Post Syndicated from xkcd.com original https://xkcd.com/2880/

Post Syndicated from xkcd.com original https://xkcd.com/2880/
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=jCdDU1LMzOw
Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/amazon-ecs-supports-a-native-integration-with-amazon-ebs-volumes-for-data-intensive-workloads/
Today we are announcing that Amazon Elastic Container Service (Amazon ECS) supports an integration with Amazon Elastic Block Store (Amazon EBS), making it easier to run a wider range of data processing workloads. You can provision Amazon EBS storage for your ECS tasks running on AWS Fargate and Amazon Elastic Compute Cloud (Amazon EC2) without needing to manage storage or compute.
Many organizations choose to deploy their applications as containerized packages, and with the introduction of Amazon ECS integration with Amazon EBS, organizations can now run more types of workloads than before.
You can run data workloads requiring storage that supports high transaction volumes and throughput, such as extract, transform, and load (ETL) jobs for big data, which need to fetch existing data, perform processing, and store this processed data for downstream use. Because the storage lifecycle is fully managed by Amazon ECS, you don’t need to build any additional scaffolding to manage infrastructure updates, and as a result, your data processing workloads are now more resilient while simultaneously requiring less effort to manage.
Now you can choose from a variety of storage options for your containerized applications running on Amazon ECS:
To learn more, see Using data volumes in Amazon ECS tasks and persistent storage best practices in the AWS documentation.
Getting started with EBS volume integration to your ECS tasks
You can configure the volume mount point for your container in the task definition and pass Amazon EBS storage requirements for your Amazon ECS task at runtime. For most use cases, you can get started by simply providing the size of the volume needed for the task. Optionally, you can configure all EBS volume attributes and the file system you want the volume formatted with.
1. Create a task definition
Go to the Amazon ECS console, navigate to Task definitions, and choose Create new task definition.

In the Storage section, choose Configure at deployment to set EBS volume as a new configuration type. You can provision and attach one volume per task for Linux file systems.

When you choose Configure at task definition creation, you can configure existing storage options such as bind mounts, Docker volumes, EFS volumes, Amazon FSx for Windows File Server volumes, or Fargate ephemeral storage.
Now you can select a container in the task definition, the source EBS volume, and provide a mount path where the volume will be mounted in the task.

You can also use $aws ecs register-task-definition --cli-input-json file://example.json command line to register a task definition to add an EBS volume. The following snippet is a sample, and task definitions are saved in JSON format.
{
"family": "nginx"
...
"containerDefinitions": [
{
...
"mountPoints": [
"containerPath": "/foo",
"sourceVoumne": "new-ebs-volume"
],
"name": "nginx",
"image": "nginx"
}
],
"volumes": [
{
"name": "/foo",
"configuredAtRuntime": true
}
]
}2. Deploy and run your task with EBS volume
Now you can run a task by selecting your task in your ECS cluster. Go to your ECS cluster and choose Run new task. Note that you can select the compute options, the launch type, and your task definition.
Note: While this example goes through deploying a standalone task with an attached EBS volume, you can also configure a new or existing ECS service to use EBS volumes with the desired configuration.

You have a new Volume section where you can configure the additional storage. The volume name, type, and mount points are those that you defined in your task definition. Choose your EBS volume types, sizes (GiB), IOPs, and the desired throughput.

You cannot attach an existing EBS volume to an ECS task. But if you want to create a volume from an existing snapshot, you have the option to choose your snapshot ID. If you want to create a new volume, then you can leave this field empty. You can choose the file system type, either ext3 or ext4 file systems on Linux.

By default, when a task is terminated, Amazon ECS deletes the attached volume. If you need the data in the EBS volume to be retained after the task exits, check Delete on termination. Also, you need to create an AWS Identity and Access Management (IAM) role for volume management that contains the relevant permissions to allow Amazon ECS to make API calls on your behalf. For more information on this policy, see infrastructure role in the AWS documentation.
You can also configure encryption on your EBS volumes using either Amazon managed keys and customer managed keys. To learn more about the options, see our Amazon EBS encryption in the AWS documentation.
After configuring all task settings, choose Create to start your task.
3. Deploy and run your task with EBS volume
Once your task has started, you can see the volume information on the task definition details page. Choose a task and select the Volumes tab to find your created EBS volume details.

Your team can organize the development and operations of EBS volumes more efficiently. For example, application developers can configure the path where your application expects storage to be available in the task definition, and DevOps engineers can configure the actual EBS volume attributes at runtime when the application is deployed.
This allows DevOps engineers to deploy the same task definition to different environments with differing EBS volume configurations, for example, gp3 volumes in the development environments and io2 volumes in production.
Now available
Amazon ECS integration with Amazon EBS is available in nine AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (Stockholm). You only pay for what you use, including EBS volumes and snapshots. To learn more, see the Amazon EBS pricing page and Amazon EBS volumes in ECS in the AWS documentation.
Give it a try now and send feedback to our public roadmap, AWS re:Post for Amazon ECS, or through your usual AWS Support contacts.
— Channy
P.S. Special thanks to Maish Saidel-Keesing, a senior enterprise developer advocate at AWS for his contribution in writing this blog post.
Post Syndicated from Raffaele Garofalo original https://aws.amazon.com/blogs/architecture/how-zurich-insurance-group-built-their-scalable-account-vending-process-using-aws-account-factory-for-terraform/
Zurich Insurance Group is a leading multi-line global insurer operating in more than 200 territories. Headquartered in Zurich, Switzerland, their main business is life and property and casualty (P&C) insurance. In 2022, Zurich began a multi-year program to accelerate their digital transformation and innovation through migration of 1,000 workloads to AWS, including core insurance and SAP workloads.
During 2022, Zurich built out their Global Cloud Foundation – a set of foundational global AWS capabilities required to begin migrating workloads to the AWS Cloud, including the Scalable Account Vending (SAV) solution that is the subject of this article.
The goal of the Global Cloud Foundation was to address common questions workload teams had when moving to the AWS Cloud:
This investment in a solid foundation is already enabling their migration program in 2023 and beyond.
As a federated global organization, Zurich Insurance Group had pockets of AWS usage in different business units in multiple geographies managed by separate regional Cloud Center of Excellence (CCOE) teams. However, there was no consistency. One of the migration program’s goals was to establish a standard set of re-usable patterns and curated services, pre-built using Terraform to minimize migration and modernization effort and maximize re-use. This required the AWS environment to be built in a consistent way.
Additionally, Zurich was moving from a managed service to self-service DevSecOps provisioning for infrastructure, and many of the workloads did not have an existing DevSecOps environment for their infrastructure, and so they needed one provisioned for them in Azure DevOps and Terraform Cloud (their DevOps toolchain), further accelerating adoption.
Therefore, the cloud workload environment needed to consist of:
Historically, these environments were created by each CCOE team through a combination of manual and semi-automated processes. The need for a scalable and automated solution came from the increase in demand for AWS Cloud workload environments. It took the CCOE up to three days to provision a single AWS account, involved manual processes by multiple employees, and meant that each workload owner needed to raise up to eight support tickets to establish their environment. In addition, pipelines often failed, and the solution did not provide the speed or flexibility required in order to scale Zurich’s cloud adoption strategy.
To address this, SAV was conceived with three main goals:
The end-to-end solution shown here was fully-implemented as infrastructure-as-code orchestrated using Zurich’s corporate-standard Azure DevOps CI/CD tooling.

