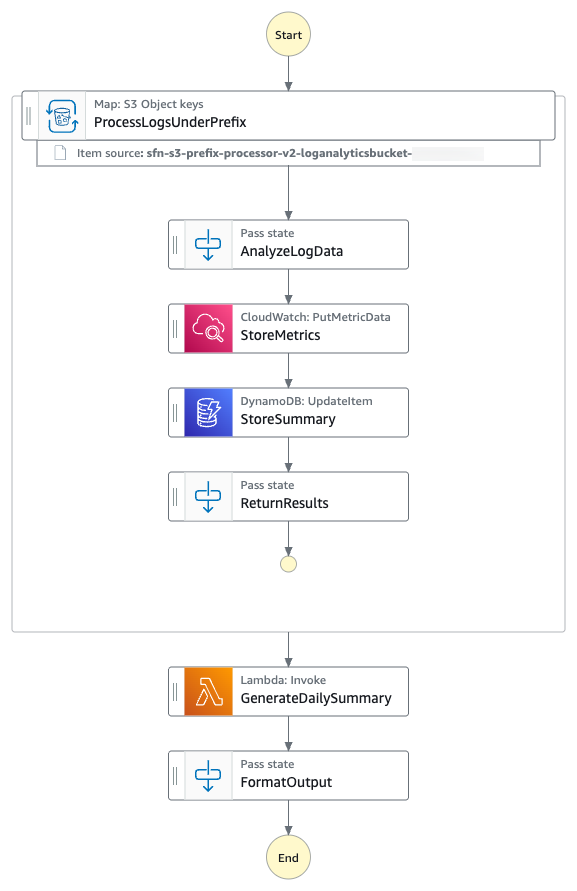
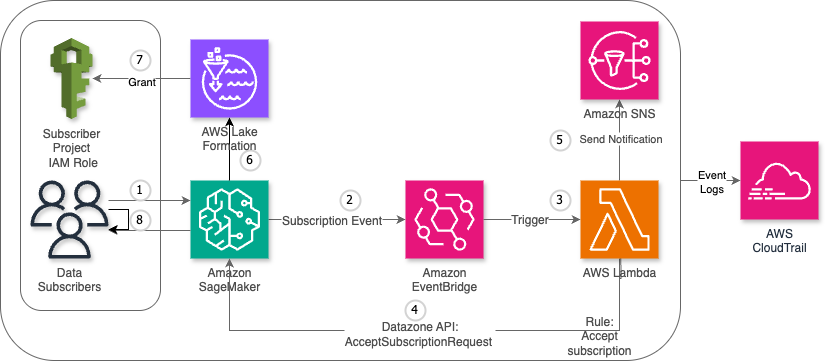
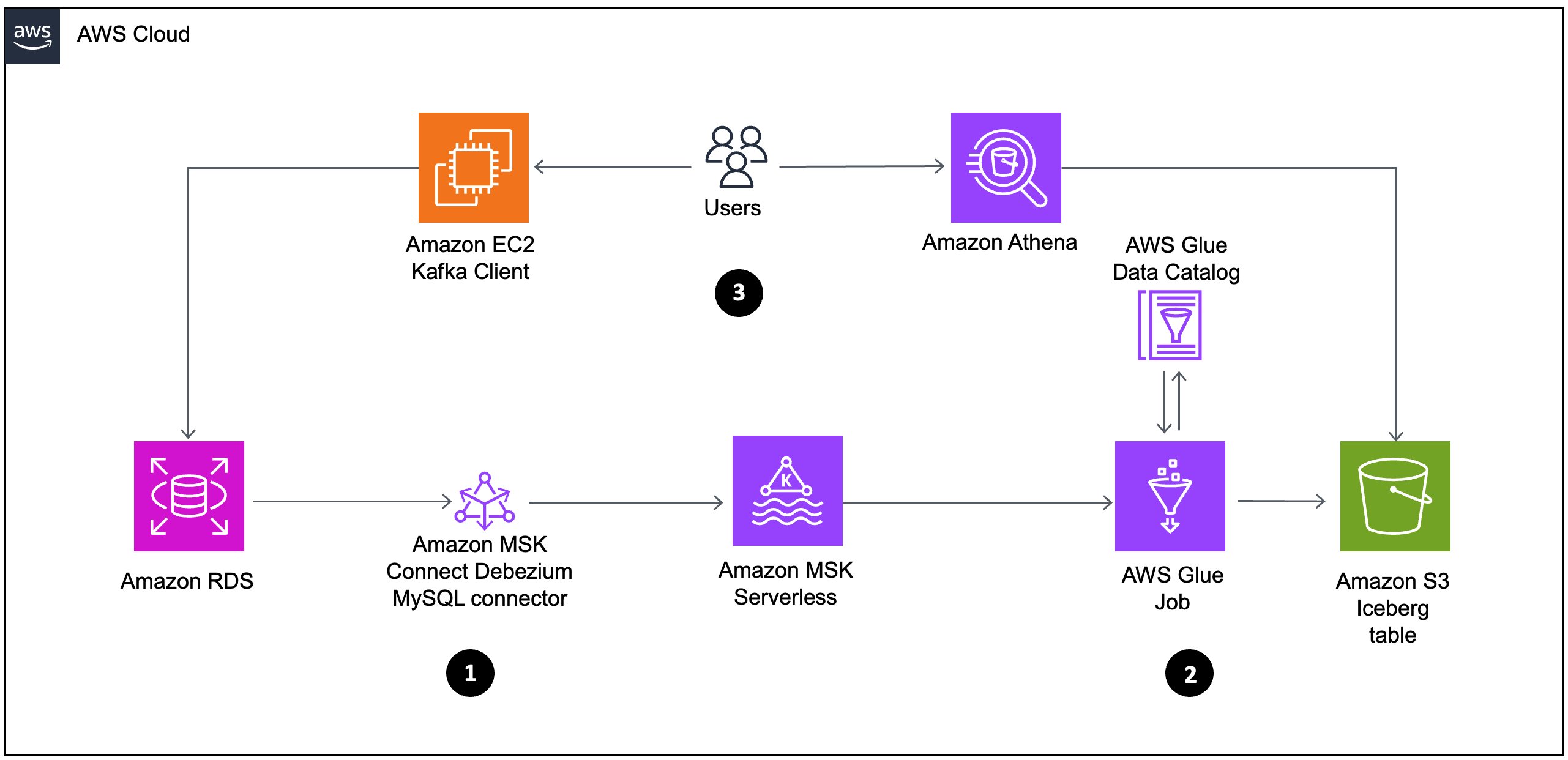
Application authorization is a critical component of modern software systems, determining what actions users can perform on specific resources. Many organizations have adopted Open Policy Agent (OPA) with its Rego policy language to implement fine-grained authorization controls across their applications and infrastructure. While OPA has proven effective for policy-as-code implementations, organizations are increasingly looking for more performant and managed services that reduce operational overhead while maintaining the flexibility and power of policy-based authorization.
Amazon Verified Permissions is a fully managed authorization service that uses the Cedar policy language to help you implement fine-grained permissions for your applications. Cedar is an open source policy language developed by AWS that provides many of the same capabilities as Rego while offering improved performance (42–60 times faster than Rego), straightforward policy authoring, and formal verification capabilities. By migrating from OPA to Verified Permissions, organizations can reduce the operational burden of managing authorization infrastructure while gaining access to a service designed specifically for scalable, secure authorization.
