Post Syndicated from Matt Silverlock original http://blog.cloudflare.com/fr-fr/hyperdrive-making-regional-databases-feel-distributed-fr-fr/

Hyperdrive vous permet d’accéder très rapidement à vos bases de données existantes à partir de Cloudflare Workers, quel que soit leur lieu d’exécution. Il vous suffit de connecter Hyperdrive à votre base de données, de modifier une ligne de code pour vous connecter via Hyperdrive, et voilà : les connexions et les requêtes sont accélérées (et spoiler : vous pouvez l’utiliser dès aujourd’hui).
En un mot, Hyperdrive s’appuie sur notre réseau mondial pour accélérer les requêtes vers vos bases de données existantes, qu’elles se situent chez un fournisseur de cloud traditionnel ou chez votre fournisseur de base de données serverless préféré. La solution réduit considérablement la latence induite par l’établissement répété de nouvelles connexions avec la base de données. En outre, elle met en cache les requêtes de lecture les plus populaires adressées à votre base de données, une opération qui évite souvent d’avoir à s’adresser à nouveau à votre base de données.
Sans Hyperdrive, l’accès à votre base de données principale (celle qui contient les profils de vos utilisateurs, votre stock de produits ou qui exécute votre application web essentielle) hébergée dans la région us-east1 d’un fournisseur de cloud traditionnel se révèlera très lent pour les utilisateurs situés à Paris, Singapour et Dubaï, et plus lent qu’il ne devrait l’être pour les utilisateurs de Los Angeles ou de Vancouver. Chaque aller-retour pouvant prendre jusqu’à 200 ms, il est facile de perdre jusqu’à une seconde (ou plus !) lors des nombreux allers-retours nécessaires à l’établissement d’une connexion, avant même d’avoir envoyé la requête visant à récupérer vos données. Le service Hyperdrive est conçu pour remédier à cette situation.
Pour démontrer les performances d’Hyperdrive, nous avons développé une application de démonstration qui envoie des requêtes consécutives à la même base de données : à la fois avec Hyperdrive et sans Hyperdrive (directement donc). L’application commence par sélectionner une base de données située dans un continent voisin : elle sélectionne ainsi une base de données hébergée aux États-Unis si vous vous trouvez en Europe, par exemple (une expérience bien trop courante pour de nombreux internautes européens). De même, si vous vous trouvez en Afrique, elle sélectionnera une base de données située en Europe (et ainsi de suite). Elle renvoie ensuite les résultats bruts d’une requête « SELECT » simple, sans moyennes ni indicateurs choisis avec soin.
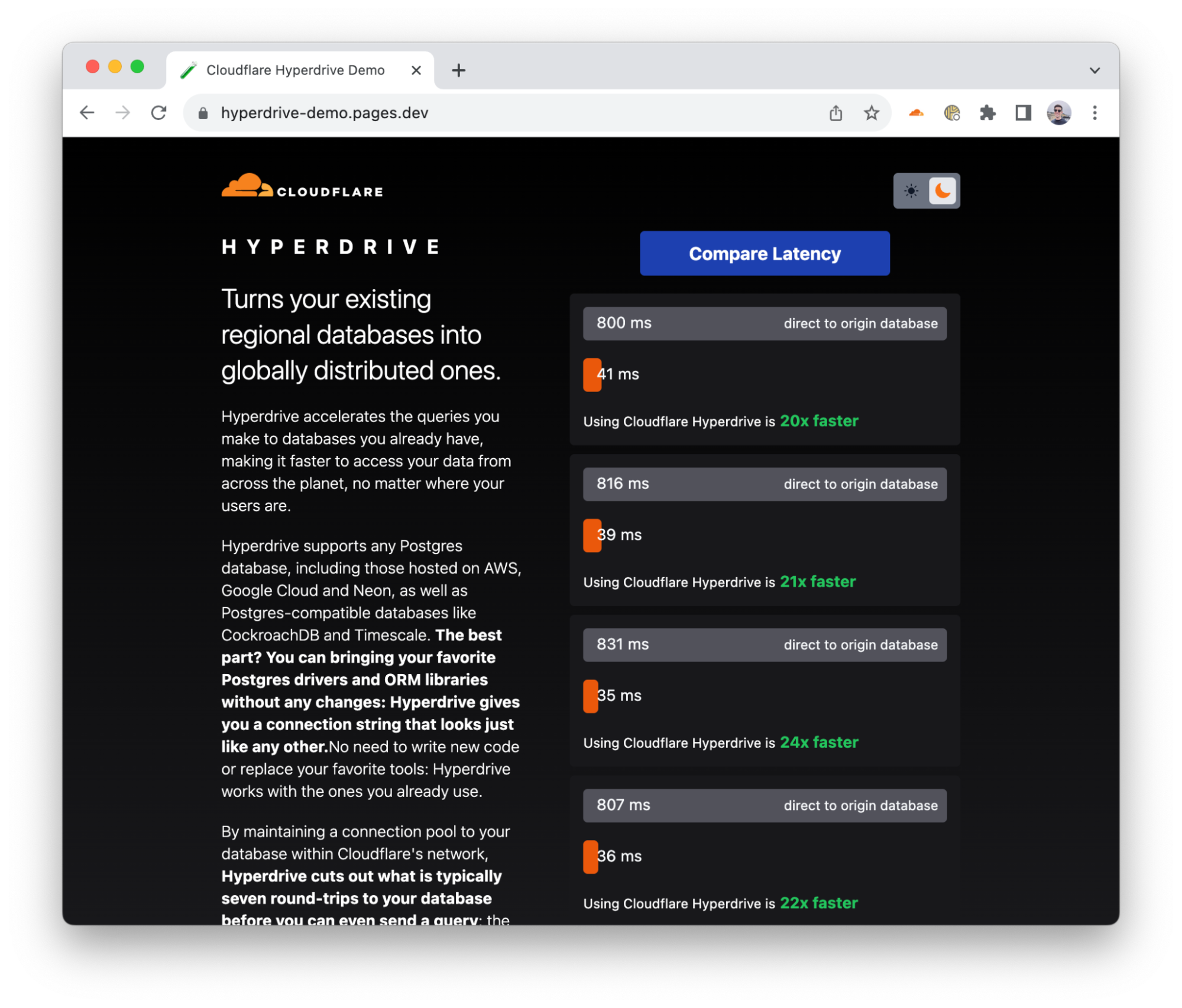
