samples, defining effective features, and finding appropriate algorithms. In this work, by relying on the knowledge and experience of streaming security experts, we define features based on the expected streaming behavior of the users and their interactions with devices. We present a systematic overview of the unexpected streaming behaviors together with a set of model-based and data-driven anomaly detection strategies to identify them.
Background on Anomaly Detection
Anomalies (also known as outliers) are defined as certain patterns (or incidents) in a set of data samples that do not conform to an agreed-upon notion of normal behavior in a given context.
There are two main anomaly detection approaches, namely, (i) rule-based, and (ii) model-based. Rule-based anomaly detection approaches use a set of rules which rely on the knowledge and experience of domain experts. Domain experts specify the characteristics of anomalous incidents in a given context and develop a set of rule-based functions to discover the anomalous incidents. As a result of this reliance, the deployment and use of rule-based anomaly detection methods become prohibitively expensive and time-consuming at scale, and cannot be used for real-time analyses. Furthermore, the rule-based anomaly detection approaches require constant supervision by experts in order to keep the underlying set of rules up-to-date for identifying novel threats. Reliance on experts can also make rule-based approaches biased or limited in scope and efficacy.
On the other hand, in model-based anomaly detection approaches, models are built and used to detect anomalous incidents in a fairly automated manner. Although model-based anomaly detection approaches are more scalable and suitable for real-time analysis, they highly rely on the availability of (often labeled) context-specific data. Model-based anomaly detection approaches, in general, are of three kinds, namely, (i) supervised, (ii) semi-supervised, and (iii) unsupervised. Given a labeled dataset, a supervised anomaly detection model can be built to distinguish between anomalous and benign incidents. In semi-supervised anomaly detection models, only a set of benign examples are required for training. These models learn the distributions of benign samples and leverage that knowledge for identifying anomalous samples at the inference time. Unsupervised anomaly detection models do not require any labeled data samples, but it is not straightforward to reliably evaluate their efficacy.
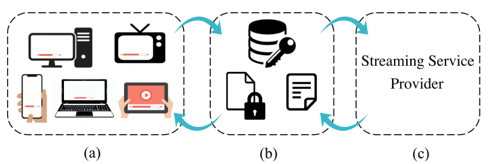
Figure 1. Schematic of a streaming service platform: (a) illustrates device types that can be used for streaming, (b) designates the set of authentication and authorization systems such as license and manifest servers for providing encrypted contents as well as decryption keys and manifests, and (c) shows the streaming service provider, as a surrogate entity for digital content providers, that interacts with the other two components.
Streaming Platforms
Commercial streaming platforms shown in Figure 1 mainly rely on Digital Rights Management (DRM) systems. DRM is a collection of access control technologies that are used for protecting the copyrights of digital media such as movies and music tracks. DRM helps the owners of digital products prevent illegal access, modification, and distribution of their copyrighted work. DRM systems provide continuous content protection against unauthorized actions on digital content and restrict it to streaming and in-time consumption. The backbone of DRM is the use of digital licenses, which specify a set of usage rights for the digital content and contain the permissions from the owner to stream the content via an on-demand streaming service.
On the client’s side, a request is sent to the streaming server to obtain the protected encrypted digital content. In order to stream the digital content, the user requests a license from the clearinghouse that verifies the user’s credentials. Once a license gets assigned to a user, using a Content Decryption Module (CDM), the protected content gets decrypted and becomes ready for preview according to the usage rights enforced by the license. A decryption key gets generated using the license, which is specific to a certain movie title, can only be used by a particular account on a given device, has a limited lifetime, and enforces a limit on how many concurrent streams are allowed.
Another relevant component that is involved in a streaming experience is the concept of manifest. Manifest is a list of video, audio, subtitles, etc. which comes in the form of a few Uniform Resource Locators (URLs) that are used by the clients to get the movie streams. Manifest is requested by the client and gets delivered to the player before the license request, and it itemizes the available streams.
Data
Data Labeling
For the task of anomaly detection in streaming platforms, as we have neither an already trained model nor any labeled data samples, we use structural a priori domain-specific rule-based assumptions, for data labeling. Accordingly, we define a set of rule-based heuristics used for identifying anomalous streaming behaviors of clients and label them as anomalous or benign. The fraud categories that we consider in this work are (i) content fraud, (ii) service fraud, and (iii) account fraud. With the help of security experts, we have designed and developed heuristic functions in order to discover a wide range of suspicious behaviors. We then use such heuristic functions for automatically labeling the data samples. In order to label a set of benign (non-anomalous) accounts a group of vetted users that are highly trusted to be free of any forms of fraud is used.
Next, we share three examples as a subset of our in-house heuristics that we have used for tagging anomalous accounts:
(i) Rapid license acquisition: a heuristic that is based on the fact that benign users usually watch one content at a time and it takes a while for them to move on to another content resulting in a relatively low rate of license acquisition. Based on this reasoning, we tag all the accounts that acquire licenses very quickly as anomalous.
(ii) Too many failed attempts at streaming: a heuristic that relies on the fact that most devices stream without errors while a device, in trial and error mode, in order to find the “right’’ parameters leaves a long trail of errors behind. Abnormally high levels of errors are an indicator of a fraud attempt.
(iii) Unusual combinations of device types and DRMs: a heuristic that is based on the fact that a device type (e.g., a browser) is normally matched with a certain DRM system (e.g., Widevine). Unusual combinations could be a sign of compromised devices that attempt to bypass security enforcements.
