Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=E3Io5AO4Nxc
STH Turns 15 Amazing Years Old
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/sth-turns-15-amazing-years-old/
Today STH turns 15, marking a decade and a half of the site and what has been perhaps the most disruptive year since the pandemic
The post STH Turns 15 Amazing Years Old appeared first on ServeTheHome.
This Day In History, June 7
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=YRxiXknOeq4
At last! Stereo Tefifon – a unique audio experience
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=nKGY0_xC3co
Избори 2024 – обновени секции, Гърция и блокиране във Facebook
Post Syndicated from Боян Юруков original https://yurukov.net/blog/2024/izbori2024-promeneni-sekcii-fb/
Утре, 9-ти юни, ще се проведат избори за европейски и национален парламент. Ще имаме възможност да гласуваме в 769 секции в 673 места зад граница. Адресите им бяха обявени в края на май, но в последната седмица на поне 12 от тях бяха променени адресите:
- о. Лефкада, Гърция
- о. Лимнос, Гърция
- Неа Перамос, Гърция
- Лондон, Норбъри, UK
- Палма де Майорка, Испания
- Бургос, Испания
- Бенидорм, Испания
- Люксембург
- Туар, Франция
- Лион, Франция
- Кройцлинген, Швейцария
- Оукланд, Нова Зеландия
Макар списъкът с адресите да е видим на сайта на Външно, не е особено прегледен и промените в секциите се намират трудно. Все пак е добра идея да се погледне преди вота утре, ако имате съмнения. Както писах преди, в последните 12 години поддържам карта достъпна в линковете горе за удобство на сънародниците ни в чужбина. Съвети за процеса на гласуване и особености на този вот ще намерите в предишната ми статия.
Изпратих адресите на близките до тях секции на над 3000 души абонирани на картата за новини, както и следващи съобщения на няколко стотин от тях засегнати от промяната на споменатите адреси. Целта е да улесня активни българи зад граница, които биха могли да предадат информацията за възможността, мястото и условията на гласуване на мрежите си от познати около тях умножавайки ефекта на кампанията.

Нещо важно, което доста хора не са наясно, е че няма нужда да сте подавали заявление, за да гласувате зад граница. Това важи както за българи установили се в друга държава, така и за пътуващи по работа или за почивка. Това означава, че ако в момента сте в Гърция, например, може да отскочите утре до която и да от секциите там само с лична карта или паспорт и да упражните гласа си. На място се попълва декларация за гласуване и са длъжни да ви допишат.
Страничен ефект от това е, че ако сте в София, в Родопите или по южното Черноморие, но настоящия и постоянния ви адрес да не е там, може да отскочите през границата до Димитровград или секциите в Гърция и Турция и да гласувате. Може да се окаже по-близко от секцията, в която следва да гласувате по адрес. Оказва се, че немалко хора го правят и е жалко, че се налага предвид колко време ефективно се блокира решеното вече въвеждане на сигурно дистанционно гласуване.

Инициативи като Glasuvam.org целят да помогнат в тази ситуация, но не са без противници. В последните два дни много хора съобщиха, че Facebook блокира споделените от тях линкове към картата, включително призивите им да се гласува по принцип. Моите публикации също бяха направо изтрити с мярката сочеща към масово подаване на сигнали за публикациите ми конкретно за този сайт. Затова не се учудвайте, ако това се случи с вас. Мога само да спекулирам какви са подбудите на въпросната група, но ми се струва, че целят да спечелят от по-малък вот какво страната, така и в чужбина. Това може да е само още една подбуда да излезем утре и да гласуваме.
Не очаквам ограниченията да бъдат вдигнати до утре. Затова споделих на няколко места тази снимка съдържаща линка. Може да я свалите и споделите и вие, ако искате да призовете другите да гласуват. Алтернативно може да потърсите в търсачките „карта избори в чужбина“ и ще излезе винаги моят сайт.

The post Избори 2024 – обновени секции, Гърция и блокиране във Facebook first appeared on Блогът на Юруков.
Седмицата (3–8 юни)
Post Syndicated from Светла Енчева original https://www.toest.bg/sedmitsata-3-8-yuni/

„Ако изборите променяха нещо, щяха да ги забранят“ – надпис с тези думи красеше центъра на София някъде през 90-те. Същият цитат (на английски) се върти из социалните мрежи и погрешно се приписва на Марк Твен. По-вероятно е крилатата фраза да принадлежи на анархистката Ема Голдман. Литературният баща на Том Сойер и Хъкълбери Фин всъщност е казал нещо тъкмо в противоположен дух:
„В тази страна [САЩ, б.а.] имаме една голяма привилегия, каквато в другите страни нямат. Когато едно управление стане абсолютно непоносимо, хората могат да се вдигнат и да го отхвърлят. Това е най-чудесната придобивка, която имаме – избирателната урна.“
На предстоящите избори за национален и европейски парламент се очаква около 60% от имащите право на глас български граждани да не го упражнят. Няма никаква гаранция, че ако всички те гласуват, резултатът ще възпроизведе точно нашите желания за електорално представителство, вътрешно- и външнополитическа ориентация. Сигурно е обаче, че тези 60% могат да променят картината до неузнаваемост. Стига да решат.
Едно стихотворение на Ерих Кестнер гласи, че доброто не съществува само̀ по себе си, а се прави от хората. И с политиката е така. Колкото и основания за разочарование от политиката у нас (и в ЕС) да има, елементарен математически факт е, че никоя партия или коалиция не е в състояние да изпълни програмата си, ако не разполага с мнозинство от 50% плюс 1 глас. Да възпроизвеждаме разпокъсани парламенти избори след избори, а после да се сърдим, че избраниците ни не са си изпълнили обещанията, не е много честно.
„Ако изборите променяха нещо, щяха да ги забранят“ е ефектна фраза, но пък невярна. Защото изборите впрочем не са даденост. Свободните и честни избори – още по-малко. Именно защото те могат да променят много неща, диктаторите не ги обичат.
В Саудитска Арабия например формата на управление е абсолютна монархия. Там не се гласува за парламент, а кралят си назначава правителство, каквото му харесва. Вече и местни избори няма. В Русия на теория има избори, но на практика не е възможно да съществува опозиция – лидерите ѝ са преследвани, съдени, убивани. В страната на Путин не е безопасно дори с празен лист да протестираш.
В България сме склонни да не оценяваме колко много имаме. Можем да гласуваме за когото искаме. Можем да протестираме. Имаме относителна свобода на словото. Да, и контролиран вот си имаме. Можем да го обезсмислим обаче – с по-висока избирателна активност.
Нищо от тези демократични придобивки обаче не е даденост. Не е даденост и мястото ни в ЕС. Самият ЕС също не е даденост. Толкова е лесно да загубим свободата, която имаме. Започва се с репресии срещу неправителствените организации, жените (ограничаване на правото на аборт например), ЛГБТИ хората. И докато се усетим, се разпростира върху всички.
На предстоящите избори, конкретно – на (не)възможните компромиси след 9 юни, е посветен и тазседмичният анализ на Емилия Милчева. Проблемът е, че в България стремежът към политически компромис се разбира не в смисъла на „съвещателната демокрация“, за която говори германският философ и социолог Юрген Хабермас, а като задкулисна консолидация на властта в ръцете на няколко лидери. Затова партиите и коалициите са много предпазливи в предизборните си заявки с кого биха управлявали заедно.
Отново за избори, но от другата страна на Атлантика, е и статията на Йоанна Елми „Ще обърне ли Палестина изборите в САЩ?“. Дали се учим да устояваме на ужаса, или се оставяме да се сварим като жаби, е въпрос на перспектива, смята Йоанна. Друг начин да бъде зададен този въпрос е може ли войната в Палестина да повлияе върху резултата на американските избори. И как.
Връщаме се в България. Докато тук на мюсюлманите преобладаващо се гледа през стереотипи – като електорат на една определена партия и/или като заплаха, – ислямската култура остава тера инкогнита. Ако ви е любопитно да разберете какво (разказват, че) сънуват мюсюлманите от Пророка Мохамед насетне и как тълкуват сънищата си, статията на Атанас Шиников „Сънуват ли джихадистите девици?“ е тъкмо за вас. На мен сънят за летящия слон с голямото мъжко (пардон, слонско) достойнство дълго няма да ми излезе от главата.
Продължаваме на културна вълна. Антония Апостолова разговаря с Крис Клийв за практиките на отказа и изкуството на живота. Писателят е специален гост на летните „Литературни срещи“ (14–15 юни 2024 г.), а интервюто с него е проведено непосредствено преди литературното му турне в България. От него може да научите защо Клийв обича да показва обикновените животи в рамките на мащабни събития, дали той може да си представи история, която не е свързана с родния му град, какво смята за спорта, както и други интересни детайли.
След като навлязохме в полето на литературата, е време Зорница Христова да ни поведе „по буквите“, като ни представи три книги. Този път избраните от нея заглавия са „Сънсет парк“ от Пол Остър, „21 разказа“ от Греъм Грийн (и двете в превод от английски на Иглика Василева) и „Верно на оригиналот“ от Николай Бойков. Макар и без пряка връзка една с друга, представени от Зорница, книгите си говорят и се заиграват помежду си. Остър и Грийн се вълнуват от представата за втори живот, а в книгата на Бойков езикът живее два живота.
Оставаме на културна вълна с три акцента от „София Прайд Филм Фест“, препоръчани от Нева Мичева. Фестивалът се завръща в столичния Дом на киното с качествена селекция от пълно- и късометражно кино, която може да гледате до 15 юни.
И тъкмо преди финала любезно напомняме, че в „Тоест“ си търсим маркетинг специалист. По обявата може да се кандидатства още седмица.
Този път не завършвам бюлетина с препоръка, защото започнах с нея. Ако трябва да я резюмирам с една дума: гласувайте.
Всекидневно правим избори, които не са пряко политически, но от които също зависи качеството на политическия живот. Такъв избор например е какви медии четем. В „Тоест“ ценим свободата на мненията, но правим разлика между позиции и факти. Фактите проверяваме, а към мненията подхождаме отговорно. Защото знаем, че медиите имат силата да променят света. Ако за вас е важно в България да има прецизни и отговорни медии с прозрачно финансиране, които не зависят от рекламодатели, имайте предвид, че не бихме могли да оцелеем без вашата подкрепа.
