Post Syndicated from George Komninos original https://aws.amazon.com/blogs/big-data/how-to-delete-user-data-in-an-aws-data-lake/
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution to delete specific users’ personal data.
In the context of the AWS big data and analytics ecosystem, every architecture, regardless of the problem it targets, uses Amazon Simple Storage Service (Amazon S3) as the core storage service. Despite its versatility and feature completeness, Amazon S3 doesn’t come with an out-of-the-box way to map a user identifier to S3 keys of objects that contain user’s data.
This post walks you through a framework that helps you purge individual user data within your organization’s AWS hosted data lake, and an analytics solution that uses different AWS storage layers, along with sample code targeting Amazon S3.
Reference architecture
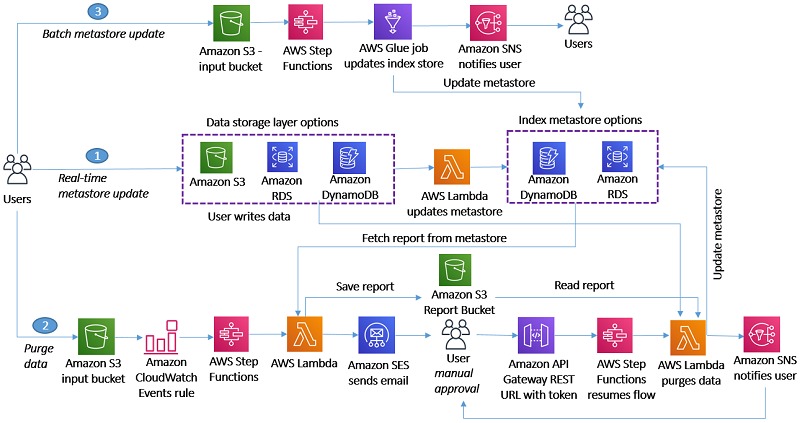
To address the challenge of implementing a data purge framework, we reduced the problem to the straightforward use case of deleting a user’s data from a platform that uses AWS for its data pipeline. The following diagram illustrates this use case.

We’re introducing the idea of building and maintaining an index metastore that keeps track of the location of each user’s records and allows us locate to them efficiently, reducing the search space.
You can use the following architecture diagram to delete a specific user’s data within your organization’s AWS data lake.

For this initial version, we created three user flows that map each task to a fitting AWS service:
Flow 1: Real-time metastore update
The S3 ObjectCreated or ObjectDelete events trigger an AWS Lambda function that parses the object and performs an add/update/delete operation to keep the metadata index up to date. You can implement a simple workflow for any other storage layer, such as Amazon Relational Database Service (RDS), Amazon Aurora, or Amazon Elasticsearch Service (ES). We use Amazon DynamoDB and Amazon RDS for PostgreSQL as the index metadata storage options, but our approach is flexible to any other technology.
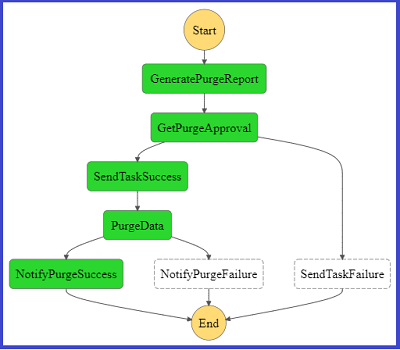
Flow 2: Purge data
When a user asks for their data to be deleted, we trigger an AWS Step Functions state machine through Amazon CloudWatch to orchestrate the workflow. Its first step triggers a Lambda function that queries the metadata index to identify the storage layers that contain user records and generates a report that’s saved to an S3 report bucket. A Step Functions activity is created and picked up by a Lambda Node JS based worker that sends an email to the approver through Amazon Simple Email Service (SES) with approve and reject links.
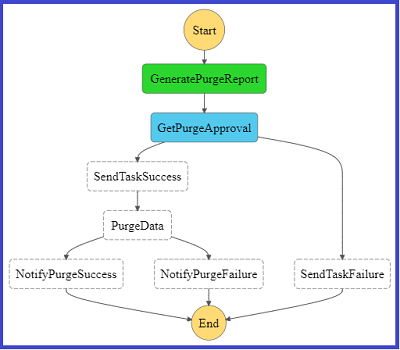
The following diagram shows a graphical representation of the Step Function state machine as seen on the AWS Management Console.

