Post Syndicated from Michael Tremante original http://blog.cloudflare.com/detecting-zero-days-before-zero-day/


We are constantly researching ways to improve our products. For the Web Application Firewall (WAF), the goal is simple: keep customer web applications safe by building the best solution available on the market.
In this blog post we talk about our approach and ongoing research into detecting novel web attack vectors in our WAF before they are seen by a security researcher. If you are interested in learning about our secret sauce, read on.
This post is the written form of a presentation first delivered at Black Hat USA 2023.
The value of a WAF
Many companies offer web application firewalls and application security products with a total addressable market forecasted to increase for the foreseeable future.
In this space, vendors, including ourselves, often like to boast the importance of their solution by presenting ever-growing statistics around threats to web applications. Bigger numbers and scarier stats are great ways to justify expensive investments in web security. Taking a few examples from our very own application security report research (see our latest report here):
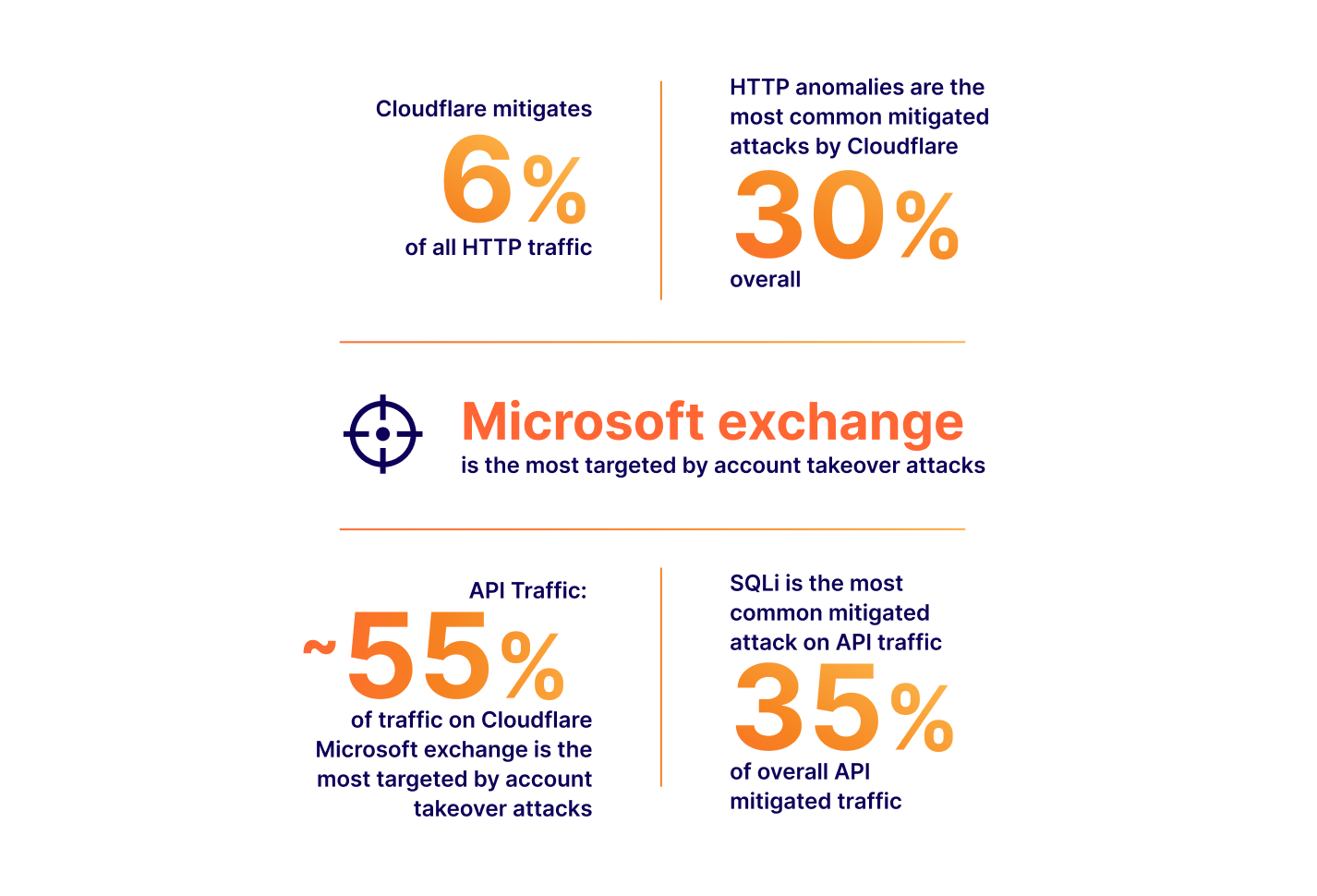
The numbers above all translate to real value: yes, a large portion of Internet HTTP traffic is malicious, therefore you could mitigate a non-negligible amount of traffic reaching your applications if you deployed a WAF. It is also true that we are seeing a drastic increase in global API traffic, therefore, you should look into the security of your APIs as you are likely serving API traffic you are not aware of. You need a WAF with API protection capabilities. And so on.
There is, however, one statistic often presented that hides a concept more directly tied to the value of a web application firewall:

This brings us to zero-days. The definition of a zero-day may vary depending on who you ask, but is generally understood to be an exploit that is not yet, or has very recently become, widely known with no patch available. High impact zero-days will get assigned a CVE number. These happen relatively frequently and the value can be implied by how often we see exploit attempts in the wild. Yes, you need a WAF to make sure you are protected from zero-day exploits.