Comic for 2024.06.08 – Swingers
Post Syndicated from Explosm.net original https://explosm.net/comics/swingers
New Cyanide and Happiness Comic
Crucial Pro DDR5-6000 UDIMM White with EXPO and XMP
Post Syndicated from John Lee original https://www.servethehome.com/crucial-pro-ddr5-6000-udimm-white-amd-expo-intel-xmp-micron/
If you want a white themed RAM in your build the Crucial Pro DDR5-6000 white supports both Intel XMP and AMD EXPO profiles
The post Crucial Pro DDR5-6000 UDIMM White with EXPO and XMP appeared first on ServeTheHome.
Friday Squid Blogging: Squid Catch Quotas in Peru
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/06/friday-squid-blogging-squid-catch-quotas-in-peru.html
Peru has set a lower squid quota for 2024. The article says “giant squid,” but that seems wrong. We don’t eat those.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
Security and Human Behavior (SHB) 2024
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/06/security-and-human-behavior-shb-2024.html
This week, I hosted the seventeenth Workshop on Security and Human Behavior at the Harvard Kennedy School. This is the first workshop since our co-founder, Ross Anderson, died unexpectedly.
SHB is a small, annual, invitational workshop of people studying various aspects of the human side of security. The fifty or so attendees include psychologists, economists, computer security researchers, criminologists, sociologists, political scientists, designers, lawyers, philosophers, anthropologists, geographers, neuroscientists, business school professors, and a smattering of others. It’s not just an interdisciplinary event; most of the people here are individually interdisciplinary.
Our goal is always to maximize discussion and interaction. We do that by putting everyone on panels, and limiting talks to six to eight minutes, with the rest of the time for open discussion. Short talks limit presenters’ ability to get into the boring details of their work, and the interdisciplinary audience discourages jargon.
Since the beginning, this workshop has been the most intellectually stimulating two days of my professional year. It influences my thinking in different and sometimes surprising ways—and has resulted in some new friendships and unexpected collaborations. This is why some of us have been coming back every year for over a decade.
This year’s schedule is here. This page lists the participants and includes links to some of their work. Kami Vaniea liveblogged both days.
Here are my posts on the first, second, third, fourth, fifth, sixth, seventh, eighth, ninth, tenth, eleventh, twelfth, thirteenth, fourteenth, fifteenth and sixteenth SHB workshops. Follow those links to find summaries, papers, and occasionally audio/video recordings of the sessions. Ross maintained a good webpage of psychology and security resources—it’s still up for now.
Next year we will be in Cambridge, UK, hosted by Frank Stajano.
Internet insights on 2024 elections in the Netherlands, South Africa, Iceland, India, and Mexico
Post Syndicated from João Tomé original https://blog.cloudflare.com/internet-insights-on-2024-elections-in-the-netherlands-south-africa-iceland-india-and-mexico

2024 is being called by the media “the” year of elections. More voters than ever are going to the polls in at least 60 countries for national elections, plus the 27 member states of the European Union. This includes eight of the world’s 10 most populous nations, impacting around half of the world’s population.
To track and analyze these significant global events, we’ve created the 2024 Election Insights report on Cloudflare Radar, which will be regularly updated as elections take place.
Our data shows that during elections, there is often a decrease in Internet traffic during polling hours, followed by an increase as results are announced. This trend has been observed before in countries like France and Brazil, and more recently in Mexico and India — where elections were held between April 19 and June 1 in seven phases. Some regions, like Comoros and Pakistan, have experienced government-directed Internet disruptions around election time.
Below, you’ll find a review of the trends we saw in elections in South Africa (May 29), to Mexico (June 2), India (April 19 – June 1) and Iceland (June 1). This includes election-related shifts in traffic, as well at attacks. For example, during the European Parliament election (June 6-9, 2024), DDoS attacks targeted Dutch political websites for two days, peaking at 73,000 requests per second.
We’ll also be keeping an eye on upcoming elections. The United Kingdom recently scheduled its general election for July 4, making it the latest addition to the electoral calendar.
Dutch political websites hit by cyber attacks
Europe: 2024 European Parliament election (June 6-9)
As mentioned above, we recently published a blog post about the cyber attack on Dutch political-related websites. The 2024 European Parliament election started in the Netherlands on June 6, and continues through June 9 in the other 26 countries that are part of the European Union. Cloudflare observed DDoS attacks targeting multiple election or politically-related Internet properties on election day in the Netherlands, as well as the preceding day.
The main June 5 DDoS attack on one of the websites peaked at 14:13 UTC (16:13 local time), reaching 73,000 requests per second (rps) in an attack that lasted for a few hours. This attack is illustrated by the blue line in the graph below, which shows that it ramped slowly over the first half of the day, and then appeared to abruptly stop at 18:06. And on June 6, the main attack on the second website peaked at 11:01 UTC (13:01 local time) with 52,000 rps.
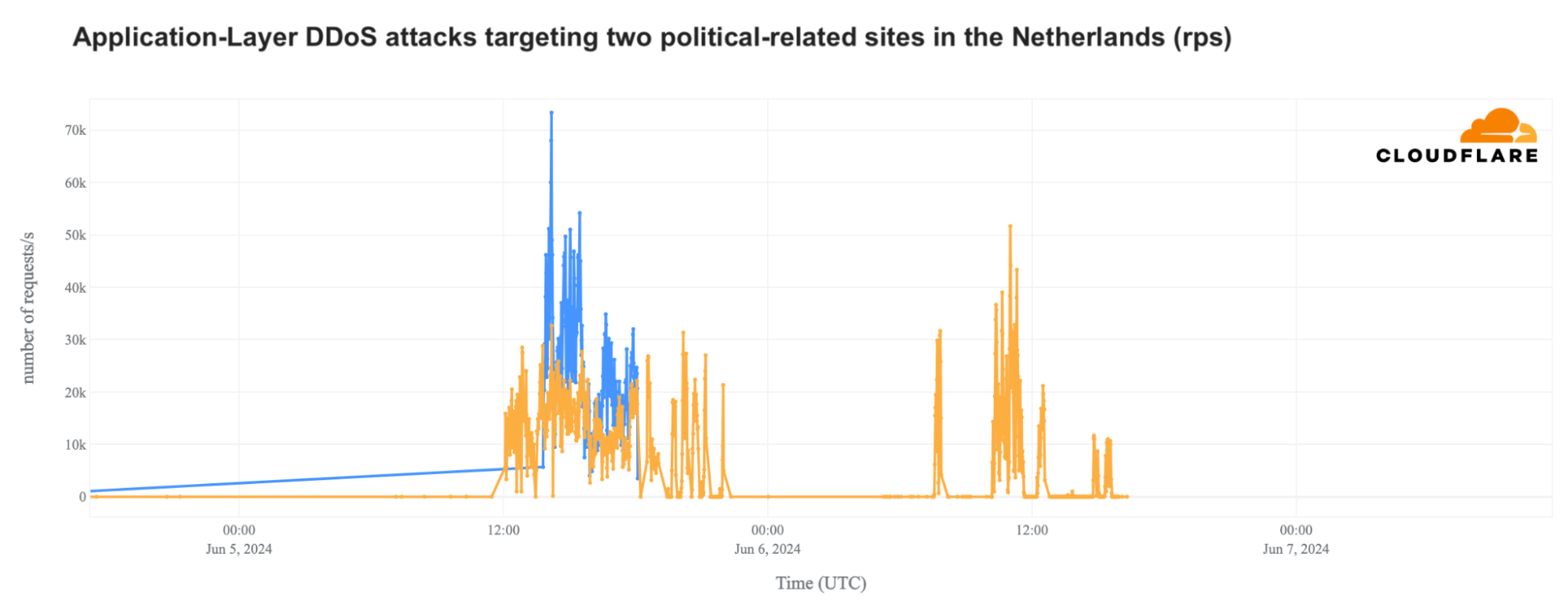
More information can be found in the dedicated blog post and the elections report.
A European Union perspective
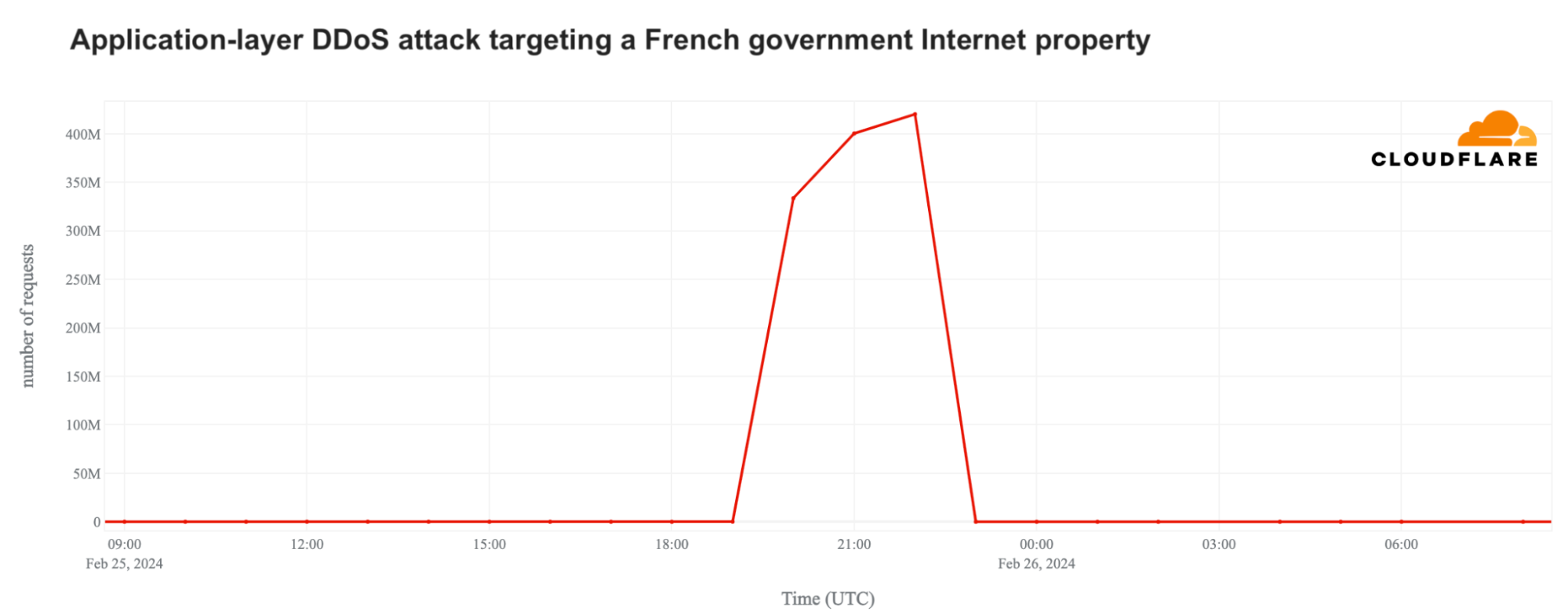
In Europe, cyberattacks have been a significant issue. In March 2024, French government websites faced attacks of “unprecedented intensity,” according to a spokesperson. Just days earlier, on February 25, 2024, Cloudflare blocked a major DDoS attack on a French government website, which reached 420 million requests per hour and lasted over three hours.
