Post Syndicated from Mia Wang original https://blog.cloudflare.com/workers-launchpad/


From our earliest days, Cloudflare has stood for helping build a better Internet that’s accessible to all. It’s core to our mission that anyone who wants to start building on the Internet should be able to do so easily, and without the barriers of prohibitively expensive or difficult to use infrastructure.
Nowhere is this philosophy more important – and more impactful to the Internet – than with our developer platform, Cloudflare Workers. Workers is, quite simply, where developers and entrepreneurs start on Day 1. It’s a full developer platform that includes cloud storage; website hosting; SQL databases; and of course, the industry’s leading serverless product. The platform’s ease-of-use and accessible pricing (all the way down to free) are critical in advancing our mission. For startups, this translates into fast, easy deployment and iteration, that scales seamlessly with predictable, transparent and cost-effective pricing. Building a great business from scratch is hard enough – we ought to know! – and so we’re aiming to take all the complexity out of your application infrastructure.
Announcing the Workers Launchpad funding program
Today, we’re taking things a step further and making it easier for startups to build the business of their dreams. We’re announcing a $1.25 billion Workers Launchpad funding program in partnership with some of the world’s leading venture capital firms. Any startup built on Workers can apply. As is the case with the Workers Platform itself, we’ve tried to make applying dead simple: it should take you less than five minutes to submit your application through the Workers Launchpad portal.
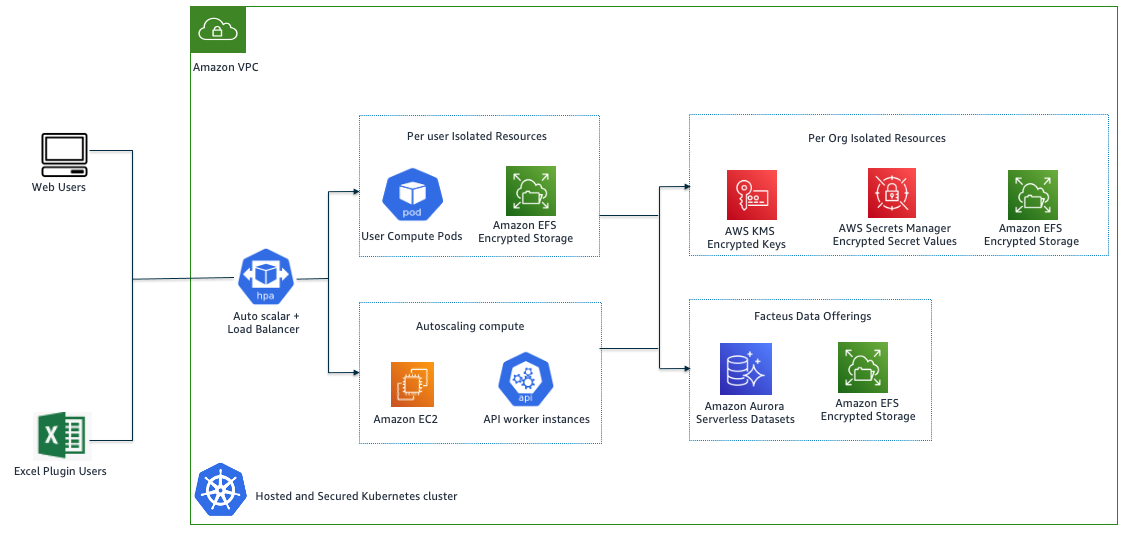
How does it work? The only requirement for being eligible for the funding program is that you’ve built your core infrastructure on Workers. If you’re new to Cloudflare and Cloudflare Workers, check out our Startup Plan to get started. We hope these resources will be helpful to all startups and help level the playing field, no matter where in the world you might be.
Once you submit your application, it will be reviewed by our Launchpad team, several of whom are former entrepreneurs and venture capital folks themselves. They’ll match promising applicants with our VC partners who have the most expertise in your space (more on them below). Every quarter, we’ll announce the winners of our Launchpad program. Winners, our “Workers Founders”, will be guaranteed the opportunity to pitch the VC partner(s) that we’ve determined would be a good match for your business. It’s a win-win all around. VCs get the opportunity to invest in businesses they know are being built on a forward-looking, world-class, development platform. Entrepreneurs get connected to world-class VCs. And for the first class of winners, we’ll have a few added perks that we describe in more detail below.
