Признавам си, че ме е страх, но това в края на краищата не отслабва решимостта ми да си свърша работата. Това заяви в интервю за “Биволъ” ресорният зам.-министър на земеделието…
I’ve just come back from a long (extended) holiday weekend here in the US and I’m still catching up on all the AWS launches that happened this past week. I’m particularly excited about some of the data, machine learning, and quantum computing news. Let’s have a look!
Last Week’s Launches The launches that caught my attention last week are the following:
Amazon EMR Serverless is now generally available – Amazon EMR Serverless allows you to run big data applications using open-source frameworks such as Apache Spark and Apache Hive without configuring, managing, and scaling clusters. The new serverless deployment option for Amazon EMR automatically scales resources up and down to provide just the right amount of capacity for your application, and you only pay for what you use. To learn more, check out Channy’s blog post and listen to The Official AWS Podcast episode on EMR Serverless.
AWS PrivateLink is now supported by additional AWS services – AWS PrivateLink provides private connectivity between your virtual private cloud (VPC), AWS services, and your on-premises networks without exposing your traffic to the public internet. The following AWS services just added support for PrivateLink:
Amazon S3 on Outposts has added support for PrivateLink to perform management operations on your S3 storage by using private IP addresses in your VPC. This eliminates the need to use public IPs or proxy servers. Read the June 1 What’s New post for more information.
AWS Panorama now supports PrivateLink, allowing you to access AWS Panorama from your VPC without using public endpoints. AWS Panorama is a machine learning appliance and software development kit (SDK) that allows you to add computer vision (CV) to your on-premises cameras. Read the June 2 What’s New post for more information.
AWS Backup has added PrivateLink support for VMware workloads, providing direct access to AWS Backup from your VMware environment via a private endpoint within your VPC. Read the June 3 What’s New post for more information.
Amazon SageMaker JumpStart now supports incremental model training and automatic tuning – Besides ready-to-deploy solution templates for common machine learning (ML) use cases, SageMaker JumpStart also provides access to more than 300 pre-trained, open-source ML models. You can now incrementally train all the JumpStart models with new data without training from scratch. Through this fine-tuning process, you can shorten the training time to reach a better model. SageMaker JumpStart now also supports model tuning with SageMaker Automatic Model Tuning from its pre-trained model, solution templates, and example notebooks. Automatic tuning allows you to automatically search for the best hyperparameter configuration for your model.
Amazon Transcribe now supports automatic language identification for multi-lingual audio – Amazon Transcribe converts audio input into text using automatic speech recognition (ASR) technology. If your audio recording contains more than one language, you can now enable multi-language identification, which identifies all languages spoken in the audio file and creates a transcript using each identified language. Automatic language identification for multilingual audio is supported for all 37 languages that are currently supported for batch transcriptions. Read the What’s New post from Amazon Transcribe to learn more.
Amazon Braket adds support for Borealis, the first publicly accessible quantum computer that is claimed to offer quantum advantage – If you are interested in quantum computing, you’ve likely heard the term “quantum advantage.” It refers to the technical milestone when a quantum computer outperforms the world’s fastest supercomputers on a well-defined task. Until now, none of the devices claimed to demonstrate quantum advantage have been accessible to the public. The Borealis device, a new photonic quantum processing unit (QPU) from Xanadu, is the first publicly available quantum computer that is claimed to have achieved quantum advantage. Amazon Braket, the quantum computing service from AWS, has just added support for Borealis. To learn more about how you can test a quantum advantage claim for yourself now on Amazon Braket, check out the What’s New post covering the addition of Borealis support.
Other AWS News Some other updates and news that you may have missed:
New AWS Heroes – A warm welcome to our newest AWS Heroes! The AWS Heroes program is a worldwide initiative that acknowledges individuals who have truly gone above and beyond to share knowledge in technical communities. Get to know them in the June 2022 introduction blog post!
AWS open-source news and updates – My colleague Ricardo Sueiras writes this weekly open-source newsletter in which he highlights new open-source projects, tools, and demos from the AWS Community. Read edition #115 here.
Upcoming AWS Events Join me in Las Vegas for Amazon re:MARS 2022. The conference takes place June 21–24 and is all about the latest innovations in machine learning, automation, robotics, and space. I will deliver a talk on how machine learning can help to improve disaster response. Say “Hi!” if you happen to be around and see me.
We also have more AWS Summits coming up over the next couple of months, both in-person and virtual.
You can now register for IMAGINE 2022 (August 3, Seattle). The IMAGINE 2022 conference is a no-cost event that brings together education, state, and local leaders to learn about the latest innovations and best practices in the cloud.
Sign up for the SQL Server Database Modernization webinar on June 21 to learn how to modernize and cost-optimize Microsoft SQL Server on AWS.
That’s all for this week. Check back next Monday for another Week in Review!
The Application Security teams at Netflix are responsible for securing the software footprint that we create to run the Netflix product, the Netflix studio, and the business. Our customers are product and engineering teams at Netflix that build these software services and platforms. The Netflix cultural values of ‘Context not Control’ and ‘Freedom and Responsibility’ strongly influence how we do Security at Netflix. Our goal is to manage security risks to Netflix via clear, opinionated security guidance, and by providing risk context to Netflix engineering teams to make pragmatic risk decisions at scale.
A few years ago, we published this blog post about how we had organized our team to focus our bandwidth on scalable investments as opposed to just traditional Appsec functions, which were not scaling well in our rapidly growing environment. We leaned into the idea of strategic security partnerships and automation investments to create more leverage for application security. This became the foundation for our current org structure with teams focused on Appsec Partnerships and Appsec Engineering. In this operating model, we provided critical Appsec operational services to Netflix — including bug bounty, pentesting, PSIRT (product security incident response), security reviews, and developer security education — via a shared on-call rotation.
Over the past few years, this model has allowed us to focus on investments like Secure by Default for baseline security controls, Security Self-Service for clear actionable guidance and Vulnerability Scanning at scale for software supply chain security. We wanted to share an update on learnings from this model, how our needs have evolved, and where we expect to go from here.
