Post Syndicated from Ilya Epshteyn original https://aws.amazon.com/blogs/security/a-sneak-peek-at-the-identity-and-access-management-sessions-for-aws-reinforce-2022/
Register now with discount code SALFNj7FaRe to get $150 off your full conference pass to AWS re:Inforce. For a limited time only and while supplies last.

AWS re:Inforce 2022 will take place in-person in Boston, MA, on July 26 and 27 and will include some exciting identity and access management sessions. AWS re:Inforce 2022 features content in the following five areas:
- Data protection and privacy
- Governance, risk, and compliance
- Identity and access management
- Network and infrastructure security
- Threat detection and incident response
The identity and access management track will showcase how quickly you can get started to securely manage access to your applications and resources as you scale on AWS. You will hear from customers about how they integrate their identity sources and establish a consistent identity and access strategy across their on-premises environments and AWS. Identity experts will discuss best practices for establishing an organization-wide data perimeter and simplifying access management with the right permissions, to the right resources, under the right conditions. You will also hear from AWS leaders about how we’re working to make identity, access control, and resource management simpler every day. This post highlights some of the identity and access management sessions that you can add to your agenda. To learn about sessions from across the content tracks, see the AWS re:Inforce catalog preview.
Breakout sessions
Lecture-style presentations that cover topics at all levels and are delivered by AWS experts, builders, customers, and partners. Breakout sessions typically conclude with 10–15 minutes of Q&A.
IAM201: Security best practices with AWS IAM
AWS IAM is an essential service that helps you securely control access to your AWS resources. In this session, learn about IAM best practices like working with temporary credentials, applying least-privilege permissions, moving away from users, analyzing access to your resources, validating policies, and more. Leave this session with ideas for how to secure your AWS resources in line with AWS best practices.
IAM301: AWS Identity and Access Management (IAM) the practical way
Building secure applications and workloads on AWS means knowing your way around AWS Identity and Access Management (AWS IAM). This session is geared toward the curious builder who wants to learn practical IAM skills for defending workloads and data, with a technical, first-principles approach. Gain knowledge about what IAM is and a deeper understanding of how it works and why.
IAM302: Strategies for successful identity management at scale with AWS SSO
Enterprise organizations often come to AWS with existing identity foundations. Whether new to AWS or maturing, organizations want to better understand how to centrally manage access across AWS accounts. In this session, learn the patterns many customers use to succeed in deploying and operating AWS Single Sign-On at scale. Get an overview of different deployment strategies, features to integrate with identity providers, application system tags, how permissions are deployed within AWS SSO, and how to scale these functionalities using features like attribute-based access control.
IAM304: Establishing a data perimeter on AWS, featuring Vanguard
Organizations are storing an unprecedented and increasing amount of data on AWS for a range of use cases including data lakes, analytics, machine learning, and enterprise applications. They want to make sure that sensitive non-public data is only accessible to authorized users from known locations. In this session, dive deep into the controls that you can use to create a data perimeter that allows access to your data only from expected networks and by trusted identities. Hear from Vanguard about how they use data perimeter controls in their AWS environment to meet their security control objectives.
IAM305: How Guardian Life validates IAM policies at scale with AWS
Attend this session to learn how Guardian Life shifts IAM security controls left to empower builders to experiment and innovate quickly, while minimizing the security risk exposed by granting over-permissive permissions. Explore how Guardian validates IAM policies in Terraform templates against AWS best practices and Guardian’s security policies using AWS IAM Access Analyzer and custom policy checks. Discover how Guardian integrates this control into CI/CD pipelines and codifies their exception approval process.
IAM306: Managing B2B identity at scale: Lessons from AWS and Trend Micro
Managing identity for B2B multi-tenant solutions requires tenant context to be clearly defined and propagated with each identity. It also requires proper onboarding and automation mechanisms to do this at scale. Join this session to learn about different approaches to managing identities for B2B solutions with Amazon Cognito and learn how Trend Micro is doing this effectively and at scale.
IAM307: Automating short-term credentials on AWS, with Discover Financial Services
As a financial services company, Discover Financial Services considers security paramount. In this session, learn how Discover uses AWS Identity and Access Management (IAM) to help achieve their security and regulatory obligations. Learn how Discover manages their identities and credentials within a multi-account environment and how Discover fully automates key rotation with zero human interaction using a solution built on AWS with IAM, AWS Lambda, Amazon DynamoDB, and Amazon S3.
