Most email newsletters you get include an invisible “image,” typically a single white pixel, with a unique file name. The server keeps track of every time this “image” is opened and by which IP address. This quirk of internet history means that marketers can track exactly when you open an email and your IP address, which can be used to roughly work out your location.
So, how does Apple Mail stop this? By caching. Apple Mail downloads all images for all emails before you open them. Practically speaking, that means every message downloaded to Apple Mail is marked “read,” regardless of whether you open it. Apples also routes the download through two different proxies, meaning your precise location also can’t be tracked.
Crypto-Gram uses Mailchimp, which has these tracking pixels turned on by default. I turn them off. Normally, Mailchimp requires them to be left on for the first few mailings, presumably to prevent abuse. The company waived that requirement for me.
In early 2020, we sat down and tried thinking if there’s a way to load third-party tools on the Internet without slowing down websites, without making them less secure, and without sacrificing users’ privacy. In the evening, after scanning through thousands of websites, our answer was “well, sort of”. It seemed possible: many types of third-party tools are merely collecting information in the browser and then sending it to a remote server. We could theoretically figure out what it is that they’re collecting, and then instead just collect it once efficiently, and send it server-side to their servers, mimicking their data schema. If we do this, we can get rid of loading their JavaScript code inside websites completely. This means no more risk of malicious scripts, no more performance losses, and fewer privacy concerns.
But the answer wasn’t a definite “YES!” because we realized this is going to be very complicated. We looked into the network requests of major third-party scripts, and often it seemed cryptic. We set ourselves up for a lot of work, looking at the network requests made by tools and trying to figure out what they are doing – What is this parameter? When is this network request sent? How is this value hashed? How can we achieve the same result more securely, reliably and efficiently? Our team faced these questions on a daily basis.
When we joined Cloudflare, the scale of everything changed. Suddenly we were on thousands of websites, serving more than 10,000 requests per second. Users are writing to us every single day over our Discord channel, the community forum, and sometimes even directly on Twitter. More often than not, their messages would be along the lines of “Hi! Can you please add support for X?” Cloudflare Zaraz launched with around 30 tools in its library, but this market is vast and new tools are popping up all the time.
Changing our trust model
In my previous blog post on how Zaraz uses Cloudflare Workers, I included some examples of how tool integrations are written in Zaraz today. Usually, a “tool” in Zaraz would be a function that prepares a payload and sends it. This function could return one thing – clientJS, JavaScript code that the browser would later execute. We’ve done our best so that tools wouldn’t use clientJS, if it wasn’t really necessary, and in reality most Zaraz-built tool integrations are not using clientJS at all.
This worked great, as long as we were the ones coding all tool integrations. Customers trusted us that we’d write code that is performant and safe, and they trusted the results they saw when trying Zaraz. Upon joining Cloudflare, many third-party tool vendors contacted us and asked to write a Zaraz integration. We quickly realized that our system wasn’t enforcing speed and safety – vendors could literally just dump their old browser-side JavaScript into our clientJS variable, and say “We have a Cloudflare Zaraz integration!”, and that wasn’t our vision at all.
We want third-party tool vendors to be able to write their own performant, safe server-side integrations. We want to make it possible for them to reimagine their tools in a better way. We also want website owners to have transparency into what is happening on their website, to be able to manage and control it, and to trust that if a tool is running through Zaraz, it must be a good tool — not because of who wrote it, but because of the technology it is constructed within. We realized that to achieve that we needed a new format for defining third-party tools.
Introducing Managed Components
We started rethinking how third-party code should be written. Today, it’s a black box – you usually add a script to your site, and you have zero clue what it does and when. You can’t properly read or analyze the minified code. You don’t know if the way it behaves for you is the same way it behaves for everyone else. You don’t know when it might change. If you’re a website owner, you’re completely in the dark.
Tools do many different things. The simple ones just collected information and sent it somewhere. Often, they’d set some cookies. Sometimes, they’d install some event listeners on the page. And widget-based tools can literally manipulate the page DOM, providing new functionality like a social media embed or a chatbot. Our new format needed to support all of this.
Managed Components is how we imagine the future of third-party tools online. It provides vendors with an API that allows them to do much more than a normal script can, including keeping code execution outside the browser. We designed this format together with vendors, for vendors, while having in mind that users’ best interest is everyone’s best interest long-term.
From the get-go, we built Managed Components to use a permission-based system. We want to provide even more transparency than Zaraz does today. As the new API allows tools to set cookies, change the DOM or collect IP addresses, all those abilities require being granted a permission. Installing a third-party tool on your site is similar to installing an app on your phone – you get an explanation of what the tool can and can’t do, and you can allow or disallow features to a granular level. We previously wrote about how you can use Zaraz to not send IP addresses to Google Analytics, and now we’re doubling down in this direction. It’s your website, and it’s your decision to make.
Every Managed Component is a JavaScript module at its core. Unlike today, this JavaScript code isn’t sent to the browser. Instead, it is executed by a Components Manager. This manager implements the APIs that are then used by the component. It dispatches server-side events that originate in the browser, providing the components with access to information while keeping them sandboxed and performant. It handles caching, storage and more — all so that the Managed Components can implement their logic without worrying so much about the surrounding.
An example analytics Managed Component can look something like this:
The above component gets notified whenever a page view occurs, and it then creates some payload with the visitor user-agent and page URL and sends that as a POST request to the vendor’s server. This is very similar to how things are done today, except this doesn’t require running any code at all in the browser.
But Managed Components aren’t just doing what was previously possible but better, they also provide dramatic new functionality. See for example how we’re exposing server-side endpoints:
export default function (manager) {
const api = manager.proxy("/api", "https://api.example.com");
const assets = manager.serve("/assets", "assets");
const ping = manager.route("/ping", (request) => new Response(204));
}
These three lines are a complete shift in what’s possible for third-parties. If granted the permissions, they can proxy some content, serve and expose their own endpoints – all under the same domain as the one running the website. If a tool needs to do some processing, it can now off-load that from the browser completely without forcing the browser to communicate with a third-party server.
Exciting new capabilities
Every third-party tool vendor should be able to use the Managed Components API to build a better version of their tool. The API we designed is comprehensive, and the benefits for vendors are huge:
Same domain: Managed Components can serve assets from the same domain as the website itself. This allows a faster and more secure execution, as the browser needs to trust and communicate with only one server instead of many. This can also reduce costs for vendors as their bandwidth will be lowered.
Website-wide events system: Managed Components can hook to a pre-existing events system that is used by the website for tracking events. Not only is there no need to provide a browser-side API to your tool, it’s also easier for your users to send information to your tool because they don’t need to learn your methods.
Server logic: Managed Components can provide server-side logic on the same domain as the website. This includes proxying a different server, or adding endpoints that generate dynamic responses. The options are endless here, and this, too, can reduce the load on the vendor servers.
Server-side rendered widgets and embeds: Did you ever notice how when you’re loading an article page online, the content jumps when some YouTube or Twitter embed suddenly appears between the paragraphs? Managed Components provide an API for registering widgets and embed that render server-side. This means that when the page arrives to the browser, it already includes the widget in its code. The browser doesn’t need to communicate with another server to fetch some tweet information or styling. It’s part of the page now, so expect a better CLS score.
Reliable cross-platform events: Managed Components can subscribe to client-side events such as clicks, scroll and more, without needing to worry about browser or device support. Not only that – those same events will work outside the browser too – but we’ll get to that later.
Pre-Response Actions: Managed Components can execute server-side actions before the network response even arrives in the browser. Those actions can access the response object, reading it or altering it.
Integrated Consent Manager support: Managed Components are predictable and scoped. The Component Manager knows what they’ll need and can predict what kind of consent is needed to run them.
The right choice: open source
As we started working with vendors on creating a Managed Component for their tool, we heard a repeating concern – “What Components Managers are there? Will this only be useful for Cloudflare Zaraz customers?”. While Cloudflare Zaraz is indeed a Components Manager, and it has a generous free tier plan, we realized we need to think much bigger. We want to make Managed Components available for everyone on the Internet, because we want the Internet as a whole to be better.
Today, we’re announcing much more than just a new format.
