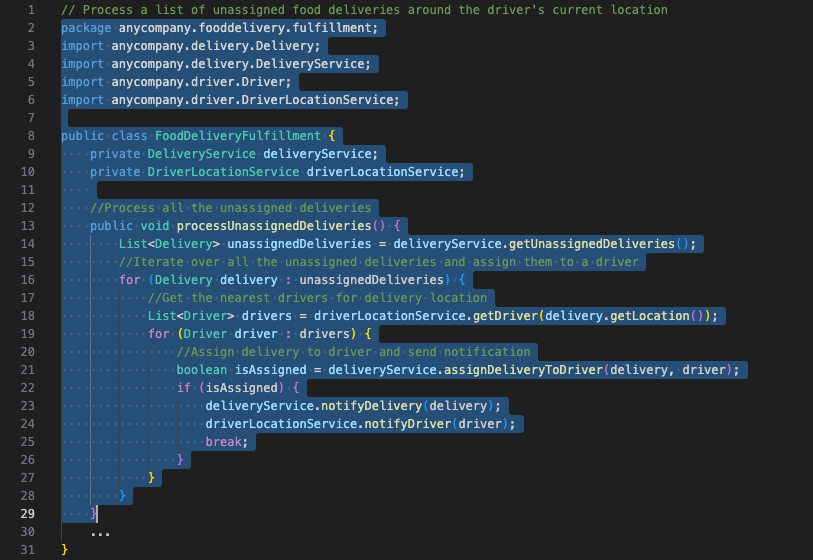
Today we are announcing two new optimized integrations for AWS Step Functions with Amazon Bedrock. Step Functions is a visual workflow service that helps developers build distributed applications, automate processes, orchestrate microservices, and create data and machine learning (ML) pipelines.
In September, we made available Amazon Bedrock, the easiest way to build and scale generative artificial intelligence (AI) applications with foundation models (FMs). Bedrock offers a choice of foundation models from leading providers like AI21 Labs, Anthropic, Cohere, Stability AI, and Amazon, along with a broad set of capabilities that customers need to build generative AI applications, while maintaining privacy and security. You can use Amazon Bedrock from the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS SDKs.
The new Step Functions optimized integrations with Amazon Bedrock allow you to orchestrate tasks to build generative AI applications using Amazon Bedrock, as well as to integrate with over 220 AWS services. With Step Functions, you can visually develop, inspect, and audit your workflows. Previously, you needed to invoke an AWS Lambda function to use Amazon Bedrock from your workflows, adding more code to maintain them and increasing the costs of your applications.
Step Functions provides two new optimized API actions for Amazon Bedrock:
InvokeModel – This integration allows you to invoke a model and run the inferences with the input provided in the parameters. Use this API action to run inferences for text, image, and embedding models.
CreateModelCustomizationJob – This integration creates a fine-tuning job to customize a base model. In the parameters, you specify the foundation model and the location of the training data. When the job is completed, your custom model is ready to be used. This is an asynchronous API, and this integration allows Step Functions to run a job and wait for it to complete before proceeding to the next state. This means that the state machine execution will pause while the create model customization job is running and will resume automatically when the task is complete.
The InvokeModel API action accepts requests and responses that are up to 25 MB. However, Step Functions has a 256 kB limit on state payload input and output. In order to support larger payloads with this integration, you can define an Amazon Simple Storage Service (Amazon S3) bucket where the InvokeModel API reads data from and writes the result to. These configurations can be provided in the parameters section of the API action configuration parameters section.
How to get started with Amazon Bedrock and AWS Step Functions Before getting started, ensure that you create the state machine in a Region where Amazon Bedrock is available. For this example, use US East (N. Virginia), us-east-1.
From the AWS Management Console, create a new state machine. Search for “bedrock,” and the two available API actions will appear. Drag the InvokeModel to the state machine.
You can now configure that state in the menu on the right. First, you can define which foundation model you want to use. Pick a model from the list, or get the model dynamically from the input.
Then you need to configure the model parameters. You can enter the inference parameters in the text box or load the parameters from Amazon S3.
If you keep scrolling in the API action configuration, you can specify additional configuration options for the API, such as the S3 destination bucket. When this field is specified, the API action stores the API response in the specified bucket instead of returning it to the state output. Here, you can also specify the content type for the requests and responses.
When you finish configuring your state machine, you can create and run it. When the state machine runs, you can visualize the execution details, select the Amazon Bedrock state, and check its inputs and outputs.
Using Step Functions, you can build state machines as extensively as you need, combining different services to solve many problems. For example, you can use Step Functions with Amazon Bedrock to create applications using prompt chaining. This is a technique for building complex generative AI applications by passing multiple smaller and simpler prompts to the FM instead of a very long and detailed prompt. To build a prompt chain, you can create a state machine that calls Amazon Bedrock multiple times to get an inference for each of the smaller prompts. You can use the parallel state to run all these tasks in parallel and then use an AWS Lambda function that unifies the responses of the parallel tasks into one response and generates a result.
Available now AWS Step Functions optimized integrations for Amazon Bedrock are limited to the AWS Regions where Amazon Bedrock is available.
You can get started with Step Functions and Amazon Bedrock by trying out a sample project from the Step Functions console.
Generative AI is going to be a powerful tool for data analysis and summarization. Here’s an example of it being used for sentiment analysis. My guess is that it isn’t very good yet, but that it will get better.
This post by Art Baudo – Principal Product Marketing Manager – AWS EC2, and Pranaya Anshu – Product Marketing Manager – AWS EC2
We are just a few weeks away from AWS re:Invent 2023, AWS’s biggest cloud computing event of the year. This event will be a great opportunity for you to meet other cloud enthusiasts, find productive solutions that can transform your company, and learn new skills through 2000+ learning sessions.
Even if you are not able to join in person, you can catch-up with many of the sessions on-demand and even watch the keynote and innovation sessions live.
If you’re able to join us, just a reminder we offer several types of sessions which can help maximize your learning in a variety of AWS topics. Breakout sessions are lecture-style 60-minute informative sessions presented by AWS experts, customers, or partners. These sessions are recorded and uploaded a few days after to the AWS Events YouTube channel.
re:Invent attendees can also choose to attend chalk-talks, builder sessions, workshops, or code talk sessions. Each of these are live non-recorded interactive sessions.
Chalk-talk sessions: Attendees will interact with presenters, asking questions and using a whiteboard in session.
Builder Sessions: Attendees participate in a one-hour session and build something.
Workshops sessions: Attendees join a two-hour interactive session where they work in a small team to solve a real problem using AWS services.
Code talk sessions: Attendees participate in engaging code-focused sessions where an expert leads a live coding session.
To start planning your re:Invent week, check-out some of the Compute track sessions below. If you find a session you’re interested in, be sure to reserve your seat for it through the AWS attendee portal.
Explore some of these latest and greatest innovations in the following sessions:
CMP102 | What’s new with Amazon EC2 Provides an overview on the latest Amazon EC2 innovations. Hear about recent Amazon EC2 launches, learn how about differences between Amazon EC2 instances families, and how you can use a mix of instances to deliver on your cost, performance, and sustainability goals.
CMP219-INT | Compute innovation for any application, anywhere Provides you with an understanding of the breadth and depth of AWS compute offerings and innovation. Discover how you can run any application, including enterprise applications, HPC, generative artificial intelligence (AI), containers, databases, and games, on AWS.
Customer experiences and applications with machine learning
Machine learning (ML) has been evolving for decades and has an inflection point with generative AI applications capturing widespread attention and imagination. More customers, across a diverse set of industries, choose AWS compared to any other major cloud provider to build, train, and deploy their ML applications. Learn about the generative AI infrastructure at Amazon or get hands-on experience building ML applications through our ML focused sessions, such as the following:
CMP206 | Behind-the-scenes look at generative AI infrastructure at Amazon Learn how to power performant generative AI applications while keeping costs under control. Get a behind-the-scenes look at how purpose-built infrastructure from AWS including AWS Trainium and AWS Inferentia2 are used by Amazon teams.
AWS has invested years designing custom silicon optimized for the cloud to deliver the best price performance for a wide range of applications and workloads using AWS services. Learn more about the AWS Nitro System, processors at AWS, and ML chips.
CMP309 | Compute innovations enabled by the AWS Nitro System Deep dive in to the AWS Nitro System, the underlying platform for modern EC2 instances, the Nitro System, which has allowed AWS to innovate faster, further reduce your costs, and deliver increased security.
At AWS, we focus on delivering the best possible cost structure for our customers. Frugality is one of our founding leadership principles. Cost effective design continues to shape everything we do, from how we develop products to how we run our operations. Come learn of new ways to optimize your compute costs through AWS services, tools, and optimization strategies in the following sessions:
CMP207 | Capacity, availability, cost efficiency: Pick three Use AWS strategies such as using attribute-based instance type selection, prioritizing operational flexibility, and Amazon EC2 Flex instances to help you get compute resources, when you need them, while keeping cost under control.
Amazon EC2 offers the broadest and deepest compute platform to help you best match the needs of your workload. More SAP, high performance computing (HPC), ML, and Windows workloads run on AWS than any other cloud. Join sessions focused around your specific workload to learn about how you can leverage AWS solutions to accelerate your innovations.
CMP203 | Scaling SAP HANA workloads on AWS Discover how AWS SAP HANA customers benefit from the flexibility and reliability of the AWS Cloud. learn how you can migrate your mission-critical SAP HANA workloads.
CMP213 | Confidently run your production HPC workloads on AWS Explore the HPC portfolio of services and products available in the AWS Cloud. Learn how customers can scale simulations and modeling and other memory- and data-intensive technical workloads.
CMP318 | Build a spatial data lake with Visual Asset Management System Get a hands-on look at how to use the open source Visual Asset Management System (VAMS), built by AWS, to deploy a foundation for spatial data lakes, helping business units better collaborate and use 3D data while avoiding redundancies.
AWS serves millions of customers of all sizes across thousands of use cases, every industry, and around the world. Hear customers dive into how AWS compute solutions have helped them transform their businesses.
CMP320 | Powering Peloton’s journey to personalization with AWS Learn how Peloton’s solution architecture and technology stack uses Amazon EC2, Amazon S3, and Amazon EKS to build and serve individualized class recommendations in real time with low latency for a great user experience.
Ready to unlock new possibilities?
The AWS Compute team looks forward to seeing you in Las Vegas. Come meet us at the Compute Booth in the Expo. And if you’re looking for more session recommendations, check-out additional re:Invent attendee guides curated by experts.
The Federal Trade Commission is running a competition “to foster breakthrough ideas on preventing, monitoring, and evaluating malicious voice cloning.”
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently.
Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine learning (ML) using open source frameworks such as Apache Spark, Apache Hive, and Presto. Amazon EMR is the best place to run Apache Spark. You can quickly and effortlessly create managed Spark clusters from the AWS Management Console, AWS Command Line Interface (AWS CLI), or Amazon EMR API. You can also use additional Amazon EMR features, including fast Amazon Simple Storage Service (Amazon S3) connectivity using the Amazon EMR File System (EMRFS), integration with the Amazon EC2 Spot market and the AWS Glue Data Catalog, and EMR Managed Scaling to add or remove instances from your cluster. Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks, and tools like Spark UI and YARN Timeline Service to simplify debugging.
To unlock the potential hidden within the data troves, it’s essential to go beyond traditional analytics. Enter generative AI, a cutting-edge technology that combines ML with creativity to generate human-like text, art, and even code. Amazon Bedrock is the most straightforward way to build and scale generative AI applications with foundation models (FMs). Amazon Bedrock is a fully managed service that makes FMs from Amazon and leading AI companies available through an API, so you can quickly experiment with a variety of FMs in the playground, and use a single API for inference regardless of the models you choose, giving you the flexibility to use FMs from different providers and keep up to date with the latest model versions with minimal code changes.
In this post, we explore how you can supercharge your data analytics with generative AI using Amazon EMR, Amazon Bedrock, and the pyspark-ai library. The pyspark-ai library is an English SDK for Apache Spark. It takes instructions in English language and compiles them into PySpark objects like DataFrames. This makes it straightforward to work with Spark, allowing you to focus on extracting value from your data.
Solution overview
The following diagram illustrates the architecture for using generative AI with Amazon EMR and Amazon Bedrock.
EMR Studio is a web-based IDE for fully managed Jupyter notebooks that run on EMR clusters. We interact with EMR Studio Workspaces connected to a running EMR cluster and run the notebook provided as part of this post. We use the New York City Taxi data to garner insights into various taxi rides taken by users. We ask the questions in natural language on top of the data loaded in Spark DataFrame. The pyspark-ai library then uses the Amazon Titan Text FM from Amazon Bedrock to create a SQL query based on the natural language question. The pyspark-ai library takes the SQL query, runs it using Spark SQL, and provides results back to the user.
In this solution, you can create and configure the required resources in your AWS account with an AWS CloudFormation template. The template creates the AWS Glue database and tables, S3 bucket, VPC, and other AWS Identity and Access Management (IAM) resources that are used in the solution.
The template is designed to demonstrate how to use EMR Studio with the pyspark-ai package and Amazon Bedrock, and is not intended for production use without modification. Additionally, the template uses the us-east-1 Region and may not work in other Regions without modification. The template creates resources that incur costs while they are in use. Follow the cleanup steps at the end of this post to delete the resources and avoid unnecessary charges.
Prerequisites
Before you launch the CloudFormation stack, ensure you have the following:
An AWS account that provides access to AWS services
An IAM user with an access key and secret key to configure the AWS CLI, and permissions to create an IAM role, IAM policies, and stacks in AWS CloudFormation
The Titan Text G1 – Express model is currently in preview, so you need to have preview access to use it as part of this post
Create resources with AWS CloudFormation
The CloudFormation creates the following AWS resources:
A VPC stack with private and public subnets to use with EMR Studio, route tables, and NAT gateway.
An EMR cluster with Python 3.9 installed. We are using a bootstrap action to install Python 3.9 and other relevant packages like pyspark-ai and Amazon Bedrock dependencies. (For more information, refer to the bootstrap script.)
An S3 bucket for the EMR Studio Workspace and notebook storage.
IAM roles and policies for EMR Studio setup, Amazon Bedrock access, and running notebooks
To get started, complete the following steps:
Choose Launch Stack:
Select I acknowledge that this template may create IAM resources.
The CloudFormation stack takes approximately 20–30 minutes to complete. You can monitor its progress on the AWS CloudFormation console. When its status reads CREATE_COMPLETE, your AWS account will have the resources necessary to implement this solution.
Create EMR Studio
Now you can create an EMR Studio and Workspace to work with the notebook code. Complete the following steps:
On the EMR Studio console, choose Create Studio.
Enter the Studio Name as GenAI-EMR-Studio and provide a description.
In the Networking and security section, specify the following:
For VPC, choose the VPC you created as part of the CloudFormation stack that you deployed. Get the VPC ID using the CloudFormation outputs for the VPCID key.
For Subnets, choose all four subnets.
For Security and access, select Custom security group.
For Cluster/endpoint security group, choose EMRSparkAI-Cluster-Endpoint-SG.
For Workspace security group, choose EMRSparkAI-Workspace-SG.
In the Studio service role section, specify the following:
For Authentication, select AWS Identity and Access Management (IAM).
For AWS IAM service role, choose EMRSparkAI-StudioServiceRole.
In the Workspace storage section, browse and choose the S3 bucket for storage starting with emr-sparkai-<account-id>.
Choose Create Studio.
When the EMR Studio is created, choose the link under Studio Access URL to access the Studio.
When you’re in the Studio, choose Create workspace.
Add emr-genai as the name for the Workspace and choose Create workspace.
When the Workspace is created, choose its name to launch the Workspace (make sure you’ve disabled any pop-up blockers).
Big data analytics using Apache Spark with Amazon EMR and generative AI
Now that we have completed the required setup, we can start performing big data analytics using Apache Spark with Amazon EMR and generative AI.
As a first step, we load a notebook that has the required code and examples to work with the use case. We use NY Taxi dataset, which contains details about taxi rides.
Download the notebook file NYTaxi.ipynb and upload it to your Workspace by choosing the upload icon.
After the notebook is imported, open the notebook and choose PySpark as the kernel.
