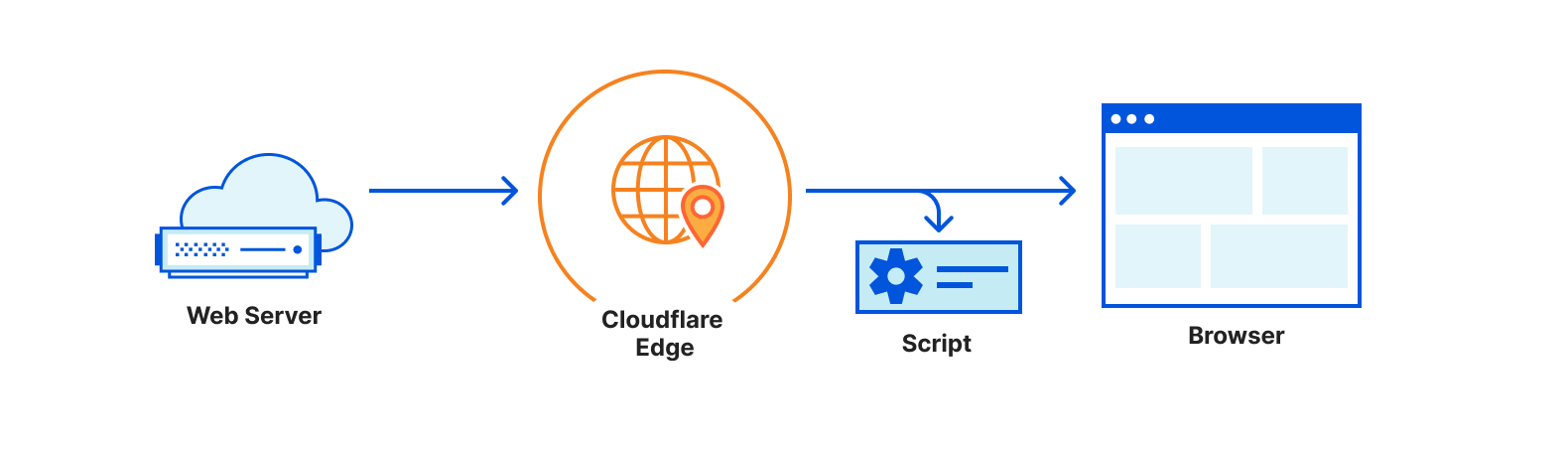
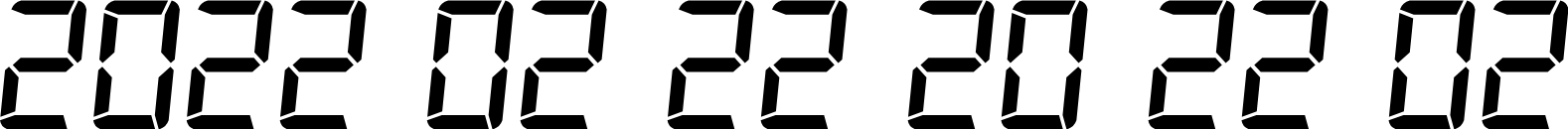When it comes to privacy, much is in your control as a website owner. You decide what information to collect, how to transmit it, how to process it, and where to store it. If you care for the privacy of your users, you’re probably taking action to ensure that these steps are handled sensitively and carefully. If your website includes no third party tools at all – no analytics, no conversion pixels, no widgets, nothing at all – then it’s probably enough! But… If your website is one of the other 94% of the Internet, you have some third-party code running in it. Unfortunately, you probably can’t tell what exactly this code is doing.
Third-party tools are great. Your product team, marketing team, BI team – they’re all right when they say that these tools make a better website. Third-party tools can help you understand your users better, embed information such as maps, chat widgets, or measure and attribute conversions more accurately. The problem doesn’t lay with the tools themselves, but with the way they are implemented – third party scripts.
Third-party scripts are pieces of JavaScript that your website is loading, often from a remote web server. Those scripts are then parsed by the browser, and they can generally do everything that your website can do. They can change the page completely, they can write cookies, they can read form inputs, URLs, track visitors and more. It is mostly a restrictions-less system. They were built this way because it used to be the only way to create a third-party tool.
Over the years, companies have suffered a lot of third party scripts. Those scripts were sometimes hacked, and started hijacking information from visitors to websites that were using them. More often, third party scripts are simply collecting information that could be sensitive, exposing the website visitors in ways that the website owner never intended.
Recently we announced that we’re open sourcing Managed Components. Managed Components are a new API to load third-party tools in a secure and privacy-aware way. It changes the way third-party tools load, because by default there are no more third-party scripts in it at all. Instead, there are components, which are controlled with a Components Manager like Cloudflare Zaraz.
In this blogpost we will discuss how to use Cloudflare Zaraz for granting and revoking permissions from components, and for controlling what information flows into components. Even more exciting, we’re also announcing the upcoming DLP features of Cloudflare Zaraz, that can report, mask and remove PII from information shared with third-parties by mistake.
How are Managed Components better
Because Managed Components run isolated inside a Component Manager, they are more private by design. Unlike a script that gets unlimited access to everything on your website, a Managed Component is transparent about what kind of access it needs, and operates under a Component Manager that grants and revokes permissions.
When you add a Managed Component to your website, the Component Manager will list all the permissions required for this component. Such permissions could be “setting cookies”, “making client-side network requests”, “installing a widget” and more. Depending on the tool, you’ll be able to remove permissions that are optional, if your website maintains a more restrictive approach to privacy.
Aside from permissions, the Component Manager also lets you choose what information is exposed to each Managed Component. Perhaps you don’t want to send IP addresses to Facebook? Or rather not send user agent strings to Mixpanel? Managed Components put you in control by telling you exactly what information is consumed by each tool, and letting you filter, mask or hide it according to your needs.
Data Loss Prevention with Cloudflare Zaraz
Another area we’re working on is developing DLP features that let you decide what information to forward to different Managed Components not only by the field type, e.g. “user agent header” or “IP address”, but by the actual content. DLP filters can scan all information flowing into a Managed Component and detect names, email addresses, SSN and more – regardless of which field they might be hiding under.
Our DLP Filters will be highly flexible. You can decide to only enable them for users from specific geographies, for users on specific pages, for users with a certain cookie, and you can even mix-and-match different rules. After configuring your DLP filter, you can set what Managed Components you want it to apply for – letting you filter information differently according to the receiving target.
For each DLP filter you can choose your action type. For example, you might want to not send any information in which the system detected a SSN, but to only report a warning if a first name was detected. Masking will allow you to replace an email address like [email protected] with [email protected], making sure events containing email addresses are still sent, but without exposing the address itself.
While there are many DLP tools available in the market, we believe that the integration between Cloudflare Zaraz’s DLP features and Managed Components is the safest approach, because the DLP rules are effectively fencing the information not only before it is being sent, but before the component even accesses it.
Getting started with Managed Components and DLP
Cloudflare Zaraz is the most advanced Component Manager, and you can start using it today. We recently also announced an integrated Consent Management Platform. If your third-party tool of course is missing a Managed Component, you can always write a Managed Component of your own, as the technology is completely open sourced.
While we’re working on bringing advanced permissions handling, data masking and DLP Filters to all users, you can sign up for the closed beta, and we’ll contact you shortly.
The Washington Post is reporting that the US Customs and Border Protection agency is seizing and copying cell phone, tablet, and computer data from “as many as” 10,000 phones per year, including an unspecified number of American citizens. This is done without a warrant, because “…courts have long granted an exception to border authorities, allowing them to search people’s devices without a warrant or suspicion of a crime.”