Figure 1. End-to-end solution using Zurich’s tooling
A single Jira Service Management request submitted by the workload owner provisions the entire cloud workload environment, which provides all the basic resources required to start migrating a workload into AWS.
In this section we will explore two key components of the SAV architecture: Environment vending using AWS Control Tower Account Factory for Terraform, and the AFT Code promotion process.

Figure 2. Environment vending pipeline overview
The environment vending workflow is structured as follows: a request for an AWS account is entered into JIRA Service Management ITSM tool. This triggers the environment vend pipeline in Azure DevOps.
AWS Control Tower Account Factory for Terraform (AFT) works by provisioning a new AWS account in response to a request in the form of an account request Terraform configuration committed to its account request GIT repository. Each account request configuration contains all information and metadata required to classify the AWS account into the proper organization structure and cost center.
The environment vend pipeline begins provisioning multiple accounts by taking the data entered on the submission form and generating a series of AFT account request Terraform configurations using Jinja templates, and committing each request to the AFT repository. The commit triggers AFT to provision the AWS accounts and to execute the Terraform modules that will deploy the account baseline and the required customizations in each vended account.
Subsequent stages of the pipeline provision the other resources using Terraform Cloud by following the same pattern as shown here:

Figure 3. Resource provisioning using Terraform Cloud
A pipeline task executes a Python script which applies a Jinja template to generate an HCL file, which is then committed to Azure DevOps git repository. This was essential in order to support ‘day-two’ management of the resources by the CCOE or workload teams that may want to use GitOps in the future. The commit triggers a run in the corresponding Terraform Cloud workspace, which provisions the resources into the linked account.
AWS Control Tower Account Factory for Terraform (AFT) uses a GitOps approach to vending and baselining of new AWS accounts using Terraform. It has workflows for creating new accounts and for deploying resources into vended accounts through its global and account customizations, which are implemented as Terraform modules. However, when applying changes to these Terraform modules there is a risk that an erroneous change can impact many, if not all, vended accounts.
Zurich Insurance Group mitigated the risk by implementing GitFlow. To modify a production configuration a process of pull request, review, and merge is triggered to ensure no breaking changes are introduced. The changes are tested in lower environments before deployment into production.
This process is illustrated here:

Figure 4. Terraform Cloud code promotion using GitFlow
By adopting AWS Control Tower Account Factory for Terraform, Zurich were able to achieve the scalability, resilience and performance to support provisioning of a projected 3000+ accounts. By compressing the process to a single ITSM request Zurich Insurance Group CCOE have been able to improve their SLA and customer satisfaction, reduce CCOE support time and effort, and secure their AWS environment with automated DevSecOps activities.
According to Eamonn Carey, Head of Cloud Engineering at Zurich Insurance Group:
“For Zurich and its journey to public cloud, scalability and compliance are crucial aspects of building and managing our cloud environments. Day-2 management plays a pivotal role in achieving both. Our scalable account vending processes and pre-created repos for day-2 management brings numerous benefits. It enables rapid delivery of our AWS accounts, enhances scalability, and promotes standardization. It ensures efficient resource provisioning, while standardized configurations ensure compliance with regulations and best practices. By combining these elements, Zurich can streamline our operations, reduce risks, and achieve optimal scalability and compliance in our cloud environments.”
Post Syndicated from Edward Sun original https://aws.amazon.com/blogs/security/how-to-customize-access-tokens-in-amazon-cognito-user-pools/
With Amazon Cognito, you can implement customer identity and access management (CIAM) into your web and mobile applications. You can add user authentication and access control to your applications in minutes.
In this post, I introduce you to the new access token customization feature for Amazon Cognito user pools and show you how to use it. Access token customization is included in the advanced security features (ASF) of Amazon Cognito. Note that ASF is subject to additional pricing as described on the Amazon Cognito pricing page.
When a user signs in to your app, Amazon Cognito verifies their sign-in information, and if the user is authenticated successfully, returns the ID, access, and refresh tokens. The access token, which uses the JSON Web Token (JWT) format following the RFC7519 standard, contains claims in the token payload that identify the principal being authenticated, and session attributes such as authentication time and token expiration time. More importantly, the access token also contains authorization attributes in the form of user group memberships and OAuth scopes. Your applications or API resource servers can evaluate the token claims to authorize specific actions on behalf of users.
With access token customization, you can add application-specific claims to the standard access token and then make fine-grained authorization decisions to provide a differentiated end-user experience. You can refine the original scope claims to further restrict access to your resources and enforce the least privileged access. You can also enrich access tokens with claims from other sources, such as user subscription information stored in an Amazon DynamoDB table. Your application can use this enriched claim to determine the level of access and content available to the user. This reduces the need to build a custom solution to look up attributes in your application’s code, thereby reducing application complexity, improving performance, and smoothing the integration experience with downstream applications.
Amazon Cognito works with AWS Lambda functions to modify your user pool’s authentication behavior and end-user experience. In this section, you’ll learn how to configure a pre token generation Lambda trigger function and invoke it during the Amazon Cognito authentication process. I’ll also show you an example function to help you write your own Lambda function.
During a user authentication, you can choose to have Amazon Cognito invoke a pre token generation trigger to enrich and customize your tokens.
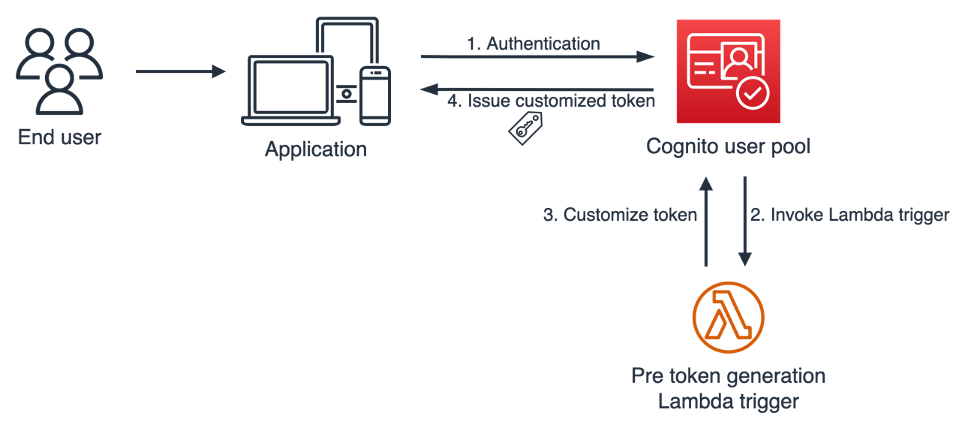
Figure 1: Pre token generation trigger flow
Figure 1 illustrates the pre token generation trigger flow. This flow has the following steps:
The pre token generation trigger flow supports OAuth 2.0 grant types, such as the authorization code grant flow and implicit grant flow, and also supports user authentication through the AWS SDK.
Your Amazon Cognito user pool delivers two different versions of the pre token generation trigger event to your Lambda function. Trigger event version 1 includes userAttributes, groupConfiguration, and clientMetadata in the event request, which you can use to customize ID token claims. Trigger event version 2 adds scope in the event request, which you can use to customize scopes in the access token in addition to customizing other claims.
In this section, I’ll show you how to update your user pool to trigger event version 2 and enable access token customization.
To enable access token customization
Figure 2: Add Lambda trigger
Figure 3: Select Lambda trigger
Figure 4: Add Lambda trigger
Now that you have enabled access token customization, I’ll walk you through a code example of the pre token generation Lambda trigger, and the version 2 trigger event. This code example examines the trigger event request, and adds a new custom claim and a custom OAuth scope in the response for Amazon Cognito to customize the access token to suit various authorization scheme.
Here is an example version 2 trigger event. The event request contains the user attributes from the Amazon Cognito user pool, the original scope claims, and the original group configurations. It has two custom attributes—membership and location—which are collected during the user registration process and stored in the Cognito user pool.
{
"version": "2",
"triggerSource": "TokenGeneration_HostedAuth",
"region": "us-east-1",
"userPoolId": "us-east-1_01EXAMPLE",
"userName": "mytestuser",
"callerContext": {
"awsSdkVersion": "aws-sdk-unknown-unknown",
"clientId": "1example23456789"
},
"request": {
"userAttributes": {
"sub": "a1b2c3d4-5678-90ab-cdef-EXAMPLE11111",
"cognito:user_status": "CONFIRMED",
"email": "[email protected]",
"email_verified": "true",
"custom:membership": "Premium",
"custom:location": "USA"
},
"groupConfiguration": {
"groupsToOverride": [],
"iamRolesToOverride": [],
"preferredRole": null
},
"scopes": [
"openid",
"profile",
"email"
]
},
"response": {
"claimsAndScopeOverrideDetails": null
}
}In the following code example, I transformed the user’s location attribute and membership attribute to add a custom claim and a custom scope. I used the claimsToAddOrOverride field to create a new custom claim called demo:membershipLevel with a membership value of Premium from the event request. I also constructed a new scope with the value of membership:USA.Premium through the scopesToAdd claim, and added the new claim and scope in the event response.
export const handler = function(event, context) {
// Retrieve user attribute from event request
const userAttributes = event.request.userAttributes;
// Add scope to event response
event.response = {
"claimsAndScopeOverrideDetails": {
"idTokenGeneration": {},
"accessTokenGeneration": {
"claimsToAddOrOverride": {
"demo:membershipLevel": userAttributes['custom:membership']
},
"scopesToAdd": ["membership:" + userAttributes['custom:location'] + "." + userAttributes['custom:membership']]
}
}
};
// Return to Amazon Cognito
context.done(null, event);
};With the preceding code, the Lambda trigger sends the following response back to Amazon Cognito to indicate the customization that was needed for the access tokens.
"response": {
"claimsAndScopeOverrideDetails": {
"idTokenGeneration": {},
"accessTokenGeneration": {
"claimsToAddOrOverride": {
"demo:membershipLevel": "Premium"
},
"scopesToAdd": [
"membership:USA.Premium"
]
}
}
}Then Amazon Cognito issues tokens with these customizations at runtime:
{
"sub": "a1b2c3d4-5678-90ab-cdef-EXAMPLE11111",
"iss": "https://cognito-idp.us-east-1.amazonaws.com/us-east-1_01EXAMPLE",
"version": 2,
"client_id": "1example23456789",
"event_id": "01faa385-562d-4730-8c3b-458e5c8f537b",
"token_use": "access",
"demo:membershipLevel": "Premium",
"scope": "openid profile email membership:USA.Premium",
"auth_time": 1702270800,
"exp": 1702271100,
"iat": 1702270800,
"jti": "d903dcdf-8c73-45e3-bf44-51bf7c395e06",
"username": "mytestuser"
}Your application can then use the newly-minted, custom scope and claim to authorize users and provide them with a personalized experience.
There are four general considerations and best practices that you can follow:
In this post, you learned how to integrate a pre token generation Lambda trigger with your Amazon Cognito user pool to customize access tokens. You can use the access token customization feature to provide differentiated services to your end users based on claims and OAuth scopes. For more information, see pre token generation Lambda trigger in the Amazon Cognito Developer Guide.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Post Syndicated from Home Assistant original https://www.youtube.com/watch?v=99lGuB4J-4o
Post Syndicated from Александър Нуцов original https://www.toest.bg/nevidimata-detsentralizatsiya-v-bulgaria/

