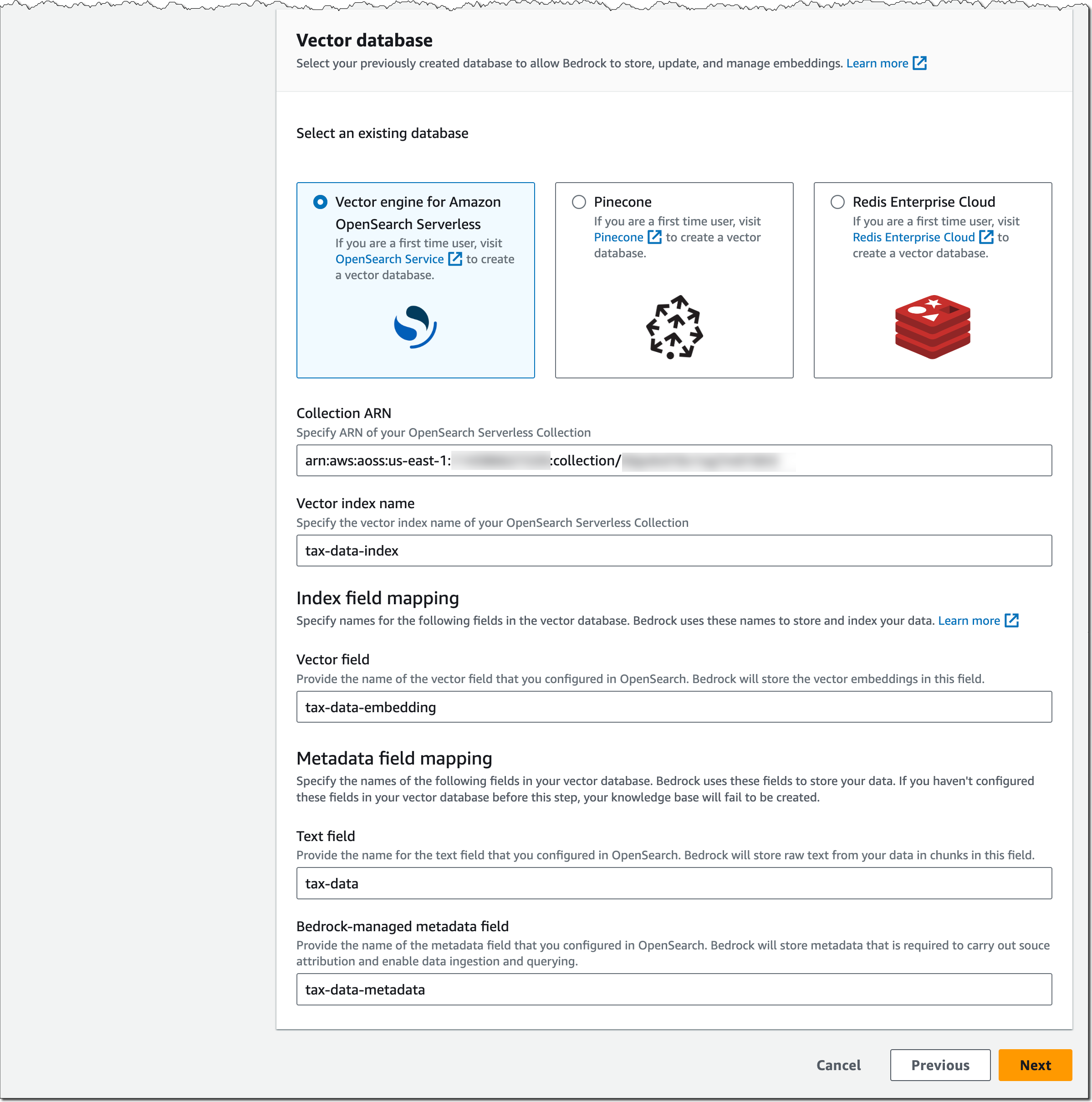
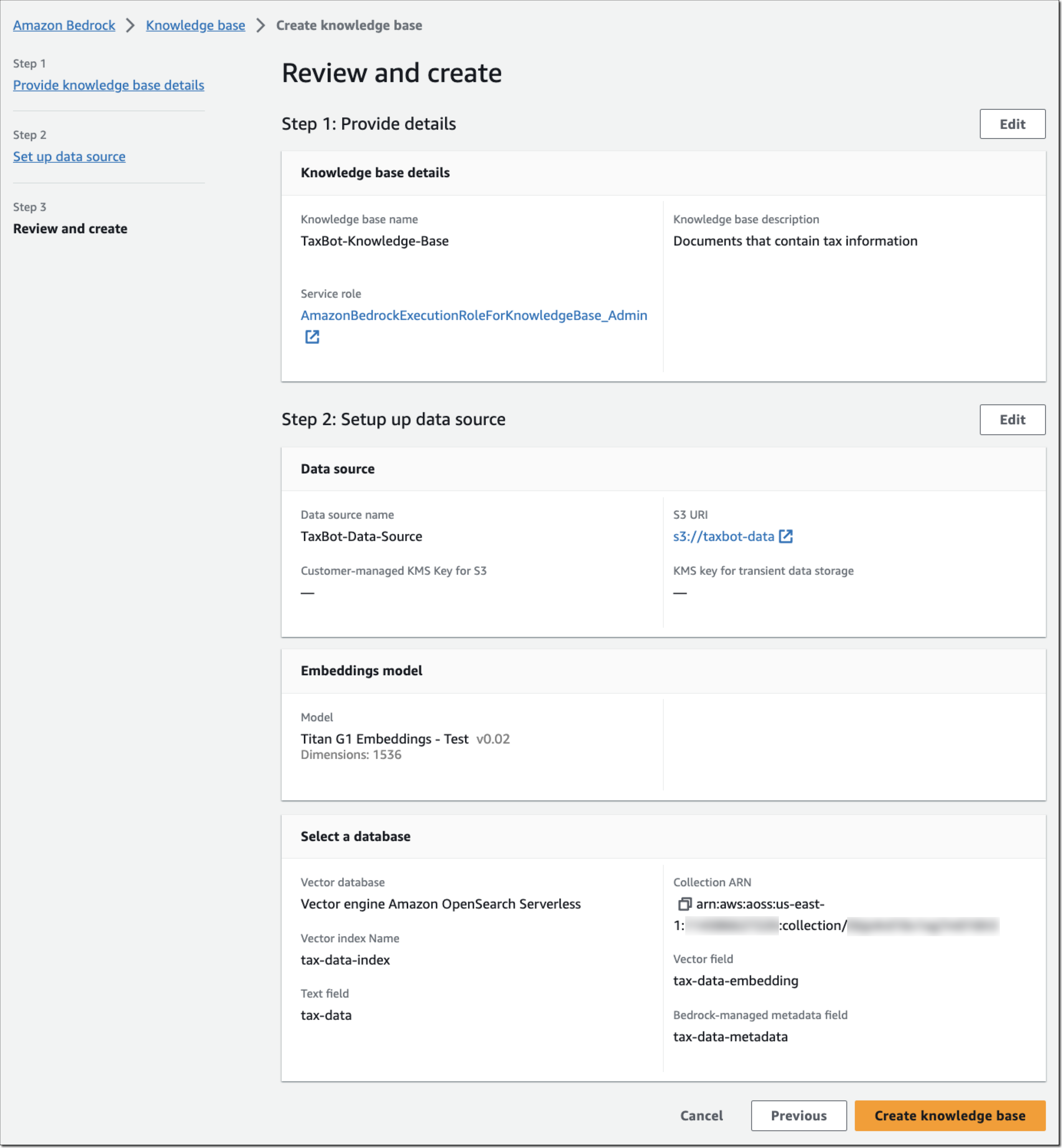
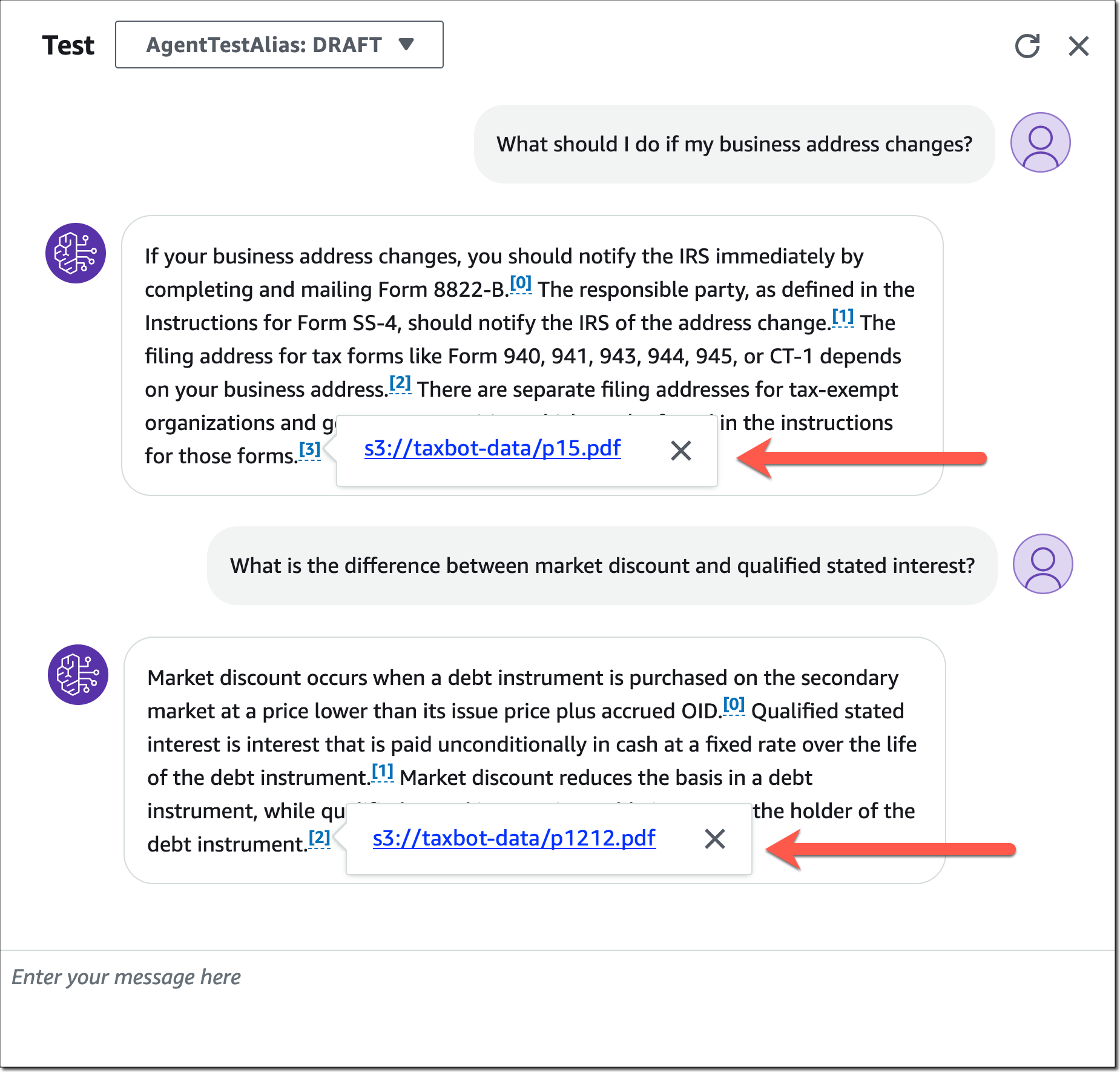
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/10/political-disinformation-and-ai.html
Elections around the world are facing an evolving threat from foreign actors, one that involves artificial intelligence.
Countries trying to influence each other’s elections entered a new era in 2016, when the Russians launched a series of social media disinformation campaigns targeting the US presidential election. Over the next seven years, a number of countries—most prominently China and Iran—used social media to influence foreign elections, both in the US and elsewhere in the world. There’s no reason to expect 2023 and 2024 to be any different.
But there is a new element: generative AI and large language models. These have the ability to quickly and easily produce endless reams of text on any topic in any tone from any perspective. As a security expert, I believe it’s a tool uniquely suited to Internet-era propaganda.
This is all very new. ChatGPT was introduced in November 2022. The more powerful GPT-4 was released in March 2023. Other language and image production AIs are around the same age. It’s not clear how these technologies will change disinformation, how effective they will be or what effects they will have. But we are about to find out.
Election season will soon be in full swing in much of the democratic world. Seventy-one percent of people living in democracies will vote in a national election between now and the end of next year. Among them: Argentina and Poland in October, Taiwan in January, Indonesia in February, India in April, the European Union and Mexico in June, and the US in November. Nine African democracies, including South Africa, will have elections in 2024. Australia and the UK don’t have fixed dates, but elections are likely to occur in 2024.