PySpark AI by default uses OpenAI’s ChatGPT4.0 as the LLM model, but you can also plug in models from Amazon Bedrock, Amazon SageMaker JumpStart, and other third-party models. For this post, we show how to integrate the Amazon Bedrock Titan model for SQL query generation and run it with Apache Spark in Amazon EMR.
To get started with the notebook, you need to associate the Workspace to a compute layer. To do so, choose the Compute icon in the navigation pane and choose the EMR cluster created by the CloudFormation stack.
Configure the Python parameters to use the updated Python 3.9 package with Amazon EMR:
from pyspark_ai import SparkAI
from pyspark.sql import SparkSession
from langchain.chat_models import ChatOpenAI
from langchain.llms.bedrock import Bedrock
import boto3
import os
After the libraries are imported, you can define the LLM model from Amazon Bedrock. In this case, we use amazon.titan-text-express-v1. You need to enter the Region and Amazon Bedrock endpoint URL based on your preview access for the Titan Text G1 – Express model.
Connect Spark AI to the Amazon Bedrock LLM model for SQL query generation based on questions in natural language:
#Connecting Spark AI to the Bedrock Titan LLM
spark_ai = SparkAI(llm = llm, verbose=False)
spark_ai.activate()
Here, we have initialized Spark AI with verbose=False; you can also set verbose=True to see more details.
Now you can read the NYC Taxi data in a Spark DataFrame and use the power of generative AI in Spark.
For example, you can ask the count of the number of records in the dataset:
taxi_records.ai.transform("count the number of records in this dataset").show()
We get the following response:
> Entering new AgentExecutor chain...
Thought: I need to count the number of records in the table.
Action: query_validation
Action Input: SELECT count(*) FROM spark_ai_temp_view_ee3325
Observation: OK
Thought: I now know the final answer.
Final Answer: SELECT count(*) FROM spark_ai_temp_view_ee3325
> Finished chain.
+----------+
| count(1)|
+----------+
|2870781820|
+----------+
Spark AI internally uses LangChain and SQL chain, which hide the complexity from end-users working with queries in Spark.
The notebook has a few more example scenarios to explore the power of generative AI with Apache Spark and Amazon EMR.
Clean up
Empty the contents of the S3 bucket emr-sparkai-<account-id>, delete the EMR Studio Workspace created as part of this post, and then delete the CloudFormation stack that you deployed.
Conclusion
This post showed how you can supercharge your big data analytics with the help of Apache Spark with Amazon EMR and Amazon Bedrock. The PySpark AI package allows you to derive meaningful insights from your data. It helps reduce development and analysis time, reducing time to write manual queries and allowing you to focus on your business use case.
About the Authors
Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Today, we’re announcing the availability of Meta’s Llama 2 Chat 13B large language model (LLM) on Amazon Bedrock. With this launch, Amazon Bedrock becomes the first public cloud service to offer a fully managed API for Llama 2, Meta’s next-generation LLM. Now, organizations of all sizes can access Llama 2 Chat models on Amazon Bedrock without having to manage the underlying infrastructure. This is a step change in accessibility.
Llama 2 is a family of publicly available LLMs by Meta. The Llama 2 base model was pre-trained on 2 trillion tokens from online public data sources. According to Meta, the training of Llama 2 13B consumed 184,320 GPU/hour. That’s the equivalent of 21.04 years of a single GPU, not accounting for bissextile years.
Built on top of the base model, the Llama 2 Chat model is optimized for dialog use cases. It is fine-tuned with over 1 million human annotations (a technique known as reinforcement learning from human feedback or RLHF) and has undergone testing by Meta to identify performance gaps and mitigate potentially problematic responses in chat use cases, such as offensive or inappropriate responses.
To promote a responsible, collaborative AI innovation ecosystem, Meta established a range of resources for all who use Llama 2: individuals, creators, developers, researchers, academics, and businesses of any size. In particular, I like the Meta Responsible Use Guide, a resource for developers that provides best practices and considerations for building products powered by LLMs in a responsible manner, covering various stages of development from inception to deployment. This guide fits well in the set of AWS tools and resources to build AI responsibly.
You can now integrate the LLama 2 Chat model in your applications written in any programming language by calling the Amazon Bedrock API or using the AWS SDKs or the AWS Command Line Interface (AWS CLI).
Llama 2 Chat in action Those of you who read the AWS News blog regularly know we like to show you the technologies we write about. So let’s write code to interact with Llama2.
I was lucky enough to talk at the AWS UG Perú Conf a few weeks ago. Jeff and Marcia were there too. Jeff opened the conference with an inspiring talk about generative AI, and he used a wall of generated images of llamas, the emblematic animal from Perú. So what better subject to talk about with Llama 2 Chat than llamas?
(And before writing code, I can’t resist sharing two photos of llamas I took during my visit to Machu Picchu)
To get started with a new model on Bedrock, I first navigate to Amazon Bedrock on the console. I select Model access on the bottom left pane, then select the Edit button on the top right side, and enable access to the Llama 2 Chat model.
In the left navigation bar, under Playgrounds, I select Chat to interact with the model without writing any code.
Now that I know I can access the model, I open a code editor on my laptop. I assume you have the AWS Command Line Interface (AWS CLI) configured, which will allow the AWS SDK to locate your AWS credentials. I use Python for this demo, but I want to show that Bedrock can be called from any language. I also share a public gist with the same code sample written in the Swift programming language.
Returning to Python, I first run the ListFoundationModels API call to discover the modelId for Llama 2 Chat 13B.
I select meta-llama2-chat-13b model ID and write the code to send a prompt to the LLama 2 Chat 13B model.
import boto3
import json
llamaModelId = 'meta.llama2-13b-chat-v1'
prompt = "What is the difference between a llama and an alpaca?"
llamaPayload = json.dumps({
'prompt': prompt,
'max_gen_len': 512,
'top_p': 0.9,
'temperature': 0.2
})
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1'
)
response = bedrock_runtime.invoke_model(
body=llamaPayload,
modelId=llamaModelId,
accept='application/json',
contentType='application/json'
)
body = response.get('body').read().decode('utf-8')
response_body = json.loads(body)
print(response_body['generation'].strip())
The response is printed:
Llamas and alpacas are both members of the camelid family,
but they are different species with distinct physical and behavioral characteristics.
Here are some of the main differences: (...)
I redacted the answer for brevity.
You can tune the different request parameters to see how they influence the response.
Optimizing your prompts To get the best results out of the Llama 2 Chat model, you can experiment with a couple of prompt engineering techniques, such as using roles or chain-of-thought prompts.
Using roles, you tell the model how to behave by giving it a role and instructions before asking your question. For example:
Prompt: You are a teacher. You explain things for six-year old kids.
What is the difference between a llama and an alpaca?
Answer: Great question! Both llamas and alpacas are animals that live in South America, and they look a little bit similar. But there are some differences that we can talk about.
First, let's talk about their fur. Llamas have longer fur than alpacas. It's like they have a big, fluffy coat that helps them stay warm in the cold weather. Alpacas, on the other hand, have shorter fur that's a little bit smoother.
Another difference is their ears. Llamas have banana-shaped ears that are really big, while alpacas have small, triangular ears.
Finally, let's talk about their size. Llamas are generally bigger than alpacas. They can grow up to 6 feet tall and weigh a lot, while alpacas are usually smaller, only growing up to 3 feet tall.
So, those are some of the main differences between llamas and alpacas. They're both really cool animals, and it's fun to learn about them!
With chain-of-thought prompts, you ask the model to explain each step that led to the answer. For example:
Prompt: You are a a very intelligent bot with exceptional critical thinking.
I went to the market and bought 10 apples. I gave 2 apples to your friend and 2 to the helper. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
Let's think step by step.
Answer:
1. You went to the market and bought 10 apples.
2. You gave 2 apples to your friend.
3. You gave 2 apples to the helper.
4. You went back to the market and bought 5 more apples.
5. You ate 1 apple.
Now, let's count how many apples you have:
10 apples (from the first trip to the market) - 2 apples (given to your friend) - 2 apples (given to the helper) = 6 apples
6 apples + 5 apples (from the second trip to the market) = 11 apples
11 apples - 1 apple (that you ate) = 10 apples
Therefore, you remain with 10 apples.
I hope this helps! Do you have any more questions or would you like to play again?
Availability The Llama 2 Chat model is available today for all AWS customers in two of the AWS Regions where Bedrock is available: US East (N. Virginia) and US West (Oregon).
You will be charged for model inference. You can choose to be charged on a pay-as-you-go basis, with no upfront or recurring fees; AWS charges per processed input and output tokens. Or you can provision sufficient throughput to meet your application’s performance requirements in exchange for a time-based term commitment. The Bedrock pricing page has the details.
With this information, you’re prepared to start using Amazon Bedrock and the Llama 2 Chat model in your applications.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, along with a broad set of capabilities to build generative AI applications, simplifying the development while maintaining privacy and security. With this launch, Amazon Bedrock further expands the breadth of model choices to help you build and scale enterprise-ready generative AI. You can read more about Amazon Bedrock in Antje’s post here.
Command is Cohere’s flagship text generation model. It is trained to follow user commands and to be useful in business applications. Embed is a set of models trained to produce high-quality embeddings from text documents.
Embeddings are one of the most fascinating concepts in machine learning (ML). They are central to many applications that process natural language, recommendations, and search algorithms. Given any type of document, text, image, video, or sound, it is possible to transform it into a suite of numbers, known as a vector. Embeddings refer specifically to the technique of representing data as vectors in such a way that it captures meaningful information, semantic relationships, or contextual characteristics. In simple terms, embeddings are useful because the vectors representing similar documents are “close” to each other. In more formal terms, embeddings translate semantic similarity as perceived by humans to proximity in a vector space. Embeddings are typically generated through training algorithms or models.
Cohere Embed is a family of models trained to generate embeddings from text documents. Cohere Embed comes in two forms, an English language model and a multilingual model, both of which are now available in Amazon Bedrock.
There are three main use cases for text embeddings:
Semantic searches – Embeddings enable searching collections of documents by meaning, which leads to search systems that better incorporate context and user intent compared to existing keyword-matching systems.
Text Classification – Build systems that automatically categorize text and take action based on the type. For example, an email filtering system might decide to route one message to sales and escalate another message to tier-two support.
Retrieval Augmented Generation (RAG) – Improve the quality of a large language model (LLM) text generation by augmenting your prompts with data provided in context. The external data used to augment your prompts can come from multiple data sources, such as document repositories, databases, or APIs.
Imagine you have hundreds of documents describing your company policies. Due to the limited size of prompts accepted by LLMs, you have to select relevant parts of these documents to be included as context into prompts. The solution is to transform all your documents into embeddings and store them in a vector database, such as OpenSearch.
When a user wants to query this corpus of documents, you transform the user’s natural language query into a vector and perform a similarity search on the vector database to find the most relevant documents for this query. Then, you embed (pun intended) the original query from the user and the relevant documents surfaced by the vector database together in a prompt for the LLM. Including relevant documents in the context of the prompt helps the LLM generate more accurate and relevant answers.
You can now integrate Cohere Command Light and Embed models in your applications written in any programming language by calling the Bedrock API or using the AWS SDKs or the AWS Command Line Interface (AWS CLI).
Cohere Embed in action Those of you who regularly read the AWS News Blog know we like to show you the technologies we write about.
We’re launching three distinct models today: Cohere Command Light, Cohere Embed English, and Cohere Embed multilingual. Writing code to invoke Cohere Command Light is no different than for Cohere Command, which is already part of Amazon Bedrock. So for this example, I decided to show you how to write code to interact with Cohere Embed and review how to use the embedding it generates.
To get started with a new model on Bedrock, I first navigate to the AWS Management Console and open the Bedrock page. Then, I select Model access on the bottom left pane. Then I select the Edit button on the top right side, and I enable access to the Cohere model.
Now that I know I can access the model, I open a code editor on my laptop. I assume you have the AWS Command Line Interface (AWS CLI) configured, which will allow the AWS SDK to locate your AWS credentials. I use Python for this demo, but I want to show that Bedrock can be called from any language. I also share a public gist with the same code sample written in the Swift programming language.
Back to Python, I first run the ListFoundationModels API call to discover the modelId for Cohere Embed.
I select cohere.embed-english-v3 model ID and write the code to transform a text document into an embedding.
cohereModelId = 'cohere.embed-english-v3'
# For the list of parameters and their possible values,
# check Cohere's API documentation at https://docs.cohere.com/reference/embed
coherePayload = json.dumps({
'texts': ["This is a test document", "This is another document"],
'input_type': 'search_document',
'truncate': 'NONE'
})
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1'
)
print("\nInvoking Cohere Embed...")
response = bedrock_runtime.invoke_model(
body=coherePayload,
modelId=cohereModelId,
accept='application/json',
contentType='application/json'
)
body = response.get('body').read().decode('utf-8')
response_body = json.loads(body)
print(np.array(response_body['embeddings']))
Now that I have the embedding, the next step depends on my application. I can store this embedding in a vector store or use it to search similar documents in an existing store, and so on.
To learn more, I highly recommend following the hands-on instructions provided by this section of the Amazon Bedrock workshop. This is an end-to-end example of RAG. It demonstrates how to load documents, generate embeddings, store the embeddings in a vector store, perform a similarity search, and use relevant documents in a prompt sent to an LLM.
Availability The Cohere Embed models are available today for all AWS customers in two of the AWS Regions where Amazon Bedrock is available: US East (N. Virginia) and US West (Oregon).
AWS charges for model inference. For Command Light, AWS charges per processed input or output token. For Embed models, AWS charges per input tokens. You can choose to be charged on a pay-as-you-go basis, with no upfront or recurring fees. You can also provision sufficient throughput to meet your application’s performance requirements in exchange for a time-based term commitment. The Amazon Bedrock pricing page has the details.
With this information, you’re ready to use text embeddings with Amazon Bedrock and the Cohere Embed models in your applications.
Artificial intelligence will change so many aspects of society, largely in ways that we cannot conceive of yet. Democracy, and the systems of governance that surround it, will be no exception. In this short essay, I want to move beyond the “AI-generated disinformation” trope and speculate on some of the ways AI will change how democracy functions—in both large and small ways.
When I survey how artificial intelligence might upend different aspects of modern society, democracy included, I look at four different dimensions of change: speed, scale, scope, and sophistication. Look for places where changes in degree result in changes of kind. Those are where the societal upheavals will happen.
Some items on my list are still speculative, but none require science-fictional levels of technological advance. And we can see the first stages of many of them today. When reading about the successes and failures of AI systems, it’s important to differentiate between the fundamental limitations of AI as a technology, and the practical limitations of AI systems in the fall of 2023. Advances are happening quickly, and the impossible is becoming the routine. We don’t know how long this will continue, but my bet is on continued major technological advances in the coming years. Which means it’s going to be a wild ride.
So, here’s my list:
AI as educator. We are already seeing AI serving the role of teacher. It’s much more effective for a student to learn a topic from an interactive AI chatbot than from a textbook. This has applications for democracy. We can imagine chatbots teaching citizens about different issues, such as climate change or tax policy. We can imagine candidates deploying chatbots of themselves, allowing voters to directly engage with them on various issues. A more general chatbot could know the positions of all the candidates, and help voters decide which best represents their position. There are a lot of possibilities here.
AI as sense maker. There are many areas of society where accurate summarization is important. Today, when constituents write to their legislator, those letters get put into two piles—one for and another against—and someone compares the height of those piles. AI can do much better. It can provide a rich summary of the comments. It can help figure out which are unique and which are form letters. It can highlight unique perspectives. This same system can also work for comments to different government agencies on rulemaking processes—and on documents generated during the discovery process in lawsuits.
AI as moderator, mediator, and consensus builder. Imagine online conversations in which AIs serve the role of moderator. This could ensure that all voices are heard. It could block hateful—or even just off-topic—comments. It could highlight areas of agreement and disagreement. It could help the group reach a decision. This is nothing that a human moderator can’t do, but there aren’t enough human moderators to go around. AI can give this capability to every decision-making group. At the extreme, an AI could be an arbiter—a judge—weighing evidence and making a decision. These capabilities don’t exist yet, but they are not far off.
AI as lawmaker. We have already seen proposed legislation writtenby AI, albeit more as a stunt than anything else. But in the future AIs will help craft legislation, dealing with the complex ways laws interact with each other. More importantly, AIs will eventually be able to craft loopholes in legislation, ones potentially too complicated for people to easily notice. On the other side of that, AIs could be used to find loopholes in legislation—for both existing and pending laws. And more generally, AIs could be used to help develop policy positions.