Кой движи света напред? Кой води войните? Къде е концентрирана властта? В индивида, държавата, наднационалните институции? В политическите науки и международните отношения това са философски въпроси, от чиито корени черпят своето начало различни научни течения и школи. Но едва ли има единствен, цялостен и правилен отговор на тях. Докато хората на власт изпълват управленските структури със своята идентичност, позиции и идеи, същите структури влияят на хората в тях и ги ограничават с установените си рамки, инструменти и норми на съществуване.
Безспорно обаче най-голям властови ресурс – административен, финансов и военен – е съсредоточен в националната държава. Държавата съществува със своите структури, модели на поведение и „инстинкти“. Подобно на човека, първичното стремление на всяка власт е самосъхранението и възпроизвеждането. Държавите и техните структури също като нас се адаптират към променящата се среда и трансформират елементи от себе си, за да оцелеят. Така историческите събития ги подтикват да делегират част от правомощията си нагоре, към наднационални институции като ООН и Европейския съюз, и надолу – към местната власт, гражданите и частния сектор.
Процеси по децентрализация текат навсякъде по света още от времето на Студената война. Първоначално те се състоят преди всичко в предаване на правомощия и функции от централната към местната власт и различни локални структури с идеята да предоставят по-качествени и ефективни услуги на своите граждани. Тук можем да включим и случаите на федерализация и засилване на федералните власти в страни с такова управление.
С падането на желязната завеса – особено в страните от бившия Източен блок – децентрализацията поема към по-значително включване на частния сектор в публичните дела и икономиката заради масовата приватизация. Отварянето на пазарите и стимулирането на частната инициатива се осъществява в по-широкия контекст на демократизация на обществата.
Впоследствие „разпръскването“ на власт придобива все по-широк смисъл. Вече говорим за включване на все повече обществени кръгове във вземането на политически решения – граждани, неправителствени организации, бизнес. Тоест от тясното разбиране за делегиране на правомощия от централната към местната власт постепенно стигаме до по-широката тема за създаване на по-справедливо и ефективно държавно управление. Именно в този по-общ смисъл ще си поговорим за децентрализацията в България.
За разлика от много други страни по света, в България липсва държавна стратегия или целенасочена държавна политика за децентрализация на властта. У нас тя се развива по-скоро по естествен път, в съзвучие със сложните социално-икономически, политически и исторически обстоятелства на средата.
Парадоксално, политическата нестабилност през последните години, незначителната избирателна активност и ниската легитимност на властта от белег за немощ на българската демокрация могат да се превърнат в първопричината за нейното надграждане.
Фрагментираният парламент без единствена доминираща партия доведе до няколко ключови последици. Първата е липсата на единен център, който да създава и променя законодателството. Това, от една страна, създава поле за битка на повече и различни гледни точки. От друга обаче, означава невъзможност за водене на единна и стабилна политика, тъй като твърде многото интереси и компромиси водят до забавяне на законодателния процес или до осакатяване на реформите.
Вторият важен момент е, че немалка част от политическите фигури, като Бойко Борисов и Румен Радев, които дълго време концентрираха огромна власт в ръцете си, постепенно загубиха този свой прерогатив. И докато самият парламент се разпокъса отвътре, конфронтацията между парламента и Президентството доведе до конституционните промени, които орязват някои правомощия на президента.
При тази липса на единни самодостатъчни властови ядра законодателният процес и политиците се нуждаят от обединяващ фактор, който да надмогне кавгите и управленската разпокъсаност. И тук все по-съществена роля играят частният и гражданският сектор. Защото бизнесите и гражданските организации предлагат надпартийни решения отвъд институционалните борби, които нямат цвят, а решават проблеми на обществената среда.
На този фон администрацията остава изключително ретроградна, а политиците често нямат време, експертност и воля да реформират закостенялото законодателство. Тези дефицити все повече се запълват от активната роля на бизнес асоциациите, неправителствените организации и гражданите с експертни познания в различни области.
Освен това държавният апарат изостава драстично от технологичното развитие на глобално ниво, което забавя модернизацията на всички сектори от обществено значение – от образование и здравеопазване до електронно правителство и дигитализация на обществените услуги. Оттам идва и нарастващата зависимост на държавата от предприемачите, които създават, развиват и предоставят технологиите.
В условията на глобализация и ускорено технологично развитие частният и гражданският сектор придобиват все по-голяма тежест и лостове за влияние върху политиците.
Нарастващата роля на бизнеса и гражданите трябва да се превърне в тенденция, така че те да участват все по-активно в политическите процеси и вземането на стратегически решения. Тук говорим за „разпръскване“ на власт от парламента и партиите, както и от правителството и министерствата надолу – към обществото.
По-силният глас на модерните бизнеси и гражданския сектор гарантира повече контрол върху дейността на политиците, повече и по-добри идеи за реформи от хора и организации с експертно знание и по-ефективни решения на конкретни проблеми на средата. А колкото по-силни и разпознаваеми сред обществото са добрите примери на хора и организации от неправителствения сектор, толкова по-голямо внимание получават те от медиите. И ако политиците откажат да се съобразяват с тях, именно медиите са тези, които могат да разобличат нередностите и да осъществяват натиск, което неизбежно води до загуба на доверие и електорат.
По отношение на дигитализацията бизнесът предоставя технологии и ноу-хау в най-различни сектори, част от които вече споменахме. През миналата година например България най-накрая създаде своя национален електронен идентификатор благодарение на разработената от Evrotrust Technologies дигитална схема Evrotrust eID.
Най-големите пробойни на държавата бизнесът се опитва да попълни в образованието. За първи път 25 бизнес организации излязоха с обща позиция за нуждата от дълбока реформа в образованието. Все повече предприемачи споделят за развитието на собствени академии, стажове и семинари, с които да обучават собствени кадри поради липса на добра подготовка на кандидатите. Инвестициите в учебната инфраструктура, като например научни лаборатории, също говорят за големия принос на бизнеса. Социални предприемачи пък развиват собствени платформи за обучение и осигуряват финансов стимул за успелите ученици и студенти.
В здравеопазването имаме все повече дигитални платформи, които улесняват достъпа до специалисти в най-различни области, осигуряват ценна информация, дигитализират работата на институциите, помагат при подбора на персонал и т.н.
В земеделието български компании предоставят технологични решения за нуждите на земеделците. Например произвеждат високотехнологична роботика за най-различни дейности, като умно косене и плевене, разработват автоматизиране на капковото напояване, осъществяват контрол на климата в закрити и открити площи при отглеждането на култури, осигуряват софтуер и специалисти, които правят измервания и анализи и прилагат добри практики за устойчиво развитие на земеделието и оптимизиране на разходите.
Сигурността и отбраната също все по-силно зависят от модерните предприемачи, най-вече при надпреварата в иновациите. НАТО има собствен иновационен акселератор – DIANA, който предоставя ресурси и тестова база за иновативните стартъпи и ги свързва с учените и крайните потребители при създаването на „дълбоки технологии“ (deep tech) с т.нар. двойна употреба за страните от Съюза. Един от ключовите партньори на DIANA в България като тестов център е институтът „Големи данни в полза на интелигентно общество“ (GATE) към СУ „Св. Климент Охридски“, който осъществява и връзката между българските компании и натовската акселераторска програма.
Това са само няколко примера за нарастващата роля на бизнеса в традиционни за държавата сфери, което постепенно ще се превърне в тенденция в контекста на технологичното развитие.
На фона на политическата нестабилност и слабата държавност българските граждани и предприемачи ще придобиват все по-ключова позиция, която ще им позволи да държат политиците отговорни и да изсветляват управленските нередности и корупционни схеми.
Децентрализацията обаче не е лек сама по себе си. Тя трябва да улесни процеса на реформиране на законодателството и модернизиране на средата, като подпомогне комуникацията между политиците и експертите/практиците от частния и гражданския сектор, така че всички да участват дейно в политическите и публичните дела.
Необходимо е създаването на повече профилирани неправителствени и граждански организации, които обединяват широки обществени кръгове, застъпват се за каузи и черпят креативни идеи и решения от практиката. Те трябва да инициират и улесняват разговора между по-широк кръг лица от гражданския, частния и държавния сектор, за да се отговори на нуждите на обществото по най-смислен и ефективен начин. И най-важното – трябва да предоставят конкретни решения на конкретни проблеми, издигайки на пиедестал идеята всяка отделна сфера от живота ни да е по-добра за всички.
Децентрализацията в България ще продължи да се реализира по-скоро по естествен път, движен от нестабилната политическа обстановка и ускореното технологично развитие. Това е шанс за създаване на по-устойчива, макар и несъвършена демокрация, с повече съвестни управленци в по-благоприятна среда за правене на политика.
Post Syndicated from digiblurDIY original https://www.youtube.com/watch?v=aFs9x0rhO1Y
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=cPFcxPuzx-s
Post Syndicated from corbet original https://lwn.net/Articles/958048/
For those of you still using DSA keys with SSH: the project has announced
its plans to remove support for that algorithm around the beginning of
2025.
The only remaining use of DSA at this point should be deeply legacy
devices. As such, we no longer consider the costs of maintaining
DSA in OpenSSH to be justified. Moreover, we hope that OpenSSH’s
final removal of this insecure algorithm accelerates its
deprecation in other SSH implementations and allows maintainers of
cryptography libraries to remove it too.
Post Syndicated from corbet original https://lwn.net/Articles/957187/
The data structure known as a “closure” first found its way into the
mainline kernel with the addition of bcache in the 3.10 development
cycle. With the advent of bcachefs in
6.7, though, it acquired a second user and was moved to the kernel’s
lib directory, making it available to other kernel users as well.
The documentation of closures in the source is better than that of many
things in the kernel, but there is still room for a gentler introduction.
Post Syndicated from Rapid7 original https://blog.rapid7.com/2024/01/11/4-questions-for-cisos-to-reduce-threat-exposure-risk/

