Post Syndicated from Емине Садкъ original https://www.toest.bg/suvremennata-turska-muzika-i-evropeyskata-scena/

Преди да започнете да четете, може да си пуснете плейлист с повече от двайсет съвременни турски банди. Ако пък нямате време за плейлисти, не пропускайте следните имена: Аyyuka; Islandman; Collectif Medz Bazar; Nekropsi; Gayes Su Akyol.
В предишните две статии говорихме за музиката на турските гастарбайтери в Германия през 60-те и 80-те години – музика, която се превръща както в дом, така и във форма на протест за стотици хиляди работници, намиращи се в една болезнено непозната страна. Представихме също и т.нар. ориенталски хип-хоп от 90-те години, служещ за съпротива срещу неонацизма и отстояване на идентичността на второто поколение турци – децата на гурбетчиите, родени през 70-те години в Германия.
В тази заключителна статия ще се фокусираме върху съвременната турска музика като цяло, която не разчита на нищо друго, освен на идентичността и автентичността си. Ще стане дума и за сливането ѝ с различни музикални форми, както и за мястото ѝ на европейската и световната сцена.
Съвременната алтернативна турска музика е отделен жанр със собствена уникалност и ритъм,
които трудно могат да бъдат сбъркани, но за да бъде поставен този жанр на мястото му в музикалните магазини, критиците най-често го причисляват към необятното и не съвсем ясно понятие World music. Според мен по-скоро е Crossing worlds music.
Във филма на Фатих Акин „Музиката на Истанбул“ (2005) членовете на една от най-емблематичните турски рок-гръндж банди – Replikas, заявяват, че дълго време са се борили с това да не принадлежат на голямата сцена и каквото и да правят, никога да не звучат така, както звучат западните банди. Накрая осъзнават, че точно в това е тяхната сила и че използването на традиционната турска (ориенталска) музика им дава по-голяма дълбочина и автентичност.
Трудно се изкоренява ориенталската мелодия от душата на един народ и е особено ценно, че сегашната турска музика успява така изкусно да вплете нишката на своето ДНК, без да звучи нито остаряло, нито досадно.
През 1934 г., по време на културните промени на Ататюрк, турската музика в радиостанциите е забранена.
На нейно място звучи класическа и европейска, но тъкмо затова повечето хора по онова време слушат египетски радиа.
Първото истинско западно влияние върху турската музика е на „Бийтълс“,
които вдъхновяват както великана на турския рок Баръш Манчо (Barış Manco), така и Джем Караджа и Еркин Корай, създали жанра анадолски рок. Преди няколко години беше осъществен проектът Аnatolian Rock Revival Project, представящ част от този стил. Освен че са преведени на английски, песните са анимирани по много красив начин.



Отляво надясно: Баръш Манчо, Джем Караджа, Еркин Корай
Бих ви окуражила да изгледате клипове на споменатите по-горе изпълнители, за да разберете колко много са повлияли на съвременните турски банди, както и защо хипарското, психеделично, груув излъчване и звучене са все още част от облика на турската алтернативна музика, част от нейната уникалност.
В този ред на мисли, не можем да продължим нататък, без да споменем BaBa ZuLa и тяхната отдаденост на експерименталния ориенталски ъндърграунд психеделичен рок, познат с изтънчеността си, доброто познаване на традиционното звучене, но и със задължителната изненада, която бих нарекла „сладка лудост“.
За мен беше удоволствие да чуя дарк-ембиънт-психеделичния албум Bu Bir Ruya („Това е сън“) през 2018-та. Албумът е част от проекта DirtMusic на Hugo Race – бивш член на бандата Nick Cave and The Bad Seeds, и BaBa ZuLa пасват невероятно. Албумът е многолик, преплита ориенталска музика и дарк ембиънт китара, а текстовете на песните са или силно политически, или твърде лични. Пее се както на английски, така и на турски. Човек би си помислил, че специално за мен са го записали този албум! Слушах го до припадък.