Looking at government or state-related websites in the European Union in 2024, there have been several spikes in attacks targeting defense organizations, European courts, and educational institutions.
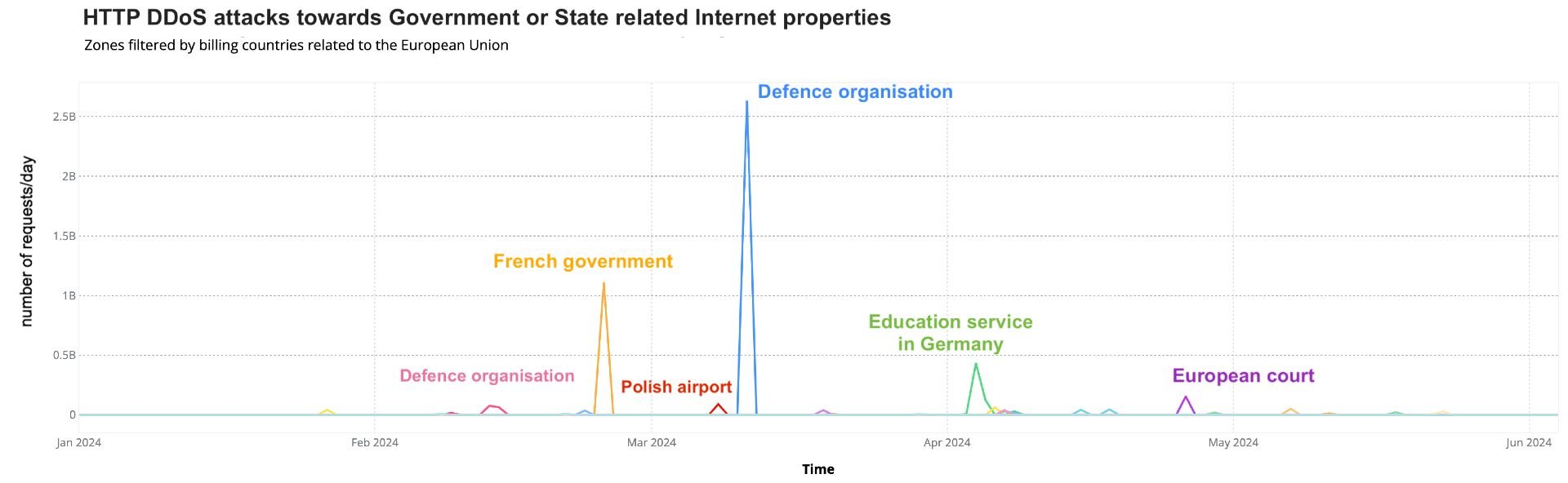
These incidents highlight the ongoing threat to critical infrastructure across Europe, with government sites frequently targeted by cyberattacks.
Mexicans go offline: early traffic drops on election day
Mexico: Presidential, Senate, and Chamber of Deputies elections (June 2)
General elections were held in Mexico on Sunday, June 2, 2024, resulting in the election of the first female president, Claudia Sheinbaum, from the Morena political party. Cloudflare data shows a typical election day pattern in Mexico, mirroring trends seen in other countries: when polling stations are open, HTTP requests dip below normal levels. On June 2, traffic decreased between 08:00 and 20:00 CST (14:00 and 02:00 UTC), gradually recovering afterward as polling stations closed at 18:00 CST. Throughout the day, traffic experienced drops of up to 11% at 09:30 and 13:00 CST, with daily traffic decreasing by 3%.
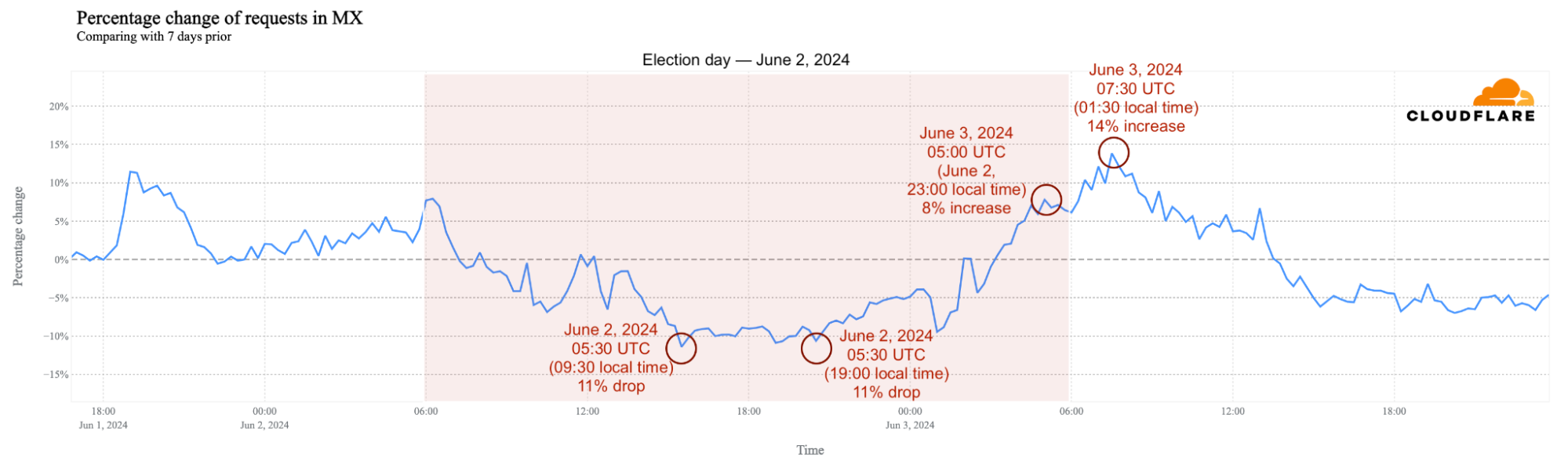
The first official results were released after 23:00 (05:00 UTC in the chart above), coinciding with an 8% increase in traffic compared to the previous week. This growth peaked at 01:30 (07:30 UTC), with a 14% surge in HTTP requests, maintaining elevated levels until 07:30 in Mexico.
A similar trend was observed at the state level, with the period between 10:00 CST and 14:00 being the one with the most significant drop in traffic, with voting taking place all over the country.
(We provide a full table of the biggest drops in traffic and the specific time of that drop on election day by Mexican state in our Radar 2024 Election Insights report).
Website trends: traffic spikes from news and election results
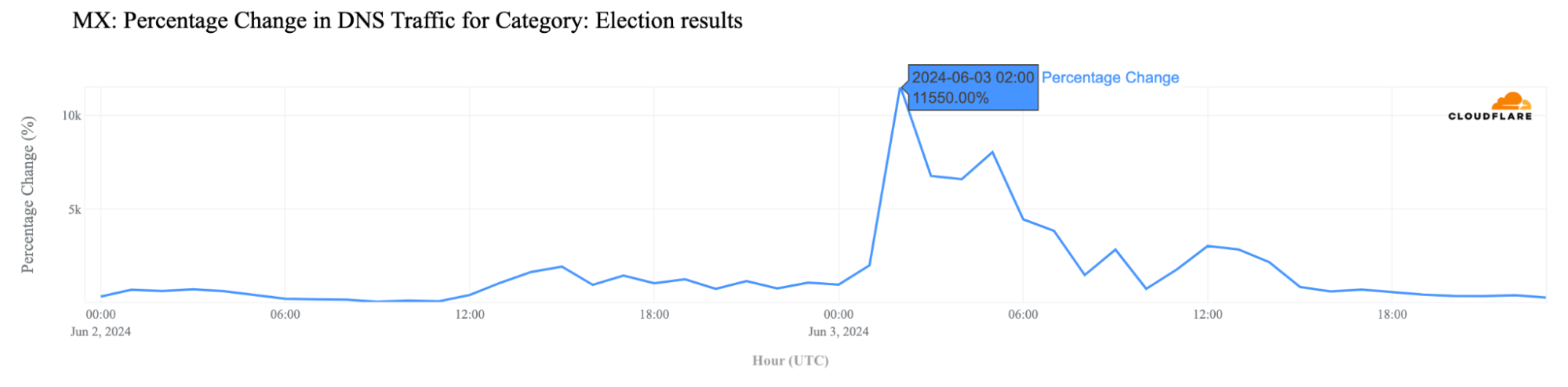
Switching to domain trends, DNS traffic (using our 1.1.1.1 resolver) to election results sites in Mexico grew by almost 116x compared to the previous week, peaking at 20:00 CST (02:00 UTC), and remained up to 80x higher, until 23:00 CST (05:00 UTC).
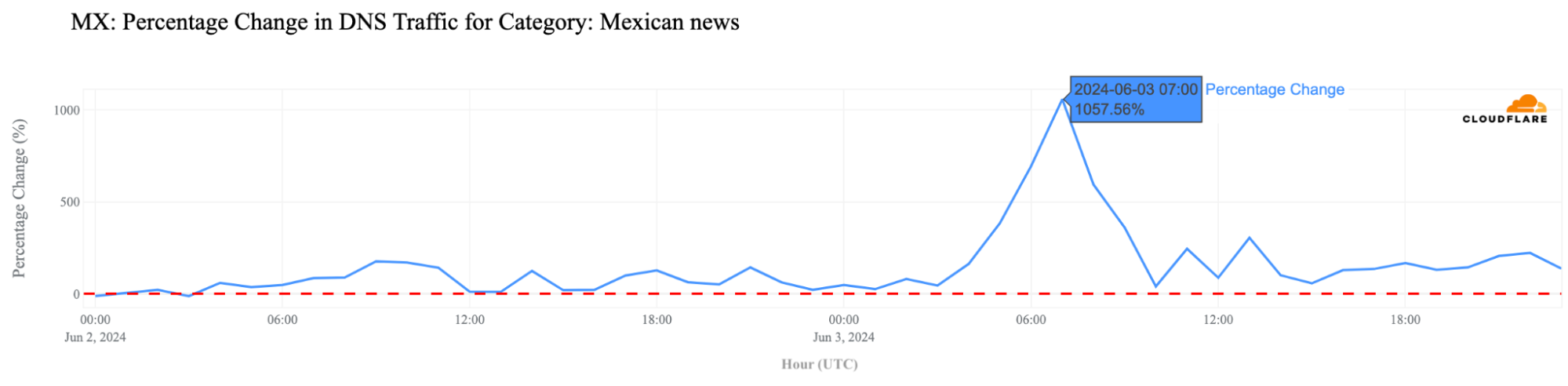
Examining news media outlets, there was noticeable growth in DNS queries on Election Day, June 2, with traffic significantly higher than the previous week in the early morning. By 20:00 CST (02:00 UTC), traffic surged to 1.8x higher, then skyrocketed to a 4.8x increase by 23:00 CST (05:00 UTC), reaching a peak at 01:00 CST (07:00 UTC) with a staggering 1057% more DNS traffic than the previous week.