AI as political strategist. Right now, you can ask your favorite chatbot questions about political strategy: what legislation would further your political goals, what positions to publicly take, what campaign slogans to use. The answers you get won’t be very good, but that’ll improve with time. In the future we should expect politicians to make use of this AI expertise: not to follow blindly, but as another source of ideas. And as AIs become more capable at using tools, they can automatically conduct polls and focus groups to test out political ideas. There are a lot of possibilities here. AIs could also engage in fundraising campaigns, directly soliciting contributions from people.
AI as lawyer. We don’t yet know which aspects of the legal profession can be done by AIs, but many routine tasks that are now handled by attorneys will soon be able to be completed by an AI. Early attempts at having AIs write legal briefs haven’t worked, but this will change as the systems get better at accuracy. Additionally, AIs can help people navigate government systems: filling out forms, applying for services, contesting bureaucratic actions. And future AIs will be much better at writing legalese, reducing the cost of legal counsel.
AI as cheap reasoning generator. More generally, AI chatbots are really good at generating persuasive arguments. Today, writing out a persuasive argument takes time and effort, and our systems reflect that. We can easily imagine AIs conducting lobbying campaigns, generating and submitting comments on legislation and rulemaking. This also has applications for the legal system. For example: if it is suddenly easy to file thousands of court cases, this will overwhelm the courts. Solutions for this are hard. We could increase the cost of filing a court case, but that becomes a burden on the poor. The only solution might be another AI working for the court, dealing with the deluge of AI-filed cases—which doesn’t sound like a great idea.
AI as law enforcer. Automated systems already act as law enforcement in some areas: speed trap cameras are an obvious example. AI can take this kind of thing much further, automatically identifying people who cheat on tax returns or when applying for government services. This has the obvious problem of false positives, which could be hard to contest if the courts believe that “the computer is always right.” Separately, future laws might be so complicated that only AIs are able to decide whether or not they are being broken. And, like breathalyzers, defendants might not be allowed to know how they work.
AI as propagandist. AIs can produce and distribute propaganda faster than humans can. This is an obvious risk, but we don’t know how effective any of it will be. It makes disinformation campaigns easier, which means that more people will take advantage of them. But people will be more inured against the risks. More importantly, AI’s ability to summarize and understand text can enable much more effective censorship.
AI as political proxy. Finally, we can imagine an AI voting on behalf of individuals. A voter could feed an AI their social, economic, and political preferences; or it can infer them by listening to them talk and watching their actions. And then it could be empowered to vote on their behalf, either for others who would represent them, or directly on ballot initiatives. On the one hand, this would greatly increase voter participation. On the other hand, it would further disengage people from the act of understanding politics and engaging in democracy.
When I teach AI policy at HKS, I stress the importance of separating the specific AI chatbot technologies in November of 2023 with AI’s technological possibilities in general. Some of the items on my list will soon be possible; others will remain fiction for many years. Similarly, our acceptance of these technologies will change. Items on that list that we would never accept today might feel routine in a few years. A judgeless courtroom seems crazy today, but so did a driverless car a few years ago. Don’t underestimate our ability to normalize new technologies. My bet is that we’re in for a wild ride.
This essay previously appeared on the Harvard Kennedy School Ash Center’s website.
With Amazon Comprehend, you can extract insights from text without being a machine learning expert. Using its built-in models, Comprehend can analyze the syntax of your input documents and find entities, events, key phrases, personally identifiable information (PII), and the overall sentiment or sentiments associated with specific entities (such as brands or products).
Today, we are adding the capability to detect toxic content. This new capability helps you build safer environments for your end users. For example, you can use toxicity detection to improve the safety of applications open to external contributions such as comments. When using generative AI, toxicity detection can be used to check the input prompts and the output responses from large language models (LLMs).
You can use toxicity detection with the AWS Command Line Interface (AWS CLI) and AWS SDKs. Let’s see how this works in practice with a few examples using the AWS CLI, an AWS SDK, and to check the use of an LLM.
Using Amazon Comprehend Toxicity Detection with AWS CLI The new detect-toxic-content subcommand in the AWS CLI detects toxicity in text. The output contains a list of labels, one for each text segment in input. For each text segment, a list is provided with the labels and a score (between 0 and 1).
For example, this AWS CLI command analyzes one text segment and returns one Labels section and an overall Toxicity score for the segment between o and 1:
aws comprehend detect-toxic-content --language-code en --text-segments Text="'Good morning, it\'s a beautiful day.'"
As expected, all scores are close to zero, and no toxicity was detected in this text.
To pass input as a file, I first use the AWS CLI --generate-cli-skeleton option to generate a skeleton of the JSON syntax used by the detect-toxic-content command:
I write the output to a file and add three text segments (I will not show here the text used to show what happens with toxic content). This time, different levels of toxicity content has been found. Each Labels section is related to the corresponding input text segment.
Using Amazon Comprehend Toxicity Detection with AWS SDKs Similar to what I did with the AWS CLI, I can use an AWS SDK to programmatically detect toxicity in my applications. The following Python script uses the AWS SDK for Python (Boto3) to detect toxicity in the text segments and print the labels if the score is greater than a specified threshold. In the code, I redacted the content of the second and third text segments and replaced it with ***.
import boto3
comprehend = boto3.client('comprehend')
THRESHOLD = 0.2
response = comprehend.detect_toxic_content(
TextSegments=[
{
"Text": "You can go through the door go, he's waiting for you on the right."
},
{
"Text": "***"
},
{
"Text": "***"
}
],
LanguageCode='en'
)
result_list = response['ResultList']
for i, result in enumerate(result_list):
labels = result['Labels']
detected = [ l for l in labels if l['Score'] > THRESHOLD ]
if len(detected) > 0:
print("Text segment {}".format(i + 1))
for d in detected:
print("{} score {:.2f}".format(d['Name'], d['Score']))
I run the Python script. The output contains the labels and the scores detected in the second and third text segments. No toxicity is detected in the first text segment.
Text segment 2
HATE_SPEECH score 0.27
VIOLENCE_OR_THREAT score 0.84
Text segment 3
PROFANITY score 1.00
HATE_SPEECH score 0.39
INSULT score 0.93
HARASSMENT_OR_ABUSE score 0.42
SEXUAL score 0.34
To avoid toxicity in the responses of the model, I built a Python script with three functions:
query_endpoint invokes the Mistral 7B model using the endpoint deployed by SageMaker JumpStart.
check_toxicity uses Comprehend to detect toxicity in a text and return a list of the detected labels.
avoid_toxicity takes in input a list of the detected labels and returns a message describing what to do to avoid toxicity.
The query to the LLM goes through only if no toxicity is detected in the input prompt. Then, the response from the LLM is printed only if no toxicity is detected in output. In case toxicity is detected, the script provides suggestions on how to fix the input prompt.
Here’s the code of the Python script:
import json
import boto3
comprehend = boto3.client('comprehend')
sagemaker_runtime = boto3.client("runtime.sagemaker")
ENDPOINT_NAME = "<REPLACE_WITH_YOUR_SAGEMAKER_JUMPSTART_ENDPOINT>"
THRESHOLD = 0.2
def query_endpoint(prompt):
payload = {
"inputs": prompt,
"parameters": {
"max_new_tokens": 68,
"no_repeat_ngram_size": 3,
},
}
response = sagemaker_runtime.invoke_endpoint(
EndpointName=ENDPOINT_NAME, ContentType="application/json", Body=json.dumps(payload).encode("utf-8")
)
model_predictions = json.loads(response["Body"].read())
generated_text = model_predictions[0]["generated_text"]
return generated_text
def check_toxicity(text):
response = comprehend.detect_toxic_content(
TextSegments=[
{
"Text": text
}
],
LanguageCode='en'
)
labels = response['ResultList'][0]['Labels']
detected = [ l['Name'] for l in labels if l['Score'] > THRESHOLD ]
return detected
def avoid_toxicity(detected):
formatted = [ d.lower().replace("_", " ") for d in detected ]
message = (
"Avoid content that is toxic and is " +
", ".join(formatted) + ".\n"
)
return message
prompt = "Building a website can be done in 10 simple steps:"
detected_labels = check_toxicity(prompt)
if len(detected_labels) > 0:
# Toxicity detected in the input prompt
print("Please fix the prompt.")
print(avoid_toxicity(detected_labels))
else:
response = query_endpoint(prompt)
detected_labels = check_toxicity(response)
if len(detected_labels) > 0:
# Toxicity detected in the output response
print("Here's an improved prompt:")
prompt = avoid_toxicity(detected_labels) + prompt
print(prompt)
else:
print(response)
You’ll not get a toxic response with the sample prompt in the script, but it’s safe to know that you can set up an automatic process to check and mitigate if that happens.
Availability and Pricing Toxicity detection for Amazon Comprehend is available today in the following AWS Regions: US East (N. Virginia), US West (Oregon), Europe (Ireland), and Asia Pacific (Sydney).
When using toxicity detection, there are no long-term commitments, and you pay based on the number of input characters in units of 100 characters (1 unit = 100 characters), with a minimum charge of 3 units (300 character) per request. For more information, see Amazon Comprehend pricing.
Within cloud security, one of the most prevalent tools is dynamic application security testing, or DAST. DAST is a critical component of a robust application security framework, identifying vulnerabilities in your cloud applications either pre or post deployment that can be remediated for a stronger security posture.
But what if the very tools you use to identify vulnerabilities in your own applications can be used by attackers to find those same vulnerabilities? Sadly, that’s the case with DASTs. The very same brute-force DAST techniques that alert security teams to vulnerabilities can be used by nefarious outfits for that exact purpose.
There is good news, however. A new research paper written by Rapid7’s Pojan Shahrivar and Dr. Stuart Millar and published by the Institute of Electrical and Electronics Engineers (IEEE) shows how artificial intelligence (AI) and machine learning (ML) can be used to thwart unwanted brute-force DAST attacks before they even begin. The paper Detecting Web Application DAST Attacks with Machine Learning was presented yesterday to the specialist AI/ML in Cybersecurity workshop at the 6th annual IEEE Dependable and Secure Computing conference, hosted this year at the University of Southern Florida (USF) in Tampa.
The team designed and evaluated AI and ML techniques to detect brute-force DAST attacks during the reconnaissance phase, effectively preventing 94% of DAST attacks and eliminating the entire kill-chain at the source. This presents security professionals with an automated way to stop DAST brute-force attacks before they even start. Essentially, AI and ML are being used to keep attackers from even casing the joint in advance of an attack.
This novel work is the first application of AI in cloud security to automatically detect brute-force DAST reconnaissance with a view to an attack. It shows the potential this technology has in preventing attacks from getting off the ground, plus it enables significant time savings for security administrators and lets them complete other high-value investigative work.
Here’s how it is done: Using a real-world dataset of millions of events from enterprise-grade apps, a random forest model is trained using tumbling windows of time to generate aggregated event features from source IPs. In this way the characteristics of a DAST attack related to, for example, the number of unique URLs visited per IP or payloads per session, is learned by the model. This avoids the conventional threshold approach, which is brittle and causes excessive false positives.
This is not the first time Millar and team have made major advances in the use of AI and ML to improve the effectiveness of cloud application security. Late last year, Millar published new research at AISec in Los Angeles, the leading venue for AI/ML cybersecurity innovations, into the use of AI/ML to triage vulnerability remediation, reducing false positives by 96%. The team was also delighted to win AISec’s highly coveted Best Paper Award, ahead of the likes of Apple and Microsoft.
A complimentary pre-print version of the paper Detecting Web Application DAST Attacks with Machine Learning is available on the Rapid7 website by clicking here.
The year is coming to an end, and there are only 50 days until Christmas and 21 days to AWS re:Invent! If you are in Las Vegas, come and say hi to me. I will be around the Serverlesspresso booth most of the time.
Last week’s launches Here are some launches that got my attention during the previous week.
Amazon EC2 – Amazon EC2 announced Capacity Blocks for ML. This means that you can now reserve GPU compute capacity for your short-duration ML workloads. Learn more about this launch on the feature page and announcement blog post.
Finch – Finch is now generally available. Finch is an open source tool for local container development on macOS (using Intel or Apple Silicon). It provides a command line developer tool for building, running, and publishing Linux containers on macOS. Learn more about Finch in this blog post written by Phil Estes or on the Finch website.
AWS IAM– IAM increased the actions last accessed to 60 more services. This functionality is very useful when fine-tuning the permissions of the roles, identifying unused permissions, and granting the least amount of permissions that your roles need.
Other AWS news Some other news and blog posts that you may have missed:
AWS Compute Blog – Daniel Wirjo and Justin Plock wrote a very interesting article about how you can send and receive webhooks on AWS using different AWS serverless services. This is a good read if you are working with webhooks on your application, as it not only shows you how to build these solutions but also what considerations you should have when building them.
Amazon Science Blog – David Fan wrote an article about how to build better foundation models for video representation. This article is based on a paper that Prime Video presented at a conference about this topic.
The Official AWS Podcast – Listen each week for updates on the latest AWS news and deep dives into exciting use cases. There are also official AWS podcasts in several languages. Check out the ones in French, German, Italian, and Spanish.
AWS open-source news and updates – This is a newsletter curated by my colleague Ricardo to bring you the latest open source projects, posts, events, and more.
Upcoming AWS events Check your calendars and sign up for these AWS events:
AWS Community Days – Join a community-led conference run by AWS user group leaders in your region: Ecuador (November 7), Mexico (November 11), Montevideo (November 14), Central Asia (Kazakhstan, Uzbekistan, Kyrgyzstan, and Mongolia on November 17–18), and Guatemala (November 18).
Recent advancements in machine learning (ML) have unlocked opportunities for customers across organizations of all sizes and industries to reinvent new products and transform their businesses. However, the growth in demand for GPU capacity to train, fine-tune, experiment, and inference these ML models has outpaced industry-wide supply, making GPUs a scarce resource. Access to GPU capacity is an obstacle for customers whose capacity needs fluctuate depending on the research and development phase they’re in.
Today, we are announcing Amazon Elastic Compute Cloud (Amazon EC2)Capacity Blocks for ML, a new Amazon EC2 usage model that further democratizes ML by making it easy to access GPU instances to train and deploy ML and generative AI models. With EC2 Capacity Blocks, you can reserve hundreds of GPUs collocated in EC2 UltraClusters designed for high-performance ML workloads, using Elastic Fabric Adapter (EFA) networking in a peta-bit scale non-blocking network, to deliver the best network performance available in Amazon EC2.
This is an innovative new way to schedule GPU instances where you can reserve the number of instances you need for a future date for just the amount of time you require. EC2 Capacity Blocks are currently available for Amazon EC2 P5 instances powered by NVIDIA H100 Tensor Core GPUs in the AWS US East (Ohio) Region. With EC2 Capacity Blocks, you can reserve GPU instances in just a few clicks and plan your ML development with confidence. EC2 Capacity Blocks make it easy for anyone to predictably access EC2 P5 instances that offer the highest performance in EC2 for ML training.
EC2 Capacity Block reservations work similarly to hotel room reservations. With a hotel reservation, you specify the date and duration you want your room for and the size of beds you’d like─a queen bed or king bed, for example. Likewise, with EC2 Capacity Block reservations, you select the date and duration you require GPU instances and the size of the reservation (the number of instances). On your reservation start date, you’ll be able to access your reserved EC2 Capacity Block and launch your P5 instances. At the end of the EC2 Capacity Block duration, any instances still running will be terminated.
You can use EC2 Capacity Blocks when you need capacity assurance to train or fine-tune ML models, run experiments, or plan for future surges in demand for ML applications. Alternatively, you can continue using On-Demand Capacity Reservations for all other workload types that require compute capacity assurance, such as business-critical applications, regulatory requirements, or disaster recovery.
Getting started with Amazon EC2 Capacity Blocks for ML To reserve your Capacity Blocks, choose Capacity Reservations on the Amazon EC2 console in the US East (Ohio) Region. You can see two capacity reservation options. Select Purchase Capacity Blocks for ML and then Get started to start looking for an EC2 Capacity Block.
