Post Syndicated from Yair Dovrat original https://blog.cloudflare.com/zaraz-supports-server-side-rendering-of-embeds

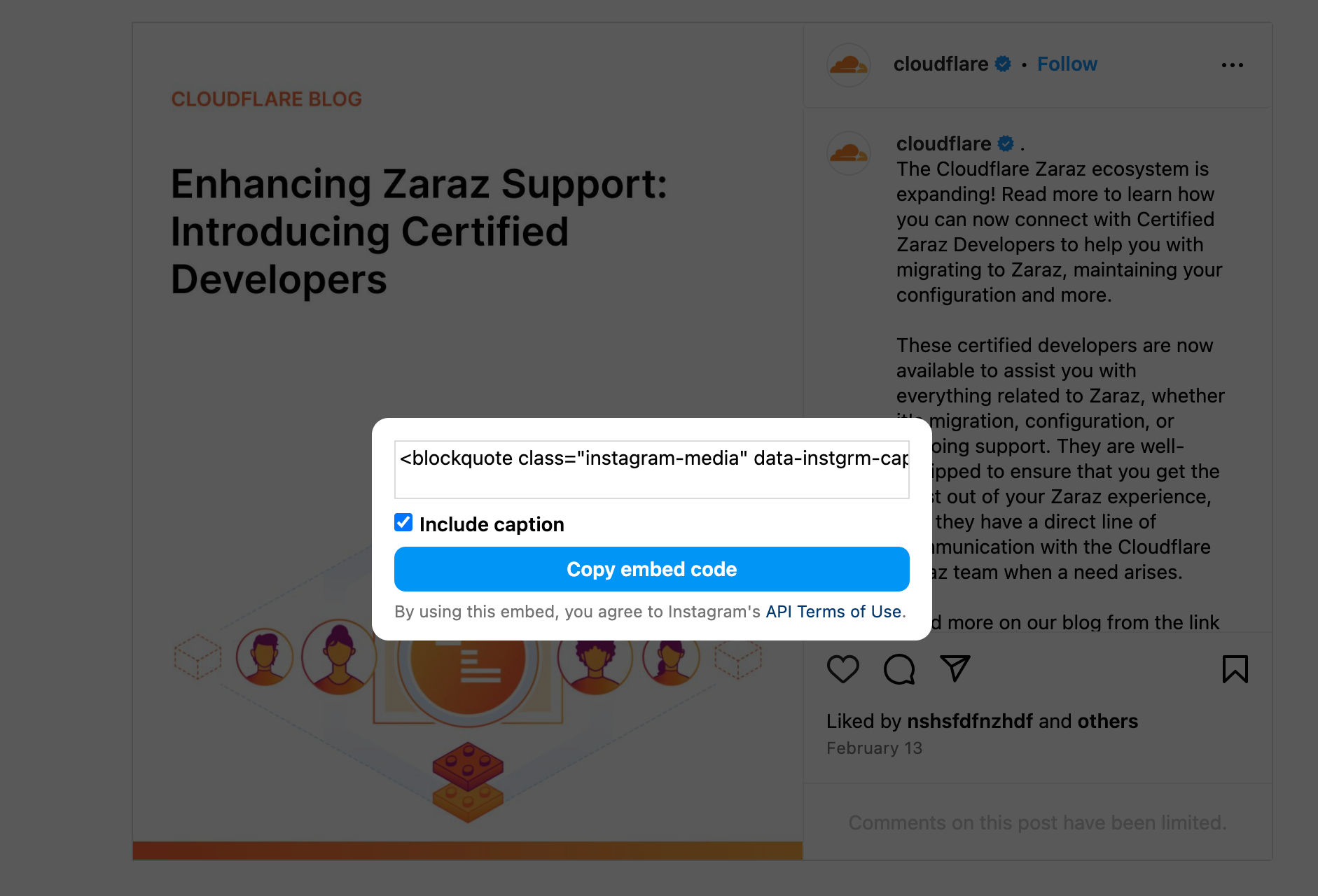
We are thrilled to announce Cloudflare Zaraz support of server-side rendering of embeds, featuring two Managed Components: X and Instagram. You can now use Cloudflare Zaraz to effortlessly embed posts from X or Instagram on your website in a performant, privacy-preserving, and secure way. Many traditional tag managers or customer data platforms rely heavily on third-party JavaScript and cookies to embed content, leading to concerns about privacy and performance. In contrast, we designed our solution to work without loading any third-party JavaScript or cookies, and furthermore to completely eliminate communication between the browser and third-party servers.