But herein hides the real value: how quickly can a WAF mitigate a new zero-day/CVE?
By definition a zero-day is not well known, and a single malicious payload could be the one that compromises your application. From a purist standpoint, if your WAF is not fast at detecting new attack vectors, it is not providing sufficient value.
The faster the mitigation, the better. We refer to this as “time to mitigate”. Any WAF evaluation should focus on this metric.
How fast is fast enough?
24 hours? 6 hours? 30 minutes? Luckily we run one of the world's largest networks, and we can look at some real examples to understand how quickly a WAF really needs to be to protect most environments. I specifically mention “most” here as not everyone is the target of a highly sophisticated attack, and therefore, most companies should seek to be protected at least by the time a zero-day is widely known. Anything better is a plus.
Our first example is Log4Shell (CVE-2021-44228). A high and wide impacting vulnerability that affected Log4J, a popular logging software maintained by the Apache Software Foundation. The vulnerability was disclosed back in December 2021. If you are a security practitioner, you have certainly heard of this exploit.
The proof of concept of this attack was published on GitHub on December 9, 2021, at 15:27 UTC. A tweet followed shortly after. We started observing a substantial amount of attack payloads matching the signatures from about December 10 at 10:00 UTC. That is about ~19 hours after the PoC was published.
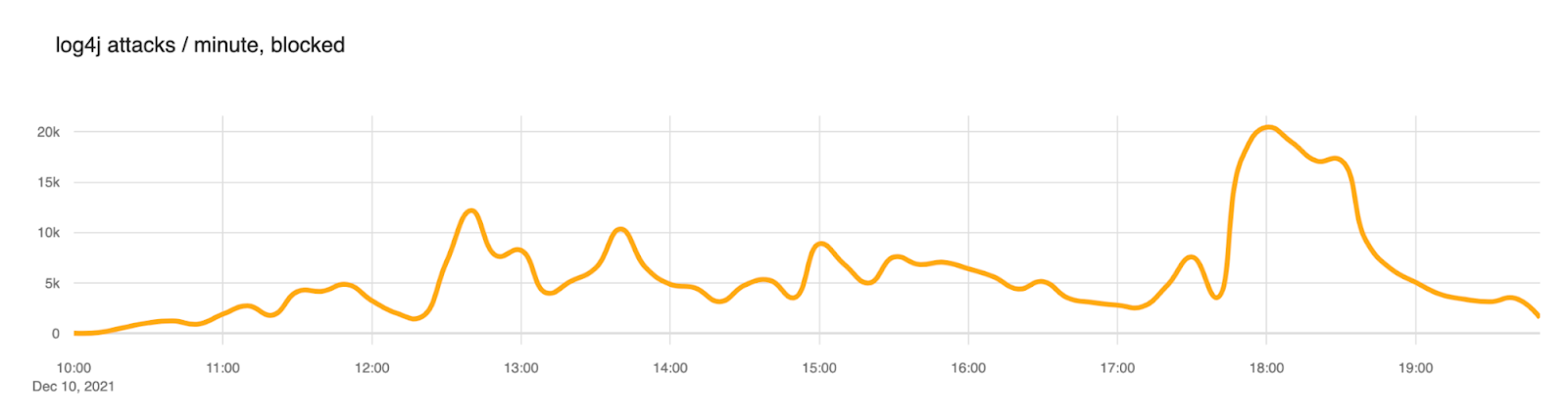
We blogged extensively about this event if you wish to read further.
Our second example is a little more recent: Atlassian Confluence CVE-2022-26134 from June 2, 2022. In this instance Atlassian published a security advisory pertaining to the vulnerability at 20:00 UTC. We were very fast at deploying mitigations and had rules globally deployed protecting customers at 23:38 UTC, before the four-hour mark.

Although potentially matching payloads were observed before the rules were deployed, these were not confirmed. Exact matches were only observed on 2022-06-03 at 10:30 UTC, over 10 hours after rule deployment. Even in this instance, we provided our observations on our blog.