Attacks: early May election-related DDoS spike
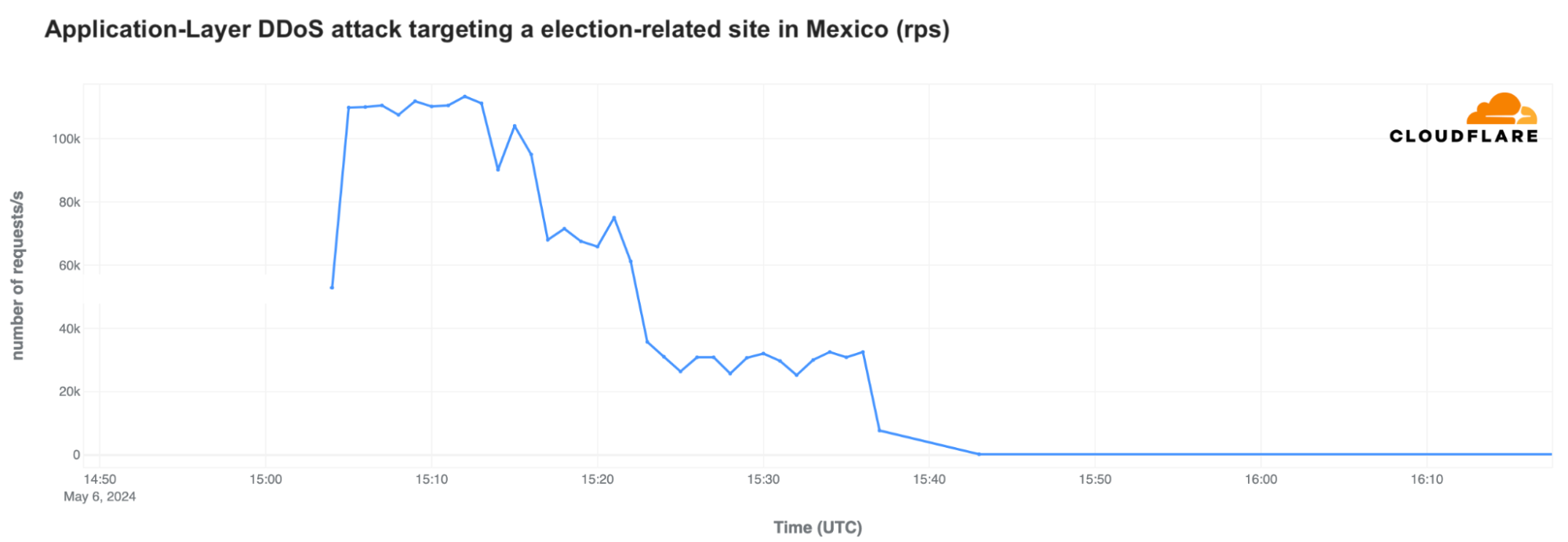
We didn’t see any unusual attacks targeting Mexico before the election, except for one targeting a state electoral organization. A specific DDoS attack on May 6 targeted a state electoral organization, reaching 130 million HTTP requests per hour, with a peak of 113,000 requests per second at 09:12 CST (15:12 UTC). The attack lasted about 30 minutes.
India’s elections: 44 days of traffic dips and mobile spikes
India: General election (April 19 – June 1)
In India, general elections were held from April 19 to June 1, 2024 in seven phases, with incumbent Prime Minister Narendra Modi winning by a smaller margin than in the previous election. More than 968 million people out of a population of 1.4 billion were eligible to vote, and there was a 66% turnout, making it the largest election in human history.
Not all states voted on the same days, leading to mixed HTTP request patterns. On April 18, the day before the first election day, traffic was 10% higher than the previous week, marking the biggest increase of the year, something we’ve seen in other elections.
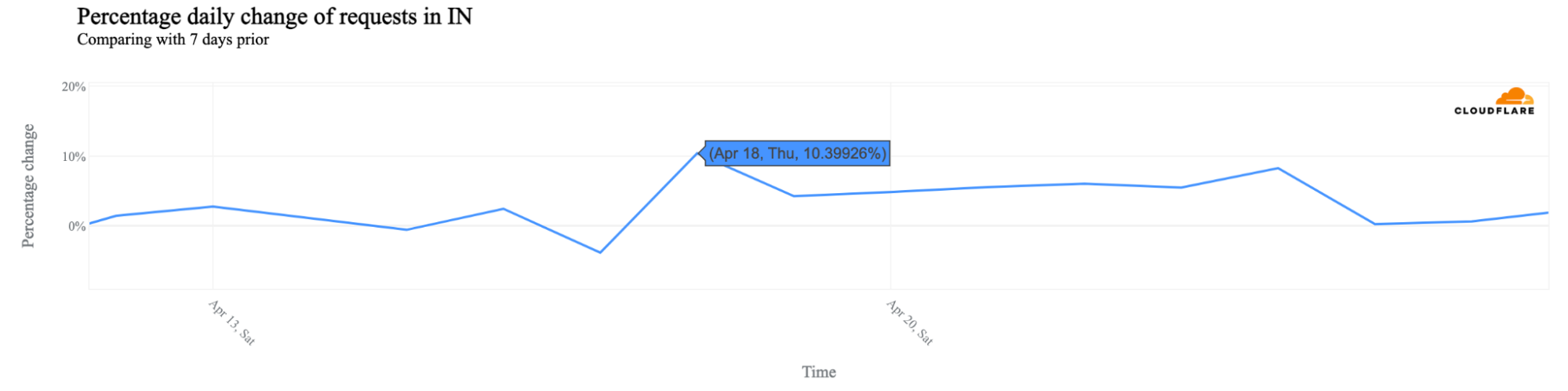
Some of the seven election days had a nationwide impact. Not all states in India voted on the same days. However, days with more constituencies or populous states participating saw bigger traffic changes. For example, May 7, 2024, saw 11 states, including the most populous ones, voting. This day (highlighted in the next chart) experienced the biggest nationwide drop in traffic, with a 6% decrease compared to the previous week. May 20 and May 25 also saw drops of 4% and 3%, respectively.
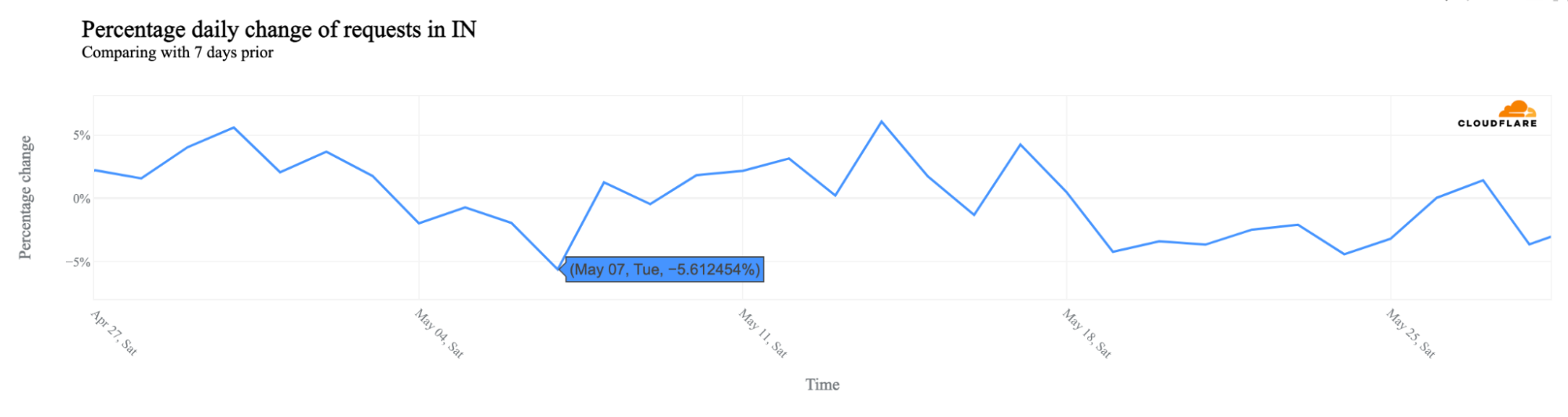
The period between 15:30 and 19:30 local time (10:00 – 14:00 UTC) typically witnessed the most significant drop in traffic on election days.
In Uttar Pradesh, the most populous Indian state, the first day of elections on April 19 saw the biggest drop (9%). May 20 and 25, with more constituencies voting, also experienced significant traffic drops, especially May 20, with traffic lower than usual between 10:30 and 22:30 UTC (05:00 – 17:00 UTC), and a 5% daily drop compared to the previous week.
In Maharashtra, home to the capital Mumbai, May 20 saw the most impact, with a 17% drop in daily traffic compared to the previous week. On this day, traffic hit its lowest point at 14:30 local time (09:00 UTC), with a drop of approximately 20%.
(We provide a full table of the states in India with the biggest drop in daily traffic over the several election days in our Radar 2024 Election Insights report).
Mobile devices first in India
India is a mobile-first country, with most election days during the week. On weekends, mobile devices are used more, especially on Sundays when they can reach 69% of all traffic. During the week, usage is typically between 61% and 62%. On election days, mobile device usage increased to around 64%.
Saturday, June 1, 2024, the last election day, was the Saturday of the year in India with the highest daily mobile device traffic percentage, reaching 68% (typically around 65-66%).