WebCM is a reference implementation of the Managed Components API. It is a complete Components Manager that we will soon release and maintain. You will be able to use it as an SDK when building your Managed Component, and you will also be able to use it in production to load Managed Components on your website, even if you’re not a Cloudflare customer. WebCM works as a proxy – you place it before your website, and it rewrites your pages when necessary and adds a couple of endpoints. This makes WebCM 100% framework-agnostic – it doesn’t matter if your website uses Node.js, Python or Ruby behind the scenes: as long as you’re sending out HTML, it supports that.
That’s not all though! We’re also going to open source a few Managed Components of our own. We converted some of our classic Zaraz integrations to Managed Components, and they will soon be available for you to use and improve. You will be able to take our Google Analytics Managed Component, for example, and use WebCM to run Google Analytics on your website, 100% server-side, without Cloudflare.
Tech-leading vendors are already joining
Revolutionizing third-party tools on the internet is something we could only do together with third-party vendors. We love third-party tools, and we want them to be even more popular. That’s why we worked very closely with a few leading companies on creating their own Managed Components. These new Managed Components extend Zaraz capabilities far beyond what’s possible now, and will provide a safe and secure onboarding experience for new users of these tools.
Drift – Drift helps businesses connect with customers in moments that matter most. Drift’s integration will let customers use their fully-featured conversation solution while also keeping it completely sandboxed and without making third-party network connections, increasing privacy and security for our users.
CrazyEgg – Crazy Egg helps customers make their websites better through visual heatmaps, A/B testing, detailed recordings, surveys and more. Website owners, Cloudflare, and Crazy Egg all care deeply about performance, security and privacy. Managed Components have enabled Crazy Egg to do things that simply aren’t possible with third-party JavaScript, which means our mutual customers will get one of the most performant and secure website optimization tools created.
We also already have customers that are eager to implement Managed Components:
Hopin Quote:
“I have been really impressed with Cloudflare’s Zaraz ability to move Drift’s JS library to an Edge Worker while loading it off the DOM. My work is much more effective due to the savings in page load time. It’s a pleasure to work with two companies that actively seek better ways to increase both page speed and load times with large MarTech stacks.” – Sean Gowing, Front End Engineer, Hopin
If you’re a third-party vendor, and you want to join these tech-leading companies, do reach out to us, and we’d be happy to support you on writing your own Managed Component.
What’s next for Managed Components
We’re working on Managed Components on many fronts now. While we develop and maintain WebCM, work with vendors and integrate Managed Components into Cloudflare Zaraz, we’re already thinking about what’s possible in the future.
We see a future where many open source runtimes exist for Managed Components. Perhaps your infrastructure doesn’t allow you to use WebCM? We want to see Managed Components runtimes created as service workers, HTTP servers, proxies and framework plugins. We’re also working on making Managed Components available on mobile applications. We’re working on allowing unofficial Managed Components installs on Cloudflare Zaraz. We’re fixing a long-standing issue of the WWW, and there’s so much to do.
We will very soon publish the full specs of Managed Components. We will also open source WebCM, the reference implementation server, as well as many components you can use yourself. If this is interesting to you, reach out to us at [email protected], or join us on Discord.
Abstract: In the post-pandemic era, video conferencing apps (VCAs) have converted previously private spaces — bedrooms, living rooms, and kitchens — into semi-public extensions of the office. And for the most part, users have accepted these apps in their personal space, without much thought about the permission models that govern the use of their personal data during meetings. While access to a device’s video camera is carefully controlled, little has been done to ensure the same level of privacy for accessing the microphone. In this work, we ask the question: what happens to the microphone data when a user clicks the mute button in a VCA? We first conduct a user study to analyze users’ understanding of the permission model of the mute button. Then, using runtime binary analysis tools, we trace raw audio in many popular VCAs as it traverses the app from the audio driver to the network. We find fragmented policies for dealing with microphone data among VCAs — some continuously monitor the microphone input during mute, and others do so periodically. One app transmits statistics of the audio to its telemetry servers while the app is muted. Using network traffic that we intercept en route to the telemetry server, we implement a proof-of-concept background activity classifier and demonstrate the feasibility of inferring the ongoing background activity during a meeting — cooking, cleaning, typing, etc. We achieved 81.9% macro accuracy on identifying six common background activities using intercepted outgoing telemetry packets when a user is muted.
A new International Data Corporation (IDC) whitepaper sponsored by AWS, Trusted Cloud: Overcoming the Tension Between Data Sovereignty and Accelerated Digital Transformation, examines the importance of the cloud in building the future of digital EU organizations. IDC predicts that 70% of CEOs of large European organizations will be incentivized to generate at least 40% of their revenues from digital by 2025, which means they have to accelerate their digital transformation. In a 2022 IDC survey of CEOs across Europe, 46% of European CEOs will accelerate the shift to cloud as their most strategic IT initiative in 2022.
In the whitepaper, IDC offers perspectives on how operational effectiveness, digital investment, and ultimately business growth need to be balanced with data sovereignty requirements. IDC defines data sovereignty as “a subset of digital sovereignty. It is the concept of data being subject to the laws and governance structures within the country it is collected or pertains to.”
IDC provides a perspective on some of the current discourse on cloud data sovereignty, including extraterritorial reach of foreign intelligence under national security laws, and the level of protection for individuals’ privacy in-country or with cross-border data transfer. The Schrems II decision and its implications with respect to personal data transfers between the EU and US has left many organizations grappling with how to comply with their legal requirements when transferring data outside the EU.
IDC provides the following background on controls in the cloud:
Cloud providers do not have unrestricted access to customer data in the cloud. Organizations retain all ownership and control of their data. Through credential and permission settings, the customer is the controller of who has access to their data.
Cloud providers use a rigorous set of organizational and technical controls based on least privilege to protect data from unauthorized access and inappropriate use.
Most cloud service operations, including maintenance and trouble-shooting, are fully automated. Should human access to customer data be required, it is temporary and limited to what is necessary to provide the contracted service to the customer. All access should be strictly logged, monitored, and audited to verify that activity is valid and compliant.
Technical controls such as encryption and key management assume greater importance. Encryption is considered fundamental to data protection best practices and highly recommended by regulators. Encrypted data processed in memory within hardware-based trusted execution environment (TEEs), also known as enclaves, can alleviate these regulatory concerns by rendering sensitive information invisible to host operating systems and cloud providers. The AWS Nitro System, the underlying platform that runs Amazon EC2 instances, is an industry example that provides such protection capability.
Independent accreditation against official standards are a recognized basis for assessing adherence to privacy and security practices. Approved by the European Data Protection Board, the EU Cloud Code of Conduct and CISPE’s Code of Conduct for Cloud Infrastructure Service Providers provide an accountability framework to help demonstrate compliance with processor obligations under GDPR Article 28. Whilst not required for GDPR compliance, CISPE requires accredited cloud providers to offer customers the option to retain all personal data in their customer content in the European Economic Area (EEA).
Greater data control and security is often cited as a driver to hosting data in-country. However, IDC notes that the physical location of the data has no bearing on mitigating data risk to cyber threats. Data residency can run counter to an organization’s objectives for security and resilience. More and more European organizations now are trusting the cloud for their security needs, as many organizations simply do not have the resource and expertise to provide the same security benefits as large cloud providers can.
FinFisher has shutdownoperations. This is the spyware company whose products were used, among other things, to spy on Turkish and Bahraini political opposition.
How do you know the code your web browser downloads when visiting a website is the code the website intended you to run? In contrast to a mobile app downloaded from a trusted app store, the web doesn’t provide the same degree of assurance that the code hasn’t been tampered with. Today, we’re excited to be partnering with WhatsApp to provide a system that assures users that the code run when they visit WhatsApp on the web is the code that WhatsApp intended.
With WhatsApp usage in the browser growing, and the increasing number of at-risk users — including journalists, activists, and human rights defenders — WhatsApp wanted to take steps to provide assurances to browser-based users. They approached us to help dramatically raise the bar for third-parties looking to compromise or otherwise tamper with the code responsible for end-to-end encryption of messages between WhatsApp users.
So how will this work? Cloudflare holds a hash of the code that WhatsApp users should be running. When users run WhatsApp in their browser, the WhatsApp Code Verify extension compares a hash of that code that is executing in their browser with the hash that Cloudflare has — enabling them to easily see whether the code that is executing is the code that should be.
The idea itself — comparing hashes to detect tampering or even corrupted files — isn’t new, but automating it, deploying it at scale, and making sure it “just works” for WhatsApp users is. Given the reach of WhatsApp and the implicit trust put into Cloudflare, we want to provide more detail on how this system actually works from a technical perspective.
