Post Syndicated from Matt Ulinski original https://aws.amazon.com/blogs/devops/using-jenkins-with-codeartifact/
Python packages are used to share and reuse code across projects. Centralized artifact storage allows sharing versioned artifacts across an organization. This post explains how you can set up two Jenkins projects. The first project builds the Python package and publishes it to AWS CodeArtifact using twine (Python utility for publishing packages), and the second project consumes the package using pip and deploys an application to AWS Fargate.
Solution overview
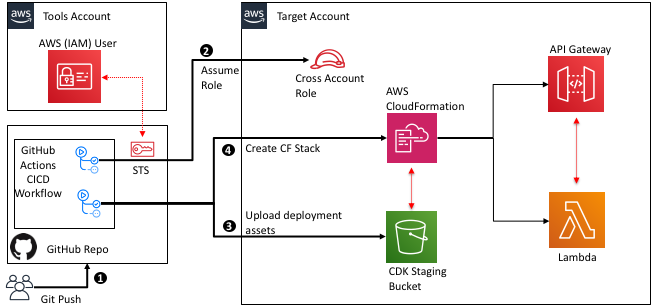
The following diagram illustrates this architecture.

The solution consists of two GitHub repositories and two Jenkins projects. The first repository contains the source code of a Python package. Jenkins builds this package and publishes it to a CodeArtifact repository.
The second repository contains the source code of a Python Flask application that has a dependency on the package produced by the first repository. Jenkins builds a Docker image containing the application and its dependencies, pushes the image to an Amazon Elastic Container Registry (Amazon ECR) registry, and deploys it to AWS Fargate using AWS CloudFormation.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- AWS account
- Amazon Virtual Private Cloud (VPC)
- GitHub account
- Git client and basic knowledge of git
- Jenkins with the following dependencies:
- AWS CLI v1.18.98 and newer, or AWS CLI v2.0.31 and newer.
- Docker
- Git
- Python 3 and pip with the following packages:
- Jenkins plugins:
To create a new Jenkins server that includes the required dependencies, complete the following steps:
- Launch a CloudFormation stack with the following link:

- Choose Next.
- Enter the name for your stack.
- Select the Amazon Elastic Compute Cloud (Amazon EC2) instance type for your Jenkins server.
- Select the subnet and corresponding VPC.
- Choose Next.
- Scroll down to the bottom of the page and choose Next.
- Review the stack configuration and choose Create stack.
AWS CloudFormation creates the following resources:
- JenkinsInstance – Amazon EC2 instance that Jenkins and its dependencies is installed on
- JenkinsWaitCondition – CloudFormation wait condition that waits for Jenkins to be fully installed before finishing the deployment
- JenkinsSecurityGroup – Security group attached to the EC2 instance that allows inbound traffic on port 8080
The stack takes a few minutes to deploy. When it’s fully deployed, you can find the URL and initial password for Jenkins on the Outputs tab of the stack.

Use the initial password to unlock the Jenkins installation, then follow the setup wizard to install the suggested plugins and create a new Jenkins user. After the user is created, the initial password no longer works.
On the Jenkins homepage, complete the following steps:
- Choose Manage Jenkins.
- Choose Manage Plugins.
- On the Available tab, search for “Docker Pipeline” and select it.

- Choose Download now and install after restart.
- Select Restart Jenkins when installation is complete and no jobs are running.


Jenkins is ready to use after it restarts. Log in with the user you created with the setup wizard.
Setting up a CodeArtifact repository
To get started, create a CodeArtifact repository to store the Python packages.
- On the CodeArtifact console, choose Create repository.
- For Repository name, enter a name (for this post, I use my-repository).
- For Public upstream repositories, choose pypi-store.
- Choose Next.

- Choose This AWS account.
- If you already have a CodeArtifact domain, choose it from the drop-down menu. If you don’t already have a CodeArtifact domain, choose a name for your domain and the console creates it for you. For this post, I named my domain my-domain.
- Choose Next.
- Review the repository details and choose Create repository.



You now have a CodeArtifact repository created, which you use to store and retrieve Python packages used by the application.
Configuring Jenkins: Creating an IAM user
- On the IAM console, choose User.
- Choose Add user.
- Enter a name for the user (for this post, I used the name Jenkins).
- Select Programmatic access as the access type.
- Choose Next: Permissions.
- Select Attach existing policies directly.
- Choose the following policies:
- AmazonEC2ContainerRegistryPowerUser – Allows Jenkins to push Docker images to ECR.
- AmazonECS_FullAccess – Allows Jenkins to deploy your application to AWS Fargate.
- AWSCloudFormationFullAccess – Allows Jenkins to update the CloudFormation stack.
- AWSCodeArtifactAdminAccess – Allows Jenkins access to the CodeArtifact repository.
- Choose Next: Tags.
- Choose Next: Review.
- Review the configuration and choose Create user.
- Record the Access key ID and Secret access key; you need them to configure Jenkins.
Configuring Jenkins: Adding credentials
After you create your IAM user, you need to set up the credentials in Jenkins.
- Open Jenkins.
- From the left pane, choose Manage Jenkins
- Choose Manage Credentials.
- Hover over the (global) domain and expand the drop-down menu.
- Choose Add credentials.