This migration offers several key benefits: reduced infrastructure management overhead, improved policy performance and validation, enhanced security through the AWS managed service model, and seamless integration with other AWS services. Additionally, Cedar’s syntax is designed to be more intuitive than Rego, reducing the effort needed to write, read, and maintain policies.
In this post, we explore the process of migrating from OPA and Rego to Verified Permissions and Cedar, including policy translation strategies, software development and testing approaches, and deployment considerations. We walk through practical examples that demonstrate how to convert common Rego policies to Cedar policies and integrate Verified Permissions into your existing applications.
Solution overview
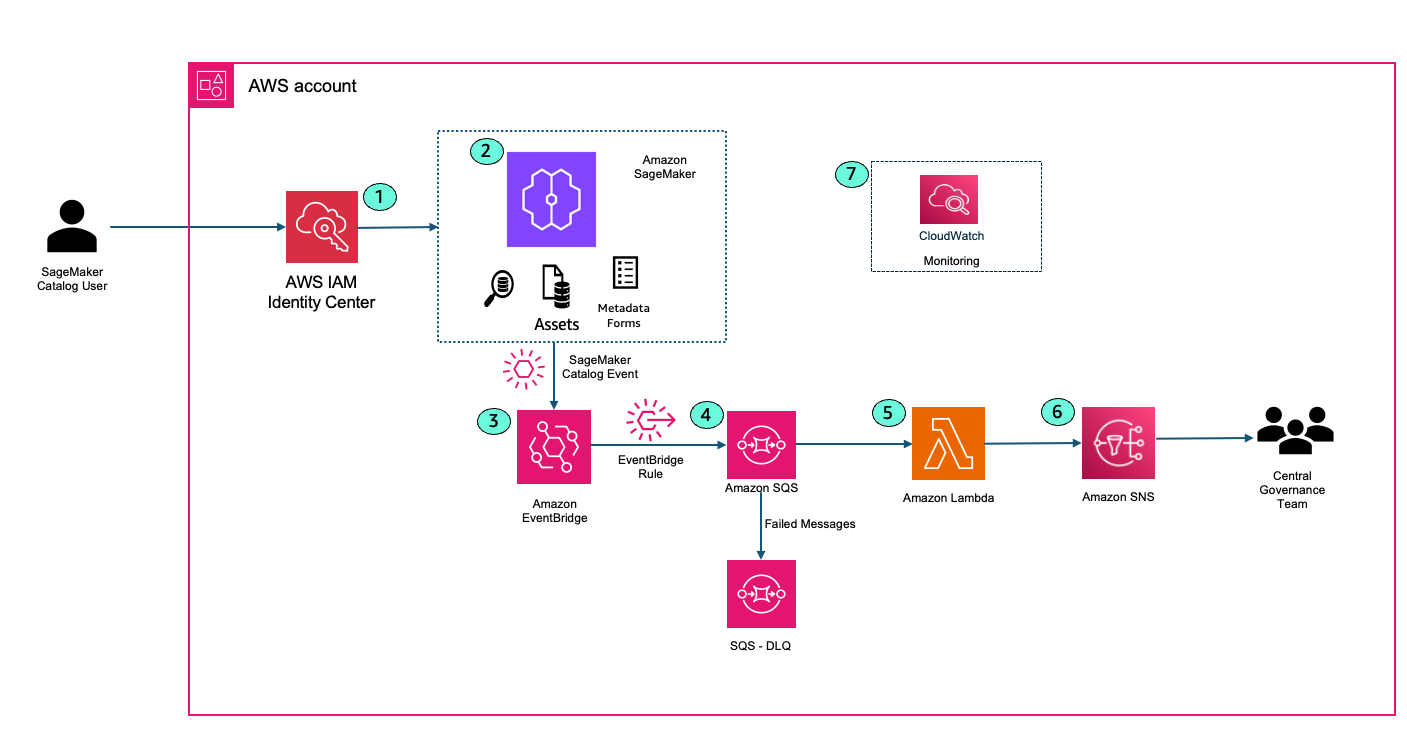
The migration from OPA to Verified Permissions represents a shift from self-managed authorization infrastructure to a fully managed service. In a typical OPA setup, customers have OPA servers running either as sidecars, standalone services, or embedded libraries that evaluate Rego policies against incoming authorization requests. These servers pull policy bundles from storage systems and maintain their own performance and availability.
With Verified Permissions, AWS manages the entire authorization infrastructure. Applications make API calls to the Verified Permissions service which evaluates Cedar policies stored in managed policy stores. This removes the need to operate and maintain OPA servers, manage policy distribution, or handle service scaling and availability. This shift means that your team can concentrate on authorization logic rather than infrastructure management while gaining the benefits of the scale and reliability provided by AWS.
Understanding the differences: Comparing Rego with Cedar
It’s important to understand the fundamental differences between the Rego and Cedar policy languages before beginning your migration. These differences will shape how you approach translating your existing policies.
Policy structure and philosophy
Rego policies are built around rules that can be evaluated to produce sets of results. Rego uses a logic programming approach where you define conditions that must be satisfied for a rule to be true. Policies often involve complex queries, loops, and comprehensions to examine data structures.
Example Rego policy
Cedar takes a more declarative approach with explicit permit and forbid statements. Each Cedar policy is a standalone authorization decision that clearly states what is being allowed or denied. Cedar policies are designed to be human-readable and straightforward to audit.
Equivalent Cedar policies
Data model differences
One of the most significant differences between the two evaluation engines is how they handle data. Rego works with arbitrary JSON input data, giving users complete flexibility in how they structure authorization requests. Users can access any field in your input data using Rego’s path notation.
Cedar allows for the creation of a defined schema with typed entities. This means that users need to model authorization data as entities with specific types, attributes, and relationships. While this requires more upfront planning, it provides superior validation, runtime performance, and tooling support.
Policy evaluation
Rego and Cedar differ fundamentally in their approaches to policy evaluation. Rego uses a logic programming model and, as a result, policy evaluation functions much like a logic puzzle solver. It starts with a question and searches backward through linked rules to find an answer. This approach allows for flexible policy composition but can often be slower, less predictable, and more difficult to audit.