Before we dive in, there’s one important thing to explicitly note: Cloudflare is providing a trusted audit endpoint to support Code Verify. Messages, chats or other traffic between WhatsApp users are never sent to Cloudflare; those stay private and end-to-end encrypted. Messages or media do not traverse Cloudflare’s network as part of this system, an important property from Cloudflare’s perspective in our role as a trusted third party.
Making verification easier
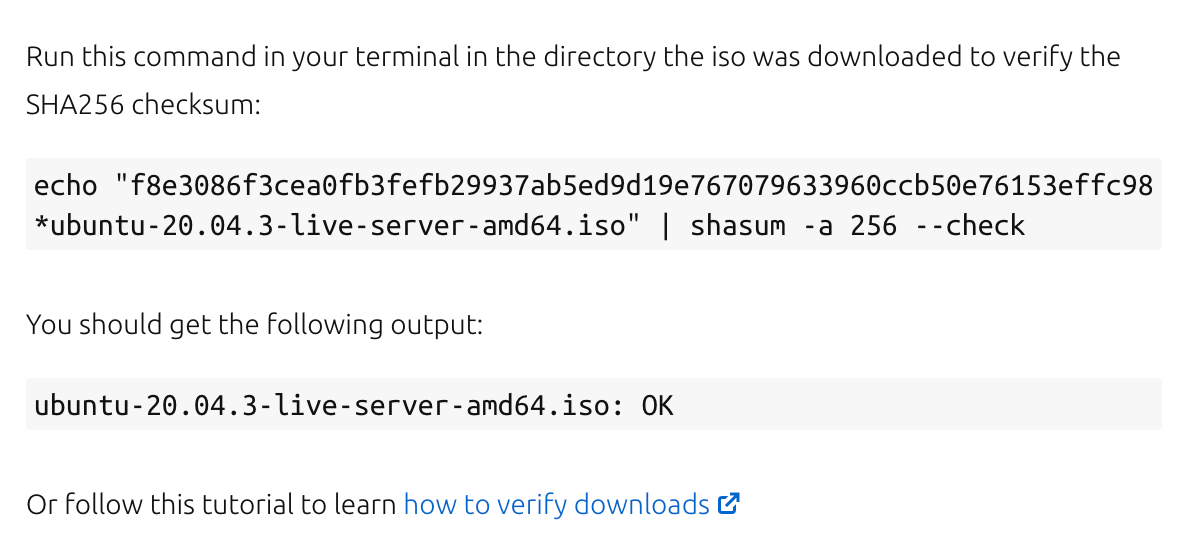
Hark back to 2003: Fedora, a popular Linux distribution based on Red Hat, has just been launched. You’re keen to download it, but want to make sure you have the “real” Fedora, and that the download isn’t a “fake” version that siphons off your passwords or logs your keystrokes. You head to the download page, kick off the download, and see an MD5 hash (considered secure at the time) next to the download. After the download is complete, you run md5 fedora-download.iso and compare the hash output to the hash on the page. They match, life is good, and you proceed to installing Fedora onto your machine.
But hold on a second: if the same website providing the download is also providing the hash, couldn’t a malicious actor replace both the download and the hash with their own values? The md5 check we ran above would still pass, but there’s no guarantee that we have the “real” (untampered) version of the software we intended to download.
Hosting the hash on the same server as the software is still common in 2022.
There are other approaches that attempt to improve upon this — providing signed signatures that users can verify were signed with “well known” public keys hosted elsewhere. Hosting those signatures (or “hashes”) with a trusted third party dramatically raises the bar when it comes to tampering, but now we require the user to know who to trust, and require them to learn tools like GnuPG. That doesn’t help us trust and verify software at the scale of the modern Internet.
This is where the Code Verify extension and Cloudflare come in. The Code Verify extension, published by Meta Open Source, automates this: locally computing the cryptographic hash of the libraries used by WhatsApp Web and comparing that hash to one from a trusted third-party source (Cloudflare, in this case).
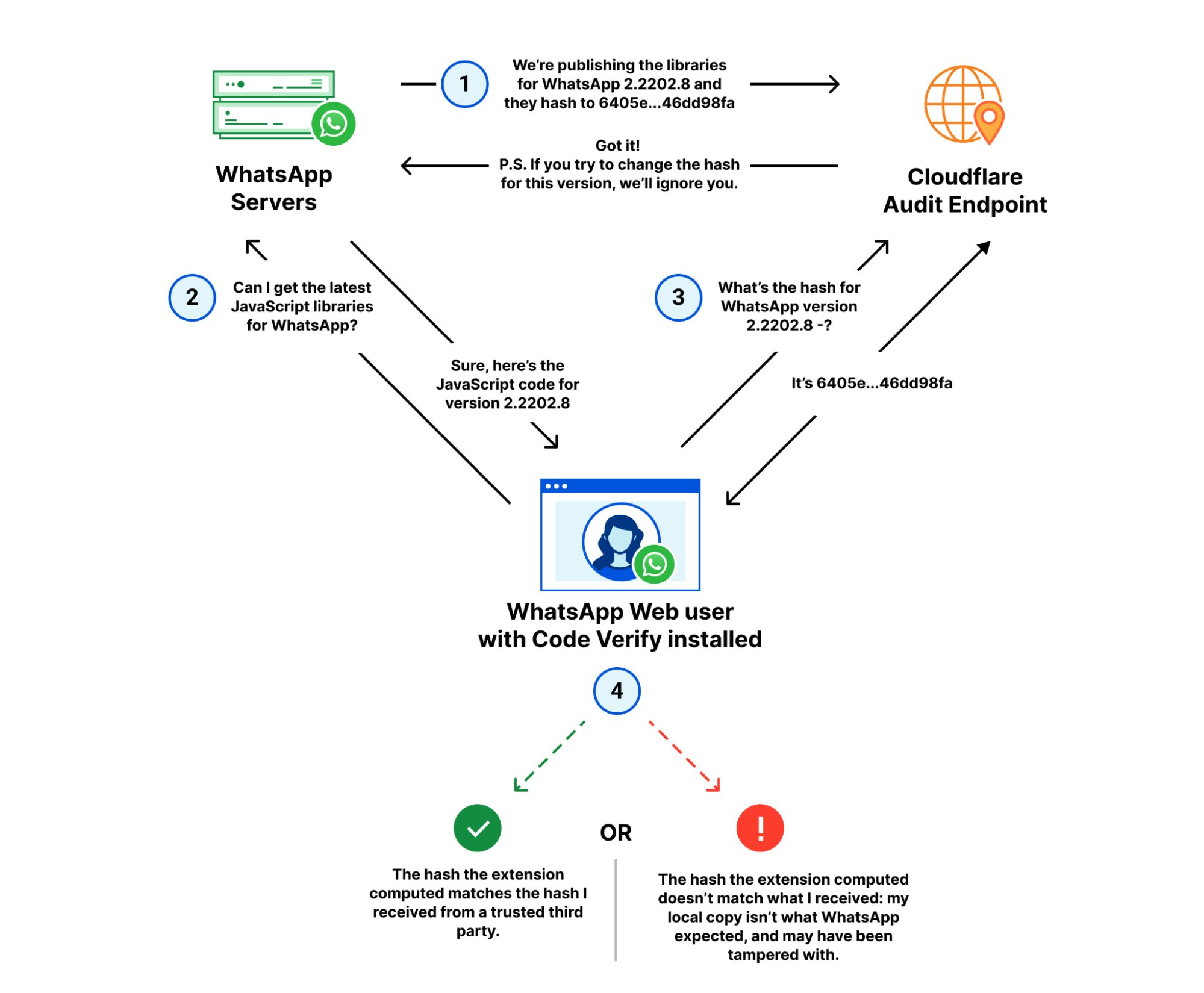
We’ve illustrated this to make how it works a little clearer, showing how each of the three parties — the user, WhatsApp and Cloudflare — interact with each other.
Broken down, there are four major steps to verifying the code hasn’t been tampered with:
WhatsApp publishes the latest version of their JavaScript libraries to their servers, and the corresponding hash for that version to Cloudflare’s audit endpoint.
A WhatsApp web client fetches the latest libraries from WhatsApp.