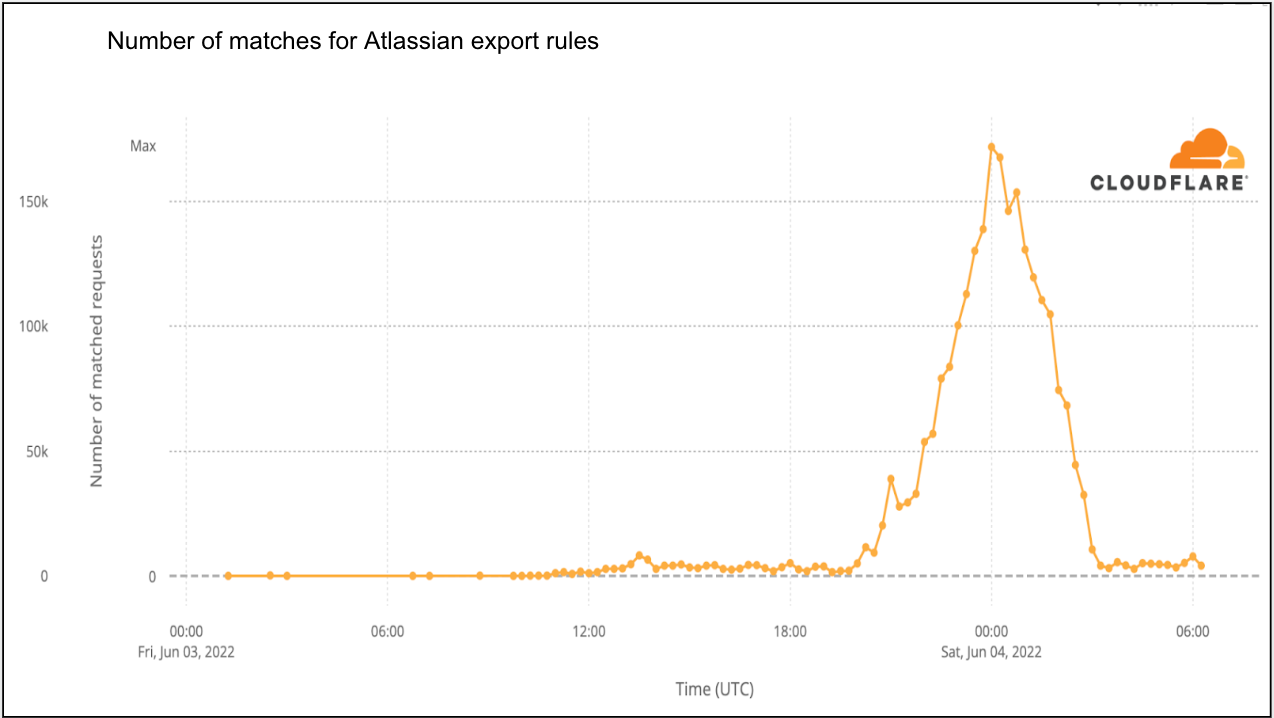
The list of examples could go on, but the data tells the same story: for most, as long as you have mitigations in place within a few hours, you are likely to be fine.
That, however, is a dangerous statement to make. Cloudflare protects applications that have some of the most stringent security requirements due to the data they hold and the importance of the service they provide. They could be the one application that is first targeted with the zero-day well before it is widely known. Also, we are a WAF vendor and I would not be writing this post if I thought “a few hours” was fast enough.
Zero (time) is the only acceptable time to mitigate!
Signatures are not enough, but are here to stay
All WAFs on the market today will have a signature based component. Signatures are great as they can be built to minimize false positives (FPs), their behavior is predictable and can be improved overtime.
We build and maintain our own signatures provided in the WAF as the Cloudflare Managed Ruleset. This is a set of over 320 signatures (at time of writing) that have been fine-tuned and optimized over the 13 years of Cloudflare’s existence.
Signatures tend to be written in ModSecurity, regex-like syntax or other proprietary language. At Cloudflare, we use wirefilter, a language understood by our global proxy. To use the same example as above, here is what one of our Log4Shell signatures looks like:
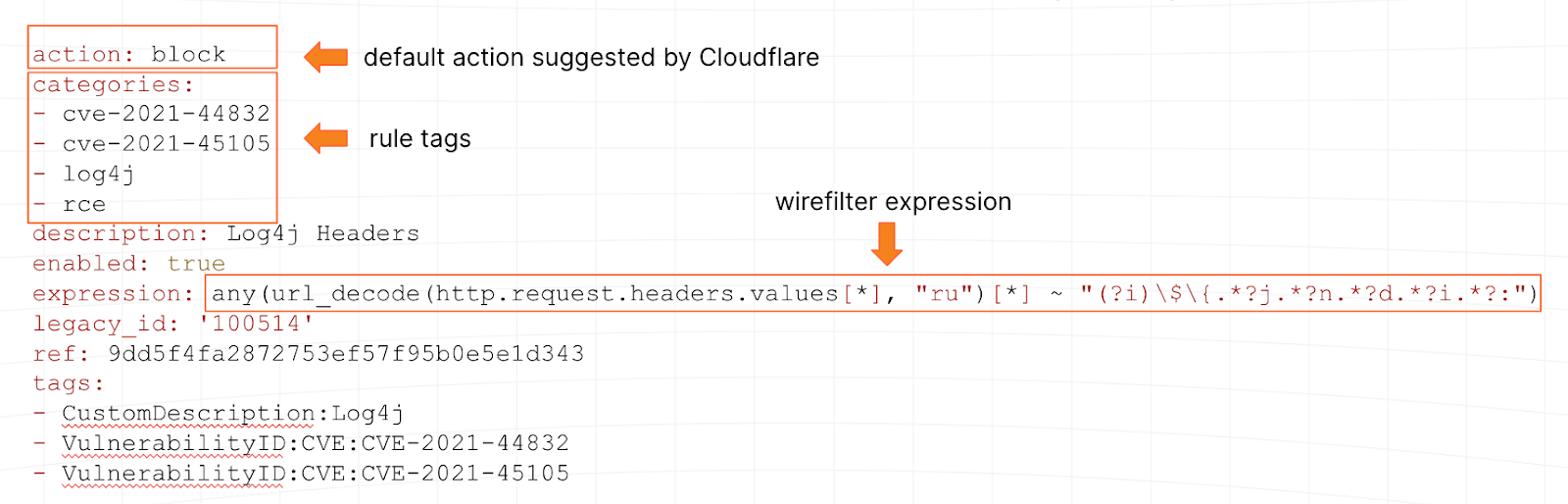
Our network, which runs our WAF, also gives us an additional superpower: the ability to test new signatures (or updates to existing ones) on over 64M HTTP/S requests per second at peak. We can tell pretty quickly if a signature is well written or not.
