Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/huffnpuff/


Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/huffnpuff/
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=fPELdVAMrHc
Post Syndicated from Explosm.net original https://explosm.net/comics/pierced
New Cyanide and Happiness Comic
Post Syndicated from Cliff Robinson original https://www.servethehome.com/noctua-fans-for-ampere-altra-max-now-on-newegg-diy-arm-server/
For those building DIY Arm servers and workstations using the Ampere Altra and Altra Max Newegg now carries Noctua coolers
The post Noctua Fans for Ampere Altra Max Now on Newegg appeared first on ServeTheHome.
Post Syndicated from Боряна Телбис original https://www.toest.bg/sedmitsata-27-may-1-yuni/

„Тоест“ си търси маркетинг специалист. Може и да сте разбрали за това търсене, защото още в началото на седмицата пуснахме специална обява, в която подробно е обяснено какъв ни се иска да бъде този човек и какво предлагаме насреща. Имаме нужда от него, за да развиваме заедно аудиторията на медията, да достигаме до повече читатели, а оттам и до повече дарители с желанието да предоставяме по-богато и по-разнообразно съдържание. Ако сме събудили вашето любопитство, моля, не го приспивайте, а кандидатствайте – или препратете обявата на приятел.
Като сме на маркетингови теми, може да споменем, че тази седмица при нас имаше още една. Тя по същество е политическа, но тръгва от маркетингов казус – билбордовете, част от предизборната кампания на ПП–ДБ. Покрай скандала с това може ли, или не може една партия да се рекламира през лидерите на конкуренцията, Емилия Милчева разсъждава и върху въпроса какъв искаме да е следващият премиер.
Седмиците преди избори обикновено, освен с билбордове и плакати на политици, са пълни и с акции, борещи купуването и продаването на гласове. Текстът на Светла Енчева е посветен на поредната операция „Респект“, която българското МВР провежда. „Поредната“, защото много се респектира в тази държава още от времето на Румен Петков като шеф на Вътрешното министерство. В „Операция „Дежавю“, или как МВР се бори с купуването на гласове“ Светла Енчева коментира МВР, което, както обикновено, обръща повече внимание на случващото се в ромските махали, защото „нагоре вече е опасно“.
Място в тазседмичния ни брой намери и първата част от пътеписа на Емине Садкъ за Тайланд. Емине поема по свой път в описанието на тази колкото далечна, толкова и попкултурно опозната вече страна и трябва да ви кажем, че ни стана вкусно, сочно, лютиво, жежко и шумно. Така добре го е разказала в „Тайланд под кожата“, че чакаме настървено втората част.
На хубаво ни замириса и от материала на Йовко Ламбрев, посветен на третата кафе вълна. Каква е тази трета вълна, къде сме били, когато са минали другите две, какво означава „добро кафе“ (и по душа добро!), къде да го намерим и как да си го приготвим. Тотално маниашки текст, заради който може и да погледнете леко снизходително домашната кафе машина, но не забравяйте, че и тя кафе (все някакво) прави, и просто вижте дали няма да е добра идея да я захранвате с по-добра суровина.
Тази седмица рубриката ни „На второ четене“ пораства с още една книга, за която по опияняващо увлекателен начин разказва Стефан Иванов. „Красноречието на сардината“ от Бил Франсоа е сборник с есета за красотата и многообразието на морския свят.
Позволявам си да цитирам финала на текста на Стефан:
Под водата глупости и лъжи не се говорят, пропагандата е кът и почти никой не упражнява самоцелна агресия срещу когото и да било. Полезни и красиви уроци. Все още ненаучени.
Вадя този цитат пред скоби най-вече заради ненаучените уроци. Струва ми се, че един от тях е този за баланса – в живеене, в говоренето, в отношението ни един към друг. Дали този урок някога е бил научен и днес отказваме да го преговаряме, или пък изобщо отричаме необходимостта от такъв урок в учебната програма по живот, е без значение. Важен е резултатът, а той е следният: отсъства баланс в обществения дебат по която и да е тема. И това ясно личи дори в начина, по който възприемаме медиите и медийното съдържание.
Конкретен пример за това може да се даде с тазседмичната статия на Искрен Иванов за политическата фигура на Бенямин Нетаняху – точно както и самият Нетаняху, тази публикация предизвика редица противоречиви реакции. Заради текста някои читатели заклеймиха редакцията на „Тоест“ като ционистка пасмина, на чиято съвест трябва да лежи погубеният без време живот на между 15 000 и 35 000 палестински деца (в различните обвинения към нас се посочват различни числа).
Уважаеми читатели на „Тоест“, медиите не са ехостаи, в които да чуваме само собствения си глас в потвърждение на собствените ни мнения, познания, каузи и въжделения. Медиите трябва да могат да предоставят свобода на авторите си да изразяват своята лична позиция, без обаче да изопачават фактите. През годините в „Тоест“ многократно са съжителствали една до друга противоречащи си позиции, но написани достатъчно аргументирано и експертно от своите автори.
Нито една от тези статии не е отворено писмо, не е петиция, под която се подписва всеки член от екипа на медията. Ние имаме различни мнения по различни въпроси. Но сме винаги на една вълна, що се отнася до разбирането ни какво е полезна медия. Тя не е дясна или лява, не е „първа“, не е „ексклузивна“, не повтаря непременно това, което искаме да чуем, за да сме спокойни, че е „правилна“. Медията е територия за обществен дебат – рационален, спокоен и аргументиран. Социалните медии – с насилническите си коментари – не са.
Излишно е да казвам, че редакцията ни е отворена за нови автори, изразяващи своите позиции аргументирано и експертно. Вие, нашите верни критично мислещи читатели, може винаги да ни препоръчвате такива автори, за да обогатим съдържанието си. Призоваваме ви да го направите и сега.
А ако трябва да се върна на конкретната полемична статия, искам само да добавя, че тя следва да бъде четена като материал за политико-цивилизационната концепция на Държавата Израел, за разделението в израелското общество, за настроенията в САЩ спрямо израелската държава – всичко това, пречупено през призмата на настоящото сеизмично управление на Нетаняху. Тя не е нито за израело-палестинския конфликт, нито за хуманитарната криза в Газа, нито за „Хамас“, нито е в прослава на Нетаняху, още по-малко пък отразява личните мнения на хората от екипа на „Тоест“.
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/marvell-extending-pcie-gen6-reach-from-3-5-inches-to-meters/
Marvell’s vision for its PCIe Gen6 retimers is extending reach from 3.5 inches to around 30 meters with its new Alaska P product line
The post Marvell Extending PCIe Gen6 Reach from 3.5 Inches to Meters appeared first on ServeTheHome.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/05/friday-squid-blogging-baby-colossal-squid.html
This video might be a juvenile colossal squid.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
Post Syndicated from jzb original https://lwn.net/Articles/976176/
KDE Eco, a KDE project focused
on reducing software’s environmental impact, has announced its Opt
Green campaign to reduce e-waste:
Over the next two years, the “Opt Green” initiative will bring what
KDE Eco has been doing for sustainable software directly to end
users. A particular target group for the project is those whose
consumer behavior is driven by principles related to the environment,
and not just price or convenience: the “eco-consumers”.Through online and offline campaigns as well as installation
workshops, we will demonstrate the power of Free Software to drive
down resource and energy consumption, and keep devices in use for the
lifespan of the hardware, not the software.Our motto: The most environmentally-friendly device is the
one you already own.
See the KDE Eco Get
Involved page for more information on how to participate.
Post Syndicated from Justin Prince original https://blog.rapid7.com/2024/05/31/new-insight-agent-support-for-arm-based-windows-in-insightvm/