It should be noted that the heuristics, even though work as a great proxy to embed the knowledge of security experts in tagging anomalous accounts, may not be completely accurate and they might wrongly tag accounts as anomalous (i.e., false-positive incidents), for example in the case of a buggy client or device. That’s up to the machine learning model to discover and avoid such false-positive incidents.
Data Featurization
A complete list of features used in this work is presented in Table 1. The features mainly belong to two distinct classes. One class accounts for the number of distinct occurrences of a certain parameter/activity/usage in a day. For instance, the dist_title_cnt feature characterizes the number of distinct movie titles streamed by an account. The second class of features on the other hand captures the percentage of a certain parameter/activity/usage in a day.
Due to confidentiality reasons, we have partially obfuscated the features, for instance, dev_type_a_pct, drm_type_a_pct, and end_frmt_a_pct are intentionally obfuscated and we do not explicitly mention devices, DRM types, and encoding formats.
Table 1. The list of streaming related features with the suffixes pct and cnt respectively referring to percentage and count
Data Statistics
In this part, we present the statistics of the features presented in Table 1. Over 30 days, we have gathered 1,030,005 benign and 28,045 anomalous accounts. The anomalous accounts have been identified (labeled) using the heuristic-aware approach. Figure 2(a) shows the number of anomalous samples as a function of fraud categories with 8,741 (31%), 13,299 (47%), 6,005 (21%) data samples being tagged as content fraud, service fraud, and account fraud, respectively. Figure 2(b) shows that out of 28,045 data samples being tagged as anomalous by the heuristic functions, 23,838 (85%), 3,365 (12%), and 842 (3%) are respectively considered as incidents of one, two, and three fraud categories.
Figure 3 presents the correlation matrix of the 23 data features described in Table 1 for clean and anomalous data samples. As we can see in Figure 3 there are positive correlations between features that correspond to device signatures, e.g., dist_cdm_cnt and dist_dev_id_cnt, and between features that refer to title acquisition activities, e.g., dist_title_cnt and license_cnt.
Figure 2. Number of anomalous samples as a function of (a) fraud categories and (b) number of tagged categories.Figure 3. Correlation matrix of the features presented in Table 1 for (a) clean and (b) anomalous data samples.
Label Imbalance Treatment
It is well known that class imbalance can compromise the accuracy and robustness of the classification models. Accordingly, in this work, we use the Synthetic Minority Over-sampling Technique (SMOTE) to over-sample the minority classes by creating a set of synthetic samples.
Figure 4 shows a high-level schematic of Synthetic Minority Over-sampling Technique (SMOTE) with two classes shown in green and red where the red class has fewer number of samples present, i.e., is the minority class, and gets synthetically upsampled.
For evaluating the performance of the anomaly detection models we consider a set of evaluation metrics and report their values. For the one-class as well as binary anomaly detection task, such metrics are accuracy, precision, recall, f0.5, f1, and f2 scores, and area under the curve of the receiver operating characteristic (ROC AUC). For the multi-class multi-label task we consider accuracy, precision, recall, f0.5, f1, and f2 scores together with a set of additional metrics, namely, exact match ratio (EMR) score, Hamming loss, and Hamming score.
Model Based Anomaly Detection
In this section, we briefly describe the modeling approaches that are used in this work for anomaly detection. We consider two model-based anomaly detection approaches, namely, (i) semi-supervised, and (ii) supervised as presented in Figure 5.
The key point about the semi-supervised model is that at the training step the model is supposed to learn the distribution of the benign data samples so that at the inference time it would be able to distinguish between the benign samples (that has been trained on) and the anomalous samples (that has not observed). Then at the inference stage, the anomalous samples would simply be those that fall out of the distribution of the benign samples. The performance of One-Class methods could become sub-optimal when dealing with complex and high-dimensional datasets. However, supported by the literature, deep neural autoencoders can perform better than One-Class methods on complex and high-dimensional anomaly detection tasks.
As the One-Class anomaly detection approaches, in addition to a deep auto-encoder, we use the One-Class SVM, Isolation Forest, Elliptic Envelope, and Local Outlier Factor approaches.
Supervised Anomaly Detection
Binary Classification: In the anomaly detection task using binary classification, we only consider two classes of samples namely benign and anomalous and we do not make distinctions between the types of the anomalous samples, i.e., the three fraud categories. For the binary classification task we use multiple supervised classification approaches, namely, (i) Support Vector Classification (SVC), (ii) K-Nearest Neighbors classification, (iii) Decision Tree classification, (iv) Random Forest classification, (v) Gradient Boosting, (vi) AdaBoost, (vii) Nearest Centroid classification (viii) Quadratic Discriminant Analysis (QDA) classification (ix) Gaussian Naive Bayes classification (x) Gaussian Process Classifier (xi) Label Propagation classification (xii) XGBoost. Finally, upon doing stratified k-fold cross-validation, we carry out an efficient grid search to tune the hyper-parameters in each of the aforementioned models for the binary classification task and only report the performance metrics for the optimally tuned hyper-parameters.
Multi-Class Multi-Label Classification: In the anomaly detection task using multi-class multi-label classification, we consider the three fraud categories as the possible anomalous classes (hence multi-class), and each data sample is assigned one or more than one of the fraud categories as its set of labels (hence multi-label) using the heuristic-aware data labeling strategy presented earlier. For the multi-class multi-label classification task we use multiple supervised classification techniques, namely, (i) K-Nearest Neighbors, (ii) Decision Tree, (iii) Extra Trees, (iv) Random Forest, and (v) XGBoost.