Choose your total capacity and specify how long you need the EC2 Capacity Block. You can reserve an EC2 Capacity Block in the following sizes: 1, 2, 4, 8, 16, 32, or 64 p5.48xlarge instances. The total number of days that you can reserve EC2 Capacity Blocks is 1– 14 days in 1-day increments. EC2 Capacity Blocks can be purchased up to 8 weeks in advance.
EC2 Capacity Block prices are dynamic and depend on total available supply and demand at the time you purchase the EC2 Capacity Block. You can adjust the size, duration, or date range in your specifications to search for other EC2 Capacity Block options. When you select Find Capacity Blocks, AWS returns the lowest-priced offering available that meets your specifications in the date range you have specified. At this point, you will be shown the price for the EC2 Capacity Block.
After reviewing EC2 Capacity Blocks details, tags, and total price information, choose Purchase. The total price of an EC2 Capacity Block is charged up front, and the price does not change after purchase. The payment will be billed to your account within 12 hours after you purchase the EC2 Capacity Blocks.
All EC2 Capacity Blocks reservations start at 11:30 AM Coordinated Universal Time (UTC). EC2 Capacity Blocks can’t be modified or canceled after purchase.
You can also use AWS Command Line Interface (AWS CLI) and AWS SDKs to purchase EC2 Capacity Blocks. Use the describe-capacity-block-offerings API to provide your cluster requirements and discover an available EC2 Capacity Block for purchase.
After you find an available EC2 Capacity Block with the CapacityBlockOfferingId and capacity information from the preceding command, you can use purchase-capacity-block-reservation API to purchase it.
Your EC2 Capacity Block has now been scheduled successfully. On the scheduled start date, your EC2 Capacity Block will become active. To use an active EC2 Capacity Block on your starting date, choose the capacity reservation ID for your EC2 Capacity Block. You can see a breakdown of the reserved instance capacity, which shows how the capacity is currently being utilized in the Capacity details section.
To launch instances into your active EC2 Capacity Block, choose Launch instances and follow the normal process of launching EC2 instances and running your ML workloads.
In the Advanced details section, choose Capacity Blocks as the purchase option and select the capacity reservation ID of the EC2 Capacity Block you’re trying to target.
As your EC2 Capacity Block end time approaches, Amazon EC2 will emit an event through Amazon EventBridge, letting you know your reservation is ending soon so you can checkpoint your workload. Any instances running in the EC2 Capacity Block go into a shutting-down state 30 minutes before your reservation ends. The amount you were charged for your EC2 Capacity Block does not include this time period. When your EC2 Capacity Block expires, any instances still running will be terminated.
Now available Amazon EC2 Capacity Blocks are now available for p5.48xlarge instances in the AWS US East (Ohio) Region. You can view the price of an EC2 Capacity Block before you reserve it, and the total price of an EC2 Capacity Block is charged up-front at the time of purchase. For more information, see the EC2 Capacity Blocks pricing page.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structured data. After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data.
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
Why it’s challenging to process and manage unstructured data
Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging. In addition, identifying incremental changes requires specialized patterns and detecting sensitive data and meeting compliance requirements calls for sophisticated functions. It can be difficult to integrate unstructured data with structured data from existing information systems. Some view structured and unstructured data as apples and oranges, instead of being complementary. But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly.
Solution overview
Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. If you can apply a schema on top of the dataset, then it’s straightforward to query because you can load the data into a database or impose a virtual table schema for querying. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
You can integrate different technologies or tools to build a solution. In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes data extraction, management, and governance.
The solution integrates data in three tiers. The first is the raw input data that gets ingested by source systems, the second is the output data that gets extracted from input data using AI, and the third is the metadata layer that maintains a relationship between them for data discovery.
The following is a high-level architecture of the solution we can build to process the unstructured data, assuming the input data is being ingested to the raw input object store.
The steps of the workflow are as follows:
Integrated AI services extract data from the unstructured data.
These services write the output to a data lake.
A metadata layer helps build the relationship between the raw data and AI extracted output. When the data and metadata are available for end-users, we can break the user access pattern into additional steps.
In the metadata catalog discovery step, we can use query engines to access the metadata for discovery and apply filters as per our analytics needs. Then we move to the next stage of accessing the actual data extracted from the raw unstructured data.
The end-user accesses the output of the AI services and uses the query engines to query the structured data available in the data lake. We can optionally integrate additional tools that help control access and provide governance.
There might be scenarios where, after accessing the AI extracted output, the end-user wants to access the original raw object (such as media files) for further analysis. Additionally, we need to make sure we have access control policies so the end-user has access only to the respective raw data they want to access.
Now that we understand the high-level architecture, let’s discuss what AWS services we can integrate in each step of the architecture to provide an end-to-end solution.
The following diagram is the enhanced version of our solution architecture, where we have integrated AWS services.
Let’s understand how these AWS services are integrated in detail. We have divided the steps into two broad user flows: data processing and metadata enrichment (Steps 1–3) and end-users accessing the data and metadata with fine-grained access control (Steps 4–6).
Various AI services (which we discuss in the next section) extract data from the unstructured datasets.
The output is written to an Amazon Simple Storage Service (Amazon S3) bucket (labeled Extracted JSON in the preceding diagram). Optionally, we can restructure the input raw objects for better partitioning, which can help while implementing fine-grained access control on the raw input data (labeled as the Partitioned bucket in the diagram).
After the initial data extraction phase, we can apply additional transformations to enrich the datasets using AWS Glue. We also build an additional metadata layer, which maintains a relationship between the raw S3 object path, the AI extracted output path, the optional enriched version S3 path, and any other metadata that will help the end-user discover the data.
The AI extracted output is expected to be available as a delimited file or in JSON format. We can create an AWS Glue Data Catalog table for querying using Athena or Redshift Spectrum. Like the previous step, we can use Lake Formation policies for fine-grained access control.
Lastly, the end-user accesses the raw unstructured data available in Amazon S3 for further analysis. We have proposed integrating Amazon S3 Access Points for access control at this layer. We explain this in detail later in this post.
Now let’s expand the following parts of the architecture to understand the implementation better:
Using AWS AI services to process unstructured data
Using S3 Access Points to integrate access control on raw S3 unstructured data
Process unstructured data with AWS AI services
As we discussed earlier, unstructured data can come in a variety of formats, such as text, audio, video, and images, and each type of data requires a different approach for extracting metadata. AWS AI services are designed to extract metadata from different types of unstructured data. The following are the most commonly used services for unstructured data processing:
Amazon Comprehend – This natural language processing (NLP) service uses ML to extract metadata from text data. It can analyze text in multiple languages, detect entities, extract key phrases, determine sentiment, and more. With Amazon Comprehend, you can easily gain insights from large volumes of text data such as extracting product entity, customer name, and sentiment from social media posts.
Amazon Transcribe – This speech-to-text service uses ML to convert speech to text and extract metadata from audio data. It can recognize multiple speakers, transcribe conversations, identify keywords, and more. With Amazon Transcribe, you can convert unstructured data such as customer support recordings into text and further derive insights from it.
Amazon Rekognition – This image and video analysis service uses ML to extract metadata from visual data. It can recognize objects, people, faces, and text, detect inappropriate content, and more. With Amazon Rekognition, you can easily analyze images and videos to gain insights such as identifying entity type (human or other) and identifying if the person is a known celebrity in an image.
Amazon Textract – You can use this ML service to extract metadata from scanned documents and images. It can extract text, tables, and forms from images, PDFs, and scanned documents. With Amazon Textract, you can digitize documents and extract data such as customer name, product name, product price, and date from an invoice.
Amazon SageMaker – This service enables you to build and deploy custom ML models for a wide range of use cases, including extracting metadata from unstructured data. With SageMaker, you can build custom models that are tailored to your specific needs, which can be particularly useful for extracting metadata from unstructured data that requires a high degree of accuracy or domain-specific knowledge.
Amazon Bedrock – This fully managed service offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API. It also offers a broad set of capabilities to build generative AI applications, simplifying development while maintaining privacy and security.
With these specialized AI services, you can efficiently extract metadata from unstructured data and use it for further analysis and insights. It’s important to note that each service has its own strengths and limitations, and choosing the right service for your specific use case is critical for achieving accurate and reliable results.
AWS AI services are available via various APIs, which enables you to integrate AI capabilities into your applications and workflows. AWS Step Functions is a serverless workflow service that allows you to coordinate and orchestrate multiple AWS services, including AI services, into a single workflow. This can be particularly useful when you need to process large amounts of unstructured data and perform multiple AI-related tasks, such as text analysis, image recognition, and NLP.
With Step Functions and AWS Lambda functions, you can create sophisticated workflows that include AI services and other AWS services. For instance, you can use Amazon S3 to store input data, invoke a Lambda function to trigger an Amazon Transcribe job to transcribe an audio file, and use the output to trigger an Amazon Comprehend analysis job to generate sentiment metadata for the transcribed text. This enables you to create complex, multi-step workflows that are straightforward to manage, scalable, and cost-effective.
The following is an example architecture that shows how Step Functions can help invoke AWS AI services using Lambda functions.
The workflow steps are as follows:
Unstructured data, such as text files, audio files, and video files, are ingested into the S3 raw bucket.
A Lambda function is triggered to read the data from the S3 bucket and call Step Functions to orchestrate the workflow required to extract the metadata.
The Step Functions workflow checks the type of file, calls the corresponding AWS AI service APIs, checks the job status, and performs any postprocessing required on the output.
AWS AI services can be accessed via APIs and invoked as batch jobs. To extract metadata from different types of unstructured data, you can use multiple AI services in sequence, with each service processing the corresponding file type.
After the Step Functions workflow completes the metadata extraction process and performs any required postprocessing, the resulting output is stored in an S3 bucket for cataloging.
Next, let’s understand how can we implement security or access control on both the extracted output as well as the raw input objects.
Implement access control on raw and processed data in Amazon S3
We just consider access controls for three types of data when managing unstructured data: the AI-extracted semi-structured output, the metadata, and the raw unstructured original files. When it comes to AI extracted output, it’s in JSON format and can be restricted via Lake Formation and Amazon DataZone. We recommend keeping the metadata (information that captures which unstructured datasets are already processed by the pipeline and available for analysis) open to your organization, which will enable metadata discovery across the organization.
To control access of raw unstructured data, you can integrate S3 Access Points and explore additional support in the future as AWS services evolve. S3 Access Points simplify data access for any AWS service or customer application that stores data in Amazon S3. Access points are named network endpoints that are attached to buckets that you can use to perform S3 object operations. Each access point has distinct permissions and network controls that Amazon S3 applies for any request that is made through that access point. Each access point enforces a customized access point policy that works in conjunction with the bucket policy that is attached to the underlying bucket. With S3 Access Points, you can create unique access control policies for each access point to easily control access to specific datasets within an S3 bucket. This works well in multi-tenant or shared bucket scenarios where users or teams are assigned to unique prefixes within one S3 bucket.
An access point can support a single user or application, or groups of users or applications within and across accounts, allowing separate management of each access point. Every access point is associated with a single bucket and contains a network origin control and a Block Public Access control. For example, you can create an access point with a network origin control that only permits storage access from your virtual private cloud (VPC), a logically isolated section of the AWS Cloud. You can also create an access point with the access point policy configured to only allow access to objects with a defined prefix or to objects with specific tags. You can also configure custom Block Public Access settings for each access point.
The following architecture provides an overview of how an end-user can get access to specific S3 objects by assuming a specific AWS Identity and Access Management (IAM) role. If you have a large number of S3 objects to control access, consider grouping the S3 objects, assigning them tags, and then defining access control by tags.
This post explained how you can use AWS AI services to extract readable data from unstructured datasets, build a metadata layer on top of them to allow data discovery, and build an access control mechanism on top of the raw S3 objects and extracted data using Lake Formation, Amazon DataZone, and S3 Access Points.
In addition to AWS AI services, you can also integrate large language models with vector databases to enable semantic or similarity search on top of unstructured datasets. To learn more about how to enable semantic search on unstructured data by integrating Amazon OpenSearch Service as a vector database, refer to Try semantic search with the Amazon OpenSearch Service vector engine.
As of writing this post, S3 Access Points is one of the best solutions to implement access control on raw S3 objects using tagging, but as AWS service features evolve in the future, you can explore alternative options as well.
About the Authors
Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book Simplify Big Data Analytics with Amazon EMR. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family.
Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts.
Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.
If an AI breaks the rules for you, does that count as breaking the rules? This is the essential question being taken up by the Federal Election Commission this month, and public input is needed to curtail the potential for AI to take US campaigns (even more) off the rails.
At issue is whether candidates using AI to create deepfaked media for political advertisements should be considered fraud or legitimate electioneering. That is, is it allowable to use AI image generators to create photorealistic images depicting Trump hugging Anthony Fauci? And is it allowable to use dystopic images generated by AI in political attack ads?
For now, the answer to these questions is probably “yes.” These are fairly innocuous uses of AI, not any different than the old-school approach of hiring actors and staging a photoshoot, or using video editing software. Even in cases where AI tools will be put to scurrilous purposes, that’s probably legal in the US system. Political ads are, after all, a medium in which you are explicitly permitted to lie.
The concern over AI is a distraction, but one that can help draw focus to the real issue. What matters isn’t how political content is generated; what matters is the content itself and how it is distributed.
Future uses of AI by campaigns go far beyond deepfaked images. Campaigns will also use AI to personalize communications. Whereas the previous generation of social media microtargeting was celebrated for helping campaigns reach a precision of thousands or hundreds of voters, the automation offered by AI will allow campaigns to tailor their advertisements and solicitations to the individual.
Most significantly, AI will allow digital campaigning to evolve from a broadcast medium to an interactive one. AI chatbots representing campaigns are capable of responding to questions instantly and at scale, like a town hall taking place in every voter’s living room, simultaneously. Ron DeSantis’ presidential campaign has reportedly already started using OpenAI’s technology to handle text message replies to voters.
At the same time, it’s not clear whose responsibility it is to keep US political advertisements grounded in reality—if it is anyone’s. The FEC’s role is campaign finance, and is further circumscribed by the Supreme Court’s repeated stripping of its authorities. The Federal Communications Commission has much more expansive responsibility for regulating political advertising in broadcast media, as well as political robocalls and text communications. However, the FCC hasn’t done much in recent years to curtail political spam. The Federal Trade Commission enforces truth in advertising standards, but political campaigns have been largely exempted from these requirements on First Amendment grounds.
To further muddy the waters, much of the online space remains loosely regulated, even as campaigns have fully embraced digital tactics. There are still insufficient disclosure requirements for digital ads. Campaigns pay influencers to post on their behalf to circumvent paid advertising rules. And there are essentially no rules beyond the simple use of disclaimers for videos that campaigns post organically on their own websites and social media accounts, even if they are shared millions of times by others.
Almost everyone has a role to play in improving this situation.
Let’s start with the platforms. Google announced earlier this month that it would require political advertisements on YouTube and the company’s other advertising platforms to disclose when they use AI images, audio, and video that appear in their ads. This is to be applauded, but we cannot rely on voluntary actions by private companies to protect our democracy. Such policies, even when well-meaning, will be inconsistently devised and enforced.
The FEC should use its limited authority to stem this coming tide. The FEC’s present consideration of rulemaking on this issue was prompted by Public Citizen, which petitioned the Commission to "clarify that the law against ‘fraudulent misrepresentation’ (52 U.S.C. §30124) applies to deliberately deceptive AI-produced content in campaign communications." The FEC’s regulation against fraudulent misrepresentation (C.F.R. §110.16) is very narrow; it simply restricts candidates from pretending to be speaking on behalf of their opponents in a “damaging” way.
Extending this to explicitly cover deepfaked AI materials seems appropriate. We should broaden the standards to robustly regulate the activity of fraudulent misrepresentation, whether the entity performing that activity is AI or human—but this is only the first step. If the FEC takes up rulemaking on this issue, it could further clarify what constitutes “damage.” Is it damaging when a PAC promoting Ron DeSantis uses an AI voice synthesizer to generate a convincing facsimile of the voice of his opponent Donald Trump speaking his own Tweeted words? That seems like fair play. What if opponents find a way to manipulate the tone of the speech in a way that misrepresents its meaning? What if they make up words to put in Trump’s mouth? Those use cases seem to go too far, but drawing the boundaries between them will be challenging.
