Post Syndicated from Sheila Busser original https://aws.amazon.com/blogs/compute/best-practices-for-hosting-regulated-gaming-workloads-in-aws-local-zones-and-on-aws-outposts/
This blog post is written by Shiv Bhatt, Manthan Raval, and Pawan Matta, who are Senior Solutions Architects with AWS.
Many industries are subject to regulations that are created to protect the interests of the various stakeholders. For some industries, the specific details of the regulatory requirements influence not only the organization’s operations, but also their decisions for adopting new technology. In this post, we highlight the workload residency challenges that you may encounter when you deploy regulated gaming workloads, and how AWS Local Zones and AWS Outposts can help you address those challenges.
Regulated gaming workloads and residency requirements
A regulated gaming workload is a type of workload that’s subject to federal, state, local, or tribal laws related to the regulation of gambling and real money gaming. Examples of these workloads include sports betting, horse racing, casino, poker, lottery, bingo, and fantasy sports. The operators provide gamers with access to these workloads through online and land-based channels, and they’re required to follow various regulations required in their jurisdiction. Some regulations define specific workload residency requirements, and depending on the regulatory agency, the regulations could require that workloads be hosted within a specific city, state, province, or country. For example, in the United States, different state and tribal regulatory agencies dictate whether and where gaming operations are legal in a state, and who can operate. The agencies grant licenses to the operators of regulated gaming workloads, which then govern who can operate within the state, and sometimes, specifically where these workloads can be hosted. In addition, federal legislation can also constrain how regulated gaming workloads can be operated. For example, the United States Federal Wire Act makes it illegal to facilitate bets or wagers on sporting events across state lines. This regulation requires that operators make sure that users who place bets in a specific state are also within the borders of that state.
Benefits of using AWS edge infrastructure with regulated gaming workloads
The use of AWS edge infrastructure, specifically Local Zones and Outposts to host a regulated gaming workload, can help you meet workload residency requirements. You can manage Local Zones and Outposts by using the AWS Management Console or by using control plane API operations, which lets you seamlessly consume compute, storage, and other AWS services.
Local Zones
Local Zones are a type of AWS infrastructure deployment that place compute, storage, database, and other select services closer to large population, industry, and IT centers. Like AWS Regions, Local Zones enable you to innovate more quickly and bring new products to market sooner without having to worry about hardware and data center space procurement, capacity planning, and other forms of undifferentiated heavy-lifting. Local Zones have their own connections to the internet, and support AWS Direct Connect, so that workloads hosted in the Local Zone can serve local end-users with very low-latency communications. Local Zones are by default connected to a parent Region via Amazon’s redundant and high-bandwidth private network. This lets you extend Amazon Virtual Private Cloud (Amazon VPC) in the AWS Region to Local Zones. Furthermore, this provides applications hosted in AWS Local Zones with fast, secure, and seamless access to the broader portfolio of AWS services in the AWS Region. You can see the full list of AWS services supported in Local Zones on the AWS Local Zones features page.
You can start using Local Zones right away by enabling them in your AWS account. There are no setup fees, and as with the AWS Region, you pay only for the services that you use. There are three ways to pay for Amazon Elastic Compute Cloud (Amazon EC2) instances in Local Zones: On-Demand, Savings Plans, and Spot Instances. See the full list of cities where Local Zones are available on the Local Zones locations page.
Outposts
Outposts is a family of fully-managed solutions that deliver AWS infrastructure and services to most customer data center locations for a consistent hybrid experience. For a full list of countries and territories where Outposts is available, see the Outposts rack FAQs and Outposts servers FAQs. Outposts is available in various form factors, from 1U and 2U Outposts servers to 42U Outposts racks, and multiple rack deployments. To learn more about specific configuration options and pricing, see Outposts rack and Outposts servers.
You configure Outposts to work with a specific AWS Region using AWS Direct Connect or an internet connection, which lets you extend Amazon VPC in the AWS Region to Outposts. Like Local Zones, this provides applications hosted on Outposts with fast, secure, and seamless access to the broader portfolio of AWS services in the AWS Region. See the full list of AWS services supported on Outposts rack and on Outposts servers.
Choosing between AWS Regions, Local Zones, and Outposts
When you build and deploy a regulated gaming workload, you must assess the residency requirements carefully to make sure that your workload complies with regulations. As you make your assessment, we recommend that you consider separating your regulated gaming workload into regulated and non-regulated components. For example, for a sports betting workload, the regulated components might include sportsbook operation, and account and wallet management, while non-regulated components might include marketing, the odds engine, and responsible gaming. In describing the following scenarios, it’s assumed that regulated and non-regulated components must be fault-tolerant.