Results and Discussion
Table 2 shows the values of the evaluation metrics for the semi-supervised anomaly detection methods. As we see from Table 2, the deep auto-encoder model performs the best among the semi-supervised anomaly detection approaches with an accuracy of around 96% and f1 score of 94%. Figure 6(a) shows the distribution of the Mean Squared Error (MSE) values for the anomalous and benign samples at the inference stage.
Table 2. The values of the evaluation metrics for a set of semi-supervised anomaly detection models.Figure 6. For the deep auto-encoder model: (a) distribution of the Mean Squared Error (MSE) values for anomalous and benign samples at the inference stage — (b) confusion matrix across benign and anomalous samples- (c) Mean Squared Error (MSE) values averaged across the anomalous and benign samples for each of the 23 features.Table 3. The values of the evaluation metrics for a set of supervised binary anomaly detection classifiers.Table 4. The values of the evaluation metrics for a set of supervised multi-class multi-label anomaly detection approaches. The values in parenthesis refer to the performance of the models trained on the original (not upsampled) dataset.
Table 3 shows the values of the evaluation metrics for a set of supervised binary anomaly detection models. Table 4 shows the values of the evaluation metrics for a set of supervised multi-class multi-label anomaly detection models.
In Figure 7(a), for the content fraud category, the three most important features are the count of distinct encoding formats (dist_enc_frmt_cnt), the count of distinct devices (dist_dev_id_cnt), and the count of distinct DRMs (dist_drm_cnt). This implies that for content fraud the uses of multiple devices, as well as encoding formats, stand out from the other features. For the service fraud category in Figure 7(b) we see that the three most important features are the count of content licenses associated with an account (license_cnt), the count of distinct devices (dist_dev_id_cnt), and the percentage use of type (a) devices by an account (dev_type_a_pct). This shows that in the service fraud category the counts of content licenses and distinct devices of type (a) stand out from the other features. Finally, for the account fraud category in Figure 7(c), we see that the count of distinct devices (dist_dev_id_cnt) dominantly stands out from the other features.
Figure 7. The normalized feature importance values (NFIV) for the multi-class multi-label anomaly detection task using the XGBoost approach in Table 4 across the three anomaly classes, i.e., (a) content fraud, (b) service fraud, and (c) account fraud.
You can find more technical details in our paper here.
Are you interested in solving challenging problems at the intersection of machine learning and security? We are always looking for great people to join us.
As a Backblaze reader, you may be familiar with our executive team—many of them were in the news, especially when we went public back in November 2021. You may have also come across some of our employees on our LinkedIn page (we’re hiring, by the way!).
But you may not be familiar with our independent board members. These experienced executive leaders play a key role in the success of Backblaze. Today, we’re excited to introduce our board members so you can learn more about them and how they’ve helped make Backblaze the company it is today.
Who Are Our Independent Board Members?
At Backblaze, we have four independent board members who work closely with the executive leadership team. As board members, they occupy a role that’s intentionally separate from our employees and founders. They provide an independent viewpoint and advise the executive team on topics such as strategy, operations, and governance. Two of our executive team members are also on the board, but what makes the independent board members different is that they don’t work for the company as employees.
Jocelyn Carter-Miller
Jocelyn grew up on the South Side of Chicago. During her childhood, she was surrounded by many successful role models. She grew up in a segregated Black community called Chatham Avalon. It’s the same community where Muhammad Ali, the Johnsons from Johnsons Publishing Company, Mahalia Jackson, and Jesse Jackson also lived and worked. The first black MBA graduate from the University of Chicago (the same university that Jocelyn attended for her MBA) lived on the same block as Jocelyn. Being a part of a Black community where everyone was accepted, supported, and loved gave her a strong sense of self-confidence and self-worth.
She also attended racially and economically diverse elementary and high schools in the Hyde Park community. This exposure to White, Latino, Black, and internationally diverse students gave her perspectives into the value of different cultures—and showed her that success had many different faces.
Today, Jocelyn serves on the Backblaze board as the Lead Independent Director. She also serves as the Chair of the Compensation Committee and as a member of the Audit Committee and Nominating and Corporate Governance Committee.
Jocelyn began her career as a Board Member when an organization called Catalyst reached out to her. Catalyst is a nonprofit that supports diverse candidates in ascending to senior corporate leadership. They contacted her about joining a financial services board. At that point, Jocelyn had a lot on her plate—she was the Chief Marketing Officer at a Fortune 500 company as well as a wife and mother of two young daughters. Although she was not interested in pursuing this opportunity due to her demanding schedule, Catalyst still convinced her to at least do an interview. A couple of months after her interview, Catalyst let her know that she got the role. Though taking on the role was going to be a stretch, she knew it was about more than simply serving on a board—it was about setting an example for representation at the very top. She decided to join the board, and since then, she has served on five corporate boards including various Fortune 500 boards.
While Jocelyn was a Board Member at Arlo Technologies, the CEO Matthew McRae told her about the opportunity to join the Backblaze board. Jocelyn decided to meet with Gleb and the rest of the leadership team. She says of that initial meeting: “They were all so enthusiastic and they seemed to have such high integrity about what they were doing, their vision, the culture, and the way they treated their employees.” Of her time on the board so far, Jocelyn continues, “I’m glad that I did. It has been fun.”