But one of their qualities (low false positive rates), along with the fact that humans have to write them, are the source of our inability to solely rely on signatures to reach zero time to mitigate. Ultimately a signature is limited by the speed at which we can write it, and combined with our goal to keep FPs low, they only match things we know and are 100% sure about. Our WAF security analyst team is, after all, limited by human speed while balancing the effectiveness of the rules.
The good news: signatures are a vital component to reach zero time to mitigate, and will always be needed, so the investment remains vital.
Getting to zero time to mitigation
To reach zero time to mitigate we need to rely on some machine learning algorithms. It turns out that WAFs are a great application for this type of technology especially combined with existing signature based systems. In this post I won’t describe the algorithms themselves (subject for another post) but will provide the high level concepts of the system and the steps of how we built it.
Step 1: create the training set
It is a well known fact in data science that the quality of any classification system, including the latest generative AI systems, is highly dependent on the quality of the training set. The old saying “garbage in, garbage out” resonates well.
And this is where our signatures come into play. As these were always written with a low false positive rate in mind, combined with our horizontal WAF deployment on our network, we essentially have access to millions of true positive examples per second to create what is likely one of the best WAF training sets available today.
We also, due to customer configurations and other tools such as Bot Management, have a pretty clear idea of what true negatives look like. In summary, we have a constant flow of training data. Additionally due to our self-service plans and the globally distributed nature of Cloudflare’s service and customer base, our data tends to be very diverse, removing a number of biases that may otherwise be present.
It is important to note at this point that we paid a lot of effort to ensure we anonymised data, removed PII, and that data boundary settings provided by our data localization suite were implemented correctly. We’ve published previously blog posts describing some of our strategies for data collection in the context of WAF use cases.
Step 2: enhance the training set
Simply relying on real traffic data is good, but with a few artificial enhancements the training set can become a lot better, leading to much higher detection efficacy.
In a nutshell we went through the process of generating artificial (but realistic) data to increase the diversity of our data even further by studying statistical distribution of existing real-world data. For example, mutating benign content with random character noise, language specific keywords, generating new benign content and so on.
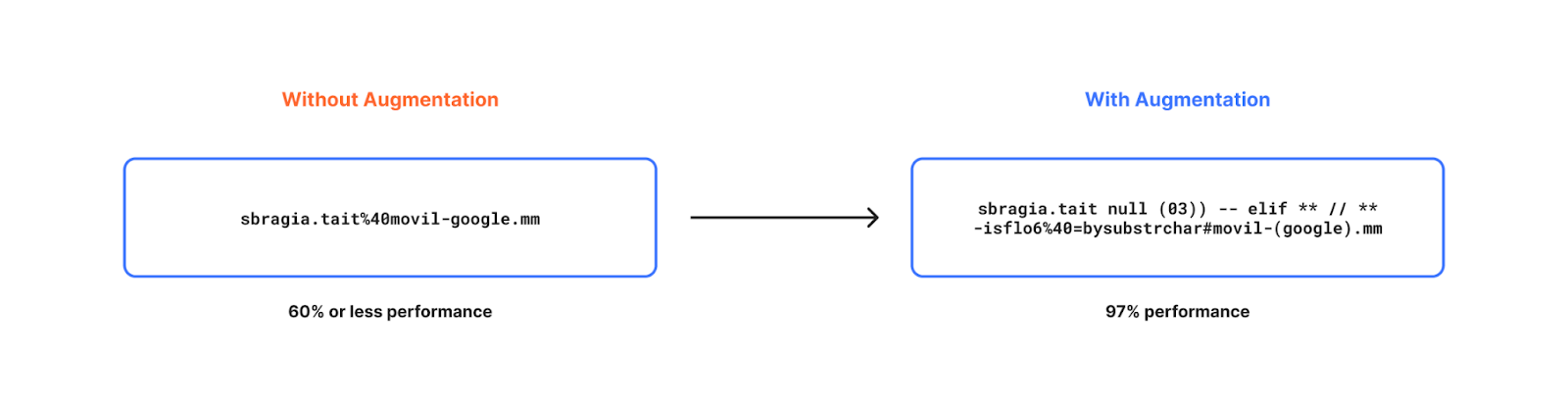
Some of the methods adopted to improve accuracy are discussed in detail in a prior blog post if you wish to read further.
Step 3: build a very fast classifier
One restriction that often applies to machine learning based classifiers running to inline traffic, like the Cloudflare proxy, is latency performance. To be useful, we need to be able to compute classification “inline” without affecting the user experience for legitimate end users. We don’t want security to be associated with “slowness”.
This required us to fine tune not only the feature set used by the classification system, but also the underlying tooling, so it was both fast and lightweight. The classifier is built using TensorFlow Lite.
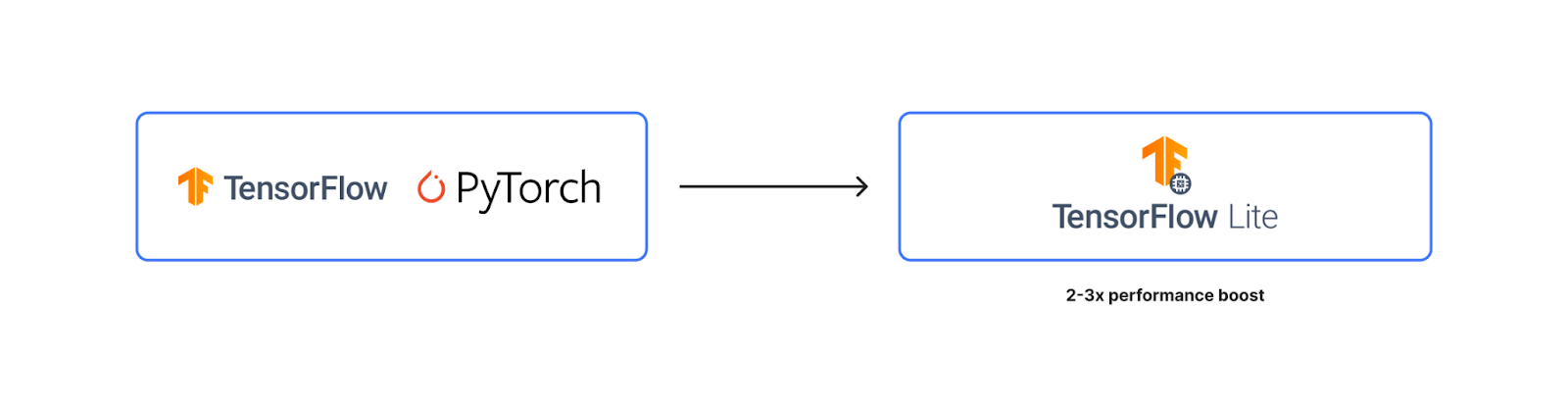
At time of writing, our classification model is able to provide a classification output under 1ms at 50th percentile. We believe we can reach 1ms at 90th percentile with ongoing efforts.
Step 4: deploy on the network
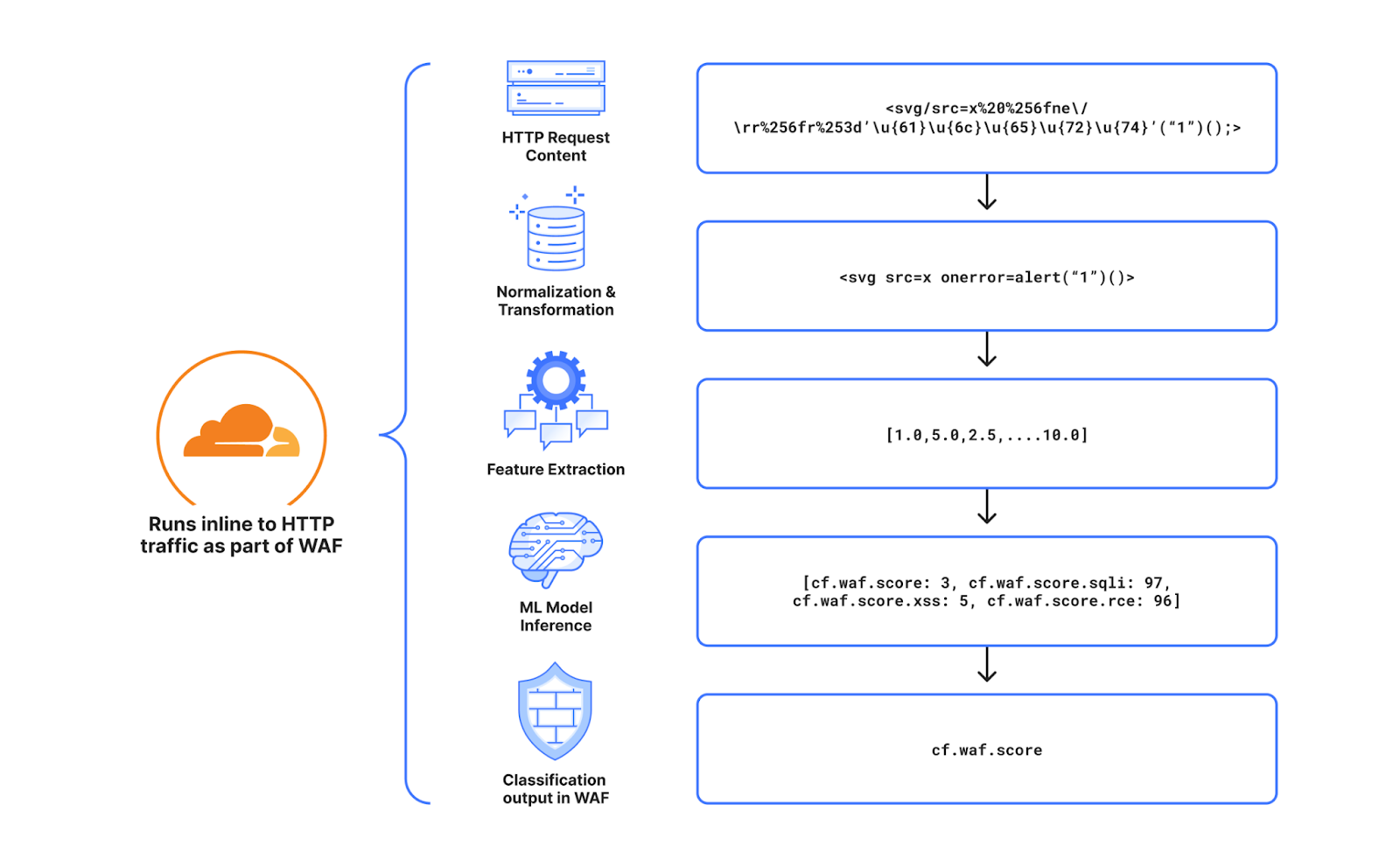
Once the classifier is ready, there is still a large amount of additional work needed to deploy on live production HTTP traffic, especially at our scale. Quite a few additional steps need to be implemented starting from a fully formed live HTTP request and ending with a classification output.
The diagram below is a good summary of each step. First and foremost, starting from the raw HTTP request, we normalize it, so it can easily be parsed and processed, without unintended consequences, by the following steps in the pipeline. Second we extract the relevant features found after experimentation and research, that would be more beneficial for our use case. To date we extract over 6k features. We then run inference on the resulting features (the actual classification) and generate outputs for the various attack types we have trained the model for. To date we classify cross site scripting payloads (XSS), SQL injection payloads (SQLi) and remote code execution payloads (RCE). The final step is to consolidate the output in a single WAF Attack Score.
Step 5: expose output as a simple interface
To make the system usable we decided the output should be in the same format as our Bot Management system output. A single score that ranges from 1 to 99. Lower scores indicate higher probability that the request is malicious, higher scores indicate the request is clean.
There are two main benefits of representing the output within a fixed range. First, using the output to BLOCK traffic becomes very easy. It is sufficient to deploy a WAF rule that blocks all HTTP requests with a score lower than $x, for example a rule that blocks all traffic with a score lower than 10 would look like this:
cf.waf.score < 10 then BLOCK
Secondly, deciding what the threshold should be can be done easily by representing the score distributions on your live traffic in colored “buckets”, and then allowing you to zoom in where relevant to validate the correct classification. For example, the graph below shows an attack that we observed against blog.cloudflare.com when we initially started testing the system. This graph is available to all business and enterprise users.
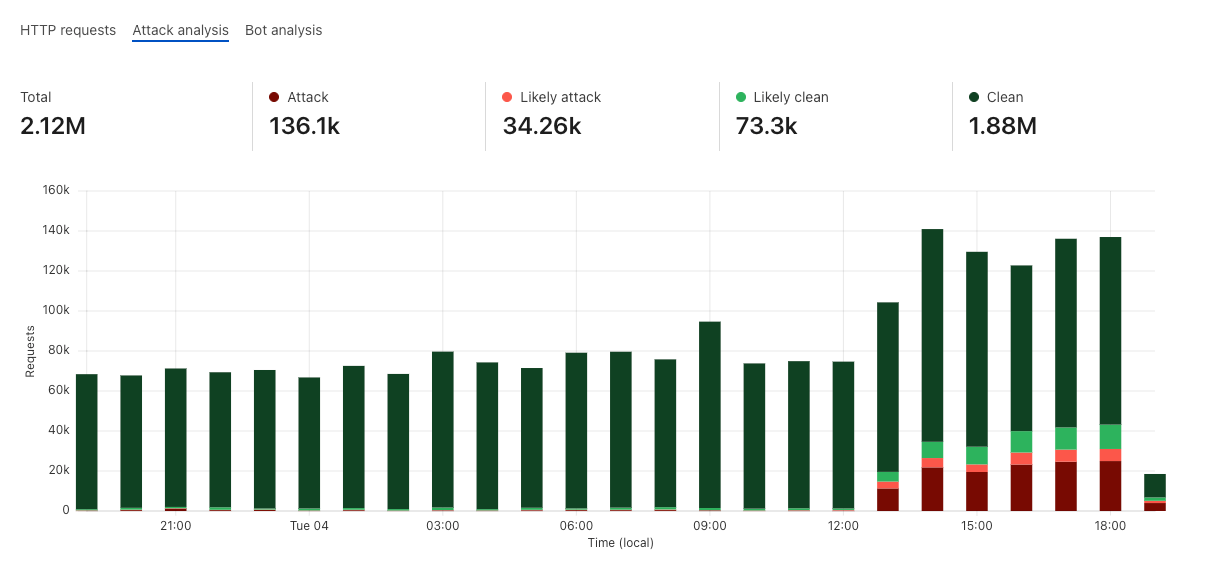
All that remains, is to actually use the score!
Success in the wild
The classifier has been deployed for just over a year on Cloudflare’s network. The main question stated at the start of this post remains: does it work? Have we been able to detect attacks before we’ve seen them? Have we achieved zero time to mitigate?
To answer this we track classification output for new CVEs that fail to be detected by existing Cloudflare Managed Rules. Of course our rule improvement work is always ongoing, but this gives us an idea on how well the system is performing.
And the answer: YES. For all CVEs or bypasses that rely on syntax similar to existing vulnerabilities, the classifier performs very well, and we have observed several instances of it blocking valid malicious payloads that were not detected by our signatures. All of this, while keeping false positives very low at a threshold of 15 or below. XSS variations, SQLi CVEs, are in most cases, a problem fully solved if the classifier is deployed.
One recent example is a set of Sitecore vulnerabilities that were disclosed in June 2023 listed below:
| CVE | Date | Score | Signature match | Classification match (score less than 10) |
|---|---|---|---|---|
| CVE-2023-35813 | 06/17/2023 | 9.8 CRITICAL | Not at time of announcement | Yes |
| CVE-2023-33653 | 06/06/2023 | 8.8 HIGH | Not at time of announcement | Yes |
| CVE-2023-33652 | 06/06/2023 | 8.8 HIGH | Not at time of announcement | Yes |
| CVE-2023-33651 | 06/06/2023 | 7.5 HIGH | Not at time of announcement | Yes |
The CVEs listed above were not detected by Cloudflare Managed Rules, but were correctly detected and classified by our model. Customers that had the score deployed in a rule in June 2023, would have been protected in zero time.
This does not mean there isn’t space for further improvement.
The classification works very well for attack types that are aligned, or somewhat similar to existing attack types. If the payload implements a brand new never seen before syntax, then we still have some work to do. Log4Shell is actually a very good example of this. If another zero-day vulnerability was discovered that leveraged the JNDI Java syntax, we are confident that our customers who have deployed WAF rules using the WAF Attack Score would be safe against it.
