Post Syndicated from Wallace Printz original https://aws.amazon.com/blogs/big-data/now-available-updated-guidance-on-the-data-analytics-lens-for-aws-well-architected-framework/
Nearly all businesses today require some form of data analytics processing, from auditing user access to generating sales reports. For all your analytics needs, the Data Analytics Lens for AWS Well-Architected Framework provides prescriptive guidance to help you assess your workloads and identify best practices aligned to the AWS Well-Architected Pillars: Operational Excellence, Security, Reliability, Performance Efficiency, and Cost Optimization. Today, we’re pleased to announce a completely revised and updated version of the Data Analytics Lens whitepaper.
Self-assess with Well-Architected design principles
The updated version of the Data Analytics Lens whitepaper has been revised to provide guidance to CxOs as well as all data personas. Within each of the five Well-Architected Pillars, we provide top-level design principles for CxOs to quickly identify areas for teams and fundamental rules that analytics workloads designers should follow. Each design principle is followed by a series of questions and best practices that architects and system designers can use to perform self-assessments. Additionally, the Data Analytics Lens includes suggestions that prescriptively explain steps to implement best practices useful for implementation teams.
For example, the Security Pillar design principle “Control data access” works with the best practice to build user identity solutions that uniquely identify people and systems. The associated suggestion for this best practice is to centralize workforce identities, which details how to use this principle and includes links to more documentation on the suggestion.
“Building Data Analytics platform or workloads is one of the complex architecture patterns. It involves multi-layered approach such as Data Ingestion, Data Landing, Transformation Layer, Analytical/Insight and Reporting. Choices of technology and service for each of these layers are wide. The AWS Well-Architected Analytics Lens helps us to design and validate with great confidence against each of the pillars. Now Cognizant Architects can perform assessments using the Data Analytics Lens to validate and help build secure, scalable and innovative data solutions for customers.”
– Supriyo Chakraborty, Principal Architect & Head of Data Engineering Guild, Cognizant Germany
– Somasundaram Janavikulam, Cloud Enterprise Architect & Well Architected Partner Program Lead, Cognizant
In addition to performing your own assessment, AWS can provide a guided experience through reviewing your workload with a Well-Architected Framework Review engagement. For customers building data analytics workloads with AWS Professional Services, our teams of Data Architects can perform assessments using the Data Analytics Lens during the project engagements. This provides you with an objective assessment of your workloads and guidance on future improvements. The integration is available now for customers of the AWS Data Lake launch offering, with additional Data Analytics offerings coming in 2022. Reach out to your AWS Account Team if you’d like to know more about these guided Reviews.
Updated architectural patterns and scenarios
In this version of the Data Analytics Lens, we have also revised the discussion of data analytics patterns and scenarios to keep up with the industry and modern data analytics practices. Each scenario includes sections on characteristics that help you plan when developing systems for that scenario, a reference architecture to visualize and explain how the components work together, and configuration notes to help you properly configure your solution.