Tout au long de la phase de tests internes, les premiers rapports d’utilisateurs et les multiples tests d’évaluation réalisés révèlent qu’Hyperdrive améliore les performances de 17 à 25 fois par rapport à l’accès direct à la base de données pour les requêtes en cache, et de 6 à 8 fois pour les requêtes et les opérations d’écriture non mises en cache. La latence de la mise en cache ne vous surprendra peut-être pas, mais nous pensons que le fait d’accélérer 6 à 8 fois les requêtes non mises en cache vous fera changer d’idée, en passant de « Je ne peux pas interroger une base de données centralisée à partir de Cloudflare Workers » à « Mais où te cachais-tu, fonctionnalité de mes rêves ?! ». Nous continuons également à travailler sur l’amélioration des performances. Nous avons déjà identifié des économies supplémentaires en termes de latence et les mettrons en œuvre dans les semaines à venir.
Le plus beau dans tout ça ? Les développeurs titulaires d’une offre Workers payante peuvent commencer à utiliser immédiatement la bêta ouverte d’Hyperdrive : pas besoin de s’inscrire sur une liste d’attente ni de parcourir de formulaires d’inscription spéciaux.
Hyperdrive ? Vous n’en avez jamais entendu parler ?
Nous travaillons sur Hyperdrive en secret depuis quelque temps, mais le fait de permettre aux développeurs de se connecter aux bases de données dont ils disposent déjà (avec leurs données, leurs requêtes et leurs outils existants) nous trotte dans la tête depuis un bon moment.
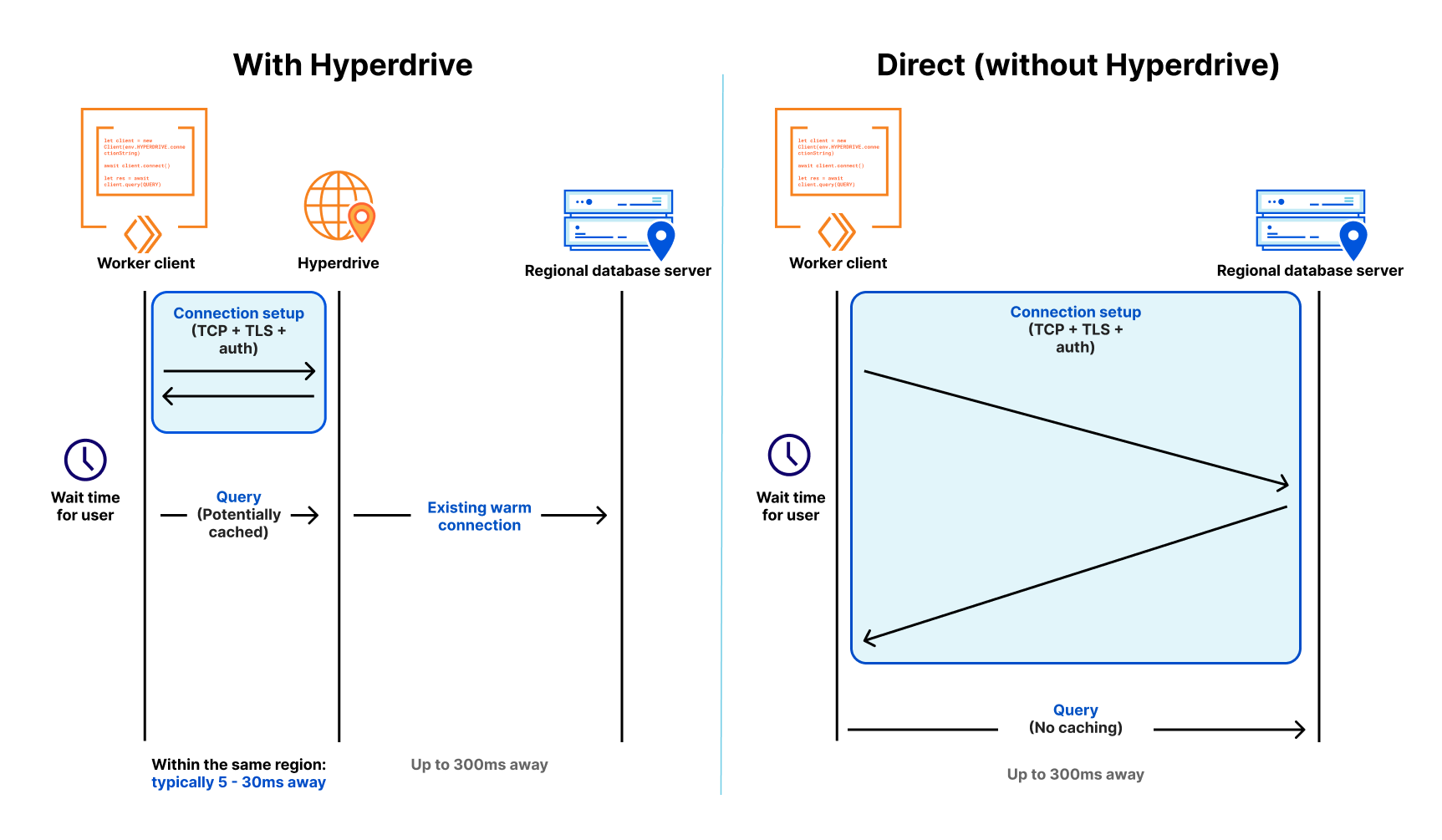
Dans un environnement cloud distribué moderne comme Workers, au sein duquel les calculs sont distribués à l’échelle mondiale (ils sont donc effectués à proximité des utilisateurs) et les fonctions de courte durée (afin de ne pas être facturé plus que nécessaire), la connexion aux bases de données traditionnelles se montre à la fois lente et non évolutive. Lente, parce qu’il faut plus de sept allers-retours (négociation TCP, négociation TLS, authentification) pour établir la connexion et non évolutive, car les bases de données telles que PostgreSQL présentent un coût en ressources par connexion plutôt élevé. Même quelques centaines de connexions à une base de données peuvent consommer une quantité importante de mémoire, indépendamment de la mémoire nécessaire pour les requêtes.
Nos amis chez Neon (un fournisseur populaire de bases de données Postgres serverless) ont d’ailleurs écrit à ce sujet. Ils ont même lancé un proxy et un pilote WebSocket permettant de réduire la surcharge de connexion, mais ils ont toujours du mal à se sortir de l’ornière. Même avec un pilote personnalisé, nous en sommes à 4 allers-retours, chacun demandant potentiellement 50 à 200 millisecondes, voire plus. Ce délai ne pose aucun problème lorsque les connexions sont de longue durée (il surviendra une fois toutes les quelques heures au mieux), mais lorsque ces connexions se limitent à une invocation de fonction individuelle et qu’elles ne restent donc utiles que pendant quelques millisecondes ou quelques minutes, votre code passe plus de temps à attendre. Il s’agit en fait d’une autre sorte de démarrage à froid. Le fait d’avoir à établir une nouvelle connexion avec votre base de données avant d’envoyer une requête implique que l’utilisation d’une base de données traditionnelle au sein d’un environnement distribué ou serverless sera vraiment lente (pour le dire gentiment).