In an ongoing effort to help security organizations gain greater visibility into threat exposure risk, we have determined four key questions every CISO should be considering based on our understanding of the recommendations of a new report from Gartner®. The report, 2024 Strategic Roadmap for Managing Threat Exposure, can help CISOs and other top executives steer away from risk by analyzing their attack surfaces for gaps.
What are the business-driven events that have already been or are currently being scoped and planned for? In analyzing threat exposure for specific events along the course of the year, a security organization will have the power to better tailor their risk mitigation approaches.
“It’s crucial to scope risk in relation to threat exposure, as this is one of the key outputs that will benefit the wider business. To do so, senior leaders must understand the exposure facing the organization, in direct relation to the impact that an exploitation of said exposure would have. Together, with this information, executives can make informed decisions to either remediate, mitigate or accept the perceived risks. Without impact context, the exposures may be addressed in isolation, leading to uncoordinated fixes relegated to individual departments exacerbating the current problems associated with most vulnerability management programs.” says the Gartner report.
Post-risk scoping, it’s a good idea to then consider if there are any measures that can be taken to better protect certain business-driven events if they have been found to have a greater chance of threat-actor exploitability.
It is also incredibly valuable to take inventory of the most critical and exposed systems in the network, along with each system’s level of visibility and its location. Having a thorough catalog of the points that are or could be the most vulnerable is a must. Just because an exploitable asset might not be considered a remediation priority, there is always the possibility it could be exploited down the line.
Within the context of the report, Gartner details a visibility framework that can aid with vulnerability prioritization:
“Coupled with accessibility is the visibility of the exploitable service, port, or asset. These technologies implement configuration to ensure that details of exploitable elements are not revealed to potential attackers, but not directly removing the possibility of their exploitation.”
Therefore, it becomes necessary to leverage technologies that can provide insights into the visibility of an asset so that – if there is currently a low likelihood of exploitability – remediation efforts can be focused elsewhere and efficiences can be gained within the security organization.
Identifying who is responsible for the deployment and management of critical IT systems is key if the security organization is to get interdepartmental buy-in for an effective plan to manage threat exposure. Sometimes there isn’t just one person responsible for a certain aspect of network management, which is important to keep in mind as efforts to mitigate threat exposure are built out.
Security personnel, as with so many business operations in which they take part, also must keep in mind that there could be pushback or slow buy-in to a plan that is perceived to lack context. To this point, the research states:
“Without impact context, the exposures may be addressed in isolation, leading to uncoordinated fixes relegated to individual departments exacerbating the current problems associated with most vulnerability management programs.”
Potential friction could also lie in the effort to convince a system owner that there is real action required – and that it could upend that team’s workflow. Effective communication will be imperative here, as will the ability to provide the visibility needed to quickly convince stakeholders that action is, indeed, needed and worth the potential interruption. The report drives home the need for allying with those responsible for risk decisions:
“From the perspective of the organization’s business risk owner, it’s important to recognize that the security team’s role is to support risk management in such a way that the owner can make informed data-driven decisions.”
It will ultimately be up to the CISO to manage and connect separate plans to both limit and eliminate threat exposure along attack surfaces. Through this effort, the CISO can demonstrate the benefits of implementing platforms to manage the growing risk of threat exposure. They’ll also be able to prove the worth of the security operations center (SOC) as both key partners in the effort to keep business secure.
We’re pleased to continually offer leading research to help you gain clarity into managing the risk of threat exposure. Read the Gartner report to better understand how a broad set of exposures can impact the workloads of a security organization – and how important it becomes to prioritize properly and communicate effectively.
Gartner, 2024 Strategic Roadmap for Managing Threat Exposure, Pete Shoard, 8 November 2023.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
Post Syndicated from jake original https://lwn.net/Articles/958029/
Security updates have been issued by Debian (chromium), Fedora (chromium, python-paramiko, tigervnc, and xorg-x11-server), Oracle (ipa, libxml2, python-urllib3, python3, and squid), Red Hat (.NET 6.0, .NET 7.0, .NET 8.0, container-tools:4.0, fence-agents, frr, gnutls, idm:DL1, ipa, kernel, kernel-rt, libarchive, libxml2, nss, openssl, pixman, python-urllib3, python3, tigervnc, tomcat, and virt:rhel and virt-devel:rhel modules), SUSE (gstreamer-plugins-bad), and Ubuntu (firefox, Go, linux-aws, linux-gcp-5.15, linux-intel-iotg-5.15, linux-iot, linux-oem-6.1, and twisted).
Post Syndicated from Caitlin Condon original https://blog.rapid7.com/2024/01/11/etr-zero-day-exploitation-of-ivanti-connect-secure-and-policy-secure-gateways/