The Code Verify browser extension subsequently fetches the hash for that version from Cloudflare over a separate, secure connection.
Code Verify compares the “known good” hash from Cloudflare with the hash of the libraries it locally computed.
If the hashes match, as they should under almost any circumstance, the code is “verified” from the perspective of the extension. If the hashes don’t match, it indicates that the code running on the user’s browser is different from the code WhatsApp intended to run on all its user’s browsers.
Security needs to be convenient
It’s this process — and the fact that is automated on behalf of the user — that helps provide transparency in a scalable way. If users had to manually fetch, compute and compare the hashes themselves, detecting tampering would only be for the small fraction of technical users. For a service as large as WhatsApp, that wouldn’t have been a particularly accessible or user-friendly approach.
This approach also has parallels to a number of technologies in use today. One of them is Subresource Integrity in web browsers: when you fetch a third-party asset (such as a script or stylesheet), the browser validates that the returned asset matches the hash described. If it doesn’t, it refuses to load that asset, preventing potentially compromised scripts from siphoning off user data. Another is Certificate Transparency and the related Binary Transparency projects. Both of these provide publicly auditable transparency for critical assets, including WebPKI certificates and other binary blobs. The system described in this post doesn’t scale to arbitrary assets – yet – but we are exploring ways in which we could extend this offering for something more general and usable like Binary Transparency.
Our collaboration with the team at WhatsApp is just the beginning of the work we’re doing to help improve privacy and security on the web. We’re aiming to help other organizations verify the code delivered to users is the code they’re meant to be running. Protecting Internet users at scale and enabling privacy are core tenets of what we do at Cloudflare, and we look forward to continuing this work throughout 2022.
1.1.1.1 sees approximately 600 billion queries per day. However, proportionally, most queries sent to this resolver are over cleartext: 89% over UDP and TCP combined, and the remaining 11% are encrypted. We care about end-user privacy and would prefer to see all of these queries sent to us over an encrypted transport using DNS-over-TLS or DNS-over-HTTPS. Having a mechanism by which clients could discover support for encrypted protocols such as DoH or DoT will help drive this number up and lead to more name encryption on the Internet. That’s where DDR – or Discovery of Designated Resolvers – comes into play. As of today, 1.1.1.1 supports the latest version of DDR so clients can automatically upgrade non-secure UDP and TCP connections to secure connections. In this post, we’ll describe the motivations for DDR, how the mechanism works, and, importantly, how you can test it out as a client.
DNS transports and public resolvers
We initially launched our public recursive resolver service 1.1.1.1 over three years ago, and have since seen its usage steadily grow. Today, it is one of the fastest public recursive resolvers available to end-users, supporting the latest security and privacy DNS transports such as HTTP/3 for DNS-over-HTTPS (DoH), as well as Oblivious DoH.
As a public resolver, all clients, regardless of type, are typically manually configured based on a user’s desired performance, security, and privacy requirements. This choice reflects answers to two separate but related types of questions:
What recursive resolver should be used to answer my DNS queries? Does the resolver perform well? Does the recursive resolver respect my privacy?
What protocol should be used to speak to this particular recursive resolver? How can I keep my DNS data safe from eavesdroppers that should otherwise not have access to it?
The second question primarily concerns technical matters. In particular, whether or not a recursive resolver supports DoH is simple enough to answer. Either the recursive resolver does or does not support it!
In contrast, the first question is primarily a matter of policy. For example, consider the question of choosing between a local network-provided DNS recursive resolver and a public recursive resolver. How do resolver features (including DoH support, for example) influence this decision? How does the resolver’s privacy policy regarding data use and retention influence this decision? More generally, what information about recursive resolver capabilities is available to clients in making this decision and how is this information delivered to clients?
These policy questions have been the topic of substantial debate in the Internet Engineering Task Force (IETF), the standards body where DoH was standardized, and is the one facet of the Adaptive DNS Discovery (ADD) Working Group, which is chartered to work on the following items (among others):
– Define a mechanism that allows clients to discover DNS resolvers that support encryption and that are available to the client either on the public Internet or on private or local networks.
– Define a mechanism that allows communication of DNS resolver information to clients for use in selection decisions. This could be part of the mechanism used for discovery, above.
In other words, the ADD Working Group aims to specify mechanisms by which clients can obtain the information they need to answer question (1). Critically, one of those pieces of information is what encrypted transport protocols the recursive resolver supports, which would answer question (2).
As the answer to question (2) is purely technical and not a matter of policy, the ADD Working Group was able to specify a workable solution that we’ve implemented and tested with existing clients. Before getting into the details of how it works, let’s dig into the problem statement here and see what’s required to address it.
Threat model and problem statement
The DDR problem is relatively straightforward: given the IP address of a DNS recursive resolver, how can one discover parameters necessary for speaking to the same resolver using an encrypted transport? (As above, discovering parameters for a different resolver is a distinctly different problem that pertains to policy and is therefore out of scope.)
This question is only meaningful insofar as using encryption helps protect against some attacker. Otherwise, if the network was trusted, encryption would add no value! A direct consequence is that this question assumes the network – for some definition of “the network” – is untrusted and encryption helps protect against this network.
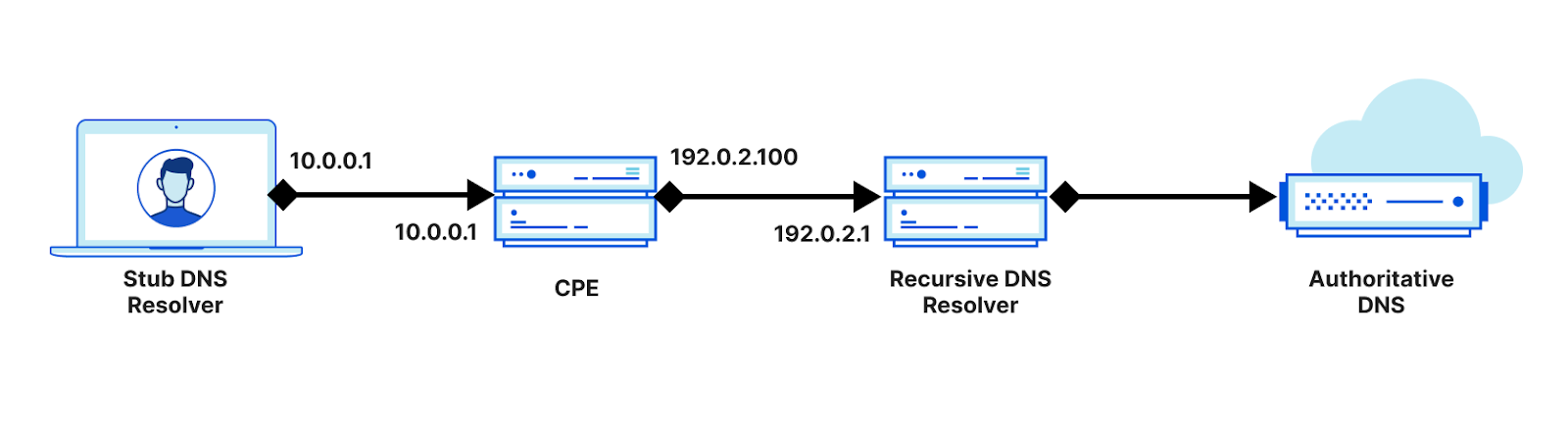
But what exactly is the network here? In practice, the topology typically looks like the following:
Typical DNS configuration from DHCP
Again, for DNS discovery to have any meaning, we assume that either the ISP or home network – or both – is untrusted and malicious. The setting here depends on the client and the network they are attached to, but it’s generally simplest to assume the ISP network is untrusted.
