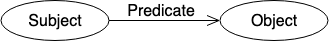In late April, thousands of professionals from all corners of the media, entertainment, and technology ecosystem assembled in Las Vegas for the National Association of Broadcasters trade show, better known as the NAB Show. We were delighted to sponsor NAB after its two year hiatus due to COVID-19. Our staff came in blazing hot and ready to hit the tradeshow floor.
One of the stars of the 2022 event was Backblaze partner LucidLink, named a Cloud Computing and Storage category winner in the NAB Show Product of the Year Awards. In this blog post, I’ll explain how to combine LucidLink’s Filespaces product with Backblaze B2 Cloud Storage and media asset management from iconik, another Backblaze partner, to optimize your media production workflow. But first, some context…
How iconik, LucidLink, and Backblaze B2 Fit in a Media Storage Architecture
The media and entertainment industry has always been a natural fit for Backblaze. Some of our first Backblaze Computer Backup customers were creative professionals looking to protect their work, and the launch of Backblaze B2 opened up new options for archiving, backing up, and distributing media assets.
As the media and entertainment industry moved to 4K Ultra HD for digital video recording over the past few years, file sizes ballooned. An hour of high quality 4K video shot at 60 frames per second can require up to one terabyte of storage. Backblaze B2 matches well with today’s media and entertainment storage demands, as customers such as Fortune Media, Complex Networks, and Alton Brown of “Good Eats” fame have discovered.
Alongside Backblaze B2, an ecosystem of tools has emerged to help professionals manage their media assets, including iconik and LucidLink. iconik’s cloud-native media management and collaboration solution gathers and organizes media securely from a wide range of locations, including Backblaze B2. iconik can scan and index content from a Backblaze B2 bucket, creating an asset for each file. An iconik asset can combine a lower resolution proxy with a link to the original full-resolution file in Backblaze B2. For a large part of the process, the production team can work quickly and easily with these proxy files, previewing and selecting clips and editing them into a sequence.
Complementing iconik and B2 Cloud Storage, LucidLink provides a high-performance, cloud-native, network-attached storage (NAS) solution that allows professionals to collaborate on files stored in the cloud almost as if the files were on their local machine. With LucidLink, a production team can work with multi-terabyte 4K resolution video files, making final edits and rendering the finished product at full resolution.
It’s important to understand that the video editing process is non-destructive. The original video files are immutable—they are never altered during the production process. As the production team “edits” a sequence, they are actually creating a series of transformations that are applied to the original videos as the final product is rendered.
You can think of B2 Cloud Storage and LucidLink as tiers in a media storage architecture. Backblaze B2 excels at cost-effective, durable storage of full-resolution video assets through their entire lifetime from acquisition to archive, while LucidLink shines during the later stages of the production process, from when the team transitions to working with the original full-resolution files to the final rendering of the sequence for release.
iconik brings B2 Cloud Storage and LucidLink together; not only can an iconik asset include a proxy and links to copies of the original video in both B2 Cloud Storage and LucidLink, iconik Storage Gateway can copy the original file from Backblaze B2 to LucidLink when full-resolution work commences, and later delete the LucidLink copy at the end of the production process, leaving the original archived in Backblaze B2. All that’s missing is a little orchestration.
The Backblaze B2 Storage Plugin for iconik
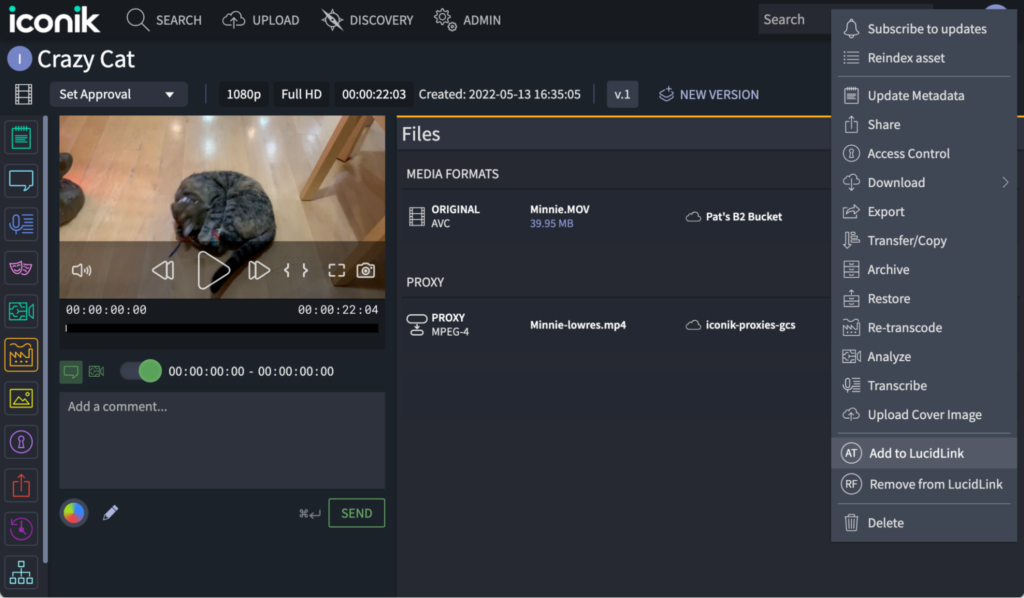
The Backblaze B2 Storage Plugin for iconik allows creative professionals to copy files from B2 Cloud Storage to LucidLink, and later delete them from LucidLink, in a couple of mouse clicks. The plugin adds a pair of custom actions to iconik: “Add to LucidLink” and “Remove from LucidLink,” applicable to one or many assets or collections, accessible from the Search page and the Asset/Collection page. You can see them on the lower right of this screenshot:
The user experience could hardly be simpler, but there is a lot going on under the covers.
There are several components involved:
The plugin, deployed as a serverless function. The initial version of the plugin is written in Python for deployment on Google Cloud Functions, but it could easily be adapted for other serverless cloud platforms.
A LucidLink Filespace.
A machine with both the LucidLink client and iconik Storage Gateway installed. The iconik Storage Gateway accesses the LucidLink Filespace as if it were local file storage.
iconik, accessed both by the user via its web interface and by the plugin via the iconik API. iconik is configured with two iconik “storages”, one for Backblaze B2 and one for the iconik Storage Gateway instance.
When the user selects the “Add to LucidLink” custom action, iconik sends an HTTP request, containing the list of selected entities, to the plugin. The plugin calls the iconik API with a request to copy those entities from Backblaze B2 to the iconik Storage Gateway. The gateway writes the files to the LucidLink Filespace, exactly as if it were writing to the local disk, and the LucidLink client sends the files to LucidLink. Now the full-resolution files are available for the production team to access in the Filespace, while the originals remain in B2 Cloud Storage.
Later, when the user selects the “Remove from LucidLink” custom action, iconik sends another HTTP request containing the list of selected entities to the plugin. This time, the plugin has more work to do. Collections can contain other collections as well as assets, so the plugin must access each collection in turn, calling the iconik API for each file in the collection to request that it be deleted from the iconik Storage Gateway. The gateway simply deletes each file from the Filespace, and the LucidLink client relays those operations to LucidLink. Now the files are no longer stored in the Filespace, but the originals remain in B2 Cloud Storage, safely archived for future use.
This short video shows the plugin in action, and walks through the flow in a little more detail:
Deploying the Backblaze B2 Storage Plugin for iconik
Don’t have a Backblaze B2 account? You can get started here, and the first 10GB are on us. We can also set up larger scale trials involving terabytes of storage—enter your details and we’ll get back to you right away.
Customize the Plugin to Your Requirements
You can use the plugin as is, or modify it to your requirements. For example, the plugin is written to be deployed on Google Cloud Functions, but you could adapt it to another serverless cloud platform. Please report any issues with the plugin via the issues tab in the GitHub repository, and feel free to submit contributions via pull requests.
In the AWS Security Profile series, I interview the people who work in Amazon Web Services (AWS) Security and help keep our customers safe and secure. This interview is with CJ Moses—previously the AWS Deputy Chief Information Security Officer (CISO), he began his role as CISO of AWS in February of 2022.
How did you get started in security? What about it piqued your interest?
I was serving in the United States Air Force (USAF), attached to the 552nd Airborne Warning and Control (AWACS) Wing, when my father became ill. The USAF reassigned me to McGuire Air Force Base (AFB) in New Jersey so that I’d be closer to him in New York. Because I was an unplanned resource, they added me to the squadron responsible for base communications. I ended up being the Base CompuSec (Computer Security) Manager, who was essentially the person who had to figure out what a firewall was and how to install it. That role required me to have a lot of interaction with the Air Force Office of Special Investigations (AFOSI), which led to me being recruited as a Computer Crime Investigator (CCI). Normally, when I’m asked what kind of plan I followed to get where I am today, I like to say, one modeled after Forrest Gump.
How has your time in the Air Force influenced your approach to cybersecurity?
It provided a strong foundation that I’ve built on with each and every experience since. My years as a CCI had me chasing hackers around the world on what was the “Wild West” of the internet. I’ve been kicked out of countries, asked (told) never to come back to others, but in the end the thing that stuck is that there is always a human on the other side of the connection. Keyboards don’t type for themselves, and therefore understanding your opponent and their intent will inform the measures you must put in place to deal with them. In the early days, we were investigating Advanced Persistent Threats (APTs) long before anyone had created that acronym, or given the actors names or fancy number designators. I like to use that experience to humanize the threats we face.
You were recently promoted to CISO of AWS. What are you most excited about in your new role?
I’m most excited by the team we have at AWS, not only the security team I’m inheriting, but also across AWS. As a CISO, it’s a dream to have an organization that truly believes security is the top priority, which is what we have at AWS. This company has a strong culture of ownership, which allows the security team to partner with the service owners to enable their business, rather than being the office of, “no, you can’t do that.” I prefer my team to answer questions with “Yes, but” or “Yes, and,” and then talk about how they can do what they need in a more secure manner.
What’s the most challenging part of being CISO?
There’s a right balance I’m working to find between how much time I’m able to spend focusing on the details and doing security, and communicating with customers about what we do. I lean on our Office of the CISO (OCISO) team to make sure we keep up a high level of customer engagement. I strive to keep the right balance between involvement in details, leading our security efforts, and engaging with our customers.
What’s your short- and long-term vision for AWS Security?
In the short term, my vision is to continue on the strong path that Steve Schmidt, former CISO of AWS and current chief security officer of Amazon, provided. In the longer term, I intend to further mechanize, automate, and scale our abilities, while increasing visibility and access for our customers.
If you could give one piece of advice to all AWS customers at scale, what would it be?
My advice to customers is to take advantage of the robust security services and resources we offer. We have a lot of content that is available for little to no cost, and an informed customer is less likely to encounter challenging security situations. Enabling Amazon GuardDuty on a customer’s account can be done with only a few clicks, and the threat detection monitoring it offers will provide organization-wide visibility and alerting.
What’s been the most dramatic change you’ve seen in the industry?
The most dramatic change I’ve seen is the elevated visibility of risk to the C-suite. These challenges used to be delegated lower in the organization to someone, maybe the CISO, who reported to the chief information officer. In companies that have evolved, you’ll find that the CISO reports to the CEO, with regular visibility to the board of directors. This prioritization of information security ensures the right level of ownership throughout the company.
Tell me about your work with military veterans. What drives your passion for this cause?
I’ve aligned with an organization, Operation Motorsport, that uses motorsports to engage with ill, injured, and wounded service members and disabled veterans. We present them with educational and industry opportunities to aid in their recovery and rehabilitation. Over the past few years we’ve sponsored a number of service members across our race teams, and I’ve personally seen the physical, and even more importantly, mental improvements for the beneficiaries who have become part of our race teams. Having started my military career during Operation Desert Shield/Storm (the buildup to and the first Gulf War), I can connect with these vets and help them to find a path and a new team to be part of.
If you had to pick any other industry, what would you want to do?
Professional motorsports. There is an incredible and not often visible alignment between the two industries. The use of data analytics (metrics focus), the culture, leadership principles, and overall drive to succeed are in complete alignment, and I’ve applied lessons learned between the two interchangeably.
What are you most proud of in your career?
I am very fortunate to come from rather humble beginnings and I’m appreciative of all the opportunities provided for me. Through those opportunities, I’ve had the chance to serve my country and, since joining AWS, to serve many customers across disparate industries and geographies. The ability to help people is something I’m passionate about, and I’m lucky enough to align my personal abilities with roles that I can use to leave the world a better place than I found it.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
The kernel tries hard to keep memory available for its present and future
needs. Should that effort fail, though, the tool of last resort is the
dreaded out-of-memory (OOM) killer, which is tasked with killing processes
on the system to free their memory and alleviate the problem. The results
of invoking the OOM killer are never going to be good, but they can be
distinctly worse if the wrong processes are chosen for an untimely end. As
one might expect, the effort to properly choose the right processes is an
ongoing effort. Most recently, Christian
König has proposed a
new mechanism to address a blind spot in the OOM killer’s
deliberations.
The post was inspired by reading a highly optimized FizzBuzz
program, which pushes output to a pipe at a rate of ~35GiB/s on my
laptop. Our first goal will be to match that speed, explaining
every step as we go along. We’ll also add an additional
performance-improving measure, which is not needed in FizzBuzz
since the bottleneck is actually computing the output, not IO, at
least on my machine.
Security updates have been issued by Debian (firefox-esr), Fedora (thunderbird and vim), Red Hat (firefox, postgresql:10, postgresql:12, and postgresql:13), Scientific Linux (firefox and rsyslog), SUSE (hdf5, hdf5, suse-hpc, postgresql14, rubygem-yajl-ruby, and udisks2), and Ubuntu (imagemagick and influxdb).
If you’re part of the huge growth in demand for cloud-based SIEM (Security Information and Event Management), claim your copy of the new Gartner® Report: “How to Deploy a SIEM Solution Successfully.”
Depending on what SIEM you choose, and how you approach the process, getting to operational and effective can take days, or months, or a lot longer.
Here are the Gartner report’s key findings:
“Ineffective security information and event management (SIEM) deployments occur when requirements and use cases are not aligned with the organization’s risks and risk tolerance.”
“Clients deploying SIEM solutions continue to take an unstructured approach when deciding which event and data sources to onboard, with the goal of getting every source in from the beginning. This leads to long and complex implementations, cost overruns, and higher probabilities of stalled or failed implementations.”
“SIEM buyers struggle to choose between on-premises, cloud, or hybrid deployments due to the complexities created by the various environments that need to be monitored, e.g., on-premises, SaaS, cloud infrastructure and platform services (CIPS), remote workers.”
SIEM centralizes and visualizes your security data to help you identify anomalies in your environment. But nearly all SIEMs require you to do a ton of customizing and configuration. Nearly all disappoint with their detections. And nearly all will exhaust you with false-positive alerts… every hour of every day… until analysts start ignoring alerts, which will surely doom you someday.
Now, here’s what we think
Rapid7 began building InsightIDR nearly a decade ago. While the threat landscape keeps changing, our mission never has: to empower you to find and extinguish evil earlier, faster, easier.
InsightIDR has never been a traditional SIEM. You should consider it if:
Fast deployment is a priority to you. InsightIDR leads the SIEM market in deployment times. With SaaS delivery and a native cloud foundation, customers can be deployed and operational in days and weeks – not months and years.
Time-to-value and tangible ROI matter to your leadership team. InsightIDR combines the best of next-gen SIEM with native extended detection and response (XDR). Get highly correlated UEBA, EDR, NDR, and Cloud detections alongside your critical security logs and policy monitoring, compliance dashboards, and reporting in a single pane of glass.
Your team is tired of false positives. InsightIDR’s expertly vetted detection library provides holistic threat coverage across your entire attack surface. An emphasis on high-fidelity, low-noise detections ensures that all alerts are relevant and ready for action.
You’re ready to accelerate your security posture. InsightIDR empowers teams to up-level their security and achieve sophisticated outcomes – without the complexity of traditional SIEMs. Embedded security orchestration and automation (SOAR) capabilities give you enviable security operations center (SOC) automation and enable even new analysts to respond like experts.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
Gartner, How to Deploy a SIEM Solution Successfully, Andrew Davies, Mitchell Schneider, Toby Bussa, Kelly Kavanagh, 7 July 2021
This post is written by Chris Williams, Solutions Architect and Thomas Moore, Solutions Architect, Serverless.
Part 1 of this blog series looks at optimizing AWS Lambda costs through right-sizing a function’s memory, and code tuning. We also explore how using Graviton2, Provisioned Concurrency and Compute Savings Plans can offer a reduction in per-millisecond billing.
Part 2 continues to explore cost optimization techniques for Lambda with a focus on architectural improvements and cost-effective logging.
Event filtering
A common serverless architecture pattern is Lambda reading events from a queue or a stream, such as Amazon SQS or Amazon Kinesis Data Streams. This uses an event source mapping, which defines how the Lambda service handles incoming messages or records from the event source.
Sometimes you don’t want to process every message in the queue or stream because the data is not relevant. For example, if IoT vehicle data is sent to a Kinesis Stream and you only want to process events where tire_pressure is < 32, then the Lambda code may look like this:
def lambda_handler(event, context):
if(event[“tire_pressure”] >=32):
return
# business logic goes here
This is inefficient as you are paying for Lambda invocations and execution time when there is no business value beyond filtering.
Lambda now supports the ability to filter messages before invocation, simplifying your code and reducing costs. You only pay for Lambda when the event matches the filter criteria and triggers an invocation.
Filtering is supported for Kinesis Streams, Amazon DynamoDB Streams and SQS by specifying filter criteria when setting up the event source mapping. For example, using the following AWS CLI command:
After applying the filter, Lambda is only invoked when tire_pressure is less than 32 in messages received from the Kinesis Stream. In this example, it may indicate a problem with the vehicle and require attention.
For more information on how to create filters, refer to examples of event pattern rules in EventBridge, as Lambda filters messages in the same way. Event filtering is explored in greater detail in the Lambda event filtering launch blog.
Avoid idle wait time
Lambda function duration is one dimension used for calculating billing. When function code makes a blocking call, you are billed for the time that it waits to receive a response.
This idle wait time can grow when Lambda functions are chained together, or a function is acting as an orchestrator for other functions. For customers who have workflows such as batch operations or order delivery systems, this adds management overhead. Additionally, it may not be possible to complete all workflow logic and error handling within the maximum Lambda timeout of 15 minutes.
Instead of handling this logic in function code, re-architect your solution to use AWS Step Functions as an orchestrator of the workflow. When using a standard workflow, you are billed for each state transition within the workflow rather than the total duration of the workflow. In addition, you can move support for retries, wait conditions, error workflows and callbacks into the state condition allowing your Lambda functions to focus on business logic.
The following example shows an example Step Functions state machine, where a single Lambda function is split into multiple states. During the wait period, there is no charge. You are only billed on state transition.
Direct integrations
If a Lambda function is not performing custom logic when it integrates with other AWS services, it may be unnecessary and could be replaced by a lower-cost direct integration.
For example, you may be using API Gateway together with a Lambda function to read from a DynamoDB table:
This could be replaced using a direct integration, removing the Lambda function:
API Gateway supports transformations to return the output response in a format the client expects. This avoids having to use a Lambda function to do the transformation. You can find more detailed instructions on creating an API Gateway with an AWS service integration in the documentation.
You can also benefit from direct integration when using Step Functions. Today, Step Functions supports over 200 AWS services and 9,000 API actions. This gives greater flexibility for direct service integration and in many cases removes the need for a proxy Lambda function. This can simplify Step Function workflows and may reduce compute costs.
Reduce logging output
Lambda automatically stores logs that the function code generates through Amazon CloudWatch Logs. This may be useful for understanding what is happening within your application in near real-time. CloudWatch Logs includes a charge for the total data ingested throughout the month. Therefore, reducing output to include only necessary information can help reduce costs.
When you deploy workloads into production, review the logging level of your application. For example, in a pre-production environment, debug logs can be beneficial in providing additional information to tune the function. Within your production workloads, you may disable debug level logs and use a logging library (such as the Lambda Powertools Python Logger). You can define a minimum logging level to output by using an environment variable, which allows configuration outside of the function code.
Structuring your log format enforces a standard set of information through a defined schema, instead of allowing variable formats or large volumes of text. Defining structures such as error codes and adding accompanying metrics leads to a reduction in the volume of text that repeats throughout your logs. This also improves the ability to filter logs for specific error types and reduces the risk of a mistyped character in a log message.
Use Cost-Effective Storage for Logs
Once CloudWatch Logs ingests data, by default it is persisted forever with a per-GB monthly storage fee. As log data ages, it typically becomes less valuable in the immediate time frame, and is instead reviewed historically on an ad-hoc basis. However, the storage pricing within CloudWatch Logs remains the same.
To avoid this, set retention policies on your CloudWatch Logs log groups to delete old log data automatically. This retention policy applies to both your existing and future log data.
Some applications logs may need to persist for months or years for compliance or regulatory requirements. Instead of keeping the logs in CloudWatch Logs, export them to Amazon S3. By doing this, you can take advantage of lower-cost storage object classes while factoring in any expected usage patterns for how or when data is accessed.
Conclusion
Cost optimization is an important part of creating well-architected solutions and this is no different when using serverless. This blog series explores some best practice techniques to help reduce your Lambda bill.
If you are already running AWS Lambda applications in production today, some techniques are easier to implement than others. For example, you can purchase Savings Plans with zero code or architecture changes, whereas avoiding idle wait time will require new services and code changes. Evaluate which technique is right for your workload in a development environment before applying changes to production.
If you are still in the design and development stages, use this blog series as a reference to incorporate these cost optimization techniques at an early stage. This ensures that your solutions are optimized from day one.
This post is written by Chris Williams, Solutions Architect and Thomas Moore, Solutions Architect, Serverless.
When you develop and architect solutions, cost-optimization should always be part of the process. This is no different for serverless applications that have been developed using AWS Lambda.
Your workloads may vary in terms of complexity, usage patterns, and technology. However, the following advice is applicable to all customers when deciding how to prioritize cost optimization with the tradeoffs of developing the application:
Efficient code makes better use of resources.
Consider the downstream services in architectural decisions.
Optimization should be a continuous cycle of improvement.
Prioritize changes that make the greatest improvements first.
The Optimizing your AWS Lambda costs blog series reviews operational and architectural guidance. It can be applied to existing Lambda functions and those that you develop in the future.
When you optimize Lambda functions, each of these components impacts the total monthly cost. This pricing applies after you exceed the AWS Free Tier that is offered for Lambda.
Right-Sizing
Right-sizing is a good starting point in the process of cost optimization. This exercise helps to identify the lowest cost for applications without affecting performance or requiring code changes.
For Lambda, this is accomplished by configuring the memory for a function, ranging anywhere from 128 MB up to 10,240 MB (10 GB). By adjusting the memory configuration, you also adjust the amount of vCPU that is available to the function during invocation. Tuning these settings provides memory- or CPU-bound applications with access to additional resources during the execution, which may lead to an overall reduced duration of invocation.
Identifying the optimal configuration for your Lambda functions may be manually intensive, especially if changes are made frequently. The AWS Lambda Power Tuning tool provides a solution powered by AWS Step Functions that can help identify the appropriate configuration. It analyzes a set of memory configurations against an example payload.
In the following example, as the memory increases for this Lambda function, the total invocation time improves. This leads to a reduction in the cost for the total execution without affecting the original performance of the function. For this function, the optimal memory configuration for the function is 512 MB, as this is where the resource utilization is most efficient for the total cost of each invocation. This varies per function, and using the tool on your Lambda functions can identify if they benefit from right-sizing.
This exercise should be completed regularly, especially if code is released frequently. Once you have identified the appropriate memory setting for your Lambda functions, you should add right-sizing to your processes. The AWS Lambda Power Tuning tool generates programmatic output that can be used by your CI/CD workflows during the release of new code, allowing the automation of memory configuration.
Performance efficiency
A key component to Lambda pricing is the total duration of the invocation. The longer the function takes to run, the more it costs and the higher the latency in your application. For this reason, it is important to ensure the code you write is as efficient as possible and follows the Lambda best practices.
At a high level, to optimize code :
Minimize deployment package size to its runtime necessities. This reduces the amount of time it takes for the package to be downloaded and unpacked.
Minimize the complexity of dependencies. Simpler frameworks often load faster.
Take advantage of execution reuse. Initialize SDK clients and database connections outside the function handler, and cache static assets locally in the /tmp directory. Subsequent invocations can reuse open connections and resources in memory and in /tmp.
Follow general coding performance best practices for your chosen language and runtime.
To help visualize the components of your application and identify performance bottlenecks, use AWS X-Ray with Lambda. You can enable X-Ray active tracing on new and existing functions by editing the function configuration. For example, with the AWS CLI:
The AWS X-Ray SDK can be used to trace all AWS SDK calls inside Lambda functions. This helps to identify any bottlenecks in the application performance. The X-Ray SDK for Python can be used to capture data for other libraries such as requests, sqlite3, and httplib, as shown in the following example:
Amazon CodeGuru Profiler is another tool that can help with code optimization. It uses machines learning algorithms to help find the most expensive lines of code and suggests ways to improve efficiency. It can be enabled on existing Lambda functions by enabling code profiling in the function configuration.
The CodeGuru console shows the results as a series of visualizations and recommendations.
Use these tools together with the documented best practices to evaluate your code’s performance when developing your serverless applications. Efficient code often means faster applications and reduced costs.
AWS Graviton2
In September 2021, Lambda functions powered by Arm-based AWS Graviton2 processors became generally available. Graviton2 functions are designed to deliver up to 19% better performance at 20% lower cost than x86. In addition to the lower billing cost when using Arm, you could also see a reduction in the function duration due to the CPU performance improvement, reducing costs even further.
You can configure both new and existing functions to target the AWS Graviton2 processor. Functions are invoked in the same way and integrations with services, applications and tools are not affected by the architecture change. Many functions only need the configuration change to take advantage of the price/performance of Graviton2. Others may require repackaging to use Arm-specific dependencies.
It’s always recommended to test your workloads before making the change. To see how much your code benefits from using Graviton2, use the Lambda Power Tuning tool to compare against x86. The tool allows you to compare two results on the same chart:
Provisioned concurrency
Where customers are looking to reduce their Lambda function cold starts or avoid burst throttling, provisioned concurrency provides execution environments that are ready to be invoked. It can also reduce total Lambda cost when there is a consistent volume of traffic. This is because the provisioned concurrency pricing model offers a lower total price when it is fully used.
Similar to the standard Lambda function pricing, there are price components for total requests, total duration, and memory configuration. In addition, there is the cost of each provisioned concurrency environment (based on its memory configuration). When this execution environment is fully utilized, the combined cost of the invocation and the execution environment can offer up to 16% savings on duration cost when compared to the regular on-demand pricing.
If you cannot maximize usage in an execution environment, provisioned concurrency can still offer a lower total price per invocation. In the following example, once it’s consumed for more than 60% of the available time, it becomes cheaper than using the on-demand pricing model. The savings increase in line with capacity usage.
To identify the invocation baseline of a Lambda function, look at the average concurrent execution metrics per hour over the previous 24 hours. This helps you to find a consistent baseline throughout the day where you are consistently using multiple execution environments.
For Lambda functions where peak invocation levels are only expected during particular windows of time, take advantage of a scheduled scaling action. Where traffic patterns are not easy to determine, you can implement Application Auto Scaling to adjust based on the current level of utilization.
Compute savings plans
AWS Savings Plans is a flexible pricing model offering lower prices compared to on-demand pricing, in exchange for a specific usage commitment (measured in $/hour) for a one- or three-year period.
Compute Savings Plans include Amazon EC2, AWS Fargate and Lambda. Lambda usage for duration and provisioned concurrency are charged at a discounted Savings Plans rate of up to 17% for a 1- or 3-year term.
You can implement Savings Plans without any function code or configuration changes. They can be a simpler way to save money for Lambda-based workloads. Before deciding to use a savings plan, analyze previous patterns to understand any variations in your month to month usage.
Conclusion
This blog post explains how Lambda pricing works and how right-sizing applications and tuning them for performance efficiency offers a more cost-efficient utilization model. The results can also reduce latency, creating a better experience for your end users.
The post explores how architectural changes such as moving to Graviton2 and configuring provisioned concurrency can provide cost reductions for the same operations. Finally, you can use Compute Savings Plans to add an additional cost reduction once you establish a baseline of usage per month.
Part 2 introduces further optimization opportunities for reducing Lambda invocations, moving to an asynchronous model, and reducing logging costs.
For more serverless learning resources, visit Serverless Land.
Българска социалистическа партия (БСП), от чиято квота е и министърът на земеделието, храните и горите Иван Иванов, ударно си назначава областните, общинските и др. кадри на местно ниво в държавните…
Луиза Славкова е основател и изпълнителен директор на Фондация „Софийска платформа“, която за поредна година организира лятно училище в гр. Белене по темите за паметта и демокрацията. Славкова е член на Консултативния съвет на Европейската мрежа за гражданско образование (NECE), през годините е била програмен мениджър в Европейския съвет за външна политика, гост-изследовател в Института за изследване на правата на човека към Колумбийския университет и съветник на министъра на външните работи Николай Младенов. Автор и редактор е на няколко книги и публикации, свързани с международни политики, демократично развитие и гражданско образование, и е съавтор на учебник по гражданско образование по учебната програма на новия предмет.
Йоанна Елми разговаря с Луиза Славкова за лятното училище, за паметта за комунистическата диктатура и за важността на гражданското образование при малки и големи.
Лятното училище се провежда под надслов „Защо ни е да помним?“. Безспорно отговорът е важен и питам и за него, но първо ми е интересно нещо друго – не е ли важно и как помним? Защото българската образователна система тежко залага на помненето на определени исторически моменти, дори на механично наизустяване, но има ли смисъл от такова помнене?
Разговорът за паметта е многопластов. И в теорията, и в практиката има различни подходи, включително радикални, според които е по-добре да не се помни нищо. Защото паметта само репродуцирала определени нагласи и никога не можело да има трайно разбирателство, особено където е имало конфликт между две групи. Ако една група от обществото е представена като палач, а друга – като жертва, помненето затвърждава тази представа. Известен представител на този подход е синът на Сюзън Зонтаг – Дейвид Рийф, който години наред отразява войните в бивша Югославия и е убеден, че е по-добре на Балканите нищо да не се помни. Аз не съм съгласна с него, но това не означава, че не обсъждаме това гледище в нашето лятно училище. Ние питаме всеки участник дали трябва да помним комунизма с неговите репресии като тоталитарен режим, или не. И оттам: ако го помним – защо да го помним?
В лятното училище не бягаме от различните пластове на разказа за комунизма, но правим разлика между наративите – които се менят – и фактите. Факт е, че комунизмът е осъден като престъпен режим редом с фашизма и националсоциализма, независимо че има българи, които никога не са чували за лагерите за политзатворници в България, тогава носещи срамното име „трудово-възпитателни общежития“ (ТВО). Носталгията по живота по време на комунизма, ако и да е измамно усещане за предвидимост, е легитимно усещане и никой от нас няма право да се присмива на тези емоции у някои хора. Но това не променя факта, че други стотици хиляди са белязани – често произволно и безвъзвратно – от режима. Така че и в лятното училище ние отваряме темата като един голям сноп, в който побираме всякакви детайли от историята на комунизма, в рамките на една седмица отсяваме и подреждаме кое е факт, кое е спомен и кое е част от държавната политика за паметта (или отсъствието на такава).
Разбира се, много по-лесно се помнят, разказват и преподават славните откъси от историята; онези, в които ние сме победители или пък жертви. Обаче как говорим за един период, в който системата на комунизма е палач, ние като общество сме и жертва, и палач, но сме и онова сиво пространство между двете крайности, където има всякакви хора – тихи свидетели на издевателства; хора, които под натиска на службите стават доносници; хора, наивно вярващи във фасадата на комунизма, и т.н. Разговорът за тази сива зона ни е особено важен. Защото нищо в живота не е само черно или бяло. И колкото по-добре разбира един млад човек, че историята на близкото минало е нещо комплексно, толкова по-вероятно е, занимавайки се с нея, да се учи на критично мислене, да размишлява за противоречията и за собствените си пристрастия, за пропагандата или за ролята на гражданското участие.
По Ваши наблюдения какви са промените, ако има такива, в преподаването на историята на тоталитарния режим на деца и студенти в последните години?
В последните години се случиха много неща. Имаше промяна в учебните програми в класовете, в които се изучава съвременна българска история, и комунизмът е застъпен много по-детайлно и най-вече правдиво. В старите програми бяха изпускани термини като „Народен съд“, „Държавна сигурност“ и още много, а в така или иначе малкото отделени часове по тази тема учениците остават с усещането, че комунизмът не е някаква история, заслужаваща внимание. По време на пандемията не успяхме да проследим какво е въздействието на промяната на учебните програми, но се надявам, че с повечето часове, посветени на този период, и познанията ще набъбват.
Разбира се, преподаването е другият препъникамък. Особено учителите, живели преди 89-та, трудно могат да се дистанцират от личния си опит и да си признаят, че историята, която те са учили като педагози, е продукт на същия пропаганден апарат, който би трябвало да могат да осъдят в клас. При по-младите учители невинаги е по-различно, защото, за съжаление, в университетите ни сред историците продължава да има ядра, които не гледат на комунизма като на престъпен режим. Самите методи на преподаване пък са другата трудност – у нас не е много популярно да се преподава с интерактивни методи, а дидактическият подход все още е най-следван. Това често води и до асоцииране на историята със скучна фактология – освен когато става въпрос за история, свързана с националните ни герои Ботев и Левски, за които впрочем също рядко се знае нещо отвъд клишетата.
Засегнахте какво липсва в преподаването и какво може да се подобри. Вие правите ли усилия в тази посока?
Усилията, които ние полагаме, са за демократизиране на самото преподаване и за постоянно създаване на актуални материали, помагала, възможности за участие в проекти в помощ на учители и местни активни граждани, които работят по темите за историята на комунизма и гражданското образование в цялата страна. В обученията си за учители наблягаме на интерактивните методи, така че в час по история или гражданско образование преподавателите да насочват учениците, да модерират процеса на работа в час, а не да държат лекции от по 45 минути. Обученията, които организираме, са базирани на тези методи, така че преподавателите изпитват сами добавената стойност на ученето през преживяване, симулация – или направо през топография, на терен. Именно това е и основен метод в работата ни в лятното училище – работа с история през преживяване на мястото, неговите обитатели сега, артефактите, запечатаните истории, спомените на очевидци.
За нас разговорите за историята на комунизма не са самоцел, те са част от опита ни да усилим значението на демократичната култура в нашето общество. Войната в Украйна е най-радикалното доказателство защо познаването на миналото е важно. То показва не само защо е от съществено значение едно общество да е демократично, в общност с други демокрации, които имат колективен ангажимент да си помагат, но и защо паметта за тоталитаризмите наистина предпазва от това една държава и най-вече гражданите ѝ да се плъзнат надолу по авторитарната крива.
Тази пролет, веднага след началото на войната в Украйна, стартирахме мащабен проект в Белене, посветен на паметта за лагера. Освен че ще разработим виртуален тур, започваме записването на разказите на малкото останали сред нас оцелели от лагера посредством нови технологии, така че техните свидетелства да останат запечатани за следващите поколения. След година вие ще можете от екраните си да водите разговор с тях и те да отговарят на въпросите ви, свързани с живота в лагера, без да сте физически на едно и също място. Тези подходи не само съхраняват паметта и запечатват гласовете на малкото оцелели сред нас, но вървят и в крак с времето и с начина, по който младите хора консумират информация.
Умишлено казвам „тоталитарен режим“ във въпросите си и забелязвам, че и Вие използвате тази формулировка в анонсите на събитието. Засегнахме темата за Украйна, затова питам: в България като че ли асоциираме тоталитаризма единствено с „комунизъм“, но днес виждаме например един руски тоталитарен режим, който няма общо с конкретна идеология и по-скоро заема от всичко по малко. Трудно ли се обясняват тези динамики на ученици и студенти?
Разбира се, ние сме запознати с дискусиите около термина „тоталитарен режим“ и водим такива помежду си като екип, но и с хората, които срещаме в различните си формати. Спорът за термина е дали един режим може да е толкова репресивен, че да е тотален в подтисничеството си и да не оставя нито една брънка от личния и обществен живот незасегната. И честно казано, като чета за броя на доносниците в България по време на комунизма, като гледам снимки за абсурдните граждански ритуали, с които партията се опитва да изземе ролята на Църквата (като гражданското кръщене например), и т.н., съм склонна да кажа, че комунизмът е тоталитарен, наистина се опитва да присъства навсякъде. Затова и щетите, които нанася на гражданската ни култура, са толкова големи, че продължаваме да не можем да се отърсим от тях. И до днес имаме очаквания държавата да се погрижи за нас, и то не в онзи социалдемократичен смисъл, а с готовност жертваме някоя от свободите си за тази грижа. Това граничи с поданическите нагласи, не с гражданските, и принадлежи към друг, отдавна отминал век.
По сходен начин са белязани и руснаците, струва ми се, въпреки че не познавам Русия толкова добре. Това ги прави и лесна жертва на пропагандата, с която ги облъчва режимът на Путин. След края на Студената война антидемократичните режими трудно влизат в калъпа на идеологиите, както ги познаваме от ХХ век, и дори на нас, възрастните, ни е трудно да се ориентираме в тази нова координатна система. Помислете само колко ни е трудно да кажем какво е популизъм, защо някои държави са полудемокрации, а други – полуавторитарни. Освен че е сложно да се обясни, защото е сложно по принцип, допълнително се затрудняваме, когато средата, в която растат младите хора, е пропутински настроена. Тези нагласи не са дълбоки, те са базирани на клишета, зад които дори няма сериозни размисли. Но те са базирани и на тази наследена култура на пасивност, а Путин има образ на мъж с твърда ръка, който брани руснаците от всички реални и (най-вече) конструирани врагове.
В този дух ми направи впечатление и преподаването на „демократични ценности“. Пандемията показа според мен, че трудно разбираме границата между лична свобода и колективно добруване, между необходими за съвместния живот правила и репресия. Същевременно виждаме, че през последните години някои европейски лидери бяха по-склонни да загърбят базови ценности в името на определена realpolitik, която всъщност често пъти води до повече беди в дългосрочен план. Как обясняваме и изобщо дефинираме демократичните ценности в такива времена? Успяваме ли да излезем от клишето, че Западът е задължително демократичен, а Изтокът – задължително недемократичен?
Аз мисля, че човек може да губи за моменти вярата си в общото благо, демокрацията, солидарността, равноправието, но това не значи, че демократичните ценности губят валидност по принцип. И да, дори сегашната ситуация с руския газ и с това кой какво е договорил с „Газпром“ може да накара човек да погледне обединена Европа с повдигната вежда. Но да капитулира тотално и цинично да каже, че всички са маскари и големите винаги печелят, е твърде елементарно. Демократичната култура, или по-скоро демократичните компетенции, които ние се опитваме да насърчаваме, не повеляват това. Те възпитават точно обратното – че демокрацията не е перфектна, но е най-свободната и най-справедлива система, която сме могли да измислим от атиняните насам. Тъй като тя е форма на управление на съжителстването ни в големи групи, няма как да бъде лесна, без конфликти, защото всички имаме различни интереси и предпочитания. Менажирането на динамиките в едно семейство е сложно, какво остава в една нация. И както нямаме очаквания отношенията в най-малките ядра да са елементарни, така не би трябвало да ги имаме и на ниво общество.
В този толкова комплексен свят е нелогично да си обясняваме нещата едновалентно или с дихотомии, въпреки че разбирам защо е примамливо, оттам и защо хората стават жертви на конспирации. Те, конспирациите, правят точно това – яхват разочарованието от сложната реалност, особено на онези, които са ощетени от нея по някакъв начин, и намират лесно, елементарно обяснение за несгодата. За съжаление обаче, рядко тези обяснения са правдиви. Те не само че създават илюзии у хората, но и елиминират изцяло собствената роля в битието, отнемат свободата на действие на човека. За мен ценностите трябва винаги с еднаква сила да се насърчават и в особено трудно моменти усещаме последствията от тяхната липса.
В работата си ние говорим повече за компетенции, отколкото за ценности. Без да навлизам в подробности, на практика компетенцията е онова, което те прави демократичен гражданин, и е комбинация от ценности, нагласи, умения – имаме безплатен видеоурок на тази тема с платформата „Уча.се“, както, между другото, и на всички други теми от учебната програма по гражданско образование за ХI и ХII клас.
Да поговорим и за самите ученици. Как приемат те програмата? Какви въпроси задават най-често? С какви впечатления идват в лятното училище и как те се променят към края на програмата?
В лятното ни училище в Белене идват всякакви младежи. Такива с познания и такива без; участници, чиито семейства имат история на репресии или пък са били облагодетелствани по време на комунизма; деца от малки и големи населени места, от цялата страна. Не изискваме знания или успех, търсим грамотно написана мотивация и обоснован интерес, та дори и той да е артикулиран като „Не зная нищо, но ми е любопитно“. Срещите с оцелели от лагера, обходът на разрушените сгради от Обект 2 в лагера „Белене“, разговорите с лектори, креативните саморефлексии със собствените снимки и написани мисли, работата с архиви от особено голямо значение в Държавния архив в Плевен, срещите с беленската общност – всичко това изисква време, за да се осмисли, преживее и подреди. Преживяването със сигурност е едно от онези неща, които остават за цял живот, защото е емоционално, свързано с мястото и с живите следи.
Въпросите, които чуваме, са от всякакво естество, но последната година ни направи впечатление, че участниците имаха нужда да говорим и за Прехода като исторически период, който им помага да осмислят комунизма. Очевидно са достатъчно далеч от Прехода, за да е той в тяхната перцепция едно безвъзвратно приключено минало. Със сигурност си тръгват с много повече познания за периода, с осъзнаване за дупките от училище, за тишината или носталгията по темата у дома, но най-вече за влиянието на периода и до днес върху нас като общество. Началото на лятното ни училище е посветено на демокрацията, защото тя е реалността на участниците. Оттам вървим хронологично назад към комунизма и завършваме с паметта в демократичното ни общество, вкл. и политизирането ѝ.
Като че ли винаги сме склонни да залагаме надеждите си на по-младите поколения. Според Вас нужни ли са обаче усилия за образоване на предишни поколения относно историческото наследство на близкото минало? Как биха изглеждали такива усилия? Планирате ли нещо подобно?
Като фондация работим точно толкова с възрастни, колкото и с млади хора. В България т.нар. гражданско образование за възрастни не е толкова популярно. Най-вероятно защото гражданското образование не е много популярно като цяло, но и защото с млади хора се работи по-лесно. Нагласите им не са толкова циментирани като тези на възрастните, затова и с тях се постига по-голямо въздействие. С възрастните са нужни по-различни подходи.
Ще дам пример – няколко пъти организираме представления със стендъп комедия, посветена на ЕС и на Прехода. Така през хумора и най-вече през интересите и естествената среда на възрастните инициираме размисли на теми като членството ни в ЕС, финансовите измерения на отворените пазари за стоки и услуги, но и обратната страна на медала – обезлюдяването и липсата на медицински кадри заради емиграцията на Запад. Работим много с преподаватели, както споменах, но нагласите не се променят бързо, възрастните не стават по-демократични от една вечер със стендъп комедия или един семинар. Изисква се работа в продължение на месеци, дори години и разбира се, е много трудно да се изолира влиянието на гражданското образование от всякакви други случки от живота на възрастния.
В този смисъл е трудно и да се каже, че именно гражданското образование за възрастни ги прави по-демократични. Но има достатъчно изследвания, които показват, че то води до по-голяма ангажираност. Че наличието на граждански организации и пространства е предпоставка за повече граждански инициативи и съответно липсата им се свързва с липсата на организиран граждански живот.
През последната седмица либерално-демократичната общност у нас (към която се причислява и авторката на този текст) намери нова персонализация на гражданското си недоволство. Става въпрос за вицепремиерката Калина Константинова. Обвинителният ѝ тон по адрес на украинските бежанци трудно може да остави безразлични хората с чувствителност към човешките права. Още повече че бягащите от агресията на Русия срещат у обществото ни многократно повече съпричастност, отколкото тези от Сирия или Афганистан. Макар в последно време това да се променя – не на последно място, в резултат на масираната проруска пропаганда у нас.
Кратко опресняване на паметта
Правителството интерпретира като изключителна щедрост от страна на държавата настаняването на украинците в луксозни хотели по морето вместо в бежански центрове и палаткови лагери. Мярката беше ограничена до 31 май, а краят ѝ съвпада с началото на туристическия сезон у нас. Говорейки за тази необичайна управленска мярка обаче, като че вече сме позабравили как точно се породи тя.
Всъщност благородната идея да се настаняват украинските бежанци в хотели съвсем не е на правителството. Хотелиерите сами решиха да проявят инициатива и гостоприемство. А после поискаха държавата да им плати за човещината, та да поспечелят нещо извън активния сезон. За разлика от частните лица, които прибраха украинци в домовете си безвъзмездно. Така правителството се оказа пред свършен факт. И тъй като държавата не беше измислила нищо по-добро, реши поне да финансира създадената система за подкрепа. При известни условия – до 40 лв. на човек за нощувка и храна при настаняване в хотели и къщи за гости, вписани в Националния туристически регистър.
Нови времена – нови мерки
Според новата мярка за настаняване на бежанците, анонсирана от заместник-премиерката по ефективно управление, те следваше да бъдат настанени в държавни бази, хотели с по-ниски категории и къщи за гости срещу 15 лв. на ден с храна или 10 – без храна. Ако се чудите колко качествени три хранения може да си осигурите за общо 5 лв., не сте единствените, които си задават този въпрос.
Все пак са се намерили, ако се вярва на правителството, достатъчно собственици на места за настаняване, които да се включат в програмата. Голяма част от тях са в планински курорти и в населени места, които не са известни туристически дестинации. Собствениците им вероятно са преценили, че и малкото държавни пари ще са повече, отколкото те обичайно биха получили. А украинците… все ще се намери с какво да ги хранят.
Къде се „изгубиха в превода“ Константинова и украинските бежанци?
Бежанците трябваше да напуснат хотелите, в които са настанени, до 31 май, а държавата – да осигури автобуси и влакове за извозването им. На тях обаче не се качи почти никой, въпреки че много от украинците вече бяха попълнили онлайн въпросник за нуждите и намеренията си. Именно това предизвика гнева на Константинова – от нейна гледна точка „неблагодарниците“ са пратили усилията на правителството на вятъра и имат претенции да продължават да си живеят в луксозни хотели по Черноморието.
Само че украинците бяха третирани като чували с картофи.От тяхна гледна точка ситуацията изглежда съвсем иначе – те просто не са получили никаква информация въпреки обещанието за отговор до 48 часа след попълването на въпросника. Ако не са научили по някакъв неформален начин, е нямало как да разберат къде и кога ще ги чакат автобусите. А къде точно ще ги закарат – това съвсем не са знаели. Проблемът е особено сериозен за имащите личен автомобил. За много от тях това е най-скъпото им имущество, оцеляло през войната, и не биха го зарязали просто ей така, за да се отправят в неизвестна посока.
Който не иска да слуша, трябва да почувства, гласи стара немска поговорка, оправдаваща боя над деца.
Обидена на „претенциозните“ украинци, Калина Константинова заяви, че вече няма да се допускат празни автобуси и влакове. Вместо това най-нуждаещите се бежанци ще бъдат транспортирани до буферни центрове, а оттам – до държавни бази във вътрешността на страната. Ако бягащите от руската агресия просто бяха получили информация, тази по същество наказателна мярка щеше да е излишна, но уви.
И така, стотици украинци бяха настанени в буферни центрове – фургони без климатици, хладилници и топла вода. Там вечерта не получиха храна, на сутринта закуска имаше, но не и подходяща за малки деца. Държавата оправдава тези условия с аргумента, че те все пак са само за 72 часа. А поуката за бягащите от Украйна е да видят какво им е на „истинските бежанци“, които „не ги глезят“. На сирийските и афганистанските майки с деца в бежански лагери да не им е леко? Щом са нуждаещи се, трябва да са благодарни и да търпят.
И няма да имат претенции, когато автобусите отново дойдат да ги отведат в неизвестна посока.
Отделен въпрос е, че някои от украинците вече имат личен лекар и не знаят дали на новото място ще могат да се сдобият с такъв. Както и че в изолирани курорти и в обезлюдени градчета не е лесно и за българи да си намерят работа, а какво остава за бежанци, които искат да се устроят и да се интегрират. В същото време има немалко фирми, които биха наели украински бежанци, две трети от които са с висше образование, но освен административните спънки, като например признаване на дипломи, трудно може да се наеме висококвалифицирана специалистка, разпределена в Паничище.
Държавата обаче не мисли особено как да облекчи пълноценното включване на бежанците от Украйна в българското общество. Едно – заради аргумента „ами те искат да си ходят“, друго – заради устойчивата нагласа у нас, че интеграцията е проблем единствено на интегриращите се. Именно тази нагласа е в основата на известната фраза „те не искат да се интегрират“. Независимо кои са „те“.
Интеграция? Това пък какво е?
Интеграцията на чужденци (и в частност на бежанци) е нещо, с което българската държава традиционно не желае да се занимава. След влизането на страната ни в Европейския съюз беше приета Национална стратегия на Република България по миграция и интеграция 2008–2015 г. Тази стратегия вървеше заедно с европейски пари за интеграция, разпределяни от българските институции за проекти. В екипа на един от първите спечелили проекти бях и аз, така че ще споделя малко личен опит.
Задачата ни беше да изработим индикатори за интеграция на имигранти. За тази цел проучихме европейския опит. Силно впечатление ми направи германската система, в която фигурираха включително такива индикатори за качеството на живот – дали чужденецът се задъхва, когато се качва по стълби. За контраст, наличните български индикатори бяха „брой подадени проекти“, „брой спечелени проекти“, „брой проведени кръгли маси“ – все в този дух. Представихме предложенията си за индикатори и… на следващата година беше обявен проект по същата тема. Така държавата плащаше за разработване на индикатори след индикатори, без да въведе никой от тях.
Ето за толкова „смислени“ дейности отиваха европейските пари за интеграция.
Стратегията за периода 2015–2020 г. вече включваше в заглавието си и думата „убежище“. И този документ си остана само на думи. Отношението към сирийските бежанци в този период показва на какво е способна държавата, ако от нея, а не от предприемчиви хотелиери зависи настаняването на бягащите от война. Единайсет хиляди бежанци от Сирия (колкото беше максималният им брой у нас в един и същи момент) се оказаха непосилно бреме. Те бяха поставени в условия, които дори при огромните усилия на доброволците си оставаха нечовешки.
В заглавието на проекта за стратегия за периода 2021–2025 г., предложен в края на управлението на ГЕРБ и „Обединени патриоти“, интеграцията изобщо отсъства. Както и убежището. До ден днешен документът не е приет, така че понастоящем България е без официална стратегия какво да прави с чуждите граждани на територията си. Като се има предвид въздействието на предишните стратегии, загубата не е голяма. Отсъствието ѝ обаче е показателно за липсата на ангажимент на държавата към чужденците (и бежанците в частност) у нас.
Това е ситуацията, която завари настоящото правителство в началото на бежанската вълна от Украйна.
На фона на приоритетите за правосъдна реформа и борба с корупцията чужденците не бяха на дневен ред. Докато един ден украинските майки с деца не започнаха да идват у нас. За разлика от комай всички премиери в най-новата ни история, отношението на Кирил Петков към бежанците беше позитивно и приемащо, а не ксенофобско. Правителството предприе редица мерки за оптимизиране на работата на институциите, включително смени ръководството на Държавната агенция за бежанците.
Ала няма как цялата система за предоставяне на публични услуги, имащи отношение към бежанците, да се подмени като с магическа пръчица. В нея работят администратори, експерти и всевъзможни служители, много от които не могат да си представят, че трябва да служат на хората, а не да упражняват власт над тях, да ги дисциплинират, наказват и унижават. Това важи за публичните услуги в България като цяло, не само по отношение на бежанците, но спрямо най-уязвимите дехуманизиращото отношение достига невъобразими висини.
И неусетно правителството претърпя трансформация.
Вместо управляващите да успеят да реформират държавната администрация, свикнала, че над бежанците се издевателства по дефиниция, се получи обратното. Не успявайки да овладее бюрократичната и ксенофобска система, правителството неусетно възприе нейната реторика. Която неприятно напомня псевдопатриотичния патос на предишното управление, от чиито прийоми настоящата власт се опитва да се еманципира.
Тази неприятна еволюция обаче си има и обратна страна – управляващите поне се опитват да поемат лична отговорност за действията на администрацията, макар и по не най-подходящия начин. Провалът на първия опит за разселване на украинците и въвеждането на новите „дисциплиниращи“ мерки се представят лично от Калина Константинова.
Затова и в личността на Константинова се персонифицира цялата промяна на отношението към украинските бежанци,
която всъщност е плод на институционална некадърност. А тя – резултат на десетилетно възпроизвеждани вредни модели. Поведението на вицепремиерката не е похвално. Но то е само върхът на айсберга, чиято основа стига надълбоко, далеч отвъд настоящото правителство. По-лесно е да хвърляме вината върху един човек, отколкото да си даваме сметка за принципите на функциониране на социалната система, част от която впрочем сме и самите ние.
За управлението на Кирил Петков настоящата ситуация е тест – дали ще продължат усилията за „продължаване на промяната“, или системата ще претопи опитващите се да я реформират. Случващото се с украинските бежанци е само един пример за ситуацията в почти всяка сфера на държавата.
Заглавна снимка: Стопкадър от видеоизявлението на заместник министър-председателката по ефективно управление Калина Константинова
In an introductory article, we talked about the importance of Graph Networks in fraud detection. In this article, we will be adding some further context on graphs, graph technology and some common use cases.
Connectivity is the most prominent feature of today’s networks and systems. From molecular interactions, social networks and communication systems to power grids, shopping experiences or even supply chains, networks relating to real-world systems are not random. This means that these connections are not static and can be displayed differently at different times. Simple statistical analysis is insufficient to effectively characterise, let alone forecast, networked system behaviour.
As the world becomes more interconnected and systems become more complex, it is more important to employ technologies that are built to take advantage of relationships and their dynamic properties. There is no doubt that graphs have sparked a lot of attention because they are seen as a means to get insights from related data. Graph theory-based approaches show the concepts underlying the behaviour of massively complex systems and networks.
What are graphs?
Graphs are mathematical models frequently used in network science, which is a set of technological tools that may be applied to almost any subject. To put it simply, graphs are mathematical representations of complex systems.
Origin of graphs
The first graph was produced in 1736 in the city of Königsberg, now known as Kaliningrad, Russia. In this city, there were two islands with two mainland sections that were connected by seven different bridges.
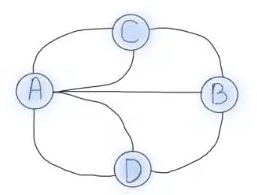
Famed mathematician Euler wanted to plot a journey through the entire city by crossing each bridge only once. Euler proceeded to abstract the four regions of the city and the seven bridges into edges but he demonstrated that the problem was unsolvable. A simplified abstract graph is shown in Fig 1.
Fig 1 Abstraction graph
The graph’s four dots represent Königsberg’s four zones, while the lines represent the seven bridges that connect them. Zones connected by an even number of bridges is clearly navigable because several paths to enter and exit are available. Zones connected by an odd number of bridges can only be used as starting or terminating locations because the same route can only be taken once.
The number of edges associated with a node is known as the node degree. If two nodes have odd degrees and the rest have even degrees, the Königsberg problem could be solved. For example, exactly two regions must have an even number of bridges while the rest have an odd number of bridges. However, as illustrated in Fig 1, no Königsberg location has an even number of bridges, rendering this problem unsolvable.
Definition of graphs
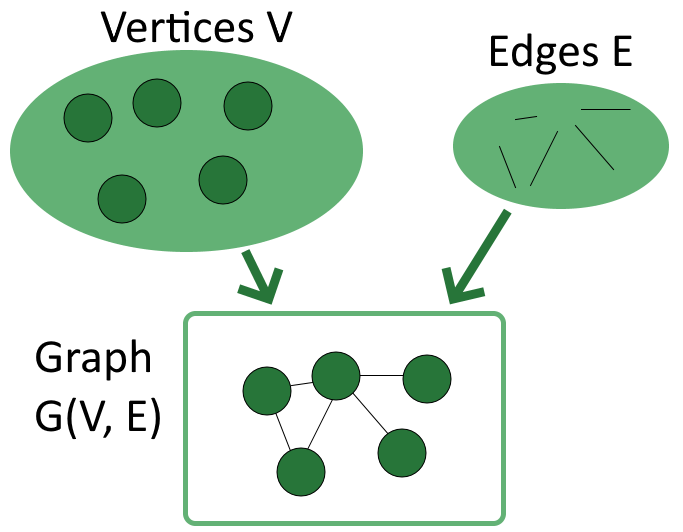
A graph is a structure that consists of vertices and edges. Vertices, or nodes, are the objects in a problem, while edges are the links that connect vertices in a graph.
Vertices are the fundamental elements that a graph requires to function; there should be at least one in a graph. Vertices are mathematical abstractions that refer to objects that are linked by a condition.
On the other hand, edges are optional as graphs can still be defined without any edges. An edge is a link or connection between any two vertices in a graph, including a connection between a vertex and itself. The idea is that if two vertices are present, there is a relationship between them.
We usually indicate V={v1, v2, …, vn} as the set of vertices, and E = {e1, e2, …, em} as the set of edges. From there, we can define a graph G as a structure G(V, E) which models the relationship between the two sets:
Fig 2 Graph structure
It is worth noting that the order of the two sets within parentheses matters, because we usually express the vertices first, followed by the edges. A graph H(X, Y) is therefore a structure that models the relationship between the set of vertices X and the set of edges Y, not the other way around.
Graph data model
Now that we have covered graphs and their typical components, let us move on to graph data models, which help to translate a conceptual view of your data to a logical model. Two common graph data formats are Resource Description Framework (RDF) and Labelled Property Graph (LPG).
Resource Description Framework (RDF)
RDF is typically used for metadata and facilitates standardised exchange of data based on their relationships. RDFs typically consist of a triple: a subject, a predicate, and an object. A collection of such triples is an RDF graph. This can be depicted as a node and a directed edge diagram, with each triple representing a node-edge-node graph, as shown in Fig 3.
Literals – data type value, i.e. text, integer, etc.
Blank nodes – have no identification; similar to anonymous or existential variables.
Let us use an example to illustrate this. We have a person with the name Art and we want to plot all his relationships. In this case, the IRI is http://example.org/art and this can be shortened by defining a prefix like ex.
In this example, the IRI http://xmlns.com/foaf/0.1/knows defines the relationship knows. We define foaf as the prefix for http://xmlns.com/foaf/0.1/. The following code snippet shows how a graph like this will look.
In the last two lines, you can see how a literal and blank node would be depicted in an RDF graph. The variable foaf:age is a literal node with the integer value of 23, while foaf:based_near is an anonymous spatial entity with a node identifier of underscore. Outside the context of this graph, o1 is a data identifier with no meaning.
Multiple IRIs, intended for use in RDF graphs, are typically stored in an RDF vocabulary. These IRIs often begin with a common substring known as a namespace IRI. In some cases, namespace IRIs are also associated with a short name known as a namespace prefix. In the example above, http://xmlns.com/foaf/0.1/ is the namespace IRI and foaf and ex are namespace prefixes.
Note: RDF graphs are considered atemporal as they provide a static snapshot of data. They can use appropriate language extensions to communicate information about events or other dynamic properties of entities.
An RDF dataset is a set of RDF graphs that includes one or more named graphs as well as exactly one default graph. A default graph is one that can be empty, and has no associated IRI or name, while each named graph has an IRI or a blank node corresponding to the RDF graph and its name. If there is no named graph specified in a query, the default graph is queried (hence its name).
Labelled Property Graph (LPG)
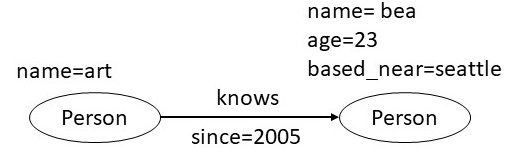
A labelled property graph is made up of nodes, links, and properties. Each node is given a label and a set of characteristics in the form of arbitrary key-value pairs. The keys are strings, and the values can be any data type. A relationship is then defined by adding a directed edge that is labelled and connects two nodes with a set of properties.
In Fig 4, we have an LPG that shows two nodes: art and bea. The bea node has two characteristics, age and proximity, that are connected by a known edge. This edge has the attribute since because it commemorates the year that art and bea first met.
Fig 4 Labelled Property Graph: Example 1
Nodes, edges and properties must be defined when designing an LPG data model. In this scenario, based_near might not be applicable to all vertices, but they should be defined. You might be wondering, why not represent the city Seattle as a node and add an edge marked as based_near that connects a person and the city?
In general, if there is a value linked to a large number of other nodes in the network and it requires additional properties to correlate with other nodes, it should be represented as a node. In this scenario, the architecture defined in Fig 5 is more appropriate for traversing based_near connections. It also gives us the ability to link any new attributes to the based_near relationship.
Fig 5 Labelled Property Graph: Example 2
Now that we have the context of graphs, let us talk about graph databases, how they help with large data queries and the part they play in Graph Technology.
Graph database
A graph database is a type of NoSQL database that stores data using network topology. The idea is derived from LPG, which represents data sets with vertices, edges, and attributes.
Vertices are instances or entities of data that represent any object to be tracked, such as people, accounts, locations, etc.
Edges are the critical concepts in graph databases which represent relationships between vertices. The connections have a direction that can be unidirectional (one-way) or bidirectional (two-way).
Properties represent descriptive information associated with vertices. In some cases, edges have properties as well.
Graph databases provide a more conceptual view of data that is closer to reality. Modelling complex linkages becomes simpler because interconnections between data points are given the same weight as the data itself.
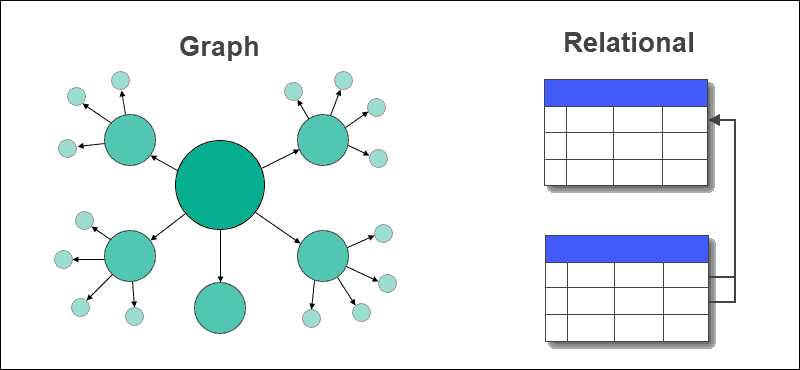
Graph database vs. relational database
Relational databases are currently the industry norm and take a structured approach to data, usually in the form of tables. On the other hand, graph databases are agile and focus on immediate relationship understanding. Neither type is designed to replace the other, so it is important to know what each database type has to offer.
Fig 6 Graph database vs relational database
There is a domain for both graph and relational databases. Graph databases outperform typical relational databases, especially in use cases involving complicated relationships, as they take a more naturalistic and flowing approach to data.
The key distinctions between graph and relational databases are summarised in the following table:
Type
Graph
Relational
Format
Nodes and edges with properties
Tables with rows and columns
Relationships
Represented with edges between nodes
Created using foreign keys between tables
Flexibility
Flexible
Rigid
Complex queries
Quick and responsive
Requires complex joins
Use case
Systems with highly connected relationships
Transaction focused systems with more straightforward relationships
Table. 1 Graph vs. Relational Databases
Advantages and disadvantages
Every database type has its advantages and disadvantages; knowing the distinctions as well as potential options for specific challenges is crucial. Graph databases are a rapidly evolving technology with improved functions compared with other database types.
Advantages
Some advantages of graph databases include:
Agile and flexible structures.
Explicit relationship representation between entities.
Real-time query output – speed depends on the number of relationships.
Disadvantages
The general disadvantages of graph databases are:
No standardised query language; depends on the platform used.
Not suitable for transactional-based systems.
Small user base, making it hard to find troubleshooting support.
Graph technology
Graph technology is the next step in improving analytics delivery. Traditional analytics is insufficient to meet complicated business operations, distribution, and analytical concerns as data quantities expand.
Graph technology aids in the discovery of unknown correlations in data that would otherwise go undetected or unanalysed. When the term graph is used to describe a topic, three distinct concepts come to mind: graph theory, graph analytics, and graph data management.
Graph theory – A mathematical notion that uses stack ordering to find paths, linkages, and networks of logical or physical objects, as well as their relationships. Can be used to model molecules, telephone lines, transport routes, manufacturing processes, and many other things.
Graph analytics – The application of graph theory to uncover nodes, edges, and data linkages that may be assigned semantic attributes. Can examine potentially interesting connections in data found in traditional analysis solutions, using node and edge relationships.
Graph database – A type of storage for data generated by graph analytics. Filling a knowledge graph, which is a model in data that indicates a common usage of acquired knowledge or data sets expressing a frequently held notion, is a typical use case for graph analytics output.
While the architecture and terminology are sometimes misunderstood, graph analytics’ output can be viewed through visualisation tools, knowledge graphs, particular applications, and even some advanced dashboard capabilities of business intelligence tools. All three concepts above are frequently used to improve system efficiency and even to assist in dynamic data management. In this approach, graph theory and analysis are inextricably linked, and analysis may always rely on graph databases.
Graph-centric user stories
Fraud detection
Traditional fraud prevention methods concentrate on discrete data points such as individual accounts, devices, or IP addresses. However, today’s sophisticated fraudsters avoid detection by building fraud rings using stolen and fake identities. To detect such fraud rings, we need to look beyond individual data points to the linkages that connect them.
Graph technology greatly transcends the capabilities of a relational database, by revealing hard-to-find patterns. Enterprise businesses also employ Graph technology to supplement their existing fraud detection skills to tackle a wide range of financial crimes, including first-party bank fraud, fraud, and money laundering.
Real-time recommendations
An online business’s success depends on systems that can generate meaningful recommendations in real time. To do so, we need the capacity to correlate product, customer, inventory, supplier, logistical, and even social sentiment data in real time. Furthermore, a real-time recommendation engine must be able to record any new interests displayed during the consumer’s current visit in real time, which batch processing cannot do.
Graph databases outperform relational and other NoSQL data stores in terms of delivering real-time suggestions. Graph databases can easily integrate different types of data to get insights into consumer requirements and product trends, making them an increasingly popular alternative to traditional relational databases.
Supply chain management
With complicated scenarios like supply chains, there are many different parties involved and companies need to stay vigilant in detecting issues like fraud, contamination, high-risk areas or unknown product sources. This means that there is a need to efficiently process large amounts of data and ensure transparency throughout the supply chain.
To have a transparent supply chain, relationships between each product and party need to be mapped out, which means there will be deep linkages. Graph databases are great for these as they are designed to search and analyse data with deep links. This means they can process enormous amounts of data without performance issues.
Identity and access management
Managing multiple changing roles, groups, products and authorisations can be difficult, especially in large organisations. Graph technology integrates your data and allows quick and effective identity and access control. It also allows you to track all identity and access authorisations and inheritances with significant depth and real-time insights.
Network and IT operations
Because of the scale and complexity of network and IT infrastructure, you need a configuration management database (CMDB) that is far more capable than relational databases. Neptune is an example of a CMDB and graph database that allows you to correlate your network, data centre, and IT assets to aid troubleshooting, impact analysis, and capacity or outage planning.
A graph database allows you to integrate various monitoring tools and acquire important insights into the complicated relationships that exist between various network or data centre processes. Possible applications of graphs in network and IT operations range from dependency management to automated microservice monitoring.
Risk assessment and monitoring
Risk assessment is crucial in the fintech business. With multiple sources of credit data such as ecommerce sites, mobile wallets and loan repayment records, it can be difficult to accurately assess an individual’s credit risk. Graph Technology makes it possible to combine these data sources, quantify an individual’s fraud risk and even generate full credit reviews.
One clear example of this is IceKredit, which employs artificial intelligence (AI) and machine learning (ML) techniques to make better risk-based decisions. With Graph technology, IceKredit has also successfully detected unreported links and increased efficiency of financial crime investigations.
Social network
Whether you’re using stated social connections or inferring links based on behaviour, social graph databases like Neptune introduce possibilities for building new social networks or integrating existing social graphs into commercial applications.
Having a data model that is identical to your domain model allows you to better understand your data, communicate more effectively, and save time. By decreasing the time spent data modelling, graph databases increase the quality and speed of development for your social network application.
Artificial intelligence (AI) and machine learning (ML)
AI and ML use statistical and analytical approaches to find patterns in data and provide insights. However, there are two prevalent concerns that arise – the quality of data and effectiveness of the analytics. Some AI and ML solutions have poor accuracy because there is not enough training data or variants that have a high correlation to the outcome.
These ML data issues can be solved with graph databases as it’s possible to connect and traverse links, as well as supplement raw data. With Graph technology, ML systems can recognise each column as a “feature” and each connection as a distinct characteristic, and then be able to identify data patterns and train themselves to recognise these relationships.
Conclusion
Graphs are a great way to visually represent complex systems and can be used to easily detect patterns or relationships between entities. To help improve graphs’ ability to detect patterns early, businesses should consider using Graph technology, which is the next step in improving analytics delivery.
Graph technology typically consists of:
Graph theory – Used to find paths, linkages and networks of logical or physical objects.
Graph analytics – Application of graph theory to uncover nodes, edges, and data linkages.
Graph database – Storage for data generated by graph analytics.
Although predominantly used in fraud detection, Graph technology has many other use cases such as making real-time recommendations based on consumer behaviour, identity and access control, risk assessment and monitoring, AI and ML, and many more.
Check out our next blog article, where we will be talking about how our Graph Visualisation Platform enhances Grab’s fraud detection methods.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Adding support for an in-kernel TLS
handshake was the topic of a combined storage and filesystem session at the 2022 Linux Storage,
Filesystem, Memory-management and BPF Summit (LSFMM). Chuck Lever and
Hannes Reinecke led the discussion on ways to add that support; they are
interested in order to provide TLS for network storage and filesystems.
But there are likely other features, such as QUIC support, that could use an in-kernel
TLS implementation.
I’d like to personally invite you to attend the Amazon Web Services (AWS) security conference, AWS re:Inforce 2022, in Boston, MA on July 26–27. This event offers interactive educational content to address your security, compliance, privacy, and identity management needs. Join security experts, customers, leaders, and partners from around the world who are committed to the highest security standards, and learn how to improve your security posture.
As the new Chief Information Security Officer of AWS, my primary job is to help our customers navigate their security journey while keeping the AWS environment safe. AWS re:Inforce offers an opportunity for you to understand how to keep pace with innovation in your business while you stay secure. With recent headlines around security and data privacy, this is your chance to learn the tactical and strategic lessons that will help keep your systems and tools secure, while you build a culture of security in your organization.
AWS re:Inforce 2022 will kick off with my keynote on Tuesday, July 26. I’ll be joined by Steve Schmidt, now the Chief Security Officer (CSO) of Amazon, and Kurt Kufeld, VP of AWS Platform. You’ll hear us talk about the latest innovations in cloud security from AWS and learn what you can do to foster a culture of security in your business. Take a look at the most recent re:Invent presentation, Continuous security improvement: Strategies and tactics, and the latest re:Inforce keynote for examples of the type of content to expect.
For those who are just getting started on AWS, as well as our more tenured customers, AWS re:Inforce offers an opportunity to learn how to prioritize your security investments. By using the Security pillar of the AWS Well-Architected Framework, sessions address how you can build practical and prescriptive measures to protect your data, systems, and assets.
Sessions are offered at all levels and for all backgrounds, from business to technical, and there are learning opportunities in over 300 sessions across five tracks: Data Protection & Privacy; Governance, Risk & Compliance; Identity & Access Management; Network & Infrastructure Security; and Threat Detection & Incident Response. In these sessions, connect with and learn from AWS experts, customers, and partners who will share actionable insights that you can apply in your everyday work. At AWS re:Inforce, the majority of our sessions are interactive, such as workshops, chalk talks, boot camps, and gamified learning, which provides opportunities to hear about and act upon best practices. Sessions will be available from the intermediate (200) through expert (400) levels, so you can grow your skills no matter where you are in your career. Finally, there will be a leadership session for each track, where AWS leaders will share best practices and trends in each of these areas.
At re:Inforce, hear directly from AWS developers and experts, who will cover the latest advancements in AWS security, compliance, privacy, and identity solutions—including actionable insights your business can use right now. Plus, you’ll learn from AWS customers and partners who are using AWS services in innovative ways to protect their data, achieve security at scale, and stay ahead of bad actors in this rapidly evolving security landscape.
A full conference pass is $1,099. However, if you register today with the code ALUMkpxagvkV you’ll receive a $300 discount (while supplies last).
We’re excited to get back to re:Inforce in person; it is emblematic of our commitment to giving customers direct access to the latest security research and trends. We’ll continue to release additional details about the event on our website, and you can get real-time updates by following @AWSSecurityInfo. I look forward to seeing you in Boston, sharing a bit more about my new role as CISO and providing insight into how we prioritize security at AWS.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
As you develop next-generation cloud-native applications and modernize existing workloads by migrating to cloud, you need cloud teams that can govern centrally with policies for security, compliance, operations and spend management.
In this edition of Let’s Architect!, we gather content to help software architects and tech leaders explore new ideas, case studies, and technical approaches to help you support production implementations for large-scale migrations.
A multi-account AWS environment helps businesses migrate, modernize, and innovate faster. With the large number of design choices, setting up a multi-account strategy can take a significant amount of time, because it involves configuring multiple accounts and services and requires a deep understanding of AWS.
This blog post shows you how AWS Control Tower helps customers achieve their desired business outcomes by setting up a scalable, secure, and governed multi-account environment. This post describes a strategic migration of 140 AWS accounts from customer Landing Zone to an AWS Control Tower-based solution.
Multi-account landing zone architecture that uses AWS Control Tower
How do you use your existing Microsoft Active Directory (AD) to reliably authenticate access for AWS accounts, infrastructure running on AWS, and third-party applications?
The architecture shown in this blog post is designed to be highly available and extends access to your existing AD to AWS, which enables your users to use their existing credentials to access authorized AWS resources and applications. This post highlights the importance of implementing a cloud authentication and authorization architecture that addresses the variety of requirements for an organization’s AWS Cloud environment.
Multi-account Complete AD architecture with trusts and AWS SSO using AD as the identity source
AWS customers often start their cloud journey with one AWS account, and over time they deploy many resources within that account. Eventually though, they’ll need to use more accounts and migrate resources across AWS Regions and accounts to reduce latency or increase resiliency.
This blog post shows four approaches to migrate resources based on type, configuration, and workload needs across AWS accounts.
As enterprises seek digital transformation, their efforts to use cloud technology within their organizations can be a bit disjointed. This video introduces you to the Cloud Center of Excellence (CCoE) and shows you how it can help transform your business via cloud adoption, migration, and operations. By using the CCoE, you’ll establish and us a cross-functional team of people for developing and managing your cloud strategy, governance, and best practices that your organization can use to transform the business using the cloud.
In May, we experienced three distinct incidents that resulted in significant impact and degraded state of availability to multiple services across GitHub.com. This report also sheds light into the billing incident that impacted GitHub Actions and Codespaces users in April.
May 20 09:44 UTC (lasting 49 minutes)
During this incident, our alerting systems detected increased CPU utilization on one of the GitHub Container registry databases. When we received the alert we immediately began investigating. Due to this preemptive monitoring added from the last incident in April at 8:59 UTC, the on-call was readily monitoring and prepared to run mitigation for this incident.
As CPU utilization on the database continued to rise, the Container registry began responding to requests with increased latency, followed by an internal server error for a percentage of requests. At this point we knew there was customer impact and changed the public status of the service. This increased CPU activity was due to a high volume of the “Put Manifest” command. Other package registries were not impacted.
The reason for the CPU utilization was that the throttling criteria configured at the API side for this command was too permissive, and a database query was found to be non-performant under that degree of scale. This caused an outage for anyone using the GitHub Container registry. Users were experiencing latency issues when pushing or pulling packages, as well as getting slow access to the packages UI.
In order to limit impact we throttled the requests from all organizations/users and to restore normal operation, we had to reset our database state by restarting our front-end servers and then the database.
To avoid this in the future, we have added separate rate limiting for operation types from specific organizations/users and will continue working on performance improvements for SQL queries.
May 27 04:26 UTC (lasting 21 minutes)
Our alerting systems detected degraded availability for API requests during this time. Due to the recency of these incidents, we are still investigating the contributing factors and will provide a more detailed update on the causes and remediations in the June Availability Report, which will be published the first Wednesday of July.
May 27 07:36 UTC (lasting 1 hour and 21 minutes)
During this incident, services including GitHub Actions, API Requests, Codespaces, Git Operations, Issues, GitHub Packages, GitHub Pages, Pull Requests, and Webhooks were impacted. As we continue to investigate the contributing factors, we will provide a more detailed update in the June Availability Report. We will also share more about our efforts to minimize the impact of similar incidents in the future.
Follow up to April 14 20:35 UTC (lasting 4 hours and 53 minutes)
As we mentioned in the April Availability Report, we are now providing a more detailed update on this incident following further investigation.
On April 14, GitHub Actions and Codespaces customers started reporting incorrect charges for metered services shown in their GitHub billing settings. As a result, customers were hitting their GitHub spending limits and unable to run new Actions or create new Codespaces. We immediately started an incident bridge. Our first step was to unblock all customers by giving unlimited Actions and Codespaces usage for no additional charge during the time of this incident.
From looking at the timing and list of recently pushed changes, we determined that the issue was caused by a code change in the metered billing pipeline. When attempting to improve performance of our metered usage processor, Actions and Codespaces minutes were mistakenly multiplied by 1,000,000,000 to convert gigabytes into bytes when this was not necessary for these products. This was due to a change to shared metered billing code that was not thought to impact these products.
To fix the issue, we reverted the code change and started repairing the corrupted data recorded during the incident. We did not re-enable metered billing for GitHub products until we had repaired the incorrect billing data, which happened 24 hours after this incident.
To prevent this incident in the future, we added a Rubocop (Ruby static code analyzer) rule to block pull requests containing non-safe billing code updates. In addition, we added anomaly monitoring for the billed quantity, so next time we are alerted before impacted customers. We also tightened the release process to require a feature flag and end-to-end test when shipping such changes.
In summary
We will continue to keep you updated on the progress and investments we’re making to ensure the reliability of our services. To receive real-time updates on status changes, please follow our status page. You can also learn more about what we’re working on on the GitHub Engineering Blog.
This post is written by Siarhei Kazhura, Solutions Architect and Riaz Panjwani, Solutions Architect.
Amazon EventBridge is a serverless event bus that can be used to ingest and process events from a variety of sources, such as AWS services and SaaS applications. With EventBridge, developers can build loosely coupled and independently scalable event-driven applications.
It can be useful to know with EventBridge when events are not able to reach the desired destination. This can be caused by multiple factors, such as:
Event pattern does not match the event rule
Event transformer failure
Event destination expects a different payload (for example, API destinations) and returns an error
EventBridge sends metrics to Amazon CloudWatch, which allows for the detection of failed invocations on a given event rule. You can also use EventBridge rules with a dead-letter queue (DLQ) to identify any failed event deliveries. The messages delivered to the queue contain additional metadata such as error codes, error messages, and the target ARN for debugging.
However, understanding why events fail to deliver is still a manual process. Checking CloudWatch metrics for failures, and then the DLQ takes time. This is evident when developing new functionality, when you must constantly update the event matching patterns and event transformers, and run tests to see if they provide the desired effect. EventBridge sandbox functionality can help with manual testing but this approach does not scale or help with automated event testing.
This post demonstrates how to automate testing for EventBridge events. It uses AWS Step Functions for orchestration, along with Amazon DynamoDB and Amazon S3 to capture the results of your events, Amazon SQS for the DLQ, and AWS Lambda to invoke the workflows and processing.
Overview
Using the solution provided in this post, users can track events from its inception to delivery and identify where any issues or errors are occurring. This solution is also customizable, and can incorporate integration tests against events to test pattern matching and transformations.
At a high level:
The event testing workflow is exposed via an API Gateway endpoint, and users can send a request.
This request is validated and routed to a Step Functions EventTester workflow, which performs the event test.
The EventTester workflow creates a sample event based on the received payload, and performs multiple tests on the sample event.
The sample event is matched against the rule that is being tested. The results are stored in an Amazon DynamoDB EventTracking table, and the transformed event payload is stored in the TransformedEventPayload Amazon S3 bucket.
The EventTester workflow has an embedded AWS Step Functions workflow called EventStatusPoller. The EventStatusPoller workflow polls the EventTracking table.
The EventStatusPoller workflow has a customizable 10-second timeout. If the timeout is reached, this may indicate that the event pattern does not match. EventBridge tests if the event does not match against a given pattern, using the AWS SDK for EventBridge.
After completing the tests, the response is formatted and sent back to the API Gateway. By default, the timeout is set to 15 seconds.
API Gateway processes the response, strips the unnecessary elements, and sends the response back to the issuer. You can use this response to verify if the test event delivery is successful, or identify the reason a failure occurred.
EventTester workflow
After an API call, this event is sent to the EventTester express workflow. This orchestrates the automated testing, and returns the results of the test.
In this workflow:
1. The test event is sent to EventBridge to see if the event matches the rule and can be transformed. The result is stored in a DynamoDB table. 2. The PollEventStatus synchronous Express Workflow is invoked. It polls the DynamoDB table until a record with the event ID is found or it reaches the timeout. The configurable timeout is 15 seconds by default. 3. If a record is found, it checks the event status.
From here, there are three possible states. In the first state, if the event status has succeeded:
4. The response from the PollEventStatus workflow is parsed and the payload is formatted. 5. The payload is stored in an S3 bucket. 6. The final response is created, which includes the payload, the event ID, and the event status. 7. The execution is successful, and the final response is returned to the user.
In the second state, if no record is found in the table and the PollEventStatus workflow reaches the timeout:
8. The most likely explanation for reaching the timeout is that the event pattern does not match the rule, so the event is not processed. You can build a test to verify if this is the issue. 9. From the EventBridge SDK, the TestEventPattern call is made to see if the event pattern matches the rule. 10. The results of the TestEventPattern call are checked. 11. If the event pattern does not match the rule, then the issue has been successfully identified and the response is created to be sent back to the user. If the event pattern matches the rule, then the issue has not been identified. 12. The response shows that this is an unexpected error.
In the third state, this acts as a catch-all to any other errors that may occur:
13. The response is created with the details of the unexpected error. 14. The execution has failed, and the final response is sent back to the user.
Event testing process
The following diagram shows how events are sent to EventBridge and their results are captured in S3 and DynamoDB. This is the first step of the EventTester workflow:
When the event is tested:
The sample event is received and sent to the EventBridge custom event bus.
A CatchAll rule is triggered, which captures all events on the custom event bus.
All events from the CatchAll rule are sent to a CloudWatch log group, which allows for an original payload inspection.
The event is also propagated to the EventTesting rule. The event is matched against the rule pattern, and if successful the event is transformed based on the transformer provided.
If the event is matched and transformed successfully, the Lambda function EventProcessor is invoked to process the transformed event payload. You can add additional custom code to this function for further testing of the event (for example, API integration with the transformed payload).
The event status is updated to SUCCESS and the event metadata is saved to the EventTracking DynamoDB table.
The transformed event payload is saved to the TransformedEventPayload S3 bucket.
If there’s an error, EventBridge sends the event to the SQS DLQ.
The Lambda function ErrorHandler polls the DLQ and processes the errors in batches.
The event status is updated to ERROR and the event metadata is saved to the EventTracking DynamoDB table.
The event payload is saved to the TransformedEventPayload S3 bucket.
EventStatusPoller workflow
When the poller runs:
It checks the DynamoDB table to see if the event has been processed.
The result of the poll is checked.
If the event has not been processed, the workflow loops and polls the DynamoDB table again.
If the event has been processed, the results of the event are passed to next step in the Event Testing workflow.
The EventTester workflow uses Express Workflows, which can handle testing high volume event workloads. For example, you can run the solution against large volumes of historical events stored in S3 or CloudWatch.
This can be achieved by using services such as Lambda or AWS Fargate to read the events in batches and run tests simultaneously. To achieve optimal performance, some performance tuning may be required depending on the scale and events that are being tested.
To minimize the cost of the demo, the DynamoDB table is provisioned with 5 read capacity units and 5 write capacity units. For a production system, consider using on-demand capacity, or update the provisioned table capacity.
Event sampling
In this implementation, the EventBridge EventTester can be used to periodically sample events from your system for testing:
Any existing rules that must be tested are provisioned via the AWS CDK.
The sampling rule is added to an existing event bus, and has the same pattern as the rule that is tested. This filters out events that are not processed by the tested rule.
SQS queue is used for buffering.
Lambda function processes events in batches, and can optionally implement sampling. For example, setting a 10% sampling rate will take one random message out of 10 messages in a given batch.
The event is tested against the endpoint provided. Note that the EventTesting rule is also provisioned via AWS CDK from the same code base as the tested rule. The tested rule is replicated into the EventTesting workflow.
The result is returned to a Lambda function, and is then sent to CloudWatch Logs.
A metric is set based on the number of ERROR responses in the logs.
An alarm is configured when the ERROR metric crosses a provided threshold.
This sampling can complement existing metrics exposed for EventBridge via CloudWatch.
Solution walkthrough
To follow the solution walkthrough, visit the solution repository. The walkthrough explains:
Prerequisites required.
Detailed solution deployment walkthrough.
Solution customization and testing.
Cleanup process.
Cost considerations.
Conclusion
This blog post outlines how to use Step Functions, Lambda, SQS, DynamoDB, and S3 to create a workflow that automates the testing of EventBridge events. With this example, you can send events to the EventBridge Event Tester endpoint to verify that event delivery is successful or identify the root cause for event delivery failures.
For more serverless learning resources, visit Serverless Land.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.