The approver selects one of the two links, which then calls an Amazon API Gateway endpoint that invokes Step Functions to resume the workflow. If you choose the approve link, Step Functions triggers a Lambda function that takes the report stored in the bucket as input, deletes the objects or records from the storage layer, and updates the index metastore. When the purging job is complete, Amazon Simple Notification Service (SNS) sends a success or fail email to the user.
The following diagram represents the Step Functions flow on the console if the purge flow completed successfully.
For the complete code base, see step-function-definition.json in the GitHub repo.
Flow 3: Batch metastore update
This flow refers to the use case of an existing data lake for which index metastore needs to be created. You can orchestrate the flow through AWS Step Functions, which takes historical data as input and updates metastore through a batch job. Our current implementation doesn’t include a sample script for this user flow.
Our framework
We now walk you through the two use cases we followed for our implementation:
- You have multiple user records stored in each Amazon S3 file
- A user has records stored in homogenous AWS storage layers
Within these two approaches, we demonstrate alternatives that you can use to store your index metastore.
Indexing by S3 URI and row number
For this use case, we use a free tier RDS Postgres instance to store our index. We created a simple table with the following code:
CREATE UNLOGGED TABLE IF NOT EXISTS user_objects (
userid TEXT,
s3path TEXT,
recordline INTEGER
);
You can index on user_id to optimize query performance. On object upload, for each row, you need to insert into the user_objects table a row that indicates the user ID, the URI of the target Amazon S3 object, and the row that corresponds to the record. For instance, when uploading the following JSON input, enter the following code:
{"user_id":"V34qejxNsCbcgD8C0HVk-Q","body":"…"}
{"user_id":"ofKDkJKXSKZXu5xJNGiiBQ","body":"…"}
{"user_id":"UgMW8bLE0QMJDCkQ1Ax5Mg","body ":"…"}
We insert the tuples into user_objects in the Amazon S3 location s3://gdpr-demo/year=2018/month=2/day=26/input.json. See the following code:
(“V34qejxNsCbcgD8C0HVk-Q”, “s3://gdpr-demo/year=2018/month=2/day=26/input.json”, 0)
(“ofKDkJKXSKZXu5xJNGiiBQ”, “s3://gdpr-demo/year=2018/month=2/day=26/input.json”, 1)
(“UgMW8bLE0QMJDCkQ1Ax5Mg”, “s3://gdpr-demo/year=2018/month=2/day=26/input.json”, 2)
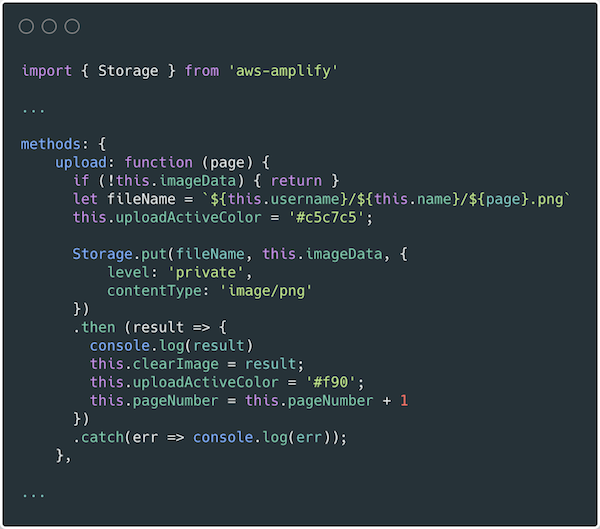
You can implement the index update operation by using a Lambda function triggered on any Amazon S3 ObjectCreated event.
When we get a delete request from a user, we need to query our index to get some information about where we have stored the data to delete. See the following code:
SELECT s3path,
ARRAY_AGG(recordline)
FROM user_objects
WHERE userid = ‘V34qejxNsCbcgD8C0HVk-Q’
GROUP BY;
The preceding example SQL query returns rows like the following:
(“s3://gdpr-review/year=2015/month=12/day=21/review-part-0.json“, {2102,529})
The output indicates that lines 529 and 2102 of S3 object s3://gdpr-review/year=2015/month=12/day=21/review-part-0.json contain the requested user’s data and need to be purged. We then need to download the object, remove those rows, and overwrite the object. For a Python implementation of the Lambda function that implements this functionality, see deleteUserRecords.py in the GitHub repo.