For hosting the non-regulated components of your regulated gaming workload, we recommend that you consider using an AWS Region instead of a Local Zone or Outpost. An AWS Region offers higher availability, larger scale, and a broader selection of AWS services.
For hosting regulated components, the type of AWS infrastructure that you choose will depend on which of the following scenarios applies to your situation:
- Scenario one: An AWS Region is available in your jurisdiction and local regulators have approved the use of cloud services for your regulated gaming workload.
- Scenario two: An AWS Region isn’t available in your jurisdiction, but a Local Zone is available, and local regulators have approved the use of cloud services for your regulated gaming workload.
- Scenario three: An AWS Region or Local Zone isn’t available in your jurisdiction, or local regulators haven’t approved the use of cloud services for your regulated gaming workload, but Outposts is available.
Let’s look at each of these scenarios in detail.
Scenario one: Use an AWS Region for regulated components
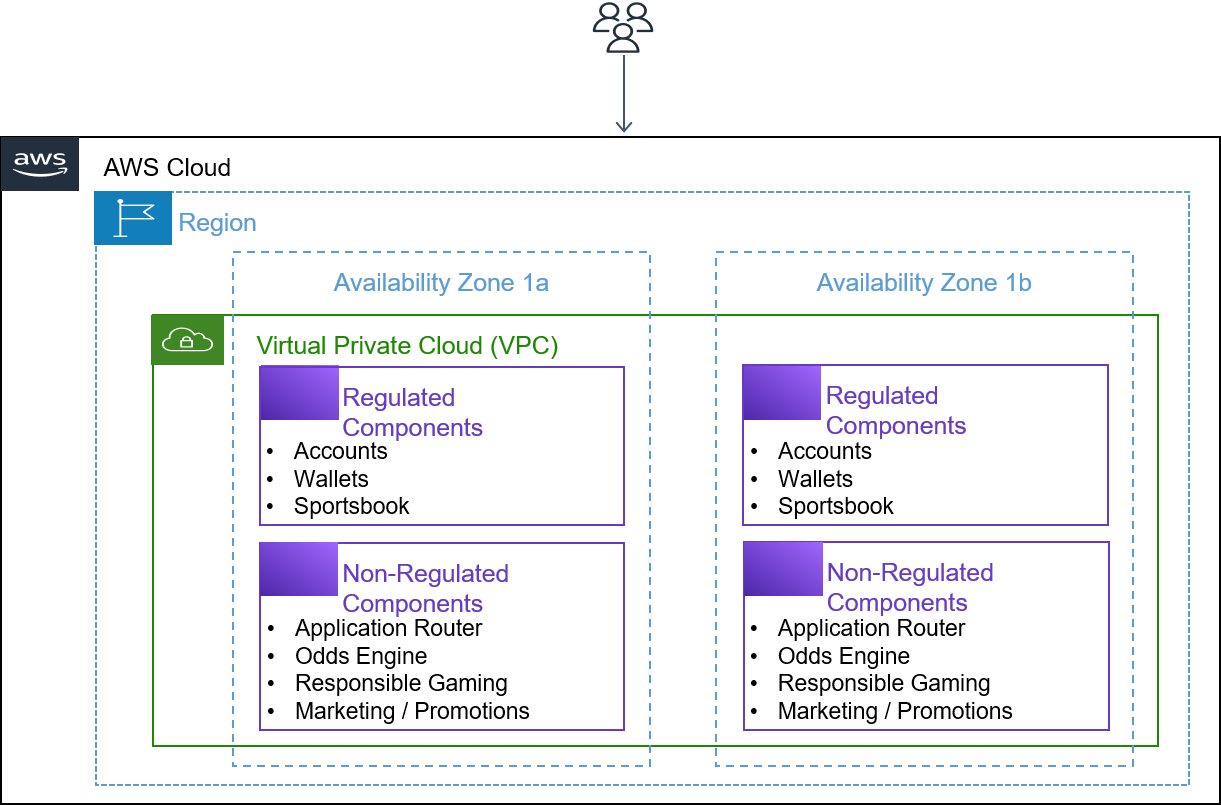
When local regulators have approved the use of cloud services for regulated gaming workloads, and an AWS Region is available in your jurisdiction, consider using an AWS Region rather than a Local Zone and Outpost. For example, in the United States, the State of Ohio has announced that it will permit regulated gaming workloads to be deployed in the cloud on infrastructure located within the state when sports betting goes live in January 2023. By using the US East (Ohio) Region, operators in the state don’t need to procure and manage physical infrastructure and data center space. Instead, they can use various compute, storage, database, analytics, and artificial intelligence/machine learning (AI/ML) services that are readily available in the AWS Region. You can host a regulated gaming workload entirely in a single AWS Region, which includes Availability Zones (AZs) – multiple, isolated locations within each AWS Region. By deploying your workload redundantly across at least two AZs, you can help make sure of the high availability, as shown in the following figure.