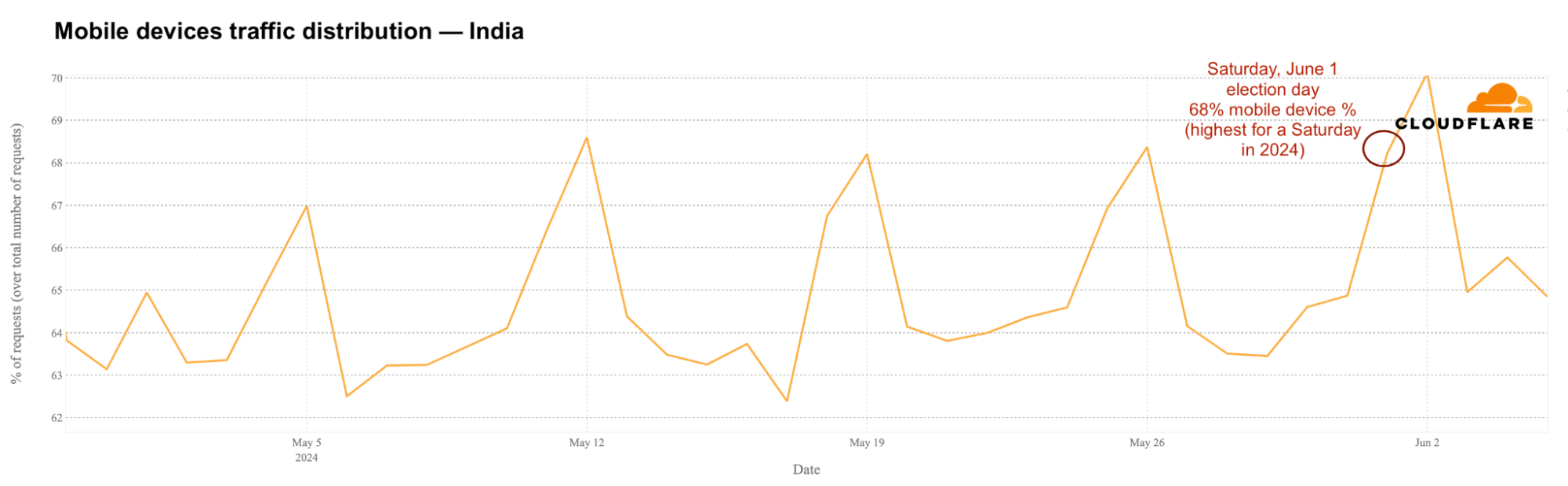
The increase in mobile device usage on election days was more noticeable during the day, particularly between 10:00 and 13:00 local time (04:30 – 07:30 UTC). May 13 and May 20 showed the biggest differences compared to typical days, reaching up to 62% during those times. In India, mobile usage during weekends is higher at night than during the day.
Attacks
Since April 2024, Cloudflare hasn’t observed any unusual or potentially election-related attacks targeting India. However, there have been large attacks on online financial services, consulting firms, and online casinos. The most targeted industries during this period have been Information Technology and Services, BFSI (Banking, Financial Services, and Insurance), and Gaming/Gambling.
Iceland’s 2024 election: impact before and after extended voting day
Iceland: Presidential election (June 1)
Iceland held its presidential election on Saturday, June 1, 2024, and Halla Tómasdóttir was elected as the new president. She is the second woman to become president in Iceland and the fourth woman to hold a top leadership position, including prime ministers.
In terms of HTTP requests, there wasn’t much change during election day. This might be because polling stations in Iceland were open from 09:00 to 22:00 local time (same as UTC), spreading out the impact. However, traffic increased the days before and after the election.
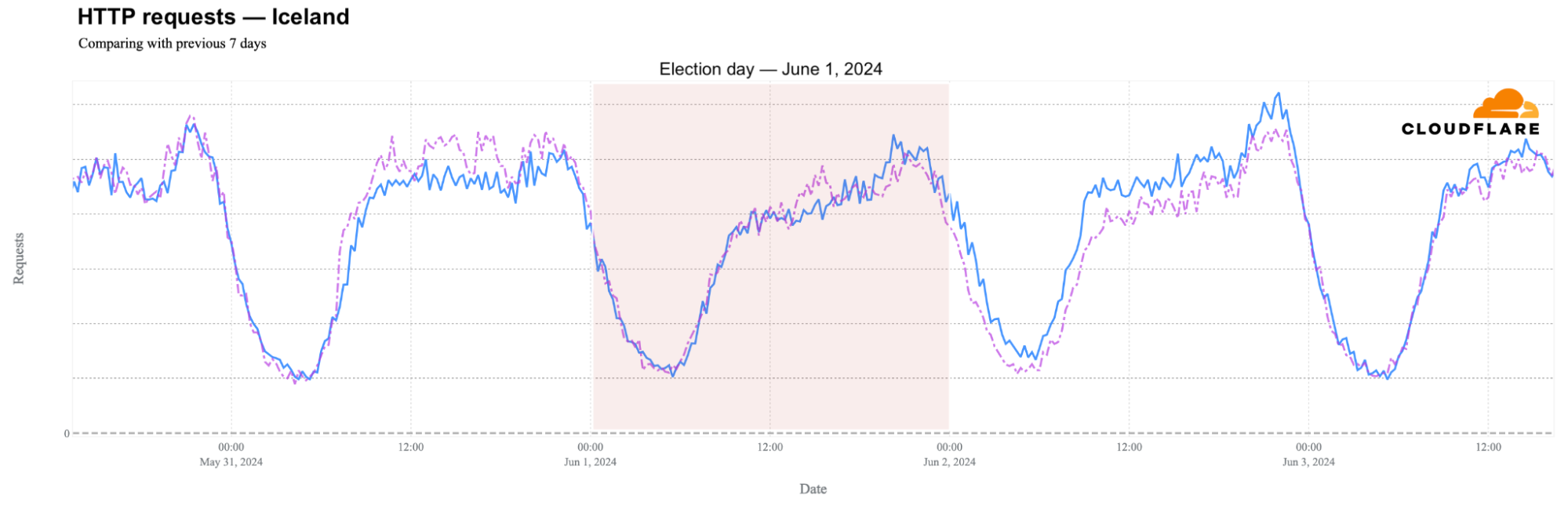
On May 31, the day before the election, daily traffic in Iceland was 7% lower than the previous week. It remained stable on election day and increased by 14% on Sunday when results were announced. This increase was only surpassed by two days in 2024:
- May 2: +17%, driven by a 9% drop the previous week due to the national holiday, the first day of summer.
- March 19: +16%, due to a volcanic eruption that led to a state of emergency, evacuations, and road closures.
Looking deeper into election day traffic with 15-minute granularity, traffic was around 12% lower between 14:00 and 16:00 local time (same as UTC), with the biggest drop, 20%, at 15:30.
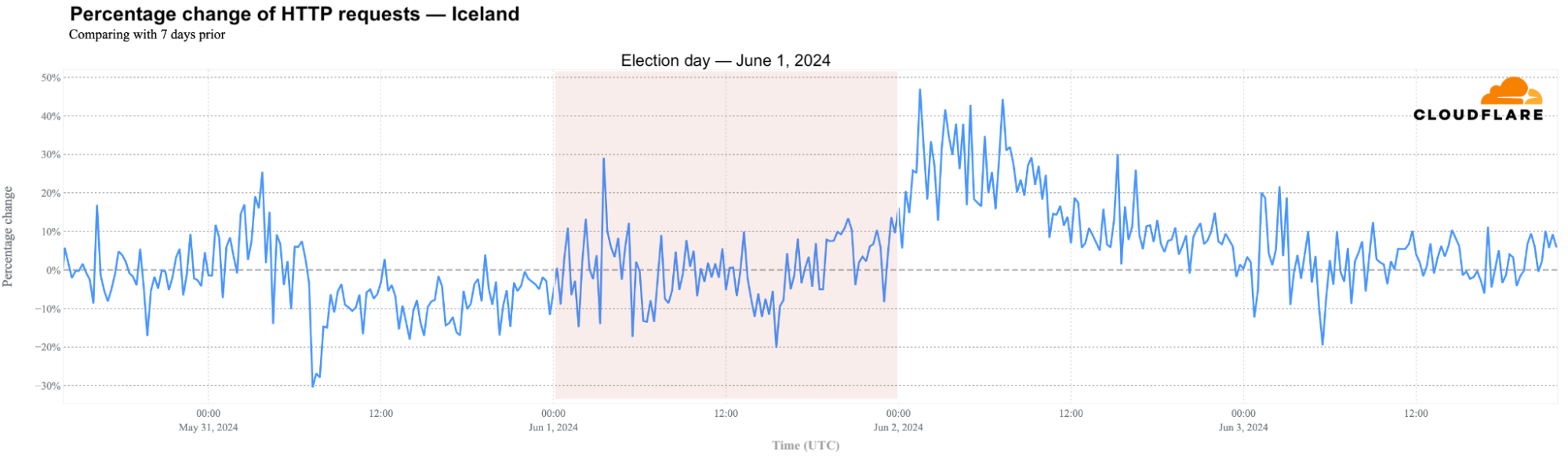
Mobile devices usage changes
June 2 and June 1, election day, were also the days in 2024 with the highest percentage of mobile device usage in Iceland, at 47% and 45%, respectively. June 1’s percentage is tied with March 2, the day the famous Blue Lagoon was evacuated due to nearby seismic activity suggesting an “imminent” volcanic eruption, and January 1, the first day of the year.
Attacks
Cloudflare didn’t observe any relevant attacks during the election period targeting Iceland and its Internet properties. Since the beginning of April 2024, the most attacked industries were Retail and Gaming.
South Africa: traffic surges pre-voting, 16% decrease during voting
South Africa: 2024 general election (May 29)
On general election day in South Africa, which took place on Wednesday, May 29, 2024, HTTP requests dipped while polling stations were open. Traffic remained lower than usual from around 05:30 local time (03:30 UTC), with a 16% drop observed at 05:45 (03:45 UTC) and a 14% decrease by 11:00 (09:00 UTC), persisting until 18:00 (16:00 UTC).
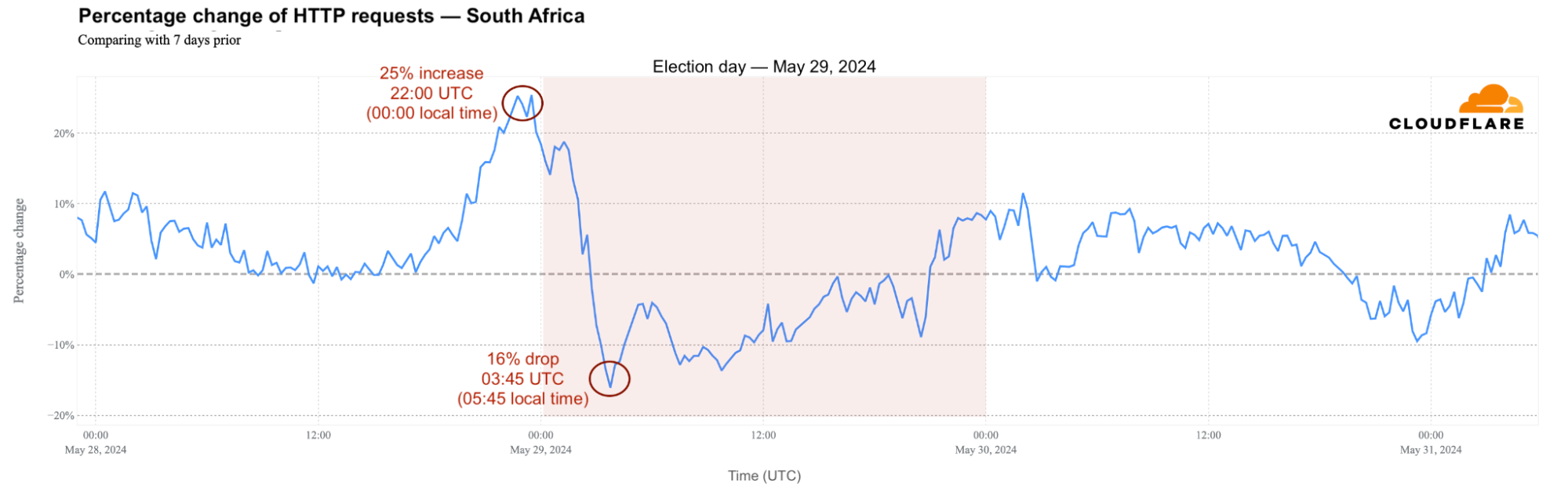
However, as shown in the chart above, the night leading up to the election saw a traffic surge, peaking at a 25% increase around midnight local time (22:00 UTC). Following the election, traffic rose compared to the previous week, with a 6% increase at 23:30 local time and a 12% to 8% rise around 04:00 and 09:00 local time (02:00 – 07:00 UTC) on May 30.
Daily traffic overall was 6% lower than the previous week, with mobile device usage increasing to 63%, compared to 57% the previous week.
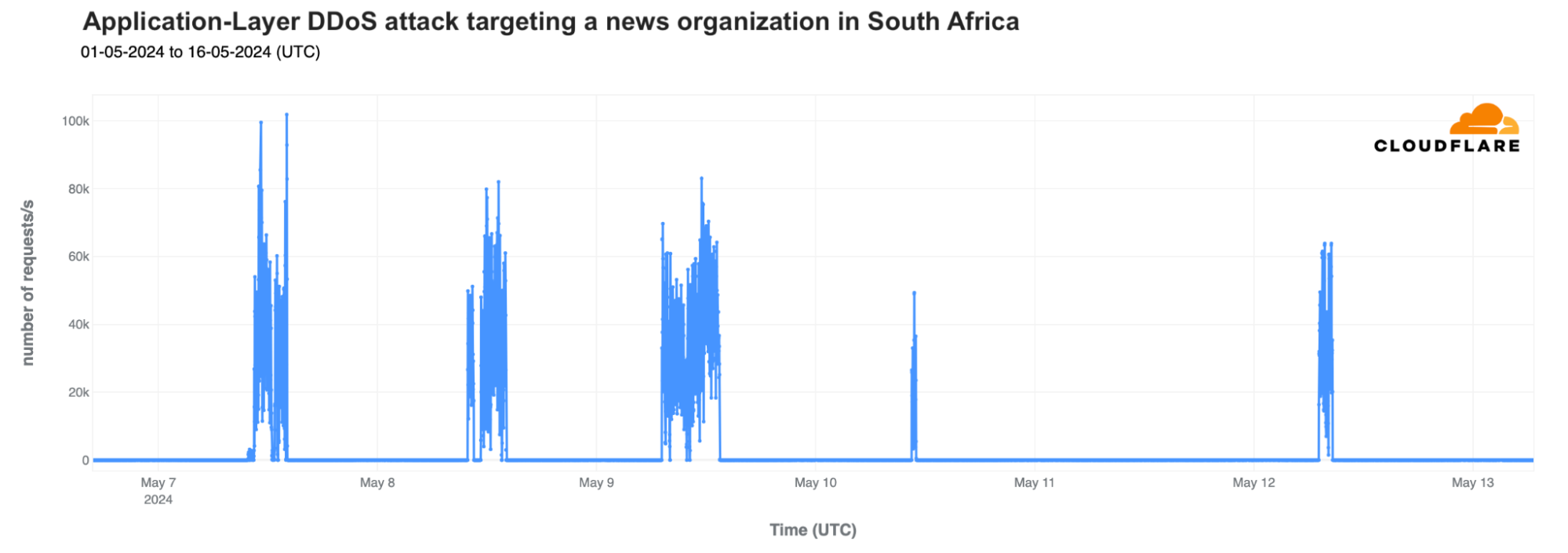
Attacks: news under attack
Cloudflare didn’t detect any major threats targeting government or election-related online platforms. However, in the lead-up to election day, on May 7, a significant DDoS attack targeted a major news site in South Africa, with 773 million daily requests. This attack peaked at 16:06 local time (14:06 UTC) with 54,000 requests per second and continued in the following days.
Geopolitics are here to stay
Elections, geopolitical changes, and disputes impact the online world. Our DDoS threat report for Q1 2024 gives a few recent examples. One notable case was the 466% surge in DDoS attacks on Sweden after its acceptance into the NATO alliance, mirroring the pattern observed during Finland’s NATO accession in 2023.
Real-world conflicts and wars often lead to Internet pattern changes, disruptions, or cyberattacks. For instance, during the first year of the war in Ukraine, and more recently, Cloudflare’s Cloudforce One thwarted a phishing attack by the Russia-aligned threat actor FlyingYeti. Our recent Project Galileo blog post also details how we protected Meduza, an independent news outlet focused on Russia, from online attacks in late 2023.
We’ve also reported (1, 2) on Internet changes, disruptions, and increased cyberattacks following the start of the Israel-Hamas war on October 7, 2023.
If you want to follow more trends and insights about the Internet and elections in particular, you can check Cloudflare Radar, and more specifically our new 2024 Elections Insights report, that we’re updating as national and European elections take place throughout the year.
[$] Ladybird browser spreads its wings
Post Syndicated from jzb original https://lwn.net/Articles/976822/
Ladybird is an open-source
project aimed at building an independent web browser, rather than
yet another browser based on Chrome. It is written in C++ and licensed under a
two-clause BSD license. The effort
began as part of the SerenityOS project, but
developer Andreas Kling announced
on June 3 that he was “forking” Ladybird as a separate project and stepping away from
SerenityOS to focus his attention on the browser completely. Ladybird
is not ready to replace Firefox or Chrome for regular use, but it is showing
great promise.
Linux nftables vulnerability exploited in the wild (CrowdStrike)
Post Syndicated from daroc original https://lwn.net/Articles/977583/
According to CrowdStrike, a
vulnerability in the Linux kernel’s nftables code
that was discovered earlier this
year is being actively exploited in the wild. The vulnerability allows for
local privilege escalation. Most distributions have already released a fix.
As noted by the exploit developer, leveraging this POC is dependent on the
kernel’s unprivileged user namespaces feature accessing nf_tables. This access
is enabled by default on Debian, Ubuntu and kernel capture-the-flag (CTF)
distributions. An attacker can then trigger the double-free vulnerability, scan
the physical memory for the kernel base address, bypass kernel address-space
layout randomization (KASLR) and access the modprobe_path kernel variable with
read/write privileges. After overwriting the modprobe_path, the exploit drops a
root shell.
Metasploit Weekly Wrap-Up 06/07/2024
Post Syndicated from Brendan Watters original https://blog.rapid7.com/2024/06/07/metasploit-weekly-wrap-up-06-07-2024/
New OSX payloads:ARMed and Dangerous

In addition to an RCE leveraging CVE-2024-5084 to gain RCE through a WordPress Hash form, this release features the addition of several new binary OSX stageless payloads with aarch64 support: Execute Command, Shell Bind TCP, and Shell Reverse TCP.
The new osx/aarch64/shell_bind_tcp payload opens a listening port on the target machine, which allows the attacker to connect to this open port to spawn a command shell using the user provided command using the execve system call on Apple silicon laptops.
The new osx/aarch64/shell_reverse_tcp payload that can connect back to the configured attacker’s RHOST and RPORT to spawn a command shell using the execve system call on Apple silicon laptops.
The new osx/aarch64/exec payload can execute arbitrary user provided commands using the execve system call on Apple silicon laptops, for example:
msf6 payload(osx/aarch64/exec) > generate -f macho cmd="/bin/bash -c 'echo 123 && echo abc && whoami && echo 🔥'" -o shell
[*] Writing 50072 bytes to shell…
And executing:
$ chmod +x ./shell
$ ./shell
123
abc
user
🔥
New module content (4)
WordPress Hash Form Plugin RCE
Authors: Francesco Carlucci and Valentin Lobstein
Type: Exploit
Pull request: #19208 contributed by Chocapikk
Path: multi/http/wp_hash_form_rce
AttackerKB reference: CVE-2024-5084
Description: This adds an exploit module that leverages a vulnerability in the WordPress Hash Form – Drag & Drop Form Builder plugin (CVE-2024-5084) to achieve remote code execution. Versions up to and including 1.1.0 are vulnerable. This allows unauthenticated attackers to upload arbitrary files, including PHP scripts, due to missing file type validation in the file_upload_action function.
OSX aarch64 Execute Command
Author: alanfoster
Type: Payload (Single)
Pull request: #18646 contributed by AlanFoster
Path: osx/aarch64/exec
Description: Add osx aarch64 exec payload.
OS X x64 Shell Bind TCP
Author: alanfoster
Type: Payload (Single)
Pull request: #18776 contributed by AlanFoster
Path: osx/aarch64/shell_bind_tcp
Description: Add osx aarch64 bind tcp payload.
OSX aarch64 Shell Reverse TCP
Author: alanfoster
Type: Payload (Single)
Pull request: #18652 contributed by AlanFoster
Path: osx/aarch64/shell_reverse_tcp
Description: Add osx aarch64 shell reverse tcp payload.
Enhancements and features (0)
None
Bugs fixed (3)
- #19209 from zgoldman-r7 – Updates multiple file format exploits to show the default settings to users when running
show options. - #19211 from sjanusz-r7 – Fixes an issue were the database management logic would default a model’s
updated_atvalue to incorrectly be set to thecreated_atvalue. - #19217 from zgoldman-r7 – Fixes path tab completion for modules when using Ruby 3.2+.