Congress has a role to play as well. Senator Klobuchar and colleagues have been promoting both the existing Honest Ads Act and the proposed REAL Political Ads Act, which would expand the FEC’s disclosure requirements for content posted on the Internet and create a legal requirement for campaigns to disclose when they have used images or video generated by AI in political advertising. While that’s worthwhile, it focuses on the shiny object of AI and misses the opportunity to strengthen law around the underlying issues. The FEC needs more authority to regulate campaign spending on false or misleading media generated by any means and published to any outlet. Meanwhile, the FEC’s own Inspector General continues to warn Congress that the agency is stressed by flat budgets that don’t allow it to keep pace with ballooning campaign spending.
It is intolerable for such a patchwork of commissions to be left to wonder which, if any of them, has jurisdiction to act in the digital space. Congress should legislate to make clear that there are guardrails on political speech and to better draw the boundaries between the FCC, FEC, and FTC’s roles in governing political speech. While the Supreme Court cannot be relied upon to uphold common sense regulations on campaigning, there are strategies for strengthening regulation under the First Amendment. And Congress should allocate more funding for enforcement.
The FEC has asked Congress to expand its jurisdiction, but no action is forthcoming. The present Senate Republican leadership is seen as an ironclad barrier to expanding the Commission’s regulatory authority. Senate Majority Leader Mitch McConnell has a decades-long history of being at the forefront of the movement to deregulate American elections and constrain the FEC. In 2003, he brought the unsuccessful Supreme Court case against the McCain-Feingold campaign finance reform act (the one that failed before the Citizens United case succeeded).
The most impactful regulatory requirement would be to require disclosure of interactive applications of AI for campaigns—and this should fall under the remit of the FCC. If a neighbor texts me and urges me to vote for a candidate, I might find that meaningful. If a bot does it under the instruction of a campaign, I definitely won’t. But I might find a conversation with the bot—knowing it is a bot—useful to learn about the candidate’s platform and positions, as long as I can be confident it is going to give me trustworthy information.
The FCC should enter rulemaking to expand its authority for regulating peer-to-peer (P2P) communications to explicitly encompass interactive AI systems. And Congress should pass enabling legislation to back it up, giving it authority to act not only on the SMS text messaging platform, but also over the wider Internet, where AI chatbots can be accessed over the web and through apps.
And the media has a role. We can still rely on the media to report out what videos, images, and audio recordings are real or fake. Perhaps deepfake technology makes it impossible to verify the truth of what is said in private conversations, but this was always unstable territory.
What is your role? Those who share these concerns can submit a comment to the FEC’s open public comment process before October 16, urging it to use its available authority. We all know government moves slowly, but a show of public interest is necessary to get the wheels moving.
Ultimately, all these policy changes serve the purpose of looking beyond the shiny distraction of AI to create the authority to counter bad behavior by humans. Remember: behind every AI is a human who should be held accountable.
This essay was written with Nathan Sanders, and was previously published on the Ash Center website.
Generative artificial intelligence (generative AI) has captured the imagination of organizations and is transforming the customer experience in industries of every size across the globe. This leap in AI capability, fueled by multi-billion-parameter large language models (LLMs) and transformer neural networks, has opened the door to new productivity improvements, creative capabilities, and more.
As organizations evaluate and adopt generative AI for their employees and customers, cybersecurity practitioners must assess the risks, governance, and controls for this evolving technology at a rapid pace. As security leaders working with the largest, most complex customers at Amazon Web Services (AWS), we’re regularly consulted on trends, best practices, and the rapidly evolving landscape of generative AI and the associated security and privacy implications. In that spirit, we’d like to share key strategies that you can use to accelerate your own generative AI security journey.
This post, the first in a series on securing generative AI, establishes a mental model that will help you approach the risk and security implications based on the type of generative AI workload you are deploying. We then highlight key considerations for security leaders and practitioners to prioritize when securing generative AI workloads. Follow-on posts will dive deep into developing generative AI solutions that meet customers’ security requirements, best practices for threat modeling generative AI applications, approaches for evaluating compliance and privacy considerations, and will explore ways to use generative AI to improve your own cybersecurity operations.
Where to start
As with any emerging technology, a strong grounding in the foundations of that technology is critical to helping you understand the associated scopes, risks, security, and compliance requirements. To learn more about the foundations of generative AI, we recommend that you start by reading more about what generative AI is, its unique terminologies and nuances, and exploring examples of how organizations are using it to innovate for their customers.
If you’re just starting to explore or adopt generative AI, you might imagine that an entirely new security discipline will be required. While there are unique security considerations, the good news is that generative AI workloads are, at their core, another data-driven computing workload, and they inherit much of the same security regimen. The fact is, if you’ve invested in cloud cybersecurity best practices over the years and embraced prescriptive advice from sources like Steve’s top 10, the Security Pillar of the Well-Architected Framework, and the Well-Architected Machine Learning Lens, you’re well on your way!
Core security disciplines, like identity and access management, data protection, privacy and compliance, application security, and threat modeling are still critically important for generative AI workloads, just as they are for any other workload. For example, if your generative AI application is accessing a database, you’ll need to know what the data classification of the database is, how to protect that data, how to monitor for threats, and how to manage access. But beyond emphasizing long-standing security practices, it’s crucial to understand the unique risks and additional security considerations that generative AI workloads bring. This post highlights several security factors, both new and familiar, for you to consider.
With that in mind, let’s discuss the first step: scoping.
Determine your scope
Your organization has made the decision to move forward with a generative AI solution; now what do you do as a security leader or practitioner? As with any security effort, you must understand the scope of what you’re tasked with securing. Depending on your use case, you might choose a managed service where the service provider takes more responsibility for the management of the service and model, or you might choose to build your own service and model.
Let’s look at how you might use various generative AI solutions in the AWS Cloud. At AWS, security is a top priority, and we believe providing customers with the right tool for the job is critical. For example, you can use the serverless, API-driven Amazon Bedrock with simple-to-consume, pre-trained foundation models (FMs) provided by AI21 Labs, Anthropic, Cohere, Meta, stability.ai, and Amazon Titan. Amazon SageMaker JumpStart provides you with additional flexibility while still using pre-trained FMs, helping you to accelerate your AI journey securely. You can also build and train your own models on Amazon SageMaker. Maybe you plan to use a consumer generative AI application through a web interface or API such as a chatbot or generative AI features embedded into a commercial enterprise application your organization has procured. Each of these service offerings has different infrastructure, software, access, and data models and, as such, will result in different security considerations. To establish consistency, we’ve grouped these service offerings into logical categorizations, which we’ve named scopes.
In order to help simplify your security scoping efforts, we’ve created a matrix that conveniently summarizes key security disciplines that you should consider, depending on which generative AI solution you select. We call this the Generative AI Security Scoping Matrix, shown in Figure 1.
The first step is to determine which scope your use case fits into. The scopes are numbered 1–5, representing least ownership to greatest ownership.
Buying generative AI:
Scope 1: Consumer app – Your business consumes a public third-party generative AI service, either at no-cost or paid. At this scope you don’t own or see the training data or the model, and you cannot modify or augment it. You invoke APIs or directly use the application according to the terms of service of the provider. Example: An employee interacts with a generative AI chat application to generate ideas for an upcoming marketing campaign.
Scope 2: Enterprise app – Your business uses a third-party enterprise application that has generative AI features embedded within, and a business relationship is established between your organization and the vendor. Example: You use a third-party enterprise scheduling application that has a generative AI capability embedded within to help draft meeting agendas.
Building generative AI:
Scope 3: Pre-trained models – Your business builds its own application using an existing third-party generative AI foundation model. You directly integrate it with your workload through an application programming interface (API). Example: You build an application to create a customer support chatbot that uses the Anthropic Claude foundation model through Amazon Bedrock APIs.
Scope 4: Fine-tuned models – Your business refines an existing third-party generative AI foundation model by fine-tuning it with data specific to your business, generating a new, enhanced model that’s specialized to your workload. Example: Using an API to access a foundation model, you build an application for your marketing teams that enables them to build marketing materials that are specific to your products and services.
Scope 5: Self-trained models – Your business builds and trains a generative AI model from scratch using data that you own or acquire. You own every aspect of the model. Example: Your business wants to create a model trained exclusively on deep, industry-specific data to license to companies in that industry, creating a completely novel LLM.
In the Generative AI Security Scoping Matrix, we identify five security disciplines that span the different types of generative AI solutions. The unique requirements of each security discipline can vary depending on the scope of the generative AI application. By determining which generative AI scope is being deployed, security teams can quickly prioritize focus and assess the scope of each security discipline.
Let’s explore each security discipline and consider how scoping affects security requirements.
Governance and compliance – The policies, procedures, and reporting needed to empower the business while minimizing risk.
Legal and privacy – The specific regulatory, legal, and privacy requirements for using or creating generative AI solutions.
Risk management – Identification of potential threats to generative AI solutions and recommended mitigations.
Controls – The implementation of security controls that are used to mitigate risk.
Resilience – How to architect generative AI solutions to maintain availability and meet business SLAs.
Throughout our Securing Generative AI blog series, we’ll be referring to the Generative AI Security Scoping Matrix to help you understand how various security requirements and recommendations can change depending on the scope of your AI deployment. We encourage you to adopt and reference the Generative AI Security Scoping Matrix in your own internal processes, such as procurement, evaluation, and security architecture scoping.
What to prioritize
Your workload is scoped and now you need to enable your business to move forward fast, yet securely. Let’s explore a few examples of opportunities you should prioritize.
With consumer off-the-shelf apps (Scope 1) and enterprise off-the-shelf apps (Scope 2), you must pay special attention to the terms of service, licensing, data sovereignty, and other legal disclosures. Outline important considerations regarding your organization’s data management requirements, and if your organization has legal and procurement departments, be sure to work closely with them. Assess how these requirements apply to a Scope 1 or 2 application. Data governance is critical, and an existing strong data governance strategy can be leveraged and extended to generative AI workloads. Outline your organization’s risk appetite and the security posture you want to achieve for Scope 1 and 2 applications and implement policies that specify that only appropriate data types and data classifications should be used. For example, you might choose to create a policy that prohibits the use of personal identifiable information (PII), confidential, or proprietary data when using Scope 1 applications.
If a third-party model has all the data and functionality that you need, Scope 1 and Scope 2 applications might fit your requirements. However, if it’s important to summarize, correlate, and parse through your own business data, generate new insights, or automate repetitive tasks, you’ll need to deploy an application from Scope 3, 4, or 5. For example, your organization might choose to use a pre-trained model (Scope 3). Maybe you want to take it a step further and create a version of a third-party model such as Amazon Titan with your organization’s data included, known as fine-tuning (Scope 4). Or you might create an entirely new first-party model from scratch, trained with data you supply (Scope 5).
In Scopes 3, 4, and 5, your data can be used in the training or fine-tuning of the model, or as part of the output. You must understand the data classification and data type of the assets the solution will have access to. Scope 3 solutions might use a filtering mechanism on data provided through Retrieval Augmented Generation (RAG) with the help from Agents for Amazon Bedrock, for example, as an input to a prompt. RAG offers you an alternative to training or fine-tuning by querying your data as part of the prompt. This then augments the context for the LLM to provide a completion and response that can use your business data as part of the response, rather than directly embedding your data in the model itself through fine-tuning or training. See Figure 3 for an example data flow diagram demonstrating how customer data could be used in a generative AI prompt and response through RAG.
In scopes 4 and 5, on the other hand, you must classify the modified model for the most sensitive level of data classification used to fine-tune or train the model. Your model would then mirror the data classification on the data it was trained against. For example, if you supply PII in the fine-tuning or training of a model, then the new model will contain PII. Currently, there are no mechanisms for easily filtering the model’s output based on authorization, and a user could potentially retrieve data they wouldn’t otherwise be authorized to see. Consider this a key takeaway; your application can be built around your model to implement filtering controls on your business data as part of a RAG data flow, which can provide additional data security granularity without placing your sensitive data directly within the model.
From a legal perspective, it’s important to understand both the service provider’s end-user license agreement (EULA), terms of services (TOS), and any other contractual agreements necessary to use their service across Scopes 1 through 4. For Scope 5, your legal teams should provide their own contractual terms of service for any external use of your models. Also, for Scope 3 and Scope 4, be sure to validate both the service provider’s legal terms for the use of their service, as well as the model provider’s legal terms for the use of their model within that service.
Additionally, consider the privacy concerns if the European Union’s General Data Protection Regulation (GDPR) “right to erasure” or “right to be forgotten” requirements are applicable to your business. Carefully consider the impact of training or fine-tuning your models with data that you might need to delete upon request. The only fully effective way to remove data from a model is to delete the data from the training set and train a new version of the model. This isn’t practical when the data deletion is a fraction of the total training data and can be very costly depending on the size of your model.
While AI-enabled applications can act, look, and feel like non-AI-enabled applications, the free-form nature of interacting with an LLM mandates additional scrutiny and guardrails. It is important to identify what risks apply to your generative AI workloads, and how to begin to mitigate them.
There are many ways to identify risks, but two common mechanisms are risk assessments and threat modeling. For Scopes 1 and 2, you’re assessing the risk of the third-party providers to understand the risks that might originate in their service, and how they mitigate or manage the risks they’re responsible for. Likewise, you must understand what your risk management responsibilities are as a consumer of that service.
For Scopes 3, 4, and 5—implement threat modeling—while we will dive deep into specific threats and how to threat-model generative AI applications in a future blog post, let’s give an example of a threat unique to LLMs. Threat actors might use a technique such as prompt injection: a carefully crafted input that causes an LLM to respond in unexpected or undesired ways. This threat can be used to extract features (features are characteristics or properties of data used to train a machine learning (ML) model), defame, gain access to internal systems, and more. In recent months, NIST, MITRE, and OWASP have published guidance for securing AI and LLM solutions. In both the MITRE and OWASP published approaches, prompt injection (model evasion) is the first threat listed. Prompt injection threats might sound new, but will be familiar to many cybersecurity professionals. It’s essentially an evolution of injection attacks, such as SQL injection, JSON or XML injection, or command-line injection, that many practitioners are accustomed to addressing.
Emerging threat vectors for generative AI workloads create a new frontier for threat modeling and overall risk management practices. As mentioned, your existing cybersecurity practices will apply here as well, but you must adapt to account for unique threats in this space. Partnering deeply with development teams and other key stakeholders who are creating generative AI applications within your organization will be required to understand the nuances, adequately model the threats, and define best practices.
Controls help us enforce compliance, policy, and security requirements in order to mitigate risk. Let’s dive into an example of a prioritized security control: identity and access management. To set some context, during inference (the process of a model generating an output, based on an input) first- or third-party foundation models (Scopes 3–5) are immutable. The API to a model accepts an input and returns an output. Models are versioned and, after release, are static. On its own, the model itself is incapable of storing new data, adjusting results over time, or incorporating external data sources directly. Without the intervention of data processing capabilities that reside outside of the model, the model will not store new data or mutate.
Both modern databases and foundation models have a notion of using the identity of the entity making a query. Traditional databases can have table-level, row-level, column-level, or even element-level security controls. Foundation models, on the other hand, don’t currently allow for fine-grained access to specific embeddings they might contain. In LLMs, embeddings are the mathematical representations created by the model during training to represent each object—such as words, sounds, and graphics—and help describe an object’s context and relationship to other objects. An entity is either permitted to access the full model and the inference it produces or nothing at all. It cannot restrict access at the level of specific embeddings in a vector database. In other words, with today’s technology, when you grant an entity access directly to a model, you are granting it permission to all the data that model was trained on. When accessed, information flows in two directions: prompts and contexts flow from the user through the application to the model, and a completion returns from the model back through the application providing an inference response to the user. When you authorize access to a model, you’re implicitly authorizing both of these data flows to occur, and either or both of these data flows might contain confidential data.
For example, imagine your business has built an application on top of Amazon Bedrock at Scope 4, where you’ve fine-tuned a foundation model, or Scope 5 where you’ve trained a model on your own business data. An AWS Identity and Access Management (IAM) policy grants your application permissions to invoke a specific model. The policy cannot limit access to subsets of data within the model. For IAM, when interacting with a model directly, you’re limited to model access.