Друг албум, който слушах безброй пъти, беше Gece („Нощ“), на една от най-нашумелите по света турскоезични банди, изпълняваща анадолски рок – Altın Gün („Златен ден“). Тя затвърди и популяризира хипарското, груув усещане за анадолския рок, но и вдигна летвата с талантливо и умело адаптиране. Групата е базирана в Амстердам. Създадена е от нидерландеца Яспер Ферхюлст (басист), бивш член на инди банда, който иска да свири анадолски рок, но не знае турски. Разлепя обяви в турските бакалии из цял Амстердам, пуска публикации в социалните мрежи и след известно време намира Мерве Дасдемир (вокал) и Ердиндж Еджевит (баглама и вокал). Така се сформира единствената (до този момент) турскoезична банда, номинирана за „Грами“ през 2019 г., която Турция разпознава като своя. Един от водещите ежедневници на Турция Hürriyet я нарича „нашата гордост на червения килим“.
Във връзка с наградите и популярността обръщам специално внимание на лейбъла GlitterBeat, част от който са BaBa ZuLa, Gaye Su Akyol и Altın Gün. Каталогът им е пъстър и пълен с качествена музика от Африка, Азия, Южна Америка и др.


Altın Gün © Sanja Marusic
През 2021 г. започва проектът #60JahreMusik, с който се отбелязва 60-годишнината на турската музика в Германия. Сайтът, в който са събрани интервюта, видеоклипове, статии за музиката на различните поколения, е наречен Истанбул-Берлин. Това е много смислен