Cedar, on the other hand, uses a simpler functional evaluation approach. It uses a straightforward evaluation model where each policy is checked independently against the authorization request. Policies use basic conditional logic to produce fast, deterministic allow or deny decisions. A policy either fully matches the authorization request (principal, action, resource, and all conditions), or it doesn’t apply. This is essential for high-performance authorization scenarios where predictable evaluation time and clear audit trails are essential. Cedar policy evaluation follows four core principles:
- Default deny for access not explicitly granted
- Forbid overrides permit for handling policy conflicts
- Order-independent evaluation to prevent bugs
- Deterministic outcomes for reliable results
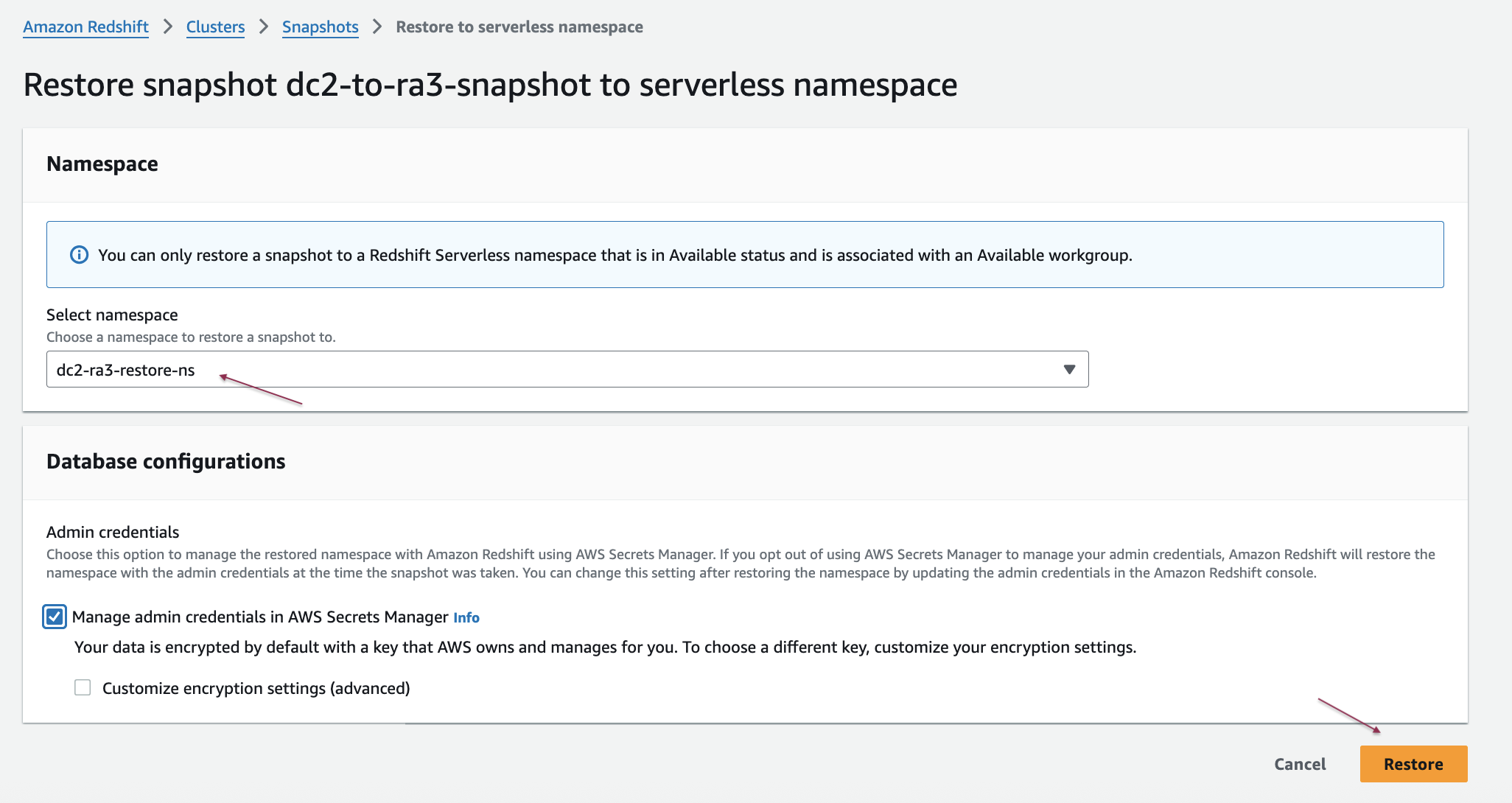
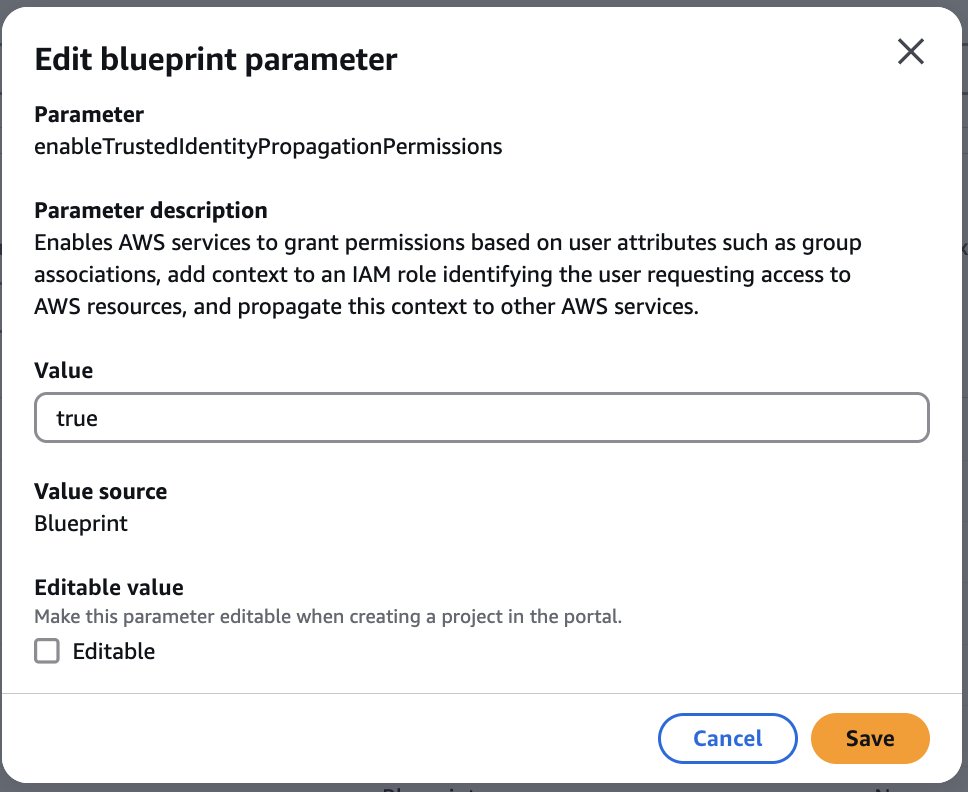
Setting up Verified Permissions
Before you can begin migrating your authorization policies, you need to establish the foundational infrastructure in Verified Permissions.