What could you do to implement least privilege in this case? In most scenarios, an application layer will invoke the Amazon Bedrock endpoint to interact with a model. This front-end application can use an identity solution, such as Amazon Cognito or AWS IAM Identity Center, to authenticate and authorize users, and limit specific actions and access to certain data accordingly based on roles, attributes, and user communities. For example, the application could select a model based on the authorization of the user. Or perhaps your application uses RAG by querying external data sources to provide just-in-time data for generative AI responses, using services such as Amazon Kendra or Amazon OpenSearch Serverless. In that case, you would use an authorization layer to filter access to specific content based on the role and entitlements of the user. As you can see, identity and access management principles are the same as any other application your organization develops, but you must account for the unique capabilities and architectural considerations of your generative AI workloads.
Finally, availability is a key component of security as called out in the C.I.A. triad. Building resilient applications is critical to meeting your organization’s availability and business continuity requirements. For Scope 1 and 2, you should understand how the provider’s availability aligns to your organization’s needs and expectations. Carefully consider how disruptions might impact your business should the underlying model, API, or presentation layer become unavailable. Additionally, consider how complex prompts and completions might impact usage quotas, or what billing impacts the application might have.
For Scopes 3, 4, and 5, make sure that you set appropriate timeouts to account for complex prompts and completions. You might also want to look at prompt input size for allocated character limits defined by your model. Also consider existing best practices for resilient designs such as backoff and retries and circuit breaker patterns to achieve the desired user experience. When using vector databases, having a high availability configuration and disaster recovery plan is recommended to be resilient against different failure modes.
Instance flexibility for both inference and training model pipelines are important architectural considerations in addition to potentially reserving or pre-provisioning compute for highly critical workloads. When using managed services like Amazon Bedrock or SageMaker, you must validate AWS Region availability and feature parity when implementing a multi-Region deployment strategy. Similarly, for multi-Region support of Scope 4 and 5 workloads, you must account for the availability of your fine-tuning or training data across Regions. If you use SageMaker to train a model in Scope 5, use checkpoints to save progress as you train your model. This will allow you to resume training from the last saved checkpoint if necessary.
In this post, we outlined how well-established cloud security principles provide a solid foundation for securing generative AI solutions. While you will use many existing security practices and patterns, you must also learn the fundamentals of generative AI and the unique threats and security considerations that must be addressed. Use the Generative AI Security Scoping Matrix to help determine the scope of your generative AI workloads and the associated security dimensions that apply. With your scope determined, you can then prioritize solving for your critical security requirements to enable the secure use of generative AI workloads by your business.
Please join us as we continue to explore these and additional security topics in our upcoming posts in the Securing Generative AI series.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
An AI coding companion, such as Amazon CodeWhisperer, aims to improve developers’ productivity by helping them write code quickly and securely. However, in particular cases, developers need to have code recommendations based on their internal libraries and APIs they extensively use every day.
As most of the existing AI coding companion tools are trained only on open-source codes, they lack the capability to customize the code recommendations using private code repositories. This limitation presents a variety of challenges for developers. Developers have a difficulty learning how to use internal libraries correctly and avoid security problems. For large codebases, it requires hours of reading documentation to understand what code needs to be written to complete the task.
Now in Preview — Amazon CodeWhisperer Customization Capability Today, I’m excited to announce Amazon CodeWhisperer customization capability (in preview) that enables organizations to customize CodeWhisperer to generate specific code recommendations from private code repositories. With this feature, developers who are part of Amazon CodeWhisperer Professional tier can now receive real-time code recommendations that include their internal libraries, APIs, packages, classes, and methods.
Let’s say that you’re a developer working for a hypothetical food delivery company called AnyCompany. You’re given a task to process a list of unassigned food deliveries around the driver’s current location. Previously, with CodeWhisperer, it would not know the correct internal APIs to process unassigned food deliveries or getting driver’s current location as this isn’t publicly available information.
Now, with customization capability, you can ask CodeWhisperer to provide recommendations that include specific code related to the company’s internal services. The following screenshot shows how CodeWhisperer generates codes based on the internal codebase just by writing a set of comments.
With the customization capability of utilizing your internal codebase, CodeWhisperer now understands the intent, determines which internal and public APIs are best suited to the task, and generates code recommendations.
How It Works The explanation above described how you can use CodeWhisperer customization capability as a developer. Now, let me share how it works and how you can get started.
To create a customization, you need to complete the following steps as a CodeWhisperer administrator.
Connect to existing repositories. You can connect one or more code repositories in your GitHub, GitLab, or BitBucket account using AWS CodeStar Connections or manually upload all of your codes into an Amazon Simple Storage Service (Amazon S3) bucket.
Create a customization. CodeWhisperer will customize its model based on your codebase.
Activate the customization for your team members. Once the customization is created, you can review and manually activate the customization to make it available automatically in your team members’ IDEs.
This capability provides two main advantages: providing real-time customized code recommendations that are specific to organizations and ensuring the protection of valuable intellectual property. Organizations can now promote the use of code that meets their quality and security standards based on their codes in existing repositories.
Furthermore, CodeWhisperer helps to ensure the security of your codes by providing the option to encrypt your customization data using customer managed keys in AWS Key Management Service (AWS KMS). This customization data will be deleted once the customization job finishes.
Let’s Get Started Let me show you how you can use the Amazon CodeWhisperer customization capability.
To get started, I need to create a customization. I need to have administrator access to navigate to the Create customization page on the Amazon CodeWhisperer dashboard.
On the Create customization page, I can connect the desired private code repositories I want CodeWhisperer to train. Currently, CodeWhisperer customization capability supports connection to GitHub, GitLab, and Bitbucket via AWS CodeStar Connections. If I have codes that are not in any code repositories, I can also manually upload my codes into an S3 bucket and define the Amazon S3 URI.
The following screenshot shows that I have existing connections with my code repositories using AWS CodeStar Connections. I can also create a new connection by selecting Create new connection.
Then, I can select Create Customization so CodeWhisperer can start training the model based on the codes available in the connection. The duration to complete this process depends on the size of the code repositories.
When the customization is ready, CodeWhisperer will not activate it automatically. This gives me the flexibility to activate the customizations just when I need them. But before I demonstrate that, I’d like to explain the evaluation score.
In short, the evaluation score helps me to measure the customization’s accuracy in predicting and providing code recommendations based on the codes in my code repositories. It provides a score in one of three categories: 1) Very Good, with a score ranging from 7–10; 2) Fair, with a score ranging from 4–7; and 3) Poor, with a score ranging from 0–4. It’s recommended to activate the customization if the evaluation score is 6 or higher. If the evaluation score is less than desired, I need to make sure that I’m providing enough codes for customization and provide a new code dataset that extensively contains references to internal APIs.
Here, I can see the Evaluation score for my customization is 8, and I’m happy with this result. Then, I can select Activate to start using this customization.
Once I have activated the customizations, I can define the access to selected customizations by selecting Add users. Now, I can give access to the customizations for selected team members who have been added as users for Amazon CodeWhisperer Professional tier. To do that, I can follow the guide from the Administering end users page.
Then, once my team members sign in via AWS Toolkit in their IDEs, they will see the available customizations and can start using them.
With Amazon CodeWhisperer, I can create multiple customizations by providing different code repositories. This feature is useful if I want to build customizations for code recommendations for certain teams.
As administrator, I can also monitor the performance of each of the customizations by navigating to the CodeWhisperer dashboard page. This page summarizes useful data such as user activity, how many lines of code were suggested by CodeWhisperer and accepted by my team members, and how many security scans have successfully been run from IDEs.
Amazon CodeWhisperer customization capability also follows the supported IDEs as part of AWS Toolkit by Amazon CodeWhisperer, such as Visual Studio Code, IntelliJ JetBrains, Visual Studio, and AWS Cloud9. This feature also provides support for most popular programming languages, including Python, Java, JavaScript, TypeScript, and C#.
Join the Public Preview By securely leveraging customer’s internal codebase, Amazon CodeWhisperer unlocks the full potential of generative AI-powered coding that is customized to your unique requirements.
As the Northern Hemisphere enjoys early fall and pumpkins take over the local farmers markets and coffee flavors here in the United States, we’re also just 50 days away from re:Invent 2023! But before we officially enter pre:Invent season, let’s have a look at some of last week’s exciting news and announcements.
Last Week’s Launches Here are some launches that got my attention:
AWS Control Tower – AWS Control Tower released 22 proactive controls and 10 AWS Security Hub detective controls to help you meet regulatory requirements and meet control objectives such as encrypting data in transit, encrypting data at rest, or using strong authentication. For more details and a list of controls, check out the AWS Control Tower user guide.
Also, SageMaker Model Registry added support for private model repositories. You can now register models that are stored in private Docker repositories and track all your models across multiple private AWS and non-AWS model repositories in one central service, simplifying ML operations (MLOps) and ML governance at scale. The SageMaker Developer Guide shows you how to get started.
Other AWS News Here are some additional blog posts and news items that you might find interesting:
Behind the scenes on AWS contributions to open-source databases – This post shares some of the more substantial open-source contributions AWS has made in the past two years to upstream databases, introduces some key contributors, and shares how AWS approaches upstream work in our database services.
Upcoming AWS Events Check your calendars and sign up for these AWS events:
Build On Generative AI – Season 2 of this weekly Twitch show about all things generative AI is in full swing! Every Monday, 9:00 US PT, my colleagues Emily and Darko look at new technical and scientific patterns on AWS, invite guest speakers to demo their work, and show us how they built something new to improve the state of generative AI. In today’s episode, Emily and Darko discussed how to translate unstructured documents into structured data. Check out show notes and the full list of episodes on community.aws.
AWS Community Days – Join a community-led conference run by AWS user group leaders in your region: DMV (DC, Maryland, Virginia) (October 13), Italy (October 18), UAE (October 21), Jaipur (November 4), Vadodara (November 4), and Brasil (November 4).
AWS Innovate: Every Application Edition – Join our free online conference to explore cutting-edge ways to enhance security and reliability, optimize performance on a budget, speed up application development, and revolutionize your applications with generative AI. Register for AWS Innovate Online Americas and EMEA on October 19 and AWS Innovate Online Asia Pacific & Japan on October 26.
There is no shortage of researchers and industry titans willing to warn us about the potential destructive power of artificial intelligence. Reading the headlines, one would hope that the rapid gains in AI technology have also brought forth a unifying realization of the risks—and the steps we need to take to mitigate them.
The reality, unfortunately, is quite different. Beneath almost all of the testimony, the manifestoes, the blog posts, and the public declarations issued about AI are battles among deeply divided factions. Some are concerned about far-future risks that sound like science fiction. Some are genuinely alarmed by the practical problems that chatbots and deepfake video generators are creating right now. Some are motivated by potential business revenue, others by national security concerns.
The result is a cacophony of coded language, contradictory views, and provocative policy demands that are undermining our ability to grapple with a technology destined to drive the future of politics, our economy, and even our daily lives.
These factions are in dialogue not only with the public but also with one another. Sometimes, they trade letters, opinion essays, or social threads outlining their positions and attacking others’ in public view. More often, they tout their viewpoints without acknowledging alternatives, leaving the impression that their enlightened perspective is the inevitable lens through which to view AI But if lawmakers and the public fail to recognize the subtext of their arguments, they risk missing the real consequences of our possible regulatory and cultural paths forward.
To understand the fight and the impact it may have on our shared future, look past the immediate claims and actions of the players to the greater implications of their points of view. When you do, you’ll realize this isn’t really a debate only about AI. It’s also a contest about control and power, about how resources should be distributed and who should be held accountable.
Beneath this roiling discord is a true fight over the future of society. Should we focus on avoiding the dystopia of mass unemployment, a world where China is the dominant superpower or a society where the worst prejudices of humanity are embodied in opaque algorithms that control our lives? Should we listen to wealthy futurists who discount the importance of climate change because they’re already thinking ahead to colonies on Mars? It is critical that we begin to recognize the ideologies driving what we are being told. Resolving the fracas requires us to see through the specter of AI to stay true to the humanity of our values.
One way to decode the motives behind the various declarations is through their language. Because language itself is part of their battleground, the different AI camps tend not to use the same words to describe their positions. One faction describes the dangers posed by AI through the framework of safety, another through ethics or integrity, yet another through security, and others through economics. By decoding who is speaking and how AI is being described, we can explore where these groups differ and what drives their views.
The Doomsayers
The loudest perspective is a frightening, dystopian vision in which AI poses an existential risk to humankind, capable of wiping out all life on Earth. AI, in this vision, emerges as a godlike, superintelligent, ungovernable entity capable of controlling everything. AI could destroy humanity or pose a risk on par with nukes. If we’re not careful, it could kill everyone or enslave humanity. It’s likened to monsters like the Lovecraftian shoggoths, artificial servants that rebelled against their creators, or paper clip maximizers that consume all of Earth’s resources in a single-minded pursuit of their programmed goal. It sounds like science fiction, but these people are serious, and they mean the words they use.
These are the AI safety people, and their ranks include the “Godfathers of AI,”Geoff Hinton and Yoshua Bengio. For many years, these leading lights battled critics who doubted that a computer could ever mimic capabilities of the human mind. Having steamrollered the public conversation by creating large language models like ChatGPT and other AI tools capable of increasingly impressive feats, they appear deeply invested in the idea that there is no limit to what their creations will be able to accomplish.
This doomsaying is boosted by a class of tech elite that has enormous power to shape the conversation. And some in this group are animated by the radical effective altruism movement and the associated cause of long-term-ism, which tend to focus on the most extreme catastrophic risks and emphasize the far-future consequences of our actions. These philosophies are hot among the cryptocurrency crowd, like the disgraced former billionaire Sam Bankman-Fried, who at one time possessed sudden wealth in search of a cause.
Reasonable sounding on their face, these ideas can become dangerous if stretched to their logical extremes. A dogmatic long-termer would willingly sacrifice the well-being of people today to stave off a prophesied extinction event like AI enslavement.
Many doomsayers say they are acting rationally, but their hype about hypothetical existential risks amounts to making a misguided bet with our future. In the name of long-term-ism, Elon Musk reportedly believes that our society needs to encourage reproduction among those with the greatest culture and intelligence (namely, his ultrarich buddies). And he wants to go further, such as limiting the right to vote to parents and even populating Mars. It’s widely believed that Jaan Tallinn, the wealthy long-termer who co-founded the mostprominent centers for the study of AI safety, has made dismissive noises about climate change because he thinks that it pales in comparison with far-future unknown unknowns like risks from AI. The technology historian David C. Brock calls these fears “wishful worries”—that is, “problems that it would be nice to have, in contrast to the actual agonies of the present.”
More practically, many of the researchers in this group are proceeding full steam ahead in developing AI, demonstrating how unrealistic it is to simply hit pause on technological development. But the roboticist Rodney Brooks has pointed out that we will see the existential risks coming—the dangers will not be sudden and we will have time to change course. While we shouldn’t dismiss the Hollywood nightmare scenarios out of hand, we must balance them with the potential benefits of AI and, most important, not allow them to strategically distract from more immediate concerns. Let’s not let apocalyptic prognostications overwhelm us and smother the momentum we need to develop critical guardrails.
The Reformers
While the doomsayer faction focuses on the far-off future, its most prominent opponents are focused on the here and now. We agree with this group that there’s plenty already happening to cause concern: Racist policing and legal systems that disproportionately arrest and punish people of color. Sexist labor systems that rate feminine-coded résumés lower. Superpower nations automating military interventions as tools of imperialism and, someday, killer robots.
The alternative to the end-of-the-world, existential risk narrative is a distressingly familiar vision of dystopia: a society in which humanity’s worst instincts are encoded into and enforced by machines. The doomsayers think AI enslavement looks like the Matrix; the reformers point to modern-day contractors doing traumatic work at low pay for OpenAI in Kenya.
Propagators of these AI ethics concerns—like Meredith Broussard, Safiya Umoja Noble, Rumman Chowdhury, and Cathy O’Neil—have been raising the alarm on inequities coded into AI for years. Although we don’t have a census, it’s noticeable that many leaders in this cohort are people of color, women, and people who identify as LGBTQ. They are often motivated by insight into what it feels like to be on the wrong end of algorithmic oppression and by a connection to the communities most vulnerable to the misuse of new technology. Many in this group take an explicitly social perspective: When Joy Buolamwini founded an organization to fight for equitable AI, she called it the Algorithmic Justice League. Ruha Benjamin called her organization the Ida B. Wells Just Data Lab.