Having the record line available allows you to perform the deletion efficiently in byte format. For implementation simplicity, we purge the rows by replacing the deleted rows with an empty JSON object. You pay a slight storage overhead, but you don’t need to update subsequent row metadata in your index, which would be costly. To eliminate empty JSON objects, we can implement an offline vacuum and index update process.
Indexing by file name and grouping by index key
For this use case, we created a DynamoDB table to store our index. We chose DynamoDB because of its ease of use and scalability; you can use its on-demand pricing model so you don’t need to guess how many capacity units you might need. When files are uploaded to the data lake, a Lambda function parses the file name (for example, 1001-.csv) to identify the user identifier and populates the DynamoDB metadata table. Userid is the partition key, and each different storage layer has its own attribute. For example, if user 1001 had data in Amazon S3 and Amazon RDS, their records look like the following code:
{"userid:": 1001, "s3":{"s3://path1", "s3://path2"}, "RDS":{"db1.table1.column1"}}
For a sample Python implementation of this functionality, see update-dynamo-metadata.py in the GitHub repo.
On delete request, we query the metastore table, which is DynamoDB, and generate a purge report that contains details on what storage layers contain user records, and storage layer specifics that can speed up locating the records. We store the purge report to Amazon S3. For a sample Lambda function that implements this logic, see generate-purge-report.py in the GitHub repo.
After the purging is approved, we use the report as input to delete the required resources. For a sample Lambda function implementation, see gdpr-purge-data.py in the GitHub repo.
Implementation and technology alternatives
We explored and evaluated multiple implementation options, all of which present tradeoffs, such as implementation simplicity, efficiency, critical data compliance, and feature completeness:
- Scan every record of the data file to create an index – Whenever a file is uploaded, we iterate through its records and generate tuples (
userid, s3Uri, row_number) that are then inserted to our metadata storing layer. On delete request, we fetch the metadata records for requested user IDs, download the corresponding S3 objects, perform the delete in place, and re-upload the updated objects, overwriting the existing object. This is the most flexible approach because it supports a single object to store multiple users’ data, which is a very common practice. The flexibility comes at a cost because it requires downloading and re-uploading the object, which introduces a network bottleneck in delete operations. User activity datasets such as customer product reviews are a good fit for this approach, because it’s unexpected to have multiple records for the same user within each partition (such as a date partition), and it’s preferable to combine multiple users’ activity in a single file. It’s similar to what was described in the section “Indexing by S3 URI and row number” and sample code is available in the GitHub repo.
- Store metadata as file name prefix – Adding the user ID as the prefix of the uploaded object under the different partitions that are defined based on query pattern enables you to reduce the required search operations on delete request. The metadata handling utility finds the user ID from the file name and maintains the index accordingly. This approach is efficient in locating the resources to purge but assumes a single user per object, and requires you to store user IDs within the filename, which might require InfoSec considerations. Clickstream data, where you would expect to have multiple click events for a single customer on a single date partition during a session, is a good fit. We covered this approach in the section “Indexing by file name and grouping by index key” and you can download the codebase from the GitHub repo.
- Use a metadata file – Along with uploading a new object, we also upload a metadata file that’s picked up by an indexing utility to create and maintain the index up to date. On delete request, we query the index, which points us to the records to purge. A good fit for this approach is a use case that already involves uploading a metadata file whenever a new object is uploaded, such as uploading multimedia data, along with their metadata. Otherwise, uploading a metadata file on every object upload might introduce too much of an overhead.
- Use the tagging feature of AWS services – Whenever a new file is uploaded to Amazon S3, we use the Put Object Tagging Amazon S3 operation to add a key-value pair for the user identifier. Whenever there is a user data delete request, it fetches objects with that tag and deletes them. This option is straightforward to implement using the existing Amazon S3 API and can therefore be a very initial version of your implementation. However, it involves significant limitations. It assumes a 1:1 cardinality between Amazon S3 objects and users (each object only contains data for a single user), searching objects based on a tag is limited and inefficient, and storing user identifiers as tags might not be compliant with your organization’s InfoSec policy.
- Use Apache Hudi – Apache Hudi is becoming a very popular option to perform record-level data deletion on Amazon S3. Its current version is restricted to Amazon EMR, and you can use it if you start to build your data lake from scratch, because you need to store your as Hudi datasets. Hudi is a very active project and additional features and integrations with more AWS services are expected.