Pour remédier à ce problème, la solution Hyperdrive accomplit deux tâches.
Tout d’abord, elle entretient un ensemble de pools de connexions avec des bases de données régionales via le réseau Cloudflare, de sorte qu’un Worker Cloudflare puisse éviter d’établir une nouvelle connexion à une base de données pour chaque requête. À la place, le Worker peut établir une connexion à Hyperdrive (une opération des plus rapides !), car Hyperdrive dispose d’un pool de connexions prêtes à l’emploi vers la base de données. Comme une base de données peut être distante de 30 ms à (bien souvent) 300 ms lors d’un unique aller-retour (sans parler des sept ou plus dont vous avez besoin pour établir une nouvelle connexion), le fait de disposer d’un pool de connexions disponibles réduit considérablement le problème de latence dont souffriraient autrement les connexions de courte durée.
Ensuite, la solution comprend la différence entre les requêtes et les transactions de lecture (non mutantes) et d’écriture (mutantes). Elle peut ainsi mettre automatiquement en cache vos requêtes de lecture les plus populaires, qui représentent plus de 80 % de l’ensemble des requêtes adressées aux bases de données au sein des applications web typiques. Il peut, par exemple, s’agir de cette liste de produits que des dizaines de milliers d’utilisateurs visitent chaque heure, des annonces publiées sur un grand site d’offres d’emploi, voire de requêtes visant des données de configuration qui changent de temps en temps. Une grande partie des ressources visées par les requêtes des utilisateurs ne changent pas souvent et le fait de les mettre en cache à proximité de l’endroit d’où l’utilisateur envoie sa requête peut accélérer considérablement l’accès à ces données pour les dix mille utilisateurs suivants. Les requêtes d’écriture, qui ne peuvent pas être réellement mises en cache de manière sûre, bénéficient toujours des pools de connexions entretenus par Hyperdrive et du réseau mondial de Cloudflare. La possibilité d’emprunter les itinéraires les plus rapides sur Internet via notre infrastructure permet là aussi de réduire la latence.
Hyperdrive fonctionne non seulement avec les bases de données PostgreSQL (dont celles de Neon, de Google Cloud SQL, d’AWS RDS, et de Timescale), mais aussi avec les bases de données compatibles PostgreSQL, comme Materialize (une puissante base de données de traitement de flux), CockroachDB (une des principales bases de données distribuées), AlloyDB de Google Cloud, et Aurora Postgres d’AWS.
Nous travaillons également à la prise en charge de MySQL, notamment avec des fournisseurs comme PlanetScale, d’ici la fin de l’année. D’autres moteurs de base de données sont prévus par la suite.