- Enter the following credentials:
- Kind – User name with password.
- Scope – Global (Jenkins, nodes, items, all child items).
- Username – Enter the Access key ID for the Jenkins IAM user.
- Password – Enter the Secret access key for the Jenkins IAM user.
- ID – Name for the credentials (for this post, I used AWS).
- Choose OK.

You use the credentials to make API calls to AWS as part of the builds.
Publishing a Python package
To publish your Python package, complete the following steps:
- Create a new GitHub repo to store the source of the sample package.
- Clone the sample GitHub repo onto your local machine.
- Navigate to the package_src directory.
- Place its contents in your GitHub repo.


When your GitHub repo is populated with the sample package, you can create the first Jenkins project.
- On the Jenkins homepage, choose New Item.
- Enter a name for the project; for example, producer.
- Choose Freestyle project.
- Choose OK.

- In the Source Code Management section, choose Git.
- Enter the HTTP clone URL of your GitHub repo into the Repository URL
- To make sure that the workspace is clean before each build, under Additional Behaviors, choose Add and select Clean before checkout.

- To have builds start automatically when a change occurs in the repository, under Build Triggers, select Poll SCM and enter
* * * * *in the Schedule

- In the Build Environment section, select Use secret text(s) or file(s).
- Choose Add and choose Username and password (separated).
- Enter the following information:
- Username –
AWS_ACCESS_KEY_ID - Password –
AWS_SECRET_ACCESS_KEY - Credentials – Select Specific Credentials and from the drop-down menu and choose the previously created credentials.

- Username –
- In the Build section, choose Add build step.
- Choose Execute shell.
- Enter the following command and replace my-domain, my-repository, and my-region with the name of your CodeArtifact domain, repository, and Region:
python3 setup.py sdist bdist_wheel aws codeartifact login --tool twine --domain my-domain --repository my-repository --region my-region python3 -m twine upload dist/* --repository codeartifact
These commands do the following:
- Build the Python package
- Run the
aws codeartifact loginAWS Command Line Interface (AWS CLI) command, which retrieves the access token for CodeArtifact and configures the twine client - Use twine to publish the Python package to CodeArtifact
- Choose Save.
- Start a new build by choosing Build Now in the left pane.After a build starts, it shows in the Build History on the left pane. To view the build’s details, choose the build’s ID number.

- To view the results of the run commands, from the build details page, choose Console Output.
- To see that the package has been successfully published, check the CodeArtifact repository on the console.







When a change is pushed to the repo, Jenkins will start a new build and attempt to publish the package. CodeArtifact will prevent publishing duplicates of the same package version, failing the Jenkins build.
If you want to publish a new version of the package, you will need to increment the version number.
The sample package uses semantic versioning (major.minor.maintenance), to change the version number modify the version='1.0.0' value in the setup.py file. You can do this manually before pushing any changes to the repo, or automatically as part of the build process by using the python-semantic-release package, or a similar solution.
Consuming a package and deploying an application
After you have a package published, you can use it in an application.
- Create a new GitHub repo for this application.
- Populate it with the contents of the application_src directory from the sample repo.


The version of the sample package used by the application is defined in the requirements.txt file. If you have published a new version of the package and want the application to use it modify the fantastic-ascii==1.0.0 value in this file.
After the repository created, you need to deploy the CloudFormation template application.yml. The template creates the following resources:
- ECRRepository – Amazon ECR repository to store your Docker image.
- Cluster – Amazon Elastic Container Service (Amazon ECS) cluster that contains the service of your application.
- TaskDefinition – ECS task definition that defines how your Docker image is deployed.
- ExecutionRole – IAM role that Amazon ECS uses to pull the Docker image.
- TaskRole – IAM role provided to the ECS task.
- ContainerSecurityGroup – Security group that allows outbound traffic to ports 8080 and 80.
- Service – Amazon ECS service that launches and manages your Docker containers.
- TargetGroup – Target group used by the Load Balancer to send traffic to Docker containers.
- Listener – Load Balancer Listener that listens for incoming traffic on port 80.
- LoadBalancer – Load Balancer that sends traffic to the ECS task.
- Choose the following link to create the application’s CloudFormation stack:
- Choose Next.
- Enter the following parameters:
- Stack name – Name for the CloudFormation stack. For this post, I use the name Consumer.
- Container Name – Name for your application (for this post, I use
application). - Image Tag – Leave this field blank. Jenkins populates it when you deploy the application.
- VPC – Choose a VPC in your account that contains two public subnets.
- SubnetA – Choose a public subnet from the previously chosen VPC.
- SubnetB – Choose a public subnet from the previously chosen VPC.
- Choose Next.
- Scroll down to the bottom of the page and choose Next.
- Review the configuration of the stack.
- Acknowledge the IAM resources warning to allow CloudFormation to create the TaskRole IAM role.
- Choose Create Stack.
After the stack is created, the Outputs tab contains information you can use to configure the Jenkins project.