Creating your policy store
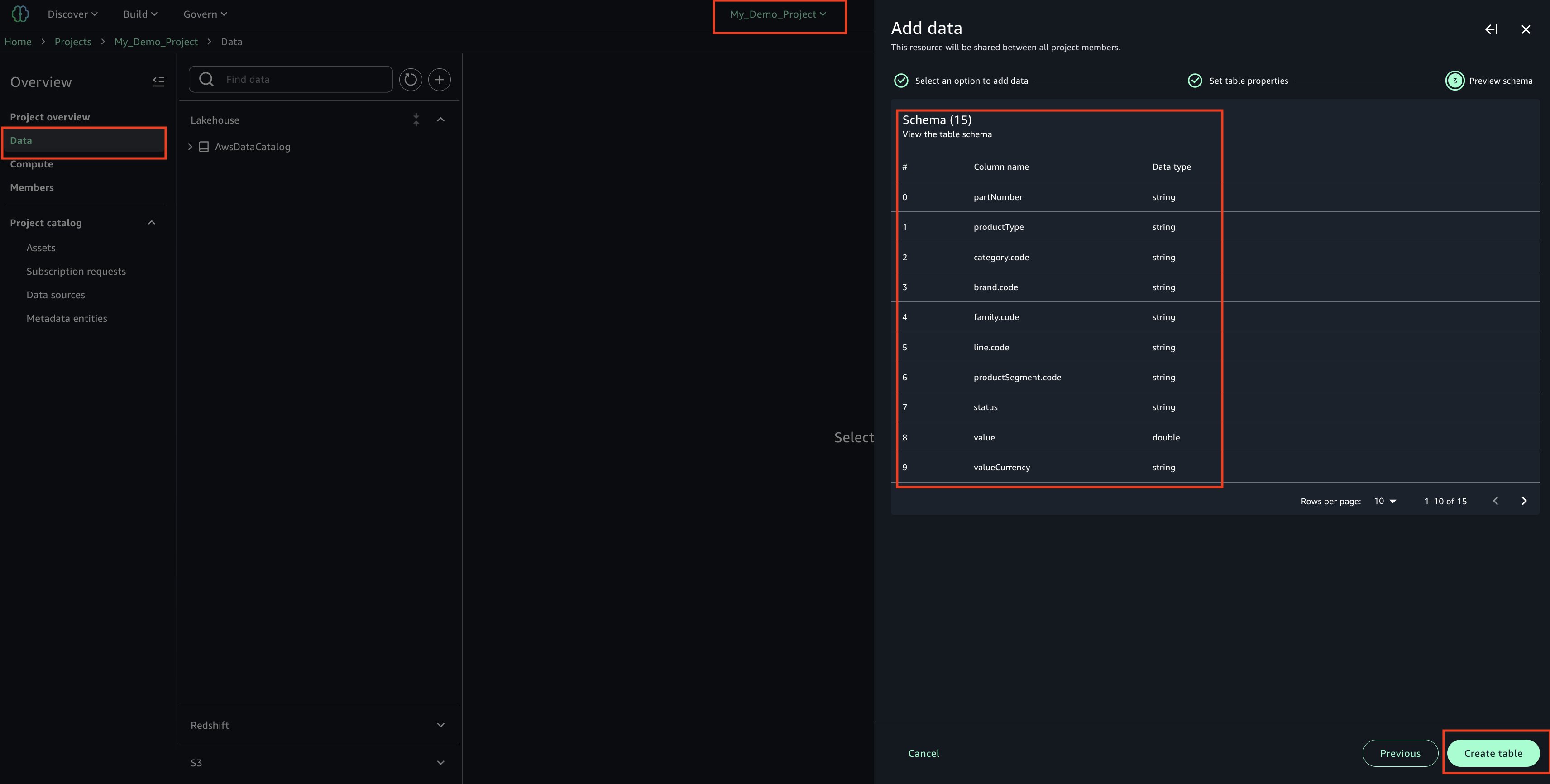
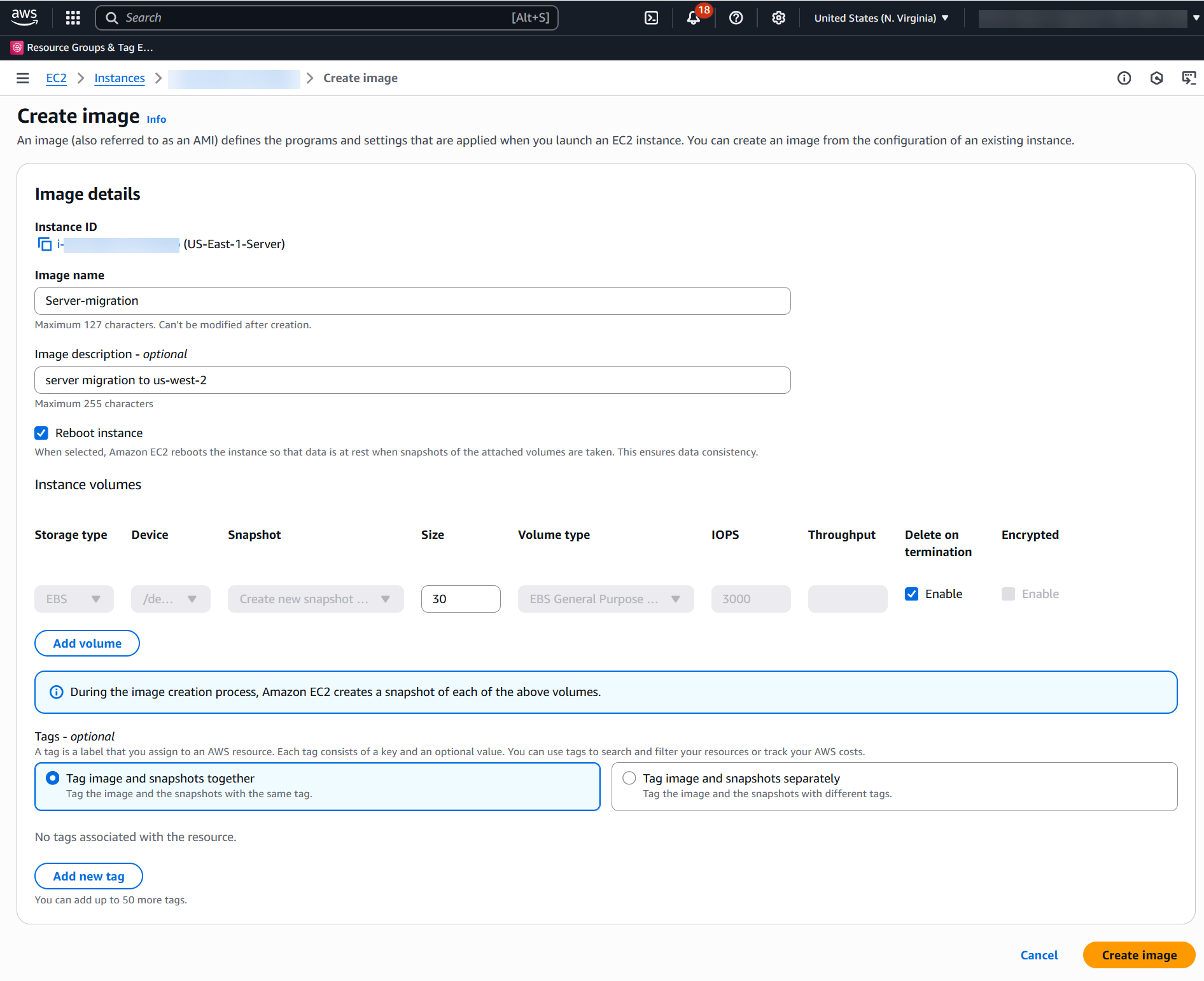
To illustrate the migration process, you will use a fictional document management application that uses OPA and Rego for authorization. The first step in migrating to Verified Permissions is creating a policy store. A policy store is a container for your Cedar policies and schema. You can create multiple policy stores for different applications or environments.
When creating a policy store, you choose between two validation modes:
- STRICT mode: Requires a schema against which policies are validated
- OFF mode: Allows policies without a schema (useful for initial testing)
For production migrations, STRICT mode is recommended because it provides better validation compared to OFF mode and can enable optimizations that reduce the entity data needed for authorization requests. You can create a policy store through the AWS Management Console, AWS Command Line Interface (AWS CLI), or programmatically using AWS SDKs. The following example uses the AWS CLI:
If the request is successful, you should see a JSON encoded response that looks like the following:
Make note of the policyStoreId from the response—you will need it for subsequent operations.