We are pleased to introduce Insight Agent support of ARM-based Windows 11 devices for both vulnerability and policy assessment within InsightVM. Customers with Windows 11 devices powered by ARM processors can now take advantage of the great performance and lower power requirements of these chips without sacrificing the agent-based visibility of their remote assets. This release coincides with enhanced vulnerability content for Windows 11 in InsightVM, providing customers with high-quality, accurate coverage. The full list of operating systems supported by the Insight Agent can be found in our documentation.
The latest generation of ARM64 chips promises excellent CPU performance and multi-day battery life on a single charge, making them more attractive than ever for enterprise and consumer devices, including laptops. As hardware and software vendors continue to bolster support for Windows on ARM, Rapid7 customers using or considering adoption of these devices can deploy the Insight Agent to Windows 11 devices immediately. The existing Windows (x64) installer – downloaded as ‘agentInstaller-x86_64.msi’ – can be used for installation, and the Insight Agent will automatically run in emulation mode. No other action is required, but do note that only InsightVM functionality is supported at this time.
You can find more information on how to download and install the Insight Agent in our Help Documentation and on the Agents page within the Insight Platform:
Customers can use the Agent Test Set feature to roll out newer versions of the Insight Agent on a select set of machines before deploying it widely.
Post Syndicated from Brendan Watters original https://blog.rapid7.com/2024/05/31/metasploit-weekly-wrap-up-05-31-2024/

In this release, we feature a double-double: two exploits each targeting two pieces of software. The first pair is from h00die targeting the Jasmine Ransomeware Web Server. The first uses CVE-2024-30851 to retrieve the login for the ransomware server, and the second is a directory traversal vulnerability allowing arbitrary file read. The second pair from Dave Yesland of Rhino Security targets Progress Flowmon with CVE-2024-2389 and it pairs well like wine with the additional and accompanying Privilege Escalation module.
Authors: chebuya and h00die
Type: Auxiliary
Pull request: #19103 contributed by h00die
Path: gather/jasmin_ransomware_dir_traversal
AttackerKB reference: CVE-2024-30851
Description: This adds an unauthenticated directory traversal and a SQLi exploit against the Jasmin ransomware web panel.
Authors: chebuya and h00die
Type: Auxiliary
Pull request: #19103 contributed by h00die
Path: gather/jasmin_ransomware_sqli
Description: This adds an unauthenticated directory traversal and a SQLi exploit against the Jasmin ransomware web panel.
Author: Dave Yesland with Rhino Security Labs
Type: Exploit
Pull request: #19150 contributed by DaveYesland
Path: linux/http/progress_flowmon_unauth_cmd_injection
AttackerKB reference: CVE-2024-2389
Description: Unauthenticated Command Injection Module for Progress Flowmon CVE-2024-2389.
Author: Dave Yesland with Rhino Security Labs
Type: Exploit
Pull request: #19151 contributed by DaveYesland
Path: linux/local/progress_flowmon_sudo_privesc_2024
Description: Privilege escalation module for Progress Flowmon unpatched feature.
None
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
commercial edition Metasploit Pro
Post Syndicated from corbet original https://lwn.net/Articles/976125/
The “pidfdfs” virtual filesystem was added to the 6.9 kernel release as a
way to export better information about running processes to user space. It
replaced a previous implementation in a way that was, on its surface, fully
compatible while adding a number of new capabilities. This transition,
which was intended to be entirely invisible to existing applications,
already ran into trouble in March, when a
misunderstanding with SELinux caused systems with pidfdfs to fail to boot
properly. That problem was quickly fixed, but it turns out that there was
one more surprise in store, showing just how hard ABI compatibility can be
at times.
Post Syndicated from Explosm.net original https://explosm.net/comics/bad-news-from-the-doctor
New Cyanide and Happiness Comic
Post Syndicated from Donnie Prakoso original https://aws.amazon.com/blogs/aws/simplify-custom-contact-center-insights-with-amazon-connect-analytics-data-lake/
Analytics are vital to the success of a contact center. Having insights into each touchpoint of the customer experience allows you to accurately measure performance and adapt to shifting business demands. While you can find common metrics in the Amazon Connect console, sometimes you need to have more details and custom requirements for reporting based on the unique needs of your business.
Starting today, the Amazon Connect analytics data lake is generally available. As announced last year as preview, this new capability helps you to eliminate the need to build and maintain complex data pipelines. Amazon Connect data lake is zero-ETL capable, so no extract, transform, or load (ETL) is needed.
Here’s a quick look at the Amazon Connect analytics data lake:

Improving your customer experience with Amazon Connect
Amazon Connect analytics data lake helps you to unify disparate data sources, including customer contact records and agent activity, into a single location. By having your data in a centralized location, you now have access to analyze contact center performance and gain insights while reducing the costs associated with implementing complex data pipelines.
With Amazon Connect analytics data lake, you can access and analyze contact center data, such as contact trace records and Amazon Connect Contact Lens data. This provides you the flexibility to prepare and analyze data with Amazon Athena and use the business intelligence (BI) tools of your choice, such as, Amazon QuickSight and Tableau.
Get started with the Amazon Connect analytics data lake
To get started with the Amazon Connect analytics data lake, you’ll first need to have an Amazon Connect instance setup. You can follow the steps in the Create an Amazon Connect instance page to create a new Amazon Connect instance. Because I’ve already created my Amazon Connect instance, I will go straight to showing you how you can get started with Amazon Connect analytics data lake.
First, I navigate to the Amazon Connect console and select my instance.