CBP’s inspection of people’s phones, laptops, tablets and other electronic devices as they enter the country has long been a controversial practice that the agency has defended as a low-impact way to pursue possible security threats and determine an individual’s “intentions upon entry” into the U.S. But the revelation that thousands of agents have access to a searchable database without public oversight is a new development in what privacy advocates and some lawmakers warn could be an infringement of Americans’ Fourth Amendment rights against unreasonable searches and seizures.
[…]
CBP conducted roughly 37,000 searches of travelers’ devices in the 12 months ending in October 2021, according to agency data, and more than 179 million people traveled that year through U.S. ports of entry.
The Federal Trade Commission (FTC) has sued Kochava, a large location data provider, for allegedly selling data that the FTC says can track people at reproductive health clinics and places of worship, according to an announcement from the agency.
“Defendant’s violations are in connection with acquiring consumers’ precise geolocation data and selling the data in a format that allows entities to track the consumers’ movements to and from sensitive locations, including, among others, locations associated with medical care, reproductive health, religious worship, mental health temporary shelters, such as shelters for the homeless, domestic violence survivors, or other at risk populations, and addiction recovery,” the lawsuit reads.
It’s a Saturday night. You open your browser, looking for nearby pizza spots that are open. If the search goes as intended, your browser will show you results that are within a few miles, often based on the assumed location of your IP address. At Cloudflare, we affectionately call this type of geolocation accuracy the “pizza test”. When you use a Cloudflare product that sits between you and the Internet (for example, WARP), it’s one of the ways we work to balance user experience and privacy. Too inaccurate and you’re getting pizza places from a neighboring country; too accurate and you’re reducing the privacy benefits of obscuring your location.
With that in mind, we’re excited to announce two major improvements to our 1.1.1.1 + WARP apps: first, an improvement to how we ensure search results and other geographically-aware Internet activity work without compromising your privacy, and second, a larger network with more locations available to WARP+ subscribers, powering even speedier connections to our global network.
A better Internet browsing experience for every WARP user
When we originally built the 1.1.1.1+ WARP mobile app, we wanted to create a consumer-friendly way to connect to our network and privacy-respecting DNS resolver.
What we discovered over time is that the topology of the Internet dictates a different type of experience for users in different locations. Why? Sometimes, because traffic congestion or technical issues route your traffic to a less congested part of the network. Other times, Internet Service Providers may not peer with Cloudflare or engage in traffic engineering to optimize their networks how they see fit, which could result in user traffic connecting to a location that doesn’t quite map to their locale or language.
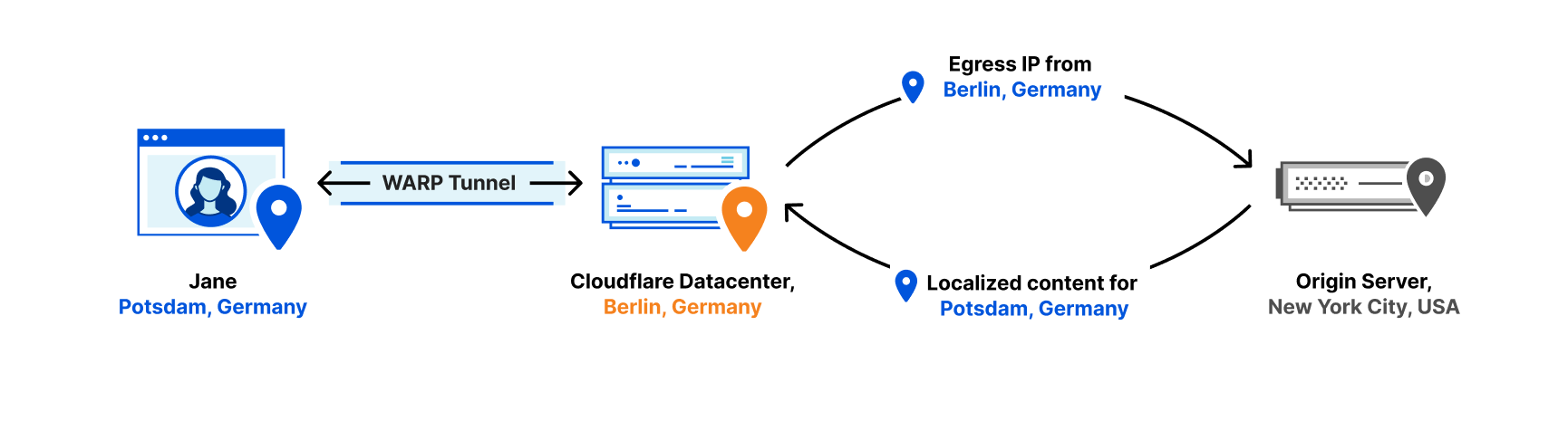
Regardless of the cause, the impact is that your search results become less relevant, if not outright confusing. For example, in somewhere dense with country borders, like Europe, your traffic in Berlin could get routed to Amsterdam because your mobile operator chooses to not peer in-country, giving you results in Dutch instead of German. This can also be disruptive if you’re trying to stream content subject to licensing restrictions, such as a person in the UK trying to watch BBC iPlayer or a person in Brazil trying to watch the World Cup.
So we fixed this. We just rolled out a major update to the service that powers WARP that will give you a geographically accurate browsing experience without revealing your IP address to the websites you’re visiting. Instead, websites you visit will see a Cloudflare IP address instead, making it harder for them to track you directly.
How it works
Traditionally, consumer VPNs deliberately route your traffic through a server in another country, making your connection slow, and often getting blocked because of their ability to flout location-based content restrictions. We took a different approach when we first launched WARP in 2018, giving you the best possible performance by routing your traffic through the Cloudflare data center closest to you. However, because not every Internet Service Provider (ISP) peers with Cloudflare, users sometimes end up exiting the Cloudflare network from a more “random” data center – one that does not accurately represent their locale.
Websites and third party services often infer geolocation from your IP address, and now, 1.1.1.1 + WARP replaces your original IP address with one that consistently and accurately represents your approximate location.
Here’s how we did it:
We ran an analysis on a subset of our network traffic to find a rough approximation of how many users we have per city.
We divided that amongst our egress IPs, using an anycast architecture to be efficient with the number of additional IPs we had to allocate and advertise per metro area.
We then submitted geolocation information of those IPs to various geolocation database providers, ensuring third party services associate those Cloudflare egress IPs with an accurate approximate location.
It was important to us to provide the benefits of this location accuracy without compromising user privacy, so the app doesn’t ask for specific location permissions or log your IP address.
An even bigger network for WARP+ users
We also recently announced that we’ve expanded our network to over 275 cities in over 100 countries. This gave us an opportunity to revisit where we offered WARP, and how we could expand the number of locations users can connect to WARP with (in other words: an opportunity to make things faster).
From today, all WARP+ subscribers will benefit from a larger network with 20+ new cities: with no change in subscription pricing. A closer Cloudflare data center means less latency between your device and Cloudflare, which directly improves your download speed, thanks to what’s called the Bandwidth-Delay Product (put simply: lower latency, higher throughput!).
As a result, sites load faster, both for those on the Cloudflare network and those that aren’t. As we continue to expand our network, we’ll be revising this on a regular basis to ensure that all WARP and WARP+ subscribers continue to get great performance.
Speed, privacy, and relevance
Beyond being able to find pizza on a Saturday night, we believe everyone should be able to browse the Internet freely – and not have to sacrifice the speed, privacy, or relevance of their search results in order to do so.