The key implementation decision of our approach is separating the storage layer we use for our data and the one we use for our metadata. As a result, our design is versatile and can be plugged in any existing data pipeline. Similar to deciding what storage layer to use for your data, there are many factors to consider when deciding how to store your index:
- Concurrency of requests – If you don’t expect too many simultaneous inserts, even something as simple as Amazon S3 could be a starting point for your index. However, if you get multiple concurrent writes for multiple users, you need to look into a service that copes better with transactions.
- Existing team knowledge and infrastructure – In this post, we demonstrated using DynamoDB and RDS Postgres for storing and querying the metadata index. If your team has no experience with either of those but are comfortable with Amazon ES, Amazon DocumentDB (with MongoDB compatibility), or any other storage layer, use those. Furthermore, if you’re already running (and paying for) a MySQL database that’s not used to capacity, you could use that for your index for no additional cost.
- Size of index – The volume of your metadata is orders of magnitude lower than your actual data. However, if your dataset grows significantly, you might need to consider going for a scalable, distributed storage solution rather than, for instance, a relational database management system.
Conclusion
GDPR has transformed best practices and introduced several extra technical challenges in designing and implementing a data lake. The reference architecture and scripts in this post may help you delete data in a manner that’s compliant with GDPR.
Let us know your feedback in the comments and how you implemented this solution in your organization, so that others can learn from it.
About the Authors
 George Komninos is a Data Lab Solutions Architect at AWS. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent 3 years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus.
George Komninos is a Data Lab Solutions Architect at AWS. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent 3 years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus.
 Sakti Mishra is a Data Lab Solutions Architect at AWS. He helps customers architect data analytics solutions, which gives them an accelerated path towards modernization initiatives. Outside of work, Sakti enjoys learning new technologies, watching movies, and travel.
Sakti Mishra is a Data Lab Solutions Architect at AWS. He helps customers architect data analytics solutions, which gives them an accelerated path towards modernization initiatives. Outside of work, Sakti enjoys learning new technologies, watching movies, and travel.

 George Komninos is a Data Lab Solutions Architect at AWS. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent 3 years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus.
George Komninos is a Data Lab Solutions Architect at AWS. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent 3 years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus. Sakti Mishra is a Data Lab Solutions Architect at AWS. He helps customers architect data analytics solutions, which gives them an accelerated path towards modernization initiatives. Outside of work, Sakti enjoys learning new technologies, watching movies, and travel.
Sakti Mishra is a Data Lab Solutions Architect at AWS. He helps customers architect data analytics solutions, which gives them an accelerated path towards modernization initiatives. Outside of work, Sakti enjoys learning new technologies, watching movies, and travel.










 Mahesh Goyal is a Data Architect in Big Data at AWS. He works with customers in their journey to the cloud with a focus on big data and data warehouses. In his spare time, Mahesh likes to listen to music and explore new food places with his family.
Mahesh Goyal is a Data Architect in Big Data at AWS. He works with customers in their journey to the cloud with a focus on big data and data warehouses. In his spare time, Mahesh likes to listen to music and explore new food places with his family. Charishma Makineni is a Technical Account Manager at AWS. She works with enterprise customers to help them build secure and scalable solutions on the AWS cloud. She is focused on Big data and Analytics technologies. Outside of work, Charishma enjoys being outdoors, gardening and experimenting with cooking.
Charishma Makineni is a Technical Account Manager at AWS. She works with enterprise customers to help them build secure and scalable solutions on the AWS cloud. She is focused on Big data and Analytics technologies. Outside of work, Charishma enjoys being outdoors, gardening and experimenting with cooking. Suresh Patnam is a Solutions Architect at AWS. He helps customers innovate on the AWS platform by building highly available, scalable, and secure architectures on Big Data and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family.
Suresh Patnam is a Solutions Architect at AWS. He helps customers innovate on the AWS platform by building highly available, scalable, and secure architectures on Big Data and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family.
