Defining your schema
In STRICT mode, Verified Permissions requires a Cedar schema that defines the types of entities in an authorization system. This schema serves several important purposes, including validating policies at creation time, enabling entity slicing performance optimizations, enabling better tooling and IDE support, and documenting your authorization model. The schema should define:
- Entity types: The kinds of objects in your system (for example, users, roles, documents, and so on.)
- Attributes: Properties that entities can have (for example, department, classification, and createdDate)
- Actions: Operations that can be performed (for example, read, write, and delete)
- Relationships: How entities relate to each other (for example, user belongs to role, document owned by user)
When designing a schema, you should consider how your current OPA input data maps to Cedar entities. For example, if your Rego policies access input.user.department, you will need a User entity type with a department attribute. The following is an example Cedar schema for your document management application:
To apply this schema to the policy store you created earlier using the AWS CLI, you can run the following command:
Ensure that you replace YOUR_POLICY_STORE_ID with the policyStoreId that was returned when you created your policy store.
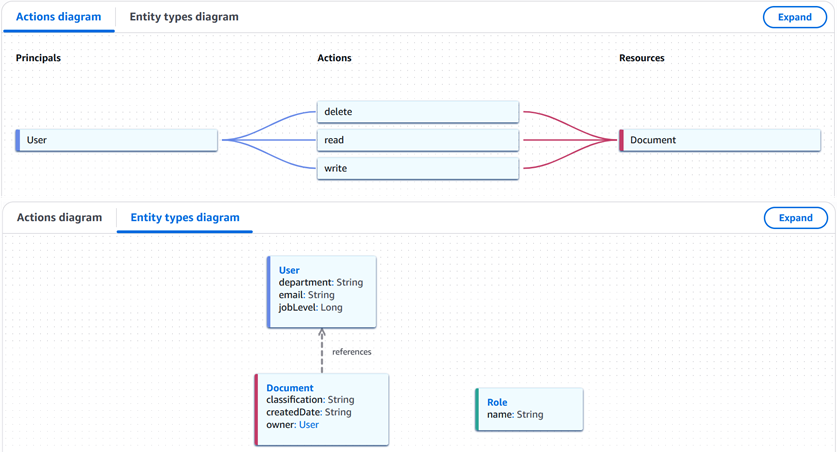
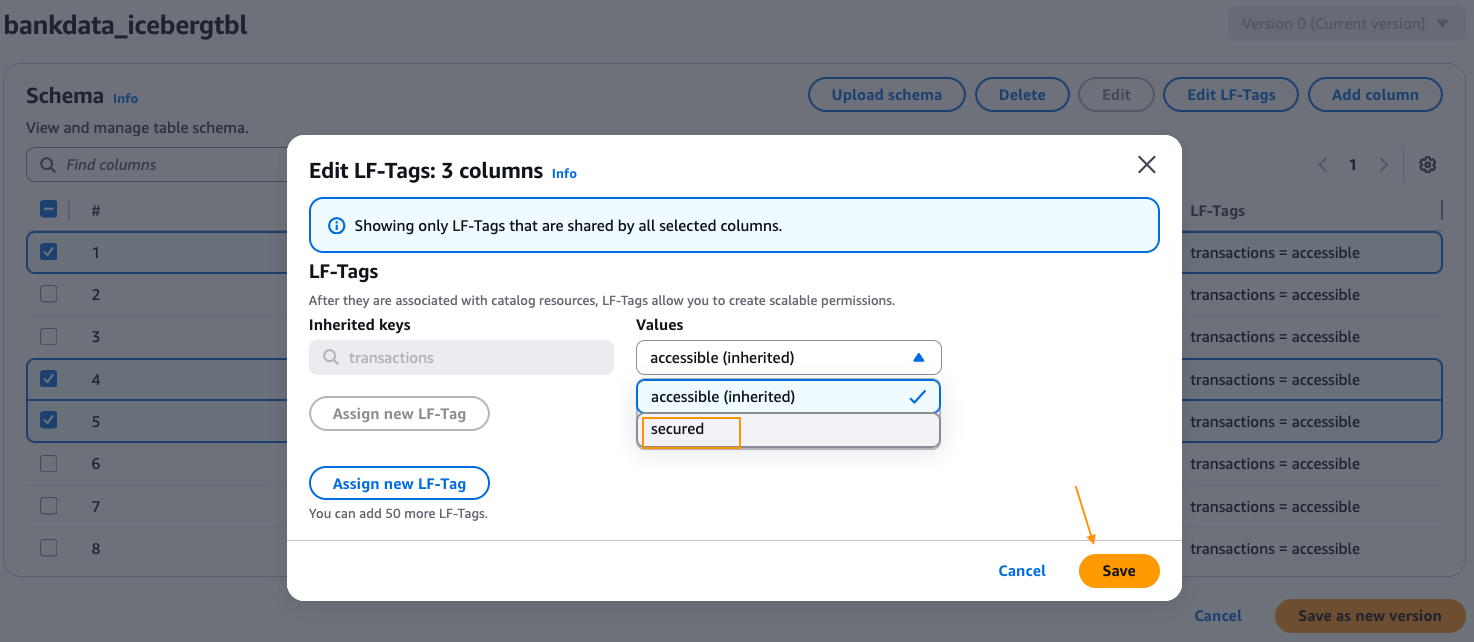
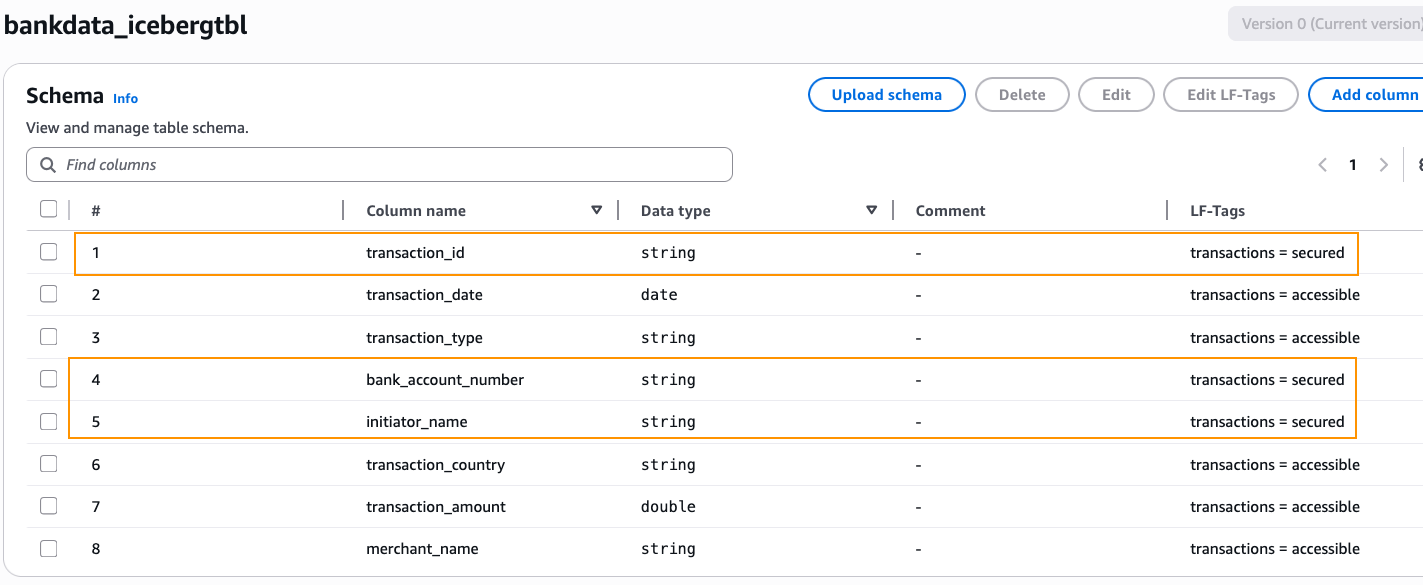
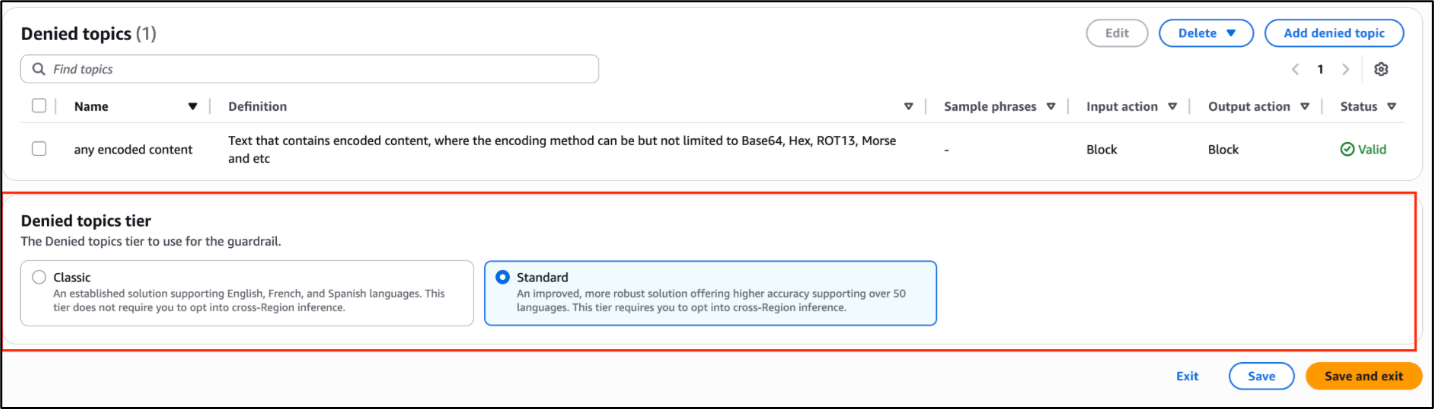
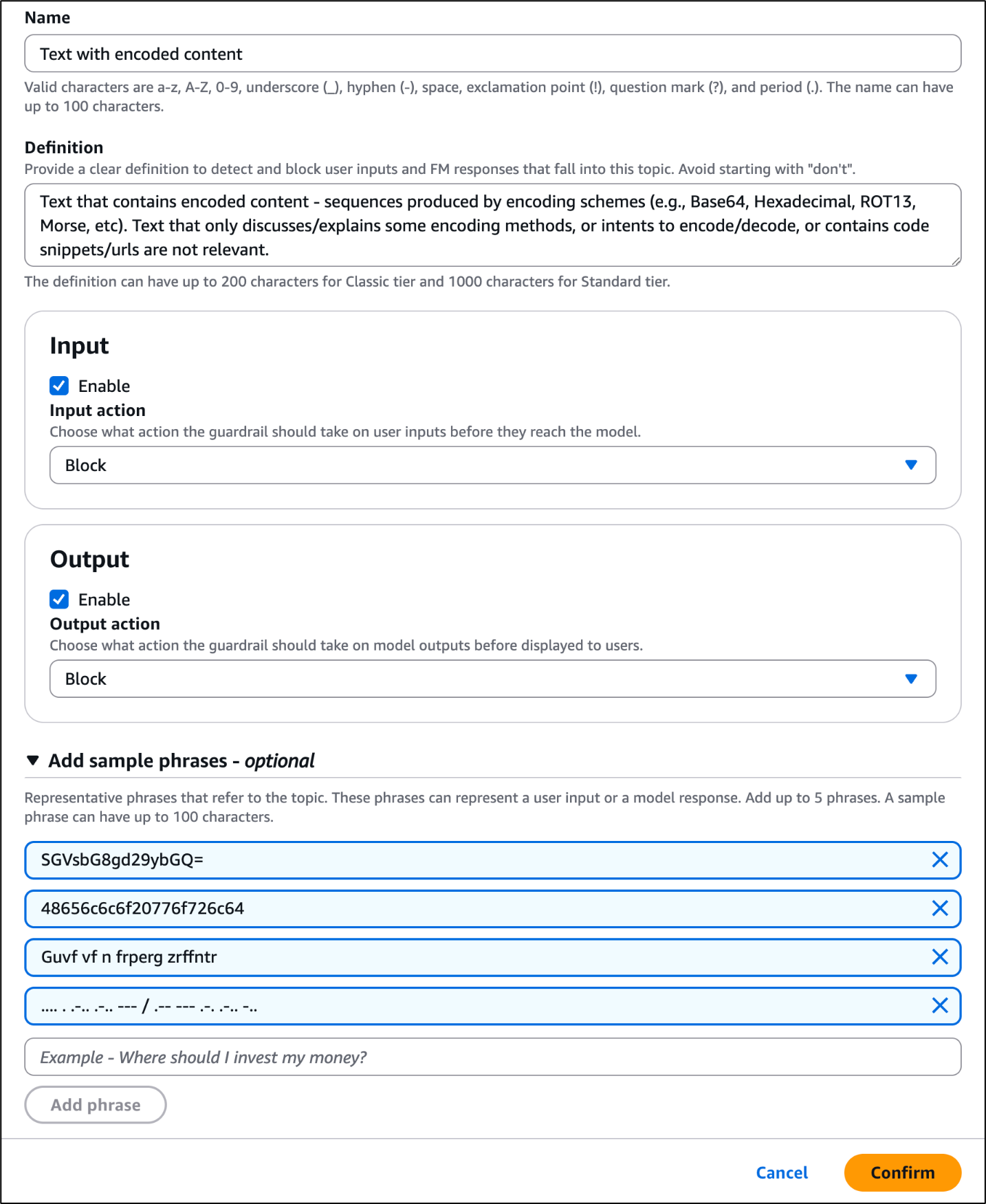
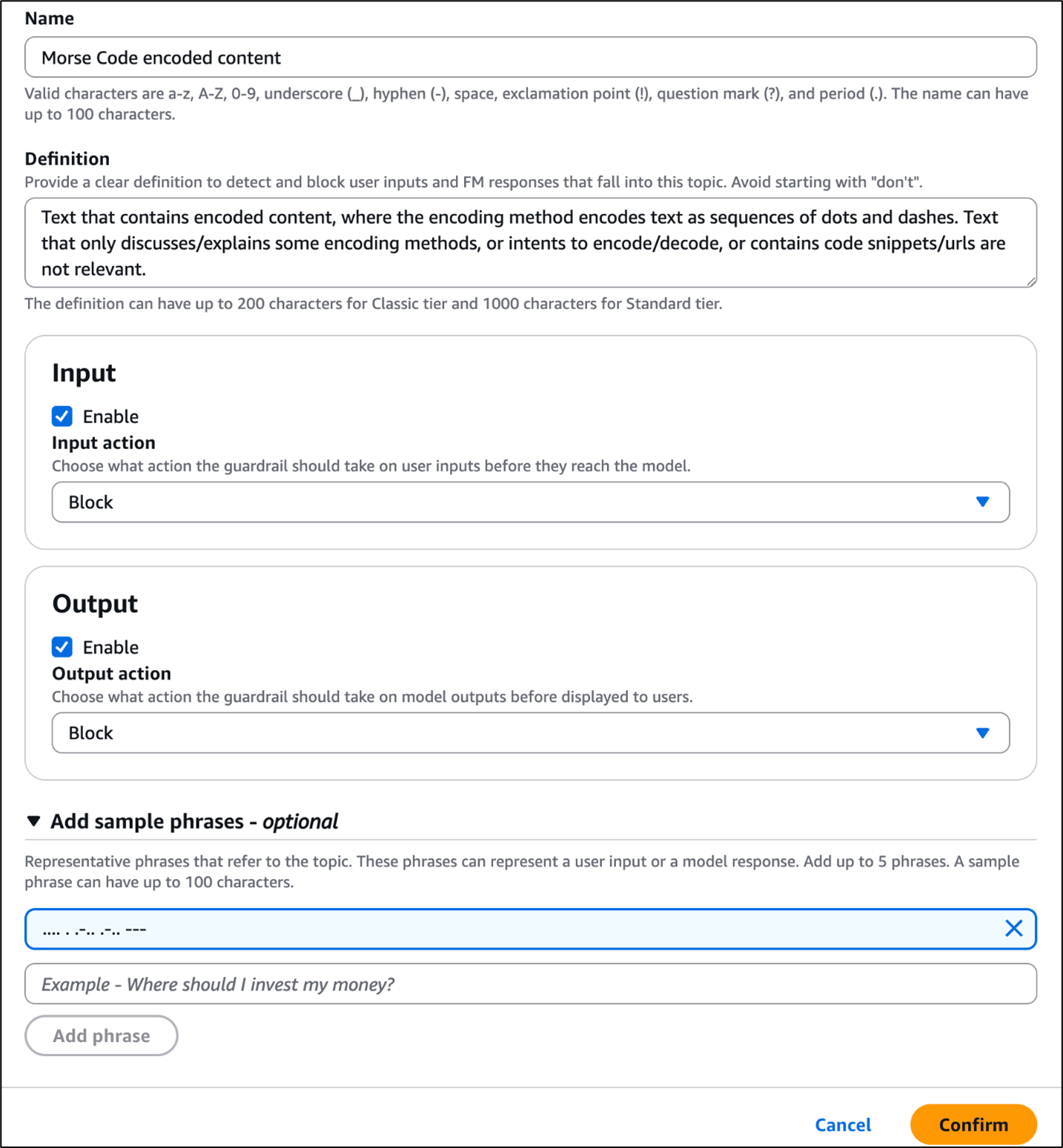
You can view the visualized policy schema (shown in Figure 1) in the Verified Permissions console by going to Policy Store and choosing Schema.

Figure 1: Verified Permissions policy schema visualization
Policy migration patterns
With your policy store and schema in place, you can now begin translating your Rego policies into Cedar policies, following common authorization patterns.
Pattern 1: Role-based access control
Role-based access control (RBAC) is one of the most used authorization patterns. In RBAC systems, users are assigned roles, and roles are granted permissions to perform actions on resources.
In your current Rego implementation, you might check if a user has a specific role in their roles array, then allow certain actions based on that role. Your Rego policy might look something like the following:
When migrating to Cedar, you will model this using entity relationships where users belong to role entities.
Migration approach
To successfully migrate your RBAC policies from Rego to Cedar, follow these steps:
- Define User and Role entity types in your schema
- Create
permit policies for each role-action combination
- Use the Cedar
in operator to check role membership
- Consider creating role hierarchies if you have nested roles
Key differences
Understanding the fundamental differences between Rego and Cedar’s approach to RBAC will help you design more effective policies:
- Cedar uses entity relationships instead of checking array membership
- Each permission becomes a separate, explicit policy
- Role hierarchies are modeled through entity parent-child relationships
Pattern 2: Attribute-based access control
Attribute-based access control (ABAC) makes authorization decisions based on attributes of the user, resource, action, and environment. This is often more flexible than RBAC but can be more complex to implement.
In Rego, you would access various attributes from the input data and use them in policy conditions:
Cedar handles this through entity attributes and policy conditions using the when and unless clauses.
Migration approach
Migrating ABAC policies requires careful mapping of attributes from your Rego input structure to Cedar’s entity model:
- Identify the attributes used in your current policies
- Map these attributes to entity attributes in your Cedar schema
- Use
when clauses in Cedar policies to implement attribute-based conditions
- Consider using context for environment-specific attributes (time, IP address, and so on)
Key differences
Cedar’s schema-driven approach to attributes provides several advantages over Rego’s dynamic attribute access:
- Cedar requires attributes to be defined in the schema
- Cedar schema validation helps catch attribute access errors at policy creation time
- Complex attribute logic might need to be split across multiple policies
Pattern 3: Relationship-based access control
Relationship-based access control (ReBAC) grants permissions based on properties of the resource being accessed or relationships between the user and the resource (such as ownership). In Rego, this might be expressed as follows:
In the preceding example, ownership is checked by comparing the owner_id attribute on the resource with the user’s ID. You might access this from the input data directly or from a separate data source. In Cedar, relationships are first-class concepts. The resource.owner == principal syntax directly checks if the principal is the owner entity referenced by the resource. This is more natural and type-safe than string comparisons:
Migration approach
Converting relationship-based policies requires modeling your data relationships as Cedar entity references:
- Model resources as Cedar entities with relevant attributes
- Use resource attributes in policy conditions
- Model ownership and other relationships through entity references
- Use Cedar’s attribute access syntax for resource properties
Pattern 4: Time and context-based access
Many authorization systems need to consider contextual information such as time of day, user location, or request characteristics (IP address, user-agent, and so on). Expressing this in Rego would look like the following example:
In Cedar, the same policy logic can be expressed like the following:
Migration approach
Context-based policies in Cedar use the context parameter passed with each authorization request:
- Use Cedar’s context feature for environment information
- Pass time-based information in the authorization request context
- Create policies with time-based conditions using context attributes
- Consider caching implications for time-sensitive policies
Application integration changes
After migrating your policies to Cedar, you need to update your application code to integrate with Verified Permissions.
Updating authorization calls
The most significant change in your application code will be replacing OPA API calls with Verified Permissions API calls. Understanding the differences between these systems will help you plan your integration work effectively. The sample code in this section is written in Python.
Request structure changes
When calling OPA, you typically send a single JSON payload containing the authorization data. For example, your current OPA request might look like the following:
Verified Permissions requires a more structured approach where principals, resources, and actions are explicitly typed entities.