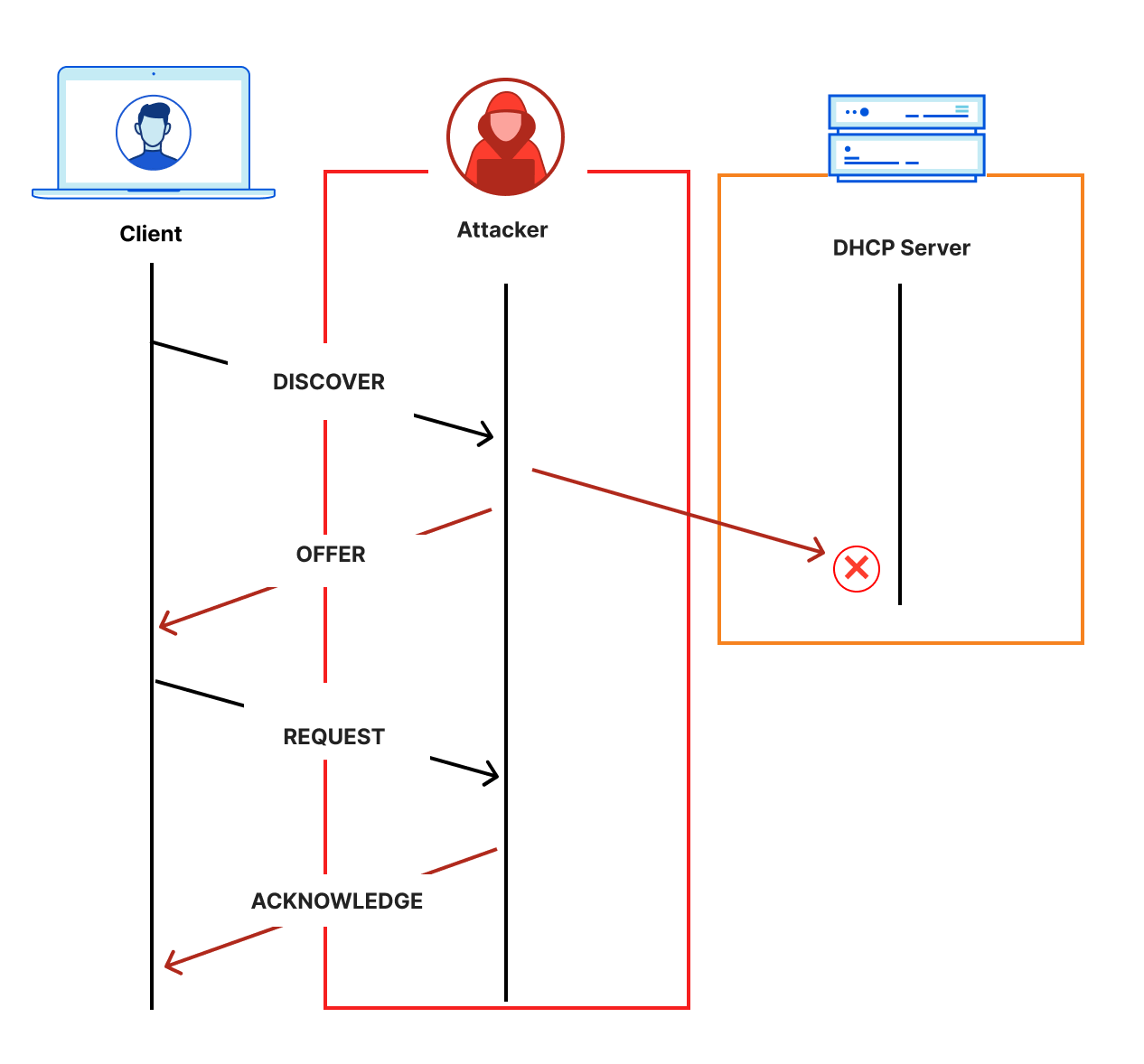
This question also makes one important assumption: clients know the desired recursive resolver address. Why is this important? Typically, the IP address of a DNS recursive resolver is provided via Dynamic Host Configuration Protocol (DHCP). When a client joins a network, it uses DHCP to learn information about the network, including the default DNS recursive resolver. However, DHCP is a famously unauthenticated protocol, which means that any active attacker on the network can spoof the information, as shown below.
Unauthenticated DHCP discovery
One obvious attacker vector would be for the attacker to redirect DNS traffic from the network’s desired recursive resolver to an attacker-controlled recursive resolver. This has important implications on the threat model for discovery.
First, there is currently no known mechanism for encrypted DNS discovery in the presence of an active attacker that can influence the client’s view of the recursive resolver’s address. In other words, to make any meaningful improvement, DNS discovery assumes the client’s view of the DNS recursive resolver address is correct (and obtained through some secure mechanism). A second implication is that the attacker can simply block any attempt of client discovery, preventing upgrade to encrypted transports. This seems true of any interactive discovery mechanism. As a result, DNS discovery must relax this attacker’s capabilities somewhat: rather than add, drop, or modify packets, the attacker can only add or modify packets.
Altogether, this threat model lets us sharpen the DNS discovery problem statement: given the IP address of a DNS recursive resolver, how can one securely discover parameters necessary for speaking to the same resolver using an encrypted transport in the presence of an active attacker that can add or modify packets? It should be infeasible, for example, for the attacker to redirect the client from the resolver that it knows at the outset to one the attacker controls.
So how does this work, exactly?
DDR mechanics
DDR depends on two mechanisms:
Certificate-based authentication of encrypted DNS resolvers.
SVCB records for encoding and communicating DNS parameters.
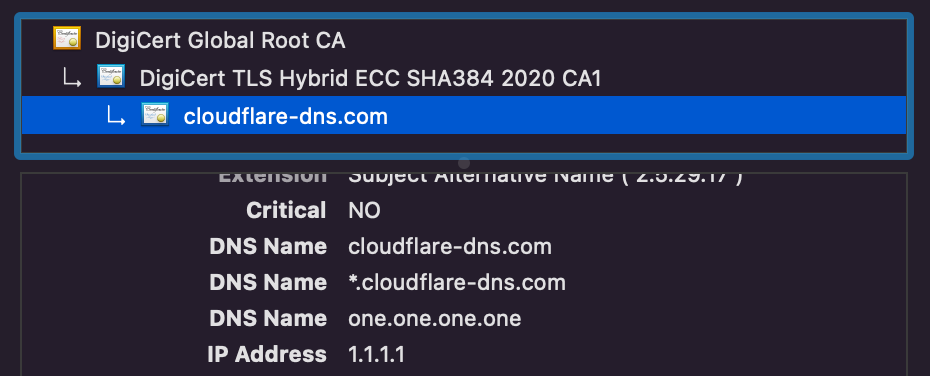
Certificates allow resolvers to prove authority for IP addresses. For example, if you view the certificate for one.one.one.one, you’ll see several IP addresses listed under the SubjectAlternativeName extension, including 1.1.1.1.
SubjectAltName list of the one.one.one.one certificate
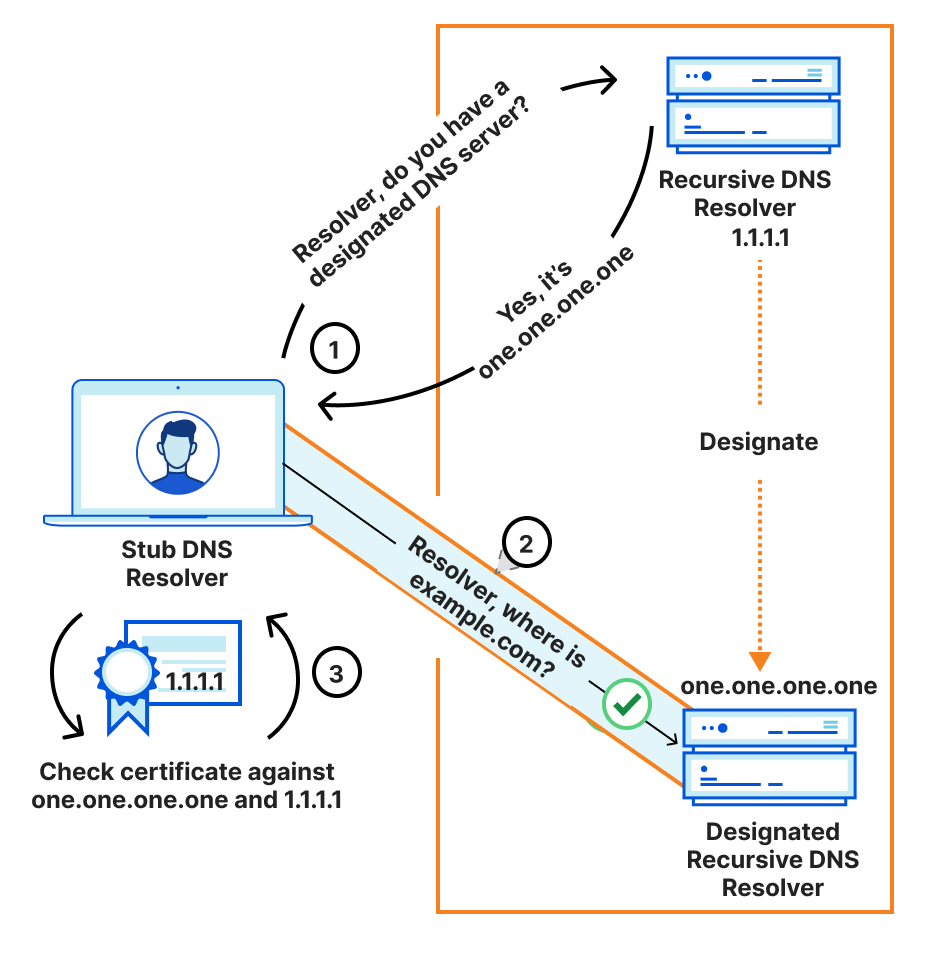
How does DDR combine these two to solve the discovery problem above? In three simple steps:
Clients query the expected DNS resolver for its designations and their parameters with a special-purpose SVCB record.