We are already working on adding more detection capabilities including web shell detection and open redirects/path traversal.
The perfect feedback loop
I mentioned earlier that our security analyst driven improvements to our Cloudflare Managed Rulesets are not going to stop. Our public changelog is full of activity and there is no sign of slowing down.
There is a good reason for this: the signature based system will remain, and likely eventually be converted to our training set generation tool. But not only that, it also provides an opportunity to speed up improvements by focusing on reviewing malicious traffic that is classified by our machine learning system but not detected by our signatures. The delta between the two systems is now one of the main focuses of attention for our security analyst team. The diagram below visualizes this concept.
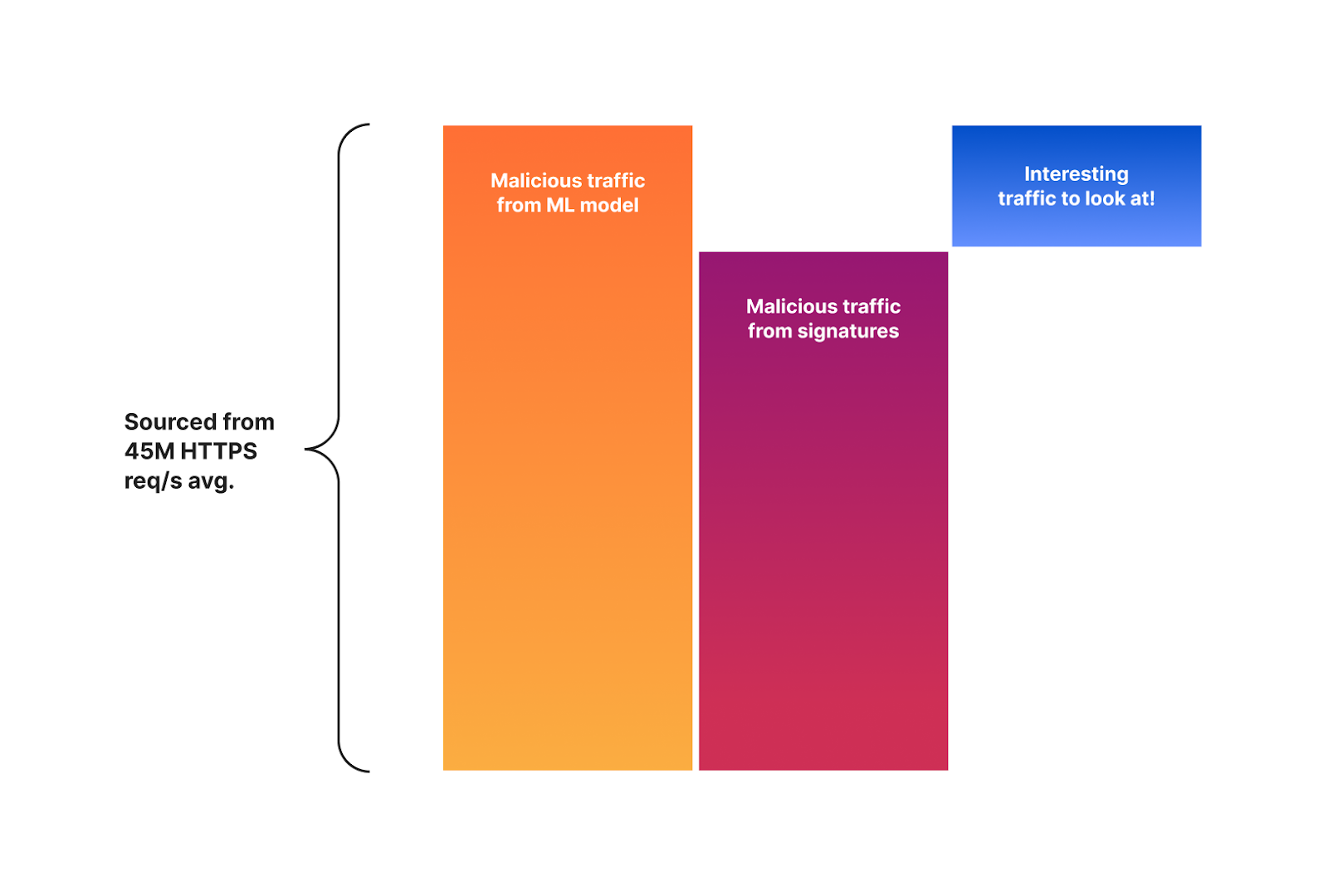
It is this delta that is helping our team to further fine tune and optimize the signatures themselves. Both to match malicious traffic that is bypassing the signatures, and to reduce false positives. You can now probably see where this is going as we are starting to build the perfect feedback loop.