On Wednesday, January 10, 2024, Ivanti disclosed two zero-day vulnerabilities affecting their Ivanti Connect Secure and Ivanti Policy Secure gateways. Security firm Volexity, who discovered the vulnerabilities, also published a blog with information on indicators of compromise and attacker behavior observed in the wild. In an attack Volexity investigated in December 2023, the two vulnerabilities were chained to gain initial access, deploy webshells, backdoor legitimate files, capture credentials and configuration data, and pivot further into the victim environment.
The two vulnerabilities in the advisory are:
Rapid7 urges customers who use Ivanti Connect Secure or Policy Secure in their environments to take immediate steps to apply the workaround and look for indicators of compromise. Volexity have released an extensive description of the attack and indicators of compromise — we strongly recommend reviewing their blog, which includes the information below:
“Volexity observed the attacker modifying legitimate ICS components and making changes to the system to evade the ICS Integrity Checker Tool. Notably, Volexity observed the attacker backdooring a legitimate CGI file (compcheck.cgi) on the ICS VPN appliance to allow command execution. Further, the attacker also modified a JavaScript file used by the Web SSL VPN component of the device in order to keylog and exfiltrate credentials for users logging into it. The information and credentials collected by the attacker allowed them to pivot to a handful of systems internally, and ultimately gain unfettered access to systems on the network.”
Ivanti Connect Secure, previously known as Pulse Connect Secure, is a security appliance that has been targeted in a range of threat campaigns in recent years. The U.S. Cybersecurity and Infrastructure Security Agency (CISA) also released a bulletin on January 10, 2024 urging Ivanti Connect Secure and Ivanti Policy Secure users to mitigate the two vulnerabilities immediately.
Counts of internet-exposed appliances vary widely depending on the query used. The following Shodan query identifies roughly 7K devices on the public internet, while looking for Ivanti’s welcome page alone more than doubles that number (but reduces accuracy): http.favicon.hash:-1439222863 html:"welcome.cgi?p=logo. Rapid7 Labs has observed scanning activity targeting our honeypots that emulate Ivanti Connect Secure appliances.
All supported versions (9.x and 22.x) of Ivanti Connect Secure and Ivanti Policy Secure are vulnerable to CVE-2023-46805 and CVE-2024-21887. Ivanti’s advisory notes that a workaround is available for CVE-2023-46805 and CVE-2024-21887. Ivanti Connect Secure and Ivanti Policy Secure customers should apply the vendor-supplied workaround immediately and investigate their environments for signs of compromise. Ivanti advises customers using unsupported versions of the product to upgrade to a supported version before applying the workaround.
Ivanti has indicated that patches will be released in a staggered schedule between January 22 and February 19, 2024 — target patch timelines can be found here.
Per Ivanti’s advisory and KB article, “Ivanti Neurons for ZTA gateways cannot be exploited when in production. If a gateway for this solution is generated and left unconnected to a ZTA controller, then there is a risk of exploitation on the generated gateway. Ivanti Neurons for Secure Access is not vulnerable to these CVEs; however, the gateways being managed are independently vulnerable to these CVEs.”
Note: Volexity indicated that adversaries have been observed wiping logs and/or disabling logging on target devices. Administrators should ensure logging is enabled. Ivanti has a built-in integrity checker tool (ICT) that verifies the image on Ivanti Connect Secure and Ivanti Policy Secure appliances and looks for modified files. Ivanti is advising customers to use the external version of this tool to check the integrity of the ICS/IPS images, since Ivanti has seen adversaries “attempting to manipulate” the internal integrity checker tool.
Our engineering team is investigating options for InsightVM and Nexpose coverage for these vulnerabilities. We will provide an update to this blog no later than 3 PM EST on Thursday, January 11, 2024.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/01/pharmacies-giving-patient-records-to-police-without-warrants.html
Add pharmacies to the list of industries that are giving private data to the police without a warrant.
Post Syndicated from Mac Bowley original https://www.raspberrypi.org/blog/teaching-ai-explainability/
In the rapidly evolving digital landscape, students are increasingly interacting with AI-powered applications when listening to music, writing assignments, and shopping online. As educators, it’s our responsibility to equip them with the skills to critically evaluate these technologies.