Scenario two: Use a Local Zone for regulated components
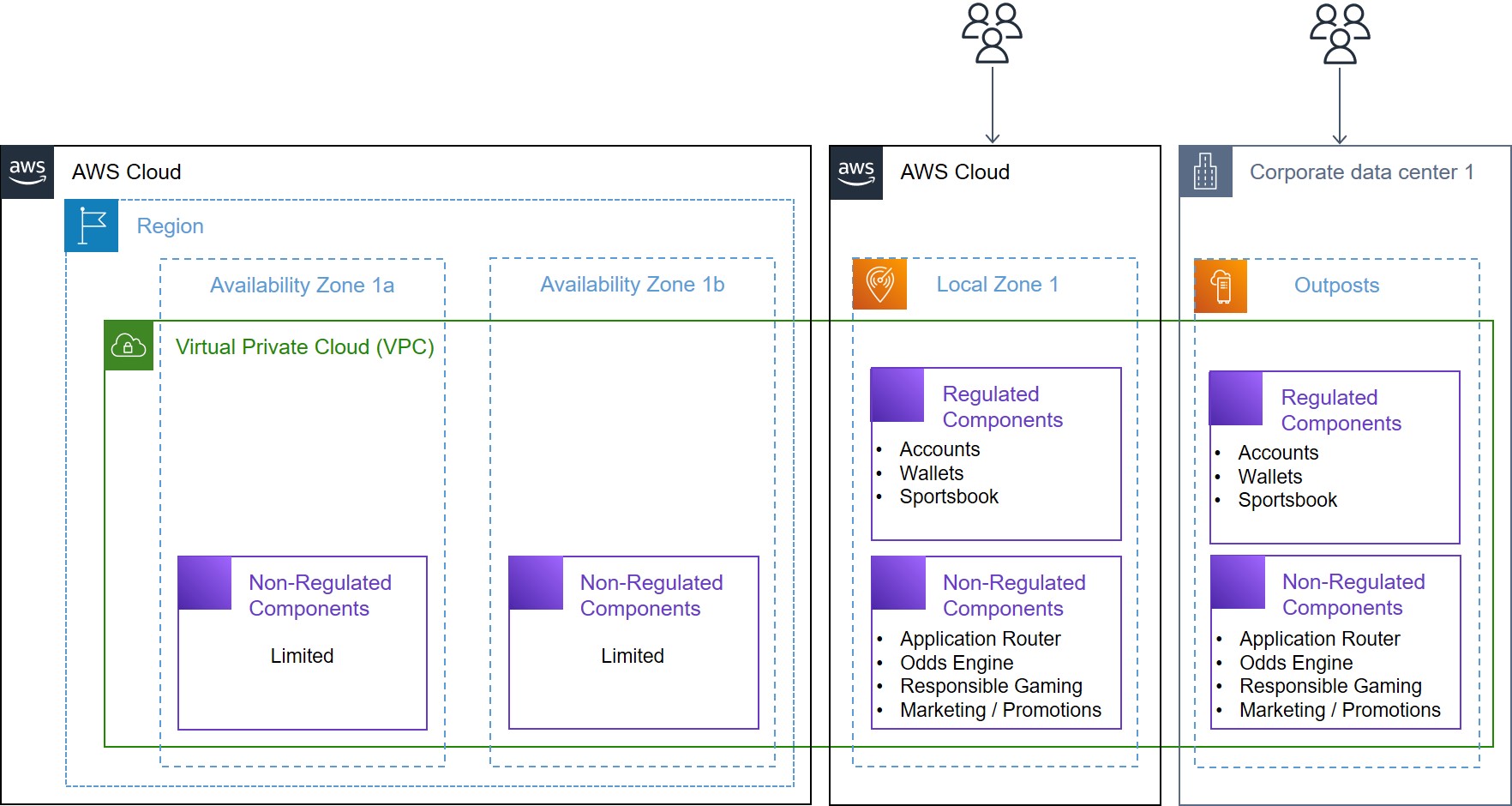
A second scenario might be that local regulators have approved the use of cloud services for regulated gaming workloads, and an AWS Region isn’t available in your jurisdiction, but a Local Zone is available. In this scenario, consider using a Local Zone rather than Outposts. A Local Zone can support more elasticity in a more cost-effective way than Outposts can. However, you might also consider using a Local Zone and Outposts together to increase availability and scalability for regulated components. Let’s consider the State of Illinois, in the United States, which allows regulated gaming workloads to be deployed in the cloud, if workload residency requirements are met. Operators in this state can host regulated components in a Local Zone in Chicago, and they can also use Outposts in their data center in the same state, for high availability and disaster recovery, as shown in the following figure.