Who are the VCs that you might get a chance to pitch to?
When we approached our friends in the venture community with our vision for the Workers Launchpad, we received incredibly positive feedback and excitement. Many have seen firsthand the competitive advantages of building on Workers through their own portfolio companies. Moreover, Cloudflare is home to one of the largest developer communities on Earth with approximately 20% of the world’s websites on our network. As such, we can play a unique role in matching great entrepreneurs with great VCs to further not only the Workers platform, but also the Internet ecosystem, for everyone.
We’re honored to announce a world-class group of VC Launch Partners supporting this program and the ecosystem of Workers-based startups:

More on why we’re doing this
So why are we doing this? The simple answer is we’re proud of our Workers Developer Platform and think that everyone should be using it. Entrepreneurs who develop on Workers can ship faster; more easily and cost-effectively; and in a way that future proofs your infrastructure:
Speed. Development velocity isn’t just a convenience for an entrepreneur. It’s a massive competitive advantage. In fact, development velocity is one of Cloudflare’s competitive advantages – we’re able to develop quickly because we build on Workers. When you develop on Workers, you don’t need to spend time configuring DNS records, maintaining certificates, scaling up clusters, or building complex deployment pipelines. Focus on developing your application, and Cloudflare will handle the rest.
Ease of use. Startup teams and founders are some of the busiest people on earth. You shouldn’t have to think about – or make complicated decisions about – IT infrastructure. Questions like: “Which availability zone should I choose?”, or “Will I be able to scale up my infrastructure in time for our next viral marketing campaign?” shouldn’t have to cross your mind! And on the Workers Platform, they don’t. The code you and your team writes automatically deploys quickly and consistently across Cloudflare’s global network in 275+ cities in over 100 countries. Cloudflare securely and scalably connects your users to your applications, regardless of where those applications are hosted or how many users suddenly sign up for your product. Developers can easily manage globally distributed applications with a programmable network that easily connects to whatever services they need to talk to.
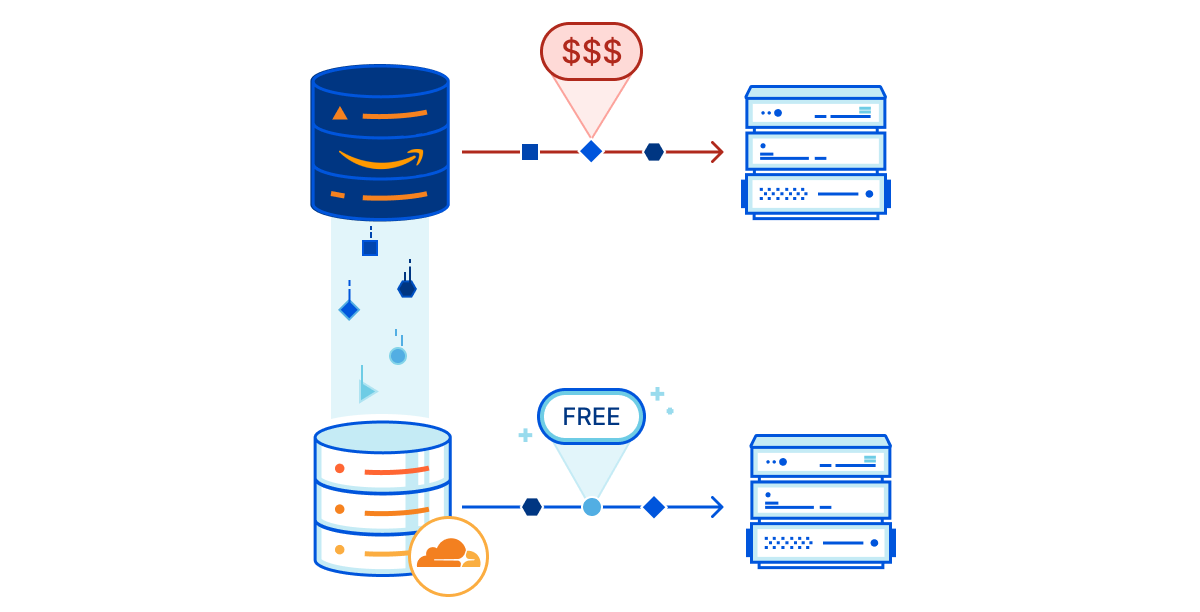
Future-proofing your infrastructure and your wallet. Cloudflare’s massive global network – that’s distributed across 275+ cities in over 100 countries – is able to scale with your business, no matter how large it grows to become. We also help you remain compliant with local laws and regulations as you expand around the world, with capabilities like Workers’ Jurisdictional Restrictions for Durable Objects. You can sleep soundly at night instead of worrying about how to level up your infrastructure in the midst of shifting regulations, and equally importantly, knowing that you will not wake up to any surprise bills. Many of us have had the experience of being charged unexpected and / or exorbitant fees from our cloud providers. For example, providers will often make it easy and free to onboard your application or data, but charge exorbitant rates when you want to move them out (i.e. egress fees). Cloudflare will never charge for egress. Our pricing is simple, and we constantly aim to be the low-cost provider, no matter how large your business grows to be.