Jocelyn explains that what makes her unique is that she brings a distinctive perspective to the boardroom as a Black woman who grew up on the South Side of Chicago. She understands what it’s like being a person of color in an environment that may not welcome or accept all of who she is. “I try to use my cultural experience as well as my gender experience to drive for an environment that allows equity for everyone, one that feels inclusive, accepting, and offers you both the opportunity to demonstrate your abilities to perform at high levels and rewards and promotes you for that,” she said. She always tries to drive and push an inclusive, equitable, and fair culture for everyone.
Jocelyn is a creative individual. She loves art and has a strong passion for interior design. Most recently, she worked with one of her friends and former colleagues on an app called Seek and Find Design that helps customers save time and money locating beautiful and inexpensive decor, while also allowing them to enhance their design sense with a community of like-minded people.
Earl Fry
Earl grew up in Honolulu, Hawaii and earned his undergraduate degree from the University of Hawaii. He worked for a couple of years in public accounting as a CPA, after which he moved to the Bay Area to earn his MBA at Stanford University. Once he graduated, he became intrigued by the tech industry and has been a part of it ever since.
At Backblaze, he serves as an independent board member. He sits on all of the Company’s committees—the Nominating and Corporate Governance Committee, Compensation Committee, and Audit Committee.
He started his career as a board member back in 2005. At the time, he was the CFO and Head of Operations at Informatica. One of the board members at Informatica founded his own SaaS company and thought Earl would be a great candidate to join the board. A few years later, he was asked to join the board of a regional bank based in Honolulu, Hawaii. The company was looking for someone who had financial experience for a public company as well as ties to Hawaii. Since Earl grew up in Hawaii and most of his family still lived there, he wanted to take this opportunity as a way to help the local business community.
Thirty years prior to joining the Backblaze board, Earl worked with Barbara Nelson, one of our other board members. Fast forward to when Backblaze was looking for another board member, and Barbara recommended Earl. After Earl spoke with Gleb, he was struck by how different and special Backblaze was: “Having been in Silicon Valley for so long, you get a little jaded sometimes in terms of how companies are founded and how things are put together. What struck me about Backblaze is that the team is so real and genuine. I just have a ton of respect for how the Founders pulled it all together.”
Growing up in Hawaii and attending public school there, Earl met people from all different backgrounds in terms of race, gender, or socioeconomic status. This made him aware of diversity as well as the biases that people may have toward certain groups. He brings this awareness into his work as a board member where he is well-positioned to be able to identify biases and work within the system to constructively foster change.
In his spare time, Earl likes to go fishing, practice rockhounding, and go fossil hunting. He picked up these hobbies as stress relievers. He calls himself a “closet paleontologist.” When he needs a break, he loves going out to the desert to disconnect from life’s demands and connect to nature and himself. He also enjoys gardening, drinking and collecting wine, and spending time with his family.
Evelyn D’An
Evelyn is the Chair of the Audit Committee at Backblaze. She also serves as a member on the Company’s Compensation Committee. She was raised in the Bronx and both of her parents are from the beautiful island of Puerto Rico. As a kid, she enjoyed math and was fortunate to attend The Bronx High School of Science, a magnet high school specializing in math and science. She attended SUNY – Albany, where she gained exposure to the business side of math and decided to focus her career on accounting. She joined Ernst & Young, one of the largest public accounting firms, and worked there for 18 and a half years. During her tenure, she became the first Hispanic female audit partner in the U.S. Southeast region.
Evelyn had already left Ernst & Young to start her own consulting business when the Sarbanes-Oxley Act was enacted in 2002, which aimed to prevent fraudulent financial reporting from businesses. At the time, there were a number of highly public misstatements of financial reports. The world of public accounting was turned upside down, and this also led to a strong need for financial expertise in the boardroom. Evelyn had the skills, experience, and credentials that companies were looking for on their boards. She got her first board position through her network in 2006, and has served on many boards over the past 16 years.
Over the years, she has seen an increase in the number of women in the boardroom. However, she believes that there needs to be more work done in getting underrepresented groups into the boardroom. Still, she believes there is hope: “One of the biggest supporters to encouraging diversity in the boardroom are the large investment banks of the world who are calling out their own portfolio companies and saying that if they don’t have diverse candidates on their board, then they will no longer invest in those companies,” she said. The pressure also comes from employees and candidates, which has made employers initiate or rethink their diversity and inclusion efforts.
Evelyn served as a Co-Chair for BoardNext, an organization that works with aspiring female directors to earn their first board seat. She loves helping her network find various board opportunities. She believes that diversity is so important in the boardroom because it allows everyone to bring in a different perspective. For example, if a company serves international customers, then having people from different cultures helps bring discussions to the boardroom about how they can serve customers in those cultures, what their needs are, and how they can share our value proposition with them.
Evelyn loves to travel, exercise (she’s almost at her 200th SoulCycle ride!), and spend time with her family and six-year-old grandson. Video chatting with him always makes her day better. She is also fortunate enough to still have her mom with her—who lives in the building next door—and they talk daily. Evelyn also enjoys cooking with friends and is working towards expanding her cooking skills beyond the basics. She’d love to learn to make Mediterranean food and sushi!
Barbara Nelson
Barbara grew up all around the world as her father was in the military. She was born in Japan and after that, she lived in many different places within the U.S. and Canada. She went to eight different schools before attending college.
Like Evelyn, Barbara always loved math, and she got her degree in Electrical Engineering from Stanford. As one of the only few women in engineering, she saw early on the diverse voice that a woman brings and the challenges in having that voice be heard.