In the near future, we’ll be investing in features to bring even more of the benefits of Cloudflare infrastructure to every 1.1.1.1 + WARP user. Stay tuned!
TheMarkup has an extensive analysis of connected vehicle data and the companies that are collecting it.
The Markup has identified 37 companies that are part of the rapidly growing connected vehicle data industry that seeks to monetize such data in an environment with few regulations governing its sale or use.
While many of these companies stress they are using aggregated or anonymized data, the unique nature of location and movement data increases the potential for violations of user privacy.
Amazon has revealed that it gives police videos from its Ring doorbells without a warrant and without user consent.
Ring recently revealed how often the answer to that question has been yes. The Amazon company responded to an inquiry from US Senator Ed Markey (D-Mass.), confirming that there have been 11 cases in 2022 where Ring complied with police “emergency” requests. In each case, Ring handed over private recordings, including video and audio, without letting users know that police had access to—and potentially downloaded—their data. This raises many concerns about increased police reliance on private surveillance, a practice that has long gone unregulated.
Police are not the customers for Ring; the people who buy the devices are the customers. But Amazon’s long-standing relationships with police blur that line. For example, in the past Amazon has given coaching to police to tell residents to install the Ring app and purchase cameras for their homes—an arrangement that made salespeople out of the police force. The LAPD launched an investigation into how Ring provided free devices to officers when people used their discount codes to purchase cameras.
Ring, like other surveillance companies that sell directly to the general public, continues to provide free services to the police, even though they don’t have to. Ring could build a device, sold straight to residents, that ensures police come to the user’s door if they are interested in footage—but Ring instead has decided it would rather continue making money from residents while providing services to police.
The new proposal—championed by Mayor London Breed after November’s wild weekend of orchestrated burglaries and theft in the San Francisco Bay Area—would authorize the police department to use non-city-owned security cameras and camera networks to live monitor “significant events with public safety concerns” and ongoing felony or misdemeanor violations.
Currently, the police can only request historical footage from private cameras related to specific times and locations, rather than blanket monitoring. Mayor Breed also complained the police can only use real-time feeds in emergencies involving “imminent danger of death or serious physical injury.”
If approved, the draft ordinance would also allow SFPD to collect historical video footage to help conduct criminal investigations and those related to officer misconduct. The draft law currently stands as the following, which indicates the cops can broadly ask for and/or get access to live real-time video streams:
The proposed Surveillance Technology Policy would authorize the Police Department to use surveillance cameras and surveillance camera networks owned, leased, managed, or operated by non-City entities to: (1) temporarily live monitor activity during exigent circumstances, significant events with public safety concerns, and investigations relating to active misdemeanor and felony violations; (2) gather and review historical video footage for the purposes of conducting a criminal investigation; and (3) gather and review historical video footage for the purposes of an internal investigation regarding officer misconduct.
Researchers have a new way to de-anonymize browser users, by correlating their behavior on one account with their behavior on another:
The findings, which NJIT researchers will present at the Usenix Security Symposium in Boston next month, show how an attacker who tricks someone into loading a malicious website can determine whether that visitor controls a particular public identifier, like an email address or social media account, thus linking the visitor to a piece of potentially personal data.
When you visit a website, the page can capture your IP address, but this doesn’t necessarily give the site owner enough information to individually identify you. Instead, the hack analyzes subtle features of a potential target’s browser activity to determine whether they are logged into an account for an array of services, from YouTube and Dropbox to Twitter, Facebook, TikTok, and more. Plus the attacks work against every major browser, including the anonymity-focused Tor Browser.
[…]
“Let’s say you have a forum for underground extremists or activists, and a law enforcement agency has covertly taken control of it,” Curtmola says. “They want to identify the users of this forum but can’t do this directly because the users use pseudonyms. But let’s say that the agency was able to also gather a list of Facebook accounts who are suspected to be users of this forum. They would now be able to correlate whoever visits the forum with a specific Facebook identity.”
This is an excellent essay outlining the post-Roe privacy threat model. (Summary: period tracking apps are largely a red herring.)
Taken together, this means the primary digital threat for people who take abortion pills is the actual evidence of intention stored on your phone, in the form of texts, emails, and search/web history. Cynthia Conti-Cook’s incredible article “Surveilling the Digital Abortion Diary details what we know now about how digital evidence has been used to prosecute women who have been pregnant. That evidence includes search engine history, as in the case of the prosecution of Latice Fisher in Mississippi. As Conti-Cook says, Ms. Fisher “conduct[ed] internet searches, including how to induce a miscarriage, ‘buy abortion pills, mifepristone online, misoprostol online,’ and ‘buy misoprostol abortion pill online,’” and then purchased misoprostol online. Those searches were the evidence that she intentionally induced a miscarriage. Text messages are also often used in prosecutions, as they were in the prosecution of Purvi Patel, also discussed in Conti-Cook’s article.
These examples are why advice from reproductive access experts like Kate Bertash focuses on securing text messages (use Signal and auto-set messages to disappear) and securing search queries (use a privacy-focused web browser, and use DuckDuckGo or turn Google search history off). After someone alerts police, digital evidence has been used to corroborate or show intent. But so far, we have not seen digital evidence be a first port of call for prosecutors or cops looking for people who may have self-managed an abortion. We can be vigilant in looking for any indications that this policing practice may change, but we can also be careful to ensure we’re focusing on mitigating the risks we know are indeed already being used to prosecute abortion-seekers.
[…]
As we’ve discussed above, just tracking your period doesn’t necessarily put you at additional risk of prosecution, and would only be relevant should you both become (or be suspected of becoming) pregnant, and then become the target of an investigation. Period tracking is also extremely useful if you need to determine how pregnant you might be, especially if you need to evaluate the relative access and legal risks for your abortion options.
It’s important to remember that if an investigation occurs, information from period trackers is probably less legally relevant than other information from your phone.
See also EFF’s privacy guide for those seeking an abortion.
Report by Georgetown’s Center on Privacy and Technology published a comprehensive report on the surprising amount of mass surveillance conducted by Immigration and Customs Enforcement (ICE).
Our two-year investigation, including hundreds of Freedom of Information Act requests and a comprehensive review of ICE’s contracting and procurement records, reveals that ICE now operates as a domestic surveillance agency. Since its founding in 2003, ICE has not only been building its own capacity to use surveillance to carry out deportations but has also played a key role in the federal government’s larger push to amass as much information as possible about all of our lives. By reaching into the digital records of state and local governments and buying databases with billions of data points from private companies, ICE has created a surveillance infrastructure that enables it to pull detailed dossiers on nearly anyone, seemingly at any time. In its efforts to arrest and deport, ICE has without any judicial, legislative or public oversight reached into datasets containing personal information about the vast majority of people living in the U.S., whose records can end up in the hands of immigration enforcement simply because they apply for driver’s licenses; drive on the roads; or sign up with their local utilities to get access to heat, water and electricity.
ICE has built its dragnet surveillance system by crossing legal and ethical lines, leveraging the trust that people place in state agencies and essential service providers, and exploiting the vulnerability of people who volunteer their information to reunite with their families. Despite the incredible scope and evident civil rights implications of ICE’s surveillance practices, the agency has managed to shroud those practices in near-total secrecy, evading enforcement of even the handful of laws and policies that could be invoked to impose limitations. Federal and state lawmakers, for the most part, have yet to confront this reality.
We’ve always known that phones—and the people carrying them—can be uniquely identified from their Bluetooth signatures, and that we need security techniques to prevent that. This new research shows that that’s not enough.