Then, on the next page, I can set up my analytics data lake by navigating to Analytics tools and selecting Add data share.

This brings up a pop-up dialog, and I first need to define the target AWS account ID. With this option, I can set up a centralized account to receive all data from Amazon Connect instances running in multiple accounts. Then, under Data types, I can select the types I need to share with the target AWS account. To learn more about the data types that you can share in the Amazon Connect analytics data lake, please visit Associate tables for Analytics data lake.

Once it’s done, I can see the list of all the target AWS account IDs with which I have shared all the data types.

Besides using the AWS Management Console, I can also use the AWS Command Line Interface (AWS CLI) to associate my tables with the analytics data lake. The following is a sample command:
$> aws connect batch-associate-analytics-data-set --cli-input-json file:///input_batch_association.json
Where input_batch_association.json is a JSON file that contains association details. Here’s a sample:
{
"InstanceId": YOUR_INSTANCE_ID,
"DataSetIds": [
"<DATA_SET_ID>"
],
"TargetAccountId": YOUR_ACCOUNT_ID
}
Next, I need to approve (or reject) the request in the AWS Resource Access Manager (RAM) console in the target account. RAM is a service to help you securely share resources across AWS accounts. I navigate to AWS RAM and select Resource shares in the Shared with me section.

Then, I select the resource and select Accept resource share.

At this stage, I can access shared resources from Amazon Connect. Now, I can start creating linked tables from shared tables in AWS Lake Formation. In the Lake Formation console, I navigate to the Tables page and select Create table.

I need to create a Resource link to a shared table. Then, I fill in the details and select the available Database and the Shared table’s region.

Then, when I select Shared table, it will list all the available shared tables that I can access. 
Once I select the shared table, it will automatically populate Shared table’s database and Shared table’s owner ID. Once I’m happy with the configuration, I select Create.

To run some queries for the data, I go to the Amazon Athena console.The following is an example of a query that I ran:

With this configuration, I have access to certain Amazon Connect data types. I can even visualize the data by integrating with Amazon QuickSight. The following screenshot show some visuals in the Amazon QuickSight dashboard with data from Amazon Connect.

Customer voice
During the preview period, we heard lots of feedback from our customers about Amazon Connect analytics data lake. Here’s what our customer say:
![]()
Joulica is an analytics platform supporting insights for software like Amazon Connect and Salesforce. Tony McCormack, founder and CEO of Joulica, said, “Our core business is providing real-time and historical contact center analytics to Amazon Connect customers of all sizes. In the past, we frequently had to set up complex data pipelines, and so we are excited about using Amazon Connect analytics data lake to simplify the process of delivering actionable intelligence to our shared customers.”
Things you need to know
Happy building,
— Donnie
Post Syndicated from Anand Komandooru original https://aws.amazon.com/blogs/big-data/implement-a-full-stack-serverless-search-application-using-aws-amplify-amazon-cognito-amazon-api-gateway-aws-lambda-and-amazon-opensearch-serverless/
Designing a full stack search application requires addressing numerous challenges to provide a smooth and effective user experience. This encompasses tasks such as integrating diverse data from various sources with distinct formats and structures, optimizing the user experience for performance and security, providing multilingual support, and optimizing for cost, operations, and reliability.
Amazon OpenSearch Serverless is a powerful and scalable search and analytics engine that can significantly contribute to the development of search applications. It allows you to store, search, and analyze large volumes of data in real time, offering scalability, real-time capabilities, security, and integration with other AWS services. With OpenSearch Serverless, you can search and analyze a large volume of data without having to worry about the underlying infrastructure and data management. An OpenSearch Serverless collection is a group of OpenSearch indexes that work together to support a specific workload or use case. Collections have the same kind of high-capacity, distributed, and highly available storage volume that’s used by provisioned Amazon OpenSearch Service domains, but they remove complexity because they don’t require manual configuration and tuning. Each collection that you create is protected with encryption of data at rest, a security feature that helps prevent unauthorized access to your data. OpenSearch Serverless also supports OpenSearch Dashboards, which provides an intuitive interface for analyzing data.
OpenSearch Serverless supports three primary use cases:
In this post, we walk you through a reference implementation of a full-stack cloud-centered serverless text search application designed to run using OpenSearch Serverless.
The following services are used in the solution:
The following diagram illustrates the solution architecture.

The workflow includes the following steps:
In the following sections, we walk you through the steps to deploy the solution, ingest data, and test the solution.
Before you get started, make sure you complete the following prerequisites:
AccessKeyId and SecretAccessKey in your local machine’s AWS profile.

You should see the default IAM statement in JSON format.

This environment name needs to be used when performing amplify init when bringing up the backend. The actions in the IAM statement are largely open (*) but restricted or limited by the target resources; this is done to satisfy the maximum inline policy length (2,048 characters).

AddionalPermissions-Amplify).

You should now see the new inline policy attached to the user.

Complete the following steps to deploy the solution:
To ingest the sample movie data into the newly created OpenSearch Serverless collection, complete the following steps:

awscurl command to save data into the collection:You should see a 200 OK response.

Make sure the file name matches the ID field in sample movie data (for example, tt1981115.mp4, tt0800369.mp4, and tt0172495.mp4). Uploading a trailer with ID tt0172495.mp4 is used as the default trailer for all movies, without having to upload one for each movie.
Access the application using the CloudFront distribution domain name. You can find this by opening the CloudFront console, choosing the distribution, and copying the distribution domain name into your browser.
Sign up for application access by entering your user name, password, and email address. The password should be at least eight characters in length, and should include at least one uppercase character and symbol.

After you’re logged in, you’re redirected to the Movie Finder home page.

You can search using a movie name, actor, or director, as shown in the following example. The application returns results using OpenSearch DSL.

If there’s a large number of search results, you can navigate through them using the pagination option at the bottom of the page. For more information about how the application uses pagination, see Paginating search results.

You can choose movie tiles to get more details and watch the trailer if you took the optional step of uploading a movie trailer.

You can sort the search results using the Sort by feature. The application uses the sort functionality within OpenSearch.