Barbara started her journey as a board member at ACE Technologies. She happened to know one of the venture capitalists who invested in the company and he encouraged her to join the board. Since then, she has served on a total of five corporate boards, and held the title of CEO on two of them.
Barbara came across the opportunity to join Backblaze through a connection she’s had for 30 years. Gleb had reached out to a trusted colleague looking for a board member and explained the background he was looking for in his ideal candidate. Barbara came recommended, and she and Gleb started a conversation about joining the Backblaze board. “I was extremely impressed by how Gleb and the founders had built such a great culture, while delivering impressive and consistent growth with only $3M of outside funding,” said Barbara. Today, Barbara is the Chair of the Nominating and Governance Committee. In addition, she is a member of the Audit Committee.
Barbara explained that as a woman, she strives to look out and advocate for other underrepresented groups and points of view. She believes that having diverse people in the boardroom helps bring a lens that looks out for inclusion.
Barbara has a passion for traveling, and she’s been to over 90 countries. She just got back from Brazil where she was tracking jaguars and tropical birds. In the future, she wants to go back and visit some of the countries that she’s been to and explore other parts of those places. In particular, she’s interested in going back to Australia to explore the Kimberley region and Western Australia. She also plays keyboard and sings for two bands—one is a classic rock band and the other is a church band. She said that if she could switch places with someone for their talent, it would be Yuja Wang, a classical pianist, or Rihanna during one of her performances. “What fun to be a REAL rock star for a day!”
So You Want to Become a Board Member at a Company? Here’s How.
All of the independent board members have had different experiences and journeys, but the one thing they all had in common was that they earned their opportunities through their networks. Here’s some of their advice on how to become a board member, if you’re interested.
Before becoming a part of a board, Evelyn recommends thinking through your “why.” Being a board member is a lot of work, so it’s important to think about your reason behind starting this journey. The second step that Evelyn suggests is thinking about what companies you’d like to work with. Consider companies and industries that align with your values, what’s important to you, and how you could potentially bring the most value to that particular organization. Lastly, she recommends going deep into corporate governance. A potential board member would need to have all their education, their network with various organizations, and knowledge about hot topics in the industry.
Earl’s advice is simple: do a really good job at work. “You never know who’s watching or where your connections will come into play,” he said. “It helps to become an expert in a couple of areas and to have very deep skills. It’s just as important to be seen as it is to get a broad understanding of how different parts of the business work together and how they are interrelated and impact each other.” He also emphasized the importance of being a good communicator and team member because what makes a board member valuable is their ability to communicate and listen well. He further explained, “Remember that the fundamental job of a board member is to be a fiduciary. The best ways that you can do that are to listen, advise, and influence.”
So how does one build their network? Evelyn suggests building your network both inside and outside of work. Internally, it’s great to connect with peers and form a network that way. Outside of work, Evelyn recommends joining organizations that are focused on corporate governance and attending events that are related to that subject. For example, you could become a member of the National Association of Corporate Directors or the Women Corporate Directors, both of which are organizations that Jocelyn and Evelyn are active members of. She also encourages people to have different types of networks because you never know where your next opportunity is going to come from. She said, “If you want something, you must say it, you must speak it, and you must share it with all of your networks.”
Being a board member is a challenging yet rewarding position. It allows one to have influence on not only a company, but also others like the shareholders, employees, customers, and the world at large.
Thank You to Our Board
We appreciate all that our board members do—Backblaze wouldn’t be where it is today without them! Thank you to our board members for helping our readers get to know them better and for bringing their diverse perspectives and knowledge to help make Backblaze a more successful company.
The Git source-code management system exists to track changes to a set of
files; the stream of commits in a Git repository
reflects the change history of those files. What is seen in Git, though, is the
final form of those commits; the changes that the patches themselves went
through on their way toward acceptance are not shown there. That history
can have value, especially while changes are still under consideration.
The proposed git
evolve subcommand is a recognition that changes themselves go
through changes and that this process might benefit from tooling support.
As stated in our OpenSSL Buffer Overflow blog post, the CVE-2022-3786 & CVE-2022-3602 vulnerabilities affecting OpenSSL’s 3.0.x versions both rely on a maliciously crafted email address in a certificate. CVE-2022-3786 can overflow an arbitrary number of bytes on the stack with the “.” character (a period), leading to a denial of service, while CVE-2022-3602 allows a crafted email address to overflow exactly four attacker-controlled bytes on the stack. OpenSSL 3.0.7 contains fixes for these vulnerabilities which was released on November 1, 2022.
As part of standard due diligence, Rapid7 evaluates the potential impact of vulnerabilities in its products. This process includes validating the existence of the vulnerable libraries or services, interdependencies, the exploitability of the vulnerability in a given context, and impacts related to applying available patches.
Rapid7’s Insight Agent and Insight Network Sensor were confirmed to be impacted by these vulnerabilities. An Insight Agent fix was released on November 2, 2022 (release version 3.1.10.34) and a Network Sensor fix was released on November 10, 2022 (release version 1.4.0.2). Rapid7’s assessment has found no other impact on our products. Checks for these vulnerabilities have been released within Nexpose and InsightVM.
Here in 2022, we have a newly declassified 2016 Inspector General report—”Misuse of Sigint Systems”—about a 2013 NSA program that resulted in the unauthorized (that is, illegal) targeting of Americans.