This version covers the following topics:
- Building a modern data architecture (formerly Lake House Architecture)
- Organize around data domains by delivering data as a product using a data mesh
- Efficiently and securely provide batch data processing
- Use streaming ingest and stream processing for real-time workloads
- Build operational analytics systems to improve business processes and performance
- Provide data visualization securely and cost-effectively at scale
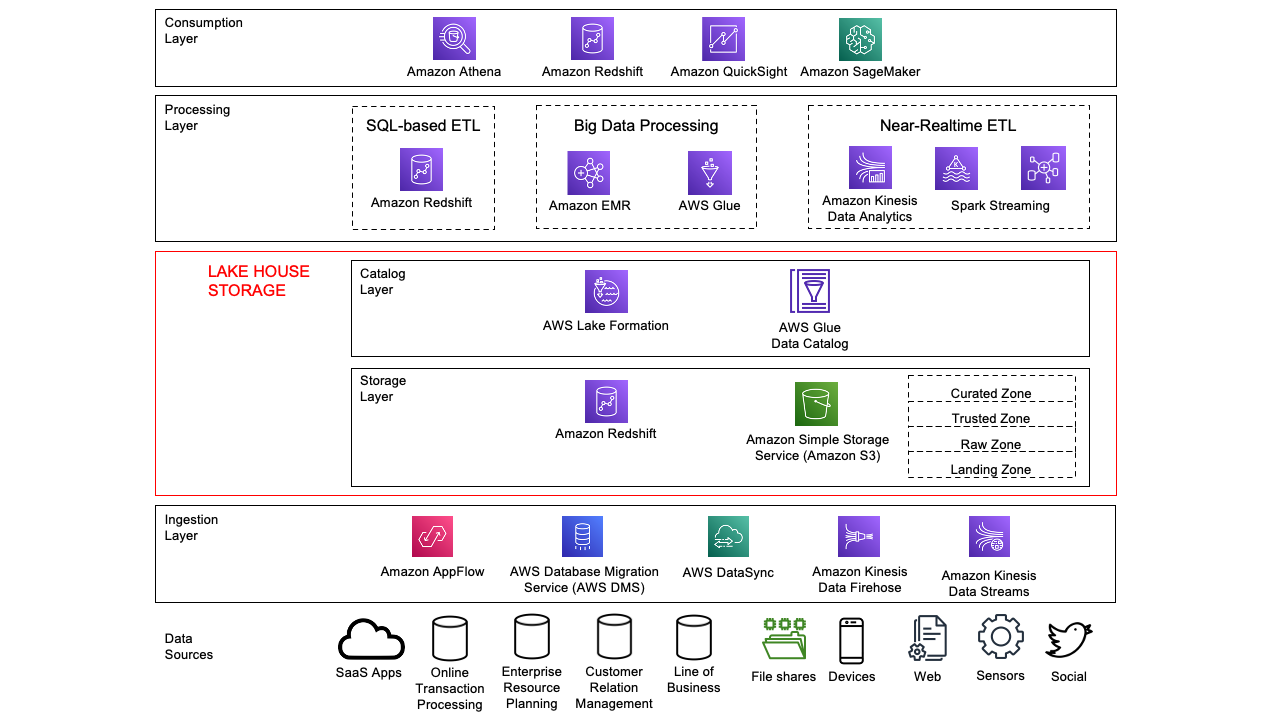
Changed from the first release, the machine learning and tenant analytics scenarios have been migrated to a separate Machine Learning Lens whitepaper and SaaS Lens whitepaper.
Conclusion
We expect this updated version will provide better guidance to validate your existing architectures, as well as provide recommendations for any gaps that identified.
For more information about building your own Well-Architected systems using the Data Analytics Lens, see the Data Analytics Lens whitepaper.
Special thanks to everyone across the AWS Solution Architecture and Data Analytics communities who contributed. These contributions encompassed diverse perspectives, expertise, and experiences in developing the new AWS Well-Architected Data Analytics Lens.
About the Authors
 Wallace Printz is a Senior Solutions Architect based in Austin, Texas. He helps customers across Texas transform their businesses in the cloud. He has a background in semiconductors, R&D, and machine learning.
Wallace Printz is a Senior Solutions Architect based in Austin, Texas. He helps customers across Texas transform their businesses in the cloud. He has a background in semiconductors, R&D, and machine learning.
 Indira Balakrishnan is a Senior Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.
Indira Balakrishnan is a Senior Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.