Many of those elections matter a lot to the countries that have run social media influence operations in the past. China cares a great deal about Taiwan, Indonesia, India, and many African countries. Russia cares about the UK, Poland, Germany, and the EU in general. Everyone cares about the United States.
And that’s only considering the largest players. Every US national election from 2016 has brought with it an additional country attempting to influence the outcome. First it was just Russia, then Russia and China, and most recently those two plus Iran. As the financial cost of foreign influence decreases, more countries can get in on the action. Tools like ChatGPT significantly reduce the price of producing and distributing propaganda, bringing that capability within the budget of many more countries.
A couple of months ago, I attended a conference with representatives from all of the cybersecurity agencies in the US. They talked about their expectations regarding election interference in 2024. They expected the usual players—Russia, China, and Iran—and a significant new one: “domestic actors.” That is a direct result of this reduced cost.
Of course, there’s a lot more to running a disinformation campaign than generating content. The hard part is distribution. A propagandist needs a series of fake accounts on which to post, and others to boost it into the mainstream where it can go viral. Companies like Meta have gotten much better at identifying these accounts and taking them down. Just last month, Meta announced that it had removed 7,704 Facebook accounts, 954 Facebook pages, 15 Facebook groups, and 15 Instagram accounts associated with a Chinese influence campaign, and identified hundreds more accounts on TikTok, X (formerly Twitter), LiveJournal, and Blogspot. But that was a campaign that began four years ago, producing pre-AI disinformation.
Disinformation is an arms race. Both the attackers and defenders have improved, but also the world of social media is different. Four years ago, Twitter was a direct line to the media, and propaganda on that platform was a way to tilt the political narrative. A Columbia Journalism Review study found that most major news outlets used Russian tweets as sources for partisan opinion. That Twitter, with virtually every news editor reading it and everyone who was anyone posting there, is no more.
Many propaganda outlets moved from Facebook to messaging platforms such as Telegram and WhatsApp, which makes them harder to identify and remove. TikTok is a newer platform that is controlled by China and more suitable for short, provocative videos—ones that AI makes much easier to produce. And the current crop of generative AIs are being connected to tools that will make content distribution easier as well.
Generative AI tools also allow for new techniques of production and distribution, such as low-level propaganda at scale. Imagine a new AI-powered personal account on social media. For the most part, it behaves normally. It posts about its fake everyday life, joins interest groups and comments on others’ posts, and generally behaves like a normal user. And once in a while, not very often, it says—or amplifies—something political. These persona bots, as computer scientist Latanya Sweeney calls them, have negligible influence on their own. But replicated by the thousands or millions, they would have a lot more.
That’s just one scenario. The military officers in Russia, China, and elsewhere in charge of election interference are likely to have their best people thinking of others. And their tactics are likely to be much more sophisticated than they were in 2016.
Countries like Russia and China have a history of testing both cyberattacks and information operations on smaller countries before rolling them out at scale. When that happens, it’s important to be able to fingerprint these tactics. Countering new disinformation campaigns requires being able to recognize them, and recognizing them requires looking for and cataloging them now.
In the computer security world, researchers recognize that sharing methods of attack and their effectiveness is the only way to build strong defensive systems. The same kind of thinking also applies to these information campaigns: The more that researchers study what techniques are being employed in distant countries, the better they can defend their own countries.
Disinformation campaigns in the AI era are likely to be much more sophisticated than they were in 2016. I believe the US needs to have efforts in place to fingerprint and identify AI-produced propaganda in Taiwan, where a presidential candidate claims a deepfake audio recording has defamed him, and other places. Otherwise, we’re not going to see them when they arrive here. Unfortunately, researchers are instead being targeted and harassed.
Maybe this will all turn out okay. There have been some important democratic elections in the generative AI era with no significant disinformation issues: primaries in Argentina, first-round elections in Ecuador, and national elections in Thailand, Turkey, Spain, and Greece. But the sooner we know what to expect, the better we can deal with what comes.
This essay previously appeared in The Conversation.














 Lastly, we published a new ebook titled “
Lastly, we published a new ebook titled “