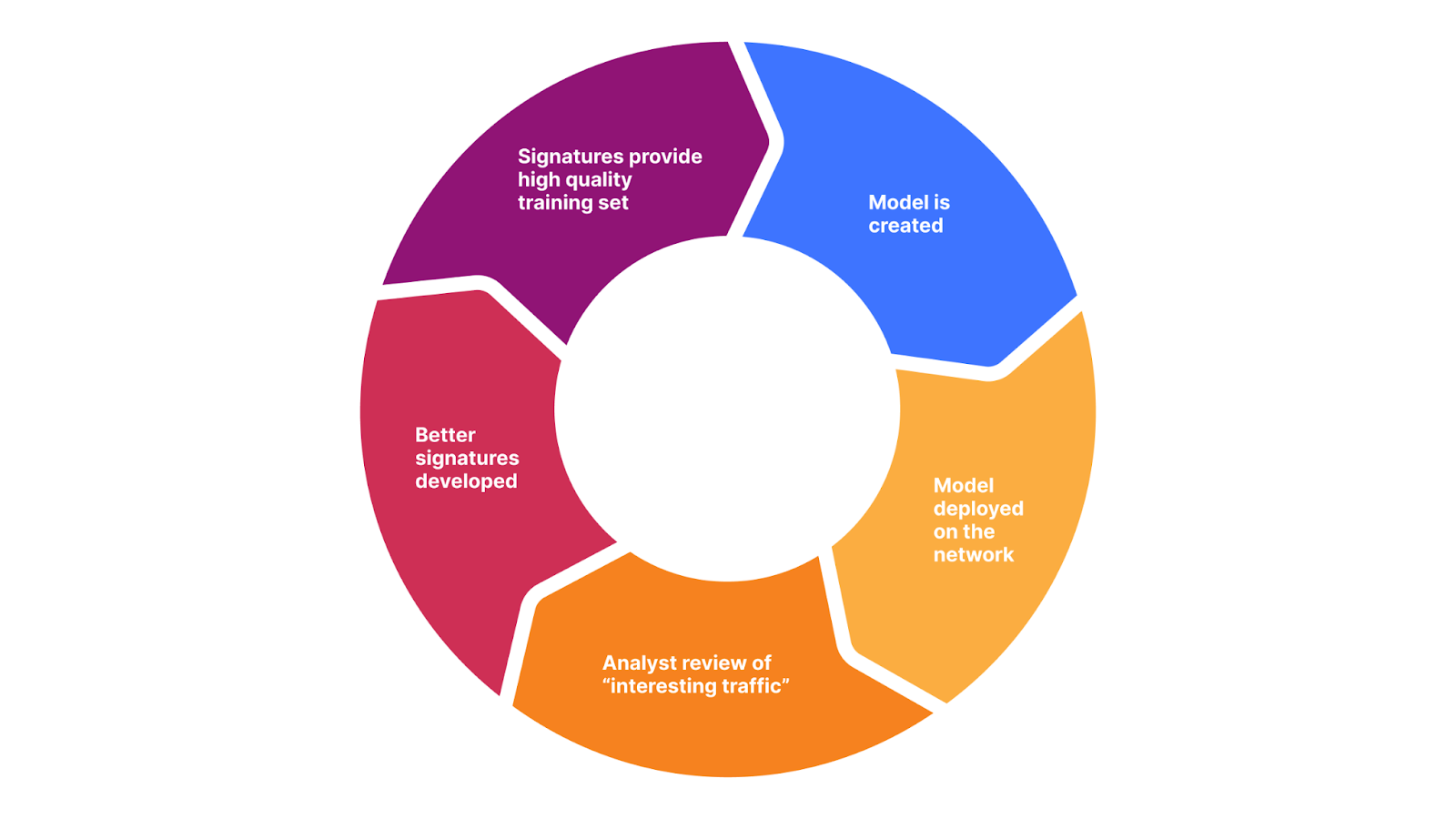
Better signatures provide a better training set (data). In turn, we can create a better model. The model will provide us with a more interesting delta, which, once reviewed by humans, will allow us to create better signatures. And start over.
We are now working to automate this entire process with the goal of having humans simply review and click to deploy. This is the leading edge for WAF zero-day mitigation in the industry.
Summary
One of the main value propositions of any web application security product is the ability to detect novel attack vectors before they can cause an issue, allowing internal teams time to patch and remediate the underlying codebase. We call this time to mitigate. The ideal value is zero.
We’ve put a lot of effort and research into a machine learning system that augments our existing signature based system to yield very good classification results of new attack vectors the first time they are seen. The system outputs a score that we call the WAF Attack Score. We have validated that for many CVEs, we are indeed able to correctly classify malicious payloads on the first attempt and provide Sitecore CVEs as an example.
Moving forward, we are now automating a feedback loop that will allow us to both improve our signatures faster, to then subsequently iterate on the model and provide even better detection.
The system is live and available to all our customers in the business or enterprise plan. Log in to the Cloudflare dashboard today to receive instant zero-day mitigation.















 Florian Mair is a Senior Solutions Architect and data streaming expert at AWS. He is a technologist that helps customers in Germany succeed and innovate by solving business challenges using AWS Cloud services. Besides working as a Solutions Architect, Florian is a passionate mountaineer, and has climbed some of the highest mountains across Europe.
Florian Mair is a Senior Solutions Architect and data streaming expert at AWS. He is a technologist that helps customers in Germany succeed and innovate by solving business challenges using AWS Cloud services. Besides working as a Solutions Architect, Florian is a passionate mountaineer, and has climbed some of the highest mountains across Europe. Benjamin Meyer is a Senior Solutions Architect at AWS, focused on Games businesses in Germany to solve business challenges by using AWS Cloud services. Benjamin has been an avid technologist for 7 years, and when he’s not helping customers, he can be found developing mobile apps, building electronics, or tending to his cacti.
Benjamin Meyer is a Senior Solutions Architect at AWS, focused on Games businesses in Germany to solve business challenges by using AWS Cloud services. Benjamin has been an avid technologist for 7 years, and when he’s not helping customers, he can be found developing mobile apps, building electronics, or tending to his cacti.