Builders’ sessions
Small-group sessions led by an AWS expert who guides you as you build the service or product on your own laptop. Use your laptop to experiment and build along with the AWS expert.
IAM351: Using AWS SSO and identity services to achieve strong identity management
Organizations often manage human access using IAM users or through federation with external identity providers. In this builders’ session, explore how AWS SSO centralizes identity federation across multiple AWS accounts, replaces IAM users and cross-account roles to improve identity security, and helps administrators more effectively scope least privilege. Additionally, learn how to use AWS SSO to activate time-based access and attribute-based access control.
IAM352: Anomaly detection and security insights with AWS Managed Microsoft AD
This builders’ session demonstrates how to integrate AWS Managed Microsoft AD with native AWS services like Amazon CloudWatch Logs and Amazon CloudWatch metrics and alarms, combined with anomaly detection, to identify potential security issues and provide actionable insights for operational security teams.
Chalk talks
Highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds.
IAM231: Prevent unintended access: AWS IAM Access Analyzer policy validation
In this chalk talk, walk through ways to use AWS IAM Access Analyzer policy validation to review IAM policies that do not follow AWS best practices. Learn about the Access Analyzer APIs that help validate IAM policies and how to use these APIs to prevent IAM policies from reaching your AWS environment through mechanisms like AWS CloudFormation hooks and CI/CD pipeline controls.
IAM232: Navigating the consumer identity first mile using Amazon Cognito
Amazon Cognito allows you to configure sign-in and sign-up experiences for consumers while extending user management capabilities to your customer-facing application. Join this chalk talk to learn about the first steps for integrating your application and getting started with Amazon Cognito. Learn best practices to manage users and how to configure a customized branding UI experience, while creating a fully managed OpenID Connect provider with Amazon Cognito.
IAM331: Best practices for delegating access on AWS
This chalk talk demonstrates how to use built-in capabilities of AWS Identity and Access Management (IAM) to safely allow developers to grant entitlements to their AWS workloads (PassRole/AssumeRole). Additionally, learn how developers can be granted the ability to take self-service IAM actions (CRUD IAM roles and policies) with permissions boundaries.
IAM332: Developing preventive controls with AWS identity services
Learn about how you can develop and apply preventive controls at scale across your organization using service control policies (SCPs). This chalk talk is an extension of the preventive controls within the AWS identity services guide, and it covers how you can meet the security guidelines of your organization by applying and developing SCPs. In addition, it presents strategies for how to effectively apply these controls in your organization, from day-to-day operations to incident response.
IAM333: IAM policy evaluation deep dive
In this chalk talk, learn how policy evaluation works in detail and walk through some advanced IAM policy evaluation scenarios. Learn how a request context is evaluated, the pros and cons of different strategies for cross-account access, how to use condition keys for actions that touch multiple resources, when to use principal and aws:PrincipalArn, when it does and doesn’t make sense to use a wildcard principal, and more.
Workshops
Interactive learning sessions where you work in small teams to solve problems using AWS Cloud security services. Come prepared with your laptop and a willingness to learn!
IAM271: Applying attribute-based access control using AWS IAM
This workshop provides hands-on experience applying attribute-based access control (ABAC) to achieve a secure and scalable authorization model on AWS. Learn how and when to apply ABAC, which is native to AWS Identity and Access Management (IAM). Also learn how to find resources that could be impacted by different ABAC policies and session tagging techniques to scale your authorization model across Regions and accounts within AWS.