Clients open a secure connection to the designated resolver, for example, one.one.one.one, authenticating the resolver against the one.one.one.one name.
Clients check that the designated resolver is additionally authenticated for the IP address of the origin resolver. That is, the certificate for one.one.one.one, the designated resolver, must include the IP address 1.1.1.1, the original designator resolver.
If this validation completes, clients can then use the secure connection to the designated resolver. In pictures, this is as follows:
DDR discovery process
This demonstrates that the encrypted DNS resolver is authoritative for the client’s original DNS resolver. Or, in other words, that the original resolver and the encrypted resolver are effectively “the same.” An encrypted resolver that does not include the originally requested resolver IP address on its certificate would fail the validation, and clients are not expected to follow the designated upgrade path. This entire process is referred to as “Verified Discovery” in the DDR specification.
Experimental deployment and next steps
To enable more encrypted DNS on the Internet and help the standardization process, 1.1.1.1 now has experimental support for DDR. You can query it directly to find out:
$ dig +short @1.1.1.1 _dns.resolver.arpa type64
QUESTION SECTION
_dns.resolver.arpa. IN SVCB
ANSWER SECTION
_dns.resolver.arpa. 300 IN SVCB 1 one.one.one.one. alpn="h2,h3" port="443" ipv4hint="1.1.1.1,1.0.0.1" ipv6hint="2606:4700:4700::1111,2606:4700:4700::1001" key7="/dns-query{?name}"
_dns.resolver.arpa. 300 IN SVCB 2 one.one.one.one. alpn="dot" port="853" ipv4hint="1.1.1.1,1.0.0.1" ipv6hint="2606:4700:4700::1111,2606:4700:4700::1001"
ADDITIONAL SECTION
one.one.one.one. 300 IN AAAA 2606:4700:4700::1111
one.one.one.one. 300 IN AAAA 2606:4700:4700::1001
one.one.one.one. 300 IN A 1.1.1.1
one.one.one.one. 300 IN A 1.0.0.1
This command sends a SVCB query (type64) for the reserved name _dns.resolver.arpa to 1.1.1.1. The output lists the contents of this record, including the DoH and DoT designation parameters. Let’s walk through the contents of this record:
This says that the DoH target one.one.one.one is accessible over port 443 (port=”443”) using either HTTP/2 or HTTP/3 (alpn=”h2,h3”), and the DoH path (key7) for queries is “/dns-query{?name}”.
Moving forward
DDR is a simple mechanism that lets clients automatically upgrade to encrypted transport protocols for DNS queries without any manual configuration. At the end of the day, users running compatible clients will enjoy a more private Internet experience. Happily, both Microsoft and Apple recently announced experimental support for this emerging standard, and we’re pleased to help them and other clients test support. Going forward, we hope to help add support for DDR to open source DNS resolver software such as dnscrypt-proxy and Bind. If you’re interested in helping us continue to drive adoption of encrypted DNS and related protocols to help build a better Internet, we’re hiring!
Radar can detect you moving closer to a computer and entering its personal space. This might mean the computer can then choose to perform certain actions, like booting up the screen without requiring you to press a button. This kind of interaction already exists in current Google Nest smart displays, though instead of radar, Google employs ultrasonic sound waves to measure a person’s distance from the device. When a Nest Hub notices you’re moving closer, it highlights current reminders, calendar events, or other important notifications.
Proximity alone isn’t enough. What if you just ended up walking past the machine and looking in a different direction? To solve this, Soli can capture greater subtleties in movements and gestures, such as body orientation, the pathway you might be taking, and the direction your head is facing — aided by machine learning algorithms that further refine the data. All this rich radar information helps it better guess if you are indeed about to start an interaction with the device, and what the type of engagement might be.
[…]
The ATAP team chose to use radar because it’s one of the more privacy-friendly methods of gathering rich spatial data. (It also has really low latency, works in the dark, and external factors like sound or temperature don’t affect it.) Unlike a camera, radar doesn’t capture and store distinguishable images of your body, your face, or other means of identification. “It’s more like an advanced motion sensor,” Giusti says. Soli has a detectable range of around 9 feet — less than most cameras — but multiple gadgets in your home with the Soli sensor could effectively blanket your space and create an effective mesh network for tracking your whereabouts in a home.
“Privacy-friendly” is a relative term.
These technologies are coming. They’re going to be an essential part of the Internet of Things.
TechCrunch is reporting — but not describing in detail — a vulnerability in a series of stalkerware apps that exposes personal information of the victims. The vulnerability isn’t in the apps installed on the victims’ phones, but in the website the stalker goes to view the information the app collects. The article is worth reading, less for the description of the vulnerability and more for the shadowy string of companies behind these stalkerware apps.
Cignpost Diagnostics, which trades as ExpressTest and offers £35 tests for holidaymakers, said it holds the right to analyse samples from seals to “learn more about human health” — and sell information on to third parties.
Individuals are required to give informed consent for their sensitive medical data to be used but customers’ consent for their DNA to be sold now as buried in Cignpost’s online documents.
A Berlin-based company has developed an AirTag clone that bypasses Apple’s anti-stalker security systems. Source code for these AirTag clones is available online.
So now we have several problems with the system. Apple’s anti-stalker security only works with iPhones. (Apple wrote an Android app that can detect AirTags, but how many people are going to download it?) And now non-AirTags can piggyback on Apple’s system without triggering the alarms.
Apple didn’t think this through nearly as well as it claims to have. I think the general problem is one that I have written about before: designers just don’t have intimate threats in mind when building these systems.
A reporter interviews a Uyghur human-rights advocate, and uses the Otter.ai transcription app.
The next day, I received an odd note from Otter.ai, the automated transcription app that I had used to record the interview. It read: “Hey Phelim, to help us improve your Otter’s experience, what was the purpose of this particular recording with titled ‘Mustafa Aksu’ created at ‘2021-11-08 11:02:41’?”
Customer service or Chinese surveillance? Turns out it’s hard to tell.
Senators have reintroduced the EARN IT Act, requiring social media companies (among others) to administer a massive surveillance operation on their users:
A group of lawmakers led by Sen. Richard Blumenthal (D-CT) and Sen. Lindsey Graham (R-SC) have re-introduced the EARN IT Act, an incredibly unpopular bill from 2020 that was dropped in the face of overwhelming opposition. Let’s be clear: the new EARN IT Act would pave the way for a massive new surveillance system, run by private companies, that would roll back some of the most important privacy and security features in technology used by people around the globe. It’s a framework for private actors to scan every message sent online and report violations to law enforcement. And it might not stop there. The EARN IT Act could ensure that anything hosted online — backups, websites, cloud photos, and more — is scanned.
There are two bills working their way through Congress that would force companies like Apple to allow competitive app stores. Apple hates this, since it would break its monopoly, and it’s making a variety of security arguments to bolster its argument. I have written a rebuttal:
I would like to address some of the unfounded security concerns raised about these bills. It’s simply not true that this legislation puts user privacy and security at risk. In fact, it’s fairer to say that this legislation puts those companies’ extractive business-models at risk. Their claims about risks to privacy and security are both false and disingenuous, and motivated by their own self-interest and not the public interest. App store monopolies cannot protect users from every risk, and they frequently prevent the distribution of important tools that actually enhance security. Furthermore, the alleged risks of third-party app stores and “side-loading” apps pale in comparison to their benefits. These bills will encourage competition, prevent monopolist extortion, and guarantee users a new right to digital self-determination.