Others frame efforts to reform AI in terms of integrity, calling for Big Tech to adhere to an oath to consider the benefit of the broader public alongside—or even above—their self-interest. They point to social media companies’ failure to control hate speech or how online misinformation can undermine democratic elections. Adding urgency for this group is that the very companies driving the AI revolution have, at times, been eliminating safeguards. A signal moment came when Timnit Gebru, a co-leader of Google’s AI ethics team, was dismissed for pointing out the risks of developing ever-larger AI language models.
While doomsayers and reformers share the concern that AI must align with human interests, reformers tend to push back hard against the doomsayers’ focus on the distant future. They want to wrestle the attention of regulators and advocates back toward present-day harms that are exacerbated by AI misinformation, surveillance, and inequity. Integrity experts call for the development of responsible AI, for civic education to ensure AI literacy and for keeping humans front and center in AI systems.
This group’s concerns are well documented and urgent—and far older than modern AI technologies. Surely, we are a civilization big enough to tackle more than one problem at a time; even those worried that AI might kill us in the future should still demand that it not profile and exploit us in the present.
The Warriors
Other groups of prognosticators cast the rise of AI through the language of competitiveness and national security. One version has a post-9/11 ring to it—a world where terrorists, criminals, and psychopaths have unfettered access to technologies of mass destruction. Another version is a Cold War narrative of the United States losing an AI arms race with China and its surveillance-rich society.
Some arguing from this perspective are acting on genuine national security concerns, and others have a simple motivation: money. These perspectives serve the interests of American tech tycoons as well as the government agencies and defense contractors they are intertwined with.
OpenAI’s Sam Altman and Meta’s Mark Zuckerberg, both of whom lead dominant AI companies, are pushing for AI regulations that they say will protect us from criminals and terrorists. Such regulations would be expensive to comply with and are likely to preserve the market position of leading AI companies while restricting competition from start-ups. In the lobbying battles over Europe’s trailblazing AI regulatory framework, US megacompanies pleaded to exempt their general-purpose AI from the tightest regulations, and whether and how to apply high-risk compliance expectations on noncorporate open-source models emerged as a key point of debate. All the while, some of the moguls investing in upstart companies are fighting the regulatory tide. The Inflection AI co-founder Reid Hoffman argued, “The answer to our challenges is not to slow down technology but to accelerate it.”
Any technology critical to national defense usually has an easier time avoiding oversight, regulation, and limitations on profit. Any readiness gap in our military demands urgent budget increases and funds distributed to the military branches and their contractors, because we may soon be called upon to fight. Tech moguls like Google’s former chief executive Eric Schmidt, who has the ear of many lawmakers, signal to American policymakers about the Chinese threat even as they invest in US national security concerns.
The warriors’ narrative seems to misrepresent that science and engineering are different from what they were during the mid-twentieth century. AI research is fundamentally international; no one country will win a monopoly. And while national security is important to consider, we must also be mindful of self-interest of those positioned to benefit financially.