Among the most notable wins, we have been able to utilize this scale focused approach to productize application security for our rapidly growing studio engineering ecosystem, standardize security baseline for all Enterprise apps, and build paved roads to provide Secure by Default Authentication & Authorization capabilities for central data engineering tools. Our focus has been on improving overall security assurance as opposed to just vulnerability prevention. We are now expanding this approach to more parts of our ecosystem. This mindset has also allowed us to invest our capacity for white-glove service towards reasonable residual risk and standard guidance so we can reduce the need for white-glove engagements in the long term (e.g., investment in an API proxy that provides baseline security controls for free as opposed to pentesting all applications that would eventually sit behind that API proxy). This approach has also allowed us to build strong relationships with central engineering teams at Netflix (Data Platform, Developer Tools, Cloud Infrastructure, IAM Product Engineering) that will continue to serve as central points of leverage for security in the long term.
However, it has not been all sunshine and rainbows. On the partnership side, the bespoke nature of each partnership means that there isn’t consistency and redundancy built into the operating model and the related partnership artifacts (e.g., Security Strategy and Roadmap, Threat Model, Deliverable Tracking, Residual Risk Criteria, etc). This leads to insufficient context sharing and high operational churn every time we have personnel changes. The partnership charter has also grown laterally into the infrastructure space as we stack our leverage bets on infrastructure components (like Service Mesh, Container Platform, etc). The skill sets and domain depth in those partnerships has further diversified the skills on the team. But this is a tradeoff on our ability to serve generalized Appsec oncall needs like bug bounty triage with high consistency. Given that partnerships focus on long-running strategic initiatives, the wins can be few and far between and that can be difficult for team motivation. We also found various areas in which security partnership work bleeds into security product solutioning and it can be difficult to identify the appropriate handoff points.
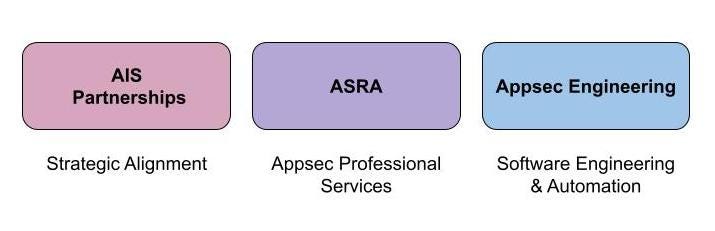
Additionally, as the complexity of our ecosystem grows, the goal of “single PoC into information security” becomes increasingly more difficult to maintain. The team is now investing in consistency and scalability of partnership artifacts and communication channels, better redundancy and context sharing on the team through squad operating models, crisper engagement criteria, and definition of done for partnership engagements.
Our Appsec Engineering team builds products to help us scale, e.g.: a dynamic Asset Inventory that understands the nuances of our bespoke engineering ecosystem and how our applications and data relate to each other. This has evolved their identity to be a software engineering team that focuses on security problems as opposed to a security engineering team that writes code/software. Our hiring has reflected that shift, and we’ve added more dedicated software engineers (SWEs) to the team to help us build out software. With this shift, we’ve incorporated engineering best practices, and our products have appropriate investments toward reliability and sustainability. As the team skews towards more software engineering focused talent, ramping up to support the shared Appsec-focused on-call has been challenging.
While originally built to support AppSec use cases around providing guidance to developers in a self-service way, interest in the rich data and relationships we have in our tools, especially our Asset Inventory, has grown. As a result, we’ve continued to invest in making our solutions scalable and accessible, so security engineers can get the data they need more easily to drive security use cases. We’ve also discovered, through interviews with engineers, that self-service guidance doesn’t stand on its own. Moving forward, the team is investing in understanding our customer use cases better, and shifting our self-service story toward higher-context, more opinionated automated guidance to ensure developers have everything they need to make truly informed decisions about the security of their applications (similar to how they might make resiliency or other product decisions).
As the Netflix business and engineering workforce has grown, our software footprint has also grown and become more heterogeneous. At the same time, partnerships have grown more and more strategic, and engineering has grown more and more software-focused. As our team specialized, what emerged was a loss of strategic focus for our AppSec Professional Services charter. These services now need more dedicated strategic investment as the volume and support needs have grown. So, we are now building out a dedicated capability focused on these critical services that are important investments to be made and can no longer be served effectively via a shared Appsec on-call. This will be our “Appsec Reviews and Assessments” function and we are hiring for passionate, early career Appsec engineers to join this group.
We will continue to learn as we go through this next phase of evolution of our program. We hope to continue to share these learnings with the broader community interested in scalable product and application security.
For larger customers, performing AWS Well-Architected (AWS WA) Framework reviews often involves a combination of different teams. Coordinating participants from each team in order to perform a review increases the time taken and is expensive. In a large organization, there are often hundreds of AWS accounts where teams can store review documents, which means there is no way to quickly identify risks or spot common issues or trends that could influence improvements.
To address this, we created a solution to help you perform reviews easier and faster. It allows workload owners to automatically populate their reviews with templated answers to questions in the AWS Well-Architected Tool (AWS WA Tool). These answers may be a shared responsibility between an application team and a centralized team such as platform, security, or finance. This way, application teams have fewer questions to answer and centralized team members have fewer reviews to attend, because answers that are common to all workloads are pre-populated in workload reviews. The solution also provides centralized reporting to provide a centralized view of AWS WA reviews conducted across the organization.
Perform Well-Architected reviews at scale
In large organizations, responsibilities are often distributed across multiple teams, for example:
A security team defines security policies for this solution and enforces them using guardrails or marketplace solutions.
A financial operations team mandates a tagging policy to allow for accurate cost cross-charging within the business.
Application teams developing internal or external facing applications use a shared platform provided by a Cloud Center of Excellence.
To perform a traditional AWS WA review for this example, you would likely need to invite representatives from each of these teams to attend the review. This is because one team would be unlikely to be able to answer the foundational questions alone.
With tens or hundreds of workloads being reviewed every year, this approach doesn’t scale. This is because representatives from central teams end up attending every review. With more people involved, scheduling reviews is difficult, the overall time required to conduct the review increases, and longer reviews with more people are more expensive to perform.
Additionally, the review document is usually created and stored in one of the application team’s AWS accounts. In a large organization, there are often hundreds of AWS accounts. This makes it difficult for leadership to get a consolidated view of the risks identified across the reviews. It also makes it almost impossible to spot common issues or trends that could influence roadmaps for organization-wide improvements.
Automatically populate templated answers for quicker, easier reviews
Our solution allows you to address these challenges by using the AWS WA Tool to create answer templates. An answer template looks like a regular AWS WA Tool workload review. However, these answers propagate automatically to application workload reviews and are visible by application workload owners during the review process. This way, where there is a shared responsibility, workload owners can see this detail and they can be confident that the inputs provided by the central teams are correct and consistent.