- #19227 from bcoles – Fixed an issue in Moodle::Login.moodle_login that reported a false negative when logging in with user’s credentials.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
commercial edition Metasploit Pro
SwitchBot Pro Lock: They FINALLY Listened!
Post Syndicated from digiblur DIY original https://www.youtube.com/watch?v=xSNDIZBUpHY
Ще обърне ли Палестина изборите в САЩ?
Post Syndicated from Йоанна Елми original https://www.toest.bg/shte-oburne-li-palestina-izborite-v-usa/

Устойчивостта, или т.нар. резилиънс (чуждицата често се използва в научни текстове в областта на психологията), е едно качествата, които са най-важни за оцеляването. Така се нарича способността ни да устояваме на травми, да оцеляваме в трудности и да се адаптираме към изключително неблагоприятни условия. Устойчивостта не е константа – тя се променя спрямо развитието ни и взаимодействието ни с околната среда. Благодарение на устойчивостта хората се учат да живеят със и въпреки тежки заболявания, инвалидност, загуба на деца и близки, в рамките на жестоки репресивни диктатури, в условия на крайна бедност и недостиг, в ужаса на войната.
Погледнато от друга страна обаче, устойчивостта може да представлява и това, което наричаме „синдром на сварената жаба“ – ако жива жаба се постави в съд с гореща вода, тя мигновено ще изскочи и ще се спаси. Но ако я поставим в съд със студена вода и постепенно повишаваме температурата, тя ще се адаптира, или ще прояви устойчивост – докато не бъде сварена до смърт.

.jpg){kind=link}
В статия за литературното списание n+1 журналистката Розина Али изброява всички думи, изречени от световни организации, политици, журналисти и свидетели на израелската офанзива в Газа от атаката на „Хамас“ през октомври насам. С натрупването на суперлативите, с натрупването на думите и ужасяващите кадри – както се случва и с руската инвазия в Украйна, както се случва и в политическия живот през последното десетилетие, в който немислимото за изричане се превърна в ежедневно заглавие и анонимен коментар – съзнанието претръпва и ужасът се нормализира. Свикваме. За това помага и относителната изолация на Запада, САЩ и Европа от горещите точки на конфликт. Засега.
Въпрос на перспектива е дали проявяваме устойчивост спрямо ужаса на времената, или се варим бавно като жаби. Едно от проявленията на този въпрос е способна ли е (не)позицията на САЩ спрямо случващото се в Палестина да обърне хода на изборите в страната през ноември. И какво изобщо би означавало това.
Tel Aviv tonight: over calling for a hostage deal and for the government to resign. Polls show most Israelis are in favor of stopping the war. The government won't let that happen. pic.twitter.com/RhO8vVkbQF
— Etan Nechin (@Etanetan23) May 25, 2024
Публикация на журналиста и писател Итън Нечин, кореспондент за израелския „Хаарец“, „Гардиън“ и др.: „Тел Авив тази вечер [25 май 2024 г.]: протести с призив за връщане на заложниците и оставка на правителството. Според анкетите по-голяма част от израелците подкрепят прекратяване на войната. Правителството на Израел не би позволило това.“
Позиция, противоречие, парадокс
Хронологията на Розина Али се състои от изказвания на представители на организации като „Оксфам“, „Лекари без граници“, Би Би Си, „Ню Йорк Таймс“, ООН, УНИЦЕФ, „Уошингтън Поуст“, Си Ен Ен, „Ню Йоркър“, „Амнести Интернешънъл“ и др.
Техните цитати са придружени от данни на контролираните от терористичната организация „Хамас“ палестински официални власти за броя на цивилните жертви, загинали под израелски удари. Заради източника си тези данни следва да се интерпретират критично, но не и да бъдат игнорирани. Организации като ООН се стараят да проверяват и обновяват данните с обективна информация с помощта на хора на терен, доколкото е възможно по време на сериозен военен конфликт. Но дори консервативните цифри представят ужасяващ брой загинали цивилни, много от които жени и деца. Освен данните и цитатите Розина Али добавя и изказвания на американски и израелски политици, както и данни за предоставените оръжия на Израел от САЩ.
Колажът е красноречив: „безпрецедентна хуманитарна криза от невиждан мащаб“; „броят на убитите деца в Газа в рамките на три седмици е по-висок от броя на убитите във въоръжени конфликти в световен план в над 20 държави в рамките на цяла година за последните три години“; „лавина от човешко страдание“; „свидетели сме на изтребване на цивилни без еквивалент и прецедент в рамките на който и да е конфликт от началото на поста ми“ (цитат от генералния секретар на ООН Антонио Гутериш); „израелската военна кампания в Газа според експерти е сред най-смъртоносните и унищожителни кампании в близката история“; „според експерти в рамките на малко повече от два месеца израелската офанзива е причинила повече щети от сриването на Алепо между 2012 и 2016 г. и унищожението на Мариупол или пропорционално на бомбардировките на съюзниците над Германия по време на Втората световна война“ (и двата цитата от „Асошиейтед Прес“).

{kind=link}
Освен данните на Али – например „В началото на декември Белият дом заобикаля Конгреса и изпраща 14 000 единици танкови муниции на Израел“ – данни на Council for Foreign Relations (CFR) показват огромното количество помощ, което САЩ осигурява на Израел. Част от причините за това са изброени в текста на Искрен Иванов, публикуван в „Тоест“ на 29 май 2024 г. Авторите на доклада в CFR – политолозите Джонатан Мастърс и Уил Мероу, също говорят за безпрецедентност: от атаката на Хамас на 7 октомври насам САЩ са предоставили огромно количество военна помощ на Израел, възлизаща по предварителни изчисления на 12,5 млрд. долара. Администрацията на президента Джо Байдън мотивира политиката си с подкрепа на правото на Израел на защита, но тази позиция губи тежест с нарастването на цивилните жертви и информацията за блокиране на хуманитарна помощ, насочена към Газа.
Хуманитарната помощ за Палестина идва от… САЩ. Мащабите обаче са различни. Още през 2021 г. държавата предоставя 5,5 млн. долара, част от които за здравеопазване, в допълнение към 90 млн. долара, насочени към специфични организации, част от ООН. Седмица след началото на конфликта ООН изчислява, че на Палестина са нужни над 1,2 млрд. долара за спешна хуманитарна помощ. На 5 юни т.г. американската агенция USAID обещава още 90 млн. долара, а армията работи за построяването на инфраструктура, която да спомогне за доставките на хуманитарни помощи за Палестина. Проектът се оценява на стойност 320 млн. долара.
Какъв е смисълът от „все по-противоречивата политика на Байдън в Израел“, както я определя „Ню Йоркър“?
Цената на realpolitik и скъсването с реалността
Политиката на Джо Байдън има две основни цели: да овладее конфликта в настоящите рамки и да предотврати прерастването му в регионален конфликт, както и да подсигури унищожението на „Хамас“ до степен, в която повторение на кръвожадната атака от 7 октомври е невъзможно, казва регионалният експерт Арън Дейвид Милър в интервю пред американското списание. Обясненията за тези цели са както лични – траекторията на Джо Байдън като политик, десетилетията му опит в Сената, отношението му към Израел, – така и политически, например вече споменатата дългогодишна политика на САЩ като съюзник на Израел.
„Бих нарекъл политиката на кабинета на Байдън пасивно-агресивна. Те са бесни на Нетаняху, и то от много време насам. Нетаняху управлява едно от най-екстремистките правителства от началото на историята на Държавата Израел. Настоящото правителство и предшестващото го управление на Нетаняху уронват фундаментални устои на връзката между САЩ и Израел, споделените ценности и общите интереси. Така че когато казвам „пасивно-агресивна“, имам предвид, че шест месеца след началото на тази война американската администрация не желае – и е неспособна – да наложи каквито и да е последствия, които аз и вие като нормални човешки същества бихме приели за реален натиск“, казва Милър.
Той описва три възможни лоста за прилагане на този натиск: прекратяване на военната помощ (почти невъзможен сценарий), промяна на позицията на САЩ в ООН (все още неизпълнено) и радикално оттегляне от преговорите за освобождаване на израелските заложници и присъединяване към гласовете на международната общност, които призовават за прекратяване на огъня от страна на Израел. Всеки един от тези сценарии обаче би предизвикал цунами от последствия и във вътрешнополитическата ситуация в САЩ. „Ако Джо Байдън иска да промени ситуацията в Газа, той трябва да открие начин да деескалира военната офанзива на Израел, да увеличи хуманитарната помощ и да предложи план за възстановяване на Газа, както и да освободи заложниците, което няма да стане със заклеймяване, открита критика или публично скъсване с израелския премиер.“
Israel's Diaspora Affairs Ministry commissioned an influence campaign primarily aimed at Black lawmakers and young progressives in the U.S. and Canada that used fake sites and accounts to promote posts that served the Israeli narrative, Haaretz reports: https://t.co/YKzPeui7EG
— Evan Hill (@evanhill) June 5, 2024
Публикация на разследващия журналист Евън Хил, „Уошингтън Поуст“: „Израелското Министерство на диаспората е поръчало кампания за влияние, насочена основно към чернокожи законодатели и млади протестиращи в САЩ и Канада, в която се използват фалшиви сайтове и профили, за да се разпространяват публикации, благоприятни за Израел, според разследване на „Хаарец“.
Проблемът е, че Америка е държава, построена върху митове и ценности, в които повечето граждани вярват искрено. Тези ценности – човешки права, свобода на изразяване, демокрация и т.н., представляват и експортен продукт, културна политика, захранват шовинизъм и усещане за превъзходство, а загубата на този ореол води до национална криза на идентичността и все по-дълбоки разделения. САЩ искат образа на спасител от Втората световна война, а не онзи на жестокостта от Виетнам или Ирак. В очите на обществото случващото се в Газа напомня по-скоро за последните и е възможно благодарение на оръжията на САЩ. Това поражда все по-голямо недоволство сред определени сегменти на обществото, както и протести, разриви в академичните среди и все по-силни политически движения, които са критични към действията на администрацията на Байдън.
Липса на алтернатива
И докато много прогресивни и демократично настроени американци се канят да бойкотират изборите и са все по-открито критични към Демократическата партия, която ще излъчи Джо Байдън като кандидат за президент за втори мандат, по-добра алтернатива всъщност няма. Още през 2021 г. Доналд Тръмп признава, че Бенямин Нетаняху не се интересува от припознаването на палестинска държава и т.нар. двустранно решение на кризата, което се състои в обособяването на две държави – Израел и Палестина. През 2017 г. Тръмп саботира собствените си усилия за мир в региона, като припозна Йерусалим за столица на Израел и премести Посолството на САЩ, допълнително нагнетявайки напрежението. Към края на мандата на Тръмп връзките с Израел са в застой.