La chaîne de connexion magique
L’un des principaux objectifs à l’origine de la conception d’Hyperdrive était de permettre aux développeurs de continuer à utiliser leurs outils existants, comme leurs pilotes, leurs générateurs de requêtes et leurs bibliothèques ORM (Object-Relational Mapper, mappeur objet-relationnel). La rapidité d’Hyperdrive n’aurait pas d’importance si nous vous avions demandé d’abandonner votre bibliothèque ORM préférée et/ou de réécrire des centaines (ou plus) de lignes de code et de tests pour bénéficier des performances de notre solution.
Pour ce faire, nous avons travaillé avec des éditeurs de pilotes open-source bien connus (notamment node-postgres et Postgres.js) afin d’aider leurs bibliothèques à prendre en charge la nouvelle API Socket TCP de Workers, qui est en cours de normalisation, et que nous espérons voir arriver dans Node.js, Deno et Bun également.
Langage partagé par les pilotes de base de données, la simple chaîne de connexion à la base de données se présente généralement ainsi :
postgres://user:[email protected]:5432/postgres
La magie d’Hyperdrive réside dans le fait que vous pouvez commencer à l’utiliser dans vos applications Workers existantes, avec vos requêtes existantes, en remplaçant simplement votre chaîne de connexion par celle générée par Hyperdrive.
Création d’un Hyperdrive
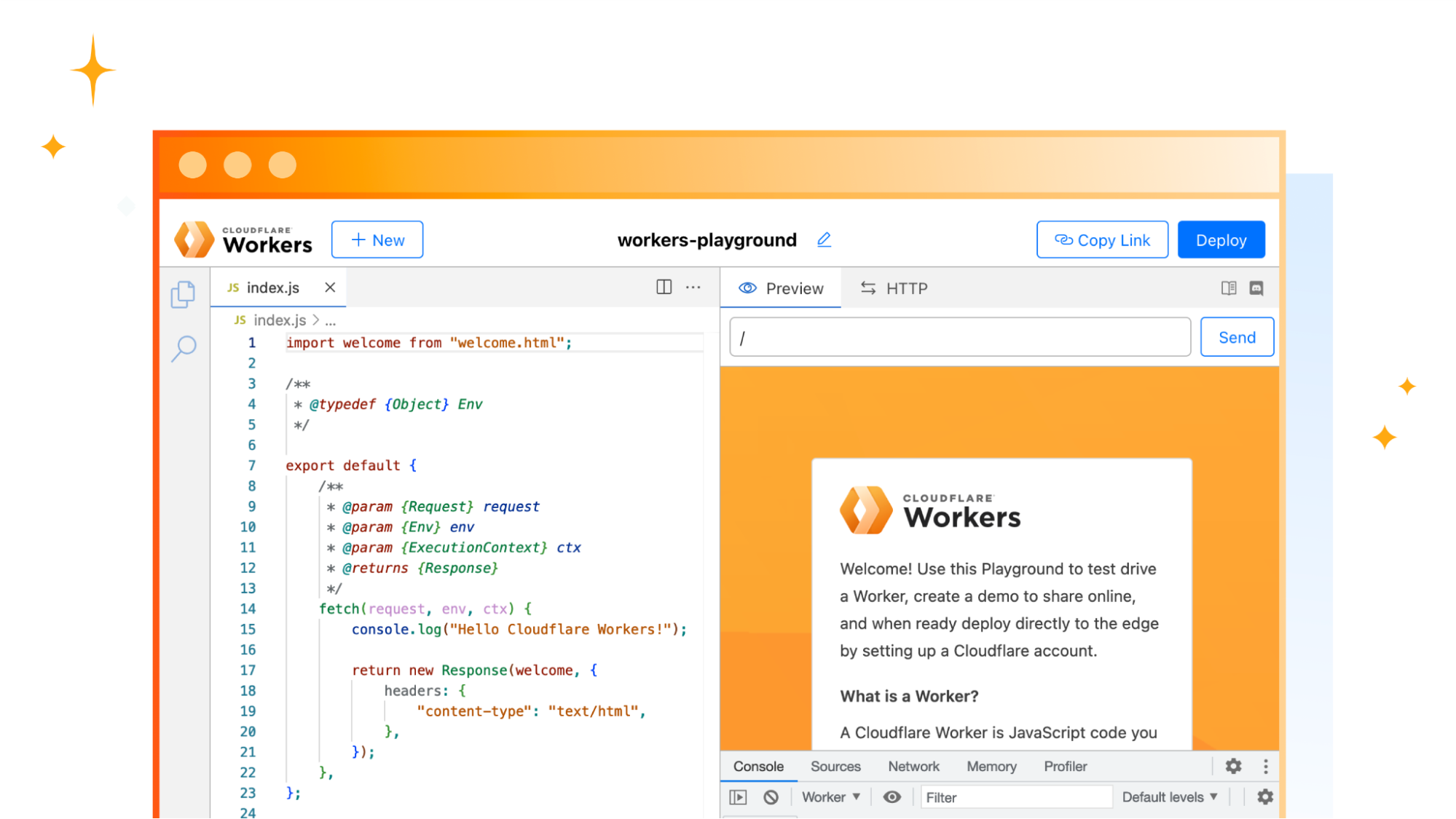
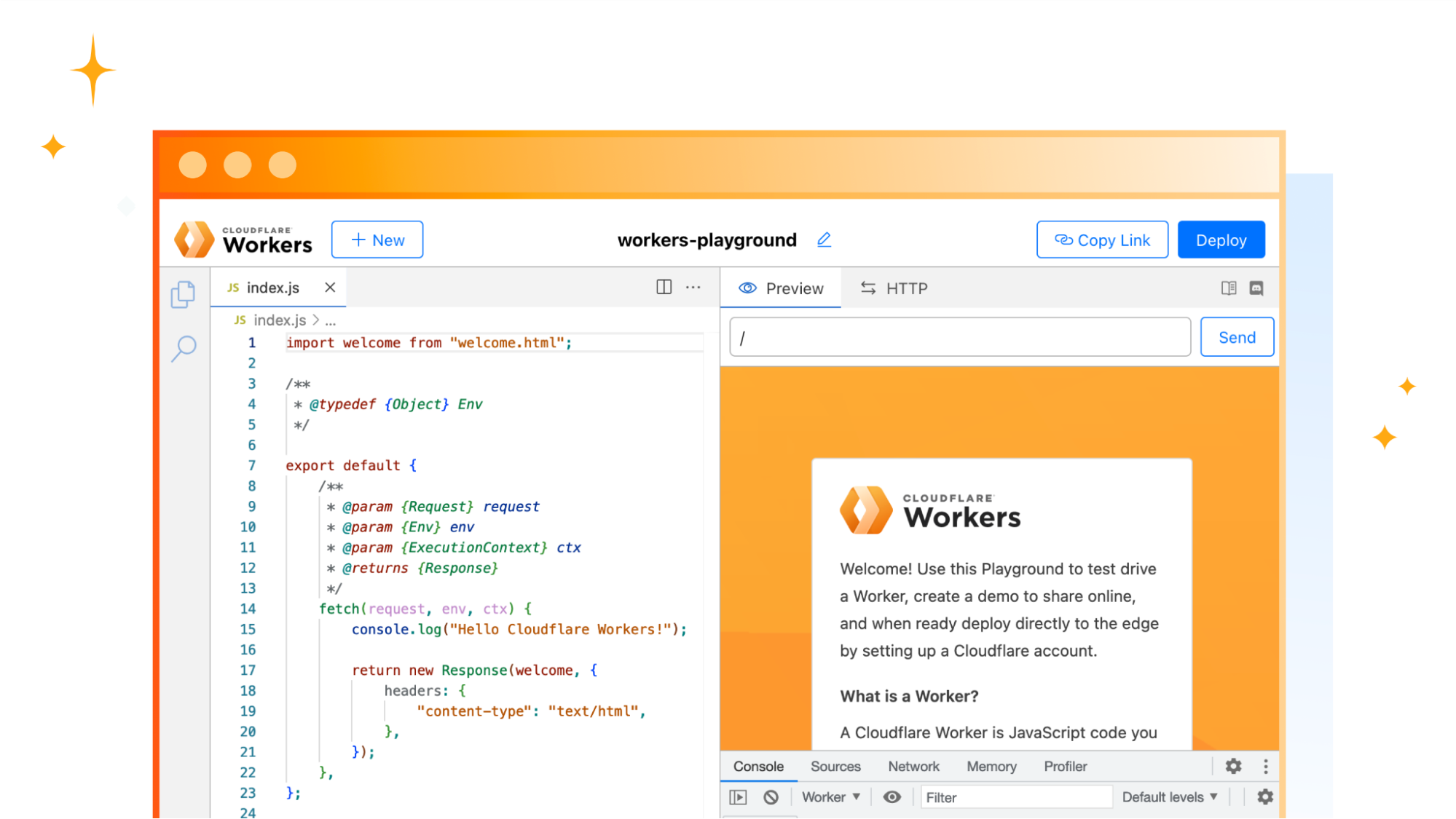
Avec une base de données existante prête à l’emploi (dans cet exemple, nous utiliserons une base de données Postgres de Neon), il suffit de moins d’une minute pour faire fonctionner Hyperdrive (oui, nous avons chronométré le temps nécessaire).
Si vous ne disposez pas d’un projet Cloudflare Workers existant, vous pouvez rapidement en créer un :