Dogfooding our own product
We’re excited about Workers not only because we’ve built our own infrastructure on it, but also because we’re seeing the incredible things others have built on it. In fact, we acquired a company built entirely on Workers at the end of last year, an Isareli start-up named Zaraz, which secures and accelerates third party web tools. Workers allowed Zaraz to replace the multiple network requests of each tool running on a website with one single request, effectively streamlining a messy web of extensions into a single lightweight application. This acquisition opened our eyes to the power of the global community that’s built on our platform, and left us motivated to help startups built on Workers find the funding, mentorship, and support needed to grow.
But wait, there’s more!
To make it even easier for startups to take advantage of all the benefits that Workers has to offer, applicants to the Workers Launchpad program who have raised less than $3 million in total external funding will automatically have the option to receive Cloudflare’s Startup Plan. This plan includes all the elements of Cloudflare’s Pro and Business Plans ($2,400 annual value) plus higher tiers of our Stream video product, our Teams Zero Trust security suite and the Workers platform. To make sure the full range of our developer platform is accessible to startups, we recently more than tripled the number of products available in this plan, which now includes email security, R2, Pages, KV, and many others.
Furthermore, all startups that apply by October 31, 2022, will be eligible to be selected for the Winter 2022 class of Workers Founders, which will unlock additional support, mentorship, and marketing opportunities. Being selected as a Workers Founder will get you a chance to practice your pitch with investors, engage with leaders from Cloudflare, and get advice on how to build a successful business from topics like recruiting to marketing, sales, and beyond during a virtual Workers Founders Bootcamp Week. The program will culminate in a virtual Demo Day, so you can show the world what you’ve been building. We’re leaning in to help promising entrepreneurs join us in our mission to help build a better Internet.
Helping make the Internet better for all
Accessibility and ease of use are core to everything we do at Cloudflare. We will always make our products and platforms so easy to use that even the smallest business or hobbyist can easily use them. We hope the Workers Launchpad funding program encourages entrepreneurs from all around the world, and from all backgrounds, to start building on Workers, and makes it easier for you to find the funding you need to build the business of your dreams.
Head to the Workers Launchpad page to apply and join the Cloudflare Developer Discord to engage with the Workers community. If you’re a VC that is interested in supporting the program, reach out to [email protected].
Cloudflare is not providing any funding or making any funding decisions, and there is no guarantee that any particular company will receive funding through the program. All funding decisions will be made by the venture capital firms that participate in the program. Cloudflare is not a registered broker-dealer, investment adviser, or other similar intermediary.










