Regular
expressions are a common feature of computer languages, especially
higher-level languages like Ruby, Perl, Python, and others, for doing
fairly sophisticated text-pattern matching. Some languages, including
Perl,
incorporate regular expressions into the language itself,
while others have classes or libraries that come with the language
installation. Python’s standard library has the re module,
which provides facilities for working with regular expressions; as a recent
discussion on the python-ideas mailing shows, though, that module has
somewhat fallen by the wayside in recent times.
AWS is pleased to announce that 15 additional AWS services have achieved Provisional Authority to Operate (P-ATO) from the Federal Risk and Authorization Management Program (FedRAMP) Joint Authorization Board (JAB).
AWS is continually expanding the scope of our compliance programs to help customers use authorized services for sensitive and regulated workloads. AWS now offers 111 AWS services authorized in the AWS US East/West Regions under FedRAMP Moderate Authorization, and 91 services authorized in the AWS GovCloud (US) Regions under FedRAMP High Authorization.
Figure 1. Newly authorized services list
Descriptions of AWS Services now in FedRAMP P-ATO
These additional AWS services now provide the following capabilities for the U.S. federal government and customers with regulated workloads:
Amazon Detective simplifies analyzing, investigating, and quickly identifying the root cause of potential security issues or suspicious activities. Amazon Detective automatically collects log data from your AWS resources, and uses machine learning, statistical analysis, and graph theory to build a linked set of data enabling you to easily conduct faster and more efficient security investigations.
Amazon FSx for Lustre provides fully managed shared storage with the scalability and performance of the popular Lustre file system.
Amazon FSx for Windows File Server provides fully managed shared storage built on Windows Server, and delivers a wide range of data access, data management, and administrative capabilities.
Amazon Kendra is an intelligent search service powered by machine learning (ML).
Amazon Lex is an AWS service for building conversational interfaces into applications using voice and text.
Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect your sensitive data in AWS.
Amazon MQ is a managed message broker service for Apache ActiveMQ and RabbitMQ that simplifies setting up and operating message brokers on AWS.
AWS CloudHSM is a cloud-based hardware security module (HSM) that lets you generate and use your own encryption keys on the AWS Cloud.
AWS Cloud Map is a cloud resource discovery service. With Cloud Map, you can define custom names for your application resources, and CloudMap maintains the updated location of these dynamically changing resources.
AWS Glue DataBrew is a new visual data preparation tool that lets data analysts and data scientists quickly clean and normalize data to prepare it for analytics and machine learning.
AWS Outposts (hardware excluded) is a fully managed service that extends AWS infrastructure, services, APIs, and tools to customer premises. By providing local access to AWS managed infrastructure, AWS Outposts enables you to build and run applications on premises using the same programming interfaces used in AWS Regions, while using local compute and storage resources for lower latency and local data processing needs.
AWS Resource Groups grants you the ability to organize your AWS resources, managing and automating tasks for large numbers of resources at the same time.
AWS Snowmobile is an Exabyte-scale data transfer service used to move extremely large amounts of data to AWS. You can transfer up to 100PB per Snowmobile, a 45-foot long ruggedized shipping container, pulled by a semi-trailer truck. After an initial assessment, a Snowmobile will be transported to your data center and AWS personnel will configure it so it can be accessed as a network storage target. After you load your data, the Snowmobile is driven back to an AWS regional data center, where AWS imports the data into Amazon Simple Storage Service (Amazon S3).
A few years ago at Sydney Summit, I had an excellent question from one of our attendees. She asked me to help her design a cost-effective, reliable, and not overcomplicated solution for protection against simple bots for her web-facing resources on Amazon Web Services (AWS). I remember the occasion because with the release of AWS WAF Bot Control, I can now address the question with an elegant solution. The Bot Control feature now makes this a matter of switching it on to start filtering out common and pervasive bots that generate over 50 percent of the traffic against typical web applications.
Reduce Unwanted Traffic on Your Website with New AWS WAF Bot Control introduced AWS WAF Bot Control and some of its capabilities. That blog post covers everything you need to know about where to start and what elements it uses for configuration and protection. This post unpacks closely-related functionalities, and shares key considerations, best practices, and how to customize for common use cases. Use cases covered include:
Limiting the crawling rate of a bot leveraging labels and AWS WAF response headers
Enabling Bot Control only for certain parts of your application with scope down statements
Prioritizing verified bots or allowing only specific ones using labels
Inserting custom headers into requests from certain bots based on their labels
Key elements of AWS WAF Bot Control fine-tuning
Before moving on to precise configuration of the bot mitigation capability, it is important to understand the components that go into the process.
Labels
Although labels aren’t unique to Bot Control, the feature takes advantage of them, and many configurations use labels as the main input. A label is a string value that is applied to a request based on matching a rule statement. One way of thinking about them is as tags that belong to the specific request. The request acquires them after being processed by a rule statement, and can be used as identification of similar requests in all subsequent rules within the same web ACL. Labels enable you to act on a group of requests that meets specific criteria. That’s because the subsequent rules in the same web ACL have access to the generated labels and can match against them.
Labels go beyond just a mechanism for matching a rule. Labels are independent of a rule’s action, as they can be generated for Block, Allow, and Count. That opens up opportunities to filter or construct queries against records in AWS WAF logs based on labels, and so implement sophisticated analytics.
A label is a string made up of a prefix, optional namespace, and a name delimited by a colon. For example: prefix:[namespace:]name. The prefix is automatically added by AWS WAF.
AWS WAF Bot Control includes various labels and namespaces:
bot:category: Type of bot. For example, search_engine, content_fetcher
bot:name: Name of a specific bot (if available). For example, scrapy, mauibot, crawler4j
bot:verified: Verified bots are generally safe for web applications. For example, googlebot and linkedin. Bot Control performs validation to confirm that such bots come from the source that they claim, using the bot confirmation detection logic described later in this section.
By default, verified bots are not blocked by Bot Control, but you can use a label to block them with a custom rule.
signal: attributes of the request indicate a bot activity. For example, non_browser_user_agent, automated_browser
These labels are added through managed bot detection logic, and Bot Control uses them to perform the following:
Known bot categorization: Comparing the request user-agent to known bots to categorize and allow customers to block by category. Bots are categorized by their function, such as scrapers, search engines, social media.
Bot confirmation: Most respectable bots provide a way to validate beyond the user-agent, typically by doing a reverse DNS lookup of the IP address to confirm the validity of domain and host names. These automatic checks will help you to ensure that only legitimate bots are allowed, and provide a signal to flag requests to downstream systems for bot detection.
Header validation: Request headers validation is performed against a series of checks to look for missing headers, malformed headers, or invalid headers.
Browser signature matching: TLS handshake data and request headers can be deconstructed and partially recombined to create a browser signature that identifies browser and OS combinations. This signature can be validated against the user-agent to confirm they match, and checked against lists of known-good browser known-bad browser signatures.
Below are a few examples of labels that Bot Control has. You can obtain the full list by calling the DescribeManagedRuleGroup API.
Although Bot Control can be enabled and start protecting your web resources with the default Block action, you can switch all rules in the rule group into a Count action at the beginning. This accomplishes the following:
Avoids false positives with requests that might match one of the rules in Bot Control but still be a valid bot for your resource.
Allows you to accumulate enough data points in the form of labels and actions on requests with them, if some of the requests matched rules in Bot Control. That enables you to make informed decisions on constructing rules for each desired bot or category and when switching them into a default action is appropriate.
Labels can be looked up in Amazon CloudWatch metrics and AWS WAF logs, and as soon as you have them, you can start planning whether exceptions or any custom rules are needed to cater for a specific scenario. This blog post explores examples of such use cases in the Common use cases sections below.
Additionally, as AWS WAF processes rules in sequential order, you should consider where the Bot Control rule group is located in your web ACL. To filter out requests that you confidently consider unwanted, you can place AWS Managed Rules rule groups—such as the Amazon IP reputation list—before the Bot Control rule group in the evaluation order. This decreases the number of requests processed by Bot Control, and makes it more cost effective. Simultaneously, Bot Control should be early enough in the rules to:
Enable label generation for downstream rules. That also provides higher visibility as a side benefit.
Decrease false positives by not blocking desired bots before they reach Bot Control.
AWS WAF Bot Control fine-tuning wouldn’t be complete and configurable without a set of recently released features and capabilities of AWS WAF. Let’s unpack them.
How to work with labels in CloudWatch metrics and AWS WAF logs
Generated labels generate CloudWatch metrics and are placed into AWS WAF logs. It enables you to see what bots and categories hit your website, and the labels associated with them that you can use for fine tuning.
CloudWatch metrics are generated with the following dimensions and metrics.
Region dimension is available for all Regions except Amazon CloudFront. When web ACL is associated with CloudFront, metrics are in the Northern Virginia Region.
WebACL dimension is the name of the WebACL
Namespace is the fully qualified namespace, including the prefix
LabelValue is the label name
Action is the terminating action (for example, Allow, Block, Count)
AWS WAF includes a shortcut to associated CloudWatch metrics at the top of the Overview page, as shown in Figure 1.
Figure 1: Title and description of the chart in AWS WAF with a shortcut to CloudWatch
Alternatively, you can find them in the WAFV2 service category of the CloudWatch Metrics section.
CloudWatch displays generated labels and the volume across dates and times, so you can evaluate and make informed decisions to structure the rules or address false positives. Figure 2 illustrates what labels were generated for requests from bots that hit my website. This example configured only a couple of explicit Allow actions, so most of them were blocked. The top section of the figure 2 shows the load from two selected labels.
Figure 2: WAFV2 CloudWatch metrics for generated Label Namespaces
In AWS WAF logs, generated labels are included in an array under the field labels. Figure 3 shows an example request with the labels array at the bottom.
Figure 3: An example of an AWS WAF log record
This example shows three labels generated for the same request. Uptimerobot follows the monitoring category label, and combining these two labels is useful to provide flexibility for configurations based on them. You can use the whole category, or be laser-focused using the label of the specific bot. You will see how and why that matters later in this blog post. The third label, non_browser_user_agent, is a signal of forwarded requests that have extra headers. For protection from bots in conjunction with labels, you can construct extra scanning in your application for certain requests.
Scope-down statements
Given that Bot Control is a premium feature and is a paid AWS Managed Rules, the ability to keep your costs in control is crucial. The scope-down statement allows you to optimize for cost by filtering out any traffic that doesn’t require inspection by Bot Control.
To address this goal, you can use scope down statements that can be applied to two broad scenarios.
You can exclude certain parts of your resource from scanning by Bot Control. Think of parts of your web site that you don’t mind being accessed by bots, typically that would be static content, such as images and CSS files. Leaving protection on everything else, such as APIs and login pages. You can also exclude IP ranges that can be considered safe from bot management. For example, traffic that’s known to come from your organization or viewers that belong to your partners or customers.
Alternatively, you can look at this from a different angle, and only apply bot management to a small section of your resources. For example, you can use Bot Control to protect a login page, or certain sensitive APIs, leaving everything else outside of your bot management.
With all of these tools in our toolkit let’s put them into perspective and dive deep into use cases and scenarios.
Common use cases for AWS WAF Bot Control fine-tuning
There are several methods for fine tuning Bot Control to better meet your needs. In this section, you’ll see some of the methods you can use.
Limit the crawling rate
In some cases, it is necessary to allow bots access to your websites. A good example is search engine bots, that crawl the web and create an index. If optimization for search engines is important for your business, but you notice excessive load from too many requests hitting your web resource, you might face a dilemma of how to slow crawlers down without unnecessarily blocking them. You can solve this with a combination of Bot Control detection logic and a rate-based rule with a response status code and header to communicate your intention back to crawlers. Most crawlers that are deemed useful have a built-in mechanism to decrease their crawl rate when you detect and respond to increased load.
To customize bot mitigation and set the crawl rate below limits that might negatively affect your web resource
In the AWS WAF console, select Web ACLs from the left menu. Open your web ACL or follow the steps to create a web ACL.
Choose the Rules tab and select Add rules. Select Add managed rule groups and proceed with the following settings:
In the AWS managed rule groups section, select the switch Add to web ACL to enable Bot Control in the web ACL. This also gives you labels that you can use in other rules later in the evaluation process inside the web ACL.
Select Add rules and choose Save
In the same web ACL, select Add rules menu and select Add my own rules and rule groups.
Using the provided Rule builder, configure the following settings:
Enter a preferred name for the rule and select Rate-based rule.
Enter a preferred rate limit for the rule. For example, 500.
Note: The rate limit is the maximum number of requests allowed from a single IP address in a five-minute period.
Select Only consider requests that match the criteria in a rule statement to enable the scope-down statement to narrow the scope of the requests that the rule evaluates.
Under the Inspect menu, select Has a label to focus only on certain types of bots.
In the Match key field, enter one of the following labels to match based on broad categories, such as verified bots or all bots identified as scraping as illustrated on Figure 4:
Alternatively, you can narrow down to a specific bot using its label:
awswaf:managed:aws:bot-control:bot:name:Googlebot
Figure 4: Label match rule statement in a rule builder with a specific match key
In the Action section, configure the following settings:
Select Custom response to enable it.
Enter 429 as the Response code to indicate and communicate back to the bot that it has sent too many requests in a given amount of time.
Select Add new custom header and enter Retry-After in the Key field and a value in seconds for the Value field. The value indicates how many seconds a bot must wait before making a new request.
Select Add rule.
It’s important to place the rule after the Bot Control rule group inside your web ACL, so that the label is available in this custom rule.
In the Set rule priority section, check that the new rate-based rule is under the existing Bot Control rule set and if not, choose the newly created rule and select Move up or Move down until the rule is located after it.
Select Save.
Figure 5: AWS WAF rule action with a custom response code
With the preceding configuration, Bot Control sets required labels, which you then use in the scope-down statement in a rate-based rule to not only establish a ceiling of how many requests you will allow from specific bots, but also communicate to bots when their crawling rate is too high. If they don’t respect the response and lower their rate, the rule will temporarily block them, protecting your web resource from being overwhelmed.
Note: If you use a category label, such as scraping_framework, all bots that have that label will be counted by your rate-based rule. To avoid unintentional blocking of bots that use the same label, you can either narrow down to a specific bot with a precise bot:name: label, or select a higher rate limit to allow a greater margin for the aggregate.
Enable Bot Control only for certain parts of your application
As mentioned earlier, excluding parts of your web resource from Bot Control protection is a mechanism to reduce the cost of running the feature by focusing only on a subset of the requests reaching a resource. There are a few common scenarios that take advantage of this approach.
To run Bot Control only on dynamic parts of your traffic
In the AWS WAF console, select Web ACLs from the left menu. Open a web ACL that you have, or follow the steps to create a web ACL.
Choose the Rules tab and select Add rules. Then select Add managed rule groups to proceed with the following settings:
In the AWS managed rule groups section, select Add to web ACL to enable Bot Control in the web ACL.
Select Edit.
Select Scope-down statement – optional and select Enable Scope-down statement.
In If a request, select doesn’t match the statement (NOT).
In the Statement section, configure the following settings:
Choose URI path in the Inspect field.
For the Match type, choose Starts with string.
Depending on the structure of your resource, you can enter a whole URI string—such as images/—in the String to match field. The string will be excluded from Bot Control evaluation.
Figure 6: A scope-down statement to match based on a string that a URI path starts with
Select Save rule.
An alternative to using string matching
As an alternative to a string match type, you can use a regex pattern set. If you don’t have a regex pattern set, create one using the following guide.
Note: This pattern matches most common file extensions associated with static files for typical web resources. You can customize the pattern set if you have different file types.
Follow steps 1-4 of the previous procedure.
In the Statement section, configure the following settings:
Choose URI path in the Inspect field.
For the Match type, choose Matches pattern from regex pattern set and select your created set in the Regex pattern set. as illustrated in Figure 7.
In Regex pattern set, enter the pattern (?i)\.(jpe?g|gif|png|svg|ico|css|js|woff2?)$
Figure 7: A scope-down statement to match based on a regex pattern set as part of a URI path
To run Bot Control only on the most sensitive parts of your application.
Another option is to exclude almost everything, by only enabling the Bot Control on the most sensitive part of your application. For example, a login page.
Note: The actual URI path depends on the structure of your application.
Inside the Scope-down statement, in the If a request menu, select matches the statement.
In the Statement section:
In the Inspect field, select URI path.
For the Match type, select Contains string.
In the String to match field, enter the string you want to match. For example, login as shown in the Figure 8.
Choose Save rule.
Figure 8: A scope-down statement to match based on a string within a URI path
To exclude more than one part of your application from Bot Control.
If you have more than one part to exclude, you can use an OR logical statement to list each part in a scope-down statement.
Inside the Scope-down statement, in the If a request menu, select matches at least one of the statements (OR).
In the Statement 1 section, configure the following settings:
Choose URI path in the Inspect field.
For the Match type choose Contains string.
In the String to match field enter a preferred value. For example, login.
In the Statement 2 section, configure the following settings:
Choose URI path in the Inspect field.
For the Match type choose Starts with string.
In the String to match field enter a preferred URI value. For example, payment/.
Select Save rule.
Figure 9 builds on the previous example of an exact string match by adding an OR statement to protect an API named payment.
Figure 9: A scope-down statement with OR logic for more sophisticated matching
Note: The visual editor on the console supports up to five statements. To add more, edit the JSON representation of the rule on the console or use the APIs.
Prioritize verified bots that you don’t want to block
Since verified bots aren’t blocked by default, in most cases there is no need to apply extra logic to allow them through. However, there are scenarios where other AWS WAF rules might match some aspects of requests from verified bots and block them. That can hurt some metrics for SEO, or prevent links from your website from properly propagating and displaying in social media resources. If this is important for your business, then you might want to ensure you protect verified bots by explicitly allowing them in AWS WAF.
To prioritize the verified bots category
In the AWS WAF menu, select Web ACLs from the left menu. Open a web ACL that you have, or follow the steps to create a web ACL. The next steps assume you already have a Bot Control rule group enabled inside the web ACL.
In the web ACL, select Add rules, and then select Add my own rules and rule groups.
Using the provided Rule builder, configure the following settings:
Enter a name for the rule in the Name field.
Under the Inspect menu, select Has a label.
In the Match key field, enter the following label to match based on the label that each verified bot has:
awswaf:managed:aws:bot-control:bot:verified
In the Action section, select Allow to confirm the action on a request match
Select Add rule. It’s important to place the rule after the Bot Control rule group inside your web ACL, so that the bot:verified label is available in this custom rule. To complete this, configure the following steps:
In the Set rule priority section, check that the rule you just created is listed immediately after the existing Bot Control rule set. If it’s not, choose the newly created rule and select Move up or Move down until the rule is located immediately after the existing Bot Control rule set.
Select Save.
Figure 10: Label match rule statement in a Rule builder with a specific match key
Allow a specific bot
Labels also enable you to single out the bot you don’t want to block from the category that is blocked. One of the common examples are third-party bots that perform monitoring of your web resources.
Let’s take a look at a scenario where UptimeRobot is used to allow a specific bot. The bot falls into a category that’s being blocked by default—bot:category:monitoring. You can either exclude the whole category, which can have a wider impact on resource than you want, or allow only UptimeRobot.
To explicitly allow a specific bot
Analyze CloudWatch metrics or AWS WAF logs to find the bot that is being blocked and its associated labels. Unless you want to allow the whole category, the label you would be looking for is bot:name: The example that follows is based on the label awswaf:managed:aws:bot-control:bot:name:uptimerobot.
From the logs, you can also verify which category the bot belongs to, which is useful for configuring Scope-down statements.
In the AWS WAF console, select Web ACLs from the left menu. Open a web ACL that you have, or follow the steps to create a web ACL. For the next steps, it’s assumed that you already have a Bot Control rule group enabled inside the webACL.
Open the Bot Control rule set in the list inside your web ACL and choose Edit
From the list of Rules find CategoryMonitoring and set to Count. This will prevent the default block action of the category.
Select Scope-down statement – optional andselect Scope-down statement. Then configure the following settings:
Inside the Scope-down statement, in the If a request menu, choose matches all the statements (AND). This will allow you to construct the complex logic necessary to block the category but allow a specified bot.
In the Statement 1 section under the Inspect menu select Has a label.
In the Match key field, enter the label of the broad category that you set to count in step number 4. In this example, it is monitoring. This configuration will keep other bots from the category blocked:
In the Statement 2 section, select Negate statement results to allow you to exclude a specific bot.
Under the Inspect menu, select Has a label.
In the Match key field, enter the label that will uniquely identify the bot you want to explicitly allow. In this example, it’s uptimerobot with the following label:
Figure 11: Label match rule statement with AND logic to single out a specific bot name from a category
Note: This approach is the best practice for analyzing and, if necessary, addressing false positives situations. You can apply exclusion to any bot, or multiple bots, based on the unique bot:name: label.
Insert custom headers into requests from certain bots
There are situations when you want to further process or analyze certain requests. or implement logic that is provided by systems in the downstream. In such cases, you can use AWS WAF Bot Control to categorize the requests. Applications later in the process can then apply the intended logic on either a broad group of requests, such as all bots within a category, or as narrow as a certain bot.
To insert a custom header
In the AWS WAF console, select Web ACLs from the left menu. Open a web ACL that you have, or follow the steps to create a web ACL. The next steps assume that you already have Bot Control rule group enabled inside the webACL.
Open the Bot Control rule set in the list inside your web ACL and choose Edit.
From the list of Rules set the targeted category to Count.
Choose Save rule.
In the same web ACL, choose the Add rules menu and select Add my own rules and rule groups.
Using the provided Rule builder, configure the following settings:
Enter a name for the rule in the Name field.
Under the Inspect menu, select Has a label.
In the Match key field, enter the label to match either a targeted category or a bot. This example uses the security category label: awswaf:managed:aws:bot-control:bot:category:security
In the Action section, select Count
Open Custom request – optional and select Add new custom header
Enter values in the Key and Value fields that correspond to the inserted custom header key-value pair that you want to use in downstream systems. The example in Figure 12 shows this configuration.
Choose Add rule.
AWS WAF prefixes your custom header names with x-amzn-waf- when it inserts them, so when you add abc-category, your downstream system sees it as x-amzn-waf-abc-category.
Figure 12: AWS WAF rule action with a custom header inserted by the service
The custom rule located after Bot Control now inserts the header into any request that it labeled as coming from bots within the security category. Then the security appliance that is after AWS WAF acts on the requests based on the header, and processes them accordingly.
This implementation can serve other scenarios. For example, using your custom headers to communicate to your Origin to append headers that will explicitly prevent caching certain content. That makes bots always get it from the Origin. Inserted headers are accessible within AWS Lambda@Edge functions and CloudFront Functions, this opens up advanced processing scenarios.
Conclusion
This post describes the primary building blocks for using Bot Control, and how you can combine and customize them to address different scenarios. It’s not an exhaustive list of the use cases that Bot Control can be fine-tuned for, but hopefully the examples provided here inspire and provide you with ideas for other implementations.
If you already have AWS WAF associated with any of your web-facing resources, you can view current bot traffic estimates for your applications based on a sample of requests currently processed by the service. Visit the AWS WAF console to view the bot overview dashboard. That’s a good starting point to consider implementing learnings from this blog to improve your bot protection.
It is early days for the feature, and it will keep gaining more capabilities, stay tuned!
If you have feedback about this blog post, submit comments in the Comments section below. If you have questions about this blog post, start a new thread on AWS WAF re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
With CrashPlan sunsetting its On-Premises backup service as of February 28, 2022, customers have some choices to make about how to handle their backups moving forward. As you think about the options—all of which require IT managers to embrace a change—we’d be remiss if we didn’t say Backblaze is ready to help with our Business Backup service for workstations. It’s quick and easy to switch over to, easy to run automatically ongoing, and cost effective.
If you’re a CrashPlan customer but you need a new backup solution, read on to understand your options. If you’re interested in working with us, you can transition from CrashPlan to Backblaze in six simple steps outlined below to protect all employee workstations from accidental data loss or ransomware, automatically and affordably.
What Options Do CrashPlan Customers Have?
CrashPlan customers have two options: transfer to CrashPlan’s Cloud Backup Service or transfer to another vendor. CrashPlan customers have until March 1, 2022 to make the decision and get started. After March 1, CrashPlan customers will lose support for their backup software. If any issues arise with backing up or restoring data, you won’t receive support to help fix the situation from CrashPlan.
CrashPlan’s Cloud Backup Service starts at $10 per endpoint per month for 0-100 endpoints, and is tiered after that. For customers looking for different pricing options or features, some CrashPlan alternatives include Carbonite and iDrive, both of which are offering promotions to attract CrashPlan customers. Keep in mind that once these promotions expire, you’re stuck paying the full price which may be higher than others. And, of course, Backblaze is an option as well.
Transferring from CrashPlan to Backblaze
So, what makes Backblaze a great fit for CrashPlan customers? We’ll share a few reasons. If you are already convinced, you can get started now by following the getting started guide in the next section of this post. If not, here are some of the benefits you’ll get with Backblaze:
Unlimited and Automatic: Lightweight Mac and PC clients back up all user data by default and are Java-free for stability—no system slow-downs or crashes.
Easy Admin and Restores: Transition in a few simple steps then easily manage and deploy at scale via a centralized admin console by choosing from a number of mass-deployment tools with multiple restore options.
Affordable and Predictable: Protect all employee workstations for just $70/computer, with no surprise charges, plus monthly, yearly, or two-year billing flexibility to suit your needs.
Safe and Secure: Defend your business data from ransomware and other threats with single sign-on, two-factor authentication, encryption at rest, encryption in transit, and ransomware protection.
Live Support: Make your transition easy with support during your transition and deployment via our customer service team and solution engineers.
Backblaze has been in the backup business for 15 years, and businesses ranging from PagerDuty to Charity: Water to Roush Auto Group rely on us for their data protection. Former CrashPlan customers who recently transitioned to Backblaze are getting the value they expected. Recently, Richard Charbonneau of Clicpomme spoke of the ease and simplicity he gained from switching:
“All our clients are managed by MDM or Munki, so it was really easy for us just to push the uninstaller for CrashPlan and package the new installer for Backblaze for every client.”
– Richard Charbonneau, Founder, Clicpomme
We invite you to join them.
Ready to Get Started?
How to Transition to Backblaze: Getting Started
You can “version off” of CrashPlan and “version on” to Backblaze Business Backup, making for a seamless transition. Simply create and configure an account with Backblaze to start backing up all employee workstations, and let CrashPlan lapse when they sunset On-Premises support on February 28.
You can retain your CrashPlan backups on premises for however long your retention policies stipulate in case you need to restore (or just deprecate those altogether if you’d rather use your on-premises storage servers for something else—it’s up to you!). Then, with Backblaze set up in parallel, you can start relying on Backblaze moving forward.
Here’s how to get started with Backblaze Business Backup.
Enter an email address and password. Then click Create Account with Groups Enabled.
You will receive a verification email. When you do, enter the code provided.
Now, create a Group for your users. There are a few reason to create a group or groups for your users, including:
To establish separate retention periods.
To use different billing methods for different groups.
To give different kinds of users customized access.
To keep your users organized according to your needs.
Choose how many licenses you would like to purchase in the Computers to Backup field, select your retention plan under Version History, then click Add a Billing Method and enter your information. When you are done, click Buy and Next (If you are not ready to proceed with adding a payment method, feel free to click “Skip Payment & Try for Free”, this will allow you to try out the product for 15 days with full functionality.)
Now that your Group is created, you have some options on how to invite users into the group. You can:
Backblaze offers a number of different deployment options to give you the most flexibility when deciding how to deploy the Backblaze client to your machines. It can be as simple as sending the invite link via Slack or in a personally crafted email to a handful of users. You can use our Invite Email option to just add email addresses to a canned invite. Or you can deploy via a silent install using RMM tools such as JAMF, SCCM, Munki and others to deploy the software to your end users. Assistance is always available from our solution engineers to help guide you through the deployment process.
Additional Configuration Considerations
With Backblaze Business Backup, you can customize your groups’ administrative access. Specify who has administrator privileges to a group simply by adding an email address to the group settings. As a group administrator, you have the ability to assist your users with restores and be aware of issues when they arise.
You can also integrate with your Single Sign-on provider—either Google or Microsoft—in the settings to improve security, reduce support calls, and free users from having to remember yet another password.
An Invitation to Try Backblaze
If you are a CrashPlan user looking to transition to a new cloud backup service for your workstations, Backblaze makes moving to the cloud easy. Reach out to us at any time for help transitioning and getting started.
The US National Cyber Director Chris Inglis wrote an essay outlining a new social contract for the cyber age:
The United States needs a new social contract for the digital age — one that meaningfully alters the relationship between public and private sectors and proposes a new set of obligations for each. Such a shift is momentous but not without precedent. From the Pure Food and Drug Act of 1906 to the Clean Air Act of 1963 and the public-private revolution in airline safety in the 1990s, the United States has made important adjustments following profound changes in the economy and technology.
A similarly innovative shift in the cyber-realm will likely require an intense process of development and iteration. Still, its contours are already clear: the private sector must prioritize long-term investments in a digital ecosystem that equitably distributes the burden of cyberdefense. Government, in turn, must provide more timely and comprehensive threat information while simultaneously treating industry as a vital partner. Finally, both the public and private sectors must commit to moving toward true collaboration — contributing resources, attention, expertise, and people toward institutions designed to prevent, counter, and recover from cyber-incidents.
The devil is in the details, of course, but he’s 100% right when he writes that the market cannot solve this: that the incentives are all wrong. While he never actually uses the word “regulation,” the future he postulates won’t be possible without it. Regulation is how society aligns market incentives with its own values. He also leaves out the NSA — whose effectiveness rests on all of these global insecurities — and the FBI, whose incessant push for encryption backdoors goes against his vision of increased cybersecurity. I’m not sure how he’s going to get them on board. Or the surveillance capitalists, for that matter. A lot of what he wants will require reining in that particular business model.
In 2021, data breaches soared past 2020 levels. This year, it’s expected to be worse. The odds are stacked against this poor guy (and you) now – but a unified extended detection and response (XDR) and SIEM restacks them in your favor.
Go to this resource-rich page for smart, fast information, and a few minutes of fun too. Don’t miss it.
Still here on this page reading? Fine, let’s talk about you.
Most CISOs like adrenaline, but c’mon
Cybersecurity isn’t for the fragile foam flowers among us, people who require shade and soft breezes. A little chaos is fun. Adrenaline and cortisol? They give you heightened physical and mental capacity. But it becomes problematic when it doesn’t stop, when you don’t remember your last 40-hour week, or when weekends and holidays are wrecked.
Work-life balance programs are funny, right?
A lot of your co-workers may be happy, but life in the SOC is its own thing. CISOs average about two years in their jobs. And 40% admit job stress has affected their relationships with their partners and/or children.
Many of your peers agree: Unified SIEM and XDR changes everything
A whopping 88% of Rapid7 customers say their detection and response has improved since they started using InsightIDR. And 93% say our unified SIEM and XDR has helped them level up and advance security programs.
You have the power to change your day. See how this guy did.
The Internet is accustomed to the fact that any two parties can exchange information securely without ever having to meet in advance. This magic is made possible by key exchange algorithms, which are core to certain protocols, such as the Transport Layer Security (TLS) protocol, that are used widely across the Internet.
Key exchange algorithms are an elegant solution to a vexing, seemingly impossible problem. Imagine a scenario where keys are transmitted in person: if Persephone wishes to send her mother Demeter a secret message, she can first generate a key, write it on a piece of paper and hand that paper to her mother, Demeter. Later, she can scramble the message with the key, and send the scrambled result to her mother, knowing that her mother will be able to unscramble the message since she is also in possession of the same key.
But what if Persephone is kidnapped (as the story goes) and cannot deliver this key in person? What if she can no longer write it on a piece of paper because someone (by chance Hades, the kidnapper) might read that paper and use the key to decrypt any messages between them? Key exchange algorithms come to the rescue: Persephone can run a key exchange algorithm with Demeter, giving both Persephone and Demeter a secret value that is known only to them (no one else knows it) even if Hades is eavesdropping. This secret value can be used to encrypt messages that Hades cannot read.
The most widely used key exchange algorithms today are based on hard mathematical problems, such as integer factorization and the discrete logarithm problem. But these problems can be efficiently solved by a quantum computer, as we have previously learned, breaking the secrecy of the communication.
There are other mathematical problems that are hard even for quantum computers to solve, such as those based on lattices or isogenies. These problems can be used to build key exchange algorithms that are secure even in the face of quantum computers. Before we dive into this matter, we have to first look at one algorithm that can be used for Key Exchange: Key Encapsulation Mechanisms (KEMs).
Two people could agree on a secret value if one of them could send the secret in an encrypted form to the other one, such that only the other one could decrypt and use it. This is what a KEM makes possible, through a collection of three algorithms:
A key generation algorithm, Generate, which generates a public key and a private key (a keypair).
An encapsulation algorithm, Encapsulate, which takes as input a public key, and outputs a shared secret value and an “encapsulation” (a ciphertext) of this secret value.
A decapsulation algorithm, Decapsulate, which takes as input the encapsulation and the private key, and outputs the shared secret value.
A KEM can be seen as similar to a Public Key Encryption (PKE) scheme, since both use a combination of public and private keys. In a PKE, one encrypts a message using the public key and decrypts using the private key. In a KEM, one uses the public key to create an “encapsulation” — giving a randomly chosen shared key — and one decrypts this “encapsulation” with the private key. The reason why KEMs exist is that PKE schemes are usually less efficient than symmetric encryption schemes; one can use a KEM to only transmit the shared/symmetric key, and later use it in a symmetric algorithm to efficiently encrypt data.
Nowadays, in most of our connections, we do not use KEMs or PKEs per se. We either use Key Exchanges (KEXs) or Authenticated Key Exchanges (AKE). The reason for this is that a KEX allows us to use public keys (solving the key exchange problem of how to securely transmit keys) in order to generate a shared/symmetric key which, in turn, will be used in a symmetric encryption algorithm to encrypt data efficiently. A famous KEX algorithm is Diffie-Hellman, but classical Diffie-Hellman based mechanisms do not provide security against a quantum adversary; post-quantum KEMs do.
When using a KEM, Persephone would run Generate and publish the public key. Demeter takes this public key, runs Encapsulate, keeps the generated secret to herself, and sends the encapsulation (the ciphertext) to Persephone. Persephone then runs Decapsulate on this encapsulation and, with it, arrives at the same shared secret that Demeter holds. Hades will not be able to guess even a bit of this secret value even if he sees the ciphertext.
In this post, we go over the construction of one particular post-quantum KEM, called FrodoKEM. Its design is simple, which makes it a good choice to illustrate how a KEM can be constructed. We will look at it from two perspectives:
The underlying mathematics: a cryptographic algorithm is built as a Matryoshka doll. The first doll is, most of the time, the mathematical base, which hardness should be strong so that security is maintained. In the post-quantum world, this is usually the hardness of some lattice problems (more on this in the next section).
The algorithmic construction : these are all the subsequent dolls that take the mathematical base and construct an algorithm out of it. In the case of a KEM, first you construct a Public Key Encryption (PKE) scheme and transform it (putting another doll on top) to make a KEM, so better security properties are attained, as we will see.
The core of FrodoKEM is a public-key encryption scheme called FrodoPKE, whose security is based on the hardness of the “Learning with Errors” (LWE) problem over lattices. Let us look now at the first doll of a KEM.
Note to the reader: Some mathematics is coming in the next sections, but do not worry, we will guide you through it.
The Learning With Errors Problem
The security (and mathematical foundation) of FrodoKEM relies on the hardness of the Learning With Errors (LWE) problem, a generalization of the classic Learning Parities with Noise problem, first defined by Regev.
In cryptography, specifically in the mathematics underlying it, we often use sets to define our operations. A set is a collection of any element, in this case, we will refer to collections of numbers. In cryptography textbooks and articles, one can often read:
Let $Z_q$ denote the set of integers $\{0, …, q-1\}$ where $(q > 2)$,
which means that we have a collection of integers from 0 to a number q (which has to be bigger than 2. It is assumed that q, in a cryptographic application, is a prime. In the main theorem, it is an arbitrary integer).
Let $\{Z^n\}_q$ denote a vector $(v1, v2, …, vn)$ of n elements, each of which belongs to $Z_q$.
The LWE problem asks to recover a secret vector $s = (s1, s2, …, sn)$ in $\{Z^n\}_q$ given a sequence of random, “approximate” linear equations on s. For instance, if $(q = 23)$ the equations might be:
[s1 + s2 + s3 + s4 ≈ 30 (mod 23)
2s1 + s3 + s5 + … + sn ≈ 40 (mod 23)
10s2 + 13s3 + 1s4 ≈ 50 (mod 23)
…]
We see the left-hand sides of the equations above are not exactly equal to the right-hand side (the equality sign is not used but rather the “≈” sign: approximately equal to); they are off by an introduced slight “error”, (which will be defined as the variable e. In the equations above, the error is, for example, the number 10). If the error was a known, public value, recovering s (the hidden variable) would be easy: after about n equations, we can recover s in a reasonable time using Gaussian elimination. Introducing this unknown error makes the problem difficult to solve (it is difficult with accuracy to find s), even for quantum computers.
An equivalent formulation of the LWE problem is:
There exists a vector s in $\{Z^n\}_q$, called the secret (the hidden variable).
There exists random variables a.
χ is a distribution, e is the integer error introduced from the distribution χ.
You have: (a, ⟨a, s⟩ + e). ⟨a, s⟩ is the inner product modulo q of s and a.
Given ⟨a, s⟩ + e ≈ b, the input to the problem is a and b, the goal is to output a guess for s which is very hard to achieve with accuracy.