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
À partir de là, nous avons juste besoin de la chaîne de connexion à notre base de données et d’une invocation rapide de la ligne de commande wrangler pour qu’Hyperdrive s’y connecte.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
Ajoutez notre Hyperdrive au fichier de configuration wrangler.toml de notre Worker :
[[hyperdrive]]
name = "HYPERDRIVE"
id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
Nous pouvons maintenant écrire un Worker (ou employer un script Worker existant) et utiliser Hyperdrive pour accélérer les connexions et les requêtes à notre base de données existante. Nous utilisons ici node-postgres, mais nous pourrions tout aussi bien utiliser Drizzle ORM.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
Le code ci-dessus est intentionnellement simple, mais j’espère que vous pouvez en voir la magie : notre pilote de base de données reçoit ainsi une chaîne de connexion d’Hyperdrive et reste indifférent. Il n’a pas besoin de connaître Hyperdrive, nous n’avons pas besoin de nous débarrasser de notre bibliothèque de génération de requêtes préférée et nous pouvons immédiatement réaliser les avantages en termes de rapidité lorsque nous envoyons des requêtes.
Les connexions sont automatiquement mises en commun et conservées, nos requêtes les plus populaires sont mises en cache et l’ensemble de notre application s’en trouve accélérée.
Nous avons également rédigé des guides pour tous les principaux fournisseurs de bases de données afin de faciliter l’intégration de ce dont vous avez besoin (une chaîne de connexion) dans Hyperdrive.
Mais la rapidité a un prix, n’est-ce pas ?
Nous considérons Hyperdrive comme un outil essentiel pour accéder à vos bases de données existantes lorsque vous développez sur Cloudflare Workers. Les bases de données traditionnelles n’ont tout simplement pas été conçues pour un monde dans lequel les clients sont distribués à l’échelle mondiale.
La mise en commun des connexions par Hyperdrive sous forme de pools sera toujours gratuite, à la fois pour les protocoles de base de données que nous prenons en charge aujourd’hui et pour les nouveaux protocoles que nous ajouterons à l’avenir. Tout comme pour notre service de protection contre les attaques DDoS et notre réseau CDN mondial, nous pensons que l’accès aux fonctionnalités principales d’Hyperdrive est trop utile pour être limité.
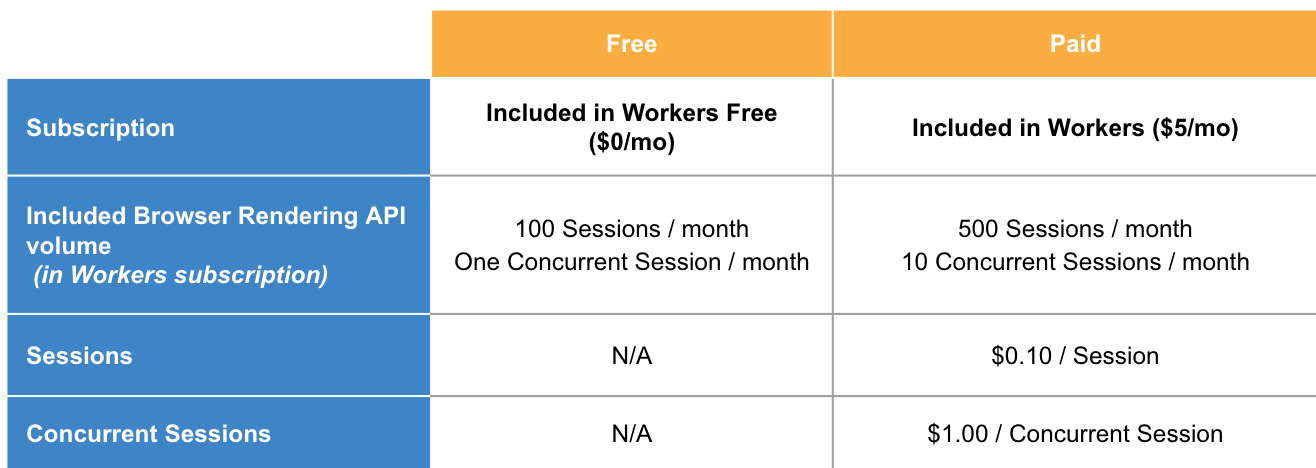
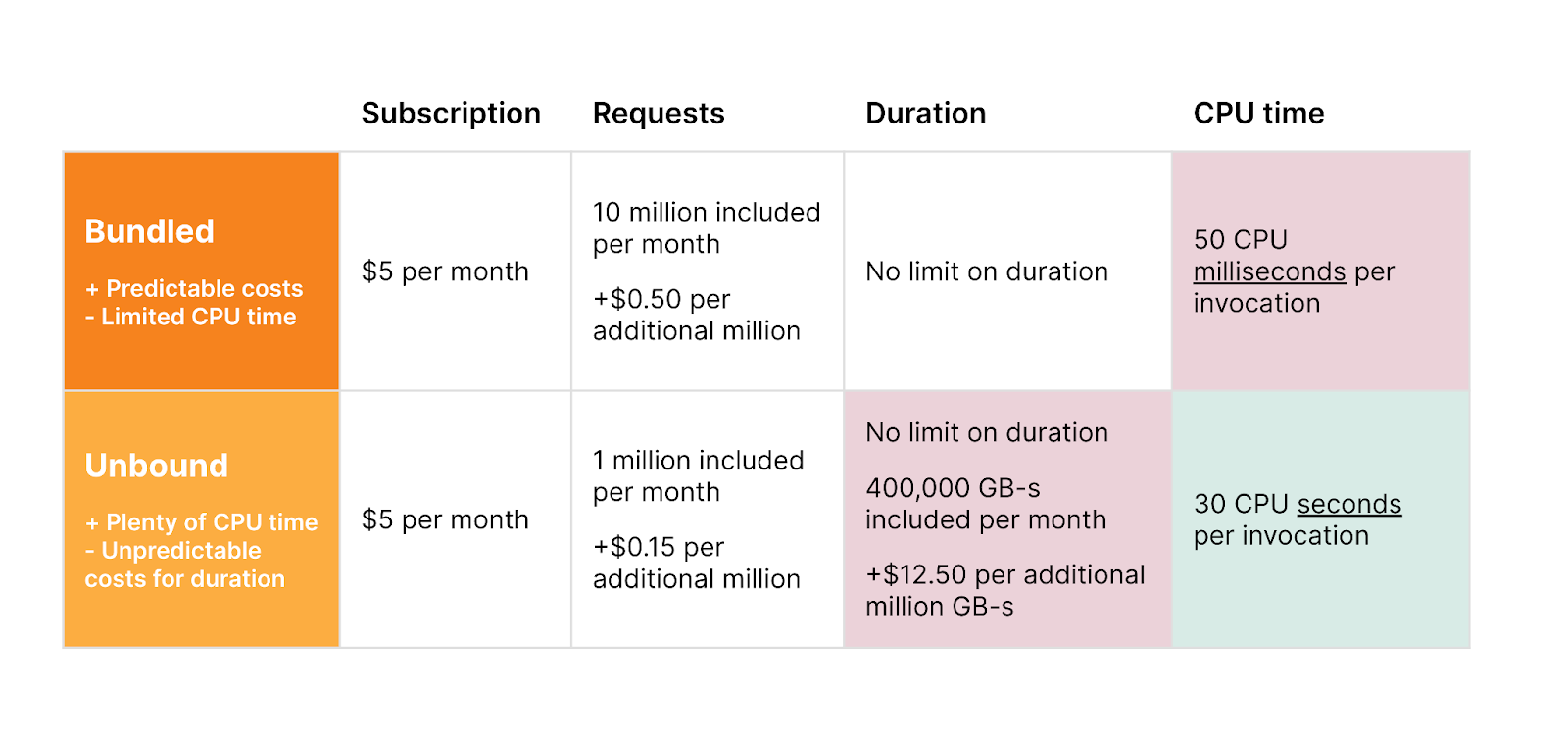
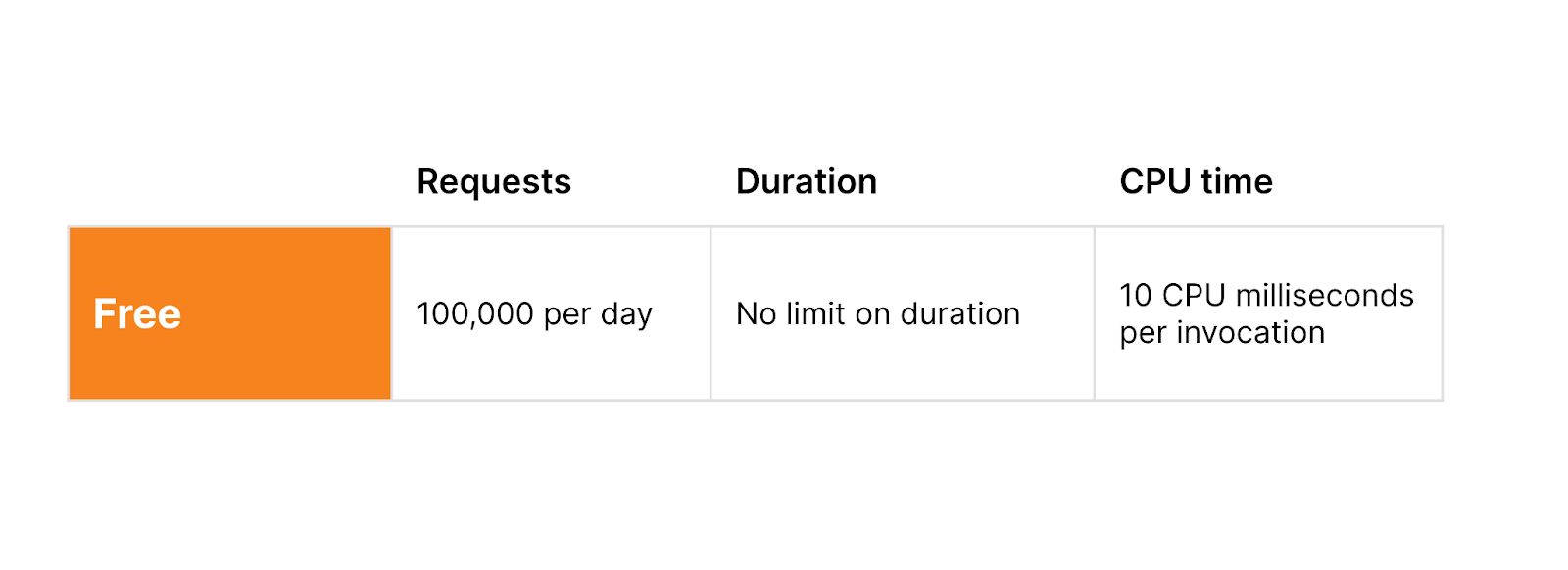
L’utilisation d’Hyperdrive ne sera pas facturée pendant la bêta ouverte, quelle que soit la manière dont vous vous en servez. Nous vous donnerons plus de détails sur la tarification d’Hyperdrive à l’approche de son lancement (début 2024), et ce bien à l’avance.
Le moment des questions
Quel est l’avenir pour Hyperdrive ?
Nous prévoyons de mettre Hyperdrive en disponibilité générale au début de l’année 2024 et nous concentrons actuellement sur la mise en place de davantage de mesures de contrôle sur la manière dont nous mettons en cache et invalidons automatiquement les ressources en nous appuyant sur les analyses des opérations d’écriture, des requêtes détaillées et des performances (bientôt !). Nous prévoyons aussi de prendre en charge davantage de moteurs de base de données (dont MySQL), tout en poursuivant nos travaux visant à rendre la solution encore plus rapide.