Happy Data Privacy Day 2022! Of course, every day is privacy day at Cloudflare, but today gives us a great excuse to talk about one of our favorite topics.
In honor of Privacy Day, we’re highlighting some key topics in data privacy and data protection that helped shape the landscape in 2021, as well as the issues we’ll be thinking about in 2022. The first category that gets our attention is the intersection of data security and data privacy. At Cloudflare, we’ve invested in privacy-focused technologies and security measures that enhance data privacy to help build the third phase of the Internet, the Privacy phase, and we expect to double down on these developments in 2022.
The second category is data localization. While we don’t think you need localization to achieve privacy, the two are inextricably linked in the EU regulatory landscape and elsewhere.
Third, recent regulatory enforcement actions in the EU against websites’ use of cookies have us thinking about how we can help websites run third-party tools, such as analytics, in a faster, more secure, and more privacy-protective way.
Lastly, we’ll continue to focus on the introduction of new or updated data protection regulations around the world, as well as regulation governing digital services, which will inevitably have implications for how personal and non-personal data is used and transferred globally.
Security to ensure Privacy
Cloudflare’s founding mission to help build a better Internet has always included focusing on privacy-first products and services. We’ve written before about how we think a key way to improve privacy is to reduce the amount of personal data flowing across the Internet. This has led to the development and deployment of technologies to help personal data stay private and keep data secure from would-be attackers. Examples of prominent technologies include Cloudflare’s 1.1.1.1 public DNS resolver — the Internet’s fastest, privacy-first public DNS resolver that does not retain any personal data about requests made — and Oblivious DNS over HTTPs (ODoH) — a proposed DNS standard co-authored by engineers from Cloudflare, Apple, and Fastly that separates IP addresses from queries, so that no single entity can see both at the same time.
We’re looking forward to continued work on privacy enhancing technologies in 2022, including efforts to generalize ODoH technology to any application HTTP traffic through Oblivious HTTP (OHTTP). Cloudflare is proud to be an active contributor to the Internet Engineering Task Force’s OHAI (Oblivious HTTP Application Intermediation) working group where Oblivious HTTP will be developed. Similar to ODoH, OHTTP allows a client to make multiple requests of a server without the server being able to link those requests to the client or to identify the requests as having come from the same client.
But there are times when retaining identity is important, such as when you are trying to access your employer’s network while working from home — something many of us have become all too familiar with over the past two years. However, organizations shouldn’t have to choose between protecting privacy and implementing Zero Trust solutions to guard their networks from common remote work pitfalls: employees working from home who fail to access their work networks through secure methods or fall victim to phishing and malware attacks.
So not only have we developed Cloudflare’s Zero Trust Services to help organizations secure their networks, we also went beyond mere security to create privacy-enhancing Zero Trust products. In 2021, the Cloudflare Zero Trust team took a big privacy step forward by building and launching Selective Logging into Cloudflare Gateway. Cloudflare Gateway is one component of our suite of services that helps enterprises secure their networks. Other components include Zero Trust access for an enterprise’s applications that allows for the authentication of users on our global network and a fast and reliable solution for remote browsing that allows enterprises to execute all browser code in the cloud.
With Selective Logging, Gateway Admins can now tailor their logs or disable all Gateway logging to fit an enterprise’s privacy posture. Admins can “Enable Logging of only Block Actions,” “Disable Gateway Logging for Personal Information,” or simply “Disable All Gateway Logging.” This allows an enterprise to decide not to collect any personal data for users who are accessing their internal organizational networks. The less personal data collected, the less chance any personal data can be stolen, leaked, or misused. Meanwhile, Gateway still protects enterprises by blocking malware or command & control sites, phishing sites, and other URLs that are disallowed by their enterprise’s security policy.
As many employers have moved to permanent remote work, at least part-time, Zero Trust solutions will continue to be important in 2022. We are excited to give those employers tools that help them secure their networks in ways that allow them to simultaneously protect employee privacy.
Of course, we can’t talk about pro-privacy security issues without mentioning the Log4j vulnerability exposed last month. That vulnerability highlighted just how critically important security is to protecting the privacy of personal data. We explained in depth how this vulnerability works, but in summary, the vulnerability allowed an attacker to execute code on a remote server. This can allow for the exploitation of Java-based Internet facing software that uses Log4j, but what makes Log4j even more insidious is that non-Internet facing software can also be exploitable as data gets passed from system to system. For example, a User-Agent string containing the exploit could be passed to a backend system written in Java that does indexing or data science and the exploit could get logged. Even if the Internet-facing software is not written in Java it is possible that strings get passed to other systems that are in Java allowing the exploit to happen.
This means that unless the vulnerability is remediated, an attacker could execute code that not only exfiltrates data from a web server but also steal personal data from non-Internet facing backend databases, such as billing systems. And because Java and Log4j are so widely used, thousands of servers and systems were impacted, which meant millions of users’ personal data was at risk.
We’re proud that, within hours of learning of the Log4j vulnerability, we rolled out new WAF rules written to protect all our customers’ sites (and our own) against this vulnerability. In addition, we and our customers were able to use our Zero Trust product, Cloudflare Access, to protect access to internal systems. Once we or a customer enabled Cloudflare Access on the identified attack surface, any exploit attempts to Cloudflare’s systems or the systems of customers would have required the attacker to authenticate. The ability to analyze server, network or traffic data generated by Cloudflare in the course of providing our service to the huge number of Internet applications that use us helped us better protect all of Cloudflare’s customers. Not only were we able to update WAF rules to mitigate the vulnerability, Cloudflare could use data to identify WAF evasion patterns and exfiltration attempts. This information enabled our customers to rapidly identify attack vectors on their own networks and mitigate the risk of harm.
As we discuss more below, we expect data localization debates to continue in 2022. At the same time, it’s important to realize that, if companies are forced to segment data by jurisdiction or to prevent access to data across jurisdictional borders, it would have been harder to mount the kind of response we were able to quickly provide to help our customers protect their own sites and networks against Log4j. We believe in ensuring both the privacy and security of data no matter what jurisdiction that data is stored in or flows through. And we believe those who would insist on data localization as a proxy for data protection above all else do a disservice to the security measures that are as important as regulations, if not more so, to protecting the privacy of personal data.
Data Localization
Data localization was a major focus in 2021 and that shows no sign of slowing in 2022. In fact, in the EU, the Austrian data protection authority (the Datenschutzbehörde) set quite the tone for this year. It published a decision January 13 stating that a European company could not use Google Analytics because it meant EU personal data was being transferred to the United States in what the regulator viewed as a violation of the EU General Data Protection Regulation (GDPR) as interpreted by the Court of Justice of the European Union’s 2020 decision in the “Schrems II” case.
We continue to disagree with the premise that the Schrems II decision means that EU personal data must not be transferred to the United States. Instead, we believe that there are safeguards that can be put in place to allow for such transfers pursuant to the EU Standard Contractual Clauses (SCCs) (contractual clauses approved by the EU Commission to enable EU personal data to be transferred outside the EU) in a manner consistent with the Schrems II decision. Cloudflare has had data protection safeguards in place since well before the Schrems II case, in fact, such as our industry-leading commitments on government data requests. We have updated our Data Processing Addendum (DPA) to incorporate the SCCs that the EU Commission approved in 2021. We also added additional safeguards as outlined in the EDPB’s June 2021 Recommendations on Supplementary Measures. Finally, Cloudflare’s services are certified under the ISO 27701 standard, which maps to the GDPR’s requirements.
In light of these measures, our EU customers can use Cloudflare’s services in a manner consistent with GDPR and the Schrems II decision. Still, we recognize that many of our customers want their EU personal data to stay in the EU. For example, some of our customers in industries like healthcare, law, and finance may have additional requirements. For these reasons, we developed our Data Localization Suite, which gives customers control over where their data is inspected and stored.
Cloudflare’s Data Localization Suite provides a viable solution for our customers who want to avoid transferring EU personal data outside the EU at a time when European regulators are growing increasingly critical of data transfers to the United States. We are particularly excited about the Customer Metadata Boundary component of the Data Localization Suite, because we have found a way to keep customer-identifiable end user log data in the EU for those EU customers who want that option, without sacrificing our ability to provide the security services our customers rely on us to provide.