Computer scientists at the University of California San Diego proved in a study published May 24 that minute imperfections in phones caused during manufacturing create a unique Bluetooth beacon, one that establishes a digital signature or fingerprint distinct from any other device. Though phones’ Bluetooth uses cryptographic technology that limits trackability, using a radio receiver, these distortions in the Bluetooth signal can be discerned to track individual devices.
[…]
The study’s scientists conducted tests to show whether multiple phones being in one place could disrupt their ability to track individual signals. Results in an initial experiment showed they managed to discern individual signals for 40% of 162 devices in public. Another, scaled-up experiment showed they could discern 47% of 647 devices in a public hallway across two days.
The tracking range depends on device and the environment, and it could be several hundred feet, but in a crowded location it might only be 10 or so feet. Scientists were able to follow a volunteer’s signal as they went to and from their house. Certain environmental factors can disrupt a Bluetooth signal, including changes in environment temperature, and some devices send signals with more power and range than others.
One might say “well, I’ll just keep Bluetooth turned off when not in use,” but the researchers said they found that some devices, especially iPhones, don’t actually turn off Bluetooth unless a user goes directly into settings to turn off the signal. Most people might not even realize their Bluetooth is being constantly emitted by many smart devices.
Last week, the French national data protection authority (the Commission Nationale de l’informatique et des Libertés or “CNIL”), published guidelines for what it considers to be a GDPR-compliant way of loading Google Analytics and similar marketing technology tools. The CNIL published these guidelines following notices that the CNIL and other data protection authorities issued to several organizations using Google Analytics stating that such use resulted in impermissible data transfers to the United States. Today, we are excited to announce a set of features and a practical step-by-step guide for using Zaraz that we believe will help organizations continue to use Google Analytics and similar tools in a way that will help protect end user privacy and avoid sending EU personal data to the United States. And the best part? It takes less than a minute.
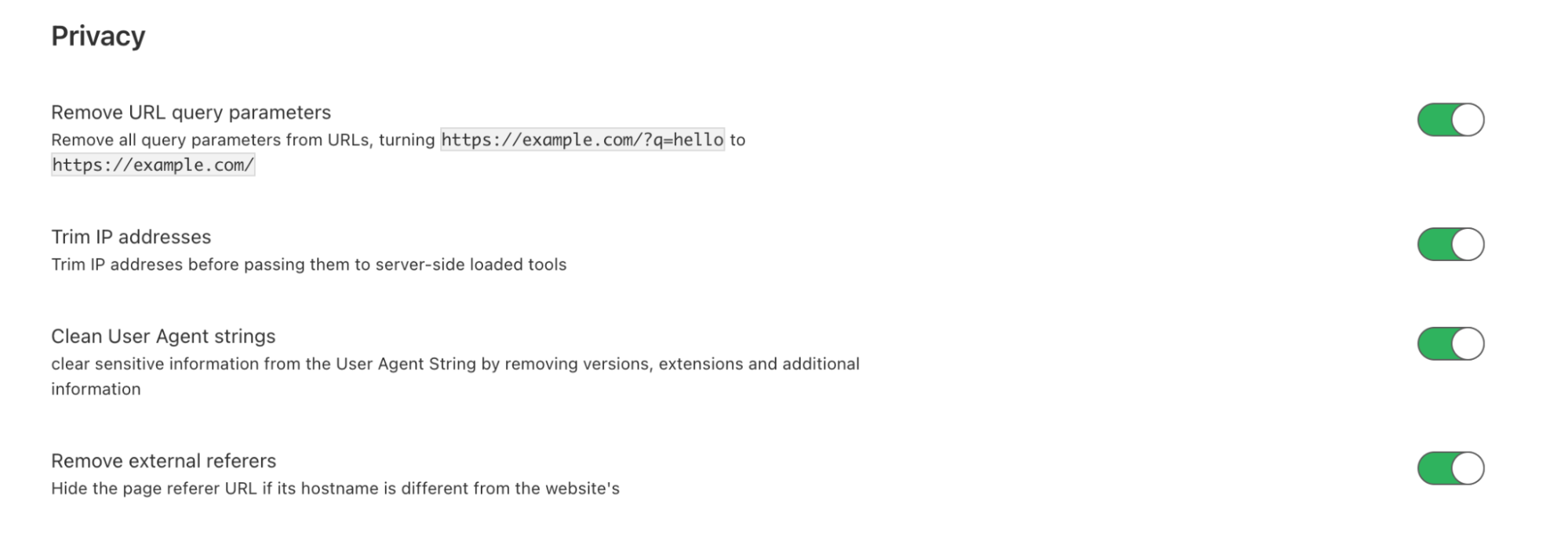
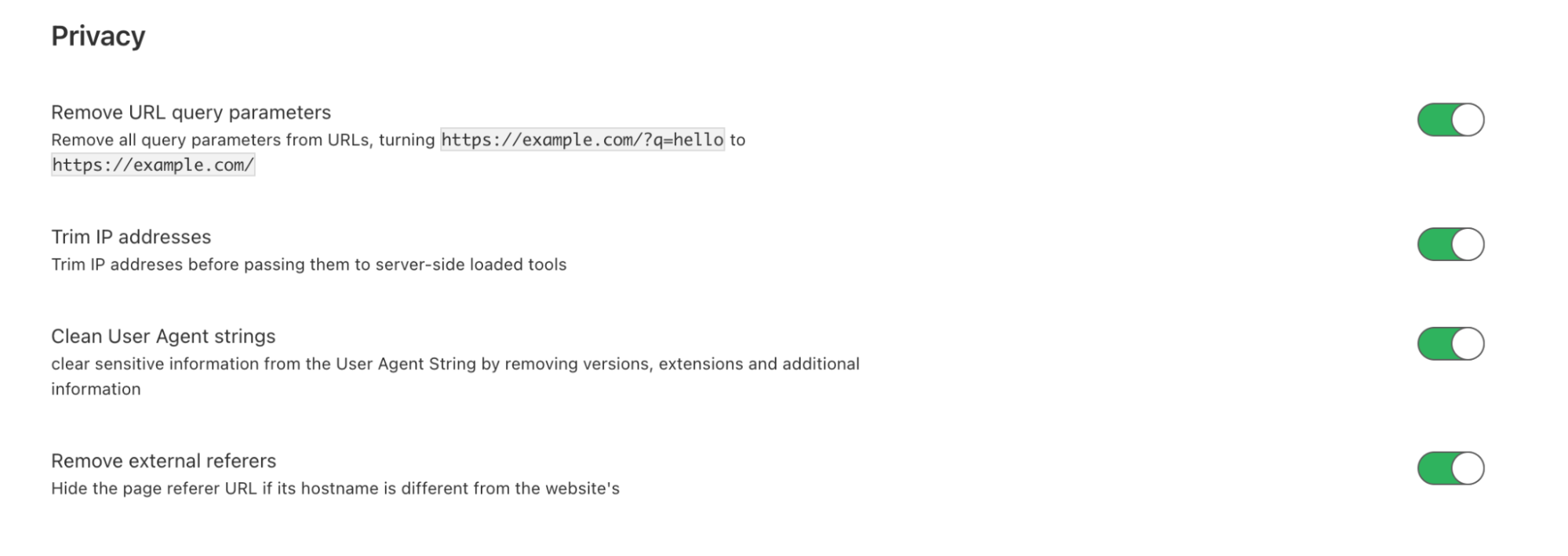
What we are releasing today is a new set of privacy features to help our customers enhance end user privacy. Starting today, on the Zaraz dashboard, you can apply the following configurations:
Remove URL query parameters: when toggled-on, Zaraz will remove all query parameters from a URL that is reported to a third-party server. It will turn https://example.com/?q=hello to https://example.com. This will allow users to remove query parameters, such as UTM, gclid, and the sort that can be used for fingerprinting. This setting will apply to all of your Zaraz integrations.
Hide originating IP address: using Zaraz to load tools like Google Analytics entirely server-side while hiding visitor IP addresses from Google and Facebook has been doable for quite some time now. This will prevent sending the visitor IP address to a third-party tool provider’s server. This feature is configured at a tool level, currently offered for Google Analytics Universal, Google Analytics 4, and Facebook Pixel. We will add this capability to more and more tools as we go. In addition to hiding visitors’ IP addresses from specific tools, you can use Zaraz to trim visitors’ IP addresses across all tools to avoid sending originating IP addresses to third-party tool servers. This option is available on the Zaraz setting page, and is considered less strict.
Clear user agent strings: when toggled on, Zaraz will clear sensitive information from the User Agent String. The User-Agent is a request header that includes information about the operating system, browser, extensions and more of the site visitor. Zaraz clears this string by removing pieces of information (such as versions, extensions, and more) that could lead to user tracking or fingerprinting. This setting will apply only to server-side integrations.
Removal of external referrers: when toggled-on, Zaraz will hide the URL of the referring page from third-party servers. If the referring URL is on the same domain, it will not hide it, to keep analytics accurate and avoid the session from “splitting”. This setting will apply to all of your Zaraz integrations.
How to set up Google Analytics with the new privacy features
We wrote this guide to help you implement our new features when using Google Analytics. We will use Google Analytics (Universal) as the example of this guide, because Google Analytics is widely used by Zaraz customers. You can follow the same principles to set up your Facebook Pixel, or other server-side integration that Zaraz offers.
Step 1: Install Zaraz on your website
Zaraz loads automatically for every website proxied by Cloudflare (Orange Clouded), no code changes are needed. If your website is not proxied by Cloudflare, you can load Zaraz manually with a JavaScript code snippet. If you are new to Cloudflare, or unsure if your website is proxied by Cloudflare, you can use this Chrome extension to find out if your site is Orange Clouded or not.
Step 2: Add Google Analytics via the Zaraz dashboard
All customers have access to the Zaraz dashboard. By default, when you add Google Analytics using the Zaraz tools library, it will load server-side. You do not need to set up any cloud environment or proxy server. Zaraz handles this for you. When you add a tool, Zaraz will start loading on your website, and a request will leave from the end user’s browser to a Cloudflare Worker that sits on your own domain. Cloudflare Workers is our edge computing platform, and this Worker will communicate directly with Google Analytics’ servers. There will be no direct communication between an end user’s browser and Google’s servers. If you wish to learn more about how Zaraz works, please read our previous posts about the unique Zaraz architecture and how we use Workers. Note that “proxying” Google Analytics, by itself, is not enough, according to the CNIL’s guidance. You will have to take more actions to make sure you set up Google Analytics properly.
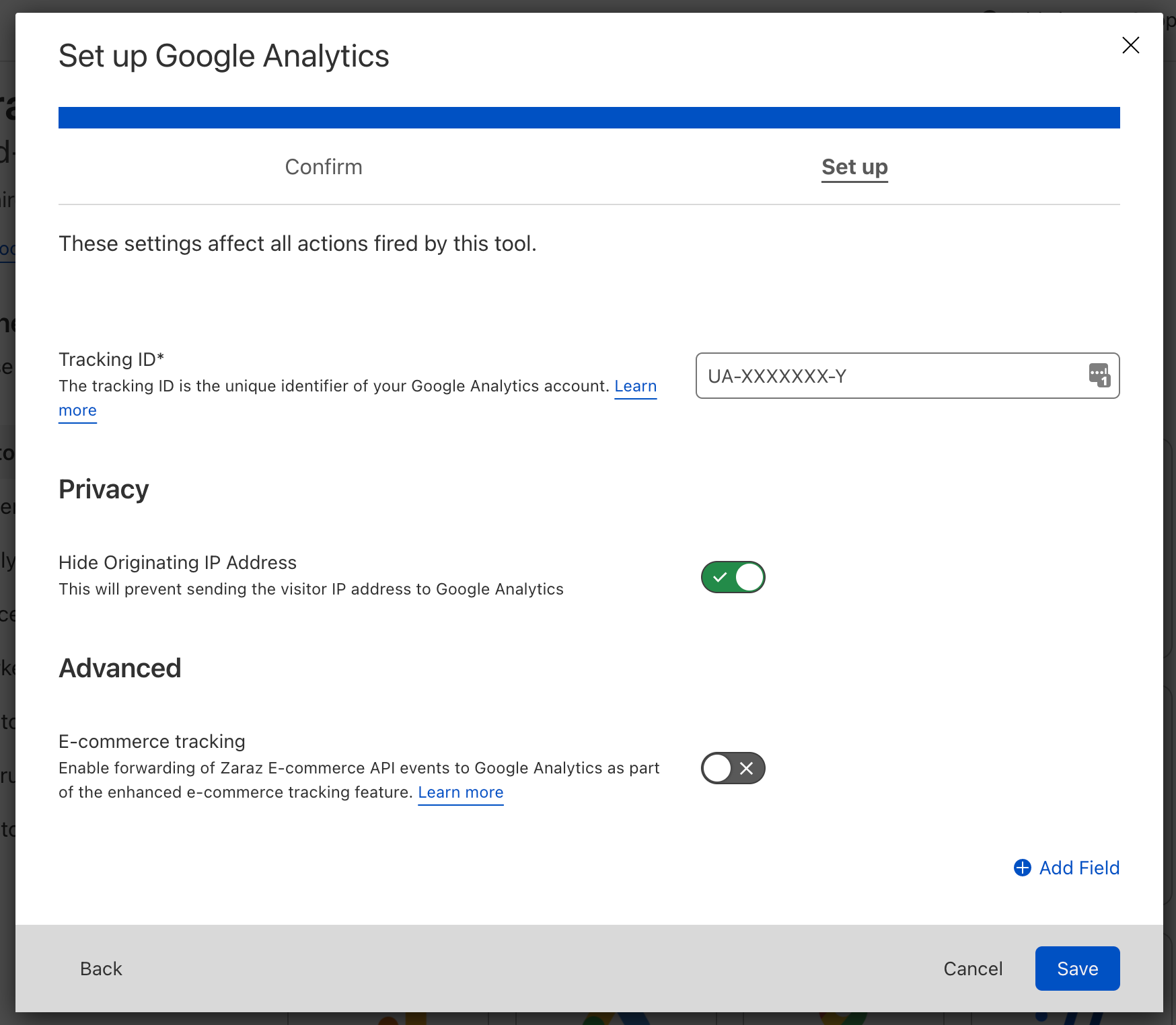
Step 3: Configure Google Analytics and hide IP addresses
All you need to do to set up Google Analytics is to enter your Tracking ID. On the tools setting screen, you would also need to toggle-on the “Hide Originating IP Address” feature. This will prevent Zaraz from sending the visitor’s IP address to Google. Zaraz will remove the IP address on the Edge, before it hits Google’s servers. If you want to make sure Zaraz will run only in the EU, review Cloudflare’s Data Localization Suite.
According to your needs, you can of course set up more complex configurations of Google Analytics, including Ecommerce tracking, Custom Dimension, fields to set, Custom Metrics, etc. Follow this guide for more instructions.
Step 4: Toggle-on Zaraz’s new privacy features
Next, you will need to toggle-on all of our new privacy features mentioned above. You can do this on the Zaraz Settings page, under the Privacy section.
Step 5: Clean your Google Analytics configuration
In this step, you would need to take actions to clean your specific Google Analytics setting. We gathered a list of suggestions for you to help preserve end user privacy:
Do not include any personal identifiable information. You will want to review the CNIL’s guidance on anonymization and determine how to apply it on your end. It is likely that such anonymization will make the unique identifier pretty much useless with most analytics tools. For example, according to our findings, features like Google Analytics’ User ID View, won’t work well with such anonymization. In such cases, you may want to stop using such analytics tools to avoid discrepancies and assure accuracy.
If you wish to hide Google Analytics’ Client ID, on the Google Analytics setting page, click “add field” and choose “Client ID”. To override the Client ID, you can insert any string as the field’s constant value. Please note that this will likely limit Google’s ability to aggregate data and will likely create discrepancies in session and user counts. Still, we’ve seen customers that are using Google Analytics to count events, and to our knowledge that should still be doable with this setting.
Clean your implementation from cross-site identifiers. This could include things like your CRM tool unique identifier, or URL query parameters passing identifiers to share them between different domains (avoid “cross-domain tracking” also known as “site linking”).
You would need to make sure not to include any personal data in your customized configuration and implementation. We recommend you go over the list of Custom Dimension, Event parameters/properties, Ecommerce Data, and User Properties to make sure they do not contain personal data. While this still demands some manual work, the good news is that soon we are about to announce a new set of Privacy features, Zaraz Data Loss Prevention, that will help you do that automatically, at scale. Stay tuned!
Step 6 – you are done! 🎉
A few more things you will want to consider is that implementing this guide will result in some limitations in your ability to use Google Analytics. For example, not collecting UTM parameters and referrers will disable your ability to track traffic sources and campaigns. Not tracking User ID, will prevent you from using the User ID View, and so on. Some companies will find these limitations extreme, but like most things in life, there is a trade-off. We’re taking a step towards a more privacy-oriented web, and this is just the beginning. In the face of new regulatory constraints, new technologies will appear which will unlock new abilities and features. Zaraz is dedicated to leading the way, offering privacy-focused tools that empower website operators and protect end users.
To wrap up, we would really appreciate any feedback on this announcement, or new feature requests you might have. You can reach out to your Cloudflare account manager, or directly to us on our Discord channel. Privacy is at the heart of everything our team is building.
We always take a proactive approach towards privacy, and we believe privacy is not only about responding to different regulations, it is about building technology that helps customers do a better job protecting their users. It is about simplifying what it takes to respect and protect user privacy and personal information. It is about helping build a better Internet.
Register now with discount code SALUZwmdkJJ to get $150 off your full conference pass to AWS re:Inforce. For a limited time only and while supplies last.
Today we want to tell you about some of the engaging data protection and privacy sessions planned for AWS re:Inforce. AWS re:Inforce is a learning conference where you can learn more about on security, compliance, identity, and privacy. When you attend the event, you have access to hundreds of technical and business sessions, an AWS Partner expo hall, a keynote speech from AWS Security leaders, and more. AWS re:Inforce 2022 will take place in-person in Boston, MA on July 26 and 27. re:Inforce 2022 features content in the following five areas:
Data protection and privacy
Governance, risk, and compliance
Identity and access management
Network and infrastructure security
Threat detection and incident response
This post will highlight of some of the data protection and privacy offerings that you can sign up for, including breakout sessions, chalk talks, builders’ sessions, and workshops. For the full catalog of all tracks, see the AWS re:Inforce session preview.
Breakout sessions
Lecture-style presentations that cover topics at all levels and delivered by AWS experts, builders, customers, and partners. Breakout sessions typically include 10–15 minutes of Q&A at the end.
DPP 101: Building privacy compliance on AWS In this session, learn where technology meets governance with an emphasis on building. With the privacy regulation landscape continuously changing, organizations need innovative technical solutions to help solve privacy compliance challenges. This session covers three unique customer use cases and explores privacy management, technology maturity, and how AWS services can address specific concerns. The studies presented help identify where you are in the privacy journey, provide actions you can take, and illustrate ways you can work towards privacy compliance optimization on AWS.
DPP201: Meta’s secure-by-design approach to supporting AWS applications Meta manages a globally distributed data center infrastructure with a growing number of AWS Cloud applications. With all applications, Meta starts by understanding data security and privacy requirements alongside application use cases. This session covers the secure-by-design approach for AWS applications that helps Meta put automated safeguards before deploying applications. Learn how Meta handles account lifecycle management through provisioning, maintaining, and closing accounts. The session also details Meta’s global monitoring and alerting systems that use AWS technologies such as Amazon GuardDuty, AWS Config, and Amazon Macie to provide monitoring, access-anomaly detection, and vulnerable-configuration detection.
DPP202: Uplifting AWS service API data protection to TLS 1.2+ AWS is constantly raising the bar to ensure customers use the most modern Transport Layer Security (TLS) encryption protocols, which meet regulatory and security standards. In this session, learn how AWS can help you easily identify if you have any applications using older TLS versions. Hear tips and best practices for using AWS CloudTrail Lake to detect the use of outdated TLS protocols, and learn how to update your applications to use only modern versions. Get guidance, including a demo, on building metrics and alarms to help monitor TLS use.
DPP203: Secure code and data in use with AWS confidential compute capabilities At AWS, confidential computing is defined as the use of specialized hardware and associated firmware to protect in-use customer code and data from unauthorized access. In this session, dive into the hardware- and software-based solutions AWS delivers to provide a secure environment for customer organizations. With confidential compute capabilities such as the AWS Nitro System, AWS Nitro Enclaves, and NitroTPM, AWS offers protection for customer code and sensitive data such as personally identifiable information, intellectual property, and financial and healthcare data. Securing data allows for use cases such as multi-party computation, blockchain, machine learning, cryptocurrency, secure wallet applications, and banking transactions.
Builders’ sessions
Small-group sessions led by an AWS expert who guides you as you build the service or product on your own laptop. Use your laptop to experiment and build along with the AWS expert.
DPP251: Disaster recovery and resiliency for AWS data protection services Mitigating unknown risks means planning for any situation. To help achieve this, you must architect for resiliency. Disaster recovery (DR) is an important part of your resiliency strategy and concerns how your workload responds when a disaster strikes. To this end, many organizations are adopting architectures that function across multiple AWS Regions as a DR strategy. In this builders’ session, learn how to implement resiliency with AWS data protection services. Attend this session to gain hands-on experience with the implementation of multi-Region architectures for critical AWS security services.
DPP351: Implement advanced access control mechanisms using AWS KMS Join this builders’ session to learn how to implement access control mechanisms in AWS Key Management Service (AWS KMS) and enforce fine-grained permissions on sensitive data and resources at scale. Define AWS KMS key policies, use attribute-based access control (ABAC), and discover advanced techniques such as grants and encryption context to solve challenges in real-world use cases. This builders’ session is aimed at security engineers, security architects, and anyone responsible for implementing security controls such as segregating duties between encryption key owners, users, and AWS services or delegating access to different principals using different policies.
DPP352: TLS offload and containerized applications with AWS CloudHSM With AWS CloudHSM, you can manage your own encryption keys using FIPS 140-2 Level 3 validated HSMs. This builders’ session covers two common scenarios for CloudHSM: TLS offload using NGINX and OpenSSL Dynamic agent and a containerized application that uses PKCS#11 to perform crypto operations. Learn about scaling containerized applications, discover how metrics and logging can help you improve the observability of your CloudHSM-based applications, and review audit records that you can use to assess compliance requirements.
DPP353: How to implement hybrid public key infrastructure (PKI) on AWS As organizations migrate workloads to AWS, they may be running a combination of on-premises and cloud infrastructure. When certificates are issued to this infrastructure, having a common root of trust to the certificate hierarchy allows for consistency and interoperability of the public key infrastructure (PKI) solution. In this builders’ session, learn how to deploy a PKI that allows such capabilities in a hybrid environment. This solution uses Windows Certificate Authority (CA) and ACM Private CA to distribute and manage x.509 certificates for Active Directory users, domain controllers, network components, mobile, and AWS services, including Amazon API Gateway, Amazon CloudFront, and Elastic Load Balancing.
Chalk talks
Highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds.
DPP231: Protecting healthcare data on AWS Achieving strong privacy protection through technology is key to protecting patient. Privacy protection is fundamental for healthcare compliance and is an ongoing process that demands legal, regulatory, and professional standards are continually met. In this chalk talk, learn about data protection, privacy, and how AWS maintains a standards-based risk management program so that the HIPAA-eligible services can specifically support HIPAA administrative, technical, and physical safeguards. Also consider how organizations can use these services to protect healthcare data on AWS in accordance with the shared responsibility model.
DPP232: Protecting business-critical data with AWS migration and storage services Business-critical applications that were once considered too sensitive to move off premises are now moving to the cloud with an extension of the security perimeter. Join this chalk talk to learn about securely shifting these mature applications to cloud services with the AWS Transfer Family and helping to secure data in Amazon Elastic File System (Amazon EFS), Amazon FSx, and Amazon Elastic Block Storage (Amazon EBS). Also learn about tools for ongoing protection as part of the shared responsibility model.
DPP331: Best practices for cutting AWS KMS costs using Amazon S3 bucket keys Learn how AWS customers are using Amazon S3 bucket keys to cut their AWS Key Management Service (AWS KMS) request costs by up to 99 percent. In this chalk talk, hear about the best practices for exploring your AWS KMS costs, identifying suitable buckets to enable bucket keys, and providing mechanisms to apply bucket key benefits to existing objects.
DPP332: How to securely enable third-party access In this chalk talk, learn about ways you can securely enable third-party access to your AWS account. Learn why you should consider using services such as Amazon GuardDuty, AWS Security Hub, AWS Config, and others to improve auditing, alerting, and access control mechanisms. Hardening an account before permitting external access can help reduce security risk and improve the governance of your resources.
Workshops
Interactive learning sessions where you work in small teams to solve problems using AWS Cloud security services. Come prepared with your laptop and a willingness to learn!
DPP271: Isolating and processing sensitive data with AWS Nitro Enclaves Join this hands-on workshop to learn how to isolate highly sensitive data from your own users, applications, and third-party libraries on your Amazon EC2 instances using AWS Nitro Enclaves. Explore Nitro Enclaves, discuss common use cases, and build and run an enclave. This workshop covers enclave isolation, cryptographic attestation, enclave image files, building a local vsock communication channel, debugging common scenarios, and the enclave lifecycle.
DPP272: Data discovery and classification with Amazon Macie This workshop familiarizes you with Amazon Macie and how to scan and classify data in your Amazon S3 buckets. Work with Macie (data classification) and AWS Security Hub (centralized security view) to view and understand how data in your environment is stored and to understand any changes in Amazon S3 bucket policies that may negatively affect your security posture. Learn how to create a custom data identifier, plus how to create and scope data discovery and classification jobs in Macie.
DPP273: Architecting for privacy on AWS In this workshop, follow a regulatory-agnostic approach to build and configure privacy-preserving architectural patterns on AWS including user consent management, data minimization, and cross-border data flows. Explore various services and tools for preserving privacy and protecting data.
DPP371: Building and operating a certificate authority on AWS In this workshop, learn how to securely set up a complete CA hierarchy using AWS Certificate Manager Private Certificate Authority and create certificates for various use cases. These use cases include internal applications that terminate TLS, code signing, document signing, IoT device authentication, and email authenticity verification. The workshop covers job functions such as CA administrators, application developers, and security administrators and shows you how these personas can follow the principal of least privilege to perform various functions associated with certificate management. Also learn how to monitor your public key infrastructure using AWS Security Hub.
If any of these sessions look interesting to you, consider joining us in Boston by registering for re:Inforce 2022. We look forward to seeing you there!
Today is the second day of the fifteenth Workshop on Security and Human Behavior, hosted by Ross Anderson and Alice Hutchings at the University of Cambridge. After two years of having this conference remotely on Zoom, it’s nice to be back together in person.
SHB is a small, annual, invitational workshop of people studying various aspects of the human side of security, organized each year by Alessandro Acquisti, Ross Anderson, Alice Hutchings, and myself. The forty or so attendees include psychologists, economists, computer security researchers, sociologists, political scientists, criminologists, neuroscientists, designers, lawyers, philosophers, anthropologists, geographers, business school professors, and a smattering of others. It’s not just an interdisciplinary event; most of the people here are individually interdisciplinary.
For the past decade and a half, this workshop has been the most intellectually stimulating two days of my professional year. It influences my thinking in different and sometimes surprising ways—and has resulted in some unexpected collaborations.
Our goal is always to maximize discussion and interaction. We do that by putting everyone on panels, and limiting talks to six to eight minutes, with the rest of the time for open discussion. Because everyone was not able to attend in person, our panels all include remote participants as well. The hybrid structure is working well, even though our remote participants aren’t around for the social program.
This year’s schedule is here. This page lists the participants and includes links to some of their work. As he does every year, Ross Anderson is liveblogging the talks.
Back in the early days of the Internet, you could physically see the hardware where your data was stored. You knew where your data was and what kind of locks and security protections you had in place. Fast-forward a few decades, and data is all “in the cloud”. Now, you have to trust that your cloud services provider is putting security precautions in place just as you would have if your data was still sitting on your hardware. The good news is, you don’t have to merely trust your provider anymore. There are a number of ways a cloud services provider can prove it has robust privacy and security protections in place.
Today, we are excited to announce that Cloudflare has taken three major steps forward in proving the security and privacy protections we provide to customers of our cloud services: we achieved a key cloud services certification, ISO/IEC 27018:2019; we completed our independent audit and received our Cloud Computing Compliance Criteria Catalog (“C5”) attestation; and we have joined the EU Cloud Code of Conduct General Assembly to help increase the impact of the trusted cloud ecosystem and encourage more organizations to adopt GDPR-compliant cloud services.
Cloudflare has been committed to data privacy and security since our founding, and it is important to us that we can demonstrate these commitments. Certification provides assurance to our customers that a third party has independently verified that Cloudflare meets the requirements set out in the standard.
ISO/IEC 27018:2019 – Cloud Services Certification
2022 has been a big year for people who like the number ‘two’. February marked the second when the 22nd Feb 2022 20:22:02 passed: the second second of the twenty-second minute of the twentieth hour of the twenty-second day of the second month, of the year twenty-twenty-two! As well as the date being a palindrome — something that reads the same forwards and backwards — on an vintage ‘80s LCD clock, the date and time could be written as an ambigram too — something that can be read upside down as well as the right way up:
When we hit 2022 02 22, our team was busy completing our second annual audit to certify to ISO/IEC 27701:2019, having been one of the first organizations in our industry to have achieved this new ISO privacy certification in 2021, and the first Internet performance & security company to be certified to it. And now Cloudflare has now been certified to a second international privacy standard related to the processing of personal data — ISO/IEC 27018:2019.1
ISO 27018 is a privacy extension to the widespread industry standards ISO/IEC 27001 and ISO/IEC 27002, which describe how to establish and run an Information Security Management System. ISO 27018 extends the standards into a code of practice for how any personal information should be protected when processed in a public cloud, such as Cloudflare’s.
What does ISO 27018 mean for Cloudflare customers?
Put simply, with Cloudflare’s certifications to both ISO 27701 and ISO 27018, customers can be assured that Cloudflare both has a privacy program that meets GDPR-aligned industry standards and also that Cloudflare protects the personal data processed in our network as part of that privacy program.
These certifications, in addition to the Data Processing Addendum (“DPA”) we make available to our customers, offer our customers multiple layers of assurance that any personal data that Cloudflare processes on their behalf will be handled in a way that meets the GDPR’s requirements.
The ISO 271018 standard contains enhancements to existing ISO 27002 controls and an additional set of 25 controls identified for organizations that are personal data processors. Controls are essentially a set of best practices that processors must meet in terms of data handling practices and transparency about those practices, protecting and encrypting the personal data processed, and handling data subject rights, among others. As an example, one of the ISO 27018 requirements is:
Where the organization is contracted to process personal data, that personal data may not be used for the purpose of marketing and advertising without establishing that prior consent was obtained from the appropriate data subject. Such consent shall not be a condition for receiving the service.
When Cloudflare acts as a data processor for our customers’ data, that data (and any personal data it may contain) belongs to our customers, not to us. Cloudflare does not track our customers’ end users for marketing or advertising purposes, and we never will. We even went beyond what the ISO control required and added this commitment to our customer DPA:
“… Cloudflare shall not use the Personal Data for the purposes of marketing or advertising…” – 3.1(b), Cloudflare Data Protection Addendum
Cloudflare achieves ISO 27018:2019 Certification
For ISO 27018, Cloudflare was assessed by a third-party auditor, Schellman, between December 2021 and February 2022. Certifying to an ISO privacy standard is a multi-step process that includes an internal and an external audit, before finally being certified against the standard by the independent auditor. Cloudflare’s new single joint certificate, covering ISO 27001:2013, ISO 27018:2019, and ISO 27701:2019 is now available to download from the Cloudflare Dashboard.
ISO 27108 isn’t all we’re announcing: as we blogged in February, Cloudflare has also been undergoing a separate independent audit for the Cloud Computing Compliance Criteria Catalog certification — also known as C5 — which was introduced by the German government’s Federal Office for Information Security (“BSI”) in 2016 and updated in 2020. C5 evaluates an organization’s security program against a standard of robust cloud security controls. Both German government agencies and private companies place a high level of importance on aligning their cloud computing requirements with these standards. Learn more about C5 here.
Today, we’re excited to announce that we have completed our independent audit and received our C5 attestation from our third-party auditors. The C5 attestation report is now available to download from the Cloudflare Dashboard.
And we’re not done yet…
When the European Union’s benchmark-setting General Data Protection Regulation (“GDPR”) was adopted four years ago this week, Article 40 encouraged:
“…the drawing up of codes of conduct intended to contribute to the proper application of this Regulation, taking account of the specific features of the various processing sectors and the specific needs of micro, small and medium-sized enterprises.”
The first code officially approved as GDPR-compliant by the EU one year ago this past weekend is ‘The EU Cloud Code of Conduct’. This code is designed to help cloud service providers demonstrate the protections they provide for the personal data they process on behalf of their customers. It covers all cloud service layers, and its compliance is overseen by accredited monitoring body SCOPE Europe. Initially, cloud service providers join as members of the code’s General Assembly, and then the second step is to undergo an audit to validate their adherence to the code.
Today, we are pleased to announce today that Cloudflare has joined the General Assembly of the EU Cloud Code of Conduct. We look forward to the second stage in this process, undertaking our audit and publicly affirming our compliance to the GDPR as a processor of personal data.
Cloudflare Certifications
Customers may now download a copy of Cloudflare’s certifications and reports from the Cloudflare Dashboard; new customers may request these from your sales representative. For the latest information about our certifications and reports, please visit our Trust Hub.
… 1The International Organization for Standardization (“ISO”) is an international, nongovernmental organization made up of national standards bodies that develops and publishes a wide range of proprietary, industrial, and commercial standards.
A surprising number of websites include JavaScript keyloggers that collect everything you type as you type it, not just when you submit a form.
Researchers from KU Leuven, Radboud University, and University of Lausanne crawled and analyzed the top 100,000 websites, looking at scenarios in which a user is visiting a site while in the European Union and visiting a site from the United States. They found that 1,844 websites gathered an EU user’s email address without their consent, and a staggering 2,950 logged a US user’s email in some form. Many of the sites seemingly do not intend to conduct the data-logging but incorporate third-party marketing and analytics services that cause the behavior.
After specifically crawling sites for password leaks in May 2021, the researchers also found 52 websites in which third parties, including the Russian tech giant Yandex, were incidentally collecting password data before submission. The group disclosed their findings to these sites, and all 52 instances have since been resolved.
“If there’s a Submit button on a form, the reasonable expectation is that it does something — that it will submit your data when you click it,” says Güneş Acar, a professor and researcher in Radboud University’s digital security group and one of the leaders of the study. “We were super surprised by these results. We thought maybe we were going to find a few hundred websites where your email is collected before you submit, but this exceeded our expectations by far.”
San Francisco police are using autonomous vehicles as mobile surveillance cameras.
Privacy advocates say the revelation that police are actively using AV footage is cause for alarm.
“This is very concerning,” Electronic Frontier Foundation (EFF) senior staff attorney Adam Schwartz told Motherboard. He said cars in general are troves of personal consumer data, but autonomous vehicles will have even more of that data from capturing the details of the world around them. “So when we see any police department identify AVs as a new source of evidence, that’s very concerning.”
Georgetown has a new report on the highly secretive bulk surveillance activities of ICE in the US:
When you think about government surveillance in the United States, you likely think of the National Security Agency or the FBI. You might even think of a powerful police agency, such as the New York Police Department. But unless you or someone you love has been targeted for deportation, you probably don’t immediately think of Immigration and Customs Enforcement (ICE).
This report argues that you should. Our two-year investigation, including hundreds of Freedom of Information Act requests and a comprehensive review of ICE’s contracting and procurement records, reveals that ICE now operates as a domestic surveillance agency. Since its founding in 2003, ICE has not only been building its own capacity to use surveillance to carry out deportations but has also played a key role in the federal government’s larger push to amass as much information as possible about all of our lives. By reaching into the digital records of state and local governments and buying databases with billions of data points from private companies, ICE has created a surveillance infrastructure that enables it to pull detailed dossiers on nearly anyone, seemingly at any time. In its efforts to arrest and deport, ICE has — without any judicial, legislative or public oversight — reached into datasets containing personal information about the vast majority of people living in the U.S., whose records can end up in the hands of immigration enforcement simply because they apply for driver’s licenses; drive on the roads; or sign up with their local utilities to get access to heat, water and electricity.
ICE has built its dragnet surveillance system by crossing legal and ethical lines, leveraging the trust that people place in state agencies and essential service providers, and exploiting the vulnerability of people who volunteer their information to reunite with their families. Despite the incredible scope and evident civil rights implications of ICE’s surveillance practices, the agency has managed to shroud those practices in near-total secrecy, evading enforcement of even the handful of laws and policies that could be invoked to impose limitations. Federal and state lawmakers, for the most part, have yet to confront this reality.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.