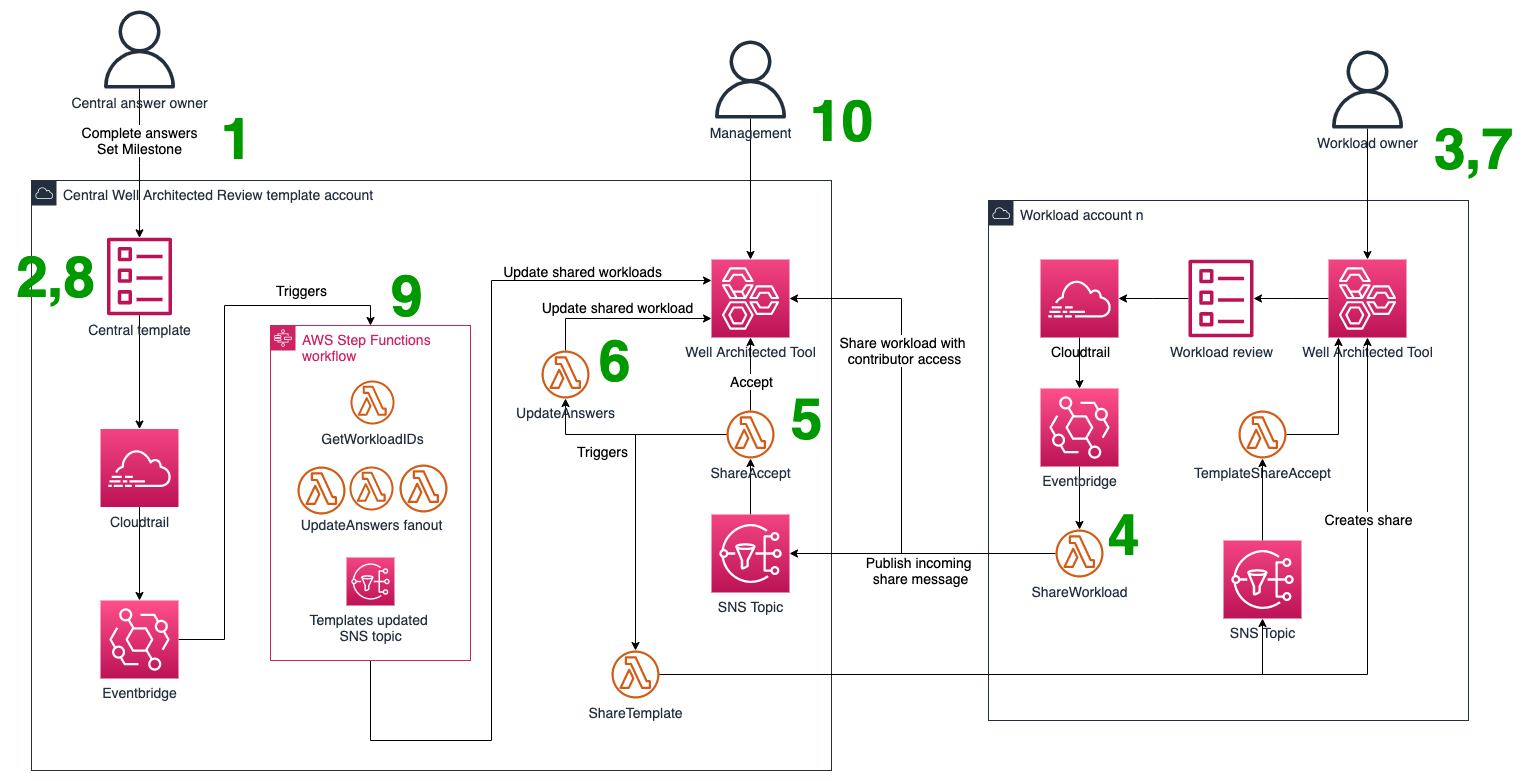
The solution operates as shown in Figure 1 and works as follows:
Central teams use the AWS WA Tool in the “central” AWS account to create workload templates. These are prefixed with “CentralTemplate” (or by a stack parameter).
The central team answers the questions they’re responsible for and marks all others as “Question does not apply to this workload”.
When an application team is ready to perform an AWS WA Framework review, they create a new workload in their workload account in the AWS WA Tool.
In the central account, a Lambda function is subscribed to the Amazon SNS topic from step 4. This function accepts the incoming share, then shares all templates back to the workload account (with read-only access).
The shared workload is then populated with templated answers from templates with the “CentralTemplate” prefix. Both the selected choices and notes are written to the shared workload. Questions in the template marked as “question does not apply to this workload” are ignored.
As the application team proceeds through the questions, they will see the pre-populated answers from the template.
Should a central team need to update their answers, they can update their template and create a milestone.
The milestone creation invokes an AWS Step Functions workflow. The workflow collects all shared workload IDs. Next, it uses a map state to fan-out the updating of all shared workloads. Whether this process should overwrite or append workload answers is configurable at deployment time.
Because all workloads are now visible in the central account, the dashboards referenced in AWS WA labs can be used for consolidated analysis of risks.
Figure 1. Solution components and workflow steps
The solution can be coupled with an Amazon QuickSight powered reporting solution to get an organization-wide view of reviews from a single account. These reviews can also be shared with your AWS account team for ongoing collaborative improvement.
Note: For some workloads, you may need additional AWS WA Framework lenses. The solution offered in this post is lens agnostic, and also supports the use of custom lenses. To deploy the solution, refer to the deployment instructions which can be found on GitHub under aws-samples.
Conclusion
In this post, we explored some of the challenges faced by large enterprises when performing AWS WA Framework reviews at scale and showed you a solution to help your teams define templated answers to particular questions in the AWS WA Tool.
You can deploy this solution to your AWS accounts today by following the deployment instructions included on the aws-samples repository.
Having these templated answers automatically propagated to application workload reviews reduces the number of questions application teams have to answer, as well as the number of attendees required for a review. With this solution, all the AWS WA Framework reviews can be viewed in a single AWS account, so you can also apply the reporting solution provided in AWS WA labs to run centralized reports against all AWS WA Framework reviews in your organization.
Looking for more architecture content?
AWS Architecture Center provides reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more!
Alyssa Rosenzweig announces
a milestone for support of Mali GPUs with free software:
The open source Panfrost driver for Mali GPUs now supports the new
Valhall architecture with fully-conformant OpenGL ES 3.1 on
Mali-G57, a Valhall GPU. The final Mesa patches are landing today,
and the required kernel patches are queued for merge upstream.
The 5.19 merge window was closed with the 5.19-rc1
release on June 5 after the addition of 13,124 non-merge changesets
to the mainline
kernel. That makes this merge window another busy one, essentially
matching the 13,204 changesets seen for 5.18. The approximately 8,500
changesets merged since our first 5.19
merge-window summary contain quite a bit of new functionality; read on
for a summary of the most interesting changes that were pulled during the
second half of this merge window.
Hey all. I’m about to head off to RSAC 2022, but I wanted to jot down some thoughts I’ve had lately on a particularly squirrelly issue that comes up occasionally in coordinated vulnerability disclosure (CVD) — the issue of silent patches, and how they tend to help focused attackers and harm IT protectors.
In the bad old days, most major software vendors were rather notorious for sweeping vulnerability reports under the rug. They made it difficult for legitimate researchers to report vulnerabilities, often by accident, occasionally on purpose. Researchers would report bugs, and those reports would fester in unobserved space, then suddenly the proof-of-concept exploit wouldn’t work any more. This was (and is) the standard silent patching model. No credit, no explanation, no CVE ID, nothing.
The justification for this approach seems pretty sensible, though. Why would a vendor go out of their way to explain what a security fix does? After all, if you know how the patch works, then you have a pretty good guess at the root cause of the vulnerability and, therefore, how the exploit works. So, by publicizing these patch details, you’re effectively leading attackers to the goods, based on your own documentation. Not cool, right?
So, the natural conclusion is that by limiting the technical details of a given vulnerability to merely the patch contents, and by withholding those details explained in plan languages and proof-of-concept exploit code and screenshots and videos and all the rest, you are limiting the general knowledge pool of people who actually understand the vulnerability and how to exploit it.
Unpacking the silent patch
This sounds like a great plan, but there’s a catch. When a software company releases a patch for software, in nearly all cases, they’re not using exotic packers, they’re not employing anti-forensics, and even if the patch data is encrypted and obfuscated, at some point it’s got to modify the code on the running software — which means that it’s all available to anyone who has a running instance of the patched software and knows how to use a debugger and a disassembler. And who uses debuggers to inspect the effects of patches? Exploit developers, pretty much exclusively.
Knowing this, let’s modify the expectations of the silent patch strategy: When you silently patch, you are intending to limit knowledge of the patched vulnerability to skilled exploit devs.
It’s still true that you’re excluding the casual attacker (or “script kiddie,” in the common parlance), and that’s great and desirable. However, you’re also excluding a huge population of IT protectors: penetration testers who are paid to write and run exploits to test defenses leap to mind, in addition to the folks who write and deploy defensive technologies like vulnerability management, intrusion detection and prevention, incident detection, and all the rest. You also exclude tech journalists, academics, and policy makers who want to understand and communicate the nature of software vulnerabilities, but who aren’t likely to bust out a disassembler.
Most significantly, you’re excluding the most important audience for your patch: the regular IT administrators and managers who need to sort out the incoming flow of patches based on some risk and severity criteria and make the call for downtime and update scheduling based on that criteria. Not all vulnerabilities are equal, and while protectors want to get around to all of them, they need to figure out which ones to apply today and which ones can wait for the next maintenance cycle.
By the way, it’s true that some of these IT professionals also have the capability to reverse-engineer your patch. In practice, people who are only interested in keeping IT humming never, ever reverse patches to see if they’re worth applying. It’s way too complicated and time-consuming. I’ve never seen a case where this is part of the decision-making process to patch now or later.
Don’t leave defenders in the dark
So now, let’s reexamine the case for silent patching yet again: When you silently patch, you are communicating vulnerability details, exclusively, to skilled, criminal attackers who are specifically targeting your product, while leaving your customers in the dark. You are intentionally withholding information from casual attackers, secondary defenders, and your customers and users who are desperate to make informed security engineering decisions involving your product or project. Oh, and let’s not forget, you’re also limiting knowledge about these fixed vulnerabilities from future employees and contributors, who very well might re-introduce the same or similar bugs in your product down the road. After all, the details are secret, even from future-you.
All this is to say, silent patching is tantamount to full disclosure to a very small audience who mostly want to hurt you and your users. Fully documented patches reach the much, much larger audience of people, present and future, who want to help you and your users. While it’s true that you are also offering educational opportunities to casual attackers along the way, I believe the global population of casual attackers is much, much smaller than your legitimate users and all the secondary and tertiary defenders who are on your side.
So, next time a vulnerability researcher states their intention of publishing details about their reported (and now patched) vulnerability, try to examine your urge to keep those details under wraps, and maybe even encourage them to be honest and transparent with their findings. The alternative is to build up the operational capabilities of the true criminal and espionage enterprises while degrading the decision-making power of IT protectors.
Register now with discount code SALUZwmdkJJ to get $150 off your full conference pass to AWS re:Inforce. For a limited time only and while supplies last.
Today we want to tell you about some of the engaging data protection and privacy sessions planned for AWS re:Inforce. AWS re:Inforce is a learning conference where you can learn more about on security, compliance, identity, and privacy. When you attend the event, you have access to hundreds of technical and business sessions, an AWS Partner expo hall, a keynote speech from AWS Security leaders, and more. AWS re:Inforce 2022 will take place in-person in Boston, MA on July 26 and 27. re:Inforce 2022 features content in the following five areas:
Data protection and privacy
Governance, risk, and compliance
Identity and access management
Network and infrastructure security
Threat detection and incident response
This post will highlight of some of the data protection and privacy offerings that you can sign up for, including breakout sessions, chalk talks, builders’ sessions, and workshops. For the full catalog of all tracks, see the AWS re:Inforce session preview.
Breakout sessions
Lecture-style presentations that cover topics at all levels and delivered by AWS experts, builders, customers, and partners. Breakout sessions typically include 10–15 minutes of Q&A at the end.
DPP 101: Building privacy compliance on AWS In this session, learn where technology meets governance with an emphasis on building. With the privacy regulation landscape continuously changing, organizations need innovative technical solutions to help solve privacy compliance challenges. This session covers three unique customer use cases and explores privacy management, technology maturity, and how AWS services can address specific concerns. The studies presented help identify where you are in the privacy journey, provide actions you can take, and illustrate ways you can work towards privacy compliance optimization on AWS.
DPP201: Meta’s secure-by-design approach to supporting AWS applications Meta manages a globally distributed data center infrastructure with a growing number of AWS Cloud applications. With all applications, Meta starts by understanding data security and privacy requirements alongside application use cases. This session covers the secure-by-design approach for AWS applications that helps Meta put automated safeguards before deploying applications. Learn how Meta handles account lifecycle management through provisioning, maintaining, and closing accounts. The session also details Meta’s global monitoring and alerting systems that use AWS technologies such as Amazon GuardDuty, AWS Config, and Amazon Macie to provide monitoring, access-anomaly detection, and vulnerable-configuration detection.
DPP202: Uplifting AWS service API data protection to TLS 1.2+ AWS is constantly raising the bar to ensure customers use the most modern Transport Layer Security (TLS) encryption protocols, which meet regulatory and security standards. In this session, learn how AWS can help you easily identify if you have any applications using older TLS versions. Hear tips and best practices for using AWS CloudTrail Lake to detect the use of outdated TLS protocols, and learn how to update your applications to use only modern versions. Get guidance, including a demo, on building metrics and alarms to help monitor TLS use.
DPP203: Secure code and data in use with AWS confidential compute capabilities At AWS, confidential computing is defined as the use of specialized hardware and associated firmware to protect in-use customer code and data from unauthorized access. In this session, dive into the hardware- and software-based solutions AWS delivers to provide a secure environment for customer organizations. With confidential compute capabilities such as the AWS Nitro System, AWS Nitro Enclaves, and NitroTPM, AWS offers protection for customer code and sensitive data such as personally identifiable information, intellectual property, and financial and healthcare data. Securing data allows for use cases such as multi-party computation, blockchain, machine learning, cryptocurrency, secure wallet applications, and banking transactions.
Builders’ sessions
Small-group sessions led by an AWS expert who guides you as you build the service or product on your own laptop. Use your laptop to experiment and build along with the AWS expert.
DPP251: Disaster recovery and resiliency for AWS data protection services Mitigating unknown risks means planning for any situation. To help achieve this, you must architect for resiliency. Disaster recovery (DR) is an important part of your resiliency strategy and concerns how your workload responds when a disaster strikes. To this end, many organizations are adopting architectures that function across multiple AWS Regions as a DR strategy. In this builders’ session, learn how to implement resiliency with AWS data protection services. Attend this session to gain hands-on experience with the implementation of multi-Region architectures for critical AWS security services.
DPP351: Implement advanced access control mechanisms using AWS KMS Join this builders’ session to learn how to implement access control mechanisms in AWS Key Management Service (AWS KMS) and enforce fine-grained permissions on sensitive data and resources at scale. Define AWS KMS key policies, use attribute-based access control (ABAC), and discover advanced techniques such as grants and encryption context to solve challenges in real-world use cases. This builders’ session is aimed at security engineers, security architects, and anyone responsible for implementing security controls such as segregating duties between encryption key owners, users, and AWS services or delegating access to different principals using different policies.
DPP352: TLS offload and containerized applications with AWS CloudHSM With AWS CloudHSM, you can manage your own encryption keys using FIPS 140-2 Level 3 validated HSMs. This builders’ session covers two common scenarios for CloudHSM: TLS offload using NGINX and OpenSSL Dynamic agent and a containerized application that uses PKCS#11 to perform crypto operations. Learn about scaling containerized applications, discover how metrics and logging can help you improve the observability of your CloudHSM-based applications, and review audit records that you can use to assess compliance requirements.
DPP353: How to implement hybrid public key infrastructure (PKI) on AWS As organizations migrate workloads to AWS, they may be running a combination of on-premises and cloud infrastructure. When certificates are issued to this infrastructure, having a common root of trust to the certificate hierarchy allows for consistency and interoperability of the public key infrastructure (PKI) solution. In this builders’ session, learn how to deploy a PKI that allows such capabilities in a hybrid environment. This solution uses Windows Certificate Authority (CA) and ACM Private CA to distribute and manage x.509 certificates for Active Directory users, domain controllers, network components, mobile, and AWS services, including Amazon API Gateway, Amazon CloudFront, and Elastic Load Balancing.
Chalk talks
Highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds.
DPP231: Protecting healthcare data on AWS Achieving strong privacy protection through technology is key to protecting patient. Privacy protection is fundamental for healthcare compliance and is an ongoing process that demands legal, regulatory, and professional standards are continually met. In this chalk talk, learn about data protection, privacy, and how AWS maintains a standards-based risk management program so that the HIPAA-eligible services can specifically support HIPAA administrative, technical, and physical safeguards. Also consider how organizations can use these services to protect healthcare data on AWS in accordance with the shared responsibility model.
DPP232: Protecting business-critical data with AWS migration and storage services Business-critical applications that were once considered too sensitive to move off premises are now moving to the cloud with an extension of the security perimeter. Join this chalk talk to learn about securely shifting these mature applications to cloud services with the AWS Transfer Family and helping to secure data in Amazon Elastic File System (Amazon EFS), Amazon FSx, and Amazon Elastic Block Storage (Amazon EBS). Also learn about tools for ongoing protection as part of the shared responsibility model.
DPP331: Best practices for cutting AWS KMS costs using Amazon S3 bucket keys Learn how AWS customers are using Amazon S3 bucket keys to cut their AWS Key Management Service (AWS KMS) request costs by up to 99 percent. In this chalk talk, hear about the best practices for exploring your AWS KMS costs, identifying suitable buckets to enable bucket keys, and providing mechanisms to apply bucket key benefits to existing objects.
DPP332: How to securely enable third-party access In this chalk talk, learn about ways you can securely enable third-party access to your AWS account. Learn why you should consider using services such as Amazon GuardDuty, AWS Security Hub, AWS Config, and others to improve auditing, alerting, and access control mechanisms. Hardening an account before permitting external access can help reduce security risk and improve the governance of your resources.
Workshops
Interactive learning sessions where you work in small teams to solve problems using AWS Cloud security services. Come prepared with your laptop and a willingness to learn!
DPP271: Isolating and processing sensitive data with AWS Nitro Enclaves Join this hands-on workshop to learn how to isolate highly sensitive data from your own users, applications, and third-party libraries on your Amazon EC2 instances using AWS Nitro Enclaves. Explore Nitro Enclaves, discuss common use cases, and build and run an enclave. This workshop covers enclave isolation, cryptographic attestation, enclave image files, building a local vsock communication channel, debugging common scenarios, and the enclave lifecycle.
DPP272: Data discovery and classification with Amazon Macie This workshop familiarizes you with Amazon Macie and how to scan and classify data in your Amazon S3 buckets. Work with Macie (data classification) and AWS Security Hub (centralized security view) to view and understand how data in your environment is stored and to understand any changes in Amazon S3 bucket policies that may negatively affect your security posture. Learn how to create a custom data identifier, plus how to create and scope data discovery and classification jobs in Macie.
DPP273: Architecting for privacy on AWS In this workshop, follow a regulatory-agnostic approach to build and configure privacy-preserving architectural patterns on AWS including user consent management, data minimization, and cross-border data flows. Explore various services and tools for preserving privacy and protecting data.
DPP371: Building and operating a certificate authority on AWS In this workshop, learn how to securely set up a complete CA hierarchy using AWS Certificate Manager Private Certificate Authority and create certificates for various use cases. These use cases include internal applications that terminate TLS, code signing, document signing, IoT device authentication, and email authenticity verification. The workshop covers job functions such as CA administrators, application developers, and security administrators and shows you how these personas can follow the principal of least privilege to perform various functions associated with certificate management. Also learn how to monitor your public key infrastructure using AWS Security Hub.
If any of these sessions look interesting to you, consider joining us in Boston by registering for re:Inforce 2022. We look forward to seeing you there!
Version 5.1 of the
Tor-oriented Tails distribution has been released. It includes some
improvements to the Tor connection assistant and to handling of
captive-portals, but the most significant change is arguably the delayed fix to a
severe security
vulnerability that had sparked suggestions that some users, at least,
should stop using Tails temporarily.
Greg Kroah-Hartman has announced the release of the 5.18.2, 5.17.13, 5.15.45, 5.10.120, 5.4.197, 4.19.246, 4.14.282, and 4.9.317 stable kernels. Each contains a set
of important fixes, as usual; users of those series should upgrade.
In something of a grab-bag session, Josef Bacik led a discussion about
various challenges that Linux kernel maintainers face, some of which lead to
burnout. The session was originally
going to be led by Darrick Wong, but he was unable to come to LSFMM, so
Bacik gathered some of Wong’s concerns and combined them with his own in a
joint storage and filesystem session at the 2022 Linux Storage,
Filesystem, Memory-management and BPF Summit (LSFMM). As part of the
discussion, Bacik presented
his view on what the role of a kernel maintainer should be, which seemed to
resonate with those present.
Recently, I had a great opportunity to work with Domino’s Pizza to evaluate an internally conceived Internet of Things (IoT)-based business solution they had designed and deployed throughout their US store locations. The goal of this research project was to understand the security implications around a large-scale enterprise IoT project and processes related to:
Acquisition, implementation, and deployment
Technology and functionality
Management and support
Laying the groundwork
I sat down with each of the internal teams involved with this project, and we discussed those key areas and how security was defined and applied within each. I gained valuable new insight into how security should play into the design and construction of a large IoT business solution, especially within the planning and acquisition phases. This opportunity allowed me to see how a security-driven organization like Domino’s approaches a large-scale project like this.
I walked away from this phase of the project with some great takeaways that should be considered on all like-minded projects:
Always consider vendor security in your risk planning and modeling
Security “must-haves” should map to your organization’s internal security policies
Assessing the security status quo
Also, as part of this research project, I conducted a full ecosystem security assessment, examining all the critical hardware components, operation software, and associated network communications. As with any large-scale enterprise implementation, we did find a few security problems. This is the main reason all projects, even those with security built in from the start, should go through a wide-ranging security assessment to flush out any shortcomings that could be lurking under the hood. Once completed, I delivered a comprehensive report, which the security teams and project developers then used to quickly create solutions for fixing the identified issues.
This also allowed me the chance to observe and discuss the processes and methodologies used by this enterprise organization for building and deploying fixes into production and doing that in a safe way to avoid impacting production.
During a typical security assessment of an enterprise-wide business solution like this, we are reminded of a couple key best-practice items that should always be considered, such as:
When testing the security for a new technology, use a holistic approach that targets the entire solutions ecosystem.
Conduct regular testing of documented security procedures — security is a moving target, and testing these procedures regularly can help identify deficiencies.
Bringing the idea to life
Once an idea is designed, built, and deployed into production, we have to make sure the deployed solution remains fully functional and secure. To accomplish that, we moved the deployed enterprise IoT solution under a structured management and support plan at Domino’s. This support structure was designed as expected to help avoid or prevent outages and security incidents that could impact production, loss of services, or loss of data, focusing on:
Again, it was nice to sit down with the various teams involved in the support infrastructure and talk security and to also see how it was not only applied to this specific project, but how the organization applied these same security methodologies across the whole enterprise.
During this final evaluation phase of this project, I was reminded of one of the most critical takeaways that many organizations — unlike Domino’s, who did it correctly — fail to apply: When deploying new embedded technology within your enterprise environment, make sure the technology is properly integrated into your organization’s patch management.
At the conclusion of this research project, I took away a greatly improved understanding of the complexity, difficulties, and security best-practice challenges a large enterprise IoT project could demand. I was pleased to see, and work with, an organization that was up to that challenge and who successfully delivered this project to their business.
If you’d like to read more detail on this security research project, check out my report here.
Security updates have been issued by Debian (clamav, firefox-esr, pidgin, and thunderbird), Fedora (dotnet3.1, firefox, kernel, vim, and webkit2gtk3), Mageia (firefox/nss/nspr, gimp, logrotate, mariadb, thunderbird, trojita, webkit2, and webmin), Oracle (thunderbird), Red Hat (compat-openssl11, postgresql:10, postgresql:12, and thunderbird), Slackware (pidgin), and SUSE (openvpn).
Linus has released 5.19-rc1 and closed the
merge window for this cycle. “Judging by the merge window, this release
is going to be on the bigger side, but certainly not breaking any records,
and nothing looks particularly odd or crazy.”
On 2022-06-02 at 20:00 UTC Attlasian released a Security Advisory relating to a remote code execution (RCE) vulnerability affecting Confluence Server and Confluence Data Center products. This post covers our current analysis of this vulnerability.
When we learned about the vulnerability, Cloudflare’s internal teams immediately engaged to ensure all our customers and our own infrastructure were protected:
Our Web Application Firewall (WAF) teams started work on our first mitigation rules that were deployed on 2022-06-02 at 23:38 UTC for all customers.
Our internal security team started reviewing our Confluence instances to ensure Cloudflare itself was not impacted.
What is the impact of this vulnerability?
According to Volexity, the vulnerability results in full unauthenticated RCE, allowing an attacker to fully take over the target application.
Active exploits of this vulnerability leverage command injections using specially crafted strings to load a malicious class file in memory, allowing attackers to subsequently plant a webshell on the target machine that they can interact with.
Once the vulnerability is exploited, attackers can implant additional malicious code such as Behinder; a custom webshell called noop.jsp, which replaces the legitimate noop.jsp file located at Confluence root>/confluence/noop.jsp; and another open source webshell called Chopper.
Our observations of exploit attempts in the wild
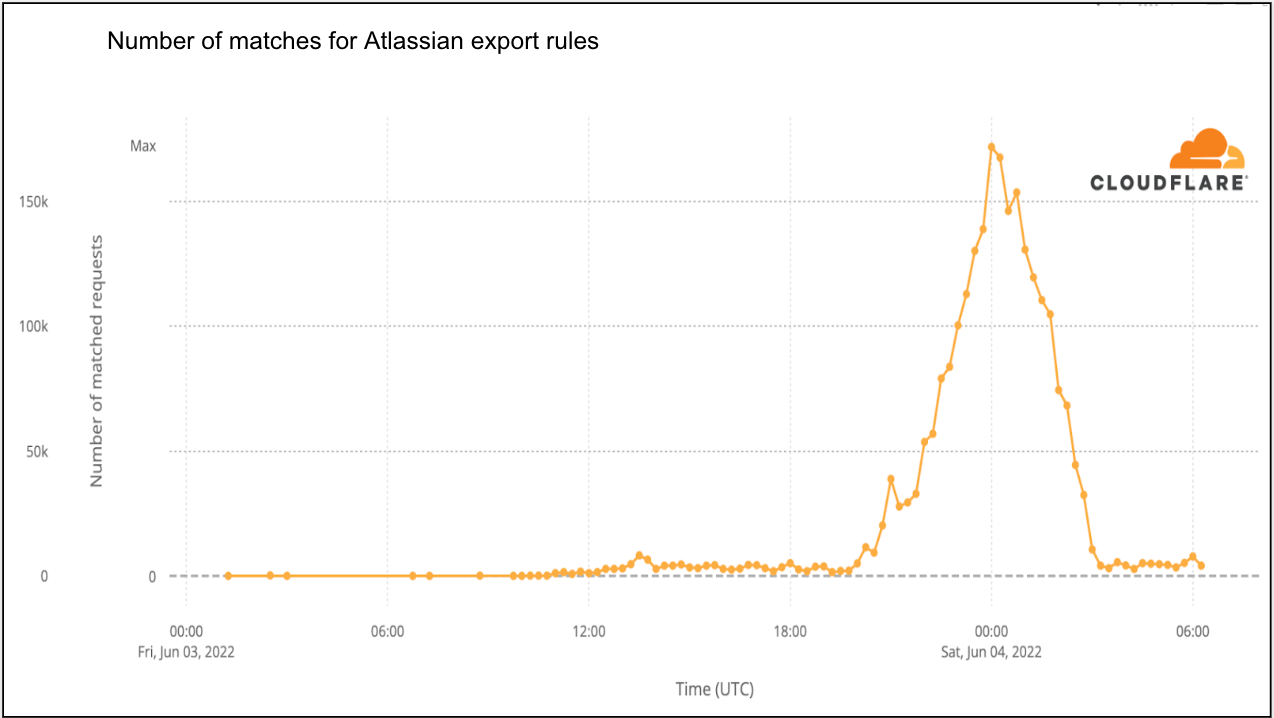
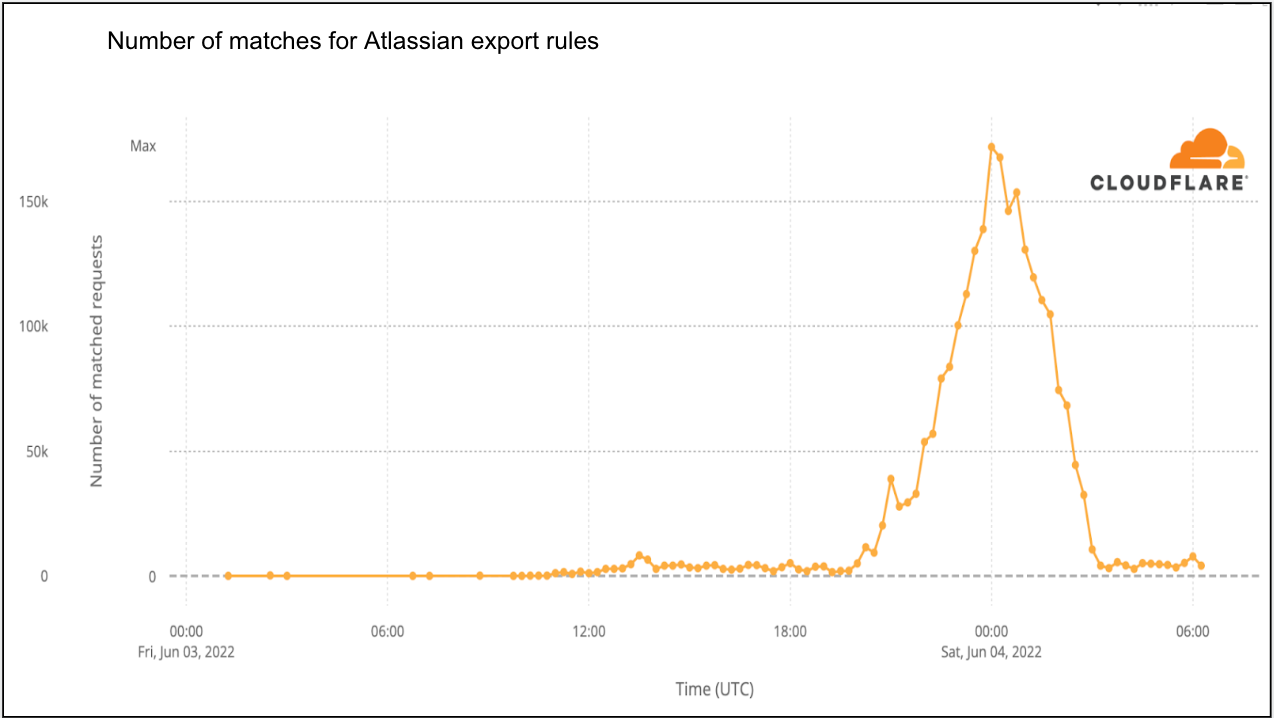
Once we learned of the vulnerability, we began reviewing our WAF data to identify activity related to exploitation of the vulnerability. We identified requests matching potentially malicious payloads as early as 2022-05-26 00:33 UTC, indicating that knowledge of the exploit was realized by some attackers prior to the Atlassian security advisory.