There are two main kinds of computational LWE problems that are difficult to solve for quantum computers (given certain choices of both q and χ):
Search, which is to recover the secret/hidden variable s by only being given a certain number of samples drawn from the distribution χ.
Decision, which is to distinguish a certain number of samples drawn from the distribution (a, ⟨a, s⟩ + e) from random samples.
The LWE problem: search and decision.
LWE is just noisy linear algebra, and yet it seems to be a very hard problem to solve. In fact, there are many reasons to believe that the LWE problem is hard: the best algorithms for solving it run in exponential time. It also is closely related to the Learning Parity with Noise (LPN) problem, which is extensively studied in learning theory, and it is believed to be hard to solve (any progress in breaking LPN will potentially lead to a breakthrough in coding theory). How does it relate to building cryptography? LWE is applied to the cryptographic applications of the type of public-key. In this case, the secret value s becomes the private key, and the values bi and ei are the public key.
So, why is this problem related to lattices? In other blog posts, we have seen that certain algorithms of post-quantum cryptography are based on lattices. So, how does LWE relate to them? One can view LWE as the problem of decoding from random linear codes, or reduce it to lattices, in particular to problems such as the Short Vector Problem (SVP) or the Shortest independent vectors problem (SIVP): an efficient solution to LWE implies a quantum algorithm to SVP and SIVP. In other blog posts, we talk about SVP, so, in this one, we will focus on the random bounded distance decoding problem on lattices.
Lattices (as seen in the image), as a regular and periodic arrangement of points in space, have emerged as a foundation of cryptography in the face of quantum adversaries; one modern problem in which they rely on is the Bounded Distance Decoding (BDD) problem. In the BDD problem, you are given a lattice with an arbitrary basis (a basis is a list of vectors that generate all the other points in a lattice. In the case of the image, it is the pair of vectors b1 and b2). You are then given a vector b3 on it. You then perturb the lattice point b3 by adding some noise (or error) to give x. Given x, the goal is to find the nearest lattice point (in this case b3), as seen in the image. In this case, LWE is an average-case form of BDD (Regev also gave a worst-case to average-case reduction from BDD to LWE: the security of a cryptographic system is related to the worst-case complexity of BDD).
The first doll is built. Now, how do we build encryption from this mathematical base? From LWE, we can build a public key encryption algorithm (PKE), as we will see next with FrodoPKE as an example.
Public Key Encryption: FrodoPKE
The second doll of the Matryoshka is using a mathematical base to build a Public Key Encryption algorithm from it. Let’s look at FrodoPKE. FrodoPKE is a public-key encryption scheme which is the building block for FrodoKEM. It is made up of three components: key generation, encryption, and decryption. Let’s say again that Persephone wants to communicate with Demeter. They will run the following operations:
Generation: Generate a key pair by taking a LWE sample (like (A, B = As + e mod q)). The public key is A, B and the private key is s. Persephone sends this public key to Demeter.
Encryption: Demeter receives this public key and wants to send a private message with it, something like “come back”. She generates two secret vectors ((s1, e1) and (e2)). She then:
Makes the sample (b1 = As1 + e1 mod q).
Makes the sample (v1 = Bs1 + e2 mod q).
Adds the message m to the most significant bit of v1.
Sends b1 and v1 to Persephone (this is the ciphertext).
Decryption: Persephone receives the ciphertext and proceeds to:
Calculate m = v1 – b1 * s and is able to recover the message, and she proceeds to leave to meet her mother.
Notice that computing v = v1- b1 * s gives us m + e2 (the message plus the error matrix sampled during encryption). The decryption process performs rounding, which will output the original message m if the error matrix e2 is carefully chosen. If not, notice that there is the potential of decryption failure.
What kind of security does this algorithm give? In cryptography, we design algorithms with security notions in mind, notions they have to attain. This algorithm, FrodoPKE (as with other PKEs), satisfies only IND-CPA (Indistinguishability under chosen-plaintext attack) security. Intuitively, this notion means that a passive eavesdropper listening in can get no information about a message from a ciphertext. Even if the eavesdropper knows that a ciphertext is an encryption of just one of two messages of their choice, looking at the ciphertext should not tell the adversary which one was encrypted. We can also think of it as a game:
A gnome can be sitting inside a box. This box takes a message and produces a ciphertext. All the gnome has to do is record each message and the ciphertext they see generated. An outside-of-the-box adversary, like a troll, wants to beat this game and know what the gnome knows: what ciphertext is produced if a certain message is given. The troll chooses two messages (m1 and m2) of the same length and sends them to the box. The gnome records the box operations and flips a coin. If the coin lands on its face, then they send the ciphertext (c1) corresponding to m1. Otherwise, they send c2 corresponding to m2. The troll, knowing the messages and the ciphertext, has to guess which message was encrypted.
IND-CPA security is not enough for all secure communication on the Internet. Adversaries can not only passively eavesdrop, but also mount chosen-ciphertext attacks (CCA): they can actively modify messages in transit and trick the communicating parties into decrypting these modified messages, thereby obtaining a decryption oracle. They can use this decryption oracle to gain information about a desired ciphertext, and so compromise confidentiality. Such attacks are practical and all that an attacker has to do is, for example, send several million test ciphertexts to a decryption oracle, see Bleichenbacher’s attack and the ROBOT attack, for example.
Without CCA security, in the case of Demeter and Persephone, what this security means is that Hades can generate and send several million test ciphertexts to the decryption oracle and eventually reveal the content of a valid ciphertext that Hades did not generate. Demeter and Persephone then might not want to use this scheme.
Key Encapsulation Mechanisms: FrodoKEM
The last figure of the Matryoshka doll is taking a secure-against-CPA scheme and making it secure against CCA. A secure-against-CCA scheme must not leak information about its private key, even when decrypting arbitrarily chosen ciphertexts. It must also be the case that an adversary cannot craft valid ciphertexts without knowing what the plaintext message is; suppose, again, that the adversary knows the messages encrypted could only be either m0 or m1. If the attacker can craft another valid ciphertext, for example, by flipping a bit of the ciphertext in transit, they can send this modified ciphertext, and see whether a message close to m1 or m0 is returned.
To make a CPA scheme secure against CCA, one can use the Hofheinz, Hovelmanns, and Kiltz (HHK) transformations (see this thesis for more information). The HHK transformation constructs an IND-CCA-secure KEM from both an IND-CPA PKE and three hash functions. In the case of the algorithm we are exploring, FrodoKEM, it uses a slightly tweaked version of the HHK transform. It has, again, three functions (some parts of this description are simplified):
Generation:
We need a hash function G1.
We need a PKE scheme, such as FrodoPKE.
We call the Generation function of FrodoPKE, which returns a public (pk) and private key (sk).
We hash the public key pkh ← G1(pk).
We chose a value s at random.
The public key is pk and the private key sk1 is (sk, s, pk, pkh).
Encapsulate:
We need two hash functions: G2 and F.
We generate a random message u.
We hash the received public key pkh with the random message (r, k) ← G2(pkh || u).
We call the Encryption function of FrodoPKE: ciphertext ← Encrypt(u, pk, r).
We hash: shared secret ← F(c || k).
We send the ciphertext and the shared secret.
Decapsulate:
We need two hash functions (G2 and F) and we have (sk, s, pk, pkh).
We receive the ciphertext and the shared secret.
We call the decryption function of FrodoPKE: message ← Decrypt(shared secret, ciphertext).
We hash: (r , k) ← G2(pkh || message).
We call the Encryption function of FrodoPKE: ciphertext1 ← Encrypt(message, pk, r).
If ciphertext1 == ciphertext, k = k0; else, k = s.
We hash: ss ← F(ciphertext || k).
We return the shared secret ss.
What this algorithm achieves is the generation of a shared secret and ciphertext which can be used to establish a secure channel. It also means that no matter how many ciphertexts Hades sends to the decryption oracle, they will never reveal the content of a valid ciphertext that Hades himself did not generate. This is ensured when we run the encryption process again in Decapsulate to check if the ciphertext was computed correctly, which ensures that an adversary cannot craft valid ciphertexts simply by modifying them.
With this last doll, the algorithm has been created, and it is safe in the face of a quantum adversary.
Other KEMs beyond Frodo
While the ring bearer, Frodo, wanders around and transforms, he was not alone in his journey. FrodoKEM is currently designated as an alternative candidate for standardization as part of the post-quantum NIST process. But, there are others:
Kyber, NTRU, Saber: which are based on variants of the LWE problem over lattices and,
Classic McEliece: which is based on error correcting codes.
The lattice-based variants have the advantage of being fast, while producing relatively small keys and ciphertexts. There are concerns about theirsecurity, which need to be properly verified, however. More confidence is found in the security of the Classic McEliece scheme, as its underlying problem has been studied for longer (It is only one year older than RSA!). It has a disadvantage: it produces extremely large public keys. Classic-McEliece-348864 for example, produces public keys of size 261,120 bytes, whereas Kyber512, which claims comparable security, produces public keys of size 800 bytes.
They are all Matryoshka dolls (including sometimes non-post-quantum ones). They are all algorithms that are placed one inside the other. They all start with a small but powerful idea: a mathematical problem whose solution is hard to find in an efficient time. They then take the algorithm approach and achieve one cryptographic security. And, by the magic of hashes and length preservation, they achieve more cryptographic security. This just goes to show that cryptographic algorithms are not perfect in themselves; they stack on top of each other to get the best of each one. Facing quantum adversaries with them is the same, not a process of isolation but rather a process of stacking and creating the big picture from the smallest one.
“FrodoKEM: Learning With Errors Key Encapsulation Algorithm Specifications and Supporting Documentation” by Erdem Alkim, Joppe W. Bos, Léo Ducas, Patrick Longa, Ilya Mironov, Michael Naehrig, Valeria Nikolaenko, Chris Peikert, Ananth Raghunathan and Douglas Stebila: https://frodokem.org/files/FrodoKEM-specification-20171130.pdf
“A Modular Analysis of the Fujisaki-Okamoto Transformation” by Dennis Hofheinz, Kathrin Hövelmanns and Eike Kiltz: https://eprint.iacr.org/2017/604.pdf
To provide authentication is no more than to assert, to provide proof of, an identity. We can claim who we claim to be but if there is no proof of it (recognition of our face, voice or mannerisms) there is no assurance of that. In fact, we can claim to be someone we are not. We can even claim we are someone that does not exist, as clever Odysseus did once.
The story goes that there was a man named Odysseus who angered the gods and was punished with perpetual wandering. He traveled and traveled the seas meeting people and suffering calamities. On one of his trips, he came across the Cyclops Polyphemus who, in short, wanted to eat him. Clever Odysseus got away (as he usually did) by wounding the cyclops’ eye. As he was wounded, he asked for Odysseus name to which the latter replied:
“Cyclops, you asked for my glorious name, and I will tell it; but do give the stranger’s gift, just as you promised. Nobody I am called. Nobody they called me: by mother, father, and by all my comrades”
(As seen in The Odyssey, book 9. Translation by the authors of the blogpost).
The cyclops believed that was Odysseus’ name (Nobody) and proceeded to tell everyone, which resulted in no one believing him. “How can nobody have wounded you?” they questioned the cyclops. It was a trick, a play of words by Odysseus. Because to give an identity, to tell the world who you are (or who you are pretending to be) is easy. To provide proof of it is very difficult. The cyclops could have asked Odysseus to prove who he was, and the story would have been different. And Odysseus wouldn’t have left the cyclops laughing.
In the digital world, proving your identity is more complex. In face-to-face conversations, we can often attest to the identity of someone by knowing and verifying their face, their voice, or by someone else introducing them to us. From computer to computer, the scenario is a little different. But there are ways. When a user connects to their banking provider on the Internet, they need assurance not only that the information they send is secured; but that they are also sending it to their bank, and not a malicious website masquerading as their provider. The Transport Layer Security (TLS) protocol provides this through digitally signed statements of identity (certificates). Digital signature schemes also play a central role in DNSSEC as well, an extension to the Domain Name System (DNS) that protects applications from accepting forged or manipulated DNS data, which is what happens during DNS cache poisoning, for example.
A digital signature is a demonstration of authorship of a document, conversation, or message sent using digital means. As with “regular” signatures, they can be publicly verified by anyone that knows that it is a signature made by someone.
A digital signature scheme is a collection of three algorithms:
A key generation algorithm, Generate, which generates a public verification key and a private signing key (a keypair).
A signing algorithm, Sign, which takes the private signing key, a message, and outputs a signature of the message.
A verification algorithm, Verify, which takes the public verification key, the signature and the message, and outputs a value stating whether the signature is valid or not.
In the case of the Odysseus’ story, what the cyclops could have done to verify his identity (to verify that he indeed was Nobody) was to ask for a proof of identity: for example, for other people to vouch that he is who he claims to be. Or he could have asked for a digital signature (attested by several people or registered as his own) attesting he was Nobody. Nothing like that happened, so the cyclops was fooled.
In the Transport Layer Security protocol, TLS, authentication needs to be executed at the time a connection or conversation is established (as data sent after this point will be authenticated until that is explicitly disabled), rather than for the full lifetime of the data (as with confidentiality). Because of that, the need to transition to post-quantum signatures is not as urgent as it is for post-quantum key exchange schemes, and we do not believe there are sufficiently powerful quantum computers at the moment that can be used to listen in on connections and forge signatures. At some point, that will no longer be true, and the transition will have to be made.
There are various candidates for authentication schemes (including digital signatures) that are quantum secure: some use cryptographic hash functions, some use problems over lattices, while others use techniques from the field of multi-party computation. It is also possible to use Key Encapsulation Mechanisms (or KEMs) to achieve authentication in cryptographic protocols.
In this post, much like in the one about Key Encapsulation Mechanisms, we will give a bird’s-eye view of the construction of one particular post-quantum signature algorithm. We will discuss CRYSTALS-Dilithium, as an example of how a signature scheme can be constructed. Dilithium is a finalist candidate in the NIST post-quantum cryptography standardization process and provides an example of a standard technique used to construct digital signature schemes. We chose to explain Dilithium here as it is a finalist and its design is straightforward to explain.
We will again build the algorithm up layer-by-layer. We will look at:
Its mathematical underpinnings: as we see in other blog posts, a cryptographic algorithm can be built as a Matryoshka doll or a Chinese box. Let us use the Chinese box analogy here. The first box, in this case, is the mathematical base, whose hardness should be strong so that security is maintained. In the post-quantum world, this is usually the hardness of some lattice or isogeny problems.
Its algorithmic construction: these are all the subsequent boxes that take the mathematical base and construct an algorithm out of it. In the case of a signature, first one constructs an identification scheme, which we will define in the next sections, and then transform it to a signature scheme using the Fiat-Shamir transformation.
The mathematical core of Dilithium is, as with FrodoKEM, based on the hardness of a variant of the Learning with Errors (LWE) problem and the Short Integer Solution (SIS) problem. As we have already talked about LWE, let’s now briefly go over SIS.
Note to the reader: Some mathematics is coming in the next sections; but don’t worry, we will guide you through it.
The Short Integer Solution Problem
In order to properly explain what the SIS problem is, we need to first start by understanding what a lattice is. A lattice is a regular repeated arrangement of objects or elements over a space. In geometry, these objects can be points; in physics, these objects can be atoms. For our purposes, we can think of a lattice as a set of points in n-dimensional space with a periodic (repeated) structure, as we see in the image. It is important to understand the meaning of n-dimensional space here: a two-dimensional space is, for example, the one that we often see represented on planes: a projection of the physical universe into a plane with two dimensions which are length and width. Historically, lattices have been investigated since the late 18th century for various reasons. For a more comprehensive introduction to lattices, you can read this great paper.
Picture of a lattice. They are found in the wild in Portugal.
What does SIS pertain to? You are given a positive integer q and a matrix (a rectangular array of numbers) A of dimensions n x m (the number of rows is n and the number of columns is m), whose elements are integers between 0 and a number q. You are then asked to find a vectorr (smaller than a certain amount, called the “norm bound”)such that Ar = 0. The conjecture is that, for a sufficiently large n, finding this solution is hard even for quantum computers. This problem is “dual” to the LWE problem that we explored in another blog post.
We can define this same problem over a lattice. Take a lattice L(A), made up of m different n-dimensional vectors y (the repeated elements). The goal is to find non-zero vectors in the lattice such that Ay = 0 (mod q) (for some q), whose size is less than a certain specified amount. This problem can be seen as trying to find the “short” solutions in the lattice, which makes the problem the Short Vector Problem (SVP) in the average case. Finding this solution is simple to do in two dimensions (as seen in the diagram), but finding the solution in more dimensions is hard.
The SIS problem as the SVP. The goal is to find the “short” vectors in the radius.
The SIS problem is often used in cryptographic constructions such as one-way functions, collision resistant hash functions, digital signature schemes, and identification schemes.
We have now built the first Chinese box: the mathematical base. Let’s take this base now and create schemes from it.
Identification Schemes
From the mathematical base of our Chinese box, we build the first computational algorithm: an identification scheme. An identification scheme consists of a key generation algorithm, which outputs a public and private key, and an interactive protocol between a prover P and a verifier V. The prover has access to the public key and private key, and the verifier only has access to the public key. A series of messages are then exchanged such that the prover can demonstrate to the verifier that they know the private key, without leaking any other information about the private key.
More specifically, a three-move (three rounds of interaction) identification scheme is a collection of algorithms. Let’s think about it in the terms of Odysseus trying to prove to the cyclops that he is Nobody:
Odysseus (the prover) runs a key generation algorithm, Generate, that outputs a public and private keypair.
Odysseus then runs a commitment algorithm, Commit, that uses the private key, and outputs a commitment Y. The commitment is nothing more than a statement that this specific private key is the one that will be used. He sends this to the cyclops.
The cyclops (the verifier) takes the commitment and runs a challenge algorithm, Challenge, and outputs a challenge c. This challenge is a question that asks: are you really the owner of the private key?
Odysseus receives the challenge and runs a response algorithm, Response. This outputs a response z to the challenge. He sends this value to the cyclops.
The cyclops runs the verification algorithm, Verify, which outputs either accept (1) or reject (0) if the answer is correct.
If Odysseus was really the owner of the private key for Nobody, he would have been able to answer the challenge in a positive manner (with a 1). But, as he is not, he runs away (and this is the last time we see him in this blogpost).
The Dilithium Identification Scheme
The basic building blocks of Dilithium are polynomials and rings. This is the second-last box of the Chinese box, and we will explore it now.
A polynomial ring, R, is a ring of all polynomials. A ring is a set in which two operations can exist: addition and multiplication of integers; and a polynomial is an expression of variables and coefficients. The “size” of these polynomials, defined as the size of the largest coefficient, plays a crucial role for these kinds of algorithms.
In the case of Dilithium, the Generation algorithm creates a k x l matrix A. Each entry of this matrix is a polynomial in the defined ring. The generation algorithm also creates random private vectors s1 and s2, whose components are elements of R, the ring. The public key is the matrix A and t = As1 + s2. It is infeasible for a quantum computer to know the secret values given just t and A. This problem is called Module-Learning With Errors (MLWE) problem, and it is a variant of LWE as seen in this blog post.