Given all we learned from Edward Snowden, this feels like a minor coda. There’s nothing really interesting in the IG document, which is heavily redacted.
Can you monitor Finland’s total real-time power consumption with Zabbix? Of course, you can! By day, I am a monitoring tech lead in a global cyber security company. By night, I monitor my home with Zabbix & Grafana and do some weird experiments with them. Welcome to my blog about this project.
After my speech at the Zabbix Summit 2022, someone asked how deeply my wife is involved with this home monitoring project, and I responded back that she usually gives me ideas by accident. You know, she’s a funny and talkative person up to the point that I call her the comment track or the voice-over of my life, so even as a non-techie, she will for sure give me new ideas.
Well, this time she gave the idea for this post on purpose — now that winter and the dark days & nights are approaching fast, she asked if Zabbix could turn our decorative seasonal lights on and off based on the current electricity price.
Of course, it can! I am anyway already monitoring the current electricity price. But let’s take it further — using Zabbix, we can also check Finland’s current real-time power consumption. It would be kind NOT to turn on the lights even during the cheap hours if our power grid would be near its maximum limit.
Hello, Fingrid
Our electricity network Fingrid offers open data for all kinds of details about our power grid, one of them being the current electricity consumption. Using their services is free, all you need is to create an account to get an API key, so I tried if I can use the API with Zabbix. Well, Zabbix integration was easy, though, due to the time constraints set by our now-10-weeks-old-baby, this current version is a bit of a kludge and not yet finished. But hey, I have this blog to write!
So, after getting my API key, I created a new HTTP agent item to my Zabbix and did parse it with Zabbix JSONPath for the value.
Why the regular expression? The value was not returned in pure numeric format, and I know it must be just my JSONPath expression that has something wrong, but to get this working today, I just brute-forced the extra characters away. I’ll fix that one day. Maybe. The most important for now is that this works; the values shown are in megawatts.
What’s next?
Now that the groundwork has been done, albeit in an ugly way, in the near future (when we actually install the seasonal lights), I can start controlling them via smart power sockets and smart lights. Thanks to the total flexibility of Zabbix, I can then create triggers such as turn on seasonal lights if electricity cost is maximum of X EUR/kWh AND Finland’s power grid total consumption is not more than Y MWh AND time of day is something when we would be awake (we would turn the lights off during the graveyard hours in any case).
I have some additional research to do; I’m sure I can find out Finland’s total power grid capacity from somewhere, maybe even via Fingrid API (I first tried it about one hour ago). But, as this winter is going to be totally different than our usual winters, Zabbix can help you in this area, too.
I have been working at Forcepoint since 2014 and just like a small part of Forcepoint’s logo, I’m trying to be green as well. — Janne Pikkarainen
This post was originally published on the author’s LinkedIn account.
От началото на 48-мото Народното събрание от Демократична България внесохме няколко законопроекта, които са свързани с електронното управление и информационните технологии. Тук ще направя кратък списък с описание на проектите (ЗИД значи Закона за изменение и допълнение, а ЗД е закон за допълнение):
ЗИД на Закона за електронното управление – този закон го писахме с екипа ми в Министерство на електронното управление. Той урежда мерки по Плана за възстановяване и устойчивост, отпадането на удостоверенията (на които гражданите са куриери в момента) и на задължението за ползване на квалифициран електронен подпис. Въвежда пълна електронизация на регистрите, електронно връчване на актове и фишове, напомняне за изтичащи документи и др.
ЗИД на Закона за движението по пътищата. Първата цел на проекта е да направим стъпки към ограничаване на рецидивистите на пътя. С пълното разбиране, че е нужна пълна реформа на административното наказване, предлагаме две неща: от една страна, задължение за МВР да спира на пътя всички автомобили, чиито собственици имат пет или повече невръчени фиша, а от друга страна задължение за публикуване на индивидуални анонимизирани данни за всички нарушения (което бях поискал от МВР като министър). Така обществото ще следи дали МВР изпълнява задължението си. Втората цел е намаляване на административната тежест и улесняване на добросъвестните водачи. Премахване на всички стикери от предното стъкло, премахване на синия талон и въвеждане на възможност за електронно плащане на фишове, без да ходим до КАТ да ни ги връчат. Затрудняваме редовните нарушители и улесняваме мнозинството добросъвестни. И повишаваме прозрачността на работата на МВР.
ЗД на Закона за обществените поръчки – целта е да се постигне максимална прозрачност и с който да се прекратят схемите с т.нар. „инженеринг“. Въвежда се задължение за публикуване на отворени данни по международен стандарт (Open contracting data standard), публикуване на договорите, които са сключени без проведени процедури (защото са изключения по закон), публикуване на заявки по рамкови договори, както и разкриване на принадлежност към ДС на членове на органите на фирми, които печелят над половин милион от обществени поръчки.
ЗИД на Закона за корпоративното подоходно облагане – въвеждане на електронни ваучери за храна. Нещо толкова просто (на пръв поглед), което се „точи“ като тема от 2015 г, най-накрая намира законодателно изражение
ЗД на Изборния кодекс – предвиждаме достъп до кода без ограничение във времето, публичен план за провеждане на изборите, извадкови проверки и задължително публикуване на криптографска информация. Така ще се елиминират опорките за ‘пипане’ на машини, а процесът ще е по-добре планиран, предвидим и вдъхващ повече доверие.
ЗИД на Гражданския процесуален кодекс – въвежда се електронно заповедно производство, като това е инструмент за облекчаване работата на свръхнатоварените съдилища, за сметка на ненатоварените.
ЗИД на Търговския закон – освен създаване на изцяло нов вид дружество с променлив капитал, подходящ за стартиращи компании, набиращи инвестиции, предвиждаме и отпадане на спесимена на подписа при регистрация на дружество за български граждани (вместо това той да се извлича от МВР).
Закон за защита на лицата, подаващи сигнали или публично оповестяващи информация за нарушения – законопроектът предвижда цялостна уредба на защитата на лицата, подаващи сигнали (whistleblowers), но в конкретния случай на сигнали за корупция, предвиждаме полу-анонимни сигнали – предлагаме сигналите да се анонимизират в момента на подаване по електронен път, с криптографски средства, като антикорупционната комисия да не може да вижда кой е подател, но данните да могат да се деанонимизират от съда, ако е нужно завеждане на дело за вреди.
ЗД на Закона за електронната търговия – въвеждаме мерки, с които големите онлайн платформи (напр. Фейсбук) да ограничат ефектна на троловете (фалшивите акаунти, които се използват с пропагандна цел), да са по-прозрачни с това кой извършва модерацията и да позволят обжалване на некоректно блокиране на профили. Т.е. на практика увеличаваме защитата на свободата на словото с процес по извънсъдебно обжалване, като същевременно не позволяваме удавянето на свободното слово в море от пропаганда.
Има още много закони, които имат нужда от осъвременяване. Съвесем скоро ще внесем изменения в Кодекса на труда за въвеждане на електронна трудова книжка, например. Но смятам, че с тази законодателна програма, облекчаваме гражданите и бизнеса, модернизираме администрацията и правим разходването на публични средства по-прозрачно.
Путин – това е Русия. Има Путин – има Русия; няма Путин – няма Русия.
Думите са изречени през 2014 г. от водещия идеолог на Кремъл и настоящ председател на руската Дума Вячеслав Володин.
Според руския журналист и опозиционер Михаил Зигар пък Путин „не съществува“. В книгата си „Владимир Путин. Неизбежните войни“ от 2015 г. Зигар проследява част от най-съществените събития от политическата му кариера и влиянието им върху властовата динамика в Русия. Авторът защитава тезата, че различните политически и олигархични кръгове, с които Путин се заобикаля, доизграждат идеите и образа му, проектирайки собствените си политически възгледи върху него.
„Колективният Путин“, както го нарича Зигар, умело лавира между тях. Като наследник на президента Борис Елцин първо попада сред хора от семейството и най-близкото му обкръжение, включително сред олигарси като Борис Березовски, Роман Абрамович и Олег Дерипаска. Избраникът наследява шефа на Елциновата администрация – Александър Волошин, който се превръща и в негов водещ съветник през първите години на управление. Бореща се за вниманието на Путин е и групата на т.нар. силоваци, които се противопоставят на либералните кръгове и контролират силовите структури или важни административни постове – например Игор Сечин и Николай Патрушев. А най-близките му политици днес в лицето на външния министър Сергей Лавров и министъра на отбраната Сергей Шойгу го съпровождат от началните етапи на политическата му кариера в Москва.
Според Зигар Путин има несравнимо индивидуално влияние в процеса по вземане на решения, но те са съобразени с „колективния Путин“, тоест с амалгамата от мнения, влияния и интереси на кръговете около президента. Въпросът дали (не)формалните властови центрове влияят на президента по-скоро хаотично, с оглед на променящите се политически обстоятелства, или той преднамерено ги инструментализира за постигане на определени цели, няма еднозначен отговор. Факт е обаче, че той нееднократно променя възгледите и политиките си, докато съсредоточава властта в собствените си ръце.
Кратка хронология на единовластието
Встъпвайки в длъжност като наследник на Елцин, Путин се сблъсква с Втората чеченска война. Първоначално тя го популяризира сред руското общество, но неблагоприятните последици продължават дълго след края ѝ. На 1 септември 2004 г. терористична група от чеченски сепаратисти щурмува училище в град Беслан, Северна Осетия, вземайки над 1000 заложници, а последвалото масово избиване на цивилни и деца коренно променя руската политическа система.
В отговор на случилото се Путин инициира законови промени, засягащи изборите за губернатори в съставните части на федерацията. От този момент общественото гласуване в съответните юрисдикции е премахнато, а губернаторите се посочват директно от президента, за да бъдат одобрени от местните парламенти впоследствие. Това на практика осигурява на Путин контрол върху Съвета на федерацията (горната камара), докато партията му „Единна Русия“ налага надмощието си в Държавната дума (долната камара).
Втората голяма стъпка към централизация е осъществена през 2007 г. под въздействието на дясната ръка на Путин по онова време – Владислав Сурков. Действащата дотогава смесена избирателна система, според която половината от депутатите в Думата се избират пропорционално, а другата половина – мажоритарно, е отменена. Гласуването оттук нататък ще се извършва на пропорционален принцип и изцяло по партийни листи, което де факто изключва възможността независими кандидати, критични към Кремъл, да влязат в парламента. Заедно с това се ограничава броят на партиите и се затягат критериите за тяхната регистрация, което според Зигар облагодетелства единствено „Единна Русия“.
Третата значима крачка към своеобразно единовластие настъпва през 2020 г., когато Путин инициира промени в Конституцията след провеждане на всеобщ референдум. Президентските мандати на кандидатите се ограничават до максимум два. Уловката тук е, че този закон не влиза в сила за самия Путин, тъй като след одобрението от Конституционния съд досегашните му четири мандата на практика се нулират. Това му позволява да се кандидатира още два пъти и да остане на власт до 2036 г.
Претендентите за поста пък трябва да са живели в Русия през последните 25 години, което лишава много от потенциалните му съперници (като например Алексей Навални) от правото да участват в надпреварата. Освен това президентът получава правото да стартира процедури по освобождаване на конституционни и върховни съдии. В комбинация с увеличените си правомощия да определя и отстранява ръководителите на силовите структури и ключови министри, включително министъра на правосъдието, президентът всъщност налага изключителен контрол и върху съдебната власт. Не на последно място, одобрените промени допускат отхвърляне на решения от международноправен характер, ако според Конституционния съд не съответстват на вътрешноправните норми.
С тези и други по-малки промени през годините – например покачването на необходимия партиен праг за влизане в парламента от 5 на 7% – Путин постепенно си гарантира институционално господство спрямо законодателната, изпълнителната и съдебната власт. Ако към това добавим и безпрекословното влияние върху медийната среда, до избухването на войната в Украйна вътрешнополитическото надмощие на Путин изглежда непоклатимо.
Идеологическа консолидация
За Путин обаче би било много по-трудно да легитимира и осъществи политиката на институционална централизация без идеологическо сплотяване на обществото. За тази цел той използва православието и отношенията си с патриарха на Руската църква – Кирил. Путин превръща православието в национална идеология, отваряйки пространство за реторическо противопоставяне между руснаците и западняците, между руската и западната култура.
Тази логика възпроизвежда антагонистичното разделение от типа „ние срещу тях“ – православните, правоверни и консервативни руснаци срещу неправославните, грешни и либерални западняци. Освен че превръща православието в инструмент за обособяване на руската национална идентичност, Путин го използва за създаване на наднационална връзка между славянските народи, приели православието. Така чрез православието и славянството се създава пропагандната идея за една по-голяма, хомогенна, „братска“ постсъветска общност, доминирана и закриляна от Русия, но застрашена от западния свят.
Същевременно близките до Путин Вячеслав Володин и Николай Патрушев развиват и прилагат концепцията за външния враг, който заплашва не само руската териториална цялост, но и руската (респективно славянската) култура, синтезирана в православието. Тази логика често добива и историческо измерение, според което през цялото си съществуване Русия бива притискана и принуждавана да се защитава, докато разпадът на Съветския съюз се третира като геополитическа катастрофа, причинена от Запада. В този смисъл идеята за „денацификация“ не е просто изобретение за оправдаване на руската агресия в Украйна, а плод на много по-стар наратив за заклеймяване на всичко прозападно и антисъветско като „фашизъм“ или „нацизъм“.
Тази реторика се използва срещу активистите на Оранжевата революция в Украйна. Същото се повтаря и по отношение на Евромайдана след отказа на проруския президент Виктор Янукович да подпише Споразумението за асоцииране на Украйна с Европейския съюз. След падането си от власт самият Янукович определя протестиращите украинци като фашисти и нацисти. Тази линия на политическо говорене се засилва още повече след незаконната анексия на Крим и последвалите събития в Източна Украйна.
Конкретните примери са много – подобна реторика руските власти и медии използват дори по адрес на Естония, която през 2007 г. решава да премести паметника на Бронзовия войник от центъра на Талин във военното си гробище. Погледната от този ъгъл, речта на Путин от 24 февруари т.г. стъпва на процеса на идеологическа консолидация, а „денацификацията“ е просто продължение на масовата руска пропаганда през последните две десетилетия.
Войната в Украйна отразява развитието на вътрешнополитическите процеси във федерацията. Вътрешната и външната политика на Путин са неразривно свързани – войната, физическа и информационна, възпроизвежда процесите на институционална централизация и идеологическо сплотяване около фигурата на президента. Те пък от своя страна улесняват решението за започване на военни действия и необходимата за тази цел вътрешна легитимация, съсредоточавайки властта над политиката и медиите, а следователно и над умовете на гражданите в ръцете на един много тесен кръг от хора.
Подобни порочни модели придобиват внушителна сила, когато международните отношения подхранват несигурността във външната политика чрез добре познатите в научните среди положения на реализма – сфери на влияние, баланс на силите и дилеми на сигурността. Затова е време да повдигнем оставяния дотук на заден план въпрос за следвоенната структура на международните отношения и сигурност. Казано по различен начин: какъв ще бъде светът след войната и в какъв мир искаме да живеем? А това е тема, заслужаваща специално внимание.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
 Възможно е да се спечели „Пулицър“ повече от веднъж. (Не е като френската награда „Гонкур“, която се присъжда само еднократно на автор, заради което Ромен Гари си измисли псевдоним, за да я вземе повторно.) Просто в историята на „Пулицър“ подобни случаи не са често срещано явление, особено ако говорим за награждаване в една и съща категория. Сред малкото автори, отличени повече от веднъж за свои романи, е американският писател Колсън Уайтхед.
Възможно е да се спечели „Пулицър“ повече от веднъж. (Не е като френската награда „Гонкур“, която се присъжда само еднократно на автор, заради което Ромен Гари си измисли псевдоним, за да я вземе повторно.) Просто в историята на „Пулицър“ подобни случаи не са често срещано явление, особено ако говорим за награждаване в една и съща категория. Сред малкото автори, отличени повече от веднъж за свои романи, е американският писател Колсън Уайтхед.