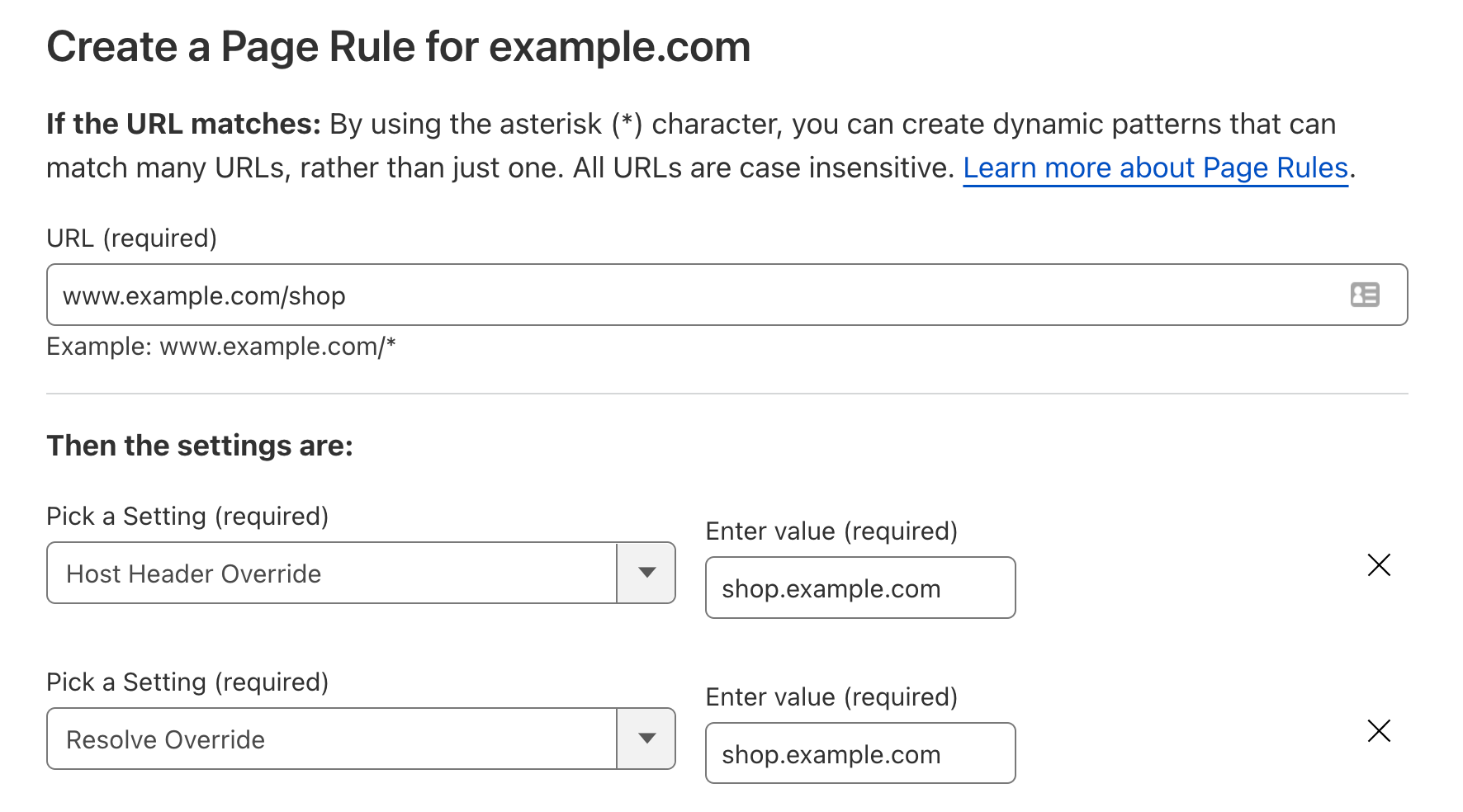
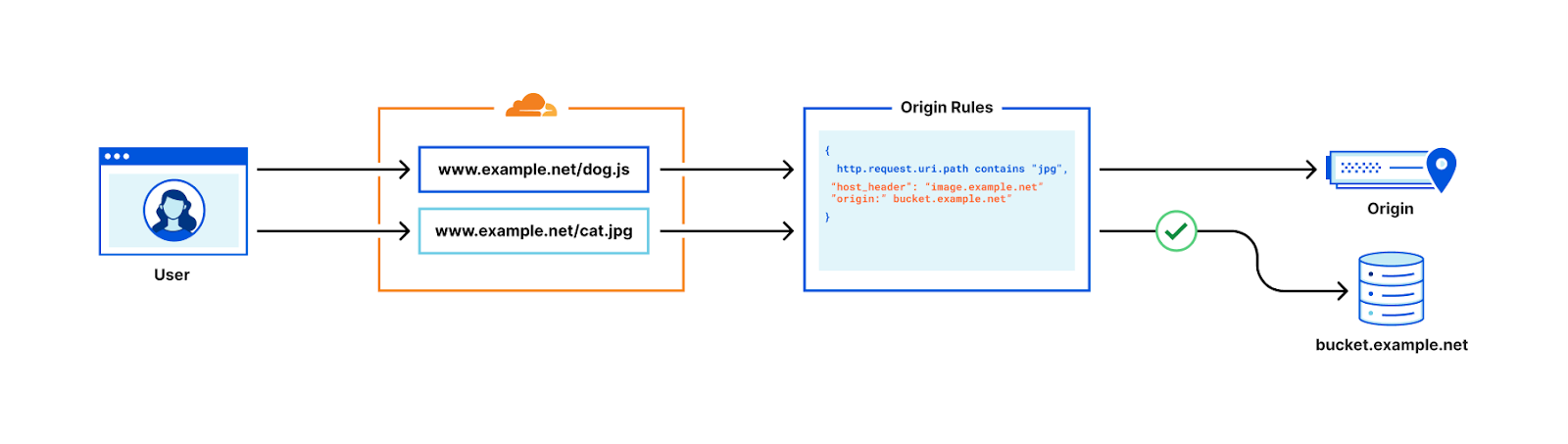



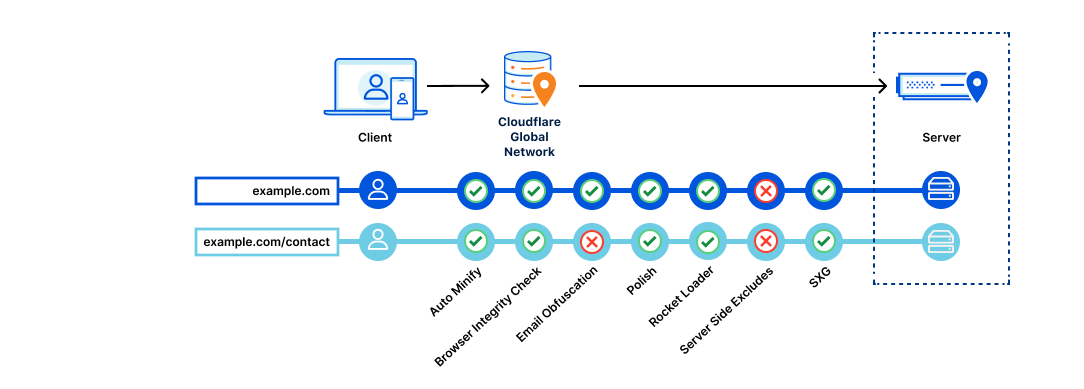


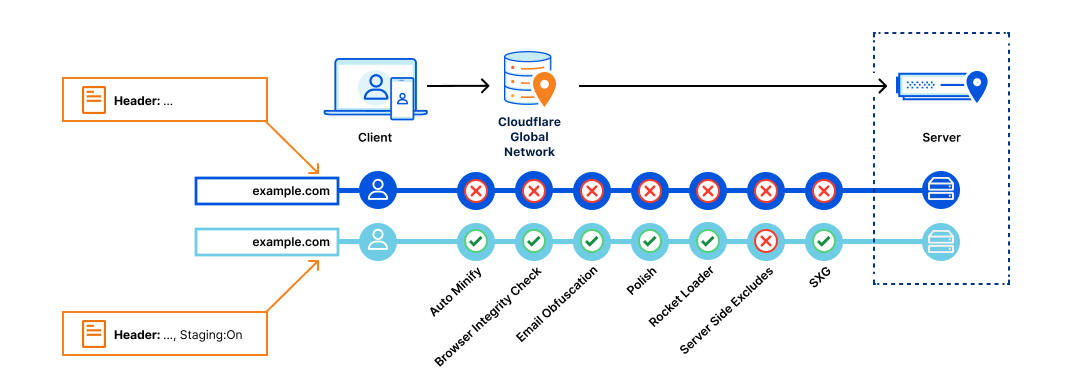













 For this specific example, we use the following information for our Azure SQL Instance:
For this specific example, we use the following information for our Azure SQL Instance: