Cranelift is an Apache-2.0-licensed
code-generation backend being developed as part
of the Wasmtime runtime for WebAssembly.
In October 2023, the Rust project made Cranelift available as an optional
component in its nightly toolchain.
Users can now use Cranelift as the code-generation backend for debug builds of
projects written in Rust,
making it an opportune time to look at what makes Cranelift different.
Cranelift is designed to compete with existing compilers by generating
code more quickly than they can, thanks to a stripped-down design that prioritizes
only the most important optimizations.
Zach Mitchell has announced the 1.0 release of Flox, a tool that lets its users install packages from nixpkgs inside portable virtual environments, and share those virtual environments with others as an alternative to Docker-style containers. Flox is based on Nix but allows users to skip learning how to work with the Nix language:
With Flox we’re providing a substantially better user experience. We provide the suite of package manager functionality with install, uninstall, etc, but we also provide an entire new suite of functionality with the ability to share environments via flox push, flox pull, and flox activate --remote.
Flox is GPLv2-licensed, and releases are available as RPMs and Debian packages for x86_64 and arm64 systems.
Sasha Levin has announced the release of the 6.8.1, 6.7.10, 6.6.22, 6.1.82, 5.15.152, 5.10.213, 5.4.272,
and 4.19.310 stable kernels. As always, they contain important fixes throughout the tree. Users of those kernels should upgrade.
Authors: asterion04 and h00die
Type: Auxiliary
Pull request: #18716 contributed by h00die
Path: admin/http/gitlab_password_reset_account_takeover
AttackerKB reference: CVE-2023-7028
Description: This adds an exploit module that leverages an account-take-over vulnerability to take control of a GitLab account without user interaction. The vulnerability lies in the password reset functionality as it’s possible to provide two email addresses so that
the reset code will be sent to both. It is therefore possible to provide the email
address of the target account as well as that of one we control, and to reset the password.
MinIO Bootstrap Verify Information Disclosure
Authors: RicterZ and joel <joel @ ndepthsecurity>
Type: Auxiliary
Pull request: #18775 contributed by 6a6f656c
Path: gather/minio_bootstrap_verify_info_disc
AttackerKB reference: CVE-2023-28432
Description: This adds an auxiliary module that leverages an information disclosure (CVE-2023-28432) in a cluster deployment of MinIO versions from RELEASE.2019-12-17T23-16-33Z and prior to RELEASE.2023-03-20T20-16-18Z. This retrieves all environment variables, including MINIO_SECRET_KEY and MINIO_ROOT_PASSWORD.
Description: This adds an exploit module that leverages an authentication bypass vulnerability in JetBrains TeamCity (CVE-2024-27198) to achieve unauthenticated RCE. The authentication bypass enables access to the REST API and creates a new administrator access token. This token can be used to upload a plugin which contains a Metasploit payload.
Enhancements and features (5)
#18835 from zgoldman-r7 – This PR reduces code duplication in the modules/exploits/windows/mssql/mssql_payload module.
#18899 from zeroSteiner – Updates the tools/payloads/ysoserial/dot_net.rb tool to add options for encoding the resulting payload as a viewstate.
#18930 from dwelch-r7 – This PR adds the ability to run a help command from within the interactive SQL prompt.
#18931 from cgranleese-r7 – Adds additional help information when interacting with an SQL session.
#18932 from adfoster-r7 – This PR adds PostgreSQL session type acceptance tests using Allure report generation as well as a local test module.
Bugs fixed (5)
#18944 from zeroSteiner – This fixes an issue when saving and loading DNS rules from the config.
#18945 from adfoster-r7 – Fixes an issue that caused a crash when running http crawler with database connected.
#18949 from zeroSteiner – This updates the DNS feature to notify the user a restart is required when the feature is enabled or disabled.
#18952 from cgranleese-r7 – Updates Postgres hashdump module to now work with newer versions of Postgres.
#18954 from adfoster-r7 – This PR fixes an issue where modules were not honoring spooler settings.
Documentation added (3)
#18868 from zeroSteiner – This adds documentation for the new DNS command.
#18937 from jjoshm – Fixes a typo in the Kerberos documentation.
#18951 from adfoster-r7 – This PR improves documentation on running Postgres acceptance tests locally.
You can always find more documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
In the second half of 2023, OpenSearch Service added the support of two new OpenSearch versions: 2.9 and 2.11 These two versions introduce new features in the search space, machine learning (ML) search space, migrations, and the operational side of the service.
With the release of zero-ETL integration with Amazon Simple Storage Service (Amazon S3), you can analyze your data sitting in your data lake using OpenSearch Service to build dashboards and query the data without the need to move your data from Amazon S3.
OpenSearch Service also announced a new zero-ETL integration with Amazon DynamoDB through the DynamoDB plugin for Amazon OpenSearch Ingestion. OpenSearch Ingestion takes care of bootstrapping and continuously streams data from your DynamoDB source.
OpenSearch Serverless announced the general availability of the Vector Engine for Amazon OpenSearch Serverless along with other features to enhance your experience with time series collections, manage your cost for development environments, and quickly scale your resources to match your workload demands.
In this post, we discuss the new releases in OpenSearch Service to empower your business with search, observability, security analytics, and migrations.
Build cost-effective solutions with OpenSearch Service
With the zero-ETL integration for Amazon S3, OpenSearch Service now lets you query your data in place, saving cost on storage. Data movement is an expensive operation because you need to replicate data across different data stores. This increases your data footprint and drives cost. Moving data also adds the overhead of managing pipelines to migrate the data from one source to a new destination.
OpenSearch Service also added new instance types for data nodes—Im4gn and OR1—to help you further optimize your infrastructure cost. With a maximum 30 TB non-volatile memory (NVMe) solid state drives (SSD), the Im4gn instance provides dense storage and better performance. OR1 instances use segment replication and remote-backed storage to greatly increase throughput for indexing-heavy workloads.
Zero-ETL from DynamoDB to OpenSearch Service
In November 2023, DynamoDB and OpenSearch Ingestion introduced a zero-ETL integration for OpenSearch Service. OpenSearch Service domains and OpenSearch Serverless collections provide advanced search capabilities, such as full-text and vector search, on your DynamoDB data. With a few clicks on the AWS Management Console, you can now seamlessly load and synchronize your data from DynamoDB to OpenSearch Service, eliminating the need to write custom code to extract, transform, and load the data.
Direct query (zero-ETL for Amazon S3 data, in preview)
OpenSearch Service announced a new way for you to query operational logs in Amazon S3 and S3-based data lakes without needing to switch between tools to analyze operational data. Previously, you had to copy data from Amazon S3 into OpenSearch Service to take advantage of OpenSearch’s rich analytics and visualization features to understand your data, identify anomalies, and detect potential threats.
However, continuously replicating data between services can be expensive and requires operational work. With the OpenSearch Service direct query feature, you can access operational log data stored in Amazon S3, without needing to move the data itself. Now you can perform complex queries and visualizations on your data without any data movement.
Support of Im4gn with OpenSearch Service
Im4gn instances are optimized for workloads that manage large datasets and need high storage density per vCPU. Im4gn instances come in sizes large through 16xlarge, with up to 30 TB in NVMe SSD disk size. Im4gn instances are built on AWS Nitro System SSDs, which offer high-throughput, low-latency disk access for best performance. OpenSearch Service Im4gn instances support all OpenSearch versions and Elasticsearch versions 7.9 and above. For more details, refer to Supported instance types in Amazon OpenSearch Service.
Introducing OR1, an OpenSearch Optimized Instance family for indexing heavy workloads
In November 2023, OpenSearch Service launched OR1, the OpenSearch Optimized Instance family, which delivers up to 30% price-performance improvement over existing instances in internal benchmarks and uses Amazon S3 to provide 11 9s of durability. A domain with OR1 instances uses Amazon Elastic Block Store (Amazon EBS) volumes for primary storage, with data copied synchronously to Amazon S3 as it arrives. OR1 instances use OpenSearch’s segment replication feature to enable replica shards to read data directly from Amazon S3, avoiding the resource cost of indexing in both primary and replica shards. The OR1 instance family also supports automatic data recovery in the event of failure. For more information about OR1 instance type options, refer to Current generation instance types in OpenSearch Service.
Enable your business with security analytics features
The Security Analytics plugin in OpenSearch Service supports out-of-the-box prepackaged log types and provides security detection rules (SIGMA rules) to detect potential security incidents.
In OpenSearch 2.9, the Security Analytics plugin added support for customer log types and native support for Open Cybersecurity Schema Framework (OCSF) data format. With this new support, you can build detectors with OCSF data stored in Amazon Security Lake to analyze security findings and mitigate any potential incident. The Security Analytics plugin has also added the possibility to create your own custom log types and create custom detection rules.
Build ML-powered search solutions
In 2023, OpenSearch Service invested in eliminating the heavy lifting required to build next-generation search applications. With features such as search pipelines, search processors, and AI/ML connectors, OpenSearch Service enabled rapid development of search applications powered by neural search, hybrid search, and personalized results. Additionally, enhancements to the kNN plugin improved storage and retrieval of vector data. Newly launched optional plugins for OpenSearch Service enable seamless integration with additional language analyzers and Amazon Personalize.
Search pipelines
Search pipelines provide new ways to enhance search queries and improve search results. You define a search pipeline and then send your queries to it. When you define the search pipeline, you specify processors that transform and augment your queries, and re-rank your results. The prebuilt query processors include date conversion, aggregation, string manipulation, and data type conversion. The results processor in the search pipeline intercepts and adapts results on the fly before rendering to next phase. Both request and response processing for the pipeline are performed on the coordinator node, so there is no shard-level processing.
Optional plugins
OpenSearch Service lets you associate preinstalled optional OpenSearch plugins to use with your domain. An optional plugin package is compatible with a specific OpenSearch version, and can only be associated to domains with that version. Available plugins are listed on the Packages page on the OpenSearch Service console. The optional plugin includes the Amazon Personalize plugin, which integrates OpenSearch Service with Amazon Personalize, and new language analyzers such as Nori, Sudachi, STConvert, and Pinyin.
Support for new language analyzers
OpenSearch Service added support for four new language analyzer plugins: Nori (Korean), Sudachi (Japanese), Pinyin (Chinese), and STConvert Analysis (Chinese). These are available in all AWS Regions as optional plugins that you can associate with domains running any OpenSearch version. You can use the Packages page on the OpenSearch Service console to associate these plugins to your domain, or use the Associate Package API.
Neural search feature
Neural search is generally available with OpenSearch Service version 2.9 and later. Neural search allows you to integrate with ML models that are hosted remotely using the model serving framework. When you use a neural query during search, neural search converts the query text into vector embeddings, uses vector search to compare the query and document embedding, and returns the closest results. During ingestion, neural search transforms document text into vector embedding and indexes both the text and its vector embeddings in a vector index.
Integration with Amazon Personalize
OpenSearch Service introduced an optional plugin to integrate with Amazon Personalize in OpenSearch versions 2.9 or later. The OpenSearch Service plugin for Amazon Personalize Search Ranking allows you to improve the end-user engagement and conversion from your website and application search by taking advantage of the deep learning capabilities offered by Amazon Personalize. As an optional plugin, the package is compatible with OpenSearch version 2.9 or later, and can only be associated to domains with that version.
Efficient query filtering with OpenSearch’s k-NN FAISS
OpenSearch Service introduced efficient query filtering with OpenSearch’s k-NN FAISS in version 2.9 and later. OpenSearch’s efficient vector query filters capability intelligently evaluates optimal filtering strategies—pre-filtering with approximate nearest neighbor (ANN) or filtering with exact k-nearest neighbor (k-NN)—to determine the best strategy to deliver accurate and low-latency vector search queries. In earlier OpenSearch versions, vector queries on the FAISS engine used post-filtering techniques, which enabled filtered queries at scale, but potentially returning less than the requested “k” number of results. Efficient vector query filters deliver low latency and accurate results, enabling you to employ hybrid search across vector and lexical techniques.
Byte-quantized vectors in OpenSearch Service
With the new byte-quantized vector introduced with 2.9, you can reduce memory requirements by a factor of 4 and significantly reduce search latency, with minimal loss in quality (recall). With this feature, the usual 32-bit floats that are used for vectors are quantized or converted to 8-bit signed integers. For many applications, existing float vector data can be quantized with little loss in quality. Comparing benchmarks, you will find that using byte vectors rather than 32-bit floats results in a significant reduction in storage and memory usage while also improving indexing throughput and reducing query latency. An internal benchmark showed the storage usage was reduced by up to 78%, and RAM usage was reduced by up to 59% (for the glove-200-angular dataset). Recall values for angular datasets were lower than those of Euclidean datasets.
AI/ML connectors
OpenSearch 2.9 and later supports integrations with ML models hosted on AWS services or third-party platforms. This allows system administrators and data scientists to run ML workloads outside of their OpenSearch Service domain. The ML connectors come with a supported set of ML blueprints—templates that define the set of parameters you need to provide when sending API requests to a specific connector. OpenSearch Service provides connectors for several platforms, such as Amazon SageMaker,Amazon Bedrock, OpenAI ChatGPT, and Cohere.
OpenSearch Service console integrations
OpenSearch 2.9 and later added a new integrations feature on the console. Integrations provides you with an AWS CloudFormation template to build your semantic search use case by connecting to your ML models hosted on SageMaker or Amazon Bedrock. The CloudFormation template generates the model endpoint and registers the model ID with the OpenSearch Service domain you provide as input to the template.
Hybrid search and range normalization
The normalization processor and hybrid query builds on top of the two features released earlier in 2023—neural search and search pipelines. Because lexical and semantic queries return relevance scores on different scales, fine-tuning hybrid search queries was difficult.
OpenSearch Service 2.11 now supports a combination and normalization processor for hybrid search. You can now perform hybrid search queries, combining a lexical and a natural language-based k-NN vector search queries. OpenSearch Service also enables you to tune your hybrid search results for maximum relevance using multiple scoring combination and normalization techniques.
Multimodal search with Amazon Bedrock
OpenSearch Service 2.11 launches the support of multimodal search that allows you to search text and image data using multimodal embedding models. To generate vector embeddings, you need to create an ingest pipeline that contains a text_image_embedding processor, which converts the text or image binaries in a document field to vector embeddings. You can use the neural query clause, either in the k-NN plugin API or Query DSL queries, to do a combination of text and images searches. You can use the new OpenSearch Service integration features to quickly start with multimodal search.
Neural sparse retrieval
Neural sparse search, a new efficient method of semantic retrieval, is available in OpenSearch Service 2.11. Neural sparse search operates in two modes: bi-encoder and document-only. With the bi-encoder mode, both documents and search queries are passed through deep encoders. In document-only mode, only documents are passed through deep encoders, while search queries are tokenized. A document-only sparse encoder generates an index that is 10.4% of the size of a dense encoding index. For a bi-encoder, the index size is 7.2% of the size of a dense encoding index. Neural sparse search is enabled by sparse encoding models that create sparse vector embeddings: a set of <token: weight> pairs representing the text entry and its corresponding weight in the sparse vector. To learn more about the pre-trained models for sparse neural search, refer to Sparse encoding models.
Neural sparse search reduces costs, improves search relevance, and has lower latency. You can use the new OpenSearch Service integrations features to quickly start with neural sparse search.
OpenSearch Ingestion updates
OpenSearch Ingestion is a fully managed and auto scaled ingestion pipeline that delivers your data to OpenSearch Service domains and OpenSearch Serverless collections. Since its release in 2023, OpenSearch Ingestion continues to add new features to make it straightforward to transform and move your data from supported sources to downstream destinations like OpenSearch Service, OpenSearch Serverless, and Amazon S3.
New migration features in OpenSearch Ingestion
In November 2023, OpenSearch Ingestion announced the release of new features to support data migration from self-managed Elasticsearch version 7.x domains to the latest versions of OpenSearch Service.
OpenSearch Ingestion also supports the migration of data from OpenSearch Service managed domains running OpenSearch version 2.x to OpenSearch Serverless collections.
In November 2023, OpenSearch Ingestion introduced persistent buffering for push-based sources likes HTTP sources (HTTP, Fluentd, FluentBit) and OpenTelemetry collectors.
By default, OpenSearch Ingestion uses in-memory buffering. With persistent buffering, OpenSearch Ingestion stores your data in a disk-based store that is more resilient. If you have existing ingestion pipelines, you can enable persistent buffering for these pipelines, as shown in the following screenshot.
OpenSearch Serverless continued to enhance your serverless experience with OpenSearch by introducing the support of a new collection of type vector search to store embeddings and run similarity search. OpenSearch Serverless now supports shard replica scaling to handle spikes in query throughput. And if you are using a time series collection, you can now set up your custom data retention policy to match your data retention requirements.
Vector Engine for OpenSearch Serverless
In November 2023, we launched the vector engine for Amazon OpenSearch Serverless. The vector engine makes it straightforward to build modern ML-augmented search experiences and generative artificial intelligence (generative AI) applications without needing to manage the underlying vector database infrastructure. It also enables you to run hybrid search, combining vector search and full-text search in the same query, removing the need to manage and maintain separate data stores or a complex application stack.
OpenSearch Serverless lower-cost dev and test environments
OpenSearch Serverless now supports development and test workloads by allowing you to avoid running a replica. Removing replicas eliminates the need to have redundant OCUs in another Availability Zone solely for availability purposes. If you are using OpenSearch Serverless for development and testing, where availability is not a concern, you can drop your minimum OCUs from 4 to 2.
OpenSearch Serverless supports automated time-based data deletion using data lifecycle policies
In December 2023, OpenSearch Serverless announced support for managing data retention of time series collections and indexes. With the new automated time-based data deletion feature, you can specify how long you want to retain data. OpenSearch Serverless automatically manages the lifecycle of the data based on this configuration. To learn more, refer to Amazon OpenSearch Serverless now supports automated time-based data deletion.
OpenSearch Serverless announced support for scaling up replicas at shard level
At launch, OpenSearch Serverless supported increasing capacity automatically in response to growing data sizes. With the new shard replica scaling feature, OpenSearch Serverless automatically detects shards under duress due to sudden spikes in query rates and dynamically adds new shard replicas to handle the increased query throughput while maintaining fast response times. This approach proves to be more cost-efficient than simply adding new index replicas.
AWS user notifications to monitor your OCU usage
With this launch, you can configure the system to send notifications when OCU utilization is approaching or has reached maximum configured limits for search or ingestion. With the new AWS User Notification integration, you can configure the system to send notifications whenever the capacity threshold is breached. The User Notification feature eliminates the need to monitor the service constantly. For more information, see Monitoring Amazon OpenSearch Serverless using AWS User Notifications.
Enhance your experience with OpenSearch Dashboards
OpenSearch 2.9 in OpenSearch Service introduced new features to make it straightforward to quickly analyze your data in OpenSearch Dashboards. These new features include the new out-of-the box, preconfigured dashboards with OpenSearch Integrations, and the ability to create alerting and anomaly detection from an existing visualization in your dashboards.
OpenSearch Dashboard integrations
OpenSearch 2.9 added the support of OpenSearch integrations in OpenSearch Dashboards. OpenSearch integrations include preconfigured dashboards so you can quickly start analyzing your data coming from popular sources such as AWS CloudFront, AWS WAF, AWS CloudTrail, and Amazon Virtual Private Cloud (Amazon VPC) flow logs.
Alerting and anomalies in OpenSearch Dashboards
In OpenSearch Service 2.9, you can create a new alerting monitor directly from your line chart visualization in OpenSearch Dashboards. You can also associate the existing monitors or detectors previously created in OpenSearch to the dashboard visualization.
This new feature helps reduce context switching between dashboards and both the Alerting or Anomaly Detection plugins. Refer to the following dashboard to add an alerting monitor to detect drops in average data volume in your services.
OpenSearch expands geospatial aggregations support
With OpenSearch version 2.9, OpenSearch Service added the support of three types of geoshape data aggregation through API: geo_bounds, geo_hash, and geo_tile.
The geoshape field type provides the possibility to index location data in different geographic formats such as a point, a polygon, or a linestring. With the new aggregation types, you have more flexibility to aggregate documents from an index using metric and multi-bucket geospatial aggregations.
OpenSearch Service operational updates
OpenSearch Service removed the need to run blue/green deployment when changing the domain managed nodes. Additionally, the service improved the Auto-Tune events with the support of new Auto-Tune metrics to track the changes within your OpenSearch Service domain.