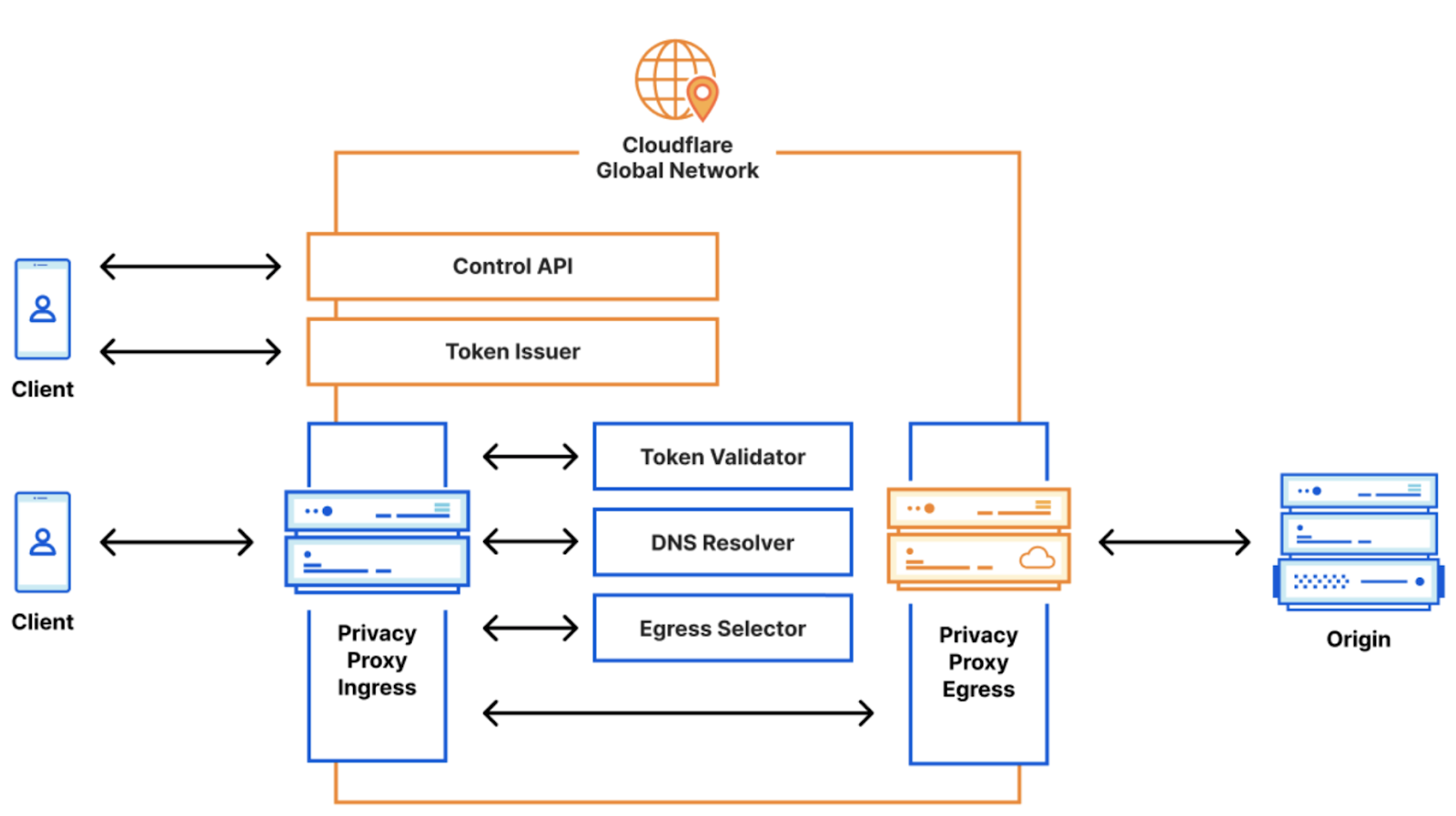
Nous travaillons également à la mise en place d’une connectivité réseau privée via Magic WAN et Cloudflare Tunnel, afin de vous permettre de vous connecter à des bases de données non exposées à l’Internet public (ou qui ne peuvent pas l’être).
Pour connecter Hyperdrive à votre base de données existante, rendez-vous dans nos documents pour les développeurs. Il suffit de moins d’une minute pour créer un Hyperdrive et mettre à jour le code existant afin de pouvoir utiliser la solution. Rejoignez le canal #hyperdrive-beta de notre Discord pour développeurs si vous souhaitez poser des questions, signaler des bugs et discuter directement avec notre équipe produits et notre équipe technique.
















 Когато се преместих от София в с. Бойково през 2020г. реших, че ще се опитам да направя нещо за тази община. Председател съм на Фондация Възраждане на българските села и сме дарили компютърни зали на десетки селца (включително и в Украйна), та се замислих дали пък не е редно да направя нещо и за общината, в която ще живея.
Когато се преместих от София в с. Бойково през 2020г. реших, че ще се опитам да направя нещо за тази община. Председател съм на Фондация Възраждане на българските села и сме дарили компютърни зали на десетки селца (включително и в Украйна), та се замислих дали пък не е редно да направя нещо и за общината, в която ще живея. Окрилен от добрите резултати, реших да се загледам в бюджета на Община Родопи. Все пак това ми е работата – финансист съм и си мисля, че разбирам от тия работи. Понеже бях гледал заседания на общинския съвет в Пловдив си помислих, че мога да гледам и тук заседанията онлайн. „Да ама не”, както казваше Петко Бочаров. Общината нямала технологичната възможност да излъчва онлайн.
Окрилен от добрите резултати, реших да се загледам в бюджета на Община Родопи. Все пак това ми е работата – финансист съм и си мисля, че разбирам от тия работи. Понеже бях гледал заседания на общинския съвет в Пловдив си помислих, че мога да гледам и тук заседанията онлайн. „Да ама не”, както казваше Петко Бочаров. Общината нямала технологичната възможност да излъчва онлайн.