To access the sample application, choose the ApplicationUrl link. Because the application has not yet been deployed, you receive an error message.
You can now create the second Jenkins project, which uses a configured through a Jenkinsfile stored in the source repository. The Jenkinsfile defines the steps that the build takes to build and deploy a Docker image containing your application.
The Jenkinsfile included in the sample instructs Jenkins to perform these steps:
- Get the authorization token for CodeArtifact:
- Start a Docker build and pass the authorization token as an argument to the build:
- Inside of Docker, the passed argument is used to configure pip to use CodeArtifact:
- Test the image by starting a container and performing a simple GET request.
- Log in to the Amazon ECR repository and push the Docker image.
- Update the CloudFormation template and start a deployment of the application.
Look at the Jenkinsfile and Dockerfile in your repository to review the exact commands being used, then take the following steps to setup the second Jenkins projects:
- Change the variables defined in the environment section at the top of the Jenkinsfile:
environment {
AWS_ACCOUNT_ID = 'Your AWS Account ID'
AWS_REGION = 'Region you used for this project'
AWS_CA_DOMAIN = 'Name of your CodeArtifact domain'
AWS_CA_REPO = 'Name of your CodeArtifact repository'
AWS_STACK_NAME = 'Name of the CloudFormation stack'
CONTAINER_NAME = 'Container name provided to CloudFormation'
CREDENTIALS_ID = 'Jenkins credentials ID'
} - Commit the changes to the GitHub repo.
- To create a new Jenkins project, on the Jenkins homepage, choose New Item.
- Enter a name for the project, for example, Consumer.
- Choose Pipeline.
- Choose OK.

- To have a new build start automatically when a change is detected in the repository, under Build Triggers, select Poll SCM and enter
* * * * *in the Schedule field.

- In the Pipeline section, choose Pipeline script from SCM from the Definition drop-down menu.
- Choose Git for the SCM
- Enter the HTTP clone URL of your GitHub repo into the Repository URL
- To make sure that your workspace is clean before each build, under Additional Behaviors, choose Add and select Clean before checkout.

- Choose Save.



The Jenkins project is now ready. To start a new job, choose Build Now from the navigation pane. You see a visualization of the pipeline as it moves through the various stages, gathering the dependencies and deploying your application.

When the Deploy to ECS stage of the pipeline is complete, you can choose ApplicationUrl on the Outputs tab of the CloudFormation stack. You see a simple webpage that uses the Python package to display the current time.

Cleaning up
To avoid incurring future charges, delete the resources created in this post.
To empty the Amazon ECR repository:
- Open the application’s CloudFormation stack.
- On the Resources tab, choose the link next to the ECRRepository
- Select the check-box next to each of the images in the repository.
- Choose Delete.
- Confirm the deletion.
To delete the CloudFormation stacks:
- On the AWS CloudFormation console, select the application stack you deployed earlier.
- Choose Delete.
- Confirm the deletion.
If you created a Jenkins as part of this post, select the Jenkins stack and delete it.
To delete the CodeArtifact repository:
- On the CodeArtifact console, navigate to the repository you created.
- Choose Delete.
- Confirm the deletion.
If you’re not using the CodeArtifact domain for other repositories, you should follow the previous steps to delete the pypi-store repository, because it contains the public packages that were used by the application, then delete the CodeArtifact domain:
- On the CodeArtifact console, navigate to the domain you created.
- Choose Delete.
- Confirm the deletion.
Conclusion
In this post I showed how you can use Jenkins to publish and consume a Python package with Jenkins and CodeArtifact. I walked you through creating two Jenkins projects, a Jenkins freestyle project that built a package and published it to CodeArtifact, and a Jenkins pipeline project that built a Docker image that used the package in an application that was deployed to AWS Fargate.
About the author
 |
Matt Ulinski is a Cloud Support Engineer with Amazon Web Services. |



















 Ease of development
Ease of development




{kind=link}
{kind=link}