A key aspect of this is understanding ‘explainability’ in AI and machine learning (ML) systems. The explainability of a model is how easy it is to ‘explain’ how a particular output was generated. Imagine having a job application rejected by an AI model, or facial recognition technology failing to recognise you — you would want to know why.

Establishing standards for explainability is crucial. Otherwise we risk creating a world where decisions impacting our lives are made by opaque systems we don’t understand. Learning about explainability is key for students to develop digital literacy, enabling them to navigate the digital world with informed awareness and critical thinking.
AI models can have a significant impact on people’s lives in various ways. For instance, if a model determines a child’s exam results, parents and teachers would want to understand the reasoning behind it.

Artists might want to know if their creative works have been used to train a model and could be at risk of plagiarism. Likewise, coders will want to know if their code is being generated and used by others without their knowledge or consent. If you came across an AI-generated artwork that features a face resembling yours, it’s natural to want to understand how a photo of you was incorporated into the training data.
Explainability is about accountability, transparency, and fairness, which are vital lessons for children as they grow up in an increasingly digital world.
There will also be instances where a model seems to be working for some people but is inaccurate for a certain demographic of users. This happened with Twitter’s (now X’s) face detection model in photos; the model didn’t work as well for people with darker skin tones, who found that it could not detect their faces as effectively as their lighter-skinned friends and family. Explainability allows us not only to understand but also to challenge the outputs of a model if they are found to be unfair.
In essence, explainability is about accountability, transparency, and fairness, which are vital lessons for children as they grow up in an increasingly digital world.
Some models, like decision trees, regression curves, and clustering, have an in-built level of explainability. There is a visual way to represent these models, so we can pretty accurately follow the logic implemented by the model to arrive at a particular output.
By teaching students about AI explainability, we are not only educating them about the workings of these technologies, but also teaching them to expect transparency as they grow to be future consumers or even developers of AI technology.
A decision tree works like a flowchart, and you can follow the conditions used to arrive at a prediction. Regression curves can be shown on a graph to understand why a particular piece of data was treated the way it was, although this wouldn’t give us insight into exactly why the curve was placed at that point. Clustering is a way of collecting similar pieces of data together to create groups (or clusters) with which we can interrogate the model to determine which characteristics were used to create the groupings.
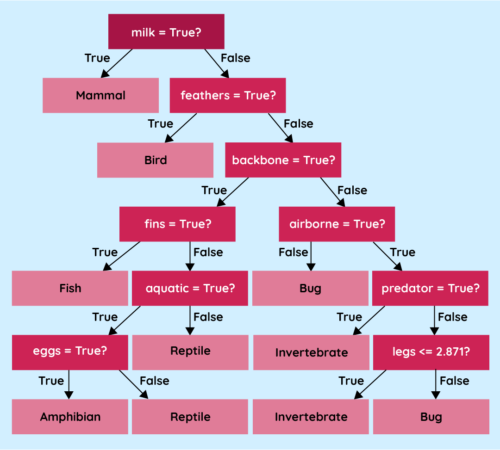
However, the more powerful the model, the less explainable it tends to be. Neural networks, for instance, are notoriously hard to understand — even for their developers. The networks used to generate images or text can contain millions of nodes spread across thousands of layers. Trying to work out what any individual node or layer is doing to the data is extremely difficult.

Regardless of the complexity, it is still vital that developers find a way of providing essential information to anyone looking to use their models in an application or to a consumer who might be negatively impacted by the use of their model.
One suggested strategy to add transparency to these models is using model cards. When you buy an item of food in a supermarket, you can look at the packaging and find all sorts of nutritional information, such as the ingredients, macronutrients, allergens they may contain, and recommended serving sizes. This information is there to help inform consumers about the choices they are making.
Model cards attempt to do the same thing for ML models, providing essential information to developers and users of a model so they can make informed choices about whether or not they want to use it.
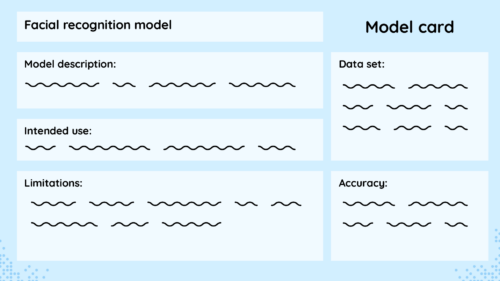
Model cards include details such as the developer of the model, the training data used, the accuracy across diverse groups of people, and any limitations the developers uncovered in testing.
Model cards should be accessible to as many people as possible.
A real-world example of a model card is Google’s Face Detection model card. This details the model’s purpose, architecture, performance across various demographics, and any known limitations of their model. This information helps developers who might want to use the model to assess whether it is fit for their purpose.
As the world settles into the new reality of having the amazing power of AI models at our disposal for almost any task, we must teach young people about the importance of transparency and responsibility.

As a society, we need to have hard discussions about where and when we are comfortable implementing models and the consequences they might have for different groups of people. By teaching students about explainability, we are not only educating them about the workings of these technologies, but also teaching them to expect transparency as they grow to be future consumers or even developers of AI technology.
Most importantly, model cards should be accessible to as many people as possible — taking this information and presenting it in a clear and understandable way. Model cards are a great way for you to show your students what information is important for people to know about an AI model and why they might want to know it. Model cards can help students understand the importance of transparency and accountability in AI.
This article also appears in issue 22 of Hello World, which is all about teaching and AI. Download your free PDF copy now.
If you’re an educator, you can use our free Experience AI Lessons to teach your learners the basics of how AI works, whatever your subject area.
The post Teaching about AI explainability appeared first on Raspberry Pi Foundation.
Post Syndicated from Атанас Шиников original https://www.toest.bg/izkustvieniyat-intelekt-na-allah/