Since our mitigation rules were put in place, we have seen a large spike in activity starting from 2022-06-03 10:30 UTC — a little more than 10 hours after the new WAF rules were first deployed. This large spike coincides with the increased awareness of the vulnerability and release of public proof of concepts. Attackers are actively scanning for vulnerable applications at time of writing.
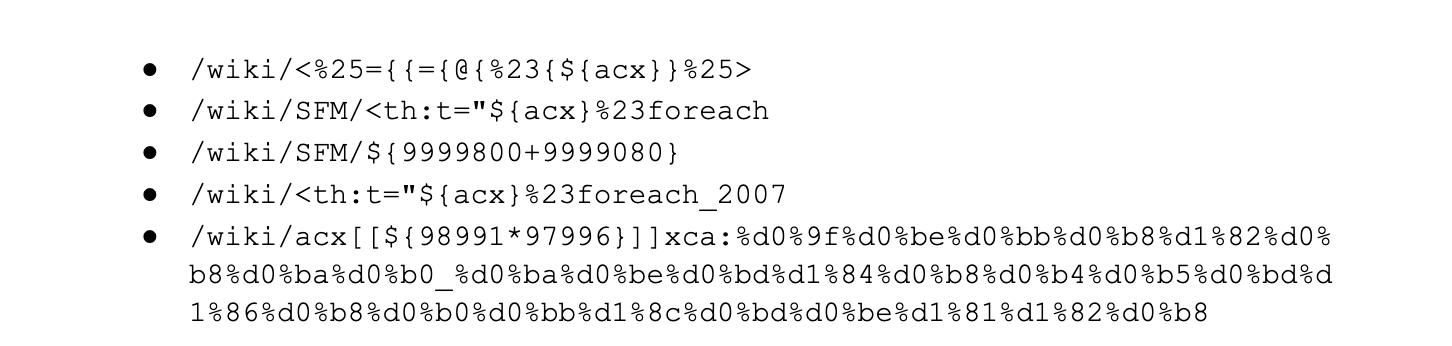
Although we have seen valid attack payloads since 2022-05-26, many payloads that started matching our initial WAF mitigation rules once the advisory was released were not valid against this specific vulnerability. Examples provided below:
The activity above indicates that actors were using scanning tools to try and identify the attack vectors. Exact knowledge of how to exploit the vulnerability may have been consolidated amongst select attackers and may not have been widespread.
The decline in WAF rule matches in the graph above after 2022-06-03 23:00 UTC is due to us releasing improved WAF rules. The new, updated rules greatly improved accuracy, reducing the number of false positives, such as the examples above.
A valid malicious URL targeting a vulnerable Confluence application is shown below:
(Where $HOSTNAME is the host of the target application.)
The URL above will run the contents of the HTTP request post body eval(#parameters.data[0]). Normally this will be a script that will download a web shell to the local server allowing the attacker to run arbitrary code on demand.
Other example URLs, omitting the schema and hostname, include:
Some of the activity we are observing is indicative of malware campaigns and botnet behavior. It is important to note that given the payload structure, other WAF rules have also been effective at mitigating particular variations of the attack. These include rule PHP100011 and PLONE0002.
Cloudflare’s response to CVE-2022-26134
We have a defense-in-depth approach which uses Cloudflare to protect Cloudflare. We had high confidence that we were not impacted by this vulnerability due to the security measures in place. We confirmed this by leveraging our detection and response capabilities to sweep all of our internal assets and logs for signs of attempted compromise.
The main actions we took in response to this incident were:
Gathered as much information as possible about the attack.
Engaged our WAF team to start working on mitigation rules for this CVE.
Searched our logs for any signs of compromise.
We searched the logs from our internal Confluence instances for any signs of attempted exploits. We supplemented our assessment with the pattern strings provided by Atlasian: “${“.
Any matches were reviewed to find out if they could be actual exploits. We found no signs that our systems were targeted by actual exploits.
As soon as the WAF team was confident of the quality of the new rules, we started deploying them to all our servers to start protecting our customers as soon as possible. As we also use the WAF for our internal systems, our Confluence instances are also protected by the new WAF rules.
We scrutinized our Confluence servers for signs of compromise and the presence of malicious implants. No signs of compromise were detected.
We deployed rules to our SIEM and monitoring systems to detect any new exploitation attempt against our Confluence instances.
How Cloudflare uses Confluence
Cloudflare uses Confluence internally as our main wiki platform. Many of our teams use Confluence as their main knowledge-sharing platform. Our internal instances are protected by Cloudflare Access. In previous blog posts, we described how we use Access to protect internal resources. This means that every request sent to our Confluence servers must be authenticated and validated in accordance with our Access policies. No unauthenticated access is allowed.
This allowed us to be confident that only Cloudflare users are able to submit requests to our Confluence instances, thus reducing the risk of external exploitation attempts.
What to do if you are using Confluence on-prem
If you are an Atlassian customer for their on-prem products, you should patch to their latest fixed versions. We advise the following actions:
Add Cloudflare Access as an extra protection layer for all your websites. Easy-to-follow instructions to enable Cloudflare Access are available here.
Enable a WAF that includes protection for CVE-2022-26134 in front of your Confluence instances. For more information on how to enable Cloudflare’s WAF and other security products, check here.
Check the logs from your Confluence instances for signs of exploitation attempts. Look for the strings /wiki/ and ${ in the same request.
Use forensic tools and check for signs of post-exploitation tools such as webshells or other malicious implants.
Indicators of compromise and attack
The following indicators are associated with activity observed in the wild by Cloudflare, as described above. These indicators can be searched for against logs to determine if there is compromise in the environment associated with the Confluence vulnerability.
Filename: conf Malicious file associated with exploit
Indicators of Attack (IOA)
#
Type
Value
Hash
1
URL String
${
String used to craft malicious payload
2
URL String
javax.script.ScriptEngineManager
String indicative of ScriptEngine manager to craft malicious payloads
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

 We also have more
We also have more