OpenSearch Service now lets you update domain manager nodes without blue/green deployment
As of early H2 of 2023, OpenSearch Service allowed you to modify the instance type or instance count of dedicated cluster manager nodes without the need for blue/green deployment. This enhancement allows quicker updates with minimal disruption to your domain operations, all while avoiding any data movement.
Previously, updating your dedicated cluster manager nodes on OpenSearch Service meant using a blue/green deployment to make the change. Although blue/green deployments are meant to avoid any disruption to your domains, because the deployment utilizes additional resources on the domain, it is recommended that you perform them during low-traffic periods. Now you can update cluster manager instance types or instance counts without requiring a blue/green deployment, so these updates can complete faster while avoiding any potential disruption to your domain operations. In cases where you modify both the domain manager instance type and count, OpenSearch Service will still use a blue/green deployment to make the change. You can use the dry-run option to check whether your change requires a blue/green deployment.
Enhanced Auto-Tune experience
In September 2023, OpenSearch Service added new Auto-Tune metrics and improved Auto-Tune events that give you better visibility into the domain performance optimizations made by Auto-Tune.
Auto-Tune is an adaptive resource management system that automatically updates OpenSearch Service domain resources to improve efficiency and performance. For example, Auto-Tune optimizes memory-related configuration such as queue sizes, cache sizes, and Java virtual machine (JVM) settings on your nodes.
With this launch, you can now audit the history of the changes, as well as track them in real time from the Amazon CloudWatch console.
Additionally, OpenSearch Service now publishes details of the changes to Amazon EventBridge when Auto-Tune settings are recommended or applied to an OpenSearch Service domain. These Auto-Tune events will also be visible on the Notifications page on the OpenSearch Service console.
Accelerate your migration to OpenSearch Service with the new Migration Assistant solution
In November 2023, the OpenSearch team launched a new open-source solution—Migration Assistant for Amazon OpenSearch Service. The solution supports data migration from self-managed Elasticsearch and OpenSearch domains to OpenSearch Service, supporting Elasticsearch 7.x (<=7.10), OpenSearch 1.x, and OpenSearch 2.x as migration sources. The solution facilitates the migration of the existing and live data between source and destination.
Conclusion
In this post, we covered the new releases in OpenSearch Service to help you innovate your business with search, observability, security analytics, and migrations. We provided you with information about when to use each new feature in OpenSearch Service, OpenSearch Ingestion, and OpenSearch Serverless.
Learn more about OpenSearch Dashboards and OpenSearch plugins and the new exciting OpenSearch assistant using OpenSearch playground.
Check out the features described in this post, and we appreciate you providing us your valuable feedback.
About the Authors
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Hajer Bouafif is an Analytics Specialist Solutions Architect at Amazon Web Services. She focuses on Amazon OpenSearch Service and helps customers design and build well-architected analytics workloads in diverse industries. Hajer enjoys spending time outdoors and discovering new cultures.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Muslim Abu Taha is a Sr. OpenSearch Specialist Solutions Architect dedicated to guiding clients through seamless search workload migrations, fine-tuning clusters for peak performance, and ensuring cost-effectiveness. With a background as a Technical Account Manager (TAM), Muslim brings a wealth of experience in assisting enterprise customers with cloud adoption and optimize their different set of workloads. Muslim enjoys spending time with his family, traveling and exploring new places.
Amazon Simple Email Service (SES) is a cloud-based email sending service that helps businesses and developers send marketing and transactional emails. We introduced the SESv1 API in 2011 to provide developers with basic email sending capabilities through Amazon SES using HTTPS. In 2020, we introduced the redesigned Amazon SESv2 API, with new and updated features that make it easier and more efficient for developers to send email at scale.
This post will compare Amazon SESv1 API and Amazon SESv2 API and explain the advantages of transitioning your application code to the SESv2 API. We’ll also provide examples using the AWS Command-Line Interface (AWS CLI) that show the benefits of transitioning to the SESv2 API.
Amazon SESv1 API
The SESv1 API is a relatively simple API that provides basic functionality for sending and receiving emails. For over a decade, thousands of SES customers have used the SESv1 API to send billions of emails. Our customers’ developers routinely use the SESv1 APIs to verify email addresses, create rules, send emails, and customize bounce and complaint notifications. Our customers’ needs have become more advanced as the global email ecosystem has developed and matured. Unsurprisingly, we’ve received customer feedback requesting enhancements and new functionality within SES. To better support an expanding array of use cases and stay at the forefront of innovation, we developed the SESv2 APIs.
While the SESv1 API will continue to be supported, AWS is focused on advancing functionality through the SESv2 API. As new email sending capabilities are introduced, they will only be available through SESv2 API. Migrating to the SESv2 API provides customers with access to these, and future, optimizations and enhancements. Therefore, we encourage SES customers to consider the information in this blog, review their existing codebase, and migrate to SESv2 API in a timely manner.
Amazon SESv2 API
Released in 2020, the SESv2 API and SDK enable customers to build highly scalable and customized email applications with an expanded set of lightweight and easy to use API actions. Leveraging insights from current SES customers, the SESv2 API includes several new actions related to list and subscription management, the creation and management of dedicated IP pools, and updates to unsubscribe that address recent industry requirements.
One example of new functionality in SESv2 API is programmatic support for the SES Virtual Delivery Manager. Previously only addressable via the AWS console, VDM helps customers improve sending reputation and deliverability. SESv2 API includes vdmAttributes such as VdmEnabled and DashboardAttributes as well as vdmOptions. DashboardOptions and GaurdianOptions.
To improve developer efficiency and make the SESv2 API easier to use, we merged several SESv1 APIs into single commands. For example, in the SESv1 API you must make separate calls for createConfigurationSet, setReputationMetrics, setSendingEnabled, setTrackingOptions, and setDeliveryOption. In the SESv2 API, however, developers make a single call to createConfigurationSet and they can include trackingOptions, reputationOptions, sendingOptions, deliveryOptions. This can result in more concise code (see below).
Another example of SESv2 API command consolidation is the GetIdentity action, which is a composite of SESv1 API’s GetIdentityVerificationAttributes, GetIdentityNotificationAttributes, GetCustomMailFromAttributes, GetDKIMAttributes, and GetIdentityPolicies. See SESv2 documentation for more details.
Why migrate to Amazon SESv2 API?
The SESv2 API offers an enhanced experience compared to the original SESv1 API. Compared to the SESv1 API, the SESv2 API provides a more modern interface and flexible options that make building scalable, high-volume email applications easier and more efficient. SESv2 enables rich email capabilities like template management, list subscription handling, and deliverability reporting. It provides developers with a more powerful and customizable set of tools with improved security measures to build and optimize inbox placement and reputation management. Taken as a whole, the SESv2 APIs provide an even stronger foundation for sending critical communications and campaign email messages effectively at a scale.
Migrating your applications to SESv2 API will benefit your email marketing and communication capabilities with:
New and Enhanced Features: Amazon SESv2 API includes new actions as well as enhancements that provide better functionality and improved email management. By moving to the latest version, you’ll be able to optimize your email sending process. A few examples include:
Increase the maximum message size (including attachments) from 10Mb (SESv1) to 40Mb (SESv2) for both sending and receiving.
Access key actions for the SES Virtual Deliverability Manager (VDM) which provides insights into your sending and delivery data. VDM provides near-realtime advice on how to fix the issues that are negatively affecting your delivery success rate and reputation.
Meet Google & Yahoo’s June 2024 unsubscribe requirements with the SES v2 SendEmail action. For more information, see the “What’s New blog”
Future-proof Your Application: Avoid potential compatibility issues and disruptions by keeping your application up-to-date with the latest version of the Amazon SESv2 API via the AWS SDK.
Improve Usability and Developer Experience: Amazon SESv2 API is designed to be more user-friendly and consistent with other AWS services. It is a more intuitive API with better error handling, making it easier to develop, maintain, and troubleshoot your email sending applications.
Migrating to the latest SESv2 API and SDK positions customers for success in creating reliable and scalable email services for their businesses.
What does migration to the SESv2 API entail?
While SESv2 API builds on the v1 API, the v2 API actions don’t universally map exactly to the v1 API actions. Current SES customers that intend to migrate to SESv2 API will need to identify the SESv1 API actions in their code and plan to refactor for v2. When planning the migration, it is essential to consider several important considerations:
Customers with applications that receive email using SESv1 API’s CreateReceiptFilter, CreateReceiptRule or CreateReceiptRuleSet actions must continue using the SESv1 API client for these actions. SESv1 and SESv2 can be used in the same application, where needed.
We recommend all customers follow the security best practice of “least privilege” with their IAM policies. As such, customers may need to review and update their policies to include the new and modified API actions introduced in SESv2 before migrating. Taking the time to properly configure permissions ensures a seamless transition while maintaining a securely optimized level of access. See documentation.
Below is an example of an IAM policy with a user with limited allow privileges related to several SESv1 Identity actions only:
When calling delete- with SESv1, SES returns 200 (or no response), even if the identity was previously deleted or doesn’t exist:
aws ses delete-identity --identity example.com
SESv2 provides better error handling and responses when calling the delete API:
aws sesv2 delete-email-identity --email-identity example.com
An error occurred (NotFoundException) when calling the DeleteEmailIdentity operation: Email identity example.com does not exist.
Hands-on with SESv1 API vs. SESv2 API
Below are a few examples you can use to explore the differences between SESv1 API and the SESv2 API. To complete these exercises, you’ll need:
AWS Account (setup) with enough permission to interact with the SES service via the CLI
SES enabled, configured and properly sending emails
A recipient email address with which you can check inbound messages (if you’re in the SES Sandbox, this email must be verified email identity). In the following examples, replace [email protected] with the verified email identity.
Your preferred IDE with AWS credentials and necessary permissions (you can also use AWS CloudShell)
Open the AWS CLI (or AWS CloudShell) and:
Create a test directory called v1-v2-test.
Create the following (8) files in the v1-v2-test directory:
destination.json (replace [email protected] with the verified email identity):
{
"Subject": {
"Data": "SESv1 API email sent using the AWS CLI",
"Charset": "UTF-8"
},
"Body": {
"Text": {
"Data": "This is the message body from SESv1 API in text format.",
"Charset": "UTF-8"
},
"Html": {
"Data": "This message body from SESv1 API, it contains HTML formatting. For example - you can include links: <a class=\"ulink\" href=\"http://docs.aws.amazon.com/ses/latest/DeveloperGuide\" target=\"_blank\">Amazon SES Developer Guide</a>.",
"Charset": "UTF-8"
}
}
}
ses-v1-raw-message.json (replace [email protected] with the verified email identity):
{
"Data": "From: [email protected]\nTo: [email protected]\nSubject: Test email sent using the SESv1 API and the AWS CLI \nMIME-Version: 1.0\nContent-Type: text/plain\n\nThis is the message body from the SESv1 API SendRawEmail.\n\n"
}
ses-v1-template.json (replace [email protected] with the verified email identity):
my-template.json (replace [email protected] with the verified email identity):
{
"Template": {
"TemplateName": "my-template",
"SubjectPart": "Greetings SES Developer, {{name}}!",
"HtmlPart": "<h1>Hello {{name}},</h1><p>Your favorite animal is {{favoriteanimal}}.</p>",
"TextPart": "Dear {{name}},\r\nYour favorite animal is {{favoriteanimal}}."
}
}
ses-v2-simple.json (replace [email protected] with the verified email identity):
{
"FromEmailAddress": "[email protected]",
"Destination": {
"ToAddresses": [
"[email protected]"
]
},
"Content": {
"Simple": {
"Subject": {
"Data": "SESv2 API email sent using the AWS CLI",
"Charset": "utf-8"
},
"Body": {
"Text": {
"Data": "SESv2 API email sent using the AWS CLI",
"Charset": "utf-8"
}
},
"Headers": [
{
"Name": "List-Unsubscribe",
"Value": "insert-list-unsubscribe-here"
},
{
"Name": "List-Unsubscribe-Post",
"Value": "List-Unsubscribe=One-Click"
}
]
}
}
}
ses-v2-raw.json (replace [email protected] with the verified email identity):
{
"FromEmailAddress": "[email protected]",
"Destination": {
"ToAddresses": [
"[email protected]"
]
},
"Content": {
"Raw": {
"Data": "Subject: Test email sent using SESv2 API via the AWS CLI \nMIME-Version: 1.0\nContent-Type: text/plain\n\nThis is the message body from SendEmail Raw Content SESv2.\n\n"
}
}
}
ses-v2-tempate.json (replace [email protected] with the verified email identity):
As mentioned above, customers who are using least privilege permissions with SESv1 API must first update their IAM policies before running the SESv2 API examples below. See documentation for more info.
As you can see from the .json files we created for SES v2 API (above), you can modify or remove sections from the .json files, based on the type of email content (simple, raw or templated) you want to send.
As you can see from the examples above, SESv2 API shares much of its syntax and actions with the SESv1 API. As a result, most customers have found they can readily evaluate, identify and migrate their application code base in a relatively short period of time. However, it’s important to note that while the process is generally straightforward, there may be some nuances and differences to consider depending on your specific use case and programming language.
Regardless of the language, you’ll need anywhere from a few hours to a few weeks to:
Update your code to use SESv2 Client and change API signature and request parameters
Update permissions / policies to reflect SESv2 API requirements
Test your migrated code to ensure that it functions correctly with the SESv2 API
Stage, test
Deploy
Summary
As we’ve described in this post, Amazon SES customers that migrate to the SESv2 API will benefit from updated capabilities, a more user-friendly and intuitive API, better error handling and improved deliverability controls. The SESv2 API also provide for compliance with the industry’s upcoming unsubscribe header requirements, more flexible subscription-list management, and support for larger attachments. Taken collectively, these improvements make it even easier for customers to develop, maintain, and troubleshoot their email sending applications with Amazon Simple Email Service. For these, and future reasons, we recommend SES customers migrate their existing applications to the SESv2 API immediately.
For more information regarding the SESv2 APIs, comment on this post, reach out to your AWS account team, or consult the AWS SESv2 API documentation:
Zip is an Amazon Pinpoint and Amazon Simple Email Service Sr. Specialist Solutions Architect at AWS. Outside of work he enjoys time with his family, cooking, mountain biking and plogging.
Vinay Ujjini
Vinay is an Amazon Pinpoint and Amazon Simple Email Service Worldwide Principal Specialist Solutions Architect at AWS. He has been solving customer’s omni-channel challenges for over 15 years. He is an avid sports enthusiast and in his spare time, enjoys playing tennis and cricket.
Dmitrijs Lobanovskis
Dmitrijs is a Software Engineer for Amazon Simple Email service. When not working, he enjoys traveling, hiking and going to the gym.
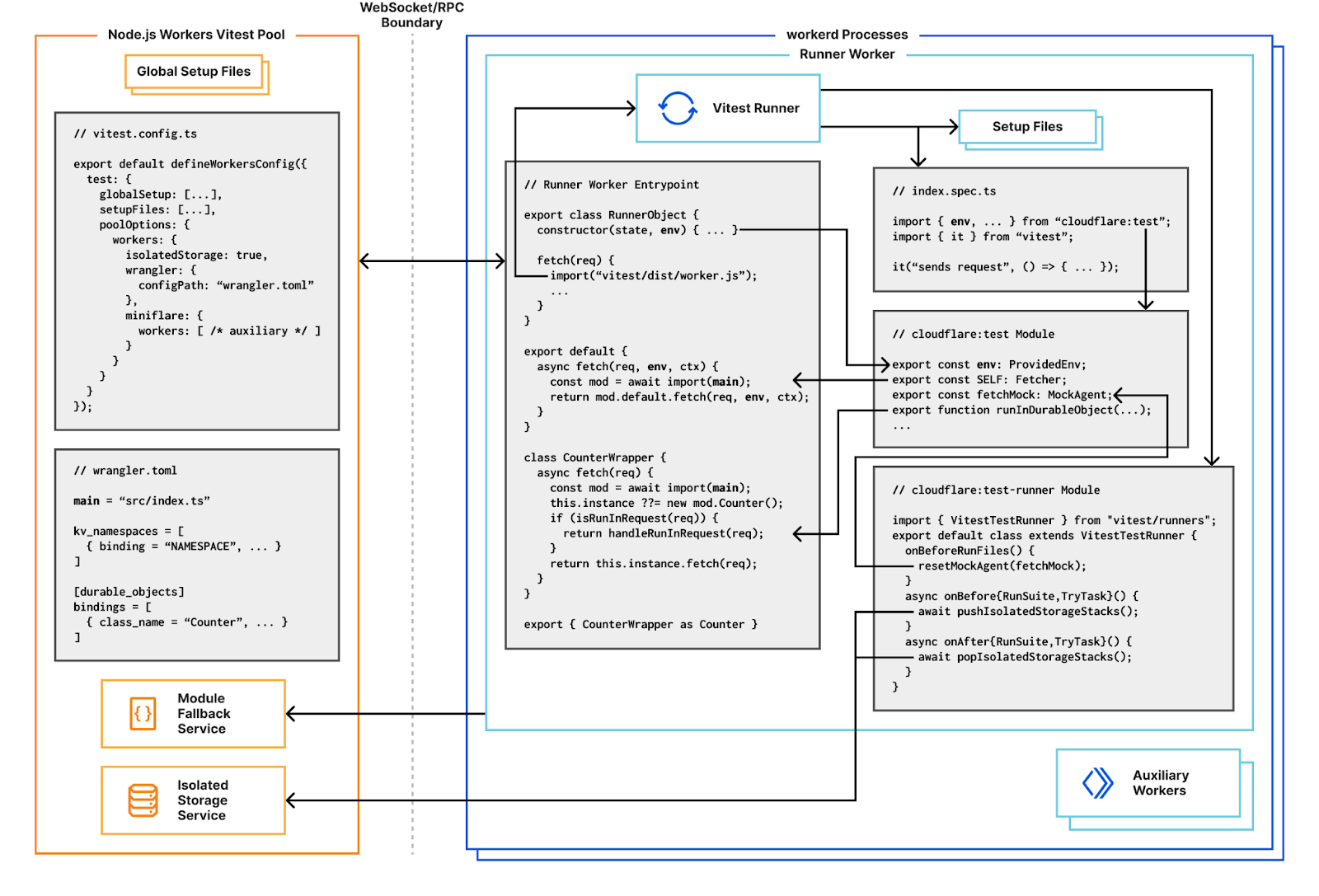
Today, we’re excited to announce a new Workers Vitest integration – allowing you to write unit and integration tests via the popular testing framework, Vitest, that execute directly in our runtime, workerd!
This integration provides you with the ability to test anything related to your Worker!
For the first time, you can write unit tests that run within the same runtime that Cloudflare Workers run on in production, providing greater confidence that the behavior of your Worker in tests will be the same as when deployed to production. For integration tests, you can now write tests for Workers that are triggered by Cron Triggers in addition to traditional fetch() events. You can also more easily test complex applications that interact with KV, R2, D1, Queues, Service Bindings, and more Cloudflare products.
For all of your tests, you have access to Vitest features like snapshots, mocks, timers, and spies.
In addition to increased testing and functionality, you’ll also notice other developer experience improvements like hot-module-reloading, watch mode on by default, and per-test isolated storage. Meaning that, as you develop and edit your tests, they’ll automatically re-run, without you having to restart your test runner.
Get started testing Workers with Vitest
The easiest way to get started with testing your Workers via Vitest is to start a new Workers project via our create-cloudflare tool:
Running this command will scaffold a new project for you with the Workers Vitest integration already set up. An example unit test and integration test are also included.
Manual install and setup instructions
If you prefer to manually install and set up the Workers Vitest integration, begin by installing @cloudflare/vitest-pool-workers from npm:
@cloudflare/vitest-pool-workers has a peer dependency on a specific version of vitest. Modern versions of npm will install this automatically, but we recommend you install it explicitly too. Refer to the getting started guide for the current supported version. If you’re using TypeScript, add @cloudflare/vitest-pool-workers to your tsconfig.json’s types to get types for the cloudflare:test module:
@cloudflare/vitest-pool-workers has a peer dependency on a specific version of vitest. Modern versions of npm will install this automatically, but we recommend you install it explicitly too. Refer to the getting started guide for the current supported version. If you’re using TypeScript, add @cloudflare/vitest-pool-workers to your tsconfig.json’s types to get types for the cloudflare:test module:
With the new Workers Vitest Integration, you can test anything exported from your Worker in both unit and integration-style tests. Within these tests, you can also test connected resources like R2, KV, and Durable Objects, as well as applications involving multiple Workers.
Writing unit tests
In a Workers context, a unit test imports and directly calls functions from your Worker then asserts on their return values. Let’s say you have a Worker that looks like this:
export function add(a, b) {
return a + b;
}
export default {
async fetch(request) {
const url = new URL(request.url);
const a = parseInt(url.searchParams.get("a"));
const b = parseInt(url.searchParams.get("b"));
return new Response(add(a, b));
}
}
After you’ve setup and installed the Workers Vitest integration, you can unit test this Worker by creating a new test file called index.spec.js with the following code:
Using the Workers Vitest integration, you can write unit tests like these for any of your Workers.
Writing integration tests
While unit tests are great for testing individual parts of your application, integration tests assess multiple units of functionality, ensuring that workflows and features work as expected. These are usually more complex than unit tests, but provide greater confidence that your app works as expected. In the Workers context, an integration test sends HTTP requests to your Worker and asserts on the HTTP responses.
With the Workers Vitest Integration, you can run integration tests by importing SELF from the new cloudflare:test utility like this:
// test/index.spec.ts
import { SELF } from "cloudflare:test";
import { it, expect } from "vitest";
import "../src";
// an integration test using SELF
it("sends request (integration style)", async () => {
const response = await SELF.fetch("http://example.com/?a=3&b=4");
expect(await response.text()).toMatchInlineSnapshot(`"7"`);
});
When using SELF for integration tests, your Worker code runs in the same context as the test runner. This means you can use mocks to control your Worker.
Testing different scenarios
Whether you’re writing unit or integration tests, if your application uses Cloudflare Developer Platform products (e.g. KV, R2, D1, Queues, or Durable Objects), you can test them. To demonstrate this, we have created a set of examples to help get you started testing.
Better testing experience === better testing
Having better testing tools makes it easier to test your projects right from the start, which leads to better overall quality and experience for your end users. The Workers Vitest integration provides that better experience, not just in terms of developer experience, but in making it easier to test your entire application.
The rest of this post will focus on how we built this new testing integration, diving into the internals of how Vitest works, the problems we encountered trying to get a framework to work within our runtime, and ultimately how we solved it and the improved DX that it unlocked.
How Vitest traditionally works
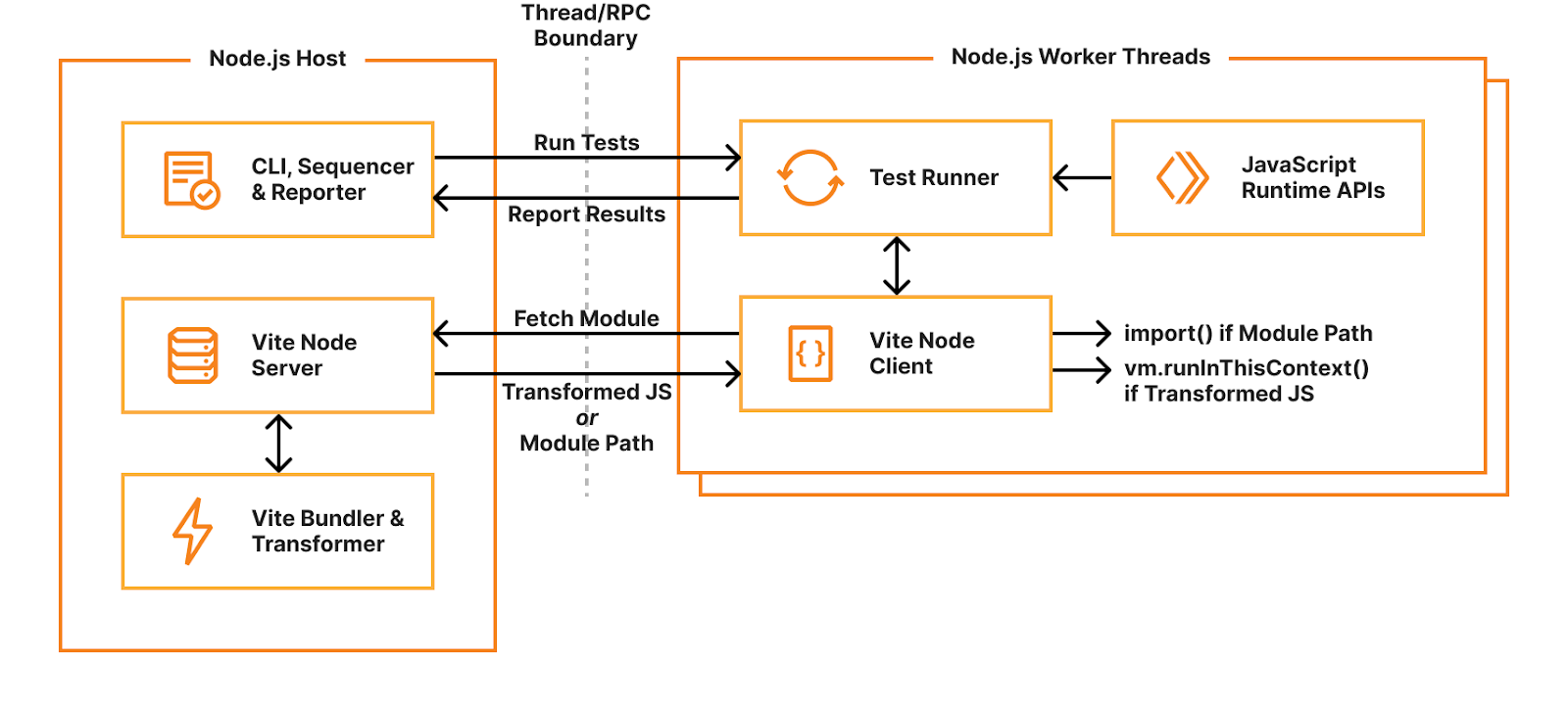
When you start Vitest’s CLI, it first collects and sequences all your test files. By default, Vitest uses a “threads” pool, which spawns Node.js worker threads for isolating and running tests in parallel. Each thread gets a test file to run, dynamically requesting and evaluating code as needed. When the test runner imports a module, it sends a request to the host’s “Vite Node Server” which will either return raw JavaScript code transformed by Vite, or an external module path. If raw code is returned, it will be executed using the node:vmrunInThisContext() function. If a module path is returned, it will be imported using dynamic import(). Transforming user code with Vite allows hot-module-reloading (HMR) — when a module changes, it’s invalidated in the module cache and a new version will be returned when it’s next imported.
Miniflare is a fully-local simulator for Cloudflare’s Developer Platform. Miniflare v2 provided a custom environment for Vitest that allowed you to run your tests inside the Workers sandbox. This meant you could import and call any function using Workers runtime APIs in your tests. You weren’t restricted to integration tests that just sent and received HTTP requests. In addition, this environment provided per-test isolated storage, automatically undoing any changes made at the end of each test. In Miniflare v2, this environment was relatively simple to implement. We’d already reimplemented Workers Runtime APIs in a Node.js environment, and could inject them using Vitest’s APIs into the global scope of the test runner.
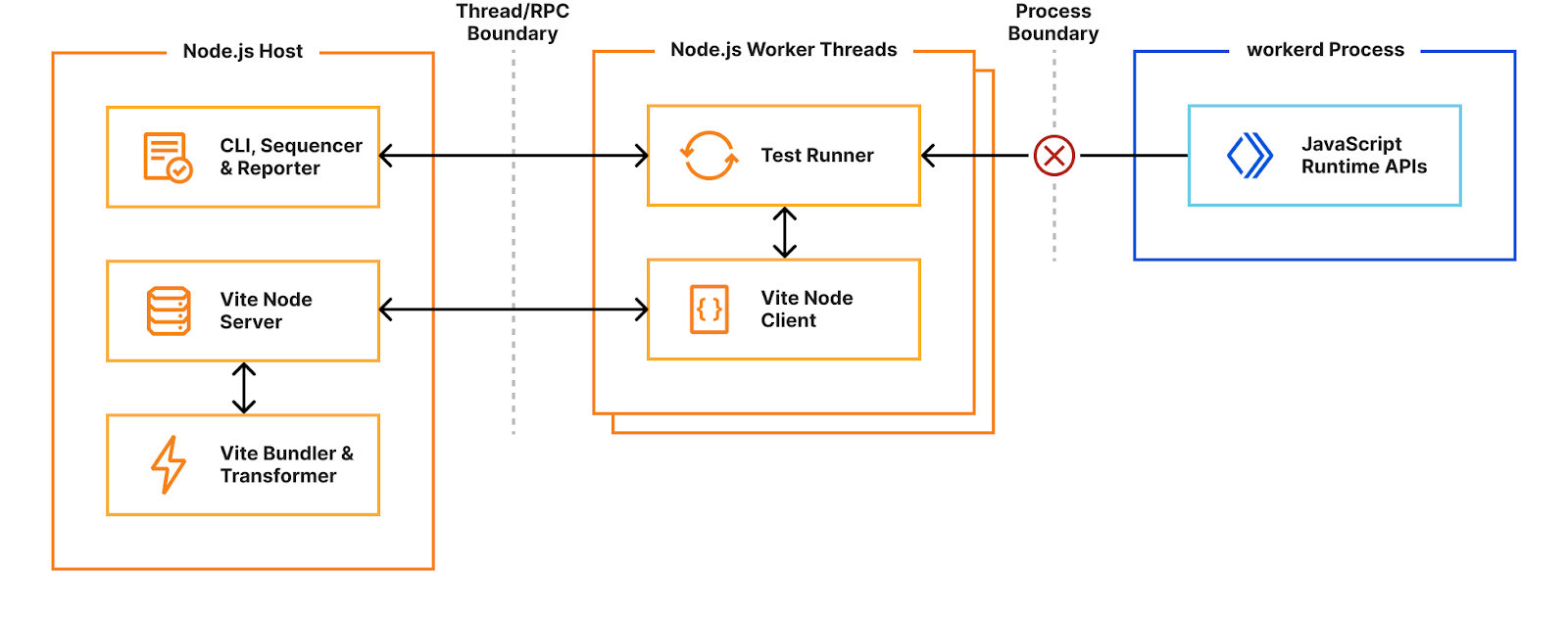
By contrast, Miniflare v3 runs your Worker code inside the same workerd runtime that Cloudflare uses in production. Running tests directly in workerd presented a challenge — workerd runs in its own process, separate from the Node.js worker thread, and it’s not possible to reference JavaScript classes across a process boundary.
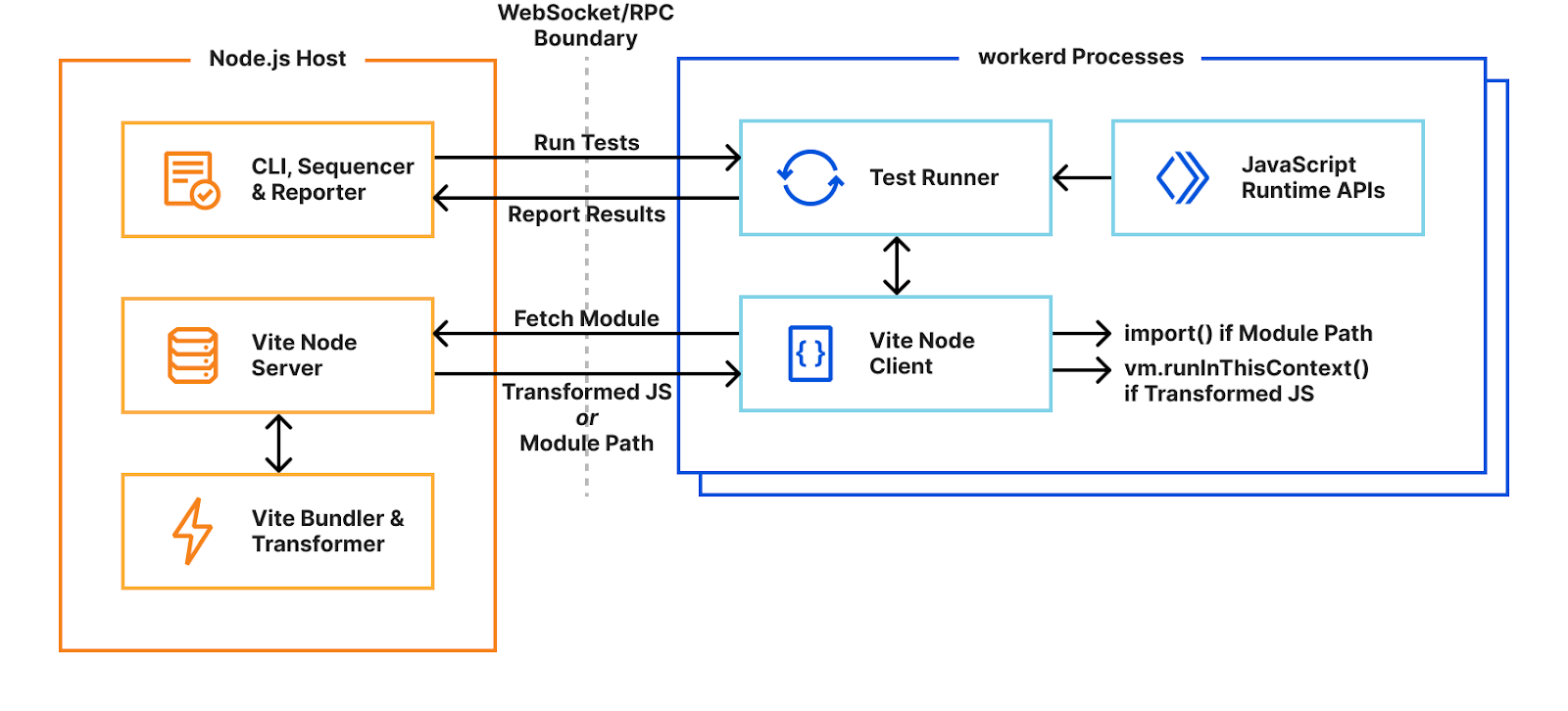
Solving the problem with custom pools
Instead, we use Vitest’s custom pools feature to run the test runner in Cloudflare Workers running locally with workerd. A pool receives test files to run and decides how to execute them. By executing the runner inside workerd, tests have direct access to Workers runtime APIs as they’re running in a Worker. WebSockets are used to send and receive serialisable RPC messages between the Node.js host and workerd process. Note we’re running the exact same test runner code originally designed for a Node-context inside a Worker here. This means our Worker needs to provide Node’s built-in modules, support for dynamic code evaluation, and loading of arbitrary modules from disk with Node-resolution behavior. The nodejs_compat compatibility flag provides support for some of Node’s built-in modules, but does not solve our other problems. For that, we had to get creative…
Dynamic code evaluation
For security reasons, the Cloudflare Workers runtime does not allow dynamic code evaluation via eval() or new Function(). It also requires all modules to be defined ahead-of-time before execution starts. The test runner doesn’t know what code to run until we start executing tests, so without lifting these restrictions, we have no way of executing the raw JavaScript code transformed by Vite nor importing arbitrary modules from disk. Fortunately, code that is only meant to run locally – like tests – has a much more relaxed security model than deployed code. To support local testing and other development-specific use-cases such as Vite’s new Runtime API, we added “unsafe-eval bindings” and “module-fallback services” to workerd.
Unsafe-eval bindings provide local-only access to the eval() function, and new Function()/new AsyncFunction()/new WebAssembly.Module() constructors. By exposing these through a binding, we retain control over which code has access to these features.
Using the unsafe-eval binding eval() method, we were able to implement a polyfill for the required vm.runInThisContext() function. While we could also implement loading of arbitrary modules from disk using unsafe-eval bindings, this would require us to rebuild workerd’s module resolution system in JavaScript. Instead, we allow workers to be configured with module fallback services. If enabled, imports that cannot be resolved by workerd become HTTP requests to the fallback service. These include the specifier, referrer, and whether it was an import or require. The service may respond with a module definition, or a redirect to another location if the resolved location doesn’t match the specifier. Requests originating from synchronous requires will block the main thread until the module is resolved. The Workers Vitest pool’s fallback service implements Node-like resolution with Node-style interoperability between CommonJS and ES modules.
Durable Objects as test runners
Now that we can run and import arbitrary code, the next step is to get Vitest’s thread worker running inside workerd. Every incoming request has its own request context. To improve overall performance, I/O objects such as streams, request/response bodies and WebSockets created in one request context cannot be used from another. This means if we want to use a WebSocket for RPC between the pool and our workerd processes, we need to make sure the WebSocket is only used from one request context. To coordinate this, we define a singleton Durable Object for accepting the RPC connection and running tests from. Functions using RPC such as resolving modules, reporting results and console logging will always use this singleton. We use Miniflare’s “magic proxy” system to get a reference to the singleton’s stub in Node.js, and send a WebSocket upgrade request directly to it. After adding a few more Node.js polyfills, and a basic cloudflare:test module to provide access to bindings and a function for creating ExecutionContexts, we’re able to write basic Workers unit tests! 🎉
Integration tests with hot-module-reloading
In addition to unit tests, we support integration testing with a special SELF service binding in the cloudflare:test module. This points to a special export default { fetch(...) {...} } handler which uses Vite to import your Worker’s main module.
Using Vite’s transformation pipeline here means your handler gets hot-module-reloading (HMR) for free! When code is updated, the module cache is invalidated, tests are rerun, and subsequent requests will execute with new code. The same approach of wrapping user code handlers applies to Durable Objects too, providing the same HMR benefits.
Integration tests can be written by calling SELF.fetch(), which will dispatch a fetch() event to your user code in the same global scope as your test, but under a different request context. This means global mocks apply to your Worker’s execution, as do request context lifetime restrictions. In particular, if you forget to call ctx.waitUntil(), you’ll see an appropriate error message. This wouldn’t be the case if you called your Worker’s handler directly in a unit test, as you’d be running under the runner singleton’s Durable Object request context, whose lifetime is automatically extended.
Most Workers applications will have at least one binding to a Cloudflare storage service, such as KV, R2 or D1. Ideally, tests should be self-contained and runnable in any order or on their own. To make this possible, writes to storage need to be undone at the end of each test, so reads by other tests aren’t affected. Whilst it’s possible to do this manually, it can be tricky to keep track of all writes and undo them in the correct order. For example, take the following two functions:
// helpers.ts
interface Env {
NAMESPACE: KVNamespace;
}
// Get the current list stored in a KV namespace
export async function get(env: Env, key: string): Promise<string[]> {
return await env.NAMESPACE.get(key, "json") ?? [];
}
// Add an item to the end of the list
export async function append(env: Env, key: string, item: string) {
const value = await get(env, key);
value.push(item);
await env.NAMESPACE.put(key, JSON.stringify(value));
}
If we wanted to test these functions, we might write something like below. Note we have to keep track of all the keys we might write to, and restore their values at the end of tests, even if those tests fail.
// helpers.spec.ts
import { env } from "cloudflare:test";
import { beforeAll, beforeEach, afterEach, it, expect } from "vitest";
import { get, append } from "./helpers";
let startingList1: string | null;
let startingList2: string | null;
beforeEach(async () => {
// Store values before each test
startingList1 = await env.NAMESPACE.get("list 1");
startingList2 = await env.NAMESPACE.get("list 2");
});
afterEach(async () => {
// Restore starting values after each test
if (startingList1 === null) {
await env.NAMESPACE.delete("list 1");
} else {
await env.NAMESPACE.put("list 1", startingList1);
}
if (startingList2 === null) {
await env.NAMESPACE.delete("list 2");
} else {
await env.NAMESPACE.put("list 2", startingList2);
}
});
beforeAll(async () => {
await append(env, "list 1", "one");
});
it("appends to one list", async () => {
await append(env, "list 1", "two");
expect(await get(env, "list 1")).toStrictEqual(["one", "two"]);
});
it("appends to two lists", async () => {
await append(env, "list 1", "three");
await append(env, "list 2", "four");
expect(await get(env, "list 1")).toStrictEqual(["one", "three"]);
expect(await get(env, "list 2")).toStrictEqual(["four"]);
});
This is slightly easier with the recently introduced onTestFinished() hook, but you still need to remember which keys were written to, or enumerate them at the start/end of tests. You’d also need to manage this for KV, R2, Durable Objects, caches and any other storage service you used. Ideally, the testing framework should just manage this all for you.
That’s exactly what the Workers Vitest pool does with the isolatedStorage option which is enabled by default. Any writes to storage performed in a test are automagically undone at the end of the test. To support seeding data in beforeAll() hooks, including those in nested describe()-blocks, a stack is used. Before each suite or test, a new frame is pushed to the storage stack. All writes performed by the test or associated beforeEach()/afterEach() hooks are written to the frame. After each suite or test, the top frame is popped from the storage stack, undoing any writes.
Miniflare implements simulators for storage services on top of Durable Objects with a separate blob store. When running locally, workerd uses SQLite for Durable Object storage. To implement isolated storage, we implement an on-disk stack of .sqlite database files by backing up the databases when “pushing”, and restoring backups when “popping”. Blobs stored in the separate store are retained through stack operations, and cleaned up at the end of each test run. Whilst this works, it involves copying lots of .sqlite files. Looking ahead, we’d like to explore using SQLite SAVEPOINTS for a more efficient solution.
Declarative request mocking
In addition to storage, most Workers will make outbound fetch() requests. For tests, it’s often useful to mock responses to these requests. Miniflare already allows you to specify an undiciMockAgent to route all requests through. The MockAgent class provides a declarative interface for specifying requests to mock and the corresponding responses to return. This API is relatively simple, whilst being flexible enough for advanced use cases. We provide an instance of MockAgent as fetchMock in the cloudflare:test module.
import { fetchMock } from "cloudflare:test";
import { beforeAll, afterEach, it, expect } from "vitest";
beforeAll(() => {
// Enable outbound request mocking...
fetchMock.activate();
// ...and throw errors if an outbound request isn't mocked
fetchMock.disableNetConnect();
});
// Ensure we matched every mock we defined
afterEach(() => fetchMock.assertNoPendingInterceptors());
it("mocks requests", async () => {
// Mock the first request to `https://example.com`
fetchMock
.get("https://example.com")
.intercept({ path: "/" })
.reply(200, "body");
const response = await fetch("https://example.com/");
expect(await response.text()).toBe("body");
});
To implement this, we bundled a stripped down version of undici containing just the MockAgent code. We then built a custom undiciDispatcher that used the Worker’s global fetch() function instead of undici’s built-in HTTP implementation based on llhttp and node:net.
Testing Durable Objects directly
Finally, Miniflare v2’s custom Vitest environment provided support for accessing the instance methods and state of Durable Objects in tests directly. This allowed you to unit test Durable Objects like any other JavaScript class—you could mock particular methods and properties, or immediately call specific handlers like alarm(). To implement this in workerd, we rely on our existing wrapping of user Durable Objects for Vite transforms and hot-module reloading. When you call the runInDurableObject(stub, callback) function from cloudflare:test, we store callback in a global cache and send a special fetch() request to stub which is intercepted by the wrapper. The wrapper executes the callback in the request context of the Durable Object, and stores the result in the same cache. runInDurableObject() then reads from this cache, and returns the result.
Note that this assumes the Durable Object is running in the same isolate as the runInDurableObject() call. While this is true for same-Worker Durable Objects running locally, it means Durable Objects defined in auxiliary workers can’t be accessed directly.
Try it out!
We are excited to release the @cloudflare/vitest-pool-workers package on npm, and to provide an improved testing experience for you.
Make sure to read the Write your first test guide and begin writing unit and integration tests today! If you’ve been writing tests using one of our previous options, our unstable_devmigration guide or our Miniflare 2 migration guide should explain key differences and help you move your tests over quickly.
If you run into issues or have suggestions for improvements, please file an issue in our GitHub repo or reach out via our Developer Discord.
Security updates have been issued by Debian (composer and node-xml2js), Fedora (baresip), Mageia (fonttools, libgit2, mplayer, open-vm-tools, and packages), Red Hat (dnsmasq, gimp:2.8, and kernel-rt), and SUSE (389-ds, gdb, kernel, python-Django, python3, python36-pip, spectre-meltdown-checker, sudo, and thunderbird).
As Zabbix 7.0 will come with the new widget framework, allowing communication between different widgets on dashboards, of course, I had to try it out.
Creating the module
The blog post title is a bit of a clickbait in the sense that this example is just 1:1 from the Zabbix Summit 2023 custom widgets workshop session. I made some very, very minor modifications to the code, mainly just changing my name and so on to manifest.json files. Since the code itself was obtained from the workshop session, I’m not going to publish it, but this much I will tease:
Beginning with Zabbix 7.0, you can create your own custom widgets with JavaScript & PHP, and easily make other widgets on the dashboard to react to clicks you made on some other widget. The manifest.json file in the root of your custom module can describe what kind of info your widget will broadcast to other dashboard widgets, or what kind of info it will be receiving and obeying. Other than that, the custom widget only has a 2.6-kilobyte JavaScript file and a 587-byte CSS file. Modules are placed under /usr/share/zabbix/modules.
Next, just like in older versions of Zabbix, to activate your module you just go to Administration->Modules and click on Scan modules. And, there you have it.
Then, in your widgets, you can enable the dynamic reactions to other widgets or dashboard query changes like this:
Great! But what will it do?
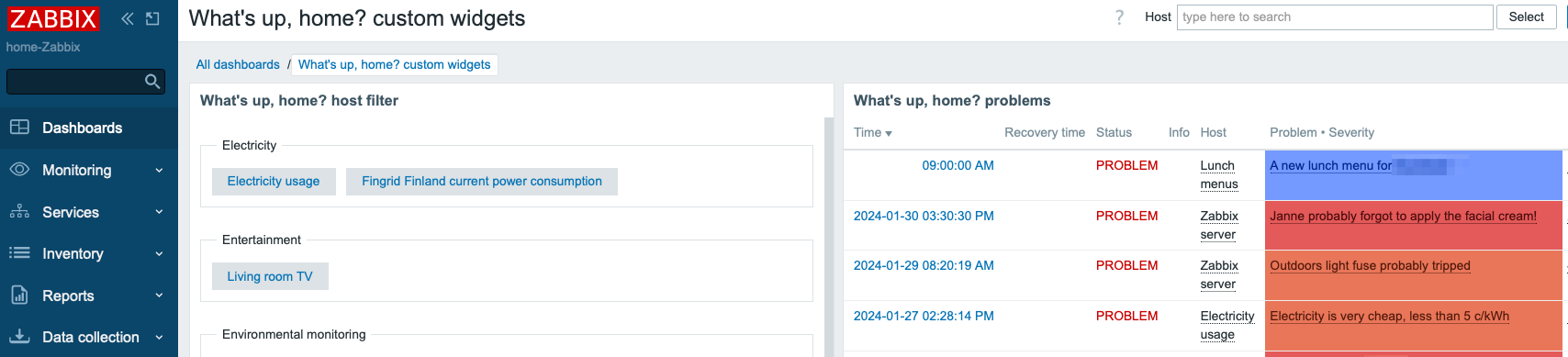
I now have a new way of filtering the visible alerts. The custom widget on the left lists my host groups and hosts that belong to them.
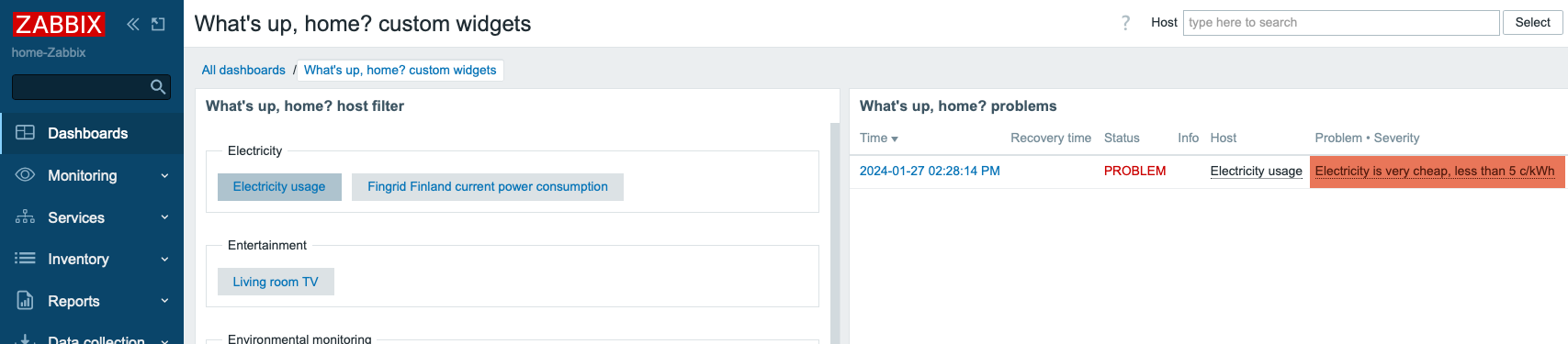
Observe what happens when I click on the Electricity usage button:
I’m not limited to only selecting one host at a time, I can click on multiple hosts. Now see what happens if I also choose Lunch menus from my hosts.
The possibilities are endless
This example is just a simple read-only example. But, as Alexei mentioned to me after my speech at the Zabbix Summit 2023, this new framework could be used for controlling stuff, too. When I have time, I’ll try to run custom scripts and do other write operations through Zabbix API and this new framework.
Having a proper control panel for switching on/off the lights, music, and other things would be really cool, and now it certainly is possible. The future of the Zabbix user interface is really exciting thanks to new custom widgets.
This post was originally published on the author’s page.
„… изглежда като коалиционно, но ние ще казваме, че е само Мария Габриел“, казва съпредседателят на „Продължаваме промяната“ Кирил Петков в записа от Националния съвет на партията в края на май миналата година. Партийният елит обсъжда бъдещия управленски формат между ПП–ДБ и ГЕРБ–СДС. Десет месеца по-късно двете политически сили преговарят за коалиционен кабинет – все едно как ще го нарекат – с първия мандат на ГЕРБ–СДС, начело на който по силата на договорената ротация е Мария Габриел.
На 25 март Габриел ще занесе в Президентството папка с имената на министрите и засега единствено сигурното е, че сред тях ще са Николай Денков (като вицепремиер), Асен Василев (на финансите), Калин Стоянов (на вътрешните работи) и Андрей Цеков (на регионалното развитие и благоустройството). Дотогава ПП–ДБ и ГЕРБ, преговарящи за състава на бъдещия кабинет, за механизма за назначения и за мястото на ДПС в разпределението на властта, ще са приключили разговорите.
След първоначалното затишие в медиите започнаха да се появяват съобщения за кои министерски кресла претендира партията на Бойко Борисов. Общото кратно между публикациите на „24 часа“, „Клуб Z“ и „Капитал“ са шестте министерства – външното, на енергетиката, на отбраната, на земеделието, на иновациите и на околната среда. Почти всички те управляват европейски програми за милиарди – с изключение на МВнР, което се оказа въпрос на престиж и трамплин към позиция в международна институция за Габриел.
Апетитите за енергетиката
Министерството на енергетиката (МЕ) и държавните предприятия и дружества под неговата опека са притегателни за всяка власт и в контекста на енергийната трансформация тези апетити нарастват в геометрична прогресия. А при разпределението и управлението на средствата в Плана за възстановяване и устойчивост (ПВУ) енергетиката няма равна.
1,6 милиарда лева по ПВУ са за изграждане на инфраструктура от съоръжения за съхранение на електроенергия с 6000 МВт/ч използваем енергиен капацитет – в близост до мощности за възобновяема енергия (ветрогенератори, фотоволтаици, ВЕЦ, геотермална енергия и др.). Над 343 млн. лв. са безвъзмездни средства за централа за комбинирано производство на топлинна и електрическа енергия от геотермални източници; 179 млн. лв. – за енергийно ефективно улично осветление; 240 млн. лв. – за домакинства, които ще поставят слънчеви инсталации за битова гореща вода и фотоволтаични системи до 10 кВп, включително системи за съхранение на електрическа енергия; 139,6 млн. лв. – за пилотни проекти за производство на зелен водород и биогаз.
Под контрола на МЕ е и друг огромен ресурс – отговорността за териториалните планове на трите въглищни района Стара Загора, Перник и Кюстендил за общо 1,1 млрд. евро (близо 2,2 млрд. лв.) и инвестиционните предложения за бизнеси.
Наред с това, съгласно приета наскоро законова промяна, и министърът на енергетиката вече ще дава становище за промяна на предназначението на земеделска земя с площ над 50 дка, когато върху нея ще се изграждат мощности за производство на възобновяема енергия. Това означава, че без министерски подпис нито един голям проект за зелена енергия няма да види бял свят.
ГЕРБ бездруго контролира държавната енергетика – правителството на премиера в оставка Николай Денков възстанови на поста изпълнителен директор на „Булгартрансгаз“ Владимир Малинов и назначи за шеф на АЕЦ „Козлодуй“ друг стар кадър на партията на Борисов – Валентин Николов. Друг енергиен шеф от времето на ГЕРБ – Петьо Иванов, оглави дружеството, което ще строи новите ядрени мощности на площадката на АЕЦ „Козлодуй“.
Кой ще има думата в земеделието?
Независимо как се казва министърът, ДПС винаги е имало контрол върху Министерството на земеделието и храните, в което също са съсредоточени значими ресурси.
За периода 2023–2027 г. Европейският съюз осигурява почти 2,6 млрд. лв. чрез различни програми, а още 335 млн. лв. предоставя държавният бюджет. От тези около 3 млрд. лв. над 590 млн. се предоставят безвъзмездно за проекти в областта на земеделието и животновъдството.
Името, спрягано за министър на земеделието, е на Георги Тахов, чиято кариера на попрището на държавните служби започва при кабинета „Орешарски“ – управлението на БСП и ДПС. Тогава той става началник на НАП – Пловдив, а служебният кабинет на президента го постави начело и на ДФ „Земеделие“.
Най-могъщият министър
Министерството на околната среда и водите управлява средствата по програма „Околна среда“ (2021–2027 г.), които надхвърлят 3,6 млрд. лв. заедно с националното съфинансиране. Близо една трета от тези средства са предвидени за разширяване и модернизация на ВиК инфраструктурата за вече консолидираните райони Велико Търново, Габрово, Плевен, София-град, Софийска област, Търговище, Хасково и Добрич. Това означава обществени поръчки за харчене на около 1,4 млрд. лв. Без София, в останалите центрове кметовете са от ГЕРБ, в Добрич – от коалиционния партньор на Борисов СДС.
Проекти, свързани с околната среда, се финансират и от Програмата за развитие на селските райони, както и от ПУДООС. Министърът на околната среда и водите обаче е по-силен от премиера – законът му дава право да спре и пусне всяко производство. Така екоминистърът в кабинета на тройната коалиция Джевдет Чакъров, настоящ съпредседател на ДПС, не одобри доклада за ОВОС на канадската компания „Дънди Прешъс Металс“ за разширение на добива им в златната мина „Челопеч“. Наред с това бавеше свикването на Висш експертен екологичен съвет, който да разгледа доклада за ОВОС за находището „Ада тепе“ в Крумовград, и така блокираше инвестиционните планове на компанията.
Вече действа скрининг за чуждите инвестиции
Министерството на иновациите и растежа управлява две европейски програми – „Конкурентоспособност и иновации в предприятията“ (2021–2027) с бюджет от близо 3 млрд. лв. и „Научни изследвания, иновации и дигитализация за интелигентна трансформация“ (2021–2027) с бюджет от 2,14 млрд. лв.
В мандата на бъдещия премиер Мария Габриел започва да действа скринингът на преките чуждестранни инвестиции в България – в съответствие с европейски регламент, за да не се допуска т.нар. корозивен капитал в стратегически сектори. През март влязоха в сила промените за скрининг на чуждестранните инвестиции, предложени от съпредседателя на ДПС Делян Пеевски, санкциониран за значима корупция по Глобалния закон „Магнитски“. По силата на закона към Министерския съвет се създава междуведомствен съвет с представители на осем министерства и на спецслужбите, който ще разглежда всяка чуждестранна инвестиция над 2 млн. евро и съответно ще я разрешава или ще я отказва.
ГЕРБ настояват да получат и министерството на отбраната (МО)
Критикуваният и от свои, и от чужди министър Тодор Тагарев обаче може и да запази поста си. Причината е до голяма степен имиджова – ако партията на Борисов получи и МО, символ на евроатлантизма, какво остава за ПП–ДБ?
Но освен това военното министерство движи големи проекти за модернизация на армията. Приоритетните проекти до 2026 г. са десет, сред които придобиване на 8 Ф-16 Блок 70 за доизграждане на изтребителна авиационна ескадрила; придобиване на нови трикоординатни радари и др. Именно поръчката за радарите, за която са предвидени 400 млн. лв., повлия на искането за смяната му. Критиката към него е, че не е изискал подобрение на офертата на френската компания „Талес“, но настояваше правителството на Денков да одобри бързо сделката.
В периода 2026–2032 г. за българската армия са предвидени други три големи проекта – специални бронирани инженерни машини за батальонните бойни групи, тактически комуникационно-информационни системи и ракетни катери за повишаване на способностите на военноморските сили. Необходимите за всичките 13 проекта средства са 6,6 млрд. лв.
Небалансирано
Ако тези промени в кабинета се осъществят, ПП–ДБ ще имат твърде малко позиции, макар че запазват Министерството на финансите. Ще се наложи да запазят проблемното Министерство на здравеопазването, което никой от партньорите не иска, бъдещото Министерство на европейското развитие, което ще бъде създадено за Николай Денков, за тях е и Министерството на правосъдието.
Предвид разкритията, че министърът на вътрешните работи Калин Стоянов е бил номинация на ГЕРБ, балансът на силите рязко се променя. Засега е ясно, че процедурите за избор на нов състав на регулатори и контролни органи няма да стартират веднага. Процедурите по номиниране и проверки за интегритет ще отнемат дълго време, а през май предстои и кампания за евроизборите. Разбира се, за ГЕРБ и ДПС подобно бавене е добре дошло – ще продължи да управлява тяхната гарнитура. Тяхната сглобка се оказа трайна, а на ПП–ДБ и ГЕРБ все така изглежда като коалиция.
C++ guru Herb Sutter writes about how we can improve the programming language for better security.
The immediate problem “is” that it’s Too Easy By Default™ to write security and safety vulnerabilities in C++ that would have been caught by stricter enforcement of known rules for type, bounds, initialization, and lifetime language safety.
His conclusion:
We need to improve software security and software safety across the industry, especially by improving programming language safety in C and C++, and in C++ a 98% improvement in the four most common problem areas is achievable in the medium term. But if we focus on programming language safety alone, we may find ourselves fighting yesterday’s war and missing larger past and future security dangers that affect software written in any language.
В това видео с моя приятел Атанас Куманов разказваме за имущественото застраховане и нещата, които голяма част от хората не подозират
– Имуществените застраховки са евтини
– По-добре е застраховката да се сключи от застраховател, а не през онлайн портал
– Имуществената застраховка в банката е задължителна при кредит, но е доста по-одобрена
– Хората живели в чужбина, по-често застраховат имуществото си
Моля използвайте приложената форма за записване на час за среща
[contact-form-7]
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.







 Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University. Hajer Bouafif is an Analytics Specialist Solutions Architect at Amazon Web Services. She focuses on Amazon OpenSearch Service and helps customers design and build well-architected analytics workloads in diverse industries. Hajer enjoys spending time outdoors and discovering new cultures.
Hajer Bouafif is an Analytics Specialist Solutions Architect at Amazon Web Services. She focuses on Amazon OpenSearch Service and helps customers design and build well-architected analytics workloads in diverse industries. Hajer enjoys spending time outdoors and discovering new cultures. Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat. Muslim Abu Taha is a Sr. OpenSearch Specialist Solutions Architect dedicated to guiding clients through seamless search workload migrations, fine-tuning clusters for peak performance, and ensuring cost-effectiveness. With a background as a Technical Account Manager (TAM), Muslim brings a wealth of experience in assisting enterprise customers with cloud adoption and optimize their different set of workloads. Muslim enjoys spending time with his family, traveling and exploring new places.
Muslim Abu Taha is a Sr. OpenSearch Specialist Solutions Architect dedicated to guiding clients through seamless search workload migrations, fine-tuning clusters for peak performance, and ensuring cost-effectiveness. With a background as a Technical Account Manager (TAM), Muslim brings a wealth of experience in assisting enterprise customers with cloud adoption and optimize their different set of workloads. Muslim enjoys spending time with his family, traveling and exploring new places.