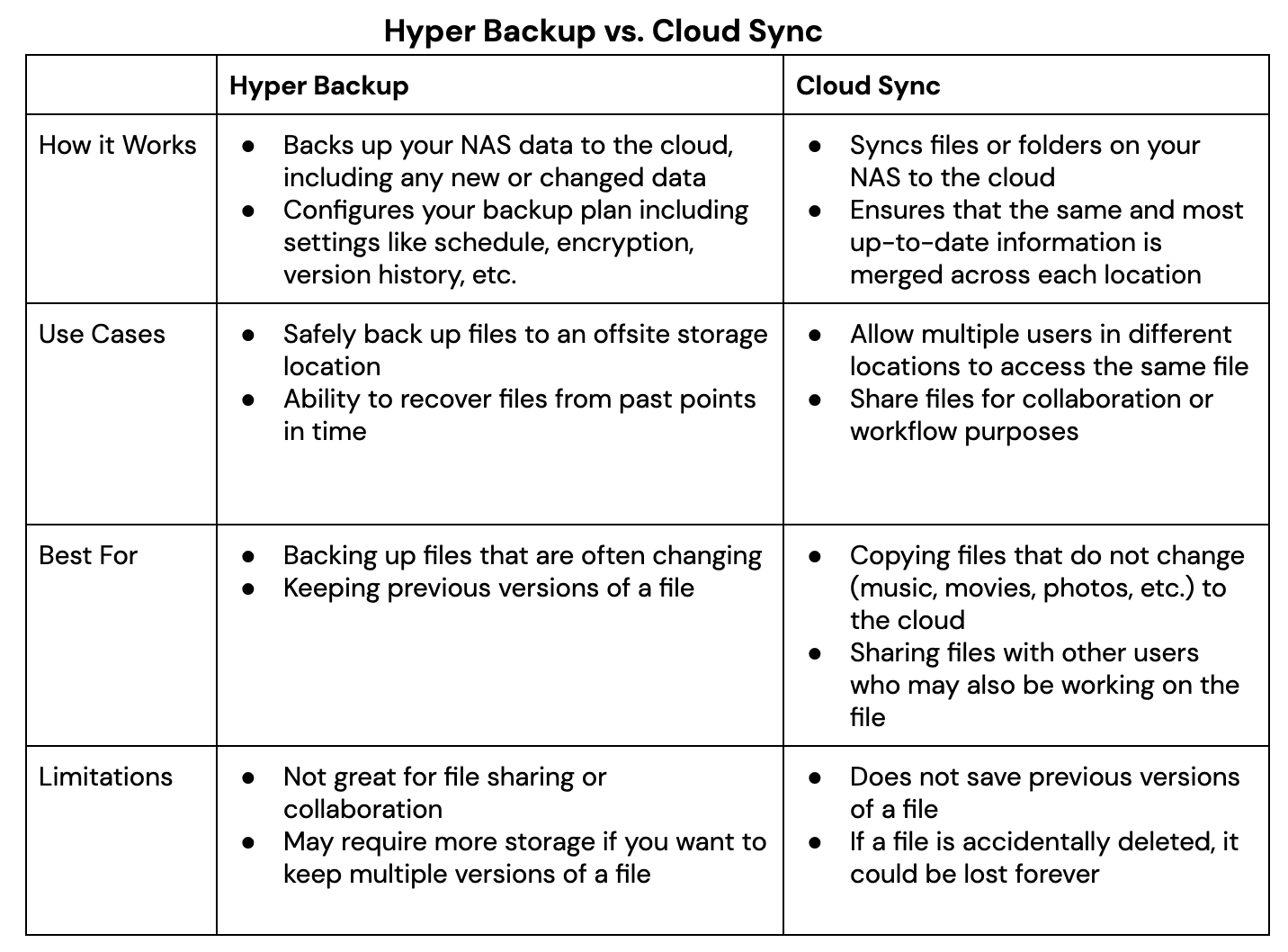 Whether you plan to utilize the backup and sync features Synology offers via Hyper Backup and Cloud Sync, securing your files to the cloud will help you create an effective
Whether you plan to utilize the backup and sync features Synology offers via Hyper Backup and Cloud Sync, securing your files to the cloud will help you create an effective