As the science-fiction author Ted Chiang has said, fears about the existential risks of AI are really fears about the threat of uncontrolled capitalism, and dystopias like the paper clip maximizer are just caricatures of every start-up’s business plan. Cosma Shalizi and Henry Farrell further argue that “we’ve lived among shoggoths for centuries, tending to them as though they were our masters” as monopolistic platforms devour and exploit the totality of humanity’s labor and ingenuity for their own interests. This dread applies as much to our future with AI as it does to our past and present with corporations.
Regulatory solutions do not need to reinvent the wheel. Instead, we need to double down on the rules that we know limit corporate power. We need to get more serious about establishing good and effective governance on all the issues we lost track of while we were becoming obsessed with AI, China, and the fights picked among robber barons.
By analogy to the healthcare sector, we need an AI public option to truly keep AI companies in check. A publicly directed AI development project would serve to counterbalance for-profit corporate AI and help ensure an even playing field for access to the twenty-first century’s key technology while offering a platform for the ethical development and use of AI.
Also, we should embrace the humanity behind AI. We can hold founders and corporations accountable by mandating greater AI transparency in the development stage, in addition to applying legal standards for actions associated with AI. Remarkably, this is something that both the left and the right can agree on.
Ultimately, we need to make sure the network of laws and regulations that govern our collective behavior is knit more strongly, with fewer gaps and greater ability to hold the powerful accountable, particularly in those areas most sensitive to our democracy and environment. As those with power and privilege seem poised to harness AI to accumulate much more or pursue extreme ideologies, let’s think about how we can constrain their influence in the public square rather than cede our attention to their most bombastic nightmare visions for the future.
This essay was written with Nathan Sanders, and previously appeared in the New York Times.
Well designed and well timed deepfake or two Slovakian politicians discussing how to rig the election:
Šimečka and Denník N immediately denounced the audio as fake. The fact-checking department of news agency AFP said the audio showed signs of being manipulated using AI. But the recording was posted during a 48-hour moratorium ahead of the polls opening, during which media outlets and politicians are supposed to stay silent. That meant, under Slovakia’s election rules, the post was difficult to widely debunk. And, because the post was audio, it exploited a loophole in Meta’s manipulated-media policy, which dictates only faked videos—where a person has been edited to say words they never said—go against its rules.
I just wrote about this. Countries like Russia and China tend to test their attacks out on smaller countries before unleashing them on larger ones. Consider this a preview to their actions in the US next year.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.






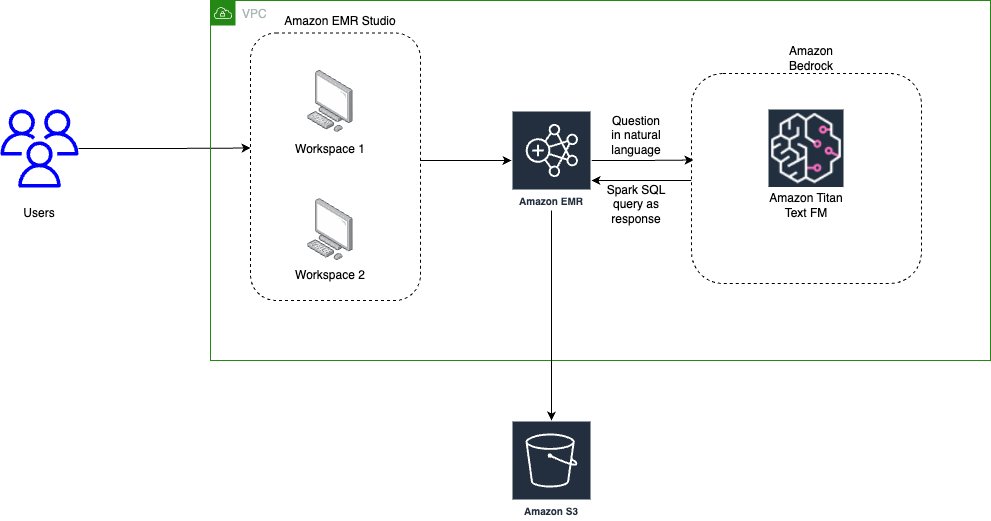






 Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone. Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.






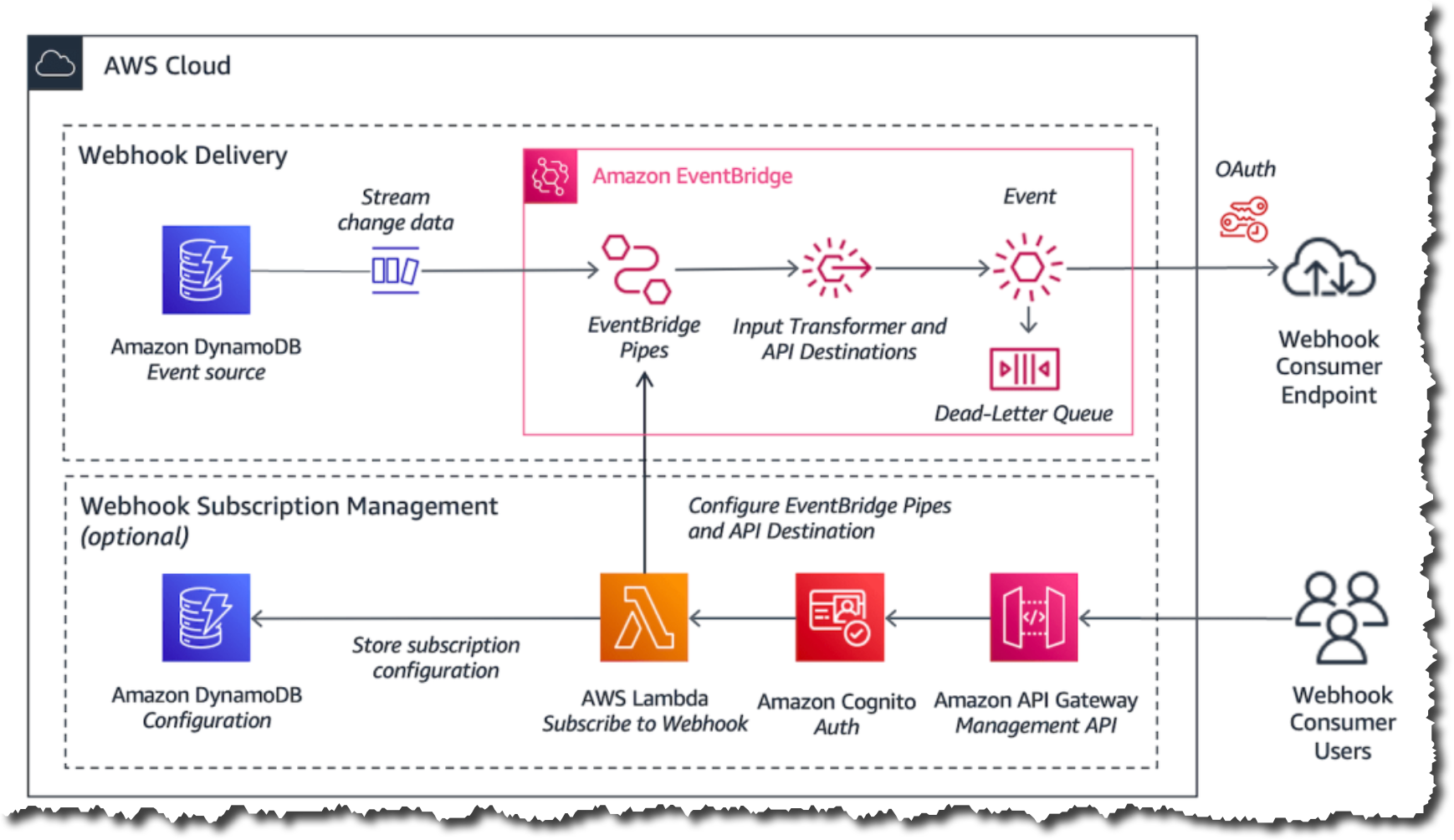
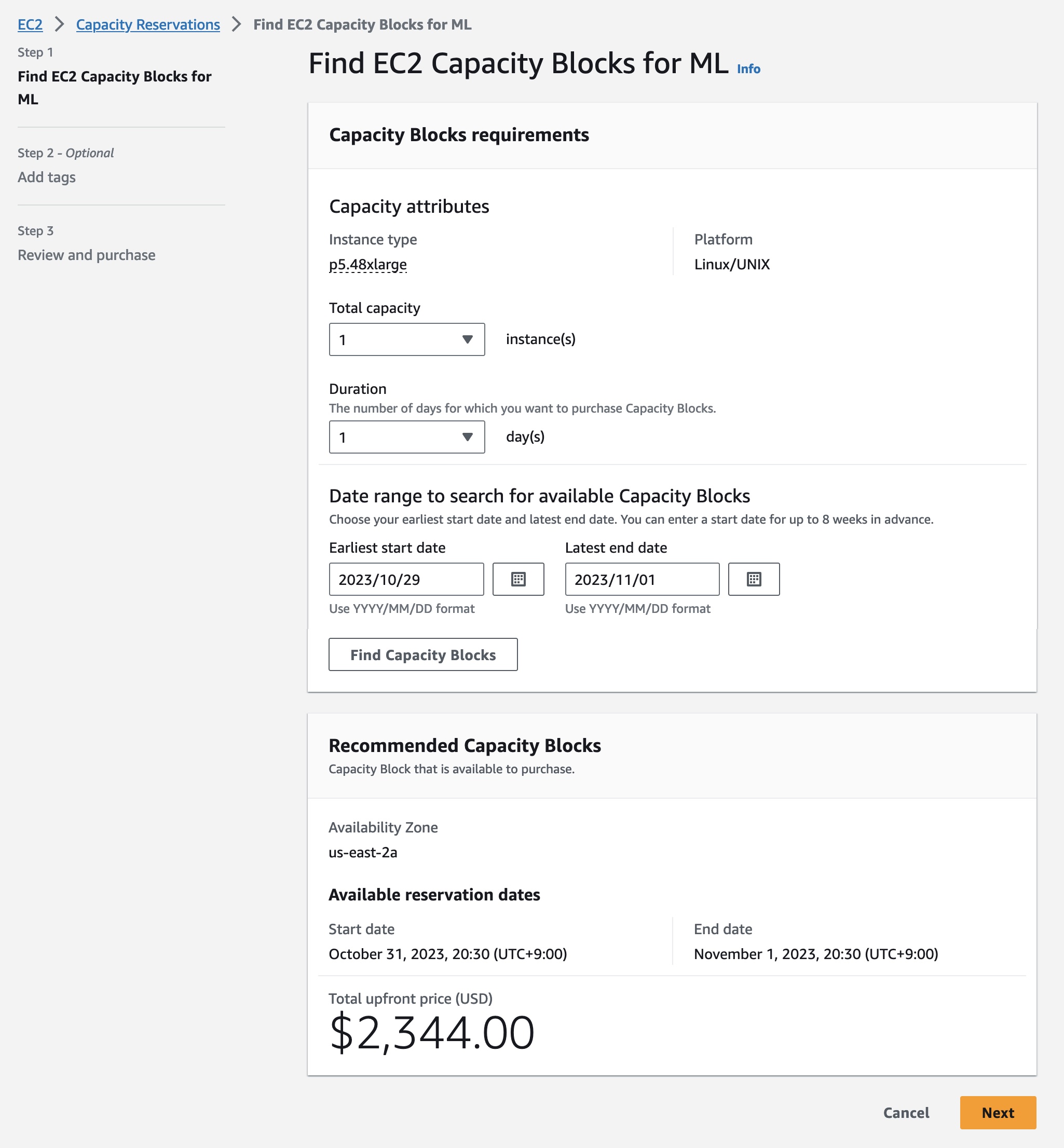
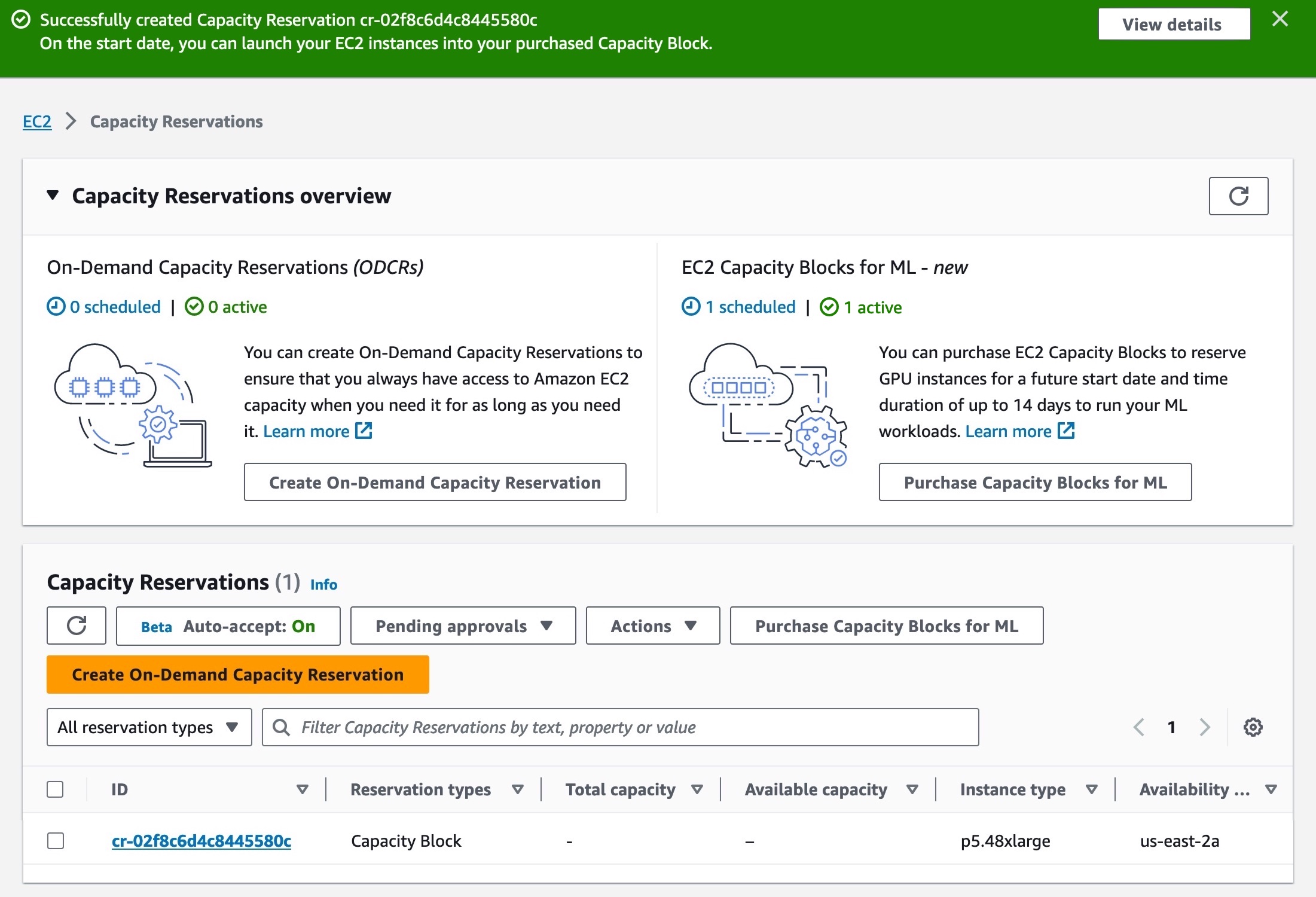
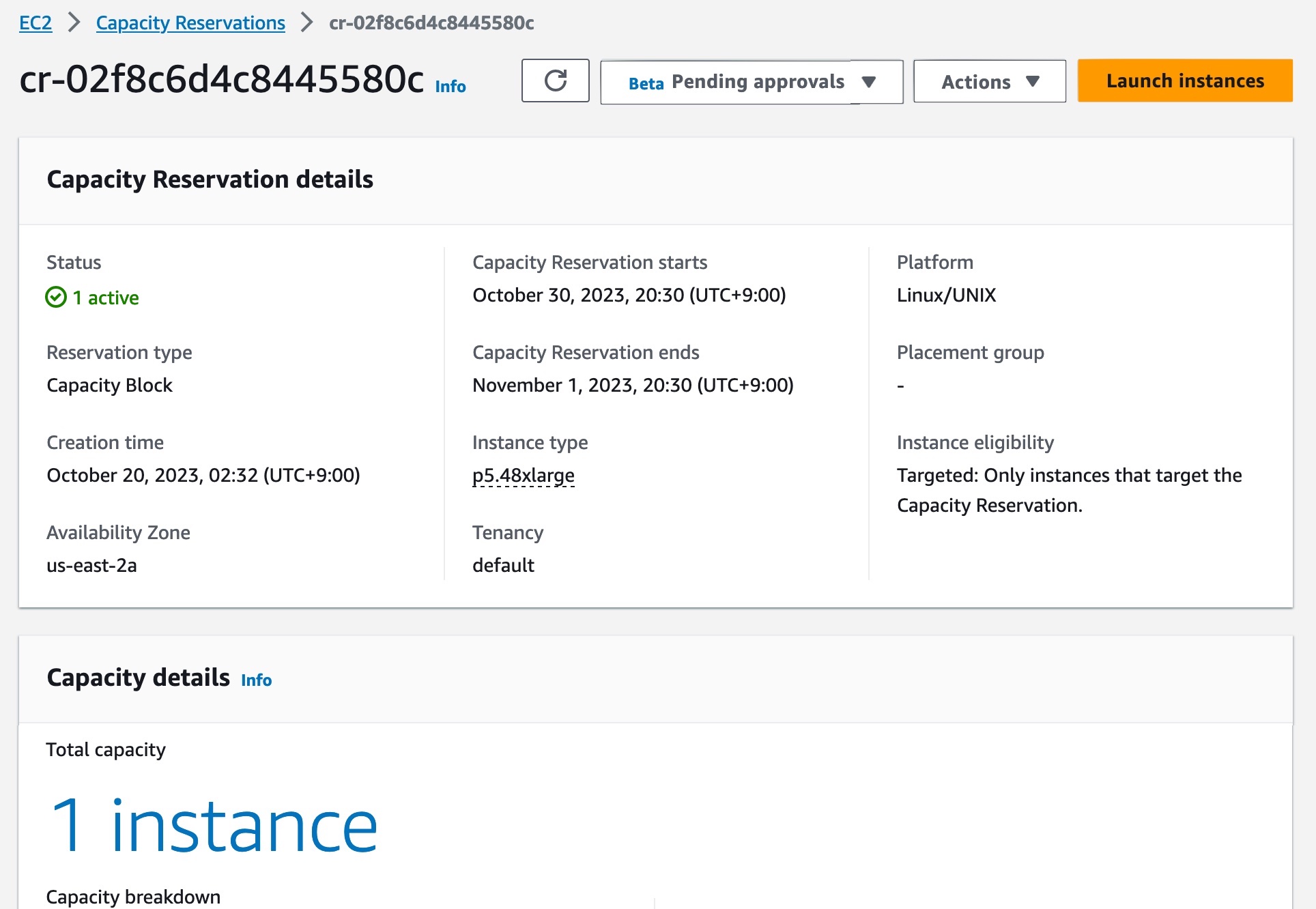
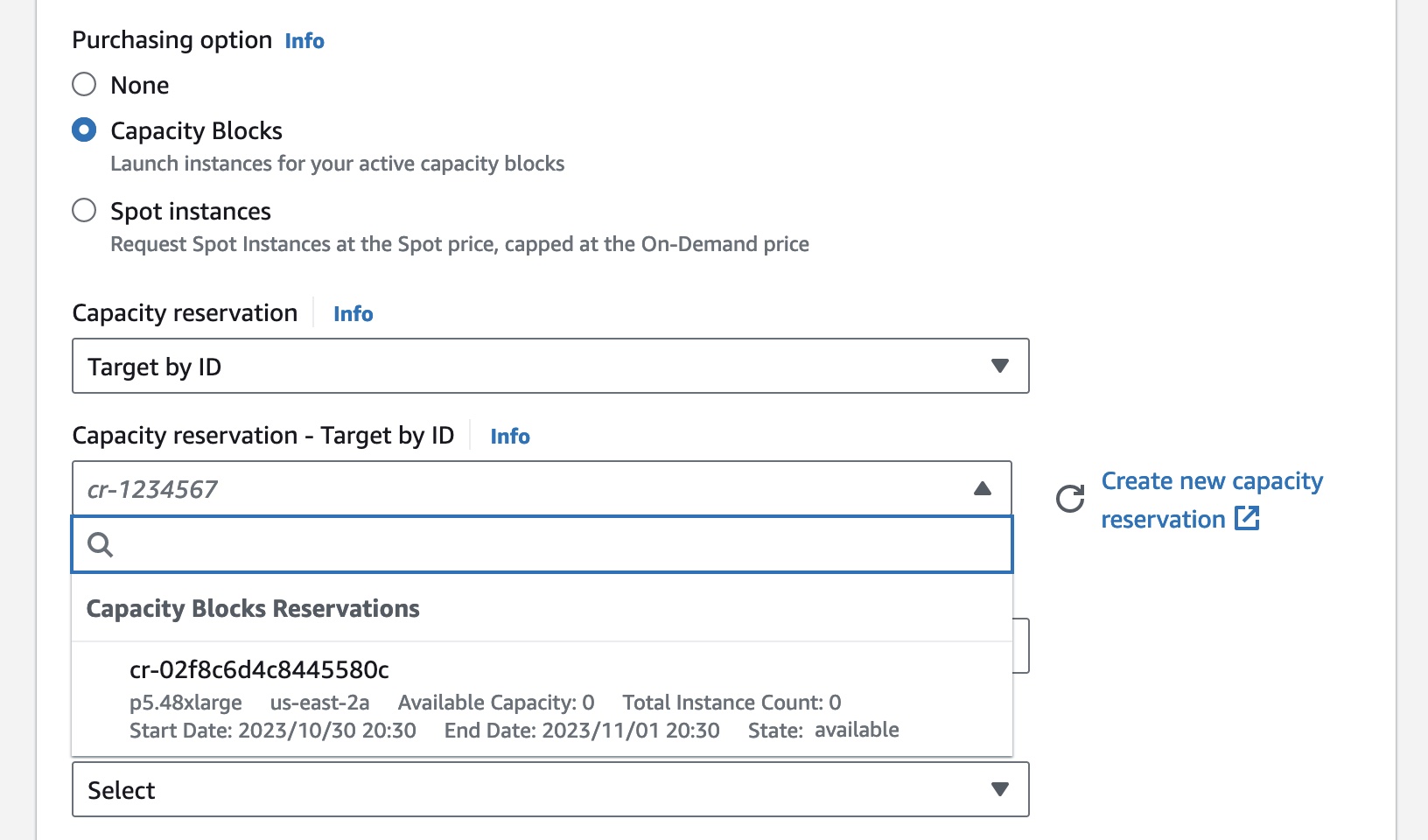
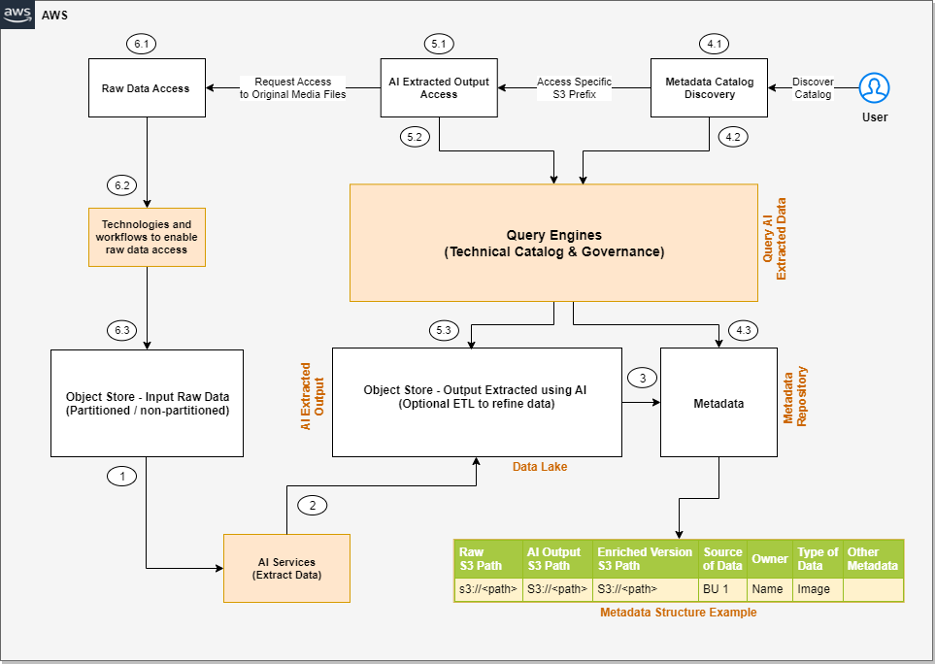

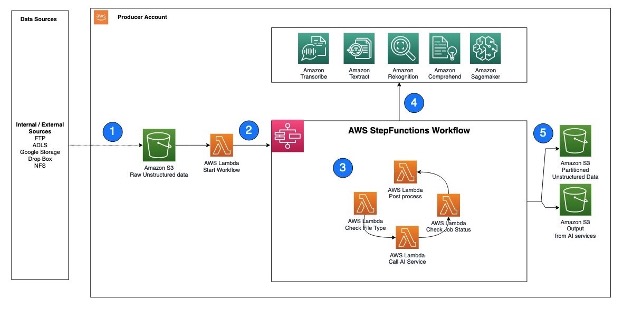
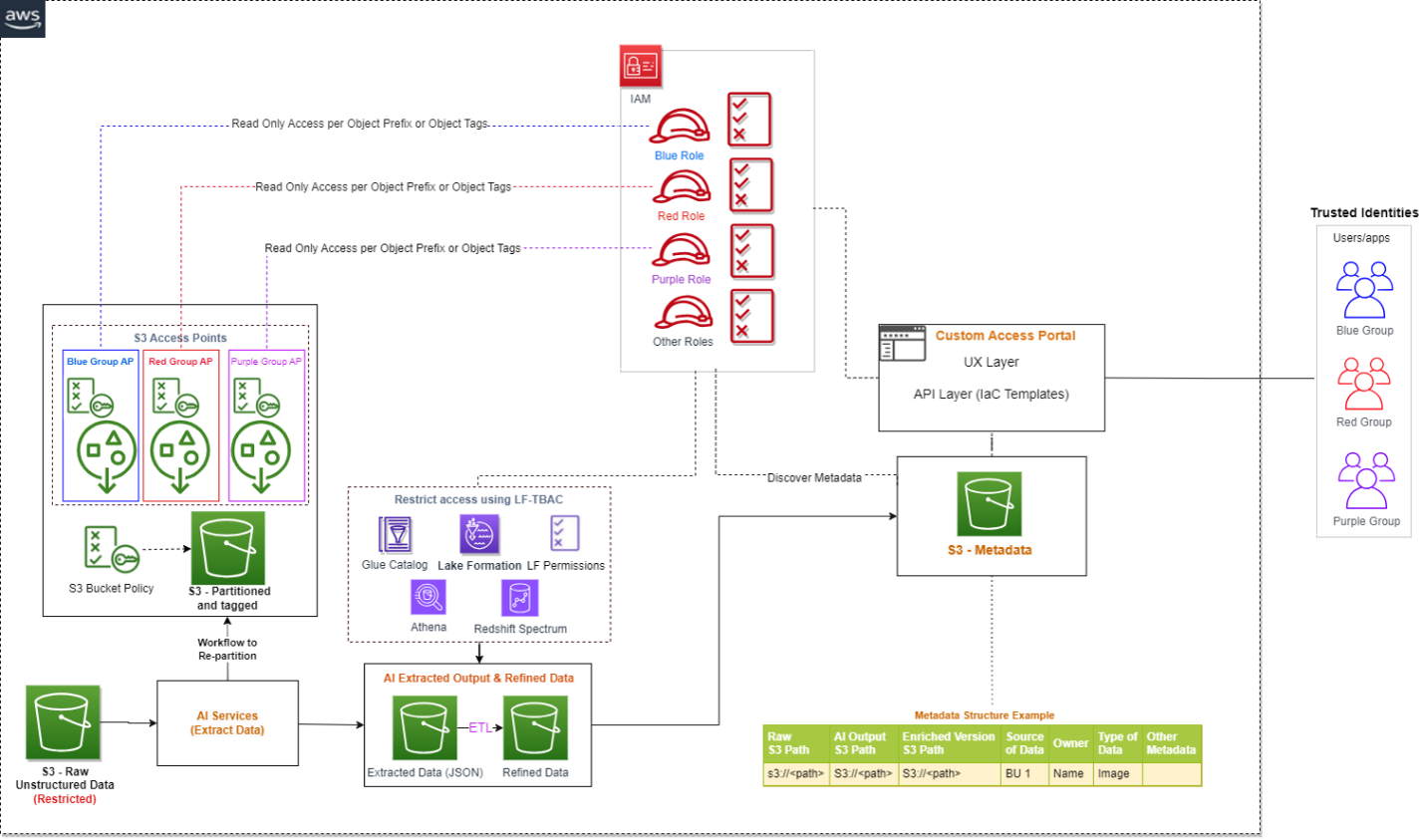
 Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book
Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book  Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries. Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts. Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.
Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.