There are many more DSL search patterns that allow for intricate searches. See Query DSL for complete details.
Monitoring is an important part of maintaining the reliability, availability, and performance of OpenSearch Serverless and your other AWS services. AWS provides Amazon CloudWatch and AWS CloudTrail to monitor OpenSearch Serverless, report when something is wrong, and take automatic actions when appropriate. For more information, see Monitoring Amazon OpenSearch Serverless.
To avoid unnecessary charges, clean up the solution implementation by running the following command at the project root folder you created using the git clone command during deployment:
You can also clean up the solution by deleting the AWS CloudFormation stack you deployed as part of the setup. For instructions, see Deleting a stack on the AWS CloudFormation console.
In this post, we implemented a full-stack serverless search application using OpenSearch Serverless. This solution seamlessly integrates with various AWS services, such as Lambda for serverless computing, API Gateway for constructing RESTful APIs, IAM for robust security, Amazon Cognito for streamlined user management, and AWS WAF for safeguarding the web application against threats. By adopting a serverless architecture, this search application offers numerous advantages, including simplified deployment processes and effortless scalability, with the benefits of a managed infrastructure.
With OpenSearch Serverless, you get the same interactive millisecond response times as OpenSearch Service with the simplicity of a serverless environment. You pay only for what you use by automatically scaling resources to provide the right amount of capacity for your application without impacting performance and scale as needed. You can use OpenSearch Serverless and this reference implementation to build your own full-stack text search application.
 Anand Komandooru is a Principal Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “Leaders are right a lot“.
Anand Komandooru is a Principal Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “Leaders are right a lot“.
 Rama Krishna Ramaseshu is a Senior Application Architect at AWS. He joined AWS Professional Services in 2022 and with close to two decades of experience in application development and software architecture, he empowers customers to build well architected solutions within the AWS cloud. His favorite Amazon leadership principle is “Learn and Be Curious”.
Rama Krishna Ramaseshu is a Senior Application Architect at AWS. He joined AWS Professional Services in 2022 and with close to two decades of experience in application development and software architecture, he empowers customers to build well architected solutions within the AWS cloud. His favorite Amazon leadership principle is “Learn and Be Curious”.
 Sachin Vighe is a Senior DevOps Architect at AWS. He joined AWS Professional Services in 2020, and specializes in designing and architecting solutions within the AWS cloud to guide customers through their DevOps and Cloud transformation journey. His favorite leadership principle is “Customer Obsession”.
Sachin Vighe is a Senior DevOps Architect at AWS. He joined AWS Professional Services in 2020, and specializes in designing and architecting solutions within the AWS cloud to guide customers through their DevOps and Cloud transformation journey. His favorite leadership principle is “Customer Obsession”.
 Molly Wu is an Associate Cloud Developer at AWS. She joined AWS Professional Services in 2023 and specializes in assisting customers in building frontend technologies in AWS cloud. Her favorite leadership principle is “Bias for Action”.
Molly Wu is an Associate Cloud Developer at AWS. She joined AWS Professional Services in 2023 and specializes in assisting customers in building frontend technologies in AWS cloud. Her favorite leadership principle is “Bias for Action”.
 Andrew Yankowsky is a Security Consultant at AWS. He joined AWS Professional Services in 2023, and helps customers build cloud security capabilities and follow security best practices on AWS. His favorite leadership principle is “Earn Trust”.
Andrew Yankowsky is a Security Consultant at AWS. He joined AWS Professional Services in 2023, and helps customers build cloud security capabilities and follow security best practices on AWS. His favorite leadership principle is “Earn Trust”.
Post Syndicated from Anna Montalat original https://aws.amazon.com/blogs/big-data/aws-named-a-leader-in-idc-marketscape-worldwide-analytic-stream-processing-software-2024-vendor-assessment/
We’re thrilled to announce that AWS has been named a Leader in the IDC MarketScape: Worldwide Analytic Stream Processing Software 2024 Vendor Assessment (doc #US51053123, March 2024).
We believe this recognition validates the power and performance of Apache Flink for real-time data processing, and how AWS is leading the way to help customers build and run fully managed Apache Flink applications. You can read the full report from IDC.
Apache Flink’s robust architecture enables real-time data processing at scale, making it a favored choice among organizations for its efficiency and speed. With its advanced features for event time processing and state management, Apache Flink empowers users to build complex stream processing applications, making it indispensable for modern data-driven organizations. Managed Service for Apache Flink takes the complexity out of Apache Flink deployment and management, letting you focus on building game-changing applications. With Managed Service for Apache Flink, you can transform and analyze streaming data in real time using Apache Flink and integrate applications with other AWS services. There are no servers and clusters to manage, and there is no compute and storage infrastructure to set up. You pay only for the resources you use.
But what does this mean for your organizations and IT teams? The following are some use cases and benefits:
Apache Flink’s versatility extends beyond single use cases. The following are just a few examples of how our customers are taking advantage of its capabilities:
By choosing Managed Service for Apache Flink, you’re joining a growing community of organizations who are unlocking the power of real-time data analysis. Get started today and see how Apache Flink can transform your data strategy, including powering the next generation of generative AI applications.
Contact us today and discover how Apache Flink can empower your business.
 Anna Montalat is the Product Marketing lead for AWS analytics and streaming data services, including Amazon Managed Streaming for Apache Kafka (MSK), Kinesis Data Streams, Kinesis Video Streams, Amazon Data Firehose, and Amazon Managed Service for Apache Flink, among others. She is passionate about bringing new and emerging technologies to market, working closely with service teams and enterprise customers. Outside of work, Anna skis through winter time and sails through summer.
Anna Montalat is the Product Marketing lead for AWS analytics and streaming data services, including Amazon Managed Streaming for Apache Kafka (MSK), Kinesis Data Streams, Kinesis Video Streams, Amazon Data Firehose, and Amazon Managed Service for Apache Flink, among others. She is passionate about bringing new and emerging technologies to market, working closely with service teams and enterprise customers. Outside of work, Anna skis through winter time and sails through summer.
Post Syndicated from corbet original https://lwn.net/Articles/976319/
The 2024 Kernel Maintainers Summit will happen on September 17 in
Vienna, Austria; it is an invitation-only event for a small group to
discuss important kernel-development problems. The call for
proposals for this gathering has now been posted. One of the best ways
to be invited to the event is to propose a topic that needs discussion in
that forum. The deadline for proposals is June 18.
Post Syndicated from digiblur DIY original https://www.youtube.com/watch?v=84rsq49Jags
Post Syndicated from Geographics original https://www.youtube.com/watch?v=fiqZrtn7LPI
Post Syndicated from Divya Konaka Satyapal original https://aws.amazon.com/blogs/devops/using-single-sign-on-sso-to-manage-project-teams-for-amazon-codecatalyst/
Amazon CodeCatalyst is a modern software development service that empowers teams to deliver software on AWS easily and quickly. Amazon CodeCatalyst provides one place where you can plan, code, and build, test, and deploy your container applications with continuous integration/continuous delivery (CI/CD) tools.
CodeCatalyst recently announced the teams feature, which simplifies management of space and project access. Enterprises can now use this feature to organize CodeCatalyst space members into teams using single sign-on (SSO) with IAM Identity Center. You can also assign SSO groups to a team, to centralize your CodeCatalyst user management.
CodeCatalyst space admins can create teams made up any members of the space and assign them to unique roles per project, such as read-only or contributor.
In this post, we will demonstrate how enterprises can enable access to CodeCatalyst with their workforce identities configured in AWS IAM Identity Center, and also easily manage which team members have access to CodeCatalyst spaces and projects. With AWS IAM Identity Center, you can connect a self-managed directory in Active Directory (AD) or a directory in AWS Managed Microsoft AD by using AWS Directory Service. You can also connect other external identity providers (IdPs) like Okta or OneLogin to authenticate identities from the IdPs through the Security Assertion Markup Language (SAML) 2.0 standard. This enables your users to sign in to the AWS access portal with their corporate credentials.
To get started with CodeCatalyst, you need the following prerequisites. Please review them and ensure you have completed all steps before proceeding:
1. Set up an CodeCatalyst space. To join a space, you will need to either:

Figure 1: CodeCatalyst Space Settings
2. Create an AWS Identity and Access Management (IAM) role. Amazon CodeCatalyst will need an IAM role to have permissions to deploy the infrastructure to your AWS account. Follow the documentation for steps how to create an IAM role via the Amazon CodeCatalyst console.
3. Once the above steps are completed, you can go ahead and create projects in the space using the available blueprints or custom blueprints.
The emphasis of this post, will be on how to manage IAM identity center (SSO) groups with CodeCatalyst teams. At the end of the post, our workflow will look like the one below:
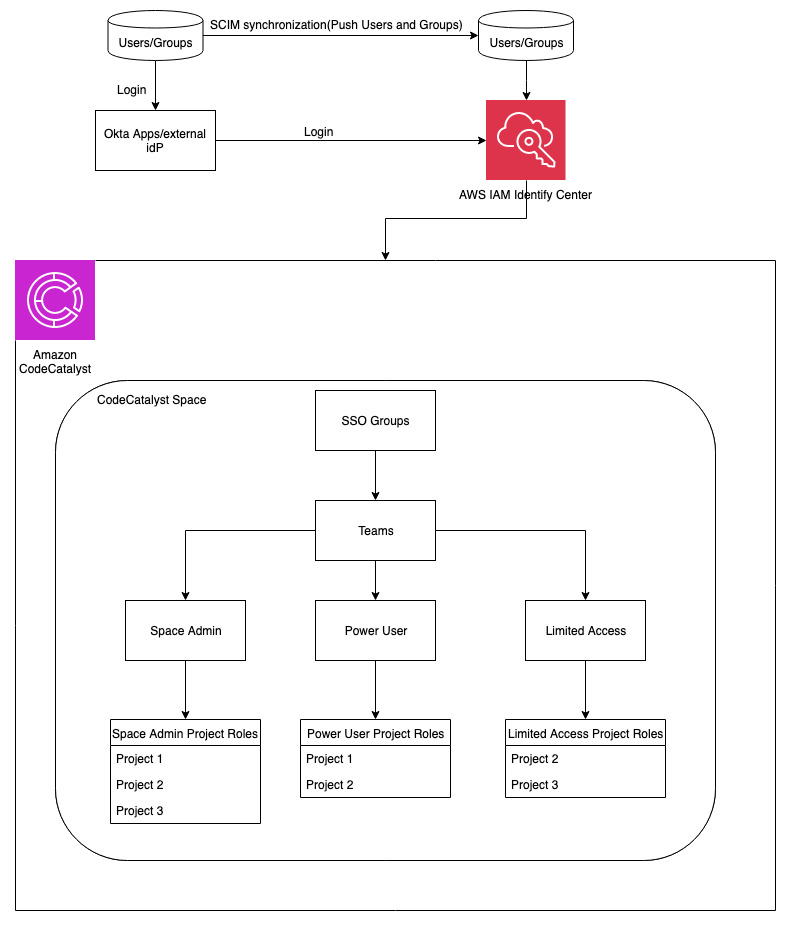
Figure 2: Architectural Diagram
For the purpose of this walkthrough, I have used an external identity provider Okta to federate with AWS IAM Identity Center to manage access to CodeCatalyst.
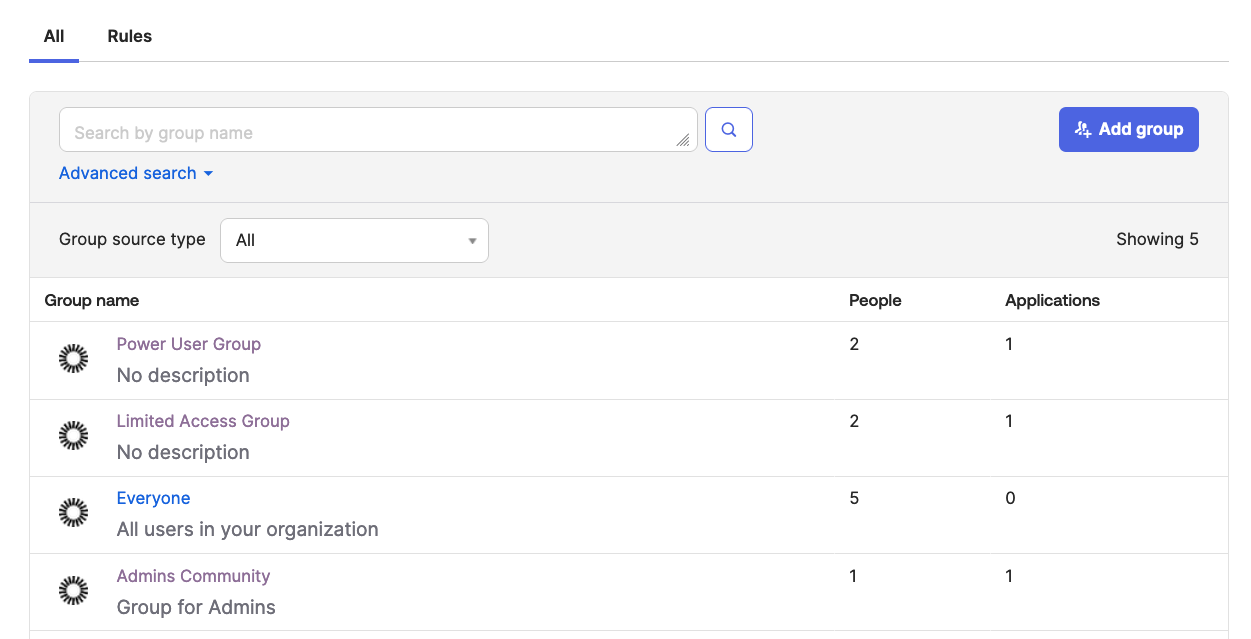
Figure 3: Okta Groups from Admin Console
You can also see the same Groups are synced with the IAM Identity Center instance from the figure below. Please note Groups and member management must be done only via external identity providers.
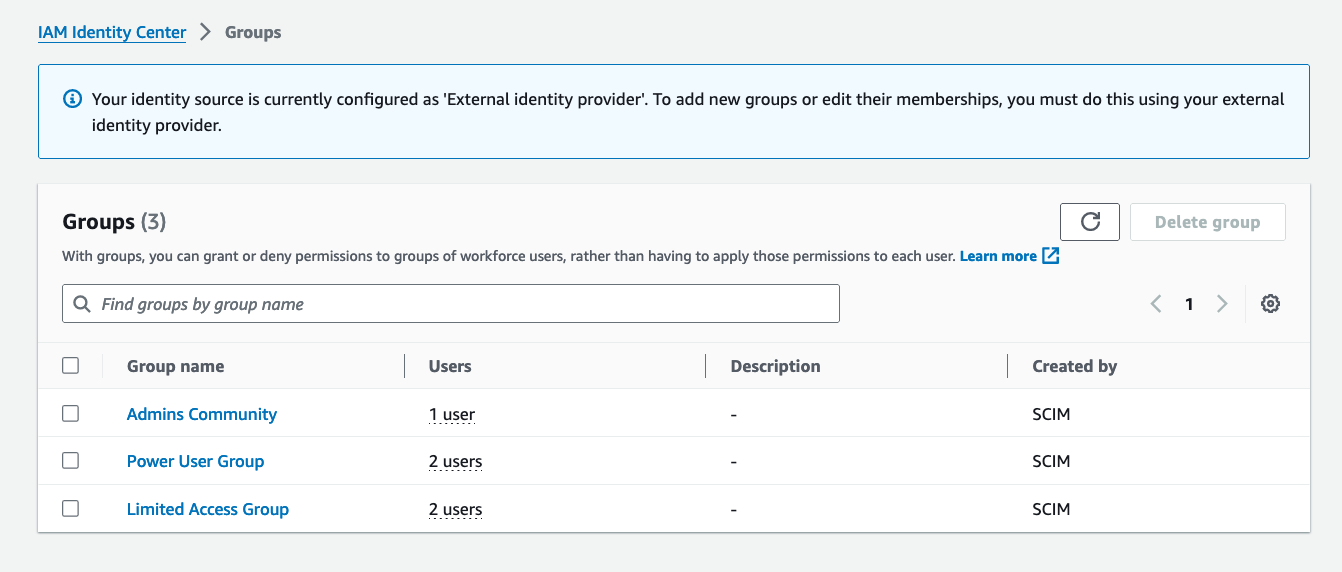
Figure 4: IAM Identity Center Groups created via SCIM synch
Now, if you go to your Okta apps and click on ‘AWS IAM Identity Center’, the AWS account ID and CodeCatalyst space that you created as part of prerequisites should be automatically configured for you via single sign-on. Developers and Administrators of the space can easily login using this integration.