Starting today, you can use Cloudflare Zaraz not only for server-side data reporting to conventional marketing and analytics tools but also for server-side content rendering on your website. We are excited to pave the way with tools that enhance security, protect user privacy, and improve performance. Take a look at it:
Embed social media content without sacrificing security and speed
Since social media platforms emerged, we have become more and more familiar with seeing posts being embedded on websites, from showcasing user testimonials on product pages to featuring posts from reporters and politicians in news articles or blogs. Traditionally, this process has involved integrating HTML and JavaScript code provided by the social media platform. While this method was quite convenient and simple to implement, it also introduces significant drawbacks in terms of security, privacy, and performance.
One of the primary concerns with using the embed scripts from these platforms is privacy. Today, there’s simply no way to embed social media content on your website without letting social media platforms collect data on your users. Very often this is done via cookies, but it is not the only way in which social media platforms collect information on your end users. More often than not, traditional embed scripts capture sensitive information from the browser and include it in the requests sent to their endpoints, and often even to other third-party endpoints. Even if they don’t explicitly collect private information, the very request made from the browser to fetch the remote JavaScript resource can potentially expose sensitive user information, such as the IP address or User Agent. This practice has already led to GDPR compliance issues in Europe with other tools, as seen in the case with Google Fonts, and poses a similar future risk with any other third-party tool, including embeds.
Security is another big risk embed scripts pose. By embedding these external scripts, websites essentially place their trust in the security of these third-party platforms. A single vulnerability in any of their dependency libraries could compromise user safety on a massive scale.
In contrast to traditional social media platform code snippets, Zaraz’s method of embedding X and Instagram posts does not load any third-party JavaScript on the client side. And not only that, by leveraging different Managed Component APIs (see code walkthrough below), Zaraz is fetching and caching all the content on the server side, and serving everything from your own domain. This means that there’s simply no direct communication between the end user’s browser and the third-party endpoint, which gives you much greater control over what information is shared with the external platform, if any.
Zaraz, running entirely on Cloudflare Workers, and with its ability to inject HTML before web content is served, also has performance advantages. Below, you can see the perfect 100 score that our X embed has received from Google PageSpeed Insights, and our ability to reach 0ms Total Blocking Time with only one request and a minimal transfer size of 12.1 KiB. To showcase the new feature, we’ve put together two identical HTML pages that are loading this tweet. One is embedding the tweet using Zaraz, the other embeds the code snippet provided by X. We then ran the Google PageSpeed Insights tests on the pages, loaded from the exact same environment.
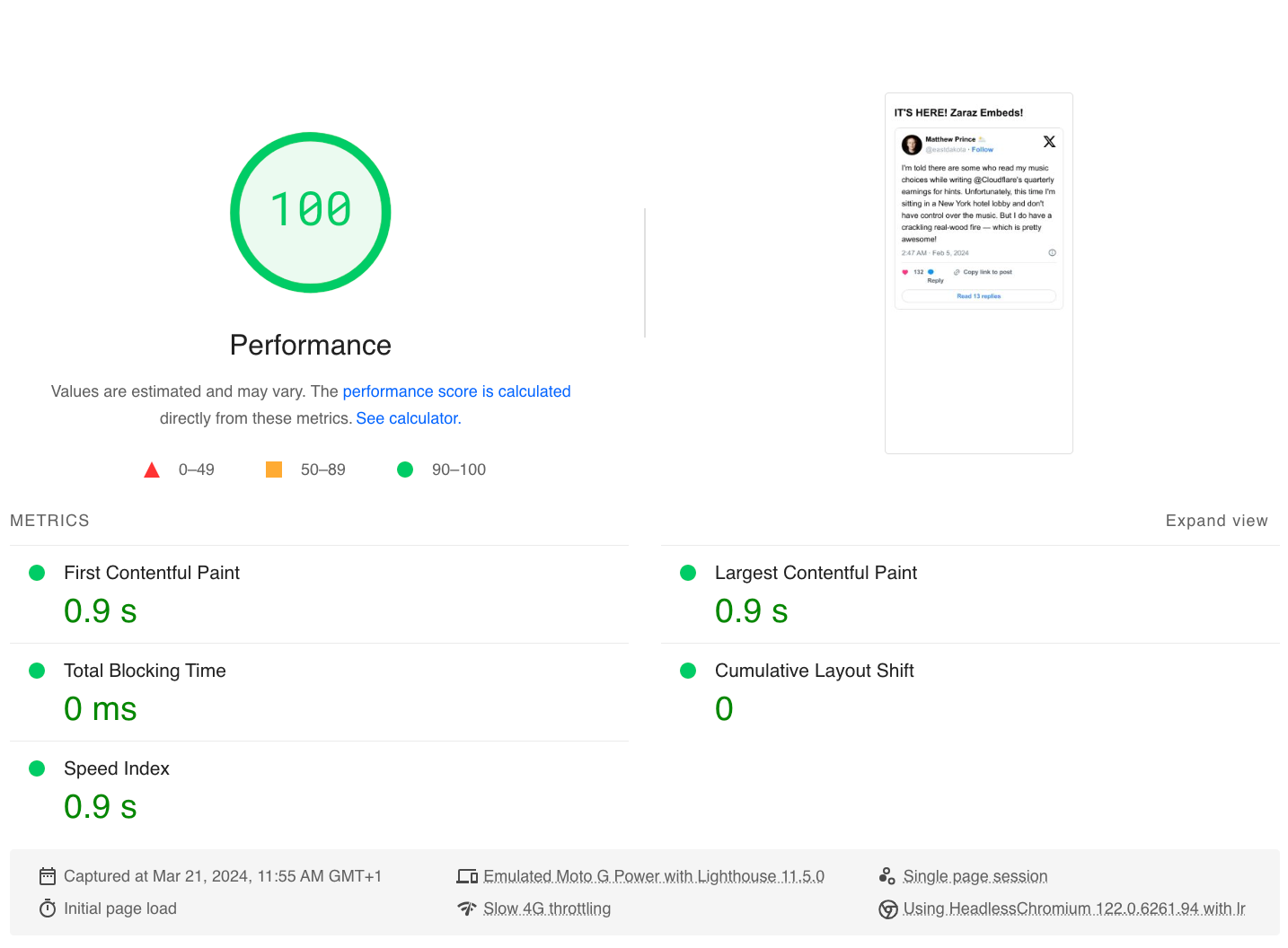
In comparison, the traditional way of embedding social media posts introduces a significant performance hit. Below are the results of the traditional embed code we tested: a 27-point decrease in the performance score, multiple requests with transfer size of 475 KiB, and 1,010 ms of Total Blocking Time (more than a second just to render this tweet!).
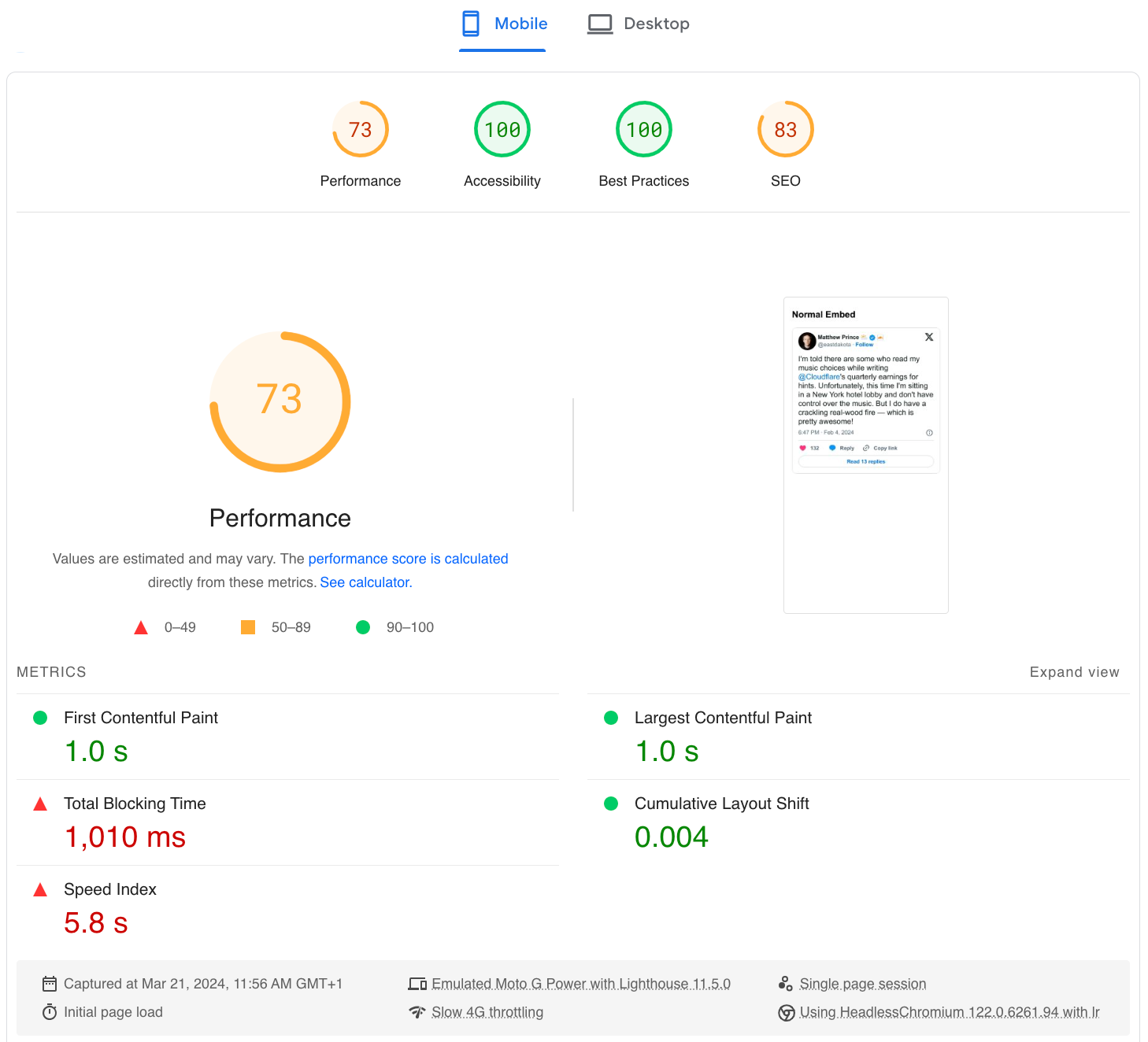
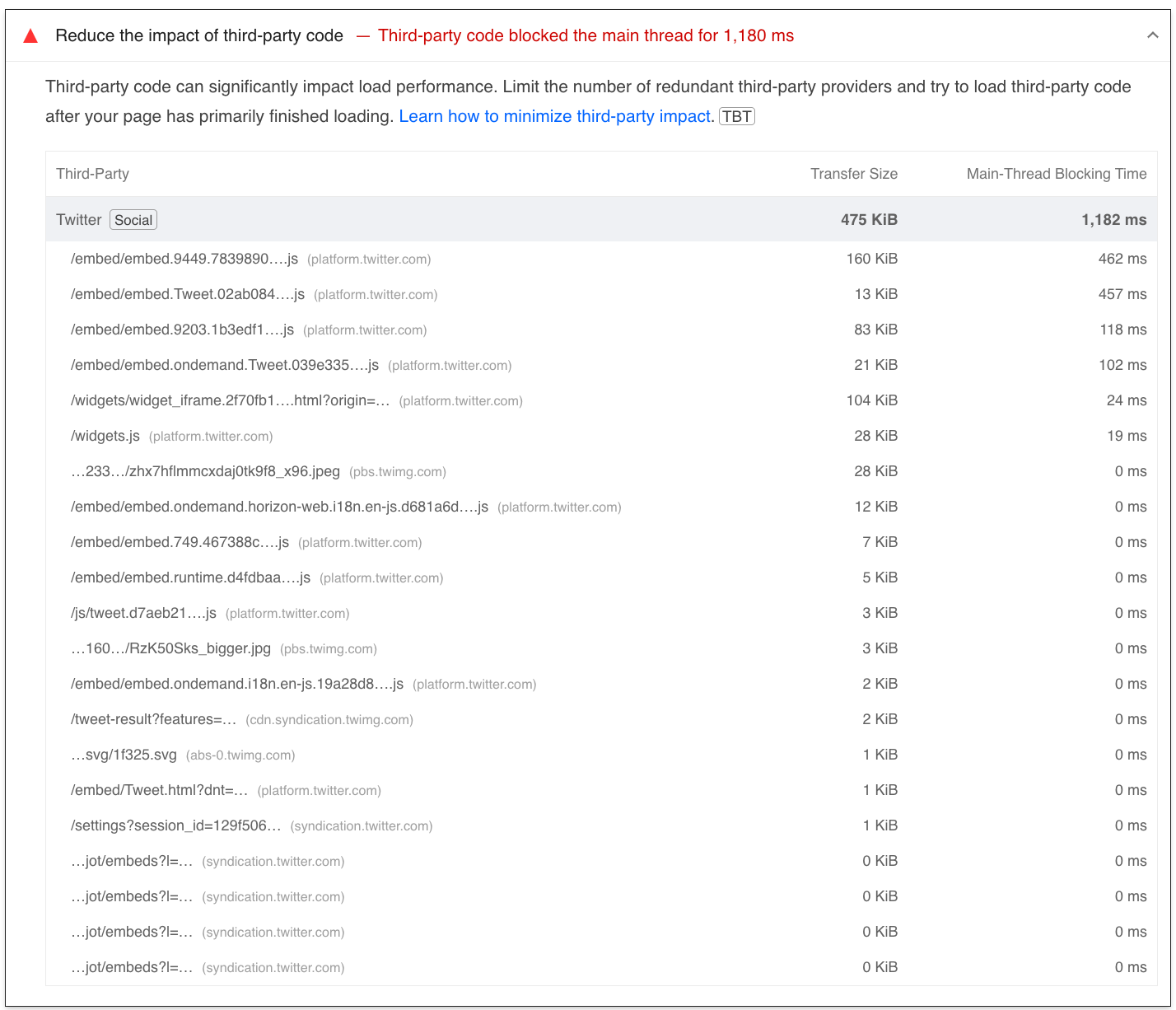
By processing content server-side, we completely eliminate the need for cookies or third-party scripts on the client’s browser, we prevent direct communication between the browser and the third-party server, and we provide a significantly faster user experience. So how does it work? Let’s dive into the code.
Using and building embeds
The X and Instagram Managed Components we’ve built are open source and available on GitHub. We took a different approach with each tool to showcase different methods for fetching content and generating the embed’s HTML and CSS. The X embed is requesting JSON from X’s endpoint, and is distributing the information received inside a templated HTML post we’ve written. The HTML template mimics the looks of the original post. The Instagram embed is requesting the actual post’s HTML generated by Instagram, manipulating it so that it doesn’t include any scripts, and routing all the images and CSS through your own domain. We outline and showcase the different processes below.
How to embed posts using Cloudflare Zaraz
Loading an embed with Cloudflare Zaraz is simple: instead of loading the Embed JavaScript provided by X or Instagram, you simply add a placeholder element to your HTML.
For X:
<twitter-post tweet-id="1754336034228171055"></twitter-post>
* Make sure to replace the tweet-id with the number shown in the embedded tweet’s URL.
For Instagram:
<instagram-post
post-url="https://www.instagram.com/p/Ct_qa1ZtmiW/"
captions="true">
</instagram-post>
* Make sure to replace the post-url with the URL of the desired post. When `captions` is set to true, the embed will include the post’s captions.
Once you’ve added the HTML to your page, activate the corresponding tools in your Cloudflare Zaraz dashboard. Click “Add new tools” to add X and Instagram. This is how your screen should look when you finish setting up your tools:
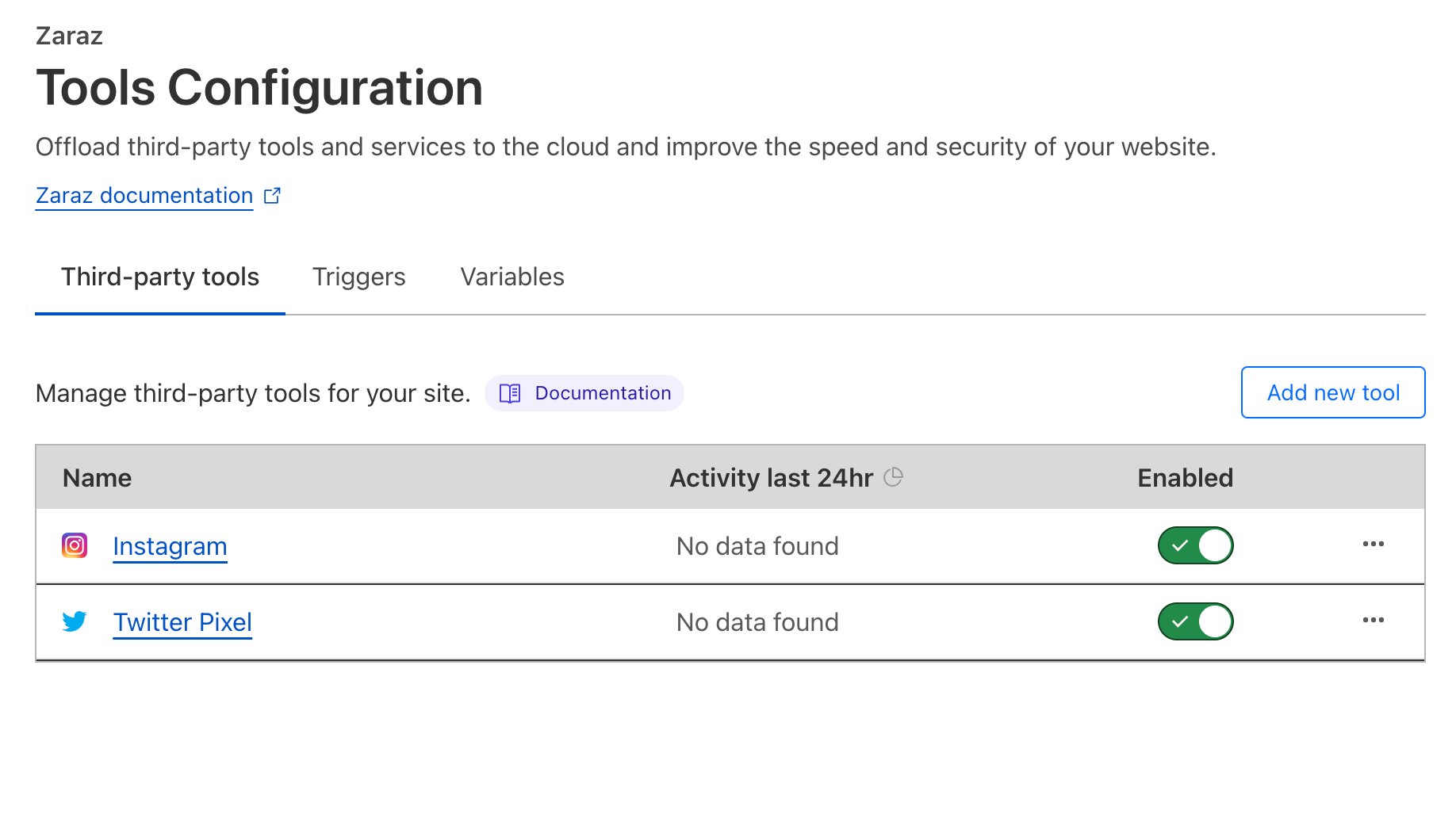
Cloudflare Zaraz will then detect placeholder elements in your HTML and replace them with the embedded social media content.
Walkthrough of the X post embed
The X Managed Component is registering the following embed:
manager.registerEmbed("post", async ({ parameters, client }) => {
// embed's logic goes here
});
Zaraz detects the placeholder element <twitter-post>, and picks up all the parameters included as HTML attributes of that element and sends them inside an object, together with the client, as the first argument of the manager.registerEmbed() function. The manager.registerEmbed() callback will return HTML. To generate the HTML, we use generic HTML and CSS templates we’ve written to construct the post. Those templates contain placeholder variables to be filled with the relevant tweet data later on.
We use Mustache, a library for rendering templates, to replace the placeholder variables spread across the HTML template. Wherever Mustache detects {{text}}, {{name}}, {{username}}, and the like in the HTML, it will replace their content with the relevant values we pass to it, like so:
//using Mustache to search for and replace placeholder variables in the post template with the tweet's content
const output = mustache.render(post, {
text,
name: user.name,
username: user.screen_name,
picture: 'data:image/jpeg;base64,' + profileImage,
datetime,
likes: numberFormatter(favorite_count, 1),
replies: numberFormatter(conversation_count, 1),
heartIcon,
commentIcon,
linkIcon,
tweetId,
xIcon,
tooltipIcon,
retweetUrl,
})
Most of the values of the variables we pass to Mustache, which contain the specific post data, are being fetched from one of X’s endpoints. This is done with a server-side fetch request. The response, containing a JSON file with all the post’s data, is then populated into the corresponding variables as shown above.
Zaraz is also caching the JSON for better performance. This is done with the Managed Components manager.useCache() method, which takes 3 arguments: name, function and expiry. Here, the function argument is using manager.fetch() to send a fetch request from the server.
(...)
// grabs the tweet-id from the parameters argument
const tweetId = parameters['tweet-id']
(...)
const tweetResponse = await manager.useCache(
'tweet_' + tweetId,
async () => {
const res = await manager.fetch( `https://cdn.syndication.twimg.com/tweet-result?id=${tweetId}&token=${randomToken}`,
{
headers: {
Accept: 'application/json',
'User-Agent': client?.userAgent || prefixedUA,
},
}
)
if (!res) {
throw new Error('Failed to fetch tweet data.')
}
return await res.text()
},
600 // cache the Tweet for 10 minutes
)
It is important to mention that all images populated in the post template, like the profile picture, are fetched server-side and cached using manager.set():
// first, we check if profile image is already cached
let profileImage = await manager.get('profileImage_' + user.screen_name)
// if not, we fetch the image server-side and cache it using `manager.set()`
if (!profileImage) {
const res = await manager.fetch(user.profile_image_url_https, {
headers: {
Accept: 'image/jpeg,image/png,image/*,*/*;q=0.8',
'User-Agent': client?.userAgent || prefixedUA,
},
method: 'GET',
})
if (res) {
const imageBuffer = await res.arrayBuffer()
profileImage = base64Encode(imageBuffer)
await manager.set('profileImage_' + user.screen_name, profileImage)
}
}
Once the post’s HTML is ready, with all the relevant content fetched and rendered, the Managed Component returns the HTML content to Zaraz. Zaraz will then use it to replace the <twitter-post> placeholder element. Because this all happens on Cloudflare, the response to the end-user’s browser will already contain the embed code.