In 2022, we will continue to fine tune our data localization offerings and expand to serve other regions where customers are finding a need to localize their data. 2021 saw China’s Personal Information Protection Law come into force with its data localization and cross-border data transfer requirements, and we are likely to see other jurisdictions, or perhaps specific industry guidelines, follow suit in 2022 in some form.
Pro-Privacy Analytics
We expect trackers (cookies, web beacons, etc.) to continue to be an area of focus in 2022 as well, and we are excited to play a role in ushering in a new era to help websites run third-party tools, such as analytics, in a faster, more secure, and more privacy-protective way. We were already thinking about privacy-first analytics in 2020 when we launched Web Analytics — a product that allowed websites to gather analytics information about their site users without using any client-side code.
Nevertheless, cookies, web beacons, and similar client-side trackers remain ubiquitous across the web. Each time a website operator uses these trackers, they open their site to potential security vulnerabilities, and they risk eroding the trust of their users who have grown weary of “cookie consent” banners and worry their personal data is being collected and tracked across the Internet. There has to be a better way, right? Turns out, there is.
As explained in greater detail in this blog post, Cloudflare’s Zaraz product not only allows a website to load faster and be more interactive, but it also reduces the amount of third-party code needed to run on a website, which makes it more secure. And this solution is also pro-privacy: it allows the website operator to have control over the data sent to third parties. Moving the execution of the third-party tools our network means website operators will be able to identify if tools are trying to collect personal data, and, if so, they can modify the data before it goes to the analytics providers (for example, strip URL queries, remove IP addresses of end users). As we’ve said so often, if we can reduce the amount of personal data that is sent across the Internet, that’s a win for privacy.
Changing Privacy Landscape
As the old saying goes, the only constant is change. And as in 2021, 2022 will undoubtedly be a year of continued regulatory changes as we see new laws enacted, amended, or coming into effect that directly or indirectly regulate the collection, use, and transborder flow of personal data.
In the United States for example, 2022 will require companies to prepare for the California Privacy Rights Act (CPRA), which goes into effect January 1, 2023. Importantly, CPRA will have “retrospective requirements”, meaning companies will need to look back and apply rules to personal data collected as of January 1, 2022. Likewise, Virginia’s and Colorado’s privacy laws are coming into force in 2023. And a number of other States, including but not limited to Florida, Washington, Indiana, and the District of Columbia, have proposed their own privacy laws. For the most part, these bills are aimed at giving consumers greater control over their personal data — such as establishing consumers’ rights to access and delete their data — and placing obligations on companies to ensure those rights are protected and respected.
Meanwhile, elsewhere in the world, we are seeing a shift in data privacy legislation. No longer are data protection laws focusing only on personal data; they are expanding to regulate the flow of all types of data. The clearest example of this is in India, where a parliamentary committee in December 2021 included recommendations that the “Personal Data Protection Bill” be renamed the “Data Protection Bill” and that its scope be expanded to include non-personal data. The bill would place obligations on organizations to extend to non-personal data the same protections that existing data protection laws extend to personal data. The implications of the proposed updates to India’s Data Protection Bill are significant. They could dramatically impact the way in which organizations use non-personal data for analytics and operational improvements.
India is not the only country to propose expanding the scope of data regulation to include non-personal data. The European Union’s Data Strategy aims to provide a secure framework enhancing data sharing with the stated goal that such sharing will drive innovation and expedite the digitalization of the European economy.
Other data privacy legislation to keep an eye on in 2022 will be Japan’s amendment to its Act on Protection of Personal Information (APPI) and Thailand’s Personal Data Protection Act (PDPA), which will come into force in 2022. Proposed amendments to Japan’s APPI include requirements to be met in order to transfer Japanese personal data outside of Japan and the introduction of data breach notification requirements. Meanwhile, like the GDPR, Thailand’s PDPA aims to protect individuals’ personal data by imposing obligations on organizations that collect, process, and transfer such personal data.
With all these privacy enhancing technologies and regulatory changes on the horizon, we expect 2022 to be another exciting year in the world of data protection and data privacy. Happy Data Privacy Day!
China is mandating that athletes download and use a health and travel app when they attend the Winter Olympics next month. Citizen Lab examined the app and found it riddled with security holes.
Key Findings:
MY2022, an app mandated for use by all attendees of the 2022 Olympic Games in Beijing, has a simple but devastating flaw where encryption protecting users’ voice audio and file transfers can be trivially sidestepped. Health customs forms which transmit passport details, demographic information, and medical and travel history are also vulnerable. Server responses can also be spoofed, allowing an attacker to display fake instructions to users.
MY2022 is fairly straightforward about the types of data it collects from users in its public-facing documents. However, as the app collects a range of highly sensitive medical information, it is unclear with whom or which organization(s) it shares this information.
MY2022 includes features that allow users to report “politically sensitive” content. The app also includes a censorship keyword list, which, while presently inactive, targets a variety of political topics including domestic issues such as Xinjiang and Tibet as well as references to Chinese government agencies.
While the vendor did not respond to our security disclosure, we find that the app’s security deficits may not only violate Google’s Unwanted Software Policy and Apple’s App Store guidelines but also China’s own laws and national standards pertaining to privacy protection, providing potential avenues for future redress.
It’s not clear whether the security flaws were intentional or not, but the report speculated that proper encryption might interfere with some of China’s ubiquitous online surveillance tools, especially systems that allow local authorities to snoop on phones using public wireless networks or internet cafes. Still, the researchers added that the flaws were probably unintentional, because the government will already be receiving data from the app, so there wouldn’t be a need to intercept the data as it was being transferred.
[…]
The app also included a list of 2,422 political keywords, described within the code as “illegalwords.txt,” that worked as a keyword censorship list, according to Citizen Lab. The researchers said the list appeared to be a latent function that the app’s chat and file transfer function was not actively using.
The US government has already advised athletes to leave their personal phones and laptops home and bring burners.
Last summer, the San Francisco police illegally used surveillance cameras at the George Floyd protests. The EFF is suing the police:
This surveillance invaded the privacy of protesters, targeted people of color, and chills and deters participation and organizing for future protests. The SFPD also violated San Francisco’s new Surveillance Technology Ordinance. It prohibits city agencies like the SFPD from acquiring, borrowing, or using surveillance technology, without prior approval from the city’s Board of Supervisors, following an open process that includes public participation. Here, the SFPD went through no such process before spying on protesters with this network of surveillance cameras.
It’s feels like a pretty easy case. There’s a law, and the SF police didn’t follow it.
Tech billionaire Chris Larsen is on the side of the police. He thinks that the surveillance is a good thing, and wrote an op-ed defending it.
I wouldn’t be writing about this at all except that Chris is a board member of EPIC, and used his EPIC affiliation in the op-ed to bolster his own credentials. (Bizarrely, he linked to an EPIC page that directly contradicts his position.) In his op-ed, he mischaracterized the EFF’s actions and the facts of the lawsuit. It’s a mess.
The plaintiffs in the lawsuit wrote a good rebuttal to Larsen’s piece. And this week, EPIC published what is effectively its own rebuttal:
One of the fundamental principles that underlies EPIC’s work (and the work of many other groups) on surveillance oversight is that individuals should have the power to decide whether surveillance tools are used in their communities and to impose limits on their use. We have fought for years to shed light on the development, procurement, and deployment of such technologies and have worked to ensure that they are subject to independent oversight through hearings, legal challenges, petitions, and other public forums. The CCOPS model, which was developed by ACLU affiliates and other coalition partners in California and implemented through the San Francisco ordinance, is a powerful mechanism to enable public oversight of dangerous surveillance tools. The access, retention, and use policies put in place by the neighborhood business associations operating these networks provide necessary, but not sufficient, protections against abuse. Strict oversight is essential to promote both privacy and community safety, which includes freedom from arbitrary police action and the freedom to assemble.
Rolling Stone is reporting that the UK government has hired the M&C Saatchi advertising agency to launch an anti-encryption advertising campaign. Presumably they’ll lean heavily on the “think of the children!” rhetoric we’reseeing in this current wave of the crypto wars. The technical eavesdropping mechanisms have shifted to client-side scanning, which won’t actually help — but since that’s not really the point, it’s not argued on its merits.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.