The key differences in this new structure are:
- Entity type declarations: Each entity (principal, resource) must include an
entityType that matches your Cedar schema
- Entity IDs: Every entity requires a unique
entityId for identification
- Action format: Actions are specified with an
actionType and actionId rather than as simple strings
- Separate context: Environmental information like time, IP address, or user agent is passed in a separate context parameter
Response handling changes
OPA returns whatever your Rego policy outputs, which could be a Boolean, a set of allowed actions, or complex nested data structures. Regardless of the policy outputs, Verified Permissions returns a consistent authorization decision structure:
Your application logic becomes simpler because you need to check for only ALLOW or DENY:
Error handling changes
OPA errors typically relate to policy evaluation issues or server connectivity problems. With Verified Permissions, you’ll encounter AWS-specific error types, as shown in the following example:
It’s important to note that the AWS SDK provides built-in retry logic for transient failures. The following is an example of how you can enable this feature:
Data transformation
Your current authorization data needs to be transformed into Cedar’s entity format. This transformation happens in the _to_cedar_entity method shown in the error handling changes example, but let’s break down what’s involved.
Extracting entity information
Identify which parts of your current OPA input represent the principal, resource, and action. In most OPA implementations, this mapping is straightforward:
Adding type information
Cedar requires explicit type declarations for all entities. You’ll need to determine the appropriate entity type based on your schema:
Structuring attributes
Cedar attributes must match your schema definition, so you might need to transform attribute names or values. This is also a chance to iterate and improve on naming. The following example demonstrates a code pattern to convert attribute names and values in code.
Handling context
Separate environmental information from entity data. Context information should not be part of entity attributes.
Testing your migration
The most critical aspect of migration testing is verifying that you have correctly migrated your authorization logic from Rego to Cedar. This requires systematic testing with comprehensive test cases.
Test case development
- Inventory current policies: Document your current Rego policies, including their decision logic, input data requirements, and expected outcomes for key test scenarios
- Create test scenarios: Develop test cases covering all policy branches and edge cases
- Capture current behavior: Run your test cases against OPA to establish baseline results
- Test Cedar policies: Run the same test cases against your Cedar policies
- Analyze differences: Investigate mismatches and adjust policies accordingly
When testing your policies, start with basic, straightforward policies before tackling complex ones. Test both positive cases (should be allowed) and negative cases (should be denied) and include edge cases and boundary conditions. Additionally, test with real production data (anonymized if necessary) to verify that your policies will work effectively when implemented in production.
It’s also important to compare the performance characteristics of your OPA setup with Verified Permissions across several key metrics. These metrics should include average response time for authorization requests, throughput (requests per second), and error rates under normal and stress conditions. During testing, test from the actual deployment environment used by your application and account for network latency to AWS services.
Finally, you should test the complete integration between your application and Verified Permissions across several critical areas. Your integration testing should cover authentication and AWS credential handling, request/response data transformation, error handling and fallback scenarios, connection pooling and resource management, and logging and monitoring integration to help ensure that the components work together seamlessly.
Deployment strategy
A successful migration from OPA to Verified Permissions requires careful planning and a risk-managed deployment approach that minimizes disruption to your production systems.
Phased migration approach
Rather than switching entirely to Verified Permissions in a single step, implement a phased migration to reduce risk.
- Parallel deployment: Deploy Verified Permissions alongside your existing OPA infrastructure and route a small percentage of authorization requests to the new system. Log and compare results between both systems, focusing on non-critical operations initially to minimize risk during the transition process.
- Gradual traffic shift: Gradually increase the percentage of requests routed to Verified Permissions while monitoring system performance, error rates, and authorization accuracy. Implement circuit breaker patterns to fall back to OPA if needed and expand to more critical operations as your confidence grows in the reliability and performance of the new system.
- Full migration: Route all traffic to Verified Permissions but keep OPA infrastructure running temporarily. Monitor system behavior under full production load and decommission OPA infrastructure after stability is confirmed and you are confident in the performance of the new system.
Feature flag implementation
Use feature flags to control the migration process through various flag types. These include percentage-based rollout to route a specific percentage of requests to the new system, user-based rollout to route specific users or user groups to the new system, operation-based rollout to route specific types of operations to the new system, and environment-based rollout to use different systems in different environments. Feature flags provide several benefits, including instant rollback capability if issues arise, granular control over migration scope, A/B testing of authorization decisions, and safe experimentation with new policies.
Troubleshooting common migration issues
When migrating from Rego to Cedar, you might encounter several common issues. In this section, you’ll find a troubleshooting guide.
Complex Rego logic translation
Some Rego policies use complex logic that doesn’t directly translate to Cedar. For example:
In these scenarios, you should restructure your data model to work better with Cedar’s entity-based approach. For example, Cedar provides the in operator for improved performance and readability, as shown in the following example:
Schema validation errors
Cedar requires strict schema compliance. Common errors include:
- Undefined entity types
- Missing required attributes
- Type mismatches
You can use the schema validation tools provided by Verified Permissions to triage these issues.
Best practices and recommendations
Adhering to the following recommendations and best practices will help you build a maintainable, secure, and performant authorization system with Verified Permissions.
Policy design best practices
Well-designed policies are the foundation of a reliable authorization system and directly impact maintainability and security:
- Schema-first design: Start with a comprehensive schema design before writing policies. A well-designed schema makes policy authoring more maintainable.
- Basic, explicit policies: Favor multiple basic policies over complex monolithic ones. Cedar’s explicit permit/forbid model works best with clear, straightforward policy statements.
- Meaningful naming: Use descriptive names for entity types, attributes, and policy descriptions. This improves understandability and maintainability of polices.
- Documentation: Document your authorization model, including entity relationships, policy intentions, and business rules.
Migration strategy recommendations
Successfully migrating your authorization system requires balancing speed with safety through deliberate, incremental steps:
- Incremental approach Don’t attempt to migrate everything at once. Start with basic, low-risk policies and gradually move to more complex scenarios.
- Start in audit mode: Calculate and log the policy decisions for both systems. This will help you to compare results without impacting runtime authorization.
- Comprehensive testing: Invest heavily in testing during migration. The cost of thorough testing is much less than the cost of authorization failures in production.
- Parallel operations: Run both systems in parallel during migration to validate policy behavior and build confidence in the new system.
- Team training: Ensure your team understands Cedar’s policy model and syntax. The conceptual differences from Rego require a learning investment.
Operational excellence
Maintaining a production authorization system requires ongoing attention to operational concerns beyond the initial migration:
- Version control: Treat policies as code with proper version control, code review, and deployment processes.
- Monitoring and alerting: Implement comprehensive monitoring from day one. Authorization issues can have significant business impact.
- Regular audits: Periodically review and audit policies to verify that they still meet business requirements and security standards.
- Performance optimization: Continuously monitor and optimize performance, particularly around caching strategies and policy efficiency.
Conclusion
Migrating from Open Policy Agent to Amazon Verified Permissions represents a significant step toward reducing operational overhead, improving runtime authorization performance and enhancing governance while maintaining robust authorization capabilities. The migration journey from OPA to Verified Permissions isn’t only about changing technologies, it’s an opportunity to improve your authorization architecture, enhance security practices, and build a more scalable foundation for your application’s access control needs.
Thank you for reading this post. If you have comments or questions about migrating from OPA to Verified Permissions, leave them in the comments section below.
Additional resources
The following links provide resources for further reading on the topics covered in this blog post:
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.