проект и единствен по рода си архив и каталог на турски музиканти, живеещи в Германия. В сайта може да се намерят статии на английски и всеки, който проявява по-голям интерес по темата, ще открие достатъчно лични истории и още музика.
Проследяването на присъствието на турската култура от последните шейсет години в Европа чрез музиката за мен е интересен начин да се ориентираме къде се намира тя на европейската карта в момента. Колкото далечна и непозната е в началото на 60-те в Германия, толкова разпознаваема е през последните няколко години.
Съвременната турска музика вече е част от европейската и световната сцена. И не се бори за нищо – просто е.
Свободна е да бъде себе си; приета е като равна. За това помагат не само глобализацията и открехнатата врата, през която успяват да преминат нови културни течения, но и стабилното присъствие на турската музика в Европа вече шест десетилетия. Помага и приемането на алтернативната западна музика в турската култура.
Културният диалог, който тече в момента, и приемствеността са важни за нас, живеещи между звуците на Изтока и Запада.
Казват, че най-лесният начин да научиш за един народ е да слушаш неговата музика. Мисля, че ние все повече се опознаваме едни други. Но този процес е крехък, затова е добре към него да се подхожда с внимание и разбиране. За да продължим да се срещаме отвъд границите, отвъд мисълта за тях.













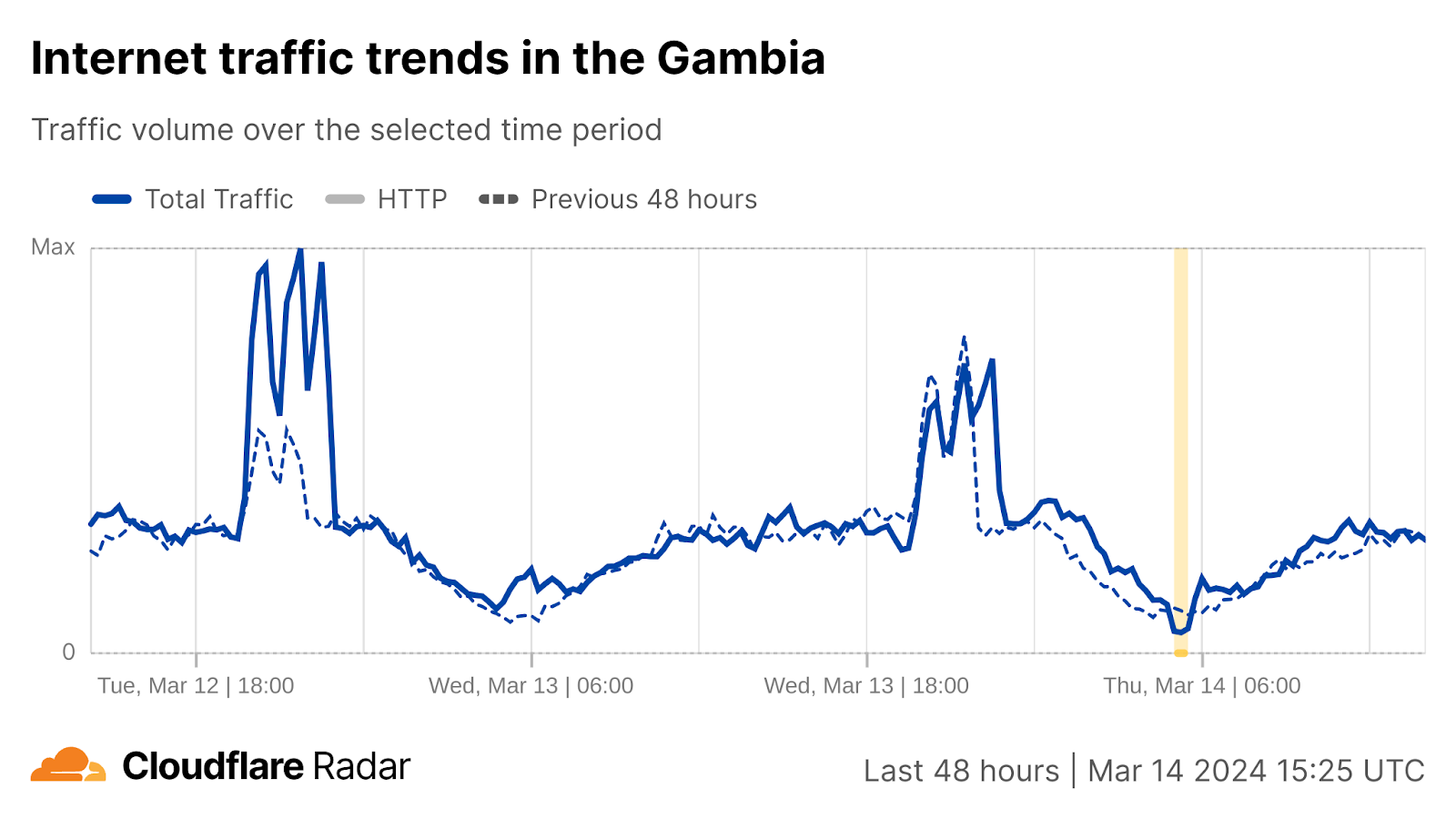
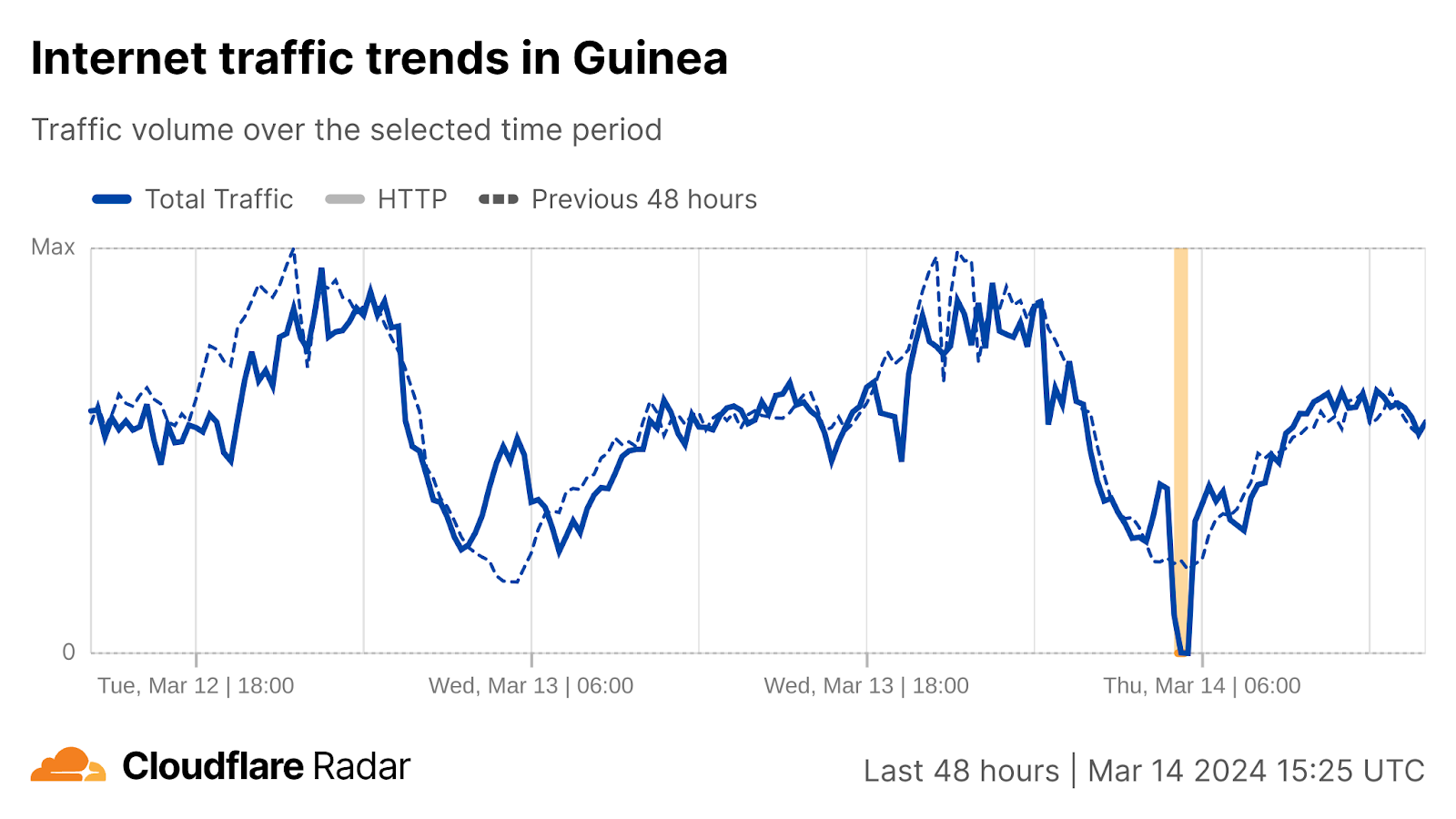
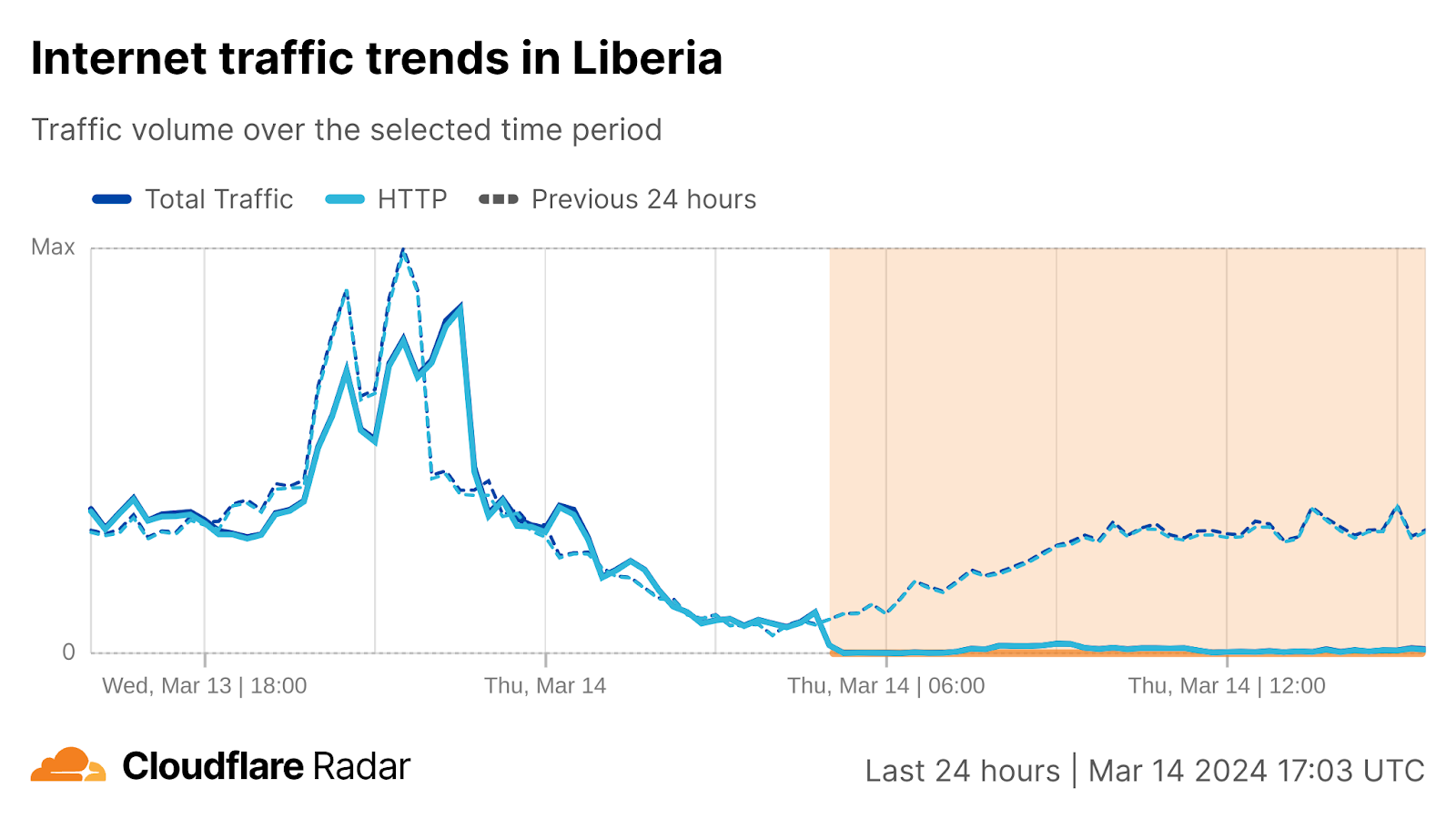


 Rivlin Pereira is Staff DevOps Engineer at VMware Tanzu Division. He is very passionate about Kubernetes and works on CloudHealth Platform building and operating cloud solutions that are scalable, reliable and cost effective.
Rivlin Pereira is Staff DevOps Engineer at VMware Tanzu Division. He is very passionate about Kubernetes and works on CloudHealth Platform building and operating cloud solutions that are scalable, reliable and cost effective. Vaibhav Pandey, a Staff Software Engineer at Broadcom, is a key contributor to the development of cloud computing solutions. Specializing in architecting and engineering data storage layers, he is passionate about building and scaling SaaS applications for optimal performance.
Vaibhav Pandey, a Staff Software Engineer at Broadcom, is a key contributor to the development of cloud computing solutions. Specializing in architecting and engineering data storage layers, he is passionate about building and scaling SaaS applications for optimal performance. Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate. Todd McGrath is a data streaming specialist at Amazon Web Services where he advises customers on their streaming strategies, integration, architecture, and solutions. On the personal side, he enjoys watching and supporting his 3 teenagers in their preferred activities as well as following his own pursuits such as fishing, pickleball, ice hockey, and happy hour with friends and family on pontoon boats. Connect with him on LinkedIn.
Todd McGrath is a data streaming specialist at Amazon Web Services where he advises customers on their streaming strategies, integration, architecture, and solutions. On the personal side, he enjoys watching and supporting his 3 teenagers in their preferred activities as well as following his own pursuits such as fishing, pickleball, ice hockey, and happy hour with friends and family on pontoon boats. Connect with him on LinkedIn. Satya Pattanaik is a Sr. Solutions Architect at AWS. He has been helping ISVs build scalable and resilient applications on AWS Cloud. Prior joining AWS, he played significant role in Enterprise segments with their growth and success. Outside of work, he spends time learning “how to cook a flavorful BBQ” and trying out new recipes.
Satya Pattanaik is a Sr. Solutions Architect at AWS. He has been helping ISVs build scalable and resilient applications on AWS Cloud. Prior joining AWS, he played significant role in Enterprise segments with their growth and success. Outside of work, he spends time learning “how to cook a flavorful BBQ” and trying out new recipes.