Шумът около новите технологии минавал през пет етапа, твърдят консултанти от ИТ сферата, където и аз заработвам насъщния. Описва ги популярната крива на очакванията, положени върху времевата ос. Първо, твърдят те, идвал пускът на иновацията: поява на нов продукт, медиен шум, всеки говори за него. Следвал пикът на свръхочакванията. Пропастта на разочарованията е третият етап, когато става ясно, че се сбъдва заглавието на Шекспировата пиеса „Много шум за нищо“. Сетне бавно покачващият се „склон на просвещението“ уталожвал развитието на продукта. Следват второ и трето поколение продукти, при което инвеститорите продължават да харчат само при условие че технологията се подобри. Най-накрая идвало платото на продуктивността, когато изобретението става част от масовата култура на крайния потребител и устойчиво доставя предсказуеми резултати.
Според последната прогноза развитието на изкуствения интелект (ИИ) в момента се позиционира някъде между пуска на технологията и пика на свръхочакванията.
Според проучване от 2023 г. 38% от инициативите, свързани с употребата на т.нар. генеративен изкуствен интелект, са насочени към подобряване на клиентското удовлетворение, тоест как да направим крайните ни потребители по-щастливи. 26% от тях се фокусират върху растежа на приходите, 17% – върху оптимизация на разходите. 7% от употребите са свързани с решения за непрекъснатост на дейностите – какво правим, за да не спира бизнесът ни при форсмажорни обстоятелства. И накрая, 12% от внедряването на решения с ИИ са в други области или не са приложими, доколкото запитването е отправено към инвеститор или към предлагащ решения за изкуствен интелект.
Интересува ме може ли ИИ да бъде мюсюлманският андроид, който сънува шериатски пасбища за електрически правоверни овце. Кой пази пазачите на вратата към изрядния помюсюлманскому начин на живот. Не просто дали мюсюлманите могат да намерят отговор на даден въпрос чрез интегриране на ИИ в търсачка, както направиха Microsoft с Bing. А би ли могъл изкуственият интелект да се превърне в легитимен източник на житейски напътствия за един последовател на исляма? Би ли могъл да влезе в почетната роба на един от авторитетите сред мюсюлманската общност? Възможно ли е някой ден притежателите на „религиозното знание“, които са „наследниците на пророците“, по известното предание от Пророка Мохамед, тези, които удържат целостта на общността от правоверни чак до настъпването на Съдния ден, да се окажат конструкти от нули и единици? Чука ли скриптът на киберходжата на вратата? Чакаме ли дигитален скрит имам като в една цифровизирана версия на шиизма?
Да, явно имам скрити помисли. Затова и започвам с прост въпрос към ChatGPT. Искам да чуя какво ще каже електронният всезнайко във връзка с мой казус в ролята ми на религиозен любопитко, който чете постоянно сборници с мюсюлмански въпроси и отговори.
Аз съм мюсюлманин, който работи с юдеи (йахуд). Позволено ли е според Свещения закон (шариа‘) да ги поздравявам сутрин?
С това нагазвам в многовековната традиция на мюсюлмански responsa – въпроси и отговори – между вярващите в Аллах и техните религиозни авторитети. Та хората, независимо от религията им, винаги са се сблъсквали с проблеми, за които няма пряко решение в свещените книги. В мюсюлманската традиция тези своеобразни диалози кристализират в жанра на т.нар. фетва (фатуа). Отговорите на авторитетни богослови се събират в сборници, четат се, разпространяват се и се използват като справочен материал. И тук терминът фетва не означава „смъртна присъда“, както понякога си мисли широката публика след скандала със „Сатанински строфи“ на Салман Рушди и смъртната присъда срещу него от аятолах Хомейни през 1989 г. или пък след нападението срещу писателя от 2022 г.
Тривиалната, общоприетата дефиниция на фетва е „необвързващо религиозно-законово мнение в отговор на даден въпрос“. Питащият не е непременно задължен да приложи решението, дадено му от признат от него авторитет. Но пък може да бъде мотивиран от силата на религиозния аргумент. И тези мнения-отговори, в зависимост от това колко е популярен отговарящият, може да имат широк обществен отзвук – както в случая със Салман Рушди или с фетвата, одобряваща обезглавяването на френския учител по история през 2020 г. Може да имат и политическо влияние – като историческите постановления на османския шейхюислям или пък мюфтията на ИДИЛ, заловен около Мосул през 2020 г.
Според този закон нещата от тукашния свят могат да бъдат разпределени в пет категории, т.нар. „шариатски постановления“, „регулации“ или „степени на позволеност“ (ахкам). На първо място са религиозните задължения (дадена повеля следва да се спазва, ако се самоопределяш като мюсюлманин), после идват препоръчителните (добре е да се извърши, похвално е), неутралните, позволени неща (например да пия ли сок от ябълка или морков), порицаемите (няма да те вкара в ада, но не го прави, по-добре е за теб). А накрая идват откровено забранените, греховни дела (ще страдаш и в тукашния, и в отвъдния свят, ако го извършиш), за тях съществува и терминът харам. И мюсюлманите – и в миналото, и днес – питат за неща, които за съвременния човек може да са скандални. Или да стоят изцяло извън периметъра на модерното секуларно схващане за духовност и отношението между религиозно, обществено и политическо.
– Мюсюлманка съм. Може ли да си направя липосукция, ако съм дебела?
– Може ли да поставя украсена с розички снимка на братовчедка ми на бюрото?
– Приложенията за онлайн запознанства и срещи допустими ли са?
– Ядат и пият ли мъчениците, отишли в рая?
– Биткойн и другите дигитални валути позволени ли са според свещения закон на Аллах?
– Може ли да нарека дъщеря си Натали?
– Живея в България, където повечето хора са неверници, трябва ли да празнувам техните празници?
– Може ли да отворя хотел, където да използвам бизнеса си с мисионерска цел за разпространение на исляма?
– Позволява ли ми религията да си поставя имплант с хормони?
– Някой открадна орган на роднина по време на операция, какво е наказанието за това?
– Може ли да търгувам със свински продукти, при условие че не ги консумирам?
– Как стои въпросът с храни, в чийто състав има посочен минимален процент алкохол?
– Ако мъжът и жената са голи по време на секс, това прави ли брака невалиден?
– Какво да сторя в случаи на домашно насилие от страна на жена ми, която ме заплашва с нож при семеен скандал?
– Защо може да работим с жени колеги само ако преди това сме били кърмени от тях?
– Какви са религиозните основания за практикуване на футбола?
Примерите по-горе са реални. Въпросите са отправени от реално съществуващи хора към реално съществуващи религиозни авторитети, но посредством електронни инструменти. Тази популярна практика е довела в днешно време до изграждането на мащабни и добре финансирани бази данни от въпроси и отговори онлайн, поддържани от екипи около даден шейх или институция. Те са интегрална част от „киберислямските среди“ (Cyber-Islamic Environments, CIE), както ги нарича Гари Р. Бунт, професор от Уелс и мой добър познат, който от години разработва дигиталното присъствие на мюсюлманските общности по света.
Влиятелни сайтове като IslamQA.info на саудитския шейх Мухаммад Салих ал-Мунадджид или пък портала IslamWeb.net, финансиран от катарското Министерство на религиозните дела, съдържат стотици хиляди запитвания от мюсюлмани по света. Сходно е положението със сайта на починалия през 2022 г. Юсуф ал-Карадауи или друг свързан с него сайт – IslamOnline.net, пуснат през 1997 г. от обществото „Ал-Балаг“ в Катар по инициатива на тамошни ИТ специалисти. Дори и страницата на нашенското Главно мюфтийство съдържа скромна секция с няколко отговора на въпроси от мюсюлманската общност тук, както и онлайн формуляр.
И каналите за интеракция с крайния потребител варират. Някъде запитванията се отправят по телефон, другаде има контактен формуляр, понякога шейховете очакват запитвания по електронна поща или пък има разработени приложения за мобилни устройства. Но всички тези канали като цяло страдат от капацитет за обработване на входящите заявки вследствие на огромното търсене на услугата.