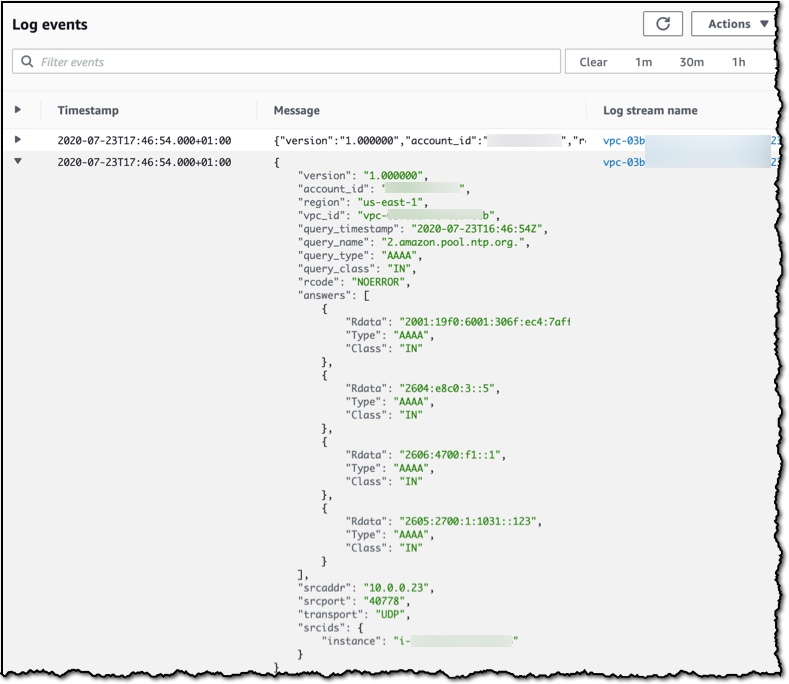
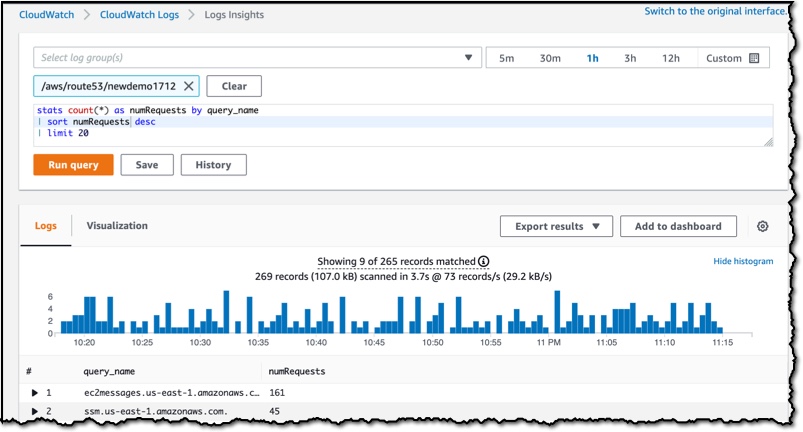
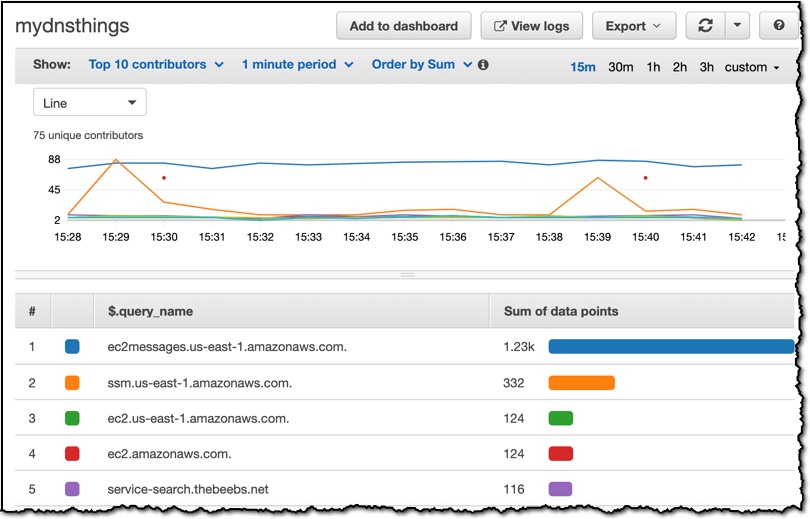 Route 53 Resolver Query Logs is available in all AWS Commercial Regions that support Route 53 Resolver Endpoints, and you can get started using either the API or the AWS Console. You do not pay for the Route 53 Resolver Query Logs, but you will pay for handling the logs in the destination service that you choose. So, for example, if you decided to use
Route 53 Resolver Query Logs is available in all AWS Commercial Regions that support Route 53 Resolver Endpoints, and you can get started using either the API or the AWS Console. You do not pay for the Route 53 Resolver Query Logs, but you will pay for handling the logs in the destination service that you choose. So, for example, if you decided to use