Walkthrough of the Instagram post embed
The Instagram post embed is built around Instagram’s own generated HTML. In contrast to the X example, which uses JSON data to populate an HTML template, this approach involves tweaking Instagram’s HTML to meet our privacy and safety requirements.
We want the Instagram embed to work without requiring direct communication between the browser and any of Instagram’s endpoints. This is done by fetching CSS content server-side, caching it, and finally serving it together with the output HTML, avoiding any network request from the browser to fetch CSS content. We also set up a route server on the customer’s own domain, from which the Managed Components serve all images. Setting up a route endpoint with Managed Components is fairly straightforward:
manager.route('/image/', async request => {
// logic to fetch and cache all images
});
After setting up routes, we fetch the HTML content of the specific Instagram post, server-side, using the manager.fetch() method. We then manipulate the HTML to fit it to the specific website and cache it using manager.useCache(). Amongst other things, changes to the HTML include setting image src and srcset attributes to serve images from your own routes, to avoid requesting images from Instagram’s endpoint (and by so doing, potentially revealing sensitive user information). As mentioned above, we also remove all scripts and stylesheet links, as we prefetch and cache all CSS content from stylesheet links server-side, in order to serve CSS and spare the browser a few additional network requests, improving privacy and performance.
The HTML manipulation is done using the Cheerio library. This is how, for example, we adjust the `src` attribute of images to redirect through our route:
$('img[src*="scontent.cdninstagram.com"]').each((i, el) => {
const img = $(el)
const src = img.attr('src')!
const newSrc = src.replace(
/^https:\/\/scontent.cdninstagram.com\/(.*)$/,
(_match, path) =>
`${hostName(client)}${imgRoute}?q=` + encodeURIComponent(path)
)
img.attr('src', newSrc)
This implementation effectively prevents any direct communication from the browser to Instagram servers, safeguarding sensitive user information such as IP addresses.
What is currently supported and what’s next for embeds
Currently, our X embed supports text tweets and the Instagram embed supports image posts. We are working to broaden our support to other media types. Beyond these improvements, we aim to extend the application of our embeds across an even broader range of tools. We invite our users and partners to collaborate with us on the Managed Component open source project, in adding support for more tools that can be rendered entirely server-side. We believe that this is the way to create a safer and faster web for everyone, and we hope that what we are launching today will inspire the community to build even better solutions together with us!
Start using embeds now by adding X and Instagram in your Zaraz dashboard.









![Hint: If you ever encounter this puzzle in a crossword app, just [term for someone with a competitive and high-achieving personality].](https://imgs.xkcd.com/comics/a_crossword_puzzle.png "Hint: If you ever encounter this puzzle in a crossword app, just [term for someone with a competitive and high-achieving personality].")



















 Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software.
Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike. Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems.
Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems. Kalaiselvi Kamaraj is a Senior Software Development Engineer with Amazon. She has worked on several projects within the Amazon Redshift query processing team and currently focusing on performance-related projects for Redshift data lakes.
Kalaiselvi Kamaraj is a Senior Software Development Engineer with Amazon. She has worked on several projects within the Amazon Redshift query processing team and currently focusing on performance-related projects for Redshift data lakes. Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.












 Hernan Garcia is a Senior Solutions Architect at AWS, based out of Amsterdam, working with enterprises in the Financial Services Industry. He specializes in application modernization and supports customers in the adoption of serverless technologies.
Hernan Garcia is a Senior Solutions Architect at AWS, based out of Amsterdam, working with enterprises in the Financial Services Industry. He specializes in application modernization and supports customers in the adoption of serverless technologies. Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.
Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.