Armed with the public and private keys, the Dilithium identification scheme proceeds as follows (some details are left out for simplicity, like the rejection sampling):
The prover wants to prove they know the private key. They generate a random secret nonce y whose coefficient is less than a security parameter. They then compute Ay and set a commitment w1 to be the “high-order”1 bits of the coefficients in this vector.
The verifier accepts the commitment and creates a challenge c.
The prover creates the potential signature z = y + cs1 (notice the usage of the random secret nonce and of the private key) and performs checks on the sizes of several parameters which makes the signature secure. This is the answer to the challenge.
The verifier receives the signature and computes w1 to be the “high-order” bits of Az−ct (notice the usage of the public key). They accept this answer if all the coefficients of z are less than the security parameter, and if w1 is equal to w0.
The identity scheme previously mentioned is an interactive protocol that requires participation from both parties. How do we turn this into a non-interactive signature scheme where one party issues signatures and other parties can verify them (the reason for this conversation is that anyone should be able to publicly verify)? Here, we place the last Chinese box.
A three-move identification scheme can be turned into a signature scheme using the Fiat–Shamir transformation: instead of the verifier accepting the commitment and sending a challenge c, the prover computes the challenge as a hash H(M || w1) of the message M and of the value w1 (computed in step 1 of the previous scheme). This is an approach in which the signer has created an instance of a lattice problem, which only the signer knows the solution to.
This in turn means that if a message was signed with a key, it could have only been signed by the person with access to the private key, and it can be verified by anyone with access to the public key.
How is this procedure related to the lattice’s problems we have seen? It is used to prove the security of the scheme: specifically the M-SIS (module SIS) problem and the LWE decisional problem.
The Chinese box is now constructed, and we have a digital signature scheme that can be used safely in the face of quantum computers.
Other Digital Signatures beyond Dilithium
In Star Trek, Dilithium is a rare material that cannot be replicated. Similarly, signatures cannot be replicated or forged: each one is unique. But this does not mean that there are no other algorithms we can use to generate post-quantum signatures. Dilithium is currently designated as a finalist candidate for standardization as part of the post-quantum NIST process. But, there are others:
Falcon, another lattice-based candidate, based on NTRU lattices.
Rainbow, a scheme based on multivariate polynomials.
We have seen examples of KEMs in other blog posts and signatures that are resistant to attacks by quantum computers. Now is the time to step back and take a look at the bigger picture. We have the building blocks, but the problem of actually building post-quantum secure cryptographic protocols with them remains, as well as making existing protocols such as TLS post-quantum secure. This problem is not entirely straightforward, owing to the trade-offs that post-quantum algorithms present. As we have carefully stitched together mathematical problems and cryptographic tools to get algorithms with the properties we desire, so do we have to carefully compose these algorithms to get the secure protocols that we need.
“A Concrete Treatment of Fiat-Shamir Signatures in the Quantum Random-Oracle Model” by Eike Kiltz, Vadim Lyubashevsky and Christian Schaffner: https://eprint.iacr.org/2017/916.pdf
1This “high-order” and “low-order” procedure decomposes a vector, and there is a specific procedure for this for Dilithium. It aims to reduce the size of the public key.
Tonga, the South Pacific archipelago nation (with 169 islands), was reconnected to the Internet this early morning (UTC) and is back online after successful repairs to the undersea cable that was damaged on Saturday, January 15, 2022, by the January 14, volcanic eruption.
After 38 days without full access to the Internet, Cloudflare Radar shows that a little after midnight (UTC) — it was around 13:00 local time — on February 22, 2022, Internet traffic in Tonga started to increase to levels similar to those seen before the eruption.
The faded line shows what was normal in Tonga at the start of the year, and the dark blue line shows the evolution of traffic in the last 30 days. Digicel, Tonga’s main ISP announced at 02:13 UTC that “data connectivity has been restored on the main island Tongatapu and Eua after undersea submarine cable repairs”.
When we expand the view to the previous 45 days, we can see more clearly how Internet traffic evolved before the volcanic eruption and after the undersea cable was repaired.
The repair ship Reliance took 20 days to replace a 92 km (57 mile) section of the 827 km submarine fiber optical cable that connects Tonga to Fiji and international networks and had “multiple faults and breaks due to the volcanic eruption”, according to Digicel.
Tonga Cable chief executive James Panuve told Reuters that people on the main island “will have access almost immediately”, and that was what we saw on Radar with a large increase in traffic persisting.
The residual traffic we saw from Tonga a few days after January 15, 2022, comes from satellite services that were used with difficulty by some businesses.
James Panuve also highlighted that the undersea work is still being finished to repair the domestic cable connecting the main island of Tongatapu with outlying islands that were worst hit by the tsunami, which, he told Reuters, could take six to nine months more.
So, for some of the people who live on the 36 inhabited islands, normal use of the Internet could take a lot longer. Tonga has a population of around 105,000, 70% of whom reside on the main island, Tongatapu and around 5% (5,000) live on the nearby island of Eua (now also connected to the Internet).
Telecommunication companies in neighboring Pacific islands, particularly New Caledonia, provided lengths of cable when Tonga ran out, said Panuve.
A world of undersea cables for the world’s communications
We have mentioned before, for example in our first blog post about the Tonga outage, how undersea cables are important to global Internet traffic that is mostly carried by a complex network that connects countries and continents.
The full submarine cable system (the first communications cables laid were from the 1850s and carried telegraphy traffic) is what makes most of the world’s Internet function between countries and continents. There are 428 active submarine cables (36 are planned), running to an estimated 1.3 million km around the globe.
World map of submarine cables. Antartida is the only continent not yet reached by a submarine telecommunications cable. Source: TeleGeography (www.submarinecablemap.com
The reliability of submarine Internet is high, especially when multiple paths are available in the event of a cable break. That wasn’t the case for the Tonga outage, given that the 827 km submarine cable only connects Fiji to the Tonga archipelago — Fiji is connected to the main Southern Cross Cable, as the next image illustrates.
Submarine Cable Map shows the undersea cables that connect Australia to Fiji and the following connections to other archipelagos like Tonga. Source: TeleGeography (www.submarinecablemap.com)
In a recent conversation on a Cloudflare TV segment we discussed the importance of undersea cables with Tom Paseka, Network Strategist who is celebrating 10 years at Cloudflare and worked previously for undersea cable companies in Australia. Here’s a clip:
India’s rapidly digitising economy needs people with IT and programming skills, as well as skills such as creativity, unstructured problem solving, teamwork, and communication. Unfortunately, too many children in India currently do not have access to digital technologies, or to opportunities to learn these technical skills.
Roadblocks to accessing digital skills
Before children and young people in India can even get a chance to learn digital skills, many of them have to overcome numerous roadblocks. India’s digital divide is entrenched due to a lack of access to electricity, to the internet, and to digital devices. In 2017–18, only 47% of Indian households received electricity for more than 12 hours a day. Moreover, only 24% of households have internet access, with the figure dropping as low as 15% in rural regions.
During the coronavirus pandemic, when children in India had to plunge head-first into adapting to restrictions, 29 million students around the country did not have access to a digital device. In addition, only 38% of households in India are digitally literate. At the Raspberry Pi Foundation, we define digital literacy as the skills and knowledge required to be an effective, safe, and discerning user of various computer systems. Digital literacy in rural regions stands far lower at 25%.
We partner with organisations in India
We are conscious that we cannot solve these massive access issues. Regardless, we are committed to moving the needle for those young people that need access to digital skills and digital literacy the most.
We partner with organisations around the country that are committed to bringing access to coding and digital skills to the most disadvantaged and digitally excluded young people. Our partnership model includes:
Co-designing learning experiences
Providing free, open-source learning resources
Designing bespoke training programmes
Supporting with technology solutions
The Pratham–Code Club programme for digital skills
Pratham means ‘first’ in Hindi, and rightly so: Pratham Education Foundation, a non-profit established in 1994, has been at the forefront of addressing gaps in the education system in India. In 2018, we joined hands with Pratham Education Foundation to introduce coding to children in hard-to-reach, disadvantaged communities around the country. We co-designed a Pratham–Code Club programme to provide youth in underserved communities with training and access to devices and learning resources. The goal of the training was to build the youth’s programming confidence so that they could go on to teach children in their communities.
To be effective, it was crucial that the programme be localised. We made adaptations to our learning resources and training content to make them more relevant to the context of the learners, and we worked with volunteer translators to translate the material into Hindi, Kannada, and Marathi.
We also provided the youth with training to use the PraDigi kit — an innovative, lightweight device, developed by Pratham Education Foundation and based on the Raspberry Pi computer — for teaching children to code.
Adapting the programme during the pandemic
In 2020, when we could no longer implement the programme the same way due to the pandemic and the ensuing disruptions, we made several adaptations:
Firstly, instead of the three-hour in-person training we had previously conducted, we hosted multiple 30-minute online sessions over a week, using cloud-based platforms like Zoom. Secondly, we used familiar apps such as WhatsApp and Facebook Workplace to share the training content.
Finally, since the Pratham staff in the communities could not bring the PraDigi kits to the remote locations during lockdowns, we adapted the training content for smartphones and tablets, using the online Scratch editor and a phone-friendly online code editor called Repl.it.
Over the course of the pandemic, we trained 300 youth from Pratham’s communities in the basics of programming and digital skills. The impact was:
62% of youth said they were now interested in jobs that included coding skills
We also surveyed the youth for what non-technical skills they had learned during the training:
66% of youth reported that they had improved their problem-solving skills
60% of youth reported that they improved their communication skills
Where we are taking the programme next
Using a train-the-trainer model, we are now scaling our programme with Pratham Education Foundation to train 3000 youth from underserved communities. Once they have completed the training, we will help these 3000 youth pave the way to programming and digital skills for 15,000 young learners around the country.
We look forward to continuing our partnership with Pratham Education Foundation to make digital skills and coding education accessible to children all over India.
Задълбочаването на кризата около Украйна и възможната допълнителна ескалация на напрежението, която би могла да доведе и до въоръжен сблъсък за пореден път, постави въпроса за енергийното обезпечаване на нуждите на Европа. В условия на директен конфликт доставките на природен газ от Русия за страните от ЕС ще бъдат силно затруднени, а в някои случаи биха могли и да спрат. През последните седмици се заговори за търсене на алтернативни източници на газ, като се споменава името на Катар.
Катар е вторият по големина износител на втечнен природен газ (ВПГ) в света (по някои оценки страната все още заема първото място към 2021 г. – б.а.). Доха е стратегически партньор на редица държави от семейството на водещите световни икономики, с договори за доставки за клиенти като Япония, Китай и Индия. С поведението си през последните десетилетия Катар си спечели репутацията на надежден и предвидим партньор и доставчик. За разлика от други производители, сред които и Русия, дори в условията на блокада от страна на своите съседи, започнала през 2017 г. и продължила почти пет години,
Катар не използва енергийните ресурси като средство за натиск.
Страната не забави и не промени условията на доставки на ВПГ, като дори при отсъстващи дипломатически отношения с Обединените арабски емирства Доха не прекрати достъпа на катарски газ към единствения в региона на Залива газопровод Dolphin, доставящ синьо гориво до ОАЕ и Оман. В знак на съпричастност през 2011 г. Катар достави допълнителни 4 млн. тона ВПГ на Япония, за да може Токио да посрещне енергийните си нужди след кризата с централата „Фукушима“. През 2021 г. Доха увеличи износа си и за Великобритания, която изпитваше трудности в енергийната сфера вследствие на Брекзит.
Достойнствата на Катар като производител и доставчик на газ са известни, но дали страната е в състояние да замени или компенсира руските доставки за ЕС, остава по-скоро неясно. Първи за този възможен сценарий заговориха във Вашингтон, изхождайки от вероятността Москва да намали или спре износа за Европа в случай на санкции срещу Русия. Опасенията, че енергийните доставки може да бъдат използвани като средство за натиск срещу ЕС и САЩ, са налице. Анализи в тази посока бяха направени от различни икономически и аналитични центрове в Европа и САЩ, като акцент се поставя на възможността
Катар да компенсира потенциалния недостиг на газ
чрез доставки в ограничени количества през терминалите за ВПГ в Европа и Великобритания. За да се осъществи това, следва да бъдат налице определени фактори, като налични свободни танкери и достатъчен капацитет на вече действащите терминали да поемат допълнителните количества в по-интензивен порядък. Не на последно място, следва да се има предвид и положението на азиатските пазари и потреблението на ВПГ там, където Катар вече има дългосрочни и стратегически договори с редица страни. В условията на постпандемично възстановяване от COVID-19 азиатските пазари бележат ръст, световните икономически гиганти изпитват остра нужда час по-скоро да бъдат възстановени доставките на стоки, което предполага и по-голямо потребление на енергийни ресурси в производството.
Друг важен елемент в политиката на доставки на Катар е и отдаваното предпочитание на дългосрочни договори с традиционни партньори. Тези договори със срок между 20 и 25 години Доха започна да подновява не толкова отдавна, като те имат ключово значение за страната, която – за разлика от периода преди 10 или 15 години, когато заемаше безусловно първо място на пазара на ВПГ – сега е в силна конкуренция със САЩ и Австралия. В този смисъл борбата за големите пазари в Югоизточна Азия, от една страна, е огромна, а от друга, Катар загуби пазара в САЩ след началото на добива на шистов газ в Северна Америка.
За Катар търговията с природен газ е въпрос на стратегически интерес и се прави по всички правила на бизнеса.
Износът и гарантираните доставки са и дял от стратегията за национална сигурност. Това пролича най-добре през 2017 г., когато ОАЕ, Саудитска Арабия и Бахрейн предприеха стъпки срещу Катар и въведоха блокада на страната. Първоначалният шок от случващото се бе туширан, след като стана ясно, че Доха не възнамерява да търси изход от кризата за сметка на намален износ. С това страната допълнително си спечели симпатиите на своите международни партньори.
В опит да разшири влиянието си днес Доха води преговори за доставка на газ и за Ирак. Доскоро двете страни трудно намираха общ език предвид политическите обстоятелства в Багдад, но днес са в диалог. Това не остава незабелязано в съседните на Катар страни, сред които Иран, както е известно, има особено влияние в Ирак. Някои анализатори смятат, че споразумение между Доха и Багдад ще постави началото на края на зависимостта от иранска електроенергия и внос на ирански газ. Тъй като Катар и Иран влизат в т.нар. газов ОПЕК (реално такъв съюз на страните производителки и износителки на природен газ не съществува – б.а.), и двете държави внимателно следят действията на своя конкурент.
За Европа доставките на синьо гориво са несъмнено ключови за оцеляването на икономиката ѝ.
Да се разчита на помощ единствено от Катар в случай на военен конфликт между Русия и Украйна е недалновидно.
Към днешна дата ЕС увеличава дела на употреба на природен газ не само поради икономически причини, но и като алтернатива на петрола и въглищата. Това води до повишаване на търсенето на природния ресурс за нуждите на бита и индустрията. На този фон големите находища на газ в Европа – в Нидерландия и Норвегия – намаляват своя капацитет, което води до по-голяма зависимост от вноса. Германия е най-големият потребител на вноса на руски газ и в случай че „Северен поток 2“ започне да функционира, делът на руските доставки ще достигне 40% (в момента е 30%). Тези обстоятелства карат Берлин да бъде внимателен в подхода си спрямо Москва и да търси изключително дипломатически подход за решаването на кризата с Украйна.
Други европейски държави, като Испания, Франция или Великобритания, поради своето географско местоположение и политика на енергийна диверсификация са по-скоро зависими от доставките на газ от Северна Африка и на ВПГ от САЩ и Катар. Предпочитанията към ВПГ на редица държави произтича и от факта, че за разлика от газопроводите, доставките по море са значително по-малко подложени на геополитически изпитания, подобни на кризата в Украйна.
В глобален план пазарът на ВПГ продължава да се разраства,
като на него (освен Катар, както бе посочено по-горе) водеща роля вече играят САЩ и Австралия, а и самата Русия. През 2021 г. Доха заяви намерението си да запази водещите си позиции на пазара на ВПГ, като до 2030 г. увеличи производството с до 70%, достигайки количества от 126 млн. тона за следващите няколко години. Съгласно изчисленията това би позволило на Доха да разполага с около 75 млн. тона газ, които емирството би могло да продава на т.нар. свободен пазар, без да е обвързано с дългосрочни договори. 75 млн. тона се равняват на около 100 млрд. куб. м газ, което е почти половината от съществуващия в момента в Европа годишен капацитет за внос на ВПГ в размер на 240 млрд. куб. м.
Дали и кога руският внос ще бъде компенсиран временно за сметка на Катар (ако въобще се стигне до такава инициатива), остава да видим. Дори и обявените намерения на Доха значително да увеличи добива не могат да успокоят пазарите и цените на електроенергията на европейския континент доказват това. Ако допуснем, че вносът на ВПГ от Катар се увеличи, Европа в момента разполага с 23 терминала, които гарантират вноса на въпросните около 240 млрд. куб. м газ, или 40% от общото потребление. Колко допълнително може да компенсира Катар, засега е неясно и няма индикации в тази посока.
Друг въпрос от изключителна важност в контекста на споровете в България за енергийната независимост и диверсификация е относно възможността някаква част от газа, който вероятно ще дойде чрез терминалите за ВПГ, да стигне до страната ни.
This post is co-authored by Dr. Yehezkel Aviv, Co-Founder and CTO of Cynamics and Sapir Kraus, Head of Engineering at Cynamics.
Cynamics provides a new paradigm of cybersecurity — predicting attacks long before they hit by collecting small network samples (less than 1%), inferring from them how the full network (100%) behaves, and predicting threats using unique AI breakthroughs. The sample approach allows Cynamics to be generic, agnostic, and work for any client’s network architecture, no matter how messy the mix between legacy, private, and public clouds. Furthermore, the solution is scalable and provides full cover to the client’s network, no matter how large it is in volume and size. Moreover, because any network gateway (physical or virtual, legacy or cloud) supports one of the standard sampling protocols and APIs, Cynamics doesn’t require any installation of appliances nor agents, as well as no network changes and modifications, and the onboarding usually takes less than an hour.
In the crowded cybersecurity market, Cynamics is the first-ever solution based on small network samples, which has been considered a hard and unsolved challenge in academia (our academic paper “Network anomaly detection using transfer learning based on auto-encoders loss normalization” was recently presented in ACM CCS AISec 2021) and industry to this day.
The problem Cynamics faced
Early in the process, with the growth of our customer base, we were required to seamlessly support the increased scale and network throughput by our unique AI algorithms. We faced a few different challenges:
How can we perform near-real-time analysis on our streaming clients’ incoming data into our AI inference system to predict threats and attacks?
How can we seamlessly auto scale our solution to be cost-efficient with no impact on the platform ingestion rate?
Because many of our customers are from the public sector, how can we do this while supporting both AWS commercial and government environments (GovCloud)?
This post shows how we used AWS managed services and in particular Amazon Kinesis Data Streams and Amazon EMR to build a near-real-time streaming AI inference system serving hundreds of production customers in both AWS commercial and government environments, while seamlessly auto scaling.
Overview of solution
The following diagram illustrates our solution architecture:
To provide a cost-efficient, highly available solution that scales easily with user growth, while having no impact on near-real-time performance, we turned to Amazon EMR.
We currently process over 50 million records per day, which translates to just over 5 billion flows, and keeps growing on a daily basis. Using Amazon EMR along with Kinesis Data Streams provided the scalability we needed to achieve inference times of just a few seconds.
Although this technology was new to us, we minimized our learning curve by turning to the available guides from AWS for best practices on scale, partitioning, and resource management.
Workflow
Our workflow contains the following steps:
Flow samples are sent by the client’s network devices directly to the Cynamics cloud. A network flow (or connection) is a set of packets with the same five-tuple ID: source-IP-address, destination-IP-address, source-port, destination-port, and protocol.
The samples are analyzed by Network Load Balancers, which forward them into an auto scaling group of stateless flow transformers running on Graviton-powered Amazon Elastic Compute Cloud (Amazon EC2) instances. With Graviton-based processors in the flow transformers, we reduced our operational costs by over 30%.
The flows are transformed to the Cynamics data format and enriched with additional information from Cynamics’ databases and in-house sources such as IP resolutions, intelligence, and reputation.
The following figures show the network scale for a single flow transformer machine over a week. The first figure illustrates incoming network packets for a single flow transformer machine.
The following shows outcoming network packets for a single flow transformer machine.
The following shows incoming network bytes for a single flow transformer machine.
The following shows outcoming network bytes for a single flow transformer machine.
The flows are sent using Kinesis Data Streams to the real-time analysis engine.
The Amazon EMR-based real-time engine consumes records in a few seconds batches using Yarn/Spark. The sampling rate of each client is dynamically tuned according to its throughput to ensure a fixed incoming data rate for all clients. We achieved this using Amazon EMR Managed Scaling with a custom policy (available with Amazon EMR versions 5.30.1 and later), which allows us to scale EMR nodes in or out based on Amazon CloudWatch metrics, with two different rules for scale-out and scale-in. The metric we created is based on the Amazon EMR running time, because our real-time AI threat detection runs on a sliding window interval of a few seconds.
The scale-out policy tracks the average running time over a period of 10 minutes, and scales the EMR nodes if it’s longer than 95% of the required interval. This allows us to prevent processing delays.
Similarly, the scale-in policy uses the same metric but measures the average over a 30-minute period, and scales the cluster accordingly. This enables us to optimize cluster costs and reduce the number of EMR nodes in off-hours.
To optimize and seamlessly scale our AI inference calls, these were made available through an ALB and another auto scaling group of servers (AI model-service).
We use Amazon DynamoDB as a fast and highly available states table.
The following figure shows the number of records processed by the Kinesis data stream over a single day.
The following shows the Kinesis data streams records rate per minute.
With the approach described in this post, Cynamics has been providing threat prediction based on near-real-time analysis of its unique AI algorithms for a constantly growing customer base in a seamless and automatically scalable way. Since first implementing the solution, we’ve managed to easily and linearly scale our architecture, and were able to further optimize our costs by transitioning to Graviton-based processors in the flow transformers, which reduced over 30% of our flow transformers costs.
We’re considering the following next steps:
An automatic machine learning lifecycle using an Amazon SageMaker Studio pipeline, which includes the following steps:
Additional cost reduction by moving the EMR instances to be Graviton-based as well, which should yield an additional 20% reduction.
About the Authors
Dr. Yehezkel Aviv is the co-founder and CTO of Cynamics, leading the company innovation and technology. Aviv holds a PhD in Computer Science from the Technion, specializing in cybersecurity, AI, and ML.
Sapir Kraus is Head of Engineering at Cynamics, where his core focus is managing the software development lifecycle. His responsibilities also include software architecture and providing technical guidance to team members. Outside of work, he enjoys roasting coffee and barbecuing.
Omer Haim is a Startup Solutions Architect at Amazon Web Services. He helps startups with their cloud journey, and is passionate about containers and ML. In his spare time, Omer likes to travel, and occasionally game with his son.
The call stack is a favorite target for attackers attempting to compromise
a running process; if an attacker finds a way to overwrite a return address
on the stack, they can redirect control to code of their choosing, leading
to a situation best described as “game over”. As a result, a great deal of
effort has gone into protecting the stack. One technique that offers
promise is a shadow stack; support for shadow stacks is thus duly showing up in
various processors. Support for protecting user-space applications with
shadow stacks is taking a bit longer; it is currently under discussion
within the kernel community, but adding this feature is trickier than one
might think. Among other things, these patches have been around for long
enough that they have developed some backward-compatibility problems of
their own.
Longtime FOSS contributor and advocate Sven Guckes has died at 55. A Twitter posting and news article (both in German) describe the Berlin-based Guckes as someone who was always ready to help users get the most out of their systems on Usenet and IRC. His home page and a Hacker News posting have more information as well. RIP.
(Thanks to Martin Michlmayr.)
Security updates have been issued by Debian (php7.4, redis, snapd, twisted, webkit2gtk, and wpewebkit), Fedora (cyrus-imapd, nodejs, phpMyAdmin, polkit, snapd, webkit2gtk3, and xen), Gentoo (chromium), openSUSE (jaw, kubevirt, virt-api-container,, opera, polkit, and sphinx), Red Hat (ruby:2.6), Slackware (expat), and SUSE (kubevirt, virt-api-container, virt-controller-container, virt-handler-container, virt-launcher-container, virt-libguestfs-tools-container, virt-operator-container and polkit).
At Cloudflare, we help to build a better Internet. In the face of quantum computers and their threat to cryptography, we want to provide protections for this future challenge. The only way that we can change the future is by analyzing and perusing the past. Only in the present, with the past in mind and the future in sight, can we categorize and unfold events. Predicting, understanding and anticipating quantum computers (with the opportunities and challenges they bring) is a daunting task. We can, though, create a taxonomy of these challenges, so the future can be better unrolled.
This is the first blog post in a post-quantum series, where we talk about our past, present and future “adventures in the Post-Quantum land”. We have written about previous post-quantum efforts at Cloudflare, but we think that here first we need to understand and categorize the problem by looking at what we have done and what lies ahead. So, welcome to our adventures!
A taxonomy of the challenges ahead that quantum computers and their threat to cryptography bring (for more information about it, read our other blog posts) could be a good way to approach this problem. This taxonomy should not only focus at the technical level, though. Quantum computers fundamentally change the way certain protocols, properties, storage and retrieval systems, and infrastructure need to work. Following the biological tradition, we can see this taxonomy as the idea of grouping together problems into spaces and the arrangement of them into a classification that helps to understand what and who the problems impact. Following the same tradition, we can use the idea of kingdoms to classify those challenges. The kingdoms are (in no particular order):
Challenges at the Protocols level, Protocolla
Challenges at the implementation level, Implementa
Challenges at the standardization level, Regulae
Challenges at the community level: Communitates
Challenges at the research level, Investigationes
Let’s explore them one by one.
The taxonomy tree of the post-quantum challenges.
Challenges at the Protocols level, Protocolla
One conceptual model of the Internet is that it is composed of layers that stack on top of each other, as defined by the Open Systems Interconnection (OSI) model. Communication protocols in each layer enable parties to interact with a corresponding one at the same layer. While quantum computers are a threat to the security and privacy of digital connections, they are not a direct threat to communication itself (we will see, though, that one of the consequences of the existence of quantum computers is how new algorithms that are safe to their attacks can impact the communication itself). But, if the protocol used in a layer aims to provide certain security or privacy properties, those properties can be endangered by a quantum computer. The properties that these protocols often aim to provide are confidentiality (no one can read the content of communications), authentication (communication parties are assured who they are talking to) and integrity (the content of the communication is assured to have not been changed in transit).
Well-known examples of protocols that aim to provide security or privacy properties to protect the different layers are:
We know how to provide those properties (and protect the protocols) against the threat of quantum computers: the solution is to use post-quantum cryptography, and, for this reason, the National Institute of Standards and Technology (NIST) has been running an ongoing process to choose the most suitable algorithms. At this protocol level, then, the problem doesn’t seem to be adding these new algorithms, as nothing impedes it from a theoretical perspective. But protocols and our connections often have other requirements or constraints. Requirements or constraints are, for example, that data to be exchanged fits into a specific packet or segment size. In the case of the Transport Control Protocol (TCP), which ensures that data packets are delivered and received in order, for example, the Maximum Segment Size — MSS — sets the largest segment size that a network-connected device can receive and, if a packet exceeds the MSS, it is dropped (certain middleboxes or software desire all data to fit into a single segment). IPv4 hosts are required to handle an MSS of 536 bytes and IPv6 hosts are required to handle an MSS of 1220 bytes. In the case of DNS, it has primarily answered queries over the User Datagram Protocol (UDP), which limits the answer size to 512 bytes unless the extension EDNS is in use. Larger packets are subject to fragmentation or to the request that TCP should be used: this results in added round-trips, which should be avoided.
Another important requirement is that the operations that algorithms execute (such as multiplication or addition) or the resources they consume (which can be time but also space/memory) are fast enough that connection times are not impacted. This is even more pressing when fast, reliable and cheap Internet access is not available, as access to this “type” of Internet is not globally available.
TLS is a protocol that needs to handle heavy HTTPS traffic load and one that gets impacted by the additional cost that cryptographic operations add. Since 2010, TLS has been deemed “not computationally expensive any more” due to the usage of fast cryptography implementations and abbreviated handshakes (by using resumption, for example). But what if we add post-quantum algorithms into the TLS handshake? Some post-quantum algorithms can be suitable, while others might not be.
Many of the schemes that are part of the third round of the NIST post-quantum process, that can be used for confidentiality, seem to have encryption and decryption performance time comparable (or faster) to fast elliptic-curve cryptography. This in turn means that, from this point of view, they can be practically used. But, what about storage or transmission of the public/private keys that they produce (an attack can be mounted, for example, to force a server into constantly storing big public keys, which can lead to a denial-of-service attack or variants of the SYN flood attack)? What about their impacts on bandwidth and latency? Does having larger keys that span multiple packets (or congestion windows) affect performance especially in scenarios with degraded networks or packet loss?
In 2019, we ran a wide-scale post-quantum experiment with Google’s Chrome Browser team to test these ideas. The goal of that experiment was to assess, in a controlled environment, the impact of adding post-quantum algorithms to the Key Exchange phase of TLS handshakes. This investigation gave us some good insight into what kind of post-quantum algorithms can be used in the Key Agreement part of a TLS handshake (mainly lattice-based schemes, or so it seems) and allowed us to test them in a real-world setting. It is worth noting that these algorithms were tested in a “hybrid mode”: a combination of classical cryptographic algorithms with post-quantum ones.
The key exchange of TLS ensures confidentiality: it is the most pressing task to update it as non-post-quantum traffic captured today can be decrypted by a quantum computer in the future. Luckily, many of the post-quantum Key Encapsulation Mechanisms (KEMs) that are under consideration by NIST seem to be well suited with minimal performance impact. Unfortunately, a problem that has arisen before when considering protocol changes is the presence and behavior of old servers and clients, and of “middleboxes” (devices that manipulate traffic —by inspecting— it for purposes other than continuing the communication process). For instance, some middleboxes assume that the first message of a handshake from a browser fits in a single network packet, which is not the case when adding the majority of post-quantum KEMs. Such false assumptions (“protocol ossification”) are not a problem unique to post-quantum cryptography: the TLS 1.3 standard is carefully crafted to work around quirks of older clients, servers and middleboxes.
While all the data seems to suggest that replacing classical cryptography by post-quantum cryptography in the key exchange phase of TLS handshakes is a straightforward exercise, the problem seems to be much harder for handshake authentication (or for any protocol that aims to give authentication, such as DNSSEC or IPsec). The majority of TLS handshakes achieve authentication by using digital signatures generated via advertised public keys in public certificates (what is called “certificate-based” authentication). Most of the post-quantum signature algorithms currently being considered for standardization in the NIST post-quantum process, have signatures or public keys that are much larger than their classical counterparts. Their operations’ computation time, in the majority of cases, is also much bigger. It is unclear how this will affect the TLS handshake latency and round-trip times, though we have a better insight now in respect to which sizes can be used. We still need to know how much slowdown will be acceptable for early adoption.
There seems to be several ways by which we can add post-quantum cryptography to the authentication phase of TLS. We can:
Change the standard to reduce the number of signatures needed.
Use different post-quantum signature schemes that fit.
Or achieve authentication in a novel way.
On the latter, a novel way to achieve certificate-based TLS authentication is to use KEMs, as their post-quantum versions have smaller sizes than post-quantum signatures. This mechanism is called KEMTLS and we ran a controlled experiment showing that it performs well, even when it adds an extra or full round trip to the handshake (KEMTLS adds half a round trip for server-only authentication and a full round-trip for mutual authentication). It is worth noting that we only experimented with replacing the authentication algorithm in the handshake itself and not all the authentication algorithms needed for the certificate chain. We used a mechanism called “delegated credentials” for this: since we can’t change the whole certificate chain to post-quantum cryptography (as it involves other actors beyond ourselves), we use this short-lived credential that advertises new algorithms. More details around this experiment can be found in our paper.
Lastly, on the TLS front, we wanted to test the notion that having bigger signatures (such as the post-quantum ones) noticeably impacts TLS handshake times. Since it is difficult to deploy post-quantum signatures to real-world connections, we found a way to emulate bigger signatures without having to modify clients. This emulation was done by using dummy data. The result of this experiment showed that even if large signatures fit in the TCP congestion window, there will still be a double-digit percentage slowdown due to the relatively low average Internet speed. This slowdown is a hard sell for browser vendors and for content servers to adopt. The ideal situation for early adoption seems to be that the six signatures and two public keys of the TLS handshake fit together within 9kB (the signatures are: two in the certificate chain, one handshake signature, one OCSP staple and two SCTs for certificate transparency).
After this TLS detour, we can now list the challenges at this kingdom, Protocolla, level. The challenges (in no order in particular) seem to be (divided into sections):
Storage of cryptographic parameters used during the protocol’s execution:
How are we going to properly store post-quantum cryptographic parameters, such as keys or certificates, that are generated for/during protocol execution (their sizes are bigger than what we are accustomed to)?
How is post-quantum cryptography going to work with stateless servers, ones that do not store session state and where every client request is treated as a new one, such as NFS, Sun’s Network File System (for an interesting discussion on the matter, see this paper)?
Long-term operations and ephemeral ones:
What are the impacts of using post-quantum cryptography for long-term operations or for ephemeral ones: will bigger parameters make ephemeral connections a problem?
Are security properties assumed in protocols preserved and could we relax others (such as IND-CCA or IND-CPA. For an interesting discussion on the matter, see this paper)?
Managing bigger keys and signatures:
What are the impacts on latency and bandwidth?
Does the usage of post-quantum increase the roundtrips at the Network layer, for example? And, if so, are these increases tolerable?
Will the increased sizes cause dropped or fragmented packets?
Devices can occasionally have settings for packets smaller than expected: a router, for example, along a network path can have a maximum transmission unit, MTU (the MSS plus the TCP and IP headers), value set lower than the typical 1,500 bytes. In these scenarios, will post-quantum cryptography make these settings more difficult (one can apply MSS clamping for some cases)?
Preservation of protocols as we know them:
Can we achieve the same security or privacy properties as we use them today?
Can protocols change: should we change, for example, the way DNSSEC or the PKI work? Can we consider this radical change?
Can we integrate and deploy novel ways to achieve authentication?
Hardware (or novel alternative to hardware) usage during protocol’s execution:
Will middleware, such as middleboxes, be able to handle post-quantum cryptography (as noted in “The Chromium Projects”)?
What will be the impacts on mobile device’s connections?
What will be the impacts on old servers and clients?
Novel attacks:
Will post-quantum cryptography increase the possibility of mounting denial of service attacks?
Challenges at the Implementation level, Implementa
The second kingdom that we are going to look at is the one that deals with the implementation of post-quantum algorithms. The ongoing NIST process is standardizing post-quantum algorithms on two fronts: those that help preserve confidentiality (KEMs) and those that provide authentication (signatures). There are other algorithms not currently part of the process that already can be used in a post-quantum world, such as hash-based signatures (for example, XMSS).
What must happen for algorithms to be widely deployed? What are the steps they need to take in order to be usable by protocols or for data at rest? The usual path that algorithms take is:
Standardization: usually by a standardization body. We will talk about it further in the next section.
Efficiency at an algorithmic level: by finding new ways to speed up operations in an algorithm. In the case of Elliptic Curve Cryptography, for example, it happened with the usage of endomorphisms for faster scalar multiplication.
Efficient software implementations: by identifying the pitfalls that cause increase in time or space consumption (in the case of ECC, this paper can illustrate these efforts), and fixing them. An optimal implementation is always dependent on the target, though: where it will be used.
Avoidance of attacks: by looking at the usual pitfalls of algorithms which, in practice, are side-channel attacks.
Implementation of post-quantum cryptography will follow (and is following) the same path. Lattice-based cryptography for KEMs, for example, has taken many steps in order to be faster than ECC (but, from a protocol level perspective, it is inefficient than them, as their parameters are bigger than ECC ones and might cause extra round-trips). Isogeny-based cryptography, on the other hand, is still too slow (due to long isogenies evaluation), but it is an active area of research.
The challenges at this kingdom, Implementa, (in no particular order) level are:
Efficiency of algorithms: can we make them faster at the software, hardware (by using acceleration or FPGA-based research) or at an algorithmic level (with new data structures or parallelization techniques) to meet the requirements of network protocols and ever-fastest connections?
Can we use new mechanisms to accelerate algorithms (such as, for example, the usage of floating point numbers as in the Falcon signature scheme)? Will this lead to portability issues as it might be dependent on the underlying architecture?
What is the asymptotic complexity of post-quantum algorithms (how they impact time and space)?
How will post-quantum algorithms work on embedded devices due to their limited capacity (see this paper for more explanations)?
How can we avoid attacks, failures in security proofs and misuse of APIs?
Can we provide correct testing of these algorithms?
Can we ensure constant-time needs for the algorithms?
What will happen in a disaster-recovery mode: what happens if an algorithm is found to be weaker than expected or is fully broken? How will we be able to remove or update this algorithm? How can we make sure there are transition paths to recover from a cryptographical weakening?
At Cloudflare, we have also worked on implementation of post-quantum algorithms. We published our own library (CIRCL) that contains high-speed assembly versions of several post-quantum algorithms (like Kyber, Dilithium, SIKE and CSIDH). We believe that providing these implementations for public use will help others with the transition to post-quantum cryptography by giving easy-to-use APIs that developers can integrate into their projects.
Challenges at the Standards level, Regulae
The third kingdom deals with the standardization process as done by different bodies of organizations (such NIST or the Internet Engineering Task Force — IETF). We have talked a little about the matter in the previous section as it involves the standardization of both protocols and algorithms. Standardization can be a long process due to the need for careful discussion, and this discussion will be needed for the standardization of post-quantum algorithms. Post-quantum cryptography is based on mathematical constructions that are not widely known by the engineering community, which can then lead to difficulty levels when standardizing.
The challenges in this kingdom, Regulae, (in no particular order) are:
The mathematical base of post-quantum cryptography is an active area of development and research, and there are some concerns in the security they give (are there new attacks in the confidentiality or authentication they give?). How will standardization bodies approach this problem?
Post-quantum cryptography introduces new models in which to analyze the security of algorithms (for example, the usage of the Quantum Random Oracle Model). Will this mean that new attacks or adversaries will not be noted at the standards level?
What will be the recommendation of migrating to post-quantum cryptography from the standards’ perspective: will we use a hybrid approach?
How can we bridge the academic/research community into the standardization community, so analysis of protocols are executed and attacks are found on time (prior to being widely deployed)1? How can we make sure that standards bodies are informed enough to make the right practical/theoretical trade-offs?
At Cloudflare, we are closely collaborating with standardization bodies to prepare the path for post-quantum cryptography (see, for example, the AuthKEM draft at IETF).
Challenges at the Community level, Comunitates
The Internet is not an isolated system: it is a community of different actors coming together to make protocols and systems work. Migrating to post-quantum cryptography means sitting together as a community to update systems and understand the different needs. This is one of the reasons why, at Cloudflare, we are organizing a second installment of the PQNet workshop (expected to be colocated with Real World Crypto 2022 on April 2022) for experts on post-quantum cryptography to talk about the challenges of putting it into protocols, systems and architectures.
The challenges in this kingdom, Comunitates, are:
What are the needs of different systems? While we know what the needs of different protocols are, we don’t know exactly how all deployed systems and services work. Are there further restrictions?
On certain systems (for example, on the PKI), when will the migration happen, and how will it be coordinated?
How will the migration be communicated to the end-user?
How will we deprecate pre-quantum cryptography?
How will we integrate post-quantum cryptography into systems where algorithms are hardcoded (such as IoT devices)?
Who will maintain implementations of post-quantum algorithms and protocols? Is there incentive and funding for a diverse set of interoperable implementations?
Challenges at the Research level, Investigationes
Post-quantum cryptography is an active area of research. This research is not devoted only to how algorithms interact with protocols, systems and architectures (as we have seen), but it is heavily interested at the foundational level. The open challenges on this front are many. We will list four that are of the most interest to us:
Are there any efficient and secure post-quantum non-interactive key exchange (NIKE) algorithms?
NIKE is a cryptographic algorithm which enables two participants, who know each others’ public keys, to agree on a shared key, without requiring any interaction. An example of a NIKE is the Diffie-Hellman algorithm. There are no efficient and secure post-quantum NIKEs. A candidate seems to be CSIDH, which is rather slow and whose security is debated.
Are there post-quantum alternatives to (V)OPRFs based protocols, such as Privacy Pass or OPAQUE?
Are there post-quantum alternatives to other cryptographic schemes such as threshold signature schemes, credential based signatures and more?
How can post-quantum algorithms be formally verified with new notions such as the QROM?
Post-Quantum Future
The future of Cloudflare is post-quantum.
What is the post-quantum future at Cloudflare? There are many avenues that we explore in this blog series. While all of these experiments have given us some good and reliable information for the post-quantum migration, we further need tests in different network environments and with broader connections. We also need to test how post-quantum cryptography fits into different architectures and systems. We are preparing a bigger, wide-scale post-quantum effort that will give more insight into what can be done for real-world connections.
In this series of blog posts, we will be looking at:
What has been happening in the quantum research world in the last years and how it impacts post-quantum efforts.
What is a post-quantum algorithm: explanations of KEMs and signatures, and their security properties.
How one integrates post-quantum algorithms into protocols.
What is formal verification, analysis and implementation, and how it is needed for the post-quantum transition.
What does it mean to implement post-quantum cryptography: we will look at our efforts making Logfwdr, Cloudflare Tunnel and Gokeyless post-quantum.
What does the future hold for a post-quantum Cloudflare.
See you in the next blogpost and prepare for a better, safer, faster and quantum-protected Internet!
If you are a student enrolled in a PhD or equivalent research program and looking for an internship for 2022, see open opportunities.
You can reach us with questions, comments, and research ideas at [email protected].
…….
1A success scenario of this is the standardization of TLS 1.3 (in comparison to TLS 1.0-1.2) as it involved the formal verification community, which helped bridge the academic-standards communities to good effect. Read the analysis of this novel process.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


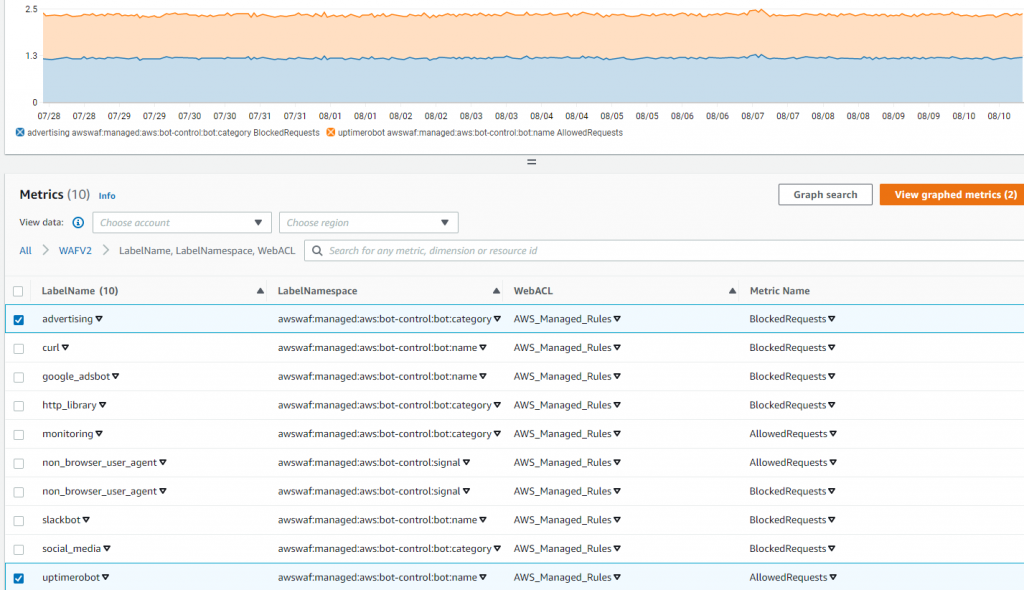
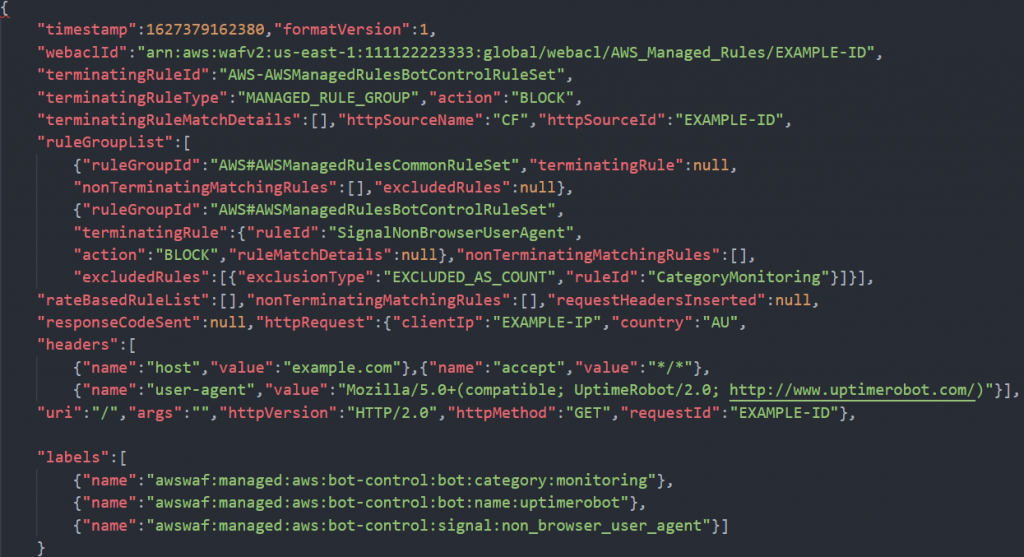

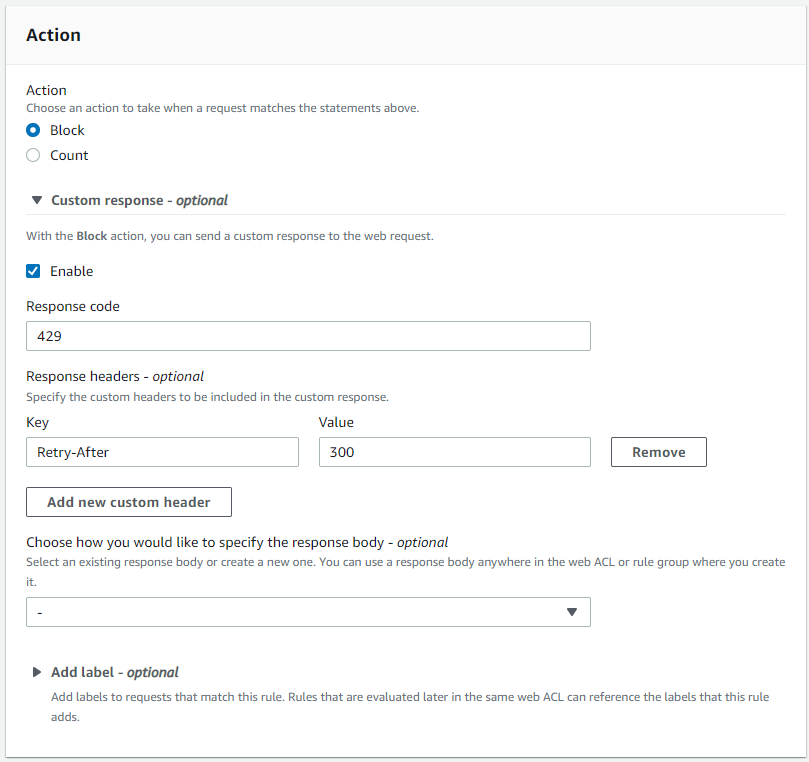



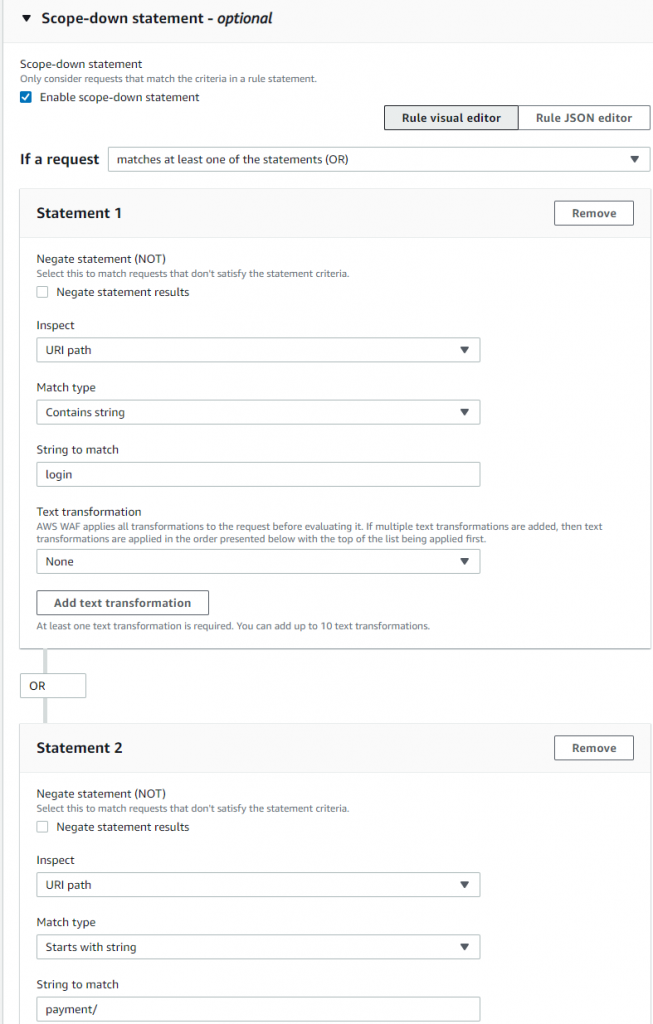
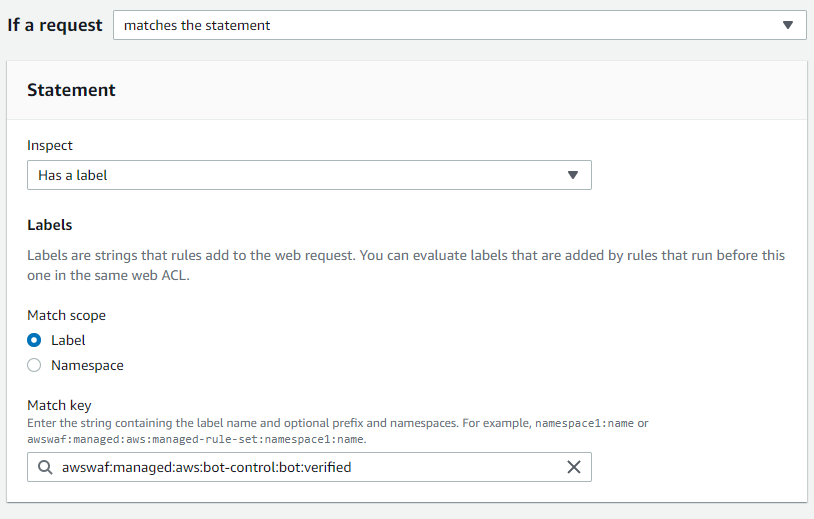
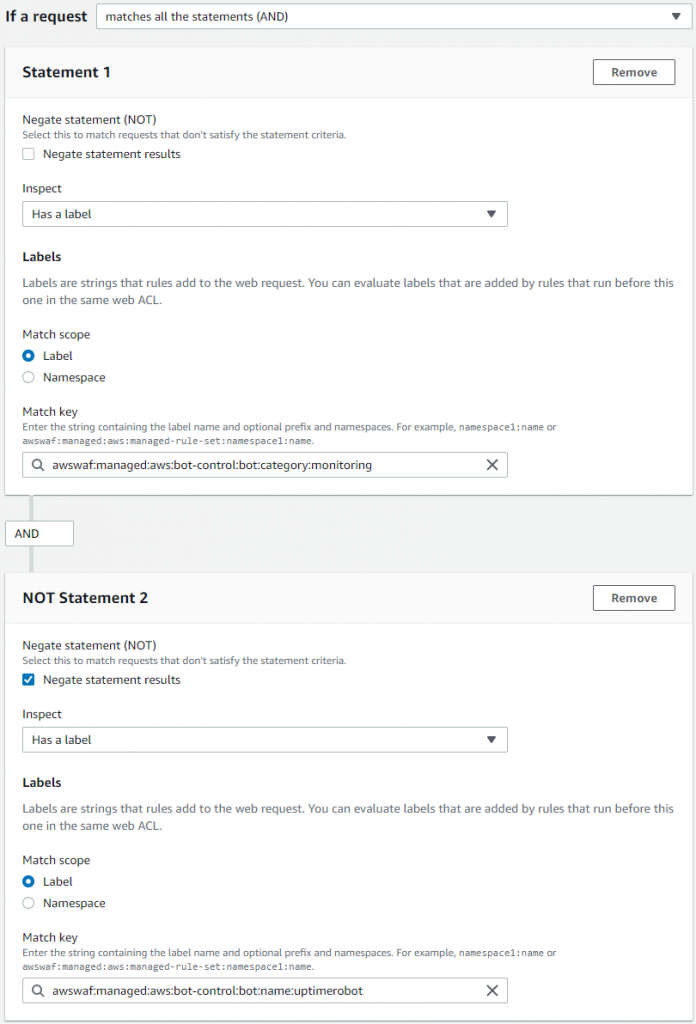
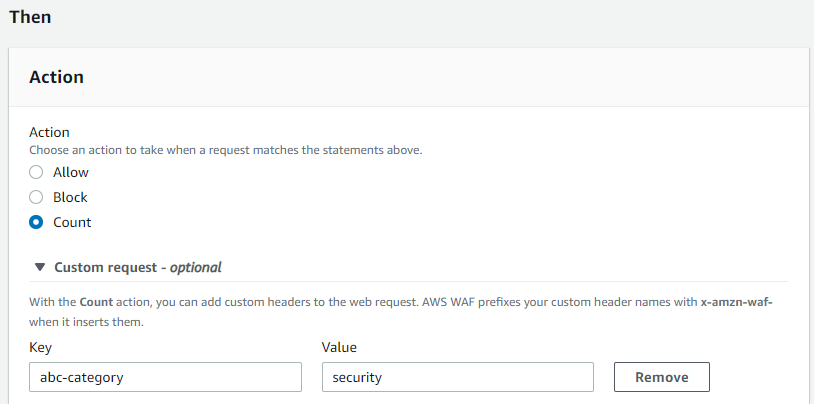


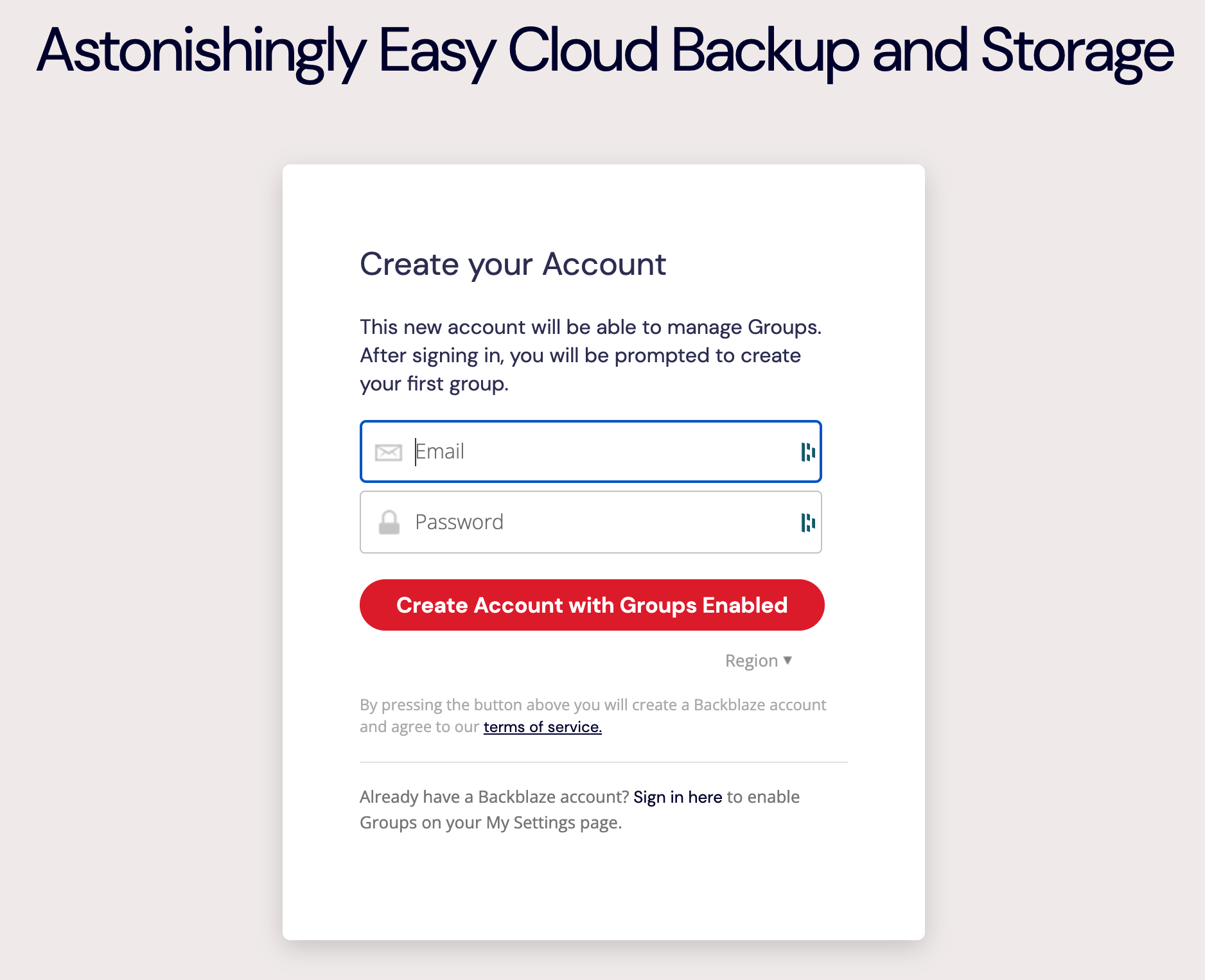
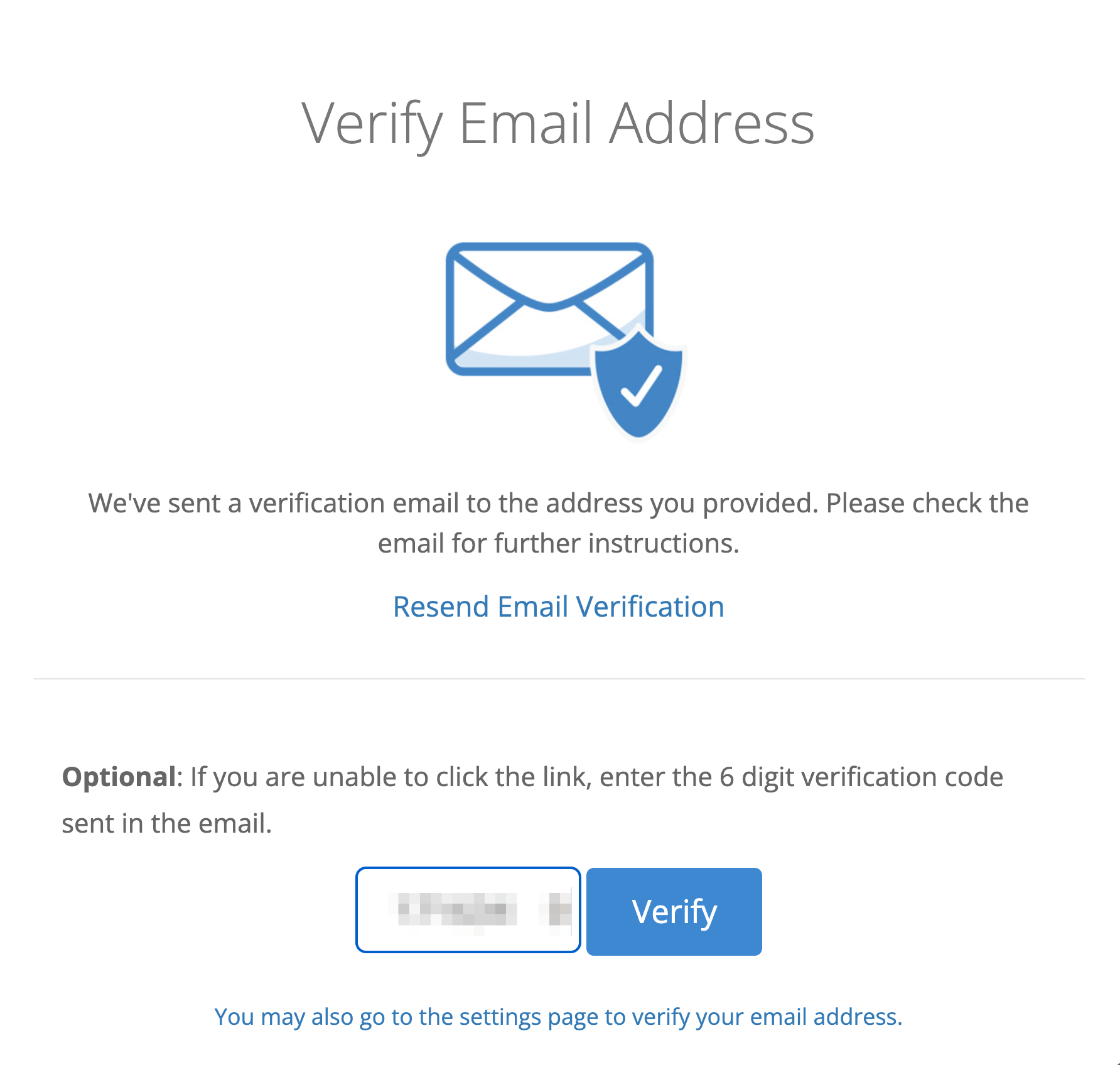
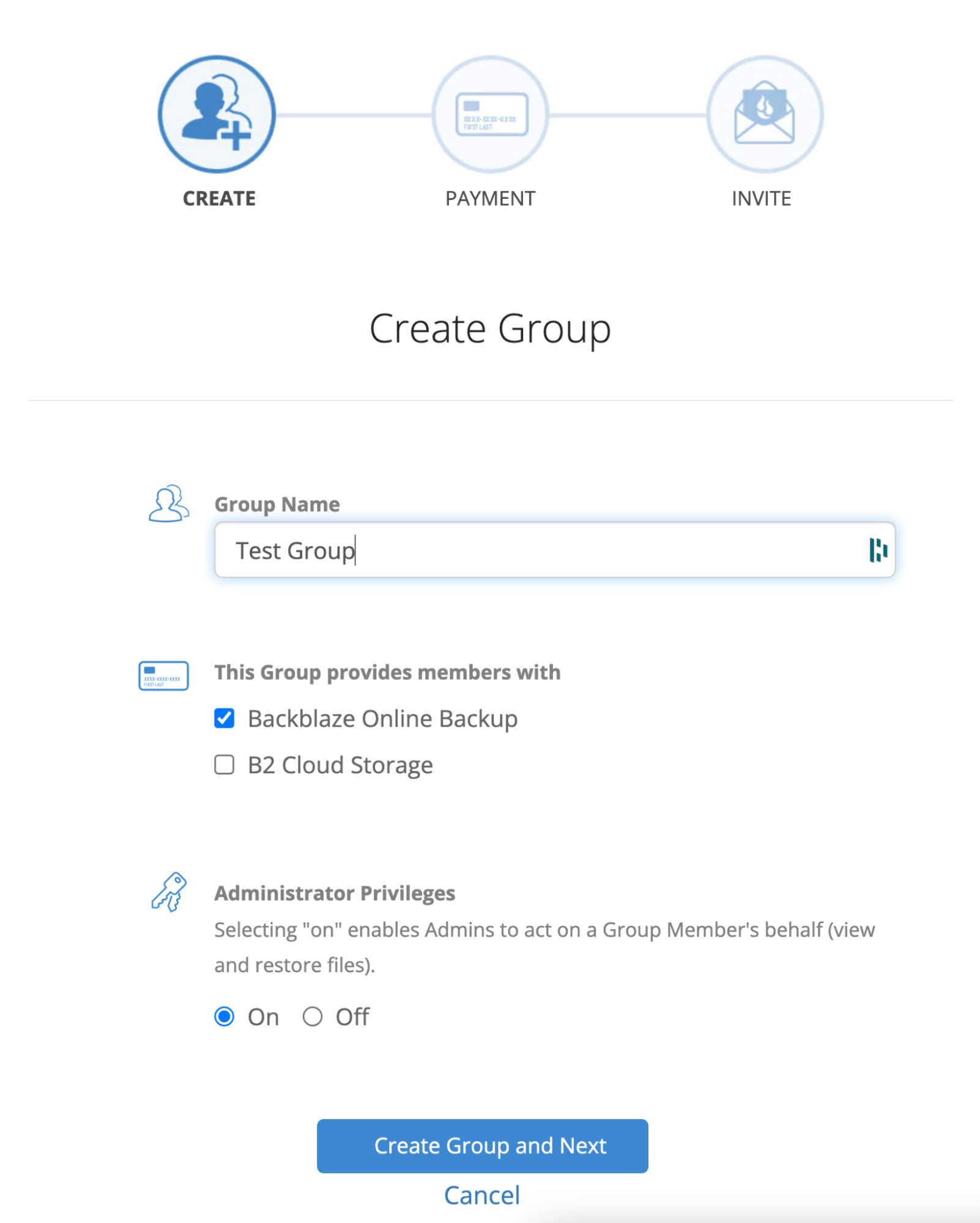
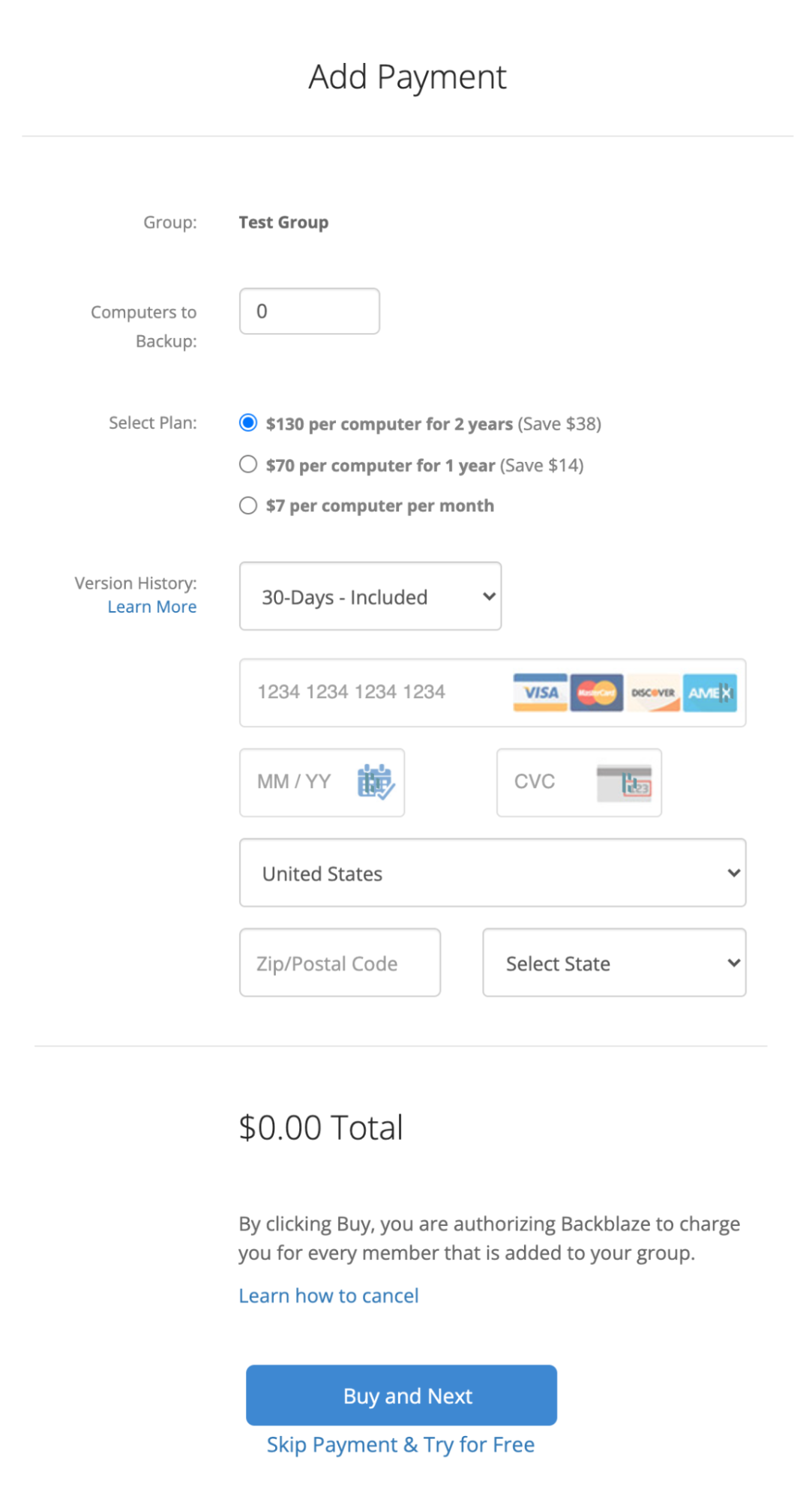





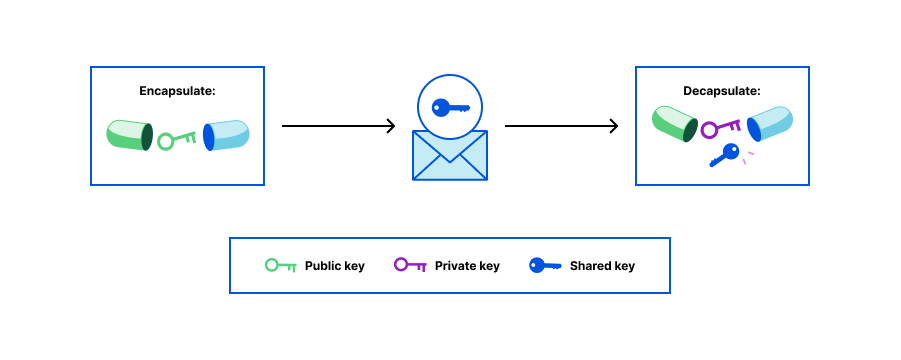


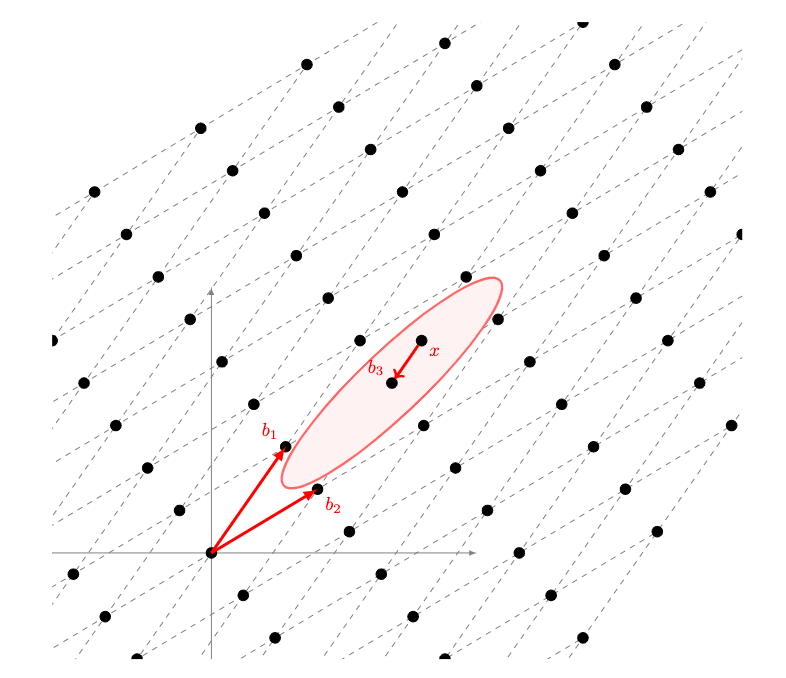






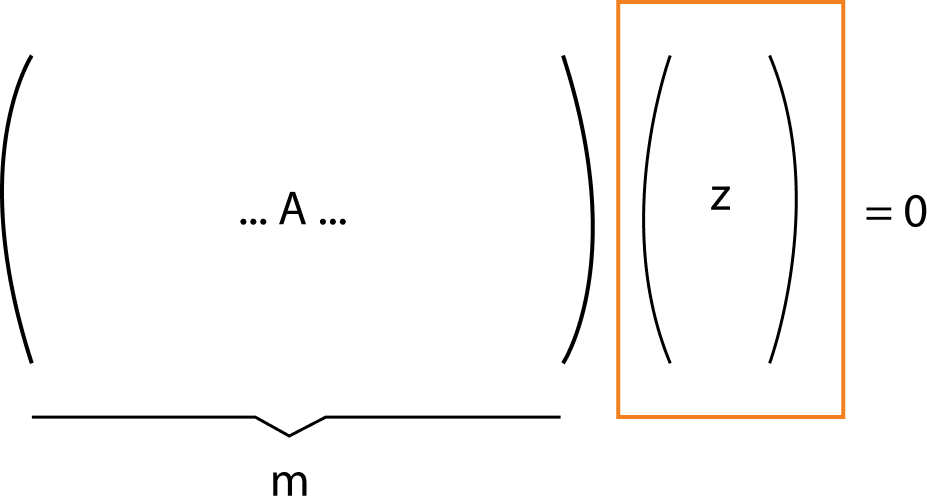
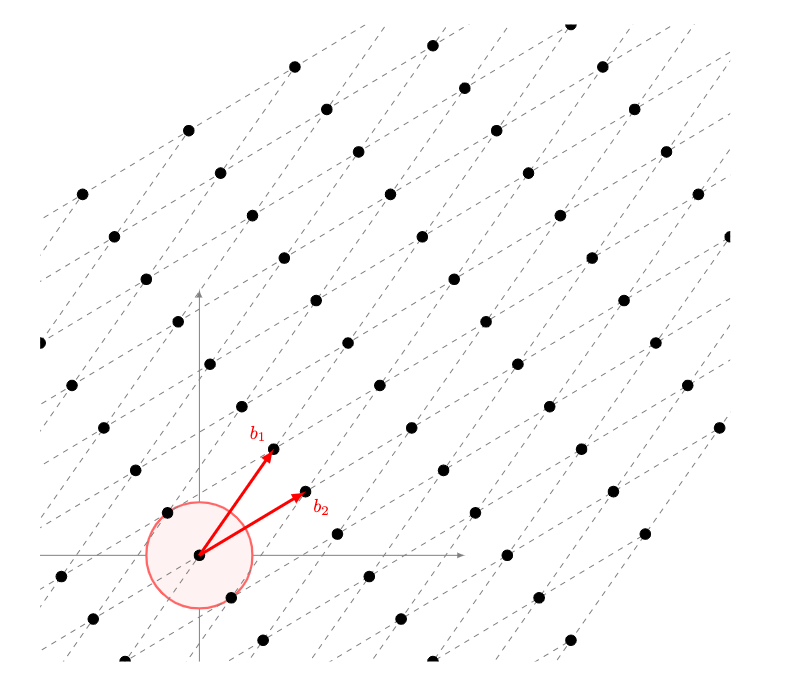


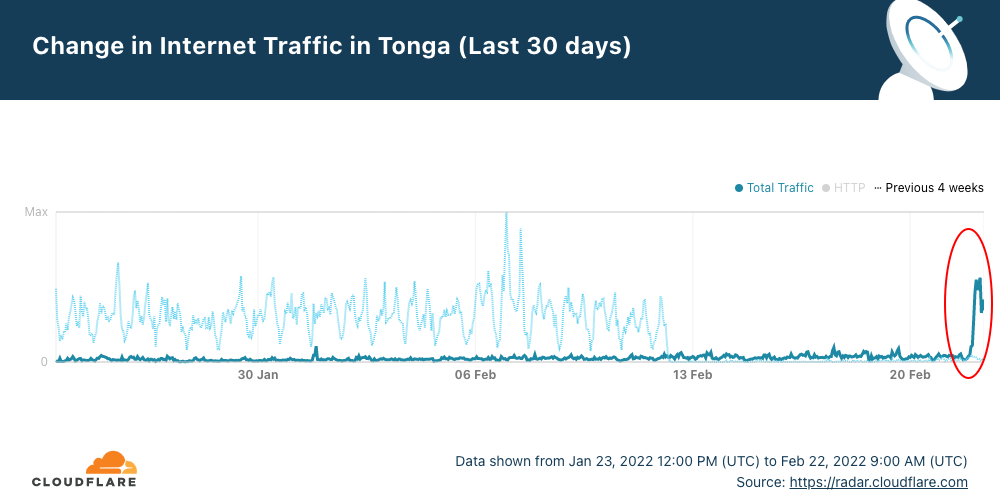
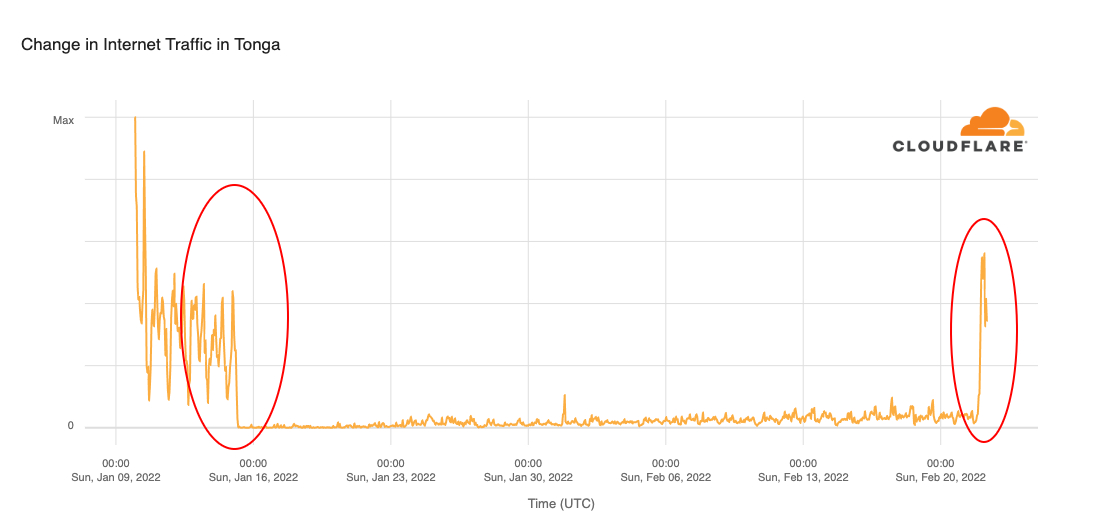
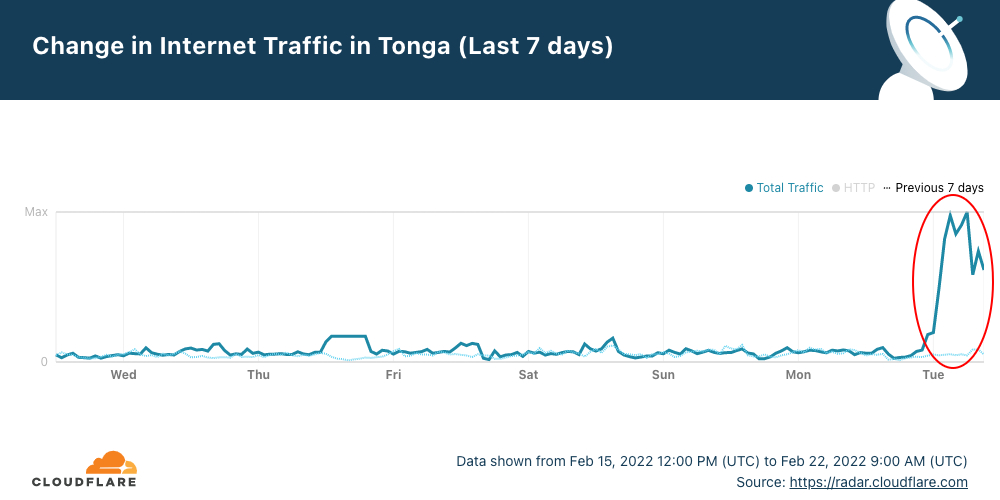
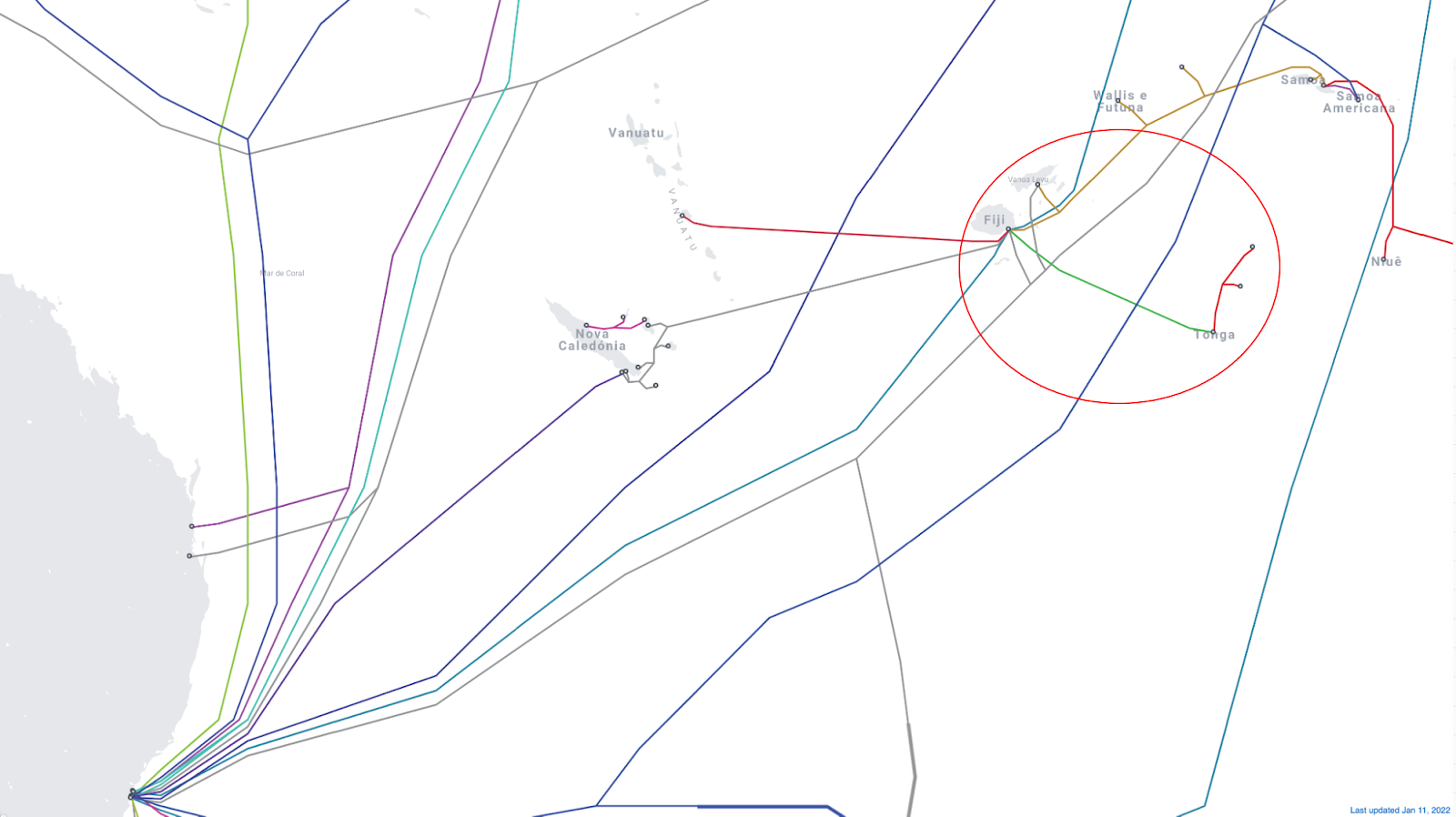





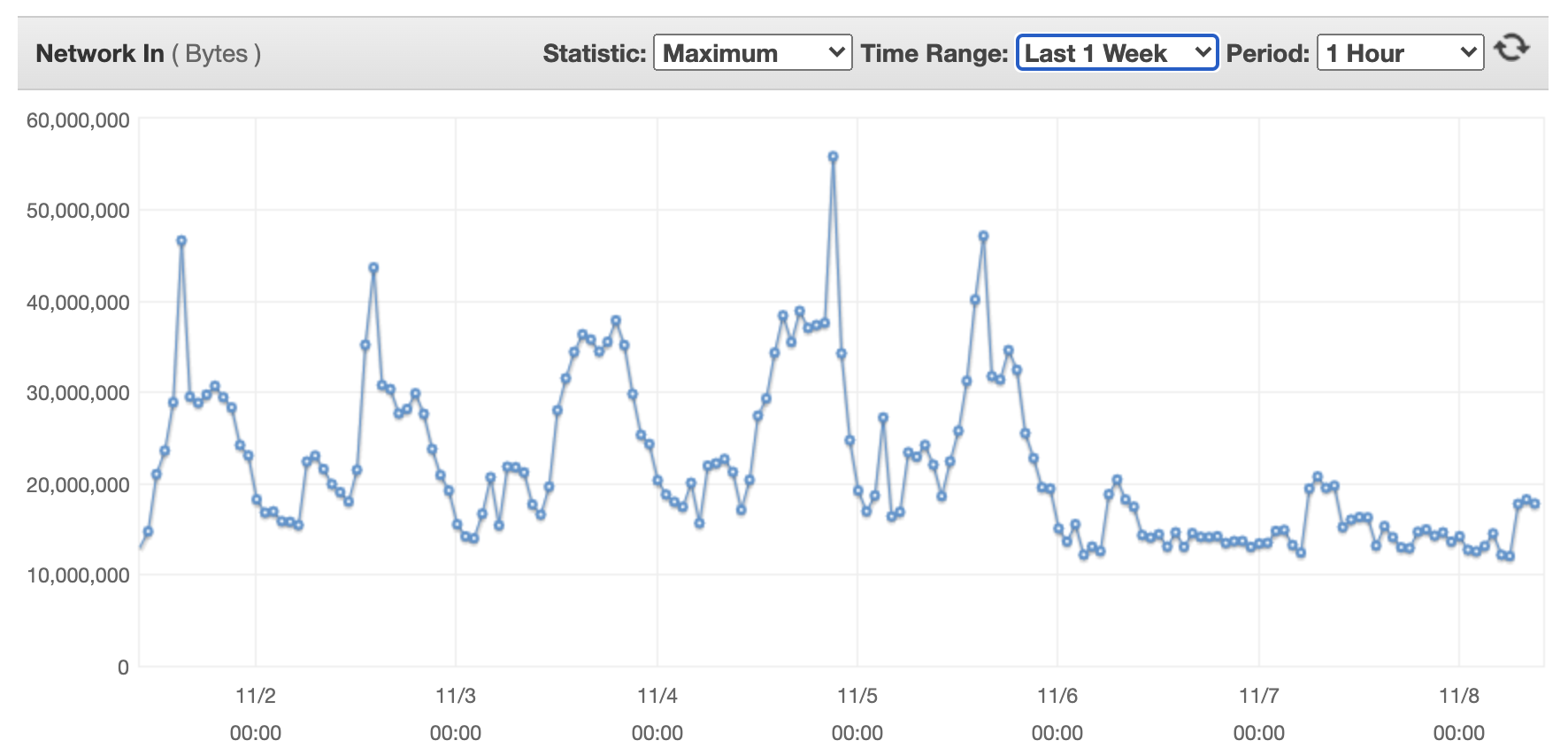
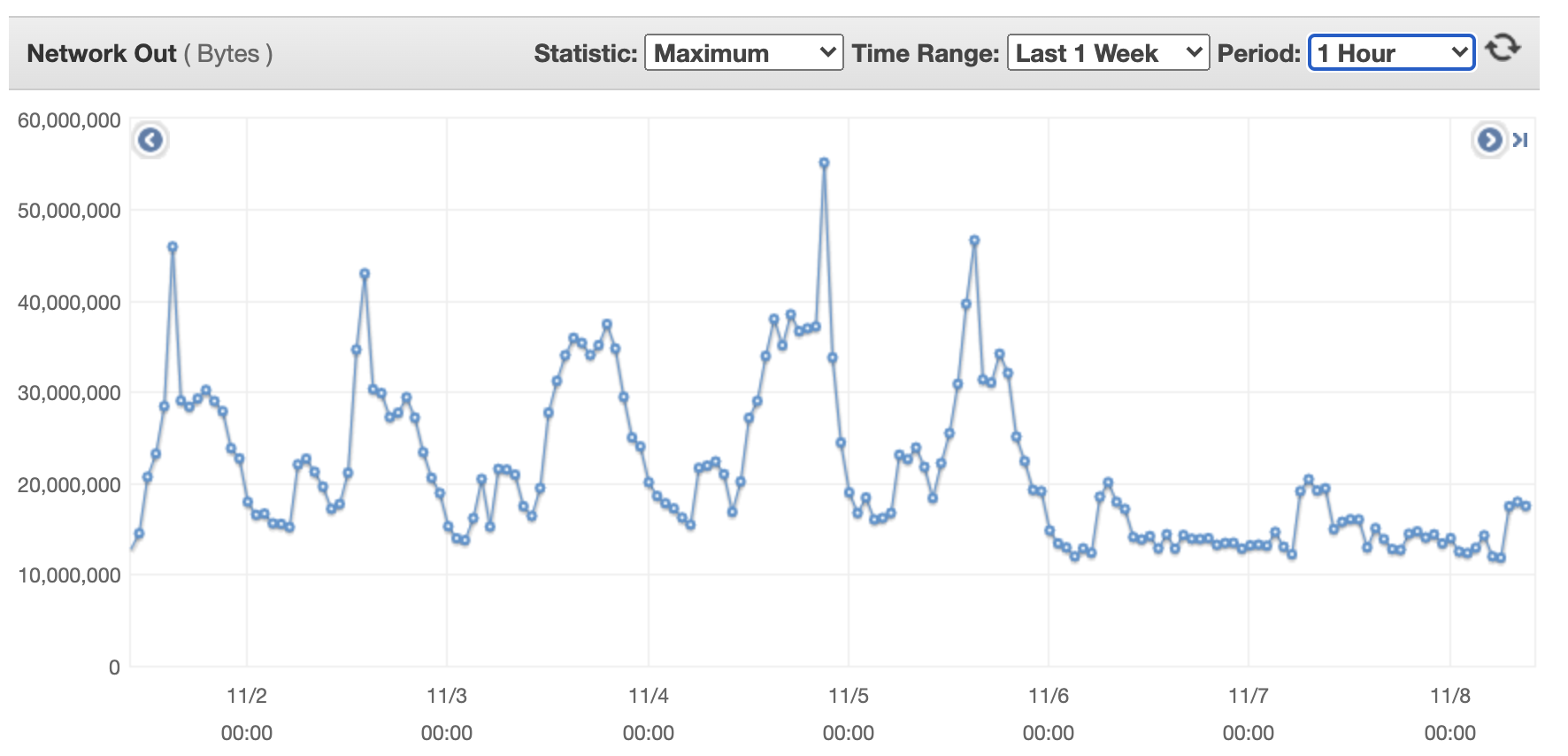

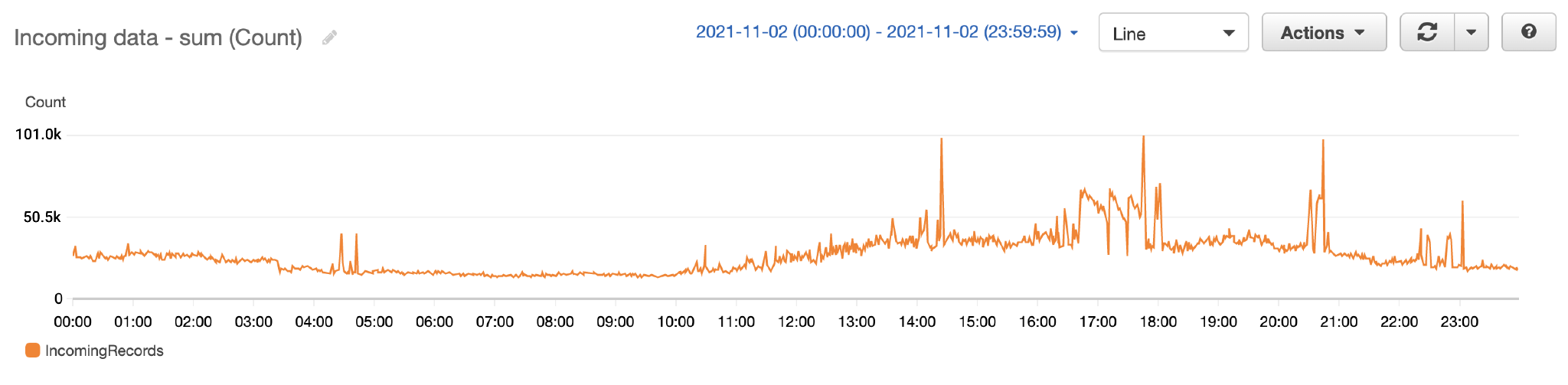




{kind=link}