… защото проблематиката е сравнително нова. Тук отговорът е донейде предсказуем. Прибягването до технологично решение за целите на отговори на религиозни въпроси е разбираема. Дихотомията „религия или технология“, изразена в почти банализираната метафора на Даниъл Лернър за „Мека или механизация“ от 1958 г., вече се възприема като изкуствена. Та историята на религиозната общност познава и други моменти, при които използването на дадена технология първоначално е възприемано като съмнително, след което се превръща в интегрална част от живота на мюсюлманите. Например навлизането на печатната преса през XIX век, което лека-полека смъква преписвачите на Корана и друга религиозна литература от пиедестала им. Или радиопредаванията и аудиокасетите, впрегнати в услуга на шейховете. Или първите версии на уебстраници, после и навлизането на Web 2.0, което повишава скоростта на обмен на информация и интерактивността в социални мрежи, блогове, приложения, както и във вече споменатите портали за фетви.
Типичен отговор на това дали изкуственият интелект е религиозно забранен (харам), се дава на катарския сайт за фетви IslamWeb.net. Слава на Аллах, казва богословът, основният принцип за окачествяването на нещата от света е, че те са позволени, докато не се появи доказателство за тяхната възбраненост и греховност. Аргументът за това общо съждение, което прилича на юридическата презумпция за невиновност до доказване на противното, е зает от позоваване на богослова Ибн Таймия от XIV век. Същият Ибн Таймия е известен и като идеологически вдъхновител на радикални мюсюлмански течения, сред които ИДИЛ, „Боко Харам“ и „Ал-Кайда“.
Друг пък мюсюлманин има по-нюансирано питане:
Уча програмиране, покрай това учим за изкуствения интелект. Като цяло се говори, че той можел да имитира човешкия ум, това позволено ли е по шариата, или способността за разсъждение следва да се схваща единствено като вложена от Аллах в човешкия род?
Отговорът е, че проблемът е само терминологичен, защото изкуственият интелект представлява единствено средство; той не може да напусне предзададените му граници, както и категорично не притежава качествата на живи същества, камо ли душа, която Аллах дава на тварите от света. А до голяма степен дефиницията на разумни и живи същества идва от Корана, за което питащият е препратен към няколко други фетви. Оттук и – ако се удържат поставените от Аллах граници – няма проблем да се разработва тази технология. Тоест ако продължим тази нишка на разсъждение, няма проблем технологията да бъде впрегната от благочестиви мюсюлмани за общите цели на медицината, образованието, програмирането, информационните технологии и прочее, а всеки специфичен случай подлежи на отделно разглеждане.
На второ място обаче стои по-конкретният въпрос:
На пръв поглед такъв умствен експеримент не е невъзможен. Направо си е изкусителен. Мюсюлманското право традиционно се възприема като основано на четири принципа (усул). На първо място стои Писанието, тоест Корана. Следват преданията на Пророка – Сунната, съставена от отдавна дефинирани текстови корпуси. На трето място идва „аналогията“ (кийас) и накрая, като че ли най-размито откъм дефиниция, стои консенсусът (иджма‘) на религиозните учени. Тези четири извора на правото се съотнасят един спрямо друг по дефиниран от юриспруденцията йерархичен начин поне от времето на имам аш-Шафии (поч. 820 г.) и неговия „Трактат“ (Рисала). Оттук и задачата на всеки религиозен учен, който участва в издаването на фетва, е лесна. Той трябва да стъпи върху предзададеното „канонично“ съдържание на Корана и Сунната и посредством формалната логика и инструментите на аналогията и консенсуса да достигне до удържимо от религиозна гледна точка решение на дадено запитване.
Всеки от четирите източника на правото може да бъде обрисуван като база данни с ограничени на брой, ако и обемни, колекции от логически свързани набори от записи.
Като че ли най-ясна е ситуацията с Писанието. Коранът съдържа 114 глави (сури), 6236 „знамения“, тоест стихове, 77 797 думи и 330 709 букви. Сурите се делят на мекански и медински според мястото на тяхното „низпославане“ от Аллах към Пророка; съществува и хронологична подредба на отделните знамения.
Подобна е ситуацията и със Сунната, поне със съдържанието на признатия за достоверен корпус от суннитите, т.нар. Сихах. Най-популярните са двата сборника на Муслим и Ал-Бухари от IX век, а в тях преданията за казаното или направеното от Пророка са тематично подредени и номерирани. Всеки отделен разказ се състои от две части. Първата съдържа споменаване на веригата от съратници на Пророка, които са го предали, т.нар. „опора“ (иснад). След това идва реалното съдържание („корпус“, „основна част“, матн).
„Аналогията“ пък невинаги е всепризнат механизъм за извеждане на религиозно валидни съждения и тук зависи от способността за изграждане на автоматизация на алгоритмите за взаимовръзка на принципа „Ако А е забранено, то Б, доколкото е сходно на А, би следвало също да се забрани“. Консенсусът е още по-проблематичен от гледна точка на това кои точно правно-богословски мнения искаме да използваме. Както с повечето случаи на употреба на ИИ, тук особено интересно би било с какво го захранваме. От кой исторически период и географски ареали приоритизираме съдържание, отдаваме ли превес на някоя от четирите правно-богословски школи (мазхаби) повече от други.
Или пък, ако се върнем към Корана и твърдим, че традицията на коранични коментари (тафсир) ни дава ключ към историческото му разбиране, на кои точно ще наблегнем. Ще го захраним ли например с един от най-ранните – този на Мукатил ибн Сулайман от VIII век като доста близък до времето на самия Пророк? Само че тафсирът на Мукатил е твърде лапидарен и не ни осветлява за по-късното богатство на традицията на тълкуване на Писанието.
Хубаво. Да му подадем тогава класици, като Ат-Табари от началото на X век. Ат-Табари обаче пише един доста обширен коментар, в който наред с всичко включва и признат за „апокрифен“, съмнителен материал. Откъде мислите, че Салман Рушди е взел историята за това как Иблис, мюсюлманският сатана (Шайтан), вдъхновява Пророка? Точно оттам. Ами къде мислите, че четем историята за създаването на прасето от слона в Ноевия ковчег? Все при Ат-Табари.
Или пък да му подадем съвременни коментари като „В сенките на Корана“ на идеолога на „Мюсюлмански братя“ и баща на салафитския джихадизъм Сайид Кутб от средата на миналия век?
Но на общо основание е ясно, че ИИ може да заеме ролята на устройство за производство на легитимни религиозни силогизми на базата на необработени данни. Не подобие на делфийския оракул, панаирна машина за случайни късметчета или гадаене по китайската Идзин, а по-скоро универсален скрипт, отговарящ на дефиницията за генеративен изкуствен интелект, който, стъпвайки на базата на предзададени входни данни, да може да отговори на всяко възможно религиозно запитване чрез изграждане на ново съдържание с добавена стойност.
Опитите за представяне на религиозните извори на исляма като структурирани релационни бази данни не са отскоро. Само че идеята за тяхното креативно комбиниране тепърва прохожда. И все пак е отпреди шума около ChatGPT.
Очаквайте продължение следващата седмица.
В рубриката „Ориент кафе“ Атанас Шиников поднася любопитни теми, свързани не толкова с горещата политика, колкото с историята и културата на Близкия изток. А той, древен и днешен, е по-близко до нас и съвремието ни, отколкото си представяме.
Post Syndicated from Rohit Kumar original https://www.servethehome.com/cheap-nicgiga-10gbase-t-adapter-mini-review-marvell-aqc113c/
This might be the cheapest 10Gbase-T adapter out there. We found a NICGIGA 10GbE card based on a low-power Marvell AQC113C NIC
The post Cheap NICGIGA 10Gbase-T Adapter Mini-Review Marvell AQC113C appeared first on ServeTheHome.
Post Syndicated from corbet original https://lwn.net/Articles/956868/
The LWN.net Weekly Edition for January 11, 2024 is available.
Post Syndicated from jake original https://lwn.net/Articles/957316/
As part of my quest to master Emacs, which
is sort of a sub-quest on the way toward learning more about Lisp, I have
spent a fair amount of time discovering various corners of the Emacs
world. One of those is the famous “Org
mode” that is used for a wide variety of organizational tasks within
the editor—and not just Emacs, but for Vim and others too.
Org mode can be
used for to-do lists, notes with interconnections between them, literate
programming, web sites, and more. Now my quests are growing quests of
their own and digging into Org mode is one of those.