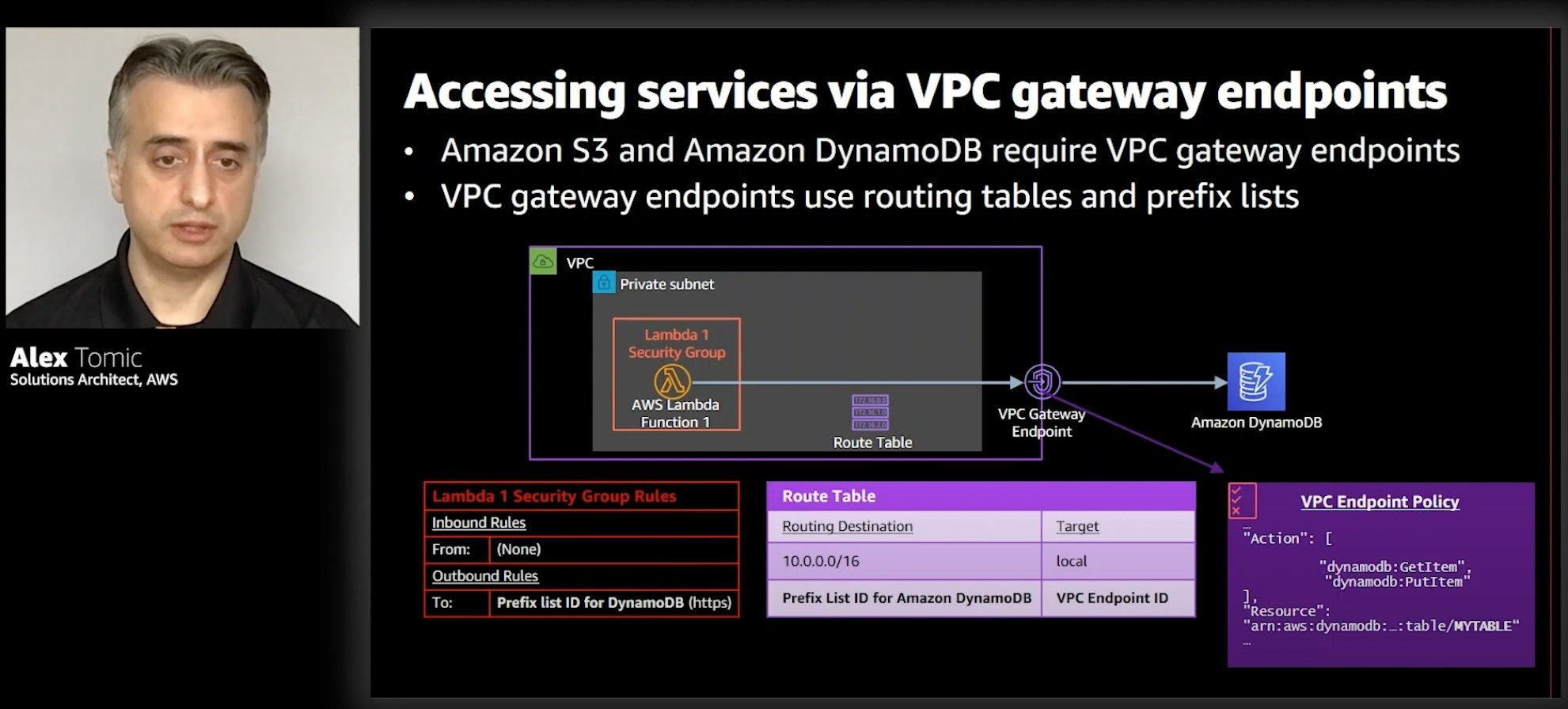
IAM371: Building a data perimeter to allow access to authorized users
In this workshop, learn how to create a data perimeter by building controls that allow access to data only from expected network locations and by trusted identities. The workshop consists of five modules, each designed to illustrate a different AWS Identity and Access Management (IAM) and network control. Learn where and how to implement the appropriate controls based on different risk scenarios. Discover how to implement these controls as service control policies, identity- and resource-based policies, and virtual private cloud endpoint policies.
IAM372: How and when to use different IAM policy types
In this workshop, learn how to identify when to use various policy types for your applications. Work through hands-on labs that take you through a typical customer journey to configure permissions for a sample application. Configure policies for your identities, resources, and CI/CD pipelines using permission delegation to balance security and agility. Also learn how to configure enterprise guardrails using service control policies.
If these sessions look interesting to you, join us in Boston by registering for re:Inforce 2022. We look forward to seeing you there!




![[Infographic] Cloud Misconfigurations: Don't Become a Breach Statistic](https://blog.rapid7.com/content/images/2022/05/miconfigurations-infographic-clip2.jpg)
![[Infographic] Cloud Misconfigurations: Don't Become a Breach Statistic](https://blog.rapid7.com/content/images/2022/05/Rapid7-Cloud-Misconfigurations-Infographic-print.png)