Figure 5: CodeCatalyst Space via SSO
Once you are in the CodeCatalyst space, you can organize CodeCatalyst space members into teams, and configure the default roles for them. You can choose one of the three roles from the list of space roles available in CodeCatalyst that you want to assign to the team. The role will be inherited by all members of the team:
Since you have the space integrated with SSO groups set up in IAM Identity Center, you can use that option to create teams and manage members using SSO groups.
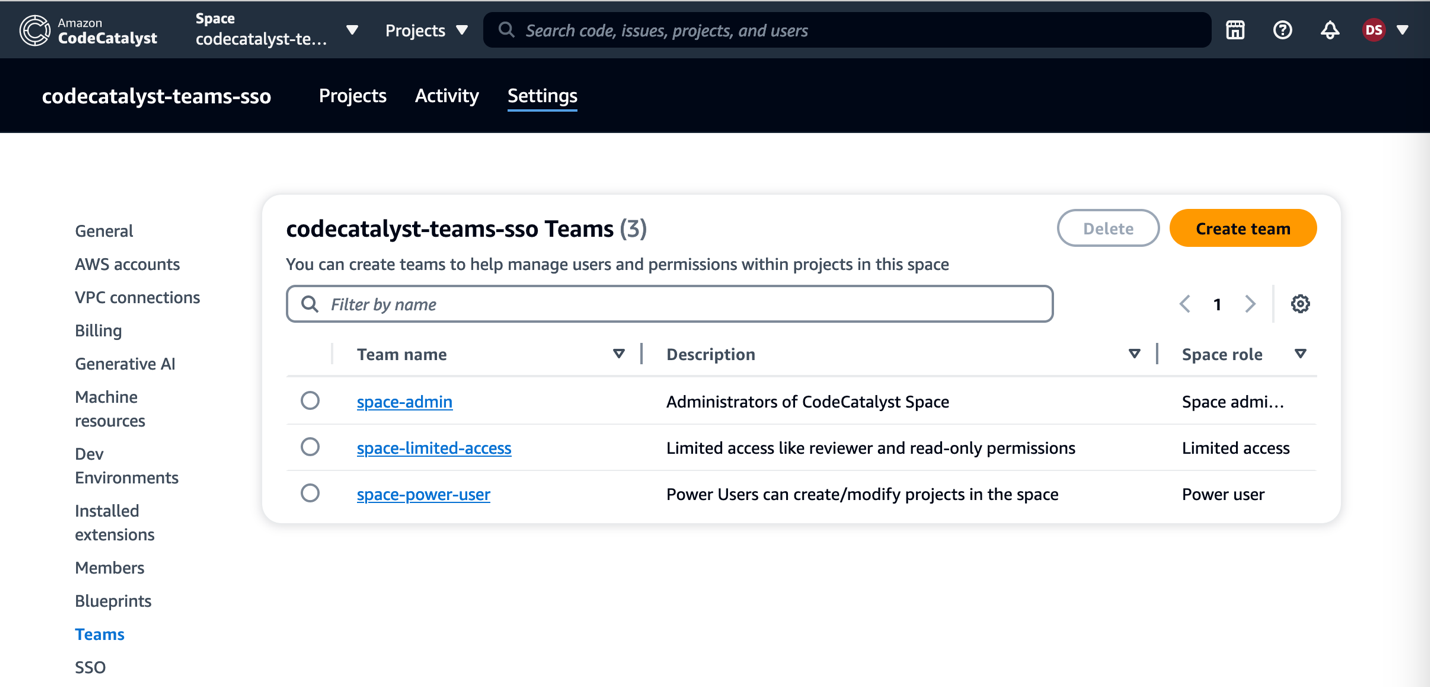
Figure 6: Managing Teams in CodeCatalyst Space
In this example here, if I go into the ‘space-admin’ team, I can view the SSO group associated with it through IAM Identity Center.
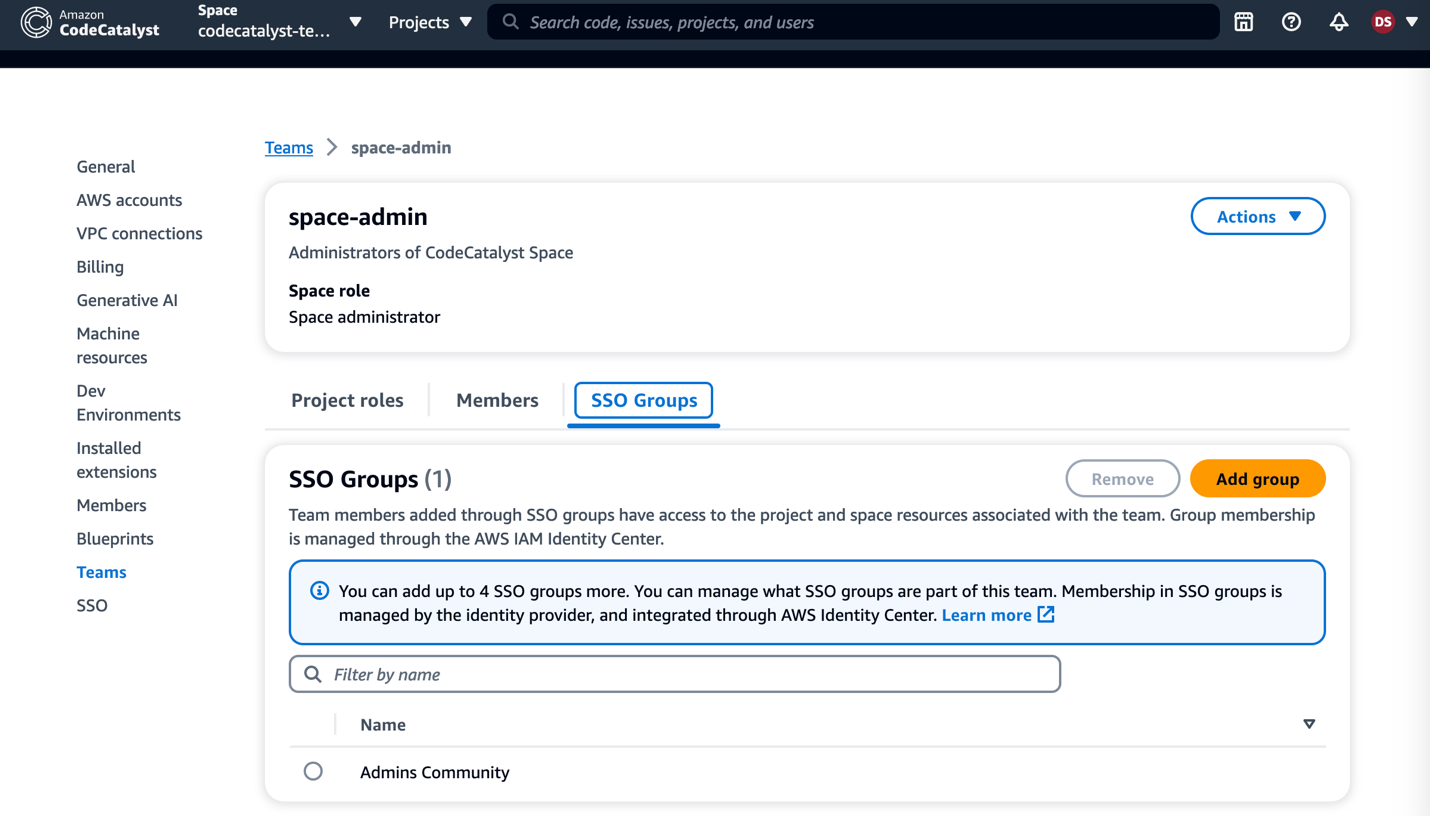
Figure 7: SSO Group association with Teams
You can now use these teams from the CodeCatalyst space to help manage users and permissions for the projects in that space. There are four project roles available in CodeCatalyst:
For the purpose of this demonstration, I have created projects from the default blueprints (I chose the modern three-tier web application blueprint) and assigned Teams to it with specific roles. You can also create a project using a default blueprint in CodeCatalyst space if you don’t already have an existing project.
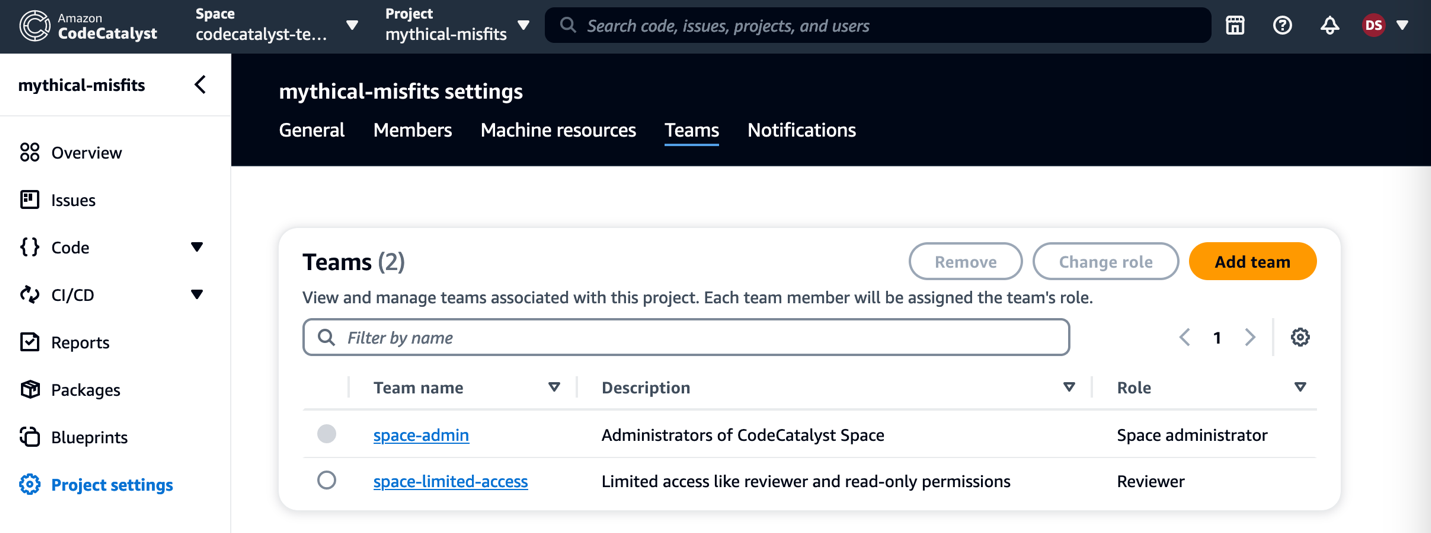
Figure 8: Teams in Project Settings
You can also view the roles assigned to each of the teams in the CodeCatalyst Space settings.
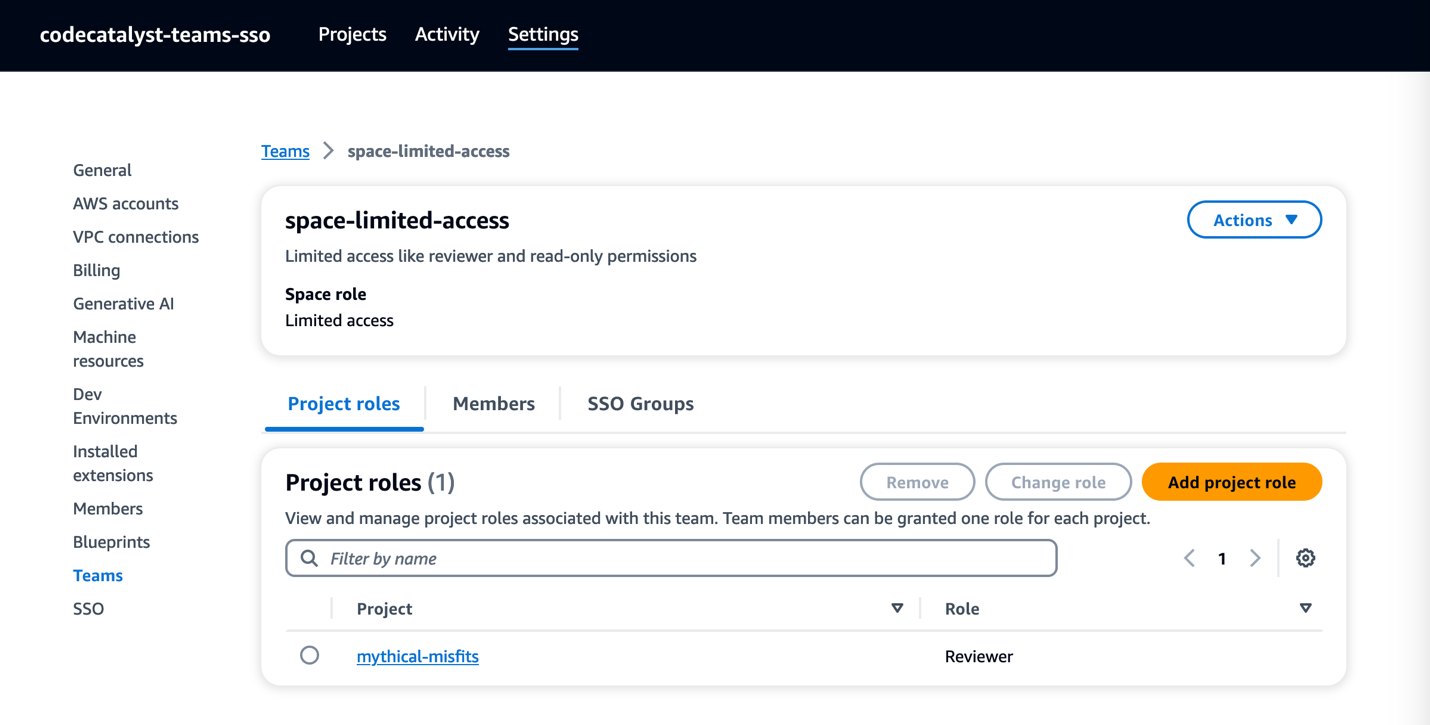
Figure 9: Project roles in Space settings
If you have been following along with this workflow, you should delete the resources you deployed so you do not continue to incur charges. First, delete the two stacks that CDK deployed using the AWS CloudFormation console in the AWS account you associated when you launched the blueprint. If you had launched the Modern three-tier web application just like I did, these stacks will have names like mysfitsXXXXXWebStack and mysfitsXXXXXAppStack. Second, delete the project from CodeCatalyst by navigating to Project settings and choosing Delete project.
In this post, you learned how to add Teams to a CodeCatalyst space and projects using SSO Groups. I used Okta for my external identity provider to connect with IAM Identity Center, but you can use your Organizations idP or any other IDP that supports SAML. You also learned how easy it is to maintain SSO group members in the CodeCatalyst space by assigning the necessary roles and restricting access when not necessary.
Post Syndicated from corbet original https://lwn.net/Articles/976211/
The developers of the Krita painting
application are celebrating
25 years of development with a detailed history of the project.
A quarter century. That’s how long we’ve been working on
Krita. Well, what would become Krita. It started out as KImageShop,
but that name was nuked by a now long-dead German lawyer. Then it
was renamed to Krayon, and that name was also nuked. Then it was
renamed to Krita, and that name stuck.