{kind=link}
На 4 април кандидат-президентът на Републиканската партия заяви, че Израел „губи медийната война“ и трябва да „приключи“ с Палестина. В характерния си стил, в който изказванията му могат да се тълкуват двояко според това към кое идеологическо племе принадлежи тълкуващият и как избере да ги интерпретира, Доналд Тръмп заяви, че „това трябва да приключи и да се върнем към мира и стига сме убивали хора. Трябва да приключат нещата. Свършвайте работата и приключвайте бързо, защото трябва да… се върнем към някаква нормалност и мир“.
Тръмп критикува опонента си за недостатъчната му подкрепа за Израел, а след това казва, отново в същия стил, че „трябва да има победа“, без да е ясно за кого, на каква цена и при какви условия. Много по-категоричен пример за позицията на републиканците са действията на бившата кандидат-президентка и представителка на САЩ в ООН Ники Хейли, която написа „Довършете ги“ върху израелска ракета, добавяйки сърчице и подписа си. Републиканската медия „Фокс Нюз“ публикува новината със заглавие, в което уточни, че ракетата била предназначена за „Хамас“. „Кандидатът на Републиканската партия се представя като най-произраелския президент в историята. Републиканската партия затвърждава имиджа си на партия, която вярва, че Израел не е способен на грешни ходове“, казва Милър пред „Ню Йоркър“.
At least 70 dead people and over 300 wounded, the majority of whom are women and children, have been brought to Al-Aqsa hospital since yesterday following heavy Israeli strikes in the Middle Area of the #Gaza strip.
— MSF International (@MSF) June 5, 2024
Публикация на „Лекари без граници“: „Най-малко 70 убити и над 300 ранени, основно деца и жени, са постъпили в болницата „Ал-Акса“ от вчера [4 юни 2024 г.], след тежки удари от страна на Израел в централните части на ивицата Газа.“
Реакцията на американците
Към необичайната за поляризираната политика на САЩ консолидация на двете партии по отношение на политиката спрямо Израел се прибавя и сложната картина на реакциите на американците спрямо конфликта. Повечето американци определят отношението си към войната в Газа като силно емоционално. Парадоксално обаче, голяма част от тях не следят конфликта в детайли. Едва половината от запитаните дават верни отговори на въпроси, свързани с конкретни факти.
Израело- и мюсюлмано-американците съвсем естествено, са много по-информирани по темата. Все пак 83% от запитаните отговарят, че конфликтът предизвиква у тях тъга, а 65% – гняв. 51% казват, че са изморени от новинарския обмен, свързан с Израел и Палестина. Едва 22% заявяват, че следят новините по темата в детайли. Стойностите са сходни сред симпатизантите на двете партии. Важен нюанс е, че следящите конфликта принадлежат към двата изявени края на политическия спектър, докато политически по-умерените респонденти отделят по-малко внимание.

{kind=link}
Едва 5% смятат, че атаките на „Хамас“ от 7 октомври са приемливи. По-голям дял счита обаче, че цялостните причини на „Хамас“ да се бори срещу Израел са валидни. 58% от американците подкрепят офанзивата на Израел срещу „Хамас“, но едва 38% определят методите на офанзивата като приемливи. 57% от респондентите симпатизират еднакво на израелците и палестинците, а като цяло тенденцията е симпатията да е по-скоро към израелците като народ, отколкото към израелското правителство и Бенямин Нетаняху. Същото важи и за палестинците.
Демографското разделение е важно, ако искаме да дадем поне донякъде верен отговор на въпроса в заглавието: респондентите под 30 години са много по-категорични в мнението, че „Хамас“ има валидни причини да атакува Израел, а младите американци като цяло са по-склонни да гледат положително на палестинците, отколкото на израелците. И все пак мнозинството (58%) от отговорилите в тази възрастова група заклеймява действията на палестинската терористична организация.

{kind=link}
Младите, образовани и по-заможни избиратели, които живеят в градовете, традиционно гласуват за демократите. Те са и тези, които изразяват най-силна симпатия към палестинската кауза и народ. Протестиращите студенти не са добра представителна извадка, но със сигурност са културен феномен, сравним с антивоенните протести в ерата на войната във Виетнам. Освен тази демографска група може да има отлив на гласове и от страна на мюсюлманите и други малцинства, които също подкрепят Демократическата партия, но и палестинската държава и прекратяването на огъня в Газа.
В допълнение, парадоксалната политика на администрацията на президента Байдън е в полза на републиканците, независимо от взетите решения: консерваторите заклеймяват протестите в университетите като хаос и провал на образователната система, която самите те определят като проядена от „марксизъм“ и „либерализъм“; вкарват в калъпа на антисемитизма всеки, изразяващ опозиция срещу избиването на цивилни палестинци (не помага това, че проявите на антисемитизъм зачестяват, макар и сред малцина); и накрая, вътрешно- и външнополитическият хаос така или иначе традиционно подкопават позицията на настоящия президент.
Няма полезен ход
Конфликтът между Израел и Палестина осветява и вътрешните проблеми в САЩ. От въпроси за цензурата и свободата на словото до печалбата от войни и разходването на ресурси за военни конфликти (позицията на САЩ спрямо Украйна също е компрометирана и разклатена, тъжно последствие), докато вътрешните кризи в страната се разрастват и пораждат все по-голямо недоволство. Поради консолидацията на корпоративни интереси и безконтролен капитализъм, ежедневните политически кризи и растящите като последствие рекордни неравенства за „обикновения човек“ и гласоподавател, живеещ далеч от метрополисите Ню Йорк, Чикаго и Лос Анджелис, ежедневието е все по-трудно и несигурно. Газа и Украйна са все по-големи абстракции; изолационизмът, радикализмът и недоверието в системата – все по-сериозни. Към това се добавят и идеологическите различия – ако гласуващите за демократите са по-склонни да проявяват емпатия и загриженост за хора отвъд пределите на своята държава, то консервативно настроените определят като приоритет просперитета на най-близките си и на малката общност.
BREAKING: Biden told @TIME that "there is every reason for people" to draw the conclusion that Israeli Prime Minister Benjamin Netanyahu is prolonging the war for his own political self-preservation
— Barak Ravid (@BarakRavid) June 4, 2024
Публикация на репортера на „Аксиос“ Барак Равид: „Байдън заявява пред „Тайм“, че „има предостатъчно основания“ хората да стигнат до заключението, че израелският премиер Бенямин Нетаняху продължава войната в името на собственото си политическо оцеляване.“
Всички тези фактори накланят везните в полза на републиканците, въпреки че съвсем прясната присъда на Доналд Тръмп според първоначални данни е успяла да промени мнението на част от независимите гласоподаватели, тоест тези, които не се идентифицират с нито една партия. Но независимо от това на кой котлон е поставена тенджерата – вляво или вдясно, – температурата се покачва.
Освен ако Израел и „Хамас“ не се съгласят с настоящото предложение за прекратяване на огъня и с последващите стъпки за двустранно решение за света, няма полезен ход. Независимо дали Америка ще реши да оттегли подкрепата от Украйна и да продължи да подкрепя Израел (вероятен сценарий при победа на Тръмп), или да направи рязък завой в политиката спрямо Израел (който ще дойде на друга геополитическа цена с оглед на интересите на Русия и Китай в региона), или пък да продължи досегашния курс (с цената на хиляди избити цивилни и вероятно напълно разрушена репутация в дългосрочен план).

{kind=link}
Когато сме принудени да претегляме чий живот е по-важен – на жертвите на зверствата на „Хамас“ от 7 октомври или на убитите цивилни палестинци например; когато се налага да се връщаме все по-назад в историята, за да подкрепим правото на една или друга страна да убива, за да съществува; когато човешкият живот се превърне в кръчмарска геополитическа сметка; когато политиката се сведе до жертване на едни, за да не бъдат жертвани други; когато хората се редуцират до едноизмерно свое качество – политическа принадлежност, религия или националност, до страна в някакъв конфликт, за да получим право да одерем човешката им кожа и да ги третираме като безлики единици с извратено удоволствие от собственото си въображаемо морално превъзходство; когато се превръщаме в онлайн запалянковци на това непрестанно дране; когато призоваваме за отнемане на правото на една или друга страна да говори, защото сме толкова освирепели, че вече не можем да понесем различна реалност от своята; когато сме толкова уморени от жестокостта и покварата на света, че изберем жестокостта и покварата на свой ред, или изберем да изключим телевизора, да игнорираме неудобните истини, да отречем тежката сложност на света, да се преструваме, че реалността не съществува… Тогава няма полезен ход, защото, независимо дали в Украйна, в Европа, в Газа, в Судан, в Китай, или другаде, точката на кипене е опасно близо. И отдавна сме привикнали с немислимото.
Заглавно изображение: Израелските отбранителни сили се подготвят за действия в Газа, 29 октомври 2023 г., IDF Spokesperson's Unit
{kind=link}
Best USB Power Outlet? 65 watt PD charging from Leviton, Topgreener, Amerisense, and More
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=GFxB0cDkw-s
Comic for 2024.06.07 – Turn On The News
Post Syndicated from Explosm.net original https://explosm.net/comics/turn-on-the-news
New Cyanide and Happiness Comic
[$] Modernizing BPF for the next 10 years
Post Syndicated from daroc original https://lwn.net/Articles/977013/
BPF was first
generalized beyond packet filtering more than a decade ago. In that time, it
has changed a lot, becoming much more capable.
Alexei Starovoitov kicked off the second day of the BPF track at the 2024
Linux Storage,
Filesystem, Memory Management, and BPF Summit by leading a session
discussing which changes to BPF are going to come in the next ten years as it
continues evolving. He proposed several ideas, including expanding the number of
registers available to BPF programs, dynamic deadlock detection, and relaxing
some existing limits of the verifier.
Security updates for Friday
Post Syndicated from daroc original https://lwn.net/Articles/977555/
Security updates have been issued by Mageia (libtiff), Oracle (cockpit, glibc, kernel, less, libxml2, linux-kernel, and tomcat), Red Hat (java-1.8.0-ibm, nghttp2, and ruby:3.3), Slackware (php), SUSE (go1.21, go1.22, and python-docker), and Ubuntu (aom and libvpx).