Scenario three: Use of Outposts for regulated components
When local regulators haven’t approved the use of cloud services for regulated gaming workloads, or when an AWS Region or Local Zone isn’t available in your jurisdiction, you can still choose to host your regulated gaming workloads on Outposts for a consistent cloud experience, if Outposts is available in your jurisdiction. If you choose to use Outposts, then note that as part of the shared responsibility model, customers are responsible for attesting to physical security and access controls around the Outpost, as well as environmental requirements for the facility, networking, and power. Use of Outposts requires you to procure and manage the data center within the city, state, province, or country boundary (as required by local regulations) that may be suitable to host regulated components, depending on the jurisdiction. Furthermore, you should procure and configure supported network connections between Outposts and the parent AWS Region. During the Outposts ordering process, you should account for the compute and network capacity required to support the peak load and availability design.
For a higher availability level, you should consider procuring and deploying two or more Outposts racks or Outposts servers in a data center. You might also consider deploying redundant network paths between Outposts and the parent AWS Region. However, depending on your business service level agreement (SLA) for regulated gaming workload, you might choose to spread Outposts racks across two or more isolated data centers within the same regulated boundary, as shown in the following figure.

Options to route ingress gaming traffic
You have two options to route ingress gaming traffic coming into your regulated and non-regulated components when you deploy the configurations that we described previously in Scenarios two and three. Your gaming traffic can come through to the AWS Region, or through the Local Zones or Outposts. Note that the benefits that we mentioned previously around selecting the AWS Region for deploying regulated and non-regulated components are the same when you select an ingress route.
Let’s discuss the benefits and trade offs for each of these options.
Option one: Route ingress gaming traffic through an AWS Region
If you choose to route ingress gaming traffic through an AWS Region, your regulated gaming workloads benefit from access to the wide range of tools, services, and capacity available in the AWS Region. For example, native AWS security services, like AWS WAF and AWS Shield, which provide protection against DDoS attacks, are currently only available in AWS Regions. Only traffic that you route into your workload through an AWS Region benefits from these services.
If you route gaming traffic through an AWS Region, and non-regulated components are hosted in an AWS Region, then traffic has a direct path to non-regulated components. In addition, gaming traffic destined to regulated components, hosted in a Local Zone and on Outposts, can be routed through your non-regulated components and a few native AWS services in the AWS Region, as shown in Figure 2.
Option two: Route ingress gaming traffic through a Local Zone or Outposts
Choosing to route ingress gaming traffic through a Local Zone or Outposts requires careful planning to make sure that tools, services, and capacity are available in that jurisdiction, as shown in the following figure. In addition, consider how choosing this route will influence the pillars of the AWS Well-Architected Framework. This route might require deploying and managing most of your non-regulated components in a Local Zone or on Outposts as well, including native AWS services that aren’t available in Local Zones or on Outposts. If you plan to implement this topology, then we recommend that you consider using AWS Partner solutions to replace the native AWS services that aren’t available in Local Zones or Outposts.

Conclusion
If you’re building regulated gaming workloads, then you might have to follow strict workload residency and availability requirements. In this post, we’ve highlighted how Local Zones and Outposts can help you meet these workload residency requirements by bringing AWS services closer to where they’re needed. We also discussed the benefits of using AWS Regions in compliment to the AWS edge infrastructure, and several reliability and cost design considerations.
Although this post provides information to consider when making choices about using AWS for regulated gaming workloads, you’re ultimately responsible for maintaining compliance with the gaming regulations and laws in your jurisdiction. You’re in the best position to determine and maintain ultimate responsibility for determining whether activities are legal, including evaluating the jurisdiction of the activities, how activities are made available, and whether specific technologies or services are required to make sure of compliance with the applicable law. You should always review these regulations